Detecting Binge Drinking and Alcohol-Related Risky Behaviours from Twitter’s Users: An Exploratory Content- and Topology-Based Analysis

 ,
,  ,
,  , and
, and 
Abstract
1. Introduction
1.1. Binge Drinking and Social Media
1.2. The Current Study
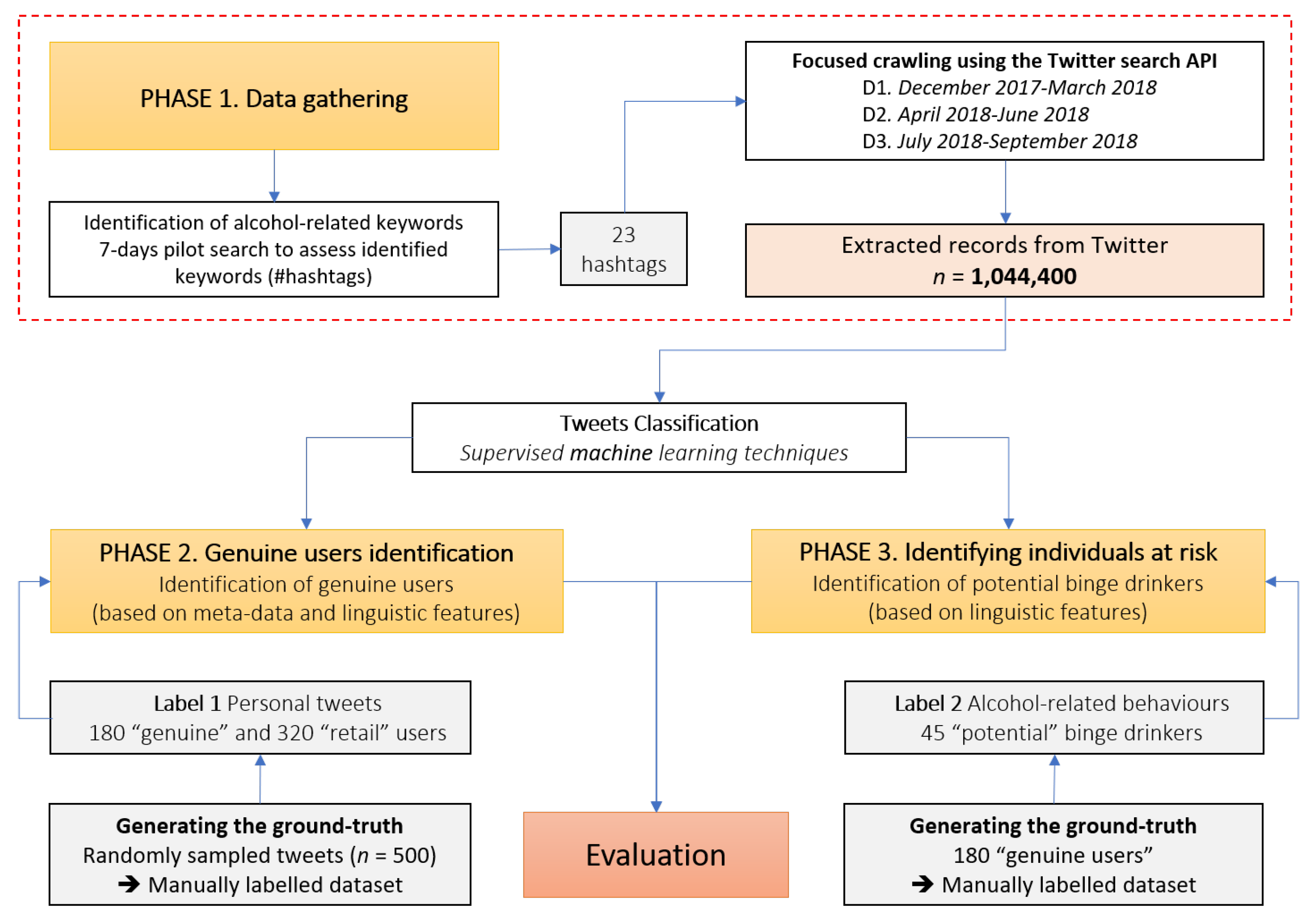
2. Materials and Methods
2.1. Phase 1: Data Gathering
- Hashtags concerning alcoholic beverages, e.g., #alcohol, #cocktail, #drinks, #rum;
- hashtags that indicate phenomena known to be typical scenarios of excessive alcohol use, such as “pub crawling” which indicates the action of drinking in different pubs on the same evening, e.g., #pubcrawl, #pubcrawling, #botellon;
- hashtags that explicitly indicate the common after-effects of drinking too much alcohol, or the condition of drunkenness, e.g., #wasted, #hangover, #toomuchalcohol, #sorehead, #drunkies, #drunkasfuck;
- hashtags that contain a direct reference to binge drinking, e.g., #bingedrinking.
- (i)
- The entire text of the tweet, discarding multimedia content;
- (ii)
- metadata associated with the tweet, such as the reactions to the tweet, expressed via retweets and likes, the date and time the tweet was created, information on geo-location if available;
- (iii)
- details of the original tweet if the post was a retweet (including information about the original author of the tweet);
- (iv)
- author’s details such as screenname (also known as handle), complete name, biography, number of tweets in their timeline, number of followees and followers, date of account creation.
2.2. Phase 2: Identification of Genuine Users with Respect to Bots, Media, and Business Accounts
2.2.1. Supervised Learning for the Identification of Genuine Users
- The number of tweets of a single account: Users with a high number of tweets are probably media, commercial, or bot accounts [46];
- the average number of hashtags per tweet: Hashtags are the “keywords” by which users identify the main topics contained in their message. A genuine user is expected to include a limited number of hashtags in a single tweet, while those who want to promote their own content often abuse of hashtags to increase the probability to find their content when using search engines [48,49];
- the average number of mentions per tweet: Mentions, i.e., citing another Twitter account by the use of the symbol ‘@’ followed by the name of another user, for conversation and discussion purposes. These interactions are more specific of real people, while commercial activities often send general messages and do not hold individual conversations with their circle of followers [49];
- the number of occurrences of personal pronouns per tweet: The use of personal pronouns is strictly connected to people. Advertising messages are often written in a “dry” and impersonal form [49];
- the average number of URLs per tweet: Links to external sites (often more than one) are frequently posted by commercial activities to move users’ browsing from Twitter to their brand’s site [46];
- the presence of URLs in the user profile: Commercial activities extensively use the platform’s advertising potential;
- the retweet/tweet ratio: Genuine users rarely re-tweet without comments, whereas accounts retweeting about a brand behave in RSS feed style [48];
- the network size: Profiles with a large number of followees and followers are likely to represent a famous person or a company;
- the followers/followees ratio: For genuine user accounts, this ratio does not deviate too far from the unit. It is reasonable to expect that one person follows a certain number of profiles in a reciprocal way. Often the imbalance is severe for famous people and businesses that tend to have a high number of followers (even in the order of tens or hundreds of thousands of units) but very few or even zero followees (because the purpose of that account is not to read the contents published by third parties);
- the presence of geo-located tweets: The use of Twitter occurs mainly via its mobile app, often with geo-localization turned on; on the other hand, desktop use is typical of business users [50];
- the number of “bad tokens” per tweet: Along with the features described above, we identified by manual inspection of a random sample of some users’ tweets, some words (bad tokens) that likely indicate a non-personal profile. Since a high number of occurrences of bad tokens suggests that the tweet has been written by a business or a bot, they were automatically eliminated from the dataset by using a Python script through the Natural Language Toolkit framework (NLTK) [51].
2.2.2. Classifying Genuine Users
Normalization
Cross-Validation
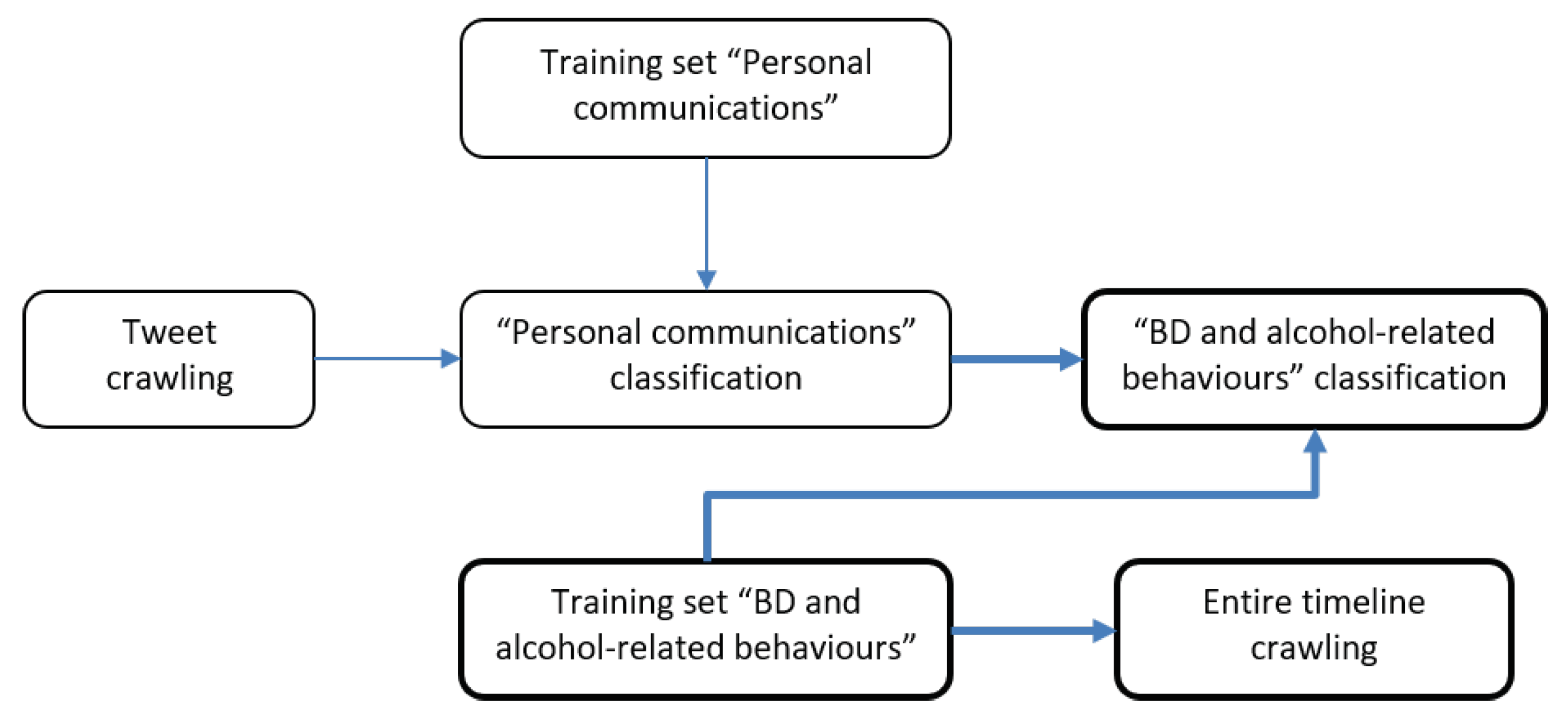
2.3. Phase 3: Identifying Potential Binge Drinkers
3. Results
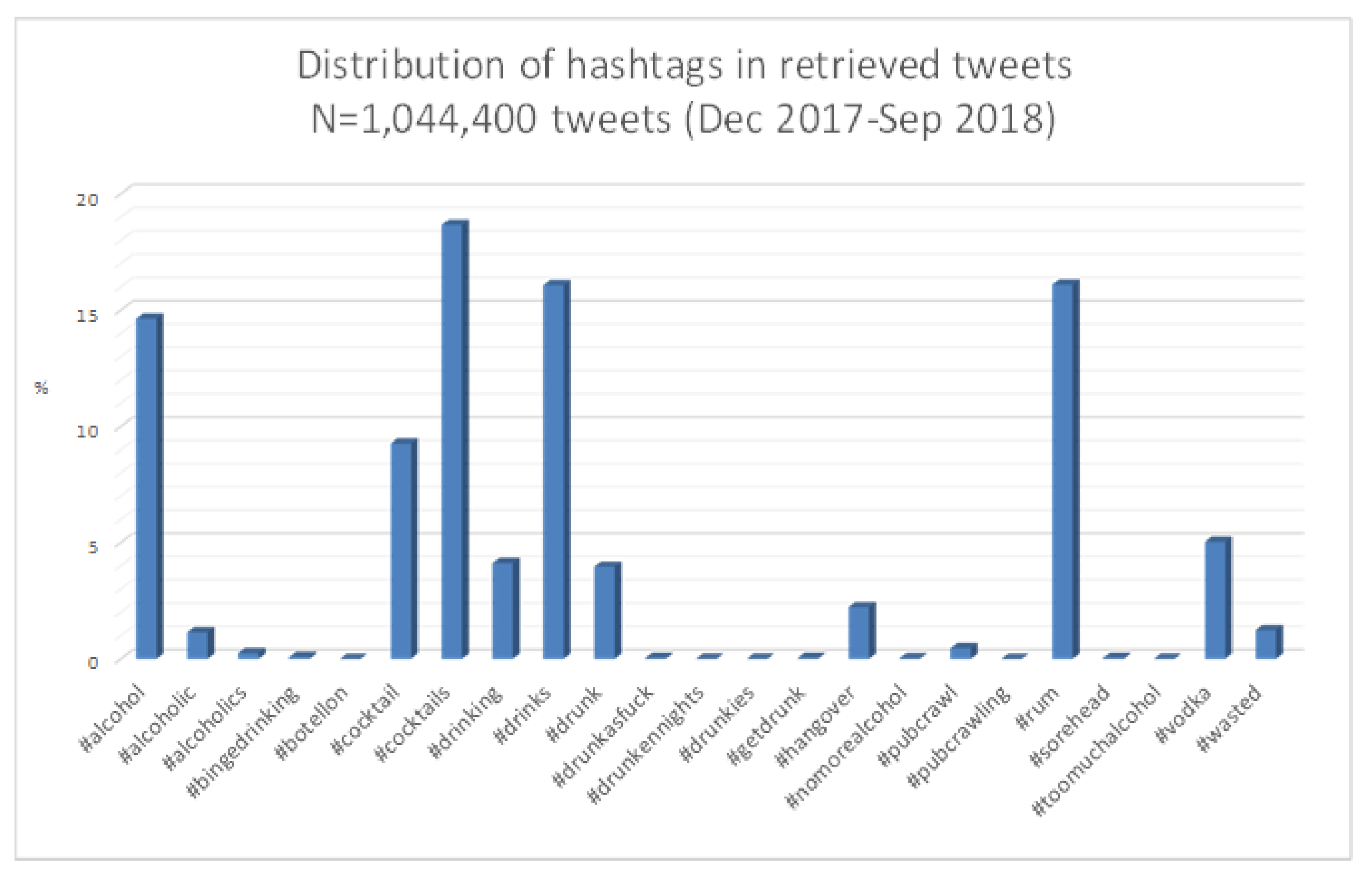
3.1. Dataset Characteristics
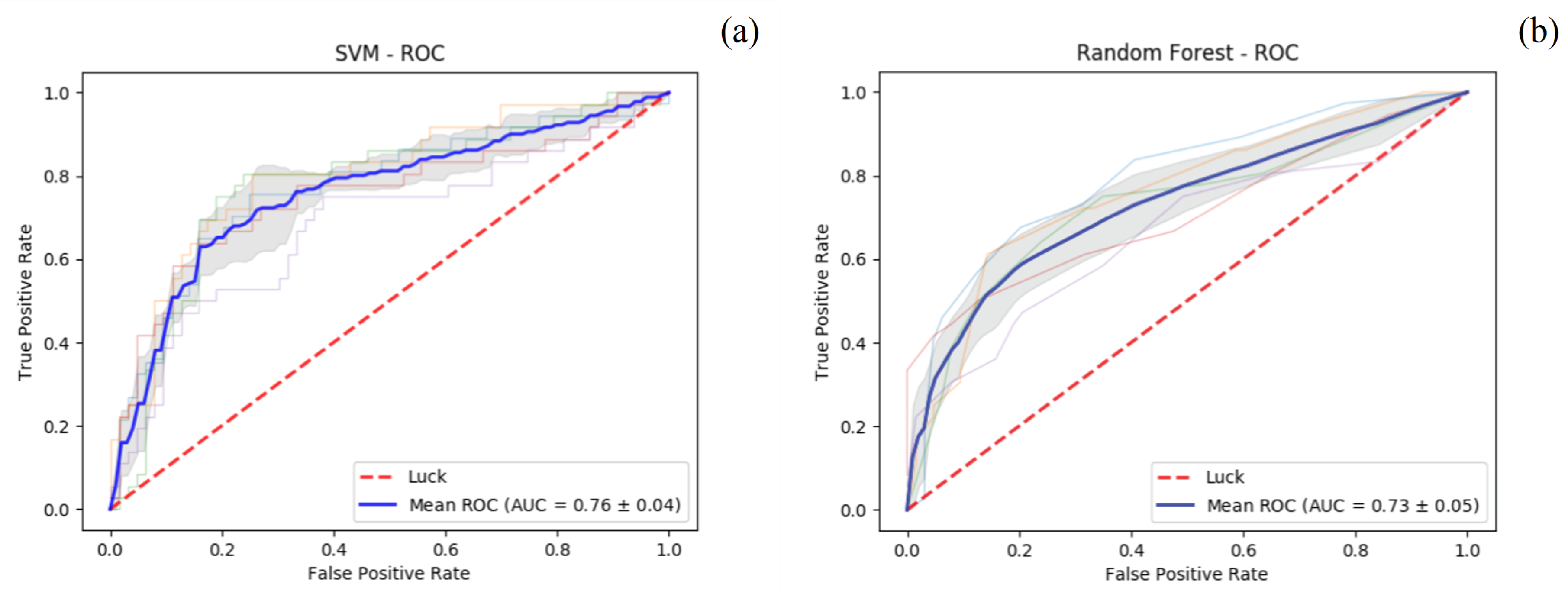
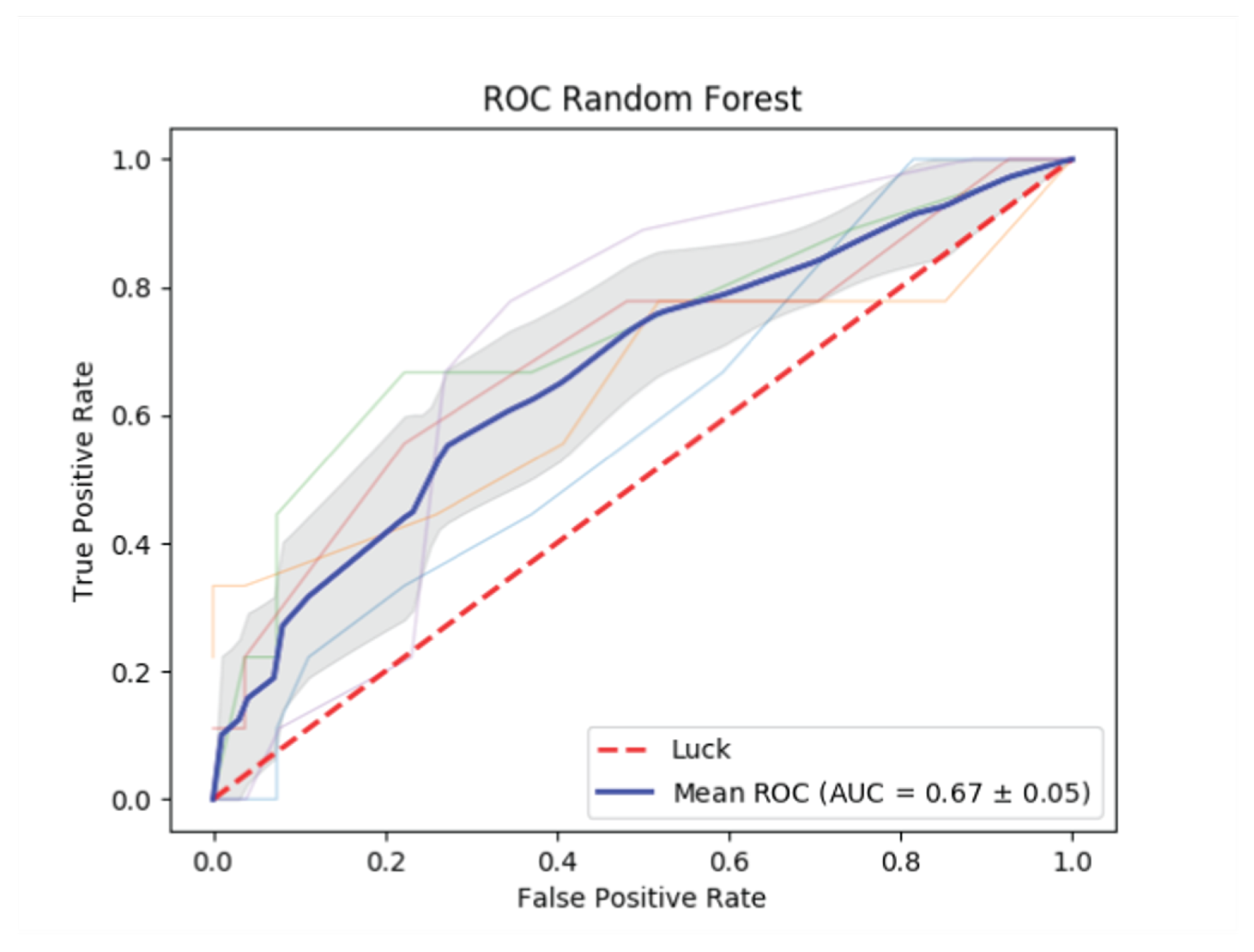
3.2. Identification of Real Users with Respect to Bots, Media, and Business Accounts
Details on Evaluation Metrics
3.3. Identification of Potential Binge Drinkers
4. Discussion
5. Preventive Implications and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Hashtags Distribution and Most Frequently Reported n-Grams
Appendix A.1. Hashtags Distribution across Datasets D1, D2, and D3

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D1 | D2 | D3 | ||
|---|---|---|---|---|
| Hashtags | December 2017–March 2018 | April–June 2018 | July–September 2018 | Total Sample |
| N (%) | 409,788 | 316,541 | 318,071 | 1,044,400 |
| #alcohol | 59,387 (14.49) | 47,658 (15.06) | 45,777 (14.39) | 152,822 (14.63) |
| #alcoholic | 4061 (0.99) | 4231 (1.34) | 3594 (1.13) | 11,886 (1.14) |
| #alcoholics | 1116 (0.27) | 711 (0.22) | 756 (0.24) | 2583 (0.25) |
| #bingedrinking | 313 (0.08) | 308 (0.10) | 249 (0.08) | 870 (0.08) |
| #botellon | 3 (0.001) | 4 (0.001) | 3 (0.001) | 10 (0) |
| #cocktail | 34,431 (8.40) | 31,901 (10.08) | 30,391 (9.55) | 96,723 (9.26) |
| #cocktails | 61,505 (15.01) | 66,746 (21.09) | 66,618 (20.94) | 194,869 (18.66) |
| #drinking | 14,745 (3.60) | 14,160 (4.47) | 14,035 (4.41) | 42,940 (4.11) |
| #drinks | 50,264 (12.27) | 56,222 (17.76) | 61,320 (19.28) | 167,806 (16.07) |
| #drunk | 16,516 (4.03) | 12,509 (3.95) | 12,330 (3.88) | 41,355 (3.96) |
| #drunkasfuck | 76 (0.02) | 278 (0.09) | 87 (0.03) | 441 (0.04) |
| #drunkennights | 35 (0.01) | 18 (0.01) | 30 (0.01) | 83 (0.01) |
| #drunkies | 36 (0.01) | 29 (0.01) | 46 (0.01) | 111 (0.01) |
| #getdrunk | 175 (0.04) | 122 (0.04) | 170 (0.05) | 467 (0.04) |
| #hangover | 9265 (2.26) | 6962 (2.20) | 6912 (2.17) | 23,139 (2.22) |
| #nomorealcohol | 146 (0.04) | 31 (0.01) | 27 (0.01) | 204 (0.02) |
| #pubcrawl | 1513 (0.37) | 1737 (0.55) | 1600 (0.50) | 4850 (0.46) |
| #pubcrawling | 7 (0.002) | 9 (0.003) | 5 (0.002) | 21 (0) |
| #rum | 67,812 (16.55) | 51,166 (16.16) | 49,078 (15.43) | 168,056 (16.09) |
| #sorehead | 185 (0.05) | 119 (0.04) | 123 (0.04) | 427 (0.04) |
| #toomuchalcohol | 63 (0.02) | 35 (0.01) | 55 (0.02) | 153 (0.01) |
| #vodka | 15,624 (3.81) | 18,876 (5.96) | 18,014 (5.66) | 52,514 (5.03) |
| #wasted | 3286 (0.80) | 2709 (0.86) | 6851 (2.15) | 12,846 (1.23) |
Appendix A.2. Most Frequently Reported Unigrams in the Three Time Periods (D1, D2, and D3)



Appendix A.3. Most Frequently Reported n-Grams for the 45 Users Identified as Binge Drinkers by Considering Dataset D4
Appendix A.3.1. Bigrams (Bigram, Cardinality)
Appendix A.3.2. Trigrams (Trigram, Cardinality)
Appendix A.4. Most Frequently Reported Unigrams in Dataset D4

References
- Parkinson, K.; Newbury-Birch, D.; Phillipson, A.; Hindmarch, P.; Kaner, E.; Stamp, E.; Vale, L.; Wright, J.; Connolly, J. Prevalence of alcohol related attendance at an inner city emergency department and its impact: A dual prospective and retrospective cohort study. Emerg. Med. J. 2016, 33, 187–193. [Google Scholar] [CrossRef] [PubMed]
- Bose, J.; Hedden, S.L.; Lipari, R.N.; Park-Lee, E. Key Substance Use and Mental Health Indicators in the United States: Results from the 2017 National Survey on Drug Use and Health (HHS Publication No. SMA 18-5068 2018). Technical report, U.S. Department of Health and Human Services, Substance Abuse and Mental Health Services Administration (SAMHSA), Center for Behavioral Health Statistics and Quality. 2018. Available online: https://www.samhsa.gov/data/sites/default/files/cbhsq-reports/NSDUHFFR2017/NSDUHFFR2017.pdf (accessed on 3 December 2019).
- Wechsler, H.; Davenport, A.; Dowdall, G.; Moeykens, B.; Castillo, S. Health and behavioral consequences of binge drinking in college: A national survey of students at 140 campuses. JAMA 1994, 272, 1672–1677. [Google Scholar] [CrossRef] [PubMed]
- Patrick, M.E.; Schulenberg, J.E.; Martz, M.E.; Maggs, J.L.; O’Malley, P.M.; Johnston, L.D. Extreme binge drinking among 12th-grade students in the United States: Prevalence and predictors. JAMA Pediatr. 2013, 167, 1019–1025. [Google Scholar] [CrossRef] [PubMed]
- Bartoli, F.; Carretta, D.; Crocamo, C.; Schivalocchi, A.; Brambilla, G.; Clerici, M.; Carrà, G. Prevalence and correlates of binge drinking among young adults using alcohol: A cross-sectional survey. J. Biomed. Biotechnol. 2014, 2014, 930795. [Google Scholar] [CrossRef]
- Rhodes, W.A.; Singleton, E.; McMillan, T.B.; Perrino, C.E. Does knowledge of college drinking policy influence student binge drinking? J. Am. Coll. Health 2005, 54, 45–49. [Google Scholar] [CrossRef]
- Miller, J.W.; Naimi, T.S.; Brewer, R.D.; Jones, S.E. Binge drinking and associated health risk behaviors among high school students. Pediatrics 2007, 119, 76–85. [Google Scholar] [CrossRef]
- Lipari, R.N. Trends in adolescent substance use and perception of risk from substance use. In The CBHSQ Report; Substance Abuse and Mental Health Services Administration: Rockville, MD, USA, 2013. [Google Scholar]
- Crocamo, C.; Bartoli, F.; Montomoli, C.; Carrà, G. Predicting young adults binge drinking in nightlife scenes: An evaluation of the D-ARIANNA Risk Estimation Model. J. Addict. Med. 2018, 12, 401–409. [Google Scholar] [CrossRef]
- De Visser, R.O.; Birch, J.D. My cup runneth over: Young people’s lack of knowledge of low-risk drinking guidelines. Drug Alcohol Rev. 2012, 31, 206–212. [Google Scholar] [CrossRef]
- Goudriaan, A.E.; Grekin, E.R.; Sher, K.J. Decision making and binge drinking: A longitudinal study. Alcohol. Clin. Exp. Res. 2007, 31, 928–938. [Google Scholar] [CrossRef]
- Goudriaan, A.E.; Grekin, E.R.; Sher, K.J. Decision making and response inhibition as predictors of heavy alcohol use: A prospective study. Alcohol. Clin. Exp. Res. 2011, 35, 1050–1057. [Google Scholar] [CrossRef]
- Carrà, G.; Crocamo, C.; Schivalocchi, A.; Bartoli, F.; Carretta, D.; Brambilla, G.; Clerici, M. Risk estimation modeling and feasibility testing for a mobile ehealth intervention for binge drinking among young people: the D-ARIANNA (Digital-Alcohol RIsk Alertness Notifying Network for Adolescents and young adults) project. Subst. Abus. 2015, 36, 445–452. [Google Scholar] [CrossRef] [PubMed]
- Carrà, G.; Crocamo, C.; Bartoli, F.; Carretta, D.; Schivalocchi, A.; Bebbington, P.E.; Clerici, M. Impact of a mobile E-Health intervention on binge drinking in young people: The digital–alcohol risk alertness notifying network for adolescents and young adults project. J. Adolesc. Health 2016, 58, 520–526. [Google Scholar] [CrossRef] [PubMed]
- Leeman, R.F.; Kulesza, M.; Stewart, D.W.; Copeland, A.L. Cluster analysis of undergraduate drinkers based on alcohol expectancy scores. J. Stud. Alcohol Drugs 2012, 73, 238–249. [Google Scholar] [CrossRef] [PubMed]
- Lukianova, N.A.; Burkatovskaya, Y.B.; Fell, E.V. Sten Score Method and Cluster Analysis: Identifying Respondents Vulnerable to Drug Abuse. In The European Proceedings of Social & Behavioural Sciences (EpSBS); Vol. 35: Research Paradigms Transformation in Social Sciences (RPTSS 2017); Future Academy: Nicosia, Cyprus, 2018; Volume 352017, pp. 779–789. [Google Scholar]
- Knoll, L.J.; Leung, J.T.; Foulkes, L.; Blakemore, S.J. Age-related differences in social influence on risk perception depend on the direction of influence. J. Adolesc. 2017, 60, 53–63. [Google Scholar] [CrossRef]
- Bond, R.M.; Fariss, C.J.; Jones, J.J.; Kramer, A.D.; Marlow, C.; Settle, J.E.; Fowler, J.H. A 61-million-person experiment in social influence and political mobilization. Nature 2012, 489, 295. [Google Scholar] [CrossRef]
- Christakis, N.A.; Fowler, J.H. Social contagion theory: examining dynamic social networks and human behavior. Stat. Med. 2013, 32, 556–577. [Google Scholar] [CrossRef]
- O’Neill, B.; Ziebland, S.; Valderas, J.; Lupiáñez-Villanueva, F. User-generated online health content: a survey of Internet users in the United Kingdom. J. Med. Internet Res. 2014, 16, e118. [Google Scholar] [CrossRef]
- Fox, S. After Dr Google: Peer-to-peer health care. Pediatrics 2013, 131, S224–S225. [Google Scholar] [CrossRef]
- Carminati, B.; Ferrari, E.; Viviani, M. A multi-dimensional and event-based model for trust computation in the Social Web. In Proceedings of the International Conference on Social Informatics (SocInfo 2012), Lausanne, Switzerland, 5–7 December 2012; Lecture Notes in Computer Science, vol 7710. Springer: Berlin/Heidelberg, Germany, 2012; pp. 323–336. [Google Scholar]
- Carminati, B.; Ferrari, E.; Viviani, M. Security and trust in online social networks. Synth. Lect. Inf. Secur. Priv. Trust 2013, 4, 1–120. [Google Scholar] [CrossRef]
- Viviani, M.; Pasi, G. Credibility in social media: opinions, news, and health information—A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2017, 7, e1209. [Google Scholar] [CrossRef]
- Damiani, E.; Viviani, M. Trading anonymity for influence in open communities voting schemata. In Proceedings of the 2009 International Workshop on Social Informatics (SocInfo 2009), Warsaw, Poland, 22–24 June 2009; pp. 63–67. [Google Scholar]
- Livraga, G.; Viviani, M. Data Confidentiality and Information Credibility in Online Ecosystems. In Proceedings of the 11th International Conference on Management of Digital EcoSystems (MEDES’19), Limassol, Cyprus, 12–14 November 2019; pp. 12–14. [Google Scholar]
- Dredze, M. How social media will change public health. IEEE Intell. Syst. 2012, 27, 81–84. [Google Scholar] [CrossRef]
- Curtis, B.L.; Lookatch, S.J.; Ramo, D.E.; McKay, J.R.; Feinn, R.S.; Kranzler, H.R. Meta-Analysis of the Association of Alcohol-Related Social Media Use with Alcohol Consumption and Alcohol-Related Problems in Adolescents and Young Adults. Alcohol. Clin. Exp. Res. 2018, 42, 978–986. [Google Scholar] [CrossRef]
- Glassman, T. Implications for College Students Posting Pictures of Themselves Drinking Alcohol on. J. Alcohol Drug Educ. 2012, 56, 1. [Google Scholar]
- Moreno, M.A.; Christakis, D.A.; Egan, K.G.; Brockman, L.N.; Becker, T. Associations between displayed alcohol references on Facebook and problem drinking among college students. Arch. Pediatr. Adolesc. Med. 2012, 166, 157–163. [Google Scholar] [CrossRef]
- Griffiths, R.; Casswell, S. Intoxigenic digital spaces? Youth, social networking sites and alcohol marketing. Drug Alcohol Rev. 2010, 29, 525–530. [Google Scholar] [CrossRef] [PubMed]
- Townshend, J.M.; Kambouropoulos, N.; Griffin, A.; Hunt, F.J.; Milani, R.M. Binge drinking, reflection impulsivity, and unplanned sexual behavior: impaired decision-making in young social drinkers. Alcohol. Clin. Exp. Res. 2014, 38, 1143–1150. [Google Scholar] [CrossRef]
- Prier, K.W.; Smith, M.S.; Giraud-Carrier, C.; Hanson, C.L. Identifying health-related topics on twitter. In Social Computing, Behavioral-Cultural Modeling and Prediction; Salerno, J., Yang, S.J., Nau, D., Chai, S.K., Eds.; Lecture Notes in Computer Science, vol 6589; SBP: College Park, MD, USA, 2011. [Google Scholar]
- Cavazos-Rehg, P.A.; Krauss, M.; Fisher, S.L.; Salyer, P.; Grucza, R.A.; Bierut, L.J. Twitter chatter about marijuana. J. Adolesc. Health 2015, 56, 139–145. [Google Scholar] [CrossRef]
- Cavazos-Rehg, P.A.; Krauss, M.J.; Sowles, S.J.; Bierut, L.J. “Hey everyone, I’m drunk.” An evaluation of drinking-related Twitter chatter. J. Stud. Alcohol Drugs 2015, 76, 635–643. [Google Scholar] [CrossRef]
- Krauss, M.J.; Grucza, R.A.; Bierut, L.J.; Cavazos-Rehg, P.A. “Get drunk. Smoke weed. Have fun”: A content analysis of tweets about marijuana and alcohol. Am. J. Health Promot. 2017, 31, 200–208. [Google Scholar] [CrossRef]
- Daniulaityte, R.; Chen, L.; Lamy, F.R.; Carlson, R.G.; Thirunarayan, K.; Sheth, A. “When ‘bad’ is ‘good’”: Identifying personal communication and sentiment in drug-related tweets. JMIR Public Health Surveill. 2016, 2, e162. [Google Scholar] [CrossRef]
- Chen, E.E.; Wojcik, S.P. A practical guide to big data research in psychology. Psychol. Methods 2016, 21, 458. [Google Scholar] [CrossRef] [PubMed]
- Greenwood, S.; Perrin, A.; Duggan, M. Social Media Update 2016. Pew Research Center. 2016. Available online: https://www.pewinternet.org/2016/11/11/social-media-update-2016 (accessed on 1 December 2019).
- Rushe, D. Twitter Reports Profit for Second Quarter in a Row and Adds 6m New Users. The Guardian. 25 April 2018. Available online: https://www.theguardian.com/technology/2018/apr/25/twitter-profit-second-quarter-social-network (accessed on 1 December 2019).
- Edwards, J. Facebook is No Longer the Most Popular Social Network for Teens. Business Insider. 24 October 2013. Available online: https://www.businessinsider.in/Facebook-Is-No-Longer-The-Most-Popular-Social-Network-For-Teens/articleshow/24668520.cms (accessed on 1 December 2019).
- Internet Live Stats. Twitter Usage Statistics. Available online: https://www.internetlivestats.com/twitter-statistics/ (accessed on 1 December 2019).
- Wongkoblap, A.; Vadillo, M.A.; Curcin, V. Researching mental health disorders in the era of social media: systematic review. J. Med. Internet Res. 2017, 19, e228. [Google Scholar] [CrossRef] [PubMed]
- Chakrabarti, S.; Van den Berg, M.; Dom, B. Focused crawling: A new approach to topic-specific Web resource discovery. Comput. Netw. 1999, 31, 1623–1640. [Google Scholar] [CrossRef]
- The Python Software Foundation. The Python Language Reference. 2019. Available online: https://docs.python.org/3/reference/ (accessed on 1 December 2019).
- Chu, Z.; Gianvecchio, S.; Wang, H.; Jajodia, S. Detecting automation of twitter accounts: Are you a human, bot, or cyborg? IEEE Trans. Depend. Secur. Comput. 2012, 9, 811–824. [Google Scholar] [CrossRef]
- Igawa, R.A.; Barbon, S., Jr.; Paulo, K.C.S.; Kido, G.S.; Guido, R.C.; Júnior, M.L.P.; da Silva, I.N. Account classification in online social networks with LBCA and wavelets. Inf. Sci. 2016, 332, 72–83. [Google Scholar] [CrossRef]
- Guo, D.; Chen, C. Detecting non-personal and spam users on geo-tagged Twitter network. Trans. GIS 2014, 18, 370–384. [Google Scholar] [CrossRef]
- Bian, J.; Topaloglu, U.; Yu, F. Towards large-scale twitter mining for drug-related adverse events. In Proceedings of the 2012 International Workshop on Smart Health and Wellbeing; ACM: Maui, HI, USA, 2012; pp. 25–32. [Google Scholar]
- Bordogna, G.; Cuzzocrea, A.; Frigerio, L.; Psaila, G.; Toccu, M. An interoperable open data framework for discovering popular tours based on geo-tagged tweets. Int. J. Intell. Inf. Database Syst. 2017, 10, 246–268. [Google Scholar] [CrossRef]
- NLTK Project. Natural Language Toolkit. NLTK 3.4.5 Documentation. 2019. Available online: https://www.nltk.org/ (accessed on 1 December 2019).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Salles, T.; Gonçalves, M.; Rodrigues, V.; Rocha, L. Improving random forests by neighborhood projection for effective text classification. Inf. Syst. 2018, 77, 1–21. [Google Scholar] [CrossRef]
- Xu, B.; Ye, Y.; Nie, L. An improved random forest classifier for image classification. In Proceedings of the 2012 IEEE International Conference on Information and Automation, Shenyang, China, 6–8 June 2012; pp. 795–800. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology; Sage Publications, Inc.: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Kim, A.E.; Hopper, T.; Simpson, S.; Nonnemaker, J.; Lieberman, A.J.; Hansen, H.; Guillory, J.; Porter, L. Using Twitter data to gain insights into e-cigarette marketing and locations of use: An infoveillance study. J. Med. Internet Res. 2015, 17, e251. [Google Scholar] [CrossRef]
- Chowdhury, G.G. Natural language processing. Annu. Rev. Inf. Sci. Technol. 2003, 37, 51–89. [Google Scholar] [CrossRef]
- Fiesler, C.; Proferes, N. “Participant” perceptions of Twitter research ethics. Soc. Media+ Soc. 2018, 4, 2056305118763366. [Google Scholar] [CrossRef]
- Twitter. Twitter Privacy. 2020. Available online: https://twitter.com/privacy (accessed on 1 December 2019).
- Rivers, C.M.; Lewis, B.L. Ethical research standards in a world of big data. F1000Research 2014, 3, 38. [Google Scholar] [CrossRef]
- Williams, M.L.; Burnap, P.; Sloan, L. Towards an ethical framework for publishing Twitter data in social research: Taking into account users’ views, online context and algorithmic estimation. Sociology 2017, 51, 1149–1168. [Google Scholar] [CrossRef]
- Lienemann, B.A.; Unger, J.B.; Cruz, T.B.; Chu, K.H. Methods for coding tobacco-related Twitter data: A systematic review. J. Med. Internet Res. 2017, 19, e91. [Google Scholar] [CrossRef]
- Huang, T.; Elghafari, A.; Relia, K.; Chunara, R. High-resolution temporal representations of alcohol and tobacco behaviors from social media data. Proc. ACM Hum. Comput. Interact. 2017, 1, 54. [Google Scholar] [CrossRef]





| D1 | D2 | D3 | |
| Time period | December 2017–March 2018 | April–June 2018 | July–September 2018 |
| Number of days | 96 | 77 | 80 |
| Number of tweets | 409,788 | 316,541 | 318,071 |
| Tweet favorite count | |||
| 0 | 73.94% | 88.42% | 89.23% |
| 1–5 | 23.62% | 11.15% | 10.36% |
| >5 | 2.45% | 0.43% | 0.41% |
| Retweeted at least once | 45.85% | 54.49% | 50.11% |
| Unique users | 144,614 | 129,808 | 131,161 |
| Users’ characteristics * | |||
| Years since account | |||
| creation median (iqr) | 5 (3–8) | 6 (3–8) | 6 (3–9) |
| Statuses count median (iqr) | 2482 (554–9751) | 3039 (663–12,376) | 2872 (657–11,523) |
| Average number of tweets | |||
| per user in the time-period | 2.78 | 2.22 | 2.35 |
| Followers count median (iqr) | 353 (88–1317) | 416 (104–1531) | 411 (114–1449) |
| Favorites count median (iqr) | 756 (116–3598) | 1071 (171–5295) | 990 (155–4849) |
| Friends count median (iqr) | 477 (160–1361) | 516 (171–1500) | 509 (177–1438) |
| URL in user’s profile | 52.59% | 51.11% | 53.36% |
| Tweet Text | User Description | User Nickname |
|---|---|---|
| abuse | addiction | addiction |
| ad | advertising | bar |
| addict/addiction | bar | blog |
| bar | blog | book |
| book | boutique | bot |
| discount | business | business |
| disease | charity | country |
| dutyfree | commercial | disease |
| free | corporate | distillery |
| freetickets | crowdfunding | drink |
| gift | dependence | fitness |
| hotline | discounts | food |
| illness | distillery | game |
| magazine | editor | grocery |
| marketing | events | hotel |
| masterclass | fitness | journal |
| motivation | follow | lifestyle |
| official | free | magazine |
| page | game | marketing |
| quit/quitting | gifts | meal |
| recipe | gin | natural |
| recovery | help | news |
| shipped | inquires | official |
| shop | magazine | performance |
| sobriety | marketing | recipe |
| sponsor/sponsored | official | recovery |
| stop | organisation | renascence |
| treatment | page | shop |
| t-shirt | promotional | social |
| tutorial | prosecco | spotlight |
| win | recipes | town |
| recovery | travel | |
| reservations | tweet | |
| shipped | win | |
| shop | ||
| store | ||
| travel | ||
| treatment | ||
| wodka |
| Frequency (Occurrence) | Frequency (Occurrence) | ||||||
|---|---|---|---|---|---|---|---|
| D1 | D2 | D3 | D1 | D2 | D3 | ||
| fan account | - | 254 | 63 | must 21 follow | 124 | 36 | 44 |
| social media | 238 | 173 | 197 | behalf diageo brands | 99 | 23 | 28 |
| love life | 216 | 155 | 172 | share anyone 21 | 96 | 27 | 32 |
| family friends | 193 | 139 | 153 | working behalf diageo | 95 | 28 | 34 |
| animal lover | 184 | 153 | 145 | 21 follow please | 95 | 25 | 33 |
| love family | 159 | 133 | 139 | diageo brands must | 84 | 19 | 23 |
| live life | 142 | 182 | 143 | brands must 21 | 84 | 18 | 23 |
| music lover | 141 | 104 | 144 | follow please enjoy | 57 | - | 16 |
| husband father | 139 | 135 | 174 | season ticket holder | 55 | 57 | 51 |
| mum 2 | 138 | 79 | 74 | please drink responsibly | 54 | 22 | 21 |
| 21 follow | 137 | - | - | please enjoy responsibly | 54 | - | 18 |
| must 21 | 134 | - | - | responsibly share anyone | 47 | 14 | 18 |
| living life | 130 | 101 | 125 | drink responsibly share | 39 | 14 | - |
| good food | 130 | 90 | 97 | love family friends | 39 | 27 | 29 |
| wife mother | 123 | 117 | 135 | bts fan account | - | 27 | - |
| loving life | 117 | 80 | 98 | fan account btstwt | - | 26 | - |
| mental health | 116 | 160 | 150 | live life smiling | - | 25 | - |
| share anyone | 115 | - | - | site last tweet | - | 20 | - |
| mum 3 | 115 | 89 | 72 | god family country | - | 18 | 21 |
| craft beer | 111 | 85 | 114 | link last tweet | - | 18 | - |
| follow us | 110 | - | 81 | love love peace | - | 18 | - |
| food wine | 103 | 80 | 91 | url last tweet | - | 16 | - |
| public health | 102 | 162 | 161 | good food good | - | 15 | - |
| follow please | 101 | - | - | love good food | - | 15 | - |
| part time | 100 | 84 | 68 | one day time | - | 29 | 38 |
| follow back | 99 | 123 | 119 | live laugh love | - | 18 | 31 |
| anyone 21 | 99 | - | - | work hard play | - | 33 | 25 |
| love music | 99 | 97 | 102 | live love laugh | - | 22 | 25 |
| food drink | 96 | 85 | 85 | hard play hard | - | 21 | - |
| working behalf | 95 | - | - | official twitter account | - | 33 | 24 |
| dog lover | 93 | 64 | 96 | love life live | - | 17 | 23 |
| video games | 89 | 77 | 85 | live life full | - | 25 | 22 |
| happily married | 89 | 81 | 74 | live life fullest | - | 22 | 22 |
| life love | 89 | 73 | 83 | makes dream work | - | 22 | 21 |
| love travel | 86 | 74 | 60 | crazy cat lady | - | 25 | 19 |
| official twitter | 86 | 76 | 66 | die hard fan | - | 18 | 19 |
| sports fan | 83 | 95 | 77 | love life love | - | 15 | 19 |
| mum two | 83 | 63 | 65 | life one day | - | - | 18 |
| views expressed | 77 | 87 | 77 | living life fullest | - | - | 18 |
| twitter account | - | 76 | - | wife mother grandmother | - | - | 18 |
| god family | - | - | 72 | follow account geotargeted | - | 24 | 18 |
| lover things | - | 70 | 83 | help tweet us | - | 24 | 18 |
| human rights | - | 67 | - | need help tweet | - | 24 | 18 |
| last tweet | - | 65 | - | tweet us careerarc | - | 24 | 18 |
| season ticket | - | 60 | - | follow follow back | - | - | 17 |
| life short | - | 59 | - | follow us instagram | - | - | 17 |
| Characteristics | N or % |
| Unique users | 45 |
| Number of tweets (users’ entire history) | 86,204 |
| Average number of tweets per user | 1959 |
| Tweet favorite count | |
| 0 | 83.16% |
| 1–5 | 15.95% |
| >5 | 0.90% |
| Users’ characteristics * | Median (iqr) |
| Years since account creation | 8 (7–10) |
| Statuses count | 2664 (849–9602) |
| Followers count | 238 (86–525) |
| Favorites count | 1085 (111–3075) |
| Friends count | 460 (166–715) |
| URL in user’s profile (%) | 45.45% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crocamo, C.; Viviani, M.; Bartoli, F.; Carrà, G.; Pasi, G. Detecting Binge Drinking and Alcohol-Related Risky Behaviours from Twitter’s Users: An Exploratory Content- and Topology-Based Analysis. Int. J. Environ. Res. Public Health 2020, 17, 1510. https://doi.org/10.3390/ijerph17051510
Crocamo C, Viviani M, Bartoli F, Carrà G, Pasi G. Detecting Binge Drinking and Alcohol-Related Risky Behaviours from Twitter’s Users: An Exploratory Content- and Topology-Based Analysis. International Journal of Environmental Research and Public Health. 2020; 17(5):1510. https://doi.org/10.3390/ijerph17051510
Chicago/Turabian StyleCrocamo, Cristina, Marco Viviani, Francesco Bartoli, Giuseppe Carrà, and Gabriella Pasi. 2020. "Detecting Binge Drinking and Alcohol-Related Risky Behaviours from Twitter’s Users: An Exploratory Content- and Topology-Based Analysis" International Journal of Environmental Research and Public Health 17, no. 5: 1510. https://doi.org/10.3390/ijerph17051510
APA StyleCrocamo, C., Viviani, M., Bartoli, F., Carrà, G., & Pasi, G. (2020). Detecting Binge Drinking and Alcohol-Related Risky Behaviours from Twitter’s Users: An Exploratory Content- and Topology-Based Analysis. International Journal of Environmental Research and Public Health, 17(5), 1510. https://doi.org/10.3390/ijerph17051510