

Explainable AI for Credit Assessment in Banks



Abstract
1. Introduction
2. Literature Review
3. Methodology
3.1. Gradient Boosting Decision Trees
3.2. LightGBM
3.3. Shapley Values
3.4. SHAP
3.5. Logistic Regression Models
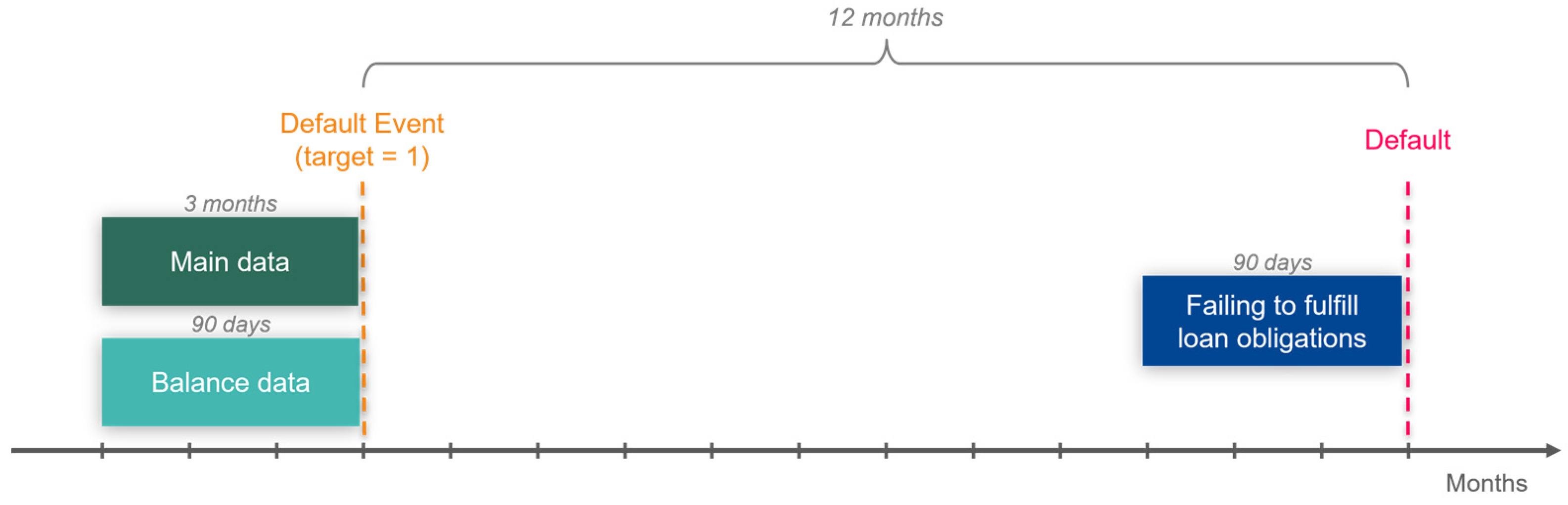
4. Data
4.1. Data Preparation for LightGBM
4.1.1. Data Filtering
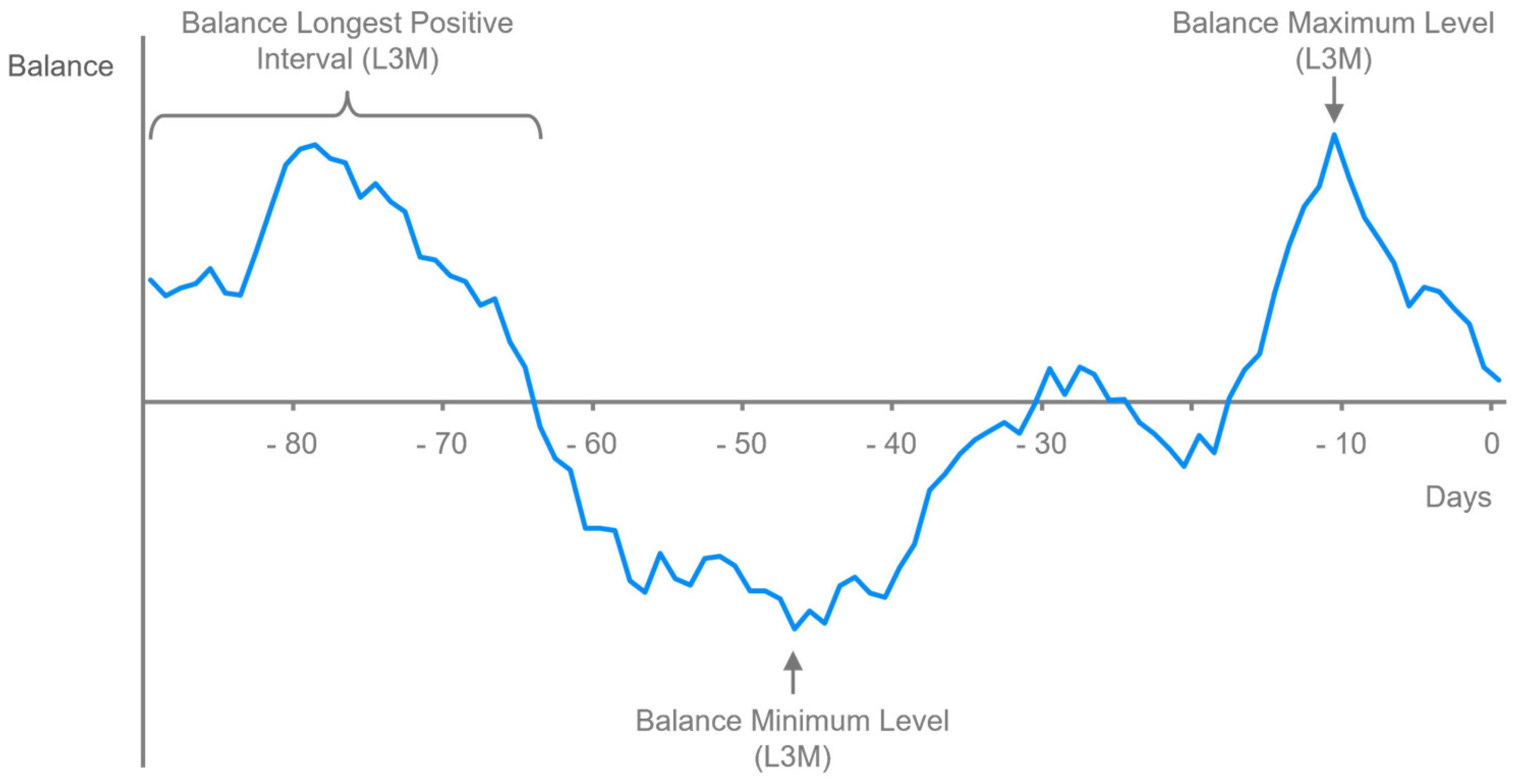
4.1.2. Feature Extraction
4.1.3. Feature Selection
4.2. Data Preparation for Logistic Regression
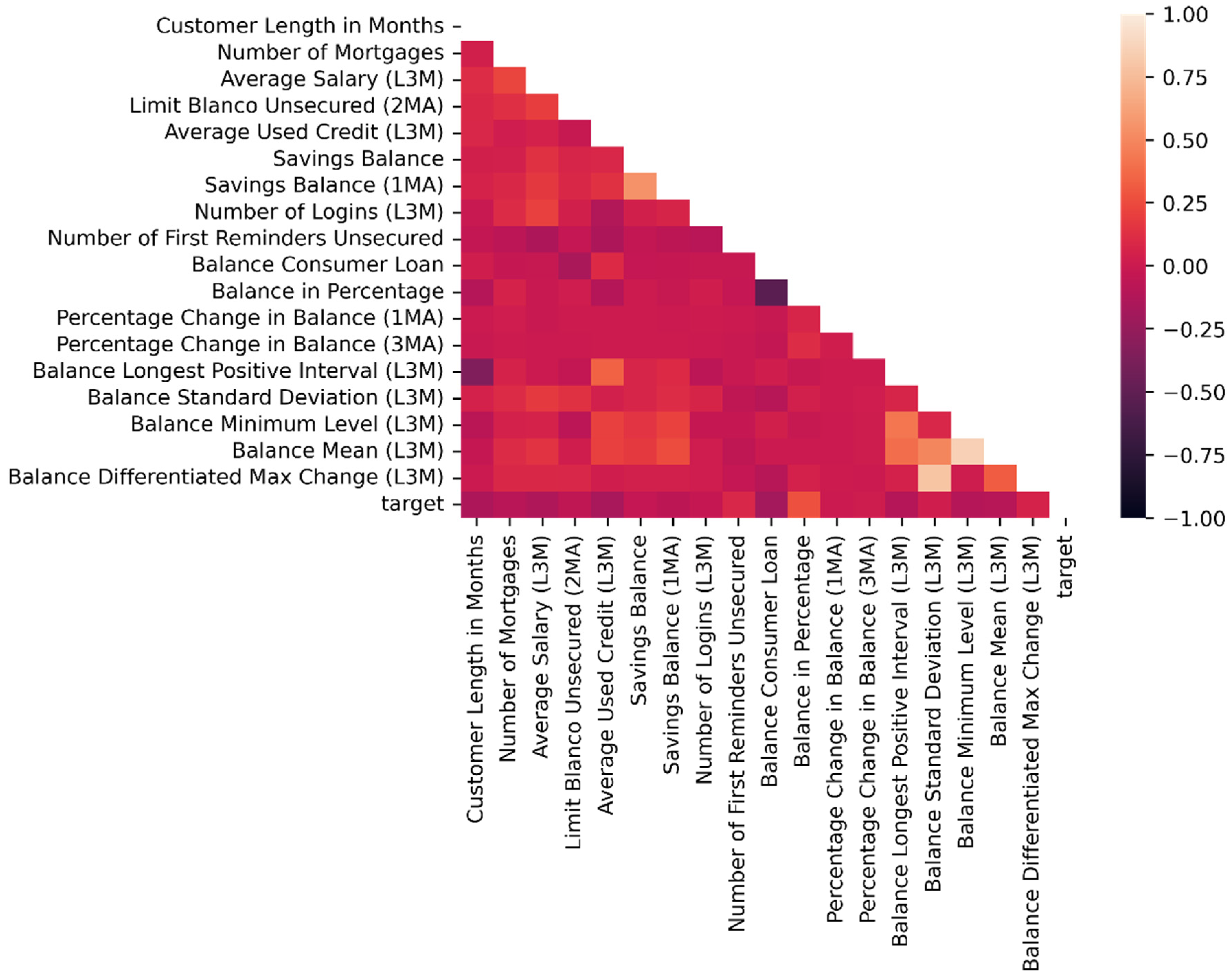
4.3. Data Visualization
5. Results
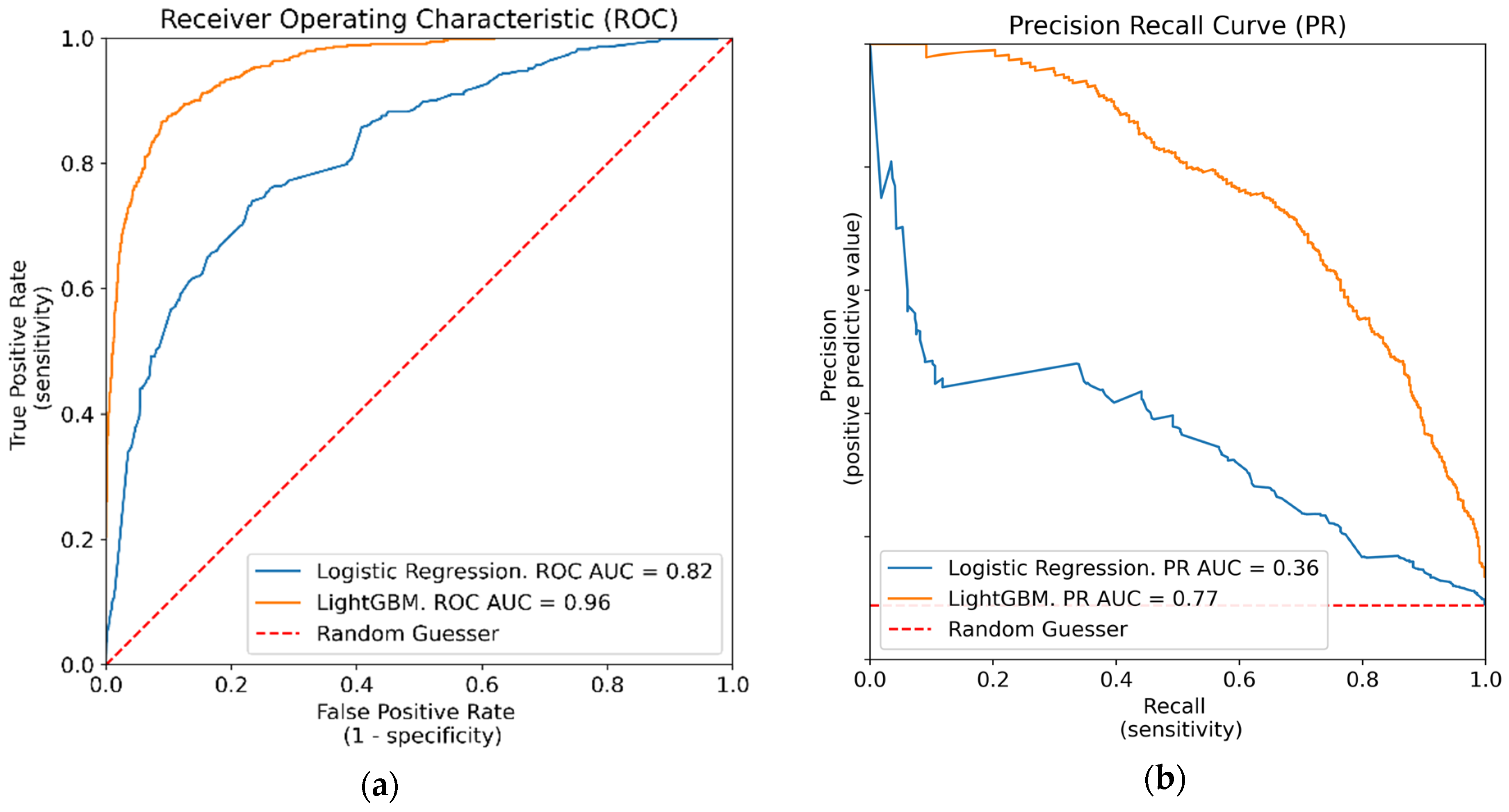
5.1. Model Evaluation
LightGBM Model Based on LR Features
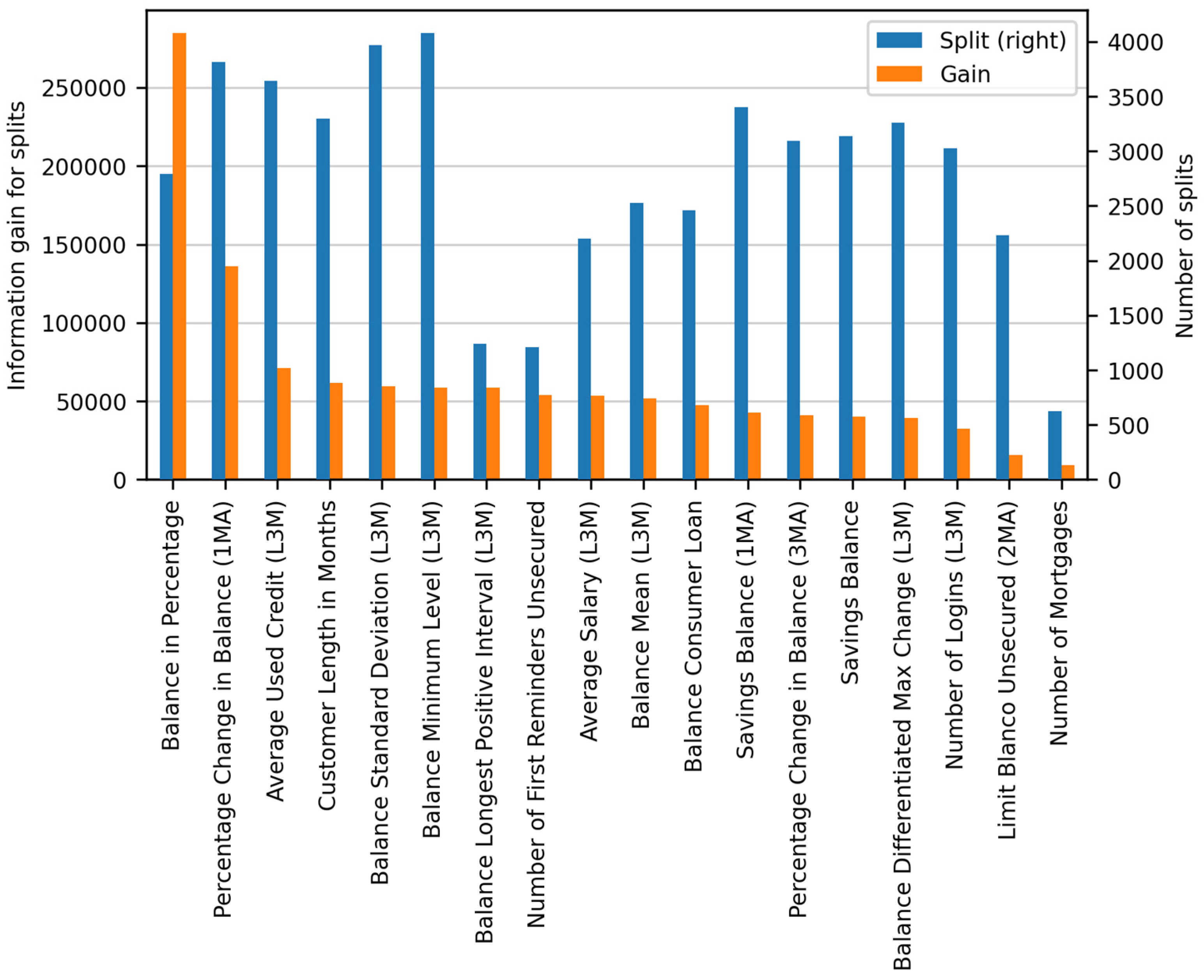
5.2. LightGBM Explainability
5.3. SHAP Explanations
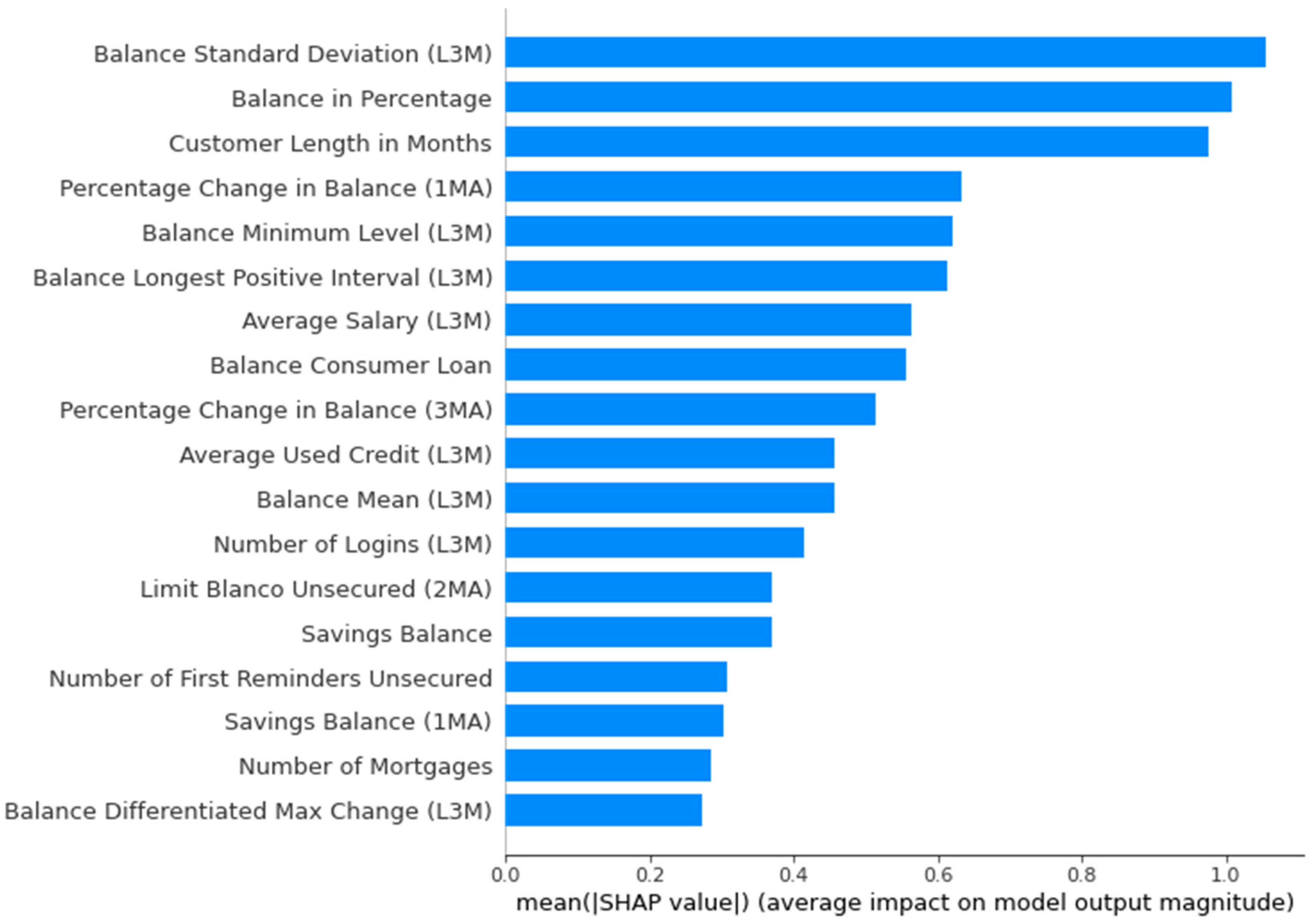
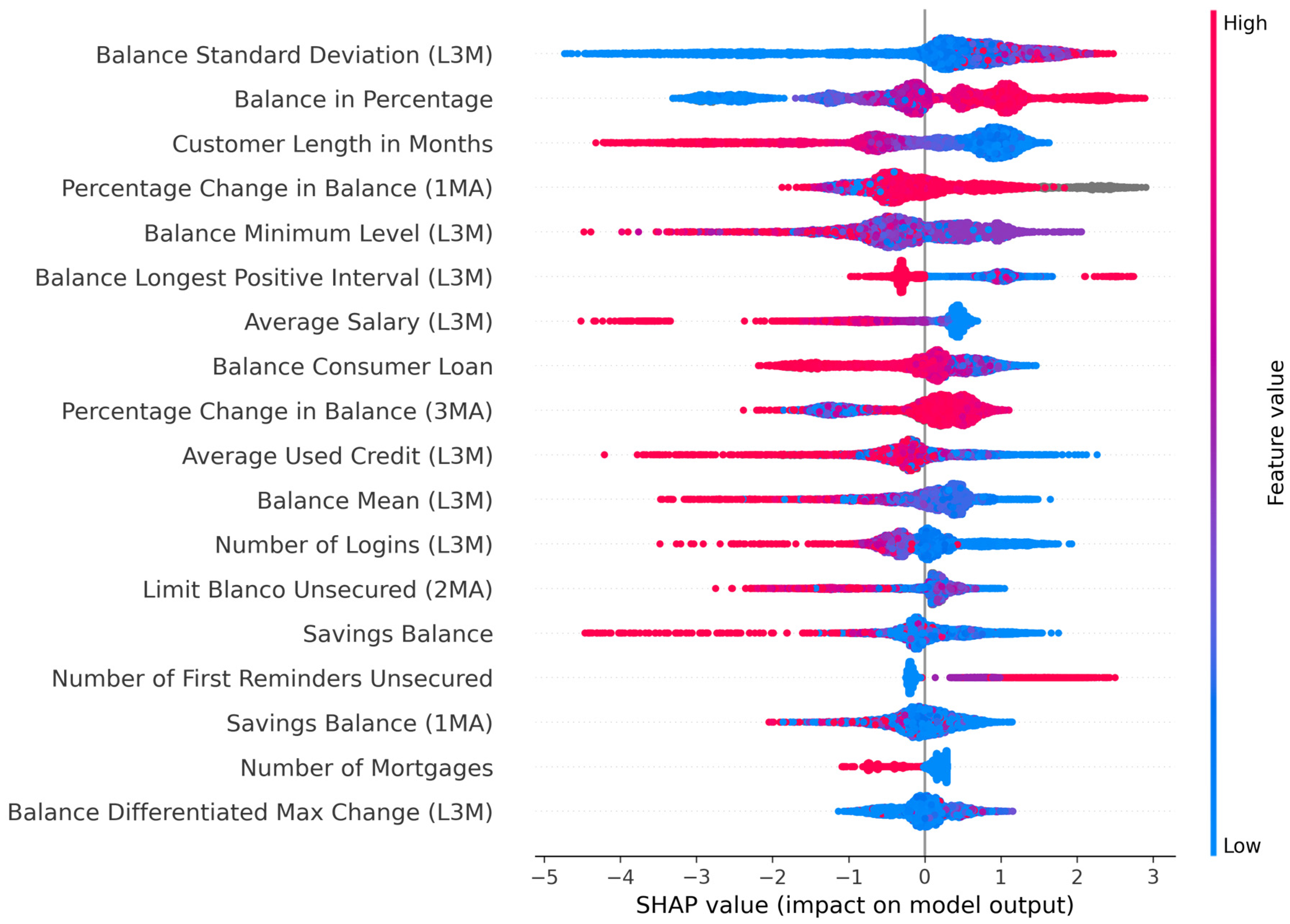
5.3.1. Global Explanations
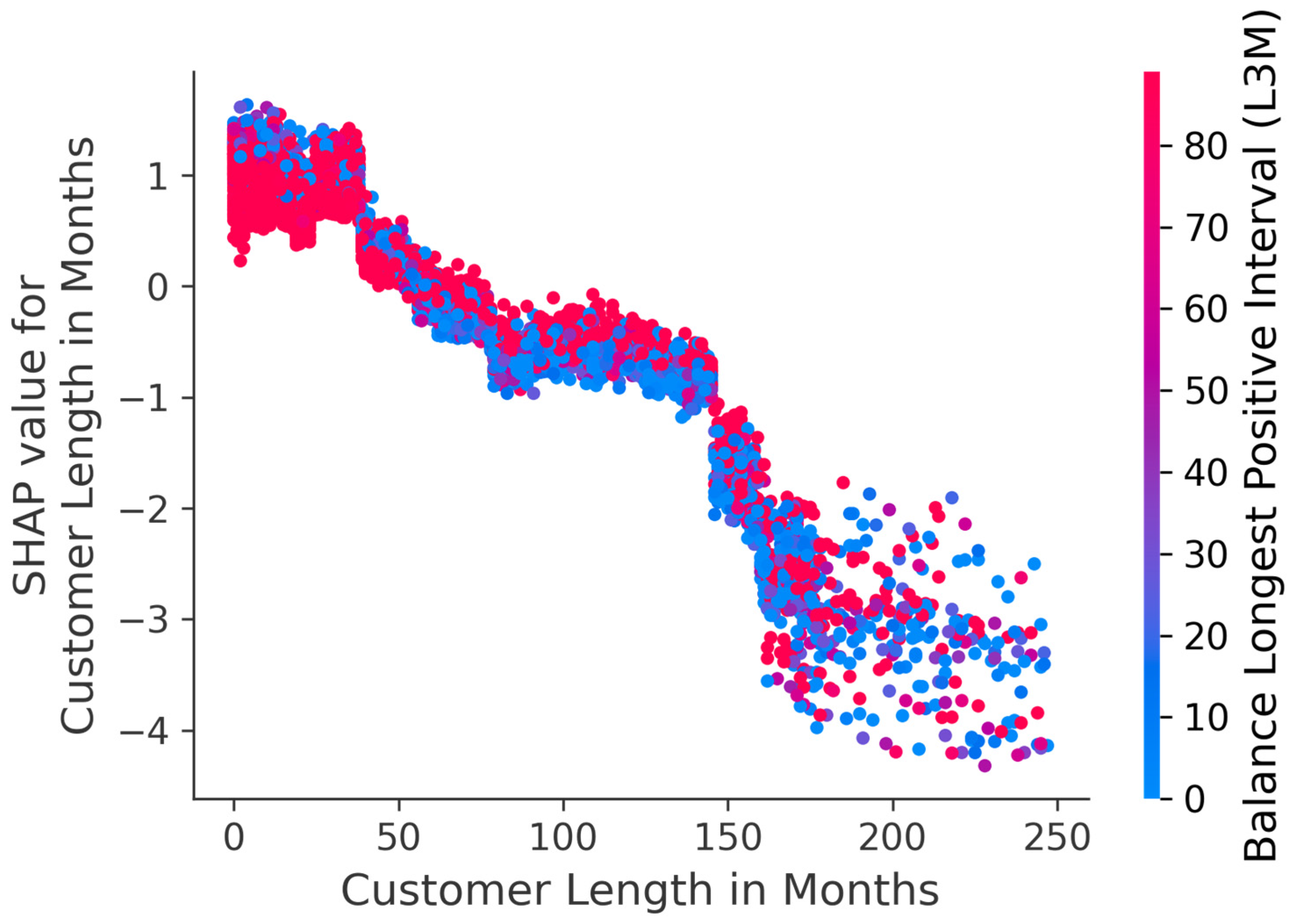
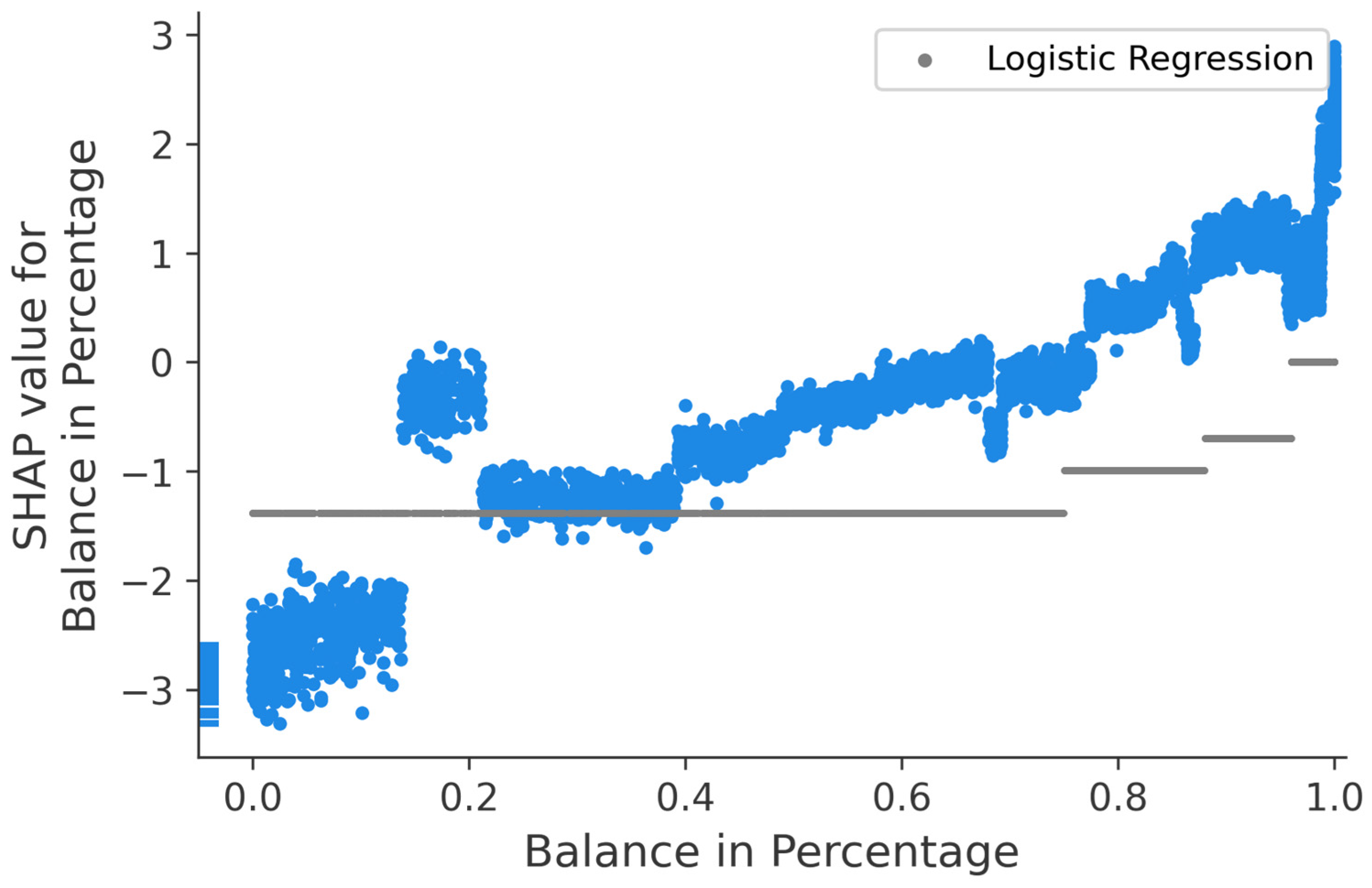
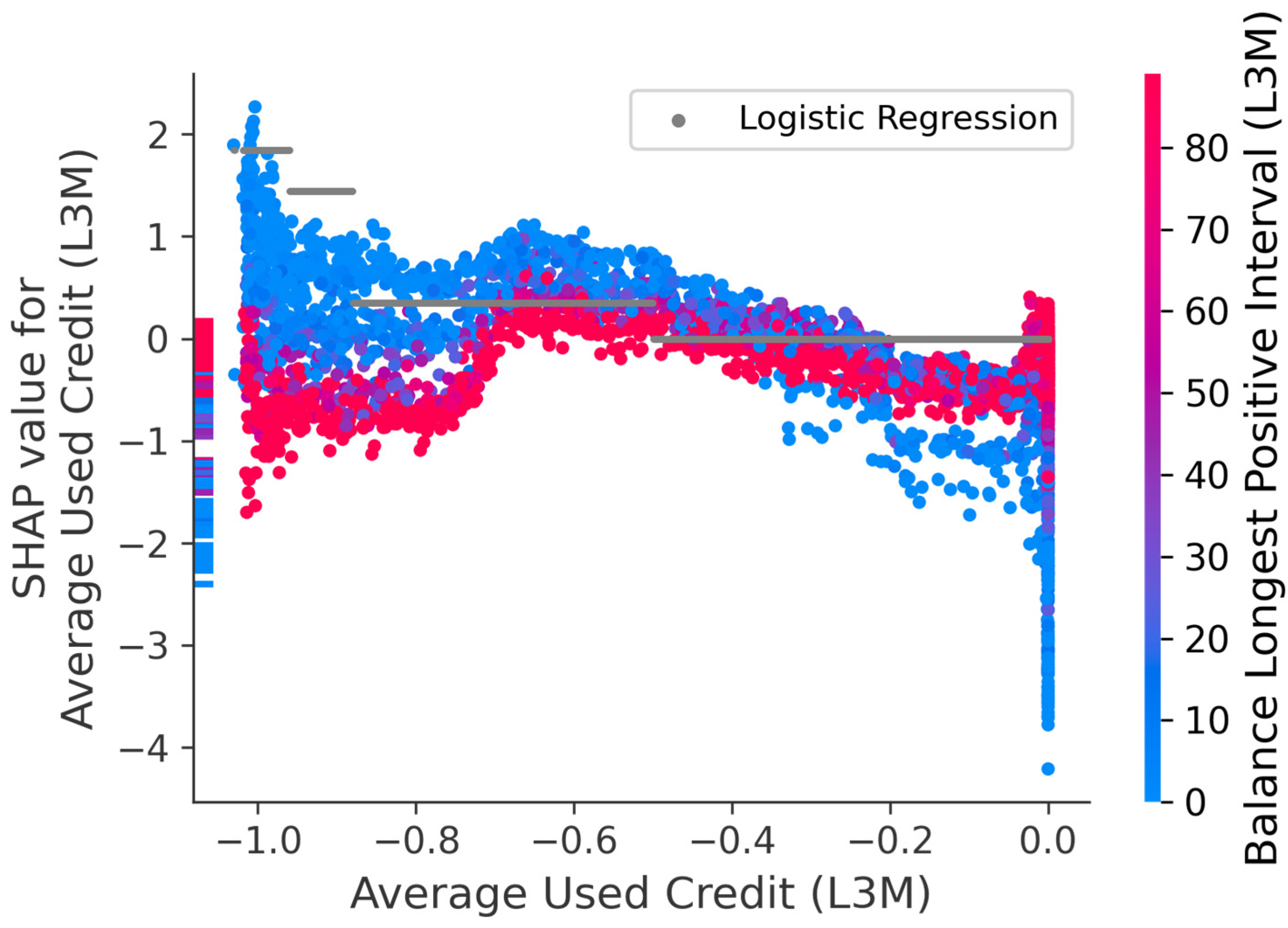
Dependence Plot
Dependence Plot with Logistic Regression Coefficients
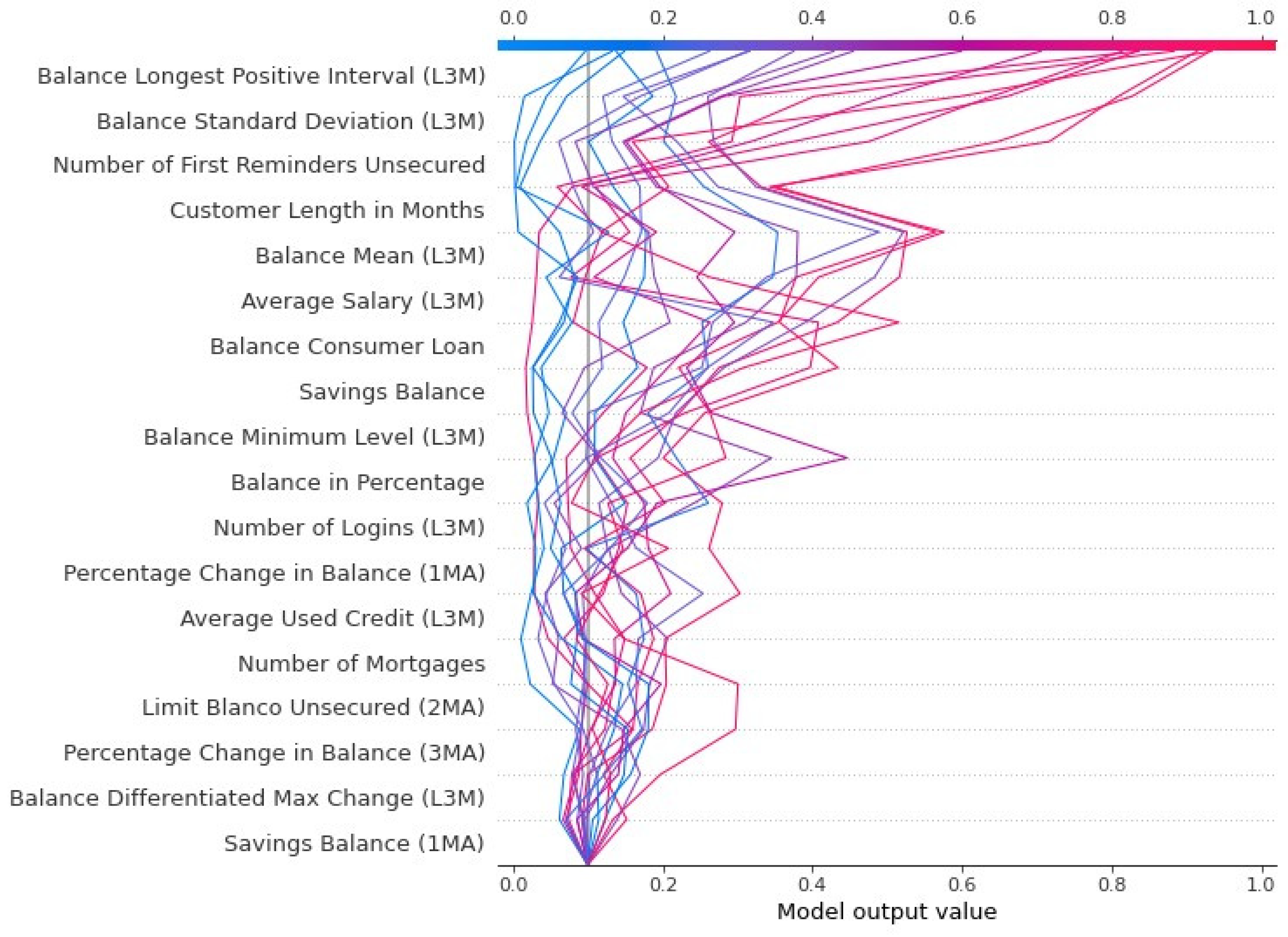
Decision Plot
5.3.2. Local Explanations
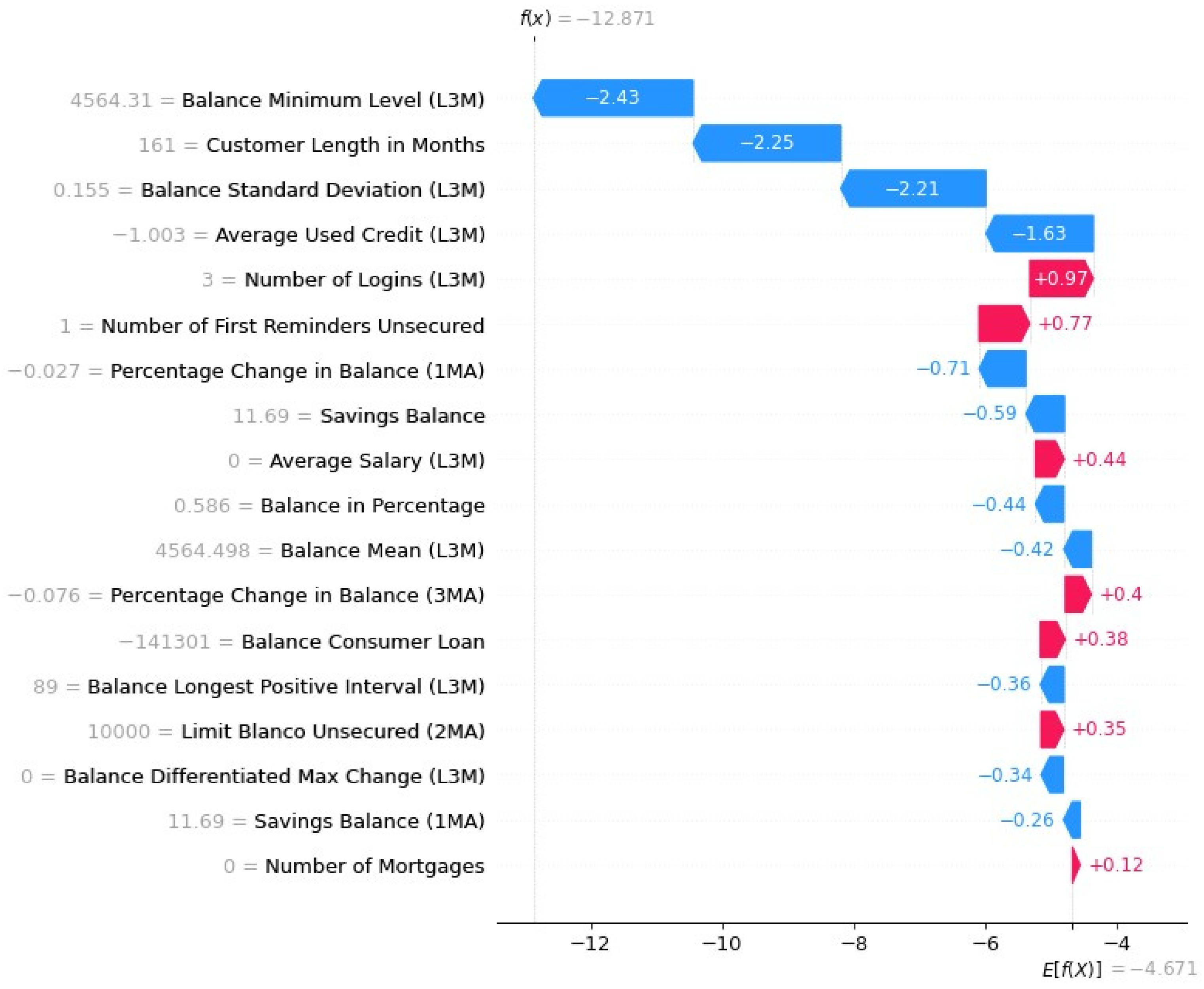
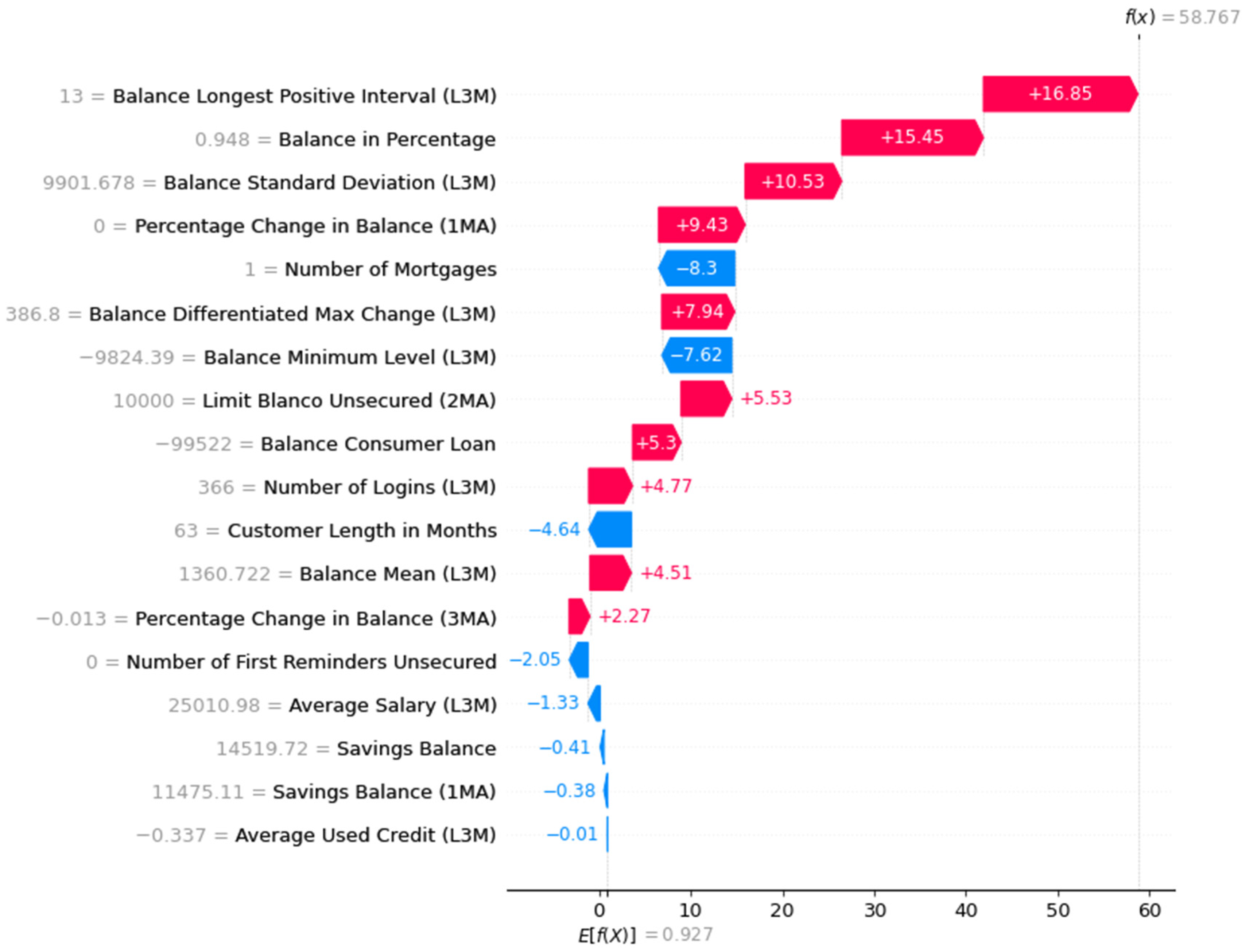
Waterfall Plot
Waterfall Plot with Probabilities
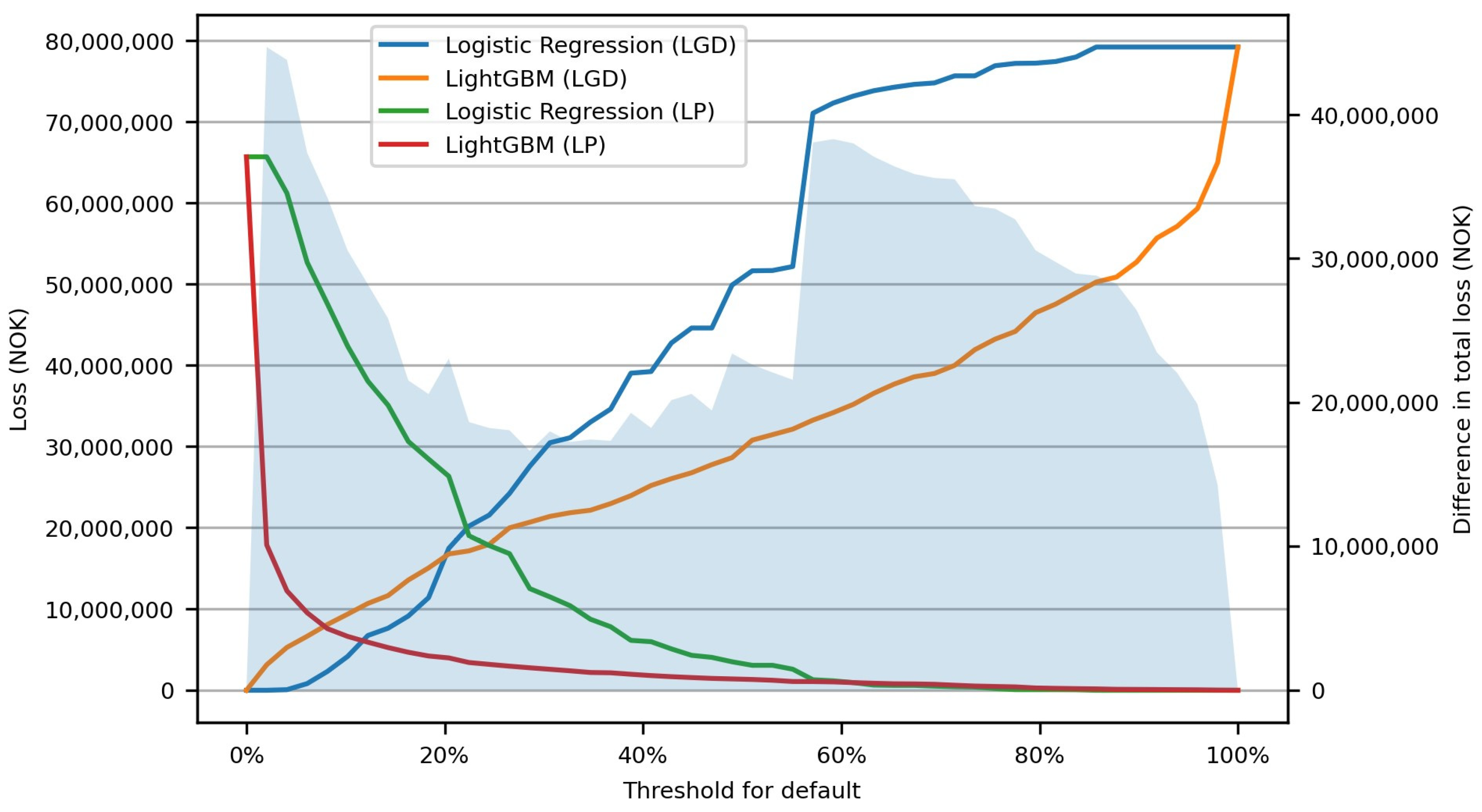
5.4. The Economic Value of a More Accurate Model
6. Conclusions
- Combining monthly customer application data (income, gender, age, etc.) with daily account data (i.e., transactions data)
- Showing why and how LightGBM outperforms the bank’s current Logistic Regression model, predicting default on unsecured consumer loans
- Exploring how XAI can improve interpretability and reliability of state-of-the-art AI models for credit default prediction
- Proposing a method for measuring the economic value of a more accurate credit default prediction model
- SHAP can ease the challenge of interpreting results
- SHAP can facilitate managers’ understanding of the credit models
- SHAP can help to justify a model’s results to supervisory authorities
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | Finansportalen.no—a service by the Norwegian Consumer Council. Loan amount: 100,000 NOK, period of repayment: 1 year (accessed 1 June 2022). |
References
- Ariza-Garzón, Miller Janny, Javier Arroyo, Antonio Caparrini, and Maria-Jesus Segovia-Vargas. 2020. Explainability of a Artificial intelligenceGranting Scoring Model in Peer-to-Peer Lending. IEEE Access 8: 64873–90. [Google Scholar] [CrossRef]
- Bartlett, Peter, Yoav Freund, Wee Sun Lee, and Robert E. Schapire. 1998. Boosting the margin: A new explanation for the effectiveness of voting methods. The Annals of Statistics 26: 1651–86. [Google Scholar] [CrossRef]
- Basel Committee on Banking Supervention. 2006. International Convergence of Capital Measurement and Capital Standards. Available online: https://www.bis.org/publ/bcbs128.pdf (accessed on 1 November 2022).
- Bastos, João A., and Sara M. Matos. 2022. Explainable models of credit losses. European Journal of Operational Research 301: 386–94. [Google Scholar] [CrossRef]
- Benhamou, Eric, Jean-Jacques Ohana, David Saltiel, and Beatrice Guez. 2021. Explainable AI (XAI) Models Applied to Planning in Financial Markets. Available online: https://openreview.net/forum?id=mJrKRgYm2f1 (accessed on 1 November 2022). [CrossRef]
- Bibal, Adrien, Michael Lognoul, Alexandre De Streel, and Benoît Frénay. 2021. Legal requirements on explainability in machine learning. Artificial Intelligence and Law 29: 149–69. [Google Scholar] [CrossRef]
- Breiman, Leo. 1998. Arcing classifier (with discussion and a rejoinder by the author). The Annals of Statistics 26: 801–49. [Google Scholar] [CrossRef]
- Brown, Iain, and Christophe Mues. 2012. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Systems with Applications 39: 3446–53. [Google Scholar] [CrossRef]
- Bücker, Michael, Gero Szepannek, Alicja Gosiewska, and Przemyslaw Biecek. 2021. Transparency, auditability, and explainability of artificial intelligencemodels in credit scoring. Journal of the Operational Research Society 73: 70–90. [Google Scholar] [CrossRef]
- Bussmann, Niklas, Paolo Giudici, Dimitri Marinelli, and Jochen Papenbrock. 2020a. Explainable AI in Fintech Risk Management. Frontiers in Artificial Intelligence 3: 26. [Google Scholar] [CrossRef]
- Bussmann, Niklas, Paolo Giudici, Dimitri Marinelli, and Jochen Papenbrock. 2020b. Explainable Machine Learning in Credit Risk Management. Computational Economics 57: 203–16. [Google Scholar] [CrossRef]
- Chen, Tianqi, and Carlos Guestrin. 2016. XGBoost: A Scalable Tree Boosting System. Paper presented at the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17; New York: ACM, vols. 13–17, pp. 785–94, ISBN 1450342329. [Google Scholar]
- Connelly, Lynne. 2020. Logistic regression. Medsurg Nursing 29: 353–54. [Google Scholar]
- Davis, Randall, Andrew W. Lo, Sudhanshu Mishra, Arash Nourian, Manish Singh, Nicholas Wu, and Ruixun Zhang. 2022. Explainable Machine Learning Models of Consumer Credit Risk. Available from the Website of the Global Association of Risk Professionals. Available online: https://www.garp.org/white-paper/explainable-machine-learning-models-of-consumer-credit-risk (accessed on 1 November 2022).
- El-Sappagh, Shaker, Jose M. Alonso, S. M. Islam, Ahmad M. Sultan, and Kyung Sup Kwak. 2021. A multilayer multimodal detection and prediction model based on explainable artificial intelligence for Alzheimer’s disease. Scientific Reports 11: 1–26. [Google Scholar] [CrossRef]
- EBA (European Banking Authority). 2021. Discussion Paper on Artificial Intelligencefor IRB Models. English. Available online: https://www.eba.europa.eu/sites/default/documents/files/document_library/Publications/Discussions/2022/Discussion%20on%20machine%20learning%20for%20IRB%20models/1023883/Discussion%20paper%20on%20machine%20learning%20for%20IRB%20models.pdf (accessed on 6 November 2022).
- European Commission. 2021a. Proposal for a Regulation of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (Artificial Intelligence Act) and Amending Certain Union Legislative Acts. English. Available online: https://eur-lex.europa.eu/resource.htAI?uri=cellar:e0649735-a372-11eb-9585-01aa75ed71a1.0001.02/DOC_1&format=PDF (accessed on 9 May 2022).
- European Commission. 2021b. White Paper On Artificial Intelligence—A European Approach to Excellence and Trust. English. Available online: https://ec.europa.eu/info/sites/default/files/commission-white-paper-artificialintelligence-feb2020_en.pdf (accessed on 11 May 2022).
- European Union, Parliament and Council. 2016. Official Journal of the European Union. L 119/41. Brussels: European Union, vol. 59. [Google Scholar]
- Freund, Yoav, and Robert E. Schapire. 1995. A desicion-theoretic generalization of on-line learning and an application to boosting. In Computational Learning Theory. Berlin/Heidelberg: Springer, pp. 23–37. ISBN 978-3-540-49195-8. [Google Scholar]
- Freund, Yoav, and Robert E. Schapire. 1999. A Short Introduction to Boosting. Journal of Japanese Society for Artificial Intelligence 14: 771–80. [Google Scholar]
- Gramegna, Alex, and Paolo Giudici. 2021. SHAP and LIME: An Evaluation of Discriminative Power in Credit Risk. Frontiers in Artificial Intelligence 4: 140. Available online: https://www.frontiersin.org/article/10.3389/frai.2021.752558 (accessed on 6 November 2022). [CrossRef] [PubMed]
- Hess, Aaron S., and John R. Hess. 2019. Logistic regression. Transfusion 59: 2197–98. [Google Scholar] [CrossRef] [PubMed]
- Hintze, Jerry L., and Ray D. Nelson. 1998. Violin Plots: A Box Plot-Density Trace Synergism. The American Statistician 52: 181–84. [Google Scholar] [CrossRef]
- Jolliffe, I. T. 1986. Principal Component Analysis and Factor Analysis. In Principal Component Analysis. New York: Springer, chap. 5. pp. 115–28. ISBN 978-14757-1904-8. [Google Scholar] [CrossRef]
- Ke, Guolin, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. 2017. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems. New York: Curran Associates, Inc., vol. 30. [Google Scholar]
- Lever, Jake, Martin Krzywinski, and Naomi Altman. 2016. Logistic regression. Nature Methods 13: 541–42. [Google Scholar] [CrossRef]
- Lundberg, Scott M., Gabriel G. Erion, and Su-In Lee. 2019. Consistent Individualized Feature Attribution for Tree Ensembles. arXiv arXiv:1802.03888. [Google Scholar]
- Lundberg, Scott, and Su-In Lee. 2017. A unified approach to interpreting model predictions. arXiv arXiv:1705.07874. [Google Scholar]
- Lundberg, Scott. 2018. How to Get SHAP Values of the Model Averaged by Folds? Available online: https://github.com/slundberg/shap/issues/337#issuecomment-441710372 (accessed on 27 November 2021).
- Misheva, Branka Hadji, Joerg Osterrieder, Ali Hirsa, Onkar Kulkarni, and Stephen Fung Lin. 2021. Explainable AI in Credit Risk Management. arXiv arXiv:2103.00949. [Google Scholar]
- Molnar, Christoph. 2019. Interpretable Machine Learning. A Guide for Making Black Box Models Explainable. SHAP (Shapley Additive Explanations): chap. 9.6. Available online: https://christophm.github.io/interpretableAI-book/shap.htAI (accessed on 6 November 2022).
- Moscato, Vincenzo, Antonio Picariello, and Giancarlo Sperlí. 2021. A benchmark of machine learning approaches for credit score prediction. Expert Systems with Applications 165: 113986. [Google Scholar] [CrossRef]
- Niedzwiedz, Piotr. 2022. Neptune Optuna Hyperparamet Optimization. Available online: https://docs.neptune.ai/integrations-and-supported-tools/hyperparameteroptimization/optuna (accessed on 6 November 2022).
- Nixon, Jeremy, Michael W. Dusenberry, Linchuan Zhang, Ghassen Jerfel, and Dustin Tran. 2019. Measuring Calibration in Deep Learning. Available online: https://arxiv.org/abs/1904.01685 (accessed on 6 November 2022). [CrossRef]
- Peng, Junfeng, Kaiqiang Zou, Mi Zhou, Yi Teng, Xiongyong Zhu, Feifei Zhang, and Jun Xu. 2021. An Explainable Artificial Intelligence Framework for the Deterioration Risk Prediction of Hepatitis Patients. Journal of Medical Systems 45: 61. [Google Scholar] [CrossRef]
- Quinto, Butch. 2020. Next-Generation Artificial intelligencewith Spark: Covers XGBoost, LightGBM, Spark NLP, Distributed Deep Learning with Keras, and More, 1st ed. New York: Apress. ISBN 9781484256695. [Google Scholar]
- Ribeiro, Marco Túlio, Sameer Singh, and Carlos Guestrin. 2016. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. arXiv arXiv:1602.04938. [Google Scholar]
- Shapley, Lloyd S. 1953. Stochastic Games. Proceedings of the National Academy of Sciences 39: 1095–100. Available online: https://www.pnas.org/content/39/10/1095.full.pdf (accessed on 6 November 2022). [CrossRef]
- Shrikumar, Avanti, Peyton Greenside, and Anshul Kundaje. 2019. Learning Important Features through Propagating Activation Differences. arXiv arXiv:1704.02685. [Google Scholar]
- Strumbelj, Erik, and Igor Kononenko. 2013. Explaining prediction models and individual predictions with feature contributions. Knowledge and Information Systems 41: 647–65. [Google Scholar] [CrossRef]
- Yang, Yimin, and Min Wu. 2021. Explainable Artificial intelligencefor Improving Logistic Regression Models. Paper presented at the 2021 IEEE 19th International Conference on Industrial Informatics (INDIN), Palma, Spain, July 21–23; pp. 1–6. [Google Scholar] [CrossRef]
- Yoo, Tae Keun, Ik Hee Ryu, Hannuy Choi, Jin Kuk Kim, In Sik Lee, Jung Sub Kim, Geunyoung Lee, and Tyler Hyungtaek Rim. 2020. Explainable Artificial intelligenceApproach as a Tool to Understand Factors Used to Select the Refractive Surgery Technique on the Expert Level. Translational Vision Science Technology 9: 8. [Google Scholar] [CrossRef] [PubMed]
- Young, H. Peyton. 1985. Monotonic solutions of cooperative games. International Journal of Game Theory 14: 65–72. [Google Scholar] [CrossRef]
- Zhang, Huan, Si Si, and Cho-Jui Hsieh. 2017. GPU-Acceleration for Large-Scale Tree Boosting. arXiv arXiv:1706.08359. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Mean | Std. Dev | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|
| Customer Length in Months | 64.4 | 59.1 | 0.0 | 17.0 | 41.0 | 108.0 | 247.0 |
| Number of Mortgages | 0.3 | 0.5 | 0.0 | 0.0 | 0.0 | 1.0 | 5.0 |
| Average Salary (L3M) | 14,905.9 | 21,945.6 | 0.0 | 0.0 | 0.0 | 0.0 | 505,969.7 |
| Limit Blanco Unsecured (2MA) | 42,913.6 | 30,217.4 | 0.0 | 20,000.0 | 40,000.0 | 60,000.0 | 150,000.0 |
| Average Used Credit (L3M) | −0.4 | 0.4 | −1.1 | −0.8 | −0.4 | 0.0 | 0.0 |
| Savings Balance | 35,722.6 | 155,915.8 | −1965.0 | 190.7 | 4087.1 | 24,913.7 | 6,253,344.9 |
| Savings Balance (1MA) | 30,458.1 | 96,637.5 | −255.4 | 161.9 | 3769.1 | 23,371.0 | 3,025,371.2 |
| Number of Logins | 68.8 | 93.1 | 0.0 | 14.0 | 39.0 | 89.0 | 1419.0 |
| Number of First Reminders Unsecured | 0.3 | 1.1 | 0.0 | 0.0 | 0.0 | 0.0 | 15.0 |
| Balance Consumer Loan | −97,884.9 | 94,672.0 | −500,000.0 | −134,114.8 | −69,094.0 | −27,986.5 | −0.4 |
| Balance in Percentage | 0.0 | 0.3 | 0.0 | 0.5 | 0.8 | 0.9 | 1.1 |
| Percentage Change in Balance (1MA) | 0.0 | 2.8 | −1.0 | −0.1 | 0.0 | 0.0 | 211.8 |
| Percentage Change in Balance (3MA) | −0.1 | 2.6 | −1.0 | −0.2 | −0.1 | 0.0 | 201.8 |
| Balance Longest Positive Interval (L3M) | 57.3 | 38.0 | 0.0 | 13.0 | 89.0 | 89.0 | 89.0 |
| Balance Standard Deviation (L3M) | 15,078.5 | 34,701.4 | 0.0 | 1462.4 | 7503.6 | 15,099.0 | 1,047,771.4 |
| Balance Minimum Level (L3M) | 1201.2 | 63,817.5 | −102,880.9 | −19,393.5 | 0.0 | 1000.5 | 1,192,793.8 |
| Balance Mean (L3M) | 20,442.1 | 80,739.1 | −100,326.1 | −4901.6 | 1291.1 | 19,573.4 | 1,277,713.6 |
| Balance Differentiated Max Change (L3M) | 26,426.8 | 103,991.6 | 0.0 | 137.7 | 3099.6 | 14,141.6 | 3,364,772.6 |
| (A) Before Pivot Transformation | ||||
| Date | Id | Features | ||
| 30.9 | A | x0A | ||
| 31.8 | A | xA1 | ||
| 31.7 | A | xA2 | ||
| 30.6 | A | xA3 | ||
| 31.5 | B | x0B | ||
| 31.3 | B | xB2 | ||
| 28.2 | B | xB3 | ||
| 31.7 | C | xC0 | ||
| (B) After pivot transformation | ||||
| Date | Id | Current | Lag 1 | Lag 2 |
| 30.9 | A | x0A | xA1 | xA3 |
| 31.5 | B | x0B | NaN | xB3 |
| 31.7 | C | xC0 | NaN | NaN |
| LightGBM | Logistic Regression | ||||
|---|---|---|---|---|---|
| Actual | Positive | Negative | Positive | Negative | |
| Predicted | |||||
| Threshold = 10% | Positive | 467 | 1170 | 464 | 3255 |
| Negative | 25 | 3926 | 28 | 1841 | |
| Threshold = 15% | Positive | 455 | 927 | 438 | 2524 |
| Negative | 37 | 4169 | 54 | 2572 | |
| Metric | LightGBM | LightGBM (LR) | Logistic Regression | |
|---|---|---|---|---|
| Threshold = 10% | F1-score | 43.90% | 26.00% | 22.00% |
| Recall | 94.90% | 97.00% | 94.30% | |
| Precision | 28.50% | 15.00% | 12.50% | |
| Accuracy | 78.60% | 51.40% | 41.20% | |
| Threshold = 15% | F1-score | 48.60% | 29.10% | 25.30% |
| Recall | 92.50% | 95.10% | 89.00% | |
| Precision | 32.90% | 17.20% | 14.80% | |
| Accuracy | 82.80% | 59.10% | 53.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Lange, P.E.; Melsom, B.; Vennerød, C.B.; Westgaard, S. Explainable AI for Credit Assessment in Banks. J. Risk Financial Manag. 2022, 15, 556. https://doi.org/10.3390/jrfm15120556
de Lange PE, Melsom B, Vennerød CB, Westgaard S. Explainable AI for Credit Assessment in Banks. Journal of Risk and Financial Management. 2022; 15(12):556. https://doi.org/10.3390/jrfm15120556
Chicago/Turabian Stylede Lange, Petter Eilif, Borger Melsom, Christian Bakke Vennerød, and Sjur Westgaard. 2022. "Explainable AI for Credit Assessment in Banks" Journal of Risk and Financial Management 15, no. 12: 556. https://doi.org/10.3390/jrfm15120556
APA Stylede Lange, P. E., Melsom, B., Vennerød, C. B., & Westgaard, S. (2022). Explainable AI for Credit Assessment in Banks. Journal of Risk and Financial Management, 15(12), 556. https://doi.org/10.3390/jrfm15120556