
Predictive Models for Forecasting Public Health Scenarios: Practical Experiences Applied during the First Wave of the COVID-19 Pandemic

 ,
,  ,
,  , , and
, , and
Abstract
:1. Introduction
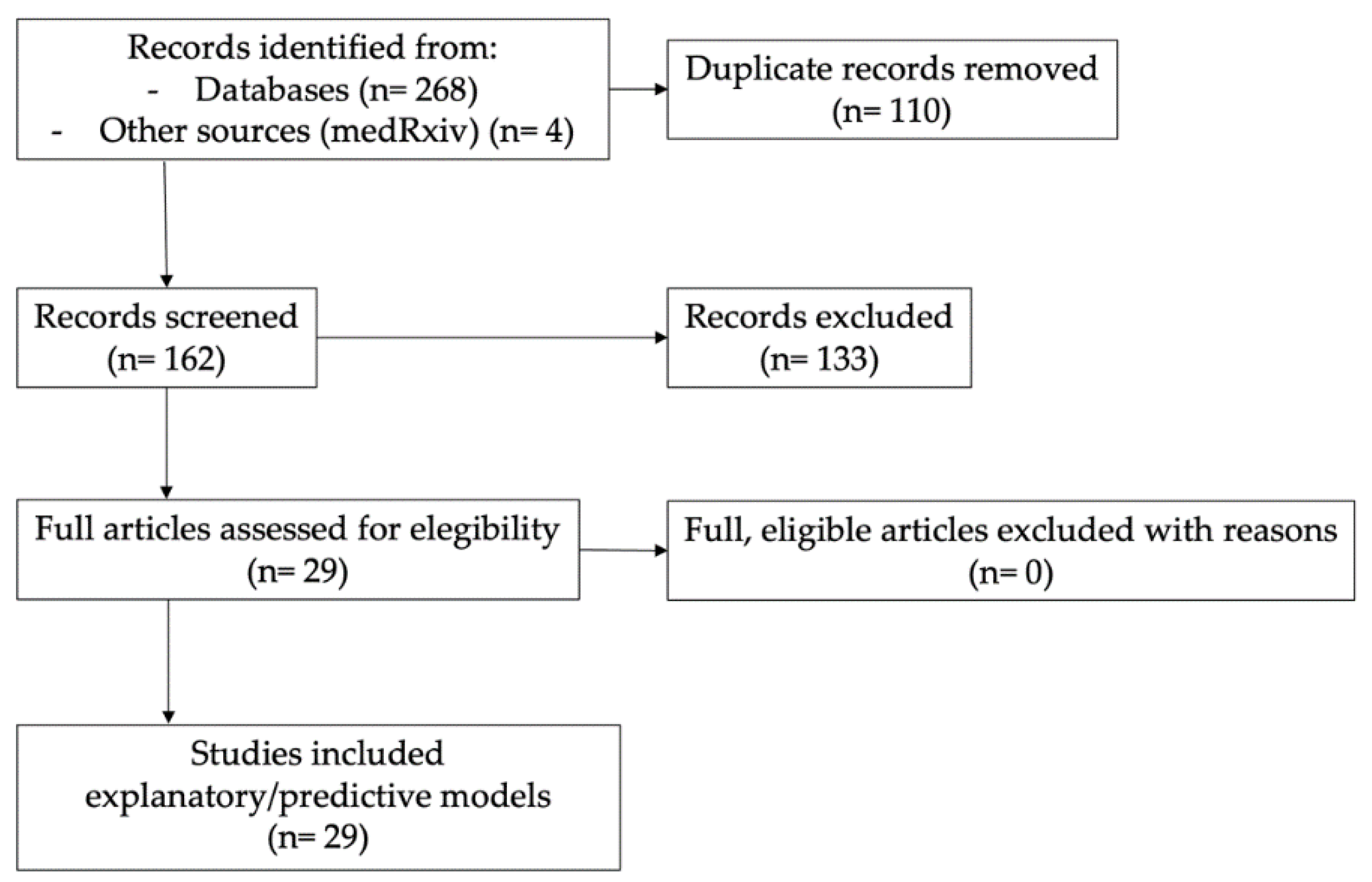
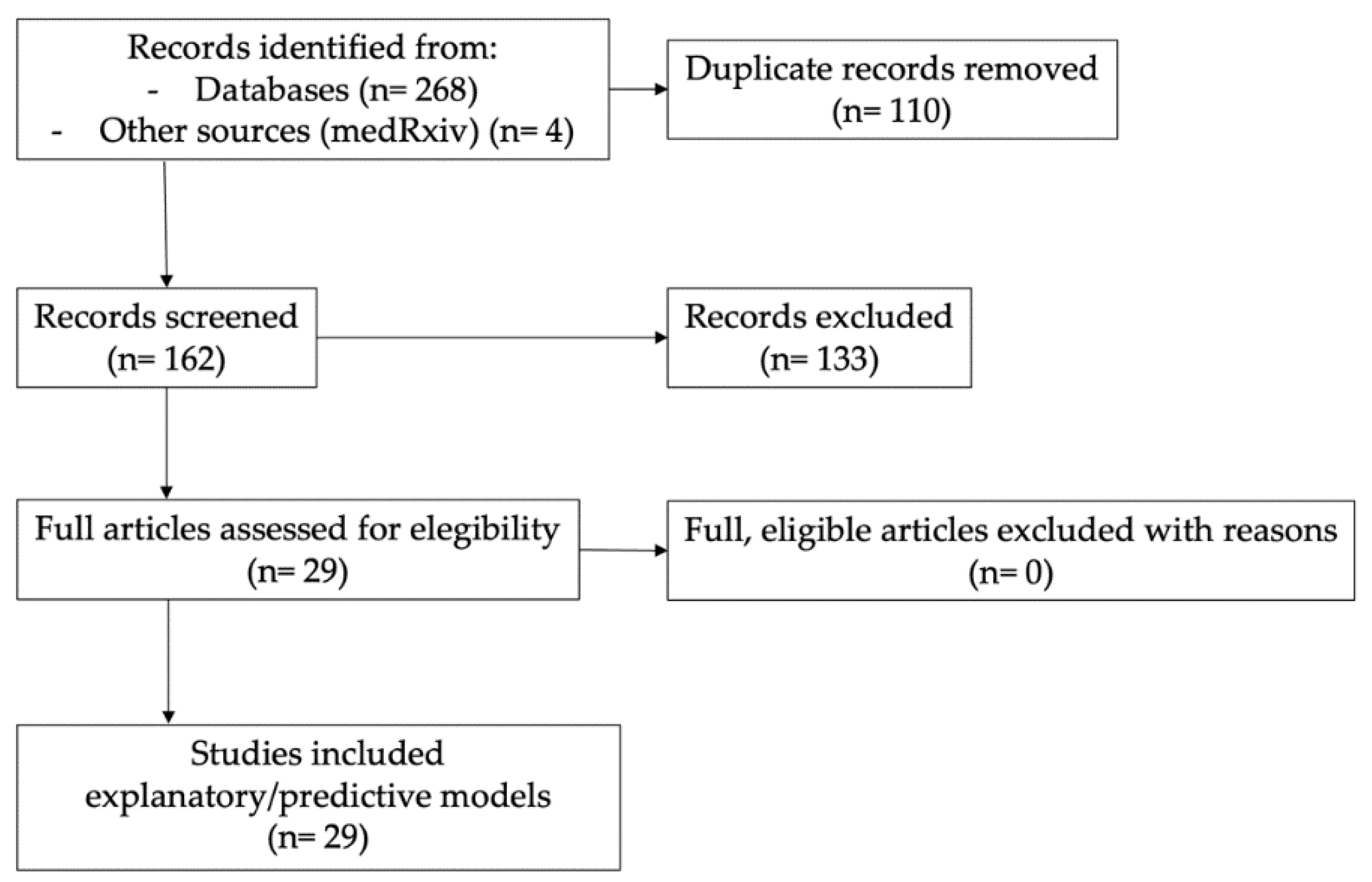
2. Materials and Methods
3. Results
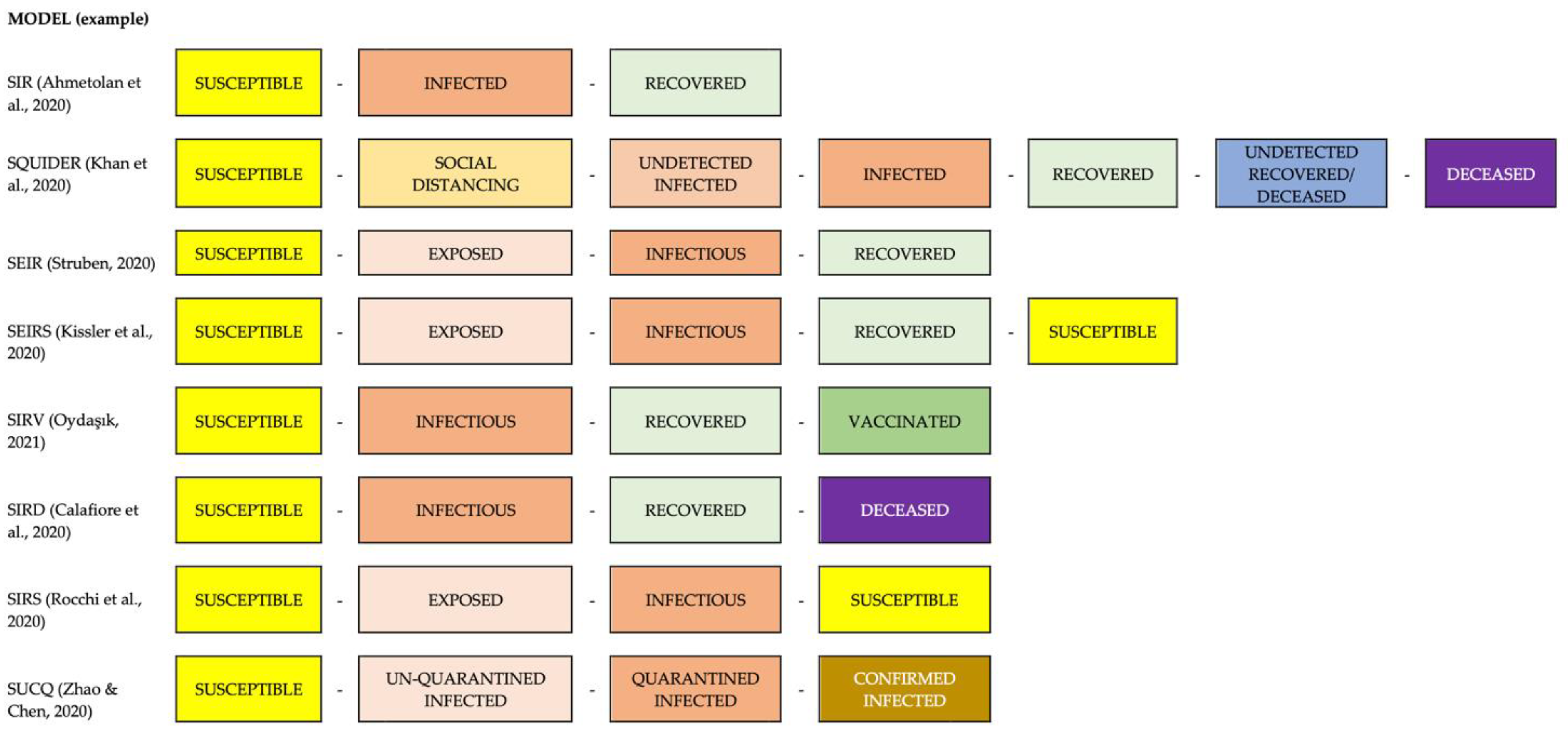
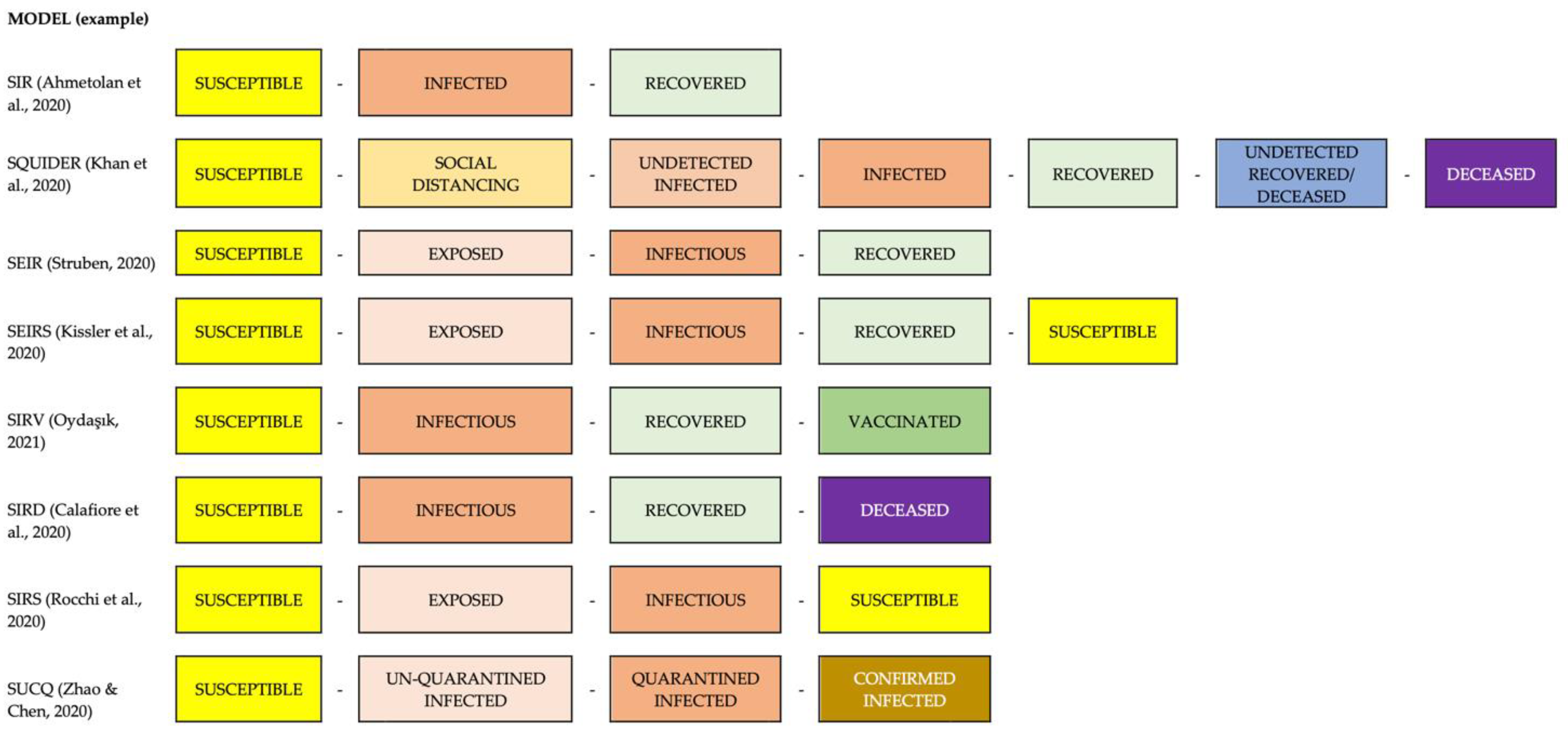
3.1. Standard Epidemiological Models
3.1.1. SIR (Susceptible-Infected-Recovered) Model
3.1.2. SQUIDER Model
3.1.3. SEIR Model
3.1.4. Time-Dependent SIR Model
3.1.5. Other Proposed Models
3.2. Data-Driven Models
3.2.1. Autoregressive-Integrated Moving Average (ARIMA) Models
3.2.2. Machine learning (ML)
3.2.3. Genetic Evolutionary Programming (GEP) Model
3.2.4. Long Short-Term Memory (LSTM) Model
3.2.5. Global Epidemic and Mobility (GLEM) Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Search Strategy
- Filters: Clinical Trial, Controlled Clinical Trial, Meta-Analysis, Pragmatic Clinical Trial, Randomized Controlled Trial, Systematic Review.
- Sort by: Publication Date
- Search details: ((“COVID-19”[All Fields] OR “COVID-19”[MeSH Terms] OR “COVID-19 vaccines”[All Fields] OR “COVID-19 vaccines”[MeSH Terms] OR “COVID-19 serotherapy”[All Fields] OR “COVID-19 serotherapy”[Supplementary Concept] OR “COVID-19 nucleic acid testing”[All Fields] OR “COVID-19 nucleic acid testing”[MeSH Terms] OR “COVID-19 serological testing”[All Fields] OR “COVID-19 serological testing”[MeSH Terms] OR “COVID-19 testing”[All Fields] OR “COVID-19 testing”[MeSH Terms] OR “SARS-CoV-2”[All Fields] OR “SARS-CoV-2”[MeSH Terms] OR “severe acute respiratory syndrome coronavirus 2”[All Fields] OR “ncov”[All Fields] OR “2019 ncov”[All Fields] OR ((“coronavirus”[MeSH Terms] OR “coronavirus”[All Fields] OR “cov”[All Fields]) AND 2019/11/01:3000/12/31[Date—Publication])) AND (((“predict”[All Fields] OR “predictabilities”[All Fields] OR “predictability”[All Fields] OR “predictable”[All Fields] OR “predictably”[All Fields] OR “predicted”[All Fields] OR “predicting”[All Fields] OR “prediction”[All Fields] OR “predictions”[All Fields] OR “predictive”[All Fields] OR “predictively”[All Fields] OR “predictiveness”[All Fields] OR “predictivities”[All Fields] OR “predictivity”[All Fields] OR “predicts”[All Fields]) AND (“model”[All Fields] OR “model s”[All Fields] OR “modeled”[All Fields] OR “modeler”[All Fields] OR “modeler s”[All Fields] OR “modelers”[All Fields] OR “modeling”[All Fields] OR “modelings”[All Fields] OR “modelization”[All Fields] OR “modelizations”[All Fields] OR “modelize”[All Fields] OR “modelized”[All Fields] OR “modelled”[All Fields] OR “modeller”[All Fields] OR “modellers”[All Fields] OR “modelling”[All Fields] OR “modellings”[All Fields] OR “models”[All Fields])) OR (“explanatory”[All Fields] AND (“model”[All Fields] OR “model s”[All Fields] OR “modeled”[All Fields] OR “modeler”[All Fields] OR “modeler s”[All Fields] OR “modelers”[All Fields] OR “modeling”[All Fields] OR “modelings”[All Fields] OR “modelization”[All Fields] OR “modelizations”[All Fields] OR “modelize”[All Fields] OR “modelized”[All Fields] OR “modelled”[All Fields] OR “modeller”[All Fields] OR “modellers”[All Fields] OR “modelling”[All Fields] OR “modellings”[All Fields] OR “models”[All Fields])))) AND (clinicaltrial[Filter] OR controlledclinicaltrial[Filter] OR meta-analysis[Filter] OR pragmaticclinicaltrial[Filter] OR randomizedcontrolledtrial[Filter] OR systematicreview[Filter])
- COVID-19: (“COVID-19” OR “COVID-19”[MeSH Terms] OR “COVID-19 Vaccines” OR “COVID-19 Vaccines”[MeSH Terms] OR “COVID-19 serotherapy” OR “COVID-19 serotherapy”[Supplementary Concept] OR “COVID-19 Nucleic Acid Testing” OR “COVID-19 nucleic acid testing”[MeSH Terms] OR “COVID-19 Serological Testing” OR “COVID-19 serological testing”[MeSH Terms] OR “COVID-19 Testing” OR “COVID-19 testing”[MeSH Terms] OR “SARS-CoV-2” OR “SARS-CoV-2”[MeSH Terms] OR “Severe Acute Respiratory Syndrome Coronavirus 2” OR “NCOV” OR “2019 NCOV” OR ((“coronavirus”[MeSH Terms] OR “coronavirus” OR “COV”) AND 2019/11/01[PDAT]: 3000/12/31[PDAT]))
- Predictive: “predict”[All Fields] OR “predictabilities”[All Fields] OR “predictability”[All Fields] OR “predictable”[All Fields] OR “predictably”[All Fields] OR “predicted”[All Fields] OR “predicting”[All Fields] OR “prediction”[All Fields] OR “predictions”[All Fields] OR “predictive”[All Fields] OR “predictively”[All Fields] OR “predictiveness”[All Fields] OR “predictives”[All Fields] OR “predictivities”[All Fields] OR “predictivity”[All Fields] OR “predicts”[All Fields]
- Models: “model”[All Fields] OR “model’s”[All Fields] OR “modeled”[All Fields] OR “modeler”[All Fields] OR “modeler’s”[All Fields] OR “modelers”[All Fields] OR “modeling”[All Fields] OR “modelings”[All Fields] OR “modelization”[All Fields] OR “modelizations”[All Fields] OR “modelize”[All Fields] OR “modelized”[All Fields] OR “modelled”[All Fields] OR “modeller”[All Fields] OR “modellers”[All Fields] OR “modelling”[All Fields] OR “modellings”[All Fields] OR “models”[All Fields]
References
- Siettos, C.I.; Russo, L. Mathematical modeling of infectious disease dynamics. Virulence 2013, 4, 295–306. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ares, S.; Manrubia, S. Prediction of the COVID-19 Epidemic Dynamics. COVID-19 Project National Center for Biotechnology (CNB)-CSIC. Available online: https://pti-saludglobal-covid19.corp.csic.es/en/prediction-of-the-covid-19-epidemic-dynamics/ (accessed on 11 March 2022).
- Feng, D.; Yan, Z.; Ostergaard, J.; Xu, Z.; Gan, D.; Zhong, J.; Zhang, N.; Dai, T. Simulation embedded artificial intelligence search method for supplier trading portfolio decision. IET Gener. Transm. Distrib. 2010, 4, 221. [Google Scholar] [CrossRef] [Green Version]
- Zhu, N.; Zhang, D.; Wang, W.; Li, X.; Yang, B.; Song, J.; Zhao, X.; Huang, B.; Shi, W.; Lu, R.; et al. A Novel Coronavirus from Patients with Pneumonia in China, 2019. N. Engl. J. Med. 2020, 382, 727–733. [Google Scholar] [CrossRef] [PubMed]
- Sanders, J.M.; Monogue, M.L.; Jodlowski, T.Z.; Cutrell, J.B. Pharmacologic Treatments for Coronavirus Disease 2019 (COVID-19): A Review. JAMA 2020, 323, 1824–1836. [Google Scholar] [CrossRef] [PubMed]
- Singhal, T. A Review of Coronavirus Disease-2019 (COVID-19). Indian J. Pediatr. 2020, 87, 281–286. [Google Scholar] [CrossRef] [Green Version]
- Scrivano, N.; Gulino, R.A.; Giansanti, D. Digital Contact Tracing and COVID-19: Design, Deployment, and Current Use in Italy. Healthcare 2021, 10, 67. [Google Scholar] [CrossRef]
- Sainani, K.L. Explanatory versus predictive modeling. PM R 2014, 6, 841–844. [Google Scholar] [CrossRef]
- Findl, J.; Suárez, J. Descriptive understanding and prediction in COVID-19 modelling. Hist. Philos. Life Sci. 2021, 43, 107. [Google Scholar] [CrossRef]
- Fanelli, D.; Piazza, F. Analysis and forecast of COVID-19 spreading in China, Italy and France. Chaos Solitons Fractals 2020, 134, 109761. [Google Scholar] [CrossRef]
- Shakeel, S.M.; Kumar, N.S.; Madalli, P.P.; Srinivasaiah, R.; Swamy, D.R. COVID-19 prediction models: A systematic literature review. Osong Public Health Res. Perspect. 2021, 12, 215–229. [Google Scholar] [CrossRef]
- Barceló, M.A.; Saez, M. Methodological limitations in studies assessing the effects of environmental and socioeconomic variables on the spread of COVID-19: A systematic review. Environ. Sci. Eur. 2021, 33, 108. [Google Scholar] [CrossRef] [PubMed]
- Salgotra, R.; Gandomi, M.; Gandomi, A.H. Time Series Analysis and Forecast of the COVID-19 Pandemic in India using Genetic Programming. Chaos Solitons Fractals 2020, 138, 109945. [Google Scholar] [CrossRef] [PubMed]
- Bartlett, M.S. Measles Periodicity and Community Size. J. R. Stat. Soc. Ser. A 1957, 120, 48. [Google Scholar] [CrossRef]
- Srivastav, A.K.; Stollenwerk, N.; Aguiar, M. Deterministic and Stochastic Dynamics of COVID-19: The Case Study of Italy and Spain. Comput. Math. Methods 2022, 2022, 5780719. [Google Scholar] [CrossRef]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. The PRISMA 2020 statement: An updated guideline for reporting systematic reviews. PLoS Med. 2021, 18, e1003583. [Google Scholar] [CrossRef]
- Shankar, S.; Mohakuda, S.S.; Kumar, A.; Nazneen, P.S.; Yadav, A.K.; Chatterjee, K.; Chatterjee, K. Systematic review of predictive mathematical models of COVID-19 epidemic. Med. J. Armed Forces India 2021, 77, S385–S392. [Google Scholar] [CrossRef]
- Ahmetolan, S.; Bilge, A.H.; Demirci, A.; Peker-Dobie, A.; Ergonul, O. What Can We Estimate From Fatality and Infectious Case Data Using the Susceptible-Infected-Removed (SIR) Model? A Case Study of Covid-19 Pandemic. Front. Med. 2020, 7, 556366. [Google Scholar] [CrossRef]
- Khan, Z.S.; Van Bussel, F.; Hussain, F. A predictive model for COVID-19 spread—With application to eight US states and how to end the pandemic. Epidemiol. Infect. 2020, 148, e249. [Google Scholar] [CrossRef]
- Struben, J. The coronavirus disease (COVID-19) pandemic: Simulation-based assessment of outbreak responses and postpeak strategies. Syst. Dyn. Rev. 2020, 36, 247–293. Available online: http://www.ncbi.nlm.nih.gov/pubmed/33041496 (accessed on 19 March 2022). [CrossRef]
- Kissler, S.M.; Tedijanto, C.; Goldstein, E.; Grad, Y.H.; Lipsitch, M. Projecting the transmission dynamics of SARS-CoV-2 through the postpandemic period. Science 2020, 368, 860–868. [Google Scholar] [CrossRef]
- Oydaşık, Ç. SIRV Model on Covid-19: An Analysis on the Implementation of Vaccination to an Epidemiological Model—Student Theses Faculty of Science and Engineering. 2021. Available online: https://fse.studenttheses.ub.rug.nl/24912/ (accessed on 11 April 2022).
- Calafiore, G.C.; Novara, C.; Possieri, C. A Modified SIR Model for the COVID-19 Contagion in Italy. In Proceedings of the 2020 59th IEEE Conference on Decision and Control (CDC), Jeju Island, Korea, 14–18 December 2020; pp. 3889–3894. [Google Scholar] [CrossRef]
- Rocchi, E.; Peluso, S.; Sisti, D.; Carletti, M. A Possible Scenario for the Covid-19 Epidemic, Based on the SI(R) Model. SN Compr. Clin. Med. 2020, 2, 501–503. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Chen, H. Modeling the epidemic dynamics and control of COVID-19 outbreak in China. Quant. Biol. 2020, 8, 11–19. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weiss Sir Ronald Ross, H. The SIR model and the Foundations of Public Health. Mater. MATemàtics Vol. 2013, 17, 1097–1887. [Google Scholar]
- Kermack, W.O.; Mckendrick, A.G. A Contribution to the Mathematical Theory of Epidemics. Proc. R. Soc. Lond. Ser. A Contain. Pap. Math. Phys. Charact. 1927, 115, 700–721. [Google Scholar]
- Acemoglu, D.; Chernozhukov, V.; Werning, I.; Whinston, M.D. Optimal targeted lockdowns in a multigroup SIR model. Am. Econ. Rev. Insights 2021, 3, 487–502. [Google Scholar] [CrossRef]
- Kudryashov, N.A.; Chmykhov, M.A.; Vigdorowitsch, M. Analytical features of the SIR model and their applications to COVID-19. Appl. Math. Model. 2021, 90, 466–473. [Google Scholar] [CrossRef]
- Cooper, I.; Mondal, A.; Antonopoulos, C.G. A SIR model assumption for the spread of COVID-19 in different communities. Chaos Solitons Fractals 2020, 139, 110057. [Google Scholar] [CrossRef]
- Hauser, A.; Counotte, M.J.; Margossian, C.C.; Konstantinoudis, G.; Low, N.; Althaus, C.L.; Riou, J. Estimation of SARS-CoV-2 mortality during the early stages of an epidemic: A modeling study in Hubei, China, and six regions in Europe. PLoS Med. 2020, 17, e1003189. [Google Scholar] [CrossRef]
- Parham, P.E.; Michael, E. Outbreak properties of epidemic models: The roles of temporal forcing and stochasticity on pathogen invasion dynamics. J. Theor. Biol. 2011, 271, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Kuniya, T. Prediction of the Epidemic Peak of Coronavirus Disease in Japan, 2020. J. Clin. Med. 2020, 9, 789. [Google Scholar] [CrossRef] [Green Version]
- Lovelace, B.J.; Higgins-Dunn, N. “False Hope” Coronavirus will Disappear in Summer like Flu, WHO Says. Available online: https://www.cnbc.com/2020/03/06/its-a-false-hope-coronavirus-will-disappear-in-the-summer-like-the-flu-who-says.html (accessed on 11 March 2022).
- Chen, Y.C.; Lu, P.E.; Chang, C.S.; Liu, T.H. A Time-Dependent SIR Model for COVID-19 with Undetectable Infected Persons. IEEE Trans. Netw. Sci. Eng. 2020, 7, 3279–3294. [Google Scholar] [CrossRef]
- Bjørnstad, O.N.; Shea, K.; Krzywinski, M.; Altman, N. The SEIRS model for infectious disease dynamics. Nat. Methods 2020, 17, 557–558. [Google Scholar] [CrossRef] [PubMed]
- Venkatasen, M.; Mathivanan, S.K.; Jayagopal, P.; Mani, P.; Rajendran, S.; Subramaniam, U.; Ramalingam, A.C.; Rajasekaran, V.A.; Indirajithu, A.; Sorakaya Somanathan, M. Forecasting of the SARS-CoV-2 epidemic in India using SIR model, flatten curve and herd immunity. J. Ambient Intell. Humaniz. Comput. 2020, 1–9. Available online: https://link.springer.com/article/10.1007/s12652-020-02641-4 (accessed on 19 March 2022). [CrossRef] [PubMed]
- Akhmetzhanov, A.R.; Mizumoto, K.; Jung, S.-M.; Linton, N.M.; Omori, R.; Nishiura, H. Estimation of the Actual Incidence of Coronavirus Disease (COVID-19) in Emergent Hotspots: The Example of Hokkaido, Japan during February-March 2020. J. Clin. Med. 2021, 10, 2392. [Google Scholar] [CrossRef] [PubMed]
- Boldog, P.; Tekeli, T.; Vizi, Z.; Dénes, A.; Bartha, F.A.; Röst, G. Risk Assessment of Novel Coronavirus COVID-19 Outbreaks Outside China. J. Clin. Med. 2020, 9, 571. [Google Scholar] [CrossRef] [Green Version]
- Abou-Ismail, A. Compartmental Models of the COVID-19 Pandemic for Physicians and Physician-Scientists. SN Compr. Clin. Med. 2020, 2, 852–858. [Google Scholar] [CrossRef] [PubMed]
- Chintalapudi, N.; Battineni, G.; Amenta, F. COVID-19 virus outbreak forecasting of registered and recovered cases after sixty day lockdown in Italy: A data driven model approach. J. Microbiol. Immunol. Infect. 2020, 53, 396–403. [Google Scholar] [CrossRef]
- Thurner, S.; Klimek, P.; Hanel, R. A network-based explanation of why most COVID-19 infection curves are linear. Proc. Natl. Acad. Sci. USA 2020, 117, 22684–22689. [Google Scholar] [CrossRef]
- Sorci, G.; Faivre, B.; Morand, S. Explaining among-country variation in COVID-19 case fatality rate. Sci. Rep. 2020, 10, 18909. [Google Scholar] [CrossRef]
- Bottino, F.; Tagliente, E.; Pasquini, L.; Di Napoli, A.; Lucignani, M.; Figà-Talamanca, L.; Napolitano, A. COVID Mortality Prediction with Machine Learning Methods: A Systematic Review and Critical Appraisal. J. Pers. Med. 2021, 11, 893. [Google Scholar] [CrossRef]
- Yan, L.; Zhang, H.-T.; Goncalves, J.; Xiao, Y.; Wang, M.; Guo, Y.; Sun, C.; Tang, X.; Jing, L.; Zhang, M.; et al. An interpretable mortality prediction model for COVID-19 patients. Nat. Mach. Intell. 2020, 2, 283–288. [Google Scholar] [CrossRef]
- Chimmula, V.K.R.; Zhang, L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef] [PubMed]
- Van den Broeck, W.; Gioannini, C.; Gonçalves, B.; Quaggiotto, M.; Colizza, V.; Vespignani, A. The GLEaMviz computational tool, a publicly available software to explore realistic epidemic spreading scenarios at the global scale. BMC Infect. Dis. 2011, 11, 37. [Google Scholar] [CrossRef] [Green Version]
- Nussbaumer-Streit, B.; Mayr, V.; Dobrescu, A.I.; Chapman, A.; Persad, E.; Klerings, I.; Wagner, G.; Siebert, U.; Ledinger, D.; Zachariah, C.; et al. Quarantine alone or in combination with other public health measures to control COVID-19: A rapid review. Cochrane Database Syst. Rev. 2020, 9, CD013574. [Google Scholar] [CrossRef]
- Kırbaş, İ.; Sözen, A.; Tuncer, A.D.; Kazancıoğlu, F.Ş. Comparative analysis and forecasting of COVID-19 cases in various European countries with ARIMA, NARNN and LSTM approaches. Chaos Solitons Fractals 2020, 138, 110015. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
| Reference | Model | Subjects | Objective | Time-Period | Results and Conclusions |
|---|---|---|---|---|---|
| Fanelli & Piazza. | SIR | COVID-19, China, Italy, France | Analyze the temporal dynamics of the coronavirus disease 2019 outbreak in China, Italy and France in the time | 22 January 2020 to 12 March 2020 | The kinetic the kinetic parameter that describes the rate of recovery seems to be the same, irrespective of the country, while the infection and death rates appear to be more variable. A simulation of the effects of drastic containment measures on the outbreak in Italy indicates that a reduction of the infection rate indeed causes a quench of the epidemic peak. |
| Ahmetolan et al. | SIR | Daily case reports and daily fatalities for China, South Korea, France, Germany, Italy, Spain, Iran, Turkey, the United Kingdom and the United States | The quantity that can be most robustly estimated from normalized data is shown to be the times of peak and the times of inflection points of the proportion of people infected. These values correspond to the peak of the epidemic and to the highest rates of increase and highest rates of decline in the number of people infected. The stability of the estimates is tested by comparing predictions based on data over long time periods. | January to May 2020 | It is observed that the basic reproduction number and the mean duration of the infectious period can be estimated only in cases where the spread of the epidemic is over (for China and South Korea in the present case). Nevertheless, it is shown that the timing of the maximum and timings of the inflection points of the proportion of infected individuals can be robustly estimated from the normalized data. The validation of the estimates by comparing the predictions with actual data has shown that the predictions were realized for all countries except the USA, as long as lockdown measures were retained. |
| Khan et al. | SQUIDER | Detected and undetected infected populations, social sequestration, release from sequestration, plus reinfection; eight US states that make up 43% of the US population (Arizona, California, Florida, Illinois, Louisiana, New Jersey, New York State and Texas) | A compartmental model is proposed to predict the coronavirus 2019 (COVID-19) spread | 22 January to 29 June 2020 | Projections based on the current situation indicate that COVID-19 will become endemic. f lockdowns had been kept in place, the number of deaths would most likely have been significantly lower in states that opened up. Additionally, we predict that decreasing the contact rate by 10%, or increasing testing by approximately 15%, or doubling lockdown compliance (from the current ~15% to ~30%) will eradicate infections in Texas within a year. Extending our fits for all of the US states, we predict about 11 million total infections (including undetected), and 8 million cumulative confirmed cases by 1 November 2020. This model predicts significantly more COVID-19 cases and deaths, with an extended duration past two years for the majority of states examined. |
| Cooper et al. | SIR | Investigate the time evolution of different populations and monitor diverse significant parameters for the spread of the disease in various communities, represented by China, South Korea, India, Australia, USA, Italy and the state of Texas in the USA. | The effectiveness of the modelling approach on the pandemic due to the spreading of the novel COVID-19 disease. The authors propose predictions on various parameters related to the spread of COVID-19 and on the number of susceptible, infected and removed populations until September 2020 | January to June 2020 | If comparing the recorded data with the data from our modelling approaches, we deduce that the spread of COVID-19 can be under control in all communities considered, if proper restrictions and strong policies are implemented to control the infection rates early from the spread of the disease. |
| Hauser et al. | SEIR | Fitted transmission model to surveillance data from Hubei Province, China, and applied the same model to six regions in Europe: Austria, Bavaria (Germany), Baden-Württemberg (Germany), Lombardy (Italy), Spain, and Switzerland. | (1) Simulate the transmission dynamics of SARS-CoV-2 using publicly available surveillance data and (2) infer estimates of SARS-CoV-2 mortality adjusted for biases and examine the CFR, the symptomatic case-fatality ratio (sCFR), and the infection-fatality ratio (IFR) in different geographic locations. | January to May 2020 | A comprehensive solution is proposed for the estimation of SARS-CoV-2 mortality from surveillance data during outbreaks. Asymptomatic case fatality rate (CFR) is not a good predictor of overall SARS-CoV-2 mortality and should not be used for policy evaluation or comparison between settings. Geographic differences in the infection-case fatality rate (IFR) suggest that a single IFR should not be applied to all settings to estimate the total size of the SARS-CoV-2 epidemic in different countries. The sCFR and IFR, adjusted for right-censoring and preferential determination of severe cases, are measures that can be used to improve and monitor clinical and public health strategies to reduce deaths from SARS-CoV-2 infection. |
| Struben J. | SEIR | South Korea, Germany, Italy, France, Sweden, and the United States | Develop a behavioral dynamic epidemic model for multifaceted policy analysis comprising endogenous virus transmission (from severe or mild/asymptomatic cases), social contacts, and case testing and reporting. | December 2019–15 May 2020 | It determines how the timing and efforts of expanding testing capacity and reducing social contact interact to affect outbreak dynamics and can explain much of the cross-country variation in outbreak pathways. Second, in the absence of scaled availability of pharmaceutical solutions, post-peak social contacts should remain well below pre-pandemic values. Third, proactive (targeted) interventions, when supplemented by general deconfinement preparedness, can significantly increase eligible post-peak social contacts. |
| Chen et al. | Time-dependent SIR | China and extended to Japan, Singapore, South Korea, Italy, and Iran. | They propose a susceptible-infected-recovered (SIR) model that is time-dependent according to two time series: (i) transmission rate at time t and (ii) recovery rate at time t: (i) the transmission rate at time t and (ii) the recovery rate at time t. This approach is not only more adaptive than traditional static SIR models, but also more robust than direct estimation methods. Note: From data provided by the Health Commission of the People’s Republic of China (NHC). | 12 February 2020 | This time-dependent SIR model is not only more adaptive than traditional static SIR models, but also more robust than direct estimation methods. The numerical results show that one-day prediction errors for the number of infected persons X(t) and the number of recovered persons R(t) are within (almost) 3% for the dataset collected from the National Health Commission of the People’s Republic of China (NHC) [1]. Moreover, we are capable of tracking the characteristics of the transmission rate and the recovering rate with respect to time t, and precisely predict the future trend of the COVID-19 outbreak in China. To address the impact of asymptomatic infections in COVID-19, we extended our SIR model by considering two types of infected persons: detectable infected persons and undetectable infected persons. Whether there is an outbreak in such a model is characterized by the spectral radius of a 2 × 2 matrix that is closely related to the basic reproduction number R0. |
| Calafiore et al. | SIRD | Italy | Analyze parameters such as the initial number of susceptible people and the proportionality factor α (number of positives detected versus unknown number of infected people) to predict the spread of COVID-19 | 23 February to 30 March 2020 | It was not possible to accurately calculate the variability of the results because of time restrictions, but it was estimated at ±78% based on previous sources |
| Venkatesen M et al. | SIR | India | The objective of this study is to provide a simple but effective explanatory model for the prediction of the future development of infection and for checking the effectiveness of containment and lockdown. A SIR model with a flattening curve and herd immunity based on a susceptible population that grows over time and difference in mortality and birth rates. | 29 January to 15 April 2020 | It illustrates how a disease behaves over time, taking variables such as the number of sensitive individuals in the community and the number of those who are immune. It accurately models the disease, considering the importance of immunization and herd immunity. The outcomes obtained from the simulation of the COVID-19 outbreak in India make it possible to formulate projections and forecasts for the future epidemic progress circumstance in India. |
| Kuniya T. | SIRS | Japan | Objective to give a prediction of the epidemic peak of COVID-19 in Japan using the real-time data, and taking into account the uncertainty due to the incomplete identification of the infected population. | 1 January to 29 February 2020 | R0 = 2.6 (95% CI, 2.4–2.8) is estimated, with an epidemic peak in the summer of 2020. Epidemiological conclusions: (1) the size of the essential epidemic is less likely to be affected by the rate of identification of the actual infectious population; (2) the intervention has a positive effect in delaying the peak of the epidemic; (3) intervention is needed over a relatively long period to effectively reduce the final size of the epidemic. |
| Rocchi et al. | SIRS | Italy | Objective: predict a potential scenario in which a balance is reached between susceptible, infected and recovered groups (something that usually occurs in epidemics). | 15 April 2020 | This model offers an analytical solution to the problem of finding possible steady states, providing the following equilibrium values: susceptible, about 17%, recovered (including deceased and healed) ranging from 79 to 81%, and infected ranging from 2 to 4%. However, it is crucial to consider that the results concerning the recovered, which at first glance are particularly impressive, include the huge proportion of asymptomatic subjects. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martin-Moreno, J.M.; Alegre-Martinez, A.; Martin-Gorgojo, V.; Alfonso-Sanchez, J.L.; Torres, F.; Pallares-Carratala, V. Predictive Models for Forecasting Public Health Scenarios: Practical Experiences Applied during the First Wave of the COVID-19 Pandemic. Int. J. Environ. Res. Public Health 2022, 19, 5546. https://doi.org/10.3390/ijerph19095546
Martin-Moreno JM, Alegre-Martinez A, Martin-Gorgojo V, Alfonso-Sanchez JL, Torres F, Pallares-Carratala V. Predictive Models for Forecasting Public Health Scenarios: Practical Experiences Applied during the First Wave of the COVID-19 Pandemic. International Journal of Environmental Research and Public Health. 2022; 19(9):5546. https://doi.org/10.3390/ijerph19095546
Chicago/Turabian StyleMartin-Moreno, Jose M., Antoni Alegre-Martinez, Victor Martin-Gorgojo, Jose Luis Alfonso-Sanchez, Ferran Torres, and Vicente Pallares-Carratala. 2022. "Predictive Models for Forecasting Public Health Scenarios: Practical Experiences Applied during the First Wave of the COVID-19 Pandemic" International Journal of Environmental Research and Public Health 19, no. 9: 5546. https://doi.org/10.3390/ijerph19095546
APA StyleMartin-Moreno, J. M., Alegre-Martinez, A., Martin-Gorgojo, V., Alfonso-Sanchez, J. L., Torres, F., & Pallares-Carratala, V. (2022). Predictive Models for Forecasting Public Health Scenarios: Practical Experiences Applied during the First Wave of the COVID-19 Pandemic. International Journal of Environmental Research and Public Health, 19(9), 5546. https://doi.org/10.3390/ijerph19095546