1. Introduction
Human beings have been historically defined by their ability to feel emotions [
1]. These different emotions affect their behaviour and decision-making processes. Furthermore, these emotions are able to provoke changes in attitudes and behaviour as well as induce irrational acts [
2]. This leads us to the study of human sentiments and the behaviour associated with them which has become a key issue of our time.
Delving into the behaviour of human beings, they can be classified as gregarious animals by definition [
3], and they usually need social interactions with other members in the community in order to maintain their emotional stability [
4]. This fact has made them prone to express emotions and communicate them to other individuals since prehistoric times. This procedure has led to developing complex societies able to collaborate and evolve to successfully pursue common goals [
5]. As a consequence of these interactions, reinforcement situations could be produced according to a specific topic which would generate a general or collective sentiment in the community.
The study of this general sentiment in a modern society constitutes an important vector to address its psychological affectation regarding different past events [
6]. On the other hand, nowadays, social networks have become the most common source of information used by humankind to express sentiments and opinions. Thus, the study of social networks has emerged as a key means of evaluating the mental health, opinions, and the general sentiment of the population with regard to any specific event [
7]. Moreover, social media can also be used to detect the trends and evolution of such events by evaluating the most common expressions (e.g., protests or complaints) and specific words (e.g., occurrence of words in similar texts) used b individuals when they manifest their sentiments or opinions [
8].
Currently, the most relevant event is the appearance of the new coronavirus named SARS-CoV-2, first identified in Wuhan, China, in early 2020 [
9]. This new pathogen is associated with a respiratory infectious disease called COVID-19 which has induced one of the most dangerous crises at a global level since World War II. The ultra-fast transmission rate of the virus [
10] is capable of leading to the collapse of hospitals and health centres with thousands of infected patients [
11]. Though the mortality rate of the virus is significantly low, there have been millions of registered deaths all over the world. For these reasons, the World Health Organisation (WHO) officially declared the situation on 11 March 2020.
This pandemic outbreak forced the implementation of a range of measures through the official statements by governments of most countries all over the world. Among these measures, unprecedented mobility restrictions and mandatory isolation requests were implemented. The populations of most countries were directly confined to their homes, and businesses were (almost in their totality) closed; thus, the economy of these countries came to a harsh standstill [
12,
13]. This situation was aggravated with mandatory quarantine periods for infected individuals who suffered the disease in a mild way, or who had been in close contact with infected people [
14].
At the social level, the social distance between individuals and the avoidance of almost any kind of physical contact were among the most relevant implemented measures. This produced modifications in the behaviour of humans. Moreover, the use of medical face masks was recommended and even mandatory in most countries. This also modified the way people behaved in close quarters, diminishing their ability to properly communicate by making gestures and facial expressions [
15].
All these considerations have led to producing frustration among the population as well as mental and psychological affectation. Thus, people have used the Internet as a way of escape, increasing virtual communication to compensate for the decrease and overall worsening of human interactions at the social level. In particular, social networks have become a main vector of expression, where individuals are capable of sharing their opinions and discomfort with the pandemic situation, whilst also searching for information about symptoms, vaccination procedures, and any kind of news related to COVID-19 [
16].
For these reasons, a comprehensive study of well-known social networks can provide valuable information regarding the feelings of the individuals during the pandemic outbreak. Thus, this study comprised four countries where Spanish is the official language, namely Chile, Mexico, Peru, and Spain. The social network evaluated was Twitter [
17], because it is one of the most used in the world and its textual content and the emoticons provided its users are relatively affordable to process.
The
EmoWeb framework [
18] was selected to evaluate of sentiments expressed by individuals on Twitter.
EmoWeb is a visual system which is able to dynamically estimate the evolution of sentimental value and to analyse the occurrence of words. It makes use of a lexicon as a seed to establish the initial sentiment polarity of predefined words. Then, the system captures the sentiment from the evaluated texts, learning new concepts and upgrading its knowledge. We note that the system was developed to analyse texts provided by the digital versions of well-known newspapers. Thus, it has to be adapted to study the textual content of social networks.
Some experiments were conducted for each of the countries of interest. They allowed illustrating the viability of the study consisting of a 5D word cloud provided by EmoWeb which dynamically evolves and trends plots that show the evolution of the sentimental values of specific keywords. These keywords are related to the COVID-19 outbreak, and they have been manually selected according to different relevant perspectives (e.g., economic or health issues).
The rest of the paper is organised as follows.
Section 2 provides the foundations of the proposed study.
Section 3 details how the information was recovered from Twitter and the processing steps that followed to generate the dynamic sentimental knowledge.
Section 4 addresses the different developed experiments to confirm the quality of the study. Finally,
Section 5 concludes and provides some future guidelines about the topic.
3. Information Gathering and Processing
The present study consists of two stages which are executed in a sequential manner. The initial phase comprises both the gathering of raw data (tweets) from the selected source of information (Twitter) and the subsequent application of proper filtering processes according to predefined sets of rules given by keywords. The first set of rules restricts the data to the context of the COVID-19 pandemic (keywords such as
covid,
covid19, and
coronavirus), producing a total of 9 million tweets during the period considered (March 2020 to March 2021). Subsequently, the second set of rules allows classifying the resulting tweets into five predefined topics of interest (
government;
health;
economy;
employment; and
vaccines). This process reduces the size of the data to 3 million tweets. To conclude, there is a final set of rules targeting the consideration of the country information, which finally produces a set containing 105,497 tweets. The
Section 3.1 provides further details on the manner in which this information is distributed among Chile, Mexico, Peru, and Spain, as well as the keywords utilised to cope with each topic.
Once the textual content of interest is available, the second phase is triggered when the aforementioned adapted version of the
EmoWeb framework processes it. This system is able to estimate the sentiment polarity of words and its evolution over time.
Section 3.2 introduces the framework and its most relevant functionalities.
3.1. Twitter Database Related to COVID-19
The resulting efforts from the filtering processes are summarised in
Table 3, illustrating the number of tweets per topic and country to be processed by
EmoWeb during the next stage. It is relevant to note that the outcomes shown in
Table 3 demand appropriate prior tweet hydration processes to effectively infer the country information (in our case, Chile, Mexico, Peru, and Spain).
The topics were selected with the aim of addressing the leading concerns of the population in terms of COVID-19 and the prospects of a short-term foreseeable future in which the world has overcome the pandemic. In this regard, for topic 1 (government), we focused on collecting opinions on the measures and corrective actions imposed by the governments of the selected countries. In this scenario, corruption (“corrupción”), management (“gestión”), politician (“político”), and democracy (“democracia”) represent some of the main driving keywords utilised as filtering rules to gather the respective tweets. As for topic 2 (health), attention is drawn to capturing viewpoints relative to the psychological impact of the pandemic and the consequences of COVID-19 themselves. Keywords such as depression (“depresión”), stress (“estrés”), psycologist (“psicólogo”), and anguish (“angustia”) are among the representative filtering candidates applied. With reference to topic 3 (economy), due care is taken to compile relevant voices mainly discussing national macroeconomic indicators and mid-term recovery strategies for companies and local businesses. Keywords such as business (“negocio”), company (“company”), debt (“deuda”), bankruptcy (“quiebra”) and GDP (gross domestic product, “PIB”) constitute the major part of the debates observed in the different countries and therefore, the filtering set. Topic 4 (employment), for its part, addresses the conversations covering the abrupt changes that occurred in the working philosophy (e.g., working from home), and moreover, the staggering increment in unemployment rates in the countries. Keywords such as Zoom, Skype, videocall (“videoconferencia”), unemployment (“desempleo”) and dismissal (“despido”) constitute some of the filtering resources used in this context. Lastly, topic 5 (vaccines) tackles the perception of the prevention methods available and the explicitly manifested state of uncertainty with regard to the level of trust in them. Keywords such as Astrazeneca, Pfizer, PCR, antigens (“antígenos”) and effectiveness (“eficacia”) depict some of the most notorious filtering instances in this respect.
To conclude,
Figure 2 exhibits one word cloud per topic. In this type of visualisations, the frequency of a word is defined by its size (the larger, the more frequent). To this end, the aforementioned set containing 3 million tweets was used. In addition, some COVID-19-related words were considered as stopwords to ensure the better visualisation of the stemming procedure applied.
3.2. The EmoWeb Framework
The present study bases its foundations on an adaptation of a former framework called
EmoWeb [
18]. This revised version aims to grant the original framework the ability to process the data streams originating on Twitter. Taking a general purpose lexicon created from the Spanish version of
SenticNet [
45] as a starting basis, the framework shows proficiency in applying text analysis techniques in conjunction with an unsupervised learning algorithm to effectively process incoming tweet datasets and extract relevant words that adhere to its lexicon, along with computed sentiment values.
The overall process is orchestrated by the use of time as a considered magnitude, which contextualises the knowledge acquired at a word level and confers the possibility of making the computed sentiments evolve. Consequently, word sentiments present a dynamic nature in which the strengthening or weakening calculations are applied according to the influence they are exerting or, in other words, following the trends detected in the input data. The framework similarly offers several visualisations for the outcomes arising from the aforementioned analysis, since similarity relationships between lexicon words through 5D word clouds and word sentiment fluctuation graphs over time are the most relevant.
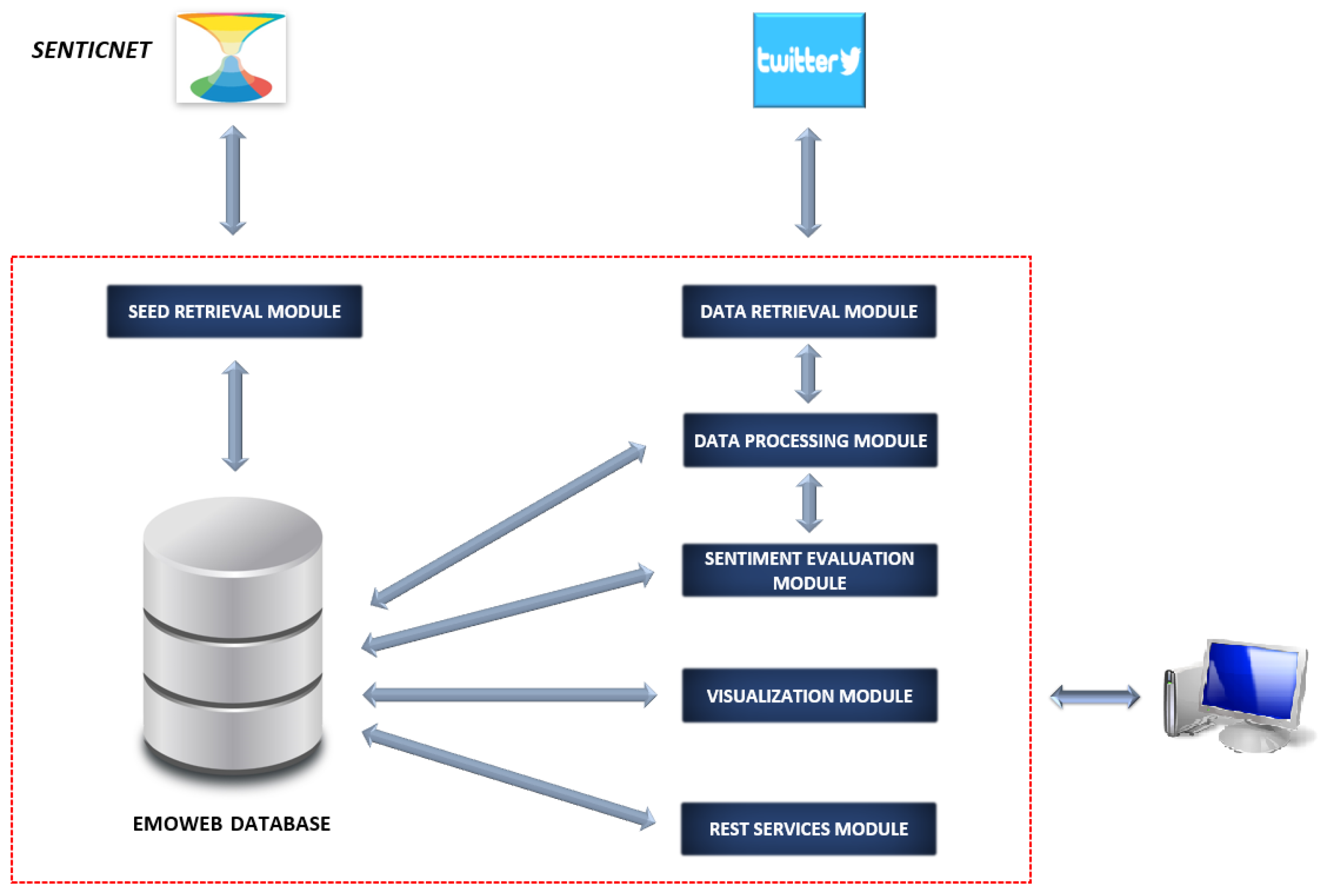
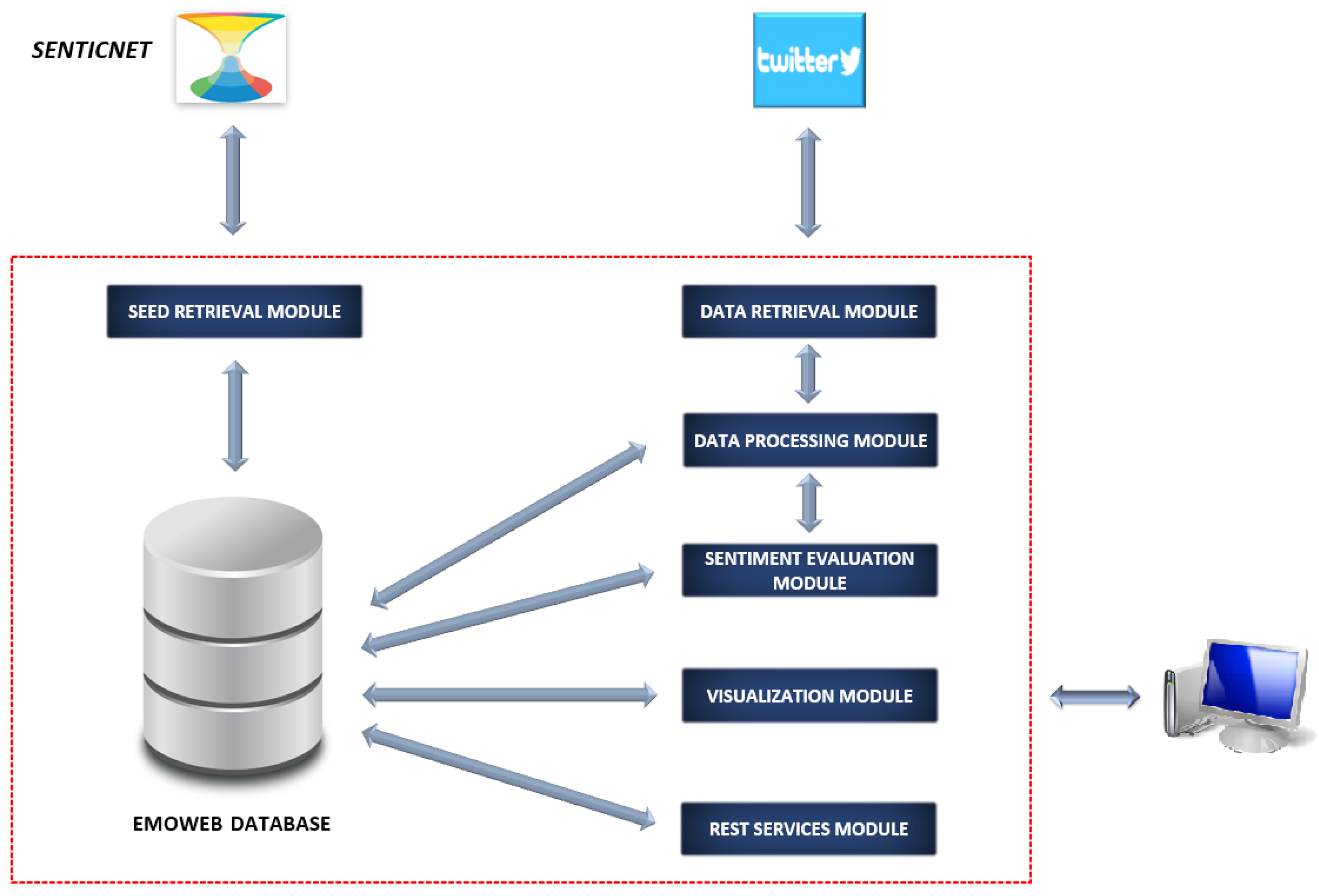
Figure 3 illustrates the architecture of the adaptation of
EmoWeb and its major internal components. The
Seed Retrieval Module takes responsibility for incorporating the commencing seed to the lexicon. This initial seed was given by the Spanish version of
SenticNet, which offers 29,630 Spanish words along with their associated numerical values in the range of [−1,1], representing the sentiment polarities. This starting lexicon is enhanced with the new words learnt during the processing of the Twitter data.
Subsequent to this initial one-off phase, the Data Retrieval Module collects an input set of tweets created on a particular calendar day d and harvests relevant and necessary information (i.e., tweet hydration) as a mandatory step prior to triggering a request for the activities concerning the Data Processing Module.
The Data Retrieval Module, for its part, conducts tweet preprocessing activities including the removal of non-relevant information (considered in this work), such as smileys, emojis, special characters, mentions and hashtags, among others. Subsequently, the cleaned tweets in addition to some metadata information (tweet ID, creation date, etc.) are stored in the internal database. Subsequently, the Data Processing Module focuses on applying NLP activities on texts such as tokenisation, lemmatisation, and part of speech (PoS) tagging methods. The removal of the Spanish-related stopwords is also covered by the exercise.
As a result, the input tweet dataset is fully processed and sentiment scores are calculated for every belonging tweet. In addition, a well-nourished list of detected words is obtained. These words are properly stored in the lexicon in case they were not present in it previously.
Following the aforementioned actions, the endeavours encompassed by the Sentiment Evaluation Module are initiated. This module is accountable for initially computing (or updating) the sentiment values of all the words stored in the lexicon according to the trends detected. For each word, these required calculations were based on the sentiment score of the tweets where the word was detected during the calendar day d under analysis and the former sentiment value stored in the lexicon for the same word under scope.
The module was also liable for the management of an internal archive that stores the historical information on the sentiment values computed for the lexicon words. This archive plays a critical role in the duties performed by the Visualisation Module.
As stated before, the Visualisation Module produces relationships between lexicon words through 5D word clouds and word–sentiment fluctuation graphs over time. These visualisations conform to the main focus of the present paper where EmoWeb is exposed to tweets related to the COVID-19 pandemic and a graphical analysis is performed to establish a comparison between the different countries of interest.
4. Experiments
In this section, different experiments are presented to show the emotional evolution during the COVID-19 pandemic in the analysed countries regarding the previously described topics. As stated previously, a total of 9 million tweets were retrieved in a first set containing tweets related to COVID-19. Subsequently, from this set and according to the filtering keywords applied to make a selection for each topic, a subset of more than 3 million tweets was created. Finally, additional filtering was applied to only consider those tweets with their country information available (official information reported by Twitter), giving a total of 105,497 tweets.
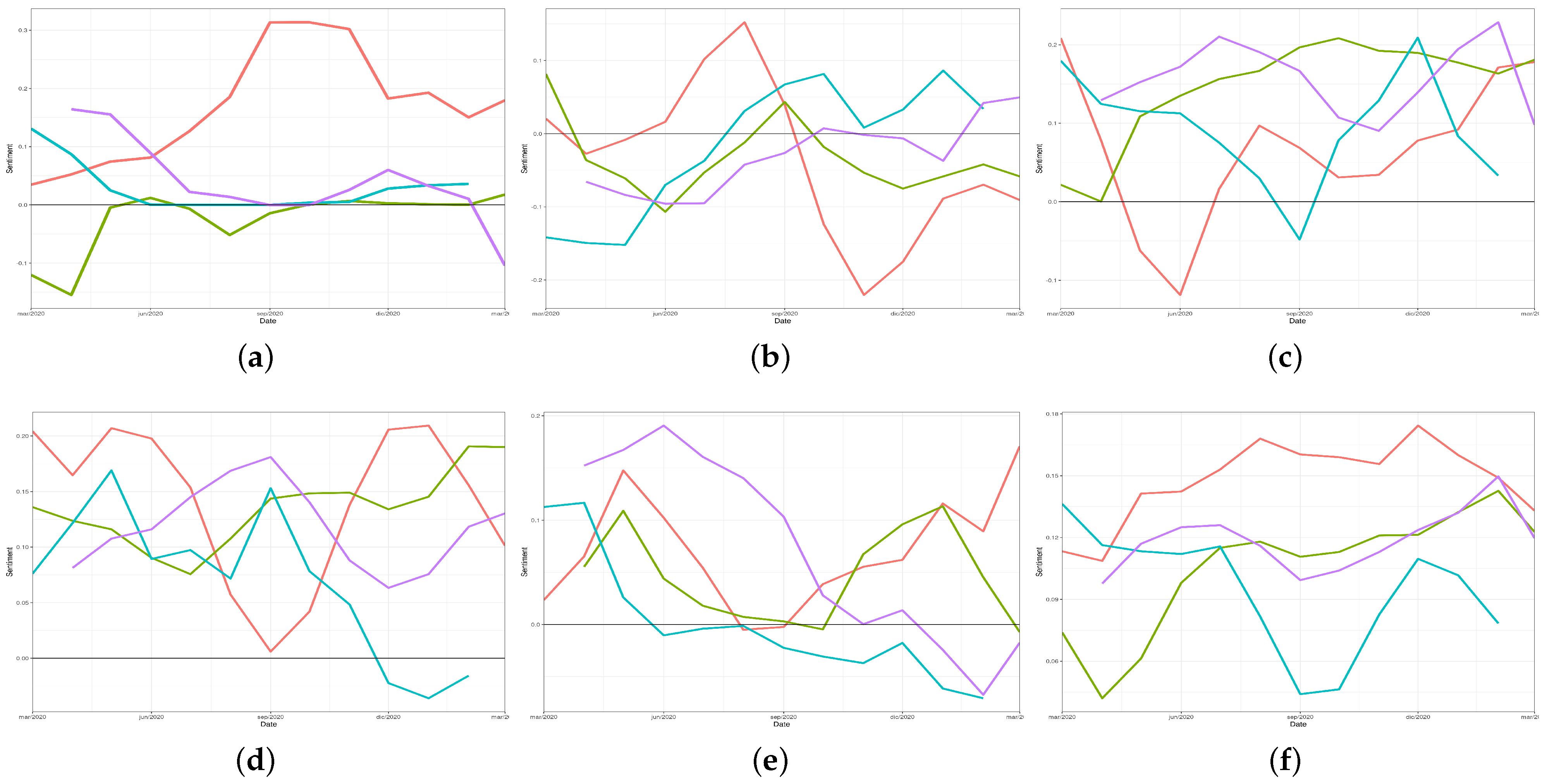
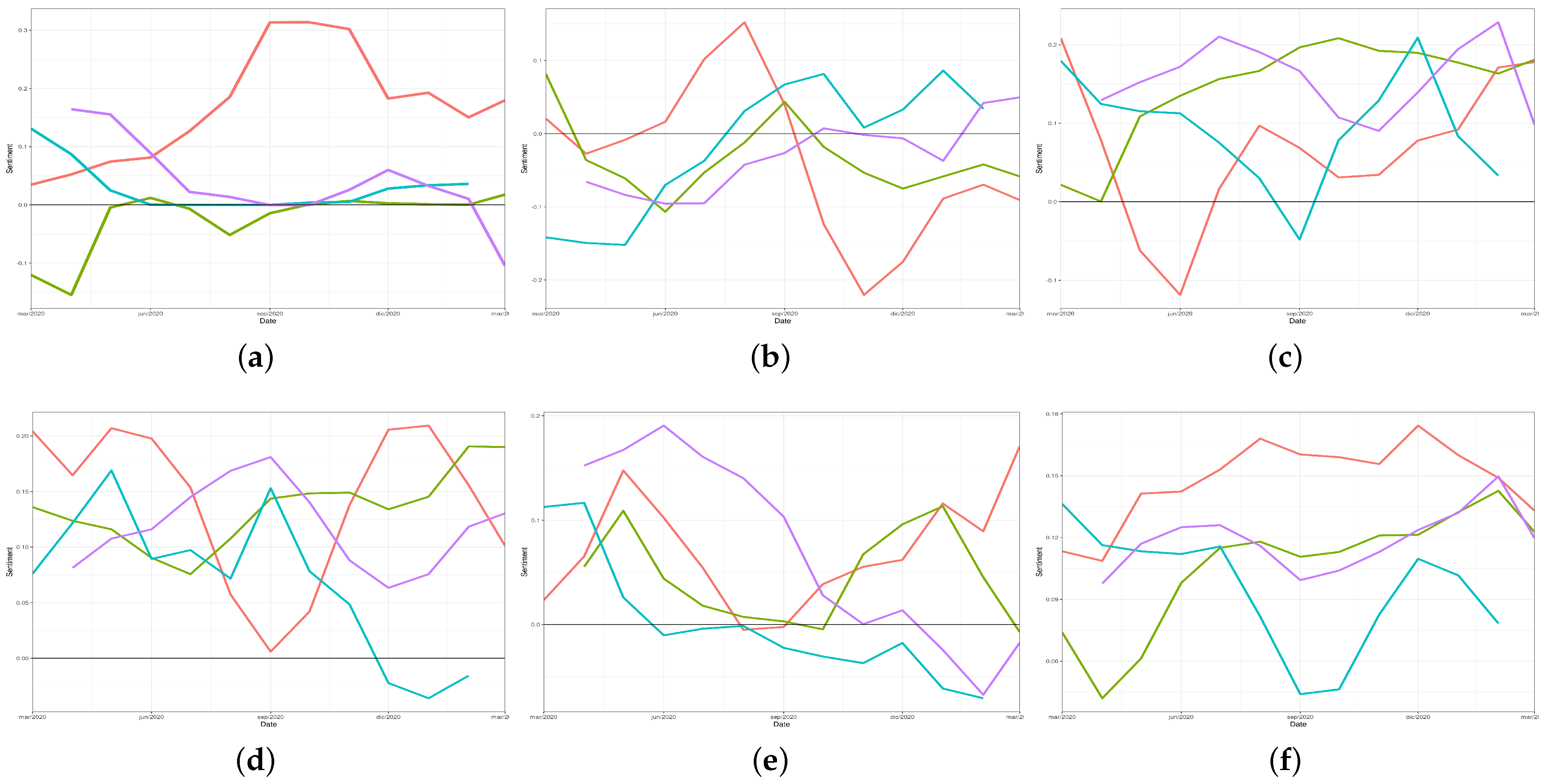
In order to compare the emotional evolution from the beginning of the pandemic in the different countries,
Figure 4 shows the classical linear graph for sentiment values’ representation for a set of words. Analysing these figures, a negative trend can be noted regarding the word
democracy (“
democracia”) (see
Figure 4a), probably as a result of the social problems associated with the dramatic reduction in the fundamental rights caused by the successive restrictions imposed by the government.
In
Figure 4b,c, the evolution of the sentiment associated with the words
depression and
recovery (“
depresión” and “
recuperación”), could be related to the number of cases and deaths in each country.
In general, the word
meeting (“
reunión”) was always associated with a positive sentiment (
Figure 4d). Regarding the expression
face mask (“
mascarilla” or “
cubrebocas”), a negative trend presented in Spain and Peru, probably associated with the population’s fatigue regarding the need for its use.
Figure 4f shows positive emotions related to the Spanish word for
vaccine (“
vacuna”) in all the considered countries. In Mexico and Spain (and to a lesser extent, Chile), there is a growing positive trend that could be associated with an increase in the number of people vaccinated.
The previous visualisation helps us understand the dynamic behaviour of the sentiments associated with some words over time, however, it is not able to extract potential relationships between them. To attend this point, word cloud visualisations were used. In these graphs, the colour of each word is related to the polarity of its sentiment. In this way, red is associated with a negative emotion and green with a positive one. The size of each word is associated with the frequency of its occurrence, being larger the more the word appeared in tweets. Finally, the distance between words represents their relationship, with smaller one being more related to one another.
Figure 5 presents the relationships between a set of words per topic (
government;
health;
economy and
employment) in different countries measured during March 2021.
For instance, regarding
government topic, the relationship between the following words is analysed in
Figure 5a for Spain:
authority (“
autoridad”);
chaos (“
caos”);
corruption (“
corrupción”);
democracy (“
democracia”);
delinquency (“
delincuencia”);
management (“
gestión”);
governmental (“
gubernamental”);
impact (“
impacto”);
political party (“
partido”); and
media (“
prensa”). First,
media and
democracy were related to the most negative and to the most positive sentiment, respectively. In addition,
authority and
corruption are words that are close to each other but present far away positions from
media and
management. The potential rationale supporting these relationships could be founded on the continuous criticism shown by the Spanish population concerning the decisions made by their government. In fact, the Spanish government has been repeatedly denounced over its management of the COVID-19 crisis. More concretely, the lack of foresight and the absence of official scientific experts supporting the decisions was the source of the majority of the complaints from the other political parties and the population. In addition, the shortage of protective material for health professionals, the purchase of defective coronavirus tests, and the distribution of thousands of faulty face masks to medical staff also created an overall sense of the government’s ineptitude.
In the case of Peru, the following words related to the
health topic are presented in
Figure 5b:
lockdown (“
encierro”);
isolation (“
aislamiento”);
depression (“
depresión”)
restriction (“
restricción”);
psychologist (“
psicólogo”);
mobility (“
movilidad");
deceased (“
fallecido”);
confinement (“
confinamiento”);
COVID; and
pandemic (“
pandemia”). Notice that
lockdown,
isolation, and
depression are negative words that appear together. The size of the word
confinement indicates that this is a constant source of discussion on social media, probably due to the fatigue induced by the lack of observable positive attitudes. Peru represents one of the countries with the highest COVID-19-related mortality rates in the world. The country is experiencing difficulties to accessing the vaccines and is also having their intensive care units completely overwhelmed. Due to these facts, regions are taking a long time overcome their assigned alert levels (currently categorised as high, very high, or extreme, with corresponding levels of restrictions in each case), which likewise leads to enforcing severe mobility, capacity and curfew restrictions, among others. The effects emerging from these circumstances could explain the negative emotions highlighted in
Figure 5b.
In Mexico (see
Figure 5c), the following words related to the
economy topic presented:
business (“
negocio”);
company (“
empresa”);
debt (“
deuda”);
consequence (“
consecuencia”);
recovery (“
recuperación”);
rescue (“
rescate”);
economic (“
económica”);
bankruptcy (“
quiebra”);
aid (“
ayudas”); and
leadership (“
liderazgo”). In this case, the most positive (
company) and negative (
debt) words appeared close to each other, which could reflect the severity of the economic crisis caused by the pandemic. The same proximity is observed in the words
consequence,
recovery, and
rescue, all of which hold a negative sentiment probably induced by the absence of the short-term expectation of seeing improvements in the economy. In fact, the highly open Mexican economy was heavily impacted by a severe reduction in the export demand. Additionally, it was also very affected by the decline in oil prices and the global market volatility. On 14 May 2020, the Mexican government announced plans to commence with the normalisation of economic activities, including a colour-based system (green–yellow–orange–red) to indicate the extent of activities allowed in the different states. Despite the coloured restrictions, cases and deaths began to rise again in December 2020, and in February 2021, they were forced back into declined due to the start of the second wave. The negative emotions shown in
Figure 5c could be derived from these aforementioned past events.
Finally, in Chile, the following words related to the
employment topic are presented in
Figure 5d:
rent (“
alquiler”);
unemployment (“
desempleo”);
meeting (“
reunión”);
boredom (“
aburrimiento”);
lockdown (“
encierro”);
dismissal (“
despido”);
jobless (“
paro” or "
desempleo”);
performance (“
rendimiento”); and
hunger (“
hambre”). Notice that the first word (
rent) is not very related to the other words. The words
dismissal,
performance, and
unemployment appear together in a clear reflection of the problems emerging from the difficulties that companies are facing to keep their staff on payroll. In fact, in March 2021, Chile remained under state of emergency and a daily nationwide curfew. The gradual plan designed by the government to reopen the economy and phase out the enforced quarantine measures presented some difficulties, since it was applied at the municipal level and depended on several criteria (reproduction rate of the virus, hospital bed occupancy, and the projected rate of regional active cases). This fact could lead to a possible reverse of the years of growth in the employment rate observed in the middle class in Chile. These circumstances could possibly be driving the negative emotions detected in
Figure 5d.
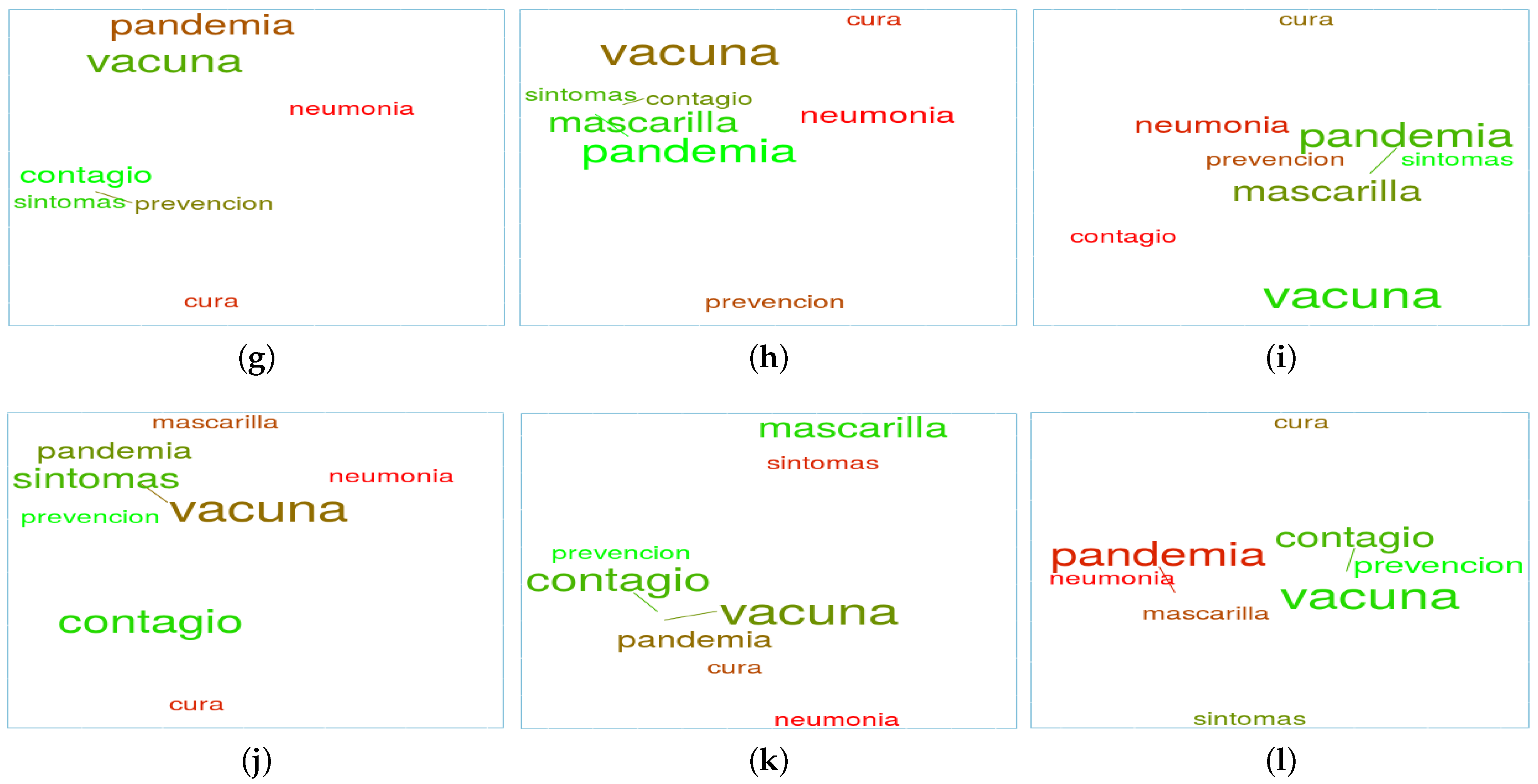
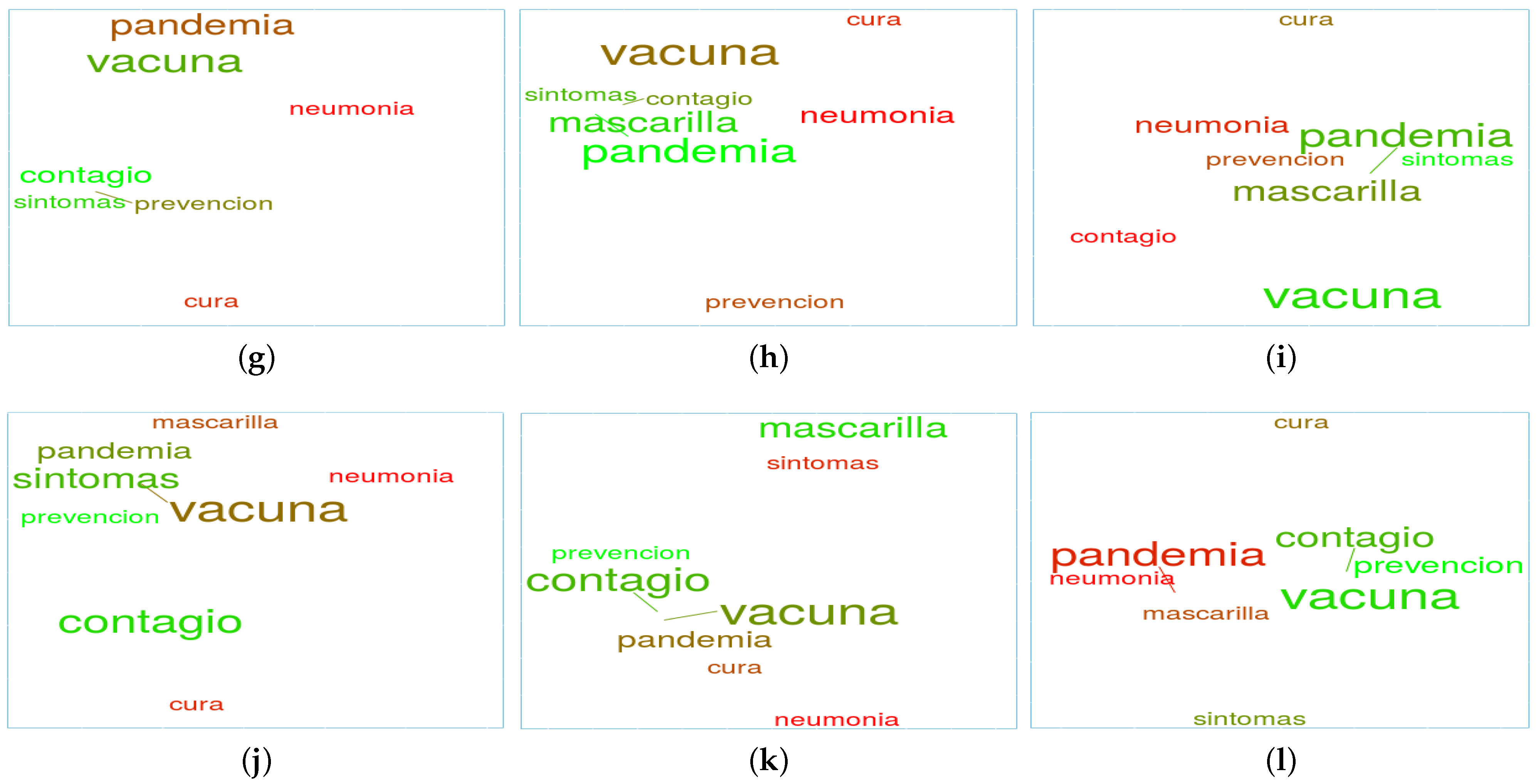
The previous analysis explored the behaviour of the different countries with a selection of relevant words for each topic. Nonetheless, it becomes possible to confer a different perspective when the same set of words is selected and word clouds are created on different dates to jointly study word positions and potential movements between dates for all the countries. As an exemplification of this strategy,
Figure 6 presents the relationships among a set of words belonging to the topic
vaccines in the different countries of interest at different moments of the pandemic (March 2020, September 2021, and March 2021). The words chosen are:
vaccine (“
vacuna”);
pandemic (“
pandemia”);
contagion (“
contagio”);
symptoms (“
síntomas”);
cure (“
cura”);
pneumonia (“
neumonía”);
face mask (“
mascarilla”); and
prevention (“
prevención”). Reasons to proceed with the aforementioned word selection are based on the impact and the number of occurrences during the period under review.
It is important to note that the same set of words is chosen for every country in such a way that a proper baseline is established and thus, comparisons can be performed. From these figures, several trends or behaviours can be observed.
For instance, in Chile, the word pandemic started with a negative sentiment (red colour) and evolved towards a positive perception (green colour) by March 2021. This could be explained by a growing hope regarding the end of the pandemic at the country level and the overall agreement (to a certain extent) on the positive appraisal for the crisis management exerted by the government. In addition, it is worth mentioning that the words vaccine and cure present considerable distance from one another for March 2021, as opposed to the initial proximity exhibited for March 2020. In line with this observation, the word symptoms similarly follows a separation process from the word vaccine, and it also reduces its frequency (i.e., size) over time. On the contrary, the words prevention and face mask closely surround the word vaccine for March 2021 (despite their considerable initial distance portrayed during March 2020). This new relationship could indicate that Twitter conversations discarded a potential short-term cure for COVID-19 and that they concentrated their efforts in discussing the prevention methods available to prevent further infections.
With regard to Mexico, it is interesting to note that words vaccine, pandemic, and cure are close to each other for March 2020 and then tend to separate over time. This quite likely reflects the initial situation with a lack of available information about COVID-19. Likewise, it may also represent the initial population concerns regarding the actual assessment of pandemic seriousness and the proper solution availability for it. The subsequent graphs allow inferring that much more meticulous conversations were taking place on Twitter from a pandemic perspective. In this regard, words such as contagion, face mask, and symptoms appear close to each other, demonstrating more awareness with respect to the pandemic. It is also relevant to note that the words vaccine and pandemic follow an ascending sentiment trend over time (colour turning light green). This serves as explicit evidence of the positive perception of the advances achieved in the fight against COVID-19.
In Peru, the word cure is always positioned far away from the rest of the words. This fact diverges from the rest of the countries, where the word cure is related to other words in at least one of the periods considered. As for the word sentiment values, some of them exhibit fluctuations over time, therefore missing a clear trend towards positive or negative value regions. This instability entails a true reflection of the apprehension and mistrust of the Peruvian population with respect to the unsuccessful courses of action taken by their government to manage the COVID-19 crisis (which some have reported to be the most severe amongst all Latin American countries). The words vaccine, contagion, and pandemic are clear instances of this behaviour.
As for Spain, it is relevant to note that the word pandemic evolved towards a very negative sentiment registered in March 2021, as well as being a word frequently found in tweets. This could be explained by the well-known Spanish population’s dissatisfaction regarding the absence of a clearly defined pro-active government strategy to deal with the COVID-19 pandemic, especially considering the extreme economic impact it has had on Spain, and the positive evolution observed in some European Union countries (France, Germany, and Portugal, among others). This tendency is also noticed in the sentiment associated with the word face mask. For this word, a negative trend is detected from September 2020 to March 2021, presumably due to the population’s disagreement on the use of face masks in open spaces when safe distance can be ensured. With respect to the potential word relationships, the graph depicted for March 2021 denotes a concern with all factors involved in the COVID-19 pandemic, whilst also being present during the previous months.
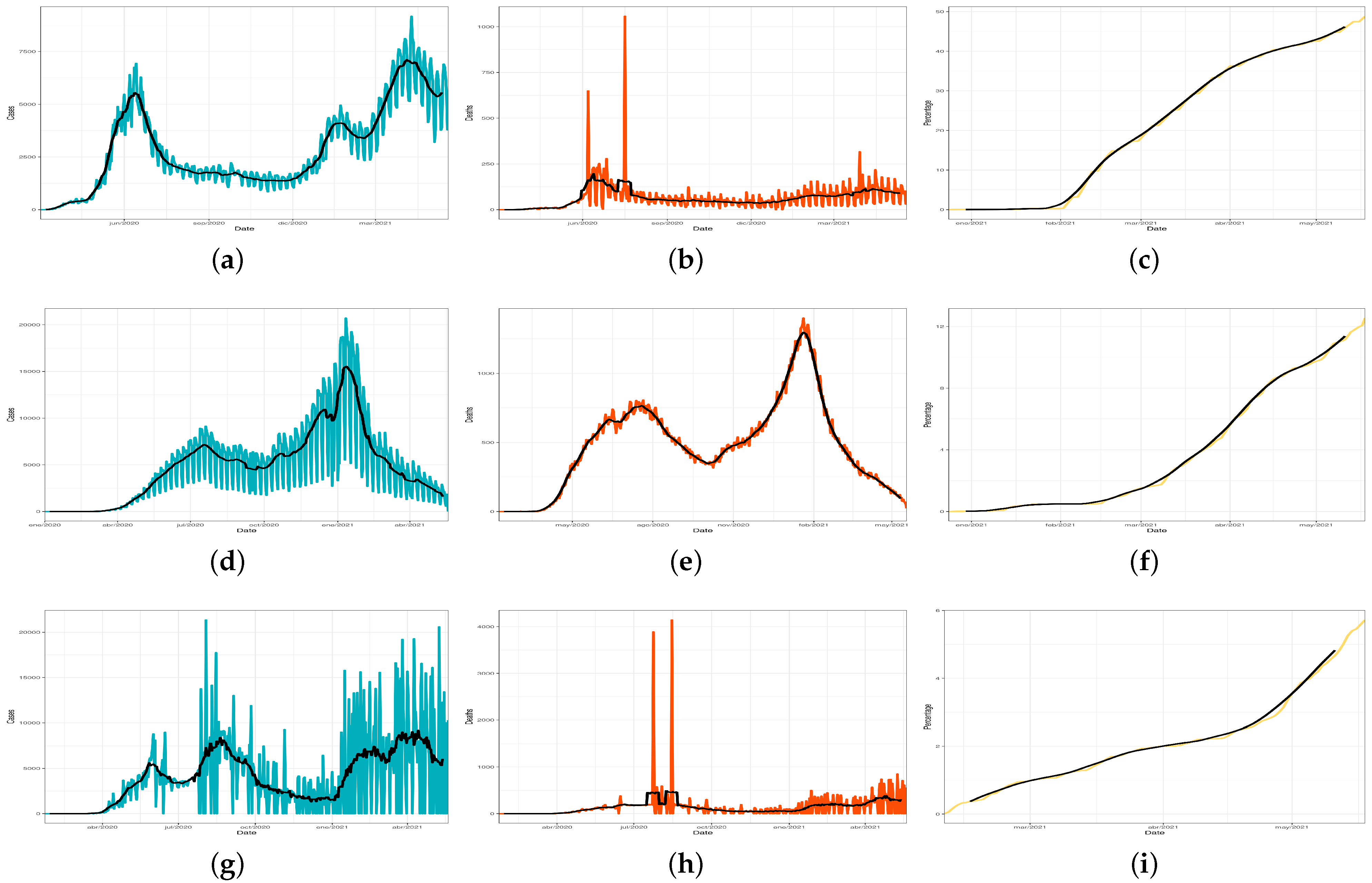
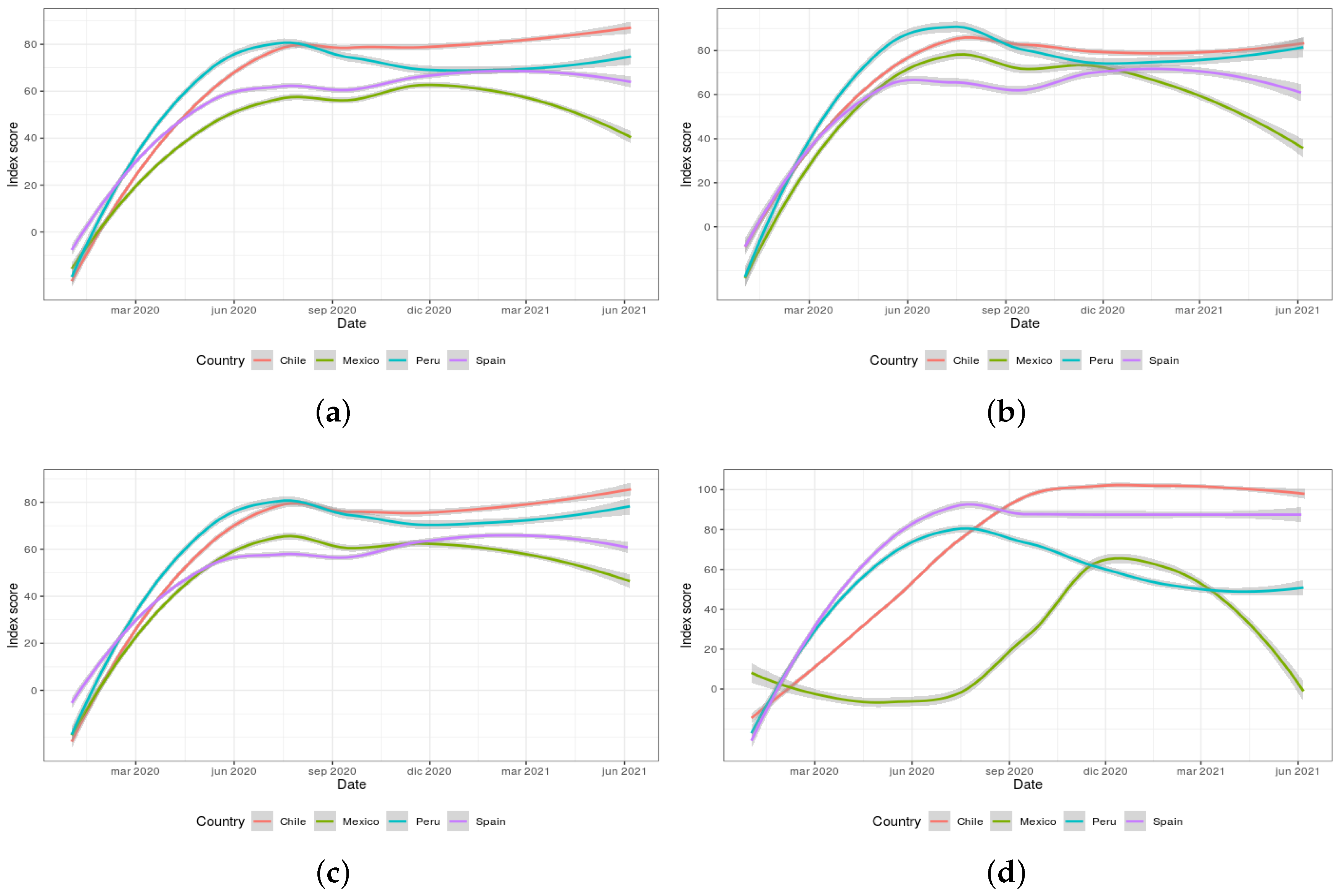
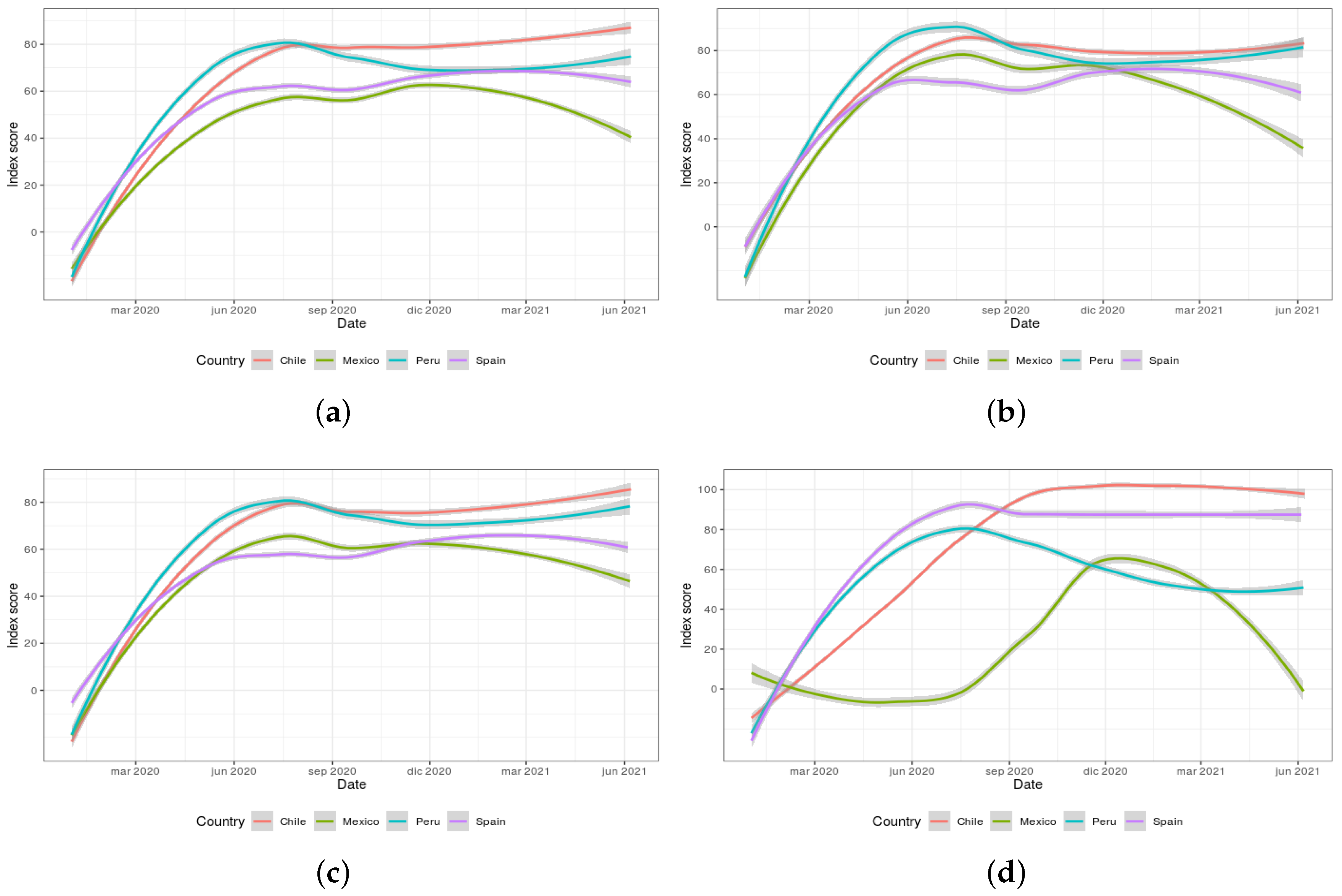
Figure 7a–d exhibit the scores of the four global indexes (overall government response, stringency, containment and health, and economic support) calculated by the OxCGRT dataset for the period from January 2020 to June 2021 for the selected countries. These indexes are calculated as an aggregation of several related individual policy response indicators. It is worth mentioning that the indexes do not provide assessment information on the enforcement of the policies or indicate a measure of the appropriateness or effectiveness of a particular government response. In addition, they do not capture the specific demographic or cultural features applicable to each country. On the contrary, the actual purpose of these indexes resides in providing a score to effectively allow cross-national comparisons of government interventions (the higher the score, the more severe the intervention).
In this regard,
Figure 7a allows inferring that all governments implemented important responses at the beginning of the pandemic, with Chile being the more interventionist country over time in comparison with Mexico. As for
Figure 7b, all countries show a similar level of stringency for December 2020 but evolve differently afterwards. Mexico becomes the country with the fastest relaxation of internal policies applied while Peru shows to be the country forced to strengthen them. In respect to
Figure 7c, it is interesting to observe that Spain was forced to make their policies stricter to face the third wave which occurred around September 2020, just after a period in which the policies had been relaxed (probably too early). In contrast, Mexico followed a relaxation of the applied policies since that month, highlighting it as the most permissive of the selected countries. Finally,
Figure 7d shows the consistency of Chile and Spain in their economic responses, clearly in contrast with those of Mexico and Peru.
The observation of the global indexes provided by the OxCGRT dataset provides some insights for further discussion of the word clouds formerly presented in
Figure 5 and
Figure 6. In
Figure 5b, Peru shows negative sentiments towards the health topic-related words, which also shows alignment with the data presented in
Figure 7c (as policies started to be enforced again around March 2021). Regarding
Figure 5c, it is interesting to note the bad perception of the economy topic in Mexico in March 2021. This fact could be explained by the fluctuations in the enforcement of the economic policies taken by the Mexican government, as illustrated in
Figure 7d. With respect to
Figure 6a–c, the overall positive evolution of the perception of the words related to the vaccines topic in Chile could be linked to the stability and clear direction shown by the government to apply policies and measures in
Figure 7a–c (as it can be inferred from the minor fluctuations displayed). Finally, with reference to
Figure 6j–l, the negative trend detected related to the Spanish population’s dissatisfaction with regard to the management decisions taken by their government could be explained by the fluctuations shown in
Figure 7a. These oscillations manifest a relevant inconsistency in the restrictions applied. In addition, an index peak can be found in March 2021, matching the negative trend detected in
Figure 6l.
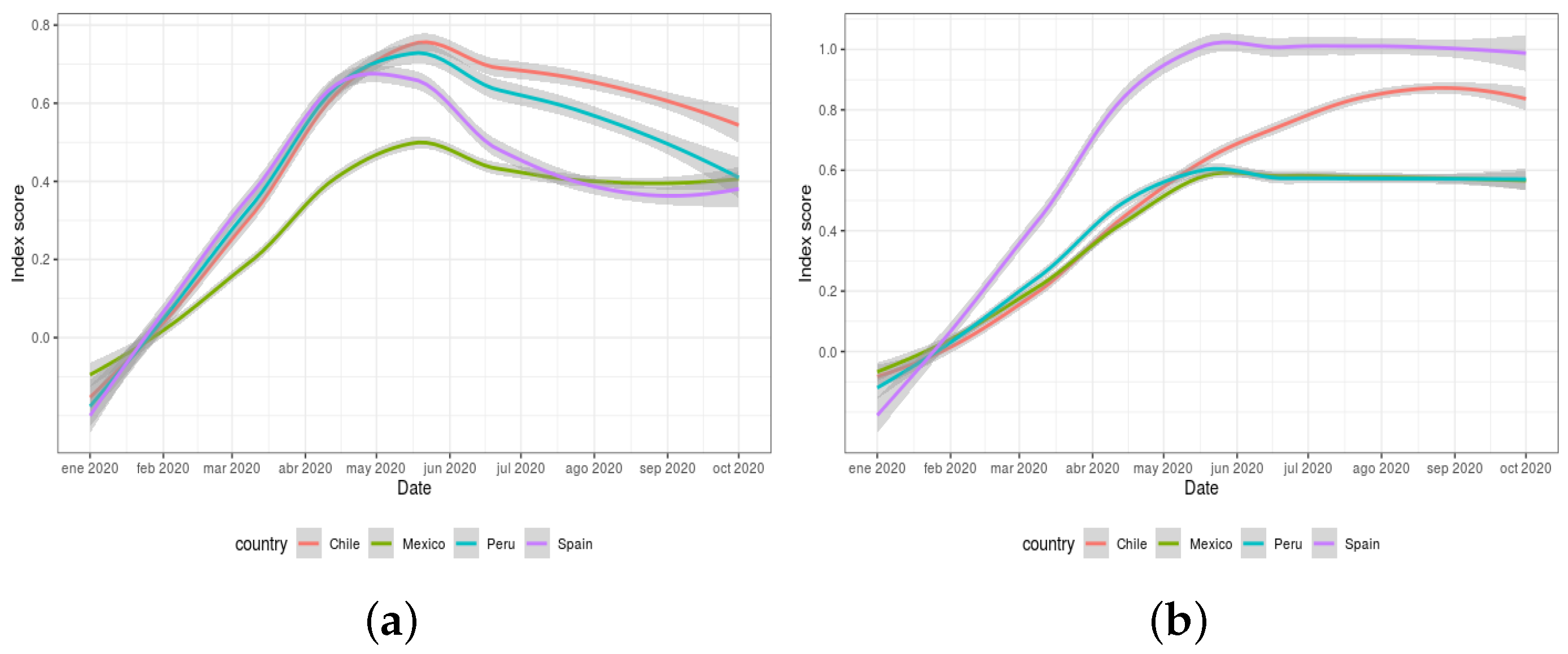
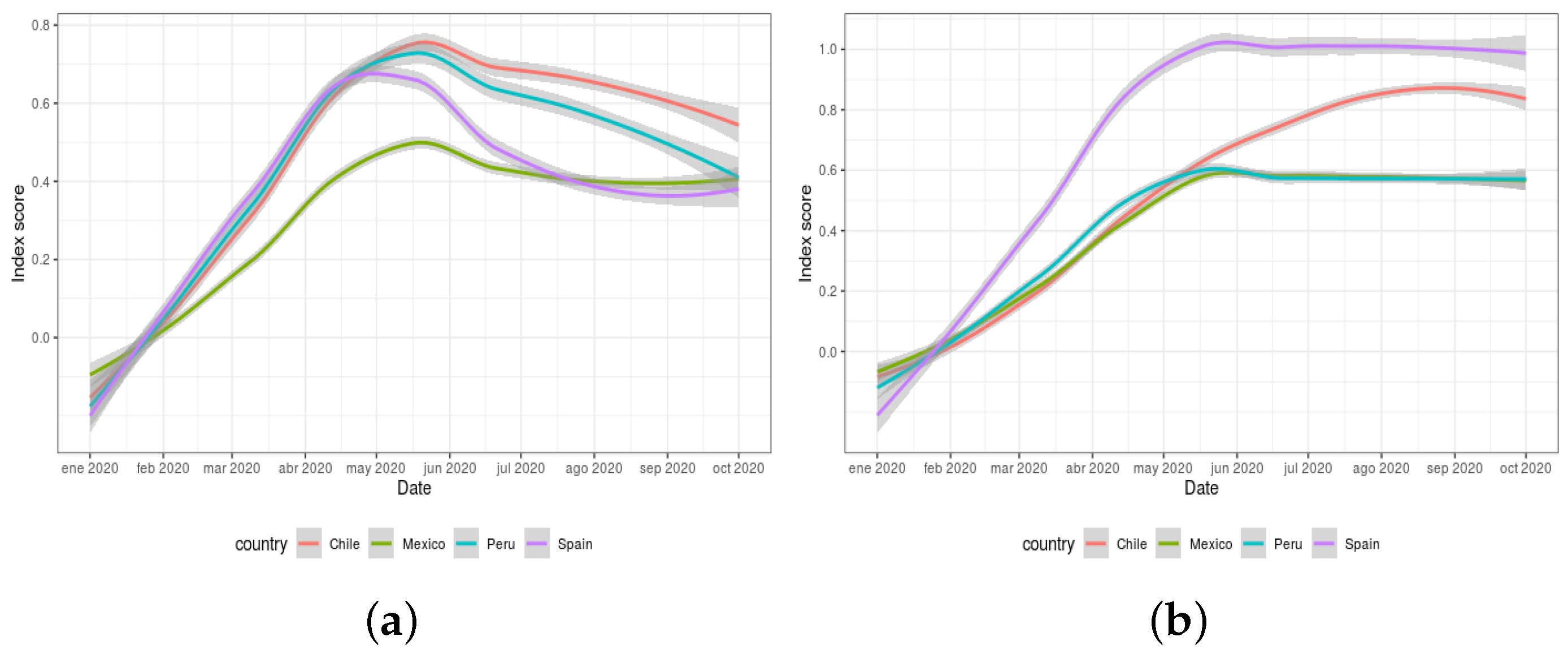
A similar contextualisation exercise can be performed by using the two global indexes defined in the Response2covid19 dataset (rigidity of public health and economic intervention measures). These indexes are calculated by the aggregation of the responses collected for a total of 20 individual policy indicators.
Figure 8a,b depict the evolution of both indexes during the period from 1 January 2020 to 1 October 2020. The values for these indexes range from 0 (no intervention) to 1 (all interventions are strict).
A comparison with the information provided in
Figure 7 for the same period of time provides certain similarities (despite the fact that the individual policies from which these global indexes were obtained actually differ). In this respect,
Figure 8a illustrates analogous information to that exhibited in
Figure 7c, with Chile and Peru close in their respective rigidity of measures, and with Mexico enforcing less restrictions than the other countries. As for
Figure 8b, it can be noticed that Spain implemented the most restrictive economic measures at the beginning of the pandemic, as also shown in
Figure 7d.
More conclusions could be stated from the word clouds obtained, especially by means of a further contextualisation process with the specific scenarios drawn by each of the countries of interest. Furthermore, augmenting the input dataset could also procure a more accurate correlation between the word relationships observed and the real factors originating them.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}