
Analysis on Risk Characteristics of Traffic Accidents in Small-Spacing Expressway Interchange





Abstract
:1. Introduction
2. Literature Review
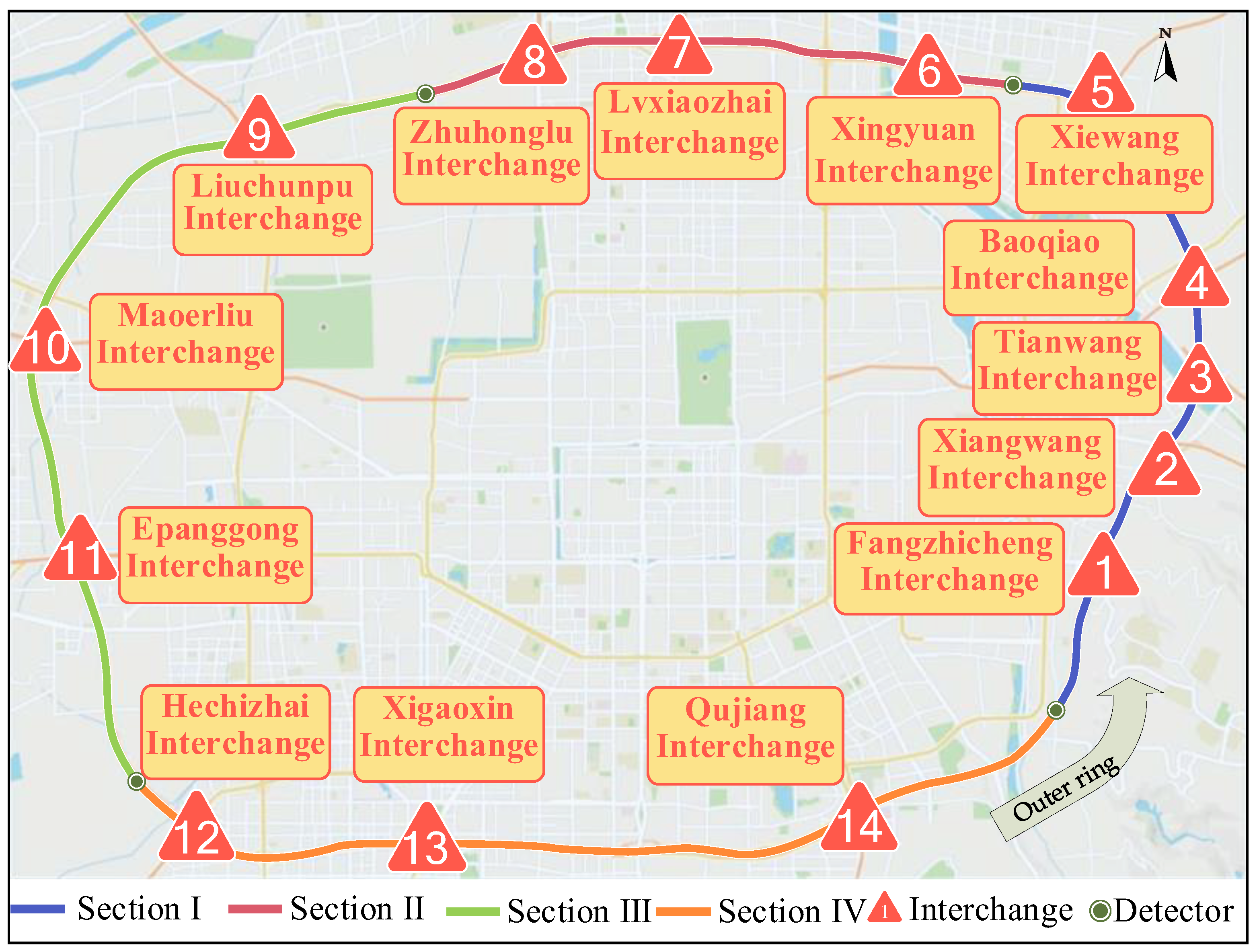
3. Study Area
4. Methods
- (i)
- LSSVM
- (ii)
- Random forest
- (iii)
- Logistic model
5. Result
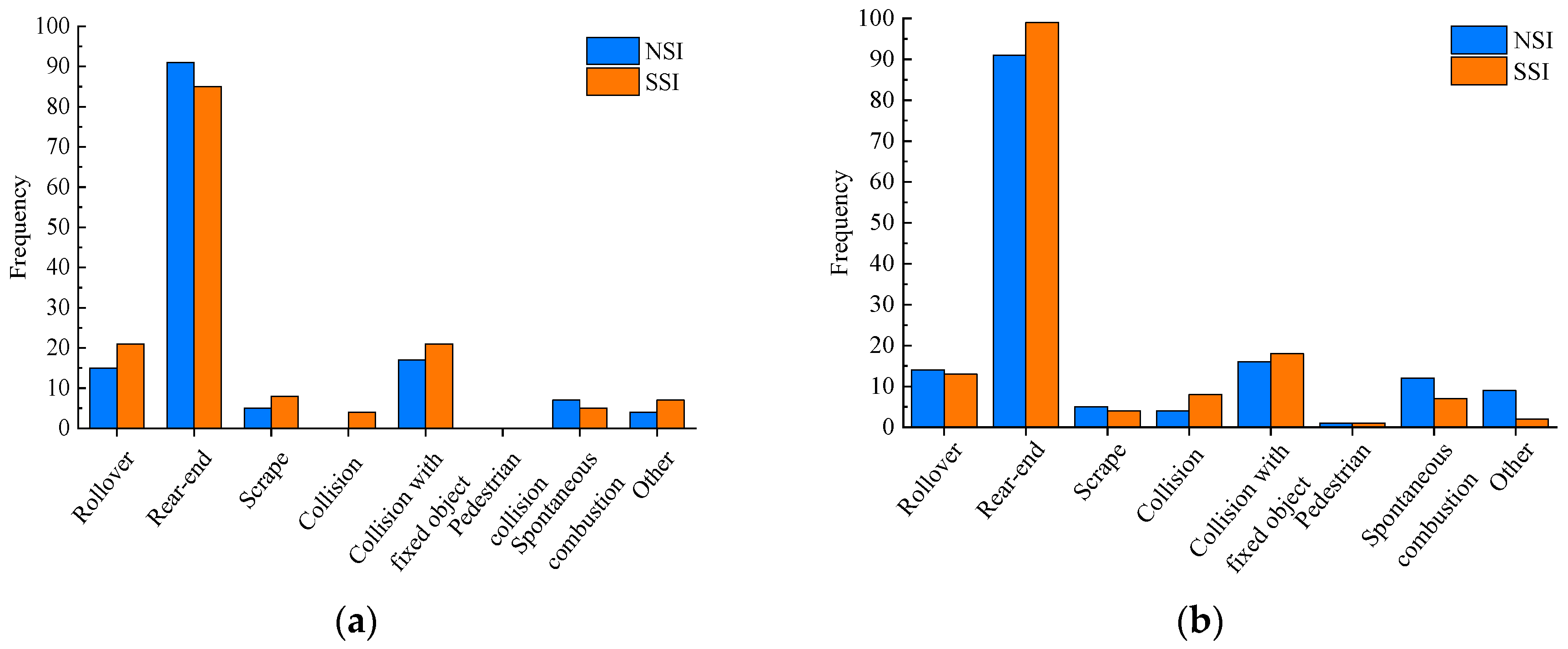
5.1. Significance Analysis of SSI Accidents
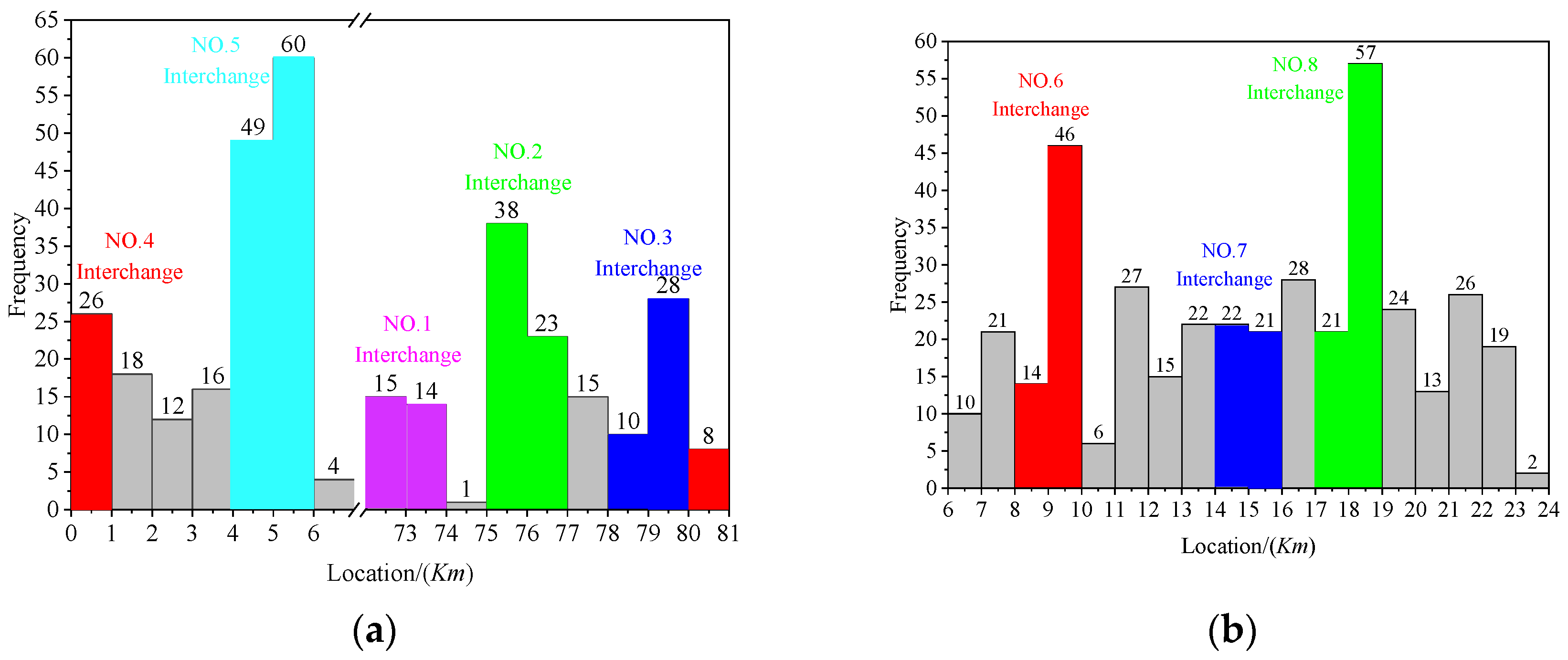
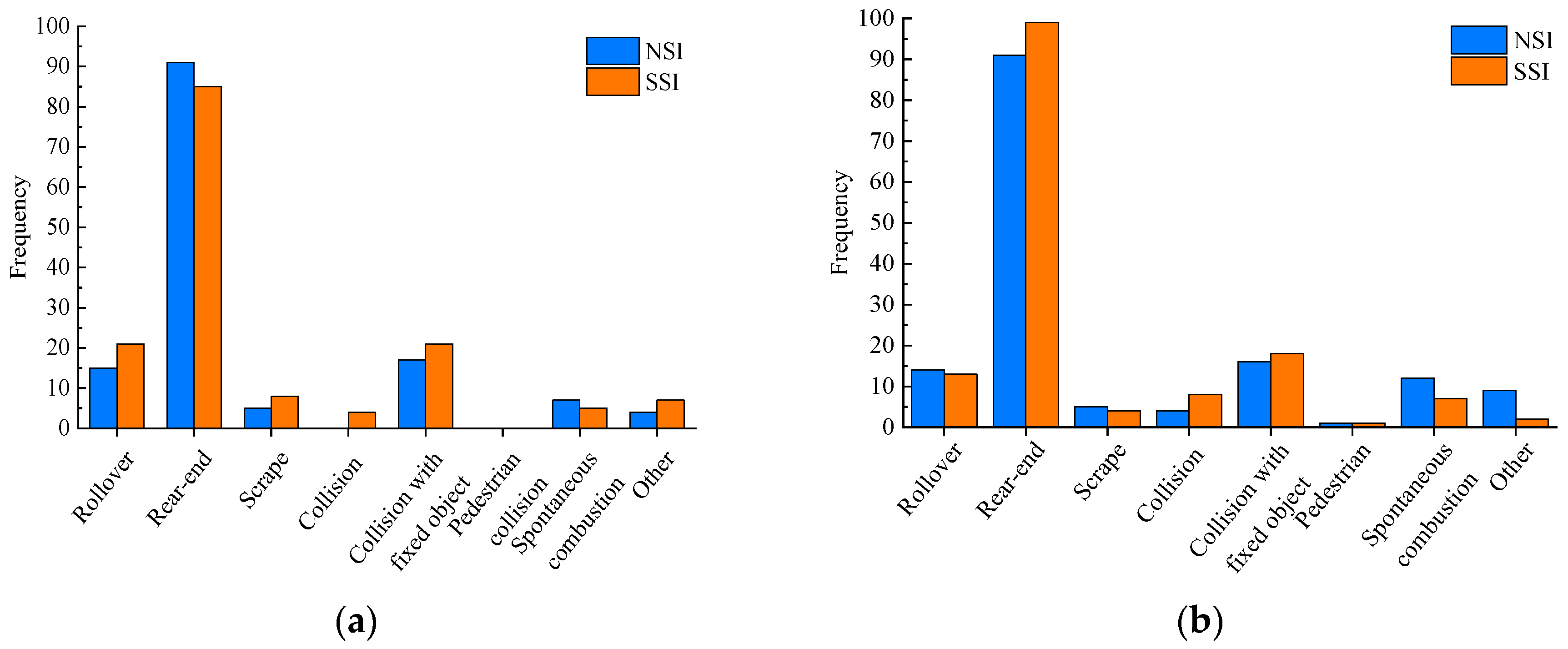
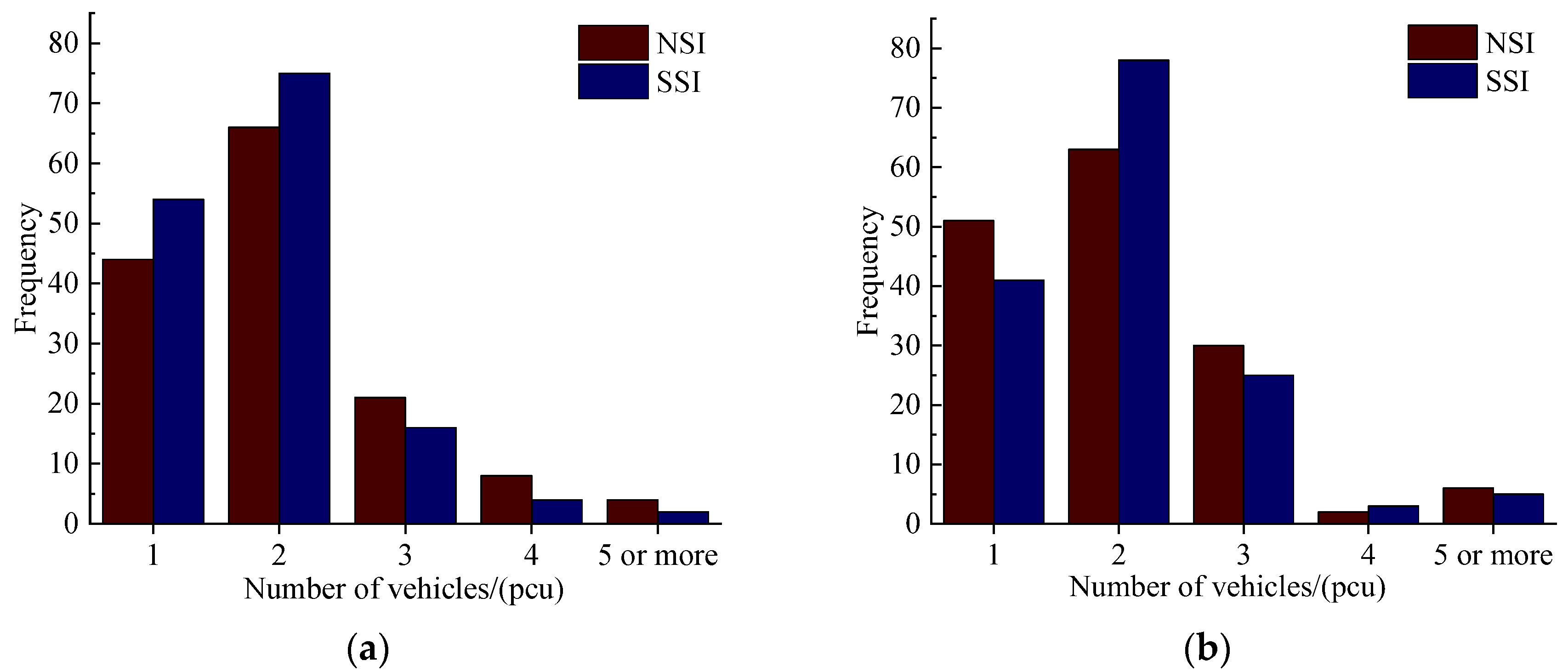
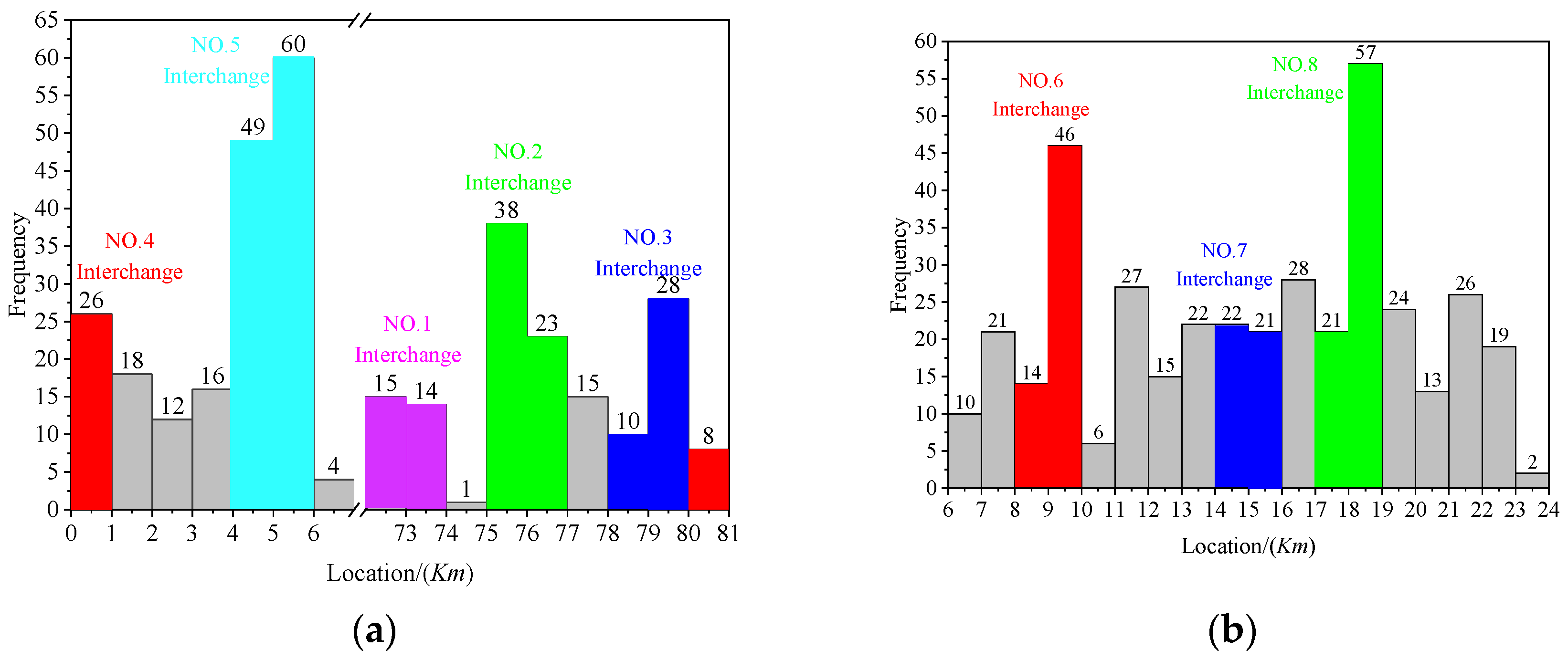
5.2. Statistical Analysis of Accidents in SSI Area
5.3. Accident Severity Casual Analysis in SSI Area
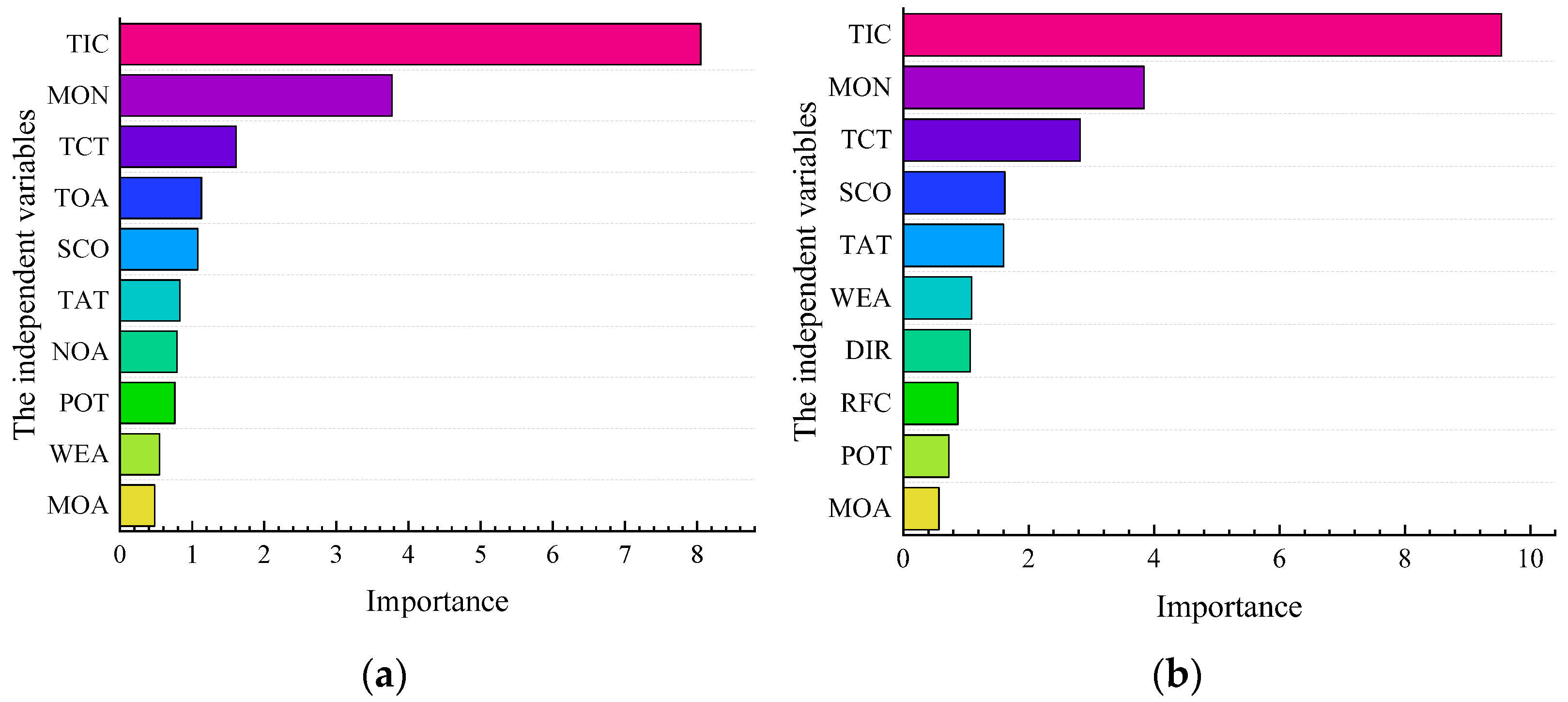
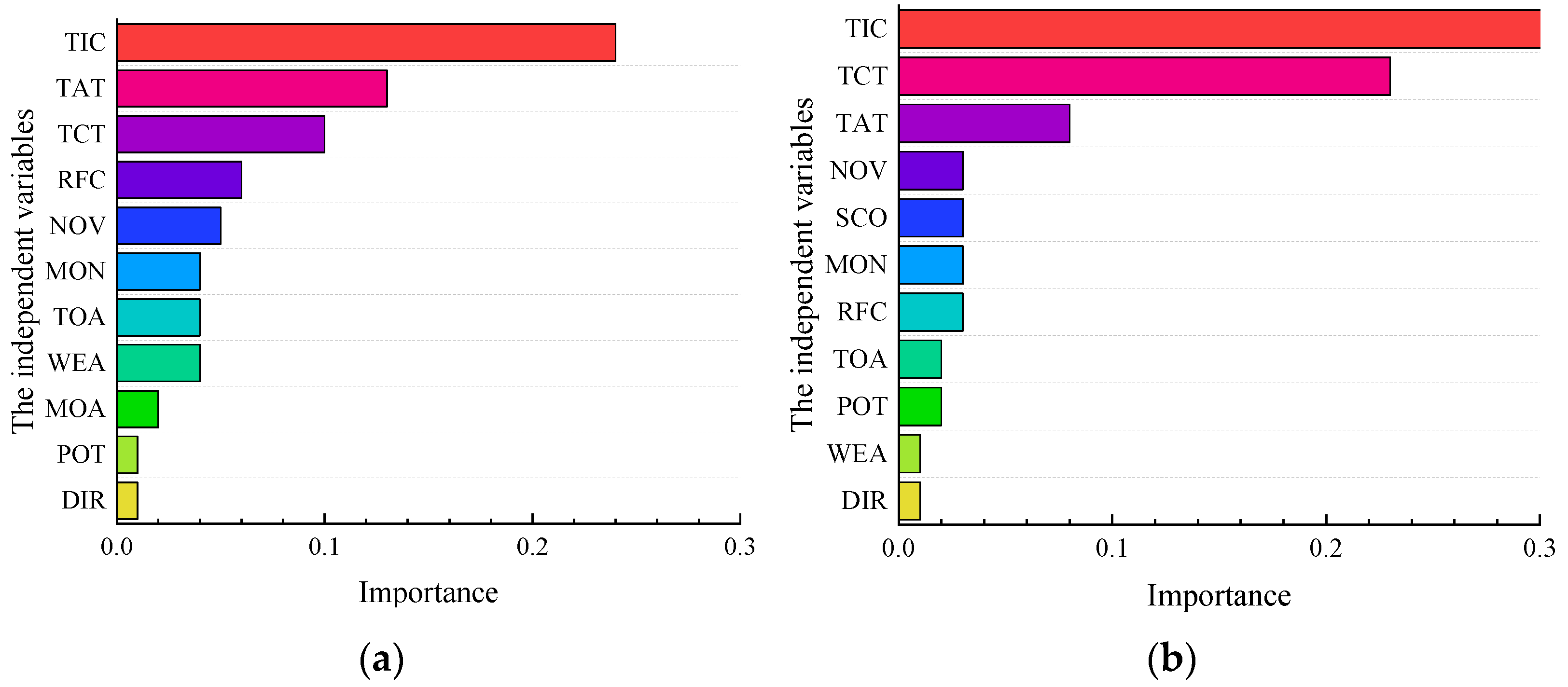
5.3.1. Variable Selection
5.3.2. Model Result
6. Discussion
7. Conclusions
- (1)
- There is a particularly negative impact on the safety of the expressway in the SSI area. The value of inner ring NAP in Sections I and II containing SSI is 27.2 and 33.7, respectively, higher than in other sections. Therefore, some safety measures should be taken to improve traffic safety in the SSI area.
- (2)
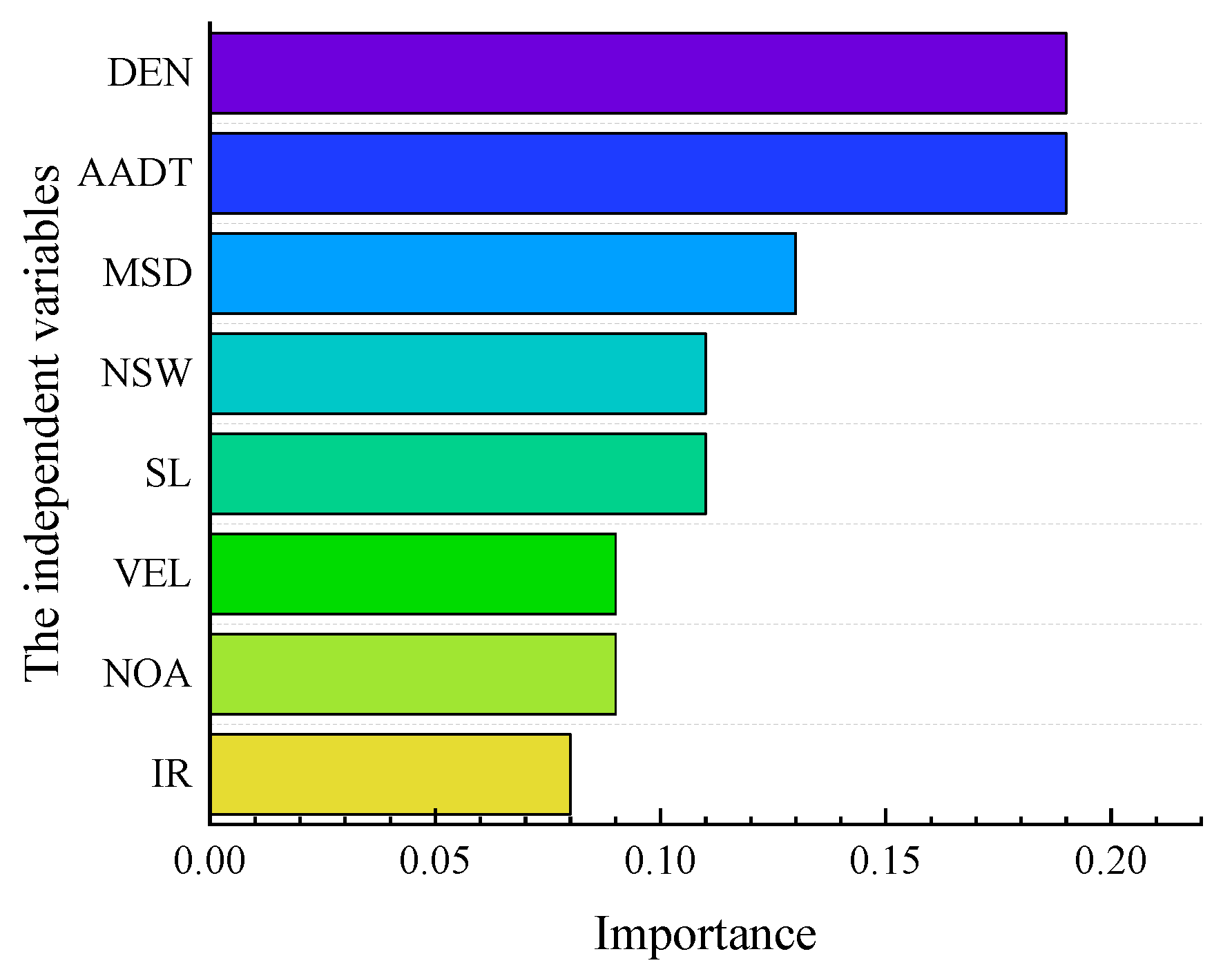
- The MSD has a specific negative impact on expressway safety. This paper ranked the importance of the eight indicators, such as MSD and AADT, by constructing the LSSVM model. The importance of DEN, AADT, and MSD was significant. Therefore, paying attention to the MSD on expressway safety is necessary.
- (3)
- TIC is the significant index of serious accidents in the SSI and NSI. This paper constructs the LSSVM, RF, and LR models, respectively. The importance of the TIC index is far greater than other indexes. Therefore, it is necessary to improve the efficiency of accident handling to reduce the severity of accidents.
- (4)
- RFC and NOV are relatively important indices of serious accidents in the SSI. LSSVM and LR models reflect that the RFC and NOV are relatively substantial, so extra attention should be paid to the SSI area’s road condition and vehicle spacing distance.
- (1)
- In future studies, the amount and type of data will be enriched, and the relationship between drivers’ factors and accidents will be fully considered.
- (2)
- Future studies will quantitatively analyze the impact of interchange spacing distance on traffic safety and find the safety threshold.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
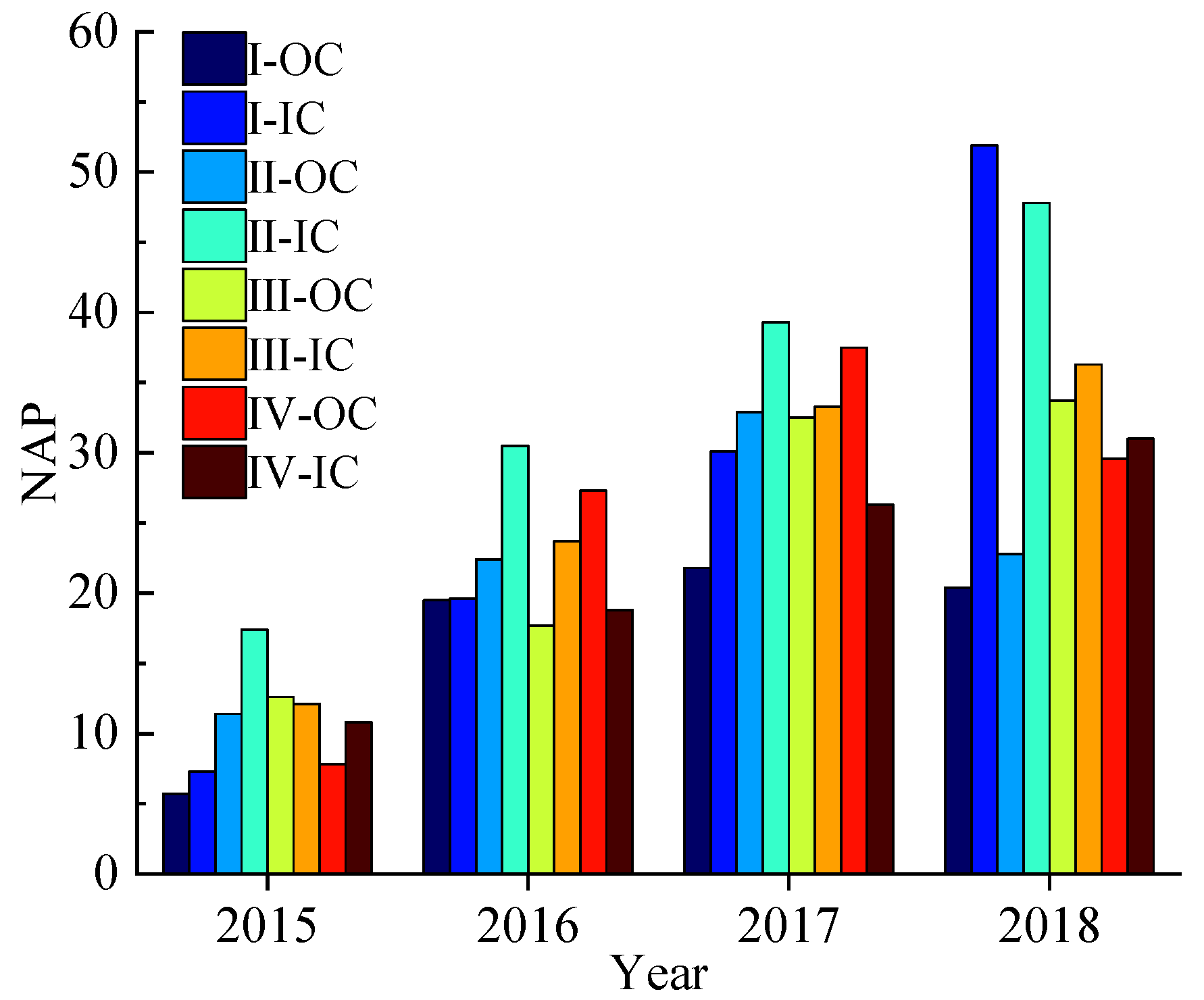{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Name | Abbreviation | Full Name |
|---|---|---|---|
| AADT | annual average daily traffic | ACS | accident severity |
| AUC | the area under the cure | DIR | direction |
| CART | classification and regression trees | FP-tree | frequent Pattern tree |
| DEN | density | ICI | interchange complexity index |
| IHSDM | interactive highway safety design model | IR | interweaving ratio |
| IC | inner ring | LR | logistic regression |
| LSSVM | least square support vector machine | MSD | mean spacing distance |
| MON | month | NSI | normal-spacing interchange |
| NAP | accident rate of 100 million vehicles per kilometer | NSW | proportion of non-sunny weather |
| NOA | the number of accidents | OC | outer ring |
| NOV | number of vehicles | POT | period of time |
| ROC | receiver operating characteristic | RF | random forest |
| ROA | road alignment | RFC | road form condition |
| SSI | small-spacing interchange | SVM | support vector machine |
| SL | section length | SCO | scope |
| TOA | time of accident | TCT | the car type |
| TAT | the accident types | TIC | time consuming |
| VEL | velocity | WEA | weather |
Appendix B
- (i)
- LSSVM
- (ii)
- Random forest
- (1)
- The bagging method is used to conduct self-sampling by putting back for a given training set T. Each sub-training set is extracted by returning from n samples of the original training set, i.e., .
- (2)
- Based on the decision tree, the binary tree corresponding to each sub-training set is formed, and the process is as follows:
- (a)
- Suppose there are a total of M attribute features, and in the decision tree of each node, select any feature from all attribute features as candidate attribute features for prediction or classification, generally speaking, and round down;
- (b)
- Calculate the Gini impurity of the selected M feature nodes, and select the minor attribute feature in Gini impurity as the optimal classification feature attribute;
- (c)
- The node is divided into two categories according to the selected optimal attribute features. Then, the sub-characteristic attribute next to the optimal attribute feature is selected from the remaining attribute features to ensure that each binary tree can fully grow.
- (3)
- Repeat operations 1 and 2 until the generated tree can accurately classify the samples in the training set, or all attribute features are used up. After that, all tree models in the operation process are combined to form a random forest model.
- (4)
- For any test samples, the final classification results of samples are often determined by a simple voting method, and the specific results are as follows:
References
- Wang, X.F.; Ding, Z.Z.; Guo, K.; Lin, Y.J. A Simulation-based comprehensive analysis for traffic efficiency and spatial distribution of risks in short weaving area of municipal interchange. J. Adv. Transp. 2021, 2021, 9968426. [Google Scholar] [CrossRef]
- Yuan, J.H.; Abdel-Aty, M.; Cai, Q.; Lee, J. Investigating drivers’ mandatory lane change behavior on the weaving section of freeway with managed lanes: A driving simulator study. Transp. Res. Part F Traffic Psychol. Behav. 2019, 62, 11–32. [Google Scholar] [CrossRef]
- Orfila, O.; Coiret, A.; Do, M.T. Modeling of dynamic vehicle-road interactions for safety-related road evaluation. Accid. Anal. Prev. 2010, 42, 1736–1743. [Google Scholar] [CrossRef] [PubMed]
- Pande, A.; Hellinga, B.; Saccomanno, F. Real-time crash prediction model for application to crash prevention in freeway traffic. Transp. Res. Rec. 2007, 1, 99–107. [Google Scholar] [CrossRef]
- Lee, C.; Abdel-Aty, M. Multiple-model framework for assessment of real-time crash risk. Transp. Res. Rec. 2003, 1, 67–77. [Google Scholar] [CrossRef]
- Basso, F.; Basso, L.J.; Bravo, F.; Pezoa, R. Real-time crash prediction in an urban expressway using disaggregated data. Transp. Res. Part C Emerg. Technol. 2018, 86, 202–219. [Google Scholar] [CrossRef]
- Lin, L.; Wang, Q.J.; Sadek, A.W. A novel variable selection method based on frequent pattern tree for real-time traffic accident risk prediction. Transp. Res. Part C Emerg. Technol. 2015, 55, 444–459. [Google Scholar] [CrossRef]
- Claros, B.; Edara, P.; Sun, C. When driving on the left side is safe: Safety of diverging diamond interchange ramp terminals. Transp. Res. Part C Emerg. Technol. 2020, 117, 133–142. [Google Scholar] [CrossRef] [PubMed]
- Hummer, J.E.; Cunninuham, C.M.; Srinivasan, R.; Warchol, S.; Claros, B.; Edara, P.; Sun, C. Safety evaluation of seven of the earlicst diverging diamond interchanges installed in the united. Transp. Res. Rec. 2016, 2583, 25–33. [Google Scholar] [CrossRef]
- Sadia, R.; Polus, A. Interchange complexity model and related safety implications. J. Transp. Eng. 2013, 5, 458–466. [Google Scholar] [CrossRef]
- Wang, L.; Abdel-Aty, M. Microscopic safety evaluation and prediction for freeway-to-freeway interchange ramps. Transp. Res. Rec. 2016, 2583, 56–64. [Google Scholar] [CrossRef]
- Qi, C. Study on Safety Evaluation Method of Expressway Interchange Based on IHSDM. Master’s Thesis, Chang’an University, Xi’an, China, 12 May 2018. [Google Scholar]
- Casado-Sanz, N.; Guirao, B.; Attard, M. Analysis of the Risk Factors Affecting the Severity of Traffic Accidents on Spanish Crosstown Roads: Sustainability and sustainable development in China. Sustainability 2020, 12, 2237. [Google Scholar] [CrossRef]
- Xu, C.C.; Wang, W.; Liu, P.; Zhang, F.W. Development of a real-time crash risk prediction model incorporating the various crash mechanisms across different traffic states. Traffic Inj. Prev. 2015, 16, 28–35. [Google Scholar] [CrossRef] [PubMed]
- Pljakić, M.; Jovanović, D.; Matović, B.; Mićić, S. Macro-level accident modeling in Novi Sad: A spatial regression approach. Accid. Anal. Prev. 2019, 132, 105259. [Google Scholar] [CrossRef] [PubMed]
- Yasmin, S.; Eluru, N.; Wang, L.; Abdel-Aty, M.A. A joint framework for static and real-time crash risk analysis. Anal. Methods Accid. Res. 2018, 18, 45–56. [Google Scholar] [CrossRef]
- Paolo, I.; Nicola, B.; Pasquale, C.; Vittorio, R.; Eirin, R. Exploring the relationships between drivers’ familiarity and two-lane rural road accidents. A multi-level study. Accid. Anal. Prev. 2018, 111, 280–296. [Google Scholar]
- Kim, K.; Li, L. Modeling fault among bicyclists and drivers involved in collisions in Hawaii, 1986–1991. Transp. Res. Rec. J. Transp. Res. Board 1996, 1538, 75–80. [Google Scholar] [CrossRef]
- Mercier, C.R.; Shelley, M.C.; Rimkus, J.; Mercier, J.M. Age and gender as predictors of injury severity in head-on highway vehicular collisions. Transp. Res. Rec. 1997, 81, 37–46. [Google Scholar] [CrossRef]
- Yau, K.K.W.; Lo, H.P.; Fung, S.H.H. Multiple-vehicle Traffic Accidents in Hong Kong. Accid. Anal. Prev. 2006, 38, 1157–1161. [Google Scholar] [CrossRef]
- Ali, S.G. Using logistic regression to estimate the influence of accident factors on accident severity. Accid. Anal. Prev. 2002, 34, 729–741. [Google Scholar]
- Chang, L.Y.; Chen, W.C. Data mining of tree-based models to analyze freeway accident frequency. J. Saf. Res. 2006, 36, 365–375. [Google Scholar] [CrossRef] [PubMed]
- Lei, T.; Peng, J.; Liu, X.L.; Luo, Q. A Bayesian network based framework for real-time crash prediction on the basic freeway segments of urban expressways. J. Adv. Transp. 2021, 2021, 373–381. [Google Scholar]
- Hossain, M.; Muromachi, Y. Crash prediction on expressway incorporating traffic flow continuity parameters based on machine learning Approach. Accid. Anal. Prev. 2012, 45, 373–381. [Google Scholar] [CrossRef]
- Moral-García, S.; Castellano, J.G.; Mantas, C.J.; Montella, A.; Abellán, J. Decision tree ensemble method for analyzing traffic accidents of novice drivers in urban areas. Entropy 2019, 21, 360. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhao, N.; Peng, L.L.; Xin, J.Z.; Liu, S.Y. Fast simulation of fully non-stationary wind fields using a new matrix factorization assisted interpolation method. Mech. Syst. Signal Process. 2022, 172, 108973. [Google Scholar] [CrossRef]
- Wang, J.H.; Liu, B.; Fu, T.; Liu, S.; Stipancic, J. Modeling when and where a secondary accident occurs. Accid. Anal. Prev. 2019, 130, 160–166. [Google Scholar] [CrossRef] [PubMed]
- Ellahyani, A.; El Ansari, M.; El Jaafari, I. Traffic sign detection and recognition based on random forests. Appl. Soft Comput. 2016, 46, 805–815. [Google Scholar] [CrossRef]
- Guo, M.; Zhao, X.H.; Yao, Y.; Yan, P.W.; Bi, C.F.; Wu, D.Y. A study of freeway crash risk prediction and interpretation based on risky driving behavior and traffic flow data. Accid. Anal. Prev. 2021, 160, 106328. [Google Scholar] [CrossRef]
- Berhanu, G. Models relating traffic safety with road environment and traffic flows on arterial roads in Addis Ababa. Accid. Anal. Prev. 2004, 36, 697–704. [Google Scholar] [CrossRef]
- Quddus, M. Exploring the relationship between average speed, speed variation, and accident rates using spatial statistical models and gis. J. Transp. Saf. Secur. 2013, 5, 27–45. [Google Scholar] [CrossRef]
- Zhao, X.H.; Ding, Y.; Yao, Y.; Zhang, Y.L.; Bi, C.F.; Su, Y.L. A multinomial logit model: Safety risk analysis of interchange area based on aggregate driving behavior data. J. Saf. Res. 2021, 80, 27–38. [Google Scholar] [CrossRef] [PubMed]
- Kaplan, S.P.; Carlo, G. A multinomial logit model: Risk factors associated with bus accident severity in the United States: A generalized ordered logit model. J. Saf. Res. 2012, 43, 171–180. [Google Scholar] [CrossRef] [PubMed]
- Cheng, J.H.; Sun, J.; Yao, K.S.; Xu, M.; Cao, Y. A variable selection method based on mutual information and variance inflation factor. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 268, 120652. [Google Scholar] [CrossRef] [PubMed]
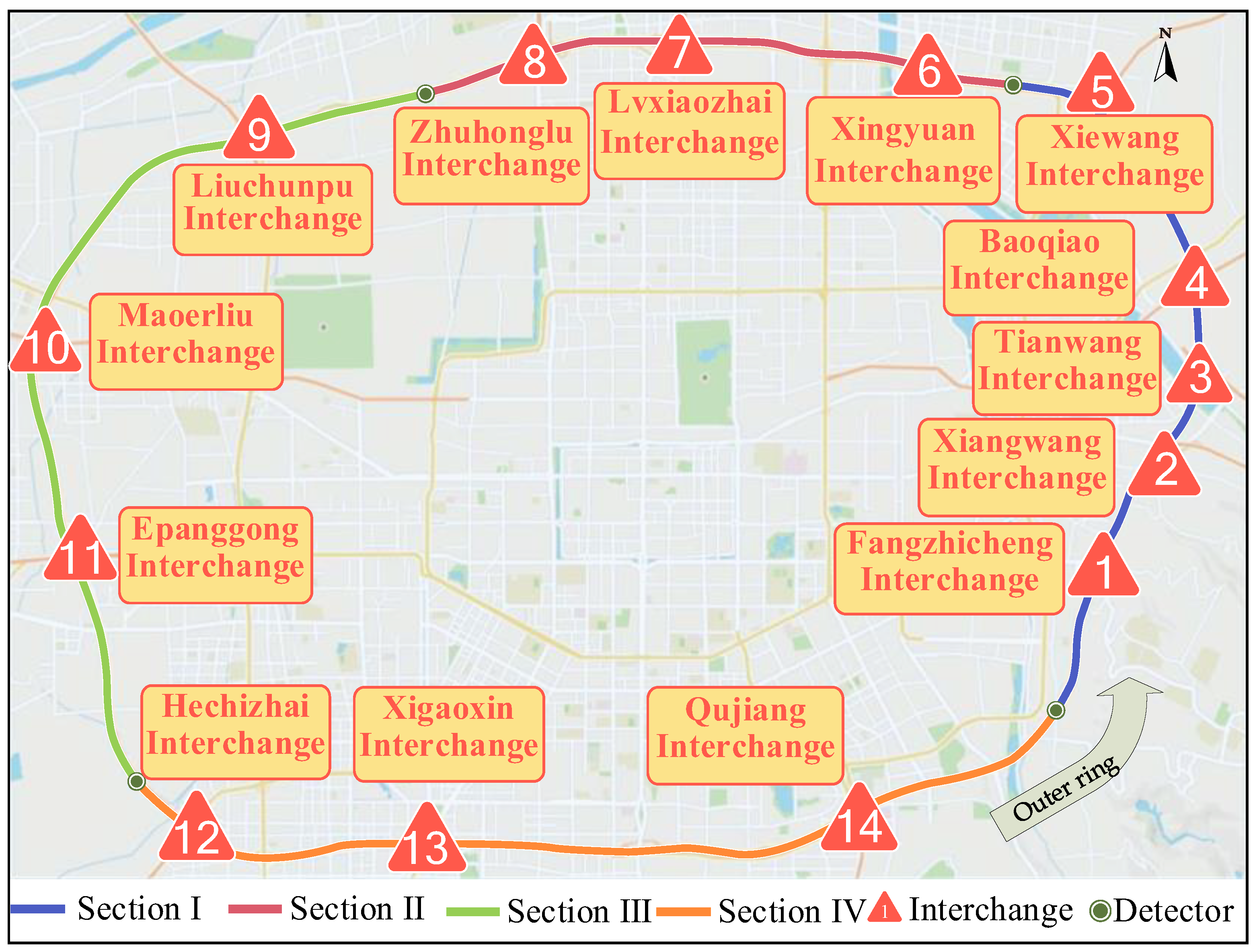

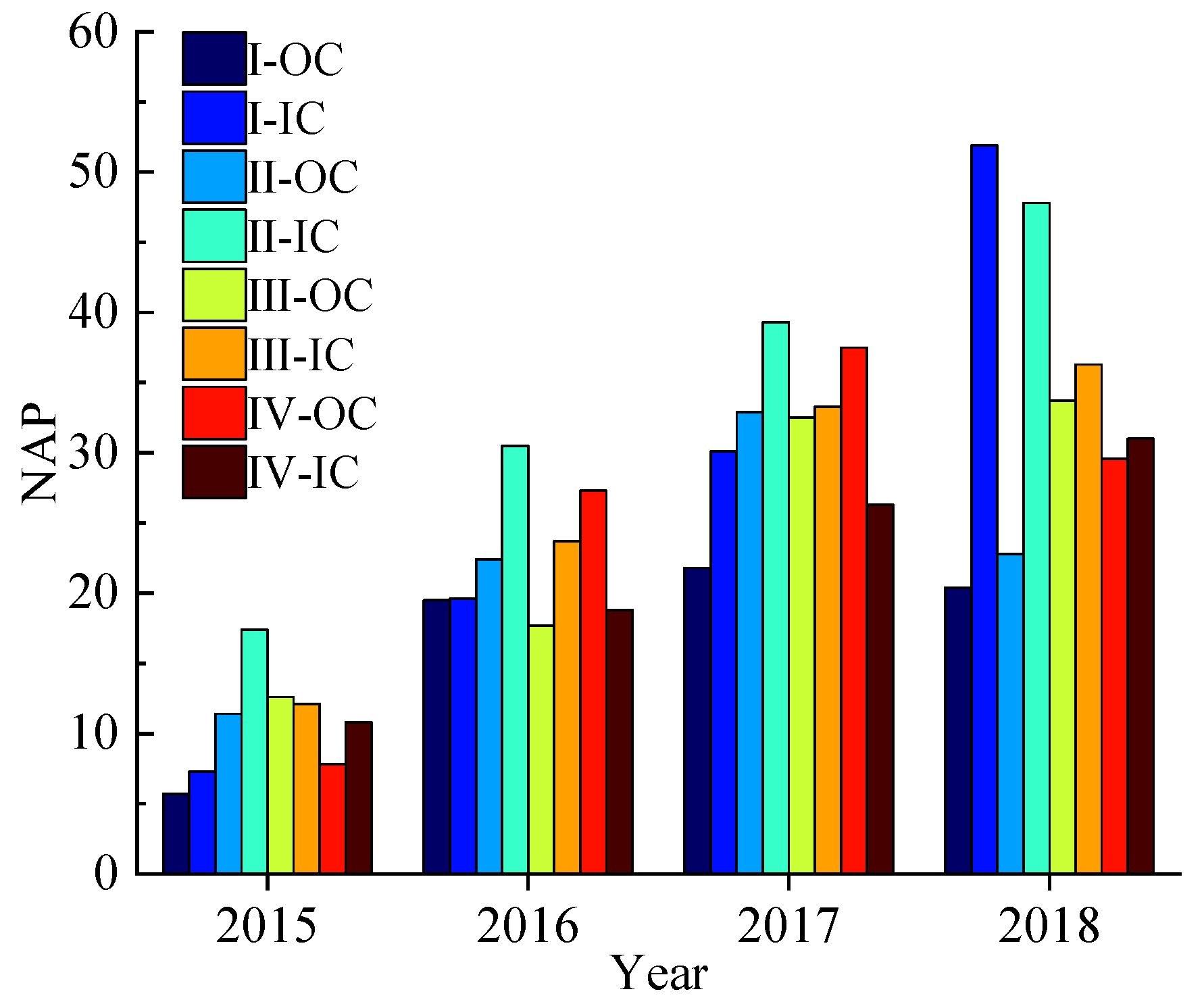

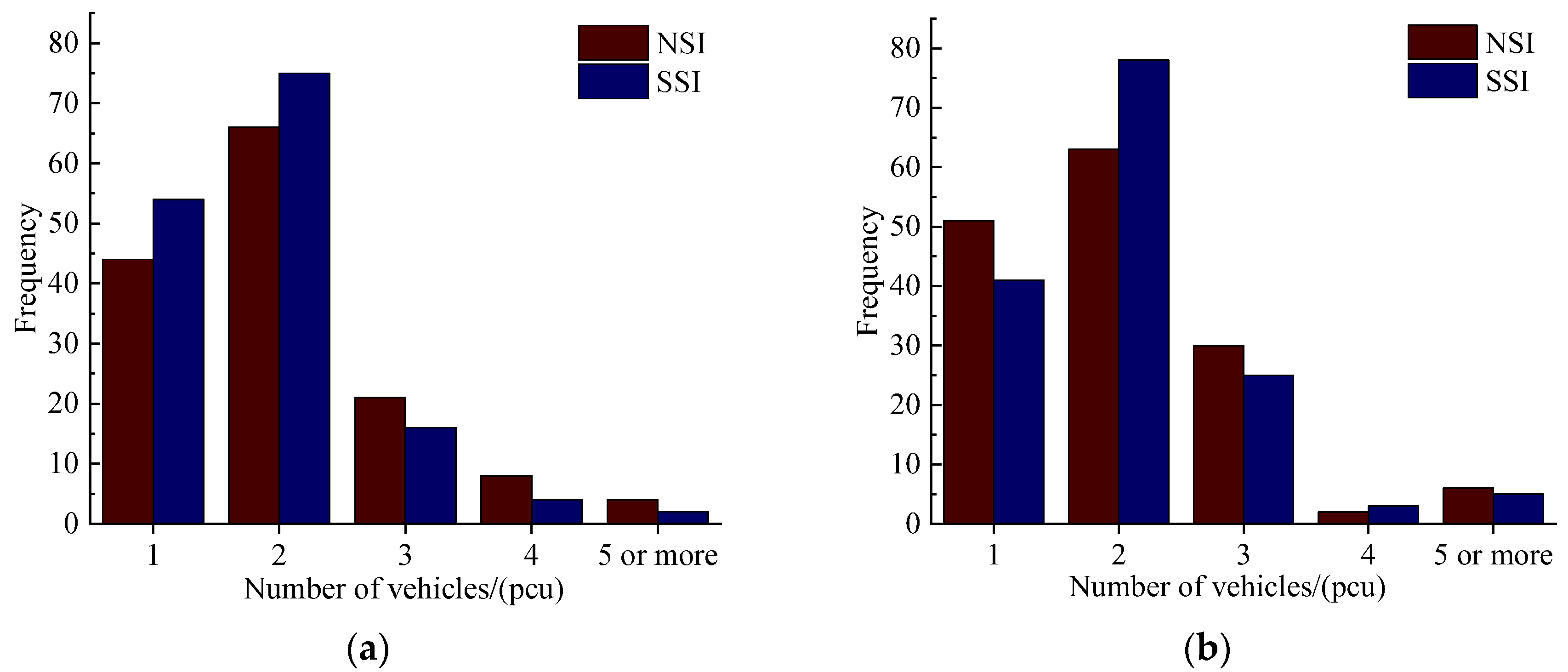

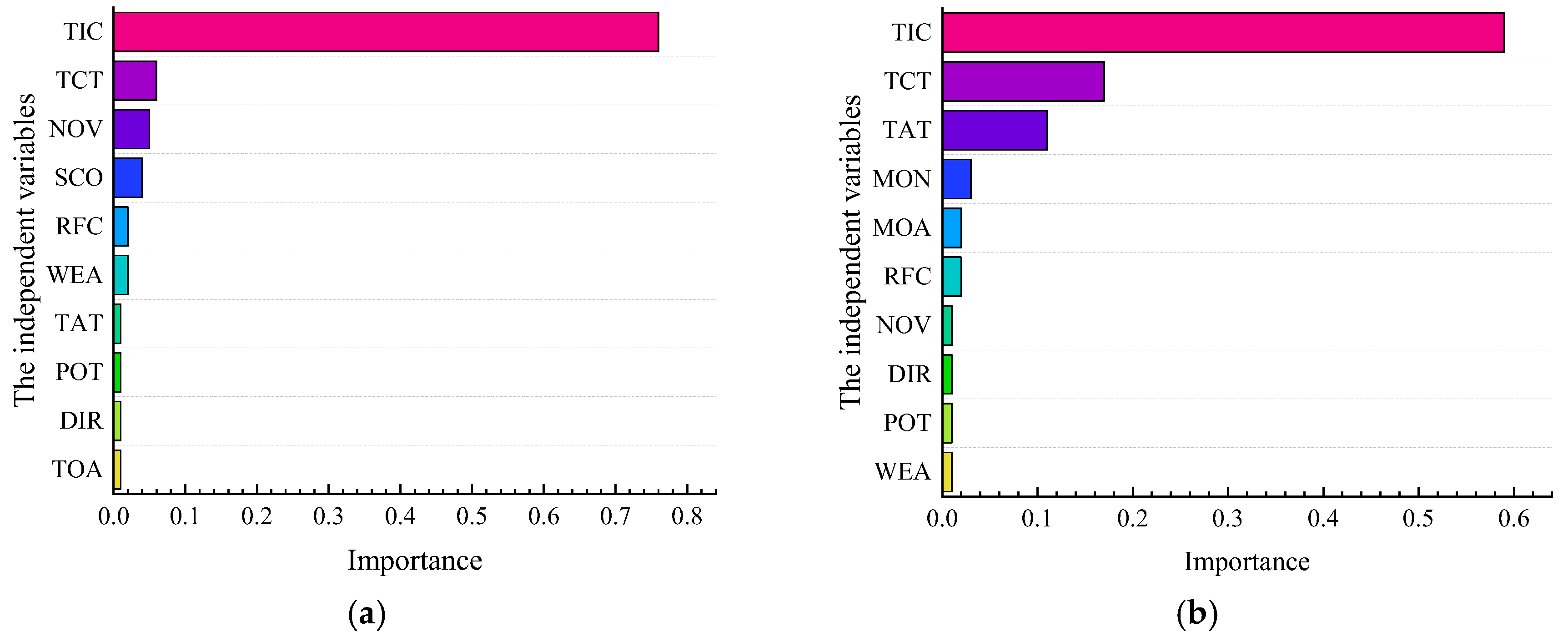

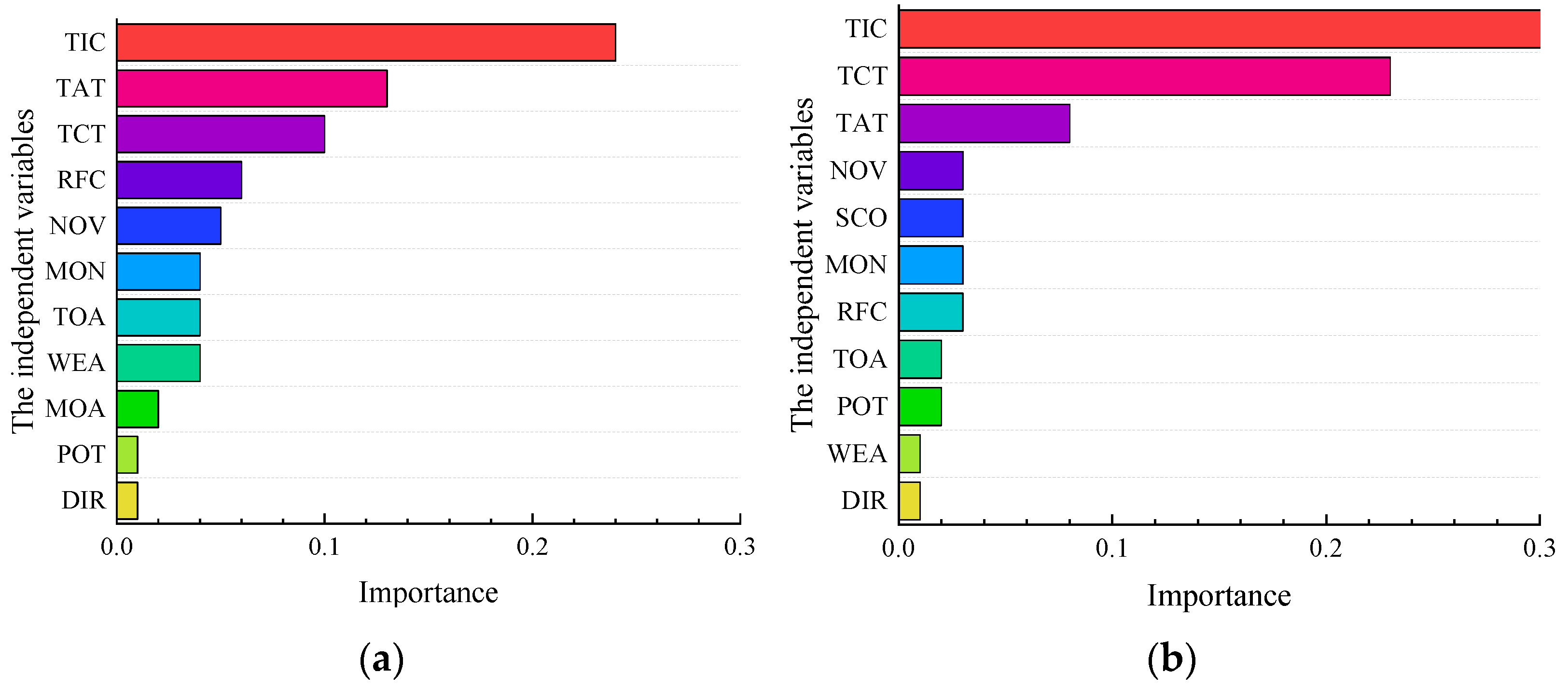
| Section | Length | Interchange Information |
|---|---|---|
| I | 17 km | 1, 2, 3, 4, 5 |
| II | 18 km | 6, 7, 8 |
| III | 22.3 km | 9, 10, 11 |
| IV | 24.5 km | 12, 13, 14, 15 |
| Location | Year | NAP | AADT (pcu/d) | VEL (km/h) | DEN (pcu/km) | IR (%) | MSD (km) | SL (km) | NSW (%) | NOA (Count) |
|---|---|---|---|---|---|---|---|---|---|---|
| I-OC | 2015 | 5.7 | 1.55 | 72.7 | 14.5 | 24 | 1.98 | 14.3 | 45 | 11 |
| 2016 | 19.5 | 1.90 | 75.2 | 14.9 | 24 | 1.98 | 14.3 | 37 | 43 | |
| 2017 | 21.8 | 2.54 | 78.3 | 16.5 | 24 | 1.98 | 14.3 | 32 | 65 | |
| 2018 | 20.4 | 2.75 | 80.4 | 16.3 | 24 | 1.98 | 14.3 | 31 | 54 | |
| I-IC | 2015 | 7.3 | 1.45 | 65.9 | 7.8 | 31 | 2.09 | 14.3 | 29 | 17 |
| 2016 | 19.6 | 1.81 | 72.1 | 11.2 | 31 | 2.09 | 14.3 | 26 | 34 | |
| 2017 | 30.1 | 2.62 | 76.9 | 17.9 | 31 | 2.09 | 14.3 | 16 | 50 | |
| 2018 | 51.9 | 3.32 | 83.9 | 19.6 | 31 | 2.09 | 14.3 | 22 | 63 | |
| II-OC | 2015 | 11.4 | 2.44 | 74.2 | 15.4 | 30 | 3.1 | 16.77 | 45 | 20 |
| 2016 | 22.4 | 2.96 | 74.3 | 19.2 | 30 | 3.1 | 16.77 | 37 | 46 | |
| 2017 | 32.9 | 3.35 | 75.4 | 20.5 | 30 | 3.1 | 16.77 | 18 | 73 | |
| 2018 | 22.8 | 3.93 | 74.9 | 25.5 | 30 | 3.1 | 16.77 | 17 | 54 | |
| II-IC | 2015 | 17.4 | 1.92 | 75.5 | 14.7 | 17 | 2.91 | 16.77 | 32 | 22 |
| 2016 | 30.5 | 2.37 | 74.9 | 14.5 | 17 | 2.91 | 16.77 | 26 | 43 | |
| 2017 | 39.3 | 2.35 | 76.2 | 14.3 | 17 | 2.91 | 16.77 | 18 | 60 | |
| 2018 | 47.8 | 3.11 | 74.6 | 20.6 | 17 | 2.91 | 16.77 | 25 | 76 | |
| III-OC | 2015 | 12.6 | 4.6 | 82.8 | 16 | 13 | 5.15 | 23 | 33 | 21 |
| 2016 | 17.7 | 3.38 | 75.8 | 11.9 | 13 | 5.15 | 23 | 23 | 22 | |
| 2017 | 32.5 | 1.19 | 76.8 | 8.8 | 13 | 5.15 | 23 | 28 | 46 | |
| 2018 | 33.7 | 0.45 | 65.9 | 4.2 | 13 | 5.15 | 23 | 26 | 51 | |
| III-IC | 2015 | 12.1 | 5.17 | 82.6 | 16 | 13 | 5.45 | 23 | 13 | 15 |
| 2016 | 23.7 | 3.78 | 77.1 | 13 | 13 | 5.45 | 23 | 17 | 29 | |
| 2017 | 33.3 | 1.71 | 77.5 | 13 | 13 | 5.45 | 23 | 21 | 48 | |
| 2018 | 36.3 | 0.67 | 69.1 | 8.4 | 13 | 5.45 | 23 | 18 | 39 | |
| IV-OC | 2015 | 7.8 | 0.75 | 66.1 | 18.4 | 16 | 2.28 | 25.7 | 19 | 21 |
| 2016 | 27.3 | 1.95 | 66.6 | 24 | 16 | 2.28 | 25.7 | 27 | 44 | |
| 2017 | 37.5 | 2.98 | 69.8 | 21.6 | 16 | 2.28 | 25.7 | 18 | 83 | |
| 2018 | 29.6 | 4.27 | 68.8 | 31.2 | 16 | 2.28 | 25.7 | 23 | 106 | |
| IV-IC | 2015 | 10.8 | 0.28 | 76.7 | 14.3 | 18 | 2.82 | 25.7 | 33 | 27 |
| 2016 | 18.8 | 1.92 | 73.1 | 23.5 | 18 | 2.82 | 25.7 | 34 | 62 | |
| 2017 | 26.3 | 3.44 | 71.9 | 24.2 | 18 | 2.82 | 25.7 | 15 | 92 | |
| 2018 | 31 | 5.15 | 67.2 | 37.7 | 18 | 2.82 | 25.7 | 20 | 111 |
| Variable | Values of Categories | Variable | Values of Categories | Variable | Values of Categories |
|---|---|---|---|---|---|
| ROA | 1. Line | POT | 1.day | TOA | 1. Working days |
| 2. Bend | 2.night | 2. Day off | |||
| MON | 1. January 2. February… 12. December | RFC | 1. Normal 2. Road surface slippery 3. Ice on the road | DIR | 1. inner circle 2. outer circle |
| WEA | 1. Sunny 2. Cloudy 3. Snow 4. Rain 5. Fog | NOV | 1. One 2. Two 3. Three 4. Four 5. More than five | TIC | Actual time/minute |
| TCT | 1. Passenger car | TAT | 1. Rollover accident 2. Rear-end accident 3. Scrape accident 4. Collision 5. Collision with fixed object accident 6. Pedestrian collision 7.Spontaneous combustion 8. Other accidents | SCO | 1. Lane one 2. Lane two 3. Lane three 4. Emergency lane 5. All 6. Emergency lane + lane one 7. Emergency lane + lane two 8. None |
| 2. Bus | |||||
| 3. Van | |||||
| 4. Large truck | |||||
| 5. Semi-trailer | |||||
| 6. Minivan | |||||
| 7. Special vehicle | |||||
| 8. Passenger car-bus mix | |||||
| 9. Van-Large truck mix | |||||
| 10. Passenger-truck hybrid | |||||
| 11. Multiple models |
| Variables | VIF | Variables | VIF | |
|---|---|---|---|---|
| MON | 4.576427 | WEA | 3.549679 | |
| TOA | 8.675889 | TCT | 2.672981 | |
| POT | 8.274022 | NOV | 5.506071 | |
| TIC | 1.327032 | TAT | 3.429347 | |
| ROA | 8.377142 | SCO | 3.153264 | |
| DIR | 8.85624 | |||
| Section | SSI | NSI | |||||
|---|---|---|---|---|---|---|---|
| Three models for severity | LSSVM | RF | Logistic | LSSVM | RF | Logistic | |
| The number of predictive variables entered | 12 | 12 | 12 | 12 | 12 | 12 | |
| Number of predictive variables in the final model | 12 | 12 | 12 | 12 | 12 | 12 | |
| Normalized type | L2 | - | - | L2 | - | - | |
| Penalty parameter (Lambda) | 0.1 | - | - | 0.1 | - | - | |
| Train set | Accuracy | 89.4% | 90.9% | 97.8% | 97% | 94% | 98.1% |
| AUC | 0.997 | 0.997 | 0.995 | 0.998 | 0.999 | 0.992 | |
| Gini | 0.994 | 0.994 | 0.988 | 0.996 | 0.998 | 0.984 | |
| Test set | Accuracy | 89.3% | 88% | 98.8% | 87.8% | 92.8% | 98.7% |
| AUC | 0.988 | 0.958 | 0.873 | 0.876 | 0.972 | 0.745 | |
| Gini | 0.996 | 0.916 | 0.746 | 0.752 | 0.944 | 0.49 | |
| Validation set | Accuracy | 92.1% | 86.7% | 96.4% | 88.1% | 92.4% | 98% |
| AUC | 0.959 | 0.995 | 0.825 | 0.944 | 0.987 | 0.814 | |
| Gini | 0.918 | 0.99 | 0.649 | 0.887 | 0.974 | 0.628 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Xu, J.; Liu, X.; Zheng, Z.; Zhang, H.; Wang, C. Analysis on Risk Characteristics of Traffic Accidents in Small-Spacing Expressway Interchange. Int. J. Environ. Res. Public Health 2022, 19, 9938. https://doi.org/10.3390/ijerph19169938
Wang Y, Xu J, Liu X, Zheng Z, Zhang H, Wang C. Analysis on Risk Characteristics of Traffic Accidents in Small-Spacing Expressway Interchange. International Journal of Environmental Research and Public Health. 2022; 19(16):9938. https://doi.org/10.3390/ijerph19169938
Chicago/Turabian StyleWang, Yanpeng, Jin Xu, Xingliang Liu, Zhanji Zheng, Heshan Zhang, and Chengyu Wang. 2022. "Analysis on Risk Characteristics of Traffic Accidents in Small-Spacing Expressway Interchange" International Journal of Environmental Research and Public Health 19, no. 16: 9938. https://doi.org/10.3390/ijerph19169938
APA StyleWang, Y., Xu, J., Liu, X., Zheng, Z., Zhang, H., & Wang, C. (2022). Analysis on Risk Characteristics of Traffic Accidents in Small-Spacing Expressway Interchange. International Journal of Environmental Research and Public Health, 19(16), 9938. https://doi.org/10.3390/ijerph19169938