
Health Misinformation Detection in the Social Web: An Overview and a Data Science Approach



Abstract
:1. Introduction
- Summarizing the characteristics of the Web, social media platforms, and health-related content being disseminated online, by considering factors of information genuineness in the health domain;
- Identifying key features (both “general-purpose” and domain-specific) that may be useful for detecting health misinformation in Web pages and social media content; this involves both synthesizing features that have been used in the literature for this purpose and investigating additional features that may be useful for the purpose considered, but employed to date for different research tasks;
- Studying the impact of such features when used in association with supervised learning techniques; this objective requires a comparison between different approaches that have been used so far to solve the problem considered, especially concerning “general” information (i.e., not health-related). This comparison involves the use of classical machine learning algorithms and the implementation of Convolutional Neural Networks, Bidirectional Long Short-Term Memory networks, and Hierarchical Attention Networks, which have been used in the literature to tackle document classification problems and are used in this work as an additional baseline for comparison;
- Evaluating the obtained results on publicly available datasets, which consider health misinformation in various communication media, in distinct forms, and with respect to various health-related topics.
2. An Overview on Health Misinformation Detection
2.1. Manual or Pseudo-Automated Approaches
- The Web is characterized by the presence of a considerable amount of incomplete or poor-quality information, accompanied, however, by the presence of some excellent content and sources;
- Using keyword searches (search by query), instead of referring to known URLs (navigational search), increases the likelihood of stumbling upon less than credible health information;
- Most users make a hasty reading of content, without doing research related to the organization, author, or source of the health information being disseminated;
- When the source is taken into account, however, institutional sites are perceived as more credible than others whose source is unknown or not authoritative [14]. Furthermore, users tend to trust content produced, sponsored, or published by health care institutions and physicians (e.g., if the content link back to, or cite, professionals in the field). Conversely, “paid links” and broken links can reduce the credibility of a site or an article. However, there is no unequivocal agreement on a particular source, but it appears that differences in judgments are attributable to demographic factors and individual circumstances [15].
2.1.1. Centralized Approaches
2.1.2. Distributed Approaches
2.2. Automated Approaches
3. Materials and Methods
3.1. Datasets
3.1.1. CoAID
- News: are considered as “credible” news those extracted from nine highly-reliable sources including public health institutions or authorities, such as: Healthline [46], ScienceDaily [47], the National Institutes of Health (NIH) [48], MedicalNews Today (MNT) [49], the Mayo Clinic [50], the Cleveland Clinic [51], WebMD [52], the World Health Organization (WHO) [53], and the Centers for Disease Control and Prevention (CDC) [54]. As for “not credible” news, the authors include those reported by various sites involved in fact-checking (e.g., WHO and MNT) as false myths.
- Claims: they are sourced from the official Web site and the official Twitter account of the WHO and from the MNT Web site. These claims are information expressed in the form of answers to common questions or false myths related to COVID-19.
3.1.2. ReCOVery
3.1.3. FakeHealth
3.1.4. Data Gathering and Cleaning
3.2. Health Misinformation Features
3.2.1. Textual Representation Features
3.2.2. Linguistic-Stylistic Features
3.2.3. Linguistic-Emotional Features
3.2.4. Linguistic-Medical Features
- Normalized count of medical terms: this is a count of the medical terms present in a given text normalized by the total number of words. Extracting this feature required the use of a Named-Entity Recognition (NER) model specially trained on medical information, namely the spaCy library [69]. Such a model is particularly suitable since it is trained on MedMentions [70], a collection of 4392 titles and abstracts published in PubMed [71], manually annotated by a team of experts. The main limitation of using this application lies in the fact that it is not able to recognize terms introduced in the medical-scientific language after the training operation (in the specific case that occurred in 2018). To overcome this, the output of the model has been supplemented with manual extraction of all terms related to COVID-19 and not present in the original dictionary. This list of words is the same as that used to generate the COVID-19 stream made available by Twitter for research purposes and accessible at the following link: https://developer.twitter.com/en/docs/labs/covid19-stream/overview/ (accessed on 3 February 2022).
- Normalized count of unique medical terms: in this case, the (normalized) unique count of medical terms is considered. The rationale behind this choice is because we expect that a high number of distinct medical terms corresponds to a higher mastery of the specific language and therefore of the specific medical domain.
- Hyperlink count: the presence of external hyperlinks can be associated with misinformation when such links point to misleading and/or advertising content. The computation of such feature was done by counting the number of hyperlinks, extracted using appropriate regular expressions.
- Normalized count of commercial terms: As illustrated in the literature [13], the higher the number of commercial terms, the less credible is perceived the related information, due to the for-profit purpose of such information. At a practical level, a list of 45 commercial terms taken from [72] (such as “sale”, “deal”, “ad”, etc.) has been compiled. The frequency of such terms in the health-related content has been computed and normalized on the basis of the total number of terms present in the considered text.
3.2.5. Propagation-Network Features
- Structural features: variables designed to capture aspects of network structure and topology. They refer to characteristics such as depth, breadth, and out-degree (in this case representing a measure of popularity) at both the global and cascade network levels;
- Temporal features: variables whose goal is to capture temporal aspects related to information dissemination. They refer to characteristics such as duration of dissemination, average speed of dissemination, and average speed of response at both the global network and cascade levels;
- Linguistic features: variables designed to capture the linguistic aspects of messages that interact with information dissemination. These variables are only applied within the micro-network, since at the retweet level, and to a large extent at the tweet level, the recorded messages are the same. This group of features relates to the sentiment analysis of the above texts both globally and at the cascade level. In this case, to assess the sentiment related to such short texts, we employed VADER [73], a lexicon and rule-based sentiment analysis tool that is particularly suitable for social media content;
- Engagement features: variables that assess the level of appreciation received by nodes expressed in the form of “favorites”.
3.2.6. User-Profile Features
3.3. Health Misinformation Detection
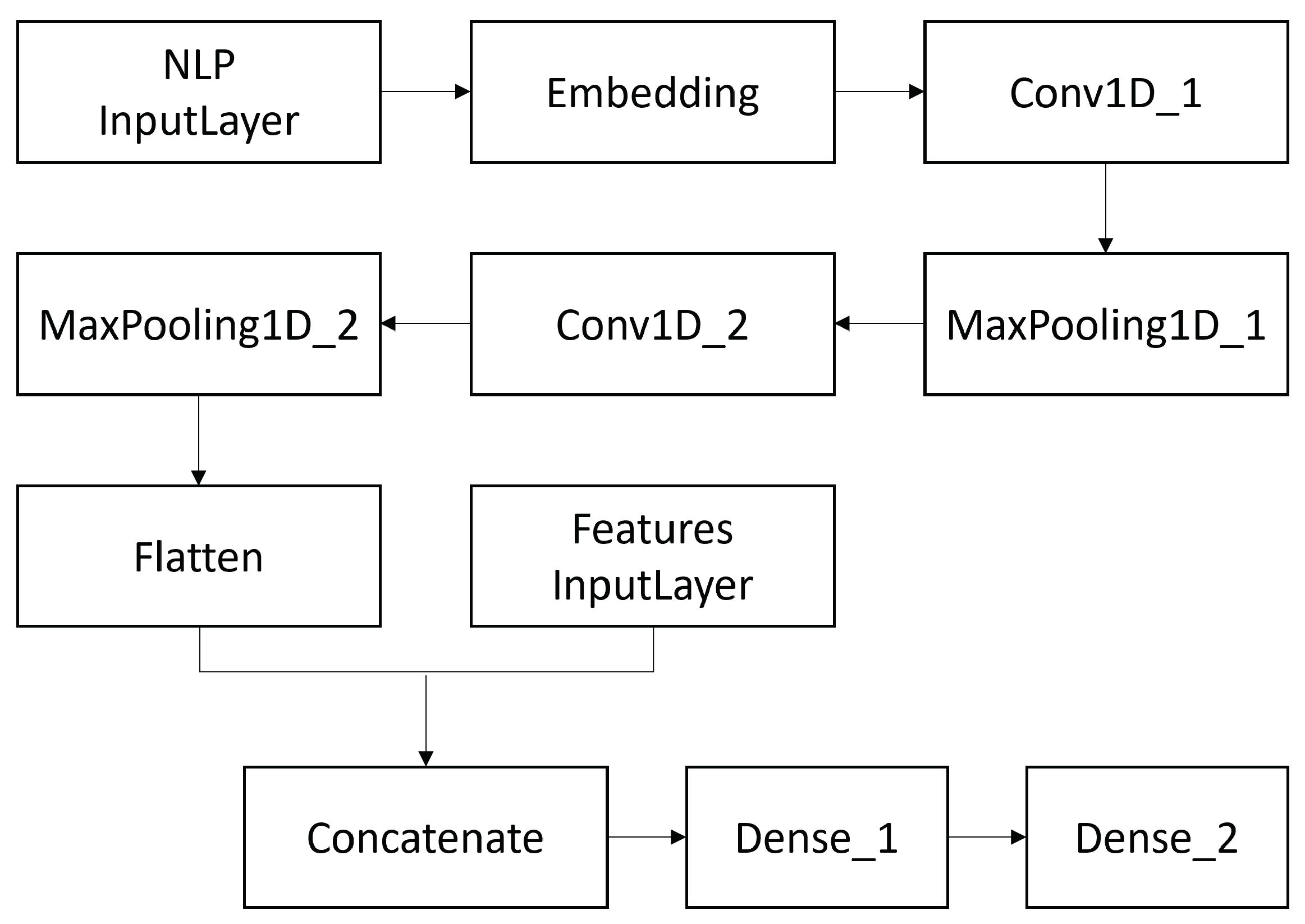
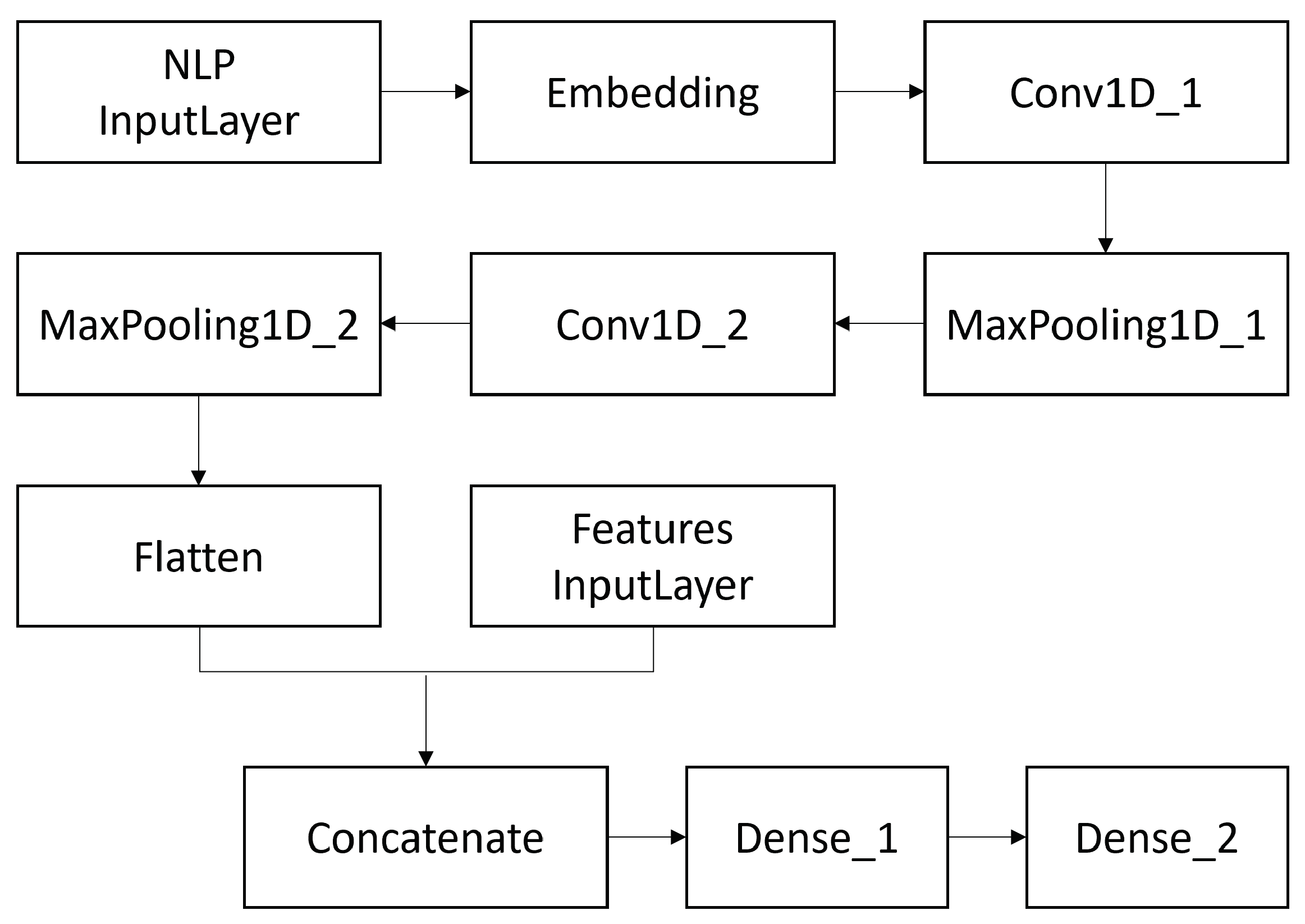
3.3.1. Convolutional Neural Networks
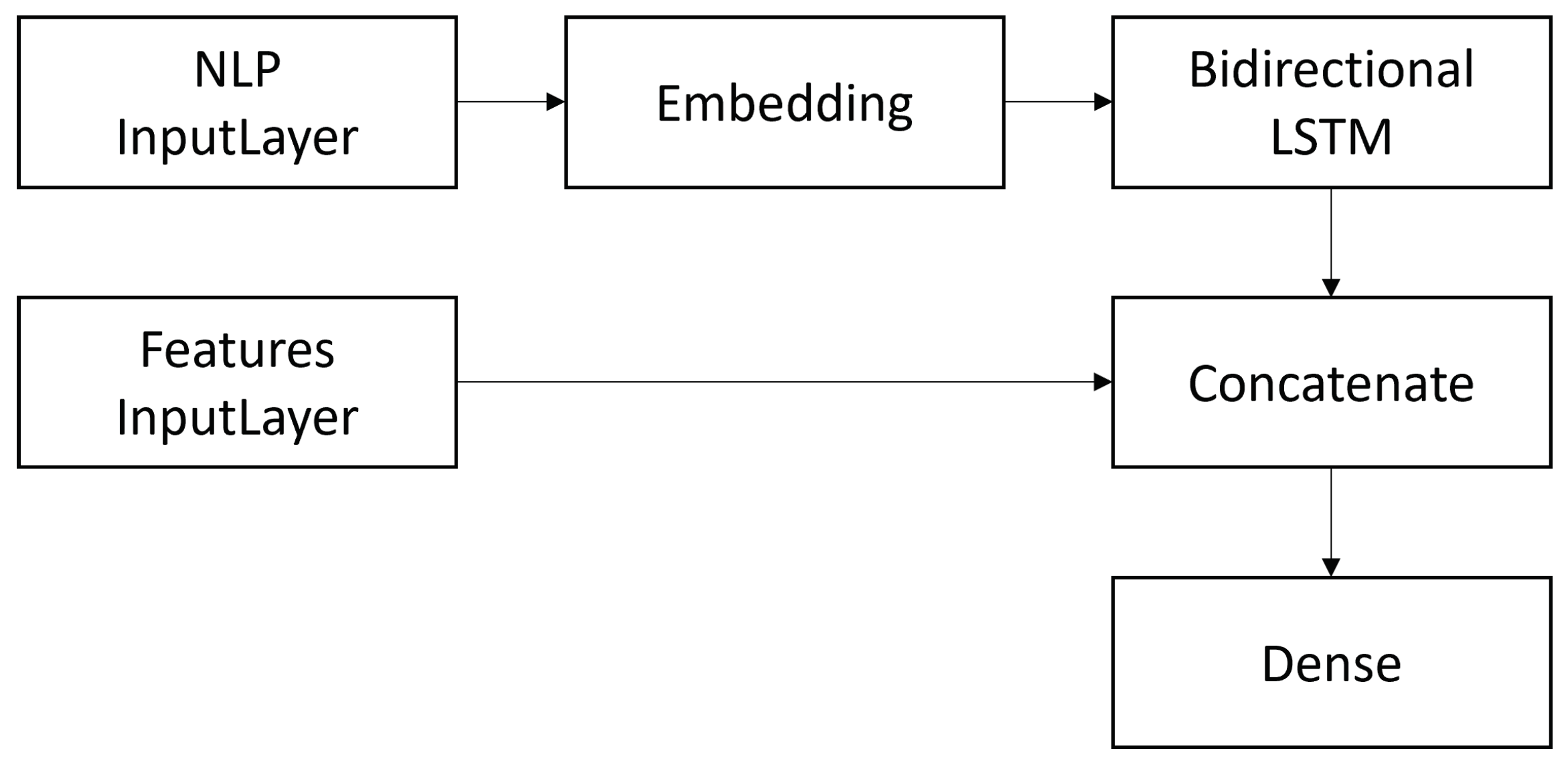
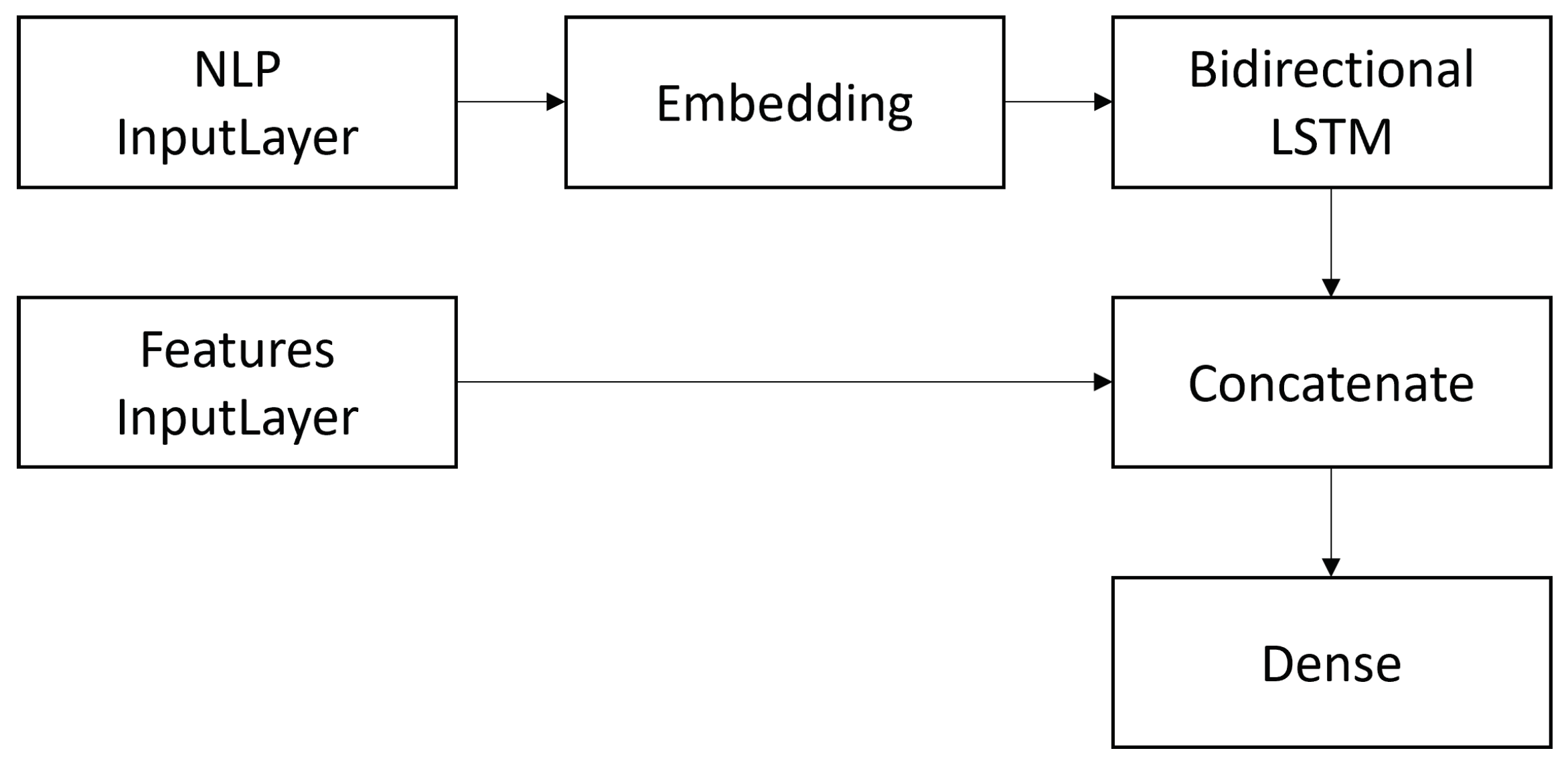
3.3.2. Bidirectional Long-Short Term Memory
4. Results
4.1. Evaluation Metrics and Technical Details
4.2. Global Evaluation Results
- ML(BoW-binary+all): ML algorithms in association with textual representation features (Bag-of-Words with binary weights) + all other features;
- ML(BoW-TF-IDF+all): ML algorithms in association with textual representation features (Bag-of-Words with TF-IDF weights) + all other features;
- ML(WE+all): ML algorithms in association with textual representation features (word embeddings) + all other features.
- Bi-LSTM(WE): Bidirectional Long-Short Term Memory classifier in association with only textual representation features (word embeddings);
- CNN(WE): Convolutional Neural Network classifier in association with only textual representation features (word embeddings);
- HPN: Hierarchical Propagation Networks in association with the propagation-network features, as proposed in [42];
- ML(LIWC): ML algorithms employed in association with the LIWC features proposed in [37].
- CNN(WE+all): Convolutional Neural Network classifier in association with textual representation features (word embeddings) + all other features;
- Bi-LSTM(WE+all): Bidirectional Long-Short Term Memory classifier in association with textual representation features (word embeddings) + all other features.
4.3. Feature Class Evaluation Results
5. Discussion
5.1. Global Evaluation
- CoAID: the CNN(WE) and CNN(WE+all) configurations are superior on every metric compared to all other configurations. ML(WE+all) is superior to ML(BoW) on both AUC and f-measure;
- ReCOVery: the ML(WE+all) configuration is superior in terms of AUC and f-measure to ML(BoW), and it is comparable to CNN(WE) in terms of both metrics;
- FakeHealth (Release): ML configurations (with both WE and BoW representations together with all the other features) are superior in terms of both AUC and f-measure to all other configurations;
- FakeHealth (Story): in terms of AUC, the ML(BoW-TF-IDF+all), CNN(WE), CNN(WE+all), and ML(LIWC) configurations turn out to be not superior to each other. ML(WE+all) and ML(LIWC) are both superior to all other configurations considering the f-measure. This is the only dataset for which ML(LIWC) has proven to be effective.
5.2. Feature Class Evaluation
- CoAID: user-profile and propagation-network features are particularly effective to tackle the problem under consideration; conversely, textual features such as linguistic-emotional, linguistic-stylistic, and linguistic-medical features are less performing;
- ReCOVery: also, in this case, user-profile and propagation-network features are those most suitable for the problem at hand, even if linguistic-stylistic features also show good effectiveness;
- FakeHealth (Release): linguistic-stylistic features show the best performance, followed, respectively, by user-profile and linguistic-medical features;
- FakeHealth (Story): linguistic-medical and linguistic-emotional features are those presenting the best effectiveness.
6. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Carminati, B.; Ferrari, E.; Viviani, M. Security and trust in online social networks. Synth. Lect. Inf. Secur. Priv. Trust. 2013, 4, 1–120. [Google Scholar] [CrossRef]
- Eysenbach, G. Medicine 2.0: Social networking, collaboration, participation, apomediation, and openness. J. Med. Internet Res. 2008, 10, e22. [Google Scholar] [CrossRef] [PubMed]
- Chou, W.Y.S.; Oh, A.; Klein, W.M. Addressing health-related misinformation on social media. JAMA 2018, 320, 2417–2418. [Google Scholar] [CrossRef] [PubMed]
- Lederman, R.; Fan, H.; Smith, S.; Chang, S. Who can you trust? Credibility assessment in online health forums. Health Policy Technol. 2014, 3, 13–25. [Google Scholar] [CrossRef]
- Metzger, M.J.; Flanagin, A.J. Credibility and trust of information in online environments: The use of cognitive heuristics. J. Pragmat. 2013, 59, 210–220. [Google Scholar] [CrossRef]
- Chinn, D. Critical health literacy: A review and critical analysis. Soc. Sci. Med. 2011, 73, 60–67. [Google Scholar] [CrossRef]
- Kickbusch, I.S. Health literacy: Addressing the health and education divide. Health Promot. Int. 2001, 16, 289–297. [Google Scholar] [CrossRef]
- Upadhyay, R.; Pasi, G.; Viviani, M. Health Misinformation Detection in Web Content: A Structural-, Content-based, and Context-aware Approach based on Web2Vec. In Proceedings of the Conference on Information Technology for Social Good, Rome, Italy, 9–11 September 2021; pp. 19–24. [Google Scholar]
- Wardle, C.; Derakhshan, H. Information disorder: Toward an interdisciplinary framework for research and policy making. Counc. Eur. 2017, 27, 1–109. [Google Scholar]
- Viviani, M.; Pasi, G. Credibility in social media: Opinions, news, and health information-a survey. Wiley Interdiscip. Rev. 2017, 7, e1209. [Google Scholar] [CrossRef]
- Eysenbach, G. From intermediation to disintermediation and apomediation: New models for consumers to access and assess the credibility of health information in the age of Web2. 0. In Building Sustainable Health Systems, Proceedings of the Medinfo 2007: Proceedings of the 12th World Congress on Health (Medical) Informatics, Brisbane, Australia, 20–24 August 2007; IOS Press: Amsterdam, The Netherlands, 2007; p. 162. [Google Scholar]
- Lemire, M.; Paré, G.; Sicotte, C.; Harvey, C. Determinants of Internet use as a preferred source of information on personal health. Int. J. Med. Inform. 2008, 77, 723–734. [Google Scholar] [CrossRef]
- Freeman, K.S.; Spyridakis, J.H. An examination of factors that affect the credibility of online health information. Tech. Commun. 2004, 51, 239–263. [Google Scholar]
- Rieh, S.Y.; Belkin, N.J. Understanding judgment of information quality and cognitive authority in the WWW. In Proceedings of the 61st Annual Meeting of the American Society for Information Science, Pittsburgh, PA, USA, 24–29 October 1998; Volume 35, pp. 279–289. [Google Scholar]
- Sbaffi, L.; Rowley, J. Trust and credibility in web-based health information: A review and agenda for future research. J. Med. Internet Res. 2017, 19, e218. [Google Scholar] [CrossRef] [PubMed]
- Eastin, M.S. Credibility assessments of online health information: The effects of source expertise and knowledge of content. J. Comput.-Mediat. Commun. 2001, 6, JCMC643. [Google Scholar] [CrossRef]
- Kinkead, L.; Allam, A.; Krauthammer, M. AutoDiscern: Rating the quality of online health information with hierarchical encoder attention-based neural networks. BMC Med. Inform. Decis. Mak. 2020, 20, 1–13. [Google Scholar] [CrossRef]
- Li, Y.; Li, X.; Lei, M. CTransE: An Effective Information Credibility Evaluation Method Based on Classified Translating Embedding in Knowledge Graphs. In International Conference on Database and Expert Systems Applications; Springer: Berlin/Heidelberg, Germany, 2020; pp. 287–300. [Google Scholar]
- DISCERN. Available online: http://www.discern.org.uk/ (accessed on 3 February 2022).
- Khazaal, Y.; Chatton, A.; Zullino, D.; Khan, R. HON label and DISCERN as content quality indicators of health-related websites. Psychiatr. Q. 2012, 83, 15–27. [Google Scholar] [CrossRef]
- Heydari, A.; ali Tavakoli, M.; Salim, N.; Heydari, Z. Detection of review spam: A survey. Expert Syst. Appl. 2015, 42, 3634–3642. [Google Scholar] [CrossRef]
- Ren, Y.; Ji, D. Learning to detect deceptive opinion spam: A survey. IEEE Access 2019, 7, 42934–42945. [Google Scholar] [CrossRef]
- Zhou, X.; Zafarani, R. A survey of fake news: Fundamental theories, detection methods, and opportunities. ACM Comput. Surv. (CSUR) 2020, 53, 1–40. [Google Scholar] [CrossRef]
- Goeuriot, L.; Suominen, H.; Pasi, G.; Bassani, E.; Brew-Sam, N.; González-Sáez, G.; Kelly, L.; Mulhem, P.; Seneviratne, S.; Gyanendra Upadhyay, R.; et al. Consumer health search at CLEF eHealth 2021. In Proceedings of the CLEF 2021 Evaluation Labs and Workshop: Online Working Notes. CEUR-WS, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Clarke, C.L.A.; Maistro, M.; Rizvi, S.; Smucker, M.D.; Zuccon, G. Overview of the TREC 2020 Health Misinformation Track. In Proceedings of the TREC 2020, Online, 16–20 November 2020. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Park, M.; Sampathkumar, H.; Luo, B.; Chen, X.W. Content-based assessment of the credibility of online healthcare information. In Proceedings of the 2013 IEEE International Conference on Big Data, Silicon Valley, CA, USA, 6–9 October 2013; pp. 51–58. [Google Scholar]
- Ferragina, P.; Scaiella, U. Tagme: On-the-fly annotation of short text fragments (by wikipedia entities). In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 1625–1628. [Google Scholar]
- Cui, L.; Seo, H.; Tabar, M.; Ma, F.; Wang, S.; Lee, D. DETERRENT: Knowledge guided graph attention network for detecting healthcare misinformation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 492–502. [Google Scholar]
- Feng, J.; Zou, L.; Ye, O.; Han, J. Web2Vec: Phishing Webpage Detection Method Based on Multidimensional Features Driven by Deep Learning. IEEE Access 2020, 8, 221214–221224. [Google Scholar] [CrossRef]
- Mukherjee, S.; Weikum, G.; Danescu-Niculescu-Mizil, C. People on drugs: Credibility of user statements in health communities. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 65–74. [Google Scholar]
- Drugs and Supplements—Mayo Clinic. Available online: https://www.mayoclinic.org/drugs-supplements/ (accessed on 3 February 2022).
- HealthBoards Message Boards. Available online: https://www.healthboards.com/ (accessed on 3 February 2022).
- Ghenai, A.; Mejova, Y. Fake cures: User-centric modeling of health misinformation in social media. In Proceedings of the ACM on Human-Computer Interaction, New York, NY, USA, November 2018; Volume 2, pp. 1–20. Available online: https://dl.acm.org/doi/10.1145/3274327 (accessed on 3 February 2022).
- Zhou, X.; Mulay, A.; Ferrara, E.; Zafarani, R. ReCOVery: A Multimodal Repository for COVID-19 News Credibility Research. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM 0), Virtual Event, Ireland, 19–23 October 2020. [Google Scholar]
- Tausczik, Y.R.; Pennebaker, J.W. The psychological meaning of words: LIWC and computerized text analysis methods. J. Lang. Soc. Psychol. 2010, 29, 24–54. [Google Scholar] [CrossRef]
- Cui, L.; Lee, D. CoAID: COVID-19 Healthcare Misinformation Dataset. arXiv 2020, arXiv:2006.00885. [Google Scholar]
- Dai, E.; Sun, Y.; Wang, S. Ginger cannot cure cancer: Battling fake health news with a comprehensive data repository. In Proceedings of the International AAAI Conference on Web and Social Media, Seattle, WA, USA, 30 March–2 April 2020; Volume 14, pp. 853–862. [Google Scholar]
- Zhao, Y.; Da, J.; Yan, J. Detecting health misinformation in online health communities: Incorporating behavioral features into machine learning based approaches. Inf. Process. Manag. 2021, 58, 102390. [Google Scholar] [CrossRef]
- Zhang, S.; Ma, F.; Liu, Y.; Pian, W. Identifying features of health misinformation on social media sites: An exploratory analysis. Libr. Hi Tech 2021. [Google Scholar] [CrossRef]
- Shu, K.; Mahudeswaran, D.; Wang, S.; Liu, H. Hierarchical propagation networks for fake news detection: Investigation and exploitation. In Proceedings of the International AAAI Conference on Web and Social Media, Atlanta, GA, USA, 8–11 June 2020; Volume 14, pp. 626–637. [Google Scholar]
- Bahad, P.; Saxena, P.; Kamal, R. Fake News Detection using Bi-directional LSTM-Recurrent Neural Network. Procedia Comput. Sci. 2019, 165, 74–82. [Google Scholar] [CrossRef]
- Asghar, M.Z.; Habib, A.; Habib, A.; Khan, A.; Ali, R.; Khattak, A. Exploring deep neural networks for rumor detection. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 4315–4333. [Google Scholar] [CrossRef]
- Wani, A.; Joshi, I.; Khandve, S.; Wagh, V.; Joshi, R. Evaluating Deep Learning Approaches for Covid19 Fake News Detection. arXiv 2021, arXiv:2101.04012. [Google Scholar]
- Healthline: Medical Information and Health Advice You Can Trust. Available online: https://www.healthline.com (accessed on 3 February 2022).
- ScienceDaily: Your Source for the Latest Research News. Available online: https://www.sciencedaily.com/ (accessed on 3 February 2022).
- National Institutes of Health (NIH)|Turning Discovery Into Health. Available online: https://www.nih.gov/ (accessed on 3 February 2022).
- MedicalNews Today (MNT)|Medical and Health Information. Available online: https://www.medicalnewstoday.com/ (accessed on 3 February 2022).
- Mayo Clinic. Available online: https://www.mayoclinic.org (accessed on 3 February 2022).
- Cleveland Clinic: Every Life Deserves World Class Care. Available online: https://my.clevelandclinic.org/ (accessed on 3 February 2022).
- WebMD—Better Information. Better Health. Available online: https://www.webmd.com/ (accessed on 3 February 2022).
- WHO|World Health Organization. Available online: https://www.who.int/ (accessed on 3 February 2022).
- Centers for Disease Control and Prevention. Available online: https://www.cdc.gov/ (accessed on 3 February 2022).
- NewsGuard—Fighting Misinformation with Journalism. Available online: https://www.newsguardtech.com/ (accessed on 3 February 2022).
- Media Bias/Fact Check—Search and Learn the Bias of News Media. Available online: https://mediabiasfactcheck.com/ (accessed on 3 February 2022).
- HealthNewsReview—Improving Your Critical Thinking about Health Care. Available online: https://www.healthnewsreview.org/ (accessed on 3 February 2022).
- Informed Medical Decision Foundation—Healthwise. Available online: https://www.healthwise.org/specialpages/imdf.aspx (accessed on 3 February 2022).
- Thomm, E.; Bromme, R. “It should at least seem scientific!” Textual features of “scientificness” and their impact on lay assessments of online information. Sci. Educ. 2012, 96, 187–211. [Google Scholar] [CrossRef]
- Wawer, A.; Nielek, R.; Wierzbicki, A. Predicting webpage credibility using linguistic features. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 1135–1140. [Google Scholar]
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From word embeddings to document distances. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 957–966. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- English Gigaword Fifth Edition—Linguistic Data Consortium. Available online: https://catalog.ldc.upenn.edu/LDC2011T07 (accessed on 3 February 2022).
- NLTK: Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 3 February 2022).
- Pozzi, F.A.; Fersini, E.; Messina, E.; Liu, B. Sentiment Analysis in Social Networks; Morgan Kaufmann: Burlington, MA, USA, 2016. [Google Scholar]
- TextBlob: Simplified Text Processing. Available online: https://textblob.readthedocs.io/en/dev/ (accessed on 3 February 2022).
- Mohammad, S.M.; Turney, P.D. NRC emotion lexicon. Natl. Res. Counc. Can. 2013, 2, 1–234. [Google Scholar]
- text2emotion|PyPI. Available online: https://pypi.org/project/text2emotion/ (accessed on 3 February 2022).
- spaCy|Industrial-Strenght Natural Language Processing in Python. Available online: https://spacy.io/ (accessed on 3 February 2022).
- Mohan, S.; Li, D. MedMentions: A Large Biomedical Corpus Annotated with UMLS Concepts. arXiv 2019, arXiv:1902.09476. [Google Scholar]
- PubMed. Available online: https://pubmed.ncbi.nlm.nih.gov/ (accessed on 3 February 2022).
- Fernández-Pichel, M.; Losada, D.; Pichel, J.C.; Elsweiler, D. Reliability Prediction for Health-related Content: A Replicability Study. In Proceedings of the European Conference on Information Retrieval, Lucca, Tuscany, Italy, 1 April 2021. [Google Scholar]
- Hutto, C.; Gilbert, E. VADER: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8. [Google Scholar]
- Shao, C.; Ciampaglia, G.L.; Varol, O.; Yang, K.C.; Flammini, A.; Menczer, F. The spread of low-credibility content by social bots. Nat. Commun. 2018, 9, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Adam—Keras. Available online: https://keras.io/api/optimizers/adam/ (accessed on 3 February 2022).
- Probabilistic Losses—Keras. Available online: https://keras.io/api/losses/probabilistic_losses/#binary_crossentropy-function (accessed on 3 February 2022).
- Hossin, M.; Sulaiman, M. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Scikit-Learn: Machine Learning in Python. Available online: https://scikit-learn.org/stable/ (accessed on 3 February 2022).
- Hall, M.A.; Smith, L.A. Feature selection for machine learning: Comparing a correlation-based filter approach to the wrapper. In Proceedings of the FLAIRS Conference, Orlando, FL, USA, 1–5 May 1999; Volume 1999, pp. 235–239. [Google Scholar]
- Semenick, D. Tests and measurements: The T-test. Strength Cond. J. 1990, 12, 36–37. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Data | CoAID | ReCOVery | FakeHealth (Release) | FakeHealth (Story) |
|---|---|---|---|---|
| Textual contents | 3555 | 2029 | 606 | 1690 |
| Tweet IDs | 151,964 | 140,820 | 47,338 | 384,073 |
| Retweet IDs | - | - | 16,959 | 92,758 |
| Reply IDs | 122,150 | - | 1575 | 20,644 |
| Data | CoAID | ReCOVery | FakeHealth (Release) | FakeHealth (Story) |
|---|---|---|---|---|
| Textual contents | 1820 | 1910 | 594 | 1498 |
| Tweet IDs | 74,722 | 42,153 | 44,547 | 315,709 |
| Retweet IDs | 65,464 | 43,024 | 16,070 | 99,971 |
| Replies IDs | 29,969 | - | 1253 | 14,472 |
| User IDs | 164,891 | 58,495 | 28,893 | 206,798 |
| Features | Examples/Explanations |
|---|---|
| Strong modals | might, could, can, would, may |
| Weak modals | should, ought, need, shall, will |
| Conditionals | if |
| Negations | no, not, neither, nor, never |
| Conclusive conjunctions | therefore, thus, furthermore |
| Subordinating conjunctions | until, despite, in spite, though |
| Following conjunctions | but, however, otherwise, yet |
| Definite determiners | the, this, that, those, these |
| Personal pronouns | I, you |
| First person | I, we, me, my, mine, us, our |
| Second person | you, your, yours |
| Third person | he, she, him, her, his, it, its |
| Question particles | why, what, when, which, who |
| Adjectives | correct, extreme, long, visible |
| Adverbs | maybe, about, probably, much |
| Proper nouns | names of places, things, etc. |
| Other nouns | other nouns |
| To be form | be, am, is are, was, were, been |
| To have form | have, has, had, having |
| Past tense verb | past tense verb |
| Gerund | gerund |
| Participle verb | past or present participle verb |
| Superlatives | superlative adjectives or adverbs |
| Exclamation | exclamation mark |
| Other | other terms |
| Dataset | Classifier | AUC | f-Measure |
|---|---|---|---|
| CoAID | CNN(WE) | 0.973 | 0.953 |
| CNN(WE+all) | 0.962 | 0.943 | |
| ML(WE+all) | 0.925 | 0.914 | |
| ML(BoW-TF-IDF+all) | 0.898 | 0.865 | |
| ML(BoW-binary+all) | 0.892 | 0.863 | |
| Bi-LSTM(WE+all) | 0.849 | 0.859 | |
| Bi-LSTM(WE) | 0.848 | 0.857 | |
| HPN | 0.844 | 0.858 | |
| ML(LIWC) | 0.669 | 0.789 |
| Dataset | Classifier | AUC | f-Measure |
|---|---|---|---|
| ReCOVery | ML(WE+all) | 0.921 | 0.848 |
| ML(BoW-TF-IDF+all) | 0.915 | 0.771 | |
| CNN(WE) | 0.913 | 0.850 | |
| ML(BoW-binary+all) | 0.903 | 0.709 | |
| CNN(WE+all) | 0.896 | 0.828 | |
| ML(LIWC) | 0.817 | 0.743 | |
| Bi-LSTM(WE+all) | 0.741 | 0.655 | |
| Bi-LSTM(WE) | 0.734 | 0.673 | |
| HPN | 0.716 | 0.694 |
| Dataset | Classifier | AUC | f-Measure |
|---|---|---|---|
| FakeHealth (Release) | ML(BoW-TF-IDF+all) | 0.693 | 0.653 |
| ML(WE+all) | 0.687 | 0.658 | |
| ML(BoW-binary+all) | 0.675 | 0.641 | |
| CNN(WE) | 0.661 | 0.602 | |
| CNN(WE+all) | 0.645 | 0.597 | |
| ML(LIWC) | 0.608 | 0.598 | |
| Bi-LSTM(WE) | 0.583 | 0.574 | |
| Bi-LSTM(WE+all) | 0.563 | 0.539 | |
| HPN | 0.581 | 0.593 | |
| FakeHealth (Story) | ML(BoW-TF-IDF+all) | 0.717 | 0.627 |
| CNN(WE) | 0.700 | 0.624 | |
| CNN(WE+all) | 0.698 | 0.655 | |
| ML(LIWC) | 0.694 | 0.704 | |
| ML(BoW-binary+all) | 0.679 | 0.609 | |
| ML(WE+all) | 0.657 | 0.706 | |
| Bi-LSTM(WE+all) | 0.656 | 0.602 | |
| Bi-LSTM(WE) | 0.654 | 0.602 | |
| HPN | 0.563 | 0.660 |
| AUC | CoAID | ReCOVery | FakeHealth (Release) | FakeHealth (Story) |
|---|---|---|---|---|
| Linguistic-emotional | 0.624 | 0.708 | 0.576 | 0.630 |
| Linguistic-stylistic | 0.601 | 0.774 | 0.625 | 0.532 |
| Linguistic-medical | 0.610 | 0.612 | 0.595 | 0.633 |
| Propagation-network | 0.729 | 0.886 | 0.525 | 0.548 |
| User-profile | 0.847 | 0.795 | 0.602 | 0.563 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Di Sotto, S.; Viviani, M. Health Misinformation Detection in the Social Web: An Overview and a Data Science Approach. Int. J. Environ. Res. Public Health 2022, 19, 2173. https://doi.org/10.3390/ijerph19042173
Di Sotto S, Viviani M. Health Misinformation Detection in the Social Web: An Overview and a Data Science Approach. International Journal of Environmental Research and Public Health. 2022; 19(4):2173. https://doi.org/10.3390/ijerph19042173
Chicago/Turabian StyleDi Sotto, Stefano, and Marco Viviani. 2022. "Health Misinformation Detection in the Social Web: An Overview and a Data Science Approach" International Journal of Environmental Research and Public Health 19, no. 4: 2173. https://doi.org/10.3390/ijerph19042173
APA StyleDi Sotto, S., & Viviani, M. (2022). Health Misinformation Detection in the Social Web: An Overview and a Data Science Approach. International Journal of Environmental Research and Public Health, 19(4), 2173. https://doi.org/10.3390/ijerph19042173