
Towards Reliable Baselines for Document-Level Sentiment Analysis in the Czech and Slovak Languages


Abstract
1. Introduction
1.1. Terminology
1.2. Challenges
- (a)
- Individual reviewer inconsistency, e.g., when the same reviewer associates their own very similarly worded reviews with different star ratings;
- (b)
- Lack of inter-reviewer calibration, e.g., high praise by an understated author can be interpreted as a lukewarm or neutral reaction by others;
- (c)
- Ratings not entirely supported by the review text, as when the review mentions only some partial aspects or details, while the rating captures the overall impression of the target, including aspects not explicitly mentioned in the text.
1.3. Approaches
2. Related Work
- We validate and correct the main baseline results for Czech reported by Habernal et al. [50] on their three datasets;
- We show that their online product review dataset from Mall.cz contains more than 18% of non-trivial duplicates and must therefore be de-duplicated before analysis;
- We demonstrate that, without deduplication, the macro F1-measure results for the Mall.cz dataset are inflated by more than 19 percentage points and thus completely unreliable;
- We establish that part-of-speech-related features have no damaging effect on machine learning algorithms, contrary to the claim made by Habernal et al. [50];
- We rehabilitate the Chi-squared metric for feature selection as being on par with the best performing metrics like Information Gain;
- We demonstrate that in feature selection experiments with Information Gain and Chi-squared metrics, the top 10% of ranked unigram and bigram features suffice for the best results regarding the online product and movie reviews, while the top 5% of ranked unigram and bigram features are optimal for the Facebook dataset;
- We reiterate an important, but often ignored, warning by Forman and Scholz [69] that different possible ways of averaging the F1-measure in cross-validation studies of highly unbalanced datasets can lead to results differing by more than 10 percentage points. This can invalidate comparisons of F1 results across different studies if incompatible ways of averaging F1 are used.
3. Summary of Relevant Experiments and Results Reported in [50]
3.1. Results for Optimum Configurations Using All Features of the Included Feature Types
3.2. Feature Selection Experiments
4. Replication Experiments and Their Results
- What are the true baseline macro-F1 results for the three datasets after deduplication?
- Is the alleged damaging effect of the POS-related features on product reviews real?
- Is the Chi-Squared metric really so detrimental to feature extraction and so different from other metrics?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positive Product Reviews (Mall.cz) | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Number of copies | 20 | 15 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Number of distinct reviews | 1 | 1 | 2 | 2 | 2 | 8 | 15 | 23 | 55 | 216 | 854 | 3427 | 7126 | 26,101 |
| Negative Product Reviews (Mall.cz) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Number of copies | 27 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Number of distinct reviews | 1 | 1 | 3 | 12 | 23 | 120 | 396 | 1072 | 4486 |
| Neutral Product Reviews (Mall.cz) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of copies | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Number of distinct reviews | 2 | 1 | 9 | 11 | 39 | 78 | 356 | 1097 | 2623 | 12,007 |
| Macro-F1 Results Category: | Facebook (%) | Product Reviews Mall.cz (%) | Movie Reviews csfd.cz (%) |
|---|---|---|---|
| Best result in [50] regardless of configuration | 69 | 75.30 | 78.50 |
| Result in [50] for “ShCl” configuration using all word unigrams and bigrams | 66 | 74.02 | 78.21 |
| Our replicated result for “ShCl” configuration using all unigrams and bigrams | 64.77 | 76.2 | 78.9 |
| Our result for “ShCl” configuration using all unigrams and bigrams AFTER DEDUPLICATION | 66.4 | 57.07 | 78.26 |
4.1. True Macro-F1 Baselines for the Three Datasets
4.2. On the Alleged Damaging Effect of POS-Related Features
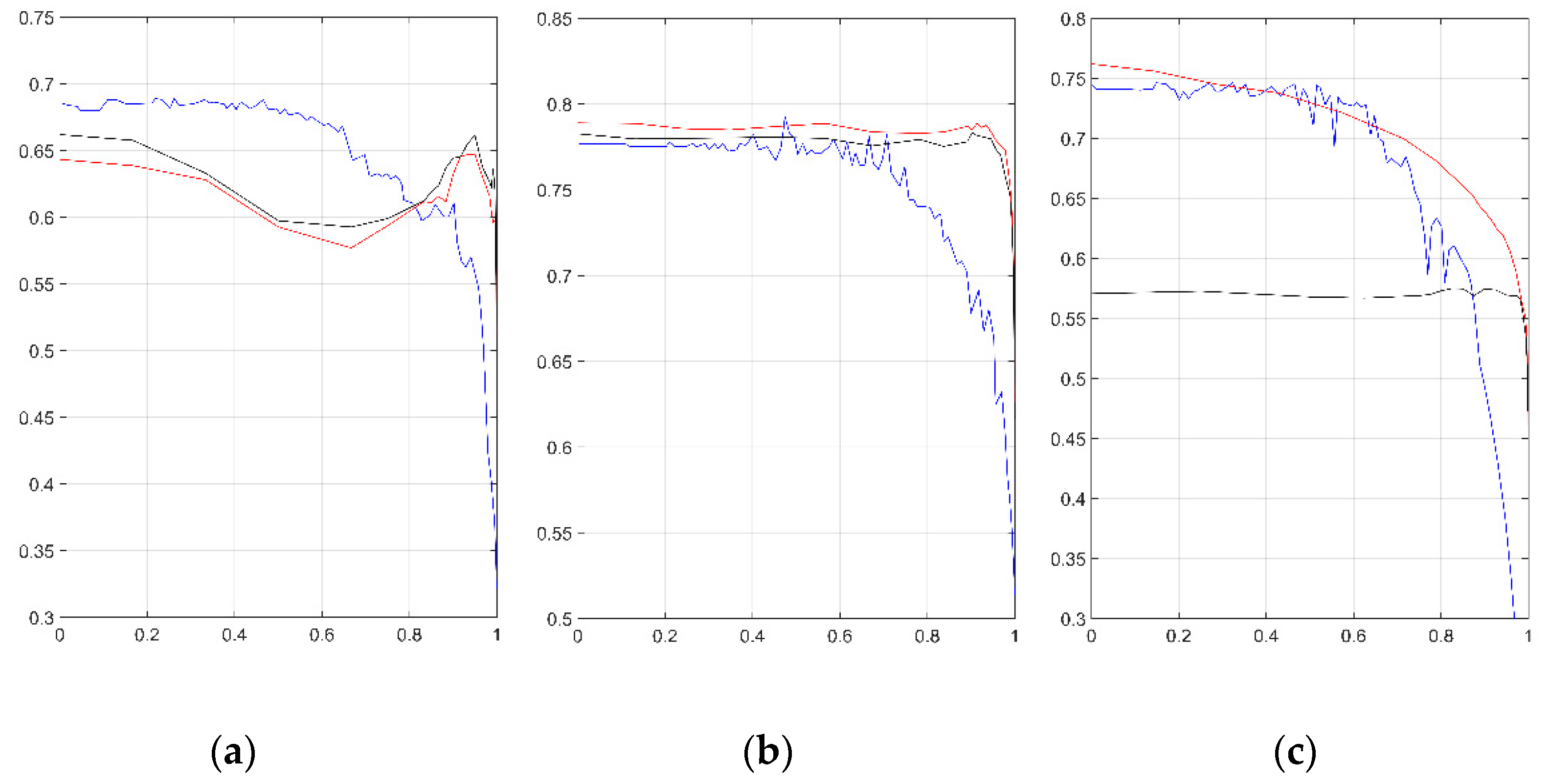
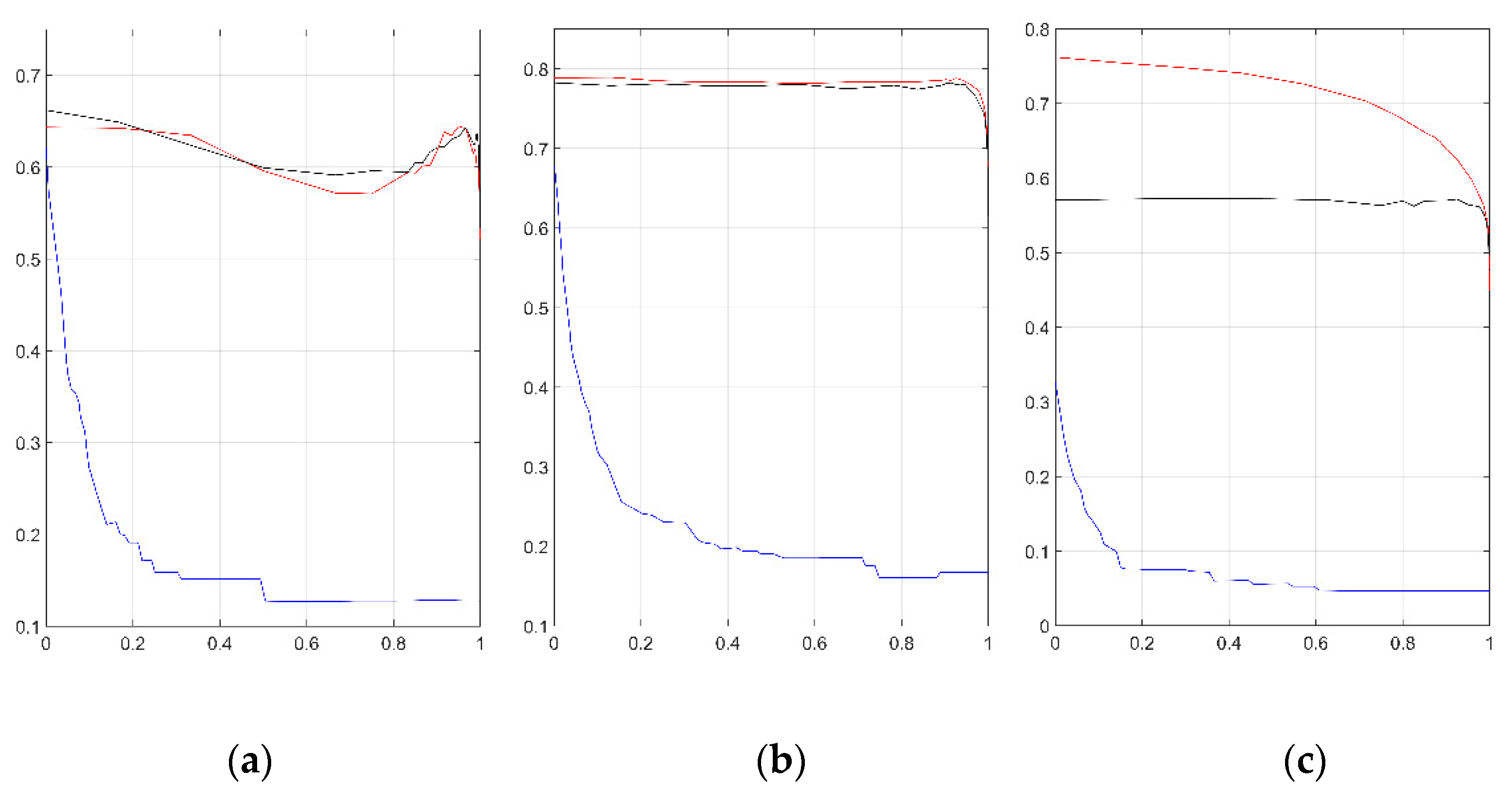
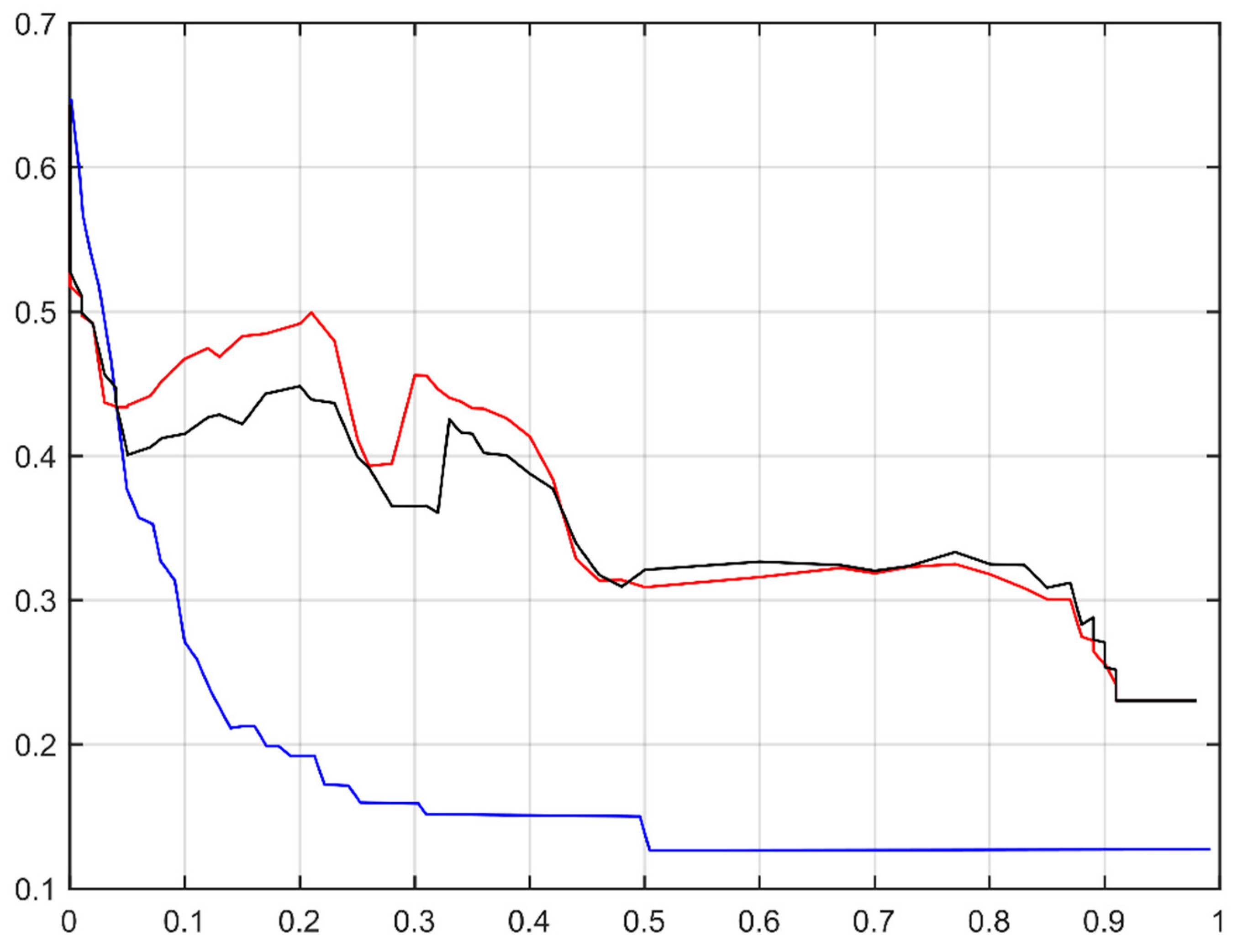
4.3. Feature Selection Experiments with the Information Gain Metric
4.4. Feature Selection Experiments with the Chi-Squared Metric
5. Discussion and Methodological Considerations
5.1. Facilitating Replication of Research Results
- (a)
- Large quantities of duplicates in the product review dataset from Mall.cz that had to be removed prior to analysis;
- (b)
- Incorrect conclusion that the POS-related features have a detrimental effect on sentiment analysis;
- (c)
- Incorrect conclusion that the Chi-squared metric is unsuitable for feature selection in sentiment analysis in Czech.
5.2. On the Comparison of Averaged F1 Scores across Studies
- The F1 score will be calculated for each fold from the precision and recall for that fold and then averaged;
- Precision and recall will be calculated for each fold, then averaged, and, finally, the “average” F1 will be calculated as a harmonic mean of the averaged values of precision and recall;
- True positives TP, false positives FP, and false negatives FN will be calculated for each fold, then averaged, and the “average” F1 will be calculated from their averages through the alternative formula.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pang, B.; Lee, L.; Vaithyanathan, S. Thumbs up? Sentiment classification using machine learning techniques. arXiv 2002, arXiv:cs/0205070. [Google Scholar]
- Turney, P.D. Thumbs up or thumbs down? Semantic orientation applied to unsupervised classification of reviews. arXiv 2002, arXiv:cs/0212032. [Google Scholar]
- Turney, P.D.; Littman, M.L. Measuring praise and criticism: Inference of semantic orientation from association. ACM Trans. Inf. Syst. (Tois) 2003, 21, 315–346. [Google Scholar] [CrossRef]
- Dave, K.; Lawrence, S.; Pennock, D.M. Mining the peanut gallery: Opinion extraction and semantic classification of product reviews. In Proceedings of the 12th International Conference on World Wide Web, Budapest, Hungary, 20–24 May 2003; pp. 519–528. [Google Scholar]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. Comput. Sci. Rev. 2018, 27, 16–32. [Google Scholar] [CrossRef]
- Liu, B. Sentiment analysis and opinion mining. Synth. Lect. Hum. Lang. Technol. 2012, 5, 1–167. [Google Scholar]
- Liu, B. Sentiment Analysis: Mining Opinions, Sentiments, and Emotions; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Pang, B.; Lee, L. Opinion mining and sentiment analysis. Found. Trends® Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Tang, H.; Tan, S.; Cheng, X. A survey on sentiment detection of reviews. Expert Syst. Appl. 2009, 36, 10760–10773. [Google Scholar] [CrossRef]
- Tsytsarau, M.; Palpanas, T. Survey on mining subjective data on the web. Data Min. Knowl. Discov. 2012, 24, 478–514. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V.; Ellsworth, P. What emotion categories or dimensions can observers judge from facial behavior? In Emotions in the Human Face, 2nd ed.; Ekman, P., Ed.; Cambridge University Press: Cambridge, UK, 1982; pp. 39–55. [Google Scholar]
- Fahrni, A.; Klenner, M. Old wine or warm beer: Target-specific sentiment analysis of adjectives. In AISB 2008 Convention Communication, Interaction and Social Intelligence 1–4 April 2008; The Society for the Study of Artificial Intelligence and Simulation of Behaviour: Brighton, UK, 2008. [Google Scholar]
- Pang, B.; Lee, L. Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales. arXiv 2005, arXiv:cs/0506075. [Google Scholar]
- Hazarika, B.; Chen, K.; Razi, M. Are numeric ratings true representations of reviews? A study of inconsistency between reviews and ratings. Int. J. Bus. Inf. Syst. 2021, 38, 85–106. [Google Scholar] [CrossRef]
- Batista, H.R.; Junior JC, G.; Miranda, M.D.; Martiniano, A.; Sassi, R.J.; Gaspar, M.A. “If We Only Knew How You Feel”—A Comparative Study of Automated vs. Manual Classification of Opinions of Customers on Digital Media. Soc. Netw. 2018, 8, 74–83. [Google Scholar] [CrossRef][Green Version]
- Stone, P.J.; Dunphy, D.C.; Smith, M.S. The General Inquirer: A Computer Approach to Content Analysis; M.I.T. Press: Cambridge, MA, USA, 1966. [Google Scholar]
- Strapparava, C.; Valitutti, A. Wordnet affect: An affective extension of wordnet. Lrec 2004, 4, 40. [Google Scholar]
- Esuli, A.; Sebastiani, F. Sentiwordnet: A publicly available lexical resource for opinion mining. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06), Genoa, Italy, 22–28 May 2006. [Google Scholar]
- Mohammad, S.; Turney, P. Emotions evoked by common words and phrases: Using mechanical turk to create an emotion lexicon. In Proceedings of the NAACL HLT 2010 Workshop on Computational Approaches to Analysis and Generation of Emotion in Text, Los Angeles, CA, USA, 5 June 2010; pp. 26–34. [Google Scholar]
- Machova, K.; Marhefka, L. Opinion classification in conversational content using n-grams. In Recent Developments in Computational Collective Intelligence; Springer: Cham, Switzerland, 2014; pp. 177–186. [Google Scholar]
- Church, K.; Hanks, P. Word association norms, mutual information, and lexicography. Comput. Linguist. 1990, 16, 22–29. [Google Scholar]
- Kim, S.M.; Hovy, E. Determining the sentiment of opinions. In Proceedings of the COLING 2004: Proceedings of the 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004; pp. 1367–1373. [Google Scholar]
- Hu, M.; Liu, B. Mining and summarizing customer reviews. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004; pp. 168–177. [Google Scholar]
- Kamps, J.; Marx, M.; Mokken, R.J.; De Rijke, M. Using WordNet to measure semantic orientations of adjectives. Lrec 2004, 4, 1115–1118. [Google Scholar]
- Osherenko, A.; André, E. Lexical affect sensing: Are affect dictionaries necessary to analyze affect? In Proceedings of the International Conference on Affective Computing and Intelligent Interaction, Lisbon, Portugal, 12–14 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 230–241. [Google Scholar]
- Machova, K.; Mach, M.; Vasilko, M. Comparison of machine learning and sentiment analysis in detection of suspicious online reviewers on different type of data. Sensors 2021, 22, 155. [Google Scholar] [CrossRef] [PubMed]
- Mohamad Sham, N.; Mohamed, A. Climate Change Sentiment Analysis Using Lexicon, Machine Learning and Hybrid Approaches. Sustainability 2022, 14, 4723. [Google Scholar] [CrossRef]
- Palomino, M.A.; Aider, F. Evaluating the Effectiveness of Text Pre-Processing in Sentiment Analysis. Appl. Sci. 2022, 12, 8765. [Google Scholar] [CrossRef]
- Ruz, G.A.; Henríquez, P.A.; Mascareño, A. Bayesian Constitutionalization: Twitter Sentiment Analysis of the Chilean Constitutional Process through Bayesian Network Classifiers. Mathematics 2022, 10, 166. [Google Scholar] [CrossRef]
- Reshi, A.A.; Rustam, F.; Aljedaani, W.; Shafi, S.; Alhossan, A.; Alrabiah, Z.; Ahmad, A.; Alsuwailem, H.; Almangour, T.A.; Alshammari, M.A.; et al. COVID-19 Vaccination-Related Sentiments Analysis: A Case Study Using Worldwide Twitter Dataset. Healthcare 2022, 10, 411. [Google Scholar] [CrossRef]
- Tesfagergish, S.G.; Kapočiūtė-Dzikienė, J.; Damaševičius, R. Zero-Shot Emotion Detection for Semi-Supervised Sentiment Analysis Using Sentence Transformers and Ensemble Learning. Appl. Sci. 2022, 12, 8662. [Google Scholar] [CrossRef]
- Li, R.; Chen, H.; Feng, F.; Ma, Z.; Wang, X.; Hovy, E. Dual graph convolutional networks for aspect-based sentiment analysis. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Virtual, 1–6 August 2021; Volume 1, pp. 6319–6329. [Google Scholar]
- Tian, Y.; Chen, G.; Song, Y. Enhancing aspect-level sentiment analysis with word dependencies. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Online, 19–23 April 2021; pp. 3726–3739. [Google Scholar]
- Mujahid, M.; Lee, E.; Rustam, F.; Washington, P.B.; Ullah, S.; Reshi, A.A.; Ashraf, I. Sentiment analysis and topic modeling on tweets about online education during COVID-19. Appl. Sci. 2021, 11, 8438. [Google Scholar] [CrossRef]
- Moreno, A.; Iglesias, C.A. Understanding Customers’ Transport Services with Topic Clustering and Sentiment Analysis. Appl. Sci. 2021, 11, 10169. [Google Scholar] [CrossRef]
- Bacco, L.; Cimino, A.; Dell’Orletta, F.; Merone, M. Explainable sentiment analysis: A hierarchical transformer-based extractive summarization approach. Electronics 2021, 10, 2195. [Google Scholar] [CrossRef]
- Lovera, F.A.; Cardinale, Y.C.; Homsi, M.N. Sentiment Analysis in Twitter Based on Knowledge Graph and Deep Learning Classification. Electronics 2021, 10, 2739. [Google Scholar] [CrossRef]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Systematic reviews in sentiment analysis: A tertiary study. Artif. Intell. Rev. 2021, 54, 4997–5053. [Google Scholar] [CrossRef]
- Hartmann, J.; Heitmann, M.; Siebert, C.; Schamp, C. More than a feeling: Accuracy and application of sentiment analysis. Int. J. Res. Mark. 2022, in press. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lehečka, J.; Švec, J.; Ircing, P.; Šmídl, L. Bert-based sentiment analysis using distillation. In Proceedings of the International Conference on Statistical Language and Speech Processing, Cardiff, UK, 14–16 October 2020; Springer: Cham, Switzerland; pp. 58–70. [Google Scholar]
- Straka, M.; Náplava, J.; Straková, J.; Samuel, D. RobeCzech: Czech RoBERTa, a monolingual contextualized language representation model. In International Conference on Text, Speech, and Dialogue; Springer: Cham, Switzerland; pp. 197–209.
- Sido, J.; Pražák, O.; Přibáň, P.; Pašek, J.; Seják, M.; Konopík, M. Czert--Czech BERT-like Model for Language Representation. arXiv 2021, arXiv:2103.13031. [Google Scholar]
- Pikuliak, M.; Grivalský, Š.; Konôpka, M.; Blšták, M.; Tamajka, M.; Bachratý, V.; Šimko, M.; Balážik, P.; Trnka, M.; Uhlárik, F. SlovakBERT: Slovak Masked Language Model. arXiv 2021, arXiv:2109.15254. [Google Scholar]
- Hupkes, D.; Veldhoen, S.; Zuidema, W. Visualisation and ‘diagnostic classifiers’ reveal how recurrent and recursive neural networks process hierarchical structure. J. Artif. Intell. Res. 2018, 61, 907–926. [Google Scholar] [CrossRef]
- Conneau, A.; Kruszewski, G.; Lample, G.; Barrault, L.; Baroni, M. What you can cram into a single vector: Probing sentence embeddings for linguistic properties. arXiv 2018, arXiv:1805.01070. [Google Scholar]
- Hewitt, J.; Manning, C.D. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4129–4138. [Google Scholar]
- Reif, E.; Yuan, A.; Wattenberg, M.; Viegas, F.B.; Coenen, A.; Pearce, A.; Kim, B. Visualizing and measuring the geometry of BERT. Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Habernal, I.; Ptáček, T.; Steinberger, J. Supervised sentiment analysis in Czech social media. Inf. Process. Manag. 2014, 50, 693–707. [Google Scholar] [CrossRef]
- Veselovská, K. Sentiment Analysis in Czech; Ústav Formální a Aplikované Lingvistiky, ÚFAL MFF UK: Praha, Czech Republic, 2017. [Google Scholar]
- Klimešová, P. Sentiment Analysis with Linguistic Knowledge. Bachelor’s Thesis, Faculty of Informatics, Masaryk University, Brno, Czech Republic, 2022. Available online: https://is.muni.cz/th/n0lnb/Sentiment_Analysis_cz.pdf (accessed on 17 October 2022).
- Smrž, P. Using WordNet for opinion mining. In Proceedings of the Third International WordNet Conference, Seogwipo, Korea, 22–26 January 2006; pp. 333–335. [Google Scholar]
- Smrž, P. Automatic acquisition of semantics-extraction patterns. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06), Genoa, Italy, 22–28 May 2006. [Google Scholar]
- Žižka, J.; Dařena, F. Automatic sentiment analysis using the textual pattern content similarity in natural language. In Proceedings of the International Conference on Text, Speech and Dialogue, Brno, Czech Republic, 6–10 September 2010; Springer: Berlin/Heidelberg, Germany; pp. 224–231. [Google Scholar]
- Veselovská, K.; Hajic, J.; Sindlerová, J. Creating annotated resources for polarity classification in Czech. In Proceedings of the 11th Conference on Natural Language Processing (KONVENS), Vienna, Austria, 19–21 September 2012; pp. 296–304. [Google Scholar]
- Červenec, R. Rozpoznávání emocí v česky psaných textech. Ph.D. Thesis, Fakulta Elektrotechniky a Komunikačních Technologií, Vysoké Učení Technické v Brně, Brno, Czech Republic, 2011. [Google Scholar]
- Habernal, I.; Ptáček, T.; Steinberger, J. Sentiment analysis in Czech social media using supervised machine learning. In Proceedings of the 4th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Atlanta, Georgia, 14 June 2013; pp. 65–74. [Google Scholar]
- Habernal, I.; Brychcín, T. Semantic spaces for sentiment analysis. In Proceedings of the International Conference on Text, Speech and Dialogue, Pilsen, Czech Republic, 1–5 September 2013; Springer: Berlin/Heidelberg, Germany; pp. 484–491. [Google Scholar]
- Brychcín, T.; Habernal, I. Unsupervised improving of sentiment analysis using global target context. In Proceedings of the International Conference Recent Advances in Natural Language Processing RANLP, Online, 1–3 September 2013; pp. 122–128. [Google Scholar]
- Kincl, T.; Novák, M.; Přibil, J.; Štrach, P. Language-independent sentiment analysis with surrounding context extension. In Proceedings of the International Conference on Social Computing and Social Media, Los Angeles, CA, USA, 2–7 August 2015; Springer: Cham, Switzerland, 2015; pp. 158–168. [Google Scholar]
- Lenc, L.; Hercig, T. Neural Networks for Sentiment Analysis in Czech. In Proceedings of the ITAT, Tatranské Matliare, Slovakia, 15–19 September 2016; pp. 48–55. [Google Scholar]
- Hercig, T.; Krejzl, P.; Hourová, B.; Steinberger, J.; Lenc, L. Detecting Stance in Czech News Commentaries. In Proceedings of the ITAT, Martinské Hole, Slovakia, 22–26 September 2017; pp. 176–180. [Google Scholar]
- Libovický, J.; Rosa, R.; Helcl, J.; Popel, M. Solving Three Czech NLP Tasks with End-to-end Neural Models. In Proceedings of the ITAT, Plejsy, Slovakia, 21–25 September 2018; pp. 138–143. [Google Scholar]
- Cano, E.; Bojar, O. Sentiment analysis of Czech texts: An algorithmic survey. arXiv 2019, arXiv:1901.02780. [Google Scholar]
- Krchnavy, R.; Simko, M. Sentiment analysis of social network posts in Slovak language. In Proceedings of the 2017 12th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Bratislava, Slovakia, 9–10 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 20–25. [Google Scholar]
- Pecar, S.; Simko, M.; Bielikova, M. Sentiment analysis of customer reviews: Impact of text pre-processing. In Proceedings of the 2018 World Symposium on Digital Intelligence for Systems and Machines (DISA), Košice, Slovakia, 23–25 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 251–256. [Google Scholar]
- Pecar, S.; Šimko, M.; Bielikova, M. Improving sentiment classification in Slovak language. In Proceedings of the 7th Workshop on Balto-Slavic Natural Language Processing, Florence, Italy, 2 August 2019; pp. 114–119. [Google Scholar]
- Forman, G.; Scholz, M. Apples-to-apples in cross-validation studies: Pitfalls in classifier performance measurement. ACM Sigkdd Explor. Newsl. 2010, 12, 49–57. [Google Scholar] [CrossRef]
- Korenek, P.; Šimko, M. Sentiment analysis on microblog utilizing appraisal theory. World Wide Web 2014, 17, 847–867. [Google Scholar] [CrossRef]
- Risch, J.; Krestel, R. Delete or not delete? Semi-automatic comment moderation for the newsroom. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; pp. 166–176. [Google Scholar]
- Balogh, Š.; Mojžiš, J.; Krammer, P. Evaluation of System Features Used for Malware Detection. In Proceedings of the Future Technologies Conference, Vancouver, BC, Canada, 28–29 November 2021; Springer: Cham, Switzerland; pp. 46–59. [Google Scholar]
- Sabo, R.; Krammer, P.; Mojžiš, J.; Kvassay, M. Identification of Spontaneous Spoken Texts in Slovak. Jazykoved. Cas. 2019, 70, 481–490. [Google Scholar] [CrossRef]
- Raeder, T.; Forman, G.; Chawla, N.V. Learning from imbalanced data: Evaluation matters. In Data Mining: Foundations and Intelligent Paradigms; Springer: Berlin/Heidelberg, Germany, 2012; pp. 315–331. [Google Scholar]



| Class | Text | Approximate English Translation (Not Part of the Dataset) |
|---|---|---|
| Facebook dataset | ||
| Negative | ani náhodou... | not even by chance… |
| Negative | ty šaty kdo jim navrhnul byl asi vožralej | The designer of their clothes must have been drunk |
| Positive | Mám ji je skvělá! | I have it it’s great! |
| Positive | moje nejoblíbenější!!! | my favourite!!! |
| Neutral | najde se nějaký sponzor? | any sponsors around here? |
| Neutral | to mam doma:-D asi to začnu používat když to stojí tolik:-D | I have that at home:-D I guess I will start using it since it costs so much:-D |
| Movie reviews from csfd.cz | ||
| Negative | tak toto se opravdu nepovedlo | so this really did not work out well |
| Negative | Moc, ale moc špatný... | Really, but really bad… |
| Positive | Jednoduše geniální. | Simply genius. |
| Positive | Film mého dětství. Super. | The film of my childhood. Super. |
| Neutral | ...a půl hvězdičky Vašíkovi Neckářovi... | ... and a half-star to Vašík Neckář... |
| Neutral | Film o ničem... s dobrými herci, ale o ničem.! | Film about nothing… with good actors, but about nothing.! |
| Product reviews from Mall.cz | ||
| Negative | vadí mi, že intenzata vůně brzy vyprchá. | it bothers me that the intensity of the fragrance evaporates soon. |
| Negative | Čekala jsem od tohoto výrobku více. | I expected more from this product. |
| Positive | splnilo očekávání, výborný na cesty | fulfilled expectations, excellent for travel |
| Positive | Skvělý pomocník při údržbě pračky. | Excellent helper for washing machine maintenance. |
| Neutral | Je hlučnější, ale pro domásí použití dostačuje. | It is a bit noisy but will do for home use. |
| Neutral | Celkem spokojenost, i když stabilita není zas až tak úžasná. | Overall satisfaction, although its stability is not overwhelming… |
| Data Pre-Processing Techniques | Feature Types | Feature Selection Methods |
|---|---|---|
| Tokenizing | Word unigrams | Chi-Squared |
| POS Tagging | Word bigrams | Information Gain |
| Named Entity Filtering | Character n-grams | Mutual Information |
| Stemming | POS-related features | Odds Ratio |
| Lemmatization | Emoticons | Relevancy Score |
| Stop-word Removal | Delta TFIDF variants (only as an alternative to word unigrams in binary classification) | |
| Lowercasing | ||
| Phonetic transcription |
| Facebook with Duplicates | Mall.cz with Duplicates | ||
|---|---|---|---|
| IG Score | Feature Name | IG Score | Feature Name |
| 5.31542105 × 10−2 | pos_VN_cnt | 2.29515576 × 10−2 | jinak_27 |
| 5.31542105 × 10−2 | pos_VN_rel | 1.39020370 × 10−2 | pos_Z_cnt |
| 4.82305556 × 10−2 | pos_A_rel | 1.38809112 × 10−2 | spokojen_1 |
| 3.00267410 × 10−2 | pos_P_cnt | 1.27684311 × 10−2 | bohužel_129 |
| 2.93030264 × 10−2 | krás_17 | 1.21083059 × 10−2 | troch_39 |
| 2.79489530 × 10−2 | pos_J_rel | 1.17427526 × 10−2 | že_5 |
| 2.79405964 × 10−2 | pos_V_cnt | 1.06867967 × 10−2 | pos_VN_rel |
| 2.79336596 × 10−2 | pos_J_cnt | 1.06843420 × 10−2 | pos_VN_cnt |
| 2.74006129 × 10−2 | pos_N_cnt | 1.01632063 × 10−2 | doporučuj_3 |
| 2.31843806 × 10−2 | pos_R_cnt | 9.90660242 × 10−³ | pos_N_cnt |
| 2.31843806 × 10−2 | pos_R_rel | 9.88890573 × 10−³ | špatn_148 |
| 2.04175911 × 10−2 | nejlepší_28 | 9.70657370 × 10−³ | pos_J_cnt |
| 1.81899721 × 10−2 | pos_P_rel | 9.70657370 × 10−³ | pos_J_rel |
| 1.73519507 × 10−2 | pos_A_cnt | 9.15182532 × 10−³ | pos_V_cnt |
| 1.62609275 × 10−2 | pos_VD_div | 8.62281841 × 10−³ | pos_R_rel |
| 1.61785256 × 10−2 | pos_D_cnt | 8.61252827 × 10−³ | pos_R_cnt |
| 1.56507796 × 10−2 | dobr+den_28675 | 7.84887959 × 10−³ | dobr_4 |
| 1.54041112 × 10−2 | pos_T_cnt | 7.75472028 × 10−³ | pos_D_cnt |
| 1.54041112 × 10−2 | pos_T_rel | 7.35274446 × 10−³ | mohl_65 |
| 1.49780643 × 10−2 | super_32 | 6.94441155 × 10−³ | pos_T_cnt |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mojžiš, J.; Krammer, P.; Kvassay, M.; Skovajsová, L.; Hluchý, L. Towards Reliable Baselines for Document-Level Sentiment Analysis in the Czech and Slovak Languages. Future Internet 2022, 14, 300. https://doi.org/10.3390/fi14100300
Mojžiš J, Krammer P, Kvassay M, Skovajsová L, Hluchý L. Towards Reliable Baselines for Document-Level Sentiment Analysis in the Czech and Slovak Languages. Future Internet. 2022; 14(10):300. https://doi.org/10.3390/fi14100300
Chicago/Turabian StyleMojžiš, Ján, Peter Krammer, Marcel Kvassay, Lenka Skovajsová, and Ladislav Hluchý. 2022. "Towards Reliable Baselines for Document-Level Sentiment Analysis in the Czech and Slovak Languages" Future Internet 14, no. 10: 300. https://doi.org/10.3390/fi14100300
APA StyleMojžiš, J., Krammer, P., Kvassay, M., Skovajsová, L., & Hluchý, L. (2022). Towards Reliable Baselines for Document-Level Sentiment Analysis in the Czech and Slovak Languages. Future Internet, 14(10), 300. https://doi.org/10.3390/fi14100300