1. Introduction
Air pollution problems are becoming increasingly serious worldwide. The primary pollutants found in cities include sulfur dioxide, ozone, nitrogen oxides, and inhalable and fine particulate matter. Fine particulate matter is an important air pollutant, which is considered the primary environmental risk factor, and it is the fourth leading risk factor for death and disability in China [
1]. In particular, PM
2.5 has the most significant effect. Long-term exposure to PM
2.5 pollution can have a severe impact on human health. Numerous epidemiological studies have shown that PM
2.5 is closely related to a variety of cerebrovascular diseases, respiratory diseases, and immune system diseases, as well as long-term or short-term mortality in hospitals [
2,
3,
4,
5]. According to a report in 2014, the PM
2.5 concentration in 90% of Chinese cities had exceeded the standard of 35 μg·m
−3, and the average number of exceeded days was 246. Therefore, studies that investigate PM
2.5 are of great significance for local pollution prevention and targeted health prevention measures.
Various modeling methods, such as spatial interpolation [
6], the atmospheric dispersion model [
7], satellite inversion [
8], and deep learning [
9,
10,
11], have been used to simulate the distribution of regional pollutants. However, many methods, such as diffusion models, require a large amount of data difficult to obtain, and it is difficult to achieve high-precision under the condition of a lack of input data resources [
12]. The land use regression (LUR) model is a multivariate regression modeling method based on the observation concentration of air pollutants and its surrounding geographical factors. This method is widely used to estimate the concentrations of outdoor air pollutants since it was improved by Briggs et al. [
13]. Due to its high accuracy and relatively low investment [
14], LUR models have a wide range of applications. Beelen et al. [
15] used an LUR model in the ESCAPE (European Study of Cohorts for Air Pollution Effects) project, which explained the variability of annual NO
2 and NO
x concentrations. Ma et al. [
16] used multi-scale LUR models to simulate the NO
2 concentration in Auckland, which performed better than the universal kriging (UK) model and the inverse distance weighting (IDW) and ordinary kriging (OK) models. Yang et al. [
17] developed LUR models to predict ultrafine particle concentrations in London, and the results showed that the LUR models had moderate to good performances within these areas. Saucy et al. [
18] used warm and cold season LUR models for NO
2 and PM
2.5 concentrations in peri-urban areas in South Africa, and it was demonstrated that the models could be successfully applied in local areas. Weissert et al. [
19] developed a microscale LUR model for a heavily trafficked road in Auckland, New Zealand. This research represented the expansibility of small-scale variability in pollutant concentrations. In China, LUR modeling has been shown to have methodological advantages and has become increasingly popular in air pollution studies in recent years [
20,
21,
22].
In human exposure and health risk assessment areas, LUR models are often used to simulate exposure concentrations [
23]. High temporal resolution pollution data can improve the precision of epidemiological studies and human exposure research. Although LUR is a reasonable and reliable modelling approach, to some degree it has the disadvantages of low temporal resolution and poor spatial portability [
16,
24]. The most common spatial predictors in LUR models include elevation, population, road network, and land use. Many studies have confirmed that these predictors can explain most of the models and have strong correlations with pollutant concentrations [
20,
25,
26].
City pollution sources and functions vary from region to region due to the different characteristics of urban layouts [
27,
28]. In particular, various urban functional areas are comprised of various points of interest (POIs) [
29]. Studies have confirmed that different functional areas with different types of POIs have differences in air pollution characteristics and attractiveness to populations [
30,
31,
32]. POIs show typical functional features at different times. For example, people tend to congregate in residential areas in the evening and gather in office places for working during the daytime. Therefore, this may result in different POI predictors related to pollutants at different times. That means that if POI predictors are added into LUR models, this may improve the precision and temporal–spatial resolution. Nori-Sarma et al. [
26] used LUR models to predict urban NO
2 exposure in Mysore, India. The study showed industrial sites and religious POIs, and these high human activity POIs were associated with higher levels of NO
2. Lu et al. [
33] developed three sets of LUR models and the independent variables were common land use data, local business permit data, and Google POI data. The results showed that models that used the Google POI data performed the best.
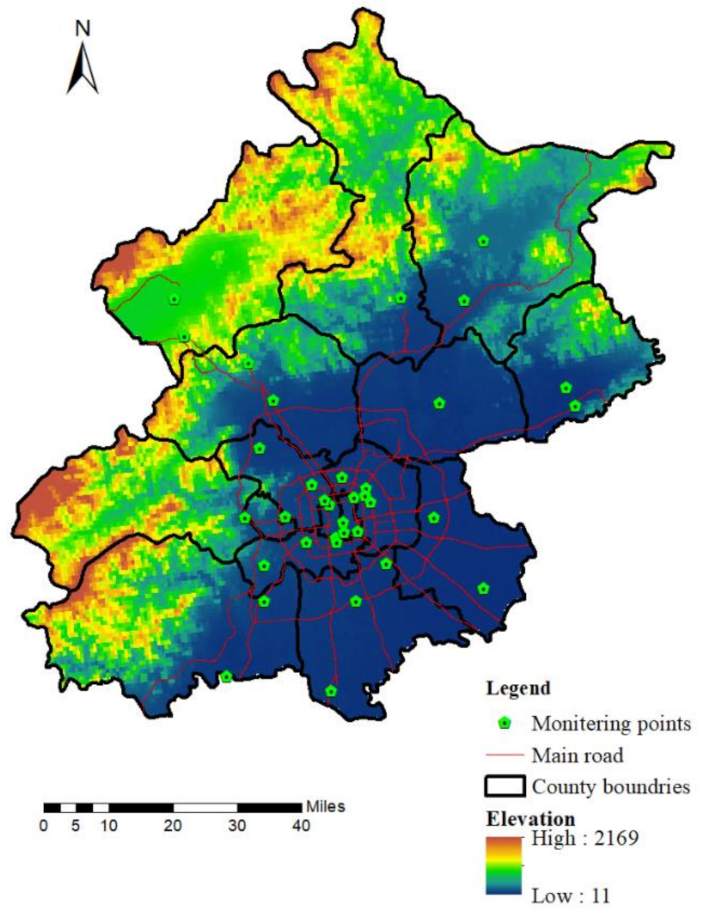
Beijing is one of the cities with the worst air pollution measures in northern China. Although Beijing has made phased progress in reducing the air pollution problem in recent years, it still exceeds the minimum limit of the China national standard (GB 3095-2012). Unlike previous studies that have used average annual and seasonal pollutant concentrations, this study uses hourly pollution concentrations from the heating season, the non-heating season, working days, and non-working days. In these LUR models, in addition to conventional predictors, such as land use, meteorological factors, population and elevation, POIs are also included. This study aims to improve the temporal resolution and model accuracy and simulate the PM2.5 distribution in Beijing during different time circumstances, and to provide guidance and reference value for continued LUR and exposure studies.
4. Discussion
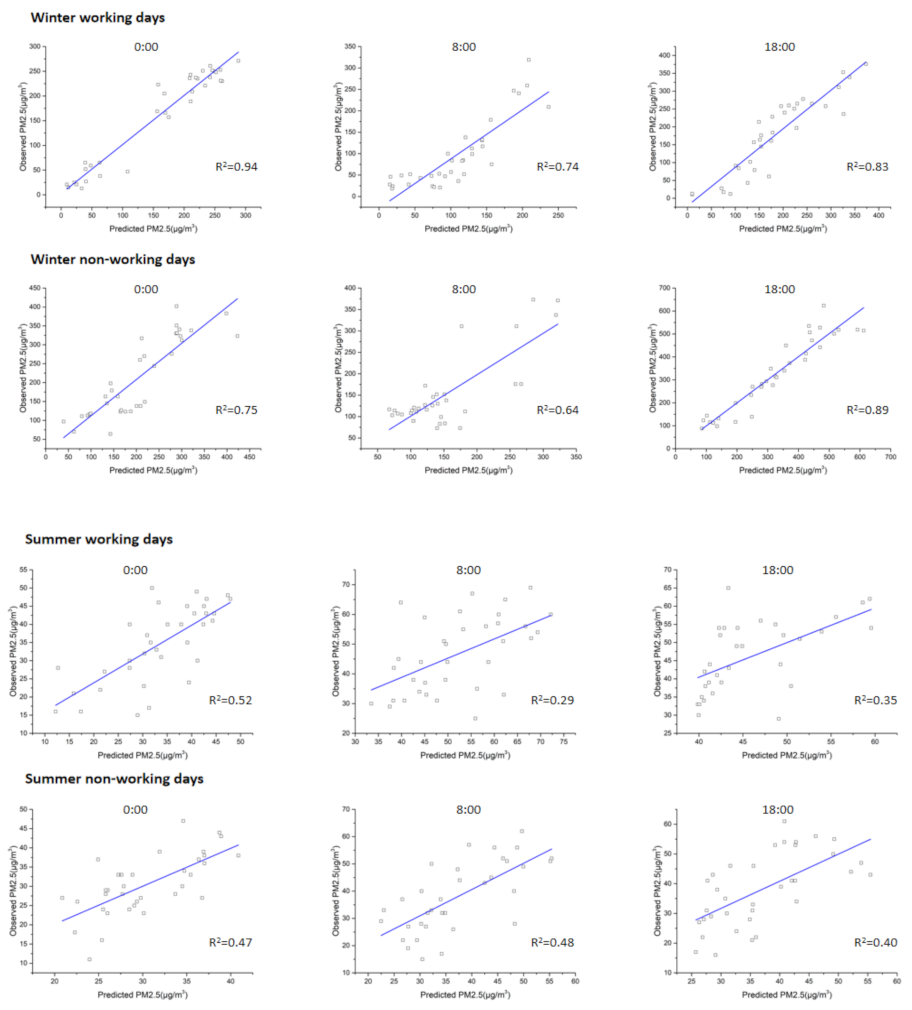
The LUR models in this study well explained the temporal and spatial variations in the PM
2.5 pollution in the study area, and hourly time precision was achieved. The winter models fitted best, and the explanatory degree of the models at several different moments ranged from 67.5% to 95.5%. These models were highly comparable compared with the LUR models utilized in previous studies. The explanation of these models was higher than the 53% explanation of the annual PM
2.5 LUR simulation for the United States [
42] and higher than 11.4–46.5% of the seasonal average PM
2.5 models for Bangkok, Thailand [
43]. In China, the model explanations were higher than that of Cai et al. [
44] to explain 65% of the spatial variability in the PM
2.5 in Taizhou, China and higher than the explanation of 61% of the PM
2.5 of the Liaoning central urban agglomeration in the model of Shi et al. [
20]. This difference can typically be explained by the measuring concentrations, predictive variables, and original variability of the geographical and socio-economic characteristics of the study area [
45].
The models for the two seasons were quite different. PM
2.5 pollutants in Beijing primarily originated from man-made emissions, including coal combustion, gasoline and diesel vehicle emissions, secondary source pollution, and straw burning on farmlands. Winter is heating season in Beijing. Due to coal combustion from Beijing and its surrounding areas, as well as less vegetation than in summer [
46], the concentration of PM
2.5 in winter was significantly higher than in summer. In addition, Beijing is affected by the high pressure from Mongolia during winter, which leads to the local accumulation of pollutants. During summer, the source of fine particulate matter primarily originates from regional traffic sources, of which there is also a portion from cross-regional transportation. Lv et al. [
47] conducted a high-time resolution particle source apportionment in Beijing showed that Baoding and Langfang in Hebei Province contributed significantly to the short-distance transportation, and this portion was not included in these models. This demonstrated that the explanation of several summer models in this study ranged between 35.4% and 66.8%, which was worse than that in winter. These results were consistent with the seasonal models of Shi et al. [
20] in which their LUR models explained 61% of the variability in winter and 52% of the variability in summer. The cross-regional transport of traffic pollution sources also explained why the models at 0:00 were greater than 8:00 on the same working days in this study. This was because during the morning rush hour at 8:00, many people from the surrounding areas enter Beijing for work, and the traffic influence produced by this portion could not be included in the models. However, the PM
2.5 pollutants at 0:00 were primarily from local sources, and nearly each impact factor was included in the model.
Previous studies have generally used the RMSE to determine the accuracy of the models [
45], but for LUR models with different spatial and temporal scales, a direct comparison of the RMSE values may have great variability. In this study, the RMSE in the winter models was generally larger than that in summer, which was due to the different background values of the pollutants in the different seasons and the spatial differences of the pollutants. Since the terrain in Beijing is high in the northwest and low in the southeast, the different topography and underlying surface affect the transmission of air pollutants [
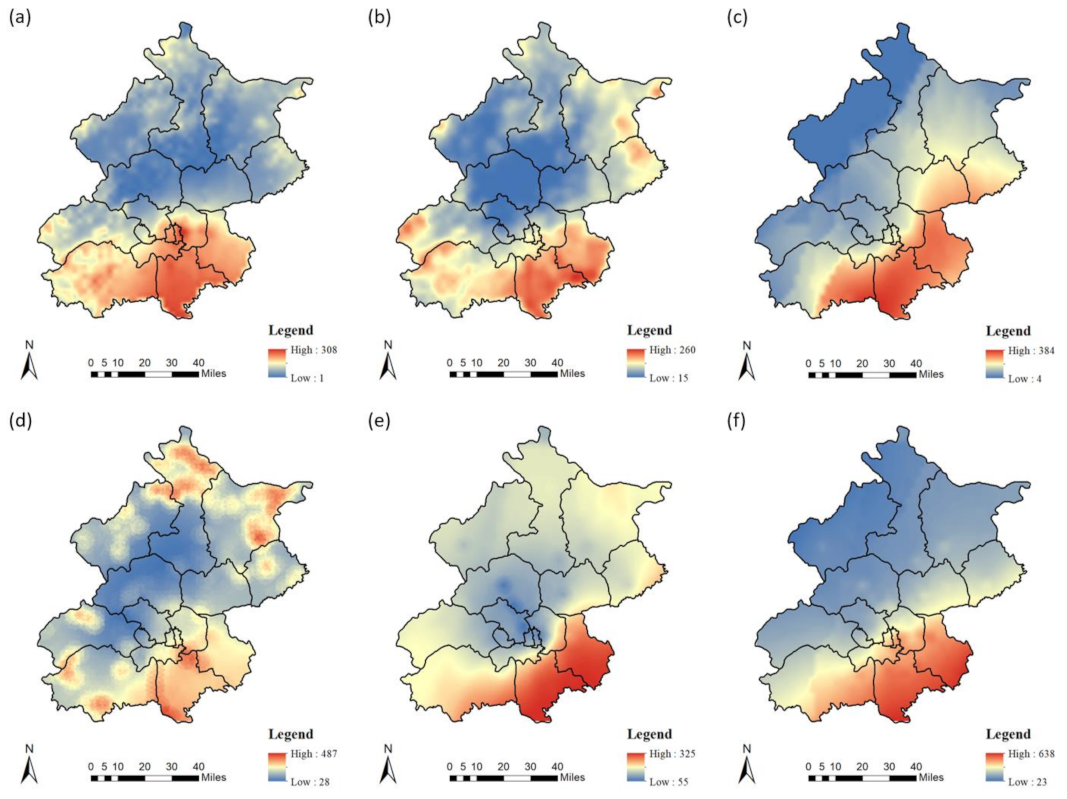
48]. In the suburbs, human activities are less affected, and the high concentration areas are primarily in the main urban area and the southern plain. As a result, the PM
2.5 concentration fitted by this model in winter reached the highest level of nearly 700 μg·m
−3, while the minimum area was less than 10 μg·m
−3. The RMSE of our summer models ranged from 5.08 μg·m
−3 to 8.24 μg·m
−3, which was not significantly different from previous studies in China [
20], but was larger than the figures from other global research [
45]. This was because the background level of PM
2.5 in China is several times or even dozens of times higher than that in Europe and the United States. The RMSE of the winter model was also larger than summer due to above reasons.
The predictive variables in the different LUR models are typically not constant due to city-specific conditions and the availability of data. Generally, most LUR studies have used annual or seasonal values. One reason is that the non-contemporaneous measurements of monitoring stations may cause temporal variability [
44]. Therefore, one significant drawback of LUR models is their low temporal resolution. The simplest method to calibrate pollutant concentrations are using observations from fixed continuous monitoring stations [
49]. This combined with meteorological, satellite data or adding other time-dependent predictive variables [
50,
51] can also improve the temporal resolution. Since the POIs presented different functional characteristics at different times, this study assumed that different types of POI variables also have time characteristics, and hourly LUR models were developed. The results showed that POIs explained the variation in pollutant concentrations at different times. Before modeling, the 13 types of POIs included in this study were all correlated with PM
2.5 concentration, and 11 types of POIs were finally included in the models. The association between POIs and pollutants and its temporal characteristics are better reflected by the attractions of POIs to the crowd [
29], which will affect the behavior of the crowd, thus explaining the variability of air pollution at that moment. The POIs included in the models, such as shopping, entertainment, medical care, science, education and culture, all have a large traffic flows near these places in daily life. The pollution produced by these vehicle traffic sources contributes to the PM
2.5 pollution at this moment to a large extent.
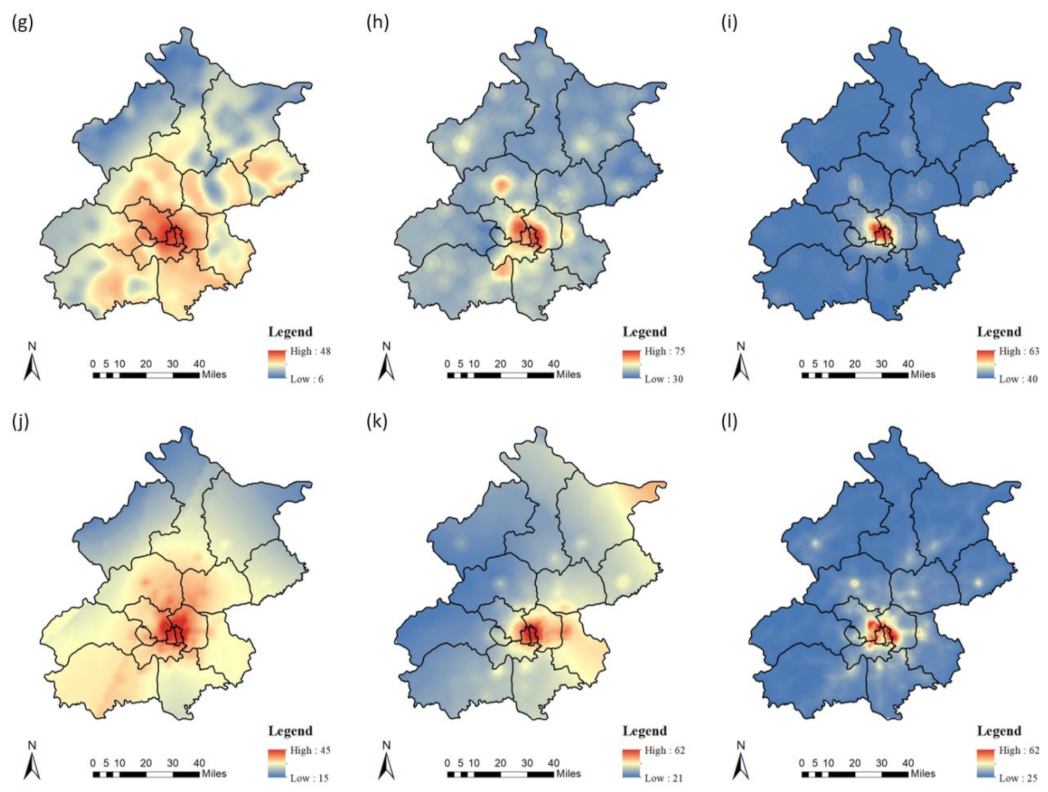
In terms of the time characteristics of POIs, it can be seen from the results that at 0:00 on summer working days and non-working days, the commercial and residential housing variables were included. This was due to the poor mobility of people in the urban area at this moment, and the crowd being concentrated near the residences. Hence, there will be some traffic source emissions. However, commercial residential areas contain a lot of commercial office buildings. In many high-tech industrial companies in Beijing, it is a normal phenomenon to work and commute after 0:00. For example, in areas such as Xierqi and Houchangcun in the Haidian District, the taxi rush often occurs after 0:00, and this is also a particular social phenomenon in China. It was also confirmed that on weekdays, commercial residence explained 41.2% of the PM
2.5 at that time, while on non-weekdays, the explanation was 39.8%. At 18:00 on summer working days, the commercial and residential variable explained 25.7% of the model. This was because people got off work during evening rush hour, and the traffic flow around business buildings and residential areas increased. In addition, there were many buses stops nearby, and this also caused pollutant increases. At 0:00 on working days and non-working days in winter, the POIs explained little of the model ranging from 5.8% to 14.3%. This was primarily because the higher background concentration of pollutants during winter is several times higher than the same time in summer. Compared with meteorological conditions, the POIs contributed a smaller proportion to the PM
2.5. Catering service POIs were also included in these models. Previous LUR models for Vancouver, Canada, and Europe have also considered the number of restaurants near the monitoring sites [
38,
52]. Like automobile exhaust, cooking fumes are also a major source of air pollution [
53]. The emission inventory performed by Jin et al. [
54] showed that in 2017, the catering industry in China released approximately 38.2 kt PM
2.5 and 47.8 kt PM
10. In this study, at 8:00 on non-working days in winter, the catering POIs explained 5.5% of the model. On non-weekdays, the passenger flow of various restaurants was more than weekdays, which also increased the emissions of restaurant lampblack. At other times during the non-working day, such as in shopping places, medical care and public facilities were also included in the model. This was because on holidays, people tend to go to these places, and many people will drive private cars or take a taxi, which cause large increases in traffic flow near these POIs and this explains the contribution of the above POIs to the entire model. For example, at 8:00 on non-working days in summer, medical care POIs explained 45.6% of the model, and public facilities POIs explained 11.6%. However, there were several types of POIs included in the model that had no obvious correlation with the places where people gather at that time. For example, at 18:00 on non-working days in summer, there should be few people in schools, but science and education POIs at that time explained 51% of the model. This is because Beijing’s super-large city characteristics lead to POI overlaps in the region. Many schools and educational institutions in Beijing are primarily located in urban areas. These POIs are not independent, and there will be other functional areas nearby, which make the pollutant source unclear. In conclusion, this study confirmed that POIs had a temporal attribute because various POIs show different attractions to the crowd.
Meteorological variables also had time attributes in the models. Meteorological conditions are the primary factors that affect the variability of pollutants with high time resolution. Studies have shown that meteorological conditions contribute greater than 70% of the daily average concentration of pollutants in China [
55]. In this study, nearly every model included meteorological variables. The relative humidity was included in all the winter models, and temperature and relative humidity were included in the summer models. Generally, except in the case of precipitation, the greater the relative humidity, the more particles attach to the water vapor, which increases the mass concentration. In the winter models, the relative humidity explained the PM
2.5 concentration between 54.9% and 86.7%, and all of them were positively correlated. The influence of air temperature on pollutants is complex and often plays a role in combination with wind speed, terrain, atmospheric junction, and other factors. The results of this model showed that temperature at 0:00 in summer was positively correlated with PM
2.5 concentration, which may have been due to air cooling at night, but land surface temperatures are higher, which makes it difficult for pollutants to diffuse. Statheropoulos et al. [
56] analyzed the air pollution factors in Athens, and the results showed that the pollutants had a significant relationship with relative humidity and wind speed. However, in many annual LUR models, meteorological variables are not included [
44,
57]. This may be due to the large temporal and spatial variability of meteorological conditions, and the impact on pollutants is more reflected at daily or hourly concentrations.
Road data also had a temporal attribute in these models. Theoretically, traffic load and vehicle density data may be significant indicators that reflect vehicle exhaust emissions during a short period of time. However, due to their complexity and unavailability, road lengths were used to represent the traffic emissions. Actually, this method has achieved good results in many studies [
17,
38,
58]. In this study, the road variables were divided into primary roads and secondary roads according to the width and vehicle capacity, and these two types of roads were all included in the models. The models containing this variable were all at 8:00 and 18:00, when the traffic flow was in the peak period and a large number of vehicle exhaust emissions become an important source of air pollutants. As can be seen from the results, the included variable buffers of the primary road were relatively large, 1500 m and 2500 m, while the buffer of the second road was only 300 m. The differences in the buffer radius reflected the characteristics of primary and secondary pollutant emissions. For the PM
2.5, both primary and secondary emissions can significantly increase its concentration [
59]. Different road types were reflected using their functions. The primary roads included urban expressways, national highways, and provincial highways, and they are mainly busy suburban roads. Due to various and complex types of motor vehicle emissions and high traffic densities, large buffer radii may be the result of the secondary discharge of pollutants. However, the secondary roads primarily included a wide distribution of roads, with a small flow of motor vehicles that resulted in a smaller possibility of pollutants spreading in a large area [
60]. Thus, they tended to affect the monitoring data in a small area.
Different from previous LUR studies, land, population, and elevation had little influence on the models in this study. This was because these models were based on the hourly time scale of PM
2.5 concentration, while predictors such as land use and population were more represented in annual or seasonal models. Son et al. [
61] improved the LUR models on an hourly time scale in Mexico, which primarily included temporal variables, such as hourly traffic density, meteorological, and holiday variables. Factors such as land use and population had no significant effect. This is consistent with the results of this study.
There currently exist few LUR studies based on hourly pollutant concentrations. In the short-term or more precise individual exposure studies, using annual or seasonal models may lead to deviations [
62]. The biggest breakthrough of this research was the realization of the hourly temporal LUR models, which provided a more accurate method for short-term exposure studies and more accurate micro-environment individual exposure studies. High-resolution simulation of regional pollutant concentrations is of great significance for travel prevention and control of residents. Currently in China, there are hourly concentration limits for pollutant emissions. In the future, there may be more precise timescale upgrades to healthy concentration standards. In addition, more pollution emission sources were identified within a short period of time, and this proved the temporal characteristics of the POIs in the models, which has significance for more accurate pollution prevention and control measures. Though we carried out LUR models for PM
2.5 and there still many researches focused on multiple pollutants, this study provides a new methodological perspective for other types of high-resolution pollutant models which is the most important significance.
However, this study still has some limitations. The best explanation of variability in the summer models was only 66.8%. Hence, there are other factors that remain to be explored during a short period of time. Second, only 35 monitoring data were used in this study, and some data were missing. Hoek et al. [
45] recommended using 40–80 pollutant monitoring stations. Additional modeling was performed at other times, but not each model could be successfully applied due to the models’ high time resolution and large pollutants variability. More accurate time variables are required to be explored to optimize the LUR models. Finally, due to the progressive linear regression principle of the LUR model itself, the model assumes a linear relationship between all predictive variables and pollutants, which is inherently limited for some variables. All of these problems require further study.









{kind=link}
{kind=link}
{kind=link}
{kind=link}