




Apple Leave Disease Detection Using Collaborative ML/DL and Artificial Intelligence Methods: Scientometric Analysis

 ,
,  ,
,  ,
,  ,
,  , and
, and 
Abstract
1. Introduction
1.1. Apple Leaves Disease Categories
1.1.1. Apple Healthy Leaves
1.1.2. Marsonina Leaf Blotch
1.1.3. Apple Necrosis Leaves
1.1.4. Apple Alternaria Leaves
1.1.5. Powdery Mildew
1.1.6. Apple Scab
1.1.7. Apple Mosaic
1.1.8. Multiple Diseases
1.2. Deep Learning Techniques
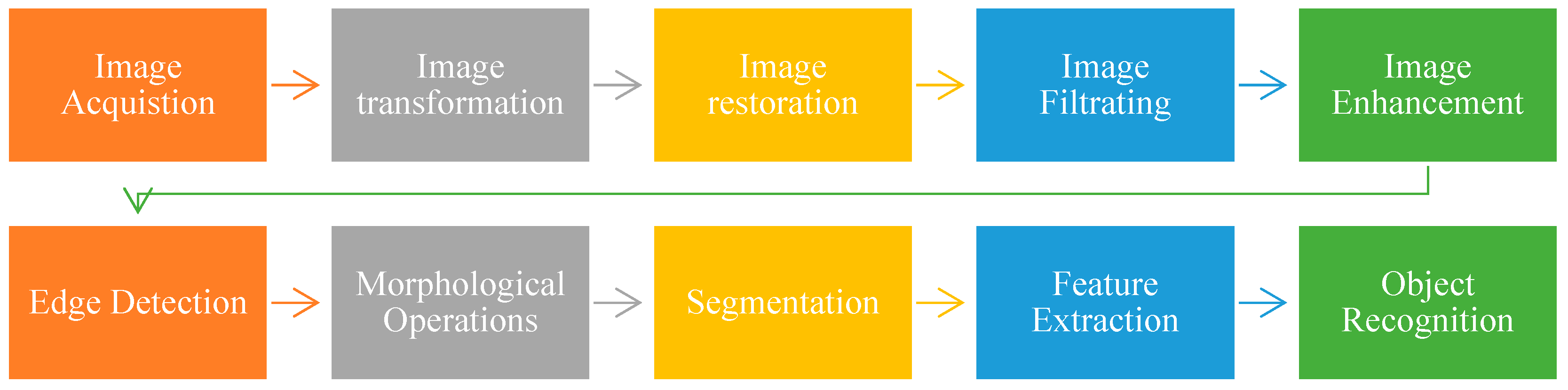
1.3. Image Segmentation
1.3.1. Edge Detection Segmentation
1.3.2. Thresholding Segmentation
1.3.3. Region-Based Segmentation
1.3.4. Feature-Based Clustering Segmentation
1.4. Need of Bibliometric Study
1.5. Bibliometric Analysis Apple Leaves Disease Detection using Artificial Intelligence
- To identify the many research publishing categories.
- To determine the linguistic style used in publications.
- To identify publication trends based on year.
- To pinpoint the regions or nations that has contributed more to the study.
- To identify patterns using various source kinds.
- To identify authors who contribute significantly.
- To spot publishing trends based on connections (college/organisation).
- To look at the publication’s citation counts.
2. Research Methodology
2.1. Initial Data Collection
2.2. Significant Keywords
2.3. Bibliometric Analysis Tools
2.3.1. Bibexcel
2.3.2. CopalRed
2.3.3. CiteSpace
2.3.4. IN-SPIRE
2.3.5. Sci2 Tool
2.3.6. Bibliometrix
2.3.7. VOSviewer
3. Bibliometric Analysis and Results
3.1. Performance Analysis
3.2. Science Mapping
3.2.1. Citation Analysis
3.2.2. Co-Citation Analysis
3.2.3. Bibliographic Coupling
3.2.4. Co-Word Analysis
3.2.5. Co-Authorship Analysis
3.3. Dataset
3.4. Publication and Citation Structure
3.5. Three Field Plot
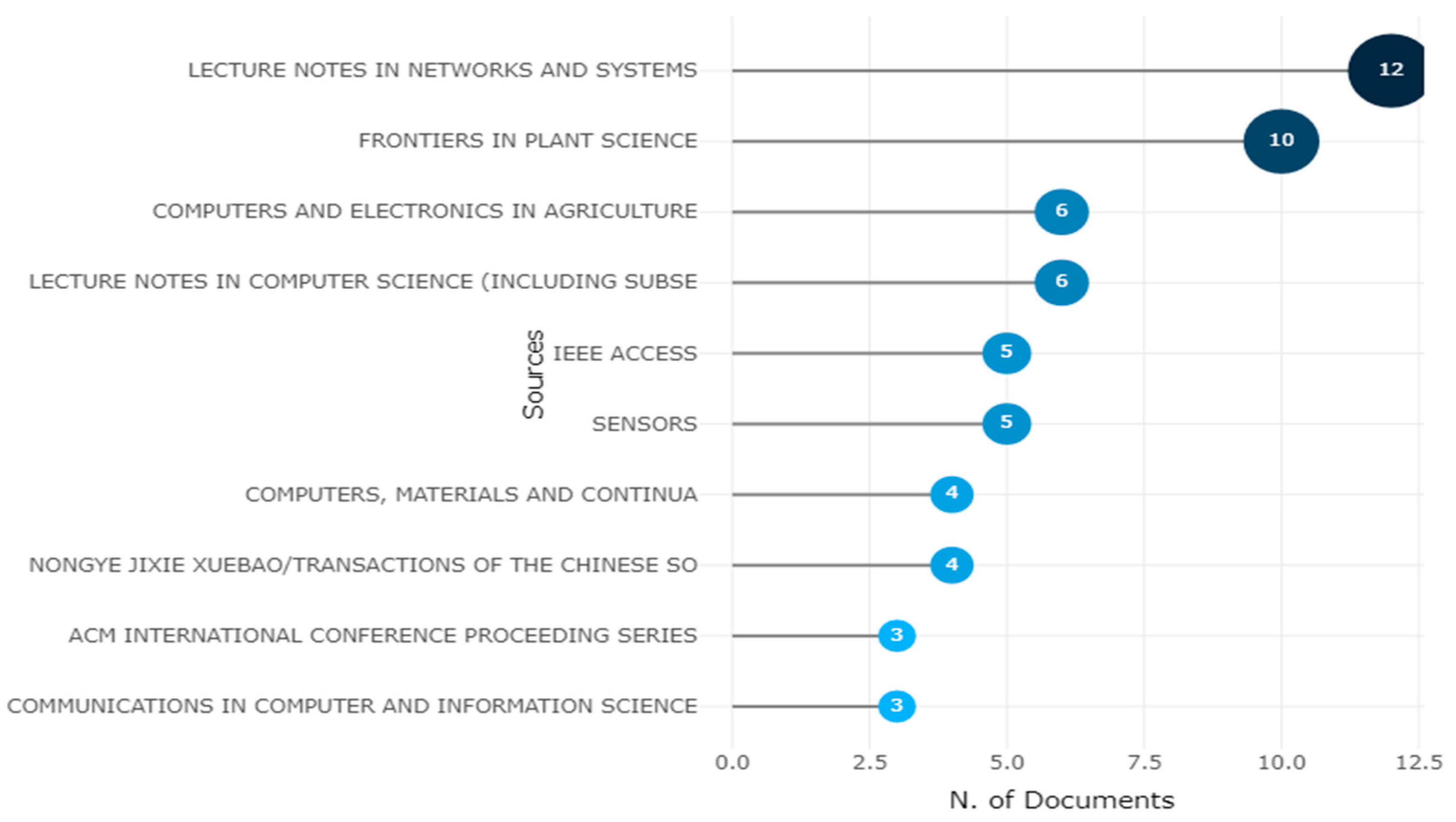
3.6. Relevant Sources
3.7. Local Cited Sources
3.8. Source Dynamics
3.9. Most Relevant Affiliation
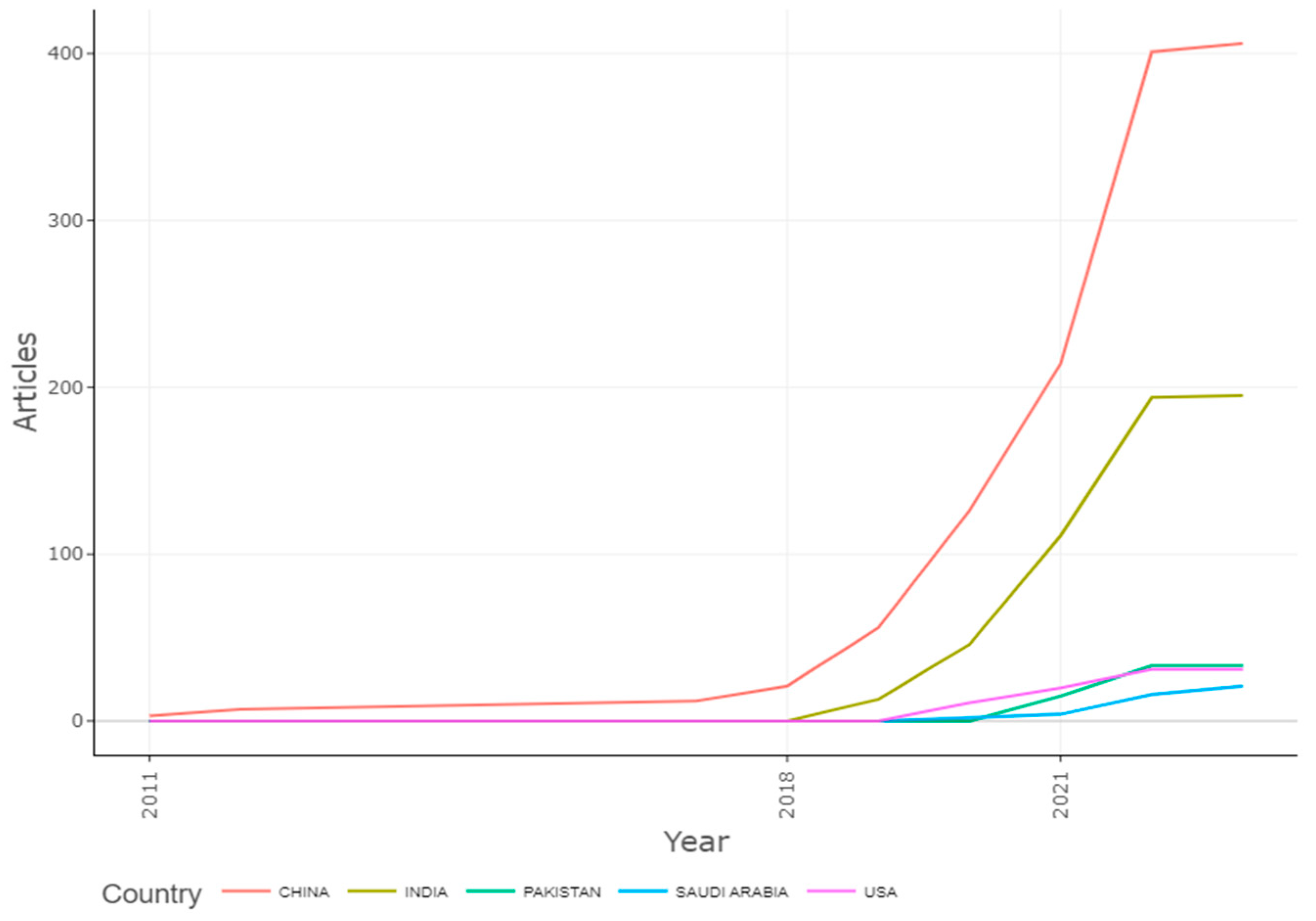
3.10. Country’s Production Overtime
3.11. Documents
3.12. WordCloud
3.13. TreeMap
4. Scientific Mapping
4.1. Conceptual Approach
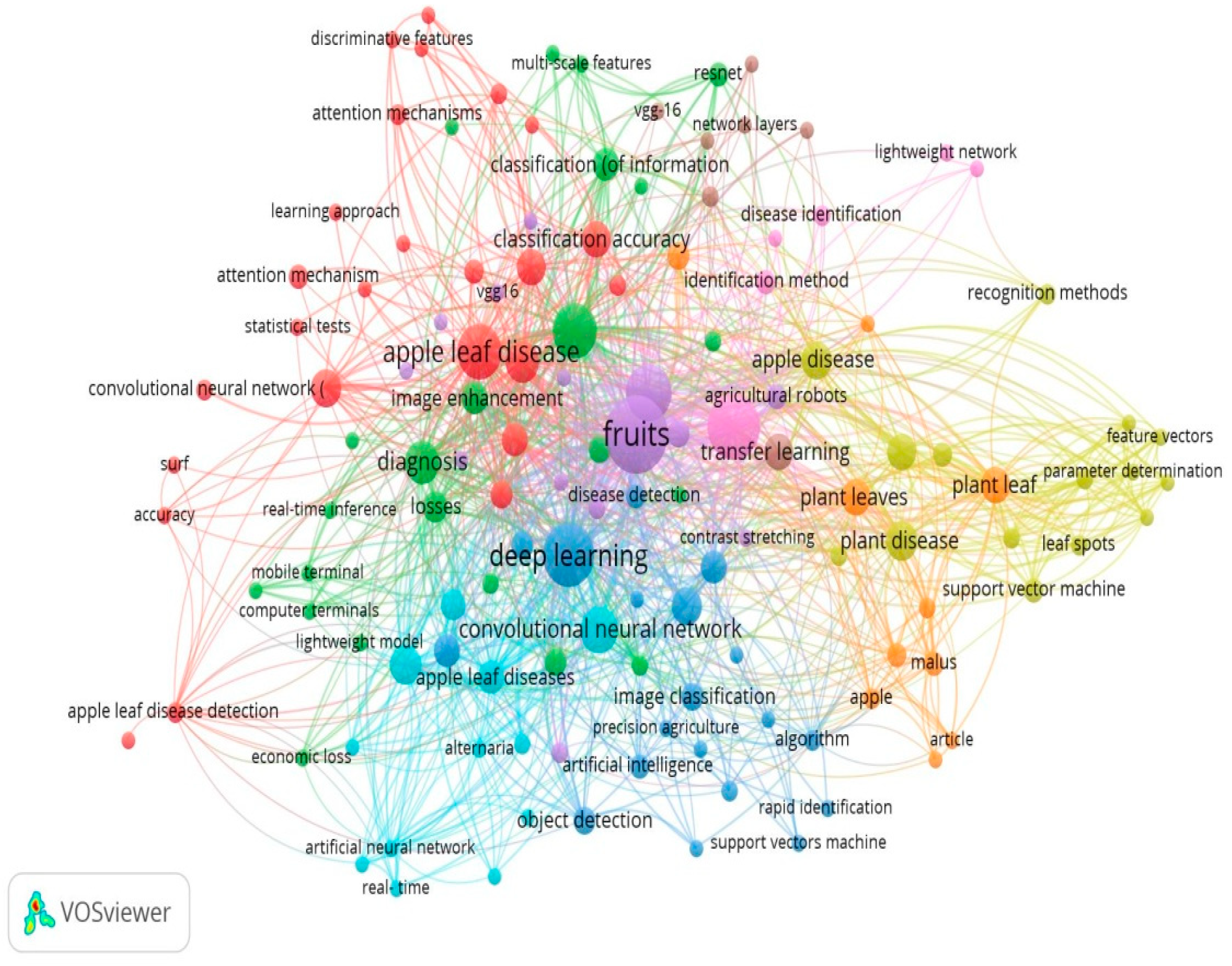
4.1.1. Keyword Co-Occurrence Network
- How can various artificial intelligence applications be used effectively in apple crop disease detection techniques?
- How computer vision is more reliable for processing of data?
- Which transfer learning is use for training of data of disease detection?
- How to evaluate performances matrices such as precision for different classes of apple leaf diseases?
- Which timeline is applicable in research for finding the best solution from all over the world intended for detection of ailments in apple leaves?
- What are the various datasets available for apple leaf disease detection in DL?
- What is the role of a deep learning model for automatic apple leaf disease detection?
- How does black spot affect apple production?
- What are the various manual and automatic detection techniques which can be used to tackle this problem?
- Which DL model shows significant efficiency in apple leaf detection?
- Why and how do leaf diseases affect agriculture yield?
- What are the various kinds of apple leaf diseases?
- What are practices for the farmers to identify apple leaf diseases?
- How do plant disease detection techniques affect the variety of crops?
4.1.2. Thematic Map
4.1.3. Factorial Analysis
5. Intellectual Structure
5.1. Bibliographic Coupling with Countries
5.2. Document X Citations
5.3. Co-Citation Analysis
5.3.1. Co-Citation Source
5.3.2. Co-Citation Author
6. Social Structure
6.1. Collaboration Network
6.1.1. Institute-Wise Collaboration
6.1.2. Country-Wise Collaboration
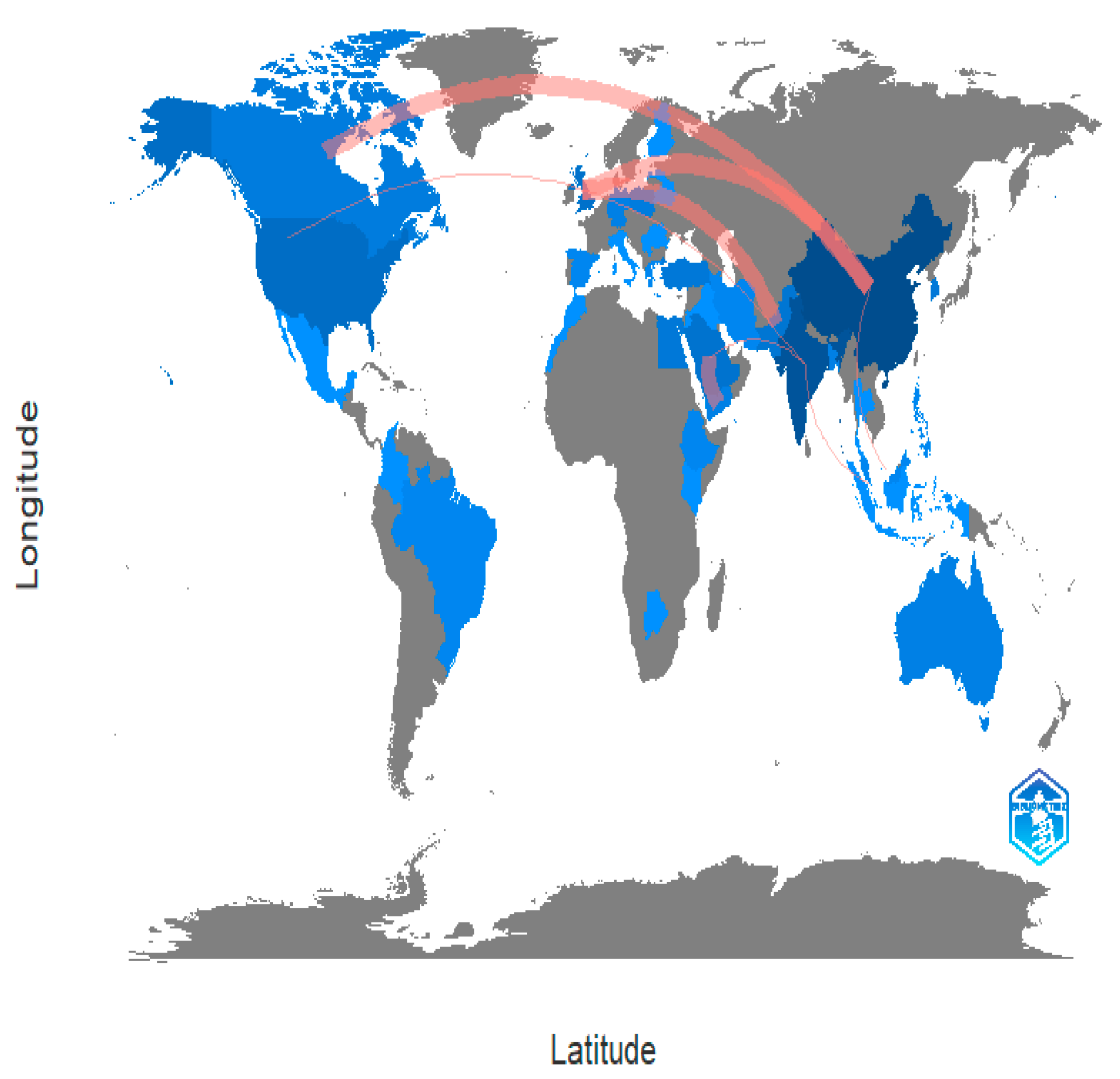
6.2. Collaboration WorldMap
7. Conclusions
8. Limitations and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Samajpati, B.J.; Degadwala, S.D. A Survey on Apple Fruit Diseases Detection and Classification. Int. J. Comput. Appl. 2015, 130, 25–32. [Google Scholar] [CrossRef]
- Khirade, S.D.; Patil, A. Plant disease detection using image processing. In Proceedings of the 2015 International Conference on Computing Communication Control and Automation, Pune, India, 26–27 February 2015; pp. 768–771. [Google Scholar] [CrossRef]
- Rao, A.; Kulkarni, S. A Hybrid Approach for Plant Leaf Disease Detection and Classification Using Digital Image Processing Methods. Int. J. Electr. Eng. Educ. 2020, 0020720920953126. [Google Scholar] [CrossRef]
- Phadikar, S.; Sil, J.; Das, A.K. Rice diseases classification using feature selection and rule generation techniques. Comput. Electron. Agric. 2013, 90, 76–85. [Google Scholar] [CrossRef]
- Rastogi, A.; Arora, R.; Sharma, S. Leaf disease detection and grading using computer vision technology & fuzzy logic. In Proceedings of the 2015 2nd International Conference on Signal Processing and Integrated Networks (SPIN), Noida, India, 19–20 February 2015; pp. 500–505. [Google Scholar] [CrossRef]
- Singh, R.; Gehlot, A.; Prajapat, M.K.; Singh, B. Artificial Intelligence in Agriculture; CRC Press: London, UK, 2021. [Google Scholar] [CrossRef]
- Li, L.; Zhang, S.; Wang, B. Apple Leaf Disease Identification with a Small and Imbalanced Dataset Based on Lightweight Convolutional Networks. Sensors 2021, 22, 173. [Google Scholar] [CrossRef] [PubMed]
- Di Franco, G.; Santurro, M. Machine learning, artificial neural networks and social research. Qual. Quant. 2020, 55, 1007–1025. [Google Scholar] [CrossRef]
- Abdullah, D.M.; Abdulazeez, A.M. Machine Learning Applications based on SVM Classification A Review. Qubahan Acad. J. 2021, 1, 81–90. [Google Scholar] [CrossRef]
- Mitra, M. K-Means Clustering in Machine Learning—A Review. Peer Nest 2019, 1, 4. [Google Scholar] [CrossRef]
- Catherine, A.O. Fuzzy C-Means Clustering Model for Identification of Students ’ Learning Preferences in Online Environment. Int. J. Comput. Appl. Inf. Technol. 2013, 4, 15–21. [Google Scholar]
- Yang, L.; Wu, X.; Zhao, D.; Li, H.; Zhai, J. An improved Prewitt algorithm for edge detection based on noised image. In Proceedings of the 2011 4th International Congress on Image and Signal Processing, Shanghai, China, 15–17 October 2011; Volume 3, pp. 1197–1200. [Google Scholar] [CrossRef]
- Doinea, M.; Boja, C. Machine Learning Techniques for Data Extraction and Classification in Computer Vision Software. In Proceedings of the 13th International Conference on INFORMATICS in ECONOMY (IE 2014), Bucharest, Romania, 15–18 May 2014. [Google Scholar]
- Guseva, A.I.; Kuznetsov, I.A. The Use of Entropy Measure for Higher Quality Machine Learning Algorithms in Text Data Processing. In Proceedings of the 2017 5th International Conference on Future Internet of Things and Cloud Workshops (FiCloudW), Prague, Czech Republic, 21–23 August 2017; pp. 47–52. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?–Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Balanda, K.P.; MacGillivray, H.L. Kurtosis: A Critical Review. Am. Stat. 1988, 42, 111–119. [Google Scholar] [CrossRef]
- Oravec, M. Feature extraction and classification by machine learning methods for biometric recognition of face and iris. In Proceedings of the ELMAR-2014, Zadar, Croatia, 10–12 September 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Dubey, S.R.; Jalal, A.S. Detection and classification of apple fruit diseases using complete local binary patterns. In Proceedings of the 2012 Third International Conference on Computer and Communication Technology, Allahabad, India, 23–25 November 2012; pp. 346–351. [Google Scholar] [CrossRef]
- Shuaibu, M.; Lee, W.S.; Schueller, J.; Gader, P.; Hong, Y.K.; Kim, S. Unsupervised hyperspectral band selection for apple Marssonina blotch detection. Comput. Electron. Agric. 2018, 148, 45–53. [Google Scholar] [CrossRef]
- Abbasi, P.A.; Ali, S.; Braun, G.; Bevis, E.; Fillmore, S. Reducing apple scab and frogeye or black rot infections with salicylic acid or its analogue on field-established apple trees. Can. J. Plant Pathol. 2019, 41, 345–354. [Google Scholar] [CrossRef]
- Sherwani, A.; Mukhtar, M. Insect Pests of Apple and Their Management Fishery biology View Project Toxicology View Project. January 2016. Available online: https://www.researchgate.net/publication/290053683 (accessed on 1 January 2020).
- Singh, S.; Gupta, S.; Tanta, A.; Gupta, R. Extraction of Multiple Diseases in Apple Leaf Using Machine Learning. Int. J. Image Graph. 2021, 22, 2140009. [Google Scholar] [CrossRef]
- Chandel, A.K.; Khot, L.R.; Sallato, B.C. Apple powdery mildew infestation detection and mapping using high-resolution visible and multispectral aerial imaging technique. Sci. Hortic. 2021, 287, 110228. [Google Scholar] [CrossRef]
- Kodors, S.; Lacis, G.; Sokolova, O.; Zhukovs, V.; Apeinans, I.; Bartulsons, T. Apple scab detection using CNN and transfer learning. Agron. Res. 2021, 19, 507–519. [Google Scholar] [CrossRef]
- Jiang, P.; Chen, Y.; Liu, B.; He, D.; Liang, C. Real-Time Detection of Apple Leaf Diseases Using Deep Learning Approach Based on Improved Convolutional Neural Networks. IEEE Access 2019, 7, 59069–59080. [Google Scholar] [CrossRef]
- Fang, T.; Chen, P.; Zhang, J.; Wang, B. Identification of Apple Leaf Diseases Based on Convolutional Neural Network. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2019; pp. 553–564. [Google Scholar] [CrossRef]
- Alsayed, A.; Alsabei, A.; Arif, M. Classification of Apple Tree Leaves Diseases using Deep Learning Methods. Int. J. Comput. Sci. Netw. Secur. 2021, 21, 324. [Google Scholar] [CrossRef]
- Chao, X.; Sun, G.; Zhao, H.; Li, M.; He, D. Identification of Apple Tree Leaf Diseases Based on Deep Learning Models. Symmetry 2020, 12, 1065. [Google Scholar] [CrossRef]
- Bonkra, A.; Noonia, A.; Kaur, A. Apple Leaf Diseases Detection System: A Review of the Different Segmentation and Deep Learning Methods. Artif. Intell. Data Sci. 2022, 263–278. [Google Scholar]
- Fu, K.; Mui, J. A survey on image segmentation. Pattern Recognit. 1981, 13, 3–16. [Google Scholar] [CrossRef]
- Shrivastava, P. A Survey of Image Classification Based Techniques. Int. J. Eng. Res. Technol. 2013, 2, 1987–1992. [Google Scholar]
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the Science and Information Conference (SAI), London, UK, 27–29 August 2014; pp. 372–378. [Google Scholar] [CrossRef]
- Bonkra, A.; Dhiman, P. IoT Security Challenges in Cloud Environment. In Proceedings of the 2021 2nd International Conference on Computational Methods in Science & Technology (ICCMST), Mohali, India, 17–18 December 2021; pp. 30–34. [Google Scholar] [CrossRef]
- Rani, R.; Khurana, M.; Kumar, A.; Kumar, N. Big data dimensionality reduction techniques in IoT: Review, applications and open research challenges. Clust. Comput. 2022, 25, 4027–4049. [Google Scholar] [CrossRef]
- Rani, R.; Khurana, M.; Sharma, D.; Moudgil, A. Comparative Study on various Storage Optimization Techniques in IoT-Cloud Ecosystem. In Proceedings of the 2021 International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 4–5 March 2021; pp. 659–663. [Google Scholar] [CrossRef]
- MacHardy, E.W. Current status of IPM in apple orchards. Crop. Prot. 2000, 19, 801–806. [Google Scholar] [CrossRef]
- Available online: https://www.apsnet.org/publications/plantdisease/backissues/Documents/1986Articles/PlantDisease70n05_480.pdf (accessed on 25 January 2023).
- Sholberg, P.; O’Gorman, D.; Bedford, K.; Lévesque, C.A. Development of a DNA Macroarray for Detection and Monitoring of Economically Important Apple Diseases. Plant Dis. 2005, 89, 1143–1150. [Google Scholar] [CrossRef] [PubMed]
- Chand-Goyal, T.; Spotts, R.A. Biological Control of Postharvest Diseases of Apple and Pear under Semi-commercial and Commercial Conditions Using Three Saprophytic Yeasts. Biol. Control 1997, 10, 199–206. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Panigrahi, A.; Chen, Y.; Kuo, C.-C.J. Analysis on gradient propagation in batch normalized residual networks. arXiv 2018, arXiv:1812.00342. [Google Scholar]
- Seber, G.A.; Lee, A. Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012; Volume 329. [Google Scholar]
- Scholkopf, B.; Smola, A. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2009, 31, 651–666. [Google Scholar] [CrossRef]
- Kotsiantis, S.; Kanellopoulos, D. Association rules mining: A recent overview. GESTS Int. Trans. Comput. Sci. Eng. 2006, 32, 71–82. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.-T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. arXiv 2016, arXiv:1602.01783. [Google Scholar]
- Albrektsson, T.; Johansson, C. Osteoinduction, osteoconduction and osseointegration. Eur. Spine J. 2001, 10 (Suppl. S2), S96–S101. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.S. Image Segmentation and Object Recognition. J. Res. Proc. 2021, 1, 101–112. [Google Scholar] [CrossRef]
- Umamaheswari, D.; Geetha, S. Review on Image Segmentation Techniques Incorporated with Machine Learning in the Scrutinization of Leukemic Microscopic Stained Blood Smear Images; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; Volume 30. [Google Scholar] [CrossRef]
- Kale, R.S.; Thorat, S. Image Segmentation Techniques with Machine Learning. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2021, 7, 232–235. [Google Scholar] [CrossRef]
- Smith, K.; Marinova, D. Use of bibliometric modelling for policy making. Math. Comput. Simul. 2005, 69, 177–187. [Google Scholar] [CrossRef]
- Donthu, N.; Kumar, S.; Mukherjee, D.; Pandey, N.; Lim, W.M. How to conduct a bibliometric analysis: An overview and guidelines. J. Bus. Res. 2021, 133, 285–296. [Google Scholar] [CrossRef]
- De Bakker, F.G.A.; Groenewegen, P.; den Hond, F. A Bibliometric Analysis of 30 Years of Research and Theory on Corporate Social Responsibility and Corporate Social Performance. Bus. Soc. 2005, 44, 283–317. [Google Scholar] [CrossRef]
- Ballew, B.S. Elsevier’s Scopus® Database. J. Electron. Resour. Med. Libr. 2009, 6, 245–252. [Google Scholar] [CrossRef]
- Börner, K.; Huang, W.; Linnemeier, M.; Duhon, R.J.; Phillips, P.; Ma, N.; Zoss, A.M.; Guo, H.; Price, M.A. Rete-netzwerk-red: Analyzing and visualizing scholarly networks using the Network Workbench Tool. Scientometrics 2010, 83, 863–876. [Google Scholar] [CrossRef]
- Sulaiman, M.A. Introduction to Microsoft Excel. Introd. Data Sci. 2021. [Google Scholar] [CrossRef]
- Yockey, R.D. Introduction to SPSS. In SPSS® Demystified; Routledge: Abingdon, UK, 2015; pp. 2–19. [Google Scholar] [CrossRef]
- Borgatti, S.; Everett, M.; Freeman, L. Ucinet for Windows: Software for Social Network Analysis (Version 6.102); Analytic Technologies: Harvard, MA, USA, 2002; pp. 12–15. [Google Scholar]
- Batagelj, V.; Mrvar, A. Pajek-Program for Large Network Analysis. Connections 1998, 21, 47–57. [Google Scholar]
- Persson, O.; Danell, R.; Schneider, J.W. How to use Bibexcel for various types of bibliometric analysis. In Celebrating Scholarly Communication Studies: A Festschrift for Olle Persson at His 60th Birthday; ISSI: Milpitas, CA, USA, 2009; Volume 5, pp. 9–24. [Google Scholar]
- Bailón-Moreno, R.; Jurado-Alameda, E.; Ruiz-Baños, R.; Courtial, J.P. Analysis of the field of physical chemistry of surfactants with the Unified Scienctometric Model. Fit of relational and activity indicators. Scientometrics 2005, 63, 259–276. [Google Scholar] [CrossRef]
- Carvalho, P.; Hitzelberger, P.; Otjacques, B.; Bouali, F.; Venturini, G. Information visualization for CSV open data files structure analysis. In Proceedings of the 6th International Conference on Information Visualization Theory and Applications, Berlin, Germany, 11–15 March 2015; pp. 101–108. [Google Scholar] [CrossRef]
- Chen, C. CiteSpace II: Detecting and visualizing emerging trends and transient patterns in scientific literature. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 359–377. [Google Scholar] [CrossRef]
- Chen, C. Searching for intellectual turning points: Progressive knowledge domain visualization. Proc. Natl. Acad. Sci. USA 2004, 101 (Suppl. 1), 5303–5310. [Google Scholar] [CrossRef] [PubMed]
- Wise, J.A. The ecological approach to text visualization. J. Am. Soc. Inf. Sci. 1999, 50, 1224–1233. [Google Scholar] [CrossRef]
- Peroni, S.; Osborne, F.; Di Iorio, A.; Nuzzolese, A.G. Research Articles in Simplified HTML: A Web-first format for HTML-based scholarly articles. PeerJ Comput. Sci. 2017, 3, e132. [Google Scholar] [CrossRef]
- Fernandez, M.; Amer-Yahia, S. Techniques for storing XML. In Proceedings of the 18th International Conference on Data Engineering, San Jose, CA, USA, 26 February–1 March 2002; Volume 323. [Google Scholar] [CrossRef]
- Hetzler, E.; Turner, A. Analysis Experiences Using Information Visualization. IEEE Comput. Graph. Appl. 2004, 24, 22–26. [Google Scholar] [CrossRef]
- Börner, K.; Biberstine, J. Sci2: A Tool of Science of Science Research and Practice Tutorial. Please (1) Get a Name Tag, (2) Download the Sci2 Tool from http://sci2.cns.iu.edu and (3) Complete the Pre-Tutorial Questionnaire; Indiana University and SciTech Strategies: Albuquerque, NM, USA, 2011. [Google Scholar]
- Mahdi, Q.; Hashim, R. Using R language to analyze and programming vital data by applying it to a human diseases. Int. J. Psychosoc. Rehabil. 2020, 24, 4079. [Google Scholar]
- Burnham, J.F. Scopus database: A review. Biomed. Digit. Libr. 2006, 3, 1–8. [Google Scholar] [CrossRef]
- Williamson, P.O.; Minter, C.I.J. Exploring PubMed as a reliable resource for scholarly communications services. J. Med. Libr. Assoc. 2019, 107, 16–29. [Google Scholar] [CrossRef] [PubMed]
- Paramothayan, N.S.; Lasserson, T.J.; Wells, A.U.; Walters, E.H. The cochrane database of systematic reviews. Ther. Res. 2002, 23, 2267–2287. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef]
- Francis, B.R.; bin Ahmad, R.; Abdullah, S.M.B. A Bibliometric Analysis on Performance Appraisal. Int. J. Acad. Res. Bus. Soc. Sci. 2021, 11, 1797–1818. [Google Scholar] [CrossRef]
- Leite, L.R.; Yagasaki, C.A.; Van Aken, E.; Martins, R.A. Bibliometric analysis of literature on performance measurement systems and sustainability. In Proceedings of the 2012 Industrial and Systems Engineering Research Conference, Orlando, FL, USA, 19–23 May 2012; pp. 504–513. [Google Scholar]
- Chen, C.; Dubin, R.; Schultz, T. Science Mapping. In Encyclopedia of Information Science and Technology, 3rd ed.; IGI Global: Hershey, PA, USA, 2014; pp. 4171–4184. [Google Scholar] [CrossRef]
- Jarneving, B. Bibliographic coupling and its application to research-front and other core documents. J. Informetr. 2007, 1, 287–307. [Google Scholar] [CrossRef]
- Efron, N.; Brennan, N.A.; Nichols, J.J. Citation Analysis of the Contact Lens Field. Optom. Vis. Sci. 2012, 89, 70–79. [Google Scholar] [CrossRef]
- Osareh, F. Bibliometrics, Citation Analysis and Co-Citation Analysis: A Review of Literature I. Libri 1996, 46, 149–158. [Google Scholar] [CrossRef]
- Surwase, G.; Sagar, A.; Kademani, B.S.; Bhanumurthy, K. Co-citation Analysis: An Overview. In Proceedings of the Creativity, Innovation and Discovery BOSLA National Conference, Mumbai, India, 16–17 September 2011. [Google Scholar]
- Khaldi, H.; Prado-Gascó, V. Bibliometric maps and co-word analysis of the literature on international cooperation on migration. Qual. Quant. 2021, 55, 1845–1869. [Google Scholar] [CrossRef]
- Ponomariov, B.; Boardman, C. What is co-authorship? Scientometrics 2016, 109, 1939–1963. [Google Scholar] [CrossRef]
- Fatehi, F.; Hassandoust, F.; Ko, R.K.; Akhlaghpour, S. General data protection regulation (GDPR) in healthcare: Hot topics and research fronts. Stud. Health Technol. Inform. 2020, 270, 1118–1122. [Google Scholar] [CrossRef]
- Pintus, E.; Sorbolini, S.; Albera, A.; Gaspa, G.; DiMauro, C.; Steri, R.; Marras, G.; Macciotta, N.P.P. Use of locally weighted scatterplot smoothing (LOWESS) regression to study selection signatures in Piedmontese and Italian Brown cattle breeds. Anim. Genet. 2013, 45, 1–11. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, Y.; He, D.; Li, Y. Identification of Apple Leaf Diseases Based on Deep Convolutional Neural Networks. Symmetry 2018, 10, 11. [Google Scholar] [CrossRef]
- Dong, C.-Z.; Catbas, F.N. A review of computer vision–based structural health monitoring at local and global levels. Struct. Health Monit. 2021, 20, 692–743. [Google Scholar] [CrossRef]
- Zhang, X.; Han, L.; Dong, Y.; Shi, Y.; Huang, W.; Han, L.; González-Moreno, P.; Ma, H.; Ye, H.; Sobeih, T. A Deep Learning-Based Approach for Automated Yellow Rust Disease Detection from High-Resolution Hyperspectral UAV Images. Remote Sens. 2019, 11, 1554. [Google Scholar] [CrossRef]
- Zhong, Y.; Zhao, M. Research on deep learning in apple leaf disease recognition. Comput. Electron. Agric. 2020, 168, 105146. [Google Scholar] [CrossRef]
- Heimerl, F.; Lohmann, S.; Lange, S.; Ertl, T. Word Cloud Explorer: Text Analytics Based on Word Clouds. In Proceedings of the 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; IEEE: Waikoloa, HI, USA, 2014; pp. 1833–1842. [Google Scholar] [CrossRef]
- Scheibel, W.; Trapp, M.; Limberger, D.; Döllner, J. A taxonomy of treemap visualization techniques. In Proceedings of the 11th International Conference on Information Visualization Theory and Applications, Valetta, Malta, 27–29 February 2020; pp. 273–280. [Google Scholar] [CrossRef]
- Liu, X. Full-Text Citation Analysis: A New Method to Enhance. J. Am. Soc. Inf. Sci. Technol. 2013, 64, 1852–1863. [Google Scholar] [CrossRef]
- Kroonenberg, P.M.; Greenacre, M.J. Correspondence Analysis. In Encyclopedia of Statistical Sciences; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar] [CrossRef]
- Khangar, N.V.; Kamalja, K.K. Multiple Correspondence Analysis and its applications. Electron. J. Appl. Stat. Anal. 2017, 10, 432–462. [Google Scholar] [CrossRef]
- Briggs, D. An Introduction to Multidimensional Measurement using Rasch models. J. Appl. Meas. 2003, 4, 87–100. [Google Scholar] [PubMed]
- Forrest, D. Thematic Maps in Geography, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; Volume 23. [Google Scholar] [CrossRef]
- Weinberg, B.H. Bibliographic coupling: A review. Inf. Storage Retr. 1974, 10, 189–196. [Google Scholar] [CrossRef]
- Lewis, Y. Research collaborations bring big rewards: The world needs more. Nature 2021, 594, 301–302. [Google Scholar]
- Pranckutė, R. Web of Science (WoS) and Scopus: The Titans of Bibliographic Information in Today’s Academic World. Publications 2021, 9, 12. [Google Scholar] [CrossRef]
- Medhi, B.; Bansal, S.; Mahendiratta, S.; Kumar, S.; Sarma, P.; Prakash, A. Collaborative research in modern era: Need and challenges. Indian J. Pharmacol. 2019, 51, 137–139. [Google Scholar] [CrossRef] [PubMed]
- Geng, Y.; Zhu, R.; Maimaituerxun, M. Bibliometric review of carbon neutrality with CiteSpace: Evolution, trends, and framework. Environ. Sci. Pollut. Res. 2022, 29, 76668–76686. [Google Scholar] [CrossRef] [PubMed]
































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Results |
|---|---|
| MAIN INFORMATION ABOUT DATA | |
| Timespan | 2011:2022 |
| Sources (Journals, Books, etc) | 134 |
| Documents | 214 |
| Annual Growth Rate % | 50.08 |
| Document Average Age | 2.08 |
| Average citations per doc | 9.916 |
| References | 4127 |
| DOCUMENT CONTENTS | |
| Keywords Plus (ID) | 1114 |
| Author’s Keywords (DE) | 503 |
| AUTHORS | |
| Authors | 678 |
| Authors of single-authored docs | 5 |
| AUTHORS COLLABORATION | |
| Single-authored docs | 15 |
| Co-Authors per Doc | 4.32 |
| International co-authorships % | 14.02 |
| DOCUMENT TYPES | |
| Article | 67 |
| Book chapter | 5 |
| conference paper | 55 |
| conference review | 8 |
| data paper | 1 |
| Review | 3 |
| Year | N | MeanTCperArt | MeanTCperYear | CitableYears |
|---|---|---|---|---|
| 2011 | 1 | 1.00 | 0.09 | 11 |
| 2012 | 1 | 27.00 | 2.70 | 10 |
| 2013 | 0 | 0.00 | 0.00 | 0 |
| 2014 | 0 | 0.00 | 0.00 | 0 |
| 2015 | 0 | 0.00 | 0.00 | 0 |
| 2016 | 0 | 0.00 | 0.00 | 0 |
| 2017 | 2 | 41.00 | 8.20 | 5 |
| 2018 | 2 | 172.50 | 43.13 | 4 |
| 2019 | 14 | 54.36 | 18.12 | 3 |
| 2020 | 42 | 10.48 | 5.24 | 2 |
| 2021 | 62 | 5.63 | 5.63 | 1 |
| 2022 | 87 | 1.34 | 0 |
| Year | Lecture Notes in Networks and Systems | Frontiers in Plant Science | Computers and Electronics in Agriculture | Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) | Sensors | Ieee Access |
|---|---|---|---|---|---|---|
| 2011 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2012 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2013 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2014 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2015 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2016 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2017 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2018 | 0 | 0 | 0 | 1 | 0 | 0 |
| 2019 | 0 | 0 | 1 | 2 | 2 | 0 |
| 2020 | 0 | 1 | 2 | 3 | 2 | 0 |
| 2021 | 5 | 5 | 3 | 5 | 4 | 3 |
| 2022 | 12 | 10 | 6 | 6 | 5 | 5 |
| Country | Documents | Citations | Total Link Strength |
|---|---|---|---|
| China | 44 | 516 | 23 |
| India | 33 | 140 | 9 |
| United Kingdom | 8 | 106 | 12 |
| Pakistan | 5 | 15 | 5 |
| Saudi Arabia | 5 | 24 | 5 |
| Canada | 4 | 6 | 4 |
| Germany | 3 | 189 | 3 |
| South Korea | 3 | 31 | 2 |
| Egypt | 4 | 2 | 1 |
| Taiwan | 4 | 27 | 1 |
| United State | 9 | 123 | 1 |
| Australia | 3 | 13 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bonkra, A.; Bhatt, P.K.; Rosak-Szyrocka, J.; Muduli, K.; Pilař, L.; Kaur, A.; Chahal, N.; Rana, A.K. Apple Leave Disease Detection Using Collaborative ML/DL and Artificial Intelligence Methods: Scientometric Analysis. Int. J. Environ. Res. Public Health 2023, 20, 3222. https://doi.org/10.3390/ijerph20043222
Bonkra A, Bhatt PK, Rosak-Szyrocka J, Muduli K, Pilař L, Kaur A, Chahal N, Rana AK. Apple Leave Disease Detection Using Collaborative ML/DL and Artificial Intelligence Methods: Scientometric Analysis. International Journal of Environmental Research and Public Health. 2023; 20(4):3222. https://doi.org/10.3390/ijerph20043222
Chicago/Turabian StyleBonkra, Anupam, Pramod Kumar Bhatt, Joanna Rosak-Szyrocka, Kamalakanta Muduli, Ladislav Pilař, Amandeep Kaur, Nidhi Chahal, and Arun Kumar Rana. 2023. "Apple Leave Disease Detection Using Collaborative ML/DL and Artificial Intelligence Methods: Scientometric Analysis" International Journal of Environmental Research and Public Health 20, no. 4: 3222. https://doi.org/10.3390/ijerph20043222
APA StyleBonkra, A., Bhatt, P. K., Rosak-Szyrocka, J., Muduli, K., Pilař, L., Kaur, A., Chahal, N., & Rana, A. K. (2023). Apple Leave Disease Detection Using Collaborative ML/DL and Artificial Intelligence Methods: Scientometric Analysis. International Journal of Environmental Research and Public Health, 20(4), 3222. https://doi.org/10.3390/ijerph20043222