
Exploring the Relationship between Urban Youth Sentiment and the Built Environment Using Machine Learning and Weibo Comments



Abstract
:1. Introduction
- To develop a novel and high-accuracy machine-learning-based method for analyzing youth sentiment in Shanghai.
- To identify the determinants of sentiment as well as its relationship with the built environment in Shanghai.
- Through the machine learning technology, which can be utilized as a sentiment feedback system for improvement of urban construction.
2. Literature Reviews
2.1. Research on the Relationship between Sentiment and Spatial Environment
2.2. Text Sentiment Analysis
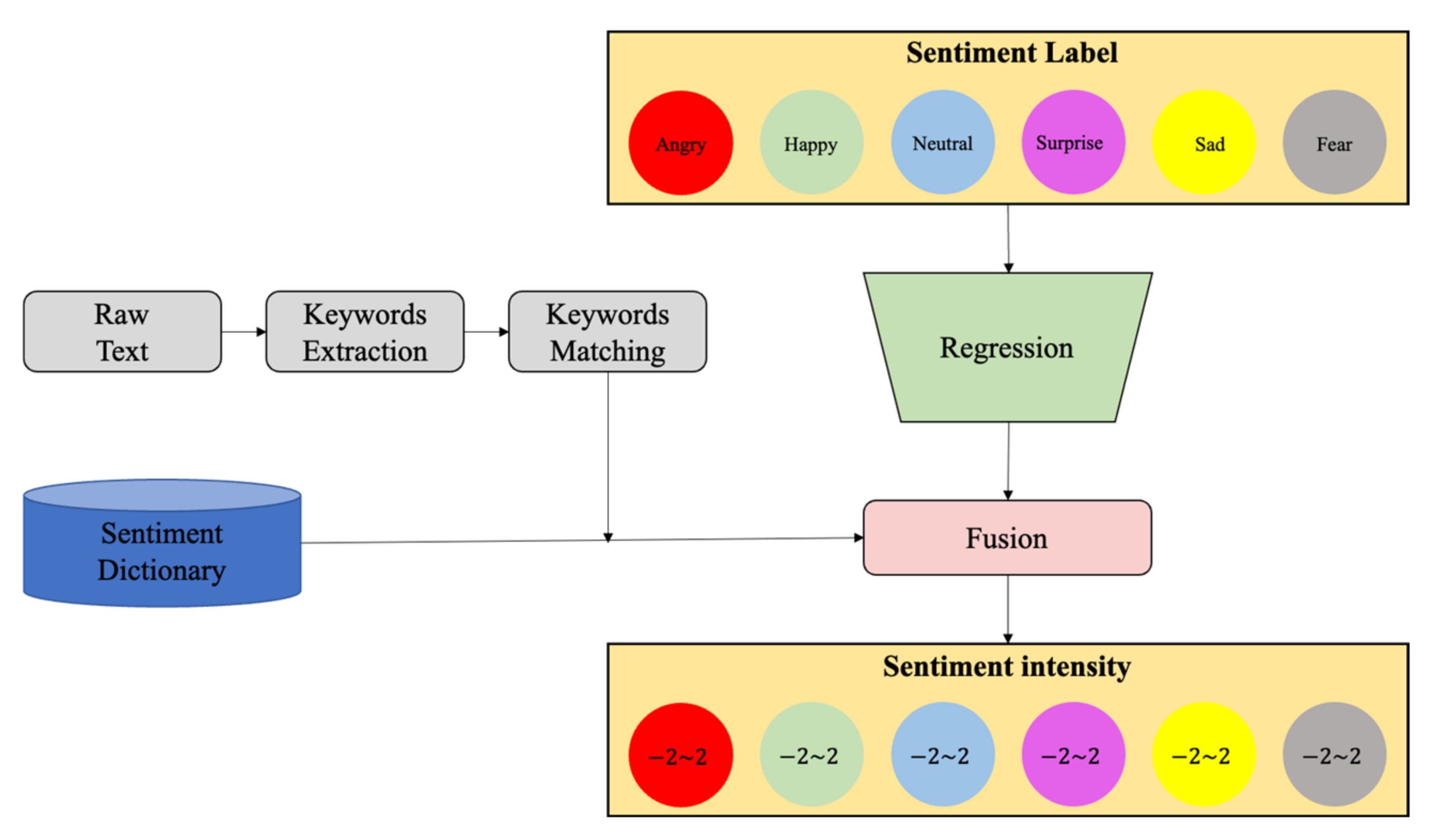
2.2.1. The Sentiment-Dictionary-Based Method
2.2.2. Machine-Learning-Based Method
2.3. Research on the Spatial Environment
3. Materials and Methods
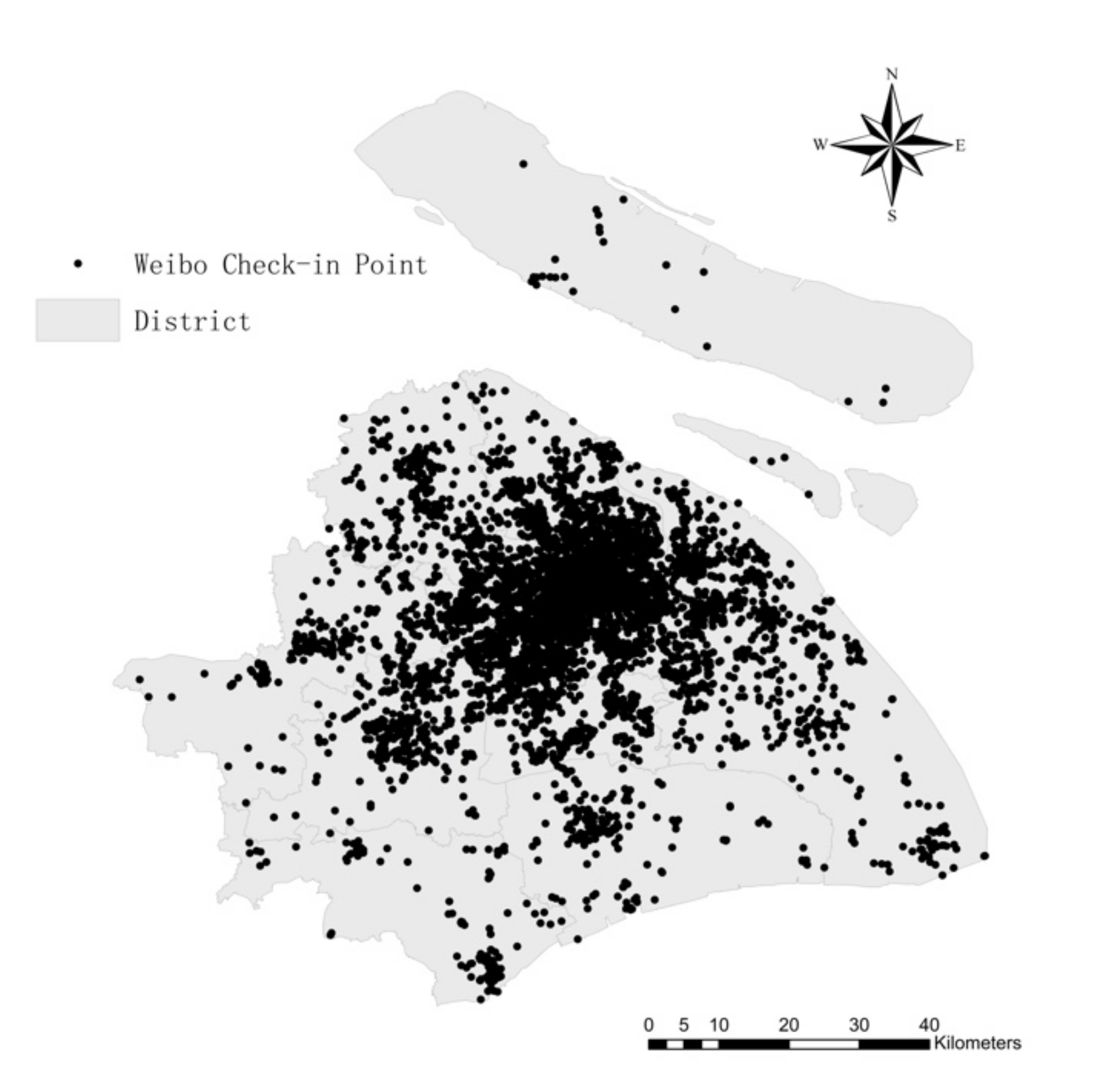
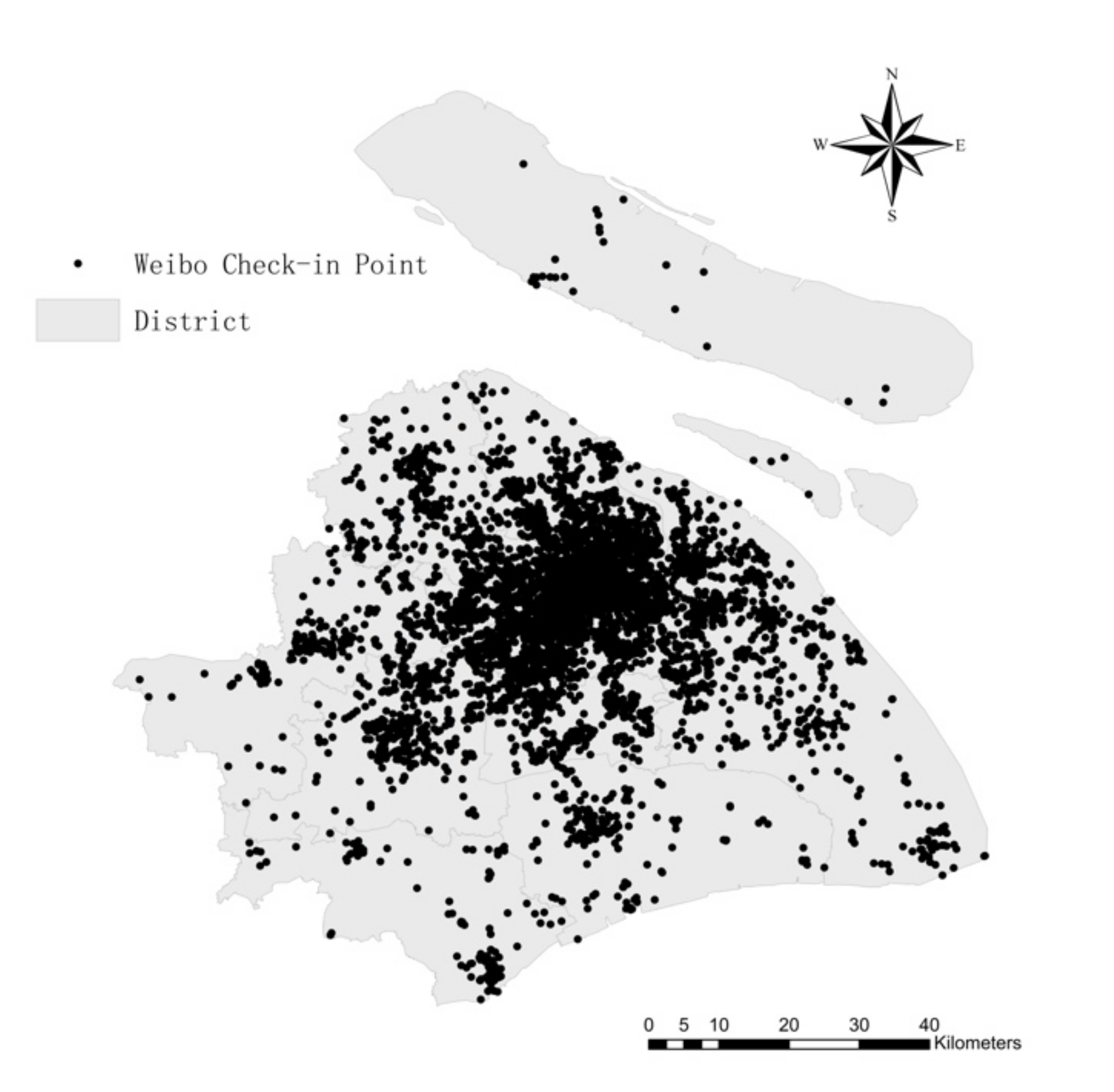
3.1. Study Area and Data Sources
3.2. Text Sentiment Classification
3.2.1. Dataset for Training and Testing
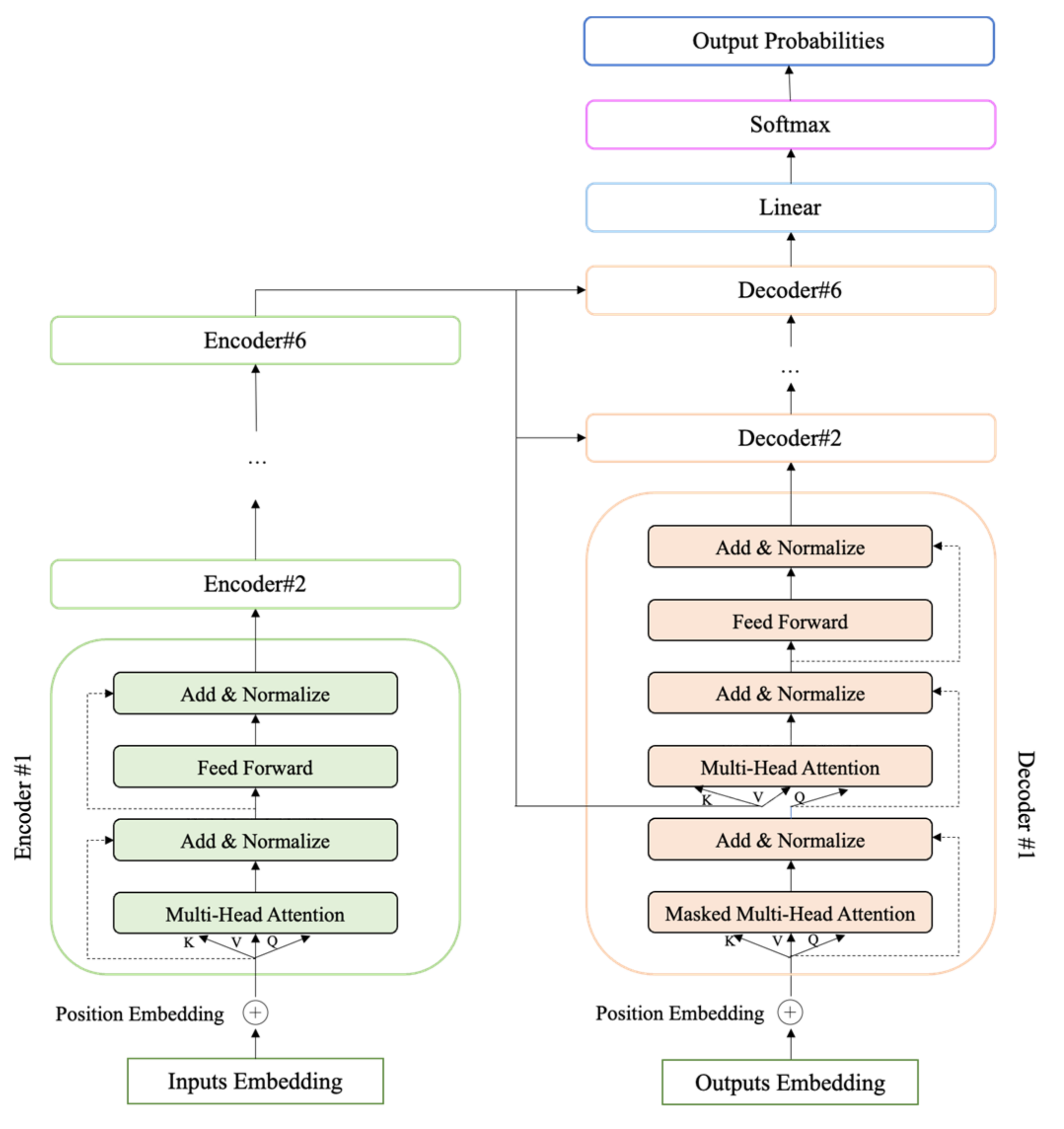
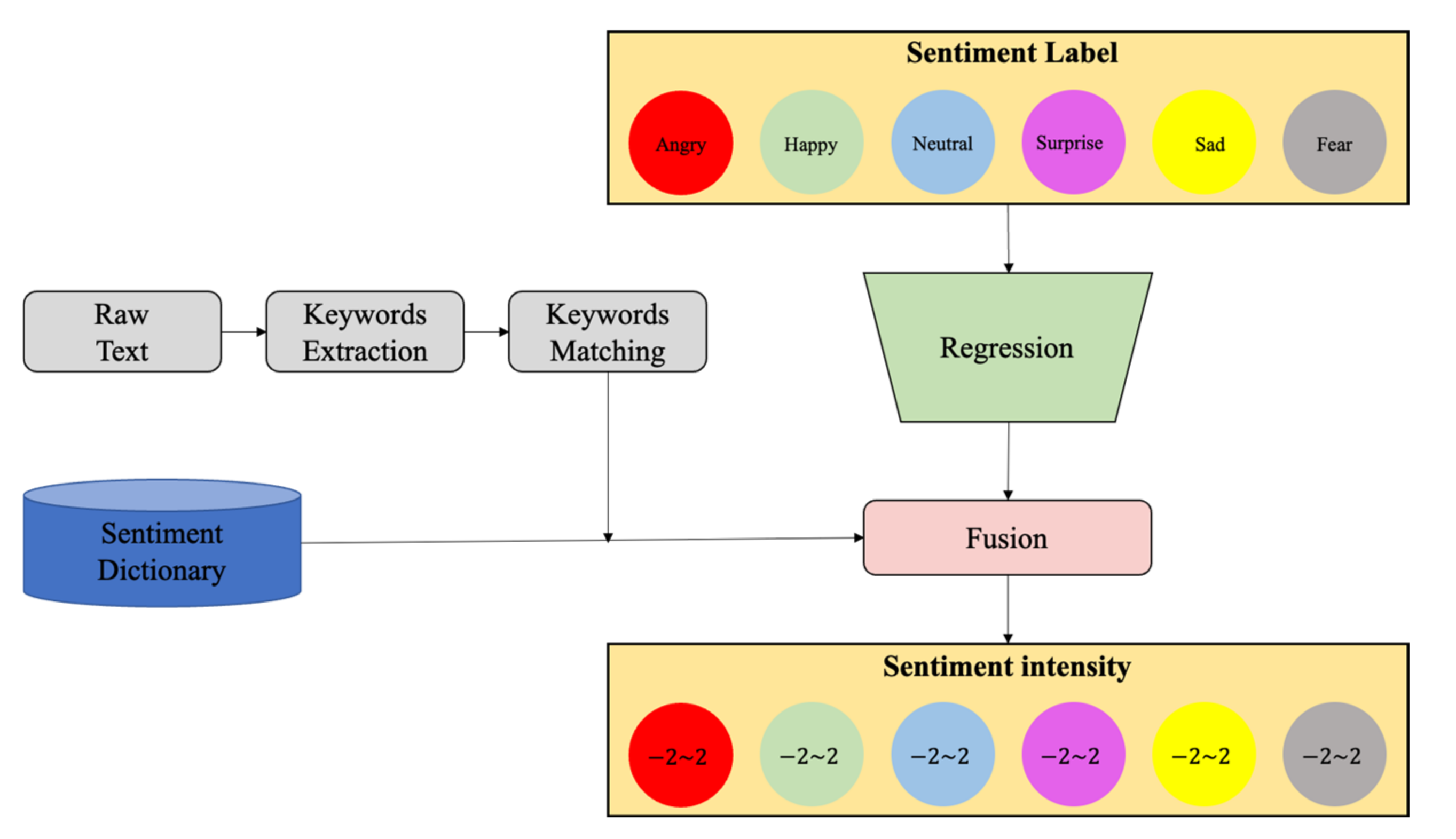
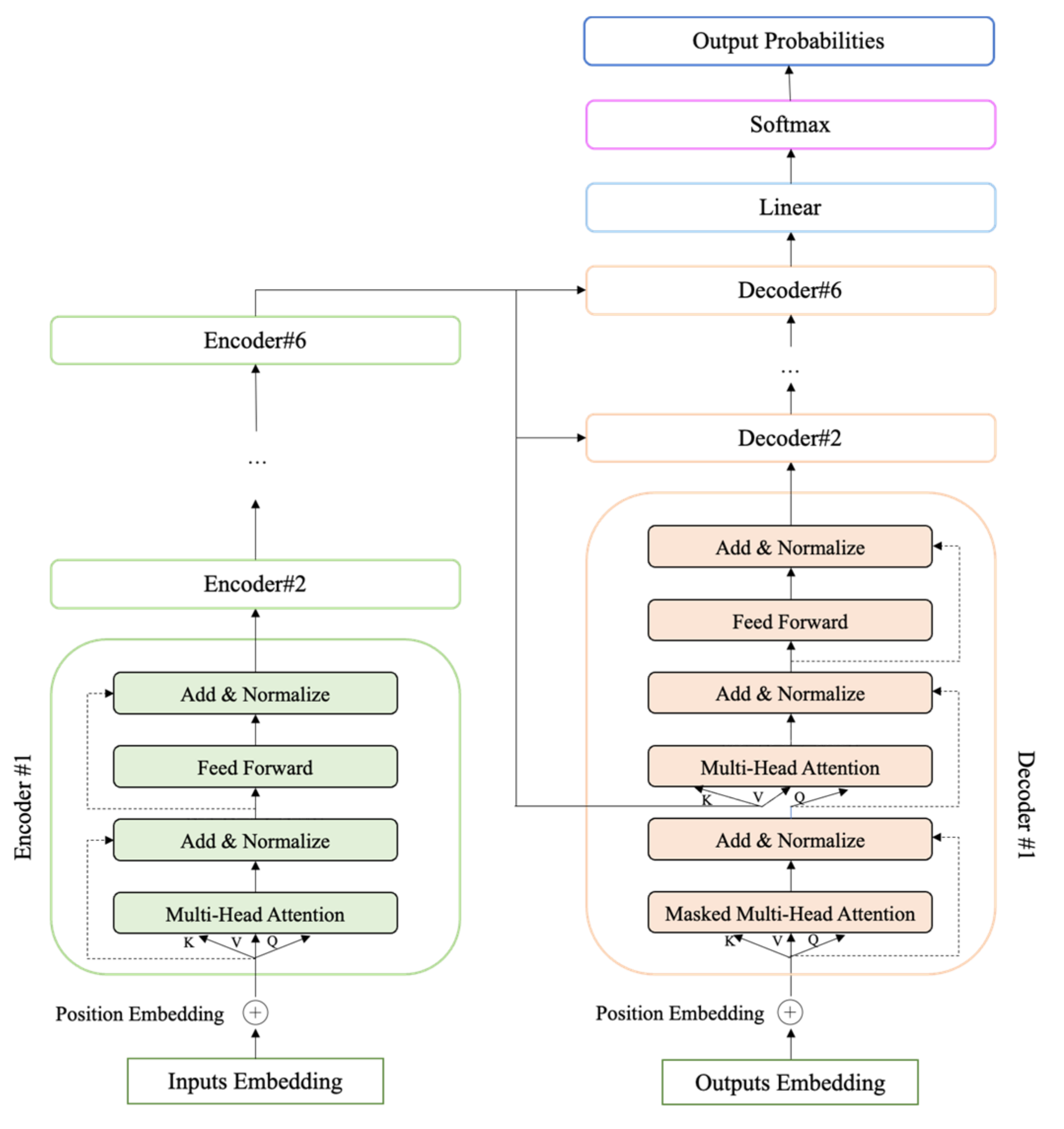
3.2.2. Framework
3.2.3. Pretrained Vocabulary Vector
3.2.4. Baseline Module
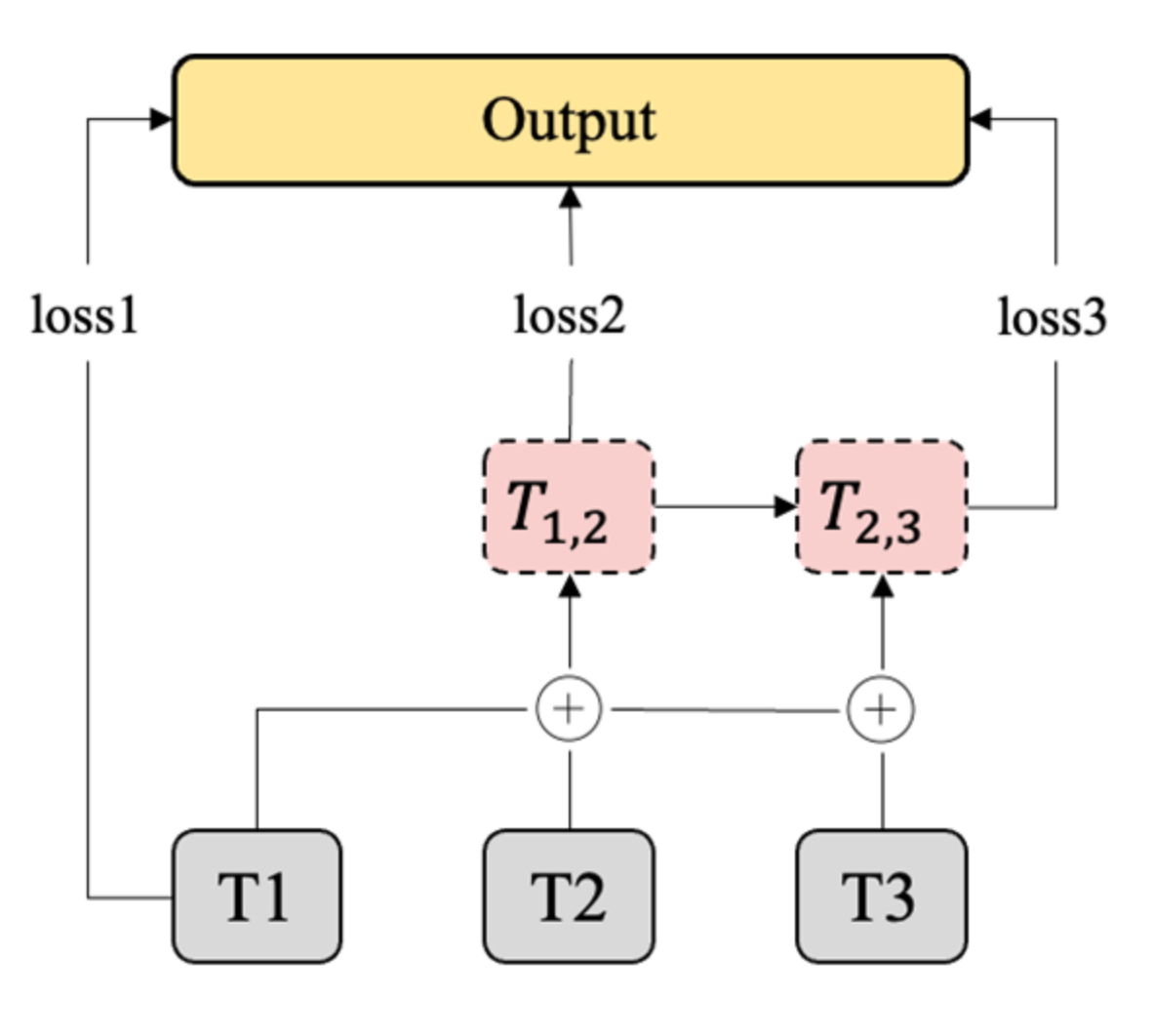
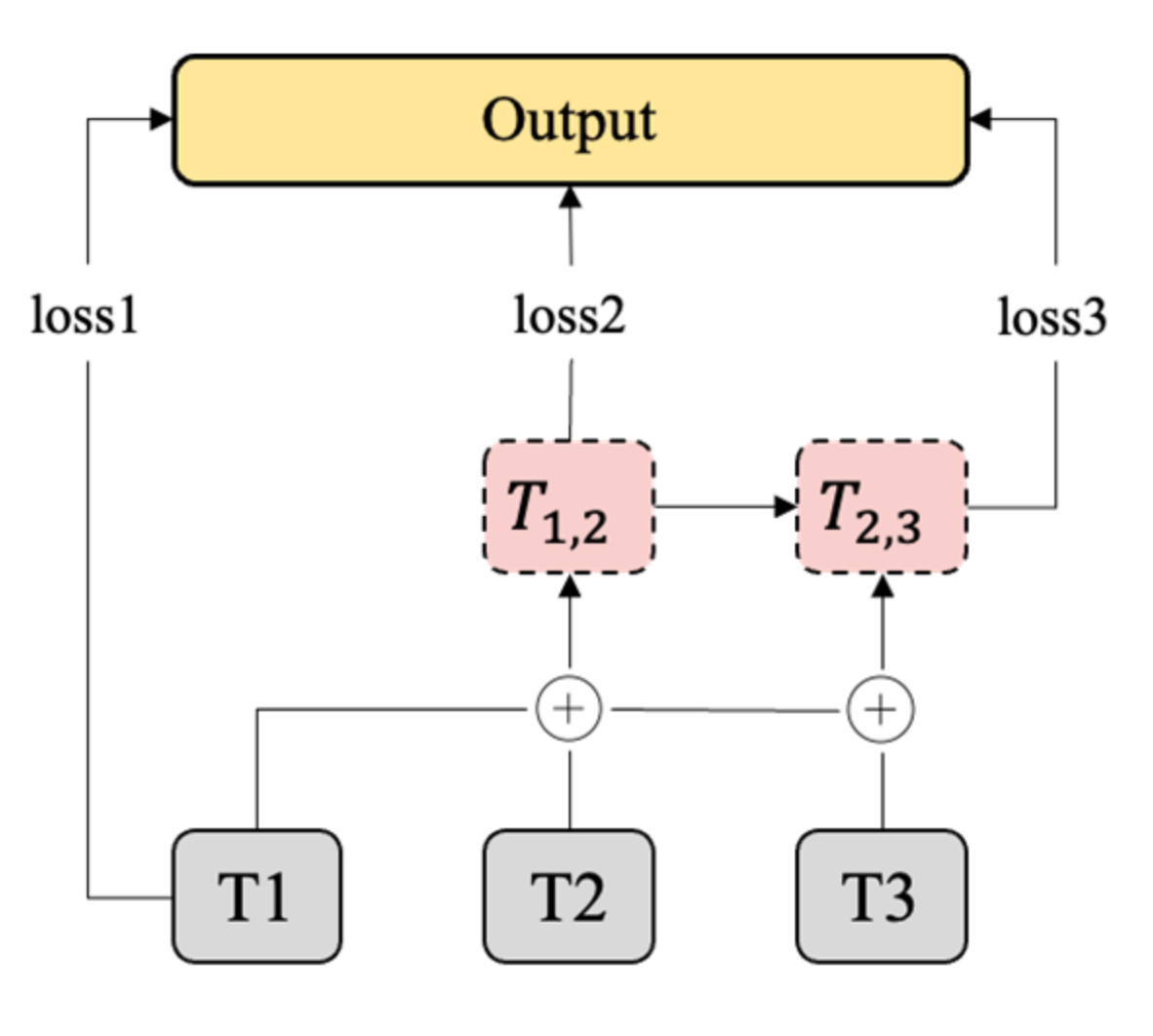
3.2.5. Refinement Module
- Multi-Loss Constraint
- 2.
- Data Augmentation
3.2.6. Reanalysis Module
3.3. Built Environment
3.3.1. Land Use Degree
3.3.2. Job–Housing Relationship
3.3.3. Road Traffic
3.3.4. Green Rate
3.3.5. Service Facilities
4. Results
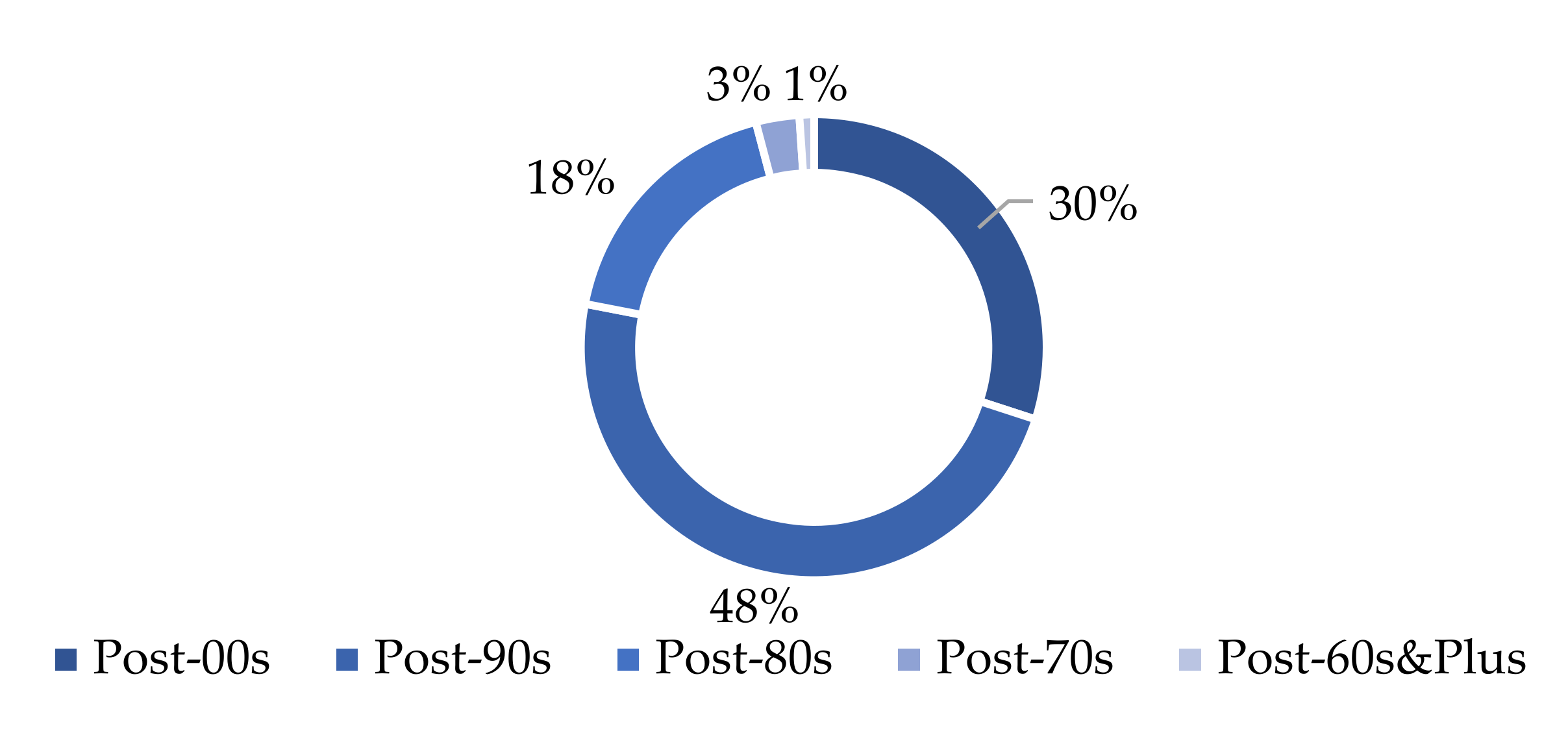
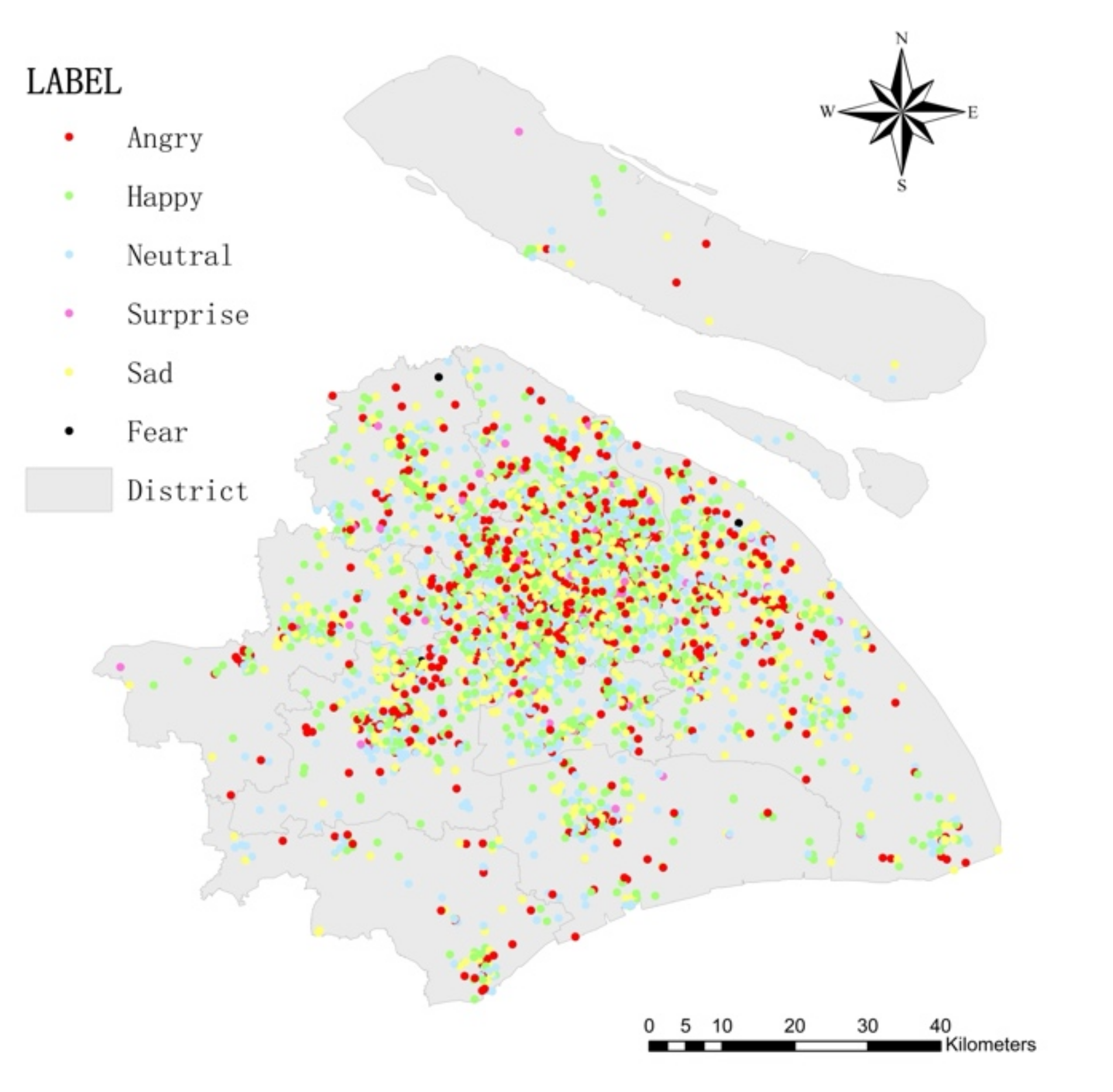
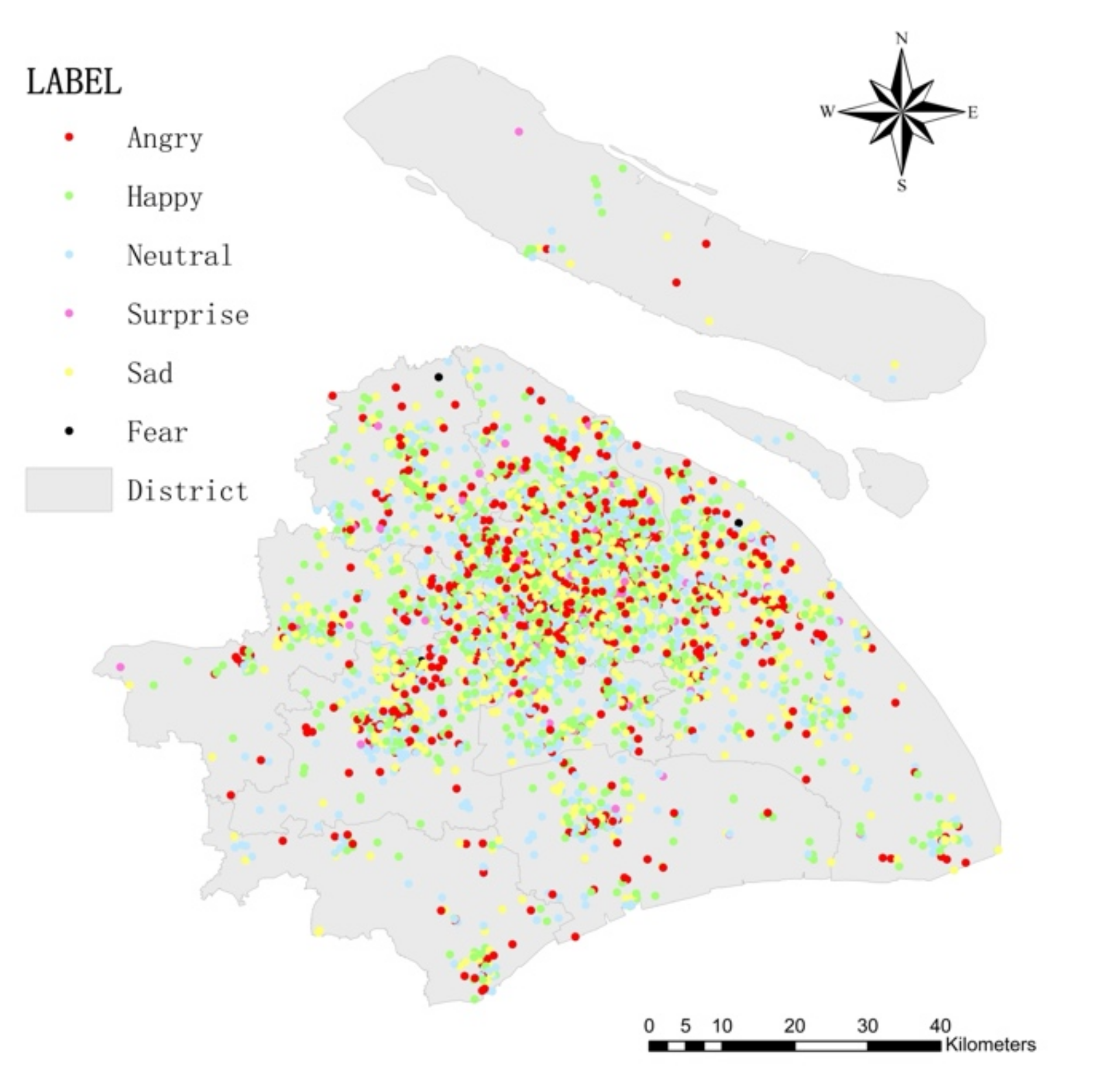
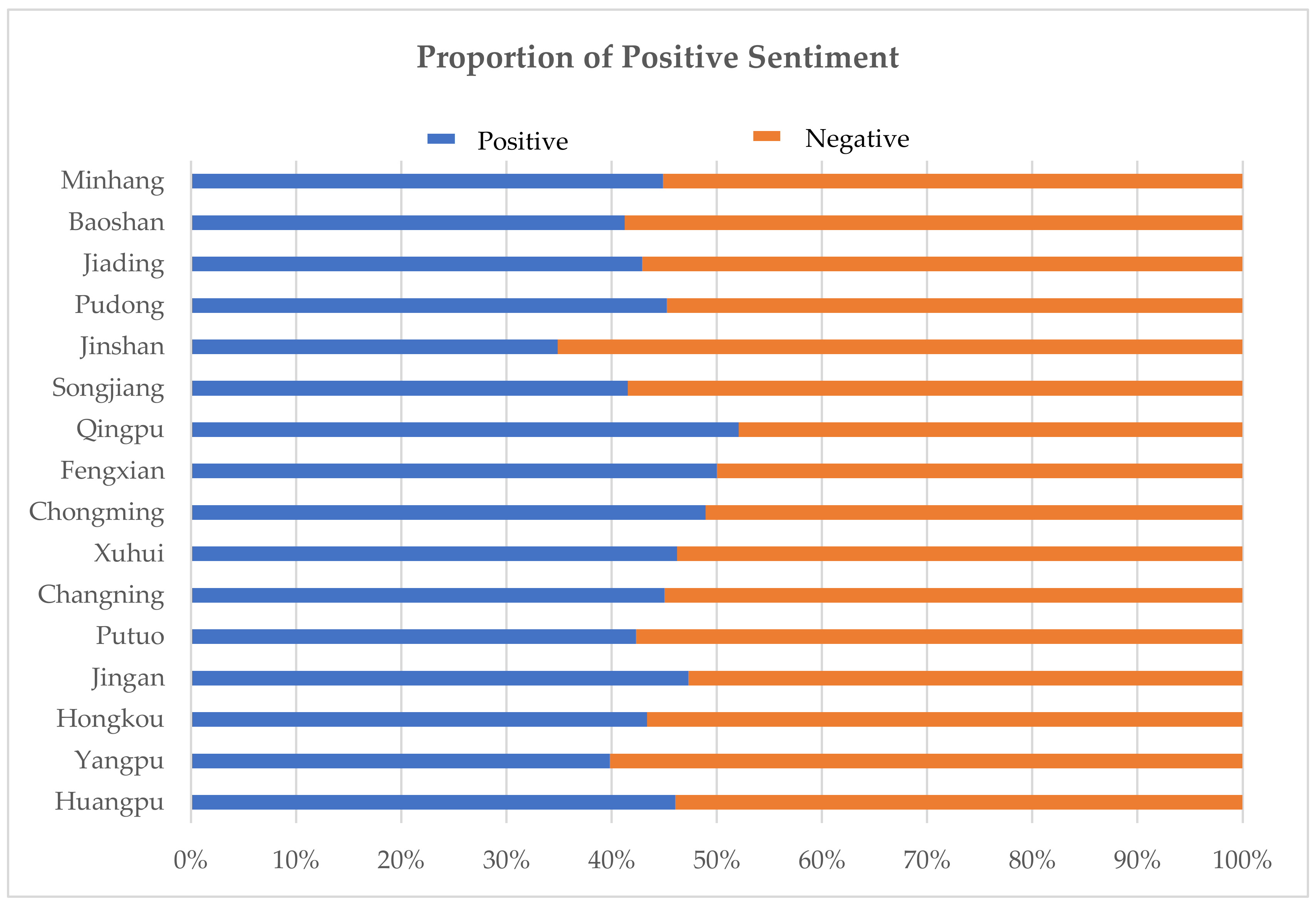
4.1. Text Sentiment Analysis
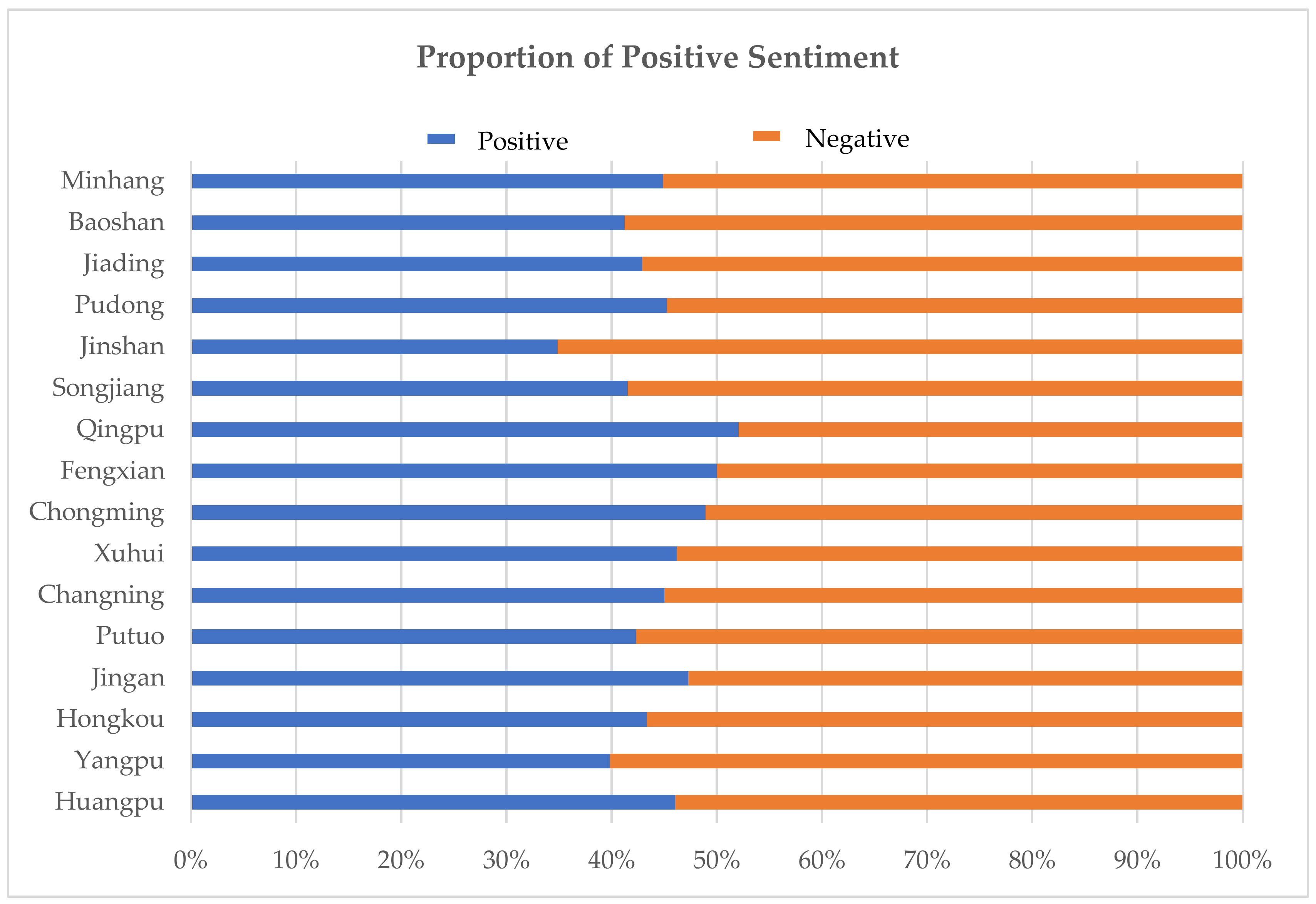
4.2. Built Environment Analysis
4.3. Correlation Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Veenstra, L.; Koole, S.L. Disarming darkness: Effects of ambient lighting on approach motivation and state anger among people with varying trait anger. J. Environ. Psychol. 2018, 60, 34–40. [Google Scholar] [CrossRef]
- Renz, T.; Leistner, P.; Liebl, A. Effects of the location of sound masking loudspeakers on cognitive performance in open-plan offices: Local sound masking is as efficient as conventional sound masking. Appl. Acoust. 2018, 139, 24–33. [Google Scholar] [CrossRef]
- Golder, S.A.; Macy, M.W. Diurnal and seasonal mood vary with work, sleep, and daylength across diverse cultures. Science 2011, 333, 1878–1881. [Google Scholar] [CrossRef] [Green Version]
- Davidson, J.; Milligan, C. Embodying Emotion Sensing Space: Introducing Emotional Geographies. Soc. Cult. Geogr. 2004, 5, 523–532. [Google Scholar] [CrossRef]
- Anderson, K.; Smith, S.J. Editorial: Emotional geographies. Trans. Inst. Br. Geogr. 2010, 26, 7–10. [Google Scholar] [CrossRef]
- Lin, Q. An Investigation of the Inclusion of Emotion in Media Geography. Master’s Thesis, Zhejiang University, Hangzhou, China, 2011. [Google Scholar]
- Wang, H.Q.; Chen, R.; Gui, L.; Fei, T. Mining emotional geography features based on Chinese Weibo data. Geomat. Info. Sci. Wuhan Univ. 2020, 45, 699–708. [Google Scholar]
- Wang, B.; Zhen, F.; Zhang, H. The dynamic changes of urban space-time activity and activity zoning based on check-in data in Sina Web. Prog. Geogr. 2015, 35, 151–160. [Google Scholar]
- Zhu, H.; Gao, Q. Review on “emotional turn” and emotional geographies in recent western geography. Geogr. Res. 2015, 34, 1394–1406. [Google Scholar]
- Jia, J.; Zhen, F.; Xi, G. A review on emotional geography: Its progress and enlightenment. World Reg. Stud. 2016, 25, 123–136. [Google Scholar]
- Dai, D.H.; Wang, Y.W.; Wang, Y.R.; Liu, S.N. Sentiment map construction based on semantic analysis of microblog data: A case study of Shenzhen city. In Proceedings of the 2021 China Urban Planning Annual Conference Proceedings, Chengdu, China, 25–30 September 2021; pp. 65–72. [Google Scholar] [CrossRef]
- Koenig, R.; Scheider, S.; Hamzi, I.; Bielik, M.; Schmitt, G.; Donath, D. Using geo statistical analysis to detect similarities in emotional responses if urban walkers to urban space. Proc. Natl. Acad. Sci. USA 2014, 98, 6911–6916. [Google Scholar]
- Chen, B.J.; Yan, T.H.; Chen, H.W. Evaluation of urban open space perception based on microblog data: A case study of Dangtu county. In Proceedings of the 2020 China Urban Planning Annual Conference Proceedings, Shenzhen, China, 5–13 December 2020; pp. 1171–1183. [Google Scholar] [CrossRef]
- Cui, L.M.; Qu, L.Y.; He, D. Evaluation of urban hot spot spatial emotion perception based on deep learning: A case study of Shanghai. Hum. Geogr. 2021, 36, 121–130. [Google Scholar]
- Cranshaw, J.; Schwartz, R.; Hong, J.; Sadeh, N. The Livehoods Project: Utilizing Social Media to Understand the Dynamics of a City; Social Science Electronic Publishing: New York, NY, USA, 2012. [Google Scholar]
- Rahim, A.I.A.; Ibrahim, M.I.; Musa, K.I.; Chua, S.-L.; Yaacob, N.M. Assessing Patient-Perceived Hospital Service Quality and Sentiment in Malaysian Public Hospitals Using Machine Learning and Facebook Reviews. Int. J. Environ. Res. Public Health 2021, 18, 9912. [Google Scholar] [CrossRef]
- Hannah, V.; William, O. Listen to the guests: Text-mining Airbnb reviews to explore indoor environmental quality. Build. Environ. 2020, 169, 106555. [Google Scholar]
- Chen, Y. Research on the Influence of Material Environment Perception on Walking Happiness in Harbin City. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2020. [Google Scholar]
- Hulliyah, K.; Awang, N.S.; Bakar, A.; Ismail, A.R. Emotion recognition and brain mapping for sentiment analysis: A review. In Proceedings of the 2017 Second International Conference on Informatics and Computing (ICIC), Jayapura, Indonesia, 1–3 November 2017; pp. 1–5. [Google Scholar]
- Xu, G.; Yu, Z.; Yao, H.; Li, F.; Meng, Y.; Wu, X. Chinese Text Sentiment Analysis Based on Extended Sentiment Dictionary. IEEE Access 2019, 7, 43749–43762. [Google Scholar] [CrossRef]
- Pan, Y.; Liang, M. Chinese Text Sentiment Analysis Based on BI-GRU and Self-attention. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 1983–1988. [Google Scholar]
- Dey, A.; Jenamani, M.; Thakkar, J.J. Sentiment Weight of N-grams in Dataset (SEND): A Feature-set for Cross-domain Sentiment Classification. In Proceedings of the 2017 Ninth International Conference on Advances in Pattern Recognition (ICAPR), Bangalore, India, 27–30 December 2017; pp. 1–6. [Google Scholar]
- Hong, W.; Min, L. A review: Text sentiment analysis methods. Comput. Eng. Sci. 2019, 41, 750–757. [Google Scholar]
- Dong, Z.; Dong, Q. Hownet-a hybrid language and knowledge resource. In Proceedings of the Natural Language Processing and Knowledge Engineering, Beijing, China, 26–29 October 2003; pp. 820–824. [Google Scholar]
- NTUSD. Chinese Emotion Words Dictionary [EB/OL]. Available online: https://download.csdn.net/download/zhangyinhua1122/11233148 (accessed on 10 January 2022).
- Esuli, A.; Sebastiani, F. Sentiwordnet: A publicly available lexical mining. Proc. Resour. Opin. LREC 2006, 6, 417–422. [Google Scholar]
- Sampson, G. Christiane Fellbaum (ed.), Wordnet: An electronic lexical database. Int. J. Lexicogr. 2000, 13, 54–58. [Google Scholar] [CrossRef]
- Turney, P.D. Thumbs up or thumbs down? In Semantic orientation applied to unsupervised classification of reviews. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 6–12 July 2002; pp. 417–424. [Google Scholar]
- Xiao, C.; Shi, S.; Lin, P.X. An analysis of community emergency projects’ implementation for public health emergencies based on social media public sentiment. J. Tongji Univ. 2021, 32, 114–124. [Google Scholar]
- Zhu, H.H.; Yu, Q.S. Study on the extraction of Chinese microblog subjective sentences based on lexicon and corpus. J. East China Norm. Univ. 2014, 2014, 62. [Google Scholar]
- Song, X.Y.; Zhao, Y.; Jin, L.-T.; Sun, Y.; Liu, T. Research on the construction of sentiment dictionary based on Word2vec. In Proceedings of the 2018 International Conference, Mexico City, Mexico, 19–20 July 2018. [Google Scholar]
- Tan, F.C. The Chinese microblog emotional tendency analysis based on sentiment dictionary. Appl. Mech. Mater. 2013, 333, 795–798. [Google Scholar] [CrossRef]
- Bai, X.; Chen, F.; Zhan, S.B. A study on sentiment computing and classification of Sina Weibo with Word2vec. In Proceedings of the 2014 IEEE International Congress on Big Data, Anchorage, AK, USA, 27 June–2 July 2014; pp. 358–363. [Google Scholar]
- Meral, M.; Diri, B. Sentiment analysis on Twitter. In Proceedings of the IEEE 2014 22nd Signal Processing and Communications Applications Conference (SIU), Trabzon, Turkey, 23–25 April 2014; pp. 690–693. [Google Scholar]
- Mohammad, S.M.; Zhu, X.; Mohammad, S. Sentiment analysis of short informal text. J. Artif. Intell. Res. 2014, 50, 723–762. [Google Scholar]
- Hanx, H.; Wang, J.L.; Zhang, M.; Wang, X. Using social media to mine and analyze public opinion related to COVID-19 in China. Int. J. Environ. Res. Public Health 2020, 17, 2788. [Google Scholar]
- Cheng, L.C.; Tsai, S.L. Deep Learning for Automated Sentiment Analysis of Social Media. In Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Vancouver, BC, Canada, 27–30 August 2019; pp. 1001–1004. [Google Scholar]
- Wang, Z.; Liu, J.; Sun, G.; Zhao, J.; Ding, Z.; Guan, X. An Ensemble Classification Algorithm for Text Data Stream based on Feature Selection and Topic Model. In Proceedings of the 2020 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 1377–1380. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning Based Text Classification: A Comprehensive Review. arXiv 2020, arXiv:2004.03705. [Google Scholar] [CrossRef]
- Dol, M.; Geetha, A. A Learning Transition from Machine Learning to Deep Learning: A Survey. In Proceedings of the 2021 International Conference on Emerging Techniques in Computational Intelligence (ICETCI), Hyderabad, India, 25–27 August 2021; pp. 89–94. [Google Scholar]
- Tai, K.S.; Socher, R.; Manning, C.D. Improved semantic representations from tree-structured long short-term memory networks. arXiv 2015, arXiv:1503.00075. [Google Scholar]
- Zhu, X.; Sobihani, P.; Guo, H. Long short-term memory over recursive structures. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 1604–1612. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Johnson, R.; Zhang, T. Semi-supervised convolutional neural networks for text categorization via region embedding. Adv. Neural Inf. Process. Syst. 2015, 28, 919–927. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the ECCV, Amsterdam, The Netherlands, 8–16 October 2016; pp. 630–645. [Google Scholar]
- Abdi, A.; Shamsuddin, S.M.; Hasan, S.; Piran, J. Deep learning-based sentiment classification of evaluative text based on Multi-feature fusion. Info. Pro. Manag. 2019, 56, 1245–1259. [Google Scholar] [CrossRef]
- Wang, Z.; Hamza, W.; Florian, R. Bilateral multi-perspective matching for natural language sentences. In Proceedings of the IJCAI, Melbourne, Australia, 19–25 August 2017; pp. 4144–4150. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. International Conference on Learning Representations (ICLR), San Diego, CA, USA,, 7–9 May 2015. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the NAACL, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Bronfenbrenner, N. The Ecology of Human Development: Experiments by Nature and Design; Harvard University Press: Cambridge, MA, USA, 1979; p. 26. [Google Scholar]
- Yang, G.X. Theoretical models and research methods of environmental psychology. Architect 1999, 55, 23–25. [Google Scholar]
- Mao, M.R.; Chu, Y.; Chen, H.; Yu, W.C. Practice of public participation in Internet planning. In Proceedings of the 2015 China Urban Planning Annual Conference Proceedings, Suzhou, China, 25–26 June 2015; pp. 19–34. [Google Scholar]
- Chen, Y.X. A Preliminary Study on the Relationship between Residents’ Emotion and Built Environment and Its Planning Application. Master’s Thesis, Nanjing University, Nanjing, China, 2015. [Google Scholar]
- Lin, J.; Sun, B.D. The influence of built Environment on subjective well-being of Urban residents: Evidence from the Labor Dynamics Survey in China. Urban Dev. Res. 2017, 24, 69–75. [Google Scholar]
- Lv, F.; Han, B.B.; Wang, B. Study on the influence of built environment on the emotional health of the elderly in cold area based on principal component analysis. Urban Archit. 2018, 24, 47–50. [Google Scholar]
- Xie, D.C.; Wang, D.; Zhong, W.J.; Yan, L.X. Evaluation and analysis of Built environment in Shanghai—Exploration based on mobile signaling data. Urban Plan. 2018, 42, 97–108. [Google Scholar]
- Xu, X.Q.; Liu, S.S. Study on soundscape and Emotion Perception in built Environment: Taking classical garden as an example. Time Archit. 2020, 5, 42–46. [Google Scholar]
- Long, Y.; Li, L.; Li, S.J.; Chen, L.; Pan, Z.M.; Yao, Y.T.; Chen, M.; Wang, Y.L.; Quan, J.; Zhang, L.X.; et al. Measurement of street walking environment index in vitality Center of Chinatown. South Archit. 2021, 1, 114–120. [Google Scholar]
- Leslie, E.; Cerin, E. Are perceptions of the local environment related to neighborhood satisfaction and mental health in adults? Prev. Med. 2008, 47, 273–278. [Google Scholar] [CrossRef]
- Ettema, D.; Schekkerman, M. How do spatial characteristics influence well-being and mental health? Comparing the effect of objective and subjective characteristics at different spatial scales. Travel Behav. Soc. 2015, 5, 56–67. [Google Scholar] [CrossRef]
- Ewing, R.; Cervero, R. Travel and the Built Environment: A Meta-analysis. J. Am. Plan. Assoc. 2010, 76, 265–294. [Google Scholar] [CrossRef]
- Yuan, Y. The Influence of Built Environment on the Distribution of Adult Outdoor Slow Physical Activity in Shenzhen. Master’s Thesis, Nanjing Normal University, Nanjing, China, 2017. [Google Scholar]
- Wang, X.; Jiao, J. A review of studies on built environment based on learning travel. Int. Urban Plan. 2018, 33, 57–62. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Researchers | Built Environment Evaluation Elements | ||||
|---|---|---|---|---|---|
| Social Env. | Land Use | Road Traffic | Eco-Space | Public Service | |
| Lin et al. [54] | Population density, Deviation index of employment and residence | Buses available | Green rate | Diversity of public facilities | |
| Lv et al. [55] | Population density | Urban spatial structure | Bus station density, Street height to width ratio | Green view rate Sky openness | |
| Xie et al. [56] | Job–housing relationship | Land use intensity | Residents’ travel behavior | ||
| Xu et al. [57] | Soundscape | ||||
| Long et al. [58] | Street crossing facilities, Motor vehicle and non-motor vehicle isolation, Walkway width | Street greening | Street facilities | ||
| Leslie [59] | Land use | Traffic safety, Street connectivity, Traffic flow | Green rate | Infrastructure | |
| Ettema [60] | Attractiveness | Accessibility, Traffic safety | Facilities | ||
| Ewing [61] | Land use | Accessibility | Green rate | ||
| Yuan [62] | Population density | Land use degree, Land type, Residential land ratio | Bus station density, Density of road network, Intersection density | Green rate | |
| Wang et al. [63] | Land use degree | Density of road network, Buses available | Density of public service | ||
| ID | Time | Longitude | Latitude | Weibo Comments |
|---|---|---|---|---|
| 1 | 19 July 13:43:43 | 121.4861 | 31.23672 | Chinese Comments: ‘好久不更博,最近把微博给忘了’. English Comments: ‘I forgot about Weibo recently, it’s been a while since I updated’. |
| 2 | 19 July 17:21:14 | 121.4422 | 31.22382 | Chinese Comments: ‘失踪人口回归’. English Comments: ‘Return of missing persons’. |
| 3 | 19 July 00:18:53 | 121.4446 | 31.22577 | Chinese Comments: ‘吃六个带两个回家,上海限定豫园奶昔也太好喝’. English Comments: ‘Eat six and take two home, Shanghai limited Yuyuan milkshakes are too good’. |
| Method | Score (Acc %) |
|---|---|
| FastText | 0.639 |
| TextCNN | 0.657 |
| TextRCNN | 0.645 |
| Transformer | 0.650 |
| Ours | 0.697 |
| District | Sentiment Label | ||||||
|---|---|---|---|---|---|---|---|
| Happy | Surprise | Neutral | Angry | Sad | Fear | Total | |
| Huangpu | 380 | 32 | 649 | 182 | 301 | 0 | 1544 |
| Yangpu | 84 | 12 | 145 | 62 | 83 | 0 | 386 |
| Hongkou | 77 | 8 | 137 | 41 | 70 | 0 | 333 |
| Jingan | 222 | 13 | 292 | 107 | 155 | 0 | 789 |
| Putuo | 107 | 3 | 136 | 67 | 83 | 1 | 397 |
| Changning | 131 | 9 | 166 | 58 | 113 | 0 | 477 |
| Xuhui | 245 | 14 | 314 | 134 | 167 | 2 | 876 |
| Chongming | 22 | 1 | 25 | 14 | 10 | 0 | 72 |
| Fengxian | 54 | 4 | 67 | 27 | 31 | 0 | 183 |
| Qingpu | 154 | 8 | 252 | 64 | 85 | 0 | 563 |
| Songjiang | 154 | 6 | 200 | 94 | 131 | 1 | 586 |
| Jinshan | 29 | 1 | 34 | 23 | 33 | 0 | 120 |
| Pudong | 684 | 48 | 900 | 370 | 516 | 4 | 2522 |
| Jiading | 131 | 8 | 131 | 74 | 111 | 1 | 456 |
| Baoshan | 122 | 10 | 133 | 80 | 108 | 0 | 453 |
| Minhang | 310 | 22 | 419 | 152 | 256 | 0 | 1159 |
| Total | 2906 | 199 | 4000 | 1549 | 2253 | 9 | 10,916 |
| District | Happy | Surprise | Angry | Sad | ||||
|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| Huangpu | 0.78 | 0.45 | −0.09 | 0.90 | 1.19 | 0.97 | −0.58 | 0.90 |
| Yangpu | 0.71 | 0.44 | −0.17 | 0.31 | 1.06 | 0.90 | −0.64 | 0.74 |
| Hongkou | 0.78 | 0.51 | −0.38 | 0.23 | 1.27 | 0.73 | −0.61 | 1.09 |
| Jingan | 0.70 | 0.52 | −0.35 | 0.40 | 1.24 | 0.80 | −0.54 | 0.93 |
| Putuo | 0.71 | 0.39 | 1.00 | 0.67 | 1.06 | 0.83 | −0.45 | 0.92 |
| Changning | 0.71 | 0.43 | −0.11 | 0.77 | 1.10 | 0.85 | −0.55 | 0.96 |
| Xuhui | 0.74 | 0.43 | −0.07 | 0.78 | 1.15 | 0.87 | −0.52 | 1.02 |
| Minhang | 0.66 | 0.53 | 0.09 | 0.72 | 1.33 | 0.88 | −0.67 | 0.89 |
| Fengxian | 0.80 | 0.64 | −0.50 | 0.25 | 1.19 | 0.97 | −0.77 | 0.50 |
| Qingpu | 0.75 | 0.43 | −0.13 | 0.61 | 1.09 | 0.99 | −0.42 | 1.16 |
| Songjiang | 0.69 | 0.54 | 1.17 | 0.47 | 1.35 | 0.55 | −0.73 | 0.86 |
| Jinshan | 0.72 | 0.48 | 1.00 | 0.00 | 1.26 | 0.63 | −0.33 | 1.19 |
| Pudong | 0.69 | 0.54 | −0.31 | 0.67 | 1.19 | 0.81 | −0.65 | 0.87 |
| Jiading | 0.77 | 0.50 | −0.50 | 0.50 | 1.05 | 0.92 | −0.46 | 1.08 |
| Baoshan | 0.81 | 0.46 | −0.10 | 0.09 | 1.14 | 0.82 | −0.65 | 0.86 |
| Chongming | 0.73 | 0.38 | 0.00 | 0.00 | 0.93 | 1.07 | −0.30 | 1.01 |
| District | Land Use Degree | Job–Housing Relationship | Road Network (km/km2) | Transportation Station | Green Rate | Shopping Facilities | Food Services | Entertainment Facilities | Medical Services | Exercise Facilities |
|---|---|---|---|---|---|---|---|---|---|---|
| Huangpu | 0.52 | 1.32 | 17.86 | 1.32 | 0.14 | 694.03 | 230.7 | 29.7 | 44.85 | 25.85 |
| Yangpu | 0.65 | 0.56 | 13.77 | 0.45 | 0.11 | 207.49 | 99.56 | 14.02 | 23.29 | 11.69 |
| Hongkou | 0.53 | 0.67 | 17.05 | 0.77 | 0.1 | 362.53 | 159 | 20.34 | 39.36 | 20.08 |
| Jingan | 0.67 | 1.01 | 16.55 | 0.71 | 0.12 | 508.99 | 183.57 | 21.09 | 40.19 | 21.28 |
| Putuo | 0.71 | 0.61 | 15.76 | 0.4 | 0.24 | 243.69 | 96.37 | 13.12 | 20.85 | 12.31 |
| Changning | 0.68 | 0.90 | 16.81 | 0.48 | 0.31 | 248.88 | 122.44 | 16.64 | 32.07 | 17.26 |
| Xuhui | 0.63 | 1.07 | 16.27 | 0.63 | 0.22 | 232.15 | 114.84 | 14.79 | 24.8 | 17.09 |
| Minhang | 0.74 | 0.51 | 6.73 | 0.27 | 0.21 | 66.06 | 31.01 | 4.36 | 4.65 | 3.53 |
| Fengxian | 0.76 | 0.37 | 3.94 | 0.15 | 0.47 | 21.1 | 6.25 | 1.11 | 1.38 | 0.47 |
| Qingpu | 0.74 | 0.40 | 3.88 | 0.15 | 0.41 | 19.15 | 6.77 | 0.76 | 1.15 | 0.54 |
| Songjiang | 0.74 | 0.35 | 5.15 | 0.17 | 0.42 | 30.36 | 13.94 | 2.05 | 2.03 | 1.22 |
| Jinshan | 0.64 | 0.43 | 4.04 | 0.21 | 0.54 | 15.28 | 4.74 | 0.86 | 1.1 | 0.35 |
| Pudong | 0.84 | 0.53 | 6.08 | 0.18 | 0.31 | 44.35 | 18.49 | 2.37 | 3.46 | 2.05 |
| Jiading | 0.77 | 0.41 | 5.8 | 0.13 | 0.33 | 41.49 | 16.15 | 1.95 | 2.74 | 1.32 |
| Baoshan | 0.78 | 0.30 | 6.67 | 0.13 | 0.55 | 72.46 | 27.9 | 3.8 | 4.69 | 2.64 |
| Chongming | 0.77 | 0.41 | 2.9 | 0.13 | 0.62 | 4.04 | 0.78 | 0.49 | 0.34 | 0.1 |
| Built Environment | Happy | Surprise | Angry | Sad |
|---|---|---|---|---|
| Land Use Degree | 0.207 | −0.143 | 0.132 | −0.238 |
| Job–housing | 0.261 | −0.590 * | −0.106 | −0.135 |
| Road Network | −0.292 | 0.462 | −0.036 | 0.016 |
| Transportation | −0.168 | 0.436 | 0.061 | 0.042 |
| Green Rate | −0.013 | −0.559 * | 0.03 | 0.051 |
| Shopping Facilities | −0.162 | 0.402 | 0.055 | −0.003 |
| Food Services | −0.198 | 0.413 | 0.024 | 0.013 |
| Entertainment | −0.225 | 0.424 | 0.033 | −0.003 |
| Medical Services | −0.205 | 0.37 | −0.003 | 0.034 |
| Exercise Facilities | −0.234 | 0.436 | 0.016 | 0.04 |
| Built Environment | Happy | Surprise | Angry | Sad |
|---|---|---|---|---|
| Land Use Degree | 0.014 * | 0.076 ** | −0.034 ** | −0.052 ** |
| Job–housing | −0.003 | −0.012 | 0.007 | 0.021 ** |
| Road Network | −0.044 ** | −0.212 ** | 0.102 ** | 0.166 ** |
| Transportation | −0.003 | −0.103 ** | 0.034 ** | 0.074 ** |
| Green Rate | 0.018 ** | 0.161 ** | −0.078 ** | −0.131 ** |
| Shopping Facilities | −0.052 ** | −0.217 ** | 0.090 ** | 0.150 ** |
| Food Services | −0.080 ** | −0.282 ** | 0.107 ** | 0.221 ** |
| Entertainment | −0.064 ** | −0.242 ** | 0.106 ** | 0.194 ** |
| Medical Services | −0.071 ** | −0.197 ** | 0.085 ** | 0.150 ** |
| Exercise Facilities | −0.053 ** | −0.268 ** | 0.117 ** | 0.205 ** |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duan, S.; Shen, Z.; Luo, X. Exploring the Relationship between Urban Youth Sentiment and the Built Environment Using Machine Learning and Weibo Comments. Int. J. Environ. Res. Public Health 2022, 19, 4794. https://doi.org/10.3390/ijerph19084794
Duan S, Shen Z, Luo X. Exploring the Relationship between Urban Youth Sentiment and the Built Environment Using Machine Learning and Weibo Comments. International Journal of Environmental Research and Public Health. 2022; 19(8):4794. https://doi.org/10.3390/ijerph19084794
Chicago/Turabian StyleDuan, Sutian, Zhiyong Shen, and Xiao Luo. 2022. "Exploring the Relationship between Urban Youth Sentiment and the Built Environment Using Machine Learning and Weibo Comments" International Journal of Environmental Research and Public Health 19, no. 8: 4794. https://doi.org/10.3390/ijerph19084794
APA StyleDuan, S., Shen, Z., & Luo, X. (2022). Exploring the Relationship between Urban Youth Sentiment and the Built Environment Using Machine Learning and Weibo Comments. International Journal of Environmental Research and Public Health, 19(8), 4794. https://doi.org/10.3390/ijerph19084794