1. Introduction
Classification is an important research topic with applications in a wide range of subjects, including finance, engineering, economics, and medicine (
Kotsiantis et al. 2007). In a classification problem, we observe a collection of observations with
p features
and their associate class label
y. The main goal is to construct a classifier, which is a mapping from the space of
to the label space of
y. The most studied problem is the so-called binary classification setup, where we usually have
. For credit cards, it is important to use the features of customers and merchants to predict whether each swipe is fraudulent or not (
Jurgovsky et al. 2018). One important application of classification in engineering is to perform traffic classification (
Dainotti et al. 2012), which could be very beneficial to improve traffic. For example, predicting an economic crisis is critical to maximize the overall welfare (
Feng et al. 2021b). When the number of features is large, we usually call the classification problem a high-dimensional one.
Fan et al. (
2012),
Mai et al. (
2012), and
Fan et al. (
2016) studied high-dimensional classification and showed the application of tumor type classification using high-dimensional gene expression data sets.
Gao et al. (
2017) further studies the post selection shrinkage method to improve the classical penalized estimator for high-dimensional classification problem. Some other related work include (
Szczygieł et al. 2014;
Michalski et al. 2018;
Tong et al. 2018; and
Dvorsky et al. 2021).
There are many well-known classifiers that have been proposed during the recent decades. First, we have the classic linear discriminant analysis (LDA), where we first divide the observations into classes where each class corresponds to a specific value of
y (e.g.,
and
), then we assume that the features in each of the two classes follow Gaussian distribution with the same covariance matrix and usually different means. This particular Gaussian assumption leads to a linear decision boundary for LDA. Quadratic discriminant analysis (QDA) relaxes the equal covariance matrix assumption, which makes the decision boundary nonlinear. Due to this, QDA is also capable of capturing interaction effects (
Tian and Feng 2021a). Another popular classification method is the so-called logistic regression, which is a special case of generalized linear models. Different from LDA and QDA, logistic regression directly models the conditional distribution of
y, given the features
, and it is usually viewed as a more robust classifier than LDA. Support vector machine (SVM) is another type of classifier which seeks the optimal separating hyperplane, and is shown to outperform many classic ones when there are many features (
Steinwart and Christmann 2008).
Breiman et al. (
2017) developed classification and regression trees (CART), which is a pure non-parametric classification method, and is applicable to various distributions for the features. Another popular non-parametric classification method is the K nearest neighbor (KNN) proposed in
Fix and Hodges (
1989). KNN works by a majority vote from the labels of
K training observations that are nearest to the new observation to be classified.
Although the classifiers described in the previous paragraph have been shown to work well in many applications, researchers have realized that a single application of these classifiers could result in unstable classification performance (
Dietterich 2000). To address this issue, there has been a surge of research interest in ensemble learning methods. Ensemble learning is a general machine learning framework, which combines multiple learning algorithms to obtain better prediction performance and increase the stability of any single algorithm (
Dietterich 2000;
Rokach 2010). Some popular examples include bagging (
Breiman 1996) and random forests (
Breiman 2001), which aggregates a collection of weak learners formed by decision trees. More recent ensemble learning methods include the random subspace method (
Ho 1998), super learner (
Van der Laan et al. 2007), model averaging (
Feng and Liu 2020;
Feng et al. 2021a;
Raftery et al. 1997), random rotation (
Blaser and Fryzlewicz 2016), random projection (
Cannings and Samworth 2017;
Durrant and Kabán 2015), and random subspace ensemble classification
Tian and Feng (
2021a,
2021b).
This paper is largely motivated by the random subspace ensemble (RaSE) classification framework (
Tian and Feng 2021b), which we will briefly review. Suppose we want to predict the class label
y from the feature vector
using
n training observations
. For a given base classifier (e.g., logistic regression), the RaSE algorithm aims to construct
weak learner, where each classifier is formed by applying the specified base classifier on a properly chosen subspace, which is a subset of the whole feature space represented as
. Taking logistic regression as an example, if the subspace contains the variables
, then we will fit a logistic regression model, but only using the 1st, 3rd, and 9th variables.. To choose each subspace,
random subspaces are generated according to a hierarchical uniform distribution and the optimal one is selected according to certain criteria (e.g., cross-validation error). The main idea is that among all the
candidate subspaces, the one that has the best criteria value tends to have the optimal quality, which will improve the performance of the final ensemble classifier. In the end, the predicted labels from the
weak learners are averaged and compared to a data-driven threshold, forming the final classifier.
Tian and Feng (
2021b) also proposed an iterative version of RaSE which updates the random subspace distribution according to the selected proportions of each feature.
Powerful though the RaSE algorithm and its iterative versions are, one major limitation is that one needs to specify a single base classifier
prior to using the RaSE framework. The success of the RaSE algorithms largely depends on whether the base classifier is suitable for the application scenario. As shown in the numerical experiments in
Tian and Feng (
2021b), the RaSE algorithm could fail to work well if the base classifier is not properly set. In this regard, blindly applying the RaSE algorithm has the risk of wrongly setting the base classifier, leading to poor performance.
The aim of this research is to address the limitation of RaSE, where only a single base classifier can be used. In particular, we aim to replace the single base classifier with a collection of base classifiers, and also develop a new framework that can adaptively choose the appropriate base classifier for a given data set. We call the new ensemble classification framework the super random subspace ensemble (Super RaSE).
The working mechanism of Super RaSE is that in addition to randomly generating the subspaces, it also generates the base classifiers to be used together with the subspaces. More specifically, instead of fixing a base classifier and using it for all subspaces, each time, the Super RaSE randomly generates the base classifier (from a collection of base classifiers) and the subspace as a pair, and then picks the best performing pair among the ones via five-fold cross validation to form one of the weak learners. Then, the predictions of the weak learners are averaged and compared to a data-driven threshold, forming the final prediction of Super RaSE.
The main contribution of the paper is three-fold. First, the Super RaSE algorithm adaptively chooses the base classifier and subspace pair, which makes it a fully model-free approach. Second, in addition to the accurate prediction performance, the Super RaSE computes the selected proportion for each base classifier among the weak learners, implying the appropriateness of each base classifier under the specific scenario, and for each of the base classifiers, the selected proportion of each feature, measuring the importance of each feature. Third, we propose an iterative Super RaSE algorithm, which updates the sampling distribution of base classifiers as well as the sampling distribution of the subspaces for each base classifier.
The rest of the paper is organized as follows. In
Section 2, we introduce the super random subspace ensemble (SRaSE) classification algorithm as well as its iteration version.
Section 3 conducts extensive simulation studies to show the superior performance of SRaSE and its iterative version by comparing them with competing methods, including the original RaSE algorithm. In
Section 4, we evaluate the SRaSE algorithms with two real data sets and show that they perform competitively. Lastly, we conclude the paper with a short discussion in
Section 5.
2. Methods
Suppose that we have
n pairs of observations
, where
p is the number of predictors and
is the class label. We use
to represent the whole feature set. We assume that the marginal densities of
for class 0 (
) and 1 (
) exist and are denoted as
and
, respectively. Thus, the joint distribution of
can be described in the following mixture model
where
y is a Bernoulli variable with success probability
. For any subspace
S, we use
to denote its cardinality. When restricting to the feature subspace
S, the corresponding marginal densities of class 0 and 1 are denoted as
and
, respectively.
Here, we are concerned with a high-dimension classification problem, where the dimensional
p is comparable or even larger than the sample size
n. In high-dimensional problems, we usually believe there are only a handful of features that contribute to the response, which is usually referred to as the
sparse classification problem. For sparse classification problems, it is of significance to accurately separate signals from noises. Following
Tian and Feng (
2021b), we introduce the definition of a discriminant set.
A feature subset S is called a discriminative set if y is conditionally independent with given , where . We call S a minimal discriminative set if it has minimal cardinality among all discriminative sets, and we denote it as .
2.1. Super Random Subspace Ensemble Classification (SRaSE)
Here, to train each weak learner (e.g., the
j-th one),
independent random subspaces are generated as
from subspace distribution
, and
base classifiers
are sampled with replacement from base classifier distribution
on the candidate base classifier set
. By default, we will be using a uniform distribution for
. However, users can use other distributions in the algorithm if they have some prior belief on which classifiers may work better. Then, for
, we train the classifier
, using only the features in
. We then choose the optimal subspace
and base classifier
pair using 5-fold cross validation. We denote the base classifier
applied on subspace
as
, where the subscript
n is used to emphasize the classifier depending on the sample with
n observations. Finally, we aggregate outputs of
to form the final decision function by taking a simple average. The whole procedure can be summarized in Algorithm 1.
| Algorithm 1: Super random subspace ensemble classification (SRaSE) |
- Input:
training data , new data , subspace distribution , integers and , the candidate base classifier set , base classifier distribution - Output:
predicted label , the selected proportion of each base classifier , and for the base classifier where , the selected proportion of each feature
![Jrfm 14 00612 i001]() |
Following
Tian and Feng (
2021b), by default, the subspace distribution
is chosen as a
hierarchical uniform distribution over the subspaces. In particular, with
D as the upper bound of the subspace size, we first generate the subspace size
d from the discrete uniform distribution over
. Then, the subspaces
are independent and follow the uniform distribution over the set
. In addition, in Step 7 of Algorithm 1, we choose the decision threshold to minimize the empirical classification error on the training set,
where
In Algorithm 1, there are two important by-products. The first one is the selected proportion of each method out of the weak learners. The higher the proportion for a method (e.g., KNN), the more appropriate it may be for particular data. In numerical studies and real data analyses, we provide more interpretations of the results.
Now, let us introduce the second by-product of Algorithm 1. For each method , we have the selected proportion of each feature . The feature selection proportion depends on the particular base method. The underlying reason is that when we use different base methods on the same data, different signals may be found. For example, if some predictors contribute to the response only through an interaction effect with other predictors, they may be detected using the quadratic discriminant analysis (QDA) method; however, they cannot be identified using the linear discriminant analysis (LDA) method since the LDA only considers the linear effects of features. These base-classifier-dependent feature selection frequencies will produce a better understanding of the working mechanism of each base classifier as well as the nature of the importance for each feature.
2.2. Iterative Super RaSE
Motivated by the fact that some base classifiers may be more appropriate under the given scenario, it could be a good idea to leverage the information we learned during the Super RaSE algorithm. In particular, the selected proportion of each method could be used to adjust the sampling distribution of the methods. In the new iterative algorithm, we will update the base classifier distribution by setting the probability mass function as the selected proportion of each method from the last iteration. This updating scheme will make the better-performing classifiers have a higher chance of being sampled in the next iteration, which could potentially increase the quality of the classifiers. On the other hand, if a certain base classifier was rarely selected in the classifiers, perhaps we want to down-weigh it in the next iteration.
In addition, regarding the feature selection proportion for each base method, we adopt a similar updating strategy as that in the original RaSE (
Tian and Feng 2021b). However, in Super RaSE, we are updating the random subspace distribution separately for each base method. For base classifier
i, the initial subspace distribution is denoted by
, where the subscript
i represents the
i-th base classifier and superscript
represents the 0-th iteration. In the
t-th iteration, we use
to represent the distribution of the subspace distribution for base classifier
i.
The updating scheme for the subspace distribution is as follows. For method i, we again first generate the subspace size d from the uniform distribution over as before. It is easy to observe that each subspace S can be equivalently represented as a binary p-dimensional vector representing whether each feature is included in S. To be more specific, the equivalent vector representation subspace S is , where . Then, we generate from a restrictive multinomial distribution with parameter , where , , and the restriction is that , where is a constant. Note that here, the parameter characterizes the subspace distribution.
We named the iterative algorithm
Iterative Super RaSE, the details of which are summarized in Algorithm 2.
| Algorithm 2: Iterative Super RaSE (SRaSE) |
- Input:
training data , new data , integers and , the candidate base classifier set , initial base classifier distribution , initial subspace distribution for each base classifier , the number of iterations T - Output:
predicted label , the selected proportion of each base classifier , and for the base classifier where , the selected proportion of each feature
![Jrfm 14 00612 i002]() |
In the iterative Super RaSE algorithm, the base classifier distribution is initially set to be , which is a uniform distribution over all base classifiers by default. As the iteration proceeds, the base classifiers that are more frequently selected will have a higher chance of being selected in the next step, resulting in a different . The adaptive nature of the iterative Super RaSE algorithm enables us to discover the best performing base methods for each data set and in turn, reduce its classification error.
Besides the base classifier distribution, the subspace distribution is also continuously updated during the iteration process. In our implementation of the algorithm, the initial subspace distribution for each base classifier
is the hierarchical uniform distribution as introduced in
Section 2.1. After running the Super RaSE algorithm once, the features that are more frequently selected are given higher weights in
. In this mechanism, we give an edge to the useful features, which could further boost the performance. In addition, for each given base classifier, the selected frequencies of each feature can be viewed as an importance measure of the features.
2.3. Parameter Specification
In the Super RaSE algorithm and its iterative version, we discussed the base classifier distribution and the subspace distribution for each base classifier in
Section 2.1 and
Section 2.2. There are a few additional parameters that need to be specified. We now discuss the details with the default values in the algorithms.
is the number of weak classifiers we want to construct during the algorithm and average over at the end. It is set to be 200 by default. Usually, the larger the , the more robust the algorithm is.
is the number of base classifier and subspace pairs among which we choose the optimal one. It is set to be 500 by default. To make sure each base classifier and the subspace combination has a fair chance of being evaluated, has to be reasonably large.
D is the maximum subspace size in the subspace distribution. Following
Tian and Feng (
2021b), we set
for the QDA base classifier and
for all the other base classifiers, where
denotes the largest integer not larger than
a.
is the candidate base classifier set. In theory, it could contain any classifier and the Super RaSE algorithm will automatically select the better-performing ones in the final weak learners. On the other hand, the more base classifiers we put inside , each base classifier has a smaller chance of being sampled in the pairs of base classifier and subspace, leading to an increased risk of missing the optimal combination. In our implementation, we set the candidate base classifier set LDA, QDA, KNN}.
T is the number of iterations in the iterative Super RaSE. From our limited numerical experience, the first two rounds of iterations lead to the most performance improvement. As a result, we use for simulation and for real data analysis.
3. Simulation Studies
In this section, we conduct extensive simulation studies on the proposed Super RaSE algorithm (Algorithm 1) and its iterative version (Algorithm 2) with candidate base classifiers set as
. In addition, we compare their performance with several competing methods, including the original RaSE with LDA, QDA, and KNN as the base classifier (
Tian and Feng 2021b), as well as LDA, QDA, KNN, and random forest (RF). We use the default values for all parameters in the Super RaSE algorithm and its iterative version (
,
).
For all experiments, we conduct 200 replicates, and report the summary of test errors (in percentage) in terms of mean and the standard deviation. We use boldface to highlight the method with minimal test error for each setting, and use italics to highlight the methods that achieve test errors within one standard deviation of the smallest error.
3.1. Model 1: LDA
The first model we consider is a sparse LDA model with settings in
Mai et al. (
2012) and
Tian and Feng (
2021b). In particular, assume
, where
. The dimension
, and we vary the training sample size
. We also independently generate a test data of size 1000.
It is easy to verify that the feature subset
is the minimal discriminative set
. In
Table 1, the performance of various methods for Model 1 under different sample sizes are presented.
As we can see, RaSE1-KNN performs the best when the sample size , and RaSE-QDA performs the best for and 1000. It is worth noting that the results for LDA and QDA are NA, due to the small sample size compared with the dimension. By inspecting the performance of the proposed Super RaSE algorithm and its iterative version, we can see that although they are not the best performing method, both SRaSE and SRaSE are within one standard error of the best performing method, showing the robustness of Super RaSE. Clearly, one iteration helps Super RaSE to have a lower test classification error.
In addition to the test classification error, it is useful to investigate the two by-products of our algorithms, namely the selected proportion of each base classifier among the classifiers, and the selected proportion of each feature among the weak learners that use a particular classifier.
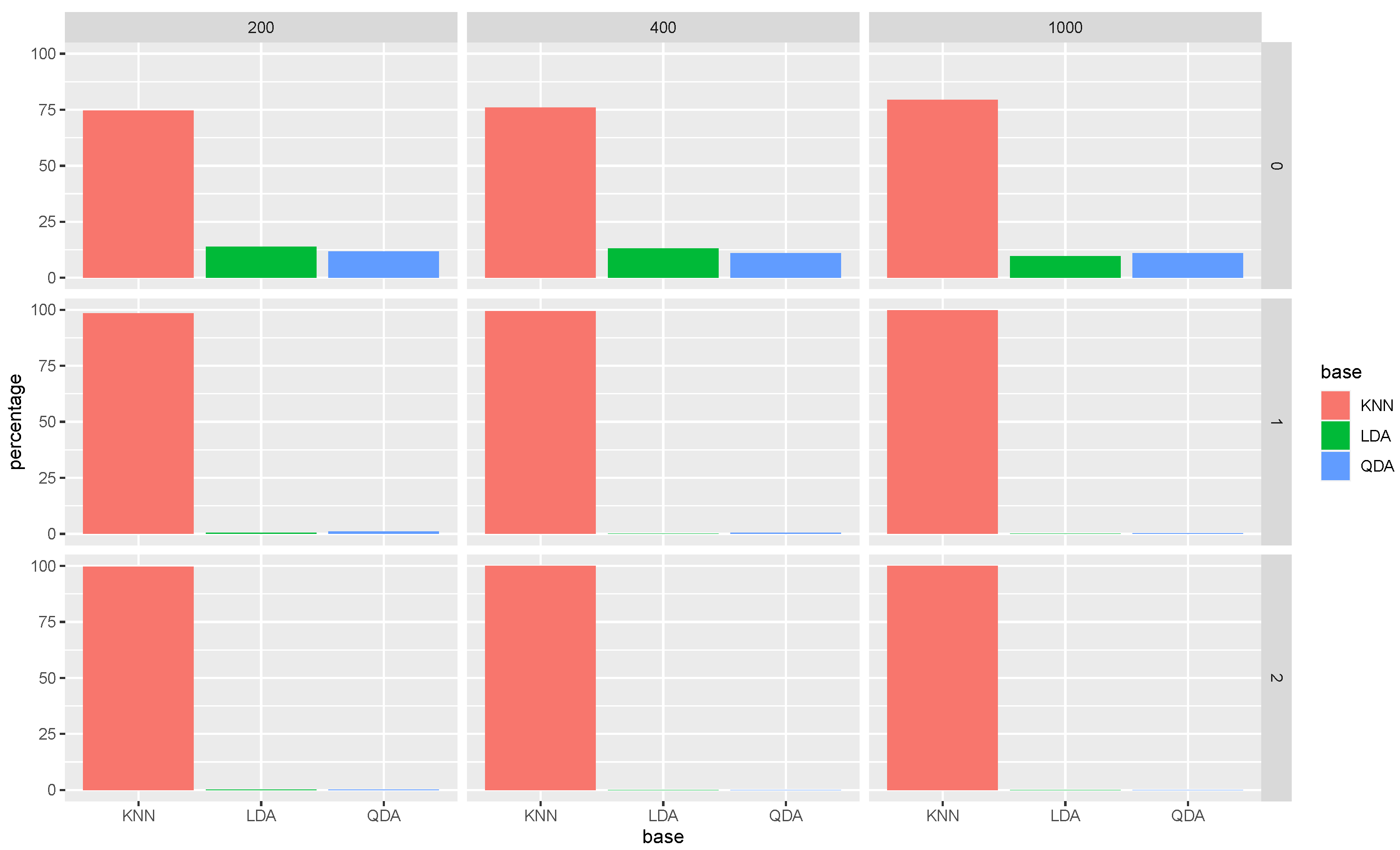
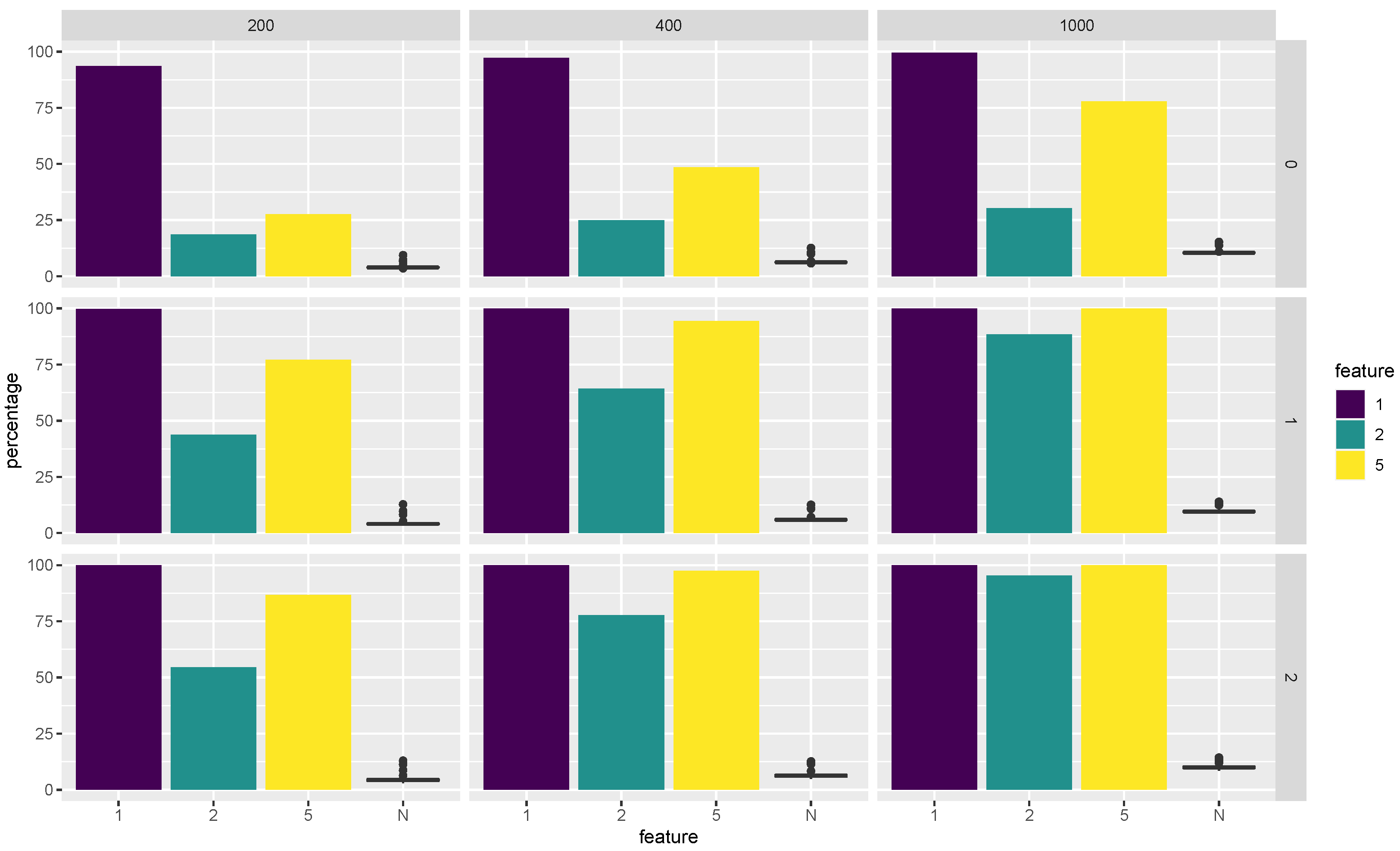
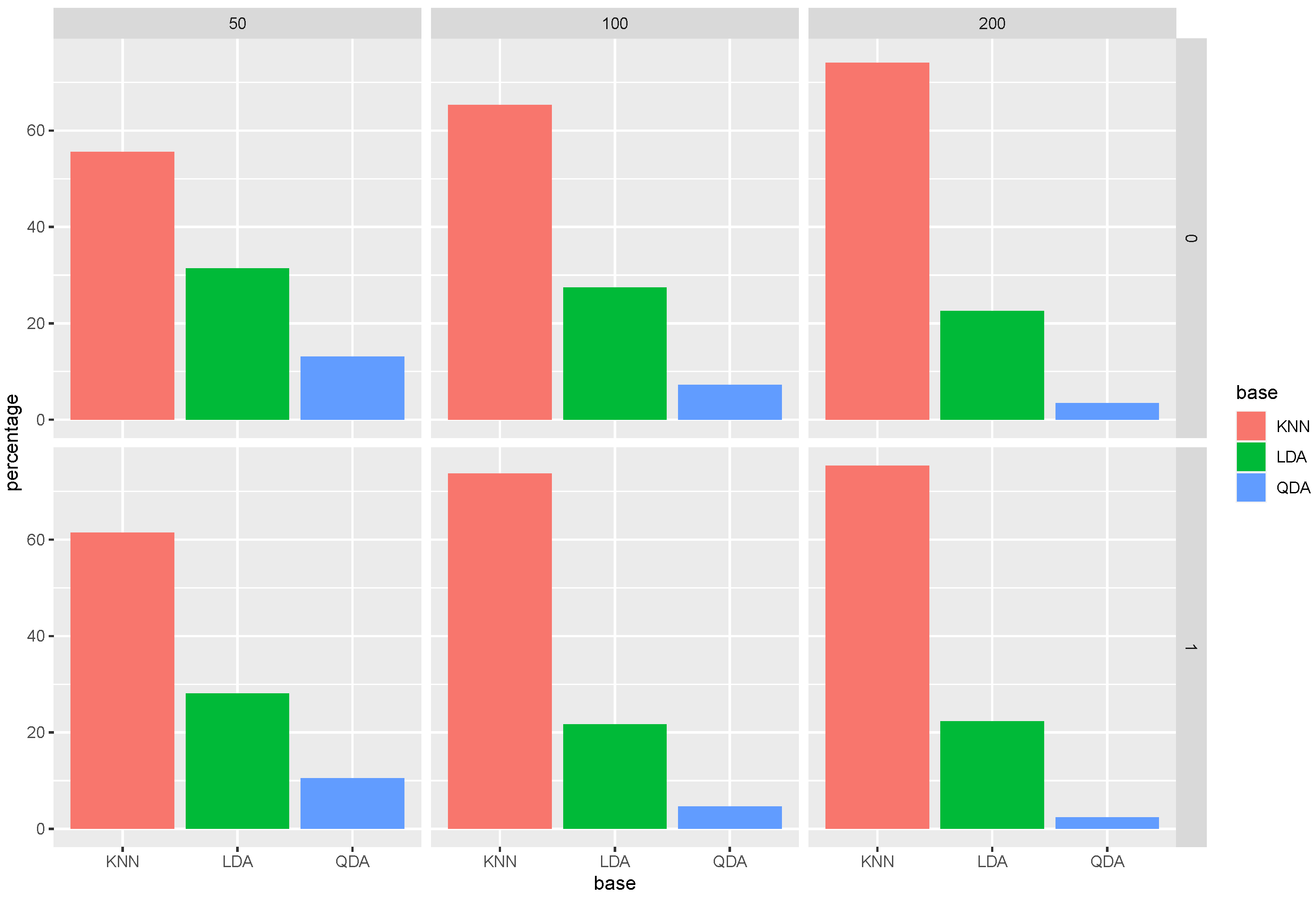
Let us take a look at
Figure 1. The first row shows the bar charts for the selection percentage of each base classifier in the Super RaSE algorithm among the 200 repetitions when the sample size
n varies in
. It shows that when
, the percentage of LDA is around 50%. As the sample size increases, the percentage of LDA also increases, showing that having a larger sample size helps us to select the model from which the data are generated.
Now, let us look at the column of ; we can see that as the iteration process moves on, the percentage of LDA is increasing as well, leading to almost 100% for SRaSE.
The second product of the Super RaSE algorithm and its iterative version is the selected frequencies for each feature among the weaker learner with a particular classifier.
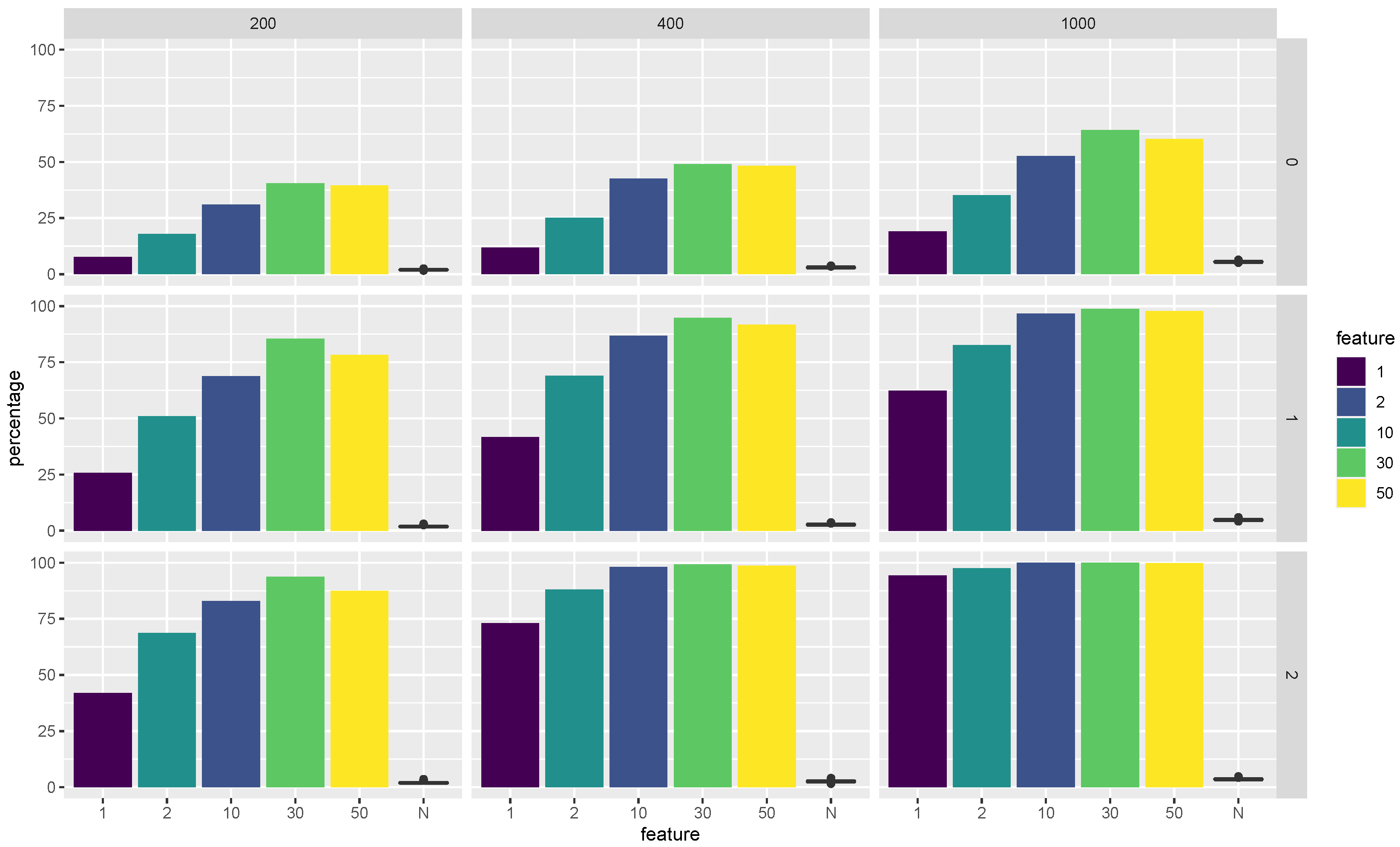
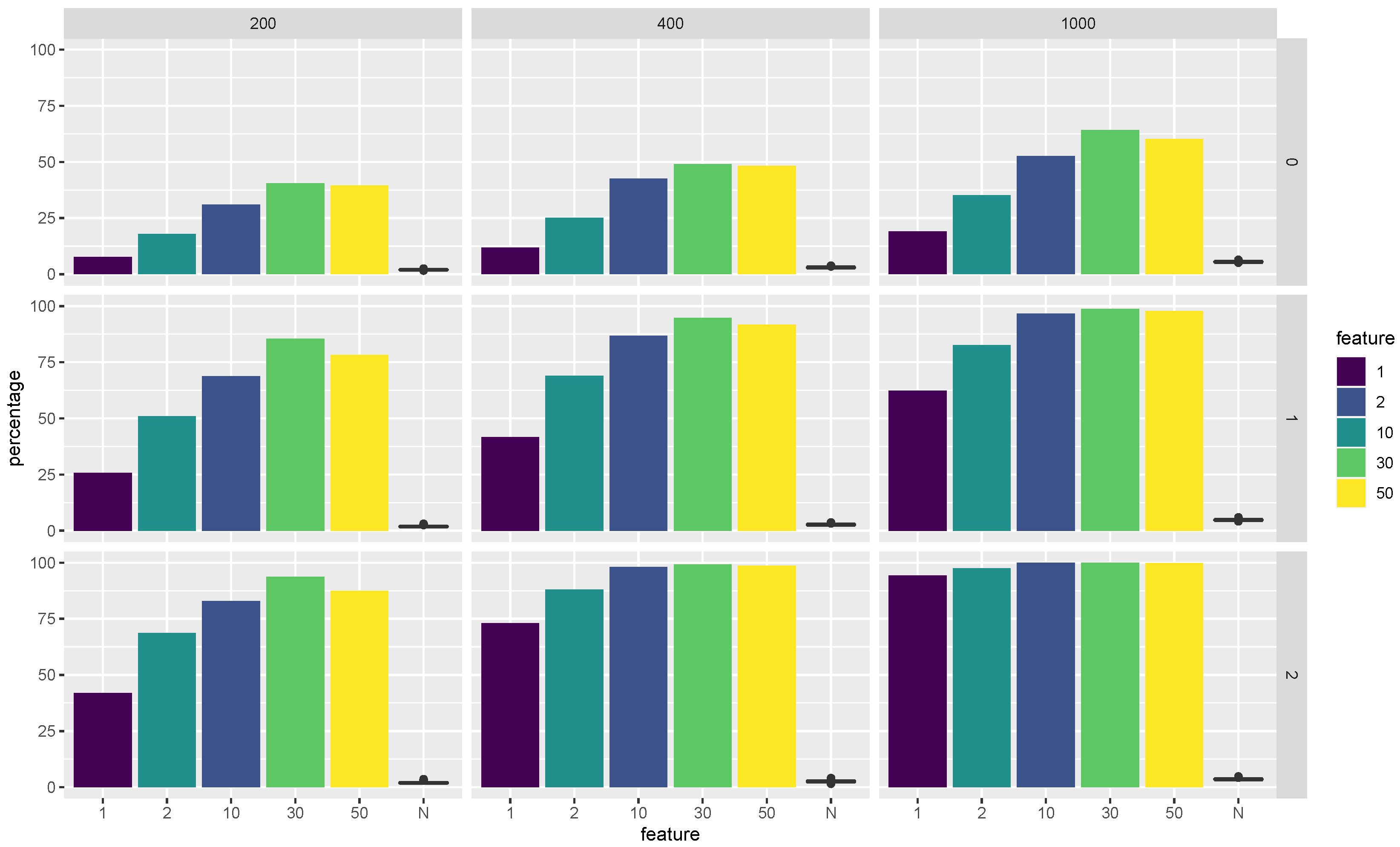
Figure 2 visualizes the selected proportions of features among all the
classifiers that use LDA as the base classifier. In particular, we show the selected proportions for each feature in the minimum discriminative set
. In the same figure, we also show a boxplot of the selected proportion of all the noisy features as a way to verify whether the Super RaSE algorithms can distinguish the important features from the noisy features.
From
Figure 2, we observe that when
, the vanilla Super RaSE algorithm does not select the important variables 2 and 5 with a high percentage. However, the iteration greatly helps the algorithm to increase the selected percentages for features 2 and 5. In addition, the increase in sample size leads to the selection of all important features with almost 100% percentage. It is also worth noting that the noise features all have a relatively small selection frequency, showing the power of feature ranking in the Super RaSE algorithms. Similar figures can also be generated for the selected proportions of features among the
classifiers that use QDA and KNN as the base classifier, respectively. For simplicity, we omit these figures in our presentation.
3.2. Model 2: QDA
, where is a banded matrix with and for and all other entries zero. The inverse covariance matrix for class 1 is , where is a sparse symmetric matrix with and all other entries zero. The dimension is and we again vary the sample size .
We can easily verify that the feature subset
is the minimal discriminative set
. In
Table 2, we present the performance of different methods for Model 2 under different sample sizes.
From the table, when and , SRaSE is the best performing method, achieving the smallest test classification error. When , SRaSE is within one standard error away from the optimal method. This result is very encouraging in the sense that Super RaSE could improve the performance of the original RaSE coupled with the true model from which the data are generated. This shows that the Super RaSE algorithms are extremely robust and avoid the need to choose a base classifier as needed in the original RaSE algorithm.
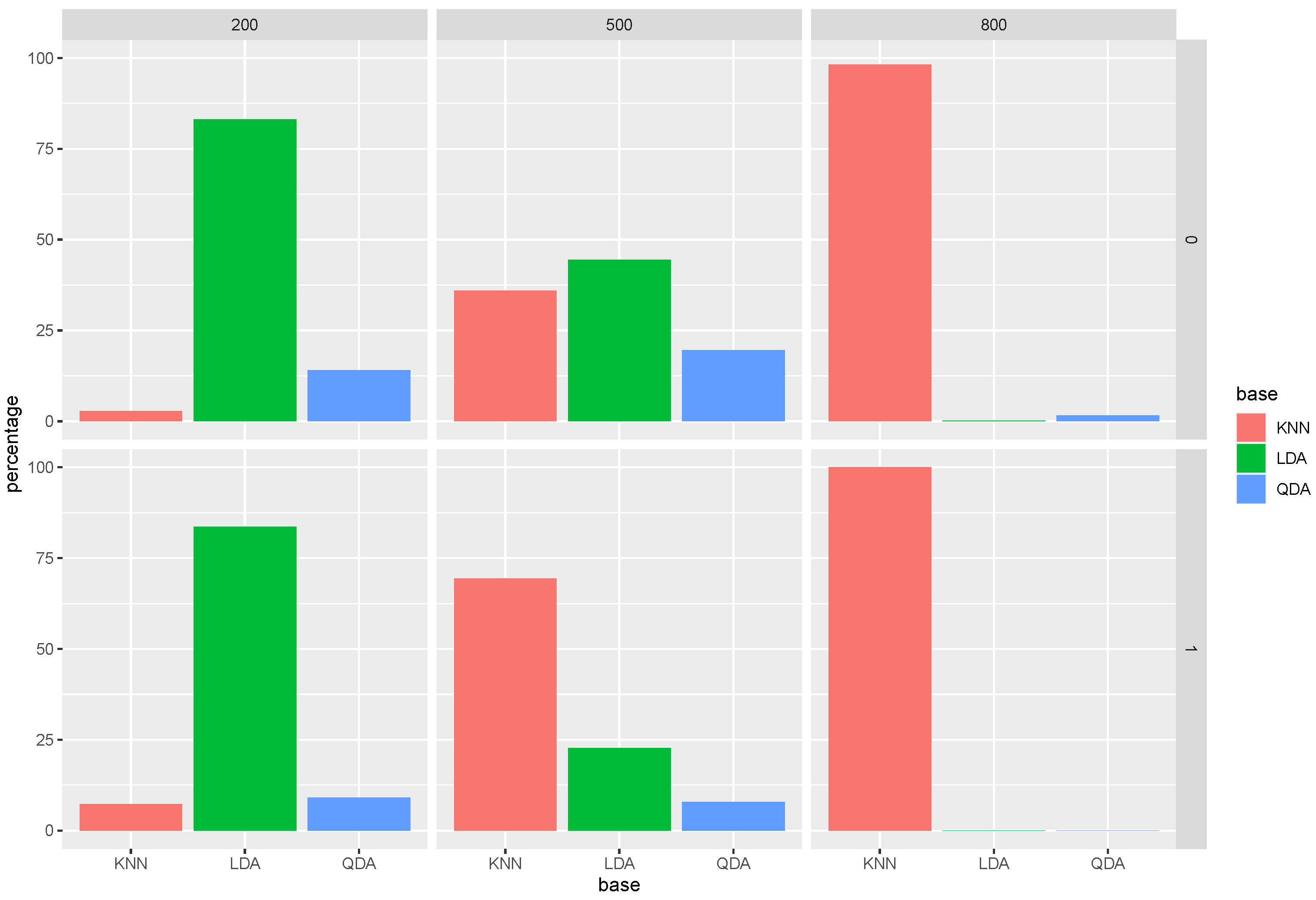
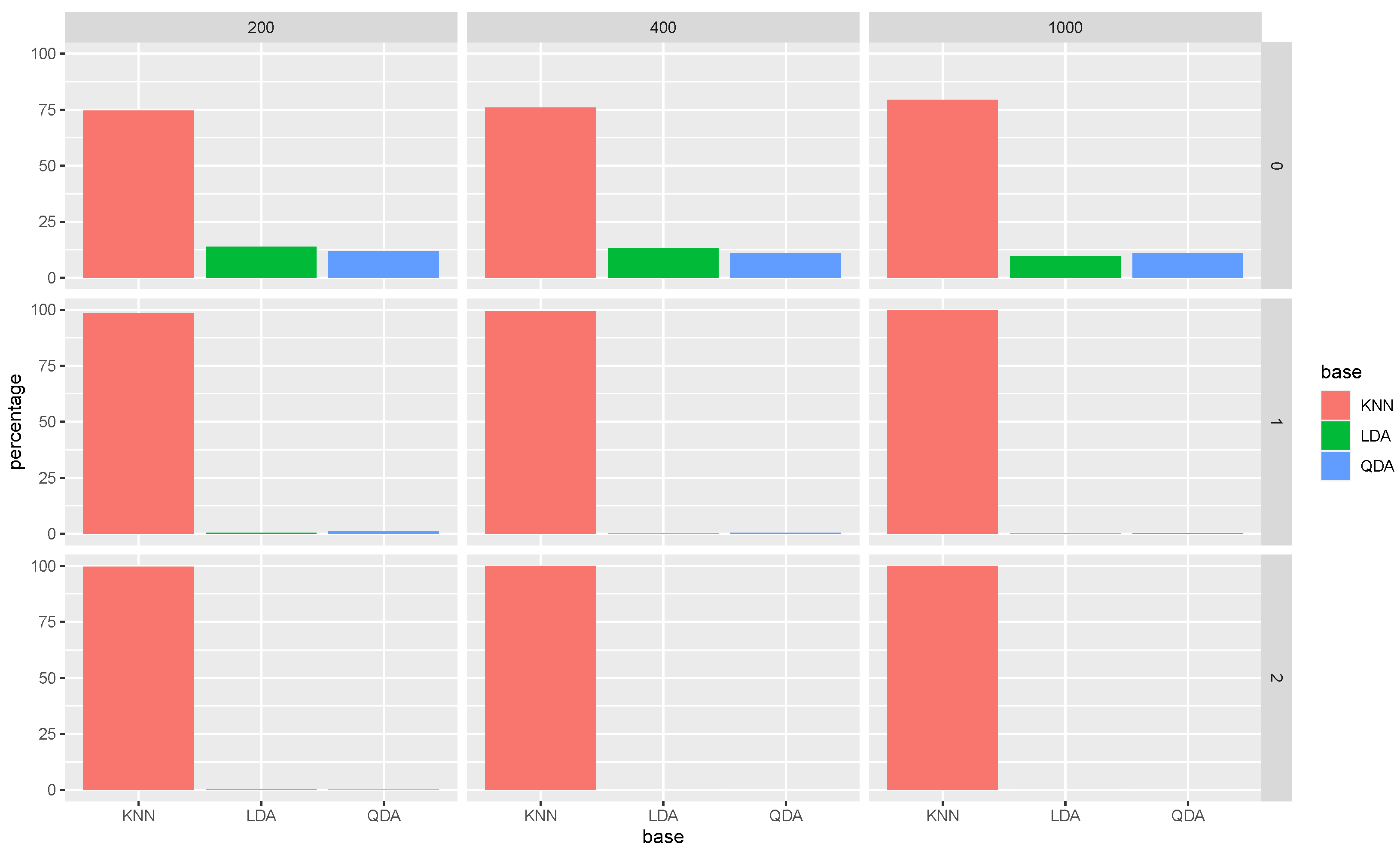
As in Model 1, we again present the average selected proportion of each base classifier in
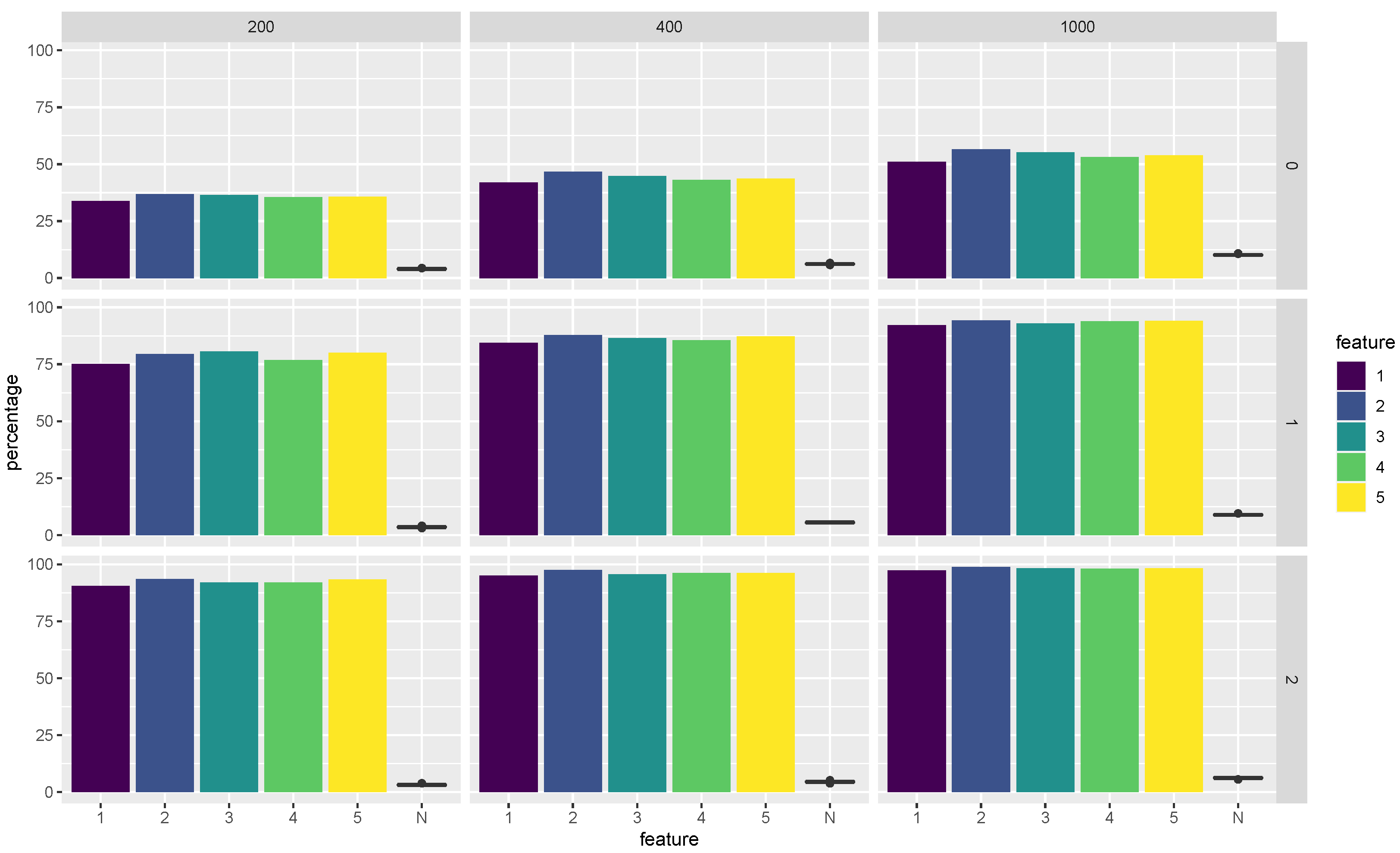
Figure 3 as well as the average selected proportion of each feature among the
weak learners with the chosen base classifier being QDA in
Figure 4. In
Figure 4, we also show a boxplot of the selected proportion of all the noisy features.
In
Figure 3, we again observe that as we iterate the Super RaSE algorithm, the proportion of QDA greatly increases, reaching almost 100 percent for RaSE
over all sample sizes. This shows that the iterative Super RaSE algorithm is able to identify the true model.
In
Figure 4, we can observe that the average selected proportions of each important feature are pretty high, showing that the Super RaSE is able to pick up the important features. In particular, when
, the iteration helps all the features to have a higher selected proportion, reaching nearly 100 percent for SRaSE
.
3.3. Model 3: KNN
Having considered two parametric models, let us move to an example where the label is generated in a non-parametric way (
Tian and Feng 2021b). We will be following the idea of nearest neighbors when assigning the labels.
The detailed data generation process is as follows. First, 10 initial points are generated i.i.d. from . Out of the 10 points, 5 are labeled as 0 and the other 5 are labeled as 1. Then, each observation pair is generated as follows. First, we randomly select one element from . Let us suppose it is , corresponding to the i-th observation. Then, the corresponding will take the label as , and the feature vector is generated as . The general idea is that we are generating a mixture of 10 Gaussian clusters that surround each of the when they are embedded in a p-dimensional space.
From the data generation process, the minimal discriminative set is
. We consider
, and
. The summary of the test classification error rates over 200 repetitions is presented in
Table 3.
From
Table 3, we can see that Super RaSE and its iterative versions still have very competitive performance compared with other methods. In particular, both SRaSE
and SRaSE
reach test errors that are within one standard deviation of the best performing method RaSE
-KNN, which uses the knowledge of the data generation process. As a method-free algorithm, Super RaSE algorithms and their iterative versions are very appealing, having similar performance as the best-performing ones without the need to specify which base classifier to use.
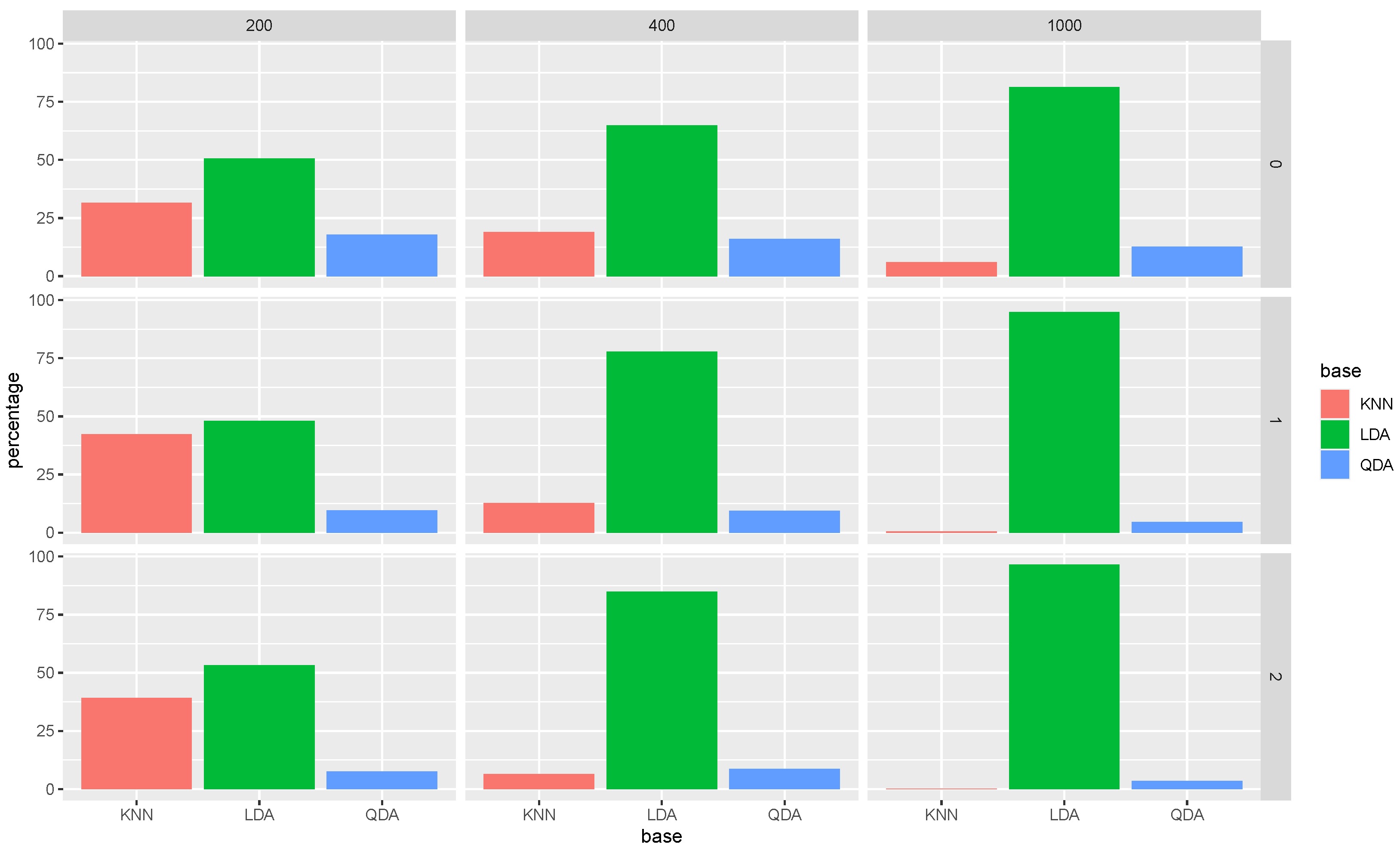
Similar to Models 1 and 2, we again present the average selected proportion of each base method in
Figure 5.
Figure 6 visualizes the selected proportions of features among all the
classifiers that use KNN as the base classifier. In addition to the bar chart for the average selected proportion of each important feature,
Figure 6 also includes a boxplot of the selected proportion of all the noisy features.
In
Figure 5, we have a similar story as
Figure 1 and
Figure 3. We can see that the average selection percentage of KNN is almost 100 percent for both SRaSE
and SRaSE
, showing that one step iteration is enough to almost always find the best classifier for this particular model.
In
Figure 6, we can see that without iteration, Super RaSE, on average, only selects the five important features with around 50 percent out of the 200 repetitions. With the help of iterations, the percentages of all five important features increase substantially, to almost 100 percent when
. This experiment shows the merit of iterative Super RaSE in terms of capturing the important features.
5. Discussion
In this work, motivated by the random subspace ensemble (RaSE) classification, we propose a new ensemble classification framework, named Super RaSE, which is a completely model-free approach. While RaSE has to be paired with a single base classifier, Super RaSE can work with a collection of base classifiers, making it more flexible and robust in applications. In particular, we recommend that the practitioners include several different base classifiers, including parametric and non-parametric ones, so as to make the Super RaSE framework more powerful. It is worth noting that as we include more base classifiers in the Super RaSE algorithm, perhaps larger values of
and
are needed so as to generate a sufficient number of random subspace and base classifier pairs among the
classifiers, and reach a more stable result with a larger
. By randomly generating the pair of base classifier and subspace, it will automatically select a collection of good base classifier and subspace pairs. Besides the superb prediction performance on the test data, the Super RaSE algorithms also provide two important by-products. The first one is a quality measure of each base classifier, which can provide insight as to which base classifiers are more appropriate for the given data. The second by-product is that, given each base classifier, the Super RaSE will also generate an important measure for each feature, which can be used for feature screening and ranking (
Fan et al. 2011;
Saldana and Feng 2018;
Yousuf and Feng 2021), just like the original RaSE (
Tian and Feng 2021a). The feature important measure can provide an interpretable machine learning model, which is very useful in understanding how the method works.
There are many possible future research directions. First, this paper only considers the binary classification problem, but there may be more than two classes in applications. How to extend the Super RaSE algorithm to the multiclass situation is an important topic. In particular, we need to find multiclass classification algorithms as well as a new decision function when we ensemble the
weak learners. In particular, the original thresholding step in line 9 of Algorithm 1 is no longer applicable. Second, in addition to the classification problem, it is also worthwhile to study the corresponding algorithm under a regression setting. To achieve this, we can change the prediction step from thresholding to a simple averaging. Third, using the selected proportion of features, it is possible to develop a variable selection or variable screening algorithm. For example, we can set a threshold for variable screening which is expected to capture important interaction effects in addition to the marginal ones. The interaction detection problem has been well studied in high-dimensional quadratic regression (
Hao et al. 2018). However, the Super RaSE will greatly expand the scope within which the interaction selection works, allowing for the interaction among features to be of different formats. Lastly, in both RaSE and Super RaSE, we use all the observations in each combination of the base classifier and a random subspace. We know that random forest is viewed as a very robust classifier, partly due to the fact that it uses a bagging sample (
Breiman 1996) for each tree during the ensemble process. This particular bagging step makes the trees uncorrected, which reduces the variable of the final classifier. A natural extension of Super RaSE is Bagging Super RaSE, which uses a bagging sample for each of the
groups. It is worth noting that it may not be a good idea to use a different bagging sample for each of the
pairs of a base classifier and an associated random subspace, due to the fact that it could lead to an unfair comparison among the
pairs.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}