1. Introduction
Bladder cancer (BC) is the most common urinary tract malignancy with approximately 550,000 new cases and 200,000 deaths worldwide yearly [
1,
2]. Urothelial cell carcinoma is the predominant histological type, which is often classified as non-muscle-invasive bladder cancer (NMIBC), or muscle-invasive bladder cancer (MIBC) depending on whether the tumour has invaded into the muscularis propria. Although only about 25% of newly diagnosed patients present with muscle invasive disease, MIBC has accounted for the majority of bladder cancer mortality [
3]. Clinically, the 5-year survival rate of MIBC is <15% despite the applications of advanced therapies over the past decades [
4], and requires frequent physical examinations, making bladder cancer the most expensive cancer to treat [
5]. An in-depth study of the molecular characteristics of different subtypes (i.e., NMIBC vs. MIBC) is therefore essential for the development of biomarkers that can target tumour progression.
In recent years, many studies have characterised the molecular characteristics at different omics levels and have resulted in the identification of promising novel biomarkers and therapeutic targets, which could improve outcomes for patients with this disease [
6]. Nevertheless, the previous studies that investigated the molecular profiles NMIBC vs. MIBC were only based on single-omics data [
7,
8,
9,
10,
11], and therefore the complexity of bladder cancer were not fully captured. In addition, the measurement of omics data differs in sample types [
12], which causes the challenge in detecting the markers with low concentrations. Thus, we need better biomarkers, especially those up- or down-regulated consistently in NMIBC or MIBC, to increase the opportunities in identifying the early stages of bladder cancer progression. Furthermore, although recent advances in high-throughput omics measurement and bioinformatics analysis have provided the platforms and opportunities for the discovery of new bladder cancer biomarkers and druggable targets [
13], there is currently a lack of comprehensive molecular profiling studies focusing on the downstream molecules, i.e., metabolites and proteins. In addition to metabolomic or proteomic markers, extracellular vesicles (EV) and gut microbiota are also useful and novel biomarker candidates due to their essential role in various pathways [
14,
15]; however, the studies investigating the EV and gut microbiota in relation to bladder cancer are largely scarce.
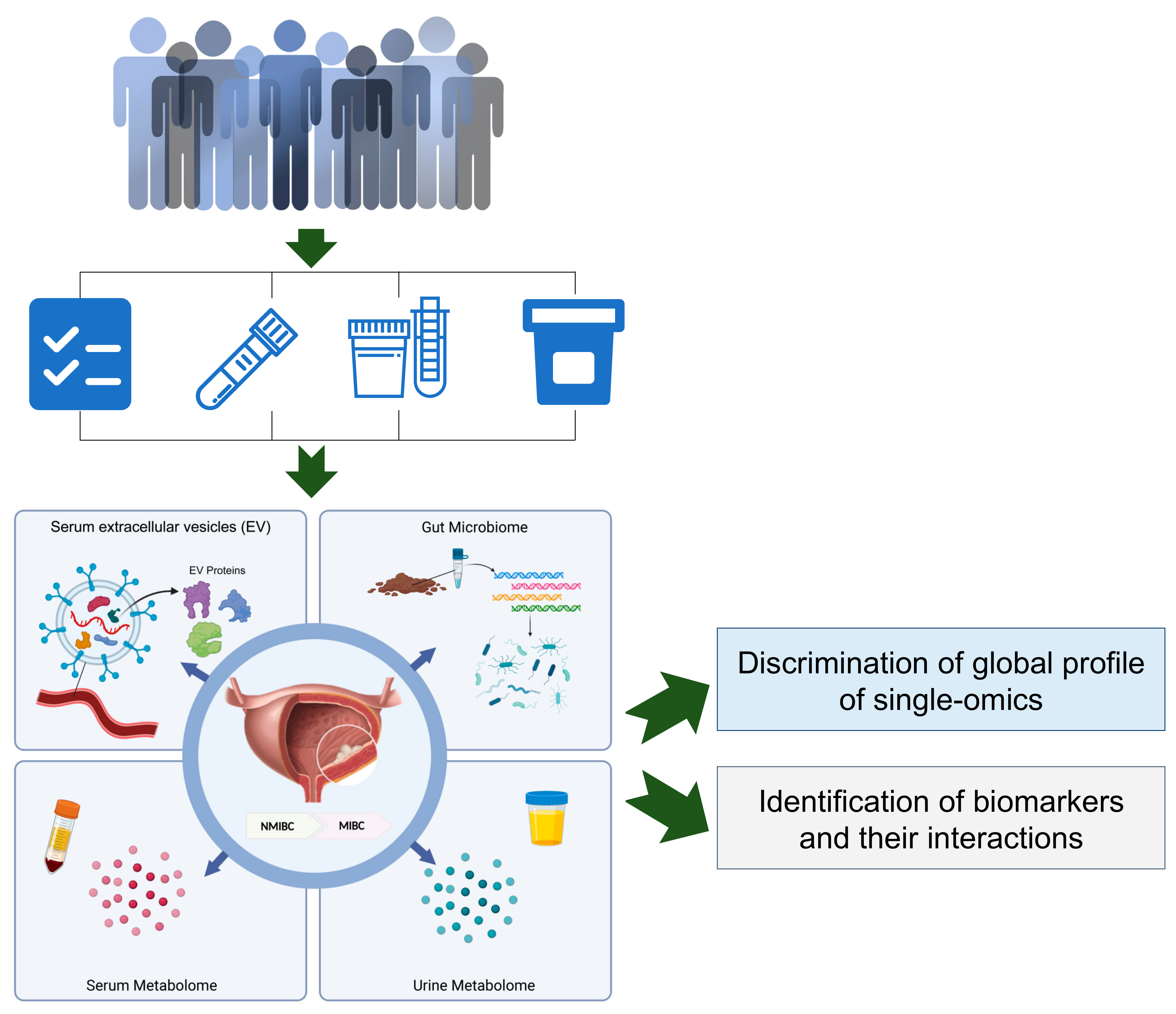
Here, we initiated a population-based study, which aimed to perform a comprehensive analysis of multi-omics including the serum metabolome, urine metabolome, stool metagenome, and serum EV proteome, with the goal of identifying biomarkers and their interactions to distinguish the NMIBC vs. MIBC patients. These results can provide preliminarily evidence and support the further study for the molecular subtyping of bladder cancer from the perspective of multi-omics.
2. Materials and Methods
To obtain a brief landscape of multi-omics for patients with NMIBC and MIBC, we designed a pilot study with measurements in laboratory tests and multi-omics (i.e., the serum metabolome, urine metabolome, serum EV proteome and gut microbiome), as presented in
Figure 1.
2.1. Participants Recruitment and Demographic Characteristics Assessment
All participants were informed about the study’s purpose during the admission interview, and voluntarily informed consent forms prior to enrolling in the study. All procedures in this study were compliant with the Declaration of Helsinki, and the study’s protocol was approved by the Ethics Committee of the Zhongda Hospital of Southeast University, Nanjing, China.
Bladder cancer patients were recruited for this study at a tertiary-care hospital in Nanjing from between 1 April 2021, and 31 July 2021. All the BC patients were local residents, and of Han ancestry. The medical records of each patient were reviewed by trained doctors or nurses, and clinicopathological characteristics of bladder cancers at the diagnosis were prospectively gathered on dedicated case report forms. None of the patients were undergoing other medical interventions. The diagnosis and progression of bladder cancer was confirmed with histology, in which the tumours were re-staged according to the 2009 American Joint Committee on TNM (Tumour, Node and Metastasis) classification of bladder tumours and graded according to the 2004 World Health Organization grading scheme [
16]. In addition, all the specimens (i.e., blood, urine, and stool) were collected before the patients went to surgery or chemotherapy. In total, 26 bladder cancer patients were included into the current study: 15 were NMIBC patients and 11 were MIBC patients.
2.2. Sample Collection and Quantification
Whole blood samples were collected after an overnight fast, stored for about 30 min in room temperature before sending the sample to the clinical chemistry laboratory using a biosafety transport box. The laboratory obtained the sample and centrifuged them at 1500× g for 10 min. Then, we collected the serum in new centrifuge tubes and immediately stored them at −80 °C. Meanwhile, the urine samples were thawed in a thermostatically controlled water bath at 37 °C and immediately centrifuged at 3900× g for 10 min. The fresh stool samples were collected into sterilised and portable plastic containers with waxed tissue paper (Epitope Diagnostics, San Diego, CA, USA), and then were transferred to a −80 °C facility within 4 h after collection.
2.3. Metabolome Measurement for Serum and Urine Sample
The blood sample was taken out from the −80 °C refrigerator and thawed on ice, then vortexed for 10 s. We mixed 50 μL of sample and 300 μL of 20% acetonitrile methanol internal standard extractant, vortexed the mixture for 3 min and centrifuged (8000× g, 4 °C) for 10 min. Then, we transferred 200 μL of the supernatant and stored it at −20 °C for 30 min. Finally, we centrifuged (8000× g, 4 °C) the sample for 3 min and took the supernatant for analysis. For the urine samples, they were taken out from the −80 °C refrigerator and thawed on ice, then vortexed for 10 s. Then, we mixed 200 μL of sample and 200 μL of 20% acetonitrile methanol internal standard extractant, vortexed the mixture for 3 min and centrifuged (8000× g, 4 °C) for 10 min. Then, 350 μL of the supernatant was transferred and dried. We reconstituted the dry residue with 150 μL of 70% methanol water, vortexed for 3 min, and sonicated it for 10 min in ice water bath. Finally, it was centrifuged (8000× g, 4 °C) for 3 min and the supernatant was taken for analysis.
The blood sample was taken out from the −80 °C refrigerator and thawed on ice until the sample is free of ice. The sample was vortexed for 10 s. Then 50 μL of sample was mixed with 300 μL of 20% acetonitrile methanol internal standard extractant, which was vortexed for 3 min, and centrifuged at 12,000 r/min for 10 min at 4 °C. After centrifugation, 200 μL of the supernatant was transferred into a centrifuge tube and stored for 30 min at −20 °C in a refrigerator. Finally, the sample was centrifuged (8000× g, 4 °C) for 3 min and then 180 μL of supernatant was taken for analysis. For the urine sample, similarly, the sample was taken out from the −80 °C refrigerator and thawed on ice until the sample was free of ice. The sample was vortexed for 10 s. Then, 200 μL of sample was mixed with 200 μL of 20% acetonitrile methanol internal standard extractant, which was vortexed for 3 min, and centrifuged at 12,000 r/min for 10 min at 4 °C. Then, 350 μL of the supernatant was transferred and dried. The dry residue was reconstituted with 150 μL of 70% methanol water, vortexed for 3 min, and sonicated for 10 min in an ice water bath. We reconstituted the dry residue with 150 μL of 70% methanol water, vortexed it for 3 min, and sonicated it for 10 min in an ice water bath. Finally, the sample was centrifuged (8000× g, 4 °C) for 3 min and then 120 μL of supernatant was taken for analysis.
The metabolome was measured according to the procedures and conditions described as follows; (1) T3 UPLC Conditions: the sample extracts were analysed using an LC-ESI-MS/MS system (UPLC, ExionLC AD 1.7, Framinghan, MA, USA
https://sciex.com.cn/, accessed on 15 October 2021; MS, QTRAP
® System, Framinghan, MA, USA,
https://sciex.com/, accessed on 15 October 2021). The analytical conditions were as follows, UPLC: column, Waters ACQUITY UPLC HSS T3 C18 (1.8 µm, 2.1 mm × 100 mm); column temperature, 40 °C; flow rate, 0.4 mL/min; injection volume, 2 μL; solvent system, water (0.1% formic acid): acetonitrile (0.1% formic acid); gradient program, 95:5 V/V at 0 min, 10:90 V/V at 11.0 min, 10:90 V/V at 12.0 min, 95:5 V/V at 12.1 min, 95:5 V/V at 14.0 min; (2) Amide UPLC Conditions: The sample extracts were analysed using an LC-ESI-MS/MS system (UPLC, ExionLC AD, 1.7, Framinghan, MA, USA,
https://sciex.com.cn/, accessed on 15 November 2021; MS, QTRAP
® System, Framinghan, MA, USA,
https://sciex.com/, accessed on 15 November 2021). The analytical conditions were as follows, UPLC: column, Waters ACQUITY UPLC BEH Amide 1.7 µm, 2.1 mm × 100 mm; column temperature, 40 °C; flow rate, 0.4 mL/min; injection volume, 2 μL; solvent system, water (25 mM Ammonium formate/0.4% Ammonia): acetonitrile; gradient program, 10:90 V/V at 0 min, 40:60 V/V at 9.0 min, 60:40 V/V at 10.0 min, 60:40 V/V at 11.0 min, 10:90 V/V at 11.1 min, 10:90 V/V at 15.0 min; (3) ESI-QTRAP-MS/MS: T3 and Hilic have the same mass spectrometry parameters. LIT and triple quadrupole (QQQ) scans were acquired on a triple quadrupole-linear ion trap mass spectrometer (QTRAP), QTRAP
® LC-MS/MS System, equipped with an ESI Turbo Ion-Spray interface, operating in positive and negative ion mode, and controlled by Analyst 1.6.3 software (Sciex). The ESI source operation parameters were as follows: source temperature 500 °C; ion spray voltage (IS) 5500 V (positive), −4500 V (negative); ion source gas I (GSI), gas II (GSII), and curtain gas (CUR) were set at 55, 60, and 25.0 psi, respectively; the collision gas (CAD) was high. Instrument tuning and mass calibration were performed with 10 and 100 μmol/L polypropylene glycol solutions in QQQ and LIT modes, respectively. A specific set of MRM transitions were monitored for each period according to the metabolites eluted within this period.
2.4. Extracellular Vesicles (EV) Proteome Measurement for Serum Sample
For EV proteome analysis, the serum samples obtained from patients with NMIBC and MIBC individuals were pooled together. These two groups of pooled serum samples were used for EV isolation and quantified by using a previously published protocol [
17]; (1) preparation of serum: a serum sample was diluted using phosphate-buffered solution (PBS), and centrifuged at 500×
g for 10 min at 4 °C to remove cells and dead cells; the supernatant was collected and centrifuged at 2000×
g for 10 min at 4 °C to remove cell debris; the supernatant was collected and centrifuged at 10,000× g for 30 min at 4 °C to remove large vesicles; the supernatant was collected and centrifuged continuously at 100,000× g for 90 min at 4 °C to remove the supernatant; then, the leftover was centrifuged at 100,000× g for 90 min at 4 °C, and the supernatant was removed. EVs were obtained by resuspending the leftover precipitate in PBS and centrifuging again at 100,000× g for 90 min; (2) EV proteolysis: the collected EVs were added into 100 μL PTS lysate and then put in a water bath at 95 °C for 10 min. Then, it was cooled to room temperature and added with 450 μL of 50 mM TEAB buffer. Lys-C enzyme was added according to the sample protein content:enzyme = 100:1 and incubated at 37 °C for 3 h. The trypsinase enzyme was added according to sample protein content:trypsin = 50:1 and incubated at 37 °C for 16 h. An amount of 50 μL of 10% TFA was used to terminate the enzymatic digestion. Five times the volume of ethyl acetate was added and vortexed for 2 min, centrifuged at 12,000×
g for 3 min, then we removed the upper layer of ethyl acetate, and repeated the process once. The samples were lyophilised, then the lyophilised samples were desalted and desalted pending mass spectrometric detection; (3) LC–MS/MS and data analysis: the desalted samples were re-solubilised using 0.1% formic acid, and appropriate amounts of peptides were taken from each case for chromatographic separation using a nanolitre flow rate Easy-nLC 1200 chromatography system (Thermo Scientific, Waltham, MA, USA). Buffer: Solution A was 0.1% formic acid in water and Solution B was 80% ACN/0.1% formic acid. The chromatographic column was equilibrated with 100% of liquid A. The sample was fed and passed through the chromatographic analytical column for gradient separation at a flow rate of 300 nL/min. The liquid phase separation gradients were as follows; 0–3 min, linear gradient of B liquid from 2 to 8%; 3–81 min, linear gradient of B liquid from 8 to 40%; 81–83 min, linear gradient of B liquid from 40 to 95%; 83–90 min, B liquid maintained at 95%. The peptides were separated and analysed by DIA (data independent acquisition) mass spectrometry using a Q-Exactive HF-X mass spectrometer (Thermo Scientific). Analysis time was 90 min, detection mode: positive ion, parent ion scan range: 390–1210
m/
z, primary mass resolution: 60,000, AGC target: 1e6, primary maximum IT: 60 ms. DIA method acquisition: 75 secondary mass spectra of the highest intensity parent ions were triggered after each full scan (full scan) MS2 scan, secondary MS resolution: 15,000, AGC target: 1e6, Maximum IT: 20 ms, Isolation window: 8
m/
z, Normalized collision energy: 27. The mass spectrometry data were analysed using the directDIA analysis function of Spectronaut™ software 16 (Schlieren, Switzerland), using the human source database downloaded from the Uniprot website (
https://www.uniprot.org, accessed on 22 March 2022) as the database for directDIA analysis, and the search library parameters were the default parameters of the BGS Factory Setting for the directDIA analysis process.
2.5. Metagenome Measurement from Stool Sample
Stool DNA extractions were carried out by a standardised CTAB procedure. DNA concentration was measured using the Qubit dsDNA Assay Kit in Qubit 2.0 Fluorometer (Life Technologies, Carlsbad, CA, USA). For DNA library preparation, a total amount of 1 μg DNA per sample was used as input material. In addition, the NEBNext Ultra DNA Library Prep Kit (NEB, Ipswich, MA, USA) was used following the manufacturer’s recommendations and index codes were added to attribute sequences to each sample. The DNA samples were fragmented by sonication to a size of approximately 350 bp. Then, the DNA fragments were end-polished, A-tailed, and ligated with the full-length adaptor for Illumina sequencing with further PCR amplification. After that, PCR products were purified (AMPure XP system) and libraries were analysed for size distribution by an Agilent2100 Bioanalyzer and quantified using real-time PCR. The clustering of the index-coded samples was performed on a cBot Cluster Generation System according to the manufacturer’s instructions. After cluster generation, the library preparations were sequenced on an Illumina HiSeq platform and 150 bp paired-end reads were generated. Finally, we obtained on average 42.4 million paired-end raw reads for each sample.
Next, raw sequencing reads were first quality-controlled with PRINSEQ (v0.20.4)8: (1) to trim the reads by quality score from the 5′ end and 3′ end with a quality threshold of 20; (2) remove read pairs when either read was <60 bp, contained “N” bases or had a quality score mean below 30; and (3) deduplicate the reads. Reads that could be aligned to the human genome (H. sapiens, UCSC hg19) were removed (aligned with Bowtie2 v2.2.5 using –reorder–no-contain–dovetail).
Functional profiling was performed with HUMAnN2 v2.8.19 (Boston, MA, USA), which maps sample reads against the sample-specific reference database to quantify gene presence and abundance in a species-stratified manner, with unmapped reads further used in a translated search against Uniref90 to include taxonomically unclassified but functionally distinct gene family abundances. We extracted the Uniref90 gene families of gut bacteria for downstream analyses. The Uniref90 gene families were then converted into KEGG Orthologs (KOs). The abundances of KOs were normalised into relative abundance for each sample. In addition, the KOs presented in less than 10% of the 1009 samples were excluded from the downstream analysis.
2.6. Data Quality Control
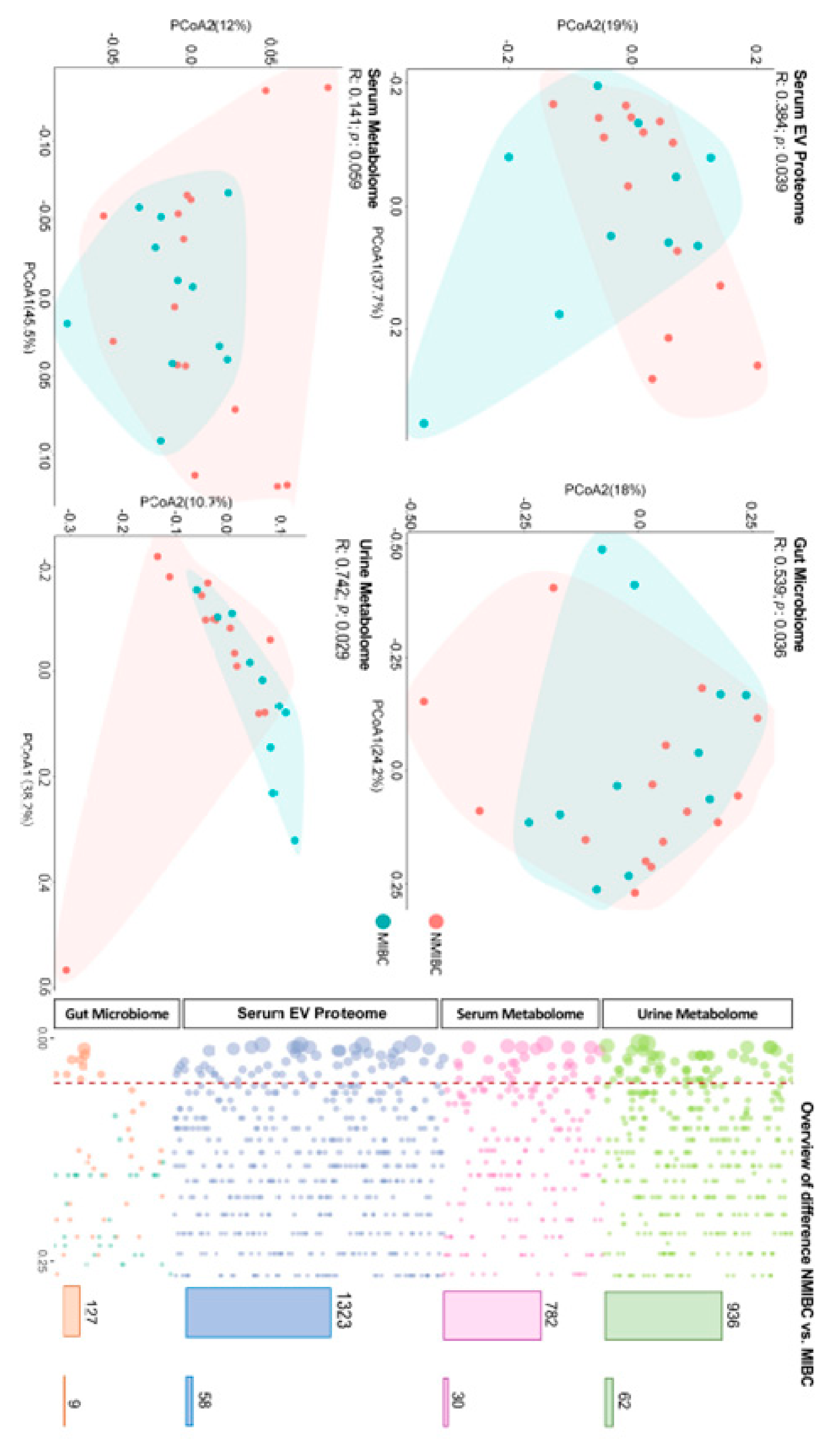
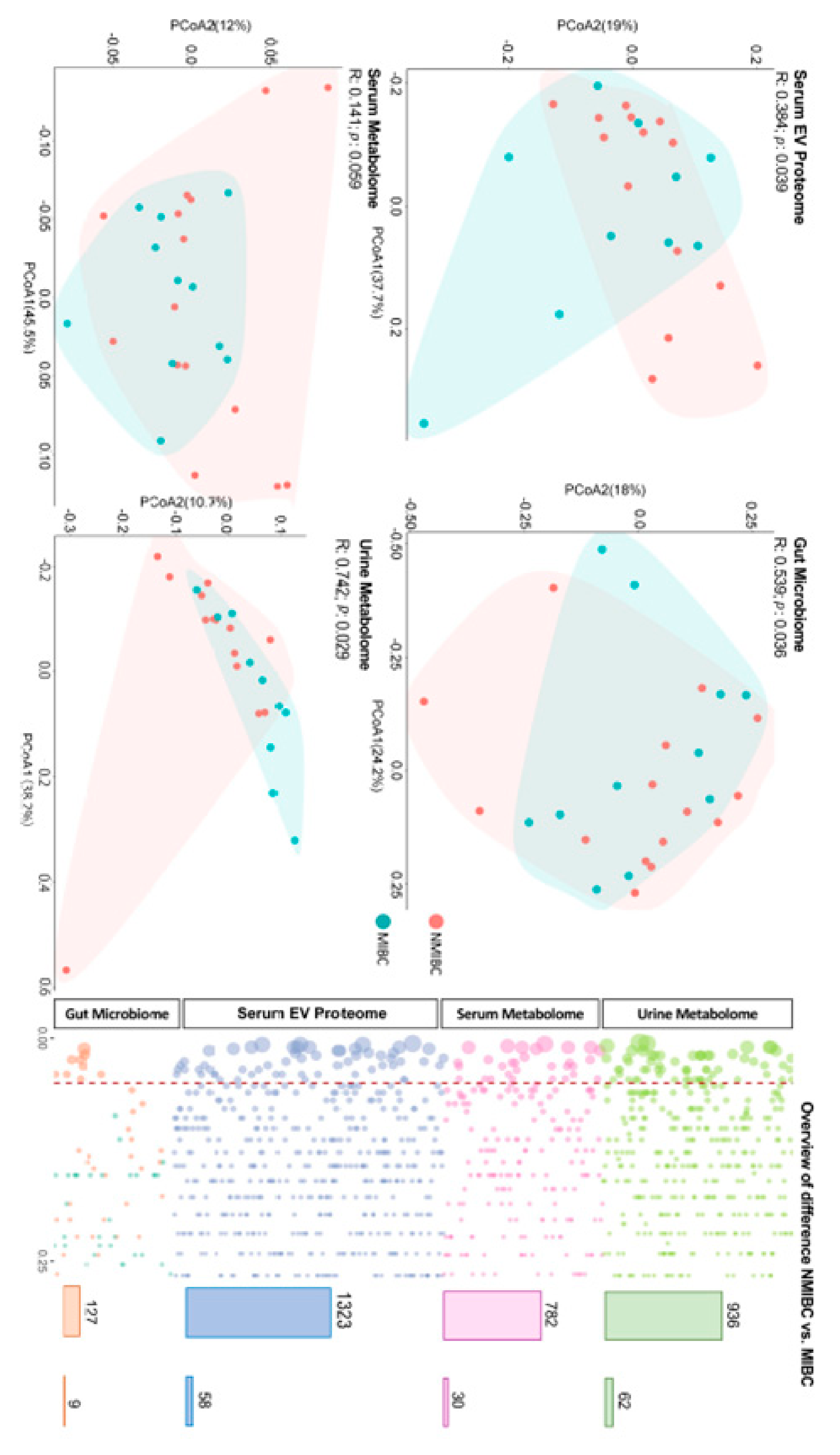
The raw data were gained for the serum metabolome (n = 782), urine metabolome (n = 936), serum EV proteome (n = 1491), gut microbiome (n = 589), then the quality of omics data was ensured at multiple steps separately. Each omics matrix contained missing values. Missing values can be due to the low abundance in certain samples or technical issues. Firstly, to remove the single-omics data with poor quality, we excluded the data with identifications missing in over the 50% of the participants. Subsequently, we imputed the missing values with 1/2 lowest values measured in each variable of the omics matrix separately. Totally, 3168 measures (including 782 serum metabolites, 936 urine metabolites, 1323 serum EV proteins and 127 gut microbes) remained eligible to be included in the further study.
2.7. Statistical and Bioinformatic Analysis
All statistical analyses were performed using Stata 15.0 (Stata Corp., College Station, TX, USA) or R (version 4.0.5). Descriptive statistics are presented as mean (±SD (standard deviation)) or median (interquartile range) for continuous variables, and frequency (percentage, %) for categorial variables (
Table 1). Principal coordinates (PCoA) analysis was used, with a permutational multivariate analysis of variance, to perform the difference of global profiles. Statistical difference between the two groups (NMIBC vs. MIBC) was assessed with the Mann–Whitney test. We used logistic regression analysis to assess the association between each identified analyte and bladder cancer progression, with adjustments of age (years, continuous), sex (male and female) and smoking status (never, former, and current smoker). The KEGG (
https://www.genome.jp/kegg/, accessed on 16 April 2022) and DrugBank (
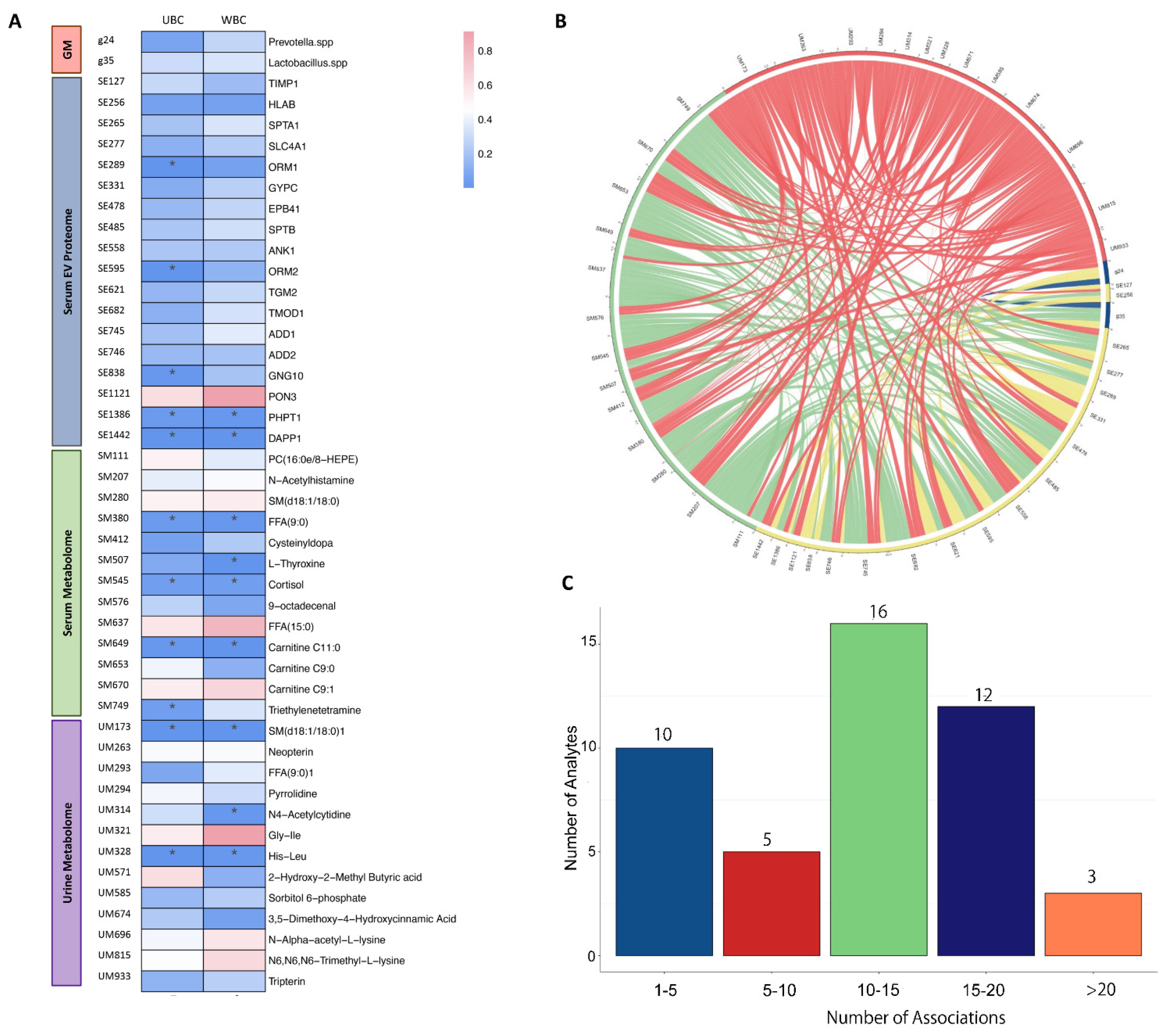
https://go.drugbank.com, accessed on 16 April 2022) databases were used to annotate the mechanistic pathways and druggable targets of identified analytes. Then, we used the Spearman correlation to investigate the correlations between the secondary pairs of identified analytes, adjusted for age, sex and smoking status. A
p value < 0.05 was considered statistically significant.
4. Discussion
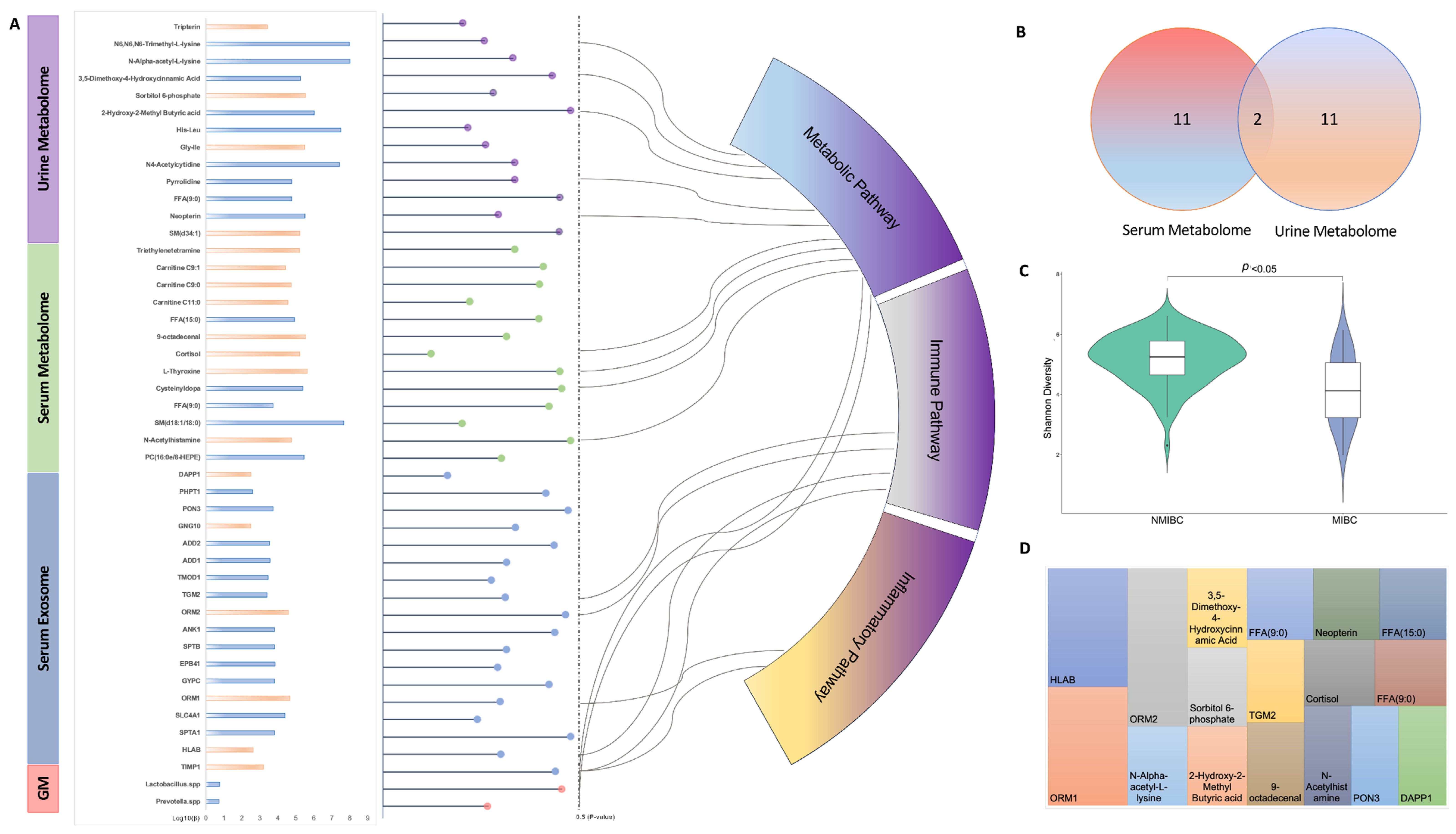
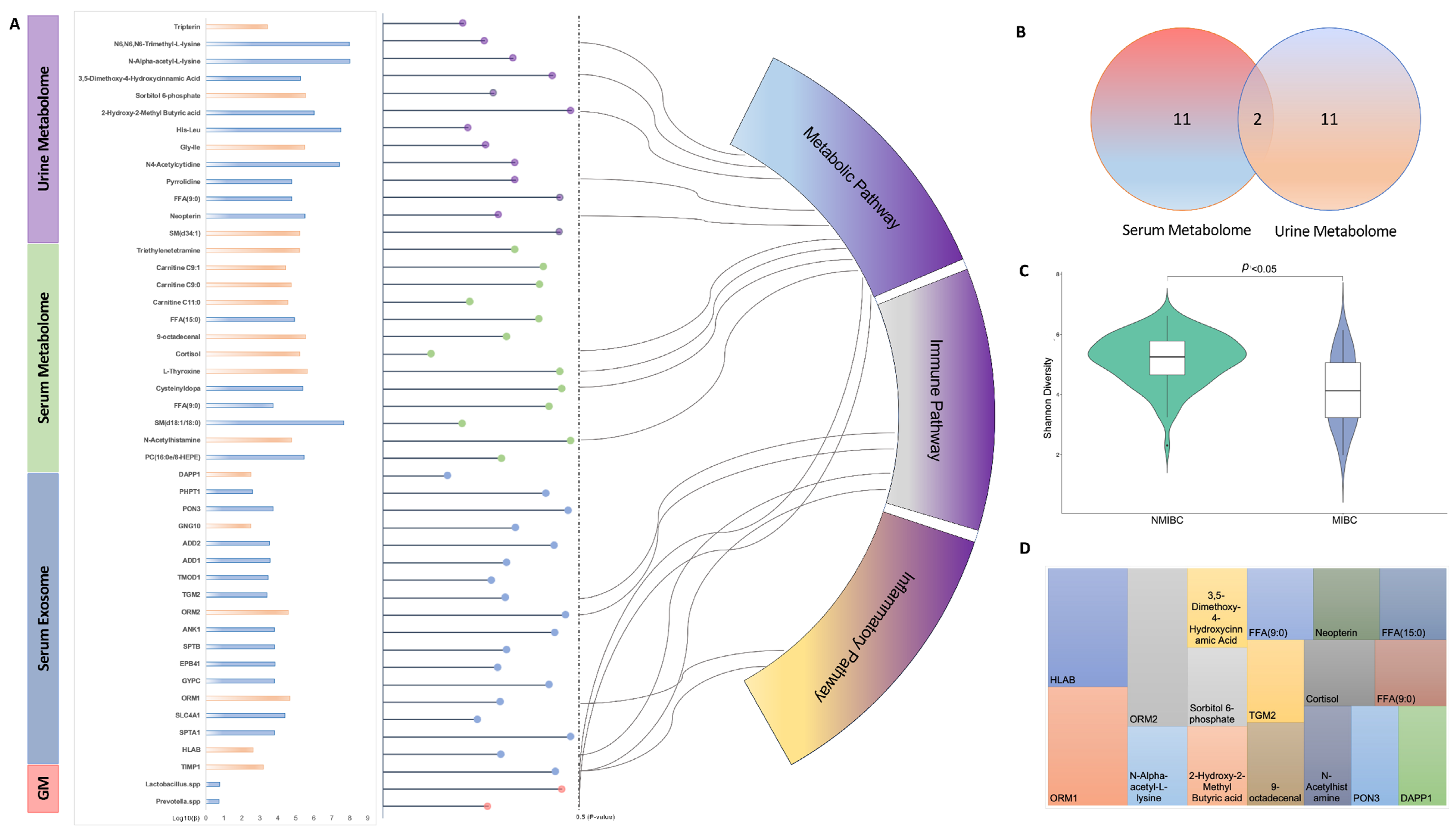
In the current pilot study, we report the single- and multi-omics signatures in response to the progression of bladder cancer (i.e., NMIBC vs. MIBC). We observed distinct global profiles of single-omics, with an identification of 46 analytes showing a significantly differentiated abundance for NMIBC vs. MIBC. While this study was not designed to identify causal links between molecules and bladder cancer prognosis, the results provide mechanistic and therapeutic benchmarks of multi-omics for the management and prevention of progression of bladder cancer, which need to be verified in future studies.
Though few studies have investigated the relationships between gut and bladder, recent studies have indicated a “gut–bladder axis” linking those two distal organs [
19,
20], where gut microbiota may play a pivotal role. With the emergence of accumulative evidence, gut microbiome has been reported to be associated with cancer occurrence and development; however, the spectrum of direct and indirect interactions between the gut microbiota and the bladder cancer remains largely unknown. Two studies conducted in Japan demonstrated a promising strategy for preventing the recurrence of bladder cancer using
Lactobacillus spp. as an intervention, which partially supports the observation in our study that the abundance of
Lactobacillus spp. was lower in MIBC when compared to NMIBC. Experimental studies have revealed that
Lactobacillus spp. can induce apoptosis in cancer cells via the activation of pro-caspases and pro-apoptotic Bax and the inactivation of the anti-apoptotic Bcl-2 proteins [
21,
22], which may reduce chemotherapy toxicity and thereby might inhibit the progression of bladder cancer. In addition, we also identified
Prevotella spp. as a distinct marker for bladder cancer progression in the current study, with a lower abundance in MIBC. Though there is no study yet to provide evidence of gut
Prevotella spp. related to bladder cancer progression, a study reported a decreased abundance in bladder cancer patients when compared to healthy controls based on a case–control design [
23]. Emerging studies in humans have linked the increased abundance of
Prevotella spp. in relation to reduction of inflammation, and thereby may be clinically important pathobionts that can participate in human disease by promoting chronic inflammation [
24]. To our knowledge, inflammation, along with separate arms of the host immune system, not only plays an important role in the development and progression of many different diseases, particularly cancers, but also serves as an important indicator of the prognosis in patients [
25]. Further studies are warranted to verify the function and mechanism of
Prevotella spp. in bladder cancer development.
As an overture of analysing the EV proteome at the circulating level, our study identified 18 serum EV proteins differentiated in NMIBC and MIBC, which were shown to be explosive as novel biomarkers for bladder cancer progression. In recent years, several studies have showed that exosomes, containing proteins, nucleic acids, carbohydrates, and lipids, could provide new non-invasive diagnostic and prognostic biomarkers in patients affected by cancers, including bladder cancer, and the lipid bilayer membrane structure has made exosomes as promising delivery vehicles for therapeutic applications [
26]. Of those EV proteins identified above, we found that eight EV proteins have been reported to have an association with certain cancer types, while the remaining 10 ones have yet to be well investigated. Amongst these, SPTA1 (Spectrin alpha chain erythrocytic 1), ORM2 and TMOD1 (Tropomodulin-1) were newly identified and have not been reported to have any association with human health. Hence, their mechanisms in distinguishment and prevention of bladder cancer progression need further investigation.
In line with a previous study [
27], our study found a distinguished metabolomic profile based on urine samples, while no difference could be observed for the global profile of the serum metabolome. This finding indicates that urinary metabolomics can be recognised as the preferred approach for biomarker identification of bladder cancer, given that environmental compounds are excreted in urine and thereby come into direct contact with the surface of the bladder [
28]. In addition, the metabolites identified in our studies with different abundances in NMIBC and MIBC were largely non-overlapped with only two metabolites co-existing, which suggests that different liquid biopsies may contain different information regarding same omics data and need to be investigated separately. The two metabolites, i.e., Nonanoic acids (C9:0) and Sphingomyelin (SM (d18:1/18:0)), were both negatively associated with the progression of bladder cancer. As one of the odd-chain fatty acids, Nonanoic acid (C9:0) was found to inhibit the expression of HDAC6, which result in an anti-cancer proliferation effect [
29]; again, the detailed mechanism needs to be confirmed in bladder cancer. For the Sphingomyelin (SM (d18:1/18:0)), no study has yet fully investigated its effect on cancer, though a study reported it could be related to Alzheimer’s disease [
30]. Due to its consistent results showing in both serum and urine, the Sphingomyelin (SM (d18:1/18:0)) may deserve to be further analysed.
Furthermore, this study showed interactions between different kinds of omics across multiple samples, which indicated bladder cancer, as a complex disease, might be affected by systemic factors. However, the network integrating multiple omics still need to be further investigated. Despite this being a pilot study, several limitations arouse our attention; the small sample size and collection provided limited power to assess differential expression in NMIBC and MIBC. With the consideration of sample size, multiple testing was not applied in the current study, which may have resulted in potential false-positive findings. While we identified some indications of single- and multiple omics, our findings warrant further investigations to confirm the biomarkers and their interactions in the context of bladder cancer progression. In addition, while high-throughput techniques offer a high-resolution view of the relevant molecules related to bladder, we cannot rule out the presence of additional, low-abundance molecules that could not be detected from the depth of multi-omics generated.
In summary, the current pilot study was initiated for investigating the progression biomarkers from the perspective of molecular omics data in Asian ancestry, which, based on the preliminarily data, has shown to be promising in monitoring the progression of bladder cancer by integrating multi-omics data. By integrating multiple data with in-depth analysis, the results gained in the current study may contribute to managing the progression, decreasing the health burden, and improving the health-related quality of life of patients with bladder cancer; hence, further research with a larger sample size and data is needed.

 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}