

Forecasting the Regional Demand for Medical Workers in Kazakhstan: The Functional Principal Component Analysis Approach

 , and
, and
Abstract
1. Introduction
- -
- Identify subtle changes in regional patterns: the method can capture how the number of doctors in certain regions changes over time, including nonlinear trends that traditional models may miss.
- -
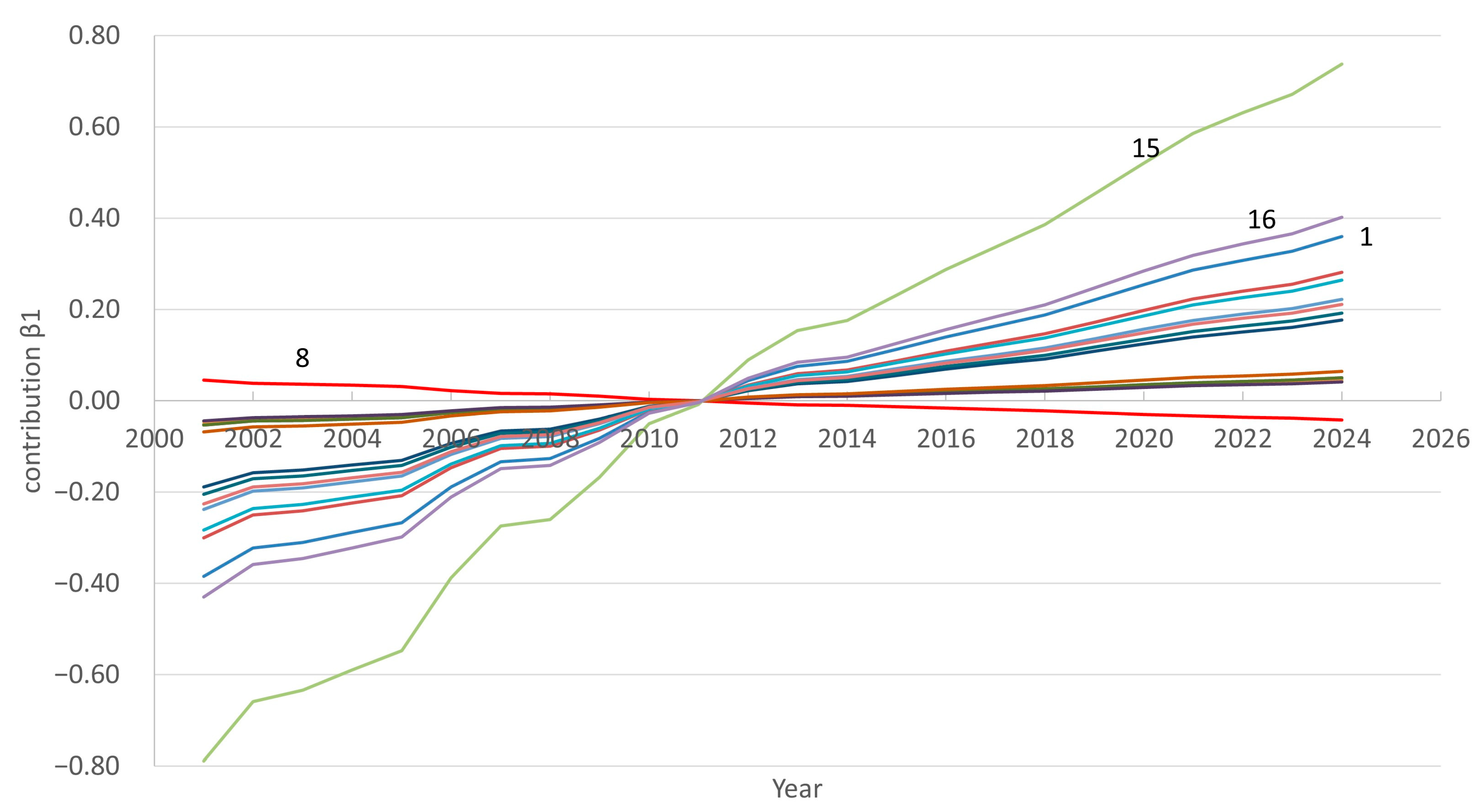
- Analyze regional shifts: the method allows you to track how the “peaks” in the number of doctors shift across regions (for example, from economically less developed regions to oil-rich regions or the capital), which may be due to an improvement in/worsening of the epidemiological situation or attractiveness. The method makes it possible to understand in which regions key changes are occurring.
- -
- Simulate long-term and short-term trends simultaneously: the functional approach includes high-order principal components, making it possible to capture complex time dynamics, such as slowdowns/accelerations or periodic fluctuations in the number of doctors associated with various reasons.
- -
- Analyze structural changes: the method can identify both general trends (for example, a general increase in the number of doctors in the Republic) and regional changes in individual regions.
2. Materials and Methods
2.1. Data Sources
2.2. Model Implementation
- The data can be represented as functional dependencies (regional and time profiles of doctor availability), which makes FPCA a suitable method.
- The data are pre-smoothed using orthogonal functions to represent them in functional form.
- It is assumed that a significant part of the variance in the data is explained by several principal components.
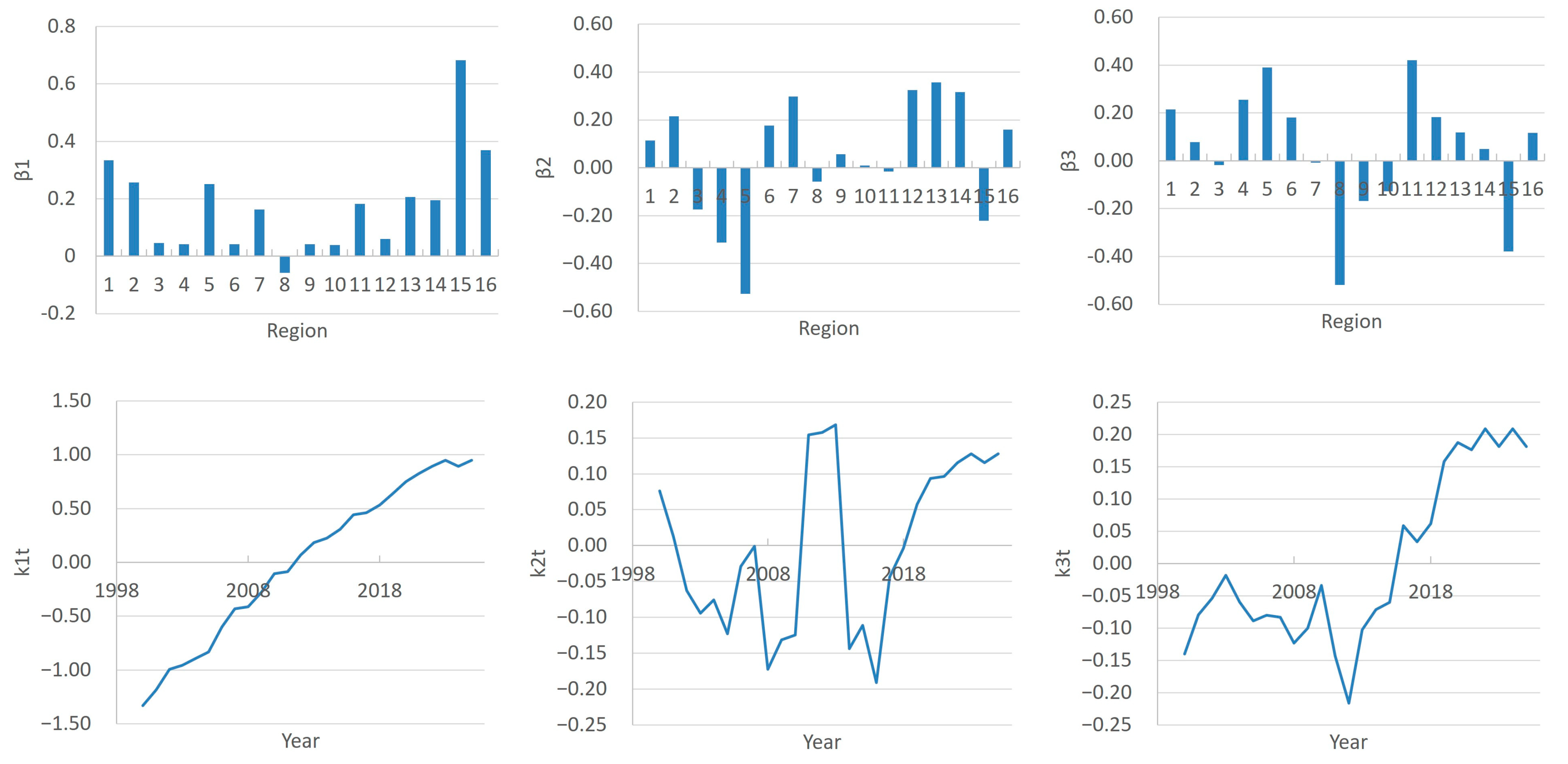
- The principal components can be interpreted in terms of national trends and regional features in the dynamics of the number of doctors.
- FPCA is similar to PCA and EFA, but is designed for functional data, which makes it the best choice in this case.
- The suitability of the method is also confirmed by the high accuracy of fitting and testing.
- Set the μ(x) as the meaning of the ft(x) across the years.
- Find βj(x) and κj(t) through a Principal Component Analysis and choose number J of them for the model.
- Choose a time series model for each of the κj(t).
- Forecast as follows: assume the last year observed is t = T. The time series model for the κj(t) provides us with h-step forecasts , which in turn give us the h-step forecasts
2.3. Model Validity
2.4. Final Forecast for 2025–2033
- -
- Bayesian Approximation: MC Dropout mimics Bayesian inference by sampling sub-networks, enabling uncertainty quantification.
- -
- Number of Passes: 100 passes balance computational cost and stable variance estimation, based on empirical guidelines.
- -
- Practical Benefits: improves robustness, quantifies uncertainty, and supports decision-making, especially for regions with variable prediction accuracy.
- -
- Implementation: dropout was re-enabled during inference, with predictions averaged over 100 samples.
3. Results
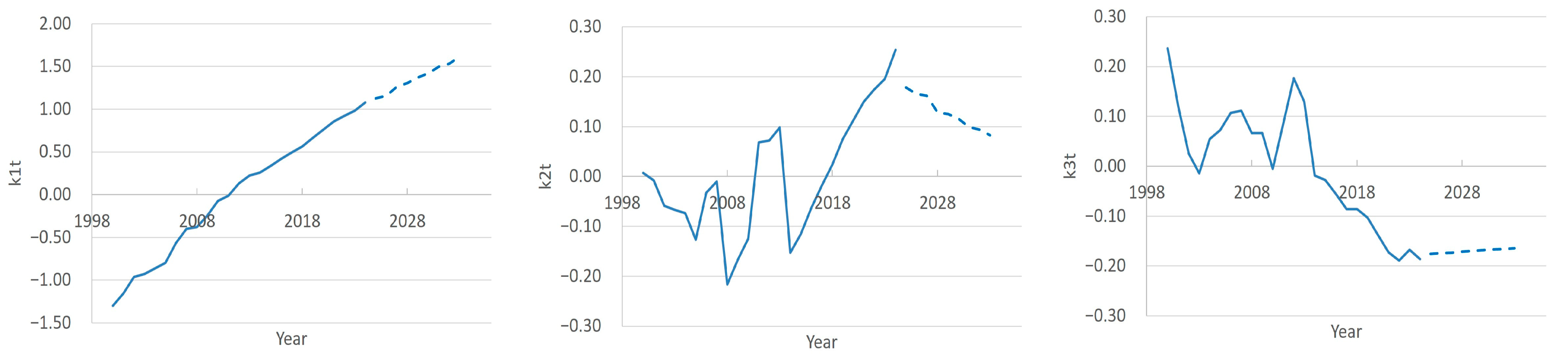
3.1. FPCA Decomposition of Region- and Time-Specific Doctor Counts
3.2. Model Accuracy Testing
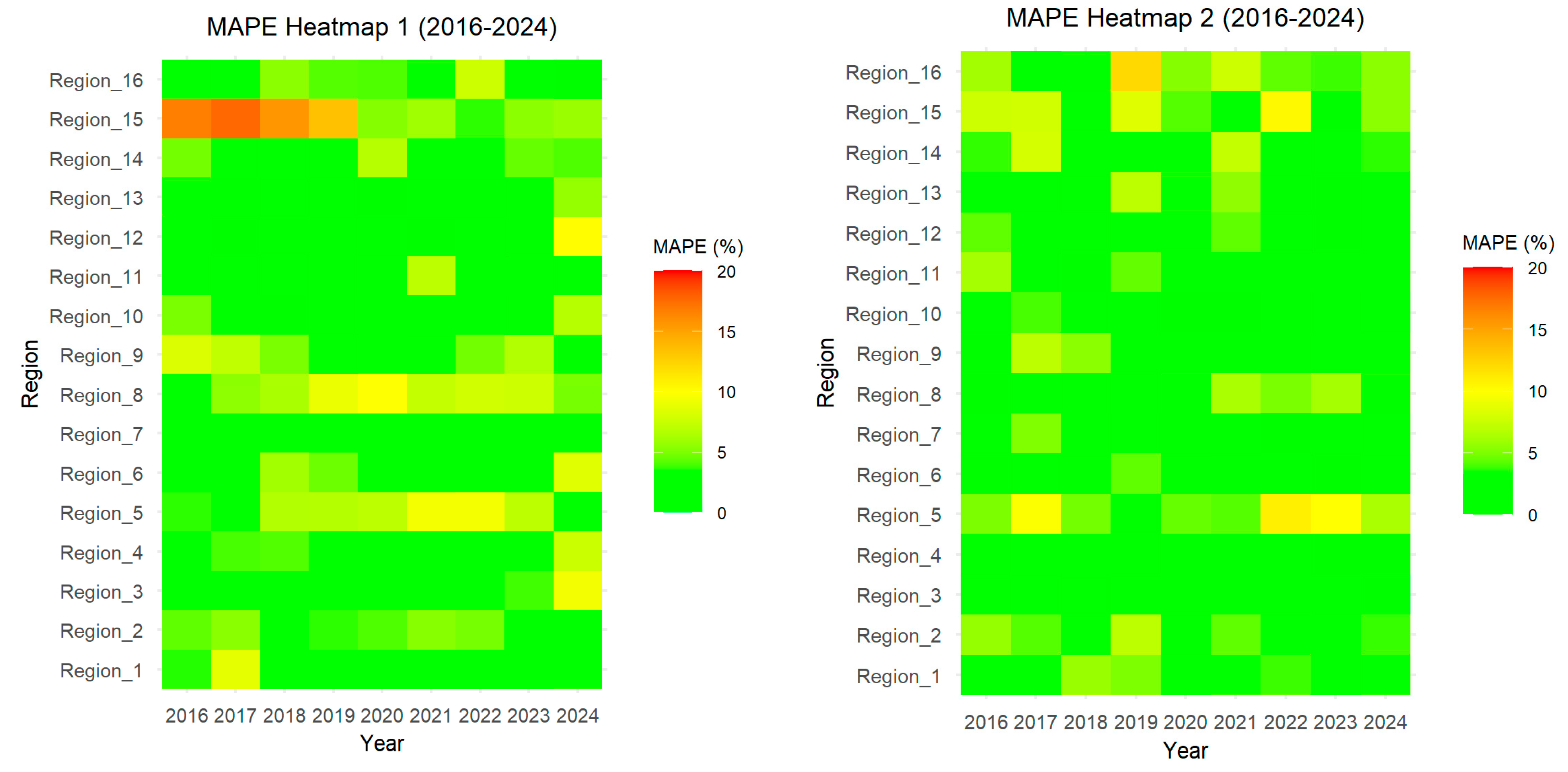
3.2.1. Goodness of Fitting on the Training Timeframe
3.2.2. Forecasting Accuracy on the Testing Timeframe
3.3. Forecasting Doctors Count to 2033
4. Discussion
5. Conclusions
- -
- Our calculations were based on real data of doctor counts in the regions of Kazakhstan. However, in all the analyzed years, there was a shortage of personnel in the country. Unfortunately, we do not have access to information on the number of vacancies by region in these years. Taking this information into account would allow us to obtain more accurate forecasts.
- -
- The need for medical personnel is influenced by various socio-economic, demographic, and epidemiological factors. Taking these factors into account in FPCA is possible but difficult, due to the uncertainty of their impact in the future. In this case, the use of scenario methods is justified.
- -
- In our study, we predicted the total number of doctors in the regions, including general practitioners and specialists. More valuable information for regulatory authorities is the forecast of doctors by specialty. This allows for the efficient allocation of resources for training specialists.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- WHO. Second Round of the National Pulse Survey on Continuity of Essential Health Services During the COVID-19 Pandemic; World Health Organization: Geneva, Switzerland, 2021.
- Analysis of Kazakhstan Republic Healthcare Human Resources, Astana. 2024. Available online: https://clck.ru/3Mrhbu (accessed on 1 October 2024).
- Mukhazhanova, B.S.; Tulegenova, R.A.; Seyduanova, L.B. Approaches to improving the effectiveness of the quality of medical services. Med. Ecol. 2025, 1, 153–163. (In Russian) [Google Scholar] [CrossRef]
- Croux, C.; RuizGazen, A. High breakdown estimators for principal components: The project-pursuit approach revisited. J. Multivar. Anal. 2005, 95, 206–226. [Google Scholar] [CrossRef]
- Ferraty, F.; Vieu, P. Nonparametric Functional Data Analysis; Springer: New York, NY, USA, 2006. [Google Scholar]
- Locantore, N.; Marron, J.S.; Simpson, D.G.; Tripoli, N.; Zhang, J.T.; Kohen, K.L. Robust principal component analysis for functional data. Test 1999, 8, 1–73. [Google Scholar] [CrossRef]
- Kneip, A.; Utikal, K.J. Inference for density families using functional principal component analysis. J. Am. Stat. Assoc. 2001, 94, 519–533. [Google Scholar] [CrossRef]
- Viviani, R.; Gron, G.; Spitzer, M. Functional principal component analysis of fMRI data. Human Brain Mapp. 2005, 24, 109–129. [Google Scholar] [CrossRef]
- Hermanussen, M.; Meigen, C. Phase variation in child and adolescent growth. Int. J. Biostat. 2007, 3, 9. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Ullah, S. Robust forecasting of mortality and fertility rates: A functional data approach. Comput. Stat. Data Anal. 2007, 51, 4942–4956. [Google Scholar] [CrossRef]
- Huang, W.; Gao, L.; Guo, W.; Cui, H.; Li, Z.; Xu, X.; Wang, G. Analysis into functional data of spectral images from bloodstains of human and two species of animal. Forensic Sci. Technol. 2021, 46, 551–558. [Google Scholar]
- Bernardi, M.S.; Carey, M.; Ramsay, J.O.; Sangalli, L.M. Modeling spatial anisotropy via regression with partial differential regularization. J. Multivar. Anal. 2018, 167, 15–30. [Google Scholar] [CrossRef]
- Newell, J.; McMillan, K.; Grant, S.; McCabe, G. Using functional data analysis to summarise and interpret lactate curves. Comput. Biol. Med. 2006, 36, 262–275. [Google Scholar] [CrossRef]
- Ryan, W.; Harrison, A.; Hayes, K. Functional data analysis of knee joint kinematics in the vertical jump. Sports Biomech. 2006, 5, 121–138. [Google Scholar] [CrossRef] [PubMed]
- Song, J.J.; Deng, W.; Lee, H.-J.; Kwon, D. Optimal classification for time-course gene expression data using functional data analysis. Comput. Biol. Chem. 2008, 32, 426–432. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.J.; Wang, L.; Gill, J.; Cao, J. Functional principal component analysis of glomerular filtration rate curves after kidney transplant. Stat. Methods Med. Res. 2018, 27, 3785–3796. [Google Scholar] [CrossRef] [PubMed]
- Lin, Z.; Wang, J.L. Mean and Covariance Estimation for Functional Snippets. J. Am. Stat. Assoc. 2022, 117, 348–360. [Google Scholar] [CrossRef]
- Karuppusami, R.; Antonisamy, B.; Premkumar, P.S. Functional principal component analysis for identifying the child growth pattern using longitudinal birth cohort data. BMC Med. Res. Methodol. 2022, 22, 76. [Google Scholar] [CrossRef]
- Dey, D.; Ghosal, R.; Merikangas, K.; Zipunnikov, V. Functional Principal Component Analysis for Continuous Non-Gaussian, Truncated, and Discrete Functional Data. Stat. Med. 2024, 43, 5431–5445. [Google Scholar] [CrossRef]
- Anderson, C.; Hafen, R.; Sofrygin, O.; Ryan, L. Members of the HBGDki community. Comparing predictive abilities of longitudinal child growth models. Stat. Med. 2019, 38, 3555–3570. [Google Scholar] [CrossRef]
- Anderson, C.; Xiao, L.; Checkley, W. Using data from multiple studies to develop a child growth correlation matrix. Stat. Med. 2019, 38, 3540–3554. [Google Scholar] [CrossRef]
- Han, K.; Hadjipantelis, P.Z.; Wang, J.-L.; Kramer, M.S.; Yang, S.; Martin, R.M.; Müller, H.-G.; Szczesniak, R.D. Functional principal component analysis for identifying multivariate patterns and archetypes of growth, and their association with long-term cognitive development. PLoS ONE 2018, 13, e0207073. [Google Scholar] [CrossRef]
- Leroux, A.; Xiao, L.; Crainiceanu, C.; Checkley, W. Dynamic Prediction in Functional Concurrent Regression with an Application to Child Growth. Stat. Med. 2018, 37, 1376–1388. [Google Scholar] [CrossRef]
- Simpkin, A.J.; Durban, M.; Lawlor, D.A.; MacDonald-Wallis, C.; May, M.T.; Metcalfe, C.; Tilling, K. Derivative estimation for longitudinal data analysis: Examining features of blood pressure measured repeatedly during pregnancy. Stat. Med. 2018, 37, 2836–2854. [Google Scholar] [CrossRef] [PubMed]
- Dean, J.A.; Wong, K.H.; Gay, H.; Welsh, L.C.; Jones, A.-B.; Schick, U.; Oh, J.H.; Apte, A.; Newbold, K.L.; Bhide, S.A.; et al. Functional data analysis applied to modeling of severe acute Mucositis and dysphagia resulting from head and neck radiation therapy. Int. J. Radiat. Oncol. Biol. Phys. 2016, 96, 820–831. [Google Scholar] [CrossRef] [PubMed]
- Salvatore, S.; Bramness, J.G.; Røislien, J. Exploring functional data analysis and wavelet principal component analysis on ecstasy (MDMA) wastewater data. BMC Med. Res. Methodol. 2016, 16, 81. [Google Scholar] [CrossRef] [PubMed]
- Salvatore, S.; Frøslie, K.F.; Røislien, J.; Zuccato, E.; Castiglioni, S.; Bramness, J. A nuanced picture of illicit drug use in 17 Italian cities through functional principal component analysis of temporal wastewater data. J. Public Health 2016, 24, 165–174. [Google Scholar] [CrossRef]
- Rostami-Tabar, B.; Hyndman, R.J. Hierarchical Time Series Forecasting in Emergency Medical Services. J. Serv. Res. 2024, 28, 278–295. [Google Scholar] [CrossRef]
- Xie, S.; Lawniczak, A.T. Fourier Spectral Domain Functional Principal Component Analysis of EEG Signals. In Pattern Recognition Applications and Methods (ICPRAM 2019); De Marsico, M., Sanniti di Baja, G., Fred, A., Eds.; Lecture Notes in Computer Science (LNIP, Volume 11996); Springer: Cham, Switzerland, 2020. [Google Scholar] [CrossRef]
- Orozco, N.; Ortiz, S.; Ospina-Tascón, G.A. Functional Data Analysis Applications in Medicine: A Systematic Review. WIREs Comput Stat. 2025, 17, e70026. [Google Scholar] [CrossRef]
- Sartini, J.; Zhou, X.; Selvin, L.; Zeger, S.; Crainiceanu, C.M. Fast Bayesian Functional Principal Components Analysis. arXiv 2024, arXiv:2412.11340. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinse, G.C. Time Series Analysis: Forecasting and Control, 4th ed.; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Bergmeir, C.; Hyndman, R.J.; Koo, B. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | MAPE | Region | MAPE |
|---|---|---|---|
| 2000 | 1.98 | 1 | 2.49 |
| 2001 | 1.31 | 2 | 2.73 |
| 2002 | 1.56 | 3 | 1.86 |
| 2003 | 1.15 | 4 | 1.12 |
| 2004 | 1.37 | 5 | 1.63 |
| 2005 | 2.02 | 6 | 1.34 |
| 2006 | 2.58 | 7 | 2.14 |
| 2007 | 2.31 | 8 | 1.8 |
| 2008 | 1.21 | 9 | 2.14 |
| 2009 | 1.12 | 10 | 1.43 |
| 2010 | 1.6 | 11 | 1.54 |
| 2011 | 2.67 | 12 | 1.58 |
| 2012 | 1.38 | 13 | 1.95 |
| 2013 | 1.91 | 14 | 1.23 |
| 2014 | 2.09 | 15 | 1.22 |
| 2015 | 1.87 | 16 | 1.94 |
| Mean | 1.76 | 1.76 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koichubekov, B.; Omarkulov, B.; Omarbekova, N.; Abdikadirova, K.; Kharin, A.; Amirbek, A. Forecasting the Regional Demand for Medical Workers in Kazakhstan: The Functional Principal Component Analysis Approach. Int. J. Environ. Res. Public Health 2025, 22, 1052. https://doi.org/10.3390/ijerph22071052
Koichubekov B, Omarkulov B, Omarbekova N, Abdikadirova K, Kharin A, Amirbek A. Forecasting the Regional Demand for Medical Workers in Kazakhstan: The Functional Principal Component Analysis Approach. International Journal of Environmental Research and Public Health. 2025; 22(7):1052. https://doi.org/10.3390/ijerph22071052
Chicago/Turabian StyleKoichubekov, Berik, Bauyrzhan Omarkulov, Nazgul Omarbekova, Khamida Abdikadirova, Azamat Kharin, and Alisher Amirbek. 2025. "Forecasting the Regional Demand for Medical Workers in Kazakhstan: The Functional Principal Component Analysis Approach" International Journal of Environmental Research and Public Health 22, no. 7: 1052. https://doi.org/10.3390/ijerph22071052
APA StyleKoichubekov, B., Omarkulov, B., Omarbekova, N., Abdikadirova, K., Kharin, A., & Amirbek, A. (2025). Forecasting the Regional Demand for Medical Workers in Kazakhstan: The Functional Principal Component Analysis Approach. International Journal of Environmental Research and Public Health, 22(7), 1052. https://doi.org/10.3390/ijerph22071052