
The Role of Entropy in Construct Specification Equations (CSE) to Improve the Validity of Memory Tests: Extension to Word Lists




Abstract
:1. Introduction
2. Materials
3. Case Study I: Analyses of Word-List Task Difficulty
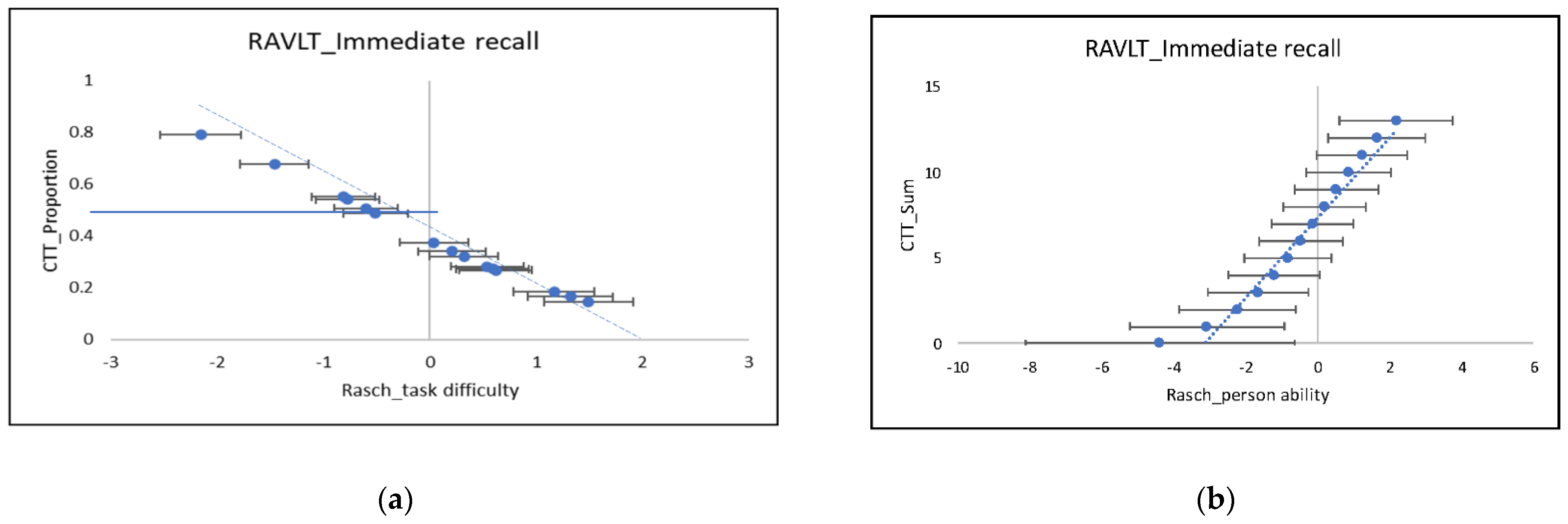
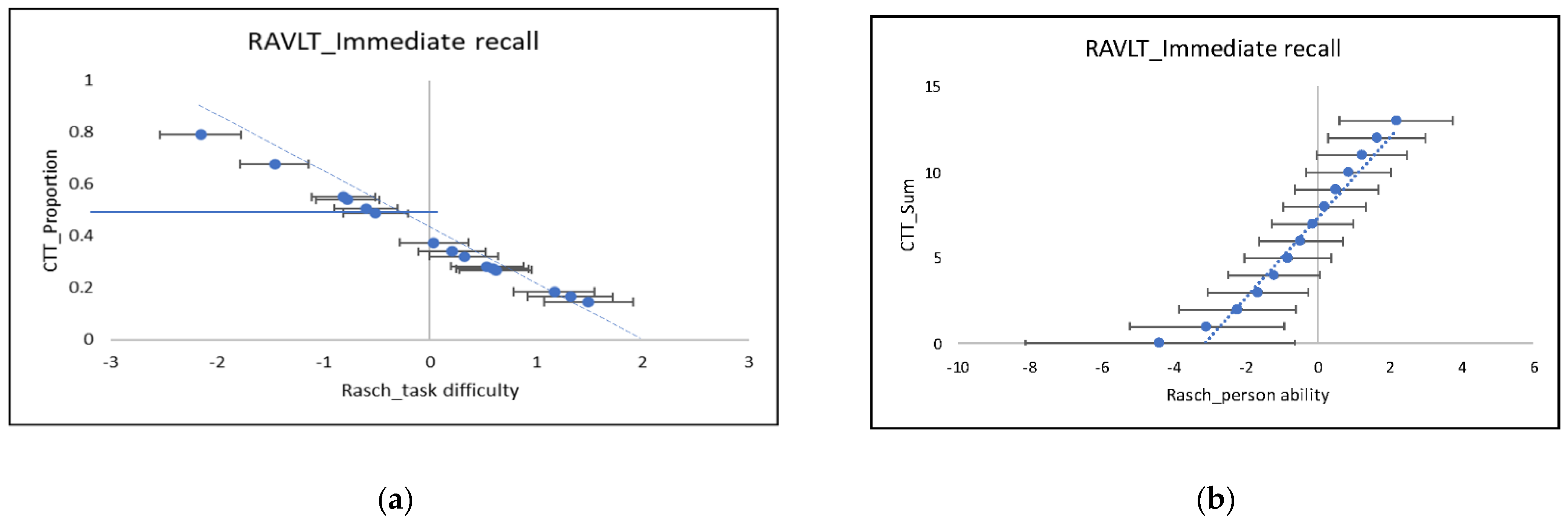
3.1. Classic Analyses in Word Learning List Tests
3.2. Modern Analyses in Word Learning List Tests
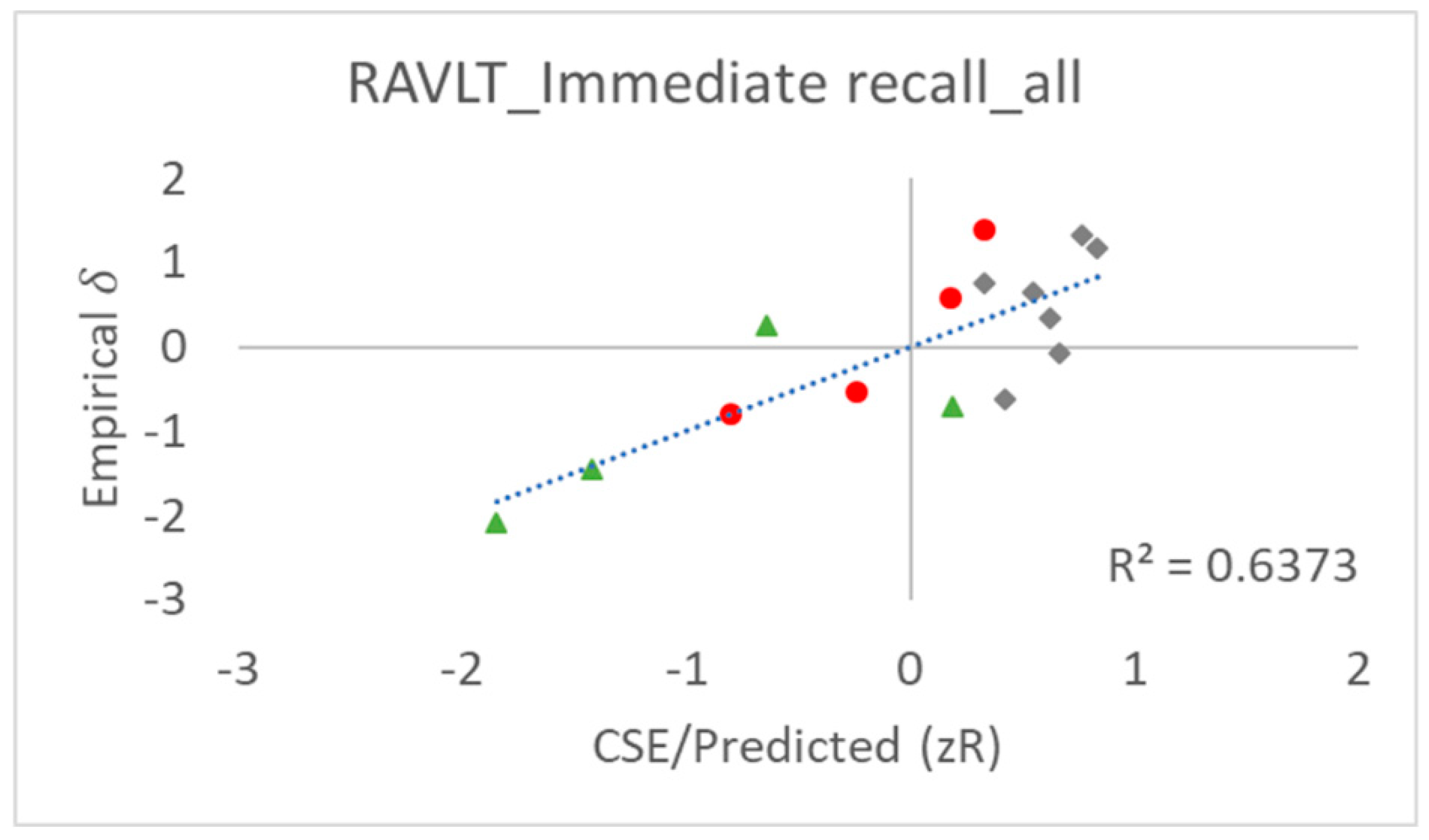
3.3. Potential, Limitations, and Implications with a Corrected Analysis of SPEs in RAVLT
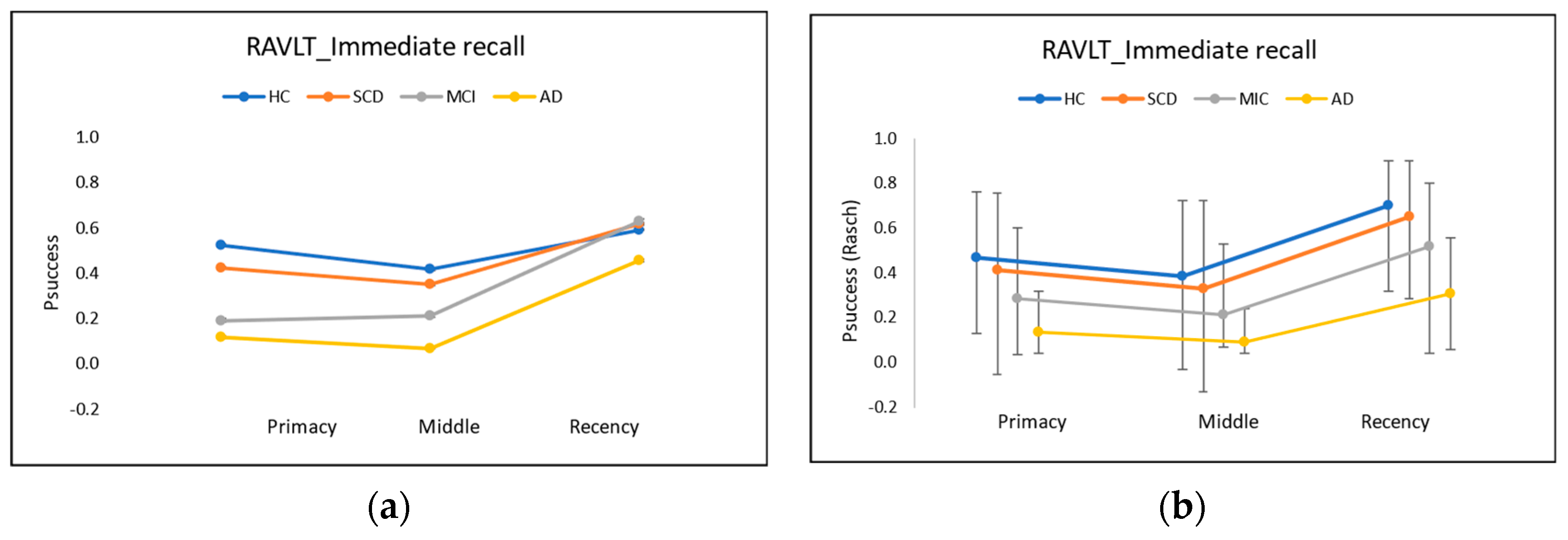
4. Case Study II: Explaining Serial Position Effects
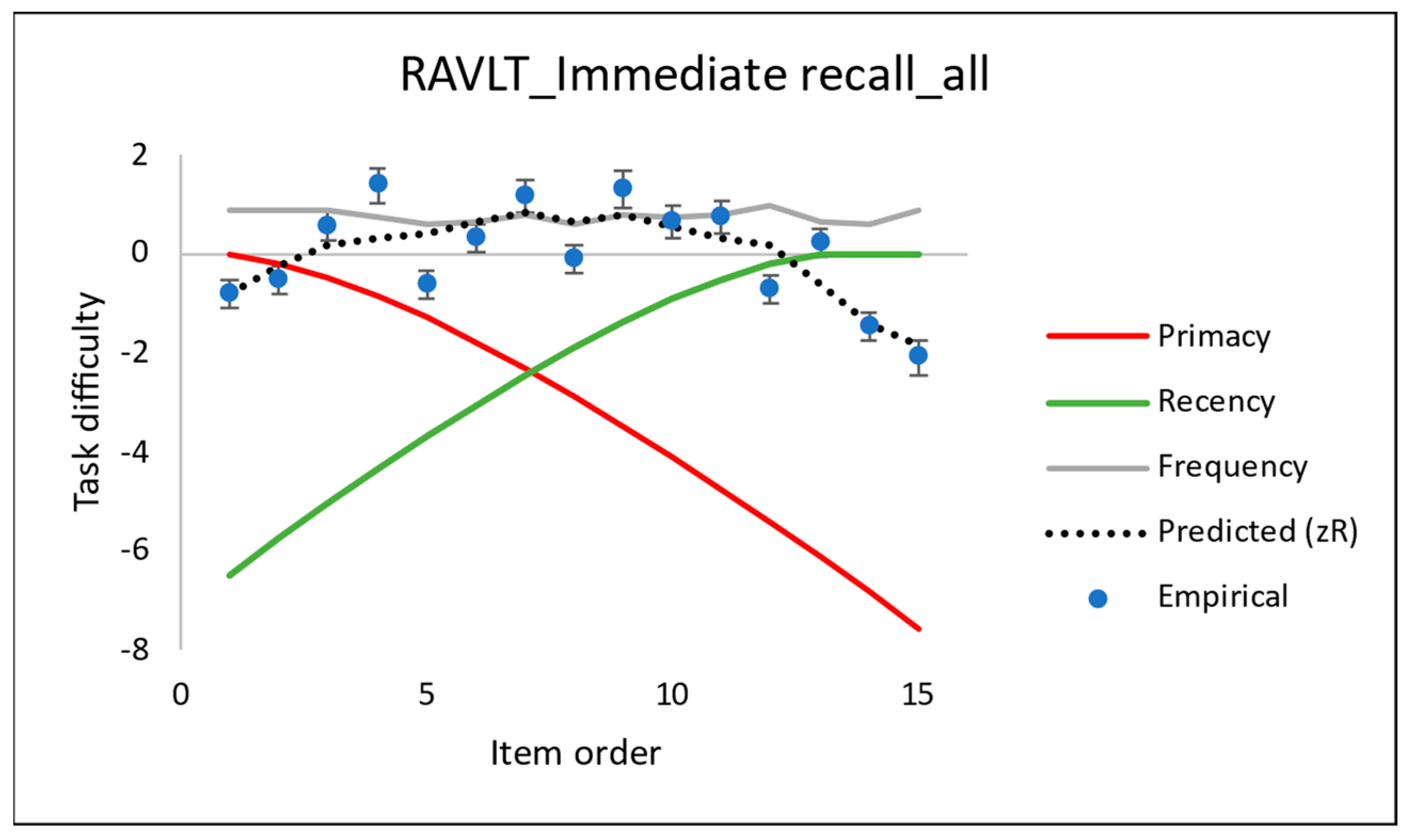
4.1. Construct Specification Equations (CSE) to Explain Task Difficulty in Word Learning Tests
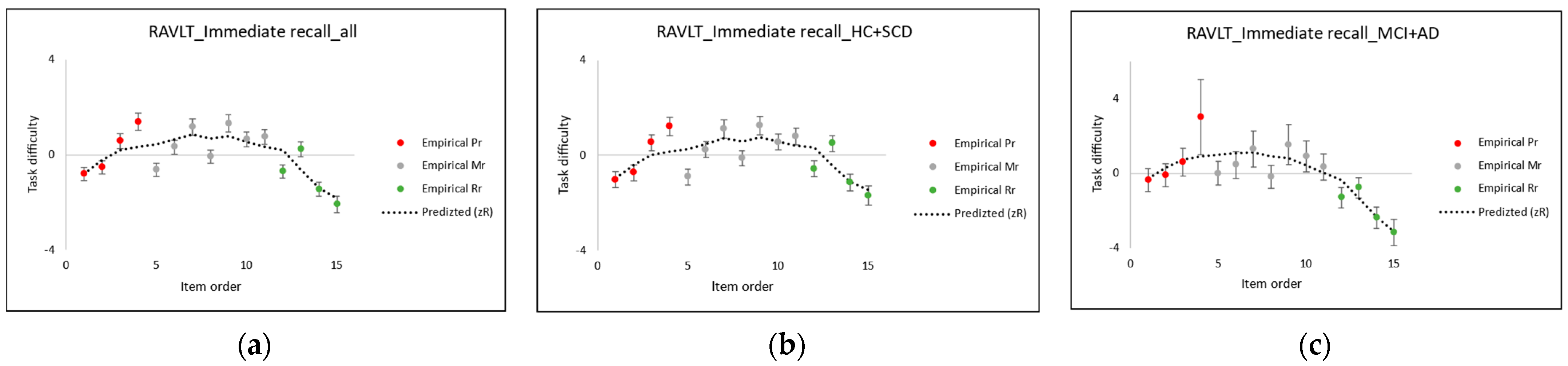
4.2. Construct Specification Equations for Cohort Subgroups
4.3. Insights into Serial Position Effects Based in Word Learning List Tests on Construct
5. Case Study III: Maintaining the Unique Metrological Properties of the Rasch Model in the Presence of Serial Position Effects
5.1. Scale Distortion and Instrument (Test Person) Discrimination in the Presence of SPE
5.2. Principal Components and Multidimensionality
5.2.1. PCA1 for CSE Formulation
5.2.2. PCA2 Rasch Logistic Regression Residuals
- “Compare the raw variance explained by the items (present case 18%) with the unexplained variance in the first contrast (present case 9%); is this ratio big enough to be a concern?” In our analysis of the data, the variance of the first Rasch dimension is about double that of the secondary dimension, but the latter is clearly noticeable.
- “Is the secondary dimension bigger by chance?” In the present case, with the eigenvalue = 2, this is the strength of approximately two items. It is not expected to have a value of more than two items by chance [26], and at least two items are needed to think of the situation as a “dimension” and not merely an idiosyncratic item, according to Linacre.
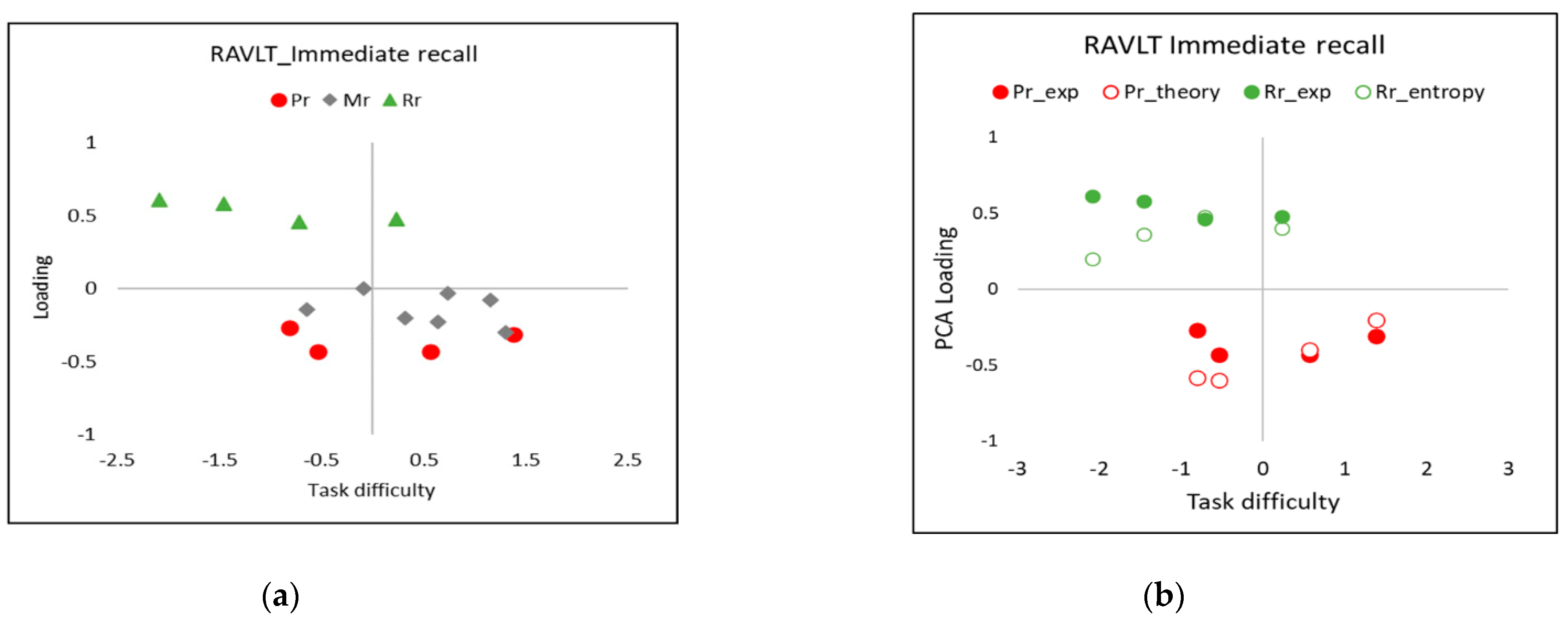
- “Does the secondary dimension have substance?” Looking at the loading plot in Figure 6a, the two SPE clusters of items—primacy and recency—are clearly separated vertically (the important direction) from the other (mid-list) cluster of items. Each cluster can be regarded to be important enough and different enough to be explained in terms of separate dimensions, as motivated in the Introduction.
- One approach to handling the multidimensionality revealed by the PCA2 analyses is to make a separate fit of the Rasch formula to each cluster of items associated with a different dimension. The significance of the differences found in the test person’s ability between logistic regression fits to the different item clusters can be assessed, for example, with statistical t-tests [27,28]. Since, in the present case, SPE such as primacy and recency only affect a few words at the start and end of a word list, this means that a separate Rasch analysis for each such small cluster would result in poor reliability in the test person’s ability estimates owing to the reduced numbers of the degrees of freedom [29]. Similarly, analyses of the portions of the whole cohort grouped by health status would also have poorer reliability. Statistical significance tests or correlation plots between sets of a person’s measures from separate Rasch analyses for each suspected dimension or each cohort group according to the cognitive status were therefore judged to not be useful in view of the relatively large uncertainties of the present data.
5.2.3. Combining the Two Kinds of PCA
- The loading coefficient should be the same as deduced in the PCA1 above (Section 5.2.1) when forming the CSE for task difficulty in terms of the entropy-based explanatory variables (Equation (6)).
- , the peculiar sensitivity of the instrument (person) in the Rasch model, will “modify” the PCA loading plots correspondingly but can be calculated from a simple differentiation of the dichotomous Rasch formula (Equation (1)) [30] to yield Equation (9). The sensitivity according to Equation (10) has a “resonance-like” behaviour, with a peak in K occurring at (the 50% point ), and the sensitivity will fall off symmetrically on either side to approach zero at each end of the task difficulty scale [30].
- The third term on the RHS of Equation (9) is any significant change, , in the task difficulty. As found experimentally (Section 5.1), the task difficulty of each item deviates the most from the basic Rasch model for the healthy cohort, both owing to the SPE—such as Primacy and Recency—as well as an overall reduction in the task difficulties across all the items: . (In contrast, members of the less cognitively healthy portion of the cohort benefit less from the Primacy and have a mid-range task difficulty close to the theoretical value of the CSE intercept).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Entropy and the Measurement Process
- the best units for metrological traceability are those with the most order, i.e., least entropy, as an example of the principle of least action;
- the change in entropy on the transmission of measurement information cannot decrease, thus allowing realistic estimates of measurement uncertainty in line with the second law of thermodynamics.
Appendix A.1. Analysing Categorical Responses
Appendix B. Entropy and Construct Specification Equations
- the valid and reliable prediction of the difficulty of new test items (e.g., to fill measurement gaps);
Appendix B.1. Construct Specification Equations (CSE): Validity and Metrology
- A linear regression of the empirical task difficulty values δj against in terms of the principal components, P;
- A conversion back from the principal components to the explanatory variables, Xk.
- Unidimensionality is an assumption of the Rasch model. A problem with the straightforward use of regression is that it will be of marginal value unless the items used form a cohesive set; that is, that the same underlying variable explains the response to every item in that set.
- The latent trait (such as task difficulty) can consist of more than one component (which may or may not belong to one and the same dimension).
- The latent trait identified should be a valid measure of the construct being assessed.
Appendix B.2. Entropy and CSE for Word Learning Tests
Appendix B.3. Linguistic Effects on Task Difficulty in Word Learning List Tests
Appendix B.4. Serial Position Effects and Task Difficulty
Appendix C. Effects of Changes in Task Difficulty on the Rasch Model’s Goodness of Fit
Appendix C.1. Principal Components and Multidimensionality
- First PC: which maximises subject to: .
- Second PC: which maximises subject to: etc.
- “PCA1” performed as the first step in a PCR (Section 4.1) when forming a CSE dealing directly with the Rasch parameters, such as task difficulty, δ, and their explanatory variables . The lack of orthogonality between the Xk gives rise to the loading of these in each PC variation; see Lpx in Section 5.2.1.
- “PCA2” based on the logistic regression of Equation (1) of the fit residuals (Section 5.2) dealing indirectly with the Rasch parameters, since the response (raw data) can be modified by instrument (person) sensitivity, as studied below in Appendix C.2.
Appendix C.2. PCA2 Rasch Logistic Regression Residuals
- Sum of squares of the explained variance is: ;
- Sum of squares of the unexplained variance is: ;
- Explained variance = .
- x-axis: task difficulty = entropy in Equation (A1), evaluated with Equation (9) or the directly measured experimental values;
- y-axis: PCA loading , (Section 5.2).
References
- Weitzner, D.S.; Calamia, M. Serial Position Effects on List Learning Tasks in Mild Cognitive Impairment and Alzheimer’s Disease. Neuropsychology 2020, 34, 467–478. [Google Scholar] [CrossRef] [PubMed]
- Murdock, B.B. The Serial Position Effect of Free Recall. J. Exp. Psychol. 1962, 64, 482–488. [Google Scholar] [CrossRef] [Green Version]
- Bayley, P.J.; Salmon, D.P.; Bondi, M.W.; Bui, B.K.; Olichney, J.; Delis, D.C.; Thomas, R.G.; Thal, L.J. Comparison of the Serial Position Effect in Very Mild Alzheimer’s Disease, Mild Alzheimer’s Disease, and Amnesia Associated with Electroconvulsive Therapy. J. Int. Neuropsychol. Soc. 2000, 6, 290–298. [Google Scholar] [CrossRef] [PubMed]
- Blachstein, H.; Vakil, E. Verbal Learning across the Lifespan: An Analysis of the Components of the Learning Curve. Aging Neuropsychol. Cogn. 2016, 23, 133–153. [Google Scholar] [CrossRef] [PubMed]
- Bruno, D.; Reiss, P.T.; Petkova, E.; Sidtis, J.J.; Pomara, N. Decreased Recall of Primacy Words Predicts Cognitive Decline. Arch. Clin. Neuropsychol. 2013, 28, 95–103. [Google Scholar] [CrossRef] [Green Version]
- Carlesimo, G.A.; Sabbadini, M.; Fadda, L.; Caltagirone, C. Different Components in Word-List Forgetting of Pure Amnesics, Degenerative Demented and Healthy Subjects. Cortex 1995, 31, 735–745. [Google Scholar] [CrossRef]
- Cunha, C.; Guerreiro, M.; de Mendonça, A.; Oliveira, P.E.; Santana, I. Serial Position Effects in Alzheimer’s Disease, Mild Cognitive Impairment, and Normal Aging: Predictive Value for Conversion to Dementia. J. Clin. Exp. Neuropsychol. 2012, 34, 841–852. [Google Scholar] [CrossRef]
- Howieson, D.B.; Mattek, N.; Seeyle, A.M.; Dodge, H.H.; Wasserman, D.; Zitzelberger, T.; Kaye, J.A. Serial Position Effects in Mild Cognitive Impairment. J. Clin. Exp. Neuropsychol. 2011, 33, 292–299. [Google Scholar] [CrossRef]
- Talamonti, D.; Koscik, R.; Johnson, S.; Bruno, D. Predicting Early Mild Cognitive Impairment with Free Recall: The Primacy of Primacy. Arch. Clin. Neuropsychol. 2020, 35, 133–142. [Google Scholar] [CrossRef]
- Hurlstone, M.J.; Hitch, G.J.; Baddeley, A.D. Memory for Serial Order across Domains: An Overview of the Literature and Directions for Future Research. Psychol. Bull. 2014, 140, 339–373. [Google Scholar] [CrossRef]
- Melin, J.; Cano, S.; Pendrill, L. The Role of Entropy in Construct Specification Equations (CSE) to Improve the Validity of Memory Tests. Entropy 2021, 23, 212. [Google Scholar] [CrossRef] [PubMed]
- Melin, J.; Pendrill, L.R.; Cano, S.J. EMPIR NeuroMET 15HLT04 consortium Towards Patient-Centred Cognition Metrics. J. Phys. Conf. Ser. 2019, 1379, 012029. [Google Scholar] [CrossRef]
- Quaglia, M.; Cano, S.; Fillmer, A.; Flöel, A.; Giangrande, C.; Göschel, L.; Lehmann, S.; Melin, J.; Teunissen, C.E. The NeuroMET Project: Metrology and Innovation for Early Diagnosis and Accurate Stratification of Patients with Neurodegenerative Diseases. Alzheimer’s Dement. 2021, 17, e053655. [Google Scholar] [CrossRef]
- Wirth, M.; Schwarz, C.; Benson, G.; Horn, N.; Buchert, R.; Lange, C.; Köbe, T.; Hetzer, S.; Maglione, M.; Michael, E.; et al. Effects of Spermidine Supplementation on Cognition and Biomarkers in Older Adults with Subjective Cognitive Decline (SmartAge)-Study Protocol for a Randomized Controlled Trial. Alzheimer’s Res. Ther. 2019, 11, 36. [Google Scholar] [CrossRef] [PubMed]
- Rey, A. L’examen Clinique En Psychologie. [The Clinical Examination in Psychology.]; Presses Universitaries De France: Paris, France, 1958; p. 222. (In French) [Google Scholar]
- Rasch, G. Studies in Mathematical Psychology: I. Probabilistic Models for Some Intelligence and Attainment Tests; Danmarks pædagogiske Institut: Copenhagen, Denmark, 1960. [Google Scholar]
- Liu, X.; Fu, Z. A Novel Recognition Strategy for Epilepsy EEG Signals Based on Conditional Entropy of Ordinal Patterns. Entropy 2020, 22, 1092. [Google Scholar] [CrossRef]
- Foldi, N.S.; Brickman, A.M.; Schaefer, L.A.; Knutelska, M.E. Distinct Serial Position Profiles and Neuropsychological Measures Differentiate Late Life Depression from Normal Aging and Alzheimer’s Disease. Psychiatry Res. 2003, 120, 71–84. [Google Scholar] [CrossRef]
- Hermann, B.P.; Seidenberg, M.; Wyler, A.; Davies, K.; Christeson, J.; Moran, M.; Stroup, E. The Effects of Human Hippocampal Resection on the Serial Position Curve. Cortex 1996, 32, 323–334. [Google Scholar] [CrossRef]
- Rue, A.L.; Hermann, B.; Jones, J.E.; Johnson, S.; Asthana, S.; Sager, M.A. Effect of Parental Family History of Alzheimer’s Disease on Serial Position Profiles. Alzheimer’s Dement. 2008, 4, 285–290. [Google Scholar] [CrossRef] [Green Version]
- Brillouin, L. Science and Information Theory, 2nd ed.; Dover Publications: New York, NY, USA, 1962. [Google Scholar]
- Melin, J.; Cano, S.J.; Göschel, L.; Fillmer, A.; Lehmann, S.; Hirtz, C.; Flöel, A.; Pendrill, L.R. Metrological References for Person Ability in Memory Tests. Meas. Sens. 2021, 18, 100289. [Google Scholar] [CrossRef]
- Melin, J.; Pendrill, L. The Role of Construct Specification Equations (CSE) and Entropy in the Measurement of Memory. In Person Centered Outcome Metrology; Springer: New York, NY, USA, 2022. [Google Scholar]
- Melin, J.; Kettunen, P.; Wallin, A.; Pendrill, L. Entropy-Based Explanations of Serial Position and Learning Effects in Ordinal Responses to Word List Tests. Accepted for IMEKO-MATHMET, Porto. 2022. Available online: https://www2.isep.ipp.pt/imekotc7-mathmet-2022/ (accessed on 12 May 2022).
- Linacre, J. Dimensionality: When Is a Test Multidimensional? Winsteps Help. Available online: https://www.winsteps.com/winman/dimensionality.htm (accessed on 5 June 2021).
- Raîche, G. Critical Eigenvalue Sizes (Variances) in Standardized Residual Principal Components Analysis. Rasch Meas. Trans. 2005, 2005, 1012. [Google Scholar]
- Hagell, P. Testing Rating Scale Unidimensionality Using the Principal Component Analysis (PCA)/t-Test Protocol with the Rasch Model: The Primacy of Theory over Statistics. Open J. Stat. 2014, 4, 456–465. [Google Scholar] [CrossRef] [Green Version]
- Smith, E.V. Detecting and Evaluating the Impact of Multidimensionality Using Item Fit Statistics and Principal Component Analysis of Residuals. J. Appl. Meas. 2002, 3, 205–231. [Google Scholar] [PubMed]
- Melin, J.; Regnault, A.; Cano, S.; Pendrill, L. Neuropsychological Assessments: Word Learning Tests and Diagnostic Potential of Serial Position Effects. In Proceedings of the International Metrology Congress, Lyon, France, 7 September 2021. [Google Scholar]
- Pendrill, L.; Petersson, N. Metrology of Human-Based and Other Qualitative Measurements. Meas. Sci. Technol. 2016, 27, 094003. [Google Scholar] [CrossRef]
- Green, K.E.; Smith, R.M. A Comparison of Two Methods of Decomposing Item Difficulties. J. Educ. Stat. 1987, 12, 369–381. [Google Scholar] [CrossRef]
- Wright, B.; Stone, M. Best Test Design; MESA Press: San Diego, CA, USA, 1979. [Google Scholar]
- Cano, S.; Barrett, L.; Zajicek, J.; Hobart, J. Dimensionality Is a Relative Concept. Mult. Scler. 2011, 17, 893–894. [Google Scholar] [CrossRef]
- Linacre, J.M. Detecting Multidimensionality: Which Residual Data-Type Works Best? J. Outcome Meas. 1998, 2, 266–283. [Google Scholar]
- Feuerstahler, L.; Wilson, M. Scale Alignment in the Between-Item Multidimensional Partial Credit Model. Appl. Psychol. Meas. 2021, 45, 268–282. [Google Scholar] [CrossRef]
- Choi, I.-H.; Wilson, M. Multidimensional Classification of Examinees Using the Mixture Random Weights Linear Logistic Test Model. Educ. Psychol. Meas. 2015, 75, 78–101. [Google Scholar] [CrossRef] [Green Version]
- Pendrill, L. Quality Assured Measurement: Unification across Social and Physical Sciences; Springer Series in Measurement Science and Technology; Springer International Publishing: Cham, Switzerland, 2019; ISBN 978-3-030-28694-1. [Google Scholar]
- Melin, J. Neurogenerative Disease Metrology and Innovation: The European Metrology Programme for Innovation & Research (EMPIR) and the NeuroMET Projects. In Proceedings of the Pacific RIM Objective Measurement Symposium, Nanjing, China, 4–6 December 2021. [Google Scholar]
- ASTM International. E11 Committee Guide for Measurement Systems Analysis (MSA); ASTM International: West Conshohocken, PA, USA, 2022. [Google Scholar]
- Carnot, L. Principes Fondamentaux de L’équilibre Et Du Mouvement; Par L.-N.-M. Carnot; Hachette Livre-Bnf: Paris, France, 2016. (In French) [Google Scholar]
- Rossi, G.B. Measurement and Probability [Elektronisk Resurs] A Probabilistic Theory of Measurement with Applications; Springer Netherlands: Dordrecht, The Netherlands, 2014; ISBN 978-94-017-8825-0. [Google Scholar]
- Pearson, K. Mathematical Contributions to the Theory of Evolution—On a Form of Spurious Correlation Which May Arise When Indices Are Used in the Measurement of Organs. Proc. R. Soc. Lond. 1896, 60, 489–498. [Google Scholar]
- Jones, L.V. The Collected Works of John W. Tukey: Philosophy and Principles of Data Analysis 1949-1964, Volume III, 1st ed.; Chapman and Hall/CRC: Boca Raton, FL, USA, 1986; ISBN 978-0-412-74250-7. [Google Scholar]
- Mosteller, F.; Tukey, J. Data Analysis and Regression: A Second Course in Statistics, 1st ed.; Pearson: London, UK, 1977; ISBN 978-0-201-04854-4. [Google Scholar]
- Linacre, J. Bernoulli Trials, Fisher Information, Shannon Information and Rasch. Rasch Meas. Trans. 2006, 20, 1062–1063. [Google Scholar]
- Pendrill, L.R.; Melin, J.; Cano, S.J. Entropy-Based Explanations of Multidimensionality in Ordinal Responses. In Joint Workshop of ENBIS and MATHMET, Virtual 2021. Available online: https://drive.google.com/drive/folders/1zVlzy3SKvbdxBdiCqe2AyDGLH7hfa-Ty (accessed on 5 June 2021).
- Moradi, E.; Hallikainen, I.; Hänninen, T.; Tohka, J. Rey’s Auditory Verbal Learning Test Scores Can Be Predicted from Whole Brain MRI in Alzheimer’s Disease. NeuroImage Clin. 2017, 13, 415–427. [Google Scholar] [CrossRef] [PubMed]
- Turetsky, V.; Bashkansky, E. Ordinal Response Variation of the Polytomous Rasch Model. METRON 2022, 1–26. [Google Scholar] [CrossRef]
- Stenner, A.J.; Smith, M. Testing Construct Theories. Percept. Mot. Ski. 1982, 55, 415–426. [Google Scholar] [CrossRef]
- Stenner, A.J.; Smith, M.; Burdick, D.S. Toward a Theory of Construct Definition. J. Educ. Meas. 1983, 20, 305–316. [Google Scholar] [CrossRef]
- Hughes, L.F.; Perkins, K.; Wright, B.D.; Westrick, H. Using a Rasch Scale to Characterize the Clinical Features of Patients with a Clinical Diagnosis of Uncertain, Probable, or Possible Alzheimer Disease at Intake. J. Alzheimer’s Dis. 2003, 5, 367–373. [Google Scholar] [CrossRef]
- Hobart, J.; Cano, S.; Posner, H.; Selnes, O.; Stern, Y.; Thomas, R.; Zajicek, J. Alzheimer’s Disease Neuroimaging Initiative. Putting the Alzheimer’s Cognitive Test to the Test II: Rasch Measurement Theory. Alzheimer’s Dement. 2013, 9, S10–S20. [Google Scholar] [CrossRef]
- Shannon, C.; Weaver, W. The Mathematical Theory of Communication; The University of Illinois Press: Urbana, IL, USA, 1964. [Google Scholar]
- Klir, G.J.; Folger, T.A. Fuzzy Sets, Uncertainty and Information, 1st ed.; Prentice Hall: Englewood Cliffs, NJ, USA, 1988; ISBN 978-0-13-345984-5. [Google Scholar]
- Pendrill, L.; Melin, J.; Cano, S.; the EMPIR NeuroMET 15HLT04 consortium. Metrological References for Health Care Based on Entropy. In Proceedings of the 19th International Congress of Metrology (CIM2019), Paris, France, 24–26 September 2019; Gazal, S., Ed.; EDP Sciences: Paris, France, 2019; p. 07001. [Google Scholar]
- Melin, J.; Cano, S.J.; Flöel, A.; Göschel, L.; Pendrill, L.R. Construct Specification Equations: ‘Recipes’ for Certified Reference Materials in Cognitive Measurement. Meas. Sens. 2021, 18, 100290. [Google Scholar] [CrossRef]
- Stenner, A.J.; Burdick, H.; Sanford, E.E.; Burdick, D.S. How Accurate Are Lexile Text Measures? J. Appl. Meas. 2006, 7, 307–322. [Google Scholar]
- Melin, J.; Cano, S.; Flöel, A.; Göschel, L.; Pendrill, L. EMPIR NeuroMET and NeuroMET2 consortiums More than a Memory Test: A New Metric Linking Blocks, Numbers, and Words. Alzheimer’s Dement. 2021, 17, e050291. [Google Scholar] [CrossRef]
- Linacre, J. Rasch Analysis First or Factor Analysis First? Rasch Meas. Trans. 1998, 11, 603. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Linguistic Data Consortium (LDC). Web 1T 5-Gram, 10 European Languages; Version 1; Catalog Number LDC2009T25; Linguistic Data Consortium (LDC): Philadelphia, PA, USA, 2009; ISBN 1-58563-525-1. [Google Scholar]
- Hobart, J.C.; Cano, S.J.; Zajicek, J.P.; Thompson, A.J. Rating Scales as Outcome Measures for Clinical Trials in Neurology: Problems, Solutions, and Recommendations. Lancet Neurol. 2007, 6, 1094–1105. [Google Scholar] [CrossRef]
- Hobart, J.; Cano, S. Improving the Evaluation of Therapeutic Interventions in Multiple Sclerosis: The Role of New Psychometric Methods. Health Technol. Assess. 2009, 13, 214. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wright, B.D. A History of Social Science Measurement. Educ. Meas. Issues Pract. 1997, 16, 33–45. [Google Scholar] [CrossRef]
- Andrich, D. Controversy and the Rasch Model: A Characteristic of Incompatible Paradigms? Med. Care 2004, 42, I7–I16. [Google Scholar] [CrossRef]
- Cano, S.J.; Pendrill, L.R.; Melin, J.; Fisher, W.P. Towards Consensus Measurement Standards for Patient-Centered Outcomes. Measurement 2019, 141, 62–69. [Google Scholar] [CrossRef]
- Hoffman, R.W.; Bezruczko, N.; Perkins, K. An External Validation Study of a Classification of Mixed Connective Tissue Disease and Systemic Lupus Erythematosus Patients. J. Appl. Meas. 2012, 13, 205–216. [Google Scholar]
- Reise, S.P. The Rediscovery of Bifactor Measurement Models. Multivar. Behav. Res. 2012, 47, 667–696. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Explanatory Variables | Empirical | CSE Quasi-Theoretical | ||||||
|---|---|---|---|---|---|---|---|---|
| Primacy (Equation (A7)) | Middle (Equation (A5)) | Recency (Equation (A8)) | Frequency (Equation (A6)) | zR (Equation (3)) | UzR | |||
| Item 1 | 0.00 | 6.31 | −8.33 | 4.80 | −0.81 | 0.28 | −0.80 | 5.28 |
| Item 2 | −0.26 | 6.31 | −7.38 | 4.85 | −0.54 | 0.28 | −0.24 | 4.86 |
| Item 3 | −0.66 | 6.31 | −6.46 | 4.88 | 0.57 | 0.30 | 0.19 | 4.48 |
| Item 4 | −1.17 | 6.31 | −5.58 | 3.99 | 1.38 | 0.36 | 0.34 | 4.16 |
| Item 5 | −1.77 | 6.31 | −4.73 | 3.25 | −0.64 | 0.28 | 0.42 | 3.92 |
| Item 6 | −2.43 | 6.31 | −3.92 | 3.56 | 0.32 | 0.30 | 0.63 | 3.76 |
| Item 7 | −3.15 | 6.31 | −3.15 | 4.31 | 1.16 | 0.34 | 0.84 | 3.71 |
| Item 8 | −3.92 | 6.31 | −2.43 | 3.39 | −0.09 | 0.28 | 0.66 | 3.79 |
| Item 9 | −4.73 | 6.31 | −1.77 | 4.41 | 1.31 | 0.36 | 0.78 | 3.96 |
| Item 10 | −5.58 | 6.31 | −1.17 | 4.06 | 0.64 | 0.32 | 0.55 | 4.22 |
| Item 11 | −6.46 | 6.31 | −0.66 | 4.27 | 0.74 | 0.32 | 0.33 | 4.56 |
| Item 12 | −7.38 | 6.31 | −0.26 | 5.44 | −0.72 | 0.28 | 0.20 | 4.97 |
| Item 13 | −8.33 | 6.31 | 0.00 | 3.57 | 0.23 | 0.30 | −0.66 | 5.40 |
| Item 14 | −9.30 | 6.31 | 0.00 | 3.24 | −1.46 | 0.30 | −1.38 | 5.87 |
| Item 15 | −10.30 | 6.31 | 0.00 | 4.93 | −2.09 | 0.34 | −1.86 | 6.36 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Melin, J.; Cano, S.; Flöel, A.; Göschel, L.; Pendrill, L. The Role of Entropy in Construct Specification Equations (CSE) to Improve the Validity of Memory Tests: Extension to Word Lists. Entropy 2022, 24, 934. https://doi.org/10.3390/e24070934
Melin J, Cano S, Flöel A, Göschel L, Pendrill L. The Role of Entropy in Construct Specification Equations (CSE) to Improve the Validity of Memory Tests: Extension to Word Lists. Entropy. 2022; 24(7):934. https://doi.org/10.3390/e24070934
Chicago/Turabian StyleMelin, Jeanette, Stefan Cano, Agnes Flöel, Laura Göschel, and Leslie Pendrill. 2022. "The Role of Entropy in Construct Specification Equations (CSE) to Improve the Validity of Memory Tests: Extension to Word Lists" Entropy 24, no. 7: 934. https://doi.org/10.3390/e24070934
APA StyleMelin, J., Cano, S., Flöel, A., Göschel, L., & Pendrill, L. (2022). The Role of Entropy in Construct Specification Equations (CSE) to Improve the Validity of Memory Tests: Extension to Word Lists. Entropy, 24(7), 934. https://doi.org/10.3390/e24070934