Robust Feature Selection-Based Speech Emotion Classification Using Deep Transfer Learning



Abstract
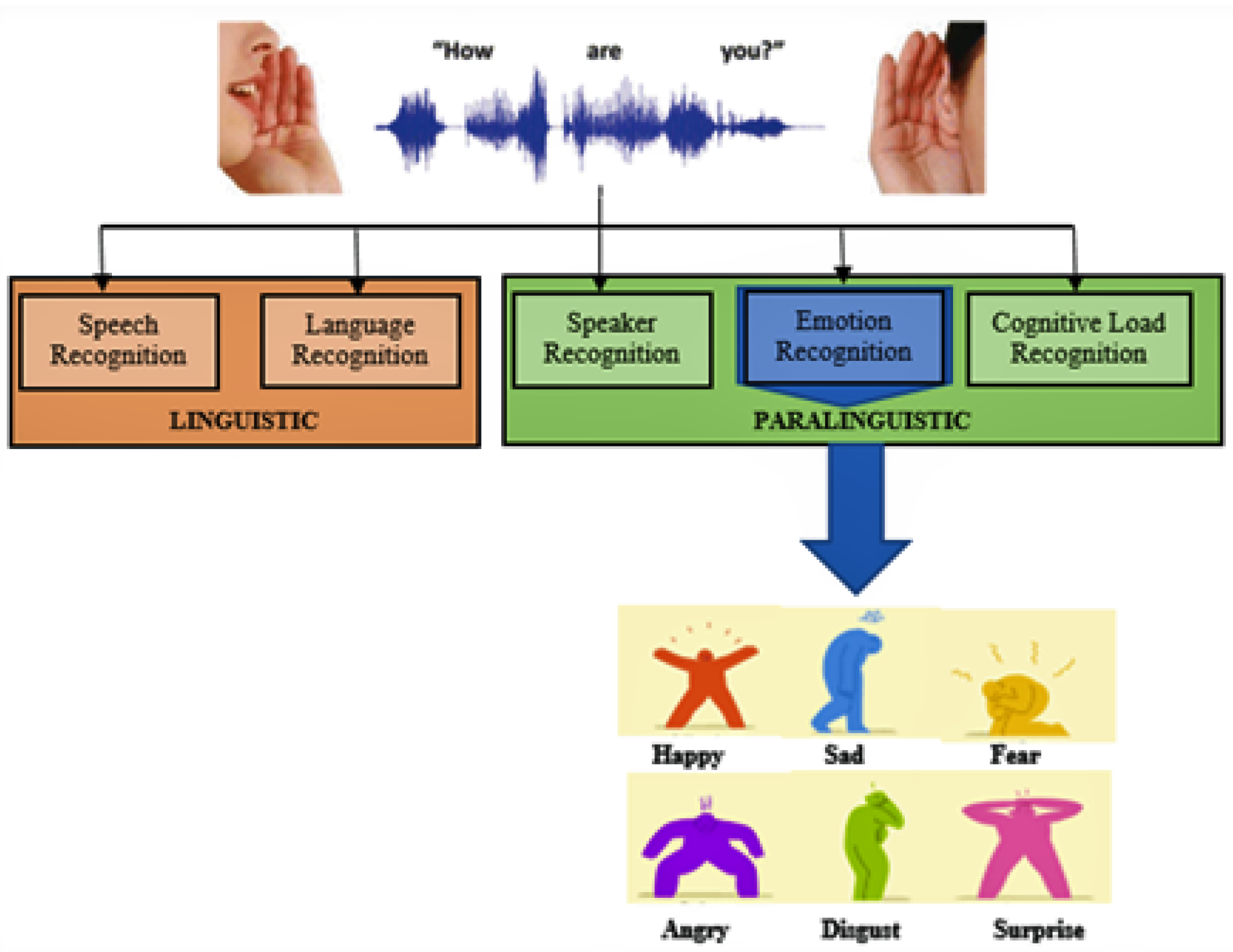
:1. Introduction
Main Contributions
- Applying an optimized deep transfer learning for feature extraction using the pretrained model on ImageNet.
- Adopting an efficient feature selection technique for selecting a discriminative feature for optimal classification of emotion, because not all features from a speech signal carry paralinguistic information relevant to accurate emotion classification.
- Reducing misclassification of emotion and computational cost, while achieving state-of-the-art and improving accuracy on three speech datasets with two different classifiers.
- Systematic performance evaluation and critical comparison of the model with other methods, which indicates a high efficiency of deep transfer learning with feature selection for SEC.
2. Literature Review and Related Works
3. Methods and Techniques
3.1. Speech Data Pre-Processing
3.2. Feature Extraction with Deep Convolutional Neural Network
3.3. Neighborhood Component Analysis (NCA) Feature Selection
| Algorithm 1: NCA Feature Selection Procedure |
| 1: procedure NCAFS (T, , , , ) ⊳ T: set of training,: initial step length, : kernel width, : parameter for regularization, : small positive integer constant; |
| 2: Initialization: … |
| 3: while |
| 4: for … do |
| 5: Compute and using with respect to (2) and (3) |
| 6: for … do |
| 7: |
| 8: t = t + 1 |
| 9: |
| 10: |
| 11: |
| 12: |
| 13: else |
| 14: |
| 15: wend |
| 16: |
| 17: return |
3.4. Classifiers
3.4.1. Multi-Layer Perceptron
3.4.2. Support Vector Machine
4. Experimental Result and Analysis
4.1. Emotion Datasets
4.1.1. TESS
4.1.2. EMO-DB
4.1.3. TESS-EMO-DB
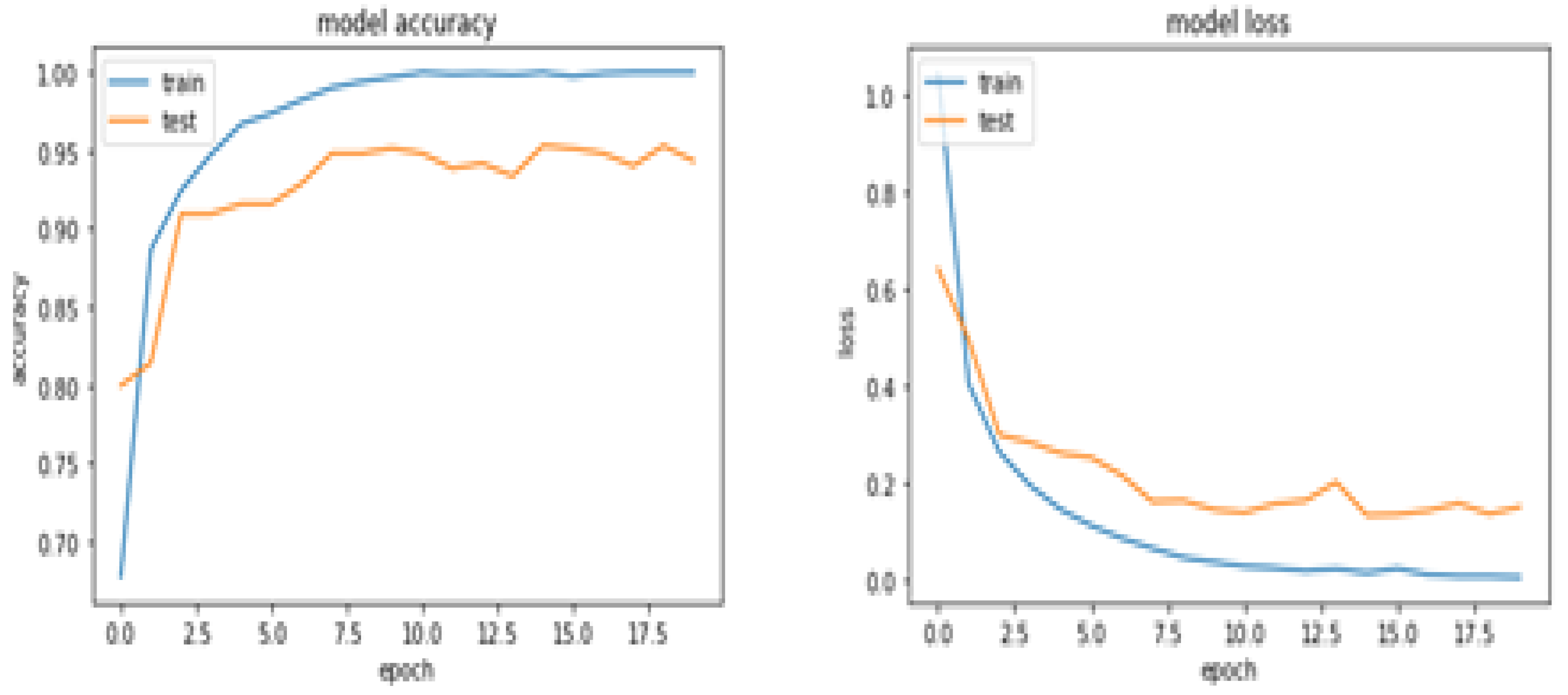
4.2. Experiment Setup
5. Result and Discussion
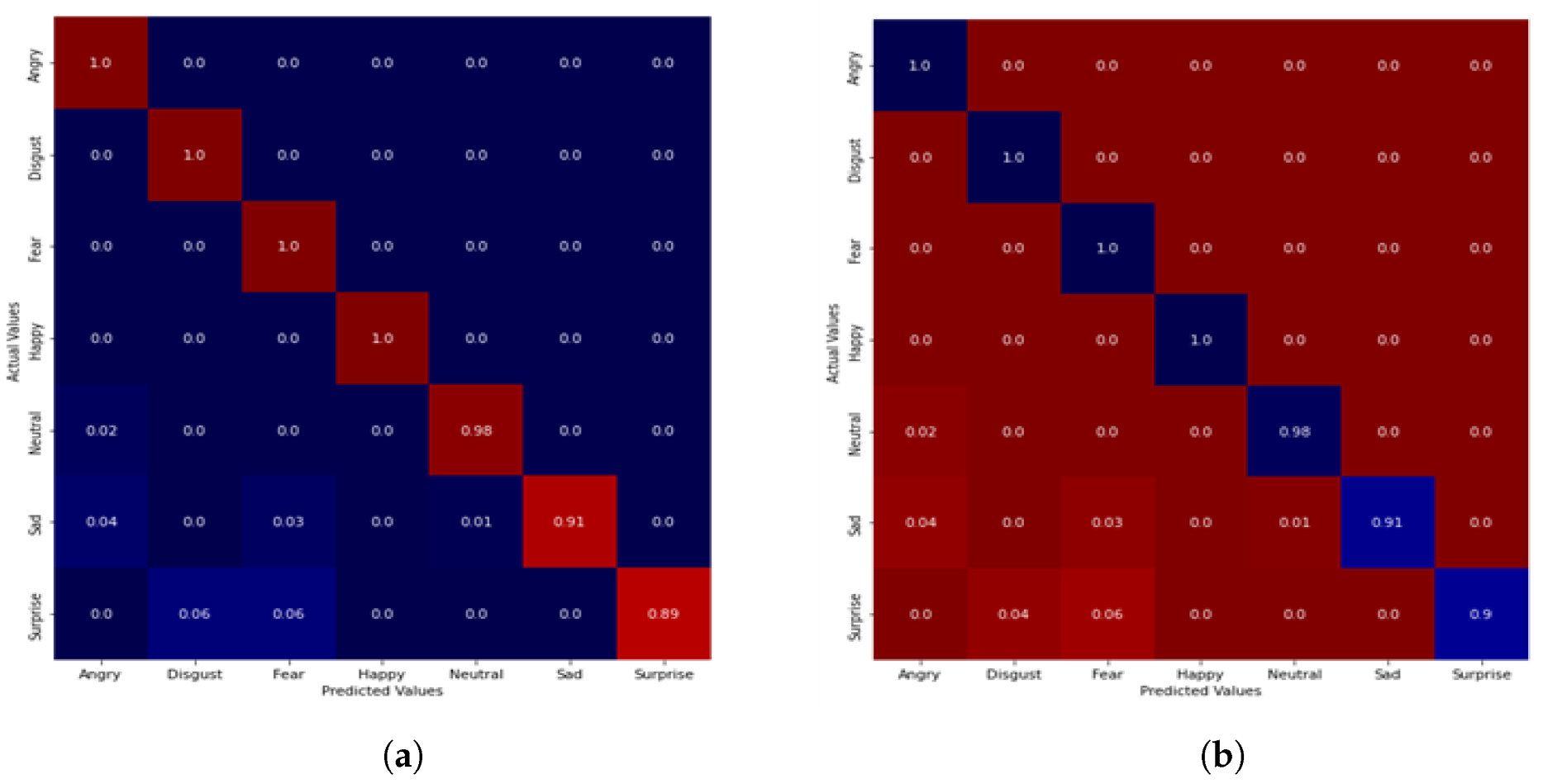
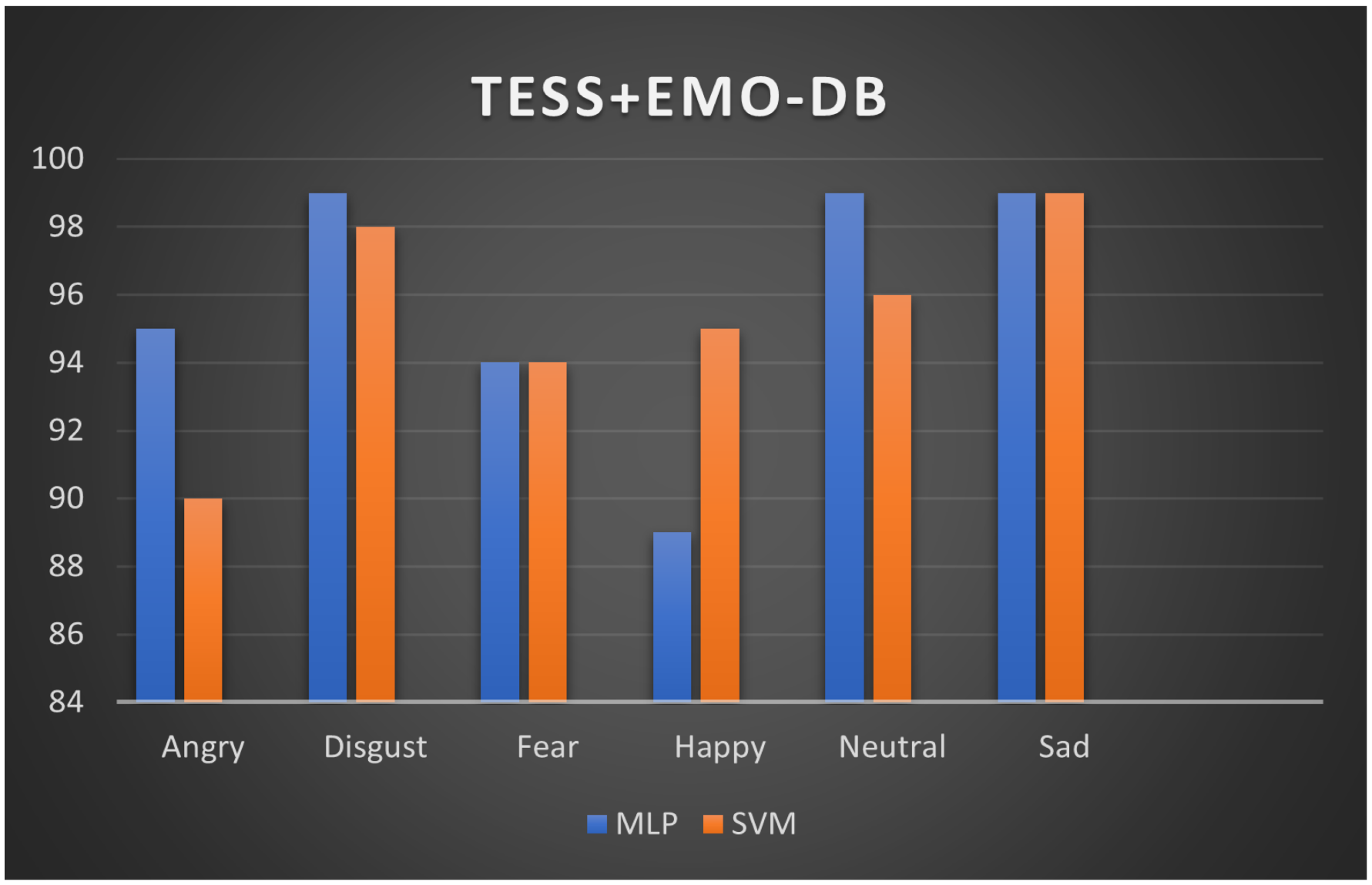
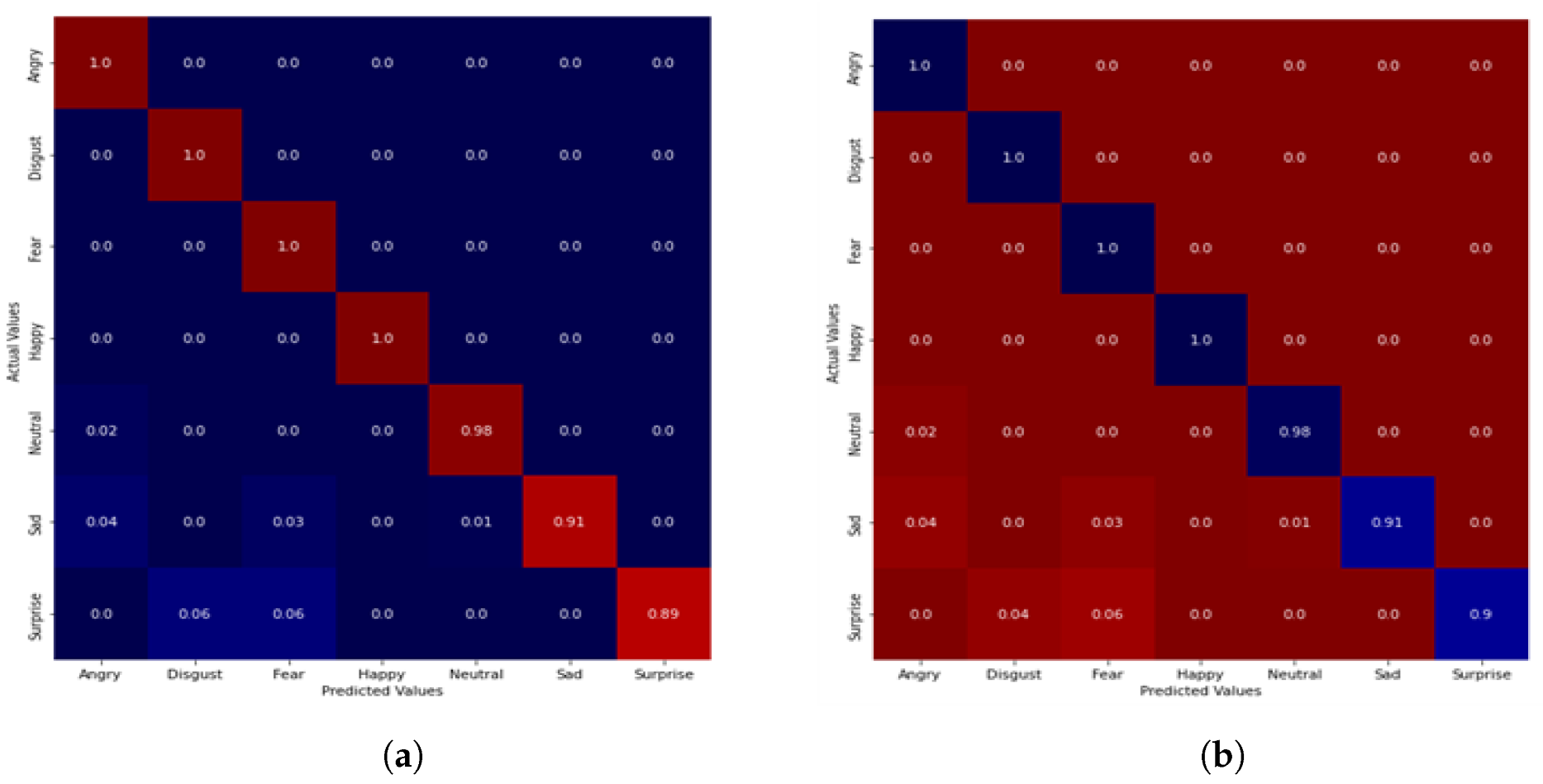
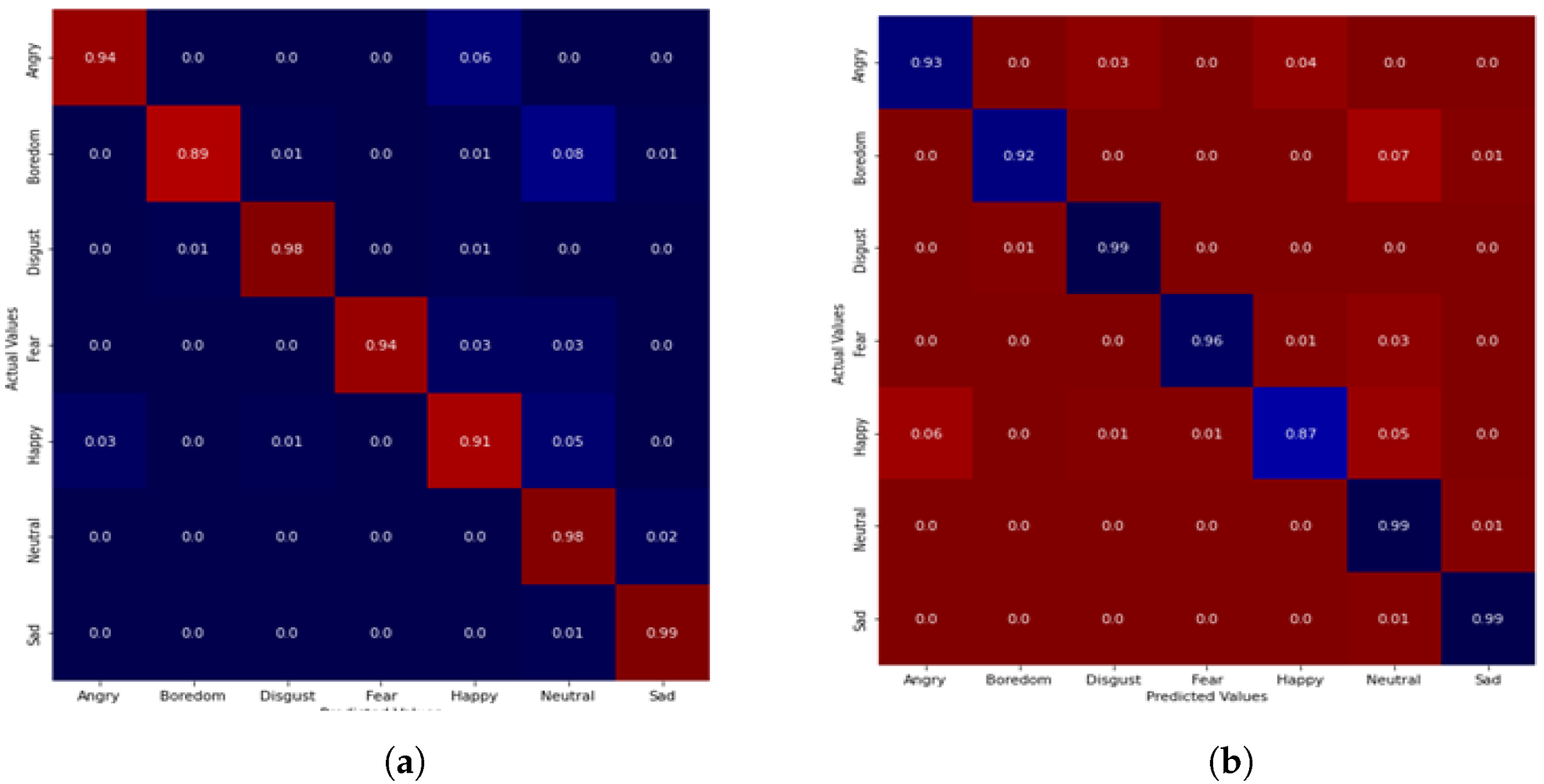
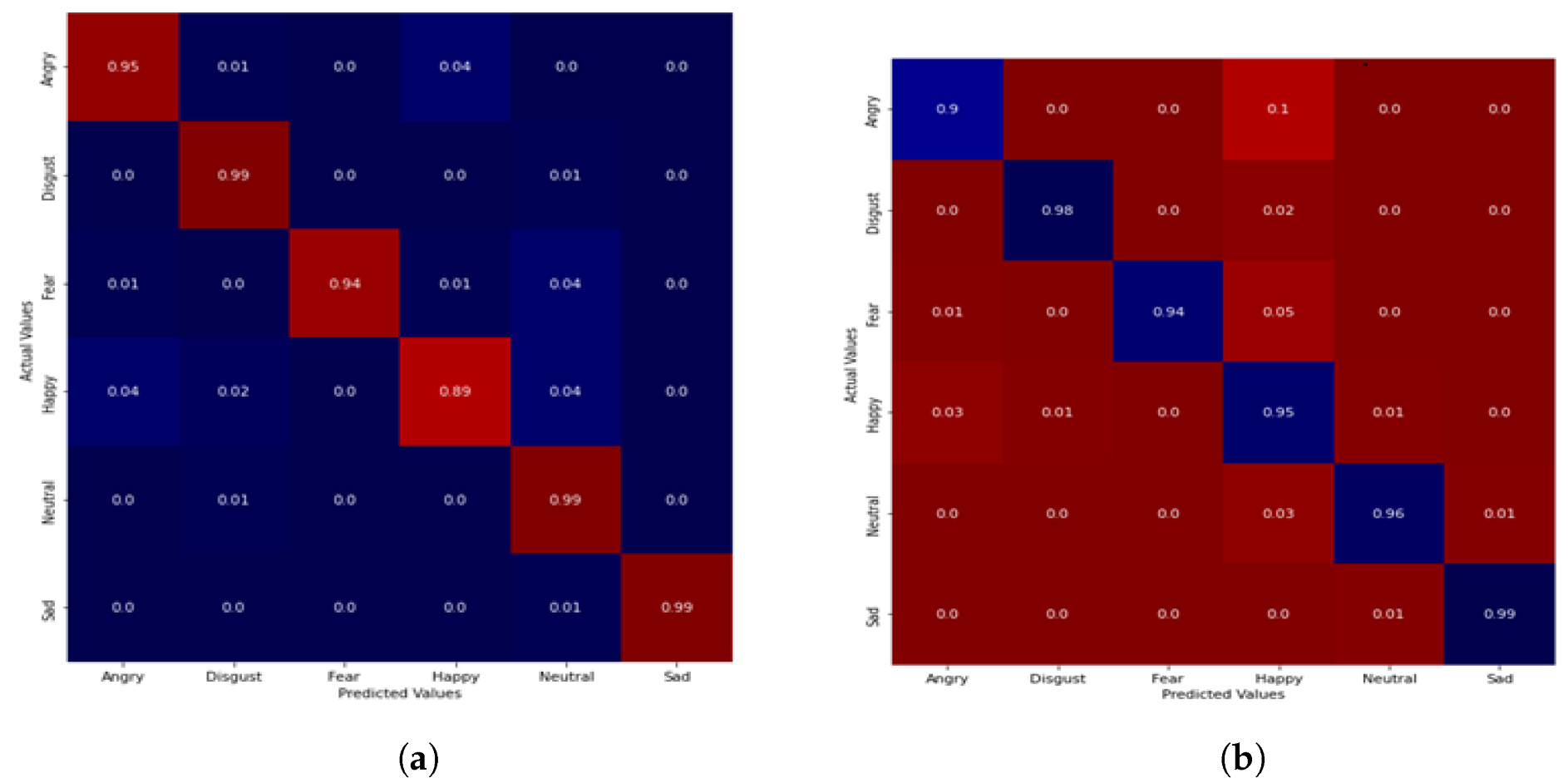
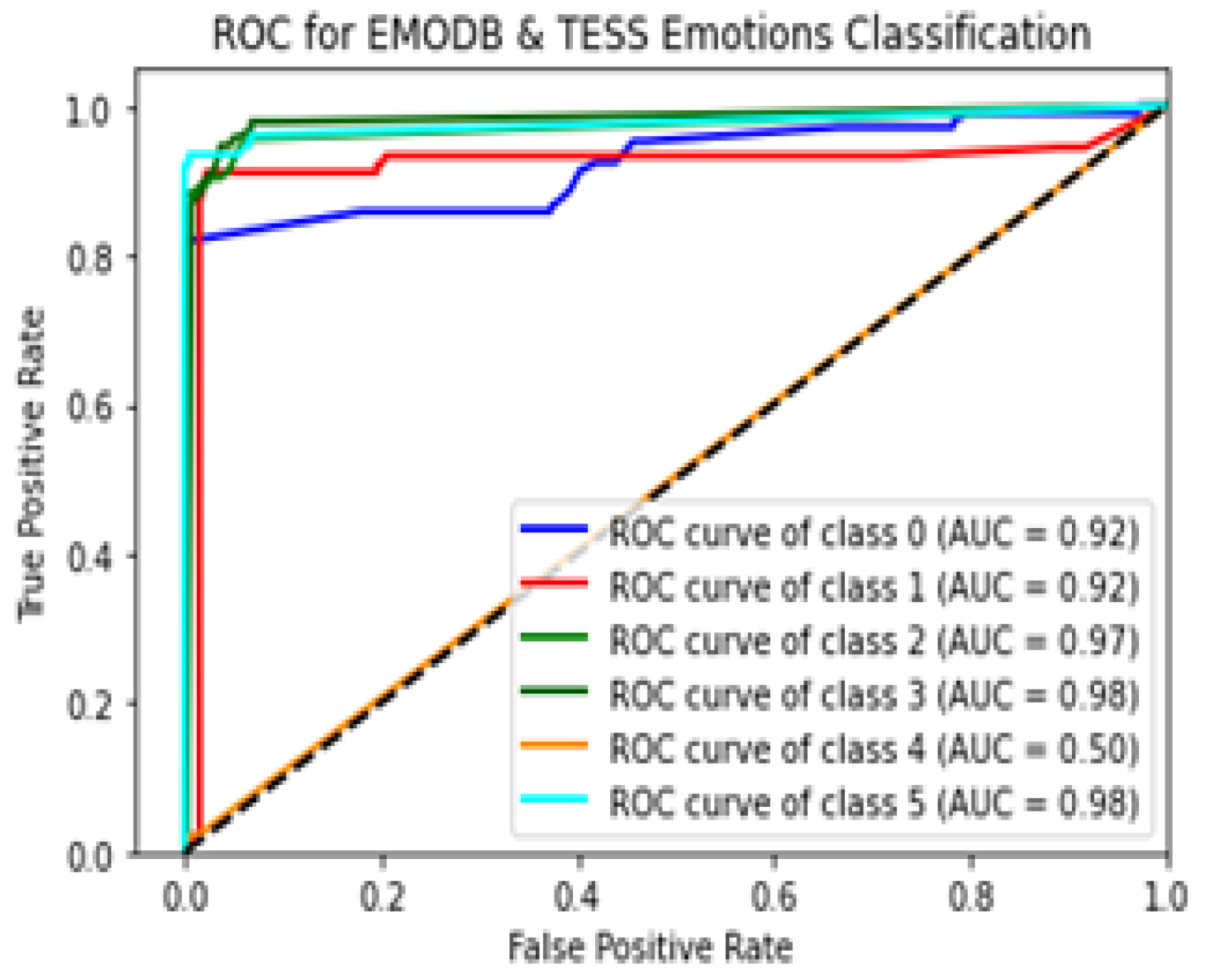
5.1. Performance Evaluation
5.2. Performance Comparison
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pusarla, A.N.; Singh, B.A.; Tripathi, C.S. Learning DenseNet features from EEG based spectrograms for subject independent emotion recognition. Biomed. Signal Process. Control 2022, 12, 74. [Google Scholar] [CrossRef]
- Krishnan, P.; Joseph, A.; Rajangam, V. Emotion classification from speech signal based on empirical mode decomposition and non-linear features. Complex Intell. Syst. 2021, 7, 1919–1934. [Google Scholar] [CrossRef]
- Jiang, W.; Wang, Z.; Jin, J.S.; Han, X.; Li, C. Speech emotion recognition with heterogeneous feature unification of deep neural network. Electronics 2019, 19, 2730. [Google Scholar] [CrossRef]
- Lieskovská, E.; Jakubec, M.; Jarina, R.; Chmulík, M.; Olave, M. A review on speech emotion recognition using deep learning and attention mechanism. Electronics 2021, 10, 1163. [Google Scholar] [CrossRef]
- Van, L.; Le Dao, T.; Le Xuan, T.; Castelli, E. Emotional Speech Recognition Using Deep Neural Networks. Sensors 2022, 22, 1414. [Google Scholar] [CrossRef]
- Topic, A.; Russo, M. Emotion recognition based on EEG feature maps through deep learning network. Eng. Sci. Technol. Int. J. 2021, 24, 1442–1454. [Google Scholar] [CrossRef]
- Moine, C.L.; Obin, N.; Roebel, A. Speaker attentive speech emotion recognition: Proceedings of the Annual Conference of the International Speech Communication Association. Interspeech 2021, 1, 506–510. [Google Scholar] [CrossRef]
- Sattar, R.; Bussoauthor, C. Emotion Detection Problem: Current Status, Challenges and Future Trends Emotion Detection Problem. In Shaping the Future of ICT: Trends in Information Technology, Communications Engineering, and Management: Global Proceedings Repository—American Research Foundation; ICCIIDT: London, UK, 2020. [Google Scholar]
- Hajarolasvadi, N.; Demirel, H. 3D CNN-based speech emotion recognition using k-means clustering and spectrograms. Entropy 2019, 22, 479. [Google Scholar] [CrossRef]
- Wang, Y.; Boumadane, A.; Heba, A. A Fine-tuned Wav2vec 2.0/HuBERT Benchmark for Speech Emotion Recognition, Speaker Verification and Spoken Language Understanding. arXiv 2021, arXiv:2111.02735. [Google Scholar]
- Luna-Jiménez, C.; Kleinlein, R.; Griol, D.; Callejas, Z.; Montero, J.; Fernández-Martínez, F. A Proposal for Multimodal Emotion Recognition Using Aural transformer on RAVDESS. Appl. Sci. 2022, 12, 327. [Google Scholar] [CrossRef]
- Bashath, S.; Perera, N.; Tripathi, S.; Manjang, K.; Dehmer, M.; Streib, F.E. A data-centric review of deep transfer learning with applications to text data. Inf. Sci. 2022, 585, 498–528. [Google Scholar] [CrossRef]
- Aggarwal, A.; Srivastava, A.; Agarwal, A.; Chahal, N.; Singh, D.; Alnuaim, A.A.; Alhadlaq, A.; Lee, H. Two-Way Feature Extraction for Speech Emotion Recognition Using Deep Learning. Sensors 2022, 22, 2378. [Google Scholar] [CrossRef]
- Badshah, A.M.; Rahim, N.; Ullah, N.; Ahmad, J.; Muhammad, K.; Lee, M.Y.; Kwon, S.; Baik, S.W. Deep features-based speech emotion recognition for smart affective services. Multimed. Tools Appl. 2019, 78, 5571–5589. [Google Scholar] [CrossRef]
- Cowen, A.S.; Keltner, D. Self-report captures 27 distinct categories of emotion bridged by continuous gradients. Proc. Natl. Acad. Sci. USA 2017, 38, E7900–E7909. [Google Scholar] [CrossRef] [PubMed]
- Oaten, M.; Stevenson, R.J.; Case, T.I. Disgust as a disease-avoidance mechanism. Psychol. Bull. 2009, 135, 303–321. [Google Scholar] [CrossRef]
- Elshaer, M.E.A.; Wisdom, S.; Mishra, T. Transfer Learning from Sound Representations for Anger Detection in Speech. arXiv 2019, arXiv:1902.02120. [Google Scholar]
- Nguyen, D.; Sridharan, S.; Nguyen, D.T.; Denman, S.; Tran, S.N.; Zeng, R.; Fookes, C. Joint Deep Cross-Domain Transfer Learning for Emotion Recognition. arXiv 2020, arXiv:2003.11136. [Google Scholar]
- Vryzas, N.; Vrysis, L.; Kotsakis, R.; Dimoulas, C. A web crowdsourcing framework for transfer learning and personalized Speech Emotion Recognition. Mach. Learn. Appl. 2021, 6, 100–132. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Optimal feature selection based speech emotion recognition using two-stream deep convolutional neural network. Int. J. Intell. Syst. 2021, 36, 5116–5135. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Appl. Soft Comput. 2021, 102, 107101. [Google Scholar] [CrossRef]
- Aouani, H.; Ayed, Y.B. Speech Emotion Recognition with deep learning. Procedia Comput. Sci. 2021, 176, 251–260. [Google Scholar] [CrossRef]
- Anvarjon, T.; Mustaqeem; Kwon, S. Deep-net: A lightweight CNN-based speech emotion recognition system using deep frequency features. Sensors 2020, 20, 5212. [Google Scholar] [CrossRef] [PubMed]
- Farooq, M.; Hussain, F.; Baloch, N.; Raja, F.; Yu, H.; Bin-Zikria, Y. Impact of feature selection algorithm on speech emotion recognition using deep convolutional neural network. Sensors 2020, 20, 6008. [Google Scholar] [CrossRef]
- Haider, F.; Pollak, S.; Albert, P.; Luz, S. Emotion recognition in low-resource settings: An evaluation of automatic feature selection methods. Comput. Speech Lang. 2020, 65, 101–119. [Google Scholar] [CrossRef]
- Zhang, H.; Gou, R.; Shang, J.; Shen, F.; Wu, Y.; Dai, G. Pre-trained Deep Convolution Neural Network Model With Attention for Speech Emotion Recognition. Front. Physiol. 2021, 12, 643202. [Google Scholar] [CrossRef] [PubMed]
- Feng, K.; Chaspari, T. A Siamese Neural Network with Modified Distance Loss For Transfer Learning in Speech Emotion Recognition. arXiv 2006, arXiv:2006.03001. [Google Scholar]
- Padi, S.; Sadjadi, S.O.; Sriram, R.D.; Manocha, D. Improved Speech Emotion Recognition using Transfer Learning and Spectrogram Augmentation. In Proceedings of the 2021 International Conference on Multimodal Interaction (ICMI ’21), Montréal, QC, Canada, 18–22 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 645–652. [Google Scholar] [CrossRef]
- Joshi, V.; Ghongade, R.; Joshi, A.; Kulkarni, R. Deep BiLSTM neural network model for emotion detection using cross-dataset approach. Biomed. Signal Process. Control 2022, 73, 103407. [Google Scholar] [CrossRef]
- Blumentals, E.; Salimbajevs, A. Emotion Recognition in Real-World Support Call Center Data for Latvian Language. In Proceedings of the ACM IUI Workshops 2022, Helsinki, Finland, 22 March 2022. [Google Scholar]
- Yao, Z.; Wang, Z.; Liu, W.; Liu, Y.; Pan, J. Speech emotion recognition using fusion of three multi-task learning-based classifiers: HSF-DNN, MS-CNN and LLD-RNN. Speech Commun. 2021, 120, 11–19. [Google Scholar] [CrossRef]
- Atila, O.; Şengür, A. Attention guided 3D CNN-LSTM model for accurate speech based emotion recognition. Appl. Acoust. 2021, 182, 108260. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Nilsson, E.G. Emotion recognition using speech and neural structured learning to facilitate edge intelligence. Eng. Appl. Artif. Intell. 2020, 94, 103775. [Google Scholar] [CrossRef]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 166, 56–76. [Google Scholar] [CrossRef]
- Zhang, S.; Li, C. Research on Feature Fusion Speech Emotion Recognition Technology for Smart Teaching. Hindawi Mob. Inf. Syst. 2022, 2022, 7785929. [Google Scholar] [CrossRef]
- Yang, W.; Wang, K.; Zuo, W. Neighborhood component feature selection for high-dimensional data. J. Comput. 2022, 7, 162–168. [Google Scholar] [CrossRef]
- Ba’abbad, I.; Althubiti, T.; Alharbi, A.; Alfarsi, K.; Rasheed, S. A Short Review of Classification Algorithms Accuracy for Data Prediction in Data Mining Applications. J. Data Anal. Inf. Process. 2021, 9, 162–174. [Google Scholar] [CrossRef]
- Wanni, T.; Gunawan, T.; Qadri, S.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Dupuis, K.; Kathleen Pichora-Fuller, M. Recognition of emotional speech for younger and older talkers: Behavioural findings from the toronto emotional speech set. Can. Acoust.-Acoust. Can. 2012, 39, 182–183. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W. A database of German emotional speech. In Proceedings of the 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2012; pp. 1517–1520. [Google Scholar] [CrossRef]
- Praseetha, V.M.; Vadivel, S. Deep learning models for speech emotion recognition. J. Comput. Sci. 2021, 14, 1577–1587. [Google Scholar] [CrossRef]
- Venkataramanan, K.; Rajamohan, H.R. Emotion Recognition from Speech. Audio Speech Process. 2021, 1–14. [Google Scholar] [CrossRef]
- Meng, H.; Yan, T.; Yuan, F.; We, H. Speech Emotion Recognition from 3D Log-Mel Spectrograms with Deep Learning Network. IEEE Access 2019, 7, 125868–125881. [Google Scholar] [CrossRef]
- Mustaqeem; Kwon, S. Clustering-Based Speech Emotion Recognition by Incorporating Learned Features and Deep BiLSTM. IEEE Access 2020, 36, 79861–79875. [Google Scholar] [CrossRef]
- Yahia Cherif, R.; Moussaouni, A.; Frahta, N.; Berimi, M. Effective speech emotion recognition using deep learning approaches for Algerian dialect. In Proceedings of the International Conference of Women in Data Science at Taif University, WiDSTaif, Taif, Saudi Arabia, 30–31 March 2021; pp. 1–6. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Emotion | Description | Expression | Class |
|---|---|---|---|
| Happiness | A state of pleasantness characterized by joyful mood | Upbeat | Positive |
| Sadness | A transitional emotion state usually characterized by grieving felling | Leathery and dampened | Negative |
| Fear | Plays a vital role in survival | Rapid heratbeat | Positive/Negative |
| Disgust | Results from unpleasant taste or smell | Retching/nauseating | Negative |
| Anger | A state of hot temper, hostility and aggression | Yelling | Negative |
| Surprise | Usually occurs when the unexpected happens | Screaming and hilarious | Positive/negative |
| Author | Techniques | Dataset | Accuracy/ Unweighted Average Recall (UAR) | Number Emotion |
|---|---|---|---|---|
| Joshi et al. [29] | DNN-BiLSTM | EEG | 58.44% | - |
| Blumetals and Salimbajos [30] | DNN-LSTM | TESS, RAVDESS, IEMOCAP | 86.02% | 7, 4 |
| Padi et al. [28] | ResNet | IEMOCAP | 66.02% | 4 |
| Feng and Chaspari [27] | SiameseNet | RAVDESS | 32.8% (UAR) | 7 |
| Zhang et al. [26] | DCNN-BiLSTMwA | EMODB, IEMOCAP | 87.86%, 68.5% | 7, 4 |
| Haider et al. [25] | AFS-SVM | EMODB, EMOVO, SAVEE | 76.9%, 41.0%, 42.4% (UAR) | 6 |
| Farooq et al. [24] | DCNN-CFS | EMODB, SAVEE, IEMOCAP, RAVDESS | 95.10%, 82.10%, 83.30%, 81.30% | 7, 4 |
| Anvarjon et al. [23] | CNN | IEMOCAP, EMODB | 77.01%, 92.02% | 7, 4 |
| Aouani and Ayed [22] | DNN | EMODB | 96.97% | 7 |
| Mustaqeem and Kwon [21] | DNN-INCA | EMODB, SAVEE, RAVDESS | 95.0%, 82.0%, 85.0% | 7 |
| Vryzas et al. [19] | CNN-VGGNet | Personalized(Web Crowd Sourcing) | 69.9% | - |
| Parameter | Value |
|---|---|
| Optimizer | Adam |
| Loss Function | Sparse Categorical Cross-Entropy |
| Activation Function | Softmax |
| Environment | CPU |
| Output Classes | 7 |
| Learning Rate | 0.001 |
| Maximum Epochs | 50 |
| MLP Hidden Neurons | 20 |
| SVM Kernel Function | Linear |
| MLP/SVM | TESS | EMO-DB | TESS-EMODB |
|---|---|---|---|
| F1-score (%) | 97.20, 97.68 | 94.40, 94.40 | 95.70, 94.90 |
| Sensitivity (%) | 99.04, 100 | 100, 100 | 99.01, 98.95 |
| Specificity (%) | 98.90, 99.80 | 100, 100 | 100, 98.85 |
| Dataset | Reference | Methods | Reported Accuracy |
|---|---|---|---|
| TESS | (2018) [41] | DNN-GRU | 89.96% |
| " | (2019) [42] | DNN-LSTM | 70.00% |
| " | (2021) [2] | IMF-SVM, KNN | 93.30% |
| " | (2022) [30] | LSTM-FCNN | 86.02% |
| " | Proposed | DCNN-NCA-MLP | 96.10% |
| EMO-DB | (2019) [43] | DCNN | 80.79% |
| " | (2020) [44] | CNN-BiLSTM | 85.50% |
| " | (2020) [22] | CNN | 89.02% |
| " | (2021) [31] | DCNN-LSTM-Attention | 87.86% |
| " | (2021) [20] | CNN-Attention | 93.00% |
| " | (2021) [45] | LSTM-CNN | 93.34% |
| " | Proposed | DCNN-NCA-MLP | 94.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Akinpelu, S.; Viriri, S. Robust Feature Selection-Based Speech Emotion Classification Using Deep Transfer Learning. Appl. Sci. 2022, 12, 8265. https://doi.org/10.3390/app12168265
Akinpelu S, Viriri S. Robust Feature Selection-Based Speech Emotion Classification Using Deep Transfer Learning. Applied Sciences. 2022; 12(16):8265. https://doi.org/10.3390/app12168265
Chicago/Turabian StyleAkinpelu, Samson, and Serestina Viriri. 2022. "Robust Feature Selection-Based Speech Emotion Classification Using Deep Transfer Learning" Applied Sciences 12, no. 16: 8265. https://doi.org/10.3390/app12168265
APA StyleAkinpelu, S., & Viriri, S. (2022). Robust Feature Selection-Based Speech Emotion Classification Using Deep Transfer Learning. Applied Sciences, 12(16), 8265. https://doi.org/10.3390/app12168265