
A Hybrid Model for Driver Emotion Detection Using Feature Fusion Approach

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
2. Related Works
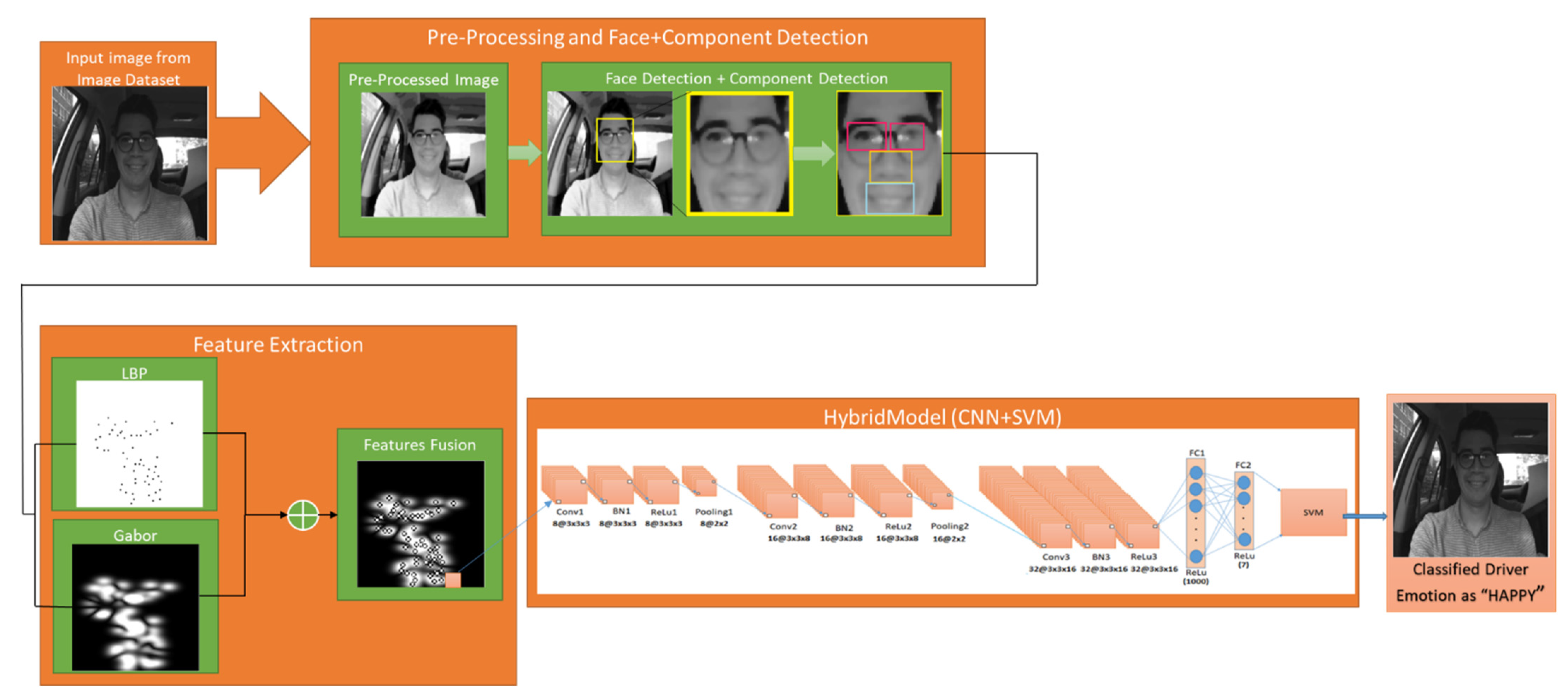
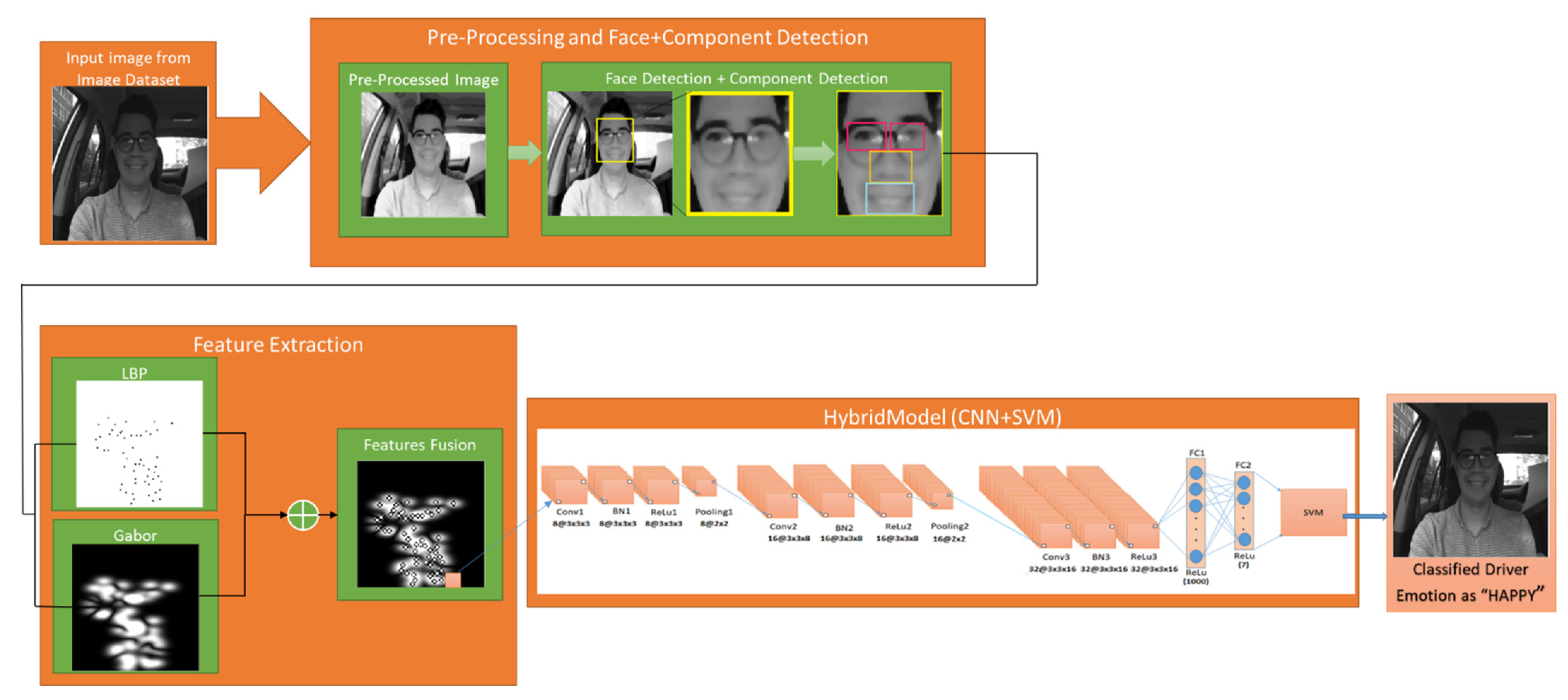
3. Proposed Hybrid Model Architecture
3.1. Image Pre-processing
3.1.1. Image Resizing
3.1.2. Noise Removal
3.1.3. Median Filter
3.1.4. Histogram Equalization
3.1.5. Wiener Filter
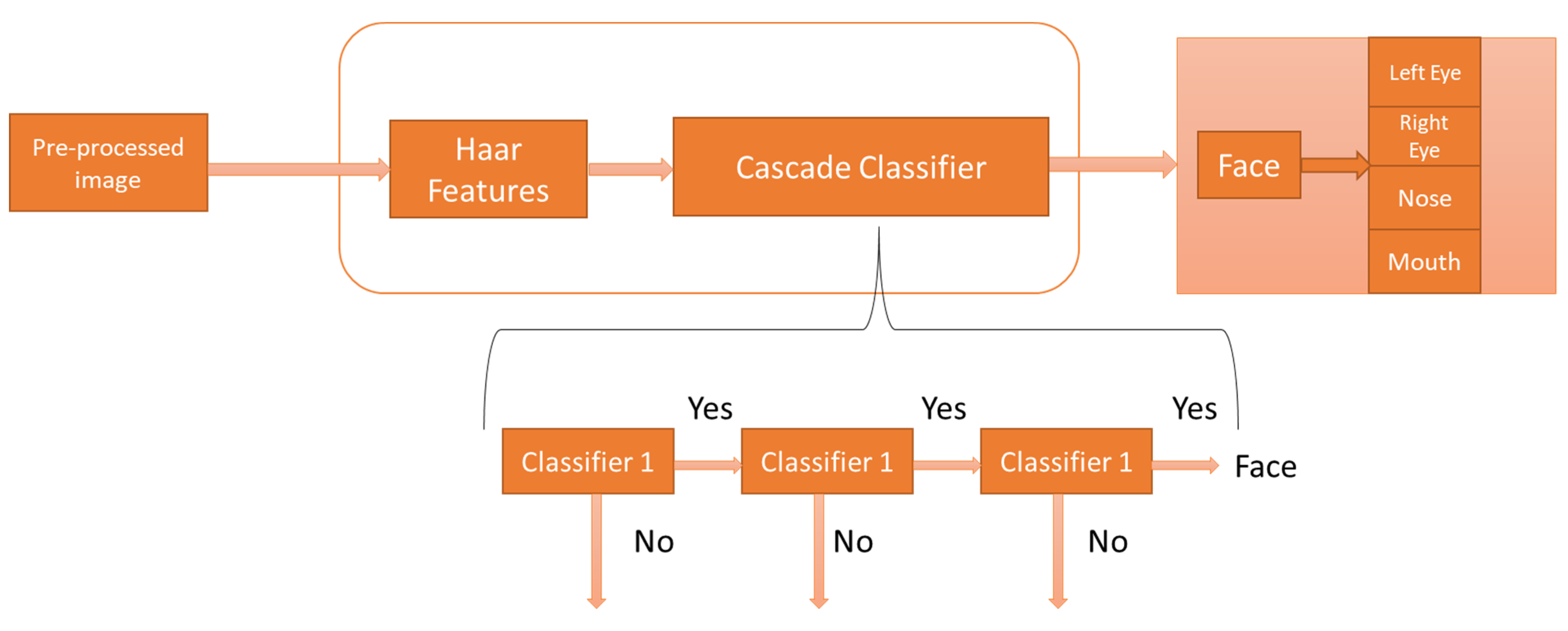
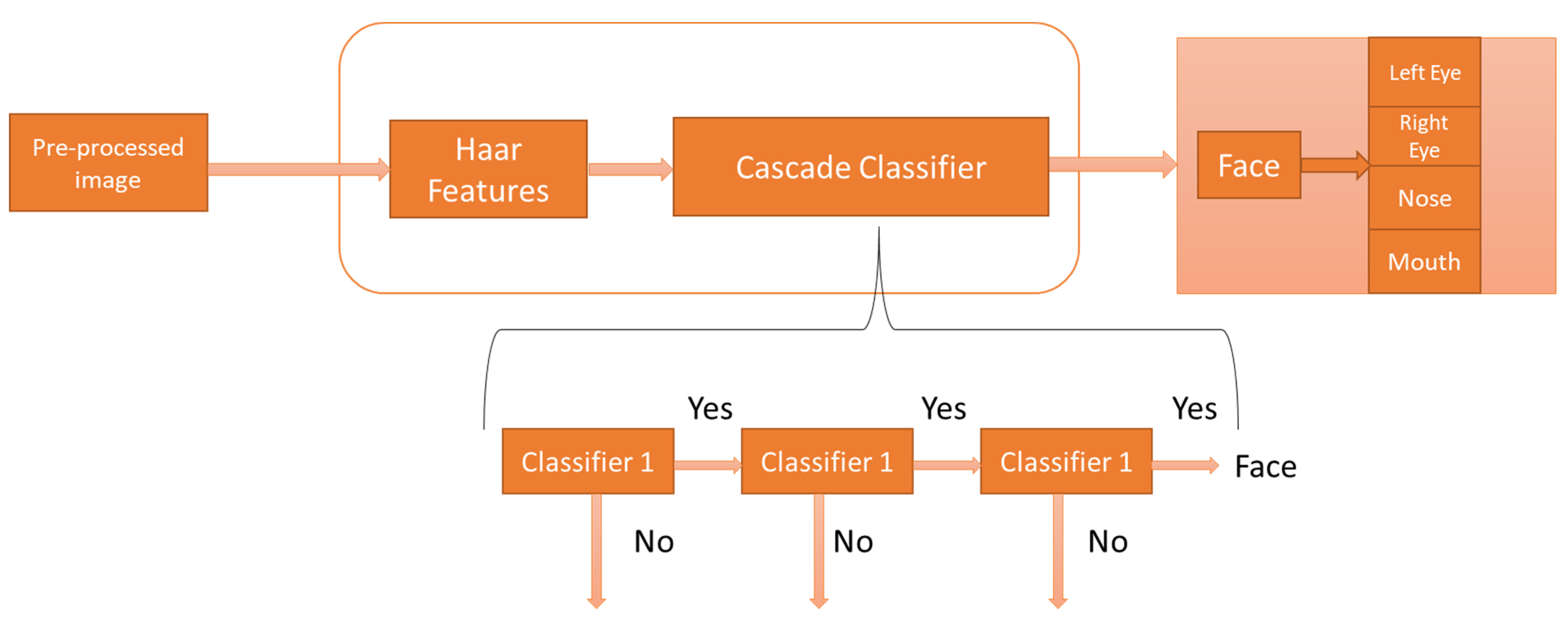
3.2. Face and Facial Components Detection
3.3. Feature Extraction
Linear Binary Pattern
- (i)
- Select a window of pixel with size mxn with the pixel intensity values ranging from 0 to 255.
- (ii)
- Split the window into individual cells.
- (iii)
- For every pixel in a given cell, the pixel is compared with its eight neighbors in a clockwise circular direction.
- (iv)
- If the pixel value at the center is greater than its neighbor pixel value, then the value is set to zero; otherwise, it will be set to one. An eight-digit binary number will be generated from each window.
- (v)
- Histogram with dimensions of mxn over the cell is computed, repeated for every combination, and normalized the resultant histogram.
- (vi)
- Concatenate all the normalized histograms can generate a feature vector.
3.4. Deep Network as Features Descriptor
3.5. Support Vector Machine (SVM) Classifier
4. Experimental Results
4.1. Implementation Details
4.2. Dataset description
4.2.1. FER 2013 Dataset
4.2.2. CK+ Dataset
4.2.3. KDEF Dataset
4.2.4. KMU-FED Dataset
4.3. Performance Evaluation
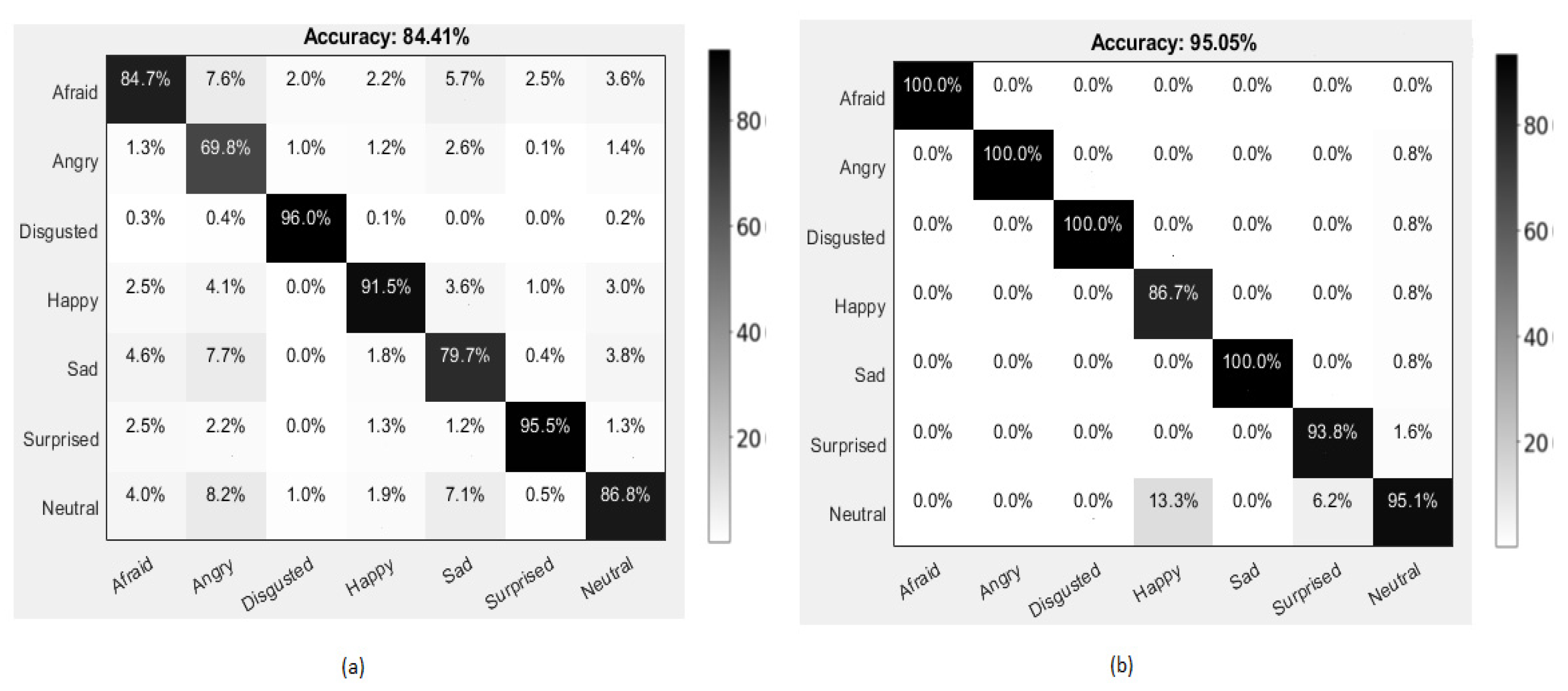
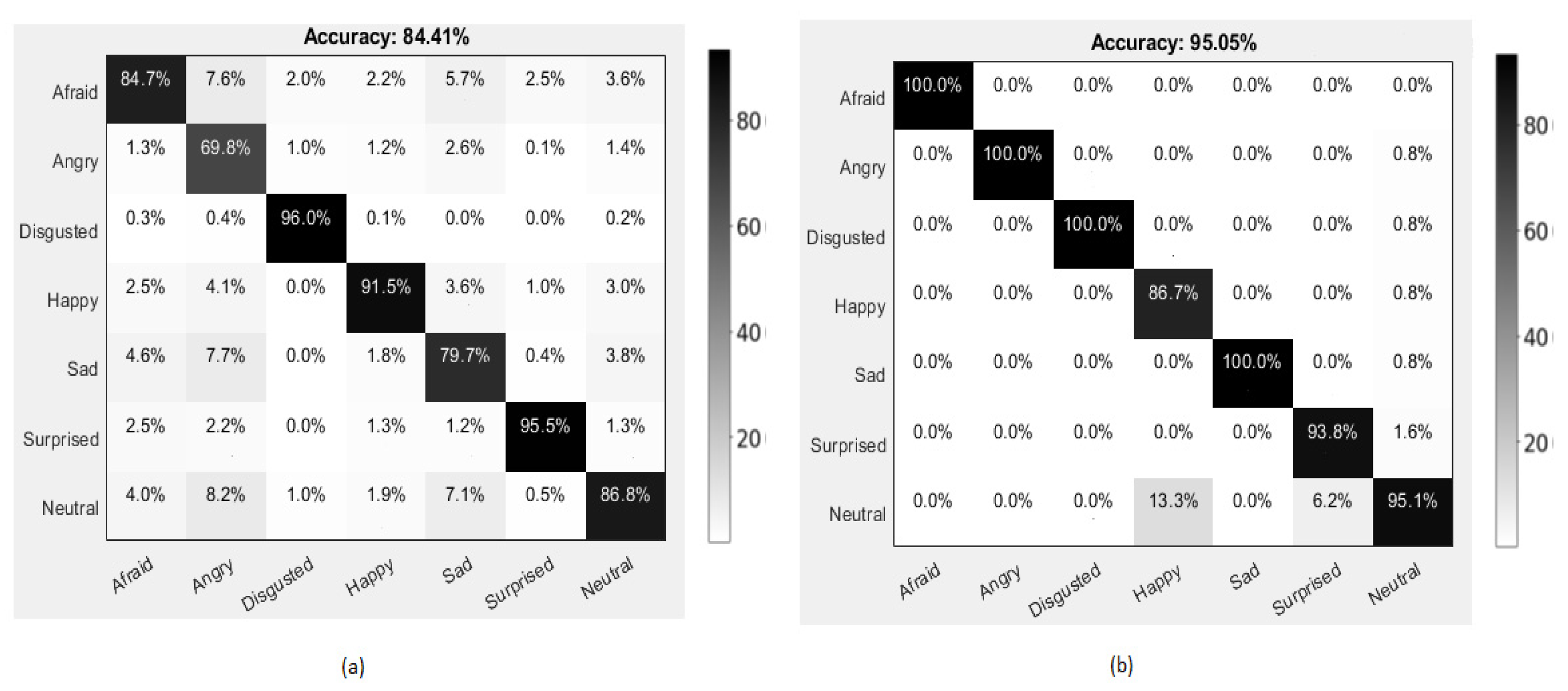
4.3.1. Experiments on FER 2013 Dataset
4.3.2. Experiments on CK+ Dataset
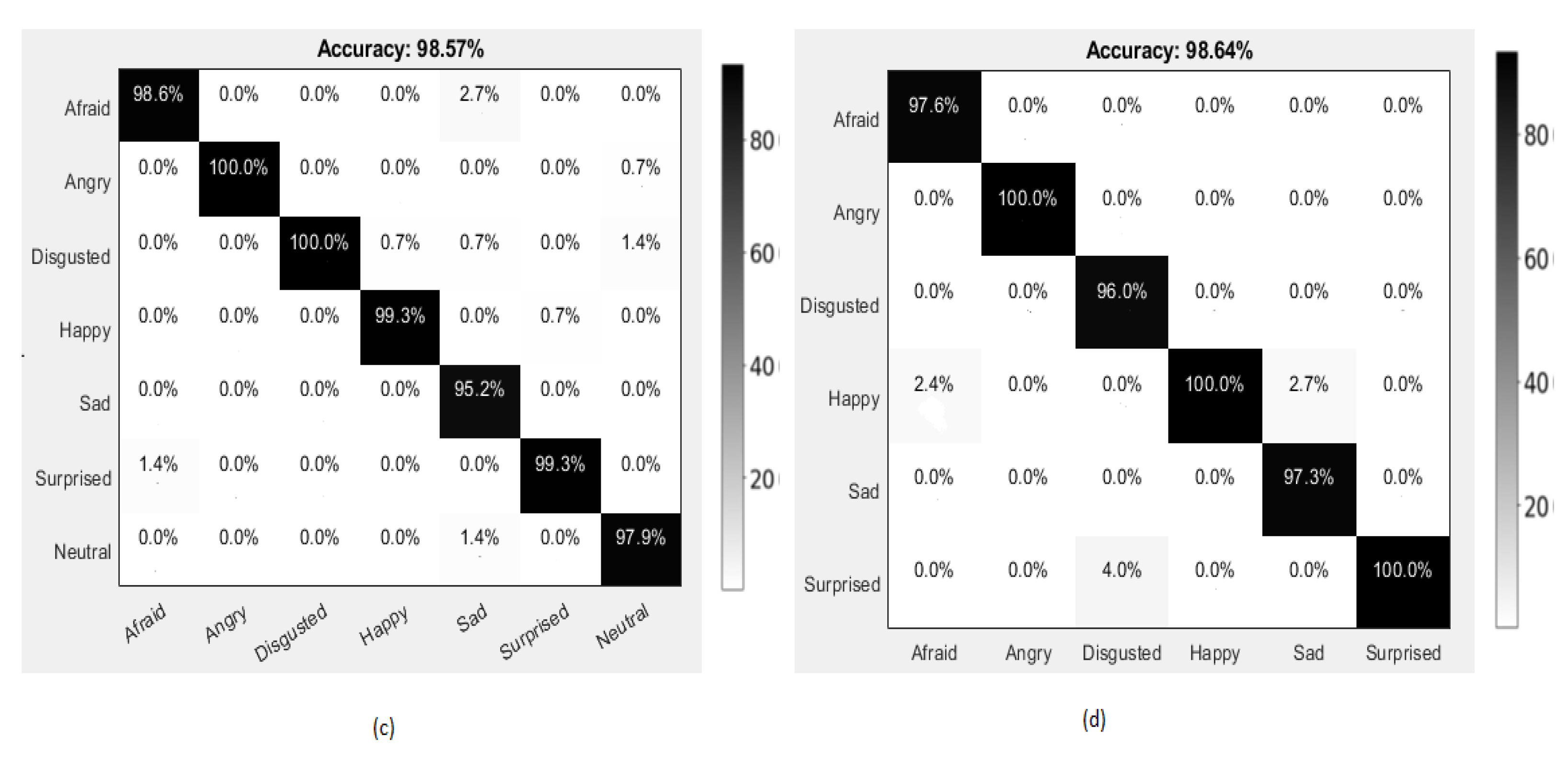
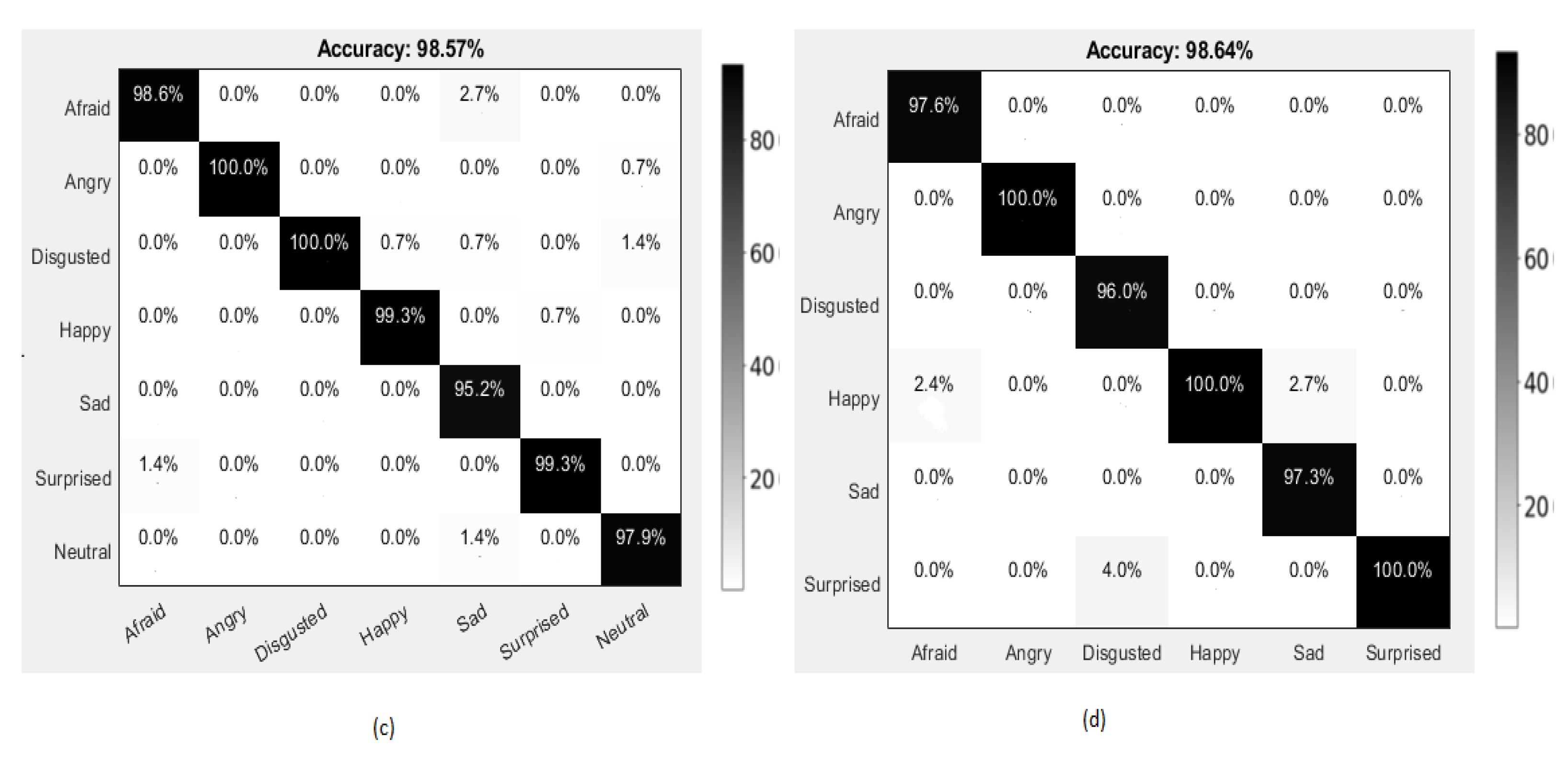
4.3.3. Experiments on KDEF Dataset
4.3.4. Experiments on KMU-FED Dataset
4.4. Emotion Recognition Results
4.5. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AAA | American Automobile Association |
| ADAS | Advanced Driver Assistance Systems |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| E.C.G | Electrocardiogram |
| E.D.A | Electrical Dermal Activity |
| E.E.G | Electroencephalogram |
| FER | Face Expression Recognition |
| LBP | Linear Binary Pattern |
| ML | Machine Learning |
| P.P.G | Photoplethysmography |
| ReLU | Rectified Linear Unit |
| ROI | Region of Interest |
| S.G.D | Stochastic Gradient Descent |
| SVM | Support Vector Machine |
References
- Kim, W.; Añorve, V.; Tefft, B.C. American Driving Survey, 2014–2017 (Research Brief); AAA Foundation for Traffic Safety: Washington, DC, USA, 2019. [Google Scholar]
- Brubacher, J.R.; Chan, H.; Purssell, E.; Tuyp, B.; Desapriya, E.; Mehrnoush, V. Prevalance of driver-related risk factors for crashing in mildly injured drivers. In Proceedings of the Twenty-Fourth Canadian Multidisciplinary Road Safety Conference, Vancouver, BC, Canada, 1–4 June 2014. [Google Scholar]
- AAA Foundation for Traffic Safety. 2020 Traffic Safety Culture Index (Technical Report); AAA Foundation for Traffic Safety: Washington, DC, USA, 2021. [Google Scholar]
- Desapriya, E.; Yassami, S.; Mehrnoush, V. Vehicle danger and older pedestrian safety. Am. J. Prev. Med. 2018, 55, 579–580. [Google Scholar] [CrossRef]
- Bhattacharya, S.; Gupta, M. A survey on: Facial emotion recognition invariant to pose, illumination and age. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Sukhavasi, S.B.; Sukhavasi, S.B.; Elleithy, K.; Abuzneid, S.; Elleithy, A. CMOS Image Sensors in Surveillance System Applications. Sensors 2021, 21, 488. [Google Scholar] [CrossRef] [PubMed]
- Zepf, S.; Hernandez, J.; Schmitt, A.; Minker, W.; Picard, R.W. Driver emotion recognition for intelligent vehicles: A survey. ACM Comput. Surv. CSUR 2020, 53, 1–30. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Liu, W.; Wang, Z.; Liu, X.; Zeng, N.; Liu, Y.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Yang, G.; Lin, Y.; Bhattacharya, P. A driver fatigue recognition model based on information fusion and dynamic Bayesian network. Inf. Sci. 2010, 180, 1942–1954. [Google Scholar] [CrossRef]
- Akin, M.; Kurt, M.B.; Sezgin, N.; Bayram, M. Estimating vigilance level by using E.E.G. and E.M.G. signals. Neural Comput. Appl. 2008, 17, 227–236. [Google Scholar] [CrossRef]
- Wang, J.; Gong, Y. Recognition of multiple ‘drivers’ emotional state. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; IEEE: New York, NY, USA, 2008; pp. 1–4. [Google Scholar]
- Ooi, J.S.K.; Ahmad, S.A.; Chong, Y.Z.; Ali, S.H.M.; Ai, G.; Wagatsuma, H. Driver emotion recognition framework based on electrodermal activity measurements during simulated driving conditions. In Proceedings of the 2016 IEEE EMBS Conference on Biomedical Engineering and Sciences (IECBES), Kuala Lumpur, Malaysia, 4–8 December 2016; IEEE: New York, NY, USA, 2016; pp. 365–369. [Google Scholar]
- Sukhavasi, S.B.; Sukhavasi, S.B.; Elleithy, K.; Abuzneid, S.; Elleithy, A. Human Body-Related Disease Diagnosis Systems Using CMOS Image Sensors: A Systematic Review. Sensors 2021, 21, 2098. [Google Scholar] [CrossRef]
- Zhan, C.; Li, W.; Ogunbona, P.; Safaei, F. A real-time facial expression recognition system for online games. Int. J. Comput. Games Technol. 2008, 2008, 542918. [Google Scholar] [CrossRef] [Green Version]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution grayscale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Jain, A.K.; Farrokhnia, F. Unsupervised texture segmentation using Gabor filters. Pattern Recognit. 1991, 24, 1167–1186. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. TIST 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN model-based approach in classification. In OTM Confederated International Conferences “On the Move to Meaningful Internet Systems”; Springer: Berlin/Heidelberg, Germany, 2003; pp. 986–996. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Processing Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Jeong, M.; Ko, B.C. Driver’s facial expression recognition in real-time for safe driving. Sensors 2018, 18, 4270. [Google Scholar] [CrossRef] [Green Version]
- Yasmin, S.; Pathan, R.K.; Biswas, M.; Khandaker, M.U.; Faruque, M.R.I. Development of a robust multi-scale featured local binary pattern for improved facial expression recogni-tion. Sensors 2020, 20, 5391. [Google Scholar] [CrossRef]
- Jeong, M.; Nam, J.; Ko, B.C. Lightweight multilayer random forests for monitoring driver emotional status. IEEE Access 2020, 8, 60344–60354. [Google Scholar] [CrossRef]
- Niu, B.; Gao, Z.; Guo, B. Facial expression recognition with LBP and ORB features. Comput. Intell. Neurosci. 2021, 2021, 8828245. [Google Scholar] [CrossRef]
- Mahesh, V.G.V.; Chen, C.; Rajangam, V.; Raj, A.N.J.; Krishnan, P.T. Shape and Texture Aware Facial Expression Recognition Using Spatial Pyramid Zernike Moments and Law’s Textures Feature Set. IEEE Access 2021, 9, 52509–52522. [Google Scholar] [CrossRef]
- Xie, S.; Hu, H. Facial expression recognition using hierarchical features with deep comprehensive multipatches aggregation convolutional neural networks. IEEE Trans. Multimed. 2018, 21, 211–220. [Google Scholar] [CrossRef]
- Puthanidam, R.V.; Moh, T.-S. A Hybrid approach for facial expression recognition. In Proceedings of the 12th International Conference on Ubiquitous Information Management and Communication, Langkawi, Malaysia, 5–7 January 2018; pp. 1–8. [Google Scholar]
- Pandey, R.K.; Karmakar, S.; Ramakrishnan, A.G.; Saha, N. Improving facial emotion recognition systems using gradient and laplacian images. arXiv 2019, arXiv:1902.05411. [Google Scholar]
- Agrawal, A.; Mittal, N. Using CNN for facial expression recognition: A study of the effects of kernel size and number of filters on accuracy. Vis. Comput. 2020, 36, 405–412. [Google Scholar] [CrossRef]
- Riaz, M.N.; Shen, Y.; Sohail, M.; Guo, M. Exnet: An efficient approach for emotion recognition in the wild. Sensors 2020, 20, 1087. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Minaee, S.; Minaei, M.; Abdolrashidi, A. Deep-emotion: Facial expression recognition using attentional convolutional network. Sensors 2021, 21, 3046. [Google Scholar] [CrossRef] [PubMed]
- Park, S.-J.; Kim, B.-G.; Chilamkurti, N. A Robust Facial Expression Recognition Algorithm Based on Multi-Rate Feature Fusion Scheme. Sensors 2021, 21, 6954. [Google Scholar] [CrossRef]
- Shehu, H.A.; Sharif, M.H.; Uyaver, S. Facial expression recognition using deep learning. AIP Conf. Proc. 2021, 2334, 070003. [Google Scholar]
- Hasani, B.; Mahoor, M.H. Facial expression recognition using enhanced deep 3D convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 30–40. [Google Scholar]
- Georgescu, M.-I.; Ionescu, R.T.; Popescu, M. Local learning with deep and handcrafted features for facial expression recognition. IEEE Access 2019, 7, 64827–64836. [Google Scholar] [CrossRef]
- Li, C.; Ma, N.; Deng, Y. Multi-network fusion based on cnn for facial expression recognition. In Proceedings of the 2018 International Conference on Computer Science, Electronics and Communication Engineering (CSECE 2018), Wuhan, China, 7–8 February 2018; Atlantis Press: Paris, France, 2018; pp. 166–169. [Google Scholar]
- Ruiz-Garcia, A.; Elshaw, M.; Altahhan, A.; Palade, V. A hybrid deep learning neural approach for emotion recognition from facial expressions for socially assistive robots. Neural Comput. Appl. 2018, 29, 359–373. [Google Scholar] [CrossRef]
- Cao, T.; Li, M. Facial expression recognition algorithm based on the combination of CNN and K-Means. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai China, 22–24 February 2019; pp. 400–404. [Google Scholar]
- Liu, S.; Tang, X.; Wang, D. Facial Expression Recognition Based on Sobel Operator and Improved CNN-SVM. In Proceedings of the 2020 IEEE 3rd International Conference on Information Communication and Signal Processing (ICICSP), Shanghai, China, 12–15 September 2020; IEEE: New York, NY, USA, 2020; pp. 236–240. [Google Scholar]
- Fei, Z.; Yang, E.; Li, D.D.-U.; Butler, S.; Ijomah, W.; Li, X.; Zhou, H. Deep convolution network based emotion analysis towards mental health care. Neurocomputing 2020, 388, 212–227. [Google Scholar] [CrossRef]
- Yang, Y.; Zhang, H.; Li, D.; Xiao, F.; Yang, S. Facial Expression Recognition Based on Transfer Learning and SVM. J. Phys. Conf. Ser. 2021, 2025, 012015. [Google Scholar] [CrossRef]
- Bhatti, Y.K.; Jamil, A.; Nida, N.; Yousaf, M.H.; Viriri, S.; Velastin, S.A. Facial expression recognition of instructor using deep features and extreme learning machine. Computational Intelligence and Neuroscience 2021, 2021, 5570870. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Mei, X.; Liu, H.; Yuan, S.; Qian, T. Detecting negative emotional stress based on facial expression in real time. In Proceedings of the 2019 IEEE 4th International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; IEEE: New York, NY, USA, 2019; pp. 430–434. [Google Scholar]
- Leone, A.; Caroppo, A.; Manni, A.; Siciliano, P. Vision-based road rage detection framework in automotive safety applications. Sensors 2021, 21, 2942. [Google Scholar] [CrossRef] [PubMed]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Viola, P.; Jones, M.J. Robust Real-Time Face Detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, T.; Thaler, D.; Lee, D.-H.; et al. Challenges in representation learning: A report on three machine learning contests. In International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 117–124. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: New York, NY, USA, 2010; pp. 94–101. [Google Scholar]
- Lundqvist, D.; Flykt, A.; Öhman, A. Karolinska directed emotional faces. Cogn. Emot. 1998. [Google Scholar] [CrossRef]
- KMU-FED. Available online: http://cvpr.kmu.ac.kr/KMU-FED.htm (accessed on 23 December 2021).
- Nearest Neighbor Interpolation. Available online: https://www.imageeprocessing.com/2017/11/nearest-neighbor-interpolation.htm (accessed on 23 December 2021).
- Cadena, L.; Zotin, A.; Cadena, F.; Korneeva, A.; Legalov, A.; Morales, B. Noise reduction techniques for processing of medical images. Proc. World Congr. Eng. 2017, 1, 5–9. [Google Scholar]
- Mustafa, W.A.; Kader, M.M.M.A. A review of histogram equalization techniques in image enhancement application. J. Phys. Conf. Ser. 2018, 1019, 012026. [Google Scholar] [CrossRef]
- Available online: https://www.owlnet.rice.edu/~elec539/Projects99/BACH/proj2/wiener.html (accessed on 30 August 2021).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Int. Conf. Mach. Learn. PMLR 2015, 37, 448–456. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- d’Ascoli, S.; Touvron, H.; Leavitt, M.L.; Morcos, A.S.; Biroli, G.; Sagun, L. ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases. arXiv 2021, arXiv:2103.10697. [Google Scholar]
- Zhu, X.; Jia, Y.; Jian, S.; Gu, L.; Pu, Z. ViTT: Vision Transformer Tracker. Sensors 2021, 21, 5608. [Google Scholar] [CrossRef] [PubMed]
- Sun, M.; Ma, H.; Kang, G.; Jiang, Y.; Chen, T.; Ma, X.; Wang, Z.; Wang, Y. VAQF: Fully Automatic Software-hardware Co-design Framework for Low-bit Vision Transformer. arXiv 2022, arXiv:2201.06618. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Databases | Parameters | Settings |
|---|---|---|
| Image Size | 256 × 256 | |
| Optimizer | Stochastic Gradient Descent (S.G.D.) | |
| CK+, | Loss Function | Cross Entropy |
| FER 2013, | Activation Function | ReLU |
| KDEF, | Batch Size | 128 |
| KMUFED | Learning rate | 0.001 |
| Epochs | 100 | |
| Momentum | 0.9 | |
| Validation Frequency | 30 |
| Databases | Parameters | Settings |
|---|---|---|
| Objective Function | Hinge loss | |
| CK+, | Solver | SGD |
| FER 2013, | Kernel | Linear |
| KDEF, KMUFED | Type | One-vs-one |
| Comparison Methods | Accuracy (%) |
|---|---|
| CNN-MNF [37] | 70.3 |
| CNN-BOVW-SVM [36] | 75.4 |
| KCNN-SVM [39] | 80.3 |
| VCNN [30] | 65.7 |
| EXNET [31] | 73.5 |
| Deep-Emotion [32] | 70.0 |
| IRCNN-SVM [42] | 68.1 |
| GLFCNN+SVM (Our Proposed Approach) | 84.4 |
| Comparison Methods | Accuracy (%) |
|---|---|
| Inception-Resnet and LSTM [35] | 93.2 |
| DCMA-CNN [27] | 93.4 |
| WRF [22] | 92.6 |
| LMRF [24] | 93.4 |
| VGG11+SVM [40] | 92.2 |
| DNN+RELM [43] | 86.5 |
| LBP+ORB+SVM [25] | 93.2 |
| MDNETWORK [33] | 96.2 |
| GLFCNN+SVM (Our Proposed Approach) | 95.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sukhavasi, S.B.; Sukhavasi, S.B.; Elleithy, K.; El-Sayed, A.; Elleithy, A. A Hybrid Model for Driver Emotion Detection Using Feature Fusion Approach. Int. J. Environ. Res. Public Health 2022, 19, 3085. https://doi.org/10.3390/ijerph19053085
Sukhavasi SB, Sukhavasi SB, Elleithy K, El-Sayed A, Elleithy A. A Hybrid Model for Driver Emotion Detection Using Feature Fusion Approach. International Journal of Environmental Research and Public Health. 2022; 19(5):3085. https://doi.org/10.3390/ijerph19053085
Chicago/Turabian StyleSukhavasi, Suparshya Babu, Susrutha Babu Sukhavasi, Khaled Elleithy, Ahmed El-Sayed, and Abdelrahman Elleithy. 2022. "A Hybrid Model for Driver Emotion Detection Using Feature Fusion Approach" International Journal of Environmental Research and Public Health 19, no. 5: 3085. https://doi.org/10.3390/ijerph19053085
APA StyleSukhavasi, S. B., Sukhavasi, S. B., Elleithy, K., El-Sayed, A., & Elleithy, A. (2022). A Hybrid Model for Driver Emotion Detection Using Feature Fusion Approach. International Journal of Environmental Research and Public Health, 19(5), 3085. https://doi.org/10.3390/ijerph19053085