Modelling of Urban Air Pollutant Concentrations with Artificial Neural Networks Using Novel Input Variables


Abstract
1. Introduction
2. Materials and Methods
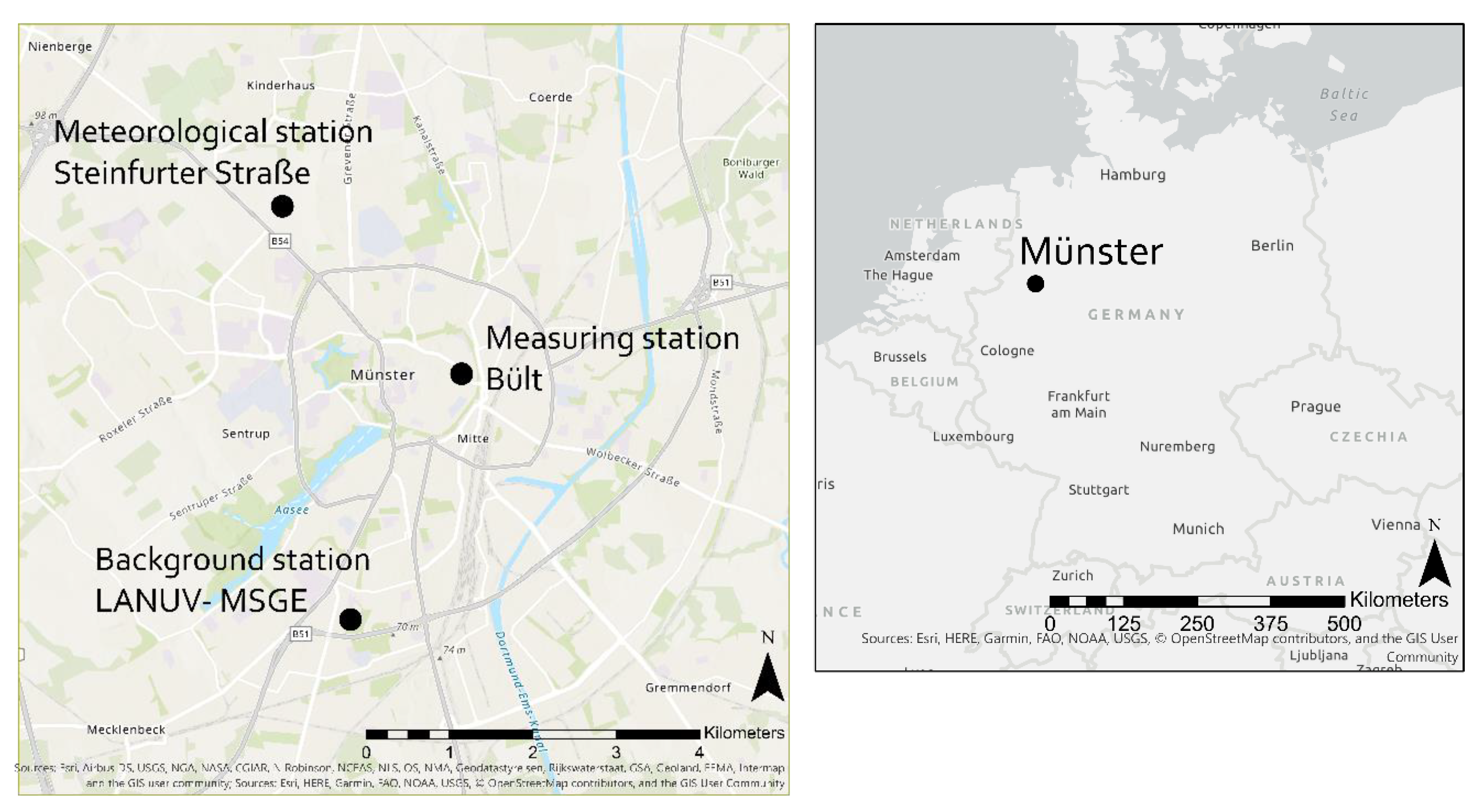
2.1. Site Description
2.2. Data Measurement and Processing
2.2.1. Meteorological Data
2.2.2. Pollutants
2.2.3. Background Data
2.2.4. Acoustics
2.2.5. Traffic
2.2.6. Time
2.2.7. Data Processing
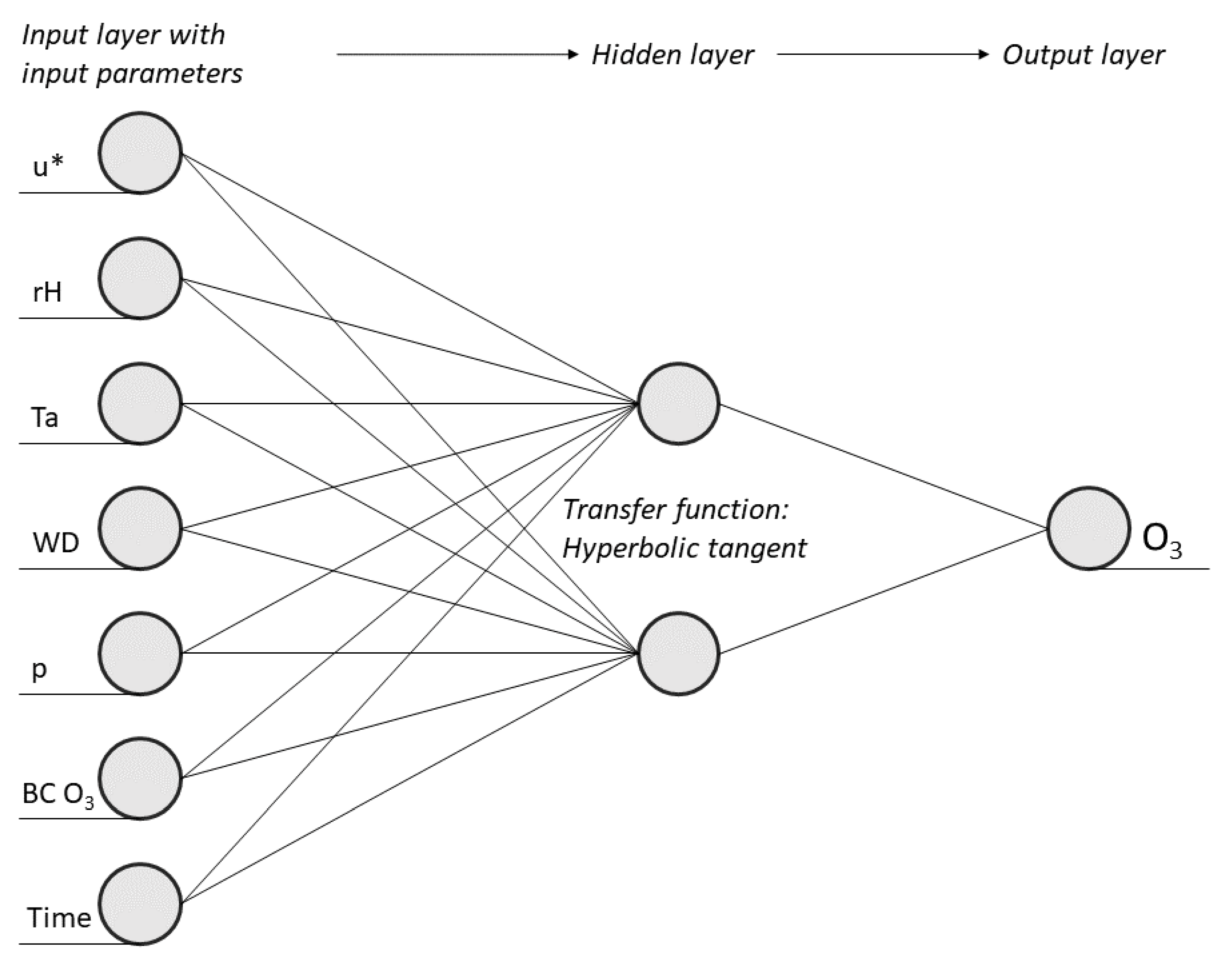
2.3. Multilayer Perceptron
2.3.1. Input Variable Selection
2.3.2. SOM-Based Stratified Data Splitting
2.3.3. Model Structure Development
2.4. Analysis of Model Performance
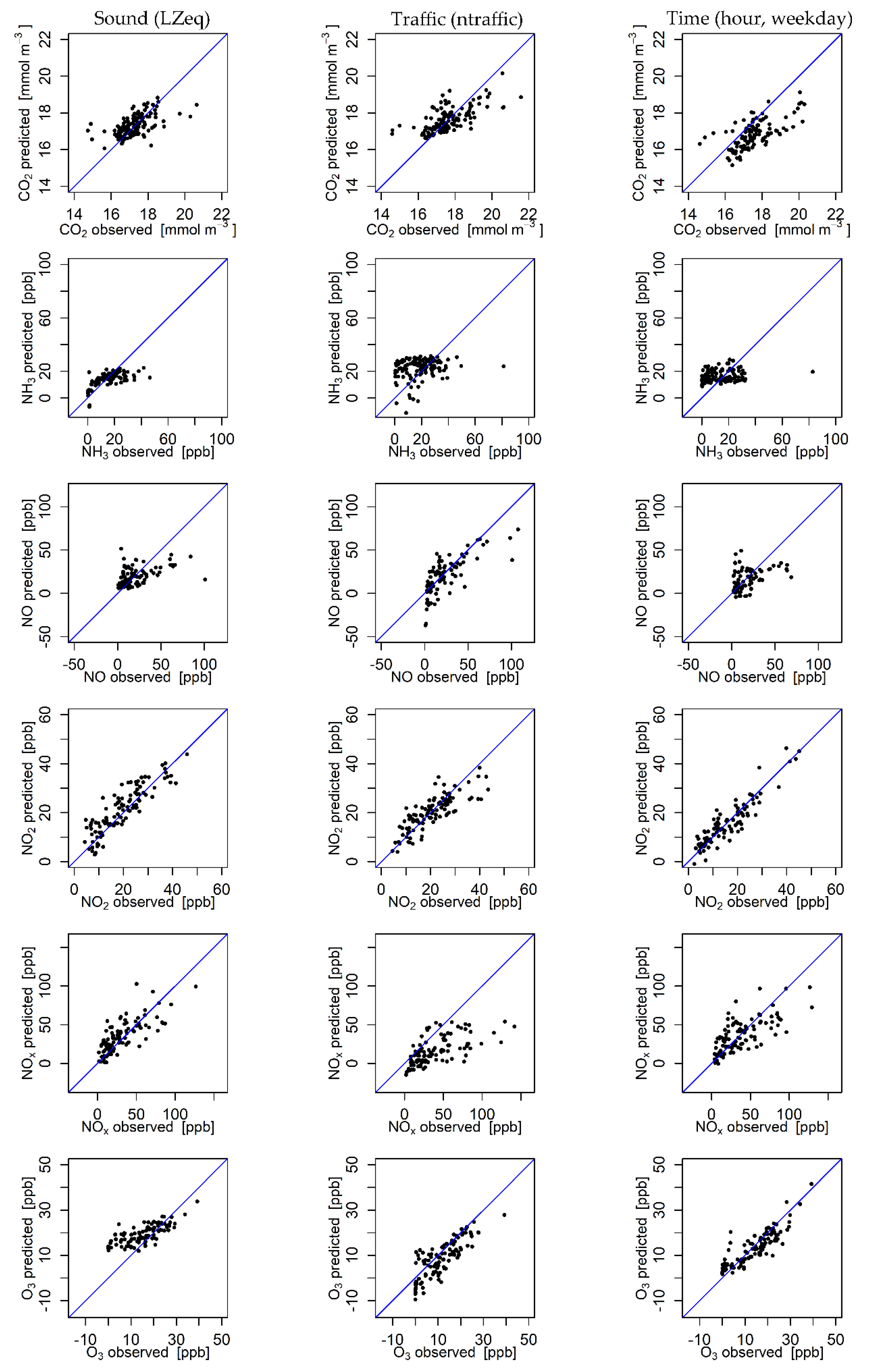
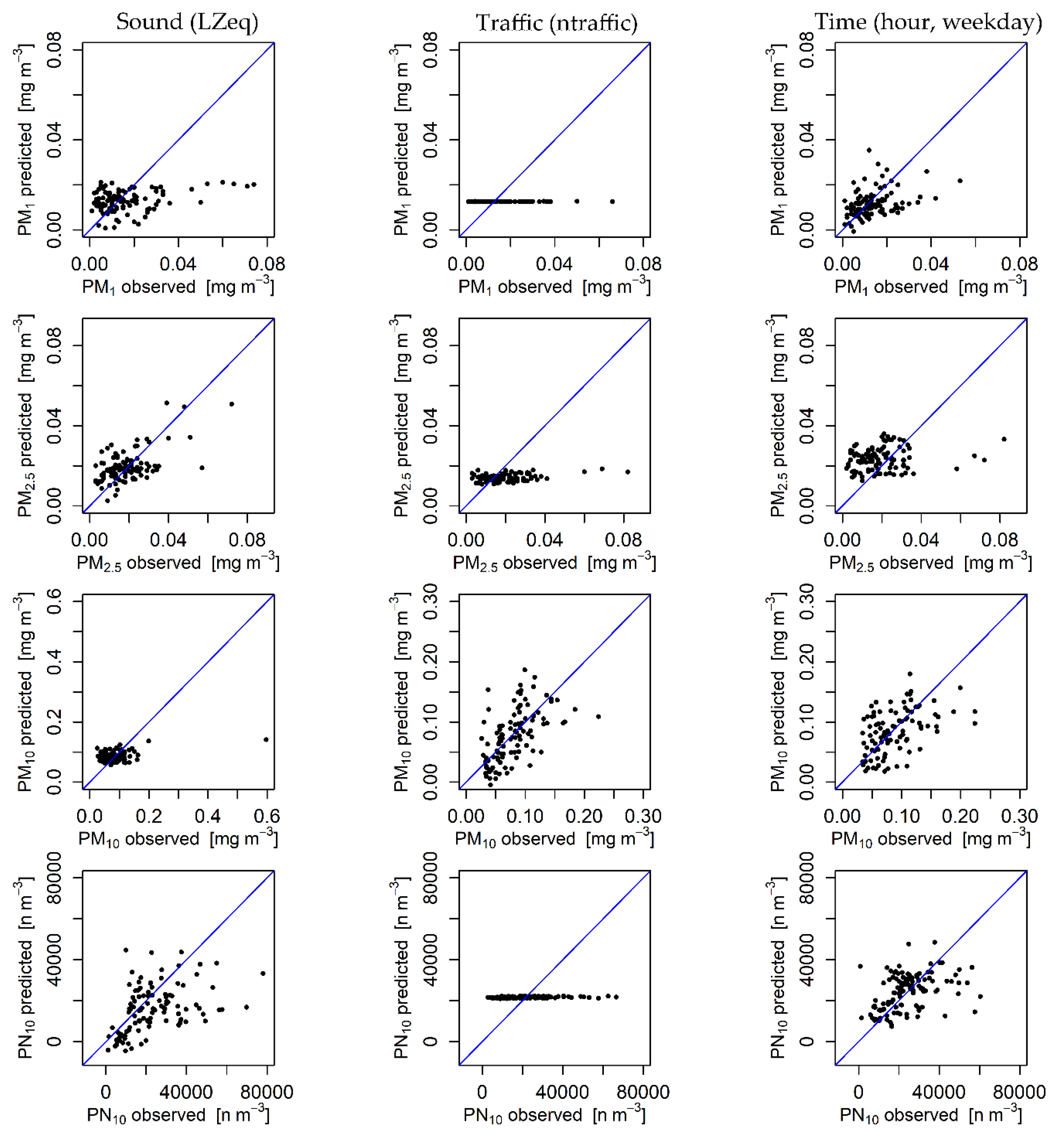
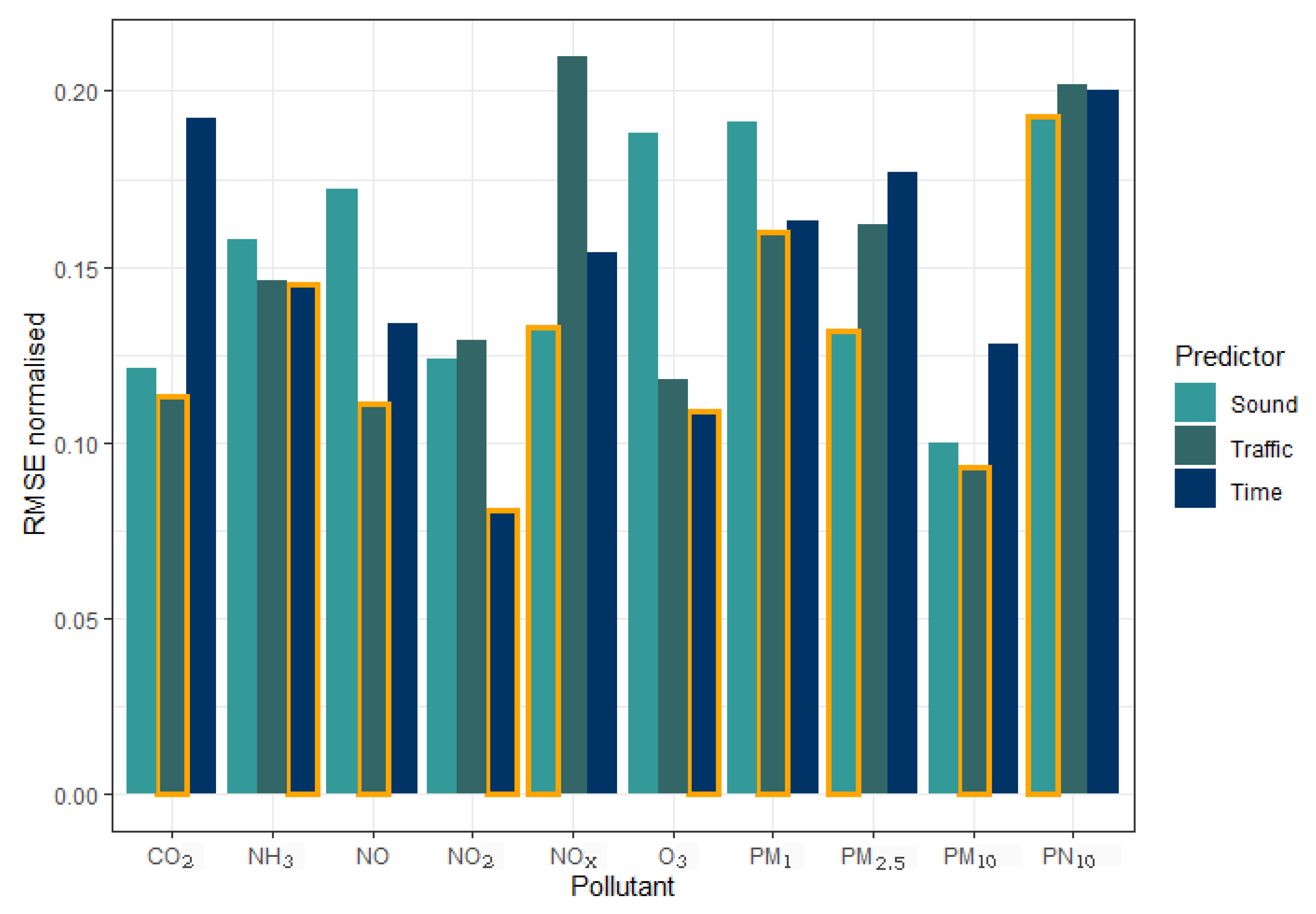
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Atkinson, R.W.; Carey, I.M.; Kent, A.J.; van Staa, T.P.; Anderson, H.R.; Cook, D.G. Long-term exposure to outdoor air pollution and incidence of cardiovascular diseases. Epidemiology 2013, 24, 44–53. [Google Scholar] [CrossRef] [PubMed]
- Heinrich, J.; Slama, R. Fine particles, a major threat to children. Int. J. Hyg. Environ. Health 2007, 210, 617–622. [Google Scholar] [CrossRef] [PubMed]
- Favarato, G.; Anderson, H.R.; Atkinson, R.; Fuller, G.; Mills, I.; Walton, H. Traffic-related pollution and asthma prevalence in children. Quantification of associations with nitrogen dioxide. Air Qual. Atmos. Health 2014, 7, 459–466. [Google Scholar] [CrossRef] [PubMed]
- Vallero, D.A. Fundamentals of Air Pollution, 5th ed.; Elsevier, Academic Press: Amsterdam, The Netherlands, 2014; pp. 197–312. [Google Scholar]
- Criteria Air Pollutants. Available online: https://www.epa.gov/criteria-air-pollutants#self (accessed on 13 December 2019).
- Richtlinie 2008/50/EG DES EUROPÄISCHEN PARLAMENTS UND DES RATES vom 21. Mai 2008 über Luftqualität und saubere Luft für Europa: Amtsblatt der Europäischen Union. Available online: https://eur-lex.europa.eu/legal-content/DE/TXT/PDF/?uri=CELEX:32008L0050&from=DE (accessed on 20 December 2019).
- Suarez-Bertoa, R.; Zardini, A.A.; Astorga, C. Ammonia exhaust emissions from spark ignition vehicles over the New European Driving Cycle. Atmos. Environ. 2014, 97, 43–53. [Google Scholar] [CrossRef]
- Sharma, M.; Kishore, S.; Tripathi, S.N.; Behera, S.N. Role of atmospheric ammonia in the formation of inorganic secondary particulate matter: A study at Kanpur, India. J. Atmos. Chem. 2007, 58, 1–17. [Google Scholar] [CrossRef]
- Behera, S.N.; Sharma, M.; Aneja, V.P.; Balasubramanian, R. Ammonia in the atmosphere: A review on emission sources, atmospheric chemistry and deposition on terrestrial bodies. Environ. Sci. Pollut. Res. Int. 2013, 20, 8092–8131. [Google Scholar] [CrossRef]
- Sector Share of Nitrogen Oxides Emissions. Available online: https://www.eea.europa.eu/data-and-maps/daviz/sector-share-of-nitrogen-oxides-emissions#tab-chart_1 (accessed on 11 December 2019).
- Viana, M.; Kuhlbusch, T.A.J.; Querol, X.; Alastuey, A.; Harrison, R.M.; Hopke, P.K.; Winiwarter, W.; Vallius, M.; Szidat, S.; Prévôt, A.S.H.; et al. Source apportionment of particulate matter in Europe: A review of methods and results. J. Aerosol Sci. 2008, 39, 827–849. [Google Scholar] [CrossRef]
- Circulatory Diseases. Available online: https://www.umweltbundesamt.de/en/topics/transport-noise/noise-effects/circulatory-diseases (accessed on 11 December 2019).
- Traffic Noise. Available online: https://www.umweltbundesamt.de/en/topics/transport-noise/traffic-noise (accessed on 11 December 2019).
- World Health Organisation Regional Office for Europe; European Commission. Burden of Disease from Environmental Noise; Quantification of Healthy Life Years Lost in Europe: Copenhagen, Denmark, 2011; p. 91. [Google Scholar]
- Wurzler, S.; Hebbinghaus, H.; Steckelbach, I.; Schulz, T.; Pompetzki, W.; Memmesheimer, M.; Jakobs, H.; Schöllnhammer, T.; Nowag, S.; Diegmann, V. Regional and local effects of electric vehicles on air quality and noise. METZ 2016, 25, 319–325. [Google Scholar] [CrossRef]
- Gloaguen, J.-R.; Can, A.; Lagrange, M.; Petiot, J.-F. Estimating traffic noise levels using acoustic monitoring: A preliminary study. Available online: https://hal.archives-ouvertes.fr/hal-01375796 (accessed on 3 October 2016).
- Dekokinick, L.; Botteldooren, D.; de Coensel, B.; Intpanis, L. Spectral noise measurements supply instantaneous traffic information for multidisciplinary mobility and traffic related projects. In Proceedings of the Internoise 2016—Towards a Quiter Future, Hamburg, Germany, 21–24 August 2016; pp. 5740–5746. [Google Scholar]
- Paas, B.; Stienen, J.; Vorländer, M.; Schneider, C. Modelling of Urban Near-Road Atmospheric PM Concentrations Using an Artificial Neural Network Approach with Acoustic Data Input. Environments 2017, 4, 1–26. [Google Scholar] [CrossRef]
- Arhami, M.; Kamali, N.; Rajabi, M.M. Predicting hourly air pollutant levels using artificial neural networks coupled with uncertainty analysis by Monte Carlo simulations. Environ. Sci. Pollut. Res. Int. 2013, 20, 4777–4789. [Google Scholar] [CrossRef]
- Cai, M.; Yin, Y.; Xie, M. Prediction of hourly air pollutant concentrations near urban arterials using artificial neural network approach. Transp. Res. Part D Transp. Environ. 2009, 14, 32–41. [Google Scholar] [CrossRef]
- Fabbian, D.; de Dear, R.; Lellyett, S. Application of artificial neural network forecasts to predict fog at canberra international airport. Weather Forecast. 2007, 22, 372–381. [Google Scholar] [CrossRef]
- Pasero, E.; Mesin, L. Artificial Neural Networks for Pollution Forecast. Air Pollut. IntechOpen 2010. [Google Scholar] [CrossRef]
- Adams, M.D.; Kanaroglou, P.S. Mapping real-time air pollution health risk for environmental management: Combining mobile and stationary air pollution monitoring with neural network models. J. Environ. Manag. 2016, 168, 133–141. [Google Scholar] [CrossRef] [PubMed]
- Gardner, M.W.; Dorling, S.R. Neural network modelling and prediction of hourly NOx and NO2 concentrations in urban air in London. Atmos. Environ. 1998, 709–719. [Google Scholar] [CrossRef]
- Rey, G.D.; Wender, K.F. Neuronale Netze. Eine Einführung in die Grundlagen, Anwendungen und Datenauswertung, 3rd ed.; Hogrefe: Bern, Switzerland, 2018; pp. 15–102. [Google Scholar]
- Prachi; Kumar, N.; Matta, G. Artificial neural network applications in air quality monitoring and management. Int. J. Environ. Rehabil. Conserv. 2011, 2, 30–64. [Google Scholar]
- Guidance Document on Modelling Quality Objectives and Benchmarking. Available online: https://fairmode.jrc.ec.europa.eu/document/fairmode/WG1/Guidance_MQO_Bench_vs3.1.1.pdf (accessed on 10 February 2020).
- LI-COR, Inc. EddyPro Software 6.2.0; LI-COR, Inc.: Lincoln, NE, USA, 2016. [Google Scholar]
- Continuous Emissions Monitoring Systems (CEMS) From A-Z: A Multi-Part Series - NOx Analyzer (Part 6). Available online: https://www.monsol.com/news/post/continuous-emissions-monitoring-systems-cems-from-a-z-a-multi-part-series-nox-analyzer-part-6 (accessed on 18 December 2019).
- Umgebungslärm NRW. Available online: https://www.umgebungslaerm-kartierung.nrw.de/ (accessed on 18 December 2019).
- NTI Audio Specifications. Technical Data XL2. Available online: https://www.nti-audio.com/Portals/0/data/en/XL2-Specifications.pdf (accessed on 14 December 2019).
- RStudio, Inc. RStudio 3.6.1: Integrated Development for R.; RStudio, Inc.: Boston, MA, USA, 2018. [Google Scholar]
- Cabaneros, S.M.; Calautit, J.K.; Hughes, B.R. A review of artificial neural network models for ambient air pollution prediction. Environ. Model. Softw. 2019, 119, 285–304. [Google Scholar] [CrossRef]
- Patterson, J.; Gibson, A. Deep Learning. A Practitioner’s Approach, 1st ed.; O’Reilly Media: Sebastopol, CA, USA, 2017. [Google Scholar]
- Goodfellow, I.; Courville, A.; Bengio, Y. Deep Learning. Das Umfassende Handbuch: Grundlagen, Aktuelle Verfahren und Algorithmen, Neue Forschungsansätze, 1st ed.; Verlags GmbH & Co. KG: Frechen, Germany, 2018; pp. 1–251. [Google Scholar]
- Introduction to FeedForward Neural Networks. Available online: https://towardsdatascience.com/feed-forward-neural-networks-c503faa46620 (accessed on 8 December 2019).
- Dijkstra, H.A. Networks in Climate; Cambridge University Press: Cambridge, UK, 2019; pp. 49–51. [Google Scholar]
- Rashid, T. Neuronale Netze Selbst Programmieren. Ein Verständlicher Einstieg Mit Python, 1st ed.; O’Reilly: Heidelberg, Germany, 2017; pp. 88–94. [Google Scholar]
- Rojas, R. Neural Networks. A Systematic Introduction; Springer: Berlin/Heidelberg, Germany, 1996; pp. 155–157. [Google Scholar]
- May, R.J.; Maier, H.R.; Dandy, G.C. Data splitting for artificial neural networks using SOM-based stratified sampling. Neural Netw. 2010, 23, 283–294. [Google Scholar] [CrossRef]
- May, R.J.; Dandy, G.C.; Maier, H.R. Review of Input Variable Selection. Methods for Artificial Neural Networks. In Artificial Neural Networks. Methodological Advances and Biomedical Applications; Suzuki, K., Ed.; IntechOpen: Shanghai, China, 2011; pp. 19–44. [Google Scholar]
- Fernando, T.M.K.G.; Maier, H.R.; Dandy, G.C. Selection of input variables for data driven models: An average shifted histogram partial mutual information estimator approach. J. Hydrol. 2008, 367, 165–176. [Google Scholar] [CrossRef]
- Sharma, A. Seasonal to interannual rainfall probabilistic forecasts for improvedwater supply management: Part 1—A strategy for systempredictor identification. J. Hydrol. 2000, 239, 232–239. [Google Scholar] [CrossRef]
- May, R.J.; Maier, H.R.; Dandy, G.C.; Fernando, T.M.K.G. Non-linear variable selection for artificial neural networks using partial mutual information. Environ. Model. Softw. 2008, 23, 1312–1326. [Google Scholar] [CrossRef]
- Bowden, G.J.; Dandy, G.C.; Maier, H.R. Input determination for neural network models in water resources applications. Part 1—Background and methodology. J. Hydrol. 2005, 301, 75–92. [Google Scholar] [CrossRef]
- Akaike, H. A NewLook at the Statistical Model Identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Reitermanová, Z. Data Splitting. In WDS’10 Proceedings of Contributed Papers; Part 1; MatfyzPress: Sokolovská, Czech Republic, 2010; pp. 31–36. [Google Scholar]
- Wu, W.; May, R.J.; Dandy, G.C.; Maier, H.R. A method for comparing data splitting approaches for developing hydrological ANN models. In Proceedings of the 6th International Congress on Environmental Modelling and Software (iEMSs), Leipzig, Germany, 1–5 July 2012. [Google Scholar]
- Geman, S.; Bienenstock, E.; Doursat, R. Neural Networks and the Bias/Variance Dilemma. Neural Comput. 1992, 4, 1–58. [Google Scholar] [CrossRef]
- Hagan, M.T.; Demuth, H.B.; Hudson Beale, M.; de Jesús, O. Neural Network Design, 2nd ed.; Martin T. Hagan: Stillwater, OK, USA, 1995; pp. 473–474. [Google Scholar]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Wilks, D.S. Statistical Methods in the Atmospheric Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2009; pp. 55–57. [Google Scholar]
- Seinfeld, J.H.; Pandis, S.N. Atmospheric Chemistry and Physics. From Air Pollution to Climate Change, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006; pp. 209, 588–613. [Google Scholar]
- Bai, Y.; Li, Y.; Wang, X.; Xie, J.; Li, C. Air pollutants concentrations forecasting using back propagation neural network based on wavelet decomposition with meteorological conditions. Atmos. Pollut. Res. 2016, 7, 557–566. [Google Scholar] [CrossRef]
- Ketzel, M.; Omstedt, G.; Johansson, C.; Düring, I.; Pohjola, M.; Oettl, D.; Gidhagen, L.; Wåhlin, P.; Lohmeyer, A.; Haakana, M.; et al. Estimation and validation of PM2.5/PM10 exhaust and non-exhaust emission factors for practical street pollution modelling. Atmos. Environ. 2007, 41, 9370–9385. [Google Scholar] [CrossRef]
- Timmers, V.R.J.H.; Achten, P.A.J. Non-exhaust PM emissions from electric vehicles. Atmos. Environ. 2016, 134, 10–17. [Google Scholar] [CrossRef]
- Gidhagen, L.; Johansson, C.; Langner, J.; Olivares, G. Simulation of NOx and ultrafine particles in a street canyon in Stockholm, Sweden. Atmos. Environ. 2004, 38, 2029–2044. [Google Scholar] [CrossRef]
- Ketzel, M.; Berkowicz, R. Modelling the fate of ultrafine particles from exhaust pipe to rural background: An analysis of time scales for dilution, coagulation and deposition. Atmos. Environ. 2004, 38, 2639–2652. [Google Scholar] [CrossRef]
- Guo, L.-C.; Zhang, Y.; Lin, H.; Zeng, W.; Liu, T.; Xiao, J.; Rutherford, S.; You, J.; Ma, W. The washout effects of rainfall on atmospheric particulate pollution in two Chinese cities. Environ. Pollut. 2016, 215, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Zellner, R. Chemie über den Wolken. … und Darunter, 1st ed.; Wiley-VCH Verlag GmbH & Co. KGaA: Weinheim, Germany, 2011; pp. 114–117. [Google Scholar]
- Klemm, O. Local and regional ozone: A student study project. J. Chem. Educ. 2001, 78, 1641–1646. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Ordering | Tuning |
|---|---|---|
| Initial Learning Rate | 0.9 | 0.1 |
| Initial Neighbourhood Size | See Table 2 | 1 |
| Epochs | 2 | 20 |
| Pollutant | Sound | Traffic | Time | |||
|---|---|---|---|---|---|---|
| Sn | Width | Sn | Width | Sn | Width | |
| CO2 | 717 | 10.046 | 783 | 10.535 | 824 | 10.829 |
| NH3 | 558 | 8.774 | 828 | 10.858 | 847 | 10.992 |
| NO | 566 | 8.841 | 574 | 8.909 | 593 | 9.067 |
| NO2 | 643 | 9.742 | 650 | 9.527 | 669 | 9.677 |
| NOx | 644 | 9.48 | 652 | 9.543 | 671 | 9.692 |
| O3 | 644 | 9.48 | 652 | 9.543 | 671 | 9.692 |
| PM1 | 658 | 9.591 | 651 | 9.535 | 687 | 9.816 |
| PM2.5 | 658 | 9.591 | 651 | 9.535 | 687 | 9.816 |
| PM10 | 646 | 9.496 | 634 | 9.400 | 670 | 9.685 |
| PN10 | 658 | 9.591 | 651 | 9.535 | 687 | 9.816 |
| Parameter | Value |
|---|---|
| Learning rate | 0.1 |
| Momentum | 0.9 |
| Max. iterations | 100,000 |
| Tolerance | 0.0001 |
| Pollutant | Input Variables+LZeq/ntraffic/time | Transfer Function, Hidden Neurons (Sound) | Transfer Function, Hidden Neurons (Traffic) | Transfer Function, Hidden Neurons (Time) |
|---|---|---|---|---|
| CO2 | Ta, p, rH, u* | H.t. 6 | L.s. 2 | L.s. 9 |
| NH3 | Ta, p, rH | H.t.15 | H.t. 1 | L.s.1 |
| NO | Ta, WD, BC NOx | H.t.6 | H.t. 10 | H.t. 10 |
| NO2 | Ta, WS, WD, rH, BC NO2 | L.s. 3 | H.t. 11 | H.t. 17 |
| NOx | Ta, WD, BC NOx | L.s. 12 | L.s. 5 | H.t. 19 |
| O3 | u*, rH, Ta, WD, p, BC O3 | H.t. 1 | H.t. 9 | H.t. 2 |
| PM1 | u*, p, Ta, rH, WD | H.t. 1 | L.s. 1 | L.s. 6 |
| PM2.5 | U*, Ta, rH, p, WD | H.t. 8 | L.s. 3 | H.t. 1 |
| PM10 | Ta, rH, WD, BC PM10 | H.t. 8 | H.t. 5 | H.t. 10 |
| PN10 | Ta, WS, WD | L.s. 6 | L.s. 4 | H.t. 7 |
| Pollutant | RMSE | rs | SD’ | SD | NMB | R | NMSD | |
|---|---|---|---|---|---|---|---|---|
| CO2 [mmol m−3] | Sound | 0.716 | 0.616 | 0.558 | 0.868 | 0.003 | 0.569 | −0.357 |
| Traffic | 0.790 | 0.695 | 0.656 | 1.082 | 0.000 | 0.685 | −0.394 | |
| Time | 1.090 | 0.665 | − ** | 1.066 | −0.042 | 0.658 | − | |
| NH3 [ppb] | Sound | 8.314 | 0.632 | 5.540 | 10.559 | −0.118 | 0.648 | −0.475 |
| Traffic | 13.474 | 0.239 | 7.667 | 12.427 | 0.205 | 0.233 | −0.383 | |
| Time | 11.968 | 0.403 | 4.307 | 12.073 | 0.312 | 0.329 | −0.643 | |
| NO [ppb] | Sound | 17.207 | 0.531 | 10.395 | 19.661 | −0.014 | 0.478 | −0.471 |
| Traffic | 16.017 | 0.751 | 21.107 | 22.433 | −0.133 | 0.739 | −0.059 | |
| Time | 21.893 | 0.390 | 12.078 | 22.799 | −0.161 | 0.346 | −0.470 | |
| NO2 [ppb] | Sound | 5.240 | 0.816 | 0.548 * | 9.496 | 0.092 | 0.878 | − |
| Traffic | 5.092 | 0.830 | 0.422 * | 8.732 | −0.017 | 0.812 | − | |
| Time | 3.811 | 0.881 | 9.115 | 9.416 | −0.002 | 0.915 | −0.032 | |
| NOx [ppb] | Sound | 16.683 | 0.761 | 20.706 | 24.359 | 0.133 | 0.751 | −0.150 |
| Traffic | 32.820 | 0.703 | 17.756 | 29.728 | −0.594 | 0.646 | −0.403 | |
| Time | 19.983 | 0.685 | 21.021 | 27.848 | −0.045 | 0.698 | −0.245 | |
| O3 [ppb] | Sound | 7.372 | 0.737 | 4.168 | 1.828 * | 0.294 | 0.750 | 1.280 |
| Traffic | 5.774 | 0.811 | 0.722 * | 8.211 | −0.271 | 0.821 | − | |
| Time | 4.526 | 0.870 | 7.506 | 9.081 | −0.057 | 0.871 | −0.173 | |
| PM1 [mg m−3] | Sound | 0.014 | 0.188 | 0.551 * | 0.014 | −0.204 | 0.315 | − |
| Traffic | 0.010 | 0.289 | − ** | 0.010 | −0.048 | 0.240 | − | |
| Time | 0.009 | 0.416 | 0.006 | 0.009 | −0.141 | 0.384 | −0.333 | |
| PM2.5 [mg m−3] | Sound | 0.009 | 0.384 | 0.008 | 0.011 | 0.049 | 0.587 | −0.273 |
| Traffic | 0.013 | 0.192 | 0.002 | 0.012 | −0.283 | 0.353 | −0.833 | |
| Time | 0.014 | 0.149 | − ** | 0.013 | 0.227 | 0.163 | − | |
| PM10 [mg m−3] | Sound | 0.057 | 0.148 | 0.016 | 0.062 | 0.066 | 0.400 | −0.742 |
| Traffic | 0.050 | 0.658 | 0.740 * | 0.057 | −0.067 | 0.536 | − | |
| Time | 0.078 | 0.519 | 0.538 * | 0.086 | −0.131 | 0.425 | − | |
| PN10 [n m−3] | Sound | 15,915.23 | 0.524 | 0.922 * | 14,946 | −0.318 | 0.449 | − |
| Traffic | 12,872.74 | 0.249 | 375.384 | 13,022.7 | 0.002 | 0.253 | −0.971 | |
| Time | 11,934.47 | 0.445 | 8858.02 | 12,321.3 | −0.002 | 0.397 | −0.281 |
| NO2 | O3 | PM2.5 | PM10 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Sound | Traffic | Time | Sound | Traffic | Time | Sound | Traffic | Time | Sound | Traffic | Time |
| 0.357 | 0.342 | 0.281 | 0.414 | 0.327 | 0.255 | 0.566 | 0.778 | 0.828 | 1.004 | 0.882 | 1.071 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goulier, L.; Paas, B.; Ehrnsperger, L.; Klemm, O. Modelling of Urban Air Pollutant Concentrations with Artificial Neural Networks Using Novel Input Variables. Int. J. Environ. Res. Public Health 2020, 17, 2025. https://doi.org/10.3390/ijerph17062025
Goulier L, Paas B, Ehrnsperger L, Klemm O. Modelling of Urban Air Pollutant Concentrations with Artificial Neural Networks Using Novel Input Variables. International Journal of Environmental Research and Public Health. 2020; 17(6):2025. https://doi.org/10.3390/ijerph17062025
Chicago/Turabian StyleGoulier, Laura, Bastian Paas, Laura Ehrnsperger, and Otto Klemm. 2020. "Modelling of Urban Air Pollutant Concentrations with Artificial Neural Networks Using Novel Input Variables" International Journal of Environmental Research and Public Health 17, no. 6: 2025. https://doi.org/10.3390/ijerph17062025
APA StyleGoulier, L., Paas, B., Ehrnsperger, L., & Klemm, O. (2020). Modelling of Urban Air Pollutant Concentrations with Artificial Neural Networks Using Novel Input Variables. International Journal of Environmental Research and Public Health, 17(6), 2025. https://doi.org/10.3390/ijerph17062025