Compositional Data Analysis in Time-Use Epidemiology: What, Why, How

 , , and
, , and
Abstract
:1. Introduction: The Time-Use Epidemiology Framework
2. Time-Use Data Convey Relative Information
3. The Rationale and Methods of CoDA
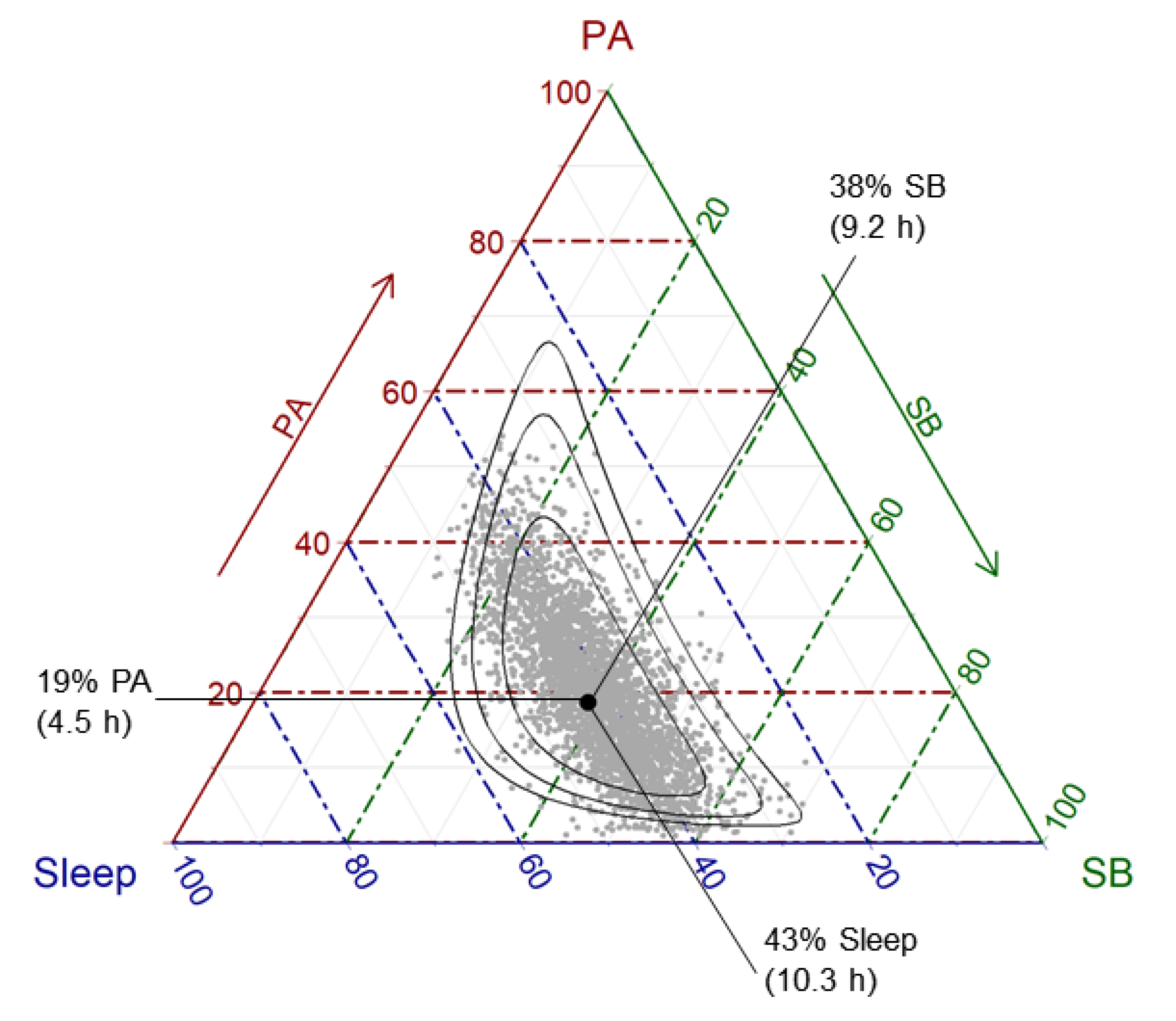
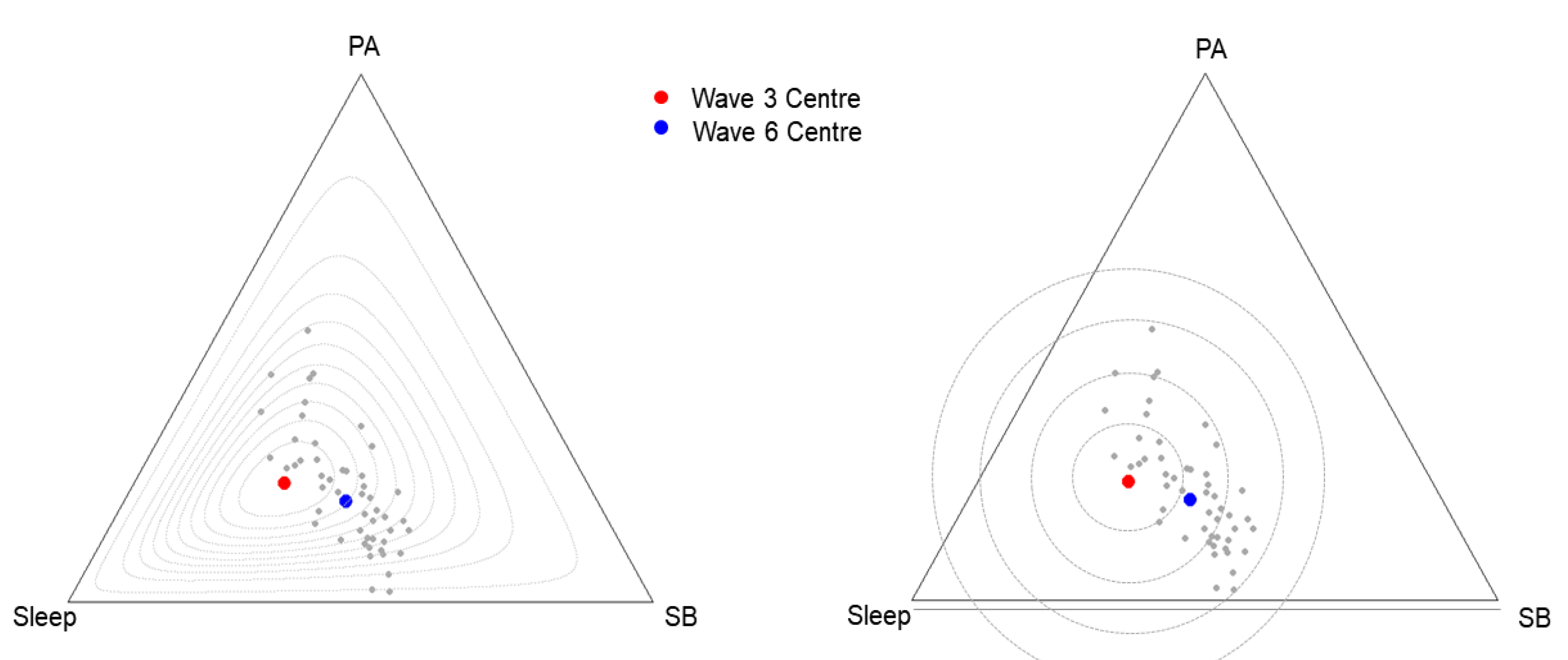
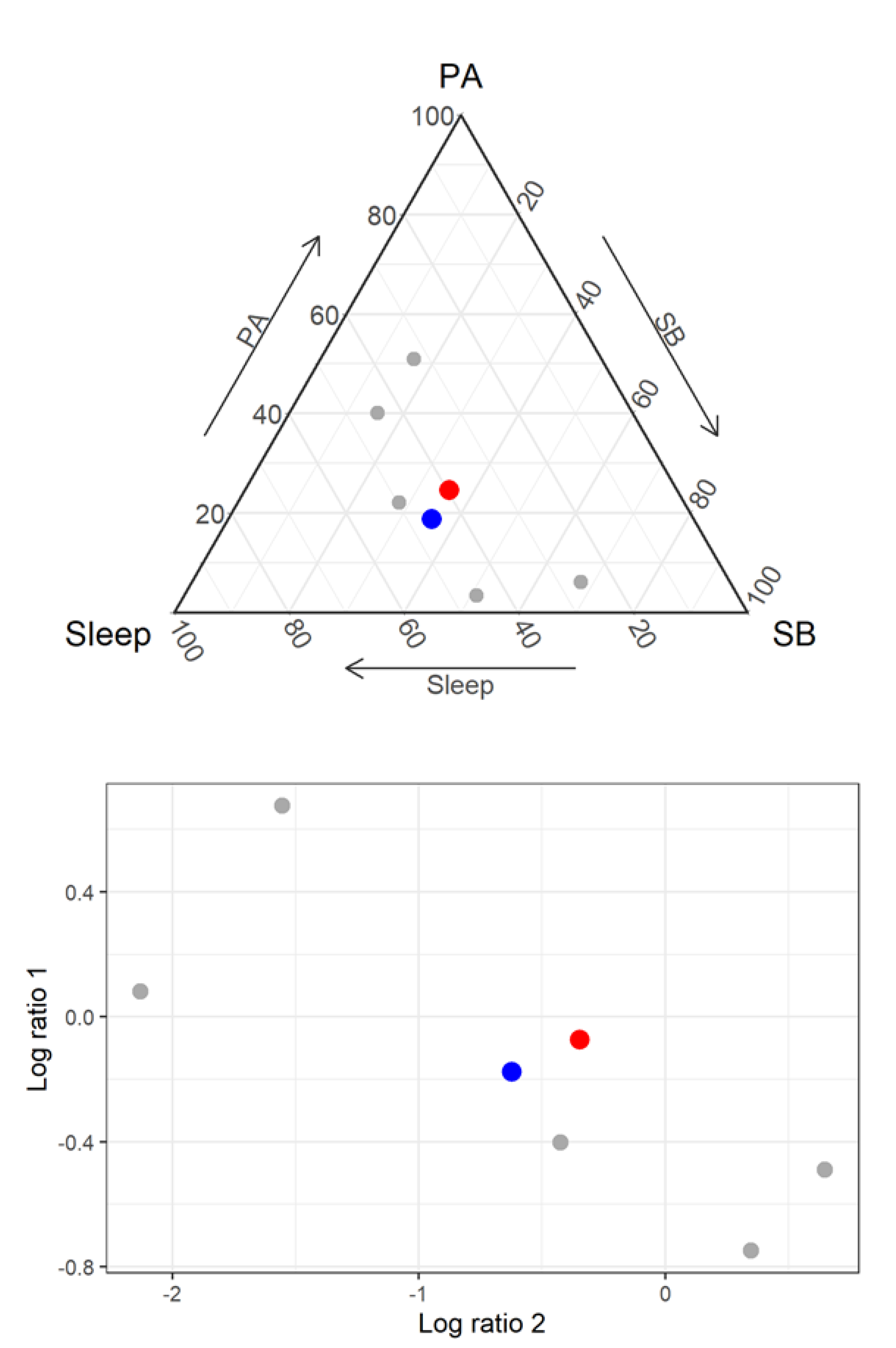
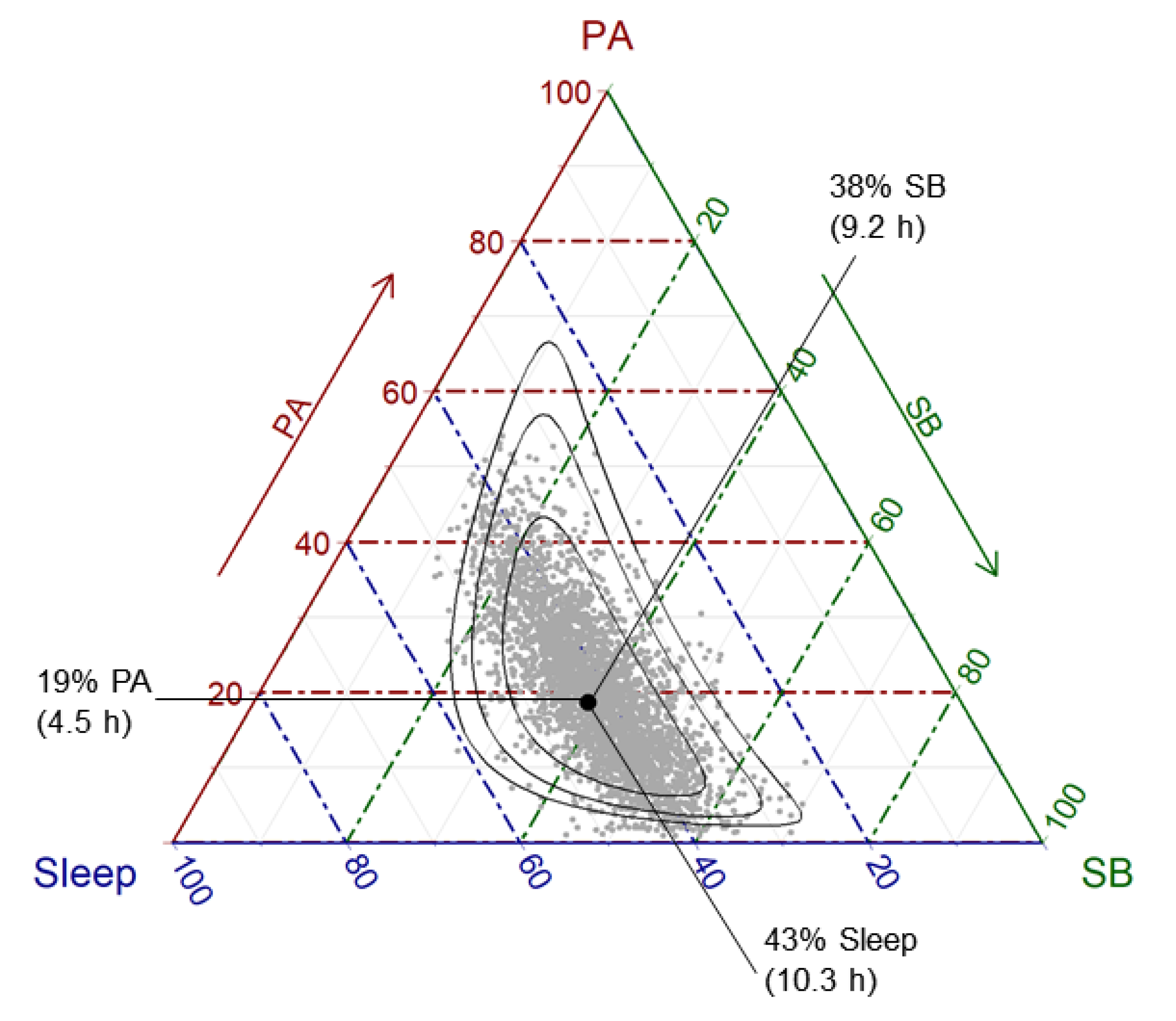
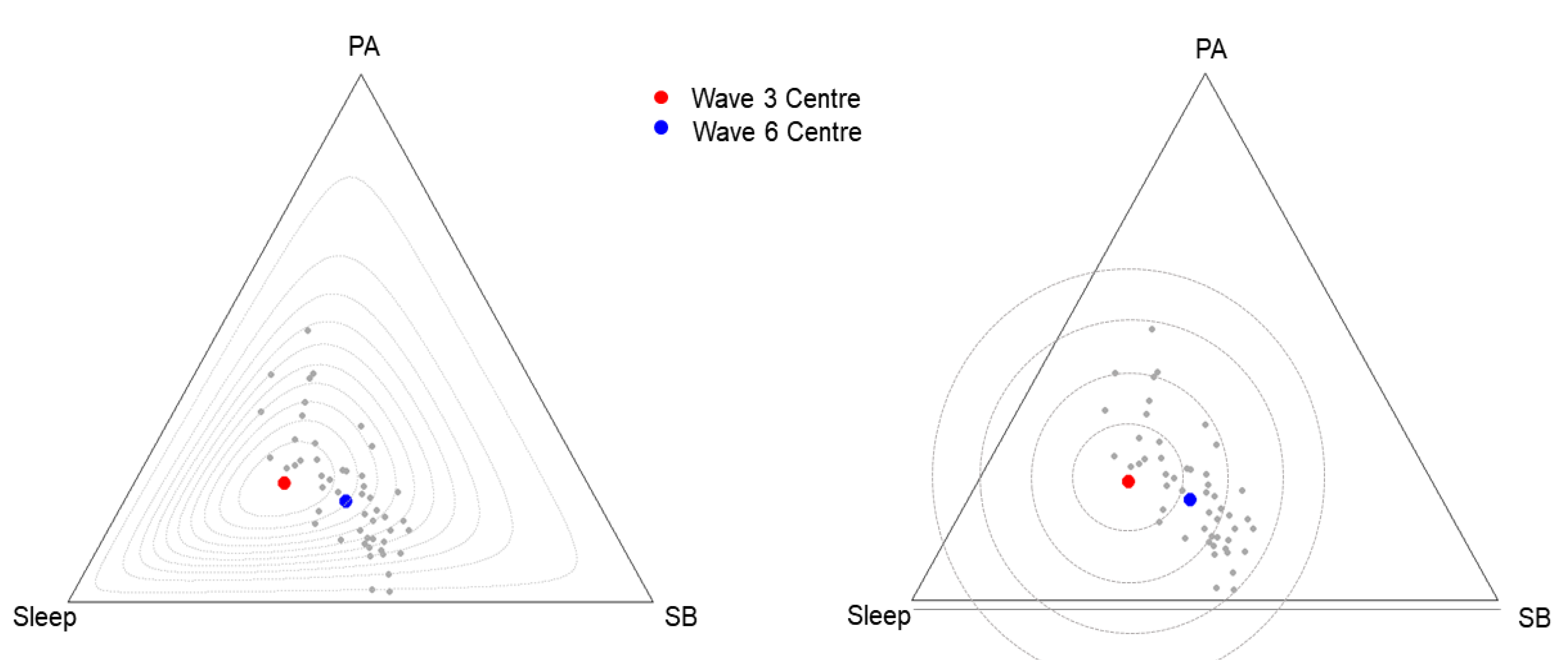
3.1. The Descriptive Analysis of Compositional Data
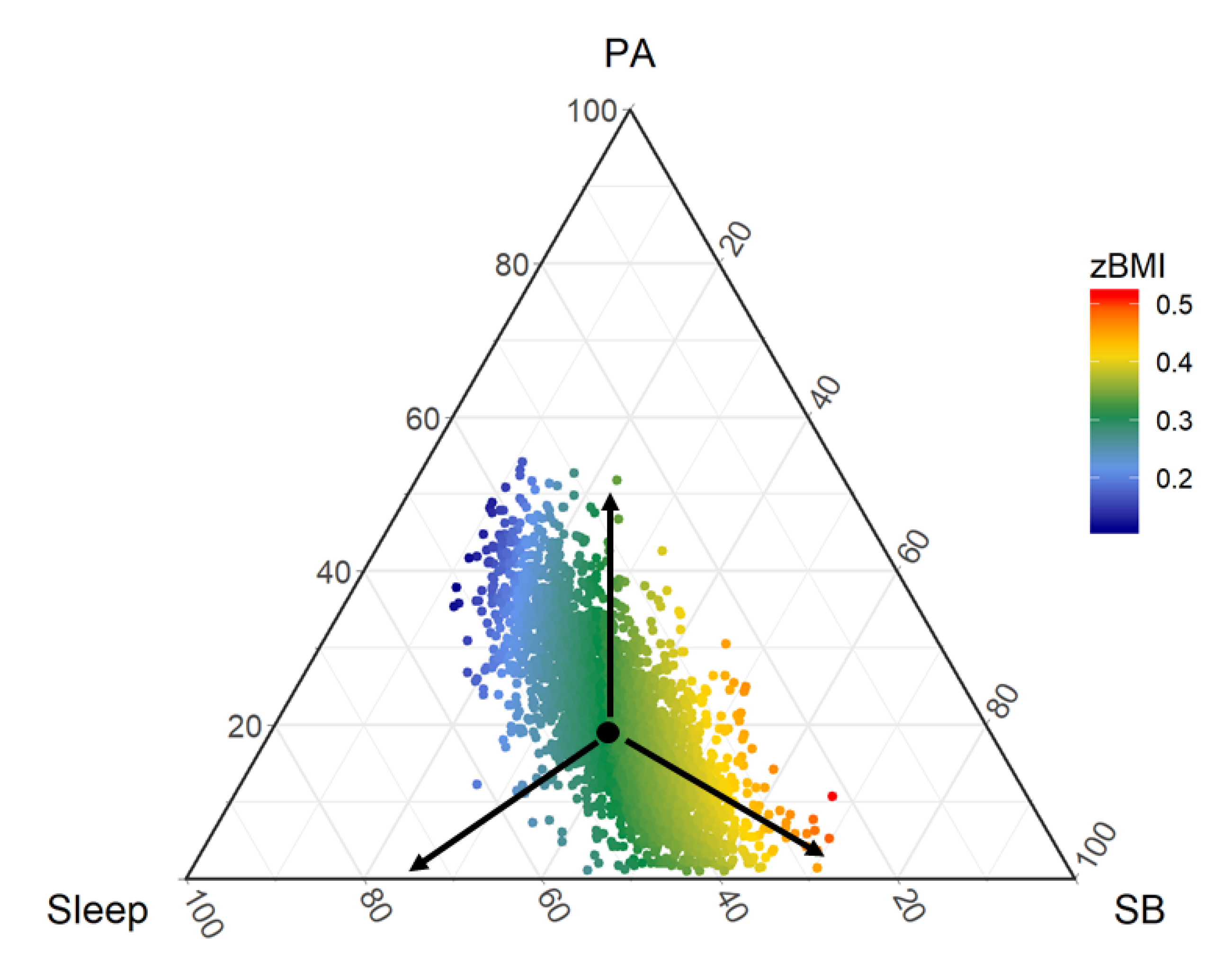
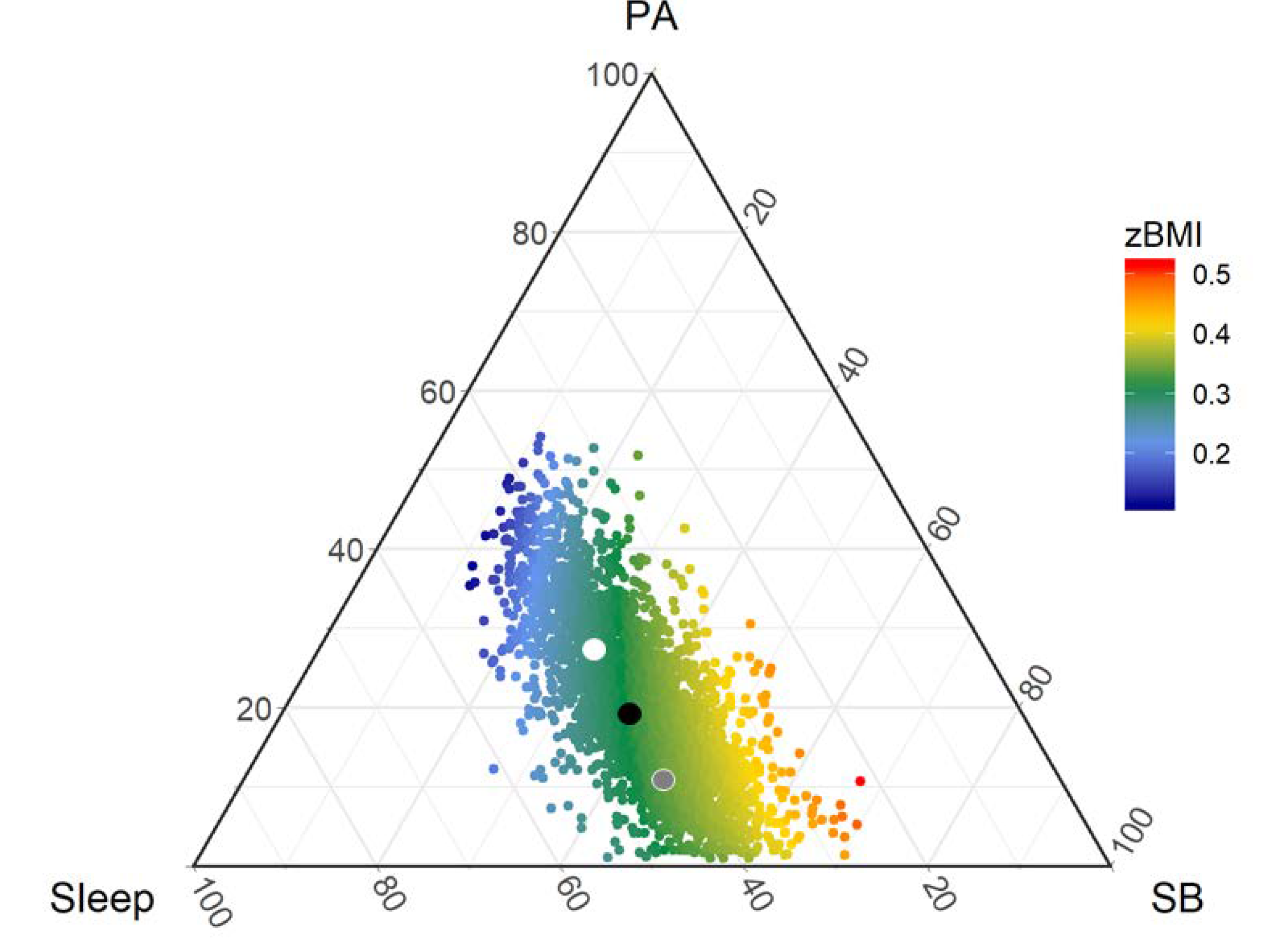
4. Understanding the Results of CoDA Studies
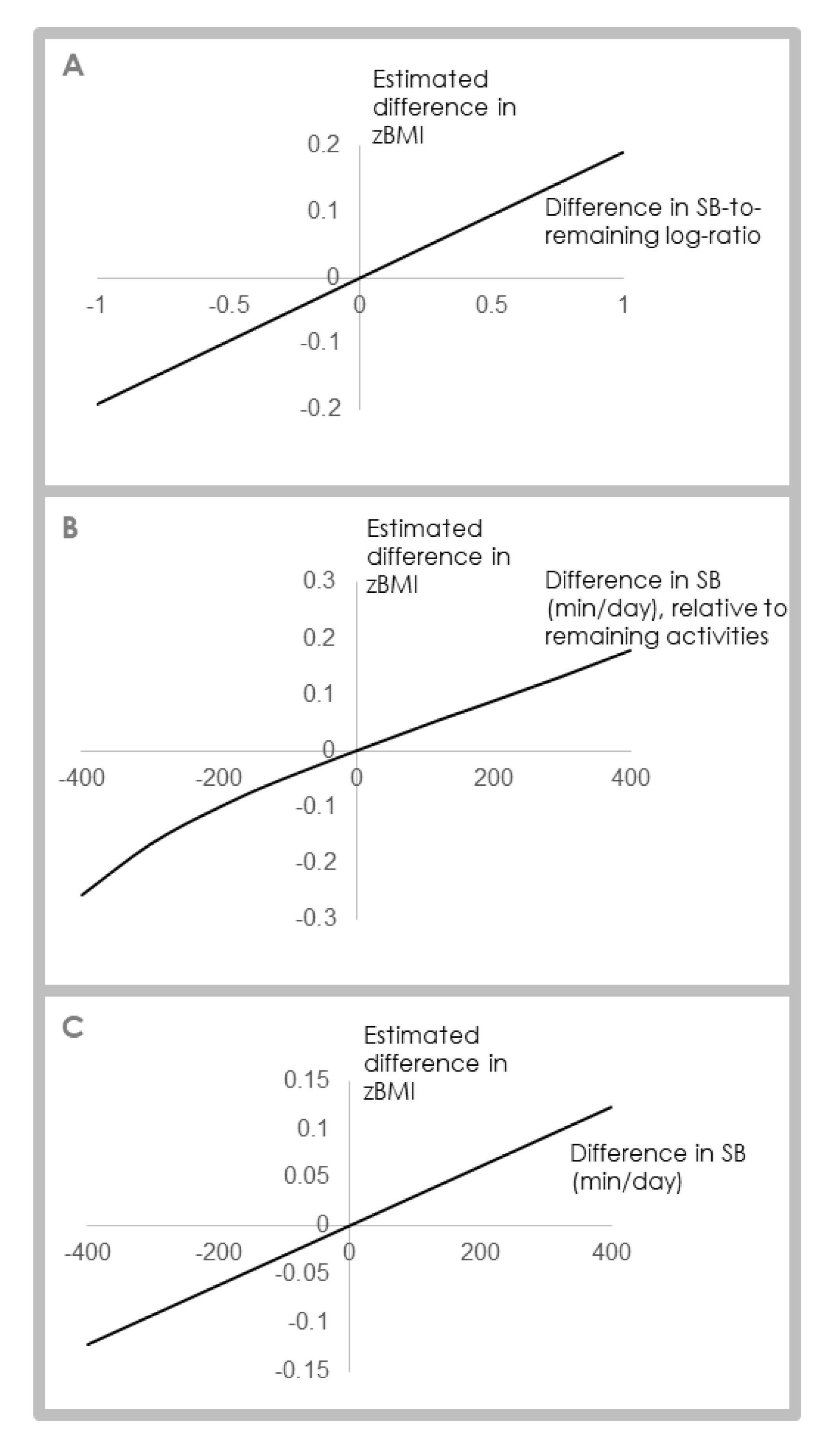
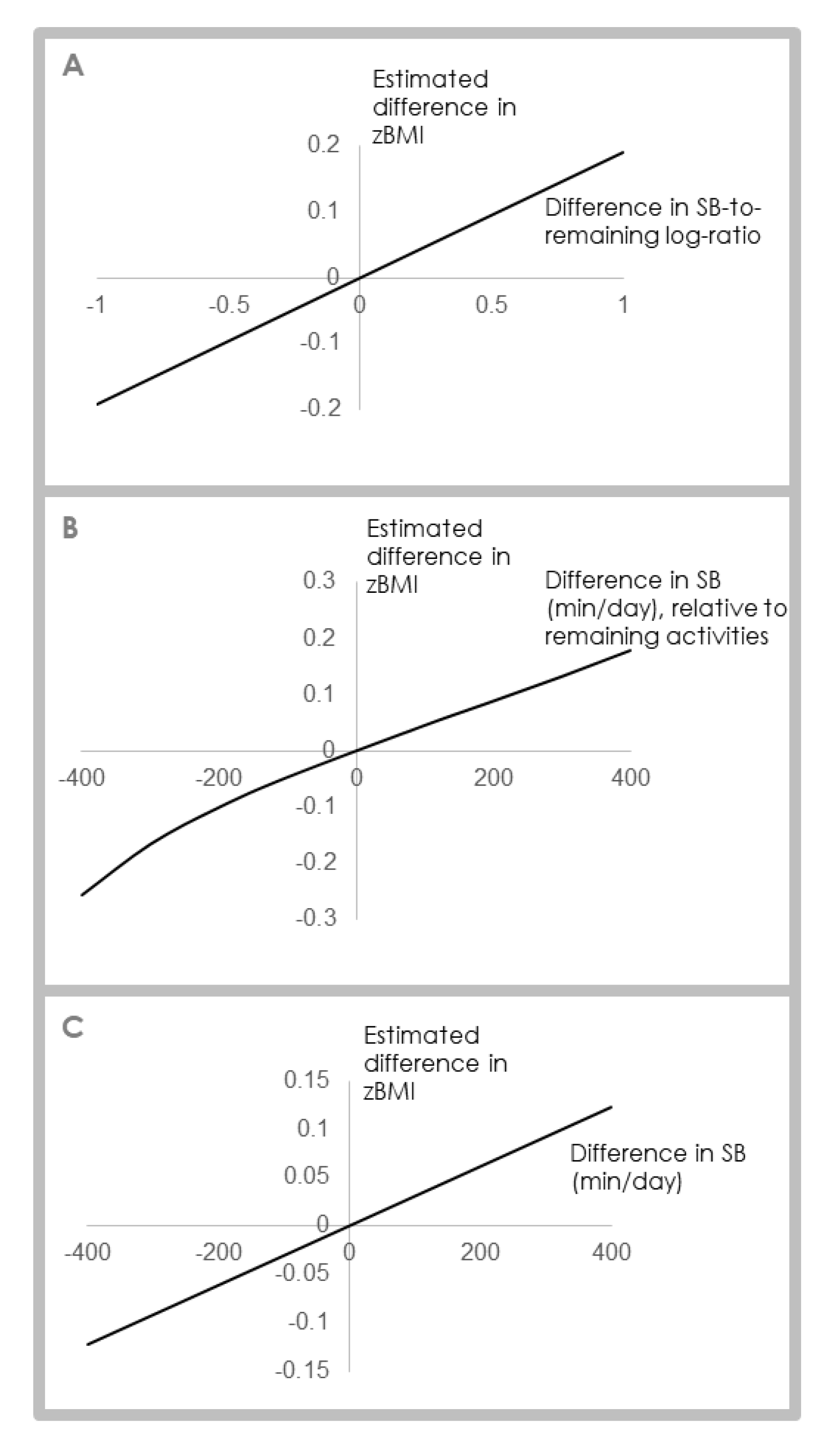
Compositional Regression Analysis
5. Challenges for CoDA
5.1. Zero Values
5.2. Multicollinearity
5.3. Non-Linearity
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Paffenbarger, R.S., Jr.; Blair, S.N.; Lee, I.-M. A history of physical activity, cardiovascular health and longevity: The scientific contributions of Jeremy N Morris, DSC, DPH, FRCP. Int. J. Epidemiol. 2001, 305, 1184–1192. [Google Scholar] [CrossRef] [PubMed]
- Shanahan, M.; Flaherty, B. Dynamic patterns of time use in adolescence. Child Develpoment 2001, 722, 385–401. [Google Scholar] [CrossRef] [PubMed]
- Chastin, S.F.; Palarea-Albaladejo, J.; Dontje, M.L.; Skelton, D.A. Combined effects of time spent in physical activity, sedentary behaviors and sleep on obesity and cardio-metabolic health markers: A novel compositional data analysis approach. PLoS ONE 2015, 1010, e0139984. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pedišić, Ž. Measurement issues and poor adjustments for physical activity and sleep undermine sedentary behaviour research—the focus should shift to the balance between sleep, sedentary behaviour, standing and activity. Kinesiology 2014, 461, 135–146. [Google Scholar]
- Pedišić, Ž.; Dumuid, D.; Olds, T. Integrating sleep, sedentary behaviour, and physical activity research in the emerging field of time-use epidemiology: Definitions, concepts, statistical methods, theoretical framework, and future directions. Kinesiology 2017, 492, 252–269. [Google Scholar]
- Matricciani, L.; Bin, Y.S.; Lallukka, T.; Kronholm, E.; Wake, M.; Paquet, C.; Dumuid, D.; Olds, T. Rethinking the sleep-health link. Sleep Health 2018, 44, 339–348. [Google Scholar] [CrossRef]
- Mellow, M.L.; Dumuid, D.; Thacker, J.S.; Dorrian, J.; Smith, A.E. Building your best day for healthy brain aging–the neuroprotective effects of optimal time use. Maturitas 2019, 125, 33–40. [Google Scholar] [CrossRef]
- Rosenberger, M.E.; Fulton, J.E.; Buman, M.P.; Troiano, R.P.; Grandner, M.A.; Buchner, D.M.; Haskell, W.L. The 24-hour activity cycle: A new paradigm for physical activity. Med. Sci. Sports Exerc. 2019, 513, 454–464. [Google Scholar] [CrossRef]
- Tremblay, M.S. Introducing 24-h movement guidelines for the early years: A new paradigm gaining momentum. J. Phys. Act. Health 2020, 17, 92–95. [Google Scholar] [CrossRef]
- Tremblay, M.S.; Carson, V.; Chaput, J.-P.; Connor Gorber, S.; Dinh, T.; Duggan, M.; Faulkner, G.; Gray, C.E.; Gruber, R.; Janson, K. Canadian 24-hour movement guidelines for children and youth: An integration of physical activity, sedentary behaviour, and sleep. Appl. Physiol. Nutr. Metab. 2016, 416, S311–S327. [Google Scholar] [CrossRef]
- Okely, A.D.; Ghersi, D.; Hesketh, K.D.; Santos, R.; Loughran, S.P.; Cliff, D.P.; Shilton, T.; Grant, D.; Jones, R.A.; Stanley, R.M. A collaborative approach to adopting/adapting guidelines-the australian 24-hour movement guidelines for the early years (birth to 5 years): An integration of physical activity, sedentary behavior, and sleep. Bmc Public Health 2017, 175, 869. [Google Scholar] [CrossRef] [PubMed]
- New Zealand Ministry of Health. Sit Less, Move More, Sleep Well: Physical Activity Guidelines for Children and Young People. Available online: http://www.health.govt.nz/system/files/documents/pages/physical-activity-guidelines-for-children-and-young-people-may17.pdf (accessed on 26 January 2020).
- DST-NRF Centre of Excellence in Human Development and Laureus “Sport for good”. South African 24-Hour Movement Guidelines for Birth to Five Years: An Integration of Physical Activity, Sitting Behaviour, Screen Time and Sleep; DST-NRF Centre of Excellence in Human Development and Laureus: Cape Town, South Africa, 2018. [Google Scholar]
- UKK Institute for Health Promotion Research. Aikuisten liikkumisen suositus [Movement Recommendations for Adults]. Available online: https://www.ukkinstituutti.fi/liikkumisensuositus/aikuisten-liikkumisen-suositus (accessed on 28 January 2020).
- Jurakic, D.; Pedišić, Ž. Croatian 24-hour guidelines for physical activity, sedentary behaviour, and sleep: A proposal based on a systematic review of literature. Medicus 2019, 282, 143–153. [Google Scholar]
- World Health Organization. Guidelines on Physical Activity, Sedentary Behaviour and Sleep for Children under 5 Years of Age; World Health Organization: Geneva, Switzerland, 2019. [Google Scholar]
- O’Hara, B.J.; Grunseit, A.; Phongsavan, P.; Bellew, W.; Briggs, M.; Bauman, A.E. Impact of the swap it, don’t stop it australian national mass media campaign on promoting small changes to lifestyle behaviors. J. Health Commun. 2016, 2112, 1276–1285. [Google Scholar] [CrossRef] [PubMed]
- Saunders, T.J.; Gray, C.E.; Poitras, V.J.; Chaput, J.-P.; Janssen, I.; Katzmarzyk, P.T.; Olds, T.; Connor Gorber, S.; Kho, M.E.; Sampson, M. Combinations of physical activity, sedentary behaviour and sleep: Relationships with health indicators in school-aged children and youth. Appl. Physiol. Nutr. Metab. 2016, 416, S283–S293. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsiros, M.D.; Samaras, M.G.; Coates, A.M.; Olds, T. Use-of-time and health-related quality of life in 10-to 13-year-old children: Not all screen time or physical activity minutes are the same. Qual. Life Res. 2017, 2611, 3119–3129. [Google Scholar] [CrossRef] [PubMed]
- Aadland, E.; Kvalheim, O.M.; Anderssen, S.A.; Resaland, G.K.; Andersen, L.B. The multivariate physical activity signature associated with metabolic health in children. Int. J. Behav. Nutr. Phys. Act. 2018, 151, 77. [Google Scholar] [CrossRef]
- Mekary, R.A.; Willett, W.C.; Hu, F.B.; Ding, E.L. Isotemporal substitution paradigm for physical activity epidemiology and weight change. Am. J. Epidemiol. 2009, 1704, 519–527. [Google Scholar] [CrossRef] [Green Version]
- Buman, M.; Winkler, E.; Kurka, J.; Hekler, E.; Baldwin, C.; Owen, N.; Ainsworth, B.; Healy, G.; Gardiner, P. Reallocating time to sleep, sedentary behaviors, or active behaviors: Associations with cardiovascular disease risk biomarkers, nhanes 2005–2006. Am. J. Epidemiol. 2014, 1793, 323–334. [Google Scholar] [CrossRef]
- Augustin, N.H.; Mattocks, C.; Faraway, J.J.; Greven, S.; Ness, A.R. Modelling a response as a function of high-frequency count data: The association between physical activity and fat mass. Stat. Methods Med. Res. 2017, 265, 2210–2226. [Google Scholar] [CrossRef] [Green Version]
- Kokoszka, P.; Reimherr, M. Introduction to Functional Data Analysis; Chapman and Hall/CRC: Boca Raton, FL, USA, 2017. [Google Scholar]
- Aitchison, J. The statistical analysis of compositional data. J. R. Stat. Soc. Ser. B 1982, 44, 139–160. [Google Scholar] [CrossRef]
- Gloor, G.; Reimann, C. Compositional analysis: A valid approach to analyze microbiome high-throughput sequencing data. Can. J. Microbiol. 2016, 62, 692–703. [Google Scholar] [CrossRef] [PubMed]
- Fernandes, A.; Reid, J.; Macklaim, J.; McMurrough, T.; Edgell, D.; Gloor, G. Unifying the analysis of high-throughput sequencing datasets: Characterizing RNA-seq, 16S rRNA gene sequencing and selective growth experiments by compositional data analysis. Microbiome 2014, 15, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aitchison, J. The Statistical Analysis of Compositional Data; Chapman & Hall: London, UK, 1986; Reprinted in 2003 by Blackburn Press; p. 416. [Google Scholar]
- Corey, J.; Gallagher, J.; Davis, E.; Marquardt, M. The Times of Their Lives: Collecting Time Use Data from Children in the Longitudinal Study of Australian Children (LSAC). Technical Paper 13; Australian Bureau of Statistics: Canberra, Australia, 2014. [Google Scholar]
- Soloff, C.; Lawrence, D.; Johnstone, R. LSAC Technical Paper No. 1. Available online: https://growingupinaustralia.gov.au/sites/default/files/tp1.pdf (accessed on 10 February 2020).
- Mateu-Figueras, G.; Pawlowsky-Glahn, V.; Egozcue, J. The normal distribution in some constrained sample spaces. Sort-Stat. Oper. Res. Trans. 2013, 371, 29–56. [Google Scholar]
- Pawlowsky-Glahn, V.; Egozcue, J. Blu estimators and compositional data. Math. Geol. 2002, 343, 259–274. [Google Scholar] [CrossRef]
- Mateu-Figueras, G.; Pawlowsky-Glahn, V.; Egozcue, J.J. The principle of working on coordinates. In Compositional Data Analysis: Theory and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2011; pp. 29–42. [Google Scholar]
- Dumuid, D.; Pedišić, Ž.; Stanford, T.E.; Martín-Fernández, J.-A.; Hron, K.; Maher, C.A.; Lewis, L.K.; Olds, T. The compositional isotemporal substitution model: A method for estimating changes in a health outcome for reallocation of time between sleep, physical activity and sedentary behaviour. Stat. Methods Med. Res. 2019, 283, 846–857. [Google Scholar] [CrossRef] [PubMed]
- Dumuid, D.; Stanford, T.E.; Martín-Fernández, J.; Pedišić, Ž.; Maher, C.A.; Lewis, L.K.; Hron, K.; Katzmarzyk, P.T.; Chaput, J.-P.; Fogelholm, M. Compositional data analysis for physical activity, sedentary time and sleep research. Stat. Methods Med. Res. 2018, 2712, 3726–3738. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Egozcue, J.J.; Pawlowsky-Glahn, V. Groups of parts and their balances in compositional data analysis. Math. Geol. 2005, 377, 795–828. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing. Available online: https://www.R-project.org/ (accessed on 20 March 2020).
- Van den Boogaart, K.G.; Tolosana-Delgado, R. “Compositions”: A unified r package to analyze compositional data. Comput. Geosci. 2008, 344, 320–338. [Google Scholar] [CrossRef]
- Templ, M.; Hron, K.; Filzmoser, P. Robcompositions: An r-package for robust statistical analysis of compositional data. In Compositional Data Analysis: Theory and Applications; Pawlowsky-Glahn, V., Buccianti, A., Eds.; John Wiley & Sons Ltd.: Hoboken, NJ, USA, 2011. [Google Scholar]
- Palarea-Albaladejo, J.; Martín-Fernández, J. Zcompositions—R package for multivariate imputation of left-censored data under a compositional approach. Chemom. Intell. Lab. Syst. 2015, 143, 85–96. [Google Scholar] [CrossRef]
- Comas-Cufí, M.; Thió-Henestrosa, S. CoDaPack 2.0: A stand-alone, multi-platform compositional software. In CoDAWork’11: 4th International Workshop on Compositional Data Analysis, Sant Feliu De Guíxols; Egozcue, J.J., Tolosana-Delgado, R., Ortego, M.I., Eds.; CoDAWork’11: Girona, Spain, 2011; Available online: http://ima.udg.edu/codapack/ (accessed on 20 February 2020).
- International Network of Time-Use Epidemiologists. Publications. Available online: https://www.intue.org/publications/ (accessed on 20 February 2020).
- Hunt, T.; Williams, M.; Olds, T.; Dumuid, D. Patterns of time use across the chronic obstructive pulmonary disease severity spectrum. Int. J. Environ. Res. Public Health 2018, 153, 533. [Google Scholar] [CrossRef] [Green Version]
- Foley, L.; Dumuid, D.; Atkin, A.J.; Olds, T.; Ogilvie, D. Patterns of health behaviour associated with active travel: A compositional data analysis. Int. J. Behav. Nutr. Phys. Act. 2018, 15, 26. [Google Scholar] [CrossRef] [PubMed]
- Foley, L.; Dumuid, D.; Atkin, A.J.; Wijndaele, K.; Ogilvie, D.; Olds, T. Cross-sectional and longitudinal associations between active commuting and patterns of movement behaviour during discretionary time: A compositional data analysis. PLoS ONE 2019, 141, e0216650. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Egozcue, J.J.; Pawlowsky-Glahn, V.; Mateu-Figueras, G.; Barcelo-Vidal, C. Isometric Logratio Transformations for Compositional Data Analysis. Math. Geol. 2003, 353, 279–300. [Google Scholar] [CrossRef]
- McGregor, D.; Palarea-Albaladejo, J.; Dall, P.; Hron, K.; Chastin, S. Cox regression survival analysis with compositional covariates: Application to modelling mortality risk from 24-h physical activity patterns. Stat. Methods Med Res. 2019, 0962280219864125. [Google Scholar] [CrossRef]
- Hron, K.; Filzmoser, P.; Thompson, K. Linear regression with compositional explanatory variables. J. Appl. Stat. 2012, 395, 1115–1128. [Google Scholar] [CrossRef]
- McGregor, D.; Carson, V.; Palarea-Albaladejo, J.; Dall, P.; Tremblay, M.; Chastin, S. Compositional analysis of the associations between 24-h movement behaviours and health indicators among adults and older adults from the canadian health measure survey. Int. J. Environ. Res. Public Health 2018, 15, 1779. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rodríguez-Gómez, I.; Mañas, A.; Losa-Reyna, J.; Rodríguez-Mañas, L.; Chastin, S.F.; Alegre, L.M.; García-García, F.J.; Ara, I. Compositional influence of movement behaviours on bone health during ageing. Med. Sci. Sports Exerc. 2019, 518, 1736–1744. [Google Scholar] [CrossRef]
- Dumuid, D.; Lewis, L.; Olds, T.; Maher, C.; Bondarenko, C.; Norton, L. Relationships between older adults’ use of time and cardio-respiratory fitness, obesity and cardio-metabolic risk: A compositional isotemporal substitution analysis. Maturitas 2018, 110, 104–110. [Google Scholar] [CrossRef]
- Carson, V.; Tremblay, M.S.; Chastin, S.F. Cross-sectional associations between sleep duration, sedentary time, physical activity, and adiposity indicators among canadian preschool-aged children using compositional analyses. BMC Public Health 2017, 175, 848. [Google Scholar] [CrossRef] [Green Version]
- Dumuid, D.; Wake, M.; Clifford, S.; Burgner, D.; Carlin, J.B.; Mensah, F.K.; Fraysse, F.; Lycett, K.; Baur, L.; Olds, T. The association of the body composition of children with 24-hour activity composition. J. Pediatrics 2019, 208, 43–49. [Google Scholar] [CrossRef]
- Grgic, J.; Dumuid, D.; Bengoechea, E.G.; Shrestha, N.; Bauman, A.; Olds, T.; Pedisic, Z. Health outcomes associated with reallocations of time between sleep, sedentary behaviour, and physical activity: A systematic scoping review of isotemporal substitution studies. Int. J. Behav. Nutr. Phys. Act. 2018, 151, 69. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carson, V.; Tremblay, M.S.; Chaput, J.-P.; Chastin, S.F. Associations between sleep duration, sedentary time, physical activity, and health indicators among canadian children and youth using compositional analyses. Appl. Physiol. Nutr. Metab. 2016, 416, S294–S302. [Google Scholar] [CrossRef] [Green Version]
- Talarico, R.; Janssen, I. Compositional associations of time spent in sleep, sedentary behavior and physical activity with obesity measures in children. Int. J. Obes. 2018, 428, 1508–1514. [Google Scholar] [CrossRef] [PubMed]
- Powell, C.; Browne, L.D.; Carson, B.P.; Dowd, K.P.; Perry, I.J.; Kearney, P.M.; Harrington, J.M.; Donnelly, A.E. Use of compositional data analysis to show estimated changes in cardiometabolic health by reallocating time to light-intensity physical activity in older adults. Sports Med. 2019, 501, 205–217. [Google Scholar] [CrossRef] [PubMed]
- Carson, V.; Tremblay, M.S.; Chaput, J.-P.; McGregor, D.; Chastin, S. Compositional analyses of the associations between sedentary time, different intensities of physical activity, and cardiometabolic biomarkers among children and youth from the united states. PLoS ONE 2019, 147, e0220009. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gupta, N.; Dumuid, D.; Korshøj, M.; Jørgensen, M.B.; Søgaard, K.; Holtermann, A. Is daily composition of movement behaviors related to blood pressure in working adults? Med. Sci. Sports Exerc. 2018, 5010, 2150–2155. [Google Scholar] [CrossRef] [PubMed]
- Aadland, E.; Kvalheim, O.M.; Anderssen, S.A.; Resaland, G.K.; Andersen, L.B. Multicollinear physical activity accelerometry data and associations to cardiometabolic health: Challenges, pitfalls, and potential solutions. Int. J. Behav. Nutr. Phys. Act. 2019, 161, 74. [Google Scholar] [CrossRef] [PubMed]
- McGregor, D.E.; Palarea-Albaladejo, J.; Dall, P.M.; del Pozo Cruz, B.; Chastin, S.F. Compositional analysis of the association between mortality and 24-hour movement behaviour from nhanes. Eur. J. Prev. Cardiol. 2019, 2047487319867783. [Google Scholar] [CrossRef] [Green Version]
- Martín-Fernández, J.; Thió-Henestrosa, S. Rounded zeros: Some practical aspects for compositional data. Geol. Soc. Lond. Spec. Publ. 2006, 2641, 191–201. [Google Scholar] [CrossRef]
- Martín-Fernández, J.A.; Barceló-Vidal, C.; Pawlowsky-Glahn, V. Dealing with zeros and missing values in compositional data sets using nonparametric imputation. Math. Geol. 2003, 353, 253–278. [Google Scholar] [CrossRef]
- Martín-Fernández, J.-A.; Hron, K.; Templ, M.; Filzmoser, P.; Palarea-Albaladejo, J. Bayesian-multiplicative treatment of count zeros in compositional data sets. Stat. Model. 2015, 152, 134–158. [Google Scholar] [CrossRef]
- Palarea-Albaladejo, J.; Martín-Fernández, J.A.; Gómez-García, J. A parametric approach for dealing with compositional rounded zeros. Math. Geol. 2007, 397, 625–645. [Google Scholar] [CrossRef]
- Martín-Fernández, J.; Palarea-Albaladejo, J.; Olea, R. Dealing with zeros. In Compositional Data Analysis: Theory and Applications; Pawlowsky-Glahm, V., Buccianti, A., Eds.; Wiley: Chicester, UK, 2011. [Google Scholar]
- Templ, M.; Hron, K.; Filzmoser, P. Exploratory tools for outlier detection in compositional data with structural zeros. J. Appl. Stat. 2017, 444, 734–752. [Google Scholar] [CrossRef]
- Kynčlová, P.; Hron, K.; Filzmoser, P. Correlation between compositional parts based on symmetric balances. Math. Geosci. 2017, 496, 777–796. [Google Scholar] [CrossRef] [Green Version]
- Filzmoser, P.; Hron, K. Correlation analysis for compositional data. Math. Geosci. 2009, 41, 905. [Google Scholar] [CrossRef]
- Alin, A. Multicollinearity. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 370–374. [Google Scholar] [CrossRef]
- Wang, H.; Meng, J.; Tenenhaus, M. Regression modelling analysis on compositional data. In Handbook of Partial Least Squares. Springer Handbooks of Computational Statistics; Esposito Vinzi, V., Chin, W., Henseler, J., Wang, H., Eds.; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Hinkle, J.; Rayens, W. Partial least squares and compositional data: Problems and alternatives. Chemom. Intell. Lab. Syst. 1995, 20, 159–172. [Google Scholar] [CrossRef]
- Harrell, F. Regression Modeling Strategies, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Ridley, K.; Olds, T.; Hill, A. The Multimedia Activity Recall for Children and Adolescents (MARCA): Development and evaluation. Int. J. Behav. Nutr. Phys. Act. 2006, 3, 10. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean Variation of the Pairwise Logratio | Center | ||||
|---|---|---|---|---|---|
| Sleep | SB | PA | (min/d) | ||
| Numerator of logratio | Sleep | 0.13 | 0.39 | 617.5 | |
| SB | −0.11 | 0.78 | 553.1 | ||
| PA | −0.83 | −0.72 | 269.4 | ||
| Mean of the pairwise logratio | |||||
| Pivot | Estimate | SE | t | p |
|---|---|---|---|---|
| Sleep vs Remaining | −0.21 | 0.11 | −1.96 | 0.045 |
| SB vs Remaining | 0.19 | 0.07 | 2.56 | 0.010 |
| PA vs Remaining | 0.02 | 0.05 | 0.37 | 0.708 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dumuid, D.; Pedišić, Ž.; Palarea-Albaladejo, J.; Martín-Fernández, J.A.; Hron, K.; Olds, T. Compositional Data Analysis in Time-Use Epidemiology: What, Why, How. Int. J. Environ. Res. Public Health 2020, 17, 2220. https://doi.org/10.3390/ijerph17072220
Dumuid D, Pedišić Ž, Palarea-Albaladejo J, Martín-Fernández JA, Hron K, Olds T. Compositional Data Analysis in Time-Use Epidemiology: What, Why, How. International Journal of Environmental Research and Public Health. 2020; 17(7):2220. https://doi.org/10.3390/ijerph17072220
Chicago/Turabian StyleDumuid, Dorothea, Željko Pedišić, Javier Palarea-Albaladejo, Josep Antoni Martín-Fernández, Karel Hron, and Timothy Olds. 2020. "Compositional Data Analysis in Time-Use Epidemiology: What, Why, How" International Journal of Environmental Research and Public Health 17, no. 7: 2220. https://doi.org/10.3390/ijerph17072220
APA StyleDumuid, D., Pedišić, Ž., Palarea-Albaladejo, J., Martín-Fernández, J. A., Hron, K., & Olds, T. (2020). Compositional Data Analysis in Time-Use Epidemiology: What, Why, How. International Journal of Environmental Research and Public Health, 17(7), 2220. https://doi.org/10.3390/ijerph17072220