1. Introduction
Despite the existence of various economic theories explaining the fluctuation of future exchange rates, as shown in
Meese and Rogoff (
1983a,
1983b), the random walk often produces better predictions for future exchange rates. More specifically, it has been shown that traditional economical models developed since the 1970s do not perform better than the random walk in predicting the out-of-sample exchange rate when using data obtained after the beginning of the floating rate system. Since the publication of these papers, many researchers have investigated this puzzle.
Cheung et al. (
2005) confirmed the work of
Meese and Rogoff (
1983a,
1983b), and demonstrated that the interest rate parity, monetary, productivity-based, and behavioral exchange rate models do not outperform the random walk for any time-period. Similarly,
Rossi (
2013) could not find a model with strong out-of-sample forecasting ability. On the contrary,
Mark (
1995) showed that the economic exchange-rate models perform better than the random walk in predicting long term exchange rates.
Amat et al. (
2018) also found that combining machine learning methodologies, traditional exchange-rate models, and Taylor-rule exchange rate models could be useful in forecasting future short-term exchange rates in the case of 12 major currencies.
Following on from these previous studies, this paper focuses on a combination of modern machine learning methodologies and economic models. The purpose of this paper is to determine whether such combinations outperform the prediction performance of random walk without drift. This model has been used as the comparison in most studies in this field since
Meese and Rogoff (
1983a,
1983b). The most profound study in this field is
Amat et al. (
2018). What distinguishes the present paper from previous studies is that instead of using an exponential weighted average strategy and sequential ridge regression with discount factors, this paper applies the random forest, support vector machine (SVM), and neural network models to four fundamental theories (uncovered interest rate parity, purchase power parity, the monetary model, and the Taylor rule models). Furthermore, the robustness of the results is thoroughly examined using six government bonds with different maturities (1, 2, 3, 5, 7, and 10 years) and four price indexes (the producer price index (PPI), the consumer price index (CPI) of all items, CPI excluding fresh food, and CPI excluding fresh food and energy) individually in three machine learning models. Together, these elements should provide concrete evidence for the results that were obtained.
In the empirical analysis, a rolling window analysis was used for a one-period-ahead forecast for the JPY/USD exchange rate. The sample data range from August 1980 until August 2019. The window size was set as 421. Hence, in total, the rolling window analysis was conducted 47 times for the individual fundamental models. The main findings of this study are as follows. First, when comparing the performance of the fundamental models combined with machine learning to that of the random walk, the root mean squared error (RMSE) results show that the fundamental models with machine learning outperform the random walk (the mean absolute percentage error (MAPE) also confirmed this result). In the Diebold–Mariano (DM) test, most of the results show significantly different predictive accuracies compared to the random walk, while some of the random forest results show the same accuracy as the random walk. Second, when comparing the performance of the fundamental models combined with machine learning, the models using the PPI show fairly good predictability in a consistent manner. This is indicated by both the RMSE and the DM test results. However, the CPI is not appropriate for predicting exchange rates, based on its poor results in the RMSE test and DM test. This result seems reasonable given that the CPI includes volatile price indicators such as food, beverages and energy.
The rest of the paper is organized as follows.
Section 2 explains the fundamental models,
Section 3 describes the data used in the empirical studies,
Section 4 describes the methodology of machine learning,
Section 5 shows the results and evaluation, and
Section 6 summarizes the main findings of the paper.
3. Data
The data used to describe macroeconomies were taken from the DataStream database. All data describe monthly frequency. This paper used government bonds with different maturities (1, 2, 3, 5, 7, and 10 years) for each country. The producer price index (PPI) and consumer price index (CPI) of all items, the CPI excluding fresh food, and the CPI excluding fresh food and energy were used to calculate the inflation rate. For the money stock, we used each country’s M1. To measure the output, we used the industrial production index, as GDP is only available quarterly. Following
Molodtsova and Papell (
2009), we used the Hodrick–Prescott filter to calculate the potential output to obtain the output gap. The exchange rates were taken from the BOJ Time-Series Data Search. The data is from the period ranging from August 1980 to August 2019. Data are described in
Table 1.
This paper used a rolling window analysis for the one-period-ahead forecast. A rolling window analysis runs an estimation iteratively, while shifting the fixed window size by one period in each analysis. The whole sample dataset ranges from the first period of August 1980 until August 2019. Here, the window size was set as 421. For example, the first window taken from August 1980 to August 2015 was used to estimate September 2015. Hence, the model uses the training data from period 1 to 421 to predict period 422 and then uses the training data from period 2 to 422 to predict period 423. This is repeated until the end of the time-series. In total, the rolling window analysis is run 47 times for one model.
There are two reasons why we used the end of month exchange rate rather than the monthly average exchange rate. First, the end of month exchange rate is often used in this field of study. Second, as mentioned in
Engel et al. (
2019), although replacing the monthly average exchange rate with the end of month exchange rate reduces the forecasting power of the Taylor rule fundamentals compared to that of the random walk (
Molodtsova and Papell 2009), it is highly possible that changes in the monthly average exchange rate are serially correlated. Thus, following
Engel et al. (
2019), this study also used the end of month exchange rate.
4. Methodologies
Here, we use the result from random walk as the benchmark test and compare its performance to three types of machine learning: random forest, support vector machine, and neural network. The results are examined using the RMSE and a DM test.
4.1. Random Forest
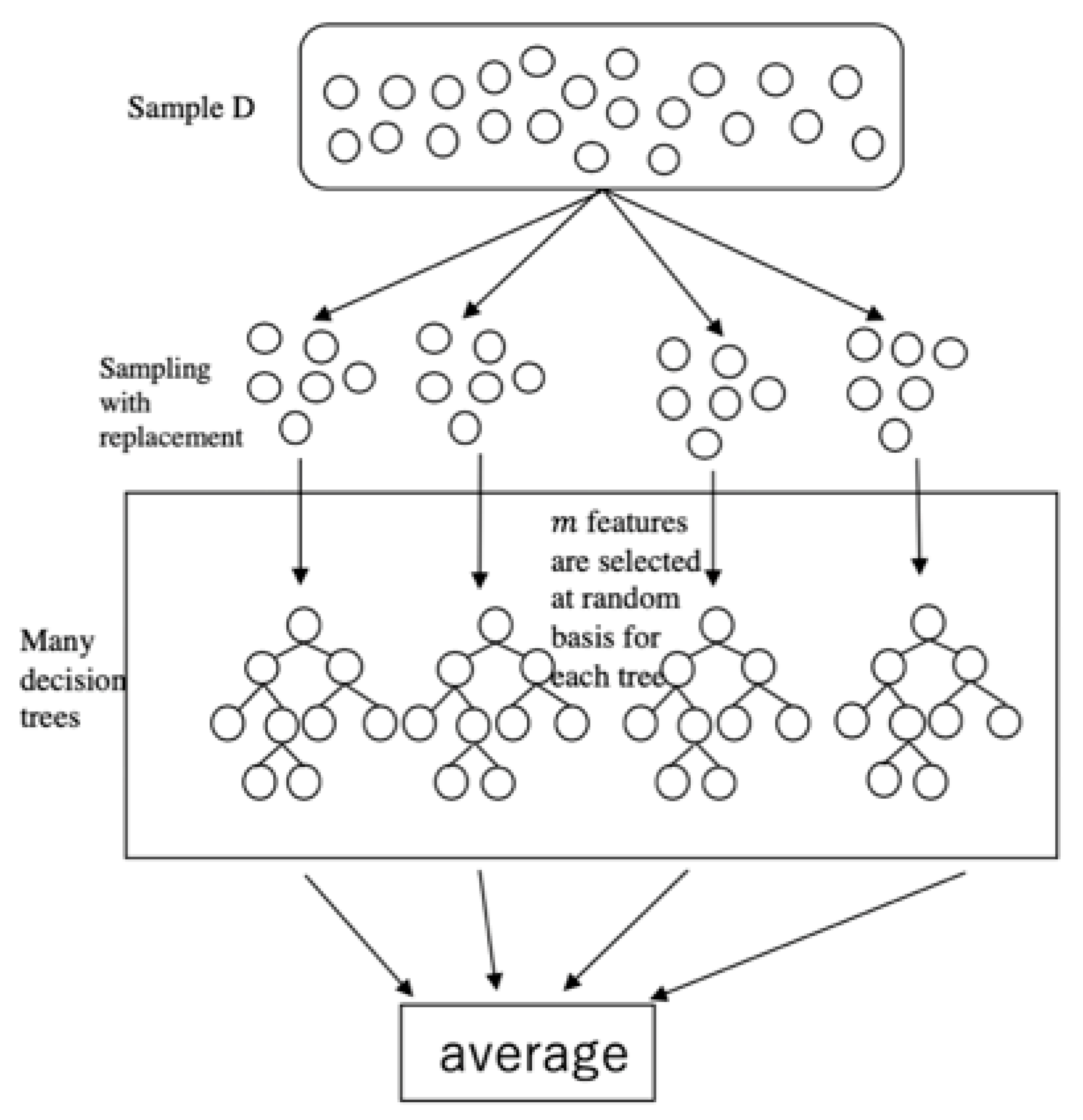
Random forest (
Breiman 2001) is an ensemble learning method that builds multiple decision trees by analyzing data features and then merges them together to improve prediction performance. This method enables us to avoid an overfitting problem when more trees are added to the forest and improves prediction performance because each tree is drawn from the original sample using bootstrap resampling and is grown based on a randomly selected feature. The uncorrelated models obtained from this method improve prediction performance, as the feature mentioned above protects individual errors from each other. In this way, an individual error will not interfere with the entire group moving toward the correct direction. The random forest produces regression trees through the following steps (
Figure 1):
Assume that there is a dataset and the target is to find the function , where is the inputs, and is the produced outputs. Let be the number of features.
Random forest randomly selects observations from the sample with a replacement to form a bootstrap sample.
Multiple trees are grown by subsets of features from the overall features. For each subset, features are selected at random.
A prediction is produced by taking the average of the predictions from all trees in the forest (in the case of a classification problem, a prediction is decided by the majority).
In this paper, X indicates the fundamental economic features, and Y is the exchange rate. D refers to all data.
4.2. Support Vector Machine
The original SVM algorithm was introduced by
Vapnik and Lerner (
1963).
Boser et al. (
1992) suggested an alternative way to create nonlinear classifiers by applying the kernel functions to maximum-margin hyperplanes.
The primary concept of SVM regression is discussed first with a linear model and then is extended to a non-linear model using the kernel functions. Given the training data
, the SVM regression can be given by
is the insensitive loss function considered in SVM from the loss function described as
The principal objective of SVM regression is to find function
with the minimum value of the loss function and also to make it as flat as possible. Thus, the model can be expressed as the following convex optimization problem:
subject to
where C determines the trade-off between the flatness of
and the amount up to which deviations larger than
are tolerable (
,
).
After solving the Lagrange function from Equations (29)–(31) and using the kernel function, the SVM model using the kernel function can be expressed as follows:
subject to
where
is the kernel function, and
are the Lagrangian multipliers. SVM can be performed by various functions, such as the linear, polynomial, or radial basis function (RBF), and sigmoid functions. This paper uses the radial basis function SVM model. The radial basis function can be expressed as follows:
Here, the best C and sigma are determined using a grid search. Depending on the size of the C parameter, there is a trade-off between the correct classification of training examples and a smooth decision boundary. A larger C does not tolerate misclassification, offering a more complicated decision function, which a smaller C does tolerate. In this way, a simpler decision function is given. The sigma parameter defines how far the influence of a single training example reaches, with low values meaning ‘far’ and high values meaning ‘close’. A larger sigma gives a great deal of weight to the variables nearby, so the decision boundary becomes wiggly. For a smaller sigma, the decision boundary resembles a linear boundary, since it also takes distant variables into consideration.
4.3. Neural Network
The feedforward neural network is the first and simplest type of neural network model. General references for this model include
Bishop (
1995),
Hertz et al. (
1991), and
Ripley (
1993,
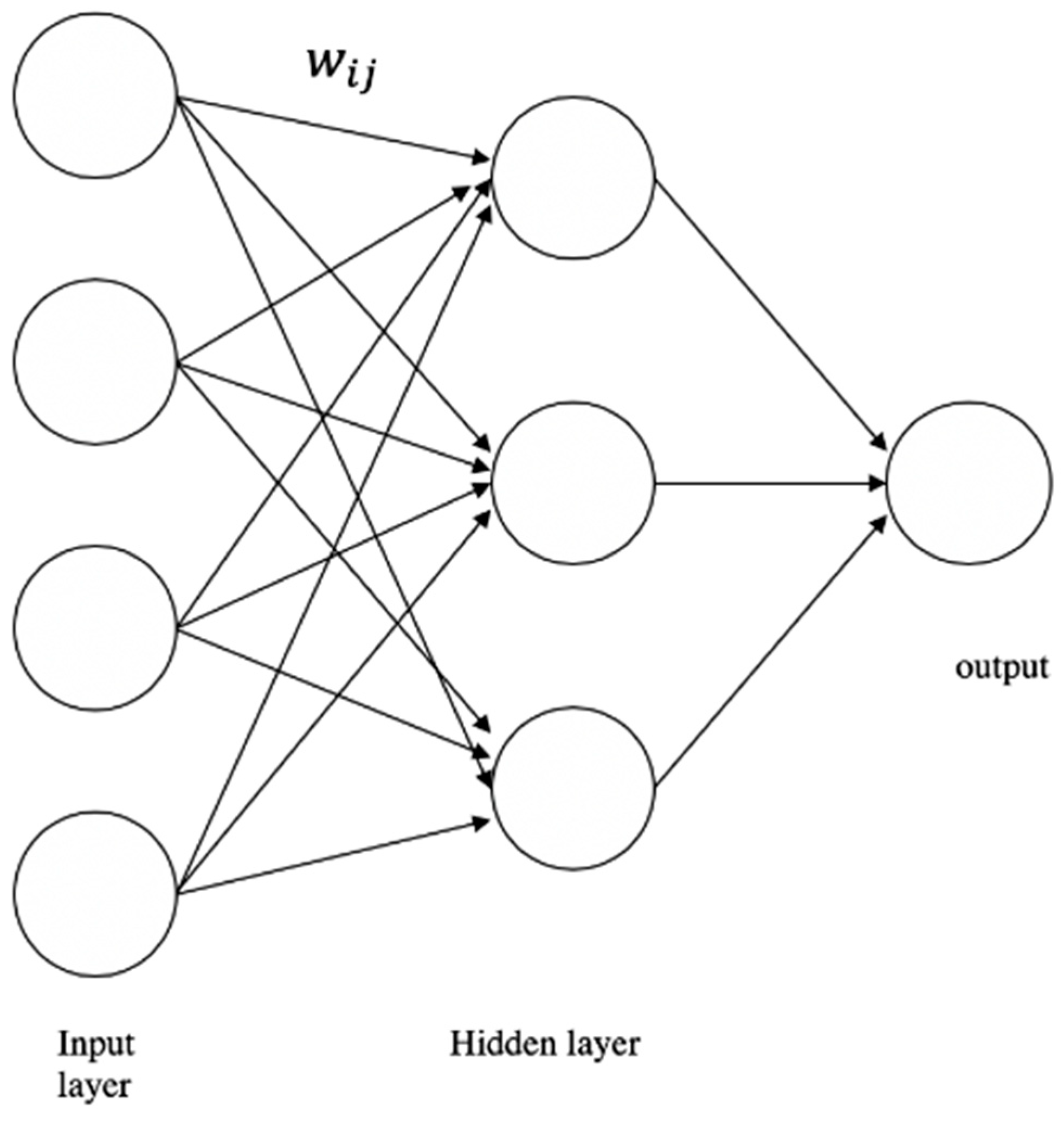
1996). This paper uses one hidden layer model, which is the simplest model, as shown in
Figure 2.
As shown in
Figure 2, the information moves forward from the input nodes, through the hidden nodes, and then reaches the output nodes.
Inputs are summed by individual nodes. Then, adding a bias (
in the
Figure 2), the result is substituted into a fixed function
(Equation (37)). The results of the output units are produced in the same process with output function
. Thus, the equation of a neural network is written as follows:
The activation function
of the hidden layer units usually takes a logistic function as
and the output function
usually takes a linear function in regression (in the case of a classification problem, the output function often takes a logistic form.)
Here, we adjust two hyper-parameters, which are the number of the units in the hidden layer C and the parameter for weight decay, using a grid search. The latter is a regularization parameter to avoid the over-fitting problem (
Venables and Ripley 2002).
6. Conclusions
Since the work of
Meese and Rogoff (
1983a,
1983b), there have been many attempts by researchers to solve the puzzle of why traditional economical models are not able to outperform the random walk in predicting out-of-sample exchange rates. In recent years,
Amat et al. (
2018) found that in combination with machine learning methodologies, traditional exchange-rate models and Taylor-rule exchange rate models can be useful for forecasting future short-term exchange rates across 12 major currencies.
In this paper, we analyzed whether combining modern machine learning methodologies with economic models could outperform the prediction performance of a random walk without drift. More specifically, this paper sheds light on the application of the random forest method, the support vector machine, and neural networks to four fundamental theories (uncovered interest rate parity, purchase power parity, the monetary model, and the Taylor rule models). The robustness of the results was also thoroughly examined using six government bonds with different maturities and four different price indexes in three machine learning models. This provides concrete evidence for predictive performance.
In the empirical analysis, a rolling window analysis was used for the one-period-ahead forecast for JPY/USD. Using sample data from between August 1980 and August 2019, there were two main findings. First, comparing the performance of the fundamental models combining machine learning with the performance obtained by the random walk, the RMSE results show that the former models outperform the random walk. In the DM test, most of the results show a significantly different predictive accuracy with the random walk, while some of the random forest results show the same accuracy as the random walk. Second, comparing the performance of the fundamental models combined with machine learning, the models using PPI show fairly good predictability in a consistent manner, from the perspective of both the size of their errors and their predictive accuracy. However, CPI does not appear to be a useful index for predicting exchange rate based on its poor results in the RMSE test and DM test.




{kind=link}
{kind=link}