
Physical Activity and Exercise: Text Mining Analysis



Abstract
:1. Introduction
2. Data and Methods
2.1. Data Retrieval
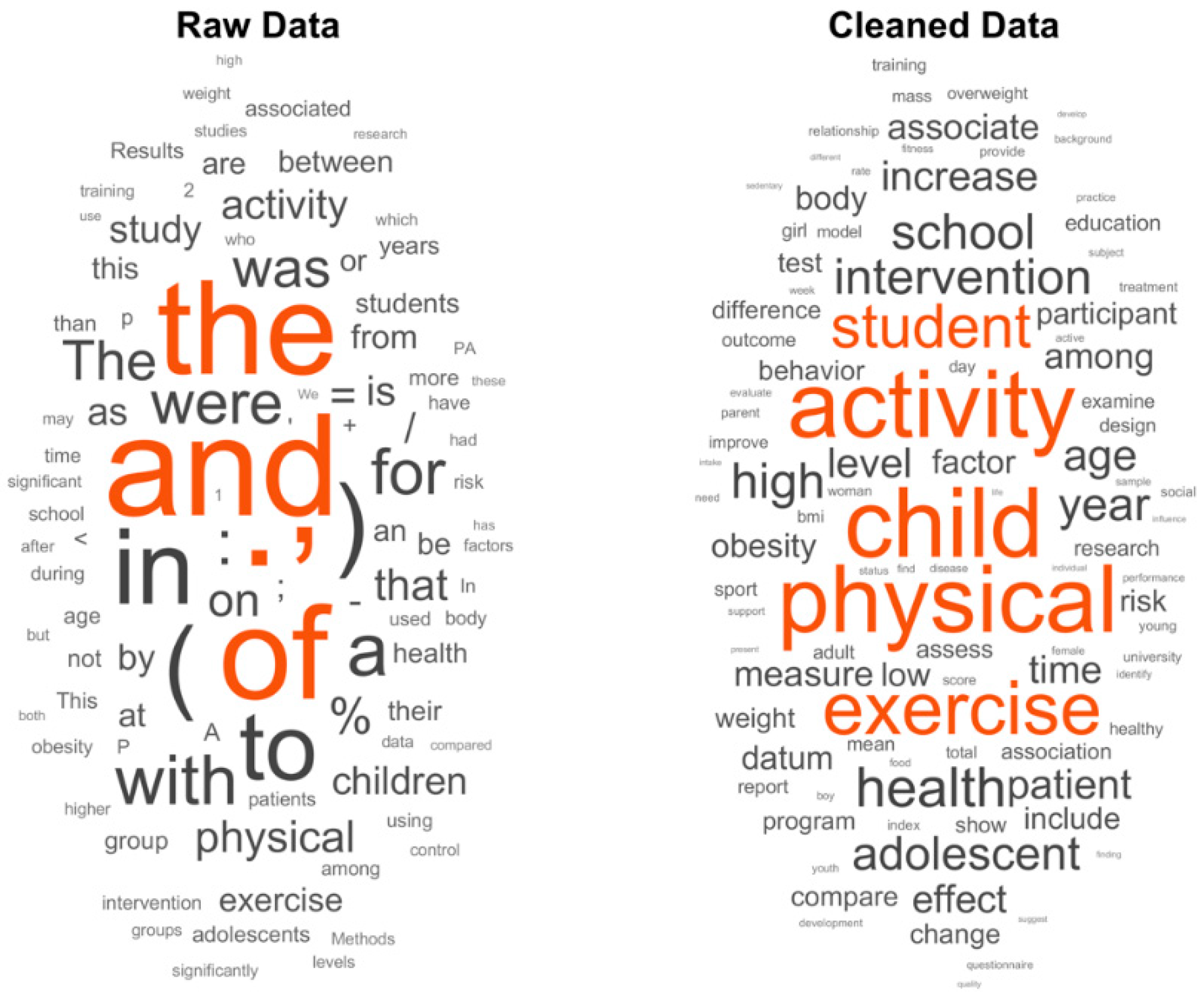
2.2. Data Pre-Processing
- removing all hyperlinks (‘http: // url’);
- punctuation marks and special characters were also removed;
- words were converted to lowercase;
- words that could add noise to the text and did not add content to the documents were eliminated (eg ‘a’, ‘and’, ‘to’), for which the list of stopwords in Matlab’s text analytics toolbox were used;
- because the abstracts of articles occasionally include the copyright and the name of the publisher, these were removed as they do not provide information on the content of the articles;
- words were normalized through a stemming process by which a morphological analysis of the words was carried out to reduce them to their roots using a predefined dictionary; to improve the process part-of-speech details were added indicating whether the words were nouns, verbs, adjectives, etc;
- finally, those words with a character length less than 2 or greater than 20 and those with a frequency in the document corpus of less than 2 were also eliminated.
2.3. Descriptive Analysis of Documents and Word Dynamics over the Months
2.4. Co-Ocurrence Analysis and Topics LDA
3. Results and Discussion
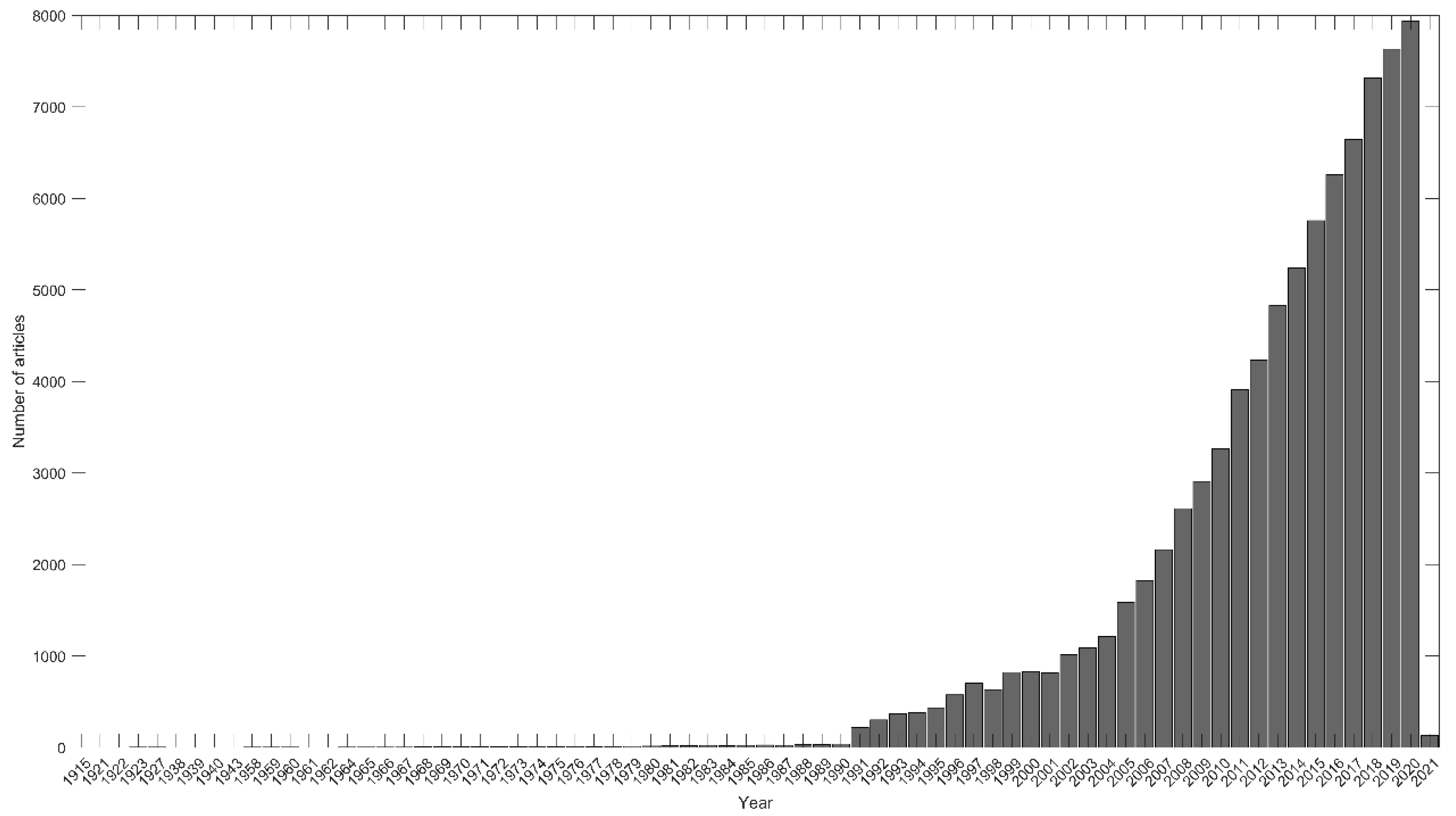
3.1. General Data of the Articles Published
3.2. Description of the Words Published in the Documents (N-Gram) and Their Dynamics over the Years
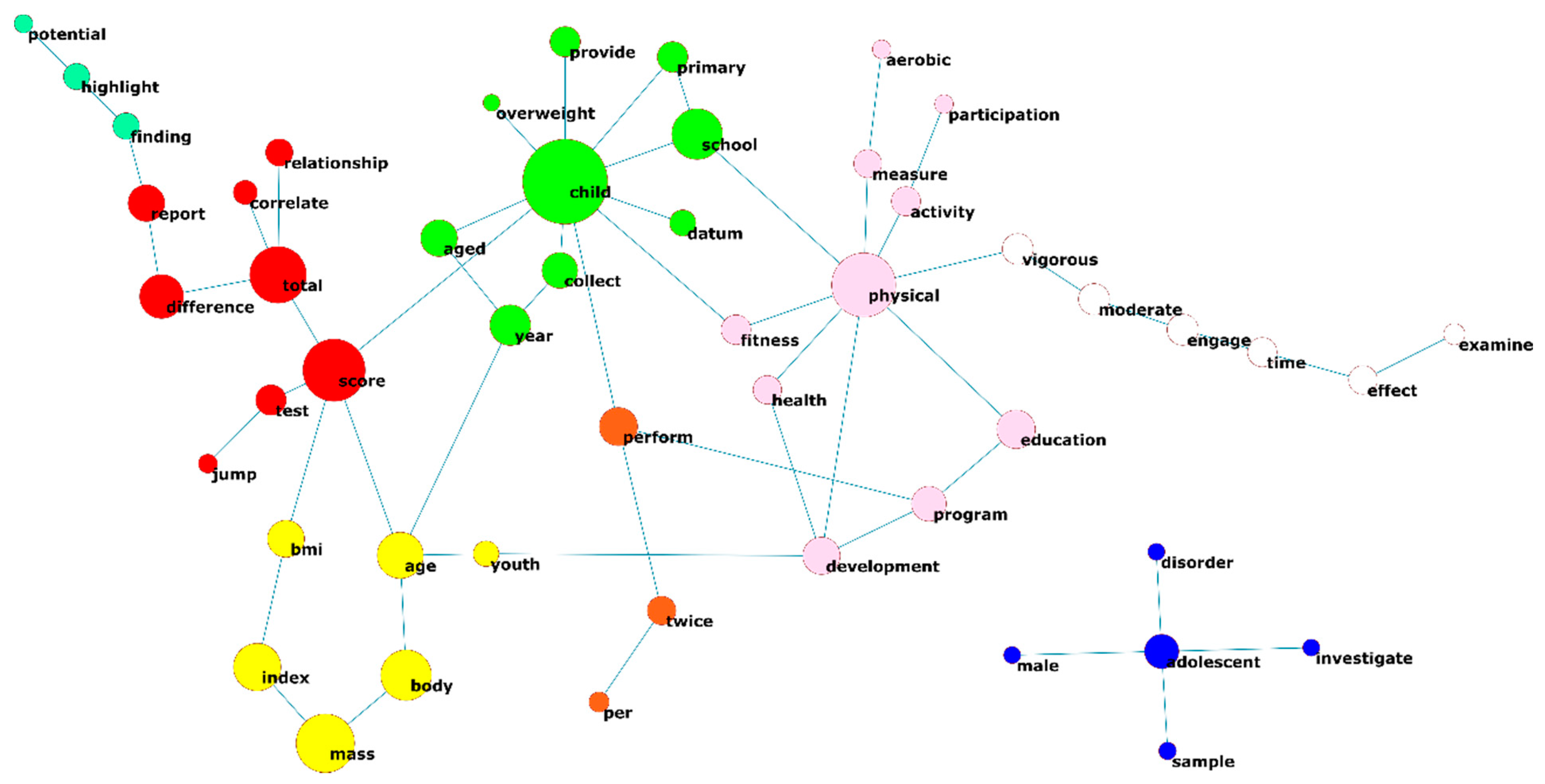
3.3. Word Co-Ocurrences
3.4. Main Topics Found in the LDA Model
4. Limitations and Future Research
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, I.-M.; Shiroma, E.J.; Lobelo, F.; Puska, P.; Blair, S.N.; Katzmarzyk, P.T. Effect of Physical Inactivity on Major Non-Communicable Diseases Worldwide: An Analysis of Burden of Disease and Life Expectancy. Lancet 2012, 380, 219–229. [Google Scholar] [CrossRef] [Green Version]
- Peset, F.; Garzón-Farinós, F.; González, L.M.; García-Massó, X.; Ferrer-Sapena, A.; Toca-Herrera, J.L.; Sánchez-Pérez, E.A. Survival Analysis of Author Keywords: An Application to the Library and Information Sciences Area. J. Assoc. Inf. Sci. Technol. 2020, 71, 462–473. [Google Scholar] [CrossRef]
- Booth, A.; Clarke, M.; Ghersi, D.; Moher, D.; Petticrew, M.; Stewart, L. An International Registry of Systematic-Review Protocols. Lancet 2011, 377, 108–109. [Google Scholar] [CrossRef]
- Eppler, M.J.; Mengis, J. The Concept of Information Overload: A Review of Literature from Organization Science, Accounting, Marketing, MIS, and Related Disciplines. Inf. Soc. 2004, 20, 325–344. [Google Scholar] [CrossRef]
- Rajman, M.; Besançon, R. Text Mining: Natural Language techniques and Text Mining applications. In Data Mining and Reverse Engineering: Searching for Semantics, Proceedings of the IFIP TC2 WG2.6 IFIP Seventh Conference on Database Semantics (DS-7), Leysin, Switzerland, 7–10 October 1997; Spaccapietra, S., Maryanski, F., Eds.; IFIP—The International Federation for Information Processing: Amsterdam, The Netherlands; Springer: Boston, MA, USA, 1998; pp. 50–64. ISBN 978-0-387-35300-5. [Google Scholar]
- Gupta, V.; Lehal, G.S. A Survey of Text Mining Techniques and Applications. JETWI 2009, 1, 60–76. [Google Scholar] [CrossRef]
- Ferreira-Mello, R.; André, M.; Pinheiro, A.; Costa, E.; Romero, C. Text Mining in Education. WIREs Data Min. Knowl. Discov. 2019, 9, e1332. [Google Scholar] [CrossRef]
- Luque, C.; Luna, J.M.; Luque, M.; Ventura, S. An Advanced Review on Text Mining in Medicine. WIREs Data Min. Knowl. Discov. 2019, 9, e1302. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, M.; Liu, L. A Review on Text Mining. In Proceedings of the 2015 6th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 23–25 September 2015; pp. 681–685. [Google Scholar]
- González, L.-M.; García-Massó, X.; Pardo-Ibañez, A.; Peset, F.; Devís-Devís, J. An Author Keyword Analysis for Mapping Sport Sciences. PLoS ONE 2018, 13, e0201435. [Google Scholar] [CrossRef] [PubMed]
- De Nooy, W.; Mrvar, A.; Batagelj, V. Exploratory Social Network Analysis with Pajek: Revised and Expanded Edition for Updated Software. In Structural Analysis in the Social Sciences, 3rd ed.; Cambridge University Press: Cambridge, UK, 2018; ISBN 978-1-108-47414-6. [Google Scholar]
- Colby, J.M. Massage and Remedial Exercises in the Treatment of Children’s Paralyses; Their Differentiation in Use. Boston Med Surg. J. 1915, 173, 696–699. [Google Scholar] [CrossRef] [Green Version]
- Chooi, Y.C.; Ding, C.; Magkos, F. The Epidemiology of Obesity. Metabolism 2019, 92, 6–10. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bhupathiraju, S.N.; Hu, F.B. Epidemiology of Obesity and Diabetes and Their Cardiovascular Complications. Circ. Res. 2016, 118, 1723–1735. [Google Scholar] [CrossRef] [PubMed]
- Tamayo, T.; Rosenbauer, J.; Wild, S.H.; Spijkerman, A.M.W.; Baan, C.; Forouhi, N.G.; Herder, C.; Rathmann, W. Diabetes in Europe: An Update. Diabetes Res. Clin. Pract. 2014, 103, 206–217. [Google Scholar] [CrossRef] [PubMed]
- Lauderdale, M.E.; Yli-Piipari, S.; Irwin, C.C.; Layne, T.E. Gender Differences Regarding Motivation for Physical Activity Among College Students: A Self-Determination Approach. Phys. Educ. 2015, 72, 153–172. [Google Scholar] [CrossRef]
- Lämmle, L.; Worth, A.; Bös, K. Socio-Demographic Correlates of Physical Activity and Physical Fitness in German Children and Adolescents. Eur. J. Public Health 2012, 22, 880–884. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haugen, T.; Ommundsen, Y.; Seiler, S. The Relationship Between Physical Activity and Physical Self-Esteem in Adolescents: The Role of Physical Fitness Indices. Pediatric Exerc. Sci. 2013, 25, 138–153. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McNeill, L.H.; Kreuter, M.W.; Subramanian, S.V. Social Environment and Physical Activity: A Review of Concepts and Evidence. Soc. Sci. Med. 2006, 63, 1011–1022. [Google Scholar] [CrossRef] [PubMed]
- Kriemler, S.; Meyer, U.; Martin, E.; van Sluijs, E.M.F.; Andersen, L.B.; Martin, B.W. Effect of School-Based Interventions on Physical Activity and Fitness in Children and Adolescents: A Review of Reviews and Systematic Update. Br. J. Sports Med. 2011, 45, 923–930. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peral-Suárez, Á.; Cuadrado-Soto, E.; Perea, J.M.; Navia, B.; López-Sobaler, A.M.; Ortega, R.M. Physical Activity Practice and Sports Preferences in a Group of Spanish Schoolchildren Depending on Sex and Parental Care: A Gender Perspective. BMC Pediatr. 2020, 20, 337. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Uni-Gram | Count | Bi-Gram | Count | Tri-Gram | Count | |||
|---|---|---|---|---|---|---|---|---|
| child | 134,829 | physical | activity | 95,660 | body | mass | index | 10,432 |
| physical | 132,159 | age | year | 14,532 | physical | activity | level | 5086 |
| activity | 131,140 | body | mass | 12,888 | mass | index | bmi | 4329 |
| exercise | 93,211 | risk | factor | 11,153 | mean | age | year | 3740 |
| student | 74,059 | mass | index | 10,898 | level | physical | activity | 3150 |
| health | 65,128 | child | adolescent | 9808 | physical | activity | sedentary | 2670 |
| intervention | 57,531 | physical | education | 7481 | increase | physical | activity | 2646 |
| school | 57,325 | activity | level | 6747 | child | aged | year | 2227 |
| high | 57,036 | quality | life | 6633 | main | outcome | measure | 2208 |
| year | 55,972 | blood | pressure | 6622 | child | physical | activity | 2146 |
| adolescent | 55,743 | aged | year | 6455 | physical | activity | among | 2103 |
| age | 52,267 | overweight | obesity | 6293 | vigorous | physical | activity | 2050 |
| increase | 48,925 | mean | age | 5936 | bone | mineral | density | 1945 |
| level | 48,081 | boy | girl | 5901 | physical | activity | child | 1920 |
| patient | 47,110 | heart | rate | 5787 | physical | activity | intervention | 1822 |
| effect | 44,719 | body | composition | 5207 | physical | activity | mvpa | 1621 |
| time | 43,529 | overweight | obese | 5157 | child | age | year | 1557 |
| measure | 41,476 | high | school | 5105 | diet | physical | activity | 1542 |
| among | 40,828 | sedentary | behavior | 4827 | high | school | student | 1451 |
| associate | 39,840 | physical | fitness | 4822 | health-related | quality | life | 1439 |
| Word | Degree | Weighted Degree | Closeness | Betweenness | Proximity Prestige |
|---|---|---|---|---|---|
| child | 10 | 50,925 | 0.268 | 0.345 | 0.267 |
| score | 5 | 27,295 | 0.251 | 0.302 | 0.250 |
| school | 3 | 18,194 | 0.244 | 0.099 | 0.243 |
| fitness | 2 | 6195 | 0.242 | 0.089 | 0.241 |
| physical | 8 | 29,026 | 0.231 | 0.280 | 0.230 |
| age | 4 | 15,114 | 0.225 | 0.085 | 0.224 |
| primary | 2 | 6643 | 0.221 | 0.000 | 0.220 |
| perform | 3 | 10,329 | 0.217 | 0.077 | 0.216 |
| development | 4 | 9822 | 0.216 | 0.059 | 0.215 |
| youth | 2 | 4617 | 0.214 | 0.046 | 0.213 |
| aged | 2 | 9579 | 0.209 | 0.007 | 0.208 |
| collect | 2 | 9028 | 0.209 | 0.007 | 0.208 |
| total | 4 | 22,562 | 0.208 | 0.182 | 0.207 |
| program | 3 | 8528 | 0.204 | 0.027 | 0.203 |
| provide | 1 | 6537 | 0.202 | 0.000 | 0.201 |
| datum | 1 | 4848 | 0.202 | 0.000 | 0.201 |
| overweight | 1 | 2006 | 0.202 | 0.000 | 0.201 |
| bmi | 2 | 9671 | 0.196 | 0.033 | 0.196 |
| test | 2 | 6527 | 0.194 | 0.029 | 0.193 |
| year | 3 | 11,696 | 0.190 | 0.006 | 0.189 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pans, M.; Madera, J.; González, L.-M.; Pellicer-Chenoll, M. Physical Activity and Exercise: Text Mining Analysis. Int. J. Environ. Res. Public Health 2021, 18, 9642. https://doi.org/10.3390/ijerph18189642
Pans M, Madera J, González L-M, Pellicer-Chenoll M. Physical Activity and Exercise: Text Mining Analysis. International Journal of Environmental Research and Public Health. 2021; 18(18):9642. https://doi.org/10.3390/ijerph18189642
Chicago/Turabian StylePans, Miquel, Joaquin Madera, Luís-Millan González, and Maite Pellicer-Chenoll. 2021. "Physical Activity and Exercise: Text Mining Analysis" International Journal of Environmental Research and Public Health 18, no. 18: 9642. https://doi.org/10.3390/ijerph18189642
APA StylePans, M., Madera, J., González, L.-M., & Pellicer-Chenoll, M. (2021). Physical Activity and Exercise: Text Mining Analysis. International Journal of Environmental Research and Public Health, 18(18), 9642. https://doi.org/10.3390/ijerph18189642