1. Introduction
The COVID-19 outbreak has severely affected countries all over the globe since December 2019. It had a tremendous impact on both society and the economy [
1,
2]. The COVID-19 epidemic became the main topic of news and research and gained a lot of attention from national and international media and researchers. A previous study on pandemic communication found that the content covered by the news media has a strong influence on how people seek information, evaluate it and make concerned decisions [
3,
4]. Indeed, in crises such as public health threats, news coverage is widely believed to have a significant impact on people’s perceptions and behavior [
5]. Since the advent of COVID-19, the number of postings about the disease has increased at a highly accelerated rate on Twitter, a popular social media platform for spreading and exchanging information. These tweets include posts by civilians and news agencies through their official Twitter accounts. Social media plays a key role in developing interest in particular topics, which could assist in addressing public concerns, increasing public satisfaction and facilitating the government’s implementation of COVID-19 prevention strategies. Based on the agenda-setting hypothesis, there is a significant link between media coverage of specific problems and public perception [
6]. Analysis of social media data helps in planning and understanding public sentiment. Machine learning classifiers, natural language processing, ensemble learning and sentiment analysis play a vital role in helping with this analysis and in useful information extraction [
7]. However, it is very difficult to determine whether various social media platforms provide vital information. This is due to several reasons, such as spelling mistakes, the use of abbreviations and semantic obscurity.
Sentiment analysis can be used to analyze data from social media sites such as blogs, wikis, micro-blogging and other online platforms [
8]. It is a type of emotional computing that classifies the text into positive, negative and neutral categories. This analysis also helps in the recognition of feelings in Twitter data (tweets). This paper analyses sentiments shared through tweets during the COVID-19 pandemic, specifically for the healthcare sector. The purpose of this study is to examine people’s reactions toward the pandemic using different machine learning algorithms and to warn society about people’s mixed opinions. The tweets are extracted by considering three prompt areas of discussion on social media in COVID-19 situations. These three areas are the COVID-19 vaccine, post-COVID-19health factors and healthcare services.
1.1. Healthcare
1.1.1. The COVID-19 Vaccine
The most debated topic on social media after the release of the COVID-19 vaccines were how they work and their consequences [
9]. As per the details available from the Centers for Disease Control (CDC), various vaccines have been approved for COVID-19 [
10,
11]. Some of the approved vaccines are Pfizer BioNTech, Covid-shield, Covaxin and Moderna. Many people have tweeted their opinions about these vaccines [
12]. Some discuss the pros and cons of vaccines after learning about their efficacy. People from different countries have different opinions about vaccination drives. In India, the first drive of COVID-19 vaccination started on 16 January 2021, with the Covid-shield and Covaxin vaccines.
1.1.2. Post-COVID-19 Health Factors
People who had mild or severe symptoms of COVID-19 recovered quickly and with fewer complications [
13], while patients with severe symptoms experienced a hard and long recovery, with most experiencing weakness, psychological and physiological disorders and fatigue [
14]. As per a telephone survey conducted by the World Health Organization (WHO), around 20% of the people in the age group between 18 and 34 have protracted symptoms [
15].
1.1.3. Healthcare Service Providers
Healthcare service providers and workers, especially providers in direct contact with COVID-19 patients, have played a leading role in the pandemic and put their lives at risk, [
16]. Sometimes, the front-line fighters deal with a variety of public assaults as well as physiological problems. They also must often cope with a lack of resources. People were expressing their opinions about the healthcare service providers during this crisis, and they were also utilizing social media to motivate frontline healthcare staff.
1.2. Contribution
The key contribution of this work is to
(1) Extract real-time Twitter data from healthcare sub-domains (COVID-19 vaccine, post-COVID-19 health factors and healthcare service providers) and use machine learning techniques to analyse and identify social media users’ narratives.
(2) Classification of users’ perceptions in the COVID-19 pandemic concerning three healthcare sub-domains: COVID-19 vaccine, post-COVID-19 health factors, and healthcare service providers with ML techniques. The purpose of this study is to understand how people are reacting to these queries and generate inferences.
2. Literature Survey
Diversified information is available in the literature based on the type of event and goal of the study. Sentiment analysis and effective computing is a field that helps in collecting public perceptions on political activities, commercial efforts, health crises and a wide range of other social events using social media platforms [
17]. The continuous advancement in the field of artificial intelligence (AI) is the key to effective computing and sentiment analysis and has potential to analyze sentiments through huge data sets [
18]. COVID-19 pandemic Twitter data analysis and swine flu Twitter data analysis were presented in articles [
19] and [
20], respectively.
A total of 242,525 healthcare tweets were collected from five Saudi Arabian areas and analyzed using K nearest neighbor, support vector machine (SVM) and naive Bayes algorithms [
21]. The study [
22] presented an analysis of 1,400,000 tweets by utilizing TF-IDF based correlation and latent Dirichlet allocation to identify key features and explore the interesting conclusions. A classification model based on clustering, TClustVID is presented in [
23], in which data was drawn from the IEEE data repository. ML algorithms, such as SVM, Poisson, negative binomial and naive Bayes models are used to determine political opinions [
24].
Many researchers presented different DL algorithms such as convolutional neural networks (CNN, recurrent neural networks (RNN) and long short-term memory (LSTM) [
25,
26] for analyzing different data. COVID-19 spread analysis using Twitter data considering travel history, age, gender and type of communication is presented in [
27,
28].
Table 1 shows some noteworthy contributions related to COVID-19 pandemic sentiment analysis. The table describes the data collection strategy, purpose, methods used, results and limitations. After the extensive literature survey, it was noted that a lot of research has been conducted on Twitter data analysis by applying different ML algorithms, even for the healthcare sector, but these works presented Twitter data analysis by considering generalized keywords such as COVID-19, corona virus, lockdown, health, etc. However, different sub-domains of the healthcare sector during the COVID-19 pandemic still need attention.
Existing work related to sentiment analysis as presented in
Table 1 shows that the Twitter data were collected through common keywords during the COVID-19 pandemic. However, the analysis by considering a specific domain such as the healthcare domain, which this article is emphasizing, was untouched until now. Our objective is to analyze people’s sentiments for the healthcare domain and for specific queries such as ‘COVID-19 vaccine’, ‘post-Covid health factors’ and ‘Healthcare service providers’.
3. Data and Methods
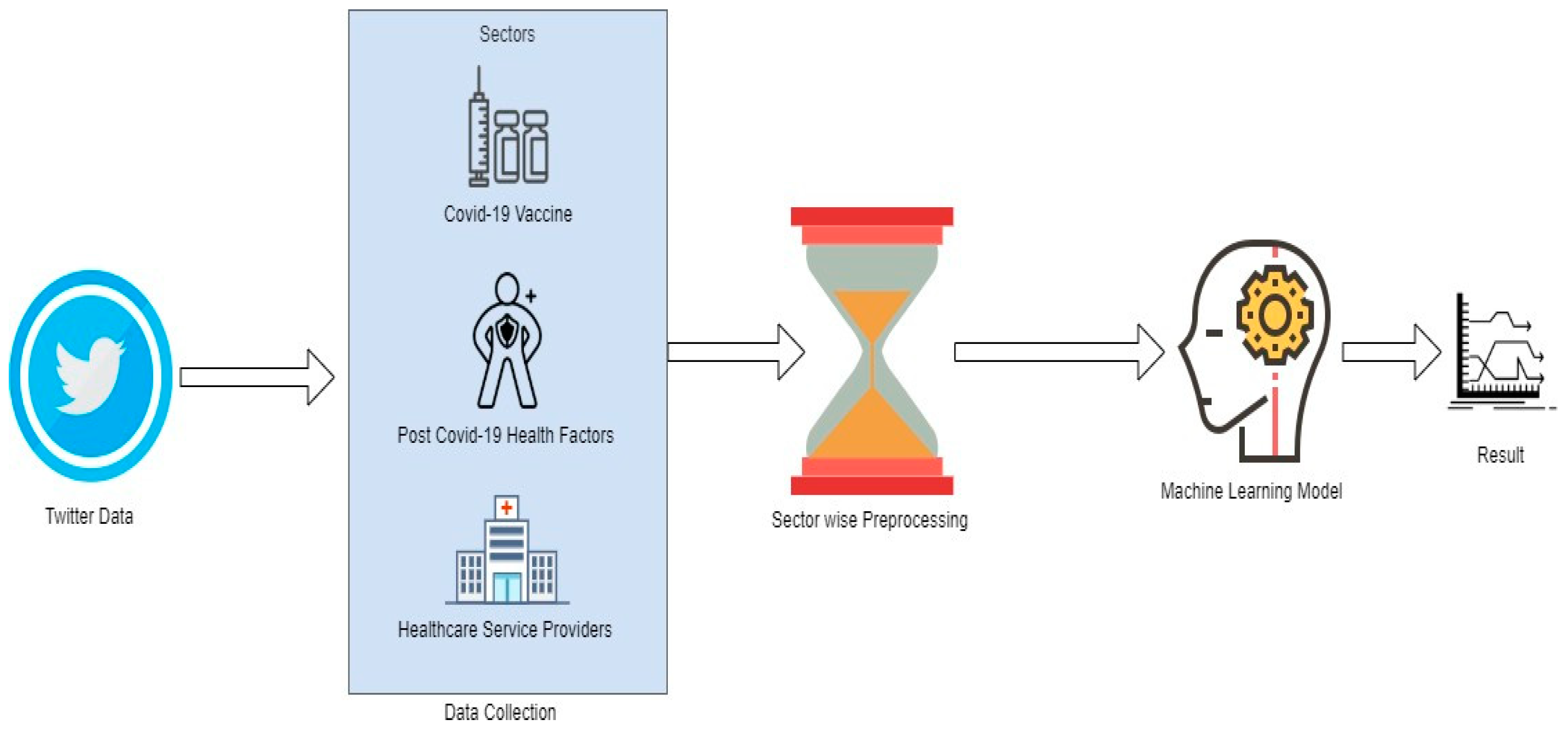
The methodology in the paper starts with collecting related tweets and extends to pre-processing for each considered query, which includes data cleaning, transformation and applying ML techniques for sentiment analysis and classification to infer the people’s opinions, as shown in
Figure 1. Classification techniques used are SVM, logistic regression (LR), multinomial naive Bayes (MNB), random forest (RF) and long short-term memory (LSTM). These multiple techniques will help in selecting the best fit model based on various performance matrices [
36,
37].
3.1. Data Collection
Data collection was conducted using the Twitter API, which requires the creation of a Twitter developer account in order to extract tweets. Token keys, API keys and secret keys are generated by a developer account so that the authorization procedure may be completed for collecting real time tweets. The Twitter data was retrieved using the Python library tweepy. The data was extracted for terms related to people’s opinions on the healthcare domain in COVID-19 scenarios, with a focus on vaccines, post-Covid health factors and healthcare service providers. The searched sample tweets are shown in
Table 2. The number of tweets considered for each query was 10,000.
Table 3 shows the date range for each query. While collecting the tweets, we set the criteria that at least one tweet should be longer than 50 characters and in the English language only.
3.2. Sectorwise Preprocessing
This section describes the preparation of the data as required by the ML models as seen in
Figure 2. Tokenizing the tweets into a series of words, phrases or paragraphs was the first step. The next step was lemmatization, by which the root words were derived, which helped in finding the real meaning of words that have been used in tweets. Especially with social media data, it is essential to take care of the exact meaning of sentiments while calculating and vectorizing the sentiment values.
3.2.1. Sentiment Calculation
The transformation of social media textual information into numerical information involves a calculative approach. Determining the attitude or the emotion of users, whether it is positive, negative or neutral requires a mathematical calculation. The Text-Blob package was used in the process of extracting the numerical sentiment values, which are float types and range from [−1, 1]. Text-blob, Vedar and Flair are three sentiment analyzers and perform wellin terms of accuracy of sentiment calculation. Text-blob was selected here for its good speed and accuracy [
38].
3.2.2. Sentiment Polarity Classification
After sentiment value calculations, the next step was to classify tweets into the categories shown in the pseudo code. The value provided by the Text-Blob package was used to determine the polarity classification. Here, we used three sentiment classifications, which included negative, neutral and positive. Each tweet’s polarity was determined by a score, which implies that if the score is greater than zero, the polarity categorization is positive; if it is equal to zero, it is neutral, and if it is less than zero, it is negative.
Pseudo code for Polarity Classification
| Start |
| Loop from i = 1 to number of tweets |
|
Calculate tweet Text polarity using TextBlob |
|
If polarity is greater than zero |
|
Tweet Text Sentiment = positive |
|
Else if polarity is less than zero |
|
Tweet Text Sentiment[i] = negative |
|
Else |
|
Tweet Text Sentiment[i] = neutral |
| End |
3.3. Machine Learning Models
3.3.1. Support Vector Machine (SVM)
SVM is a vector-based learning system that is administered. In order to classify the data, vectors are drawn on the space. Hyper planes are used to draw conclusions and classify the data points by keeping the various classes of the data as far apart as possible. The machine is trained and hyper planes are generated using labelled data points. When completely new datasets are given, the machine quickly segregates them into one of the available classes. SVMs are applied in practice using a kernel. The capability to comprehend the hyper plane is achieved through linear algebra. It employs the inner product of supplied data instead of the observations themselves. Obtaining the sum of the products of each pair of input values yields the inner product. For example, the inner product of input vectors (a, b) and (c, d) is a*c + b*d, where a, b, c and dare symbolic vectors representations. The dot product of input and support vector, which is derived using the subsequent equation, is used to anticipate the inputs:
The input data’s inner product is computed using all of the data’s support vectors, and the coefficients of and (for input values) must be determined using a learning technique while training. SVMs are less likely to over-fit and generalize better than other classifiers with more ability to fit the training data. SVM has many text classification applications and is suitable for Twitter data analysis.
3.3.2. Logistic Regression (LR)
Logistic regression is a supervised classification approach that categorizes individuals into groups using a logistic function. For a given collection of features (or inputs), X; the target variable (or output), Y can only take discrete values. Logistic regression, contrary to popular assumption, is a regression model. The model creates a regression model to forecast the likelihood that a given data entry belongs to the “1” category. The sigmoid function is commonly employed as a logistic function, since it has the property of rising swiftly and exceeding the carrying capacity of the environment. The LR model detects a vector of variables in text classification and then calculates the coefficients for each input variable. The probability scale is constantly between 0 (never happens) and 1 (happens). In the case of binary classification, the likelihood of testing positive and not testing positive will equal 1. In logistic regression, the logistic function or sigmoid function is used to calculate probability. The logistic function is a basic S-shaped curve that converts input into a number between 0 and 1.
is the output, where , is the slope, is the y intercept, and x is the independent variable.
3.3.3. Random Forest (RF)
Random forest is a technique for machine learning that can be used to solve problems involving regression and classification. It implements ensemble learning, a technique for solving complex problems by combining several classification algorithms. The random forest approach is made up of many decision trees. Bagging and/or bootstrapping clustering are used to train the random forest strategy’s ‘forest’. Bagging is a meta-algorithm that enhances the efficiency of machine learning algorithms by combining them. The outcome is determined by the random forest classifier, which is dependent on the decision tree forecasting. It makes forecasts by averaging the output of different trees. As the number of trees increases, so does the accuracy of the outcome. The disadvantage of the decision tree algorithms is overcome by the random forest method. It reduces dataset over-fitting and improves precision. The random forest method is capable of accurately classifying massive volumes of data and is suitable for tweet classification.
3.3.4. Multinomial Naïve Bayes (MNB)
The multinomial naïve Bayes procedure is a popular probabilistic learning method in the area of natural language processing (NLP). The naïve Bayes classifier is composed of several algorithms, all of which share one point in common: each feature is classified unrelated to any other feature. The presence or absence of one feature has no direct effect on the absence or presence of any other feature. The naïve Bayes classifier is a group of probabilistic schemes that are based on the Bayes’ principle and the naïve concept of conditional independence across each pair of features and is able to predict tags from a text, which may be an email, any news or a tweet. The tagging of text is performedon a probability basis from a sample; the tag with the highest probability is selected. It considers a feature vector, which stores the frequency of appearance of a term. The probability
is calculated by the Bayes theorem in which the probable outcomes class is
c, and
x is the delivered case to be recognized, which represents some specific characteristics.
Naïve Bayes predicts a text’s tag. It calculates search tag’s probability for a given text and outputs the tag with the highest probability.
3.3.5. Long Short-Term Memory (LSTM)
Recurrent neural networks (RNN) are one of the most widely used algorithms for sequential data, and they learn from past experience. The major problem with RNN is the long-term dependency, also known as the “vanishing gradient problem”, which means it does not perform well when working with vast amounts of data. LSTM has been introduced for taking care of long dependency problems, which helps in dealing with long textual data very accurately. This is the reason LSTM could be the best model to analyze social media data effectively. It is a particular category of recurrent neural network that is capable of learning long-term data relationships. The model’s recurring module makes it possible because it has up to four interconnected layers. An LSTM module consists of a cell state and three gates, allowing it to selectively comprehend, unlearn or recall information from each unit. In LSTM, the cell state allows information to pass through units without being affected by some linear interactions. Each unit has an input, an output and a forget gate, which adds or subtracts data from the cell state. A sigmoid function is employed by the forget gate to evaluate whether the information from the earlier cell state should be overlooked. To regulate the information flow into the latest cell state, the input gate performs a point-wise multiplication of ‘sigmoid’ and ‘tanh’. Finally, the gate in output decides which data to transfer to the next concealed state.
3.3.6. Experimental Work
Python3 Libraries such asnumpy, scipy, scikit-learn, keras, pandas, nltk, tweepy, matplotlib, etc. were used to build a predictive model and sentiment identification using ML models. The parameters used for different models are:
SVM:
loss function = ‘squared_hinge’
max_iteration = 1000
LR:
solver = ‘lbfgs’,
max_iter = 1000
RF:
n_estimators = 100,
criterion = ‘gini’
MNB:
alpha (smoothing parameter) = 1.0
LSTM:
Loss = ‘categorical_crossentropy’,
Optimizer = ‘adam’
activation function = ‘softmax’
The remaining parameters for all models were kept on their default values.
3.4. Performance Evaluation Matrix
Classifier accuracy is measured with the help of a confusion matrix. This matrix provides the number of right and wrong predictions by comparing actual target values. It consists of four parameters: (1) true positive (TP): shows how many actual true values the model predicted as true; (2) true negative (TN): shows how many actual false values the model predicted as false; (3) false positive (FP): shows how many actual false values are predicted as true; and (4) false negative (FN): shows how many actual true values are predicted as false.
3.4.1. Accuracy
Accuracy shows the percentage of right predictions. The formula for accuracy calculation is presented in Equation (4),
3.4.2. Precision
This attribute shows how regularly a model predicts a true positive. Low values for this parameter show large numbers of false positives. The formula for computing precision is presented in Equation (5),
3.4.3. Recall
Accuracy does not provide the information about FP and FN. In some cases, values of FN and FP are substantial. Recall and F1 score show a very significant role in these cases. Recall shows information regarding false negative predictions. Lower values of the recall parameter mean a large number of false negatives. The formula for Recall is presented in Equation (6),
3.4.4. F1 Score
This parameter is obtained by combining recall and precision. A high value of recall shows a low number of false negatives and false positives. Equation (7) present formulas for the F1 score,
4. Results
4.1. Word Cloud Visualization
Visualization provides a deeper understanding of data and the types of information that may be extracted from them. We depicted the word clouds using the Python3 NLTK library to investigate the various types of terms tweeted by users and visualize the frequently occurring words for all considered domains.
Figure 3a–c show word clouds visualization for COVID-19 vaccine, post-Covid health factors and healthcare service providers, respectively. Each figure contains word clouds for three sentiments which are positive, negative and neutral.
Figure 3a shows that the most frequently used words for the ‘COVID-19 vaccine’ query for positive sentiments were ‘dose’, ‘first’, ‘available’, ‘appointment’ ‘slots’, ‘clinic’, etc.; frequently used words for negative sentiments were ‘world’, ‘day’, ‘dose’, ‘India’, ‘still’, ‘kids’, ‘vaccine’, ‘people’, etc.; and frequently used words for neutral sentiments were ‘slots’, ‘Covid’, ‘may’, ‘vaccinated’, etc. The words ‘please’, ‘first’, right were available only in the positive sentiment word cloud, while the words ‘wrong’, sick, death were present only in the negative sentiment word cloud.
Figure 3b shows the that most frequently used words for ‘the post-Covid health factors’ query for positive sentiments were ‘Covid pandemic’, ‘support’, ‘metal health’, ‘impact’, ‘report’, ‘young’, ‘people’, etc.; frequently used words for negative sentiments were ‘mental health’, ‘long-term’, ‘impact’, ‘student’, ‘research’, ‘Covid lockdown’, etc.; and frequently used words for neutral sentiments were ‘health’, ‘education’, ‘mental health’, ‘health outcome’, ‘discuss’, ‘healthcare’, ‘impact’, etc. The words ‘study’, ‘school’, ‘work’, ‘join’ were present only in the word cloud of positive sentiments, while the word ‘long-term’ was present only in the word cloud of negative sentiment.
Figure 3c shows that the most frequently used words for ‘healthcare service provider’ query for positive sentiments were ‘care’, ‘service’, ‘home’, ‘need’, ‘destroy’, ‘provider’, ‘right’, etc.; for negative sentiments were ‘mental health’, ‘patient’, ‘fraud’, ‘medical taxes’, ‘care’, ‘government’, etc.; and for neutral sentiments were ‘health outcome’, ‘response’, ‘healthcare’, ‘service’, ‘home’, ‘largest owner’, ‘feeds’, ‘million’, etc. The words ‘right’ and ‘provider’ were present only in the word cloud of positive sentiments, while the word ‘medical taxes’ was present only in the word cloud of negative sentiment.
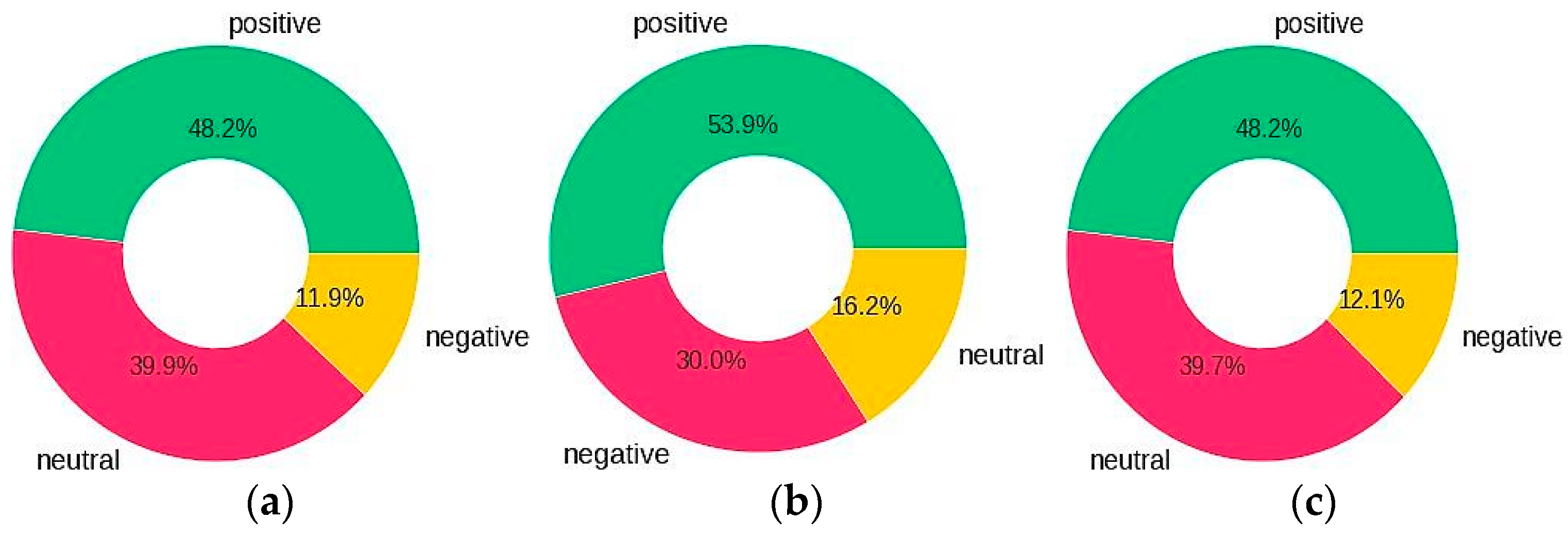
4.2. Tweets Polarity and Percentage
Figure 4a–c show the percentage of polarity of tweets after sentiment labelling for all domains for the COVID-19 vaccine, post-Covid health factors and healthcare service provider queries, respectively. By exploring the sentiments for all queries, the results show that for the ‘COVID-19 vaccine’ query, 48.2%, 11.9% and 39.9% of the tweets people shared were classified as positive, negative and neutral sentiments, respectively. For the ‘post-Covid health factors’ query, 48.2%, 12.1% and 39.7% of the tweets people shared were classified as positive, negative and neutral sentiments, respectively. For ‘health care service providers’ query, 53.8%, 16.2% and 30.0% were positive, negative and neutral sentiments, respectively.
The results present assessment with the employed five ML models: SVM, LR, RF, MNB and LSTM. We divided the collected data into training (75% of data) and test sets (25% of data) to evaluate the models. The outcomes of all algorithms considered were evaluated using F1 score, precision, recall and accuracy (for the test sets).
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8 show the value of these parameters for SVM, LR, RF, MNB and LSTM, respectively.
5. Discussion
The goal of this work is to extract tweets from healthcare sub-domains around the world and assess sentiments during the COVID-19 pandemic. COVID-19 has had a devastating impact on individuals, both directly and indirectly. Affected individuals have shared their health related experiences on social media platforms. A flood of data is continuously being produced as a result of COVID-19’s continued effect. Analyzing this enormous volume of data using conventional statistical methods is difficult.
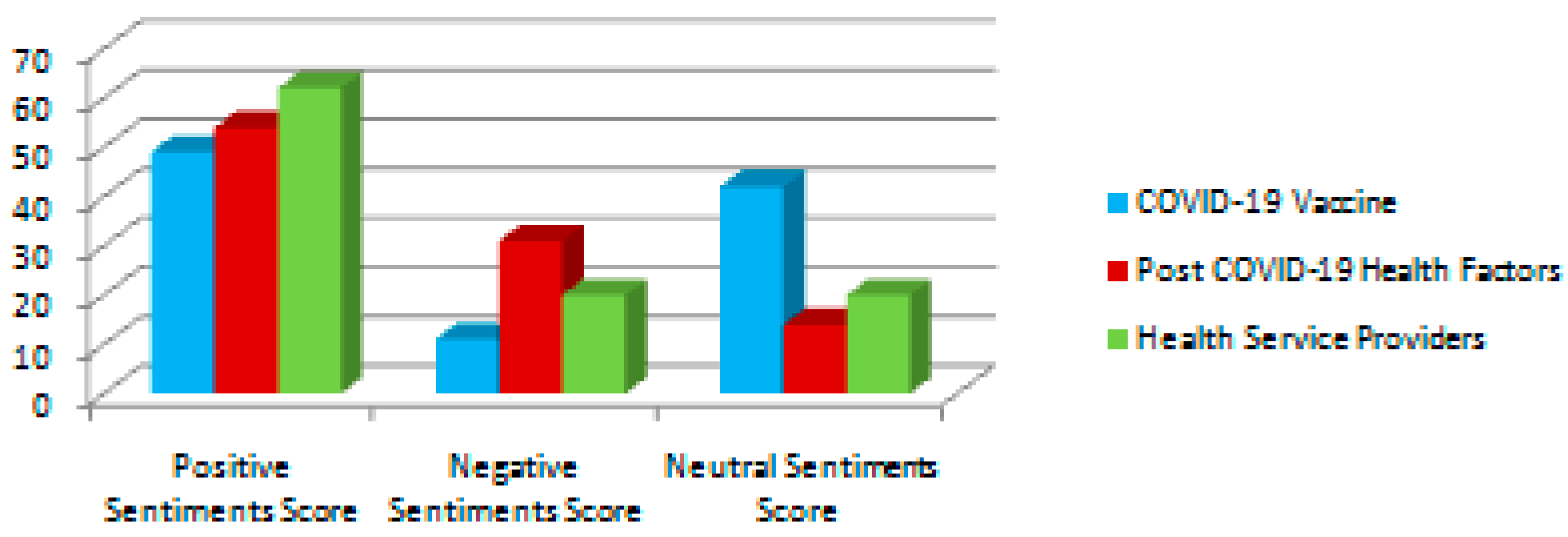
Figure 5 shows the comparison of the sentiment percentage of each query. It depicts that the most positive sentiments were collected for the ‘healthcare service provider’ query, which leads to the inference that people are very happy with the healthcare service providers. They appreciate the efforts and hard work of doctors, nurses, hospital management and government support services. The query ‘Post-Covid health factor’ received the most negative sentiments, indicating that people experienced numerous negative post-Covid issues.
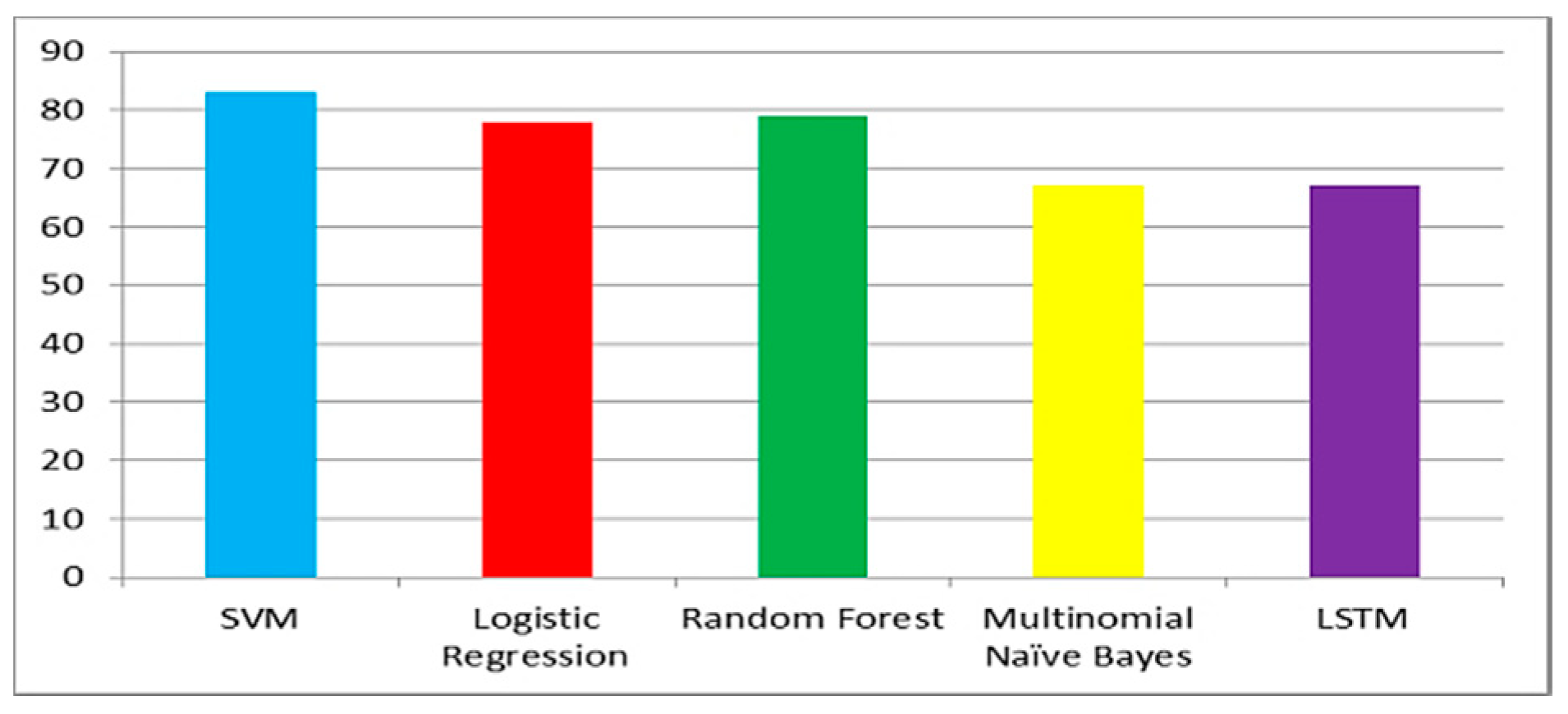
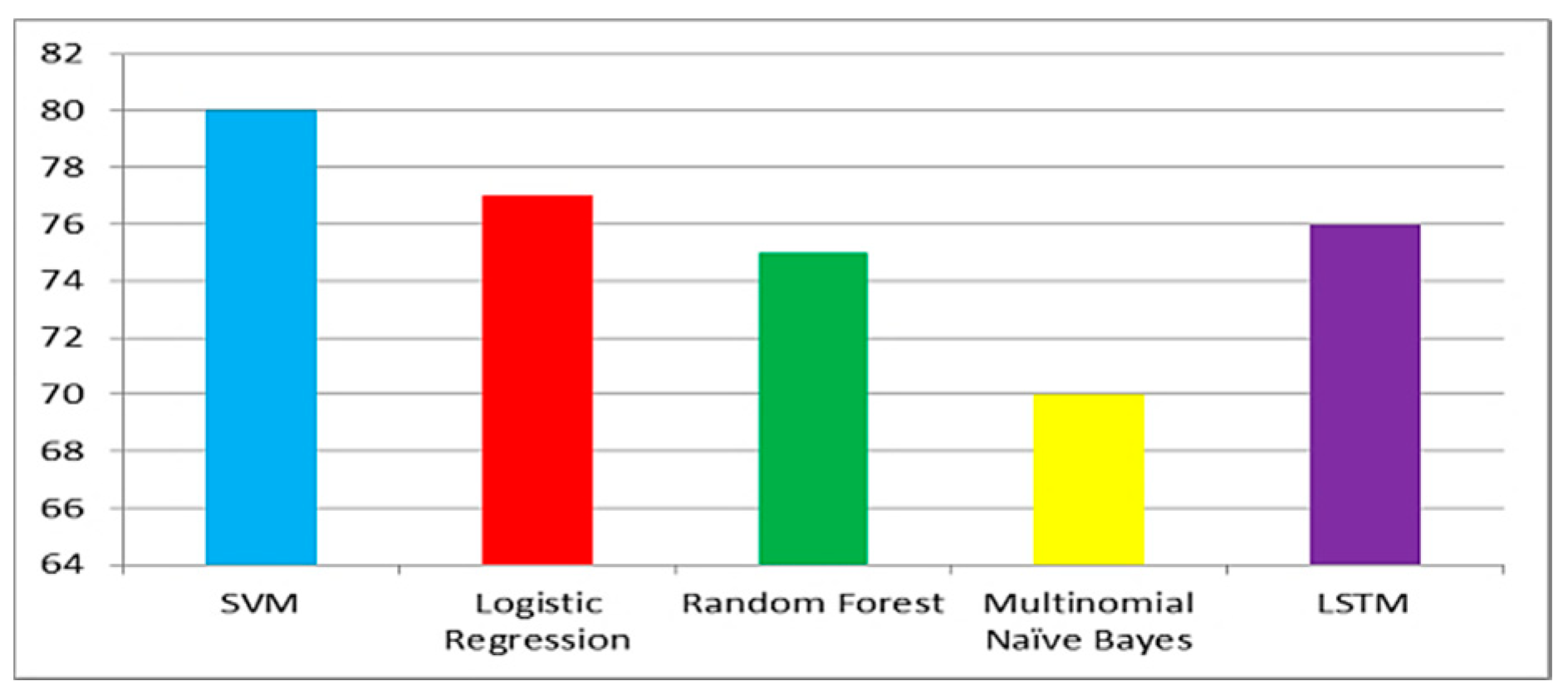
Figure 6,
Figure 7 and
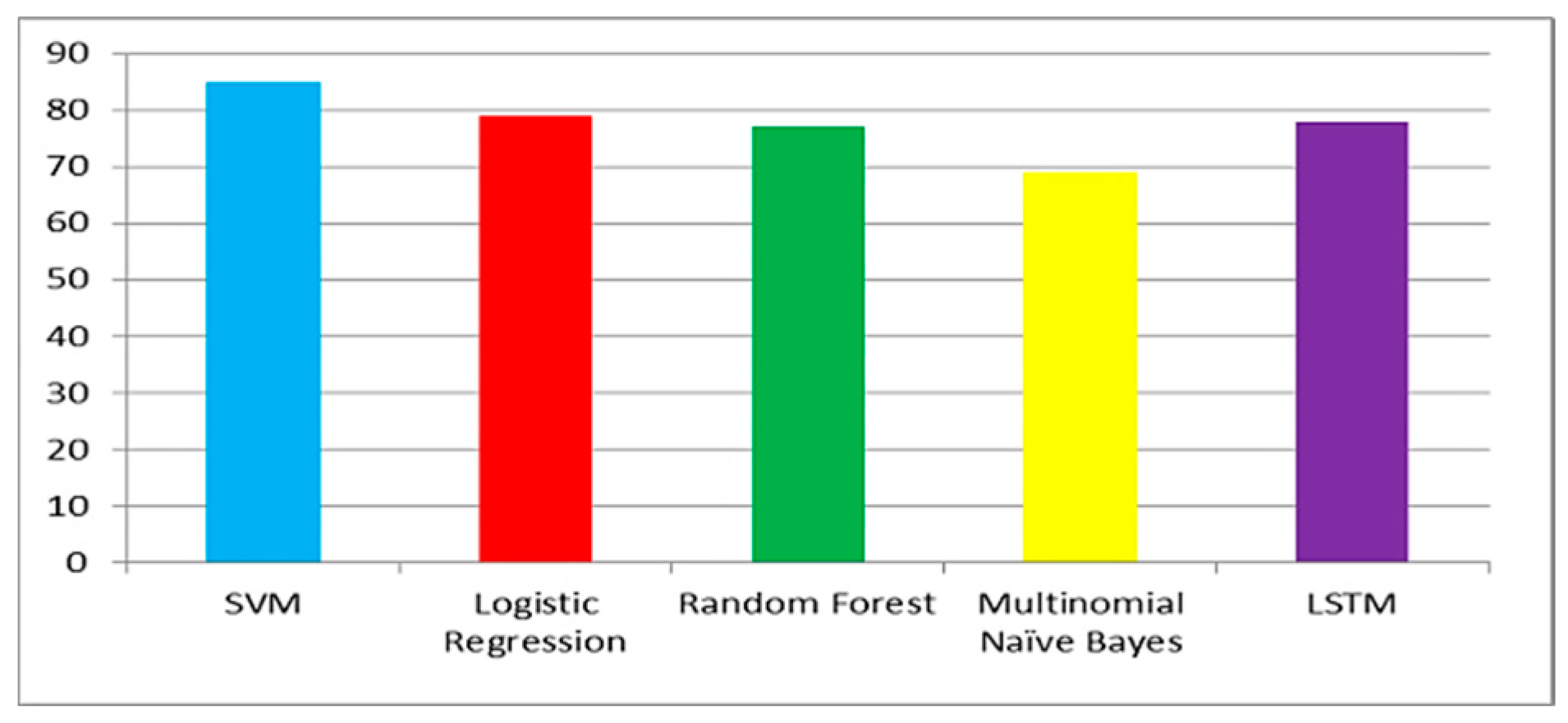
Figure 8 show the accuracy comparison of all considered ML models for each query. Prediction accuracy values calculated by SVM, LR, RF, MNB and LSTM for ‘COVID-19 vaccine’ query are 85%, 79%, 77%, 69% and 78%, respectively. Prediction accuracy values calculated by SVM, LR, RF, MNB and LSTM for ‘post-Covid health factors’ query are 83%, 78%, 79%, 67% and 71%, respectively. Prediction accuracy values calculated by SVM, LR, RF, MNB and LSTM for ‘healthcare service providers’ query are 80%, 77%, 75%, 70% and 76% respectively. These results indicate that SVM provided the highest accuracy for all queries when compared with the other considered models.
Different kinds of performance metrics give us a clear idea of how to deal with large and imbalanced datasets. It is very difficult to manage Twitter data because of the imbalanced ratio of positive, negative and neutral tweets. Apart from accuracy, we tested the F1 score as well and found that for the ‘COVID-19 vaccine’ query, the highest scores for negative sentiments, neutral sentiments and positive sentiments were 0.54, 0.88 and 0.89, respectively, and they were achieved through SVM. The maximum F1 score obtained for positive sentiments was 0.89.The highest values of F1 scores for the ‘post-Covid health factors’ query for negative sentiments, neutral sentiments and positive sentiments were 0.8, 0.74 and 0.87, respectively, and were achieved through SVM. For positive sentiments, the maximum F1 score obtained was 0.87.The highest values of F1 scores for the ‘healthcare service provider’ query for negative sentiments, neutral sentiments and positive sentiments were 0.61, 0.87 and 0.74, respectively, and were achieved through SVM. For positive sentiments, the maximum F1 score obtained was 0.87.
In all queries, the maximum F1 score was achieved through SVM for positive sentiments, which implies that there are very few false positives and false negatives predicted by SVM for positive sentiments. In future, more Tweets can be extracted to assess the impact of pandemics in other domains such as, education, economy, food industry, tours and travel industry and disaster management. The novel machine learning approaches such asmeta-heuristic-algorithm-based tuning; the ensemble approach and hybrid modes can be utilized for sentiment predictions in different domains.
6. Conclusions
Social media platforms serve as a forum for people to express themselves and their ideas. Policymakers may benefit from an examination of these ideas. The novelty of this work is the sentiment analysis on the basis of a specific domain query, which is healthcare. For the case of the COVID-19 pandemic, we selected Twitter data from three sub-domains of healthcare: COVID-19 vaccine, post-Covid health factors and healthcare service providers, for analysis. Analysis was conducted through sentiment visualization and ML procedures.
The practical application of sentiment analysis lies in the decision solutions to handle the pandemic situations more effectively. The correct analysis of sentiments will help in protecting emotional health of people during the pandemic.
Sentiment visualization is offered using the aid of word clouds, pi-charts and bar charts. These visualization tools depict that maximum positive sentiments were collected for the query ‘healthcare service provider’, while the maximum negative sentiments were collected for the query ‘post-Covid health factors’. The ML algorithms considered in this work are SVM, LR, RF, MNB and LSTM. The accuracy, precision, recall and F1 score of all machine learning algorithms were determined. SVM achieved the maximum F1 score, precision, recall and accuracy, which were 0.89 (for positive sentiment tweets), 0.92 (for neutral sentiment tweets) and 0.85 (for negative sentiment tweets), respectively, for the COVID-19 vaccine query.
Author Contributions
Conceptualization, S.A. and A.K.; methodology, S.K.J. and A.K.; software, S.A. and A.K.; validation, S.A., S.K.J. and A.K.; formal analysis, S.S., A.K. and S.K.J.; investigation, S.A.; resources, S.A. and S.S.; data curation, A.K.; writing—original draft, S.A., S.S. and S.K.J.; writing—review and editing, S.A., S.S. and S.K.J.; visualization, A.K.; supervision, S.A.; project administration, S.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Iwendi, C.; Bashir, A.K.; Peshkar, A.; Sujatha, R.; Chatterjee, J.M.; Pasupuleti, S.; Mishra, R.; Pillai, S.; Jo, O. COVID-19 Patient Health Prediction Using Boosted Random Forest Algorithm. Front. Public Health 2020, 8, 357. [Google Scholar] [CrossRef] [PubMed]
- Aslam, B.; Javed, A.R.; Chakraborty, C.; Nebhen, J.; Raqib, S.; Rizwan, M. Blockchain and ANFIS Empowered IoMT Application for Privacy Preserved Contact Tracing in COVID-19 Pandemic. Pers. Ubiquitous Comput. 2021, 22, 1–17. [Google Scholar] [CrossRef] [PubMed]
- An, S. How Do the News Media Frame Crises? A Content Analysis of Crisis News Coverage. Rev. Elsevier 2009, 35, 107–112. [Google Scholar] [CrossRef]
- Ayoub, A.; Mahboob, K.; Javed, A.R.; Rizwan, M.; Gadekallu, T.R.; Abidi, M.H.; Alkahtani, M. Classification and Categorization of COVID-19 Outbreak in Pakistan. Comput. Mater. Contin. 2021, 69, 1253–1269. [Google Scholar] [CrossRef]
- Jianqiang, Z.; Xiaolin, G. Comparison research on text pre-processing methods on twitter sentiment analysis. IEEE Access 2017, 5, 2870–2879. [Google Scholar] [CrossRef]
- Cinelli, M.; Quattrociocchi, W.; Galeazzi, A.; Valensise, C.M.; Brugnoli, E.; Schmidt, A.L.; Zola, P.; Zollo, F.; Scala, A. The COVID-19 social media infodemi. Sci. Rep. 2020, 10, 16598. [Google Scholar] [CrossRef] [PubMed]
- Onan, A.; Korukoğlu, S.; Bulut, H. Ensemble of Keyword Extraction Methods and Classifiers in Text Classification. Expert Syst. Appl. 2016, 57, 232–247. [Google Scholar] [CrossRef]
- Dragoni, M.; Poria, S.; Cambria, E. OntoSenticNet: A commonsense ontology for sentiment analysis. IEEE Intell. Syst. 2018, 33, 77–85. [Google Scholar] [CrossRef]
- Chadwick, A.; Kaiser, J.; Vaccari, C.; Freeman, D.; Lambe, S.; Loe, B.S.; Vanderslott, S.; Lewandowsky, S.; Conroy, M.; Ross, A.R.; et al. Online social endorsement and Covid-19 vaccine hesitancy in the United Kingdom. Soc. Media Soc. 2021, 7, 20563051211008817. [Google Scholar] [CrossRef]
- MacDonald, N.E. Vaccine hesitancy: Definition, scope and determinants. Vaccine 2015, 33, 4161–4164. [Google Scholar] [CrossRef]
- Cascini, F.; Pantovic, A.; Al-Ajlouni, Y.; Failla, G.; Ricciardi, W. Attitudes, acceptance and hesitancy among the general population worldwide to receive the COVID-19 vaccines and their contributing factors: A systematic review. Eclinicalmed. 2021, 40, 101113. [Google Scholar] [CrossRef] [PubMed]
- Mishra, R.; Urolagin, S.; Jothi, J.A.A. Sentiment Analysis for Poi Recommender Systems. In Proceedings of the Seventh International Conference on Information Technology Trends (ITT), Abu Dhabi, United Arab Emirates, 25–26 November 2020; pp. 174–179. [Google Scholar] [CrossRef]
- Munblit, D.; Nicholson, T.R.; Needham, D.M.; Seylanova, N.; Parr, C.; Chen, J.; Kokorina, A.; Sigfrid, L.; Buonsenso, D.; Bhatnagar, S.; et al. Studying the post-COVID-19 condition: Research challenges, strategies, and importance of Core Outcome Set development. BMC Med. 2022, 20, 50. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Leon, S.; Wegman-Ostrosky, T.; Perelman, C.; Sepulveda, R.; Rebolledo, P.A.; Cuapio, A.; Villapol, S. More than 50 long-term effects of COVID-19: A systematic review and meta-analysis. Sci. Rep. 2021, 11, 16144. [Google Scholar] [CrossRef]
- What Are the Long-Term Effects of Coronavirus (COVID-19)? Available online: https://www.medicalnewstoday.com/articles/long-term-effects-of-coronavirus (accessed on 22 June 2021).
- Morshed, S.A.; Khan, S.S.; Tanvir, R.B.; Nur, S. Impact of COVID-19 Pandemic on Ride-Hailing Services Based on Large-Scale Twitter Data Analysis. J. Urban Manag. 2021, 10, 155–165. [Google Scholar] [CrossRef]
- Onan, A. Sentiment Analysis on Product Reviews Based on Weighted Word Embeddings and Deep Neural Networks. Wiley Online Libr. 2020, 33, e5909. [Google Scholar] [CrossRef]
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Kaila, D.P.; Prasad, D.A. Informational Flow on Twitter–Corona Virus Outbreak–Topic Modelling Approach. Int. J. Adv. Res. Eng. Technol. 2020, 11, 128–134. [Google Scholar]
- Szomszor, M.; Kostkovaand, P.; Louis, C.S. Twitter Informatics: Tracking and Understanding Public Reaction during the 2009 Swine Flu Pandemic. ieeexplore.ieee.org. In Proceedings of the IEEE WIC ACM International Conference on Web Intelligence (WI), Lyon, France, 22–27 August 2011. [Google Scholar]
- Aljameel, S.S.; Alabbad, D.A.; Alzahrani, N.A.; Alqarni, S.M.; Alamoudi, F.A.; Babili, L.M.; Aljaafary, S.K.; Alshamrani, F.M. A Sentiment Analysis Approach to Predict an Individual’s Awareness of the Precautionary Procedures to Prevent COVID-19 Outbreaks in Saudi Arabia. Int. J. Environ. Res. Public Health 2021, 18, 218. [Google Scholar] [CrossRef]
- Alomari, E.; Katib, I.; Albeshri, A.; Mehmood, R. COVID-19: Detecting government pandemic measures and public concerns from Twitter arabic data using distributed machine learning. Int. J. Environ. Res. Public Health 2021, 18, 282. [Google Scholar] [CrossRef]
- Behl, S.; Rao, A.; Aggarwal, S.; Chadha, S.; Pannu, H.S. Twitter for disaster relief through sentiment analysis for COVID-19 and natural hazard crises. Int. J. Disaster Risk Reduct. 2021, 55, 102101. [Google Scholar] [CrossRef]
- Hasan, A.; Moin, S.; Karim, A.; Shamshirband, S. Machine learning-based sentiment analysis for twitter accounts. Math. Comput. Appl. 2018, 23, 11. [Google Scholar] [CrossRef]
- Khatri, A.; Agrawal, S.; Chatterjee, J.M. Wheat Seed Classification: Utilizing Ensemble Machine Learning Approach. Sci. Program. 2022, 2022, 2626868. [Google Scholar] [CrossRef]
- Agrawal, M.; Agrawal, S. A Systematic Review on Artificial Intelligence/Deep Learning Applications and Challenges to battle against COVID-19 Pandemic. Disaster Adv. 2021, 14, 90–99. [Google Scholar] [CrossRef]
- Bhatnagar, V.; Poonia, R.C.; Nagar, P.; Kumar, S.; Singh, V.; Raja, L.; Dass, P. Descriptive analysis of COVID-19 patients in the context of India. J. Interdiscip. Math. 2021, 24, 489–504. [Google Scholar] [CrossRef]
- Jalil, Z.; Abbasi, A.; Javed, A.R.; Khan, M.B.; Hasanat, M.H.A.; Malik, K.M.; Saudagar, A.K.J. Covid-19 related sentiment analysis using state-of-the-art machine learning and deep learning techniques. Front. Public Health 2021, 9, 812735. [Google Scholar] [CrossRef]
- Barkur, G.; Kamath, G.B. Sentiment analysis of nationwide lockdown due to COVID 19 outbreak: Evidence from India. Asian J. Psychiatr. 2020, 51, 102089. [Google Scholar] [CrossRef] [PubMed]
- Samuel, J.; Ali, G.M.N.; Rahman, M.M.; Esawi, E.; Samuel, Y. COVID-19 public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep sentiment classification and topic discovery on novel coronavirus or COVID-19 online discussions: NLP using LSTM recurrent neural network approach. IEEE J. Biomed. Health Inform. 2020, 24, 2733–2742. [Google Scholar] [CrossRef]
- Manguri, K.H.; Ramadhan, R.N.; Amin, P.R.M. Twitter sentiment analysis on worldwide COVID-19 outbreaks. Kurd. J. Appl. Res. 2020, 5, 54–65. [Google Scholar] [CrossRef]
- Arpaci, I.; Alshehabi, S.; Al-Emran, M.; Khasawneh, M.; Mahariq, I.; Abdeljawad, T.; Hassanien, A.E. Analysis of twitter data using evolutionary clustering during the COVID-19 pandemic. Comput. Mater. Contin. 2020, 65, 193–204. [Google Scholar] [CrossRef]
- Yousefinaghani, S.; Dara, R.; Mubareka, S.; Papadopoulos, A.; Sharif, S. An analysis of COVID-19 vaccine sentiments and opinions on Twitter. Int. J. Infect. Dis. 2021, 108, 256–262. [Google Scholar] [CrossRef] [PubMed]
- Sarker, A.; Lakamana, S.; Hogg-Bremer, W.; Xie, A.; Al-Garadi, M.A.; Yang, Y.C. Self-reported COVID-19 symptoms on Twitter: An analysis and a research resource. J. Am. Med. Inform. Assoc. 2020, 27, 1310–1315. [Google Scholar] [CrossRef] [PubMed]
- Pandya, V.; Somthankar, A.; Shrivastava, S.S.; Patil, M. December. Twitter Sentiment Analysis Using Machine Learning and Deep Learning Techniques. In Proceedings of the 2021 2nd International Conference on Communication, Computing and Industry 4.0 (C2I4), CMR Institute of Technology, Bengaluru, India, 16–17 December 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for COVID-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef] [PubMed]
- Sentamilselvan, K.; Suresh, P.; Kamalam, G.K.; Mahendran, S.; Aneri, D. Detection on sarcasm using machine learning classifiers and rule based approach. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2021; Volume 1055. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}