
Administrative Data in Cardiovascular Research—A Comparison of Polish National Health Fund and CRAFT Registry Data

 ,
,  ,
,  , , ,
, , ,
Abstract
1. Introduction
2. Materials and Methods
2.1. Individual Health Record (IHR)—Data Obtained through Manual Chart Review
2.2. National Health Fund (NHF)—Administrative Data
2.3. CHA2DS2VASc and HASBLED Scores
2.4. Statistical Analysis
3. Results
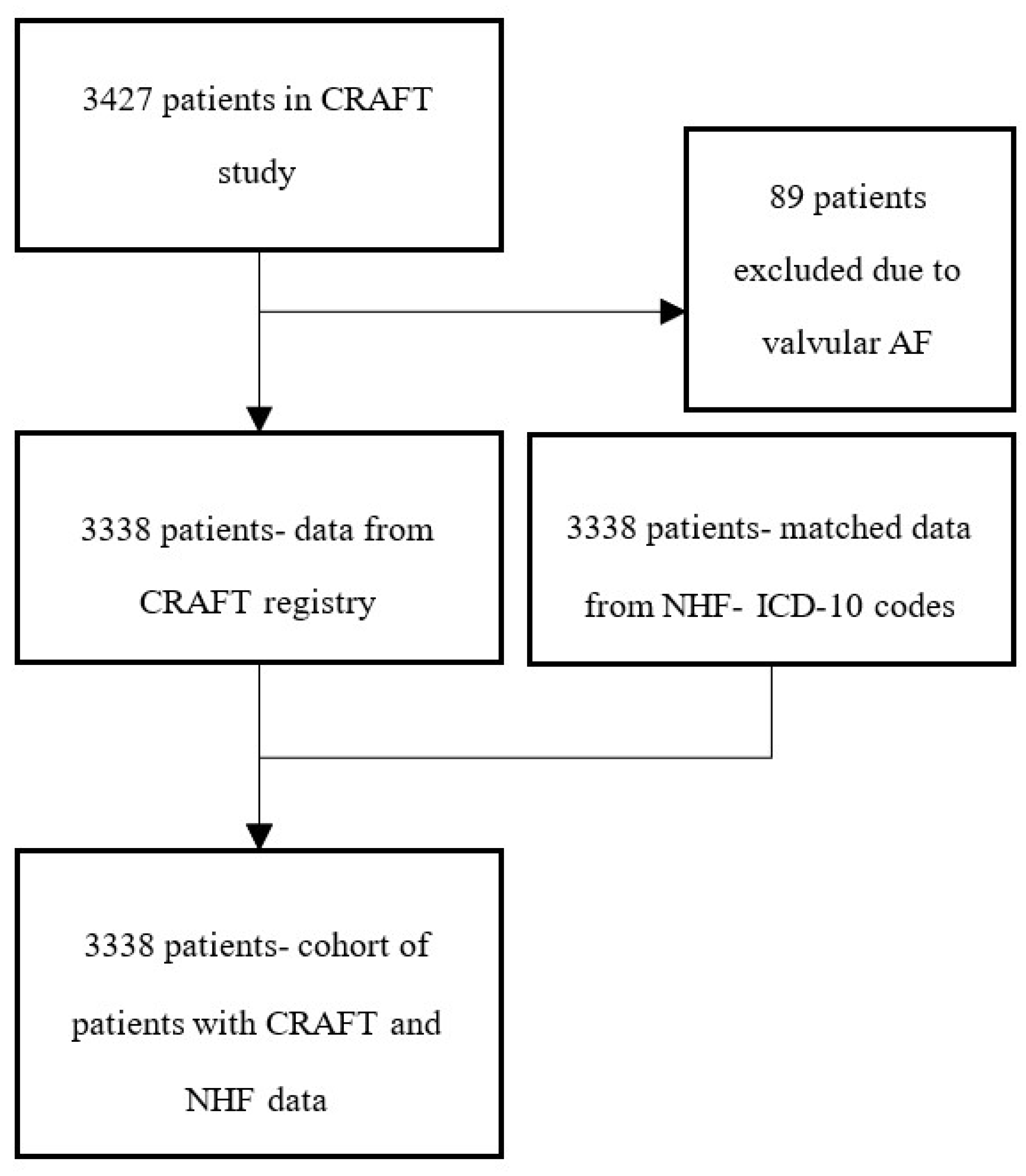
3.1. Study Population
3.2. IHR vs. NHF Data
4. Discussion
Limitations
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hindricks, G.; Potpara, T.; Dagres, N.; Arbelo, E.; Bax, J.J.; Blomström-Lundqvist, C.; Boriani, G.; Castella, M.; Dan, G.A.; Dilaveris, P.E.; et al. 2020 ESC Guidelines for the diagnosis and management of atrial fibrillation developed in collaboration with the European Association for Cardio-Thoracic Surgery (EACTS). Eur. Heart J. 2021, 42, 373–498. [Google Scholar] [CrossRef] [PubMed]
- Lee, D.S.; Donovan, L.; Austin, P.C.; Gong, Y.; Liu, P.P.; Rouleau, J.L.; Tu, J.V. Comparison of coding of heart failure and comorbidities in administrative and clinical data for use in outcomes research. Med. Care 2005, 43, 182–188. [Google Scholar] [CrossRef] [PubMed]
- Lip, G.Y.H.; Keshishian, A.; Li, X.; Hamilton, M.; Masseria, C.; Gupta, K.; Luo, X.; Mardekian, J.; Friend, K.; Nadkarni, A.; et al. Effectiveness and Safety of Oral Anticoagulants Among Nonvalvular Atrial Fibrillation Patients. Stroke 2018, 49, 2933–2944. [Google Scholar] [CrossRef] [PubMed]
- Ray, W.A.; Chung, C.P.; Murray, K.T.; Smalley, W.E.; Daugherty, J.R.; Dupont, W.D.; Stein, C.M. Association of Oral Anticoagulants and Proton Pump Inhibitor Cotherapy With Hospitalization for Upper Gastrointestinal Tract Bleeding. JAMA 2018, 320, 2221–2230. [Google Scholar] [CrossRef]
- Schmidt, M.; Schmidt, S.A.J.; Sandegaard, J.L.; Ehrenstein, V.; Pedersen, L.; Sørensen, H.T. The Danish National Patient Registry: A review of content, data quality, and research potential. Clin. Epidemiol. 2015, 7, 449–490. [Google Scholar] [CrossRef] [PubMed]
- Quach, S.; Blais, C.; Quan, H. Administrative data have high variation in validity for recording heart failure. Can. J. Cardiol. 2010, 26, 306–312. [Google Scholar] [CrossRef]
- Kaspar, M.; Fette, G.; Güder, G.; Seidlmayer, L.; Ertl, M.; Dietrich, G.; Greger, H.; Puppe, F.; Störk, S. Underestimated prevalence of heart failure in hospital inpatients: A comparison of ICD codes and discharge letter information. Clin. Res. Cardiol. 2018, 107, 778–787. [Google Scholar] [CrossRef] [PubMed]
- Balsam, P.; Tymińska, A.; Ozierański, K.; Zaleska, M.; Żukowska, K.; Szepietowska, K.; Maciejewski, K.; Peller, M.; Grabowski, M.; Lodziński, P.; et al. Randomized controlled clinical trials versus real-life atrial fibrillation patients treated with oral anticoagulants. Do we treat the same patients? Cardiol. J. 2020, 27, 590–599. [Google Scholar] [CrossRef] [PubMed]
- Balsam, P.; Ozieranski, K.; Tyminska, A.; Zukowska, K.; Zaleska, M.; Szepietowska, K.; Maciejewski, K.; Peller, M.; Grabowski, M.; Lodzinski, P.; et al. Comparison of clinical characteristics of real-life atrial fibrillation patients treated with vitamin K antagonists, dabigatran, and rivaroxaban: Results from the CRAFT study. Kardiol. Pol. 2018, 76, 889–898. [Google Scholar] [CrossRef] [PubMed]
- Lip, G.Y.; Nieuwlaat, R.; Pisters, R.; Lane, D.A.; Crijns, H.J. Refining clinical risk stratification for predicting stroke and thromboembolism in atrial fibrillation using a novel risk factor-based approach: The euro heart survey on atrial fibrillation. Chest 2010, 137, 263–272. [Google Scholar] [CrossRef] [PubMed]
- Parikh, R.; Mathai, A.; Parikh, S.; Chandra Sekhar, G.; Thomas, R. Understanding and using sensitivity, specificity and predictive values. Indian J. Ophthalmol. 2008, 56, 45–50. [Google Scholar] [CrossRef] [PubMed]
- Yao, R.J.R.; Andrade, J.G.; Deyell, M.W.; Jackson, H.; McAlister, F.A.; Hawkins, N.M. Sensitivity, specificity, positive and negative predictive values of identifying atrial fibrillation using administrative data: A systematic review and meta-analysis. Clin. Epidemiol. 2019, 11, 753–767. [Google Scholar] [CrossRef] [PubMed]
- Shah, R.U.; Mukherjee, R.; Zhang, Y.; Jones, A.E.; Springer, J.; Hackett, I.; Steinberg, B.A.; Lloyd-Jones, D.M.; Chapman, W.W. Impact of Different Electronic Cohort Definitions to Identify Patients With Atrial Fibrillation From the Electronic Medical Record. J. Am. Heart Assoc. 2020, 9, e014527. [Google Scholar] [CrossRef]
- McCormick, N.; Lacaille, D.; Bhole, V.; Avina-Zubieta, J.A. Validity of heart failure diagnoses in administrative databases: A systematic review and meta-analysis. PLoS ONE 2014, 9, e104519. [Google Scholar] [CrossRef] [PubMed]
- So, L.; Evans, D.; Quan, H. ICD-10 coding algorithms for defining comorbidities of acute myocardial infarction. BMC Health Serv. Res. 2006, 6, 161. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Lee, S.; Martin, E.; D’Souza, A.G.; Doktorchik, C.T.A.; Jiang, J.; Lee, S.; Eastwood, C.A.; Fine, N.; Hemmelgarn, B.; et al. Enhancing ICD-Code-Based Case Definition for Heart Failure Using Electronic Medical Record Data. J. Card. Fail. 2020, 26, 610–617. [Google Scholar] [CrossRef] [PubMed]
- Joos, C.; Lawrence, K.; Jones, A.E.; Johnson, S.A.; Witt, D.M. Accuracy of ICD-10 codes for identifying hospitalizations for acute anticoagulation therapy-related bleeding events. Thromb. Res. 2019, 181, 71–76. [Google Scholar] [CrossRef] [PubMed]
- Chang, T.E.; Lichtman, J.H.; Goldstein, L.B.; George, M.G. Accuracy of ICD-9-CM Codes by Hospital Characteristics and Stroke Severity: Paul Coverdell National Acute Stroke Program. J. Am. Heart Assoc. 2016, 5, e003056. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Condition | IHR N, % (CI) | NHF N, % (CI) | p-Value | Sensitivity | Specificity | PPV | NPV | Accuracy | Cohen’s Kappa * |
|---|---|---|---|---|---|---|---|---|---|
| AF | 3338 100% (99.9–100.0) | 2766 83% (81.5–84.1) | <0.001 | 0.83 | - | - | - | - | - |
| Severe bleeding | 255/3336 7.6% (6.8–8.6) | 409 12.3% (11.2–13.4) | <0.001 | 0.24 | 0.89 | 0.15 | 0.93 | 0.84 | 0.01 |
| Alcohol consumption | 33/3330 1% (0.7–1.4) | 377 11.3% (10.3–12.4) | <0.001 | 0.48 | 0.89 | 0.04 | 0.99 | 0.88 | 0.06 |
| CKD for HASBLED | 94/3325 2.8% (2.3–3.4) | 557 16.7% (15.5–18) | <0.001 | 0.56 | 0.84 | 0.1 | 0.99 | 0.84 | 0.12 |
| CKD | 706/3325 21.2% (19.9–22.7) | 557 16.7% (15.5–18) | <0.001 | 0.34 | 0.88 | 0.43 | 0.83 | 0.76 | 0.23 |
| Liver disease | 80/3148 2.5% (2–3.2) | 346 10.4% (9.4–11.4) | <0.001 | 0.15 | 0.90 | 0.04 | 0.98 | 0.88 | 0.02 |
| HF | 1207/3333 36.2% (34.6–37.9) | 1823 54.6% (52.9–56.3) | <0.001 | 0.82 | 0.61 | 0.55 | 0.86 | 0.69 | 0.39 |
| Hypertension | 2389/3334 71.7% (70.1–73.2) | 2768 82.9% (81.2–84.2) | <0.001 | 0.89 | 0.32 | 0.77 | 0.53 | 0.73 | 0.23 |
| Diabetes and prediabetic conditions | 874/3325 26.3% (25–27.8) | 1108 33.2% (32–34.8) | <0.001 | 0.79 | 0.83 | 0.63 | 0.92 | 0.82 | 0.58 |
| Stroke/TIA/ other thromboembolic events | 430/3330 12.9% (11.8–14.1) | 850 25.5% (24–27) | <0.001 | 0.69 | 0.81 | 0.35 | 0.95 | 0.79 | 0.35 |
| Atherosclerosis | 1430 42.8% (41.2–44.5) | 2390 71.6% (70–73.1) | <0.001 | 0.88 | 0.40 | 0.53 | 0.83 | 0.61 | 0.26 |
| CAD | 1386 41.5% (40–43.2) | 2298 68.9% (67.3–70.4) | <0.001 | 0.86 | 0.43 | 0.52 | 0.81 | 0.61 | 0.26 |
| COPD | 293/3333 8.8% (7.8–9.8) | 735 22% (20.6–23.5) | <0.001 | 0.71 | 0.83 | 0.28 | 0.97 | 0.82 | 0.32 |
| Smoking history | 175/3328 5.3% (4.6–6.1) | 326 9.8% (8.8–10.8) | <0.001 | 0.10 | 0.90 | 0.06 | 0.95 | 0.86 | 0.004 |
| HASBLED ≥ 3 | 86/3124 2.8% (2.2–3.4) | 487 14.6% (13.4–15.8) | <0.001 | 0.38 | 0.86 | 0.07 | 0.98 | 0.85 | 0.08 |
| CHA2DS2VASc for recommended anticoagulation | 2390/3316 72.1% (70.5–73.6) | 2816 84.4% (83.1–85.6) | <0.001 | 0.96 | 0.44 | 0.82 | 0.79 | 0.81 | 0.46 |
| IHR Median [Q1–Q3] | NHF Median [Q1–Q3] | p Value | |
|---|---|---|---|
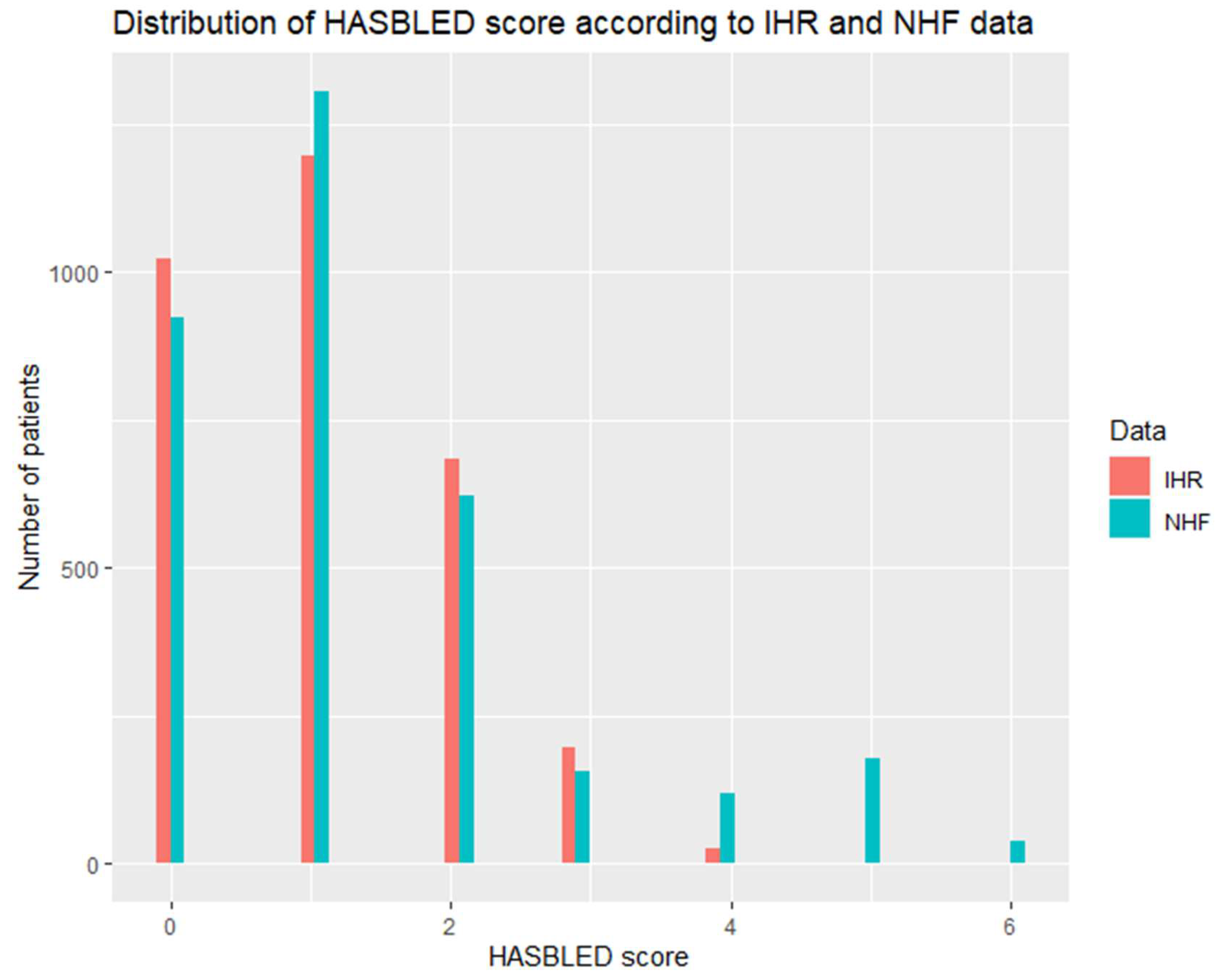
| HASBLED | 1 [0–1] 3124 | 1 [0–2] | <0.001 |
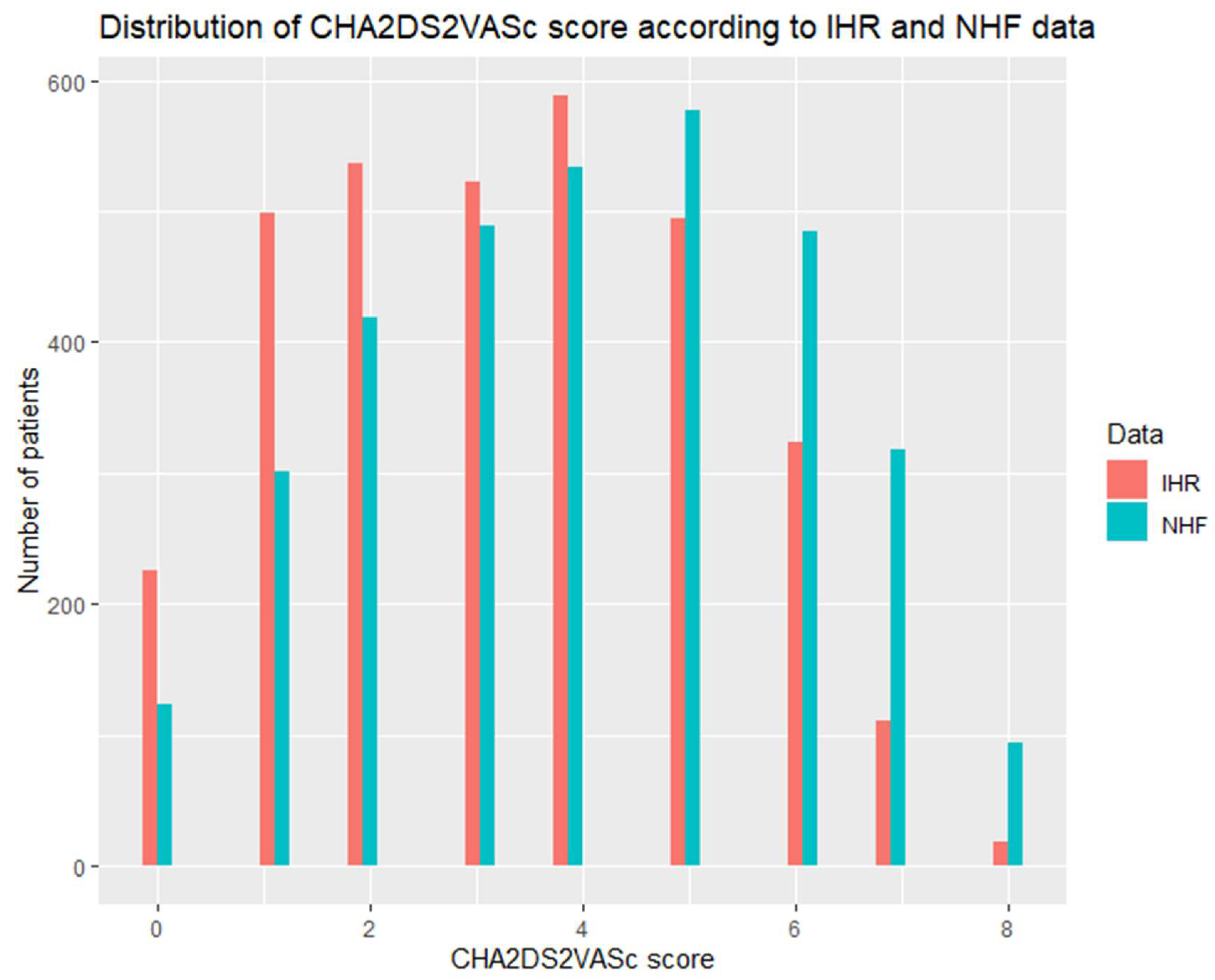
| CHA2DS2VASc | 3 [2–5] 3316 | 4 [2–6] | <0.001 |
| Condition | IHR N = 3338 N, % (CI) | NHF N = 2766 N, % (CI) | p-Value |
|---|---|---|---|
| Severe bleeding | 255/3336 7.6% (6.8–8.6) | 378 13.7% (12.4–15) | <0.001 |
| Alcohol consumption | 33/3330 1% (0.7–1.4) | 360 13% (11.8–14.3) | <0.001 |
| CKD for HASBLED | 94/3325 2.8% (2.3–3.4) | 524 18.9% (17.5–20.5) | <0.001 |
| CKD | 706/3325 21.2% (19.9–22.7) | 524 18.9% (17.5–20.5) | 0.03 |
| Liver disease | 80/3148 2.5% (2–3.2) | 343 12.4% (11.2–13.7) | <0.001 |
| HF | 1207/3333 36.2% (34.6–37.9) | 1576 57% (55.1–59) | <0.001 |
| Hypertension | 2389/3334 71.7% (70.1–73.2) | 2408 87% (85.8–88) | <0.001 |
| Diabetes | 874/3325 26.3% (25–27.8) | 951 34.4% (32.6–36.2) | <0.001 |
| Stroke/TIA/other thromboembolic events | 430/3330 12.9% (11.8–14.1) | 758 27.4% (25.8–29.1) | <0.001 |
| Atherosclerosis | 1430 42.8% (41.2–44.5) | 2066 74.7% (73–76.3) | <0.001 |
| COPD | 293/3333 8.8% (7.8–9.8) | 671 24.3% (22.7–25.9) | <0.001 |
| CAD | 1386 41.5% (40–43.2) | 1998 72.2% (70.5–73.9) | <0.001 |
| Smoking history | 175/3328 5.3% (4.6–6.1) | 323 11.7% (10.5–13) | <0.001 |
| HASBLED ≥ 3 | 86/3124 2.8% (2.2–3.4) | 470 17% (15.6–18.4) | <0.001 |
| HASBLED, median [Q1–Q3] | 1 [0–1] | 1 [0–2] | <0.001 |
| CHA2DS2VASc for recommended anticoagulation | 2390/3316 72.1% (70.5–73.6) | 2364 85.5% (84.1–86.7) | <0.001 |
| CHA2DS2VASc, median [Q1–Q3] | 3.000 [2–5] | 4.0 [3–6] | <0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maciejewski, C.; Ozierański, K.; Basza, M.; Lodziński, P.; Śliwczyński, A.; Kraj, L.; Krajsman, M.J.; Prado Paulino, J.; Tymińska, A.; Opolski, G.; et al. Administrative Data in Cardiovascular Research—A Comparison of Polish National Health Fund and CRAFT Registry Data. Int. J. Environ. Res. Public Health 2022, 19, 11964. https://doi.org/10.3390/ijerph191911964
Maciejewski C, Ozierański K, Basza M, Lodziński P, Śliwczyński A, Kraj L, Krajsman MJ, Prado Paulino J, Tymińska A, Opolski G, et al. Administrative Data in Cardiovascular Research—A Comparison of Polish National Health Fund and CRAFT Registry Data. International Journal of Environmental Research and Public Health. 2022; 19(19):11964. https://doi.org/10.3390/ijerph191911964
Chicago/Turabian StyleMaciejewski, Cezary, Krzysztof Ozierański, Mikołaj Basza, Piotr Lodziński, Andrzej Śliwczyński, Leszek Kraj, Maciej Janusz Krajsman, Jefte Prado Paulino, Agata Tymińska, Grzegorz Opolski, and et al. 2022. "Administrative Data in Cardiovascular Research—A Comparison of Polish National Health Fund and CRAFT Registry Data" International Journal of Environmental Research and Public Health 19, no. 19: 11964. https://doi.org/10.3390/ijerph191911964
APA StyleMaciejewski, C., Ozierański, K., Basza, M., Lodziński, P., Śliwczyński, A., Kraj, L., Krajsman, M. J., Prado Paulino, J., Tymińska, A., Opolski, G., Cacko, A., Grabowski, M., & Balsam, P. (2022). Administrative Data in Cardiovascular Research—A Comparison of Polish National Health Fund and CRAFT Registry Data. International Journal of Environmental Research and Public Health, 19(19), 11964. https://doi.org/10.3390/ijerph191911964