In this section, we will review some of the frequently applied model selection and model averaging estimators in the existing literature. We start by defining a simple linear model from which the corresponding model selection and model averaging estimators will be defined, respectively, in the following subsections. Consider a simple linear model given by
where
is a
vector of exogenous regressors, and
is a
parameter vector with only
number of nonzero parameters. We further assume that
and that the error term
. The literature on model selection and model averaging is large and continues to grow with time. Our review below is limited to the most frequently used model selection and model averaging estimators.
2.1. Model Selection
The traditional best subsets approach predating the class of penalized least squares estimators is generally computationally costly and highly unstable due to the discrete nature of the selection algorithm, as pointed out in
Fan and Li (
2001). The subsequent stepwise approach, which is essentially a variation of the best subsets approach, frequently fails to generate a solution path that leads to the global minimum. In addition, both approaches assume all variables are relevant, even if the underlying true model might have a sparse representation. Then came the class of penalized least squares estimators, which minimize the loss function subjected to some forms of penalty. Some of the frequently applied penalized least squares estimators include the ridge estimator, the LASSO-type estimators, the SCAD estimator, and the MCP estimator.
Hoerl and Kennard (
1970) introduced the original ridge estimator with an
penalty. The ridge estimator is defined as
where
is the so-called tuning parameter.
Tibshirani (
1996) introduced an
-penalty and constructed the LASSO estimator as follows:
Compared to the best subsets approach, where all possible subsets need to be evaluated for variable selection, both of the ridge and LASSO estimators conduct the selection and estimation of the parameters simultaneously, thus gaining computational savings. However, both estimators fail to satisfy the oracle properties, due to inconsistent selection and asymptotic bias. The oracle properties describe the ability of an estimator to perform the same asymptotically, as if we knew the true specification of the model beforehand. In the high-dimensional parametric estimation literature, an oracle efficient estimator is therefore able to simultaneously identify the nonzero parameters and achieve optimal estimation of the nonzero parameters. However,
Fan and Li (
2001) and
Zou (
2006), among others, questioned whether the LASSO satisfies the oracle properties.
Thus, various LASSO-type estimators have been developed since then to overcome the selection bias of the original ridge and LASSO estimator.
Zou and Hastie (
2005) introduced the elastic net estimator by averaging between the
penalty and
penalty. Specifically, the elastic net estimator is defined as
where depending on the choices of the two tuning parameters,
and
, the elastic net estimator combines the properties of the ridge estimator and the LASSO estimator and enjoys the oracle properties.
Zou (
2006) further introduced a LASSO-type estimator, namely the adaptive LASSO estimator, which is defined as
where the adaptive weights
with
, and
denotes any root-n consistent estimator for
. The adaptive LASSO estimator also fulfills the oracle properties.
Fan and Li (
2001) proposed the smoothly clipped absolute deviation (SCAD) penalty estimator, which features a symmetric non-concave penalty function that leads to sparse solutions. The SCAD estimator is defined as
where the continuously differentiable penalty function
is defined as
and
defaults to
following the recommendation from Fan and Li (2001).
Zhang (
2010) introduced the minimax concave penalty (MCP) estimator, which produces nearly unbiased variable selection. The MCP estimator is defined as
where the continuously differentiable penalty function
is defined as
and
defaults to 3, as suggested by
Breheny and Huang (
2011).
2.1.1. Choice of Tuning Parameter
Tuning parameters play a crucial role in the optimization problem for the aforementioned penalized least squares estimators to achieve consistent selection and optimal estimation. There exists an extensive debate in the model selection literature regarding the proper choice for the tuning parameter. Two of the frequently applied approaches used to select the tuning parameter are the n-fold cross-validation (CV), or the generalized cross-validation (GCV) approach, and the information criterion (IC)-based approach. In practice, the CV approach could also be computationally costly for big datasets.
The traditional IC approaches have been modified for the selection of the tuning parameters in the penalized least squares framework.
Shi and Tsai (
2002) have shown that the BIC, under certain conditions, can consistently identify the true model when the number of parameters and the size of the true model are finite. For scenarios where the number of parameters diverges with the increase in the sample size,
Wang et al. (
2009) proposed a modified BIC for the selection of the tuning parameter. This criterion yields consistent selection and reduces asymptotic risks.
Fan and Tang (
2013) further introduced a generalized information criterion (GIC) for determining the optimal tuning parameters in penalty estimators. They proved that the tuning parameters selected by such a GIC produce consistent variable selection and generate computational savings.
Regarding the generation of the candidate tuning parameters in the penalized likelihood framework,
Tibshirani et al. (
2010) first introduced the cyclical coordinate descent algorithm to compute the solution path for generalized linear models with convex penalties such as LASSO and Elastic Net. This algorithm helps generate a set of candidate tuning parameters to facilitate the selection of the optimal tuning parameter.
Breheny and Huang (
2011) further applied this algorithm to calculate the solution path for non-convex penalty estimators such as the SCAD and MCP estimators. They compared the performances of some of the popular penalty estimators such as the LASSO, SCAD, and MCP estimators for variable selection in sparse models. Their simulation study and data examples indicated that the choice of the tuning parameter greatly affects the outcome of the variable selection.
2.1.2. Post-Selection Estimators
Despite decent selection performance from the current mainstream penalized least squares estimators, there is not yet a unified approach in estimating the distribution of such estimators, due to the complicated constraints and penalty functions.
Knight and Fu (
2000);
Pötscher and Leeb (
2009) and
Pötscher and Schneider (
2009), among others, investigated the distributions of LASSO-type and SCAD estimators and concluded that they tend to be highly non-normal. This ushered in the burgeoning development in post-model-selection inferential methods.
Hansen (
2014) stated that the distributions for the model selection and model averaging estimators are highly non-normal but routinely ignored in practice.
Belloni and Chernozhukov (
2013) proposed the OLS post-LASSO estimator, which, under certain assumptions, outperforms the LASSO estimator in reducing asymptotic risks associated with high-dimensional sparse models. The OLS post-LASSO estimator utilizes the LASSO estimator as a variable selection operator in the first step and reverts back to the OLS estimator to produce parameter estimates for the selected model in the second step. Such an estimator avoids the complicated penalty functions in estimating the distribution of the estimator in the second step and thus yields easier access to inference that is solely based on the OLS estimator. Inspired by the OLS post-LASSO estimator, other post-selection estimators could be constructed with the tuning parameters in the penalty function selected by either the BIC or GCV approach.
For example, an OLS post-SCAD(BIC) estimator can be constructed with the tuning parameter in the penalty function selected by the BIC approach. More specifically, let be the set of candidate tuning parameters and with .
Given any
and
defaulting to 3.7, the SCAD estimator from Equation (
6) evaluated at
gives
The BIC evaluated at this
is defined as
, which is given by
where the values for
originate from an exponentially decaying grid as in
Tibshirani et al. (
2010). Let
denote the set of nonzero parameters of the model when evaluated at
, and more specifically,
. For any set
, let
represent its cardinality. Then,
gives the number of nonzero parameters of the model when evaluated at
, and
is a constant.
Shi and Tsai (
2002) have shown that the above BIC with
consistently identifies the true model when both
p and
are finite.
The estimate of the optimal tuning parameter is denoted by
, which is the solution to the following problem:
Consequently,
minimizes the SCAD penalized objective function given by Equation (
6); i.e.,
Denoting
, we define the OLS post-SCAD(BIC) estimator as
where
is an
vector, which is the
column of the predictor matrix
X, and
is the
parameter.
In the same vein, other OLS post-selection estimators such as the OLS post-MCP (BIC or GCV) estimator could also be constructed for comparing the finite sample performances. The OLS post-MCP (BIC or GCV) estimator minimizes, respectively, the BIC and the GCV in the estimation for the optimal tuning parameter. It is worth pointing out that for the penalized estimators that are already oracle efficient, post-selection estimators such as the OLS post-SCAD estimator do not outperform the SCAD estimator asymptotically. That being said, there could be differences in the finite sample performances between the penalized least squares estimators and the OLS post-selection estimators. Even for the same estimator, different tuning parameter selection approaches could also yield different selection outcomes.
2.1.3. Measures of Selection and Estimation Accuracy
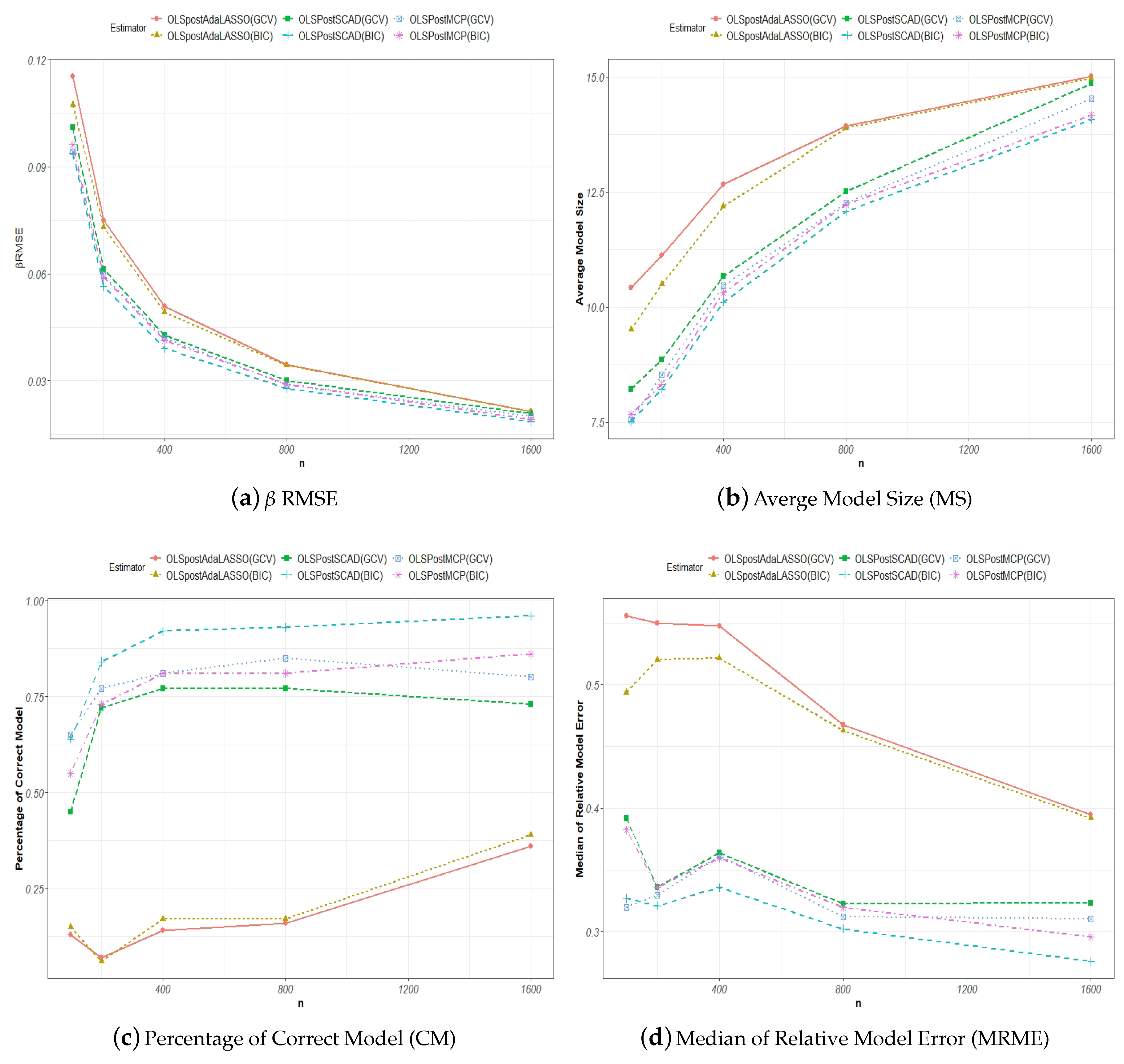
To evaluate the performance of the shrinkage estimators, various measures for variable selection and estimation accuracy have been introduced in the literature.
Wang et al. (
2009) used the model size (MS), the percentage of the correctly identified true model (CM), and the median of relative model error (MRME) to evaluate the finite sample performances of the adaptive LASSO and SCAD estimators with tuning parameters selected either by the GCV or BIC approach.
The model size, MS, for the true model is defined as the number of nonzero parameters or , where is the dimension for the nonzero parameters. For any model selection procedure, ideally, the estimated model size should tend to asymptotically, and . This measure evaluates the precision with which the said selection procedure estimates the number of nonzero parameters from the data. In the context of Monte Carlo simulations, the average is taken over all of the estimated MSs, which are generated per each round of simulation.
The correct model CM is revealed as the true model if the said model selection procedure accurately yields the right nonzero parameters. The CM measure is defined as
An estimation of the model is only considered correct if the above criterion is satisfied, where all of the non-zero and zero parameters are correctly identified. The higher the correction rate over a number of simulation runs, the better the performance for an estimator.
The model prediction error (ME) for a model selection procedure is defined as
where
represents any estimator such as a penalized least squares estimator. The relative model error (RME) is the ratio of the model prediction error to that of the naive OLS estimator of the model given by Equation (
1). For example, the RME for the SCAD estimator is given by
For a given number of Monte Carlo replications, the median of the RME (MRME) is used to evaluate the finite sample performance of the said model selection estimator.
2.2. Model Averaging
On the other hand, an alternative to model selection in handling modeling uncertainties is model averaging. In general, the model averaging estimator is defined as
where
represents the weight assigned to the
model of an
number of candidate models, and
is a weight vector in the unit simplex in
with
, such that
Over time, various estimators have been proposed for estimating the weight vector,
w, for averaging the candidate models.
Buckland et al. (
1997) proposed the smoothed information criterion model averaging estimator, where the weight for the
model,
, can be estimated as
where
, the information criterion evaluated at the
model, is defined as
with
being the maximized likelihood value and
being the penalty term that takes the form of
for the smoothed Akaike information criterion (S-AIC) and
for the smoothed BIC (S-BIC).
Hansen (
2007) proposed a Mallows model averaging (MMA) estimator whose weight choice is estimated as
where the model averaging estimator
is defined as
and the projection matrix for model
s is defined as
Moreover, the effective number of parameters,
, is defined as
where
equals the number of parameters in model
s. The
term can be estimated using the variance of a larger model in the set of the candidate models according to
Hansen (
2007).
Under certain assumptions,
Hansen (
2007) showed that the MMA minimizes the mean squared prediction error (MSPE), and
Gao et al. (
2016) showed that the MMA can produce smaller mean squared errors (MSEs) than the OLS estimator.
Wan et al. (
2010) further relaxed the assumptions of discrete weights and nested regression models that are required by the asymptotic optimality conditions for the MMA to continuous weights without imposing ordering on the predictors.
Hansen and Racine (
2012) proposed the heteroskedasticity-consistent jackknife model averaging (JMA) estimator. The weight choice for the JMA estimator is defined as
where
with
being the leave-one-out residual vector from the
model.
Schomaker (
2012) further explored the role of the tuning parameters in the shrinkage averaging estimator (SAE) post model selection. The SAE estimates
by averaging over a set of candidate shrinkage estimators,
, which are calculated with a sequence of tuning parameters. For example, an SAE that averages over an
number of candidate
from an
-fold cross-validation procedure can be defined as
where
as one of the
competing tuning parameters. The weights for the SAE are calculated as follows:
where
with
being the residual vector for the
cross-validation.
In this paper, we aim to explore the possibility of combining the model selection and model averaging methods in dealing with modeling uncertainty. We expect that the specifications of the candidate models guided by the appropriate choice of tuning parameter could significantly reduce modeling uncertainty given sparse models.







{kind=link}
{kind=link}
{kind=link}
{kind=link}