
Drone-Based Water Level Detection in Flood Disasters

Abstract
:1. Introduction
2. Related Work
Flood Damage Detection and Assessment
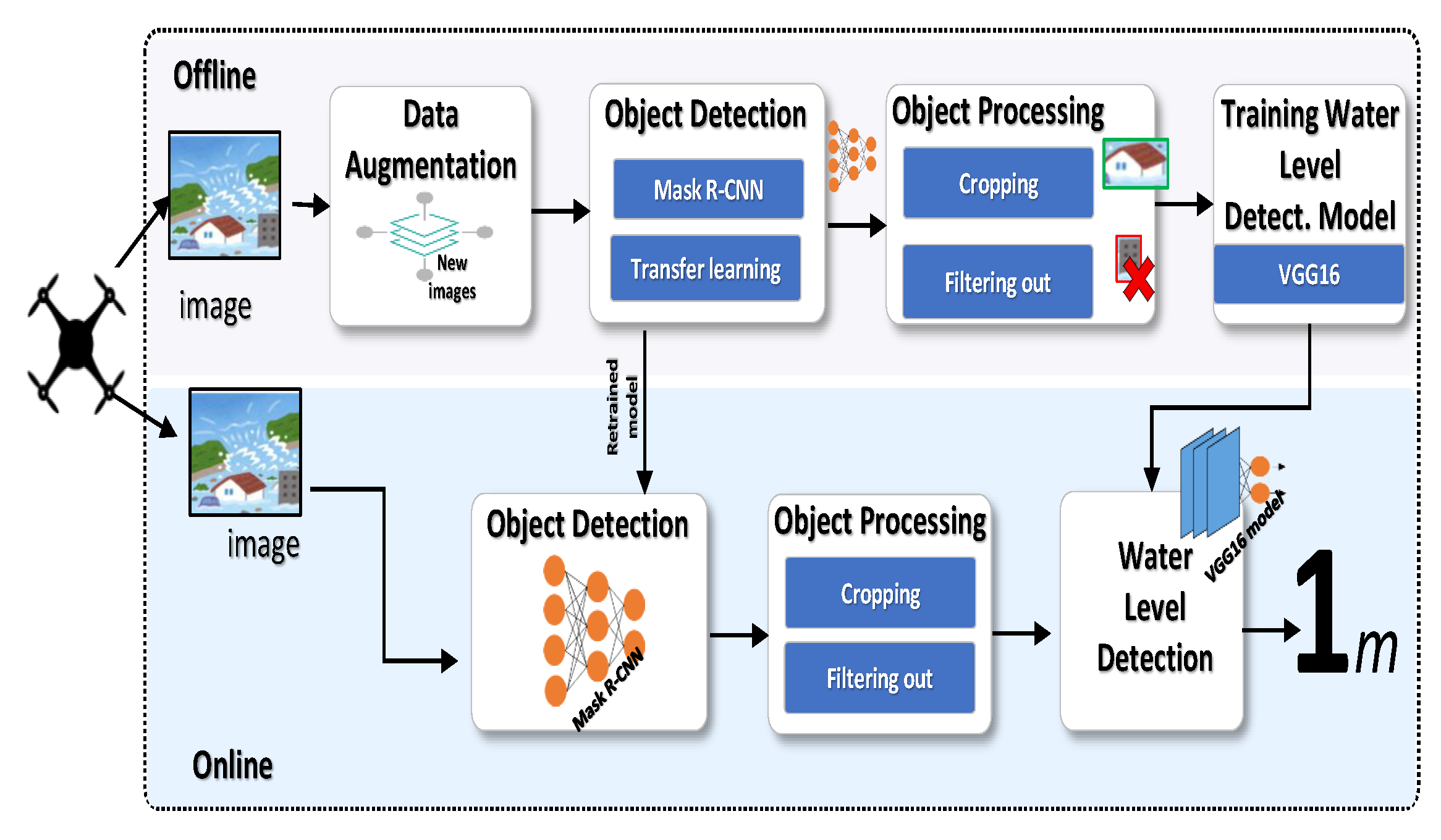
3. Drone-Based Flood Damage Assessment
3.1. System Overview
3.2. Dataset Preparation
3.2.1. Image Collection
3.2.2. Image Selection
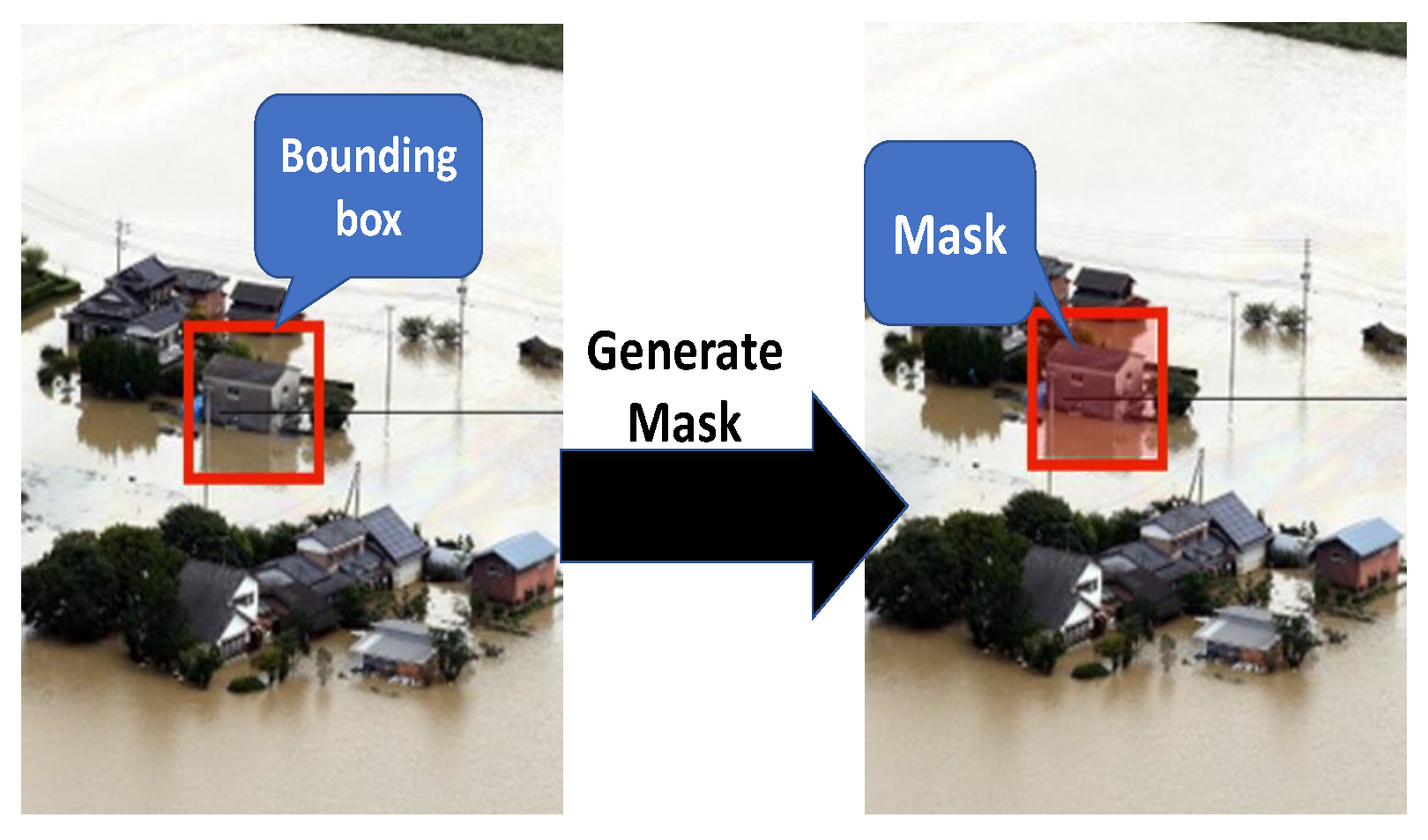
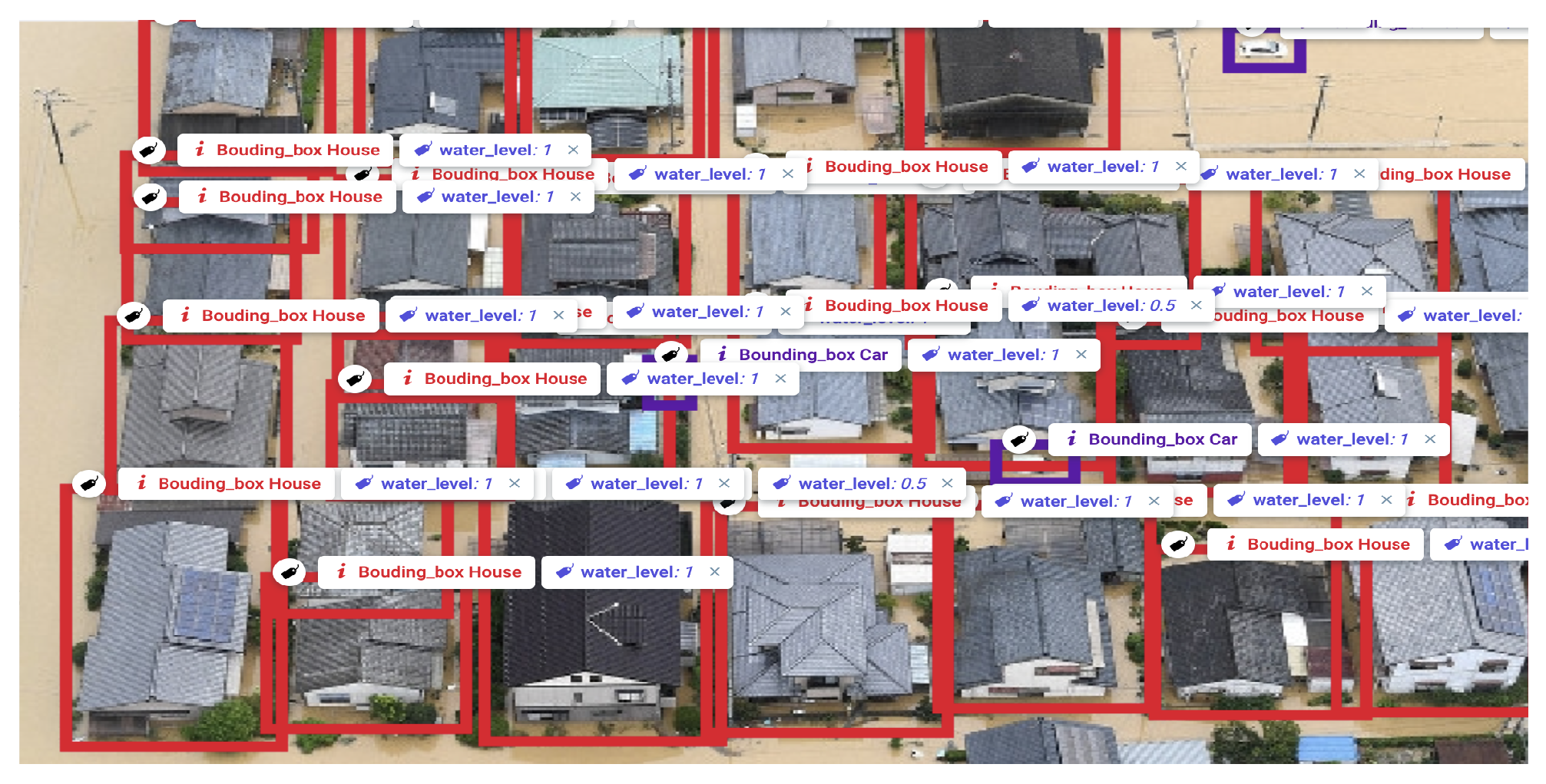
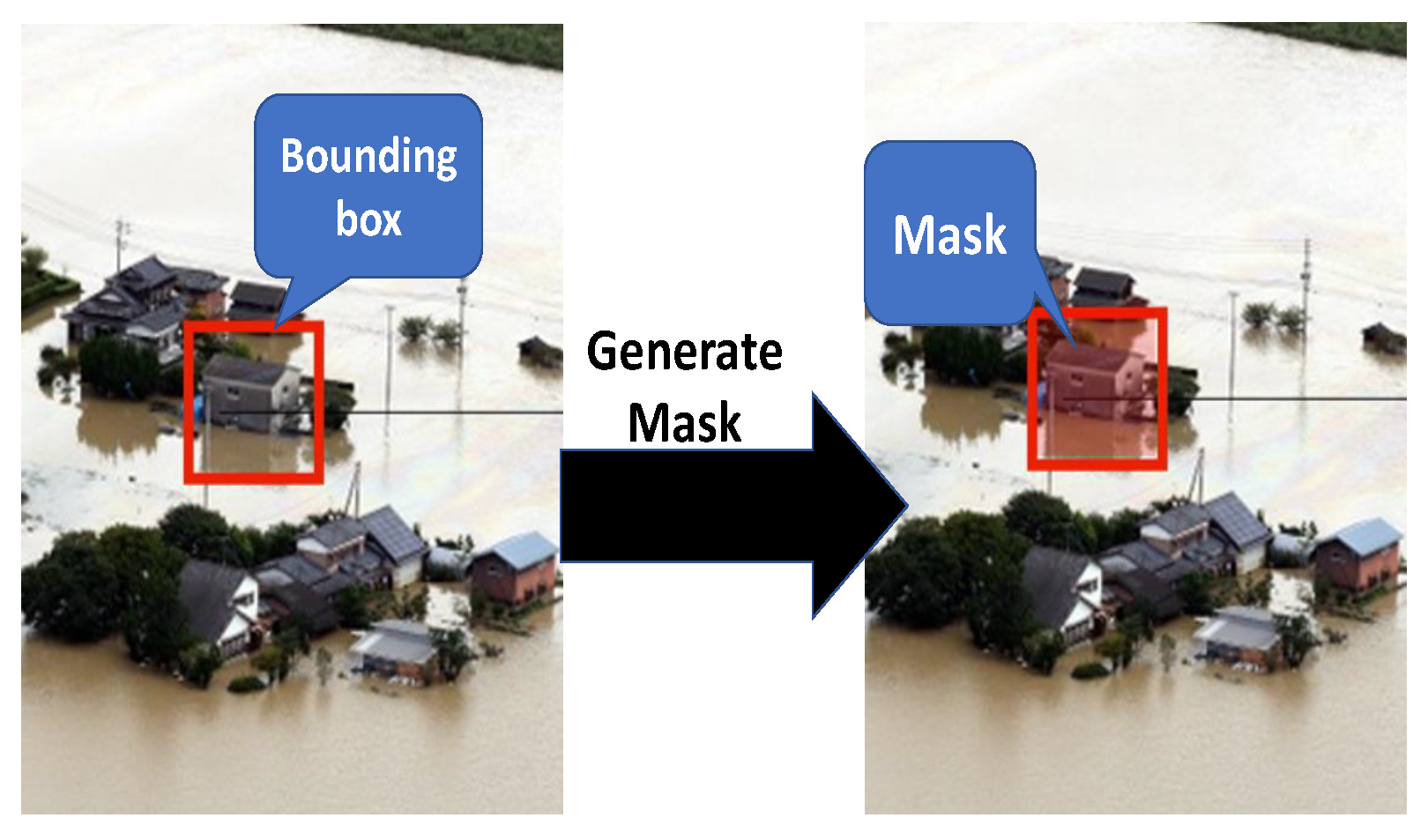
3.2.3. Annotation
- (1)
- Houses and cars with the same level of roofs have the same elevation.
- (2)
- Houses and cars with the same elevation are submerged to the same water level.
- (3)
- In addition, buildings different from houses such as schools and hospitals as well as those which appear too small in the images are excluded as these images may deceive the detection model.
3.3. Data Augmentation
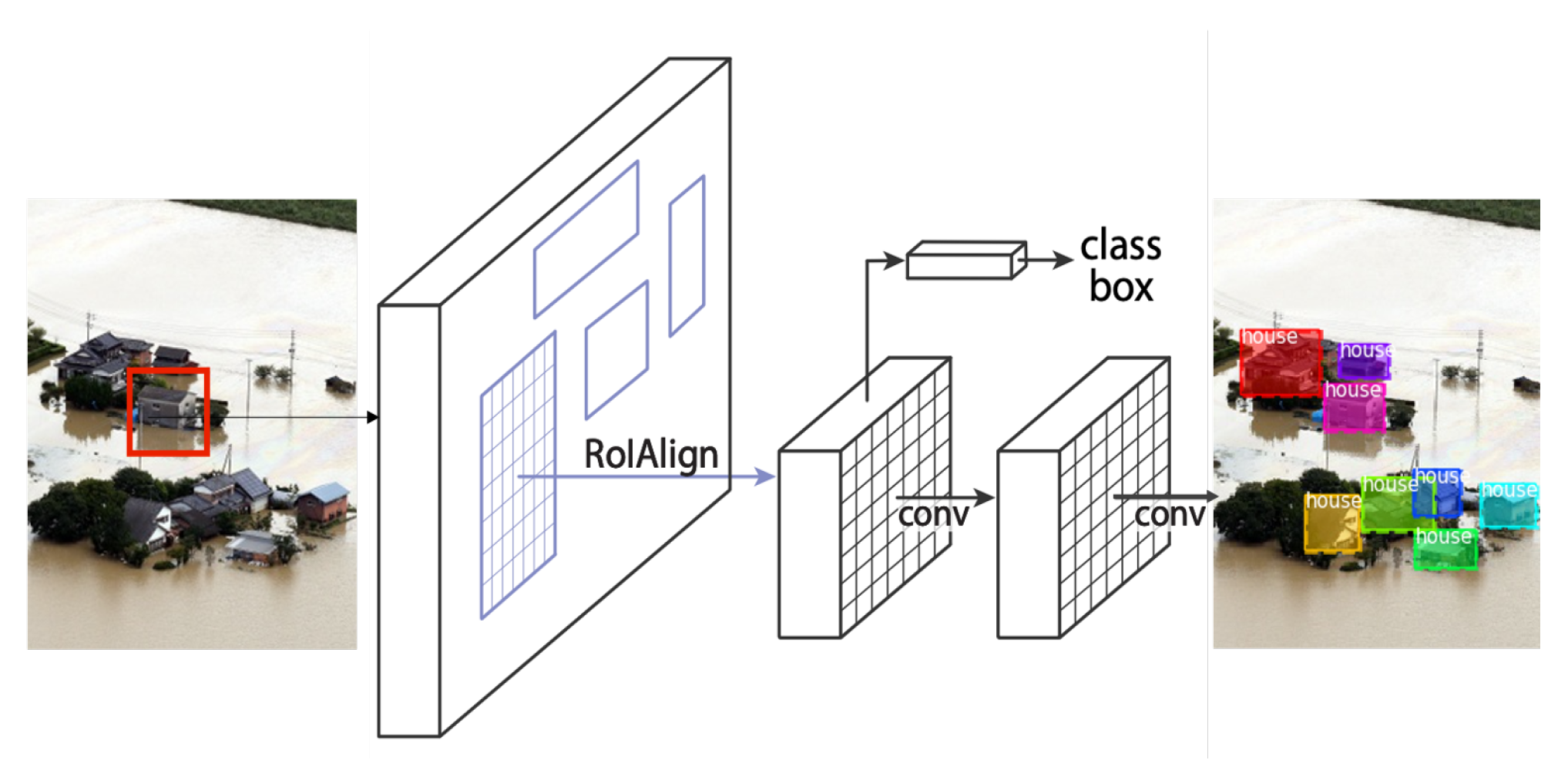
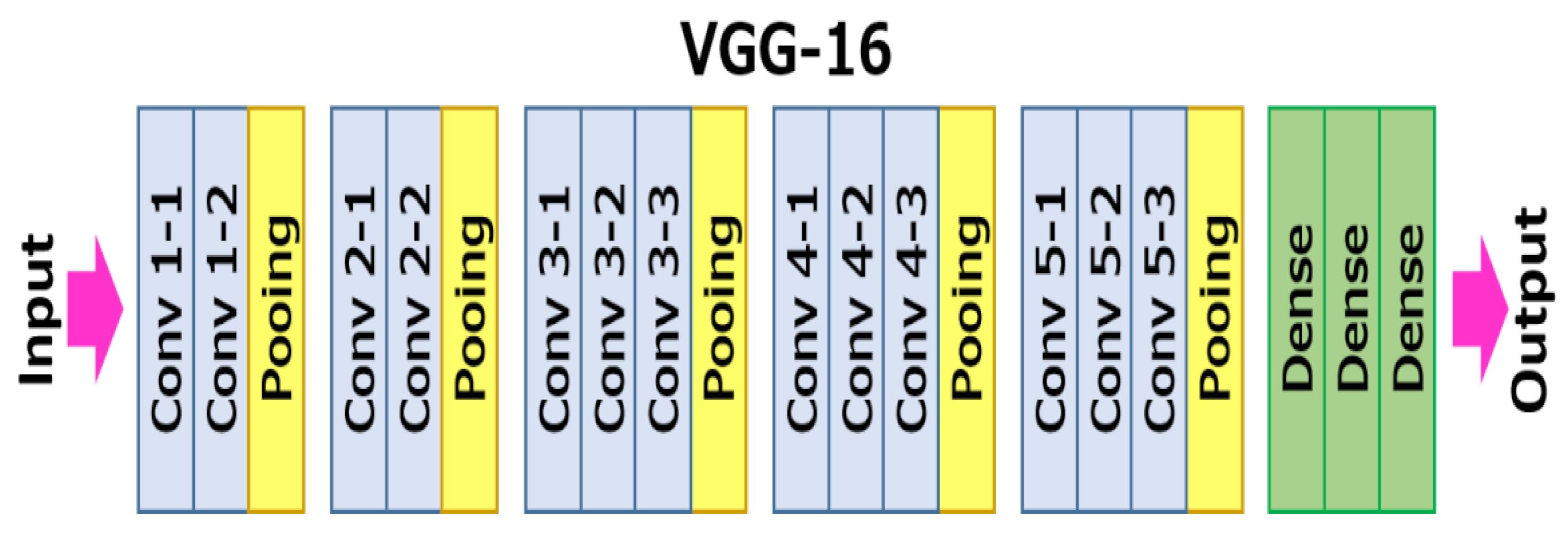
3.4. Object Detection
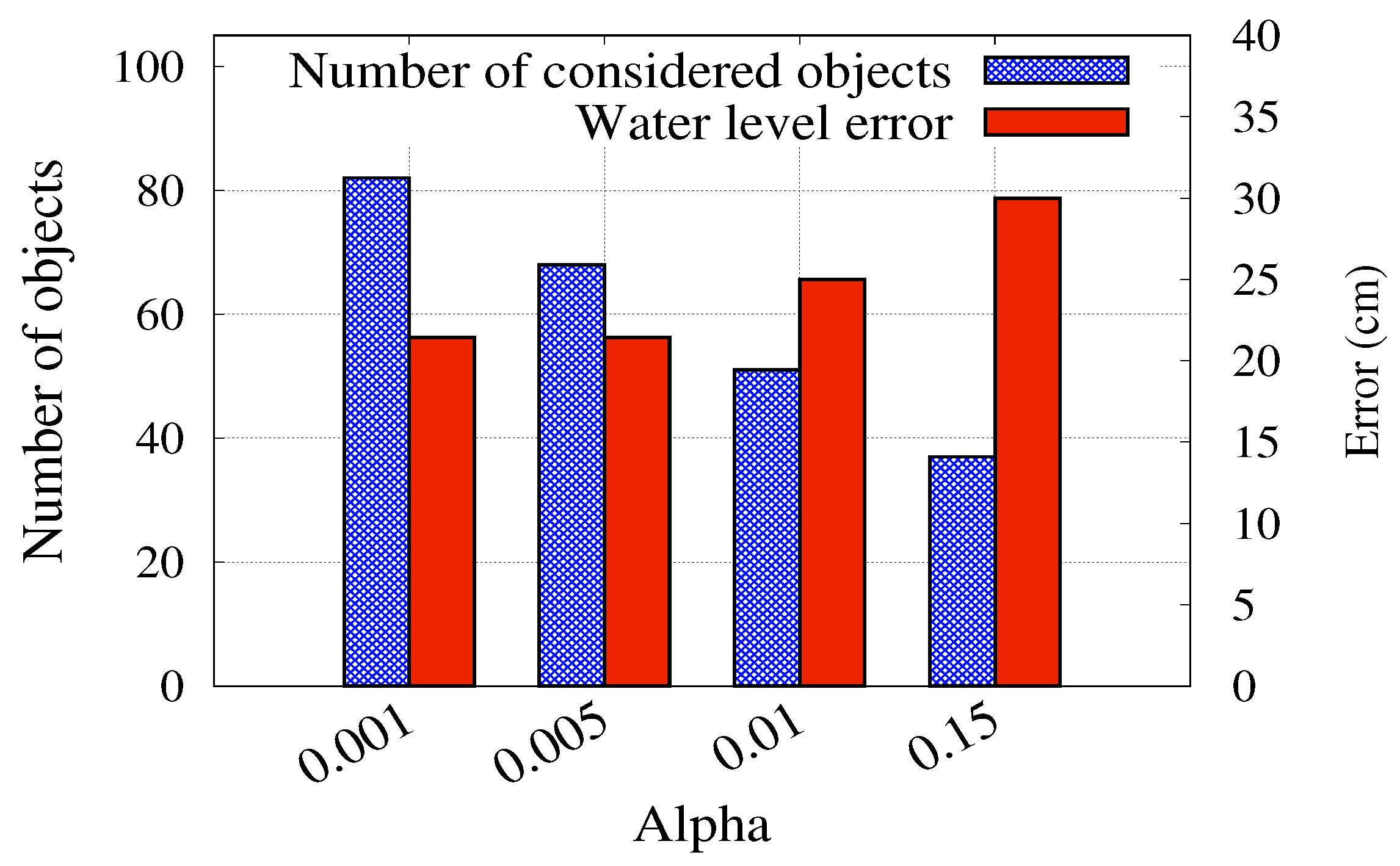
3.5. Water Level Estimation
4. Evaluation
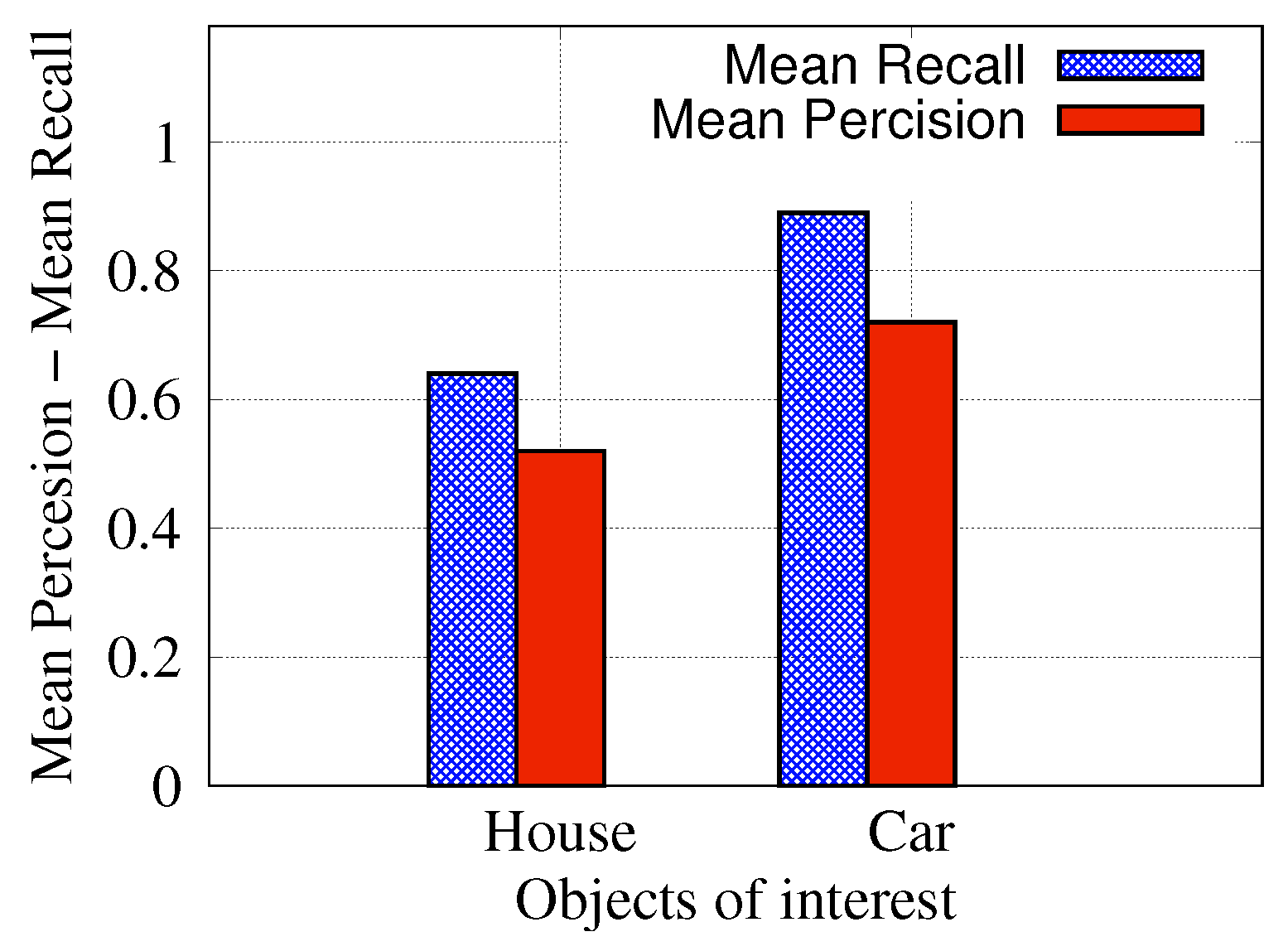
4.1. Object Detection
4.2. Water Level Estimation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dominguez, C.; Melgar, A. Heavy Rains and Floods Leave Dozens Dead in Southeastern Brazil. Available online: https://edition.cnn.com/2020/01/27/americas/rains-floods-minas-gerais-brazil-intl/index.html (accessed on 10 January 2020).
- Wattles, J. Hurricane Harvey: 70% of Home Damage Costs Aren’t Covered by Insurance. Available online: https://money.cnn.com/2017/09/01/news/hurricane-harvey-cost-damage-homes-flood/index.html (accessed on 27 December 2019).
- Hirabayashi, Y.; Mahendran, R.; Koirala, S.; Konoshima, L.; Yamazaki, D.; Watanabe, S.; Kim, H.; Kanae, S. Global flood risk under climate change. Nat. Clim. Chang. 2013, 3, 816–821. [Google Scholar] [CrossRef]
- Vitousek, S.; Barnard, P.L.; Fletcher, C.H.; Frazer, N.; Erikson, L.; Storlazzi, C.D. Doubling of coastal flooding frequency within decades due to sea-level rise. Sci. Rep. 2017, 7, 1399. [Google Scholar] [CrossRef] [PubMed]
- Zheng, G.; Zong, H.; Zhuan, X.; Wang, L. High-Accuracy Surface-Perceiving Water Level Gauge with Self-Calibration for Hydrography. IEEE Sens. J. 2010, 10, 1893–1900. [Google Scholar] [CrossRef]
- Marin-Perez, R.; García-Pintado, J.; Gómez, A.S. A Real-Time Measurement System for Long-Life Flood Monitoring and Warning Applications. Sensors 2012, 12, 4213–4236. [Google Scholar] [CrossRef]
- Megan, A.; Witherow, C.S.; Winter-Arboleda, I.M.; Elbakary, M.I.; Cetin, M.; Iftekharuddin, K.M. Floodwater detection on roadways from crowdsourced images. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2018, 7, 529–540. [Google Scholar]
- Chaudhary, P.; D’Aronco, S.; Moy de Vitry, M.; Leitão, J.; Wegner, J. Flood-Water Level Estimation from Social Media Images. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 4, 5–12. [Google Scholar] [CrossRef] [Green Version]
- de Vitry, M.M.; Kramer, S.; Wegner, J.D.; Leitão, J.P. Scalable Flood Level Trend Monitoring with Surveillance Cameras using a Deep Convolutional Neural Network. Hydrol. Earth Syst. Sci. 2019, 23, 4621–4634. [Google Scholar] [CrossRef] [Green Version]
- Pandey, R.K.; Cretaux, J.F.; Bergé-Nguyen, M.; Tiwari, V.M.; Drolon, V.; Papa, F.; Calmant, S. Water level estimation by remote sensing for the 2008 flooding of the Kosi River. Int. J. Remote Sens. 2014, 35, 424–440. [Google Scholar] [CrossRef]
- Chen, S.; Liu, H.; You, Y.; Mullens, E.; Hu, J.; Yuan, Y.; Huang, M.; He, L.; Luo, Y.; Zeng, X.; et al. Evaluation of High-Resolution Precipitation Estimates from Satellites during July 2012 Beijing Flood Event Using Dense Rain Gauge Observations. PLoS ONE 2014, 9, e89681. [Google Scholar] [CrossRef]
- Martinis, S.; Twele, A.; Voigt, S. Towards operational near real-time flood detection using a split-based automatic thresholding procedure on high resolution TerraSAR-X data. Nat. Hazards Earth Syst. Sci. 2009, 9, 303–314. [Google Scholar] [CrossRef]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 3 February 2020).
- Lo, S.W.; Wu, J.H.; Lin, F.P.; Hsu, C.H. Cyber Surveillance for Flood Disasters. Sensors 2015, 15, 2369–2387. [Google Scholar] [CrossRef] [Green Version]
- Abolghasemi, V.; Anisi, M.H. Compressive Sensing for Remote Flood Monitoring. IEEE Sens. Lett. 2021, 5, 1–4. [Google Scholar] [CrossRef]
- Abdullahi, S.I.; Habaebi, M.H.; Abd Malik, N. Intelligent flood disaster warning on the fly: Developing IoT-based management platform and using 2-class neural network to predict flood status. Bull. Electr. Eng. Inform. 2019, 8, 706–717. [Google Scholar] [CrossRef]
- Kao, C.C.; Lin, Y.S.; Wu, G.D.; Huang, C.J. A comprehensive study on the internet of underwater things: Applications, challenges, and channel models. Sensors 2017, 17, 1477. [Google Scholar] [CrossRef] [Green Version]
- Bartos, M.; Wong, B.; Kerkez, B. Open storm: A complete framework for sensing and control of urban watersheds. Environ. Sci. Water Res. Technol. 2018, 4, 346–358. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Prodeedings of International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Spearman Rank Correlation Coefficient. In The Concise Encyclopedia of Statistics; Springer: New York, NY, USA, 2008; pp. 502–505. [CrossRef]
- Jiang, J.; Qin, C.Z.; Yu, J.; Cheng, C.; Liu, J.; Huang, J. Obtaining urban waterlogging depths from video images using synthetic image data. Remote Sens. 2020, 12, 1014. [Google Scholar] [CrossRef] [Green Version]
- Hofmann, J.; Schüttrumpf, H. floodGAN: Using Deep Adversarial Learning to Predict Pluvial Flooding in Real Time. Water 2021, 13, 2255. [Google Scholar] [CrossRef]
- Vandaele, R.; Dance, S.L.; Ojha, V. Automated water segmentation and river level detection on camera images using transfer learning. In Proceedings of the 42nd DAGM German Conference (DAGM GCPR 2020), Tübingen, Germany, 28 September–1 October 2020; pp. 232–245. [Google Scholar]
- Ufuoma, G.; Sasanya, B.F.; Abaje, P.; Awodutire, P. Efficiency of camera sensors for flood monitoring and warnings. Sci. Afr. 2021, 13, e00887. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of Computer Vision (ECCV 2014); Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Chaudhary, P.; D’Aronco, S.; Leitão, J.P.; Schindler, K.; Wegner, J.D. Water level prediction from social media images with a multi-task ranking approach. ISPRS J. Photogramm. Remote Sens. 2020, 167, 252–262. [Google Scholar] [CrossRef]
- Pereira, J.; Monteiro, J.; Silva, J.; Estima, J.; Martins, B. Assessing flood severity from crowdsourced social media photos with deep neural networks. Multimed. Tools Appl. 2020, 79, 26197–26223. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Abbas, M.; Elhamshary, M.; Rizk, H.; Torki, M.; Youssef, M. WiDeep: WiFi-based Accurate and Robust Indoor Localization System using Deep Learning. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications (PerCom) Recognition, Kyoto, Japan, 11–15 March 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. PMLR 2019, 97, 6105–6114. [Google Scholar]
- Guan, Q.; Huang, Y.; Zhong, Z.; Zheng, Z.; Zheng, L.; Yang, Y. Diagnose like a radiologist: Attention guided convolutional neural network for thorax disease classification. arXiv 2018, arXiv:1801.09927. [Google Scholar]
- Hao, H.; Wang, Y. Leveraging multimodal social media data for rapid disaster damage assessment. Int. J. Disaster Risk Reduct. 2020, 51, 101760. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Sieberth, T.; Wackrow, R.; Chandler, J.H. Automatic detection of blurred images in UAV image sets. ISPRS J. Photogramm. Remote Sens. 2016, 122, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Rizk, H.; Elgokhy, S.; Sarhan, A. A hybrid outlier detection algorithm based on partitioning clustering and density measures. In Proceedings of the Tenth International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 23–24 December 2015; pp. 175–181. [Google Scholar] [CrossRef]
- Elmogy, A.; Rizk, H.; Sarhan, A. OFCOD: On the Fly Clustering Based Outlier Detection Framework. Data 2021, 6, 1. [Google Scholar] [CrossRef]
- Jung, A.B.; Wada, K.; Crall, J.; Tanaka, S.; Graving, J.; Reinders, C.; Yadav, S.; Banerjee, J.; Vecsei, G.; Kraft, A.; et al. Imgaug. 2020. Available online: https://github.com/aleju/imgaug (accessed on 1 February 2020).
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Świnoujście, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Abayomi-Alli, O.O.; Damaševičius, R.; Misra, S.; Maskeliūnas, R. Cassava disease recognition from low-quality images using enhanced data augmentation model and deep learning. Expert Syst. 2021, 38, e12746. [Google Scholar] [CrossRef]
- Mu, D.; Sun, W.; Xu, G.; Li, W. Random Blur Data Augmentation for Scene Text Recognition. IEEE Access 2021, 9, 136636–136646. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Matterport, I. Matterport: 3D Camera, Capture & Virtual Tour Platform|Matterport. 2020. Available online: https://matterport.com/ (accessed on 17 December 2021).
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Erdélyi, V.; Rizk, H.; Yamaguchi, H.; Higashino, T. Learn to See: A Microwave-based Object Recognition System Using Learning Techniques. In Adjunct Proceedings of the International Conference on Distributed Computing and Networking, Nara, Japan, 5–8 January 2021; pp. 145–150. [Google Scholar] [CrossRef]
- Rizk, H.; Yamaguchi, H.; Higashino, T.; Youssef, M. A Ubiquitous and Accurate Floor Estimation System Using Deep Representational Learning. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020; pp. 540–549. [Google Scholar]
- Alkiek, k.; Othman, A.; Rizk, H.; Youssef, M. Deep Learning-based Floor Prediction Using Cell Network Information. In Proceedings of the 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020. [Google Scholar] [CrossRef]
- Rizk, H. Solocell: Efficient indoor localization based on limited cell network information and minimal fingerprinting. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019. [Google Scholar] [CrossRef] [Green Version]
- Rizk, H.; Abbas, M.; Youssef, M. Device-independent cellular-based indoor location tracking using deep learning. Pervasive Mob. Comput. 2021, 75, 101420. [Google Scholar] [CrossRef]
- Fahmy, I.; Ayman, S.; Rizk, H.; Youssef, M. MonoFi: Efficient Indoor Localization Based on Single Radio Source And Minimal Fingerprinting. In Proceedings of the 29th International Conference on Advances in Geographic Information Systems, Beijing, China, 2–5 November 2021; pp. 674–675. [Google Scholar] [CrossRef]
- Rizk, H.; Shokry, A.; Youssef, M. Effectiveness of Data Augmentation in Cellular-based Localization Using Deep Learning. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Rizk, H.; Youssef, M. MonoDCell: A Ubiquitous and Low-Overhead Deep Learning-Based Indoor Localization with Limited Cellular Information. In Proceedings of the 27th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Chicago, IL, USA, 5–8 November 2019; pp. 109–118. [Google Scholar] [CrossRef] [Green Version]
- Rizk, H.; Torki, M.; Youssef, M. CellinDeep: Robust and Accurate Cellular-Based Indoor Localization via Deep Learning. IEEE Sens. J. 2019, 19, 2305–2312. [Google Scholar] [CrossRef]
- Rizk, H.; Yamaguchi, H.; Youssef, M.; Higashino, T. Gain without pain: Enabling fingerprinting-based indoor localization using tracking scanners. In Proceedings of the Proceedings of the 28th International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2020. [Google Scholar]
- Rizk, H.; Abbas, M.; Youssef, M. Omnicells: Cross-device cellular-based indoor location tracking using deep neural networks. In Proceedings of the IEEE International Conference on Pervasive Computing and Communications (PerCom), Austin, TX, USA, 23–27 March 2020; pp. 1–10. [Google Scholar] [CrossRef]
- VGG16—Convolutional Network for Classification and Detection. 2018. Available online: https://neurohive.io/en/popular-networks/vgg16/ (accessed on 17 December 2021).






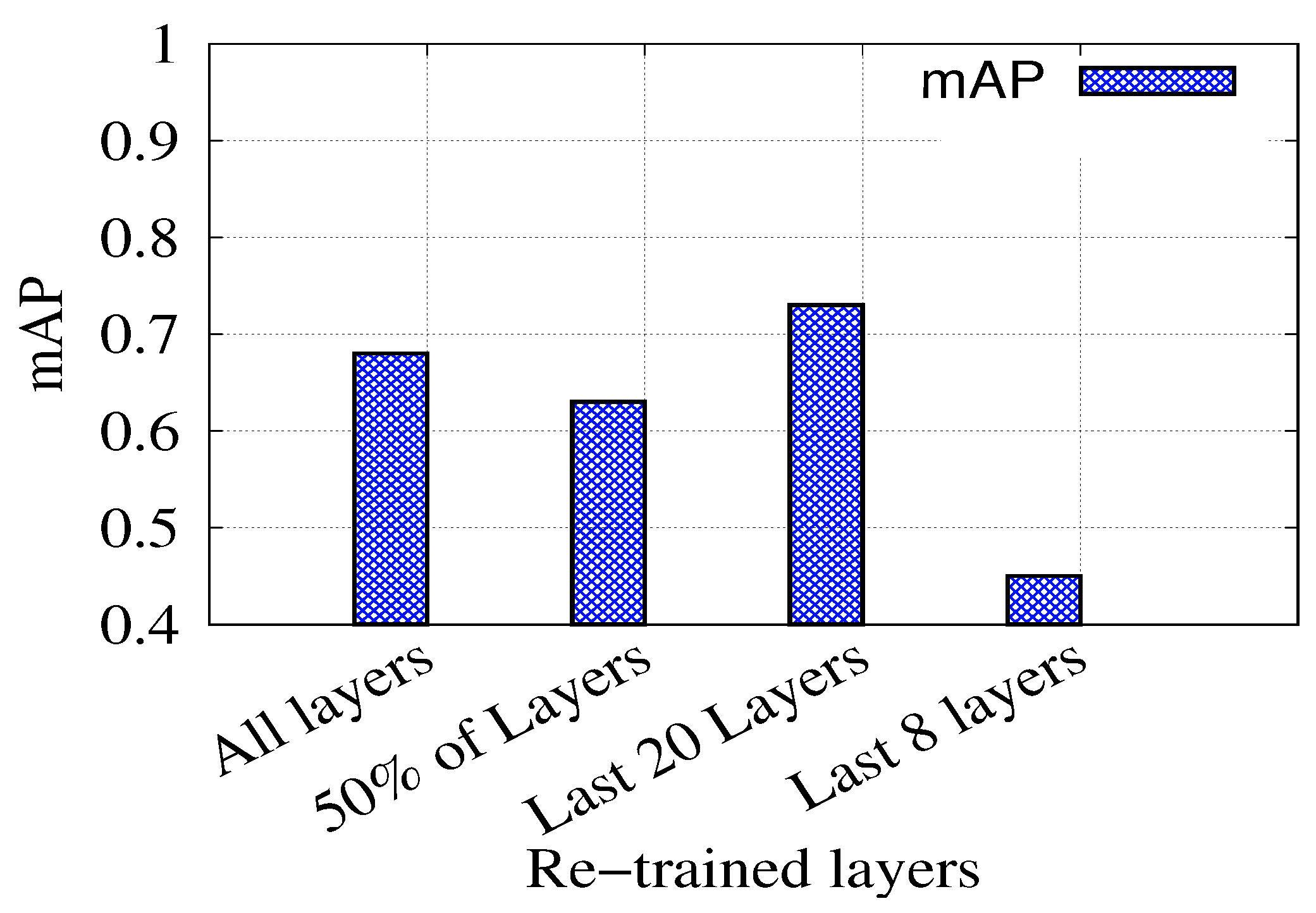

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
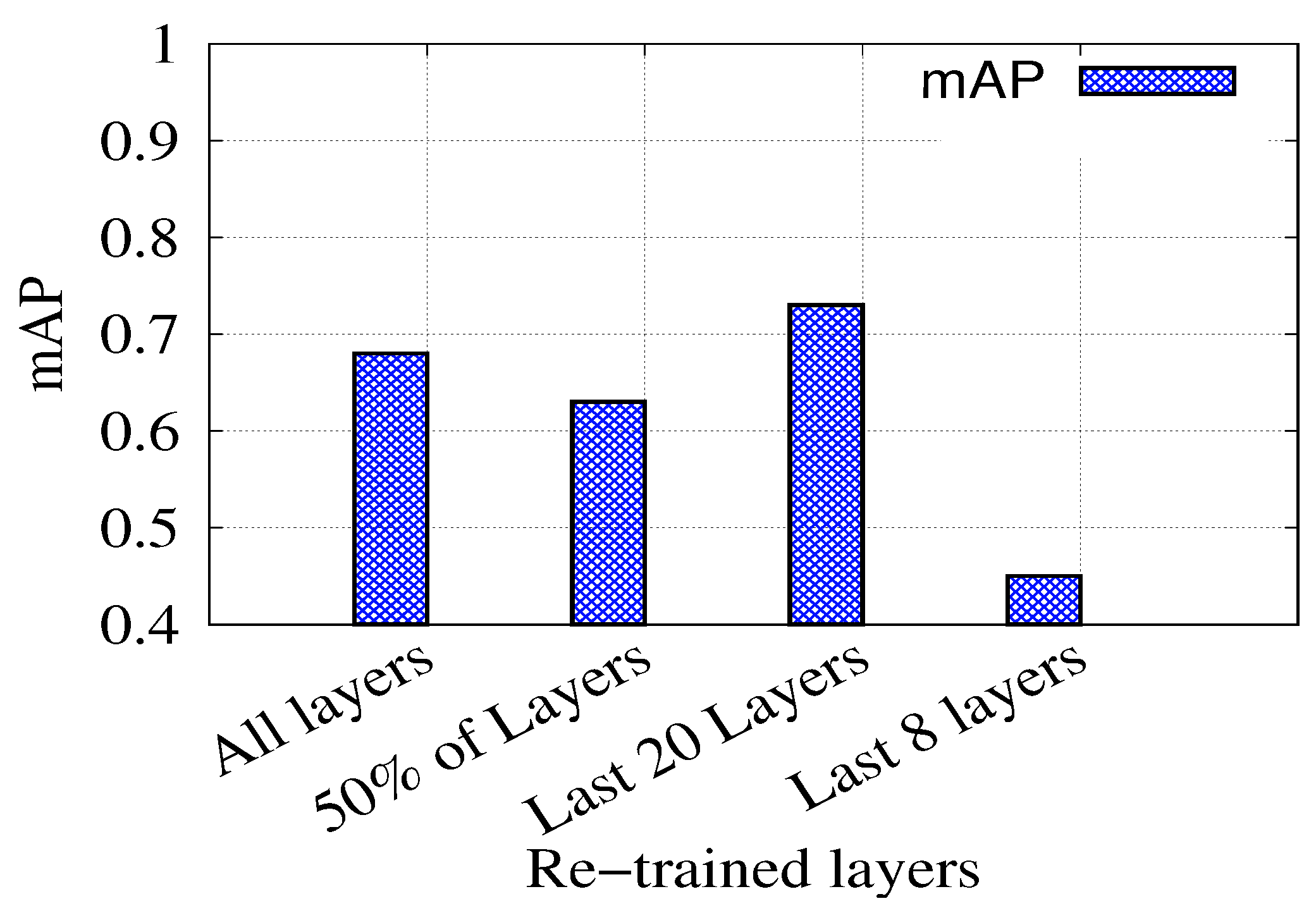{kind=link}
{kind=link}
| Learning Rate | #ROIs | Training Layer | Input Image Size | Epochs |
|---|---|---|---|---|
| 0.001 | 128 | Heads Layer | 512 × 512 × 3 | 100 |
| mAP | Average Precision | Average Recall |
|---|---|---|
| 0.73 | 0.71 | 0.79 |
| Total | House | Car | 0 m | 0.5 m | 1 m | 1.5 m | 2 m | 2.5 m | 3 m |
|---|---|---|---|---|---|---|---|---|---|
| 627 | 366 | 261 | 120 | 207 | 134 | 77 | 7 | 81 | 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rizk, H.; Nishimur, Y.; Yamaguchi, H.; Higashino, T. Drone-Based Water Level Detection in Flood Disasters. Int. J. Environ. Res. Public Health 2022, 19, 237. https://doi.org/10.3390/ijerph19010237
Rizk H, Nishimur Y, Yamaguchi H, Higashino T. Drone-Based Water Level Detection in Flood Disasters. International Journal of Environmental Research and Public Health. 2022; 19(1):237. https://doi.org/10.3390/ijerph19010237
Chicago/Turabian StyleRizk, Hamada, Yukako Nishimur, Hirozumi Yamaguchi, and Teruo Higashino. 2022. "Drone-Based Water Level Detection in Flood Disasters" International Journal of Environmental Research and Public Health 19, no. 1: 237. https://doi.org/10.3390/ijerph19010237
APA StyleRizk, H., Nishimur, Y., Yamaguchi, H., & Higashino, T. (2022). Drone-Based Water Level Detection in Flood Disasters. International Journal of Environmental Research and Public Health, 19(1), 237. https://doi.org/10.3390/ijerph19010237