Identification of Core Suppliers Based on E-Invoice Data Using Supervised Machine Learning



Abstract
1. Introduction
2. Literature Review
2.1. Supplier Segmentation
2.2. E-Invoice
- -
- Date of the invoice;
- -
- Name and contact details of the supplier and buyer;
- -
- Description and unit price of the product; and
- -
- The total amount charged.
3. Methods
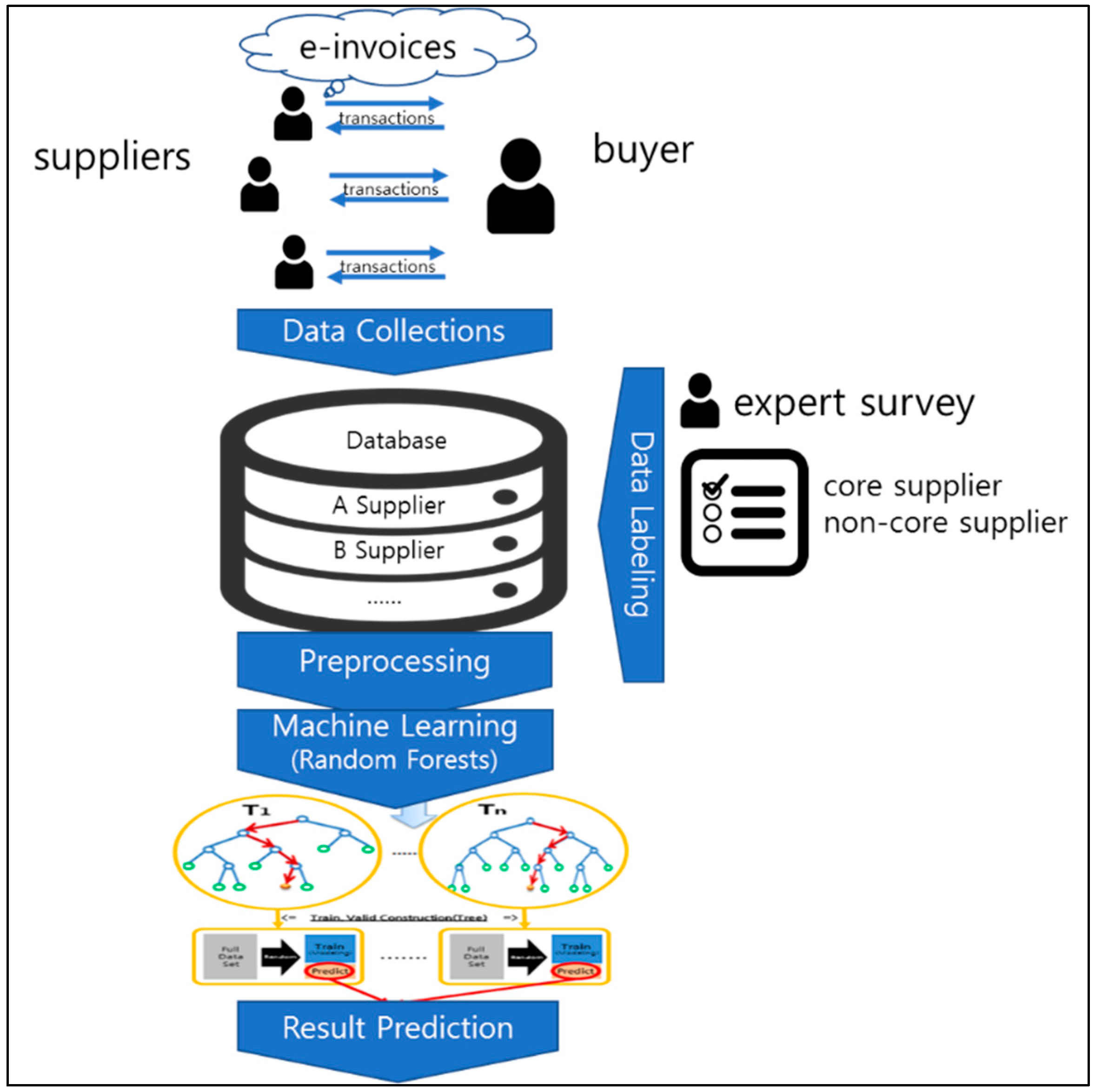
3.1. Overview
3.2. Random Forests (RF)
3.3. Data Preprocessing
3.3.1. Total Cost of Purchase
3.3.2. Transaction Frequency/Cycle
3.3.3. Percentage of Critical Items
3.3.4. Duration of Partnership
3.3.5. Monthly Purchase over the Last 12 Months
3.3.6. Synchronization Index
4. Case Study Results
4.1. Case: Automobile Components Manufacturer
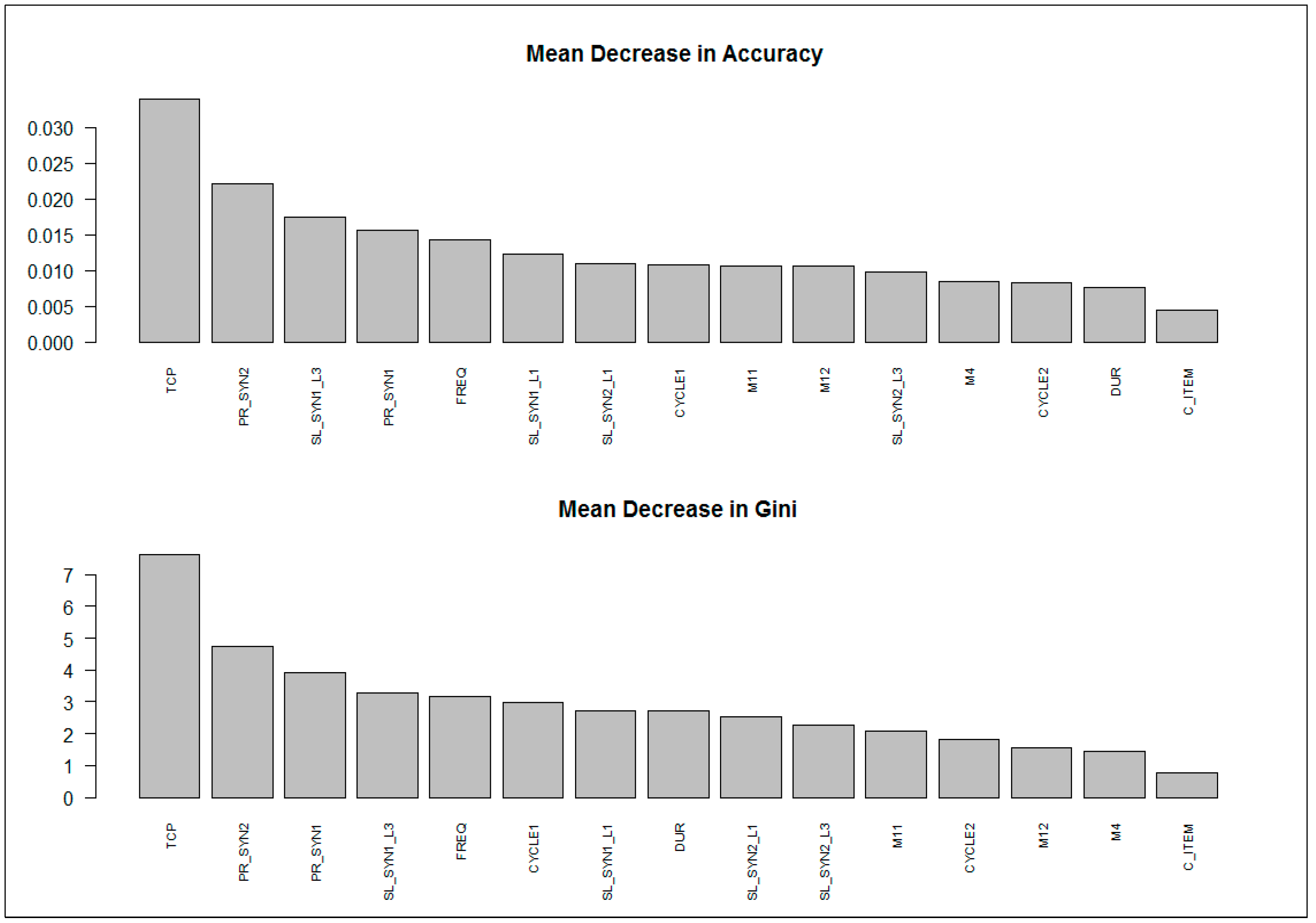
4.2. Results
5. Implications
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Anderson, James C., and James A. Narus. 1990. A Model of Distributor Firm and Manufacturer Firm Working Partnerships. Journal of Marketing 54: 42–58. [Google Scholar] [CrossRef]
- Archer, Kellie J., and Ryan V. Kimes. 2008. Empirical characterization of random forest variable importance measures. Computational Statistics and Data Analysis 52: 2249–60. [Google Scholar] [CrossRef]
- Barney, Jay B., and William G. Ouchi. 1986. Organizational Economics. San Francisco: Jossey-Bass. [Google Scholar]
- Bensaou, Mustapha. 1999. Portfolios of Buyer-Supplier Relationships. Sloan Management Review 40: 35. [Google Scholar]
- Berndt, Donald, and James Clifford. 1994. Using dynamic time warping to find patterns in time series. Workshop on Knowledge Discovery in Databases 398: 359–70. [Google Scholar]
- Breiman, Leo. 2001. Random Forests. Machine Learning 45: 5–32. [Google Scholar] [CrossRef]
- Breiman, Leo. 2002. Manual-Setting up, Using, and Understanding Random Forests. Available online: https://www.stat.berkeley.edu/~breiman/Using_random_forests_v4.0.pdf (accessed on 11 August 2018).
- Brown, Iain, and Christophe Mues. 2012. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Systems with Applications 39: 3446–53. [Google Scholar] [CrossRef]
- Caniëls, Marjolein C. J., and Cees J. Gelderman. 2005. Purchasing strategies in the Kraljic matrix—A power and dependence perspective. Journal of Purchasing and Supply Management 11: 141–55. [Google Scholar] [CrossRef]
- Carter, Joseph R. 1997. Supply positioning at SGX Corporation. Best Practices in Purchasing and Supply Chain Management 1: 5–8. [Google Scholar]
- Chang, Chin-Jui, Huai-Chien Kuo, Chen-Yuan Chen, Tsung-Hao Chen, and Pei-Yin Chung. 2013. Retracted: Ergonomic Techniques for a Mobile E-Invoice System: Operational Requirements of an Information Management System. Human Factors and Ergonomics in Manufacturing & Service Industries 23: 582–89. [Google Scholar]
- Chen, Injazz J., Antony Paulraj, and Augustine A. Lado. 2004. Strategic purchasing, supply management, and firm performance. Journal of Operations Management 22: 505–23. [Google Scholar] [CrossRef]
- Choi, Thomas Y., and Janet L. Hartley. 1996. An Exploration of Supplier Selection Practices across the Supply Chain. Journal of Operations Management 14: 333–43. [Google Scholar] [CrossRef]
- Cox, Andrew. 1996. Relational Competence and Strategic Procurement Management. European Journal of Purchasing and Supply Management 2: 57–70. [Google Scholar] [CrossRef]
- Dyer, Jeffrey H., Dong Sung Cho, and Wujin Cgu. 1998. Strategic Supplier Segmentation: The Next “Best Practice” in Supply Chain Management. California Management Review 40: 57–77. [Google Scholar] [CrossRef]
- Ellram, Lisa M. 1991. Supply-Chain Management: The Industrial Organisation Perspective. International Journal of Physical Distribution & Logistics Management 21: 13–22. [Google Scholar]
- Ferreira, Luís Miguel D. F., Amílcar Arantes, and Alexander A. Kharlamov. 2015. Development of a purchasing portfolio model for the construction industry: An empirical study. Production Planning & Control 26: 377–92. [Google Scholar]
- Gelderman, Cees J., and Dennis R. Mac Donald. 2008. Application of Kraljic’s Purchasing Portfolio Matrix in an Undeveloped Logistics Infrastructure: The Staatsolie Suriname Case. Journal of Transnational Management 13: 77–92. [Google Scholar] [CrossRef]
- Gelderman, Cees J., and Janjaap Semeijn. 2006. Managing the global supply base through purchasing portfolio management. Journal of Purchasing and Supply Management 12: 209–17. [Google Scholar] [CrossRef]
- Gelderman, Cees J., and Arjan J. van Weele. 2002. Strategic Direction through Purchasing Portfolio Management: A Case Study. The Journal of Supply Chain Management 38: 30–37. [Google Scholar] [CrossRef]
- Gelderman, Cees J., and Arjan J. van Weele. 2003. Handling measurement issues and strategic directions in Kraljic’s purchasing portfolio model. Journal of Purchasing and Supply Management 9: 207–16. [Google Scholar] [CrossRef]
- Hallikas, Jukka, Kaisu Puumalainen, Toni Vesterinen, and Veli Matti Virolainen. 2005. Risk-Based Classification of Supplier Relationships. Journal of Purchasing and Supply Management 11: 72–82. [Google Scholar] [CrossRef]
- Hamori, Shigeyuki, Minami Kawai, Takahiro Kume, Yuji Murakami, and Chikara Watanabe. 2018. Ensemble Learning or Deep Learning? Application to Default Risk Analysis. Journal of Risk and Financial Management 11: 12. [Google Scholar] [CrossRef]
- Ishwaran, Hemant, Udaya B. Kogalur, Eiran Z. Gorodeski, Andy J. Minn, and Michael S. Lauer. 2010. High-dimensional variable selection for survival data. Journal of the American Statistical Association 105: 205–17. [Google Scholar] [CrossRef]
- Keifer, Steve. 2011. E-invoicing: The catalyst for financial supply chain efficiencies. Journal of Payments Strategy & Systems 5: 38–35. [Google Scholar]
- Kotsiantis, Sotiris B. 2007. Supervised Machine Learning: A Review of Classification Techniques. Informatica 31: 249–68. [Google Scholar] [CrossRef]
- Kraljic, Peter Pl Peter. 1983. Purchasing must become supply management. Harvard Business Review 61: 109–17. [Google Scholar]
- Lambert, Douglas M., Margaret A. Emmelhainz, and John T. Gardner. 1996. Developing and Implementing Supply Chain Partnerships. The International Journal of Logistics Management 7: 1–18. [Google Scholar] [CrossRef]
- Lai, Kee Hung, T. C. E. Cheng, and A. C. L. Yeung. 2005. Relationship stability and supplier commitment to quality. International Journal of Production Economics 96: 397–410. [Google Scholar] [CrossRef]
- Li, Ruey-Hsia, and Geneva Belford. 2002. Instability of decision tree classification algorithms. Paper presented at 8th SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, July 23–25. [Google Scholar] [CrossRef]
- Liu, Xiaobing, and Jia Xu. 2008. Research on the Purchasing Portfolio Approach for Steel Industry. Proceedings of the World Congress on Intelligent Control and Automation (WCICA), Chongqing, China, June 25–27. [Google Scholar] [CrossRef]
- Lian, Jiunn Woei. 2015. Critical factors for cloud based e-invoice service adoption in Taiwan: An empirical study. International Journal of Information Management 35: 98–109. [Google Scholar] [CrossRef]
- Liaw, Andy, and Mattew Wiener. 2002. Classification and Regression by Random Forest. R News 2: 18–22. [Google Scholar] [CrossRef]
- Luong, Chuong, and Nikolai Dokuchaev. 2018. Forecasting of Realised Volatility with the Random Forests Algorithm. Journal of Risk and Financial Management 11: 61. [Google Scholar] [CrossRef]
- Masella, Cristina, and Andrea Rangone. 2000. A Contingent Approach to the Design of Vendor Selection Systems for Different Types of Co-Operative Customer/Supplier Relationships. International Journal of Operations & Production Management 20: 70–84. [Google Scholar] [CrossRef]
- Mayer, Abby. 2014. Supply Chain Metrics That Matter: A Focus on Aerospace & Defense. Available online: http://supplychaininsights.com/wp-content/uploads/2014/03/Supply_Chain_Metrics_That_Matter-A_Focus_on_Aerospace__Defense-18_MAR_2014.pdf (accessed on 1 September 2018).
- Medeiros, Marlene, and Luciano Ferreira. 2018. Development of a purchasing portfolio model: An empirical study in a Brazilian hospital. Production Planning & Control 29: 571–85. [Google Scholar]
- Montgomery, Robert T., Jeffrey A. Ogden, and Bradley C. Boehmke. 2017. A quantified Kraljic Portfolio Matrix: Using decision analysis for strategic purchasing. Journal of Purchasing and Supply Management. 24: 192–203. [Google Scholar] [CrossRef]
- Mueen, Abdullah, and Eamonn Keogh. 2016. Extracting optimal performance from dynamic time warping. Paper presented at the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, August 13–17. [Google Scholar]
- Olsen, Rasmus Friis, and Lisa M. Ellram. 1997. A portfolio approach to supplier relationships. Industrial Marketing Management 26: 101–13. [Google Scholar] [CrossRef]
- Padhi, Sidhartha S., Stephan M. Wagner, and Vijay Aggarwal. 2012. Positioning of commodities using the Kraljic Portfolio Matrix. Journal of Purchasing and Supply Management 18: 1–8. [Google Scholar] [CrossRef]
- Parasuraman, A. 1980. Vendor Segmentation: An Additional Level of Market Segmentation. Industrial Marketing Management 9: 59–62. [Google Scholar] [CrossRef]
- Park, Jongkyung, Kitae Shin, Tai-Woo Chang, and Jinwoo Park. 2010. An integrative framework for supplier relationship management. Industrial Management & Data Systems 110: 495–515. [Google Scholar] [CrossRef]
- Ramon-Jeronimo, Juan, and Raquel Florez-Lopez. 2018. What Makes Management Control Information Useful in Buyer–Supplier Relationships? Journal of Risk and Financial Management 11: 31. [Google Scholar] [CrossRef]
- Rezaei, Jafar, and Roland Ortt. 2013. Multi-Criteria Supplier Segmentation Using a Fuzzy Preference Relations Based AHP. European Journal of Operational Research 225: 75–84. [Google Scholar] [CrossRef]
- Svensson, Göran. 2004. Supplier Segmentation in the Automotive Industry: A Dyadic Approach of a Managerial Model. International Journal of Physical Distribution & Logistics Management 34: 12–38. [Google Scholar] [CrossRef]
- Suwisuthikasem, Sukanya, and Songsri Tangsripairoj. 2008. E-Tax Invoice System using Web Services technology: A case study of the Revenue Department of Thailand. Paper presented at 9th ACIS International Conference Software Engineering, Artificial Intelligence, Networking and Parallel/Distributed Computing, Phuket, Thailand, August 6–8. [Google Scholar] [CrossRef]
- Tormene, Paolo, Toni Giorgino, Silvana Quaglini, and Mario Stefanelli. 2009. Matching incomplete time series with dynamic time warping: An algorithm and an application to post-stroke rehabilitation. Artificial Intelligence in Medicine 45: 11–34. [Google Scholar] [CrossRef] [PubMed]
- Van Weele, Arjan J. 2010. Purchasing & Supply Chain Management: Analysis, Strategy, Planning and Practice. Andover: Cengage Learning EMEA. [Google Scholar]
- Wagner, Stephan M., Christoph Bode, and Philipp Koziol. 2009. Supplier default dependencies: Empirical evidence from the automotive industry. European Journal of Operational Research 199: 150–61. [Google Scholar] [CrossRef]
- Wagner, Stephan M., and Jean L. Johnson. 2004. Configuring and managing strategic supplier portfolios. Industrial Marketing Management 33: 717–30. [Google Scholar] [CrossRef]
- Wagner, Stephan M., Sidhartha S. Padhi, and Christoph Bode. 2013. The procurement process. Industrial Engineer 45: 34–39. [Google Scholar]
- Williamson, Oliver E. 1979. Transaction-cost economics: The governance of contractual relations. The Journal of Law and Economics 22: 233–61. [Google Scholar] [CrossRef]
- Zhang, Guoqiang, Eddy Patuwo, and Michael Hu. 1998. Forecasting with artificial neural networks: The state of the art. International Journal of Forecasting 14: 35–62. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Name | Description | Type |
|---|---|---|---|
| 1 | TCP | Total cost of purchase: Total purchased cost from a supplier during the analysis period. | Numeric |
| 2 | FREQ | Transaction Frequency: Total number of transactions with a supplier during the analysis period. | Numeric |
| 3 | CYCLE1 | Transaction Cycle: Average interval between transactions with a supplier. | Numeric |
| 4 | CYCLE2 | Transaction Cycle: Standard deviation of intervals between transactions with a supplier. | Numeric |
| 5 | C_ITEM | Percentage of critical items’ transaction: Supplier’s ratio of the purchase cost of the top three item categories to the total purchase cost. | Numeric |
| 6 | DUR | Duration of partnership: Time duration between the first and the last transaction with a supplier | Numeric |
| 7 | {M1,M2,…, M12} | Monthly purchases over the last 12 months: monthly purchase cost of a supplier over the last 12 months. Mj denotes a monthly purchase j months ago. | Numeric |
| 8 | PR_SYN1 | Synchronization index: Similarity between a monthly purchase of a supplier’s primary item and a monthly purchase of a buyer. | Numeric |
| 9 | PR_SYN2 | Synchronization index: Similarity between a monthly purchase from a supplier and a monthly purchase of a buyer. | Numeric |
| 10 | SL_SYN1 {L1, L3} | Synchronization index: Similarity between a monthly purchase of a supplier’s primary item and a monthly revenue of a buyer. L1 indicates a one-month time lag and L3 indicates a three-month time lag. | Numeric |
| 11 | SL_SYN1 {L1, L3} | Synchronization index: Similarity between a monthly purchase from a supplier and a monthly revenue of a buyer. L1 indicates a one-month time lag and L3 indicates a three-month time lag. | Numeric |
| Actual Class | |||
|---|---|---|---|
| Core Supplier | Non-Core Supplier | ||
| Predicted Class | Core Supplier | TP (True Positive) | FP (False Positive) |
| Non-Core Supplier | FN (False Negative) | TN (True Negative) | |
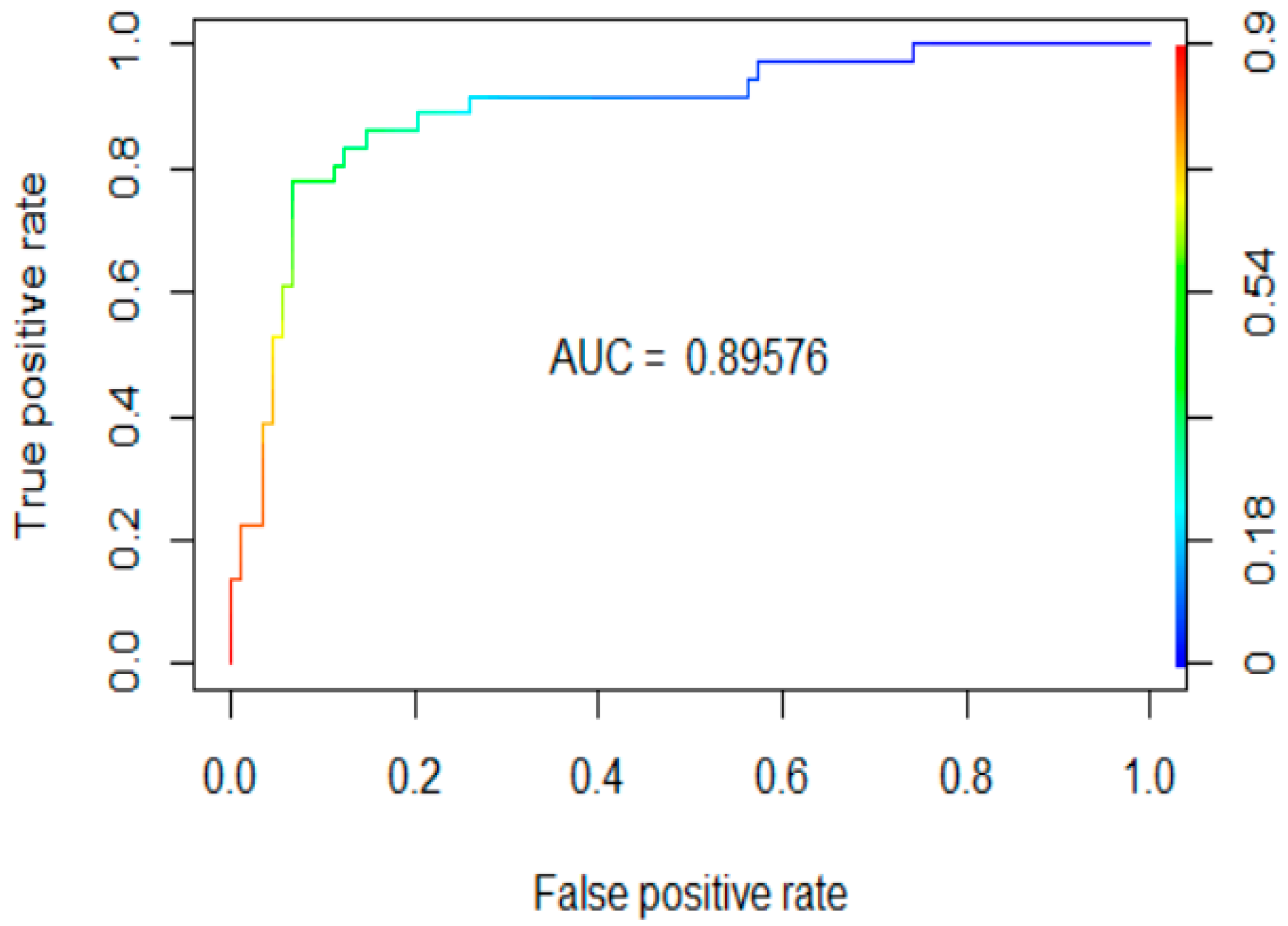
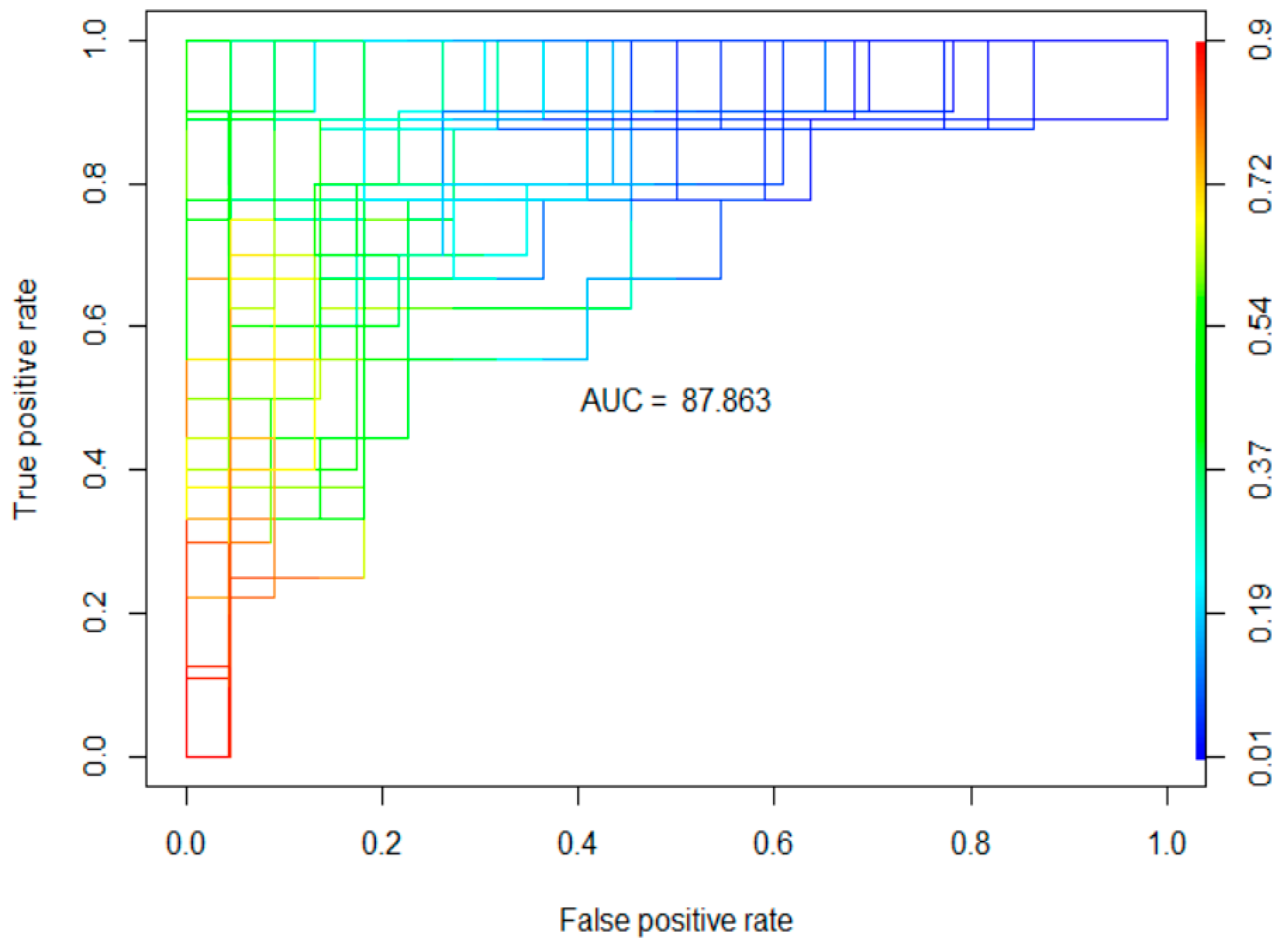
| Test Data | Threshold | Accuracy | Weighted F1-Score | Recall | Precision | AUC |
|---|---|---|---|---|---|---|
| OOB | 0.5 | 84.38 (3.16) | 71.84 (6.23) | 69.63 (7.82) | 74.41(5.23) | 89.58 |
| 0.47 | 85.26 (3.83) | 76.94 (4.96) | 84.62 (6.7) | 71.24 (7.96) | ||
| Cross-validation | 0.5 | 81.71 (7.09) | 66.52 (12.18) | 63.56 (14.98) | 72.76 (15.92) | 87.86 (7.3) |
| 0.47 | 80.4 (11.13) | 70.43 (11.81) | 78.14 (16.77) | 67.68 (16.99) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, J.-s.; Yeo, H.; Cho, N.-W.; Ahn, T. Identification of Core Suppliers Based on E-Invoice Data Using Supervised Machine Learning. J. Risk Financial Manag. 2018, 11, 70. https://doi.org/10.3390/jrfm11040070
Hong J-s, Yeo H, Cho N-W, Ahn T. Identification of Core Suppliers Based on E-Invoice Data Using Supervised Machine Learning. Journal of Risk and Financial Management. 2018; 11(4):70. https://doi.org/10.3390/jrfm11040070
Chicago/Turabian StyleHong, Jung-sik, Hyeongyu Yeo, Nam-Wook Cho, and Taeuk Ahn. 2018. "Identification of Core Suppliers Based on E-Invoice Data Using Supervised Machine Learning" Journal of Risk and Financial Management 11, no. 4: 70. https://doi.org/10.3390/jrfm11040070
APA StyleHong, J.-s., Yeo, H., Cho, N.-W., & Ahn, T. (2018). Identification of Core Suppliers Based on E-Invoice Data Using Supervised Machine Learning. Journal of Risk and Financial Management, 11(4), 70. https://doi.org/10.3390/jrfm11040070