
Deblurring Ghost Imaging Reconstruction Based on Underwater Dataset Generated by Few-Shot Learning


Abstract
:1. Introduction
- (1)
- The FUIGN method is proposed to obtain paired underwater datasets whose fuzzy class contains underwater images with different blurring degrees. Training FUIGN requires only the asymmetric underwater dataset, which reduces the amount of real underwater fuzzy data.
- (2)
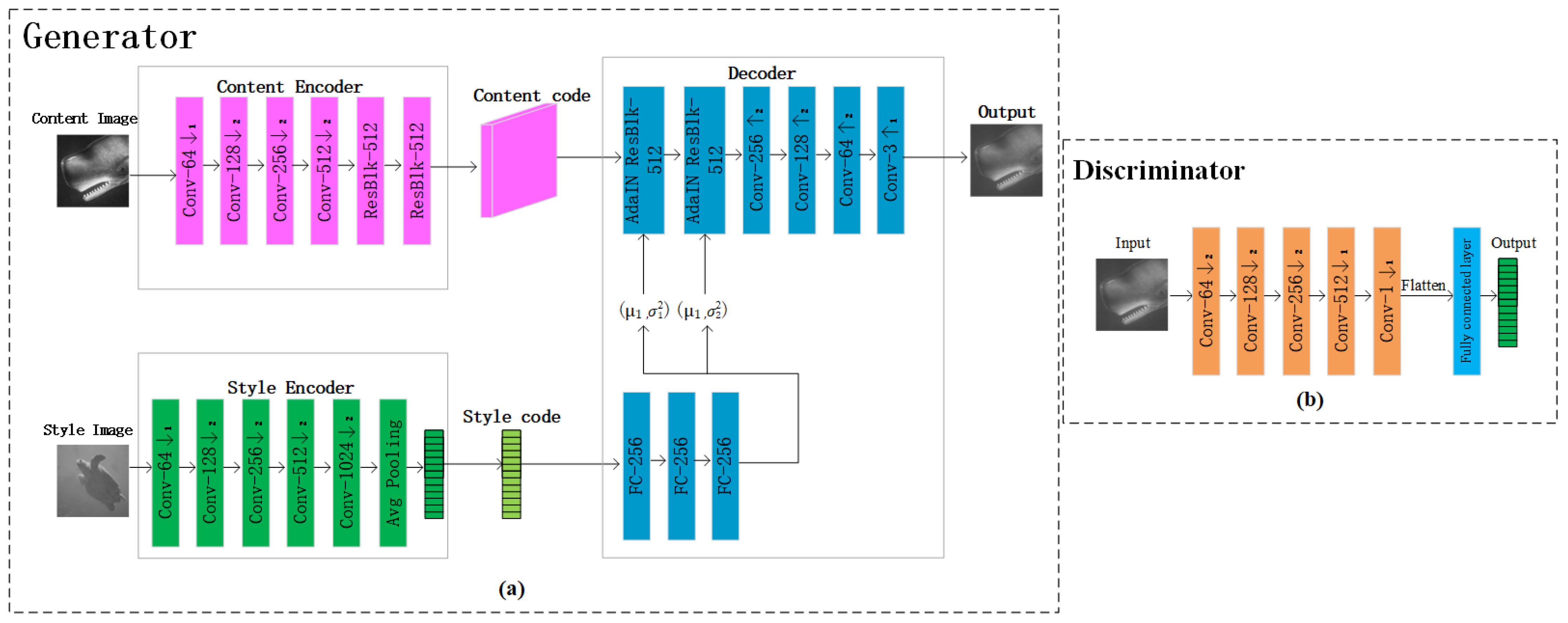
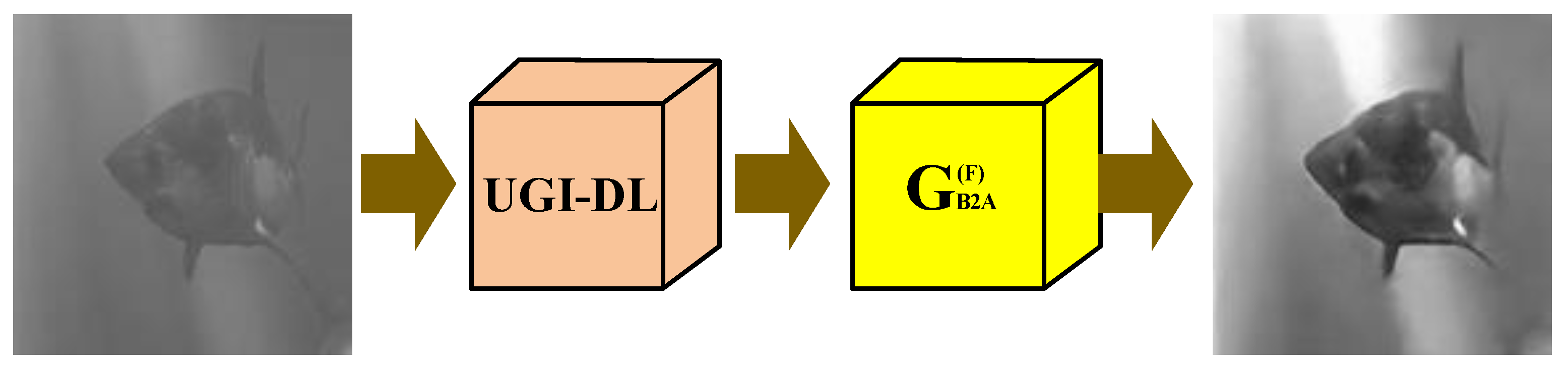
- The UDGI-FS method is proposed to obtain reconstructed underwater results with high quality. The reconstruction method consists of two parts: UGI-DL used to reconstruct the underwater image and the used to decrease the blurring degree of the output of UGI-DL. The generator of UGI-DL adopts a modified U-Net with res-net block and double skip connections, and the attention gate is added in each skip connection. The is the generator of FUIGN.
- (3)
- Simulation and experimental results demonstrate that the paired underwater datasets generated by FUIGN are better than those of the Cycle-GAN method, which meets the training requirements of the UDGI-FS. In addition, the reconstructed underwater results generated by the UDGI-FS method at a low sampling rate have a high clarity degree, which indicates that the proposed UGI-FS is suitable for the reconstruction of an underwater image.
2. Method
2.1. UDGI-FS Imaging Scheme
2.2. Theory and Forward Imaging Model
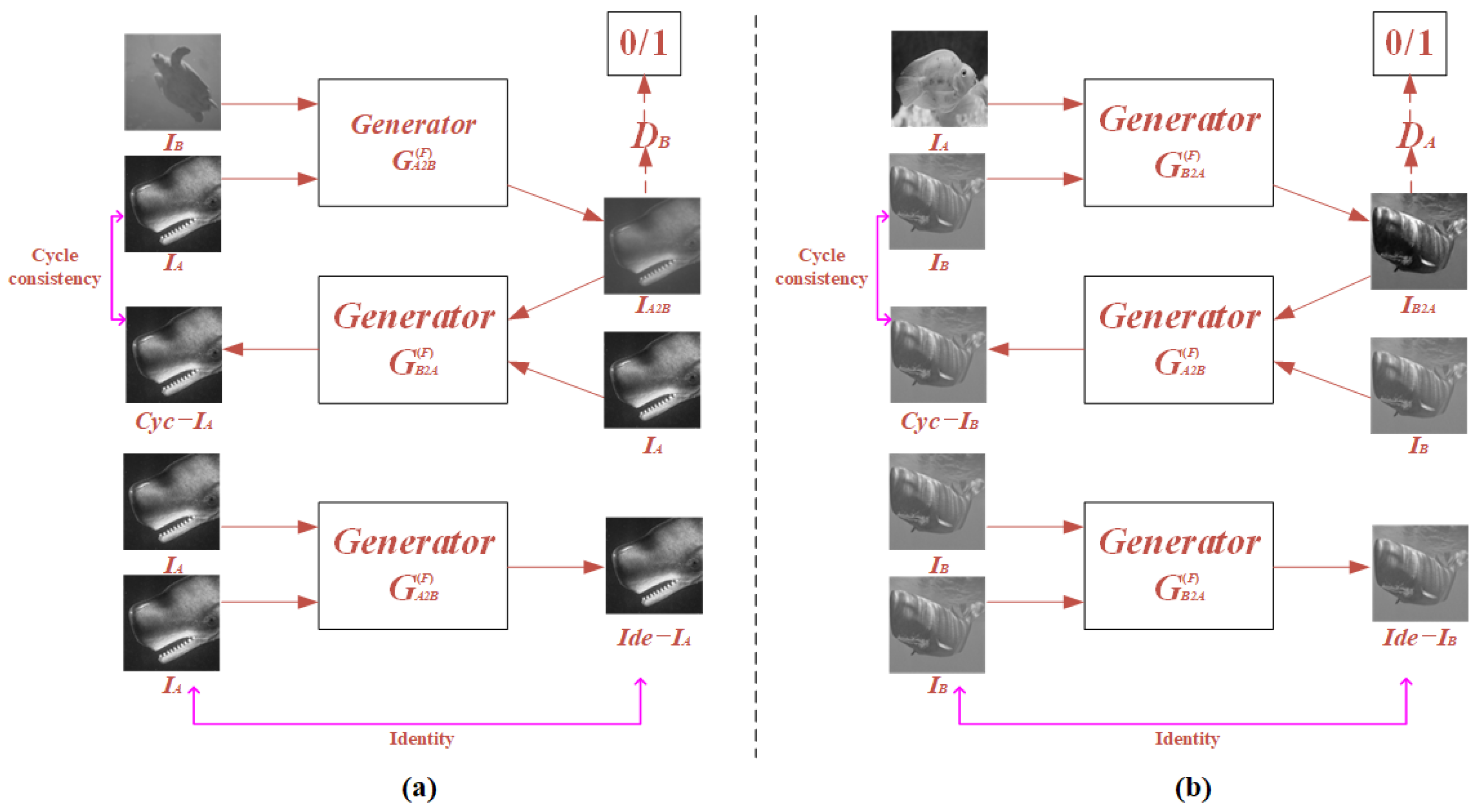
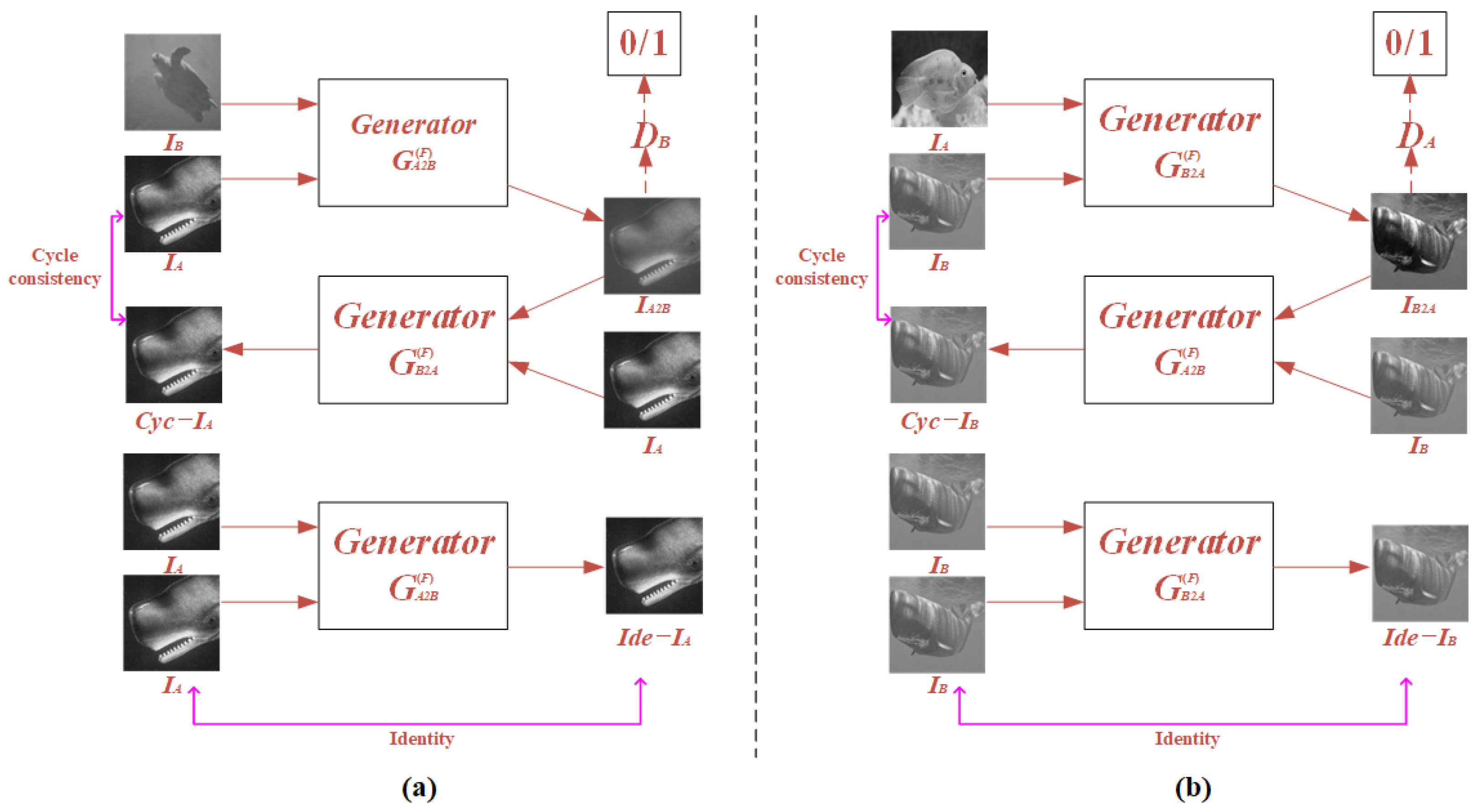
2.3. Preparation of Paired Training Dataset with FUIGN
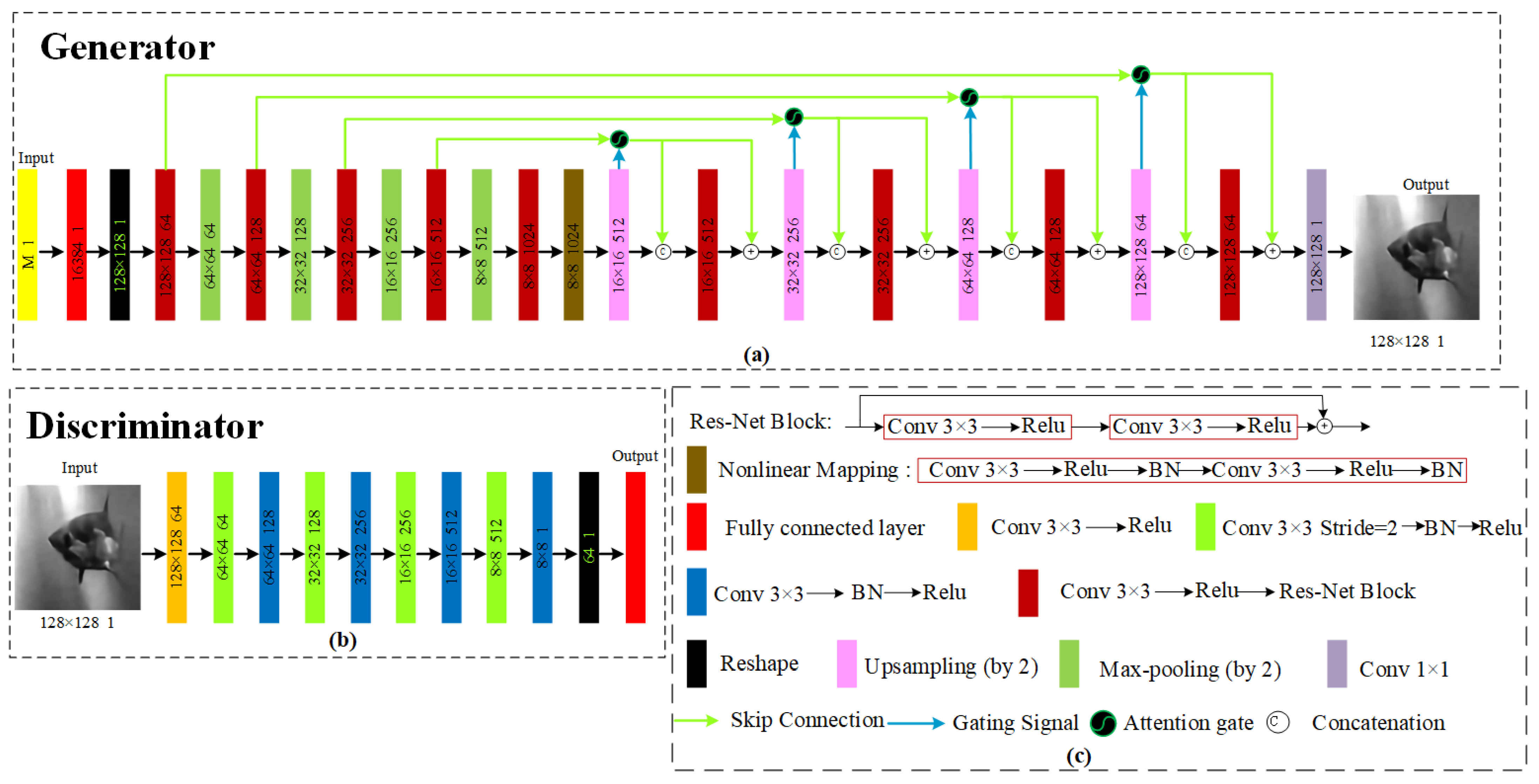
2.4. Reconstruction of Network Structure
3. Numerical Simulation Results
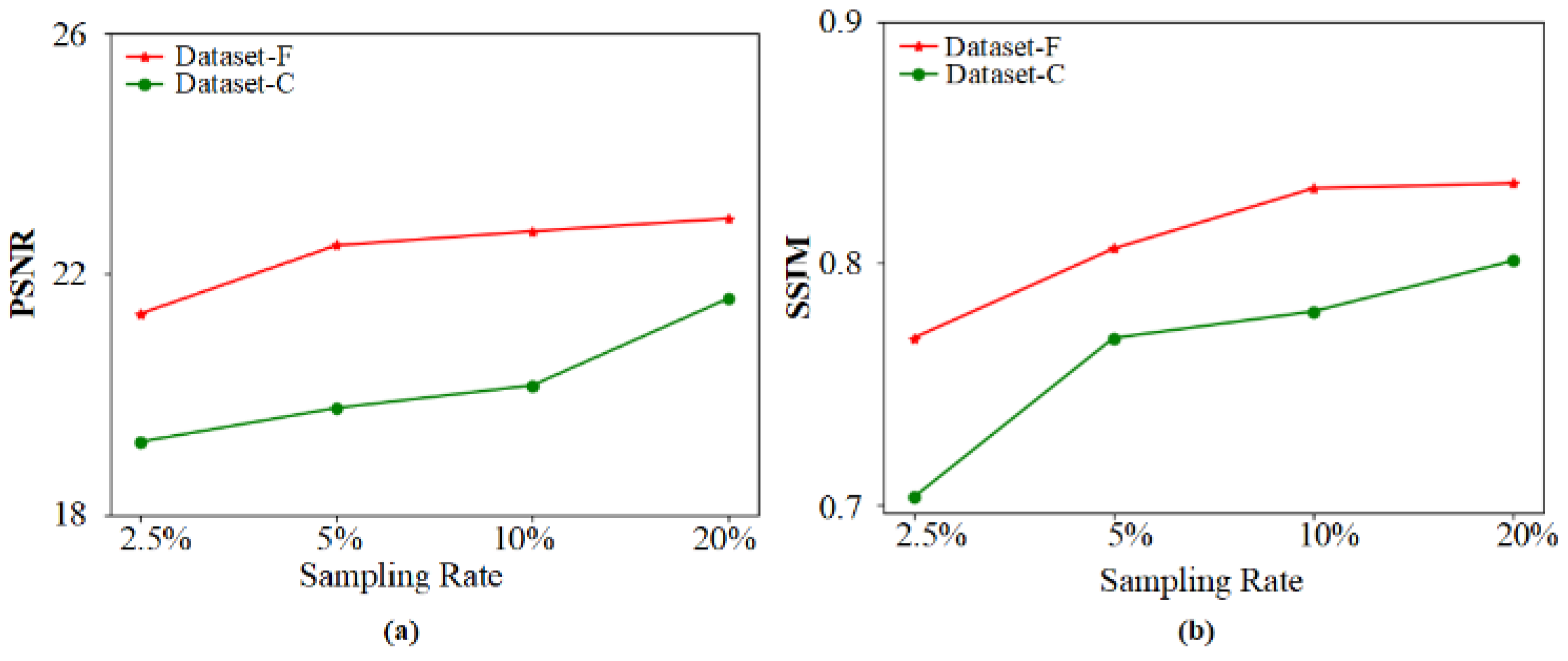
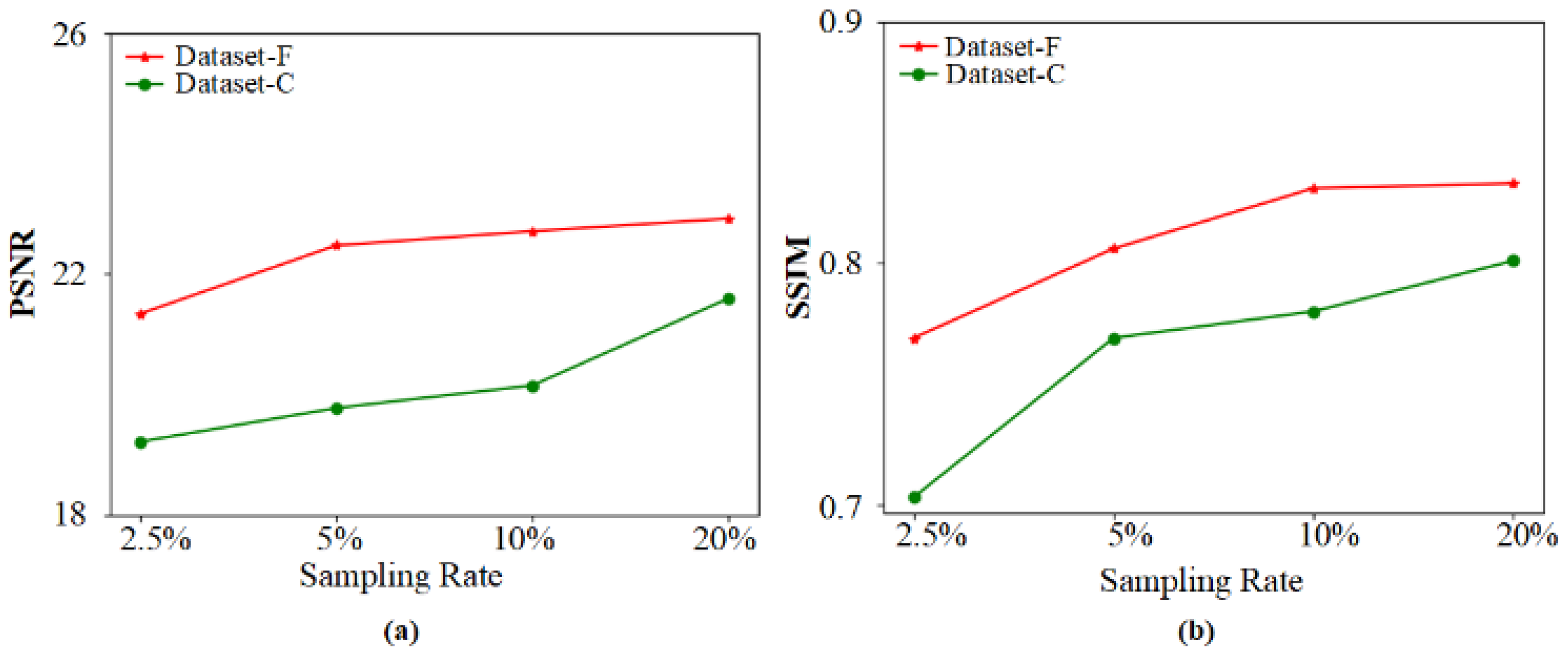
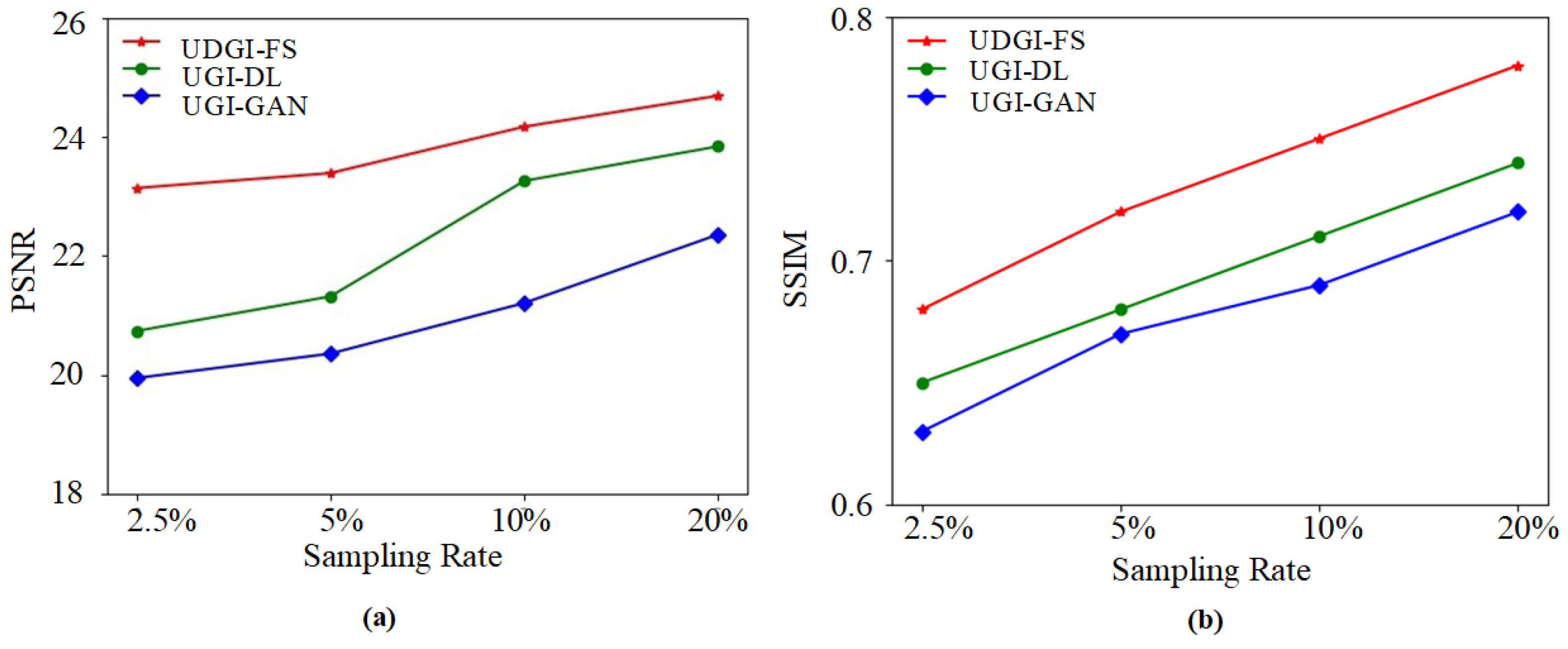
3.1. Generate Dataset Comparisons
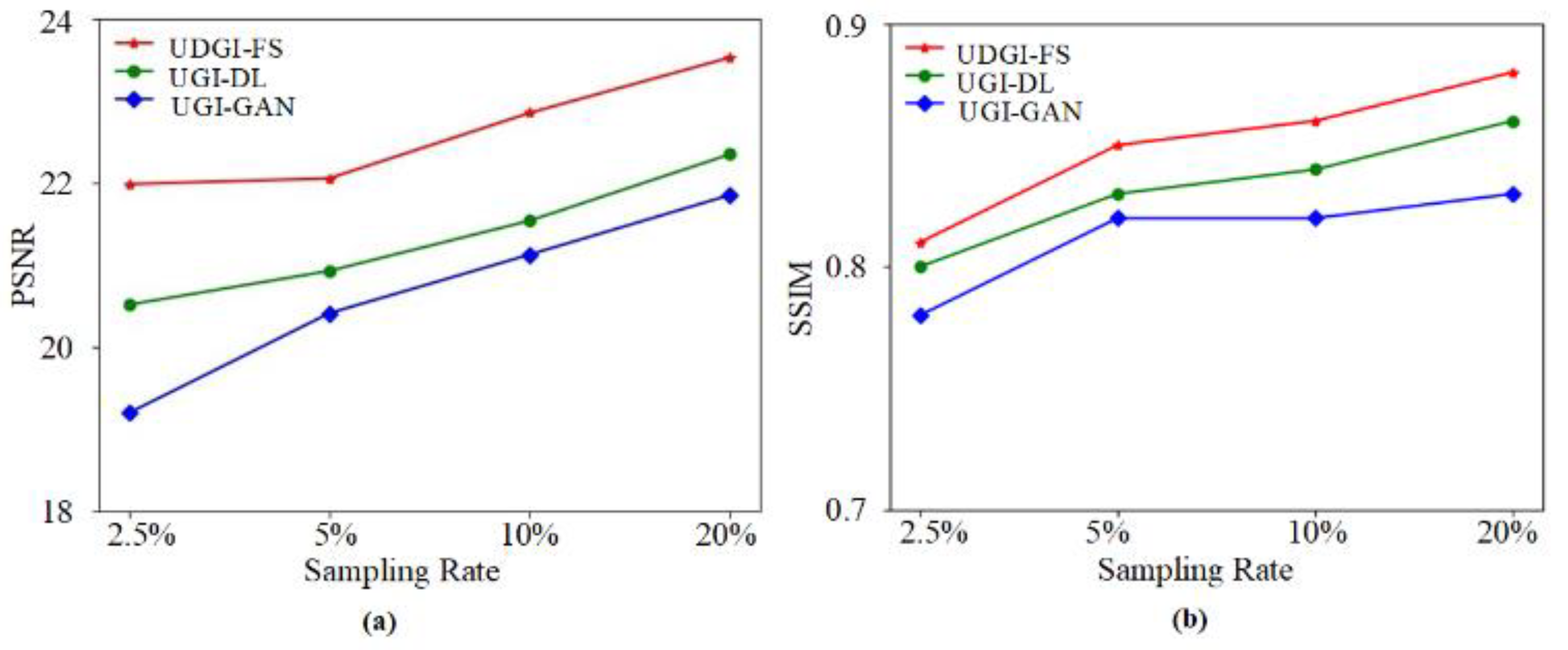
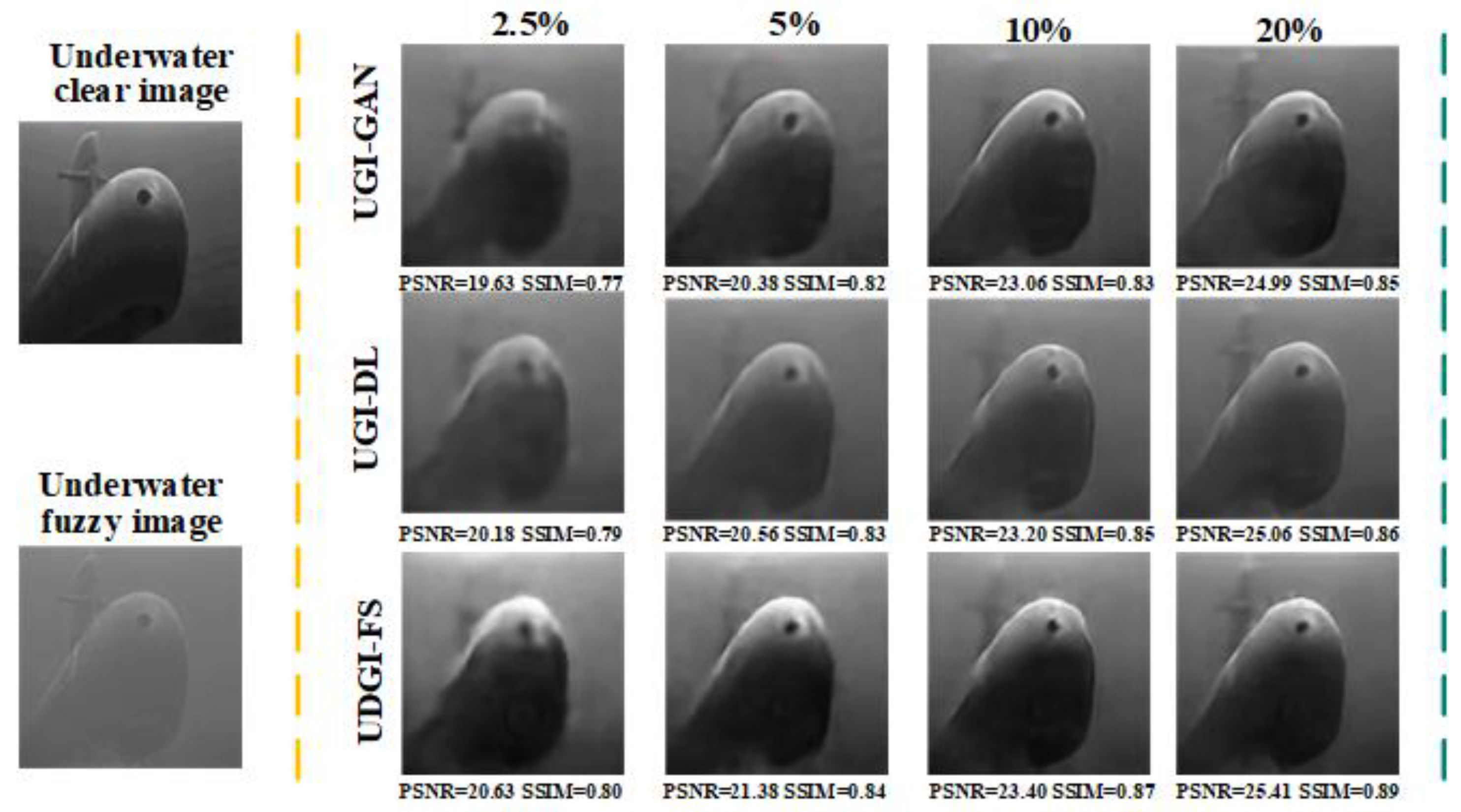
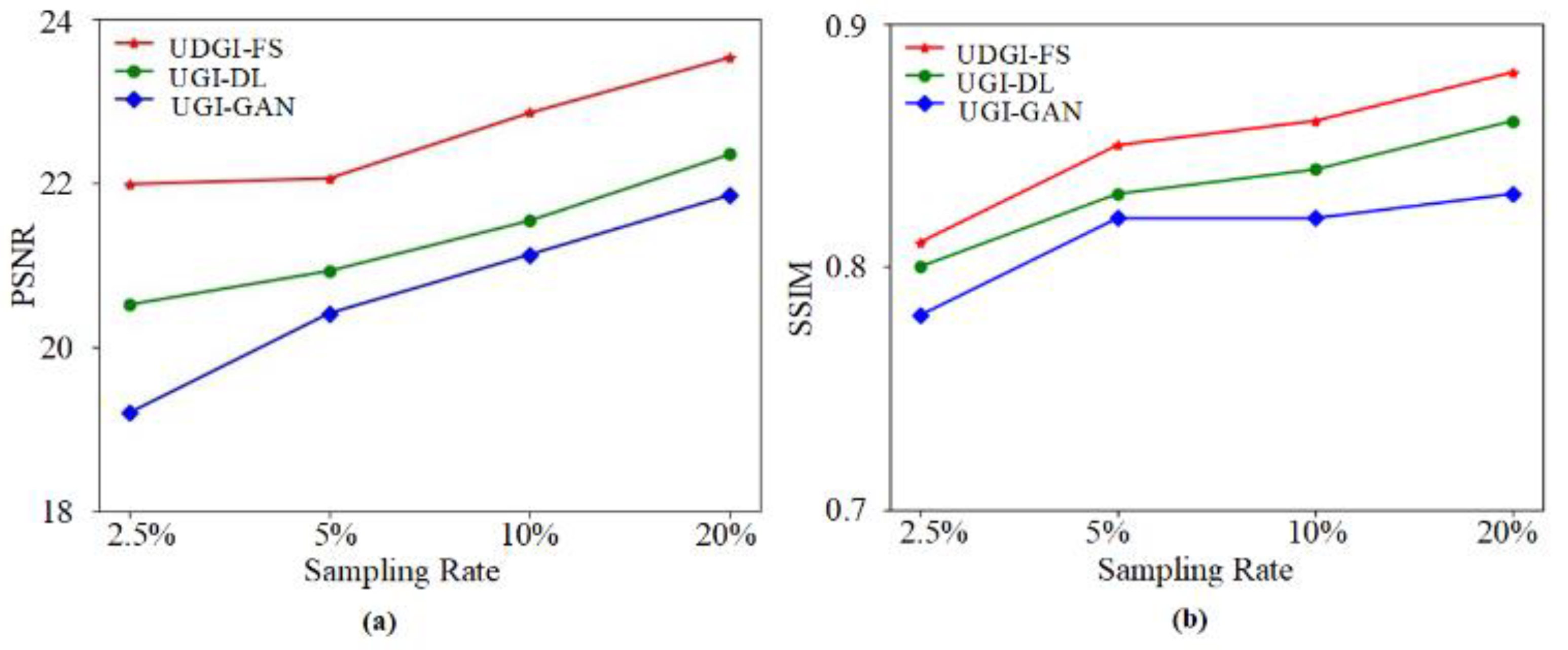
3.2. Numerical Simulations
4. Experimental Methods
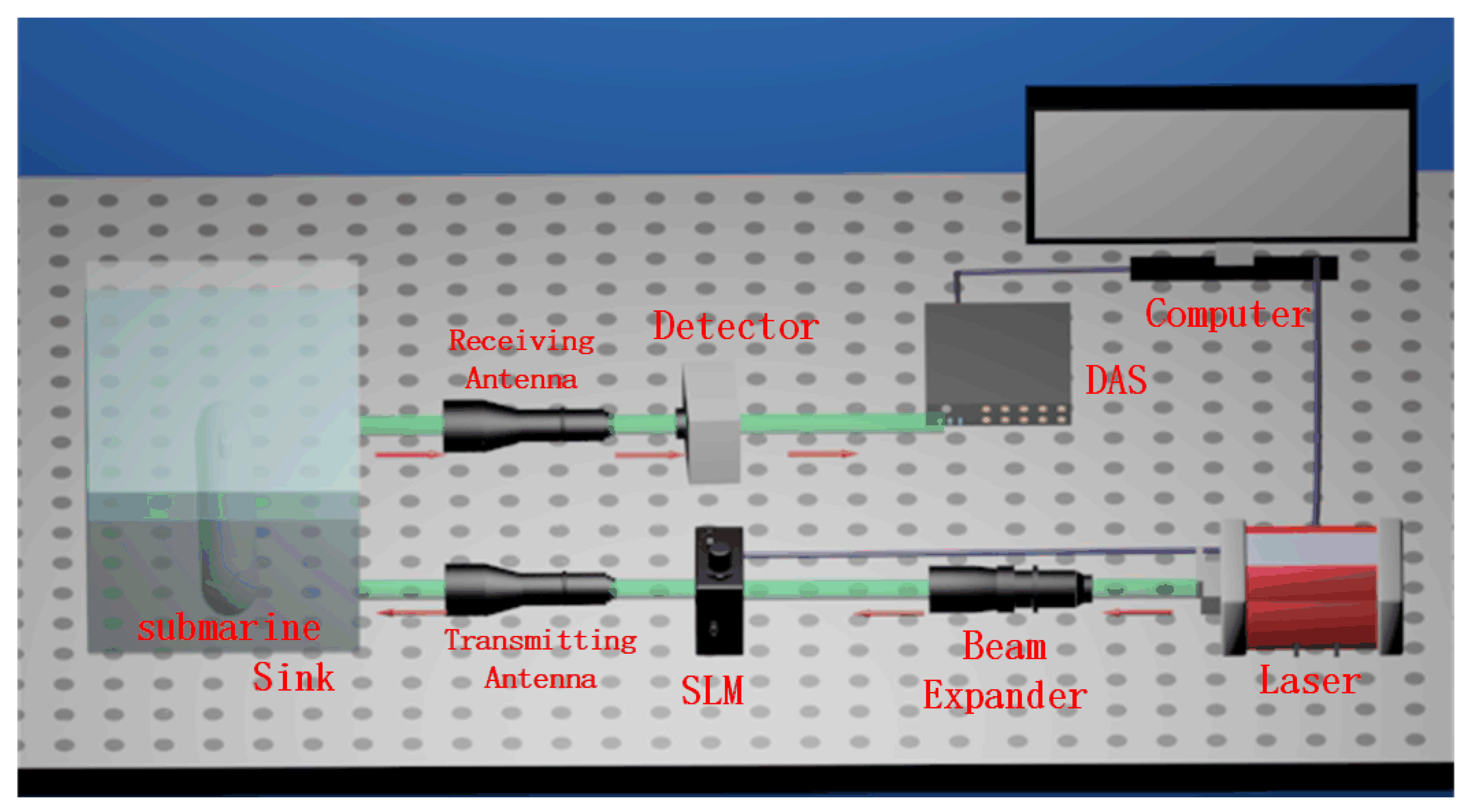
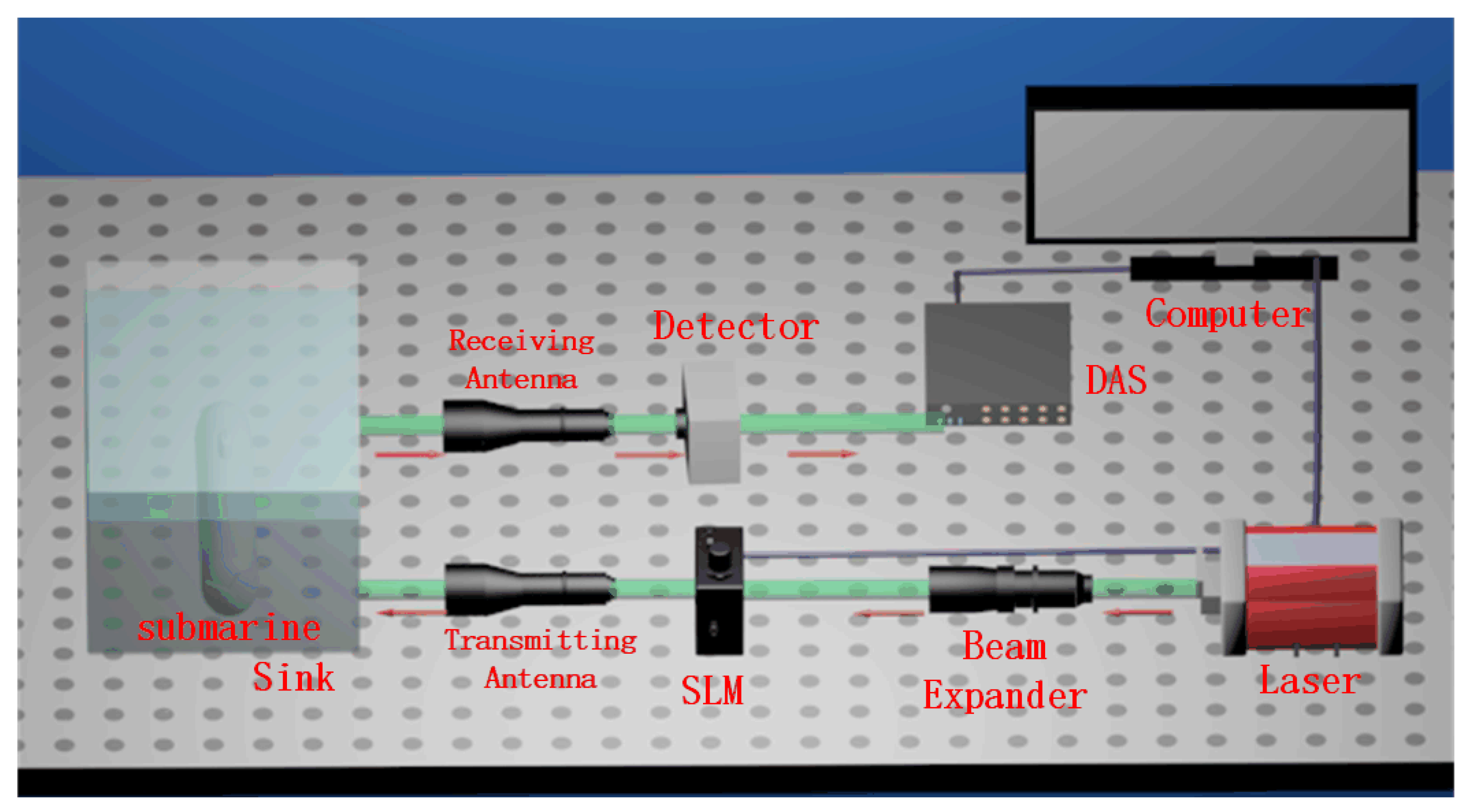
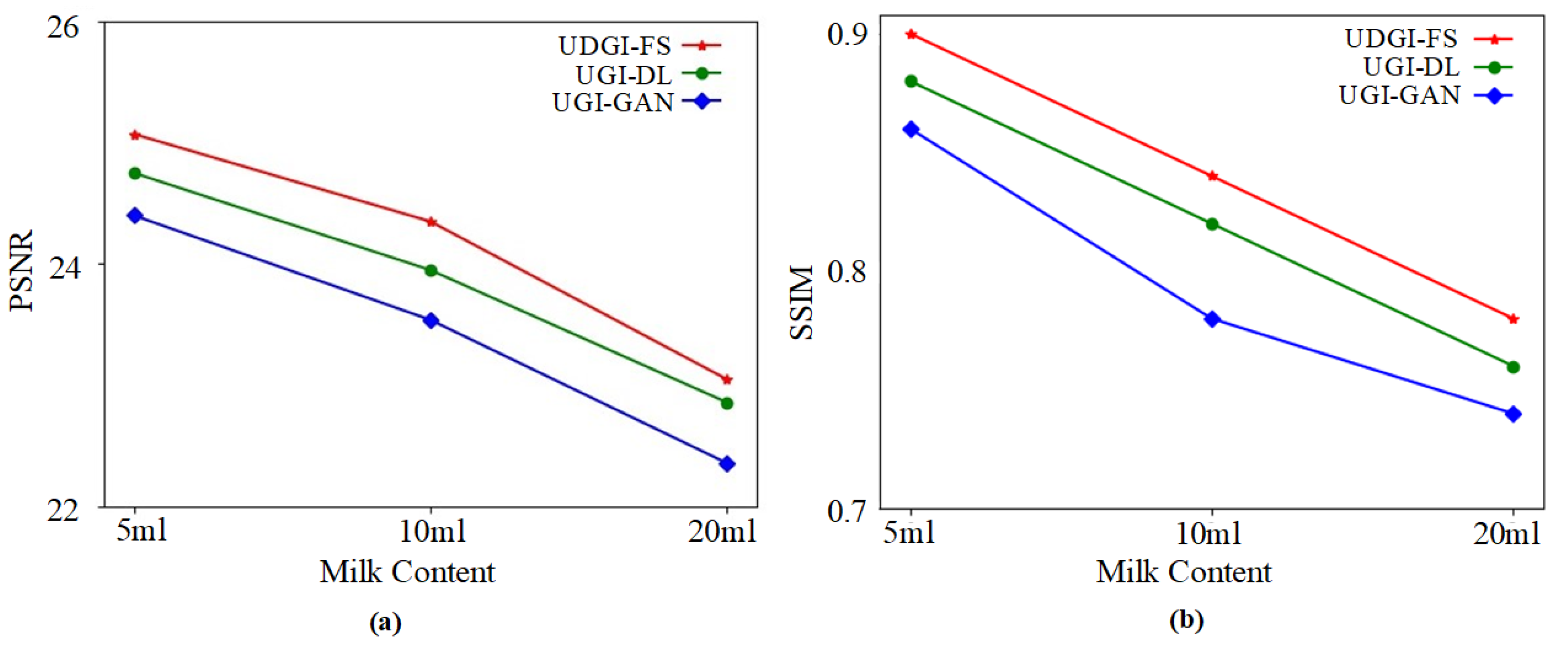
4.1. Experimental Setup
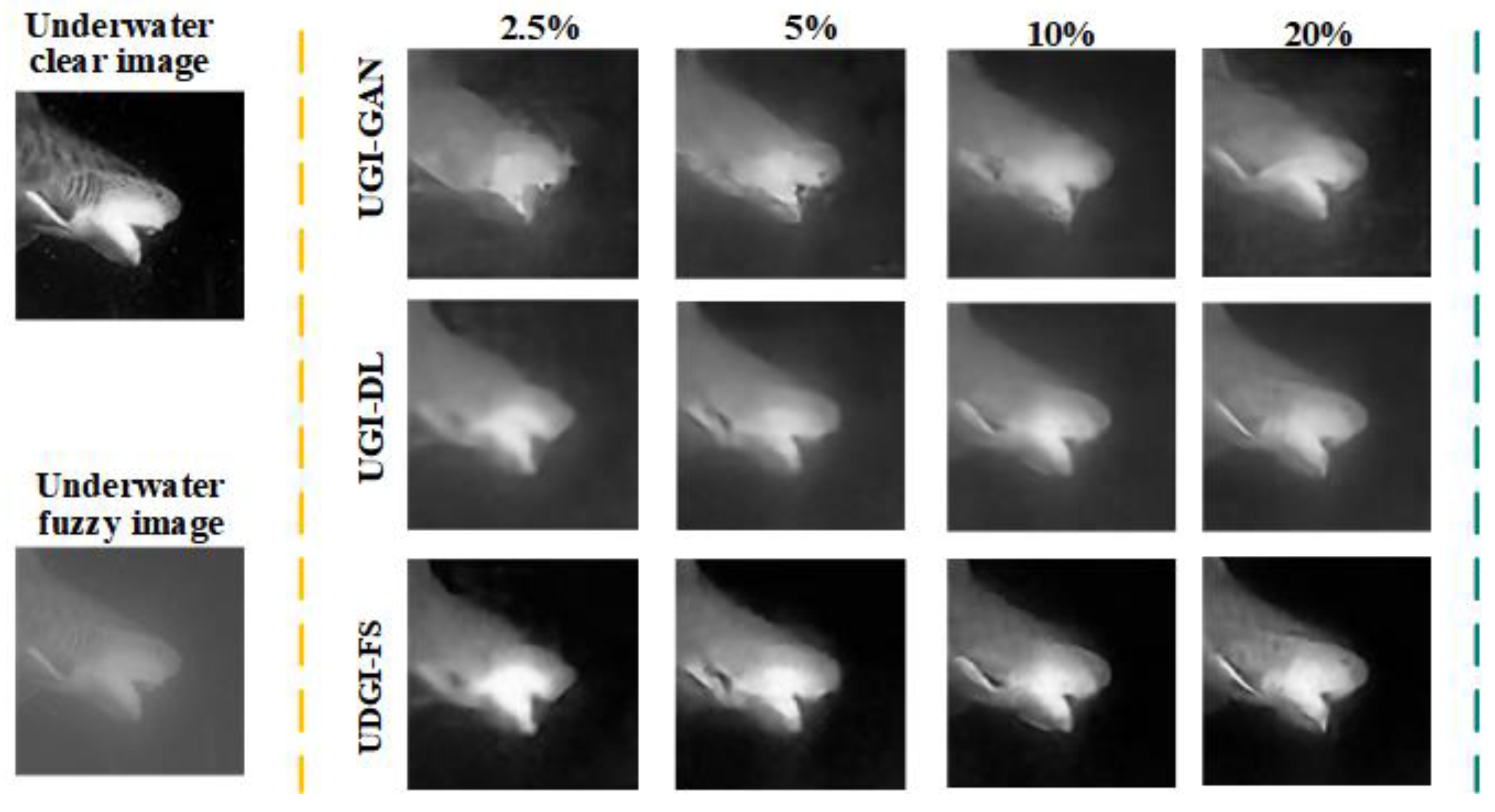
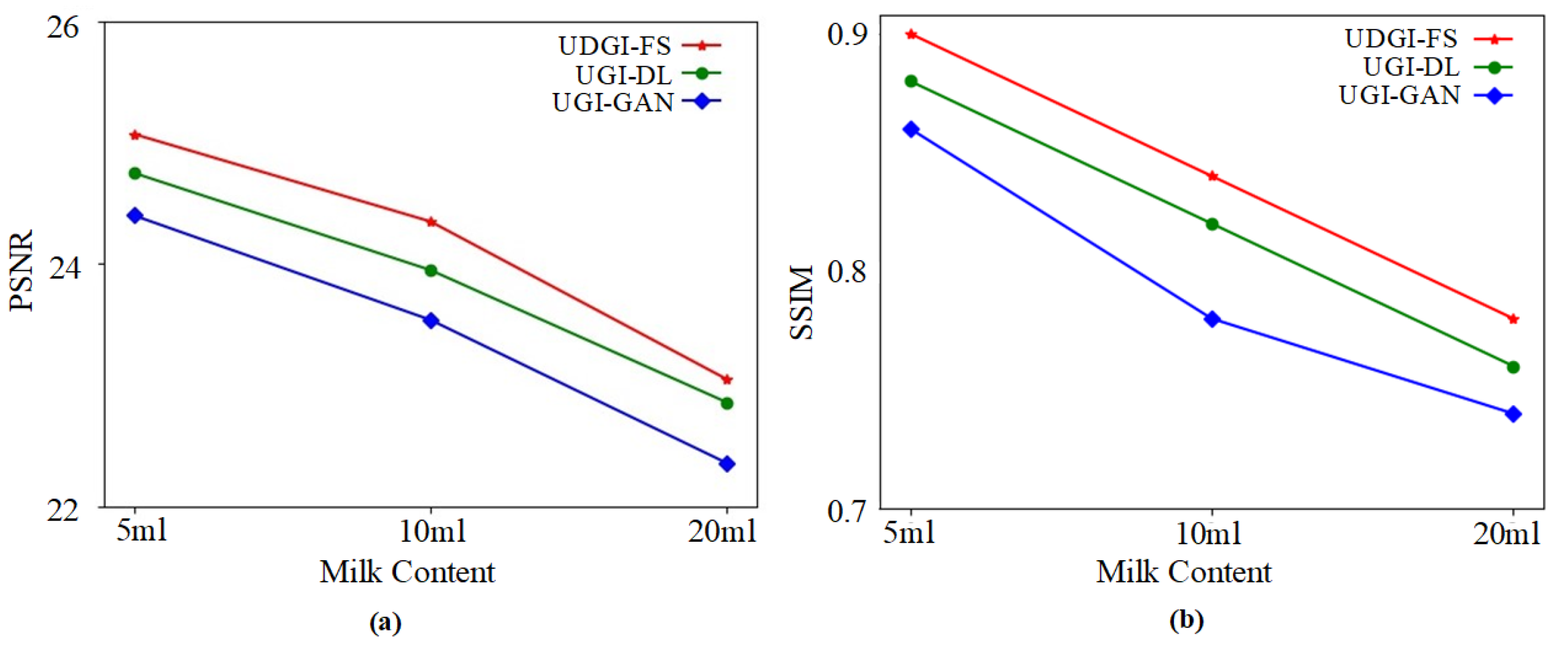
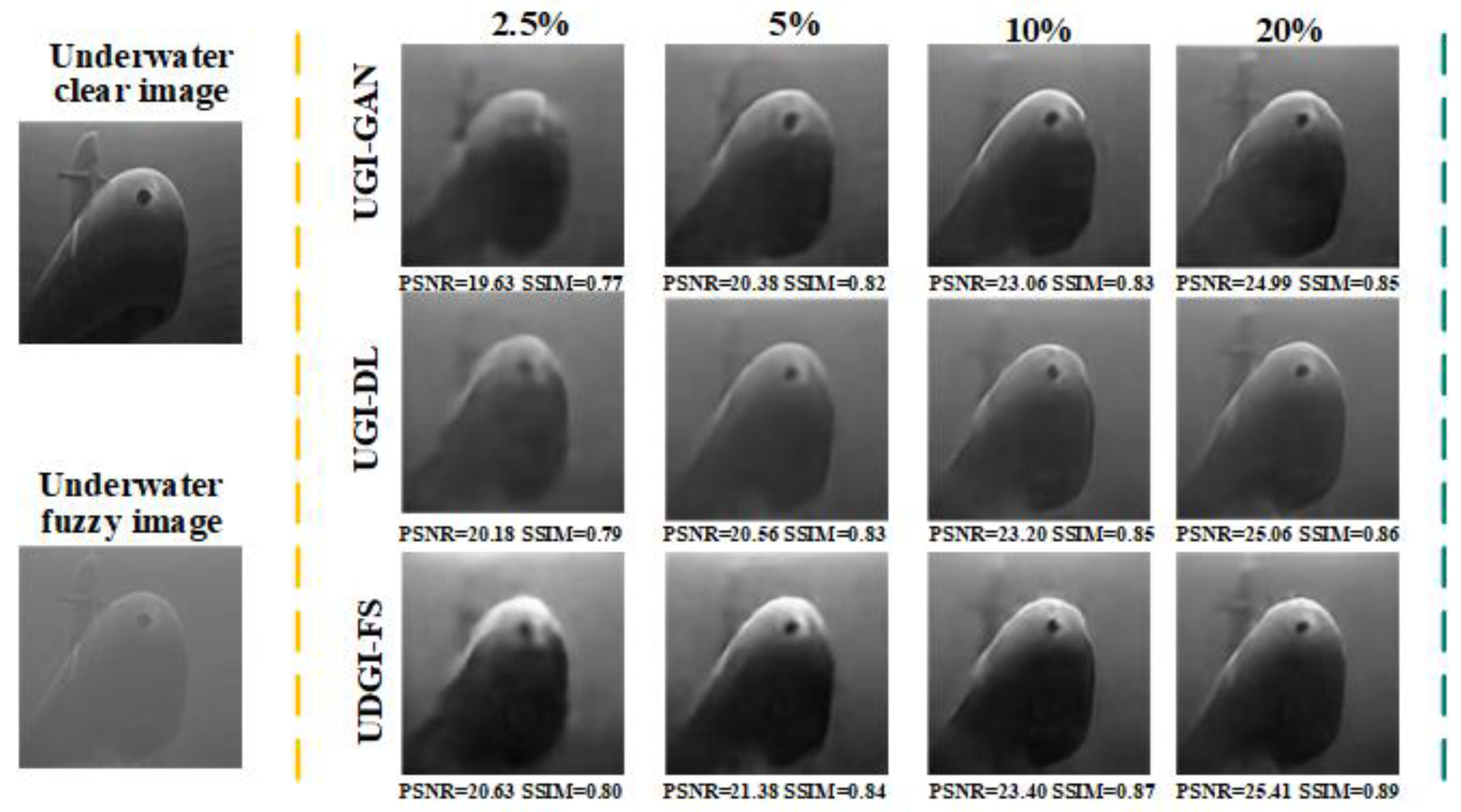
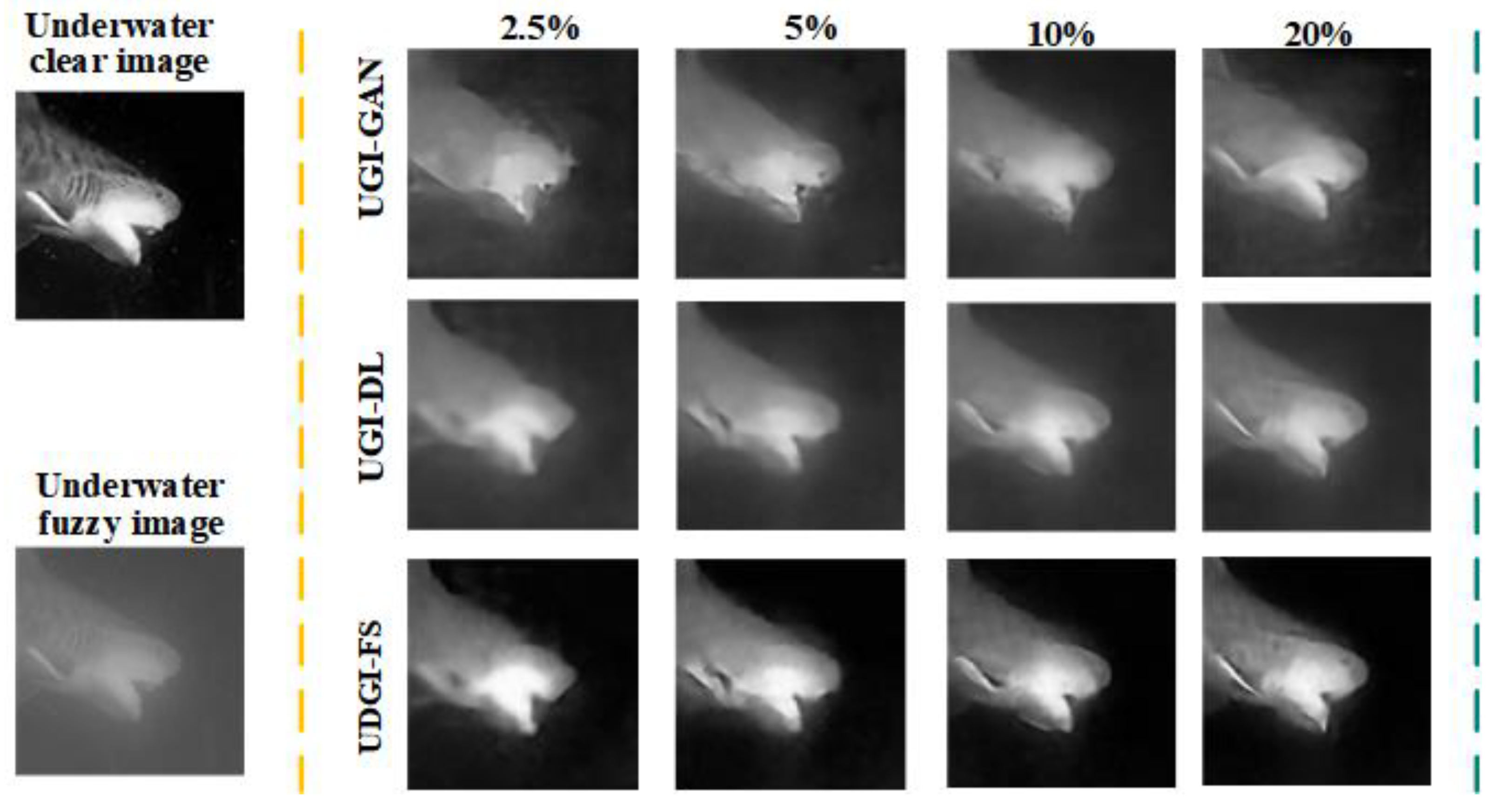
4.2. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, F.; Tillberg, P.; Boyden, E. Expansion microscopy. Science 2015, 347, 543–548. [Google Scholar] [CrossRef] [PubMed]
- Amer, K.; Elbouz, M.; Alfalou, A.; Brosseau, C.; Hajjami, J. Enhancing underwater optical imaging by using a low-pass polarization fifilter. Opt. Express 2019, 27, 621–643. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Wei, Y.; Han, P.; Yang, K.; Bai, L.; Shao, X. Polarization-based exploration for clear underwater vision in natural illumination. Opt. Express 2019, 27, 3629–3641. [Google Scholar] [CrossRef] [PubMed]
- Mariani, P.; Quincoces, I.; Haugholt, K.; Chardard, Y.; Visser, A.; Yates, C.; Piccinno, G.; Reali, G.; Risholm, P.; Thielemann, J. Range-gated imaging system for underwater monitoring in ocean environment. Sustainability 2019, 11, 162. [Google Scholar] [CrossRef]
- Sun, M.; Wang, H.; Huang, J. Improving the performance of computational ghost imaging by using a quadrant detector and digital micro-scanning. Sci. Rep. 2019, 9, 4105–4110. [Google Scholar] [CrossRef]
- Pittman, T.; Shih, Y.; Strekalov, D.; Sergienko, A. Optical imaging by means of two-photon quantum entanglement. Phys. Rev. A 1995, 52, 3429–3432. [Google Scholar] [CrossRef]
- Erkmen, B. Computational ghost imaging for remote sensing. J. Opt. Soc. Am. A 2012, 29, 782–789. [Google Scholar] [CrossRef]
- Tian, N.; Guo, Q.; Wang, A.; Xu, D.; Fu, L. Fluorescence ghost imaging with pseudothermal light. Opt. Lett. 2011, 36, 3302–3304. [Google Scholar] [CrossRef]
- Totero Gongora, J.; Olivieri, L.; Peters, L.; Tunesi, J.; Cecconi, V.; Cutrona, A.; Tucker, R.; Kumar, V.; Pasquazi, A.; Peccianti, M. Route to Intelligent Imaging Reconstruction via Terahertz Nonlinear Ghost Imaging. Micromachines 2020, 11, 521. [Google Scholar] [CrossRef]
- Ma, S.; Hu, C.; Wang, C.; Liu, Z.; Han, S. Multi-scale ghost imaging LiDAR via sparsity constraints using push-broom scanning. Opt. Commun. 2019, 448, 89–92. [Google Scholar] [CrossRef]
- Shapiro, J. Computational ghost imaging. Phys. Rev. A 2008, 78, 061802. [Google Scholar] [CrossRef]
- Li, G.; Yang, Z.; Zhao, Y.; Yan, R.; Liu, X.; Liu, B. Normalized iterative denoising ghost imaging based on the adaptive threshold. Laser. Phys. Lett. 2019, 14, 25207. [Google Scholar] [CrossRef]
- Yang, C.; Wang, C.; Guan, J.; Zhang, C.; Guo, S.; Gong, W.; Gao, F. Scalar-matrix-structured ghost imaging. Photonics Res. 2016, 4, 281–285. [Google Scholar] [CrossRef]
- O-oka, Y.; Fukatsu, S. Differential ghost imaging in time domain. Appl. Phys. Lett. 2017, 111, 61106. [Google Scholar] [CrossRef]
- Wang, L.; Zhao, S. Fast reconstructed and high-quality ghost imaging with fast Walsh-Hadamard transform. Photonics Res. 2016, 4, 240–244. [Google Scholar] [CrossRef]
- Yuan, S.; Yang, Y.; Liu, X.; Zhou, X.; Wei, Z. Optical image transformation and encryption by phase-retrieval-based double random-phase encoding and compressive ghost imaging. Opt. Laser. Eng. 2018, 100, 105–110. [Google Scholar] [CrossRef]
- Zhu, R.; Li, G.; Guo, Y. Compressed-Sensing-based Gradient Reconstruction for Ghost Imaging. Int. J. Theor. Phys. 2019, 58, 1215–1226. [Google Scholar] [CrossRef]
- Chen, Q.; Chamoli, S.; Yin, P.; Wang, X.; Xu, X. Active Mode Single Pixel Imaging in the Highly Turbid Water Environment Using Compressive Sensing. IEEE Access 2019, 7, 159390–159401. [Google Scholar] [CrossRef]
- Xu, Z.; Chen, W.; Penuelas, J.; Padgett, M.; Sun, M. 1000 fps computational ghost imaging using LED-based structured illumination. Opt. Express 2018, 26, 2427–2434. [Google Scholar] [CrossRef]
- Yang, X.; Jiang, P.; Jiang, M.; Xu, L.; Wu, L.; Yang, C.; Zhang, W.; Zhang, J.; Zhang, Y. High imaging quality of Fourier single pixel imaging based on generative adversarial networks at low sampling rate. Opt. Laser. Eng. 2021, 140, 106533. [Google Scholar] [CrossRef]
- Rizvi, S.; Cao, J.; Zhang, K.; Hao, Q. DeepGhost: Real-time computational ghost imaging via deep learning. Sci. Rep. 2020, 10, 2045–2322. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Wang, H.; Wang, H.; Li, G.; Situ, G. Learning from simulation: An end-to-end deep-learning approach for computational ghost imaging. Opt. Express 2019, 27, 25560–25572. [Google Scholar] [CrossRef] [PubMed]
- He, Y.; Wang, G.; Dong, G.; Zhu, S.; Chen, H.; Zhang, A.; Xu, Z. Ghost Imaging Based on Deep Learning. Sci. Rep. 2018, 8, 6469. [Google Scholar] [CrossRef] [PubMed]
- Lyu, M.; Wang, W.; Wang, H.; Wang, H.; Li, G.; Chen, N.; Situ, G. Deep-learning-based ghost imaging. Sci. Rep. 2017, 7, 17865. [Google Scholar] [CrossRef]
- Shimobaba, T.; Endo, Y.; Nishitsuji, T.; Takahashi, T.; Nagahama, Y.; Hasegawa, S.; Sano, M.; Hirayama, R.; Kakue, T.; Shiraki, A.; et al. Computational ghost imaging using deep learning. Opt. Commun. 2018, 413, 147–151. [Google Scholar] [CrossRef]
- Zhang, D.; Yin, R.; Wang, T.; Liao, Q.; Li, H.; Liao, Q.; Liu, J. Ghost imaging with bucket detection and point detection. Opt. Commun. 2018, 412, 146–149. [Google Scholar] [CrossRef]
- Yang, X.; Yu, Z.; Xu, L.; Hu, J.; Wu, L.; Yang, C.; Zhang, W.; Zhang, J.; Zhang, Y. Underwater ghost imaging based on generative adversarial networks with high imaging quality. Opt. Express 2021, 29, 28388. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kim, H.; Hwang, C.; Kim, K.; Roh, J.; Moon, W.; Kim, S.; Lee, B.; Oh, S.; Hahn, J. Anamorphic optical transformation of an amplitude spatial light modulator to a complex spatial light modulator with square pixels [invited]. Appl. Opt. 2014, 53, 139–146. [Google Scholar] [CrossRef]
- Piotrowski, P.; Napiorkowski, J. A comparison of methods to avoid overfitting in neural networks training in the case of catchment runoff modelling. J. Hydrol. 2013, 476, 97–111. [Google Scholar] [CrossRef]
- Zhu, J.; Park, T.; Isola, P.; Efros, A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2243–2251. [Google Scholar]
- Liu, M.; Huang, X.; Mallya, A.; Karras, T.; Aila, T.; Lehtinen, J.; Kautz, J. Few-shot unsupervised image-to-image translation. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 10551–10560. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Falk, T.; Mai, D.; Bensch, R.; Çiçek, Ö.; Abdulkadir, A.; Marrakchi, Y.; Böhm, A.; Deubner, J.; Jäckel, Z.; Seiwald, K.; et al. U-Net: Deep learning for cell counting, detection, and morphometry. Nat. Methods 2019, 16, 67–70. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.J.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.G.; Hammerla, N.; Kainz, B. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Wang, Z.; Huang, M.; Zhu, Q. Smoke detention in storage yard based on parallel deep residual network. Laser. Opt. Prog. 2018, 55, 152–158. [Google Scholar]
- Schlemper, J.; Oktay, O.; Schaap, M.; Heinrich, M.; Kainz, B.; Glocker, B.; Rueckert, D. Attention gated networks: Learning to leverage salient regions in medical images. Med. Image Anal. 2019, 53, 197–207. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Vasudevan, S. Mutual Information Based Learning Rate Decay for Stochastic Gradient Descent Training of Deep Neural Networks. Entropy 2020, 22, 560. [Google Scholar] [CrossRef]
- Rajinikanth, V.; Joseph Raj, A.; Thanaraj, K.; Naik, G. A Customized VGG19 Network with Concatenation of Deep and Handcrafted Features for Brain Tumor Detection. Appl. Sci. 2020, 10, 3429. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M. Image Quality Assessment through FSIM, SSIM, MSE and PSNR—A Comparative Study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Training Duration | Reconstruction Duration |
|---|---|---|
| UDGI-FS | 24 h | 65 ms |
| UGI-DL | 24 h | 35 ms |
| UGI-GAN | 23 h | 25 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Yu, Z.; Jiang, P.; Xu, L.; Hu, J.; Wu, L.; Zou, B.; Zhang, Y.; Zhang, J. Deblurring Ghost Imaging Reconstruction Based on Underwater Dataset Generated by Few-Shot Learning. Sensors 2022, 22, 6161. https://doi.org/10.3390/s22166161
Yang X, Yu Z, Jiang P, Xu L, Hu J, Wu L, Zou B, Zhang Y, Zhang J. Deblurring Ghost Imaging Reconstruction Based on Underwater Dataset Generated by Few-Shot Learning. Sensors. 2022; 22(16):6161. https://doi.org/10.3390/s22166161
Chicago/Turabian StyleYang, Xu, Zhongyang Yu, Pengfei Jiang, Lu Xu, Jiemin Hu, Long Wu, Bo Zou, Yong Zhang, and Jianlong Zhang. 2022. "Deblurring Ghost Imaging Reconstruction Based on Underwater Dataset Generated by Few-Shot Learning" Sensors 22, no. 16: 6161. https://doi.org/10.3390/s22166161
APA StyleYang, X., Yu, Z., Jiang, P., Xu, L., Hu, J., Wu, L., Zou, B., Zhang, Y., & Zhang, J. (2022). Deblurring Ghost Imaging Reconstruction Based on Underwater Dataset Generated by Few-Shot Learning. Sensors, 22(16), 6161. https://doi.org/10.3390/s22166161