
“Not Sure Sharing Does Anything Extra for Me”: Understanding How People with Cardiovascular Disease Conceptualize Sharing Personal Health Data with Peers


{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Background
1.2. Objective
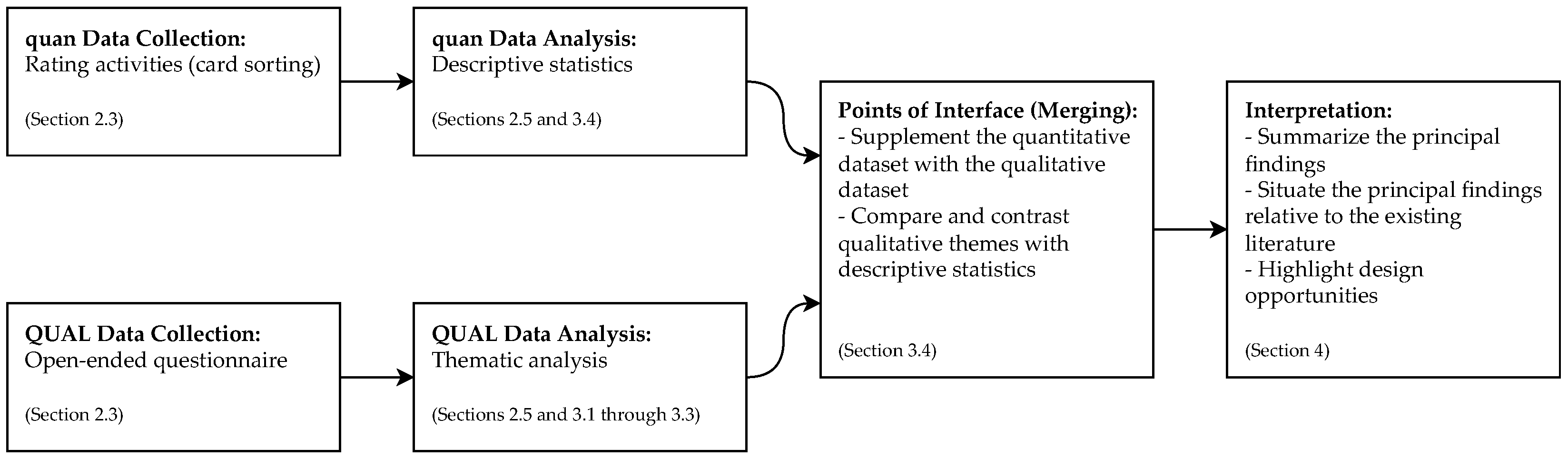
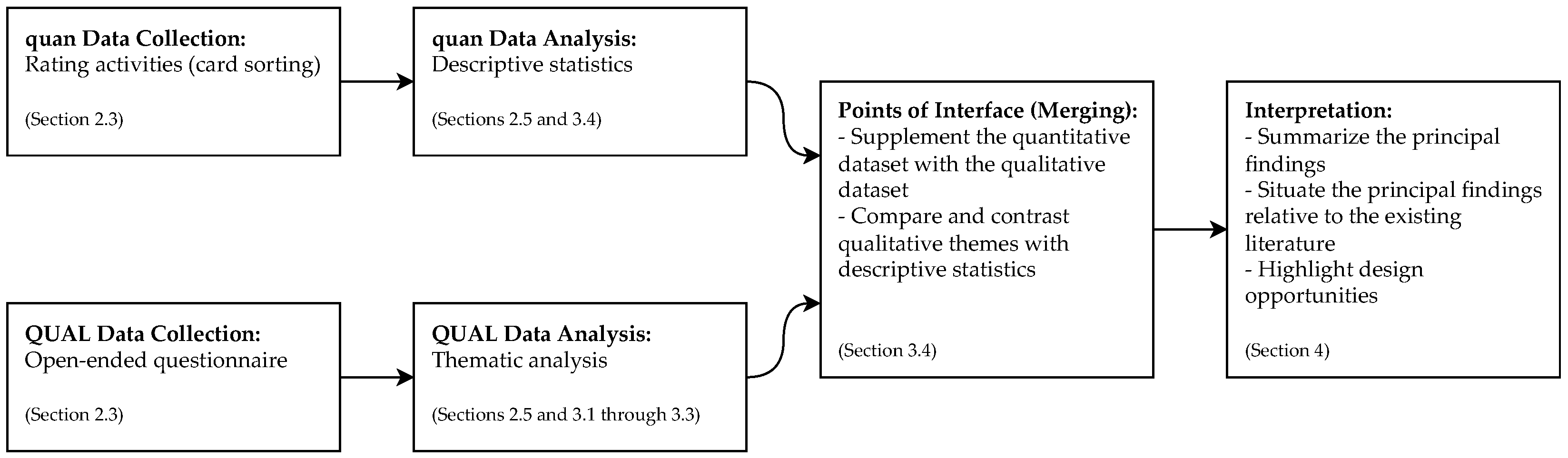
2. Materials and Methods
2.1. Study Design
2.2. Participants
2.3. Materials
2.4. Procedure
2.5. Analysis
3. Results
3.1. Theme 1: “Not Sure Sharing Does Anything Extra for Me”
I usually prefer to manage [things] myself. [It’s] my problem and I have the solution. … Don’t look anywhere else for info—it’s all a bit personal for me. Nor do I need any contact with other sufferers. … When I go to see the medical team, I want them to tell me all the detail they have—the rest of the time I prefer to try to put it to the back of my mind and just deal with my own condition on my own. (P2)
On the whole for me presonally [sic] I have lived with the condition for quite a few years and dont [sic] feel it neccessary [sic] to interact in that way [sharing data with peers]. (P30, male, 55–64 y/o, CAD, five years or more after diagnosis.)
I’m not sure how I would make use of a peers [sic] data. I’m not sure beyond knowing we have the same condition if it is helpful or not to know their numbers … if stats would really help others or not since we all have different baselines, I suppose at a certain point though any symptom can become an ’alarm’ symptom so it’s good to be informed of those numbers (for example like a fever or heart rate that is dangerously high), of course I don’t go to the hospital even when my heart rate is above 190 though I am sure for some that [it] is a rate that would send them to seek emergency medical care. So I find it should be up to [the] individual or the individuals [sic] doctors when to seek or not to seek medical care. (P25, female, 35–44 y/o, CAD, five years or more after diagnosis.)
I am also a little afraid of my peers [sic] data because maybe my data doesnt [sic] fit theirs to [sic] well which might lead to thoughts that my data is off. Even though it probably fits my body etc. … I might excange [sic] data with a person who is close to my attributes. But again—I am not entirely certain I would use this app function at all as it [sharing data with peers] might get me more worried about my own condition in comparison than without. (P20)
It is difficult to find peers whose advice you can take on [sic] face value … thinking about this and the polarisation of society into left and right politics; vaxxers and anti-vaxxers; homeopathy or allopathic medicine, one might want an optional profile page where you can indicate some of your ’beliefs’/occupation/education level so I know if I can trust you. This has become important recently. … If someone is an anti-vaxxer, I do not want to take advice from them. (P3, female, 65–74 y/o, CAD, two years or more after diagnosis, but less than five.)
3.2. Theme 2: “Comparing Apples with Apples and Not with Pears”: Affordances and Drivers of Connecting with Similar Others
I think sharing health information can be really helpful. … On the one hand, it motivates me when I compare the results of others [with mine], and on the other hand, others can be motivated by me. This is important as a good fun, but it also has the character of taking care of your health. … Maybe it would help someone and motivate someone to act when they saw that my health data was improving. (P17, male, 25–34 y/o, CAD, one year or more after diagnosis, but less than two.)
I like sharing personal health data with peers because … other people may have similar experiences so I can fell [sic] less alone. I don’t like it when people who have no idea on this subject advise other people or give their opinion. (P5, female, 18–24 y/o, HF, five years or more after diagnosis.)
I like the idea of comparing my data with peers who are similar to me (comparing apples with apples). … The peers whose personal health data interest me are females in the same age bracket and of similar body weight or BMI [body mass index]—not [the] time since diagnosis. It helps to contextualise and compare with people in the same scenario—compare apples with apples and not with pears. (P3)
Age, weight, height and sex for comparison purposes. I would hope such an app would possibly have [the] anonymous messaging capability, to allow for other requests to be made (e.g., “I notice you’ve had a steady decline in your weight over the last 2 months. How have you managed that?”). (P27, male, 65–74 y/o, CAD, five years or more after diagnosis.)
Perhaps it would be helpful for them [peers] to see in case they too are experiencing similar symptoms and have not yet been diagnosed by a doctor or they have a doctor not taking them seriously and only diagnosing them with anxiety (which [was] what I personally experienced for years until a doctor took me seriously), so maybe seeing and comparing the [symptoms] could help them get diagnosed and get help more quickly. (P25)
[Sharing data with peers] would be good to know what other people in a similar situation are doing [and] how they are being effected [sic] by the things they do and monitor. … It is often good to ask and talk to people who have similar problems. Sometimes they can offer good advice which you hadn’t thought of. (P31, male, 75 years or older, HF, five years or more after diagnosis.)
What I like about sharing information with people with this condition is that they can find out how that person is being treated or what follow-up is being given. (P14, male, 18–24 y/o, HF, five years or more after diagnosis.)
I like the thought of having information from others that have heart issues. … I think this info would be valuable and help me with new ideas to better live and treat the disease. (P22)
While I (we) know not everyone responds to the same treatment, it is nice to know about things I have not yet tried. For example, a lot of people with POTS [postural orthostatic tachycardia syndrome] drink something called liquid IV, I never knew about the product until I saw information about it from my mutuals on Tiktok. I did try it but did not like the taste, so stuck with the propel electrolyte water for my daily hydration needs, which I have shared with other mutuals on private facebook [sic] support groups and Tiktok. … I would advise they [peers] ask their doctor first before trying anything whether it be a product or pt [physical therapy] exercise. (P25)
I like the idea of sharing this data, because with that and seeing other ppl [sic] like me I wouldn’t feel like I’m ’worse’, ’different’ etc. … I feel like reading about other people [sic] problems would make me feel more normal, like im [sic] not the only one. (P24)
I believe I would have stressed less knowing others were experiencing this [too]. I wouldnt [sic] have felt so alone in my fear. (P22)
I think it seems very positive to share, to know and tell the things that happen with me are normal and reassure me or other in similar conditions. (P21, female, 55–64 y/o, CAD, one year or more after diagnosis, but less than two.)
Overall, I think it can be a good thing to share data with peers. By doing this, I feel that the overall health of people can improve, although it may not make much difference at an individual level, particularly if you are already confident about what weight and BP [blood pressure] should apply to you. (P29)
I would not mind disclosing my personal health data to whom ever [sic] wants to know what I have and what I did to help me. If it can help only 1 person, it would be great. (P23)
I would share all my data in hopes to help someone. (P22)
3.3. Theme 3: “I Take All Advice from My Peers with a Pinch of Salt”: Or How to Analytically Engage in Data Sharing with Peers
I believe that the information that other people give about their condition could be helpful, however, it would not be reliable for a person to base himself on this, since there has to be a professional in the area. (P14)
I would listen to them and then assess if the advice seems valid, and then I [would] confirm the advice with my dr. or even other peers. (P23)
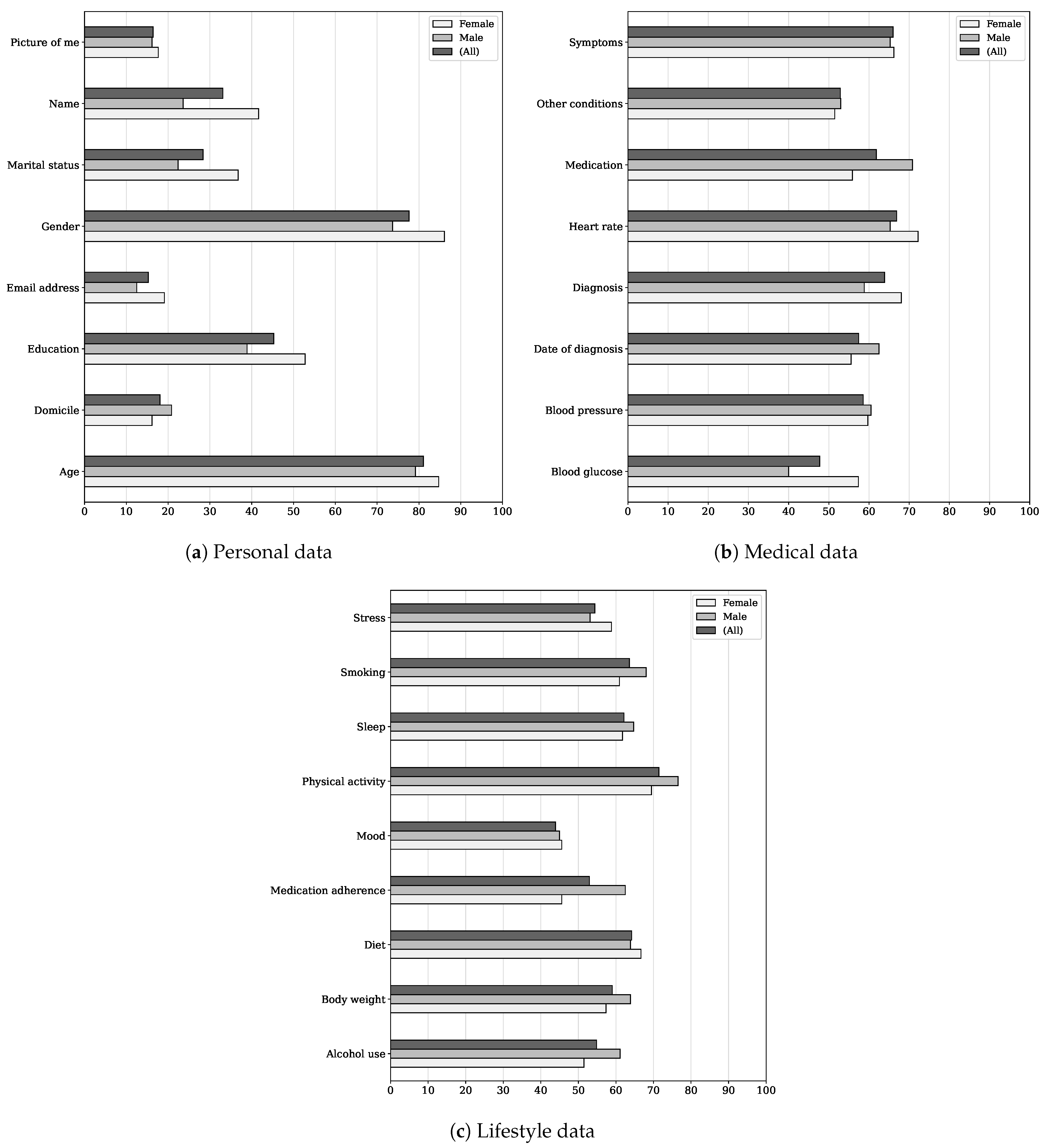
3.4. Conceptualization(s) Expressed through Rating Activities
The app most propably [sic] have [sic] a database for all the people using [it], the app itself sort [sic] different kinds of stuff together, and decides which group have [sic] the same problems. It then suggests that the differrent [sic] people could get in touch via the app. If both parties agee [sic], the app can put you in contact with each other, or you can chat annonomously [sic] with each other. (P23)
4. Discussion
4.1. Principal Findings
4.2. Comparison with Prior Work
4.3. Limitations and Strengths
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Riegel, B.; Moser, D.K.; Buck, H.G.; Dickson, V.V.; Dunbar, S.B.; Lee, C.S.; Lennie, T.A.; Lindenfeld, J.; Mitchell, J.E.; Treat-Jacobson, D.J.; et al. Self-care for the prevention and management of cardiovascular disease and stroke: A scientific statement for healthcare professionals from the American Heart Association. J. Am. Heart Assoc. 2017, 6, e006997. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- O’Kane, A.A.; Park, S.Y.; Mentis, H.; Blandford, A.; Chen, Y. Turning to peers: Integrating understanding of the self, the condition, and others’ experiences in making sense of complex chronic conditions. Comput. Support. Coop. Work (CSCW) 2016, 25, 477–501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Penrod, J.; Hupcey, J.E.; Shipley, P.Z.; Loeb, S.J.; Baney, B. A model of caregiving through the end of life: Seeking normal. West. J. Nurs. Res. 2012, 34, 174–193. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Genuis, S.K.; Bronstein, J. Looking for “normal”: Sense making in the context of health disruption. J. Assoc. Inf. Sci. Technol. 2017, 68, 750–761. [Google Scholar] [CrossRef]
- Vaala, S.E.; Lee, J.M.; Hood, K.K.; Mulvaney, S.A. Sharing and helping: Predictors of adolescents’ willingness to share diabetes personal health information with peers. J. Am. Med. Inform. Assoc. 2018, 25, 135–141. [Google Scholar] [CrossRef] [PubMed]
- Frost, J.; Vermeulen, I.E.; Beekers, N. Anonymity versus privacy: Selective information sharing in online cancer communities. J. Med. Internet Res. 2014, 16, e2684. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, S.; Chen, X.; Wang, L.; Gao, B.; Zhu, Q. Health information privacy concerns, antecedents, and information disclosure intention in online health communities. Inf. Manag. 2018, 55, 482–493. [Google Scholar] [CrossRef]
- Bussone, A.; Kasadha, B.; Stumpf, S.; Durrant, A.C.; Tariq, S.; Gibbs, J.; Lloyd, K.C.; Bird, J. Trust, identity, privacy, and security considerations for designing a peer data sharing platform between people living with HIV. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–27. [Google Scholar] [CrossRef]
- Zhu, H.; Colgan, J.; Reddy, M.; Choe, E.K. Sharing patient-generated data in clinical practices: An interview study. AMIA Annu. Symp. Proc. 2016, 2016, 1303–1312. [Google Scholar] [PubMed]
- Simpson, E.; Brown, R.; Sillence, E.; Coventry, L.; Lloyd, K.; Gibbs, J.; Tariq, S.; Durrant, A.C. Understanding the Barriers and Facilitators to Sharing Patient-Generated Health Data Using Digital Technology for People Living with Long-Term Health Conditions: A Narrative Review. Front. Public Health 2021, 9, 641424. [Google Scholar] [CrossRef]
- Creswell, J.W.; Clark, V.L.P. Designing and Conducting Mixed Methods Research, 3rd ed.; Sage Publications: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Braun, V.; Clarke, V.; Boulton, E.; Davey, L.; McEvoy, C. The online survey as a qualitative research tool. Int. J. Soc. Res. Methodol. 2021, 24, 641–654. [Google Scholar] [CrossRef]
- Braun, V.; Clarke, V. Successful Qualitative Research: A Practical Guide for Beginners; Sage: Thousand Oaks, CA, USA, 2013. [Google Scholar]
- Willig, C. Introducing Qualitative Research in Psychology; McGraw-Hill Education, Open University Press: Maidenhead, UK, 2013. [Google Scholar]
- Eyal, P.; David, R.; Andrew, G.; Zak, E.; Ekaterina, D. Data quality of platforms and panels for online behavioral research. Behav. Res. Methods 2021, 1–20. [Google Scholar] [CrossRef]
- Chandler, J.J.; Paolacci, G. Lie for a dime: When most prescreening responses are honest but most study participants are impostors. Soc. Psychol. Personal. Sci. 2017, 8, 500–508. [Google Scholar] [CrossRef] [Green Version]
- Buskermolen, D.O.; Terken, J. Co-constructing stories: A participatory design technique to elicit in-depth user feedback and suggestions about design concepts. In Proceedings of the 12th Participatory Design Conference: Exploratory Papers, Workshop Descriptions, Industry Cases-Volume 2, Roskilde, Denmark, 12–16 August 2012; pp. 33–36. [Google Scholar]
- Mamykina, L.; Smaldone, A.M.; Bakken, S.R. Adopting the sensemaking perspective for chronic disease self-management. J. Biomed. Inform. 2015, 56, 406–417. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sherwin, K. Card Sorting: Uncover Users’ Mental Models for Better Information Architecture. 2018. Available online: https://www.nngroup.com/articles/card-sorting-definition/ (accessed on 18 March 2022).
- Braun, V.; Clarke, V. Using thematic analysis in psychology. Qual. Res. Psychol. 2006, 3, 77–101. [Google Scholar] [CrossRef] [Green Version]
- Clarke, V.; Braun, V. Thematic analysis. In Encyclopedia of Critical Psychology; Teo, T., Ed.; Springer: New York, NY, USA, 2014; pp. 1947–1952. [Google Scholar]
- Byrne, D. A worked example of Braun and Clarke’s approach to reflexive thematic analysis. Qual. Quant. 2021, 56, 1391–1412. [Google Scholar] [CrossRef]
- Reicher, S. Against methodolatry: Some comments on Elliott, Fischer, and Rennie. Br. J. Clin. Psychol. 2000, 39, 1–6. [Google Scholar] [CrossRef]
- Braun, V.; Clarke, V. One size fits all? What counts as quality practice in (reflexive) thematic analysis? Qual. Res. Psychol. 2021, 18, 328–352. [Google Scholar] [CrossRef]
- Dinev, T.; Hart, P. An extended privacy calculus model for e-commerce transactions. Inf. Syst. Res. 2006, 17, 61–80. [Google Scholar] [CrossRef]
- Bandura, A. Self-efficacy: Toward a unifying theory of behavioral change. Psychol. Rev. 1977, 84, 191–215. [Google Scholar] [CrossRef] [PubMed]
- Warner, L.M.; French, D.P. Self-Efficacy Interventions. In The Handbook of Behavior Change; Hagger, M.S., Cameron, L.D., Hamilton, K., Hankonen, N., Lintunen, T., Eds.; Cambridge University Press: Cambridge, UK, 2020; pp. 461–478. [Google Scholar]
- Krahe, M.; Milligan, E.; Reilly, S. Personal health information in research: Perceived risk, trustworthiness and opinions from patients attending a tertiary healthcare facility. J. Biomed. Inform. 2019, 95, 103222. [Google Scholar] [CrossRef]
- Cornwell, B.; Schafer, M.H. Social networks in later life. In Handbook of Aging and the Social Sciences, 8th ed.; George, L.K., Ferraro, K.F., Eds.; Academic Press: Cambridge, MA, USA, 2016; pp. 181–201. [Google Scholar]
- Ma, L.; Krishnan, R.; Montgomery, A.L. Latent homophily or social influence? An empirical analysis of purchase within a social network. Manag. Sci. 2015, 61, 454–473. [Google Scholar] [CrossRef]
- Qiao, W.; Yan, Z.; Wang, X. Join or not: The impact of physicians’ group joining behavior on their online demand and reputation in online health communities. Inf. Process. Manag. 2021, 58, 102634. [Google Scholar] [CrossRef]
- Litman, J.A. Epistemic curiosity. In Encyclopedia of the Sciences of Learning; Seel, N.M., Ed.; Springer: New York, NY, USA, 2012; pp. 1162–1165. [Google Scholar]
- Mussel, P. Epistemic curiosity and related constructs: Lacking evidence of discriminant validity. Personal. Individ. Differ. 2010, 49, 506–510. [Google Scholar] [CrossRef]
- Cacioppo, J.T.; Petty, R.E. The need for cognition. J. Personal. Soc. Psychol. 1982, 42, 116–131. [Google Scholar] [CrossRef]
- Goff, M.; Ackerman, P.L. Personality-intelligence relations: Assessment of typical intellectual engagement. J. Educ. Psychol. 1992, 84, 537–552. [Google Scholar] [CrossRef]
- Digman, J.M. Personality structure: Emergence of the five-factor model. Annu. Rev. Psychol. 1990, 41, 417–440. [Google Scholar] [CrossRef]
- Ma, X.; Hancock, J.; Naaman, M. Anonymity, intimacy and self-disclosure in social media. In Proceedings of the 2016 CHI conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 3857–3869. [Google Scholar]
- Trepte, S.; Scharkow, M.; Dienlin, T. The privacy calculus contextualized: The influence of affordances. Comput. Hum. Behav. 2020, 104, 106115. [Google Scholar] [CrossRef]
- Wintle, B.C.; Fraser, H.; Wills, B.C.; Nicholson, A.E.; Fidler, F. Verbal probabilities: Very likely to be somewhat more confusing than numbers. PLoS ONE 2019, 14, e0213522. [Google Scholar] [CrossRef]
- Ho, E.H.; Budescu, D.V.; Dhami, M.K.; Mandel, D.R. Improving the communication of uncertainty in climate science and intelligence analysis. Behav. Sci. Policy 2015, 1, 43–55. [Google Scholar] [CrossRef]
- Saito, N. Internet Literacy in Japan. 2015. Available online: https://www.oecd-ilibrary.org/science-and-technology/internet-literacy-in-japan_5js0cqpxr6bq-en (accessed on 10 May 2022).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cerón-Guzmán, J.A.; Tetteroo, D.; Hu, J.; Markopoulos, P. “Not Sure Sharing Does Anything Extra for Me”: Understanding How People with Cardiovascular Disease Conceptualize Sharing Personal Health Data with Peers. Int. J. Environ. Res. Public Health 2022, 19, 9508. https://doi.org/10.3390/ijerph19159508
Cerón-Guzmán JA, Tetteroo D, Hu J, Markopoulos P. “Not Sure Sharing Does Anything Extra for Me”: Understanding How People with Cardiovascular Disease Conceptualize Sharing Personal Health Data with Peers. International Journal of Environmental Research and Public Health. 2022; 19(15):9508. https://doi.org/10.3390/ijerph19159508
Chicago/Turabian StyleCerón-Guzmán, Jhon Adrián, Daniel Tetteroo, Jun Hu, and Panos Markopoulos. 2022. "“Not Sure Sharing Does Anything Extra for Me”: Understanding How People with Cardiovascular Disease Conceptualize Sharing Personal Health Data with Peers" International Journal of Environmental Research and Public Health 19, no. 15: 9508. https://doi.org/10.3390/ijerph19159508
APA StyleCerón-Guzmán, J. A., Tetteroo, D., Hu, J., & Markopoulos, P. (2022). “Not Sure Sharing Does Anything Extra for Me”: Understanding How People with Cardiovascular Disease Conceptualize Sharing Personal Health Data with Peers. International Journal of Environmental Research and Public Health, 19(15), 9508. https://doi.org/10.3390/ijerph19159508