
Nanopore Detection Assisted DNA Information Processing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Principles and History of Single-Molecule Detection
2.1. General Principles of Biological Nanopore Detection Technology
2.2. Development of Nanopore Detection Technology
2.3. Categories of Nanopores
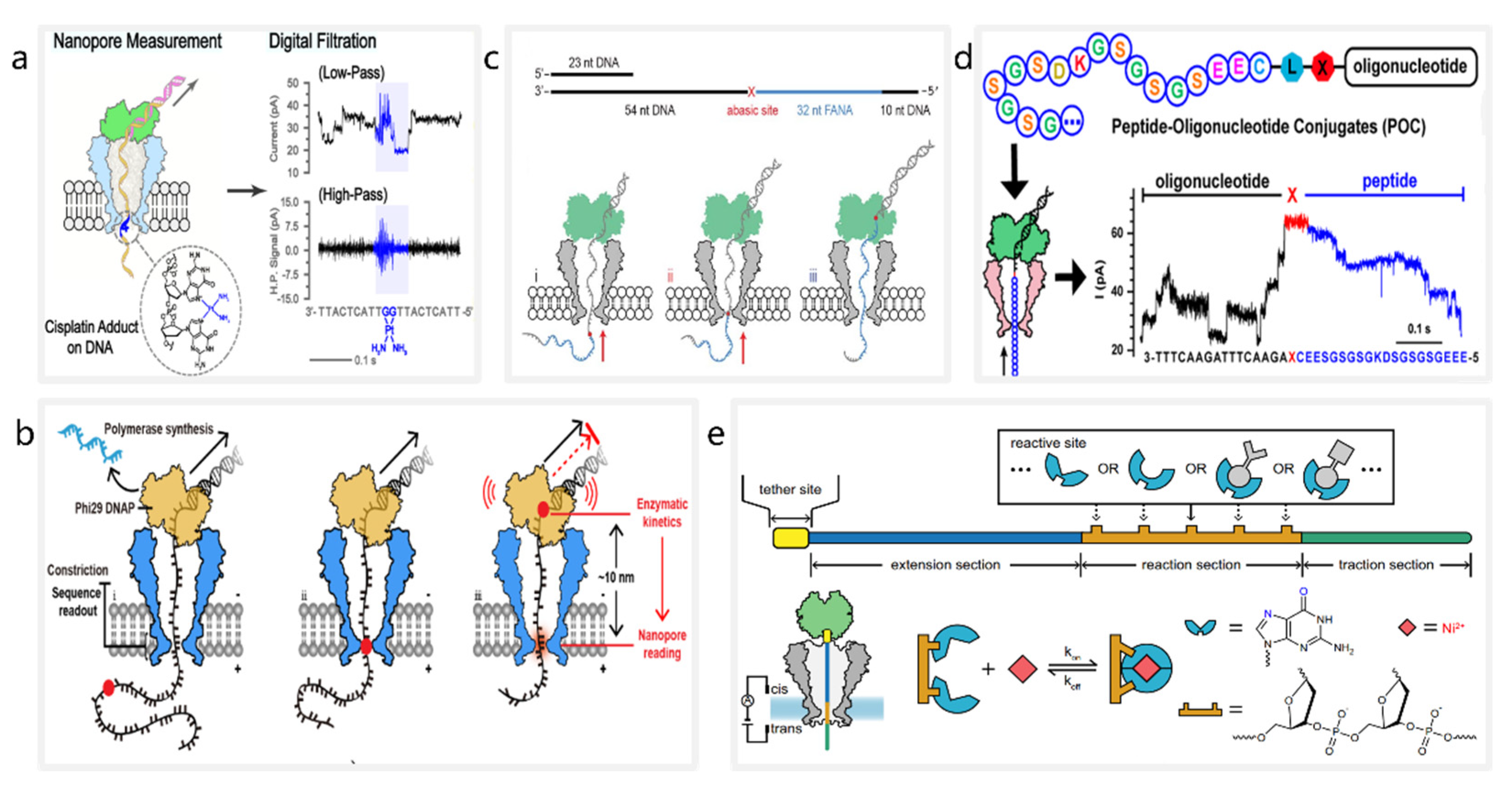
3. Nanopores Detect Specific Modifications Carried by DNA Molecules
3.1. Detection of DNA Lesions
3.2. Detection of Nucleic Acids
3.3. Detection of Peptides and Proteins
3.4. Detection of Inorganic Chemical Molecules
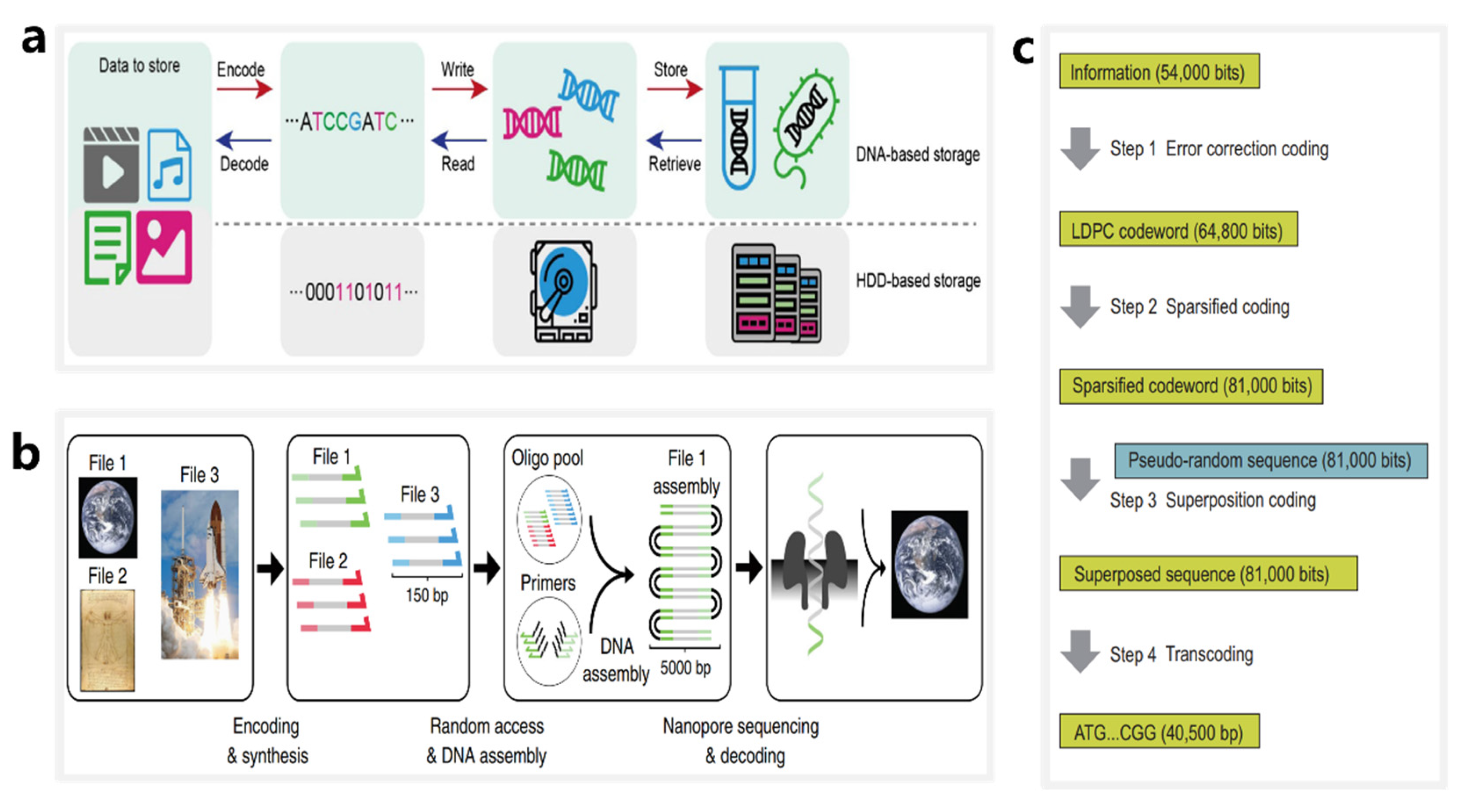
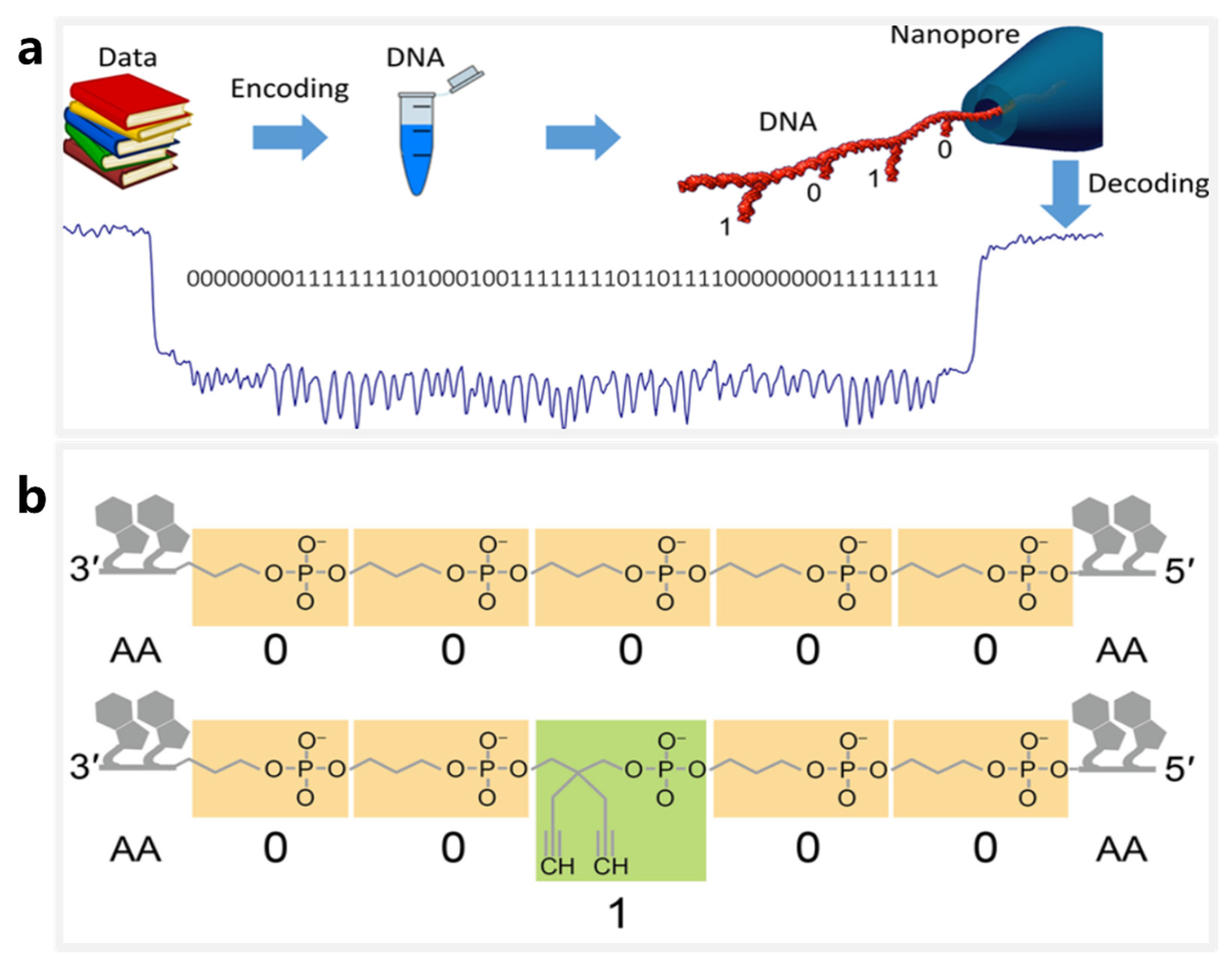
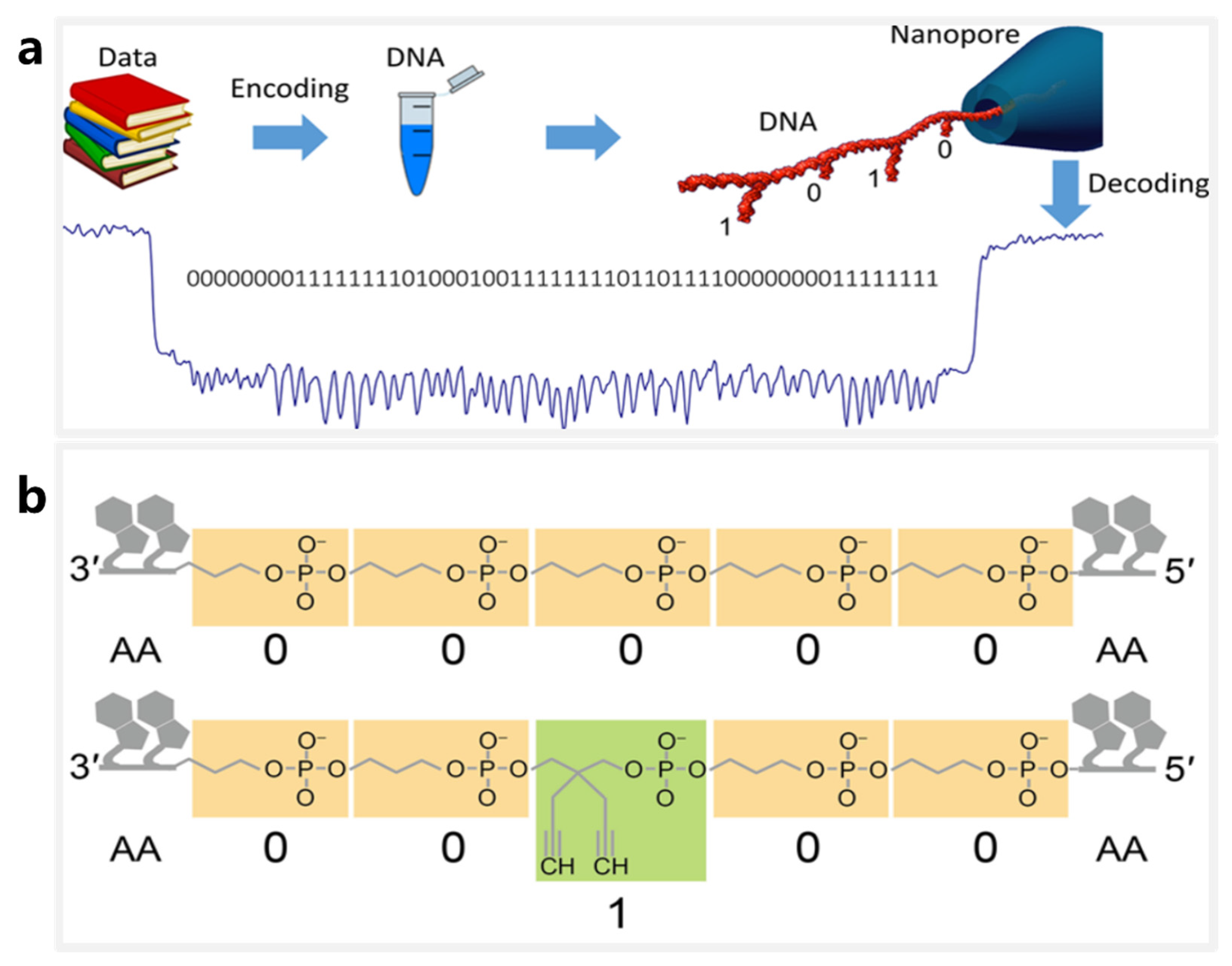
4. DNA Storage Based on Nanopore Sequencing Technology
4.1. DNA Storage Based on Synthetic DNA Sequences
4.2. DNA Storage Using DNA Nanostructures and Modifications as Information Carriers
5. Applications of AI in Nanopore Data Processing and DNA Information Technology
5.1. Base Calling
5.2. Biomolecule Detection
5.3. DNA Storage
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhirnov, V.; Zadegan, R.M.; Sandhu, G.S.; Church, G.M.; Hughes, W.L. Nucleic acid memory. Nat. Mater. 2016, 15, 366–370. [Google Scholar] [PubMed]
- Goda, K.; Kitsuregawa, M. The History of Storage Systems. Proc. IEEE Inst. Electr. Electron. Eng. 2012, 100, 1433–1440. [Google Scholar]
- Anžel, A.; Heider, D.; Hattab, G. The visual story of data storage: From storage properties to user interfaces. Comput. Struct. Biotechnol. J. 2021, 19, 4904–4918. [Google Scholar] [PubMed]
- Andrae, A.S.G.; Edler, T. On Global Electricity Usage of Communication Technology: Trends to 2030. Challenges 2015, 6, 117–157. [Google Scholar]
- Church, G.M.; Gao, Y.; Kosuri, S. Next-generation digital information storage in DNA. Science 2012, 337, 1628. [Google Scholar] [CrossRef]
- Allentoft, M.E.; Collins, M.; Harker, D.; Haile, J.; Oskam, C.L.; Hale, M.L.; Campos, P.F.; Samaniego, J.A.; Gilbert, M.T.; Willerslev, E.; et al. The half-life of DNA in bone: Measuring decay kinetics in 158 dated fossils. Proc. Biol. Sci. 2012, 279, 4724–4733. [Google Scholar]
- Bhat, W.A. Bridging data-capacity gap in big data storage. Future Gener. Comput. Syst. 2018, 87, 538–548. [Google Scholar]
- Jaeger, L.; Chworos, A. The architectonics of programmable RNA and DNA nanostructures. Curr. Opin. Struct. Biol. 2006, 16, 531–543. [Google Scholar]
- Ishmukhametov, I.; Batasheva, S.; Rozhina, E.; Akhatova, F.; Mingaleeva, R.; Rozhin, A.; Fakhrullin, R. DNA/Magnetic Nanoparticles Composite to Attenuate Glass Surface Nanotopography for Enhanced Mesenchymal Stem Cell Differentiation. Polymers 2022, 14, 344. [Google Scholar] [CrossRef]
- Dong, Y.; Sun, F.; Ping, Z.; Ouyang, Q.; Qian, L. DNA storage: Research landscape and future prospects. Natl. Sci. Rev. 2020, 7, 1092–1107. [Google Scholar]
- Heckel, R.; Shomorony, I.; Ramchandran, K.; David, N. Fundamental limits of DNA storage systems. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 3130–3134. [Google Scholar]
- Merrifield, B. Solid phase synthesis. Science 1986, 232, 341–347. [Google Scholar] [PubMed]
- Belitsky, J.M.; Nguyen, D.H.; Wurtz, N.R.; Dervan, P.B. Solid-phase synthesis of DNA binding polyamides on oxime resin. Bioorg. Med. Chem. 2002, 10, 2767–2774. [Google Scholar] [PubMed]
- Sikkema-Raddatz, B.; Johansson, L.F.; de Boer, E.N.; Almomani, R.; Boven, L.G.; van den Berg, M.P.; van Spaendonck-Zwarts, K.Y.; van Tintelen, J.P.; Sijmons, R.H.; Jongbloed, J.D. Targeted next-generation sequencing can replace Sanger sequencing in clinical diagnostics. Hum. Mutat. 2013, 34, 1035–1042. [Google Scholar] [PubMed]
- Cao, C.; Long, Y.-T. Biological Nanopores: Confined Spaces for Electrochemical Single-Molecule Analysis. Acc. Chem. Res. 2018, 51, 331–341. [Google Scholar]
- Oukhaled, A.; Bacri, L.; Pastoriza-Gallego, M.; Betton, J.-M.; Pelta, J. Sensing Proteins through Nanopores: Fundamental to Applications. ACS Chem. Biol. 2012, 7, 1935–1949. [Google Scholar]
- Mereuta, L.; Asandei, A.; Seo, C.H.; Park, Y.; Luchian, T. Quantitative Understanding of pH- and Salt-Mediated Conformational Folding of Histidine-Containing, β-Hairpin-like Peptides, through Single-Molecule Probing with Protein Nanopores. ACS Appl. Mater. Interfaces 2014, 6, 13242–13256. [Google Scholar]
- Hornblower, B.; Coombs, A.; Whitaker, R.D.; Kolomeisky, A.; Picone, S.J.; Meller, A.; Akeson, M. Single-molecule analysis of DNA-protein complexes using nanopores. Nat. Methods 2007, 4, 315–317. [Google Scholar]
- Mathé, J.; Visram, H.; Viasnoff, V.; Rabin, Y.; Meller, A. Nanopore unzipping of individual DNA hairpin molecules. Biophys. J. 2004, 87, 3205–3212. [Google Scholar] [CrossRef]
- Luchian, T.; Park, Y.; Asandei, A.; Schiopu, I.; Mereuta, L.; Apetrei, A. Nanoscale Probing of Informational Polymers with Nanopores. Applications to Amyloidogenic Fragments, Peptides, and DNA–PNA Hybrids. Acc. Chem. Res. 2019, 52, 267–276. [Google Scholar] [CrossRef]
- Desai, T.A.; Hansford, D.J.; Kulinsky, L.; Nashat, A.H.; Rasi, G.; Tu, J.; Wang, Y.; Zhang, M.; Ferrari, M. Nanopore technology for biomedical applications. Biomed. Microdevices 1999, 2, 11–40. [Google Scholar] [CrossRef]
- Chen, W.; Han, M.; Zhou, J.; Ge, Q.; Wang, P.; Zhang, X.; Zhu, S.; Song, L.; Yuan, Y. An artificial chromosome for data storage. Natl. Sci. Rev. 2021, 8, nwab028. [Google Scholar] [CrossRef]
- Organick, L.; Ang, S.D.; Chen, Y.-J.; Lopez, R.; Yekhanin, S.; Makarychev, K.; Racz, M.Z.; Kamath, G.; Gopalan, P.; Nguyen, B.; et al. Random access in large-scale DNA data storage. Nat. Biotechnol. 2018, 36, 242–248. [Google Scholar] [CrossRef]
- Schneider, G.F.; Dekker, C. DNA sequencing with nanopores. Nat. Biotechnol. 2012, 30, 326–328. [Google Scholar] [CrossRef] [PubMed]
- Goto, Y.; Akahori, R.; Yanagi, I.; Takeda, K.-i. Solid-state nanopores towards single-molecule DNA sequencing. J. Hum. Genet. 2020, 65, 69–77. [Google Scholar] [CrossRef] [PubMed]
- Clarke, J.; Wu, H.-C.; Jayasinghe, L.; Patel, A.; Reid, S.; Bayley, H. Continuous base identification for single-molecule nanopore DNA sequencing. Nat. Nanotechnol. 2009, 4, 265–270. [Google Scholar] [CrossRef] [PubMed]
- Traversi, F.; Raillon, C.; Benameur, S.M.; Liu, K.; Khlybov, S.; Tosun, M.; Krasnozhon, D.; Kis, A.; Radenovic, A. Detecting the translocation of DNA through a nanopore using graphene nanoribbons. Nat. Nanotechnol. 2013, 8, 939–945. [Google Scholar] [CrossRef]
- Riedl, J.; Ding, Y.; Fleming, A.M.; Burrows, C.J. Identification of DNA lesions using a third base pair for amplification and nanopore sequencing. Nat. Commun. 2015, 6, 8807. [Google Scholar] [CrossRef]
- Fleming, A.M.; Mathewson, N.J.; Howpay Manage, S.A.; Burrows, C.J. Nanopore Dwell Time Analysis Permits Sequencing and Conformational Assignment of Pseudouridine in SARS-CoV-2. ACS Cent. Sci. 2021, 7, 1707–1717. [Google Scholar] [CrossRef]
- Yan, S.; Wang, L.; Wang, Y.; Cao, Z.; Zhang, S.; Du, X.; Fan, P.; Zhang, P.; Chen, H.Y.; Huang, S. Non-binary Encoded Nucleic Acid Barcodes Directly Readable by a Nanopore. Angew. Chem. Int. Ed. 2022, 61, e202116482. [Google Scholar] [CrossRef]
- Jia, W.; Hu, C.; Wang, Y.; Liu, Y.; Wang, L.; Zhang, S.; Zhu, Q.; Gu, Y.; Zhang, P.; Ma, J.; et al. Identification of Single-Molecule Catecholamine Enantiomers Using a Programmable Nanopore. ACS Nano 2022, 16, 6615–6624. [Google Scholar] [CrossRef]
- Liu, P.; Kawano, R. Recognition of Single-Point Mutation Using a Biological Nanopore. Small Methods 2020, 4, 2000101. [Google Scholar] [CrossRef]
- Wang, F.; Zahid, O.K.; Swain, B.E.; Parsonage, D.; Hollis, T.; Harvey, S.; Perrino, F.W.; Kohli, R.M.; Taylor, E.W.; Hall, A.R. Solid-State Nanopore Analysis of Diverse DNA Base Modifications Using a Modular Enzymatic Labeling Process. Nano Lett. 2017, 17, 7110–7116. [Google Scholar] [CrossRef] [PubMed]
- Ying, Y.L.; Zhang, J.; Gao, R.; Long, Y.T. Nanopore-based sequencing and detection of nucleic acids. Angew Chem. Int. Ed. Engl. 2013, 52, 13154–13161. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Chen, X.; Zhou, S.; Roozbahani, G.M.; Zhang, Y.; Wang, D.; Guan, X. Displacement chemistry-based nanopore analysis of nucleic acids in complicated matrices. ChemComm 2018, 54, 13977–13980. [Google Scholar] [CrossRef] [PubMed]
- Workman, R.E.; Tang, A.D.; Tang, P.S.; Jain, M.; Tyson, J.R.; Razaghi, R.; Zuzarte, P.C.; Gilpatrick, T.; Payne, A.; Quick, J.; et al. Nanopore native RNA sequencing of a human poly(A) transcriptome. Nat. Methods 2019, 16, 1297–1305. [Google Scholar] [CrossRef]
- Nakane, J.J.; Akeson, M.; Marziali, A. Nanopore sensors for nucleic acid analysis. J. Phys. Condens. Matter 2003, 15, R1365. [Google Scholar] [CrossRef]
- Deamer, D.W.; Branton, D. Characterization of nucleic acids by nanopore analysis. Acc. Chem. Res. 2002, 35, 817–825. [Google Scholar] [CrossRef]
- Derrington, I.M.; Craig, J.M.; Stava, E.; Laszlo, A.H.; Ross, B.C.; Brinkerhoff, H.; Nova, I.C.; Doering, K.; Tickman, B.I.; Ronaghi, M.; et al. Subangstrom single-molecule measurements of motor proteins using a nanopore. Nat. Biotechnol. 2015, 33, 1073–1075. [Google Scholar] [CrossRef]
- Yusko, E.C.; Bruhn, B.R.; Eggenberger, O.M.; Houghtaling, J.; Rollings, R.C.; Walsh, N.C.; Nandivada, S.; Pindrus, M.; Hall, A.R.; Sept, D.; et al. Real-time shape approximation and fingerprinting of single proteins using a nanopore. Nat. Nanotechnol. 2017, 12, 360–367. [Google Scholar] [CrossRef]
- Waduge, P.; Hu, R.; Bandarkar, P.; Yamazaki, H.; Cressiot, B.; Zhao, Q.; Whitford, P.C.; Wanunu, M. Nanopore-Based Measurements of Protein Size, Fluctuations, and Conformational Changes. ACS Nano 2017, 11, 5706–5716. [Google Scholar] [CrossRef]
- Wei, X.; Ma, D.; Zhang, Z.; Wang, L.Y.; Gray, J.L.; Zhang, L.; Zhu, T.; Wang, X.; Lenhart, B.J.; Yin, Y.; et al. N-Terminal Derivatization-Assisted Identification of Individual Amino Acids Using a Biological Nanopore Sensor. ACS Sens. 2020, 5, 1707–1716. [Google Scholar] [CrossRef] [PubMed]
- Wloka, C.; Van Meervelt, V.; van Gelder, D.; Danda, N.; Jager, N.; Williams, C.P.; Maglia, G. Label-Free and Real-Time Detection of Protein Ubiquitination with a Biological Nanopore. ACS Nano 2017, 11, 4387–4394. [Google Scholar] [CrossRef]
- Afshar Bakshloo, M.; Kasianowicz, J.J.; Pastoriza-Gallego, M.; Mathé, J.; Daniel, R.; Piguet, F.; Oukhaled, A. Nanopore-Based Protein Identification. J. Am. Chem. Soc. 2022, 144, 2716–2725. [Google Scholar] [CrossRef] [PubMed]
- Shimizu, K.; Mijiddorj, B.; Usami, M.; Mizoguchi, I.; Yoshida, S.; Akayama, S.; Hamada, Y.; Ohyama, A.; Usui, K.; Kawamura, I.; et al. De novo design of a nanopore for single-molecule detection that incorporates a β-hairpin peptide. Nat. Nanotechnol. 2022, 17, 67–75. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Wang, H.; Chen, X.; Wang, Y.; Zhou, D.; Liang, L.; Wang, L.; Wang, D.; Guan, X. Single-molecule Study on the Interactions between Cyclic Nonribosomal Peptides and Protein Nanopore. ACS Appl. Bio Mater. 2020, 3, 554–560. [Google Scholar] [CrossRef] [PubMed]
- Reiner, J.E.; Kasianowicz, J.J.; Nablo, B.J.; Robertson, J.W. Theory for polymer analysis using nanopore-based single-molecule mass spectrometry. Proc. Natl. Acad. Sci. USA 2010, 107, 12080–12085. [Google Scholar] [CrossRef]
- Neher, E.; Sakmann, B. Single-channel currents recorded from membrane of denervated frog muscle fibres. Nature 1976, 260, 799–802. [Google Scholar] [CrossRef]
- Ishii, Y.; Yanagida, T. Single molecule detection in life sciences. Single Mol. 2000, 1, 5–16. [Google Scholar] [CrossRef]
- Arroyo, J.O.; Kukura, P. Non-fluorescent schemes for single-molecule detection, imaging and spectroscopy. Nat. Photonics 2016, 10, 11–17. [Google Scholar] [CrossRef]
- Lelek, M.; Gyparaki, M.T.; Beliu, G.; Schueder, F.; Griffié, J.; Manley, S.; Jungmann, R.; Sauer, M.; Lakadamyali, M.; Zimmer, C. Single-molecule localization microscopy. Nat. Rev. Methods Primers 2021, 1, 39. [Google Scholar] [CrossRef]
- Yuana, Y.; Oosterkamp, T.H.; Bahatyrova, S.; Ashcroft, B.; Garcia Rodriguez, P.; Bertina, R.M.; Osanto, S. Atomic force microscopy: A novel approach to the detection of nanosized blood microparticles. J. Thromb. Haemost. 2010, 8, 315–323. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhao, L.; Yao, Y.; Guo, X. Single-Molecule Nanotechnologies: An Evolution in Biological Dynamics Detection. ACS Appl. Bio Mater. 2020, 3, 68–85. [Google Scholar] [CrossRef]
- Jain, M.; Olsen, H.E.; Paten, B.; Akeson, M. The Oxford Nanopore MinION: Delivery of nanopore sequencing to the genomics community. Genome Biol. 2016, 17, 239. [Google Scholar] [CrossRef]
- Huo, W.; Ling, W.; Wang, Z.; Ya, L.; Zhou, M.; Ren, M.; Li, X.; Li, J.; Xia, Z.; Liu, X.; et al. Miniaturized DNA Sequencers for Personal Use: Unreachable Dreams or Achievable Goals. Front. Nanotechnol. 2021, 3, 628861. [Google Scholar] [CrossRef]
- Maglia, G.; Heron, A.J.; Stoddart, D.; Japrung, D.; Bayley, H. Analysis of single nucleic acid molecules with protein nanopores. Meth. Enzymol. 2010, 475, 591–623. [Google Scholar]
- Deamer, D.; Akeson, M.; Branton, D. Three decades of nanopore sequencing. Nat. Biotechnol. 2016, 34, 518–524. [Google Scholar] [CrossRef] [PubMed]
- Firnkes, M.; Pedone, D.; Knezevic, J.; Döblinger, M.; Rant, U. Electrically facilitated translocations of proteins through silicon nitride nanopores: Conjoint and competitive action of diffusion, electrophoresis, and electroosmosis. Nano Lett. 2010, 10, 2162–2167. [Google Scholar] [CrossRef] [PubMed]
- Song, L.; Hobaugh, M.R.; Shustak, C.; Cheley, S.; Bayley, H.; Gouaux, J.E. Structure of staphylococcal alpha-hemolysin, a heptameric transmembrane pore. Science 1996, 274, 1859–1866. [Google Scholar] [CrossRef]
- Walker, B.W.; Kasianowicz, J.J.; Krishnasastry, M.V.; Bayley, H. A pore-forming protein with a metal-actuated switch. Prod. Eng. 1994, 7, 655–662. [Google Scholar] [CrossRef]
- Kasianowicz, J.J.; Brandin, E.; Branton, D.; Deamer, D. Characterization of Individual Polynucleotide Molecules Using a Membrane Channel. Proc. Natl. Acad. Sci. USA 1996, 93, 13770–13773. [Google Scholar] [CrossRef]
- Akeson, M.; Branton, D.; Kasianowicz, J.J.; Brandin, E.; Deamer, D.W. Microsecond time-scale discrimination among polycytidylic acid, polyadenylic acid, and polyuridylic acid as homopolymers or as segments within single RNA molecules. Biophys. J. 1999, 77, 3227–3233. [Google Scholar] [CrossRef] [Green Version]
- Butler, T.Z.; Pavlenok, M.; Derrington, I.M.; Niederweis, M.; Gundlach, J.H. Single-molecule DNA detection with an engineered MspA protein nanopore. Proc. Natl. Acad. Sci. USA 2008, 105, 20647–20652. [Google Scholar] [CrossRef]
- Manrao, E.A.; Derrington, I.M.; Laszlo, A.H.; Langford, K.W.; Hopper, M.K.; Gillgren, N.; Pavlenok, M.; Niederweis, M.; Gundlach, J.H. Reading DNA at single-nucleotide resolution with a mutant MspA nanopore and phi29 DNA polymerase. Nat. Biotechnol. 2012, 30, 349–353. [Google Scholar] [CrossRef]
- Manrao, E.A.; Derrington, I.M.; Pavlenok, M.; Niederweis, M.; Gundlach, J.H. Nucleotide discrimination with DNA immobilized in the MspA nanopore. PLoS ONE 2011, 6, e25723. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Guan, X.; Zhang, S.; Liu, Y.; Wang, S.; Fan, P.; Du, X.; Yan, S.; Zhang, P.; Chen, H.-Y. Structural-profiling of low molecular weight RNAs by nanopore trapping/translocation using Mycobacterium smegmatis porin A. Nat. Commun. 2021, 12, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Roozbahani, G.M.; Chen, X.; Zhang, Y.; Wang, L.; Guan, X. Nanopore detection of metal ions: Current status and future directions. Small Methods 2020, 4, 2000266. [Google Scholar] [CrossRef] [PubMed]
- Soskine, M.; Biesemans, A.; Moeyaert, B.; Cheley, S.; Bayley, H.; Maglia, G. An engineered ClyA nanopore detects folded target proteins by selective external association and pore entry. Nano Lett. 2012, 12, 4895–4900. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, L.Q.; Tian, K. The aerolysin nanopore: From peptidomic to genomic applications. Nanoscale 2018, 10, 13857–13866. [Google Scholar] [CrossRef]
- Long, Z.; Zhan, S.; Gao, P.; Wang, Y.; Lou, X.; Xia, F. Recent Advances in Solid Nanopore/Channel Analysis. Anal. Chem. 2018, 90, 577–588. [Google Scholar] [CrossRef]
- Howorka, S.; Siwy, Z. Nanopore analytics: Sensing of single molecules. Chem. Soc. Rev. 2009, 38, 2360–2384. [Google Scholar] [CrossRef]
- van den Berg, A.; Wessling, M. Silicon for the perfect membrane. Nature 2007, 445, 726. [Google Scholar] [CrossRef] [PubMed]
- Hu, R.; Tong, X.; Zhao, Q. Four Aspects about Solid-State Nanopores for Protein Sensing: Fabrication, Sensitivity, Selectivity, and Durability. Adv. Healthc. Mater. 2020, 9, 2000933. [Google Scholar] [CrossRef] [PubMed]
- Kleefen, A.; Pedone, D.; Grunwald, C.; Wei, R.; Firnkes, M.; Abstreiter, G.; Rant, U.; Tampé, R. Multiplexed Parallel Single Transport Recordings on Nanopore Arrays. Nano Lett. 2010, 10, 5080–5087. [Google Scholar] [CrossRef] [PubMed]
- Roman, J.; Jarroux, N.; Patriarche, G.; Français, O.; Pelta, J.; Le Pioufle, B.; Bacri, L. Functionalized Solid-State Nanopore Integrated in a Reusable Microfluidic Device for a Better Stability and Nanoparticle Detection. ACS Appl. Mater. Interfaces 2017, 9, 41634–41640. [Google Scholar] [CrossRef] [PubMed]
- Storm, A.J.; Chen, J.H.; Ling, X.S.; Zandbergen, H.W.; Dekker, C. Fabrication of solid-state nanopores with single-nanometre precision. Nat. Mater. 2003, 2, 537–540. [Google Scholar] [CrossRef] [PubMed]
- Freedman, K.J.; Otto, L.M.; Ivanov, A.P.; Barik, A.; Oh, S.-H.; Edel, J.B. Nanopore sensing at ultra-low concentrations using single-molecule dielectrophoretic trapping. Nat. Commun. 2016, 7, 10217. [Google Scholar] [CrossRef]
- Garaj, S.; Hubbard, W.; Reina, A.; Kong, J.; Branton, D.; Golovchenko, J.A. Graphene as a subnanometre trans-electrode membrane. Nature 2010, 467, 190–193. [Google Scholar] [CrossRef]
- Gasparyan, L.; Mazo, I.; Simonyan, V.; Gasparyan, F. DNA Sequencing: Current State and Prospects of Development. Biophys. J. 2019, 09, 169–197. [Google Scholar] [CrossRef]
- Shi, W.; Friedman, A.K.; Baker, L.A. Nanopore Sensing. Anal. Chem. 2017, 89, 157–188. [Google Scholar] [CrossRef]
- Schibel, A.E.; An, N.; Jin, Q.; Fleming, A.M.; Burrows, C.J.; White, H.S. Nanopore detection of 8-oxo-7,8-dihydro-2′-deoxyguanosine in immobilized single-stranded DNA via adduct formation to the DNA damage site. J. Am. Chem. Soc. 2010, 132, 17992–17995. [Google Scholar] [CrossRef]
- Perera, R.T.; Fleming, A.M.; Johnson, R.P.; Burrows, C.J.; White, H.S. Detection of benzo[a]pyrene-guanine adducts in single-stranded DNA using the α-hemolysin nanopore. Nanotechnology 2015, 26, 074002. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rouse, J.; Jackson, S.P. Interfaces between the detection, signaling, and repair of DNA damage. Science 2002, 297, 547–551. [Google Scholar] [CrossRef] [PubMed]
- Zhou, B.B.; Elledge, S.J. The DNA damage response: Putting checkpoints in perspective. Nature 2000, 408, 433–439. [Google Scholar] [CrossRef] [PubMed]
- Ma, F.; Yan, S.; Zhang, J.; Wang, Y.; Wang, L.; Wang, Y.; Zhang, S.; Du, X.; Zhang, P.; Chen, H.-Y.; et al. Nanopore Sequencing Accurately Identifies the Cisplatin Adduct on DNA. ACS Sens. 2021, 6, 3082–3092. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Wang, Y.; Wang, Y.; Zhang, P.; Chen, H.-Y.; Huang, S. Discrimination between Different DNA Lesions by Monitoring Single-Molecule Polymerase Stalling Kinetics during Nanopore Sequencing. Nano Lett. 2022, 22, 5561–5569. [Google Scholar] [CrossRef]
- Taylor, A.I.; Arangundy-Franklin, S.; Holliger, P. Towards applications of synthetic genetic polymers in diagnosis and therapy. Curr. Opin. Chem. Biol. 2014, 22, 79–84. [Google Scholar] [CrossRef]
- Feldman, A.W.; Romesberg, F.E. Expansion of the Genetic Alphabet: A Chemist’s Approach to Synthetic Biology. Acc. Chem. Res. 2018, 51, 394–403. [Google Scholar] [CrossRef]
- Pinheiro, V.B.; Arangundy-Franklin, S.; Holliger, P. Compartmentalized Self-Tagging for In Vitro-Directed Evolution of XNA Polymerases. Curr. Protoc. Nucleic Acid Chem. 2014, 57, 9. [Google Scholar] [CrossRef]
- Yan, S.; Li, X.; Zhang, P.; Wang, Y.; Chen, H.Y.; Huang, S.; Yu, H. Direct sequencing of 2′-deoxy-2′-fluoroarabinonucleic acid (FANA) using nanopore-induced phase-shift sequencing (NIPSS). Chem. Sci. 2019, 10, 3110–3117. [Google Scholar] [CrossRef]
- Piguet, F.; Ouldali, H.; Pastoriza-Gallego, M.; Manivet, P.; Pelta, J.; Oukhaled, A. Identification of single amino acid differences in uniformly charged homopolymeric peptides with aerolysin nanopore. Nat. Commun. 2018, 9, 966. [Google Scholar] [CrossRef]
- Movileanu, L.; Schmittschmitt, J.P.; Scholtz, J.M.; Bayley, H. Interactions of peptides with a protein pore. Biophys. J. 2005, 89, 1030–1045. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yan, S.; Zhang, J.; Wang, Y.; Guo, W.; Zhang, S.; Liu, Y.; Cao, J.; Wang, Y.; Wang, L.; Ma, F.; et al. Single Molecule Ratcheting Motion of Peptides in a Mycobacterium smegmatis Porin A (MspA) Nanopore. Nano Lett. 2021, 21, 6703–6710. [Google Scholar] [CrossRef] [PubMed]
- Brinkerhoff, H.; Kang, A.S.; Liu, J.; Aksimentiev, A.; Dekker, C. Multiple rereads of single proteins at single–amino acid resolution using nanopores. Science 2021, 374, 1509–1513. [Google Scholar] [CrossRef] [PubMed]
- Jia, W.; Hu, C.; Wang, Y.; Gu, Y.; Qian, G.; Du, X.; Wang, L.; Liu, Y.; Cao, J.; Zhang, S.; et al. Programmable nano-reactors for stochastic sensing. Nat. Commun. 2021, 12, 5811. [Google Scholar] [CrossRef] [PubMed]
- Guo, J.; Amini, S.; Lei, Q.; Ping, Y.; Agola, J.O.; Wang, L.; Zhou, L.; Cao, J.; Franco, S.; Noureddine, A.; et al. Robust and Long-Term Cellular Protein and Enzymatic Activity Preservation in Biomineralized Mammalian Cells. ACS Nano 2022, 16, 2164–2175. [Google Scholar] [CrossRef] [PubMed]
- Baoutina, A.; Bhat, S.; Partis, L.; Emslie, K.R. Storage Stability of Solutions of DNA Standards. Anal. Chem. 2019, 91, 12268–12274. [Google Scholar] [CrossRef] [PubMed]
- Shendure, J.; Balasubramanian, S.; Church, G.M.; Gilbert, W.; Rogers, J.; Schloss, J.A.; Waterston, R.H. DNA sequencing at 40: Past, present and future. Nature 2017, 550, 345–353. [Google Scholar] [CrossRef]
- Kohll, A.X.; Antkowiak, P.L.; Chen, W.D.; Nguyen, B.H.; Stark, W.J.; Ceze, L.; Strauss, K.; Grass, R.N. Stabilizing synthetic DNA for long-term data storage with earth alkaline salts. ChemComm 2020, 56, 3613–3616. [Google Scholar] [CrossRef]
- Hao, Y.; Li, Q.; Fan, C.; Wang, F. Data Storage Based on DNA. Small Struct. 2021, 2, 2000046. [Google Scholar] [CrossRef]
- Lopez, R.; Chen, Y.-J.; Dumas Ang, S.; Yekhanin, S.; Makarychev, K.; Racz, M.Z.; Seelig, G.; Strauss, K.; Ceze, L. DNA assembly for nanopore data storage readout. Nat. Commun. 2019, 10, 2933. [Google Scholar] [CrossRef]
- Liu, H.; Wang, J.; Song, S.; Fan, C.; Gothelf, K.V. A DNA-based system for selecting and displaying the combined result of two input variables. Nat. Commun. 2015, 6, 10089. [Google Scholar] [CrossRef] [PubMed]
- Ge, Z.; Gu, H.; Li, Q.; Fan, C. Concept and Development of Framework Nucleic Acids. J. Am. Chem. Soc. 2018, 140, 17808–17819. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Kong, J.; Zhu, J.; Ermann, N.; Predki, P.; Keyser, U.F. Digital Data Storage Using DNA Nanostructures and Solid-State Nanopores. Nano Lett. 2019, 19, 1210–1215. [Google Scholar] [CrossRef] [PubMed]
- Bell, N.A.W.; Keyser, U.F. Digitally encoded DNA nanostructures for multiplexed, single-molecule protein sensing with nanopores. Nat. Nanotechnol. 2016, 11, 645–651. [Google Scholar] [CrossRef]
- Cao, C.; Krapp, L.F.; Al Ouahabi, A.; König, N.F.; Cirauqui, N.; Radenovic, A.; Lutz, J.F.; Peraro, M.D. Aerolysin nanopores decode digital information stored in tailored macromolecular analytes. Sci. Adv. 2020, 6, eabc2661. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Zaremba, W.; Sutskever, I.; Vinyals, O. Recurrent Neural Network Regularization. arXiv 2014, arXiv:1409.2329. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Taniguchi, M.; Minami, S.; Ono, C.; Hamajima, R.; Morimura, A.; Hamaguchi, S.; Akeda, Y.; Kanai, Y.; Kobayashi, T.; Kamitani, W.; et al. Combining machine learning and nanopore construction creates an artificial intelligence nanopore for coronavirus detection. Nat. Commun. 2021, 12, 3726. [Google Scholar] [CrossRef]
- Arima, A.; Tsutsui, M.; Washio, T.; Baba, Y.; Kawai, T. Solid-state nanopore platform integrated with machine learning for digital diagnosis of virus infection. Anal. Chem. 2020, 93, 215–227. [Google Scholar] [CrossRef]
- Ledergerber, C.; Dessimoz, C. Base-calling for next-generation sequencing platforms. Brief. Bioinform. 2011, 12, 489–497. [Google Scholar] [CrossRef] [PubMed]
- David, M.; Dursi, L.J.; Yao, D.; Boutros, P.C.; Simpson, J.T. Nanocall: An open source basecaller for Oxford Nanopore sequencing data. Bioinformatics 2017, 33, 49–55. [Google Scholar] [CrossRef]
- Boža, V.; Brejová, B.; Vinař, T. DeepNano: Deep recurrent neural networks for base calling in MinION nanopore reads. PLoS ONE 2017, 12, e0178751. [Google Scholar] [CrossRef] [PubMed]
- Stoiber, M.; Brown, J. BasecRAWller: Streaming Nanopore Basecalling Directly from Raw Signal. bioRxiv 2017, 133058. [Google Scholar] [CrossRef]
- Teng, H.; Cao, M.D.; Hall, M.B.; Duarte, T.; Wang, S.; Coin, L.J.M. Chiron: Translating nanopore raw signal directly into nucleotide sequence using deep learning. GigaScience 2018, 7, giy037. [Google Scholar] [CrossRef]
- Liu, Q.; Fang, L.; Yu, G.; Wang, D.; Xiao, C.-L.; Wang, K. Detection of DNA base modifications by deep recurrent neural network on Oxford Nanopore sequencing data. Nat. Commun. 2019, 10, 2449. [Google Scholar] [CrossRef]
- Ni, P.; Huang, N.; Nie, F.; Zhang, J.; Zhang, Z.; Wu, B.; Bai, L.; Liu, W.; Xiao, C.-L.; Luo, F.; et al. Genome-wide detection of cytosine methylations in plant from Nanopore data using deep learning. Nat. Commun. 2021, 12, 5976. [Google Scholar] [CrossRef]
- Ni, P.; Huang, N.; Zhang, Z.; Wang, D.P.; Liang, F.; Miao, Y.; Xiao, C.L.; Luo, F.; Wang, J. DeepSignal: Detecting DNA methylation state from Nanopore sequencing reads using deep-learning. Bioinformatics 2019, 35, 4586–4595. [Google Scholar] [CrossRef]
- Doroschak, K.; Zhang, K.; Queen, M.; Mandyam, A.; Strauss, K.; Ceze, L.; Nivala, J. Rapid and robust assembly and decoding of molecular tags with DNA-based nanopore signatures. Nat. Commun. 2020, 11, 5454. [Google Scholar] [CrossRef]
- Buterez, D. Scaling up DNA digital data storage by efficiently predicting DNA hybridisation using deep learning. Sci. Rep. 2021, 11, 20517. [Google Scholar] [CrossRef]
- Rang, F.J.; Kloosterman, W.P.; de Ridder, J. From squiggle to basepair: Computational approaches for improving nanopore sequencing read accuracy. Genome Biol. 2018, 19, 90. [Google Scholar] [CrossRef] [PubMed]
- Bayley, H. Nanopore sequencing: From imagination to reality. Clin. Chem. 2015, 61, 25–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, Z.; Liang, Y.; Yang, J. Nanopore Detection Assisted DNA Information Processing. Nanomaterials 2022, 12, 3135. https://doi.org/10.3390/nano12183135
Song Z, Liang Y, Yang J. Nanopore Detection Assisted DNA Information Processing. Nanomaterials. 2022; 12(18):3135. https://doi.org/10.3390/nano12183135
Chicago/Turabian StyleSong, Zichen, Yuan Liang, and Jing Yang. 2022. "Nanopore Detection Assisted DNA Information Processing" Nanomaterials 12, no. 18: 3135. https://doi.org/10.3390/nano12183135
APA StyleSong, Z., Liang, Y., & Yang, J. (2022). Nanopore Detection Assisted DNA Information Processing. Nanomaterials, 12(18), 3135. https://doi.org/10.3390/nano12183135