Blockchain Economical Models, Delegated Proof of Economic Value and Delegated Adaptive Byzantine Fault Tolerance and their implementation in Artificial Intelligence BlockCloud


Abstract
1. Introduction
2. AIBC Overview
2.1. AIBC Key Innovation
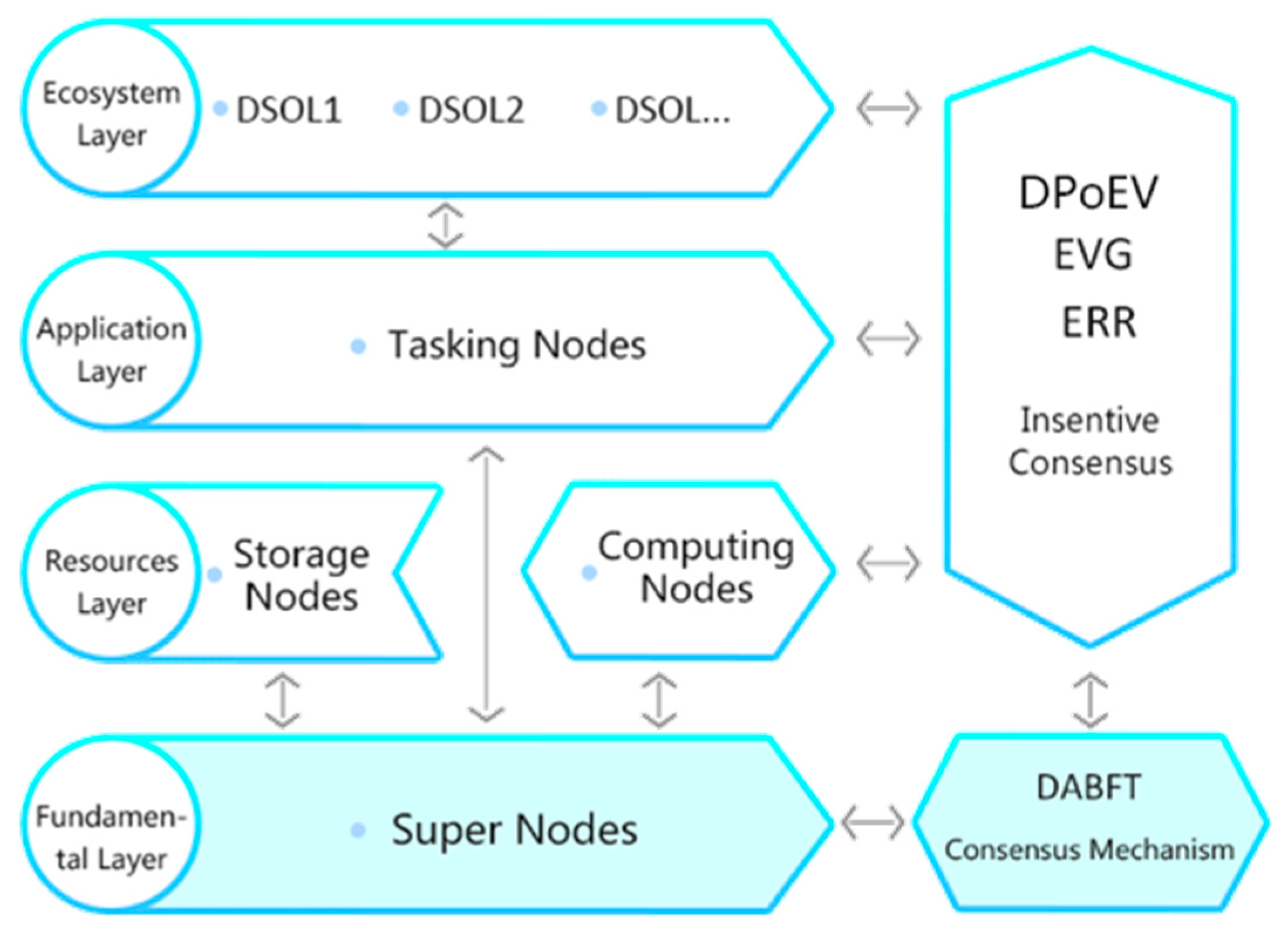
2.2. AIBC Architecture
- The fundamental layer (or blockchain layer) that conducts the essential blockchain functions, namely distributed consensus-based block proposition, validation, and ledger recording. The nodes delegated to perform these fundamental blockchain services are the super nodes.
- The resource layer that provides the essential ecosystem services, namely, computing power and storage space. The AIBC ecosystem is based on the concept that resources are to be shared, and these resources are provided by the computing nodes and storage nodes. While their functions are different, the computing nodes and storage nodes can physically or virtually be collocated or coincide.
- The application layer that requests resources. Each application scenario is initiated by a tasking node. In the AIBC ecosystem, tasking nodes are the ones that have needs for computing power and storage space, thus it is their responsibility to initiate tasks, which in turn drive the generation of economic value.
- The ecosystem layer that comprises physical/virtual entities that own or operate the nodes. For example, a tasking node can be a financial trading firm that needs resources from a number of computing nodes, which can be other trading firms or server farms that provides computing power.
2.3. AIBC Two-Consensus Implementation
3. Review of Literature and Practice on Major Consensus Algorithms
3.1. Proof-Based Consensus Algorithms
3.1.1. PoW (Proof of Work) Workload Proof Consensus
3.1.2. PoS (Proof of Stake) Equity Proof Consensus and DPoS
3.1.3. PoI (Proof of Importance) Importance Proof Consensus
3.1.4. PoD (Proof of Devotion) Contribution Proof Consensus
3.1.5. PoA (Proof of Authority) Identity Proof Consensus
3.1.6. PoET (Proof of Elapsed Time) Sample Size Proof Consensus
3.1.7. PoSpace (Proof of Space) Disk Space Proof Consensus
3.2. Vote-Based Consensus Algorithms
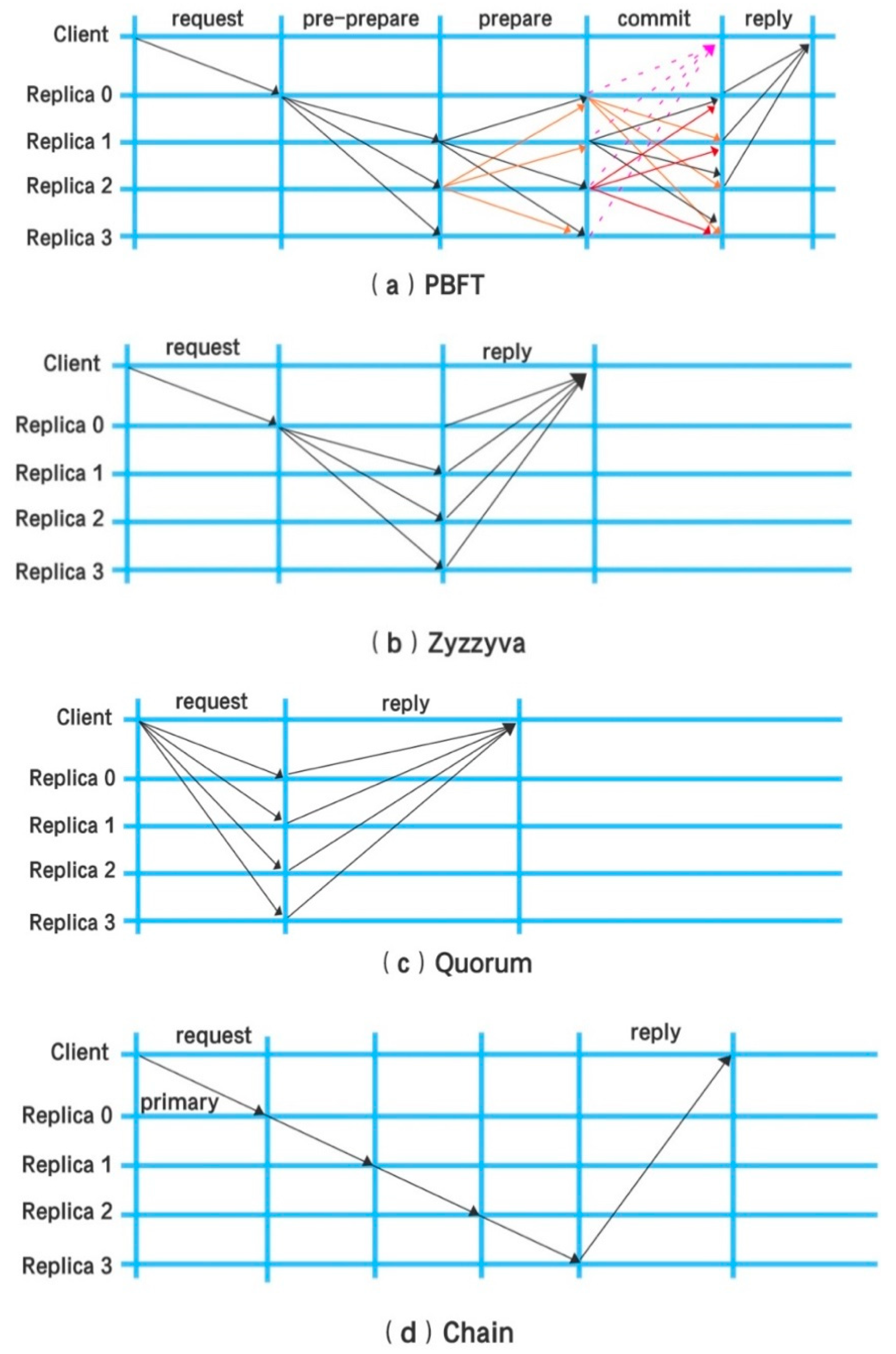
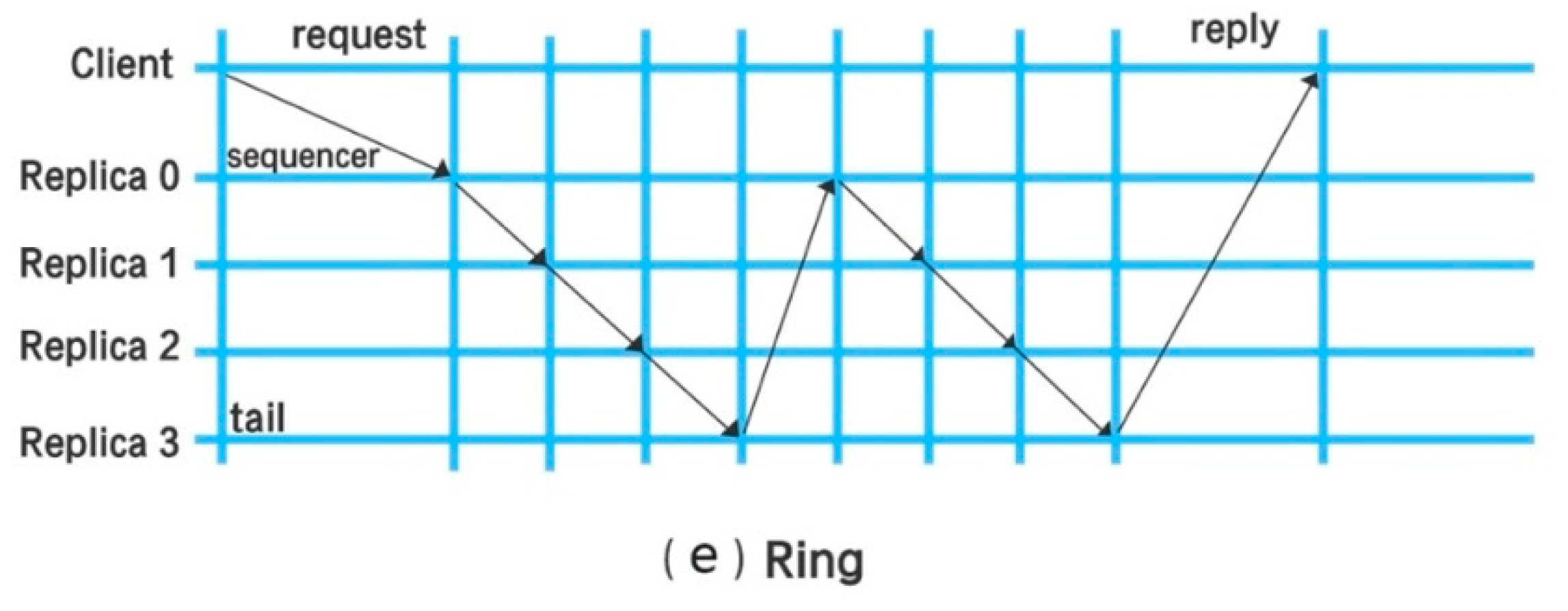
3.2.1. BFT Distributed Consistency Consensus Algorithms
3.2.2. CFT Distributed Consistency Consensus Algorithms
3.3. Flaws of Existing Consensus Algorithms
3.4. Multi-Protocol Consensus Algorithms
4. AIBC Economic Models
4.1. Economic Model Overview
- That it has gold-like intrinsic value but not its physical scarcity.
- That it can be mined at the exact pace as the economic growth.
- And that it can be put into and taken out of circulation instantaneously and in sync with economic reality.
4.2. Economic Model Implementation Overview
5. Delegated Proof of Economic Value (DPoEV)
5.1. DPoEV Overview
- At the genesis of the AIBC, the EVG mechanism accurately assesses the economic value, or initial wealth (“base wealth”) of the knowledge in the entire ecosystem (all participating nodes: super nodes, tasking nodes, computing nodes and storage nodes to be explained in the next few sections), and comes up with a system-wide wealth map. The DPoEV then issues an initial supply of CFTX tokens according to the assessment.
- Afterward, the EVG updates the wealth map of the entire ecosystem on a real-time basis, with detailed wealth information of each and every node in the ecosystem. In the AIBC ecosystem, wealth generation is driven by tasks. The EVG assesses the incremental wealth brought about by a task, and the DPoEV issues fresh tokens accordingly. This enables the ecosystem to dynamically adjust the money (token) supply to prevent any macroeconomic level deflation and inflation in a very precise manner. Essentially, the DPoEV supervises monetary policy in a decentralized ecosystem.
- The DPoEV monitors the real-time transactions among participating nodes of a task and manages the token award mechanism. After an amount of tokens is created for a task, the DPoEV distributes tokens to nodes that participate in the task. The number of tokens awarded to each node, as well as transaction costs (gas) attributed to the node, depending on that node’s contribution to the task.
- In an open and free trade economic system with no restrictions, it is quite likely that a few resource nodes will accumulate a tremendous level of production capability (computing power and storage space) and experience (task relevancy), who may then be given a majority of tasks/assignments due to a “rule of relevancy” ranking scheme. This would accelerate wealth generation for these dominating nodes in a speed that is unfair to other resource nodes. This is where a “rule of wealth” scheme comes in as a counter-balance, as the DPoEV can elect to grant assignments to nodes with lowest levels of wealth. If, however, there are simply not enough low wealth level resource nodes, which renders the “rule of wealth” ineffective, a “rule of fairness” scheme then comes to play. The “rule of fairness” imposes tariff levies on the dominating nodes, which are then distributed to resource nodes with a low probability of winning assignments. Thus, the DPoEV also functions as a “world trade organization” that enforces fair trade in a decentralized ecosystem.
- When there are multiple tasks on the ecosystem simultaneously competing for limited resources, the DPoEV decides on a real-time basis whether and how to adjust the value of each task, based on factors such as that how many similar tasks have been initiated and completed in the past and the historical values of these tasks. This prevents initially high-value tasks dominating the limited resources and encourages initially low-value tasks to be proposed. Thus, on the microeconomic level, the DPoEV dynamically balances the supply and demand of tasks. If, in rare cases, the aggregated outcome of task value adjustments is in conflict with the macroeconomic level goal (no inflation or deflation), a value-added tax (VAT) liability (in case of inflation) or a VAT credit (in case of deflation) can be posted on a separate ledger, of which the amount can be used to adjust the next round of macroeconomic level fresh token issuance. Thus the DPoEV provides a central-bank-like open market operations service in a decentralized ecosystem.
- Finally, the DPoEV conducts periodical true-up as an extra layer of defense for housekeeping purposes. One of the key activities during true-up is for the DPoEV to “burn” surplus tokens that have been created, however, have not been awarded to participating nodes because of economic policy constraints. This is somewhat equivalent to central banks’ action of currency withdrawal, which is a macroeconomic tool to destroy currency with low circulation efficiency.
- The DPoEV is essentially conducted by the super nodes to ensure performance and efficiency in the ecosystem, this is where the “D (Delegated)” in DPoEV comes from.
5.2. Economic Value Graph (EVG) Overview
5.2.1. Knowledge Graph Overview
5.2.2. EVG Implementation
5.3. Economic Relevancy Ranking (ERR)
- Time criticalness: How much time a task takes before a task timer expires.
- Computing intensity: How much computing power is required to complete the task and associated assignments.
- The Frequency of transactions: Higher transaction frequency improves liquidity, which further increases transaction frequency. Higher transaction frequency allows a faster growth of wealth, however, brings higher demand to the network and database framework.
- The Scale of transactions: Larger transaction scale improves liquidity, which further increases the transaction scale. Larger transaction scale allows a faster growth of wealth, however, brings higher demand to the network and database framework.
- Required propagation: Stronger propagation in terms of bandwidth means improved liquidity, which improves transaction frequency and scale. Stronger propagation allows a faster growth of wealth, however, brings higher demand to the network and database framework.
- Optional data requirement: What and how much data is required to complete the task and associated assignments, and more importantly, where the data is stored.
- Consistency. A ranking score, once recorded, cannot be altered through paying more cost by the tasking node (for task ranking) or the service node (for service node ranking). However, the ranking score does change as both the tasking and service nodes do evolve. Adjustment to the ranking score can only be conducted by DPoEV through the DABFT consensus.
- Computability. The ERR ranking scores need to be retrieved by the DPoEV instantly, thus the ERR algorithm requires low computational complexity.
- Deterministicness. The ERR algorithm should produce identical results on all nodes for the same service node.
5.4. DPoEV Advantages
6. Delegated Adaptive Byzantine Fault Tolerance (DABFT)
6.1. DABFT Design Goals
6.2. DABFT Adaptive Approach
6.3. DABFT Algorithm Design
6.3.1. New Block Generation
6.3.2. Consensus Building Process
- is the conditional residual vector at time t given the previous state .
- is the conditional covariance matrix of .
- is the conditional correlation matrix of
- is the normalization matrix for .
- and are diagonal coefficient matrices for .
- is the standardized residue vector of .
- and are estimator matrices for .
- is the unconditional correlation matrix of .
6.3.3. Fork Selection
6.3.4. Voting Rules
- The consensus process of a single block has a strict sequence. Only after the total number of votes in the first stage reaches 2/3 majority, can the next stage of consensus start.
- The consensus of a subsequent block does not need to wait until the consensus of the current block is concluded. The consensuses of multiple blocks can be concurrent, however not completely out of order. Generally, after the consensus of the current block is 2/3 completed, the consensus of a subsequent block can start.
6.3.5. Incentive Analysis
6.4. Attack-Proof
6.5. Dynamic Sharding
7. Conclusions
Funding
Conflicts of Interest
References
- Abd-El-Malek, Michael, Gregory R. Ganger, Garth R. Goodson, Michael K. Reiter, and Jay J. Wylie. 2005. Fault-scalable Byzantine Fault-Tolerant Services. Association for Computing Machinery 39: 59–74. [Google Scholar] [CrossRef]
- American Economic Association. 1936. The Elasticity of the Federal Reserve Note. The American Economic Review 26: 683–90. [Google Scholar]
- Androulaki, Elli, Artem Barger, Vita Bortnikov, Christian Cachin, Konstantinos Christidis, Angelo De Caro, David Enyeart, Christopher Ferris, Gennady Laventman, Yacov Manevich, and et al. 2018. Hyperledger fabric: A distributed operating system for permissioned blockchains. Paper presented at the Thirteenth EuroSys Conference, Porto, Portugal, April 23–26; Available online: https://arxiv.org/pdf/1801.10228.pdf (accessed on 24 November 2019).
- Aublin, Pierre-Louis, Sonia Ben Mokhtar, and Vivien Quéma. 2013. RBFT: Redundant Byzantine Fault Tolerance. Paper presented at the 2013 IEEE 33rd International Conference on Distributed Computing Systems, Philadelphia, PA, USA, July 8–11. [Google Scholar]
- Bahsoun, Jean-Paul, Rachid Guerraoui, and Ali Shoker. 2015. Making BFT Protocols Really Adaptive. Paper presented at the 2015 IEEE International Parallel and Distributed Processing Symposium, Hyderabad, India, May 25–26; pp. 904–13. [Google Scholar] [CrossRef]
- Barro, Robert, and Vittorio Grilli. 1994. European Macroeconomics. chp. 8, Figure 8.1. Beijing: Macmillan, p. 139. ISBN 0-333-57764-7. [Google Scholar]
- Belotti, Marianna, Nikola Božić, Guy Pujolle, and Stefano Secci. 2019. A Vademecum on Blockchain Tech- nologies: When, Which and How. IEEE Communications Surveys & Tutorials. Available online: https://hal.sorbonne-universite.fr/hal-01870617/document (accessed on 24 November 2019). [CrossRef]
- Board of Governors of the Federal Reserve System. 1943. Banking and Monetary Statistics 1914–1941. Washington: Board of Governors of the Federal Reserve System, p. 671. [Google Scholar]
- Bonneau, Joseph, Andrew Miller, Jeremy Clark, Arvind Narayanan, Joshua A. Kroll, and Edward W. Felten. 2015. SoK: Research Perspectives and Challenges for Bitcoin and Cryptocurrencies. Paper presented at the 2015 IEEE Symposium on Security and Privacy, San Jose, CA, USA, May 17–21; Available online: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7163021 (accessed on 24 November 2019). [CrossRef]
- BTS. 2018. The BitShares Blockchain. Available online: https://www.bitshares.foundation/papers/BitSharesBlockchain.pdf (accessed on 24 November 2019).
- Buffett, Warren. 2018. Available online: https://www.cnbc.com/2018/05/07/warren-buffett-on-bitcoin-it-doesnt-produce-anything.html (accessed on 24 November 2019).
- Buterin, Vitalik. 2013. What Proof of Stake Is and Why It Matters. Available online: https://bitcoinmagazine.com/articles/what-proof-of-stake-is-and-why-it-matters-1377531463 (accessed on 24 November 2019).
- Buterin, Vitalik. 2014. Ethereum: A Next-Generation Smart Contract and Decentralized Application Platform. Available online: https://github.com/ethereum/wiki/wiki/White-Paper (accessed on 24 November 2019).
- Buterin, Vitalik. 2018. On Sharding Blockchains. Available online: https://github.com/ethereum/wiki/wiki/Sharding-FAQs#what-is-the-basic-idea-behind-sharding (accessed on 24 November 2019).
- Castro, Miguel, and Barbara Liskov. 2002. Practical Byzantine Fault Tolerance and Proactive Recovery. ACM Transactions on Computer Systems 20: 398–461. [Google Scholar] [CrossRef]
- Chase, Brad, and Ethan MacBrough. 2018. Analysis of the XRP Ledger Consensus Protocol. Available online: https://arxiv.org/pdf/1802.07242.pdf (accessed on 24 November 2019).
- Cowling, James, Daniel Myers, Barbara Liskov, Rodrigo Rodrigues, and Liuba Shrira. 2006. HQ Replication: A Hybrid Quorum Protocol for Byzantine Fault Tolerance. Paper presented at the 7th USENIX Symposium on Operating Systems Design and Implementation, Seattle, WA, USA, November 6–8; pp. 177–90. [Google Scholar]
- Driscoll, Kevin, Brendan Hall, Håkan Sivencrona, and Phil Zumsteg. 2003. Byzantine Fault Tolerance, from Theory to Reality. In International Conference on Computer Safety, Reliability, and Security. Berlin/Heidelberg: Springer, pp. 235–48. ISSN 0302-9743. [Google Scholar] [CrossRef]
- Eichengreen, Barry J. 1995. Golden Fetters: The Gold Standard and the Great Depression, 1919–1939. Oxford: Oxford University Press. ISBN 0-19-510113-8. [Google Scholar]
- Engle, Robert F., and Kevin Sheppard. 2001. Theoretical and Empirical Properties of Dynamic Conditional Correlation Multivariate GARCH. Cambridge: National Bureau of Economic Research. [Google Scholar]
- Engle, Robert. 2002. Dynamic conditional correlation: A simple class of multivariate Generalized Autoregressive Conditional Heteroscedasticity models. Journal of Business and Economic Statistics 20: 339–50. [Google Scholar] [CrossRef]
- EOS. 2018. EOS White Paper. Available online: https://github.com/EOSIO/Documentation/blob/master/TechnicalWhitePaper.md (accessed on 24 November 2019).
- Goldberg, Dror. 2005. Famous Myths of Fiat Money. Journal of Money, Credit and Banking 37: 957–67. [Google Scholar] [CrossRef]
- Goodman, George Jerome Waldo. 1981. Paper Money. New York: Dell Pub Co., pp. 165–66. [Google Scholar]
- Governatori, Guido, Florian Idelberger, Zoran Milosevic, Regis Riveret, Giovanni Sartor, and Xiwei Xu. 2018. On legal contracts, imperative and declarative smart contracts, and blockchain systems. Artificial Intelligence and Law 26: 377–409. [Google Scholar] [CrossRef]
- Guerraoui, Rachid, Nikola Knežević, Vivien Quéma, and Marko Vukolić. 2010. The next 700 bft protocols. Paper presented at the 5th European Conference on Computer Systems, Paris, France, April 13–16; pp. 363–76. [Google Scholar]
- Guerraoui, Rachid, Nikola Knezevic, Vivien Quema, and Marko Vukolic. 2011. Stretching BFT. Lausanne: EPFL. [Google Scholar]
- Herlihy, Maurice. 2018. Blockchains from a Distributed Computing Perspective. Communications of the ACM 62: 78–85. [Google Scholar] [CrossRef]
- Intel. 2017a. PoET 1.0 Specification. Available online: https://sawtooth.hyperledger.org/docs/core/releases/latest/architecture/poet.html (accessed on 24 November 2019).
- Intel. 2017b. Hyperledger Sawtooth Raft Documentation. Available online: https://sawtooth.hyperledger.org/docs/raft/nightly/master/ (accessed on 24 November 2019).
- Kemmerer, Edwin Walter. 1994. Gold and the Gold Standard: The Story of Gold Money Past, Present and Future. Princeton: McGraw-Hill Book, Company, Inc., p. 134. ISBN 9781610164429. [Google Scholar]
- Keynes, John Maynard. 1920. Economic Consequences of the Peace. New York: Harcourt, Brace and Howe. [Google Scholar]
- King, Sunny, and Scott Nadal. 2012. PPCoin: Peer-to-Peer Crypto-Currency with Proof-of-Stake. Available online: https://peercoin.net/assets/paper/peercoin-paper.pdf (accessed on 24 November 2019).
- Kotla, Ramakrishna, Lorenzo Alvisi, Mike Dahlin, Allen Clement, and Edmund Wong. 2009. Zyzzyva: Speculative Byzantine Fault Tolerance. ACM Transactions on Computer Systems 27: 7. [Google Scholar] [CrossRef]
- Lamport, Leslie, Robert Shostak, and Marshall Pease. 1982. The Byzantine Generals Problem. ACM Transactions on Programming Languages and Systems 4: 382–401. [Google Scholar] [CrossRef]
- Li, Xiaoqi, Peng Jiang, Ting Chen, Xiapu Luo, and Qiaoyan Wen. 2018. A survey on the security of blockchain systems. arXiv arXiv:1802.06993v2. [Google Scholar] [CrossRef]
- LKC. 2018. LuckyBlock Whitepaper. Available online: https://luckyblock.com/static/whitepaper.pdf (accessed on 24 November 2019).
- LTC. 2018. Comparison between Litecoin and Bitcoin. Available online: https://litecoin.info/index.php/Comparison_between_Litecoin_and_Bitcoin (accessed on 24 November 2019).
- Mayer, David A. 2010. Gold standard at Google Books the Everything Economics Book: From Theory to Practice, Your Complete Guide to Understanding Economics Today (Everything Series). New York: Simon and Schuster, pp. 33–34. ISBN 978-1-4405-0602-4. [Google Scholar]
- Nakamoto, Satoshi. 2008. Bitcoin: A Peer-to-Peer Electronic Cash System. arXiv arXiv:43543534534v343453. [Google Scholar]
- NAS. 2018. NAS White Paper. Available online: https://nebulas.io/docs/NebulasTechnicalWhitepaper.pdf (accessed on 24 November 2019).
- NEM. 2018. NEM White Paper. Available online: https://nem.io/wp-content/themes/nem/files/NEM_techRef.pdf (accessed on 24 November 2019).
- NEO. 2018. NEO White Paper. Available online: https://github.com/neo-project/docs/blob/master/en-us/index.md (accessed on 24 November 2019).
- Nguyen, Giang-Truong, and Kyungbaek Kim. 2017. A Survey about Consensus Algorithms Used in Blockchain. Journal of Information Processing Systems 14: 101–28. [Google Scholar]
- NXT. 2015. NXT Whitepaper (Blocks). Revision 4, Nxt v1.2.2. Available online: https://bravenewcoin.com/assets/Whitepapers/NxtWhitepaper-v122-rev4.pdf (accessed on 24 November 2019).
- Ongaro, Diego, and John Ousterhout. 2014. In Search of an Understandable Consensus Algorithm. Paper presented at the 2014 USENIX Annual Technical Conference (USENIX ATC ‘14), Philadelphia, PA, USA, June 19–20; pp. 305–19. [Google Scholar]
- ONT. 2017. Ontology Technical W. Available online: https://github.com/ontio/Documentation/blob/master/Ontology-technology-white-paper-EN.pdf (accessed on 24 November 2019).
- Park, Sunoo, Krzysztof Pietrzak, Joël Alwen, Georg Fuchsbauer, and Peter Gazi. 2015. Spacecoin: A Cryptocurrency Based on Proofs of Space. Available online: https://eprint.iacr.org/2015/528 (accessed on 24 November 2019).
- Pike, Douglas, Patrick Nosker, David Boehm, Daniel Grisham, Steve Woods, and Joshua Marston. 2015. Proof-of-Stake-Time. Available online: https://vericonomy.ams3.cdn.digitaloceanspaces.com/documents/VeriCoinPoSTWhitePaper10May2015.pdf (accessed on 24 November 2019).
- Rosic, Ameer. 2018. What Are Ethereum Nodes and Sharding? Available online: https://blockgeeks.com/guides/what-are-ethereum-nodes-and-sharding/ (accessed on 24 November 2019).
- Schwartz, David, Noah Youngs, and Arthur Britto. 2014. The Ripple Protocol Consensus Algorithm. Available online: https://ripple.com/files/ripple_consensus_whitepaper.pdf (accessed on 24 November 2019).
- Shoker, Ali, and Jean-Paul Bahsoun. 2013. BFT Selection. Paper presented at the International Conference of Networked Systems, Marrakech, Morocco, May 2–4. [Google Scholar]
- Smola, Alex J., and Bernhard Schölkopf. 2004. A tutorial on support vector regression. Statistics and Computing 14: 199–222. [Google Scholar] [CrossRef]
- Sultan, Karim, Umar Ruhi, and Rubina Lakhani. 2018. Conceptualizing Blockchains: Characteristics & Applications. Paper presented at the 11th IADIS International Conference Information Systems 2018, Lisbon, Portugal, April 14–16; Available online: https://arxiv.org/pdf/1806.03693v1.pdf (accessed on 24 November 2019).
- Tschorsch, Florian, and Björn Scheuermann. 2016. Bitcoin and Beyond: A Technical Survey on Decentralized Digital Currencies. IEEE Communications Surveys & Tutorials 18: 2084–123. [Google Scholar] [CrossRef]
- VET. 2018. VET White Paper. Available online: https://github.com/vechain/thor (accessed on 24 November 2019).
- Wang, Wenbo, Dinh Thai Hoang, Peizhao Hu, Zehui Xiong, Dusit Niyato, Ping Wang, Yonggang Wen, and Dong In Kim. 2019. A Survey on Consensus Mechanisms and Mining Strategy Management in Blockchain Networks. IEEE Access 7: 22328–70. [Google Scholar] [CrossRef]
- Watthananona, Julaluk, and A. Mingkhwanb. 2012. Optimizing Knowledge Management using Knowledge Map. Procedia Engineering 32: 1169–77. [Google Scholar] [CrossRef][Green Version]
- Weber, Warren E. 2015. Available online: http://www.bankofcanada.ca/wp-content/uploads/2015/12/bitcoin-standard-lessons.pdf (accessed on 24 November 2019).
- WTO. 2015. Understanding the WTO, Handbook. Available online: https://www.wto.org/English/Thewto_E/whatis_e/tif_e/understanding_e.pdf (accessed on 24 November 2019).
| 1 | VBFT is proposed by Ontology. It is a consensus algorithm that combines PoS, VRF (Verifiable Random Function), and BFT. |
| 2 | November, 2019. |
| 3 | The and are full matrices made of row vectors for individual BFT flavors, while is actually a column matrix. The mathematical representation in this subsection is simplified just to illustrate the analysis process without losing a “high-level” accuracy. |
| 4 | Essentially, this is a Dynamic Conditional Correlation (DCC) for multivariate time-series analysis with a DCC (1,1) specification (Engle and Sheppard 2001; Engle 2002). |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Blockchain | Dual Token | Multi Consensus | Consensus Token | Payment Token | Blockchain Consensus | Incentive Consensus | Consensus Family |
|---|---|---|---|---|---|---|---|
| Bitcoin (Nakamoto 2008). | No. | No. | BTC. | PoW. | Proof-based. | ||
| Ethereum (Buterin 2013). | No. | No. | ETH. | PoW/PoS. | Proof-based. | ||
| Litecoin (LTC 2018). | No. | No. | LTC. | PoW. | Proof-based. | ||
| PeerCoin (King and Nadal 2012). | No. | No. | ATOM. | PoS. | Proof-based. | ||
| NXT (NXT 2015). | No. | No. | XTZ. | PoS. | Proof-based. | ||
| EOS (EOS 2018). | No. | No. | EOS. | DPoS. | Proof-based. | ||
| Bitshares (BTS 2018). | No. | No. | BTS. | DPoS. | Proof-based. | ||
| NEM (NEM 2018). | No. | No. | NEM. | PoI. | Proof-based. | ||
| NAS (NAS 2018). | No. | No. | NAS. | PoD. | Proof-based. | ||
| VET (VET 2018). | No. | No. | VET. | PoA. | Proof-based. | ||
| Hyperledger Sawtooth PoET (Intel 2017a). | No. | No. | Platform. | PoET. | Proof-based. | ||
| SpaceMint (Park et al. 2015). | No. | No. | Space. | PoSpace. | Proof-based. | ||
| Hyperledge Fabric (Androulaki et al. 2018). | No. | No. | Platform. | PBFT. | Vote-based: BFT. | ||
| NEO (NEO 2018). | No. | No. | NEO. | DBFT. | Vote-based: BFT. | ||
| Ripple (Schwartz et al. 2014; Chase and MacBrough 2018). | No. | No. | XRP. | Ripple/XRP. | Vote-based: BFT. | ||
| Hyperledger Sawtooth Raft (Intel 2017b). | No. | No. | Platform. | Raft. | Vote-based: CFT. | ||
| LuckyBlock (LKC 2018). | Yes. | No. | LKC. | LuckyS. | PoW-PoS mix. | Proof-based. | |
| Ontology (ONT 2017). | Yes. | No. | ONT. | ONG. | VBFT. | Vote-based: BFT. | |
| VeriCoin/Verium (Pike et al. 2015). | Yes. | Yes. | VRC. | VRM. | PoWT. | PoST. | Proof-based. |
| Artificial Intelligence BlockCloud (AIBC). | Yes. | Yes. | DSOL. | CFTX. | DPoEV. | DABFT. | Vote-based: Adaptive BFT. |
| Economic Value. (CFTX Token) | Total Economic Value | Initial Economic Value | Incremental Economic Value-Task 1 | Incremental Economic Value-Task k | Incremental Economic Value-Task K |
|---|---|---|---|---|---|
| Super Node 1. | 1,250,000. | 1,000,000. | 1000. | 750. | 500.. |
| …. | …. | …. | …. | …. | ….. |
| Super Node NS. | 2,100,000. | 2,000,000. | 2000. | 1500. | 1000.. |
| Tasking Node 1. | 75,000. | 50,000. | 50. | 30. | 25.. |
| …. | …. | …. | …. | …. | ….. |
| Tasking Node NT. | 125,000. | 75,000. | 75. | 60. | 50.. |
| Computing Node 1. | 200,000. | 100,000. | 100. | 90. | 75.. |
| …. | …. | …. | …. | …. | ….. |
| Computing Node NC. | 300,000. | 250,000. | 250. | 175. | 100.. |
| Storage Node 1. | 200,000. | 150,000. | 150. | 80. | 25.. |
| …. | …. | …. | …. | …. | ….. |
| Storage Node NST. | 350,000. | 300,000. | 300. | 175. | 75.. |
| Economic Relevancy Ranking (ERR Score) | Task 1 | … | … | Task i | … | … | Task N | |
|---|---|---|---|---|---|---|---|---|
| 0.39 | 0.59 | 0.46 | ||||||
| Time Criticalness | Score | 100 | … | … | 50 | … | … | 75 |
| Weight | 0.15 | 0.05 | 0.25 | |||||
| Normalization Coefficient | 100 | 100 | 100 | |||||
| Computing Intensity | Score | 25 | … | … | 75 | … | … | 100 |
| Weight | 0.15 | 0.25 | 0.15 | |||||
| Normalization Coefficient | 100 | 100 | 100 | |||||
| Frequency of Transactions | Score | 5,000 | … | … | 250,000 | … | … | 100,000 |
| Weight | 0.25 | 0.25 | 0.15 | |||||
| Normalization Coefficient | 1,000,000 | 1,000,000 | 1,000,000 | |||||
| Scale of Transactions | Score | 5 | … | … | 8 | … | … | 3 |
| Weight | 0.25 | 0.25 | 0.15 | |||||
| Normalization Coefficient | 10 | 10 | 10 | |||||
| Required Propagation | Score | 350 | … | … | 500 | … | … | 150 |
| Weight | 0.15 | 0.15 | 0.15 | |||||
| Normalization Coefficient | 1,000 | 1,000 | 1,000 | |||||
| Data Requirement | Score | 50 | … | … | 75 | … | … | 25 |
| Weight | 0.05 | 0.05 | 0.15 | |||||
| Normalization Coefficient | 100 | 100 | 100 | |||||
| Economic Relevancy Ranking (ERR Score) | Super Node 1 | … | … | Computing Node 1 | … | … | Service Node 1 | |
|---|---|---|---|---|---|---|---|---|
| 0.50 | 0.35 | 0.70 | ||||||
| Consistency | Score | 50 | … | … | 25 | … | … | 35 |
| Weight | 0.50 | 0.70 | 0.25 | |||||
| Normalization Coefficient | 100 | 100 | 100 | |||||
| Computability | Score | 50 | … | … | 60 | … | … | 75 |
| Weight | 0.30 | 0.20 | 0.30 | |||||
| Normalization Coefficient | 100 | 100 | 100 | |||||
| Deterministicness | Score | 50 | … | … | 50 | … | … | 85 |
| Weight | 0.20 | 0.10 | 0.45 | |||||
| Normalization Coefficient | 100 | 100 | 100 | |||||
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Q. Blockchain Economical Models, Delegated Proof of Economic Value and Delegated Adaptive Byzantine Fault Tolerance and their implementation in Artificial Intelligence BlockCloud. J. Risk Financial Manag. 2019, 12, 177. https://doi.org/10.3390/jrfm12040177
Deng Q. Blockchain Economical Models, Delegated Proof of Economic Value and Delegated Adaptive Byzantine Fault Tolerance and their implementation in Artificial Intelligence BlockCloud. Journal of Risk and Financial Management. 2019; 12(4):177. https://doi.org/10.3390/jrfm12040177
Chicago/Turabian StyleDeng, Qi. 2019. "Blockchain Economical Models, Delegated Proof of Economic Value and Delegated Adaptive Byzantine Fault Tolerance and their implementation in Artificial Intelligence BlockCloud" Journal of Risk and Financial Management 12, no. 4: 177. https://doi.org/10.3390/jrfm12040177
APA StyleDeng, Q. (2019). Blockchain Economical Models, Delegated Proof of Economic Value and Delegated Adaptive Byzantine Fault Tolerance and their implementation in Artificial Intelligence BlockCloud. Journal of Risk and Financial Management, 12(4), 177. https://doi.org/10.3390/jrfm12040177