2.1. Stochastic Volatility
There have been numerous empirical studies of changes in volatility in various stock, currency, and commodities markets. The findings in volatility research have implications for option pricing, volatility estimation, and the degree to which volatility shocks persist. These research questions have been approached by means of different models and methodologies.
Taylor (
1982) suggested a novel SV approach, and
Taylor (
1994) developed the SV model as follows: if
denotes the prices of an asset at time
and assuming no dividend payments, the returns on the asset can be defined, in the context of discrete time periods, as:
Volatility is customarily indicated by
, and prices are described by a stochastic differential equation:
with
W a standard Weiner process. If
and
are constants,
has a normal distribution, and:
with
independent and identically distributed
Equation (
3) can be generalised by replacing
with a positive random variable
, to give:
where
In circumstances where the returns process
can be presented by Equation (
4),
Taylor (
1994) calls
the stochastic volatility for period
t. His definition assumes that
follows a normal distribution.
The stochastic process
generates realised volatilities
which, in general, are not observable. For any realisation,
:
The mixture of these conditional normal distributions defines the unconditional distribution of , which will have excess kurtosis whenever has positive variance and is independent of .
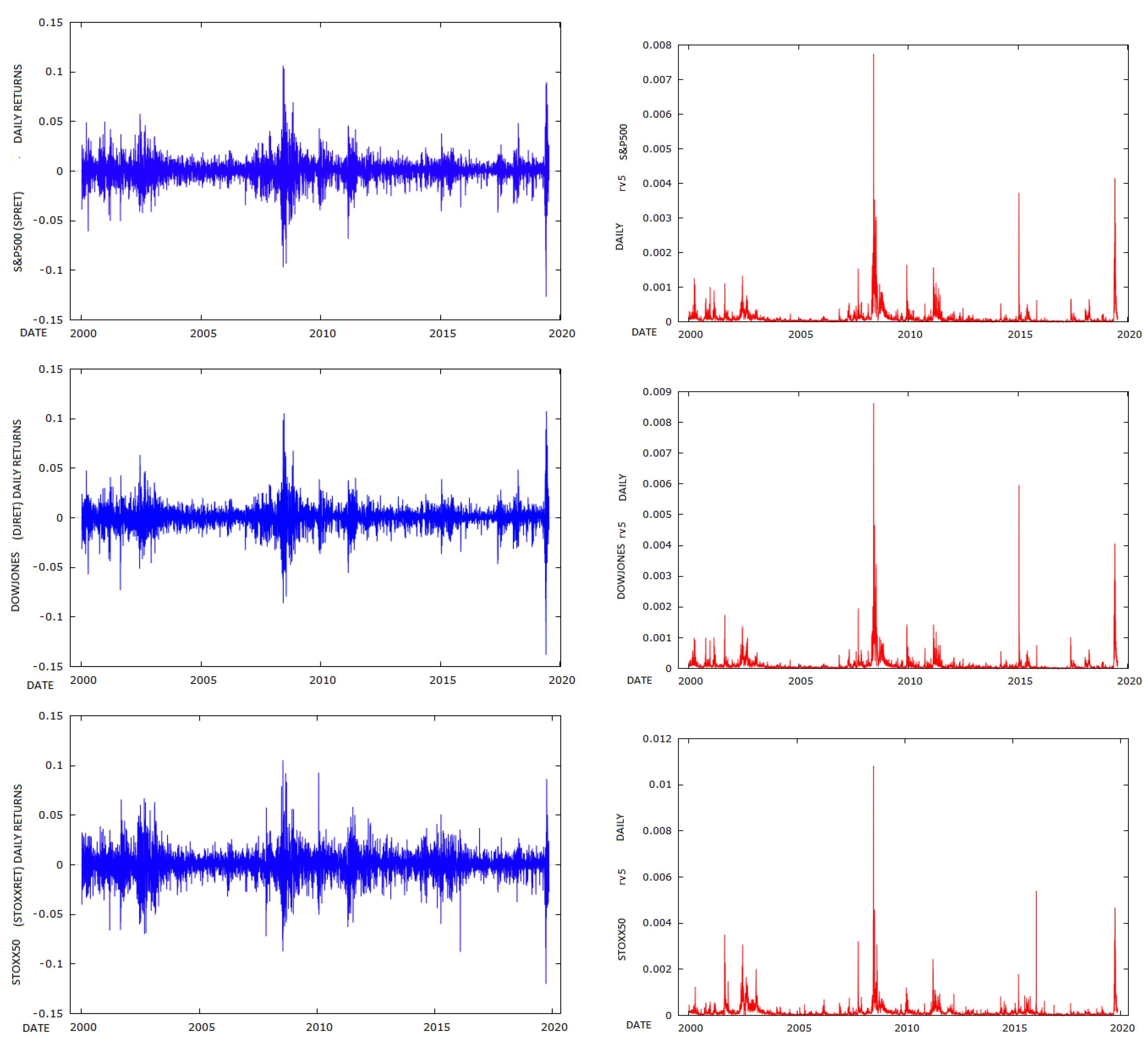
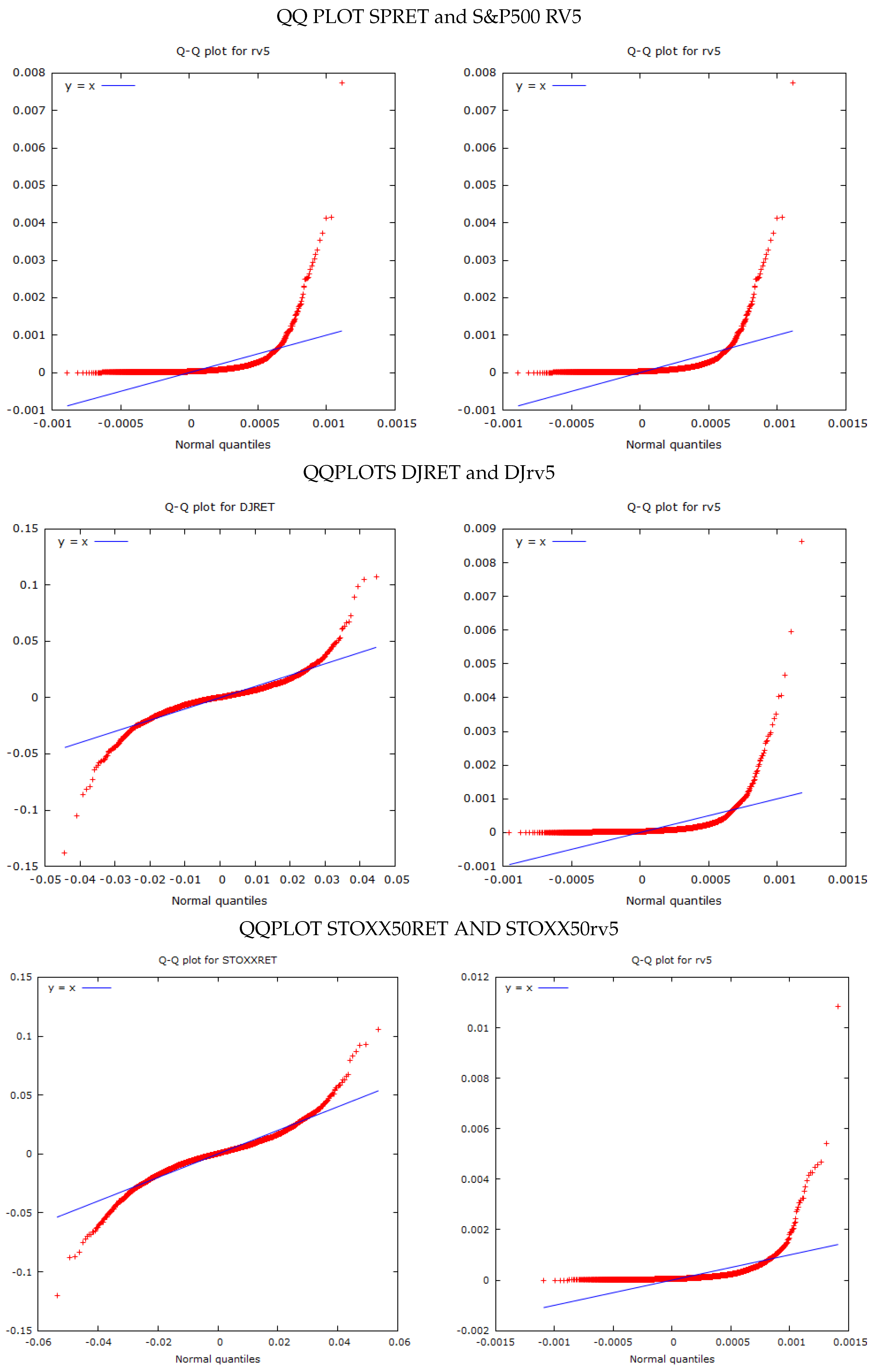
In the empirical section which follows, I use the RV of the S&P500, DOW JONES and STOXX50 indices, sampled at 5-minute intervals provided by Oxford Man, as a proxy for the true realised volatility. I then compare the estimates of volatility obtained from SV and GARCH(1,1) models, using the RV estimates as a benchmark.
Taylor (
1994, p. 3) suggests using “capital letters to represent random variables and lower case letters to represent outcomes”. I shall follow that convention. Given observed returns of
the conditional variance for period
t is:
Taylor (
1994) notes that, in general, the random variable
, which generates the observed conditional variance
is not, in general, equal to
. A convenient way to use economic theory to motivate changes in volatility is to assume that returns are generated by a number of intra-period price revisions, as in the manner of
Clark (
1973) and
Tauchen and Pitts (
1983).
It is assumed that there are
price revisions during trading day
t, each caused by unpredictable information. Let event
i on day
t change the logarithmic price by
, with:
If we assume that
and is independent of the random variable
, with
, then:
The above model suggests that squared volatility is proportional to the amount of price information.
The lack of standard software to estimate such a model is addressed by
Kastner and Frühwirth-Schnatter (
2014) who propose an efficient MCMC estimation scheme which is implemented in the R stochvol package,
Kastner (
2016).
Kastner (
2016, p. 2) proceeds by “letting
be a vector of returns, with mean zero. An intrinsic feature of the SV model is that each observation
is assumed to have its ’own’ contemporaneous variance,
, which relaxes the usual assumption of homoscedasticity”. It is assumed that the logarithm of this variance follows an autoregressive process of order one. This assumption is fundamentally different to GARCH models, where the time-varying conditional volatility is assumed to follow a deterministic instead of a stochastic evolution.
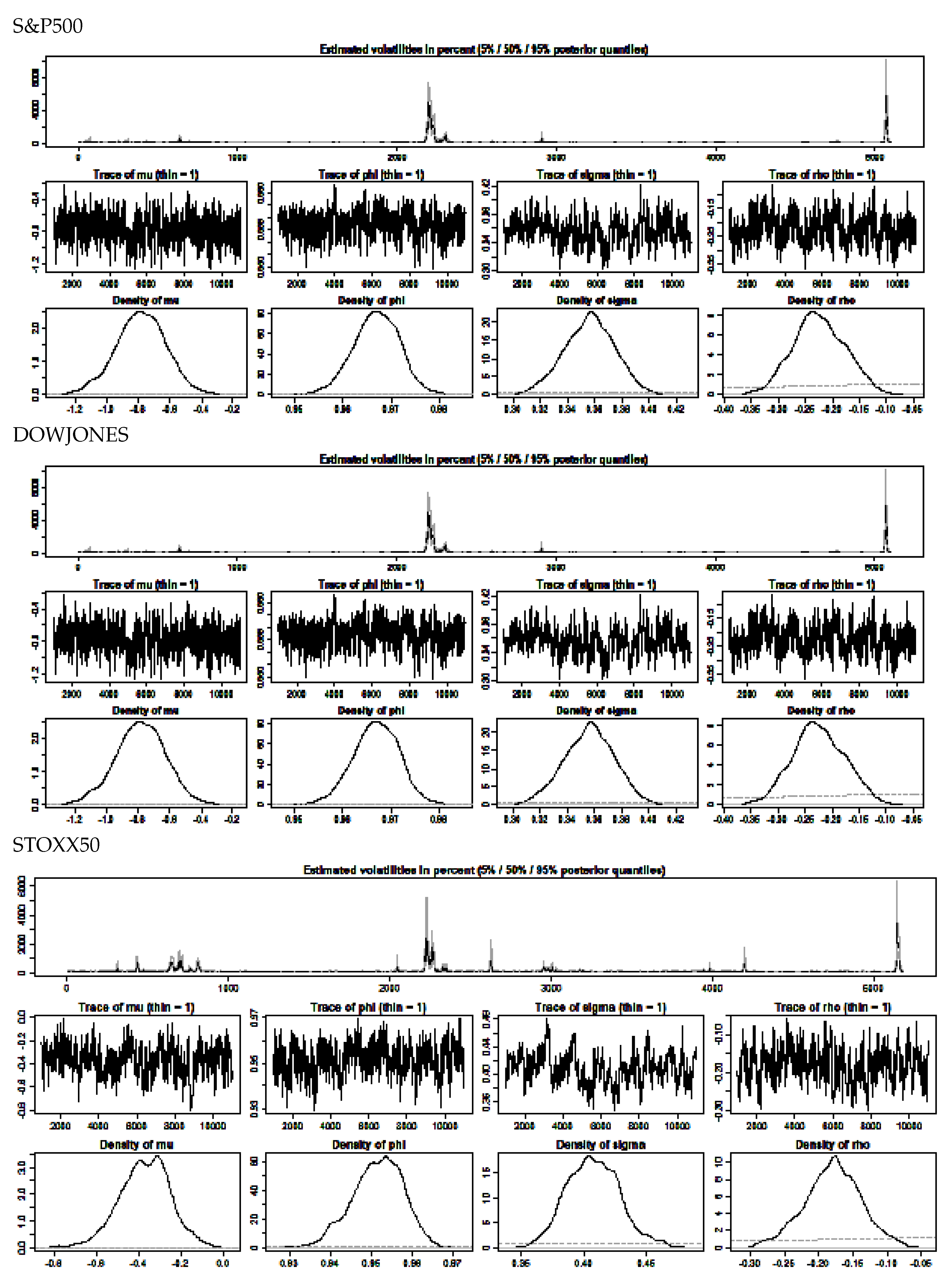
The centered parameterization of the SV model can be given as:
where
denotes the normal distribution with mean
and variance
.
is the vector of parameters which consists of the level of the log variance
, the persistence of log variance,
, and the volatility of log variance,
The process
which features in equations (10) and (11) is the unobserved or latent time-varying volatility process.
Kastner (
2016, p. 4) remarks that: “A novel and crucial feature of the algorithm implemented in stochvol is the usage of a variant of the “ancillarity-sufficiency interweaving strategy” (ASIS) which was suggested in the general context of state-space models by
Yu and Meng (
2011). ASIS exploits the fact that, for certain parameter constellations, sampling efficiency improves substantially when considering a non-centered version of a state-space model”.
Another key feature of the algorithm used in stochvol is the joint sampling of all instantaneous volatilities “all without a loop” (AWOL), a technique with links to
Rue (
2001) and as discussed in
McCausland et al. (
2011). The combination of these features enables the R package stochvol to estimate SV models efficiently even when large datasets are involved.
Kastner et al. (
2017) suggest that the multivariate factor stochastic volatility (SV) model (
Chib et al. 2006) provides a means of uniting simplicity with flexibility and robustness. It is simple in the sense that the potentially high-dimensional observation space is reduced to a lower-dimensional orthogonal latent factor space. It is flexible in the sense that these factors are allowed to exhibit volatility clustering, and it is robust in the sense that idiosyncratic deviations are themselves stochastic volatility processes, thereby allowing for the degree of volatility co-movement to be time-varying.
Hosszejni and Kastner (
2019) set up a factor SV model employed in the factorstochvol package in R, and the analysis also uses code from this package.
2.2. ARCH and GARCH
Engle (
1982) developed the Autoregressive Conditional Heteroskedasticity (ARCH) model that incorporates all past error terms. It was generalised to GARCH by
Bollerslev (
1986) to include lagged term conditional volatility. GARCH predicts that the best indicator of future variance is a weighted average of long-run variance, the predicted variance for the current period, and any new information in this period, as captured by the squared residuals.
Consider a time series
where
is the conditional expectation of
at time
and
is the error term. The basic GARCH model has the following specification:
in which
and
(usually a positive fraction), to ensure a positive conditional variance,
(see
Tsay (
1987)). The ARCH effect is captured by the parameter
which represents the short-run persistence of shocks to returns,
captures the GARCH effect that contributes to long-run persistence, and
measures the persistence of the impact of shocks to returns to long-run persistence. A GARCH(1,1) process is weakly stationary if
. (See the discussion in
Allen et al. (
2013).
We contrast the estimates of volatility from the SV model with those from a GARCH(1,1) model, and assess which better explains the behaviour of the RV of FTSE sampled at 5-minute intervals.
2.4. Historical Volatility Model
Poon and Granger (
2005) discuss various practical issues involved in forecasting volatility. They suggest that the HISVOL model has the following form:
where
is the expected standard deviation at time
t,
is the weight parameter, and
is the historical standard deviation for periods indicated by the subscripts.
Poon and Granger (
2005) suggest that this group of models include the random walk, historical averages, autoregressive (fractionally integrated) moving average, and various forms of exponential smoothing that depend on the weight parameter
.
We use a simple form of this model in which the estimate of
is the previous day’s demeaned squared return.
Poon and Granger (
2005) review 66 previous studies, and suggest that implied standard deviations appear to perform best, followed by historical volatility and GARCH which have roughly equal performance. They also note that, at the time of writing, there were insufficient studies of SV models to come to any conclusions about this class of models. This observation provides the motivation for the current study which assesses the performance of all three classes of models. It also provides the motivation to use a crude rule of thumb in the form of 20 lags of daily squared demeaned returns. The choice of 20 lags is conditioned by
Corsi’s (
2009) “Heterogeneous Autoregressive model of Realized Volatility” (HAR) model, as discussed in the next section. A feature of this model is that it includes estimates of daily, weekly, and monthly ex-post realised volatility. The crude HISVOL model adopted in the paper takes 20 lags as an approximation for this, as it roughly represents a month of trading days.
Barndorff-Nielsen and Shephard (
2003) point out that taking the sums of squares of increments of log-prices has a long tradition in the financial economics literature. See, for example,
Poterba and Summers (
1986),
Schwert (
1989),
Taylor and Xu (
1997),
Christensen and Prabhala (
1998),
Dacorogna et al. (
1998), and
Andersen et al. (
2001). (
Shephard and Sheppard (
2010), p 200, footnote 4) note that: “Of course, the most basic realised measure is the squared daily return”. We utilise this approach as the basis of our historical volatility model.
2.5. Heterogenous Autoregressive Model (HAR)
Corsi (
2009, p. 174) suggests “an additive cascade model of volatility components defined over different time periods. The volatility cascade leads to a simple AR-type model in the realized volatility with the feature of considering different volatility components realized over different time horizons and which he termed as a “Heterogeneous Autoregressive model of Realized Volatility”.
Corsi (
2009) suggests that the model successfully achieves the purpose of reproducing the main empirical features of financial returns (long memory, fat tails, and self-similarity) in a parsimonious way. He writes his model as:
where
is the daily integrated volatility, and
and
are respectively the daily, weekly, and monthly (ex post) observed realized volatilities, and
.
Corsi (
2009) inspires the HISVOL model adopted in the paper, which uses lags of historical RV estimates, but, in the current case, lags of squared demeaned daily close-to-close returns are employed.
A further justification for the approach adopted in the current study is provided by a recent publication by
Perron and Shi (
2020), who show that squared low-frequency daily returns can be expressed in terms of the temporal aggregation of a high-frequency series. They explore the links between the spectral density function of squared low-frequency and high-frequency returns. They analyze the properties of the spectral density function of realized volatility, constructed from squared returns with different frequencies under temporal aggregation. However, for the low frequency data on S&P 500 returns, they cannot infer whether the noise is stationary long memory but a long-memory process appears needed to explain the features related to high frequency S&P 500 futures. However, they caution that they cannot explain this difference and that it may also be related to the fact that they have used both spot and futures series for the S&P500 in the case of the high frequency data.
Perron and Shi (
2020, p. 14), suggest that: “that both the realized volatility and the squared daily returns contain the same information about long memory. However, the squared daily returns contain a larger noise component than does the realized volatility”. The current paper uses the long-memory component of low frequency squared daily demeaned returns to capture this long memory feature and to provide an approximation to a HAR model. The paper does not apply a full HAR model as the intention is to explore whether a simple HISVOL rule of thumb model, based on lagged squared demeaned returns, performs as well as standard GARCH or SV models. It is clear that a full HAR specification is likely to perform better, though
Perron and Shi (
2020) suggest that many of the HAR’s long memory features will be captured by the approach adopted in the paper.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}