
Selecting External Controls for Internal Cases Using Stratification Score Matching Methods


Abstract
:1. Introduction
2. Materials and Methods
2.1. Demonstration 1
2.2. Demonstration 2
3. Results
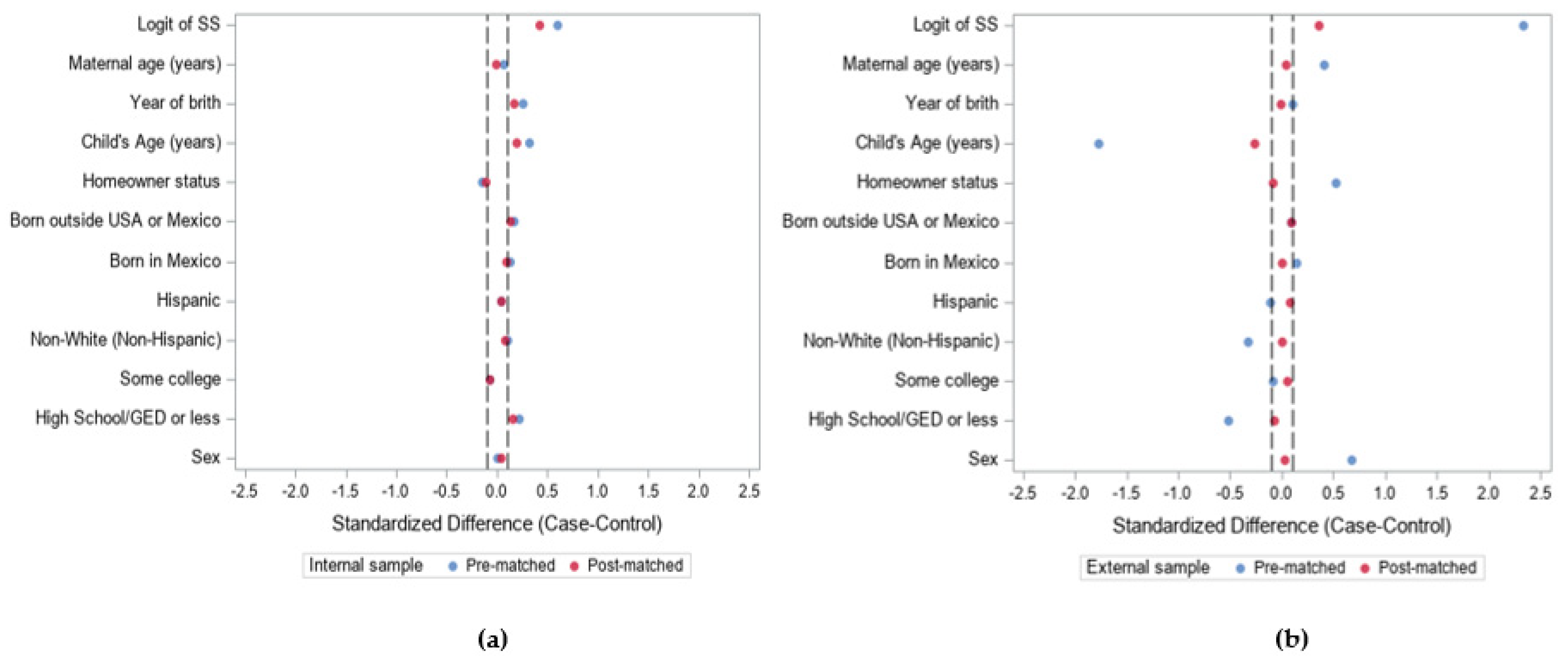
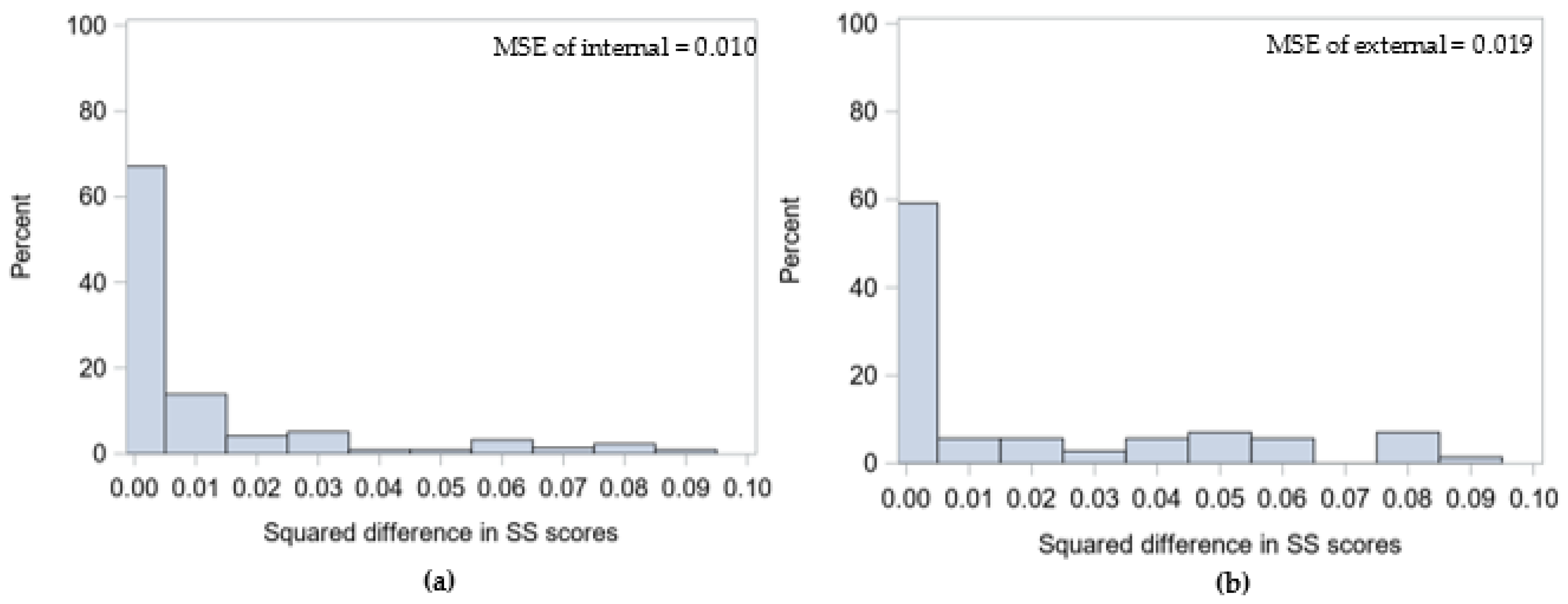
3.1. Demonstration 1
3.2. Demonstration 2
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Viet, S.M.; Falman, J.C.; Merrill, L.S.; Faustman, E.M.; Savitz, D.A.; Mervish, N.; Barr, D.B.; Peterson, L.A.; Wright, R.; Balshaw, D. Human Health Exposure Analysis Resource (HHEAR): A model for incorporating the exposome into health studies. Int. J. Hyg. Environ. Health 2021, 235, 113768. [Google Scholar] [CrossRef]
- Balshaw, D.M.; Collman, G.W.; Gray, K.A.; Thompson, C.L. The Children’s Health Exposure Analysis Resource (CHEAR): Enabling Research into the Environmental Influences on Children’s Health Outcomes. Curr. Opin. Pediatrics 2017, 29, 385. [Google Scholar] [CrossRef] [PubMed]
- Lewallen, S.; Courtright, P. Epidemiology in practice: Case-control studies. Community Eye Health 1998, 11, 57. [Google Scholar] [PubMed]
- Dey, T.; Mukherjee, A.; Chakraborty, S. A practical overview of case-control studies in clinical practice. Chest 2020, 158, S57–S64. [Google Scholar] [CrossRef] [PubMed]
- Stuart, E.A. Matching methods for causal inference: A review and a look forward. Stat. Sci. 2010, 25, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Mansournia, M.A.; Jewell, N.P.; Greenland, S. Case–control matching: Effects, misconceptions, and recommendations. Eur. J. Epidemiol. 2018, 33, 5–14. [Google Scholar] [CrossRef]
- Stürmer, T.; Brenner, H. Degree of matching and gain in power and efficiency in case-control studies. Epidemiology 2001, 12, 101–108. [Google Scholar] [CrossRef]
- D’Agostino, R.B., Jr. Propensity score methods for bias reduction in the comparison of a treatment to a non-randomized control group. Stat. Med. 1998, 17, 2265–2281. [Google Scholar] [CrossRef]
- Allen, A.S.; Satten, G.A. Control for confounding in case-control studies using the stratification score, a retrospective balancing score. Am. J. Epidemiol. 2011, 173, 752–760. [Google Scholar] [CrossRef]
- Rosenbaum, P.R.; Rubin, D.B. The central role of the propensity score in observational studies for causal effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Ono, Y.; Tanaka, Y.; Sako, K.; Tanaka, M.; Fujimoto, J. Association between sports-related concussion and mouthguard use among college sports players: A case-control study based on propensity score matching. Int. J. Environ. Res. Public Health 2020, 17, 4493. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.-W.; Liou, S.-H.; Hsueh, Y.-M.; Lyu, W.-S.; Liu, C.-S.; Liu, H.-J.; Chung, M.-C.; Hung, P.-H.; Chung, C.-J. Risk of Alzheimer’s disease with metal concentrations in whole blood and urine: A case–control study using propensity score matching. Toxicol. Appl. Pharmacol. 2018, 356, 8–14. [Google Scholar] [CrossRef] [PubMed]
- Hertz-Picciotto, I.; Croen, L.A.; Hansen, R.; Jones, C.R.; van de Water, J.; Pessah, I.N. The CHARGE study: An epidemiologic investigation of genetic and environmental factors contributing to autism. Environ. Health Perspect. 2006, 114, 1119–1125. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Centers for Disease Control and Prevention (CDC). National Health and Nutrition Examination Survey Data; U.S. Department of Health and Human Services, Centers for Disease Control and Prevention: Hyattsville, MD, USA, 2016.
- Austin, P.C. A comparison of 12 algorithms for matching on the propensity score. Stat. Med. 2014, 33, 1057–1069. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Austin, P.C. A critical appraisal of propensity-score matching in the medical literature between 1996 and 2003. Stat. Med. 2008, 27, 2037–2049. [Google Scholar] [CrossRef] [PubMed]
- Lunt, M. Selecting an appropriate caliper can be essential for achieving good balance with propensity score matching. Am. J. Epidemiol. 2014, 179, 226–235. [Google Scholar] [CrossRef]
- Cochran, W.G.; Rubin, D.B. Controlling bias in observational studies: A review. Sankhyā Indian J. Stat. Ser. A 1973, 417–446. [Google Scholar]
- Coca-Perraillon, M. Local and global optimal propensity score matching. In Proceedings of the SAS Global Forum, Boston, MA, USA, 16 April 2007; pp. 1–9. [Google Scholar]
- Austin, P.C. Balance diagnostics for comparing the distribution of baseline covariates between treatment groups in propensity-score matched samples. Stat. Med. 2009, 28, 3083–3107. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, A.; Husain, A.; Love, T.E.; Gambassi, G.; Dell’Italia, L.J.; Francis, G.S.; Gheorghiade, M.; Allman, R.M.; Meleth, S.; Bourge, R.C. Heart failure, chronic diuretic use, and increase in mortality and hospitalization: An observational study using propensity score methods. Eur. Heart J. 2006, 27, 1431–1439. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, M.I.; White, M.; Ekundayo, O.J.; Love, T.E.; Aban, I.; Liu, B.; Aronow, W.S.; Ahmed, A. A history of atrial fibrillation and outcomes in chronic advanced systolic heart failure: A propensity-matched study. Eur. Heart J. 2009, 30, 2029–2037. [Google Scholar] [CrossRef]
- Bennett, D.H.; Busgang, S.A.; Kannan, K.; Parsons, P.J.; Takazawa, M.; Palmer, C.D.; Schmidt, R.J.; Doucette, J.T.; Schweitzer, J.B.; Gennings, C. Environmental exposures to pesticides, phthalates, phenols and trace elements are associated with neurodevelopment in the CHARGE study. Environ. Int. 2022, 161, 107075. [Google Scholar] [CrossRef] [PubMed]
- Normand, S.-L.T.; Landrum, M.B.; Guadagnoli, E.; Ayanian, J.Z.; Ryan, T.J.; Cleary, P.D.; McNeil, B.J. Validating recommendations for coronary angiography following acute myocardial infarction in the elderly: A matched analysis using propensity scores. J. Clin. Epidemiol. 2001, 54, 387–398. [Google Scholar] [CrossRef]
- Arpino, B.; Cannas, M. Propensity score matching with clustered data. An application to the estimation of the impact of caesarean section on the Apgar score. Stat. Med. 2016, 35, 2074–2091. [Google Scholar] [CrossRef]
- Shelton, J.F.; Geraghty, E.M.; Tancredi, D.J.; Delwiche, L.D.; Schmidt, R.J.; Ritz, B.; Hansen, R.L.; Hertz-Picciotto, I. Neurodevelopmental disorders and prenatal residential proximity to agricultural pesticides: The CHARGE study. Environ. Health Perspect. 2014, 122, 1103. [Google Scholar] [CrossRef] [Green Version]
- Kannan, K.; Stathis, A.; Mazzella, M.J.; Andra, S.S.; Barr, D.B.; Hecht, S.S.; Merrill, L.S.; Galusha, A.L.; Parsons, P.J. Quality assurance and harmonization for targeted biomonitoring measurements of environmental organic chemicals across the Children’s Health Exposure Analysis Resource laboratory network. Int. J. Hyg. Environ. Health 2021, 234, 113741. [Google Scholar] [CrossRef]
- Austin, P.C.; Small, D.S. The use of bootstrapping when using propensity-score matching without replacement: A simulation study. Stat. Med. 2014, 33, 4306–4319. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Barker, D.; Robinson, R. Medical Research Council Environmental Epidemiology, U., Fetal and infant origins of adult disease, London. Br. Med. J. 1992, 301, 1111. [Google Scholar] [CrossRef] [Green Version]
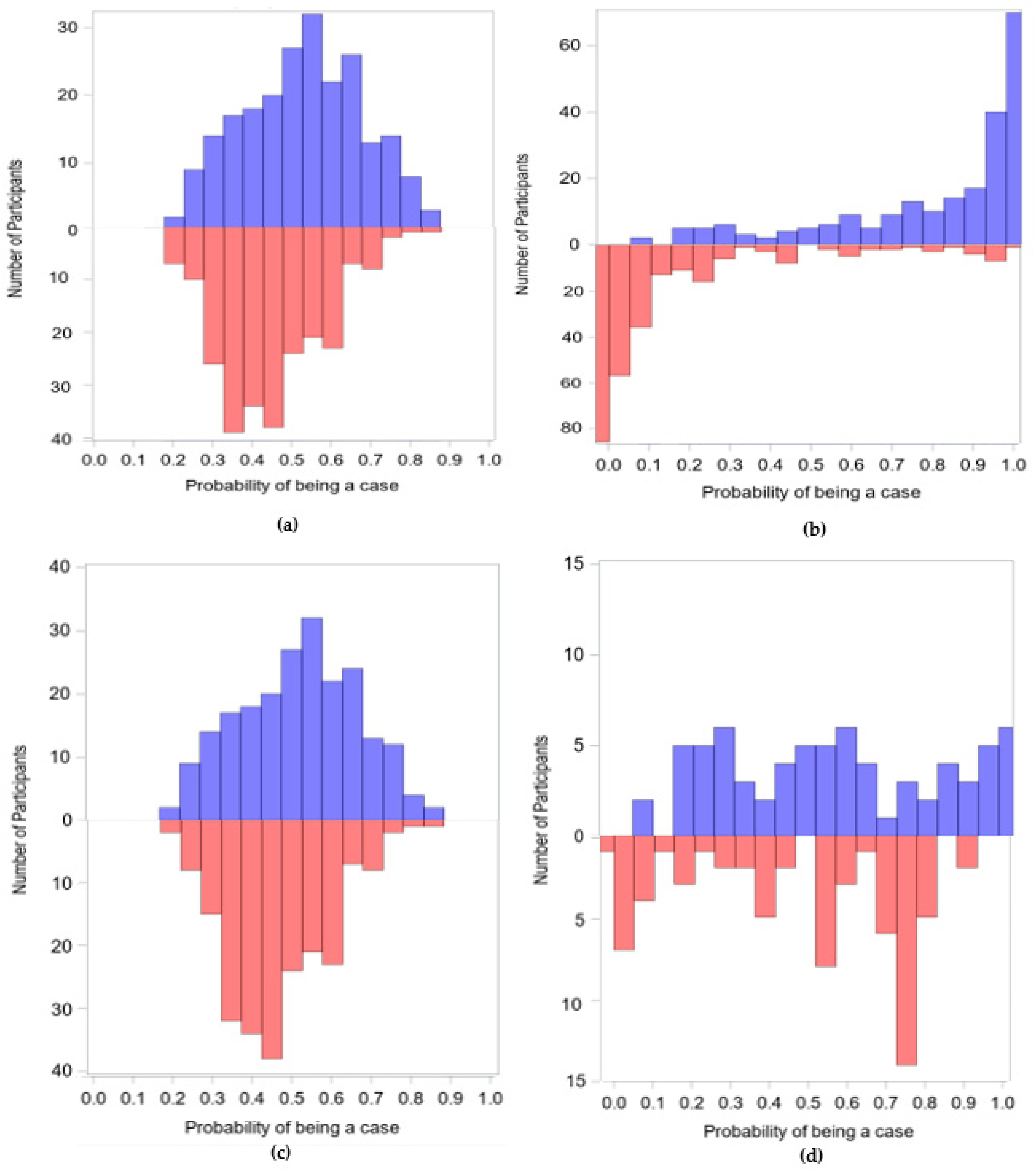
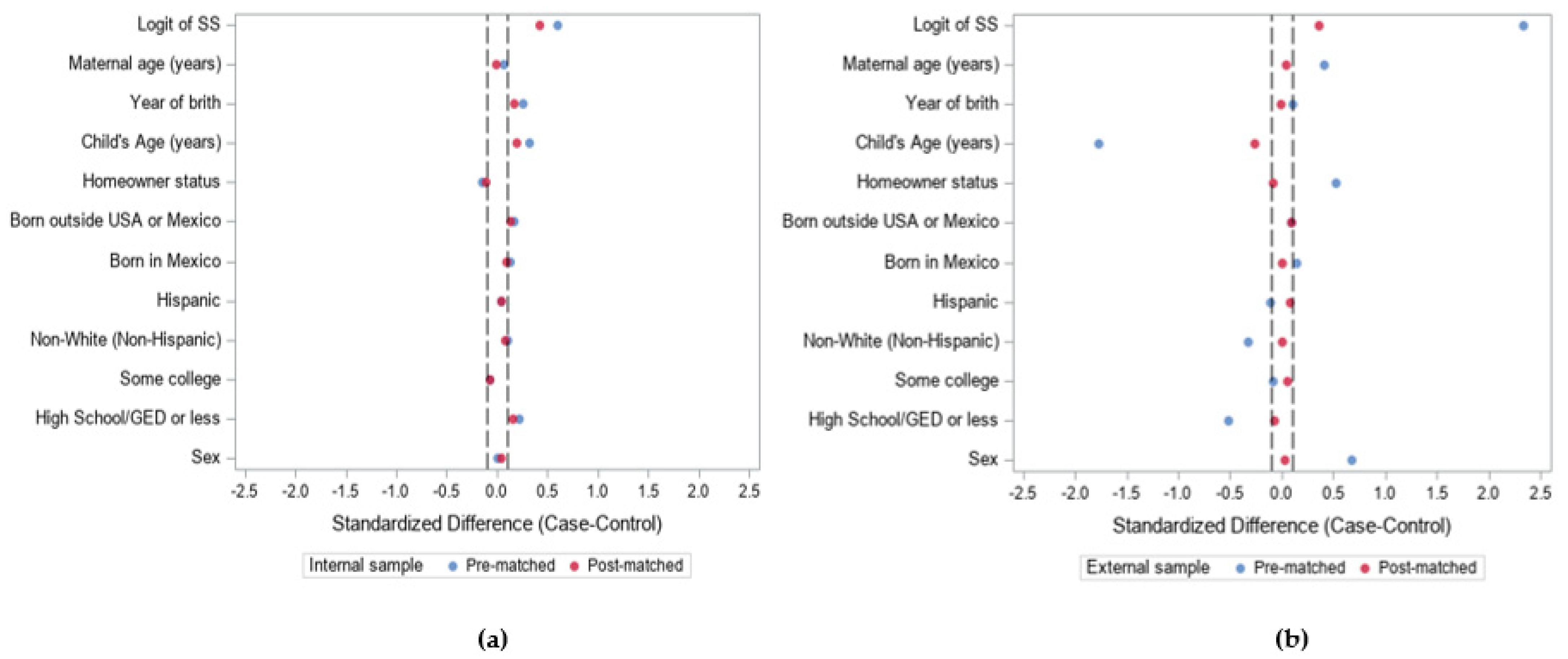
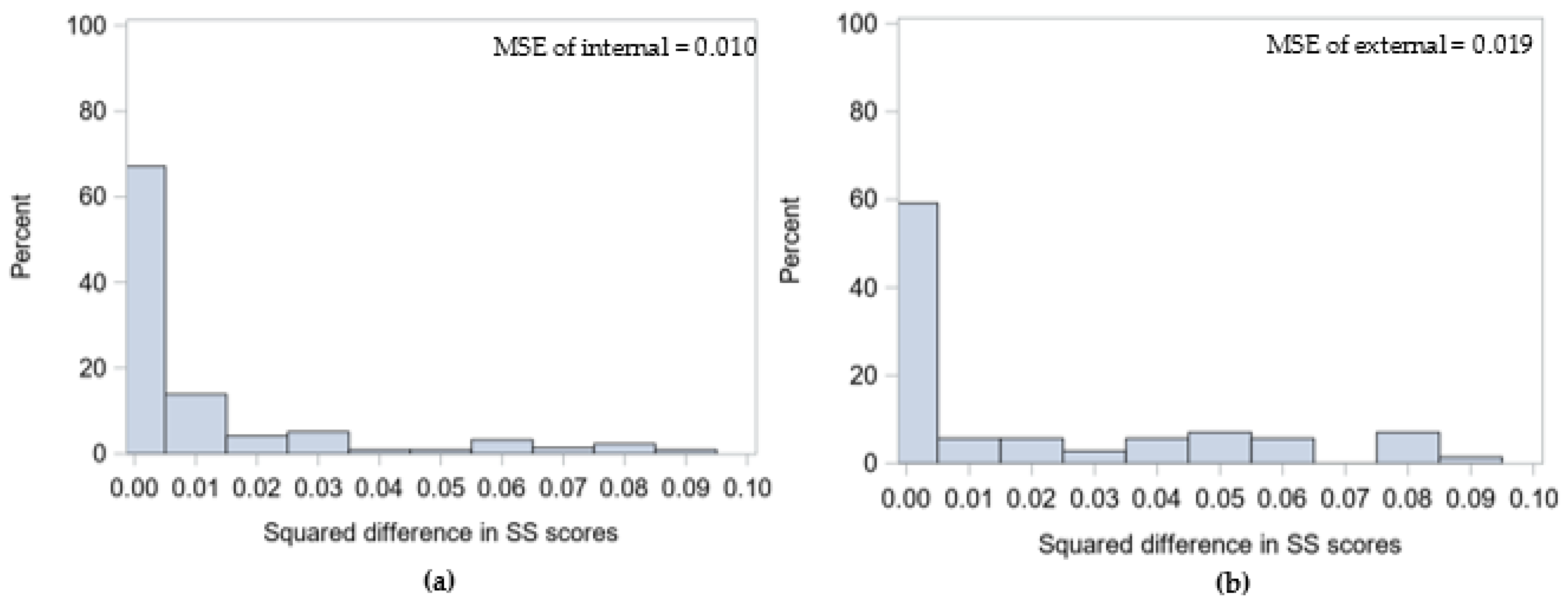

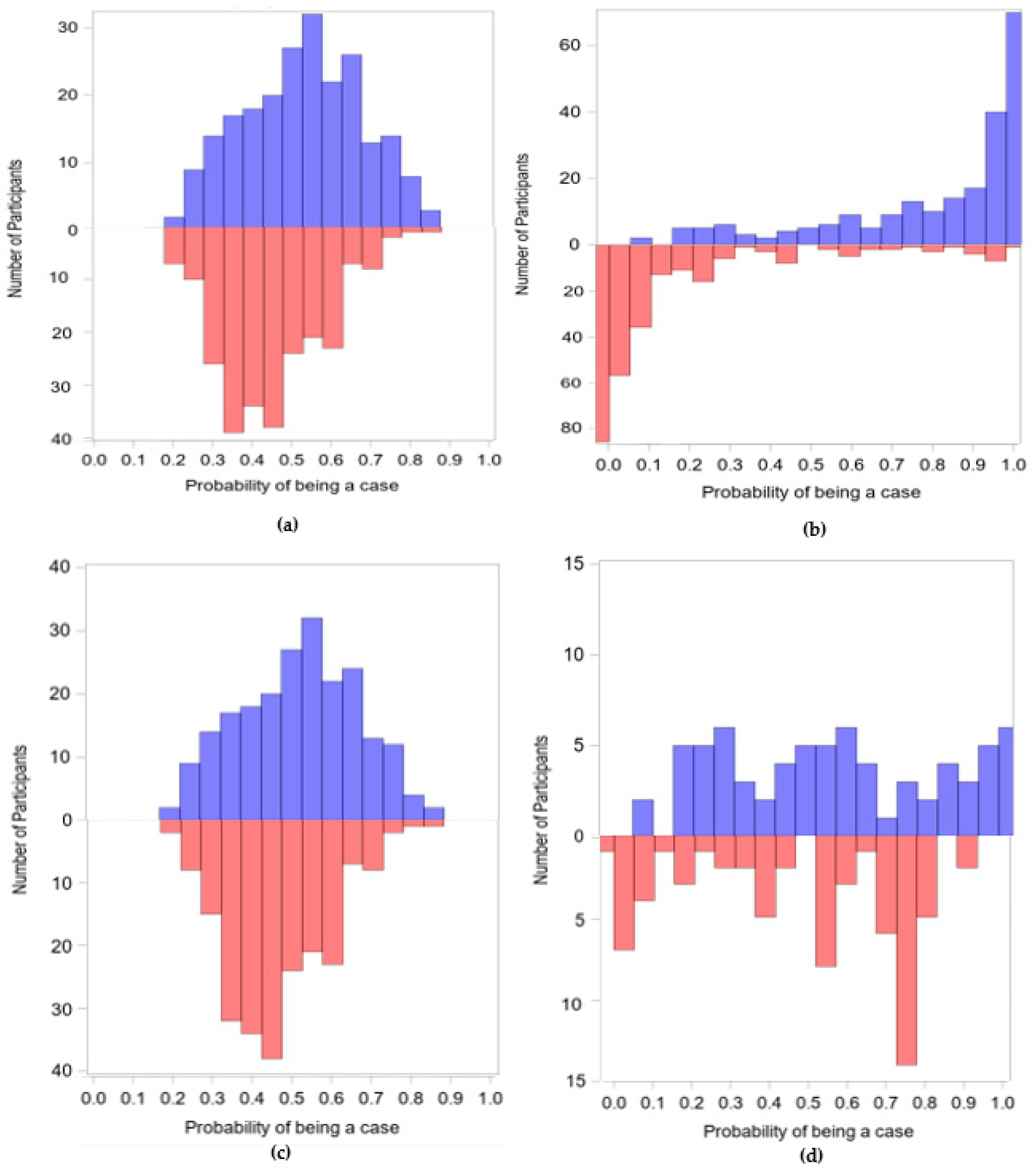{kind=link}
{kind=link}
{kind=link}
| Before Matching | After Matching | |||||
|---|---|---|---|---|---|---|
| Cases (N = 225) | Controls (N = 241) | p-Value a | Cases (N = 216) | Controls (N = 216) | p-Value a | |
| Age of child (years) | 4.07 (0.72) | 3.83 (0.75) | <0.001 | 4.05 (0.73) | 3.91 (0.71) | 0.043 |
| Year of birth | 2007.26 (3.22) | 2006.47 (2.91) | 0.006 | 2007.19 (3.24) | 2006.67 (2.91) | 0.081 |
| Maternal age (years) | 30.74 (5.76) | 30.37 (5.39) | 0.476 | 30.60 (5.69) | 30.63 (5.40) | 0.952 |
| Sex | ||||||
| Female (ref) | 43 (19%) | 46 (19%) | 0.995 | 39 (18%) | 43 (20%) | 0.624 |
| Male | 182 (81%) | 195 (81%) | 177 (82%) | 173 (81%) | ||
| Maternal education | ||||||
| Bachelor/graduate/professional (ref) | 109 (48%) | 129 (53%) | 0.310 0.003 | 108 (50%) | 113 (52%) | 0.312 0.038 |
| Some college | 73 (32%) | 89 (37%) | 70 (32%) | 80 (37%) | ||
| High school/GED or less | 43 (19%) | 23 (10%) | 38 (18%) | 23 (11%) | ||
| Child’s race | ||||||
| White (non-Hispanic) (ref) | 107 (48%) | 132 (55%) | 0.161 0.652 | 105 (49%) | 118 (55%) | 0.355 0.584 |
| Non-White (non-Hispanic) | 55 (24%) | 46 (19%) | 52 (24%) | 44 (20%) | ||
| Hispanic | 63 (28%) | 63 (26%) | 59 (27%) | 54 (25%) | ||
| Birth place of mom | ||||||
| U.S.A. (ref) | 166 (74%) | 205 (85%) | 0.081 0.022 | 163 (75%) | 181 (84%) | 0.208 0.104 |
| Mexico | 18 (8%) | 10 (4%) | 15 (7%) | 9 (4%) | ||
| Outside the U.S.A. or Mexico | 41 (18%) | 26 (11%) | 38 (18%) | 26 (12%) | ||
| Homeowner status | ||||||
| No (ref) | 73 (32%) | 58 (24%) | 0.044 | 68 (31%) | 54 (25%) | 0.135 |
| Yes | 152 (68%) | 183 (76%) | 148 (69%) | 162 (75%) | ||
| Stratification score | 0.53 (0.15) | 0.54 (0.09) | <0.001 | 0.52 (0.14) | 0.46 (0.12) | <0.001 |
| Before Matching | After Matching | |||||
|---|---|---|---|---|---|---|
| Cases (N = 225) | Controls (N = 265) | p-Value a | Cases (N = 71) | Controls (N = 71) | p-Value a | |
| Age of child (years) | 4.07 (0.72) | 5.52 (0.90) | <0.001 | 4.44 (0.52) | 4.69 (1.21) | 0.112 |
| Year of birth | 2007.26 (3.22) | 2006.87 (4.12) | <0.001 | 2008.15 (3.14) | 2008.21 (5.09) | 0.937 |
| Maternal age (years) | 30.74 (5.76) | 28.04 (7.56) | <0.001 | 29.92 (6.37) | 29.69 (6.73) | 0.838 |
| Sex | ||||||
| Female (ref) | 43 (19%) | 145 (55%) | <0.001 | 21 (30%) | 22 (31%) | 0.855 |
| Male | 182 (81%) | 120 (45%) | 50 (70%) | 49 (69%) | ||
| Maternal education | ||||||
| Bachelor/graduate/professional (ref) | 109 (48%) | 43 (16%) | 0.256 <0.001 | 25 (35%) | 24 (34%) | 0.730 0.573 |
| Some college | 73 (32%) | 99 (37%) | 28 (39%) | 26 (37%) | ||
| High school/GED or less | 43 (19%) | 123 (47%) | 18 (25%) | 21 (29%) | ||
| Child’s race/ethnicity | ||||||
| White (non-Hispanic) (ref) | 107 (48%) | 63 (24%) | <0.001 0.025 | 23 (32%) | 26 (37%) | 1.000 0.593 |
| Non-White (non-Hispanic) | 55 (24%) | 112 (42%) | 23 (32%) | 23 (32%) | ||
| Hispanic | 63 (28%) | 90 (34%) | 25 (25%) | 22 (31%) | ||
| Birth place of mom | ||||||
| U.S.A. (ref) | 166 (74%) | 217 (82%) | <0.001 <0.001 | 53 (75%) | 56 (79%) | 1.000 0.494 |
| Mexico | 18 (8%) | 10 (4%) | 5 (7%) | 5 (7%) | ||
| Outside the U.S.A. or Mexico | 41 (18%) | 38 (14%) | 13 (18%) | 10 (14%) | ||
| Homeowner status | ||||||
| No (ref) | 73 (32%) | 167 (63%) | 35 (49%) | 31 (44%) | ||
| Yes | 152 (68%) | 98 (37%) | <0.001 | 36 (51%) | 40 (56%) | 0.501 |
| Stratification score | 0.81 (0.24) | 0.16 (0.24) | <0.001 | 0.57 (0.27) | 0.49 (0.27) | 0.060 |
| OR (95% CI) | p-Value | |
|---|---|---|
| Frequency matched (N = 466 total participants) | 1.20 (1.09, 1.33) | <0.001 |
| Internally matched (N = 216 pairs) | 1.15 (1.04, 1.27) | 0.005 |
| Externally matched (N = 71 pairs) | 1.16 (0.98, 1.37) | 0.080 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Busgang, S.A.; Waller, L.A.; Colicino, E.; D’Agostino, R., Jr.; Hertz-Picciotto, I.; Gennings, C. Selecting External Controls for Internal Cases Using Stratification Score Matching Methods. Int. J. Environ. Res. Public Health 2022, 19, 2549. https://doi.org/10.3390/ijerph19052549
Busgang SA, Waller LA, Colicino E, D’Agostino R Jr., Hertz-Picciotto I, Gennings C. Selecting External Controls for Internal Cases Using Stratification Score Matching Methods. International Journal of Environmental Research and Public Health. 2022; 19(5):2549. https://doi.org/10.3390/ijerph19052549
Chicago/Turabian StyleBusgang, Stefanie A., Lance A. Waller, Elena Colicino, Ralph D’Agostino, Jr., Irva Hertz-Picciotto, and Chris Gennings. 2022. "Selecting External Controls for Internal Cases Using Stratification Score Matching Methods" International Journal of Environmental Research and Public Health 19, no. 5: 2549. https://doi.org/10.3390/ijerph19052549
APA StyleBusgang, S. A., Waller, L. A., Colicino, E., D’Agostino, R., Jr., Hertz-Picciotto, I., & Gennings, C. (2022). Selecting External Controls for Internal Cases Using Stratification Score Matching Methods. International Journal of Environmental Research and Public Health, 19(5), 2549. https://doi.org/10.3390/ijerph19052549