1. Introduction
Air quality monitoring is one of the major challenges that European institutions jointly with national and local administrations are facing in terms of environmental protection. In particular, the 2008 European Air Quality Directive (AQD) 2008/50/EC [
1] requires EU Member States to design appropriate air quality plans for zones where the air quality does not comply with the AQD limit values. In the last few decades, European countries implemented various modeling methods to assess the effects of local and regional emission abatement policy options on air quality and human health [
2]. On the one side, they include scenario approaches, in which running a chemical-physical simulation model with and without a specific emission source allows for quantifying the impact on air quality levels [
3,
4]. On the other side, they also include more comprehensive and multidisciplinary approaches, such as Integrated Assessment Models (IAM), which combine simultaneously many features of the economy, society, and scientific findings. These models are based on the combination of multiple mathematical tools and allow for assessing the impact of environmental policies or to improve the air quality control system. Typical tools are the full cost-benefit analyses [
5], in which abatement measures, costs, and benefits are expressed in monetary units, optimization, and spatial analysis [
6,
7].
In areas such as Northern Italy, where the industrial transition in the 1990s reduced coal burning and sulphur concentration, the large majority of environmental studies focus their attention on toxic pollutants that are produced by thermic vehicle engines and house heating plants. These are known to generate serious health effects [
8]. Total nitrogen oxides (NO
), nitrogen dioxide (NO
), and particulates matters (PM
and PM
) belong to this class.
According to the above EU rules, governments adopted standards and quantitative limits for pollutant emissions to make economic agents responsible and implement abatement policies. In particular, the maximum concentration for NO
and NO
is set to 40
g/m
annual average and 200
g/m
hourly not to be exceeded more than 18 times in a single year.
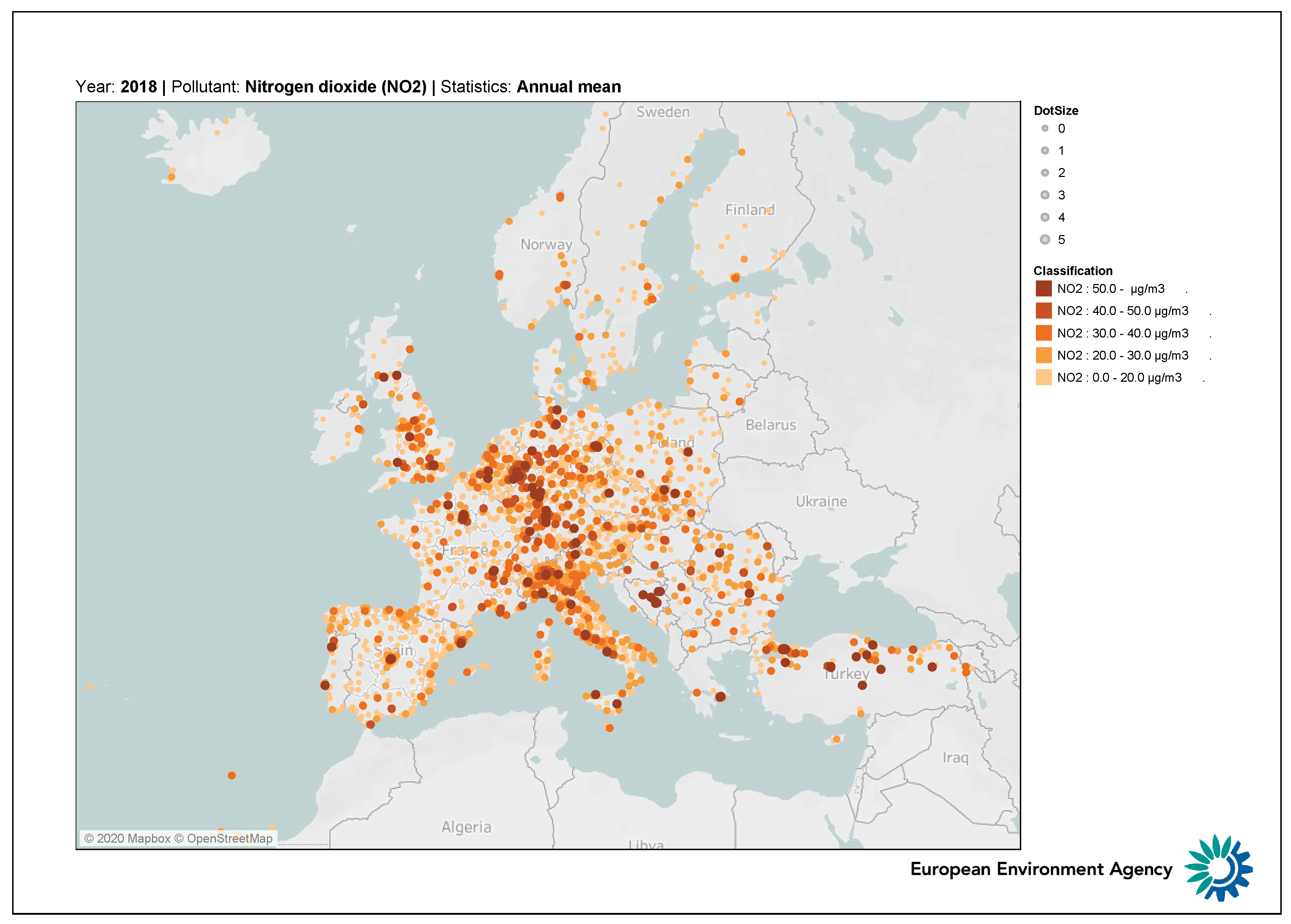
Figure 1 represents the average concentration levels of NO
in Europe for the year 2018. The Po basin in Northern Italy stands out as a heavily polluted area with difficulties in pollution management. The negative impact on society is not limited to health only. There is increasing evidence showing that bad air quality in general, and high NO
concentrations in particular, impact the economy, including finance [
9] and tourism [
10].
The present paper analyses the introduction of the first phase of an air quality control policy in the municipality of Milan, which started on 25 February 2019 and directly acts on traffic rules. The administration defined an extended limited traffic zone, named Area B (
https://www.comune.milano.it/aree-tematiche/mobilita/area-b), where the access and circulation for the most polluting vehicles, as well as those longer than 12 meters, have some partial restrictions, enforced by a monitoring system of entrance gates controlling each license plate and imposing a fine on unauthorized vehicles. The access prohibition concerns Euro 0 petrol vehicles and a large part of Euro 0, 1, 2, and 3 diesel vehicles, with specific exemptions for public transport, itinerant traders, and residents, and it is active from Monday to Friday during business hours (from 7:30 a.m. to 7:30 p.m.), except holidays. According to the municipality of Milan, the share of cars registered in the Milan metropolitan area and involved in the restrictions in 2019 is close to 17%, while the share of freight transport vehicles is around 53% [
11]. Area B is a progressive policy divided into various phases, which will concern an increasing number of vehicle classes. In terms of NOx emissions, the administration expects a reduction of 4–5% per year until 2022 and a reduction of 11% between 2023 and 2026. The policy will be fully operative within October 2030.
Area B extends the previously existing limited traffic zone, Area C, which covers just the historical city centre. The physical coverage of the two restriction zones is represented in
Figure 2, which highlights the arrangement of both within the city borders. Area B covers almost the entire area of the city, excluding extreme peripheral districts.
Statistical literature on air quality grew up sharply in the last decades. Two main statistical modeling directions have been developed. One has a focus on pollutants concentration and the other on human exposure. Regarding the latter, recent advances are based on crowdsourced data, such as smartphone data modeling [
12]. Regarding pollutants concentrations, increasing attention is being given to latent component models; see, as an example [
13] and for the problem of misalignment. In particular, the use of the INLA-SPDE approach for misalignment between pollutant concentration and epidemiological data [
14] and PCA based methods with missing data [
15].
When the territory under study is large and spatial correlation is important, spatio-temporal models are appropriate. See, for example, the multivariate state space approach of Calculli et al. [
16], which is capable of handling jointly PM
NO
and weather variables, the approach of Menezes et al. [
17] for modeling daily NO
trends in Portugal. Moreover, the land-use regression model (LUR) under a state space approach has been used for modeling air pollution in Tehran [
18]. Despite this growing spatial literature, time series analysis methods have been recently developed to understand the effect of meteorology on pollutant concentration [
19], which will be the main focus of this paper.
The previous Milan limited traffic zone, known as Area C, has already been treated in literature by Fassò [
20], who analyzed its introduction through spatio-temporal models, by Invernizzi et al. [
21], who considered its impact on black carbon, and by Percoco [
22] who considered its effect on traffic. Moreover, similar problems have been studied for London "sulphur-free zone" [
23] and the "low emission zone" in Munich [
24]. In Fassò [
20], the author considered both particulates and nitrogen oxides and observed the presence of a more pronounced permanent reduction of the latter within the restricted area, despite the data showing a strong spatial variability depending on the type of pollutant. This is consistent with the known emissions pattern of particulate matters and nitrogen oxides. The latter are mainly primary gaseous pollutants and can be directly attributed to anthropogenic sources, such as car traffic and house heating. Moreover, from the so-called INEMAR emission inventory [
25], in Milan province, 68% of NOx and only 41% of PM10 are due to road traffic. Hence, in this first study of Area B, we will take into account NO
and NO
and postpone the analysis of PM10 and PM2.5 to further research. To adjust for confounding factors, we will consider weather conditions in Milan, the main calendar events, and the concentration levels of oxides observed in neighbouring towns, as in a pseudo-treatment-control approach.
The study aims to identify and quantify variations in pollutant levels due to the above described Area B. Hence, the present paper will try to investigate and test the following two scientific hypotheses:
Hypothesis 1. The introduction of Area B achieved significant changes in pollution concentration for the city of Milan;
Hypothesis 2. The variation occurred homogeneously on the territory and the stations do not show spatial variability of the effects.
The first hypothesis aims to quantify the impact of the policy on pollution levels measured by several air quality stations scattered around the city and to assess whether this evidence is significantly supported by the data. The impact is evaluated both regarding the statistical significance of the estimates, the absolute magnitudes of the coefficients, and their signs. From the policy maker perspective, the expected coefficients should be negative, indicating a reduction effect on concentrations due to the car traffic restrictions. However, given the complexity of the phenomenon, a change of opposite sign cannot be ruled out either. The second research hypothesis is dedicated to the comparison of the estimates for the considered stations: the effect can be considered homogeneous when the sign and the magnitude of the coefficients for all the stations are similar.
The paper is structured as follows.
Section 2 describes the dataset and the methodologies used for the analyses. In particular, we briefly explain the composition of both weather and air quality monitoring systems in Milan, available data sources, and metadata information. Then, we present the methodologies implemented for the preliminary analysis and the state space approach to time series analysis for air quality data.
Section 3 reports and discusses the empirical results of the estimated models and their implications.
Section 4 concludes the paper discussing the two research hypotheses in light of what emerged from the data analysis and gives some hints for future research developments.
2. Materials and Methods
In this section, we present the structure of the ARPA dataset and briefly introduce the methodologies implemented for the analyses.
Section 2.1 introduces the data source for the Milan case study and the spatio-temporal structure of the data and provides a brief description of the variables taken into consideration.
Section 2.2 designs the preliminary analysis, which introduces a temporal treatment-control experiment to highlighting the differences in concentration levels before and after the policy intervention.
Section 2.3 gives a detailed overview of the use of state space models in time series analysis for the study of air quality data, including also a specific subsection for model selection and policy intervention.
2.1. Data
2.1.1. Air Quality and Weather Monitoring Network in Milan
Data on pollution and weather conditions of Lombardy are collected from the Lombardy Regional Agency for Environmental Protection (ARPA Lombardia), which makes a large open data portal fully available to users (
https://www.dati.lombardia.it/). The agency manages a diffuse monitoring system distributed among the regional territory and counting on hundreds of monitoring stations collecting intra-daily information on climate and pollution through sensors.
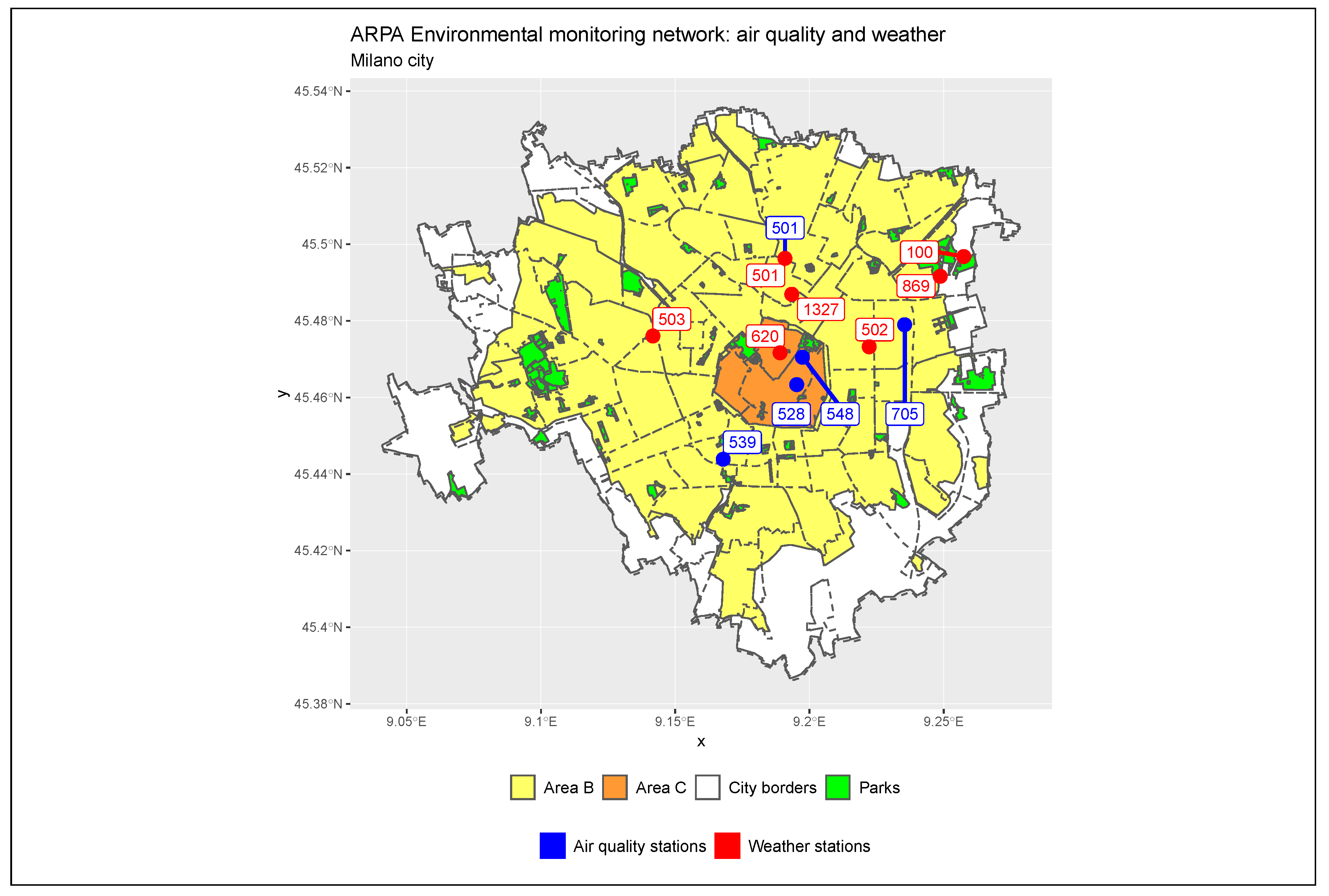
Installed within the borders of Milan are seven weather monitoring stations and five air quality monitoring stations. Air quality stations are classified according to a taxonomy system that identifies the type and function in the network. The stations Liguria (ARPA code 539), Marche (ARPA code 501), Senato (ARPA code 548), and Verziere (ARPA code 528) are urban traffic control units: sensors installed near important roads and intersections in order to accurately quantify the pollution generated by traffic. The station Città Studi (ARPA code 705) is instead of type urban background, that is, the station is located in such a position that the level of pollution is not mainly influenced by specific sources but by the integrated contribution of all the upwind sources at the station with respect to the predominant directions of the winds on the site [
8]. The seven weather stations are Marche (ARPA code 501), Lambrate (ARPA code 100), Zavattari (ARPA code 503), Brera (ARPA code 620), Feltre (ARPA code 869), Rosellini (ARPA code 1327), and Juvara (ARPA code 502).
Figure 2 georeferences on the map the exact position of each station and allows for identifying the position with respect to Area B and Area C. Air quality stations are represented as blue points, while weather stations are the red points. Marche station (ARPA code 501), in the upper side of the map, is the only one to collect both weather and pollution data and is represented with a double label, the first one blue and the second red.
The spatial distribution of the stations is not uniform: air quality stations cover northern, eastern, central, and southern parts of the city, leaving the western districts uncovered; climate stations cover in detail the city centre and all the northern neighbours but are not installed in the south.
2.1.2. Temporal Coverage, Pollutants, and Weather Measures
The analysis presented in this paper takes into account daily measures from 1 January 2014 to 30 September 2019, generating an overall sample of 2099 daily observations.
The whole, the monitoring system provides information about many urban pollutants, such as carbon dioxide, particulates, and oxides. All the pollutants are measured as g/m. As already stated in the Introduction, we focus our attention on concentrations of total nitrogen oxides (NO) and nitrogen dioxide (NO), which are mainly primary gaseous pollutants, hence considered as proxies of pollution emissions due to human activities, first of all car traffic.
Weather stations provide measures of local temperature (C), rainfall (cumulated mm), humidity (%), global radiation (W/m), wind speed (m/s), and wind direction. The wind direction is expressed in clockwise degrees from to ; for example, identifies winds going from east to west. To make results easier to interpret, we decide to aggregate the measurements on wind direction and speed by constructing a set of new variables that describe the average speed in the four quadrants of the compass rose. The Northeast quadrant (Q) corresponds to degrees between 0 and 90, the Southeast quadrant (Q) to degrees from 90 to 180, the Southwest quadrant (Q) to degrees from 180 to 270 and the Northwest quadrant (Q) to the remaining values lying between 270 and 360 degrees.
These measures will be used in the modeling part to capture local weather conditions specific to the city of Milan. Instead of using the data referring to the weather station closest to each air quality station, we preferred to aggregate each of the climate variables through a daily city average valid for each pollution station. In this way, the subsequent models will be fully comparable guaranteeing the maximum possible spatial coverage.
2.1.3. Anthropogenic Activities
Human activities, and therefore the quality of the air we breathe, are often affected by calendar events that are recorded based on national, local, and religious holidays and weekends. Calendar effects are captured by a set of covariates, which identify the weekends and the main Italian holidays, both religious and secular. Holidays are collected in a dummy variable named Holidays, while the weekends are contained in a dummy variable named WeekEnd. Specific effects related to the behavior of people can be observed when holidays coincide with the weekend; therefore, we considered two terms of interaction between the two dummies. The interaction terms include those holidays that fall on Saturday, denoted as Saturday:Holiday, and those on which they fall on Sunday, which is Sunday:Holiday.
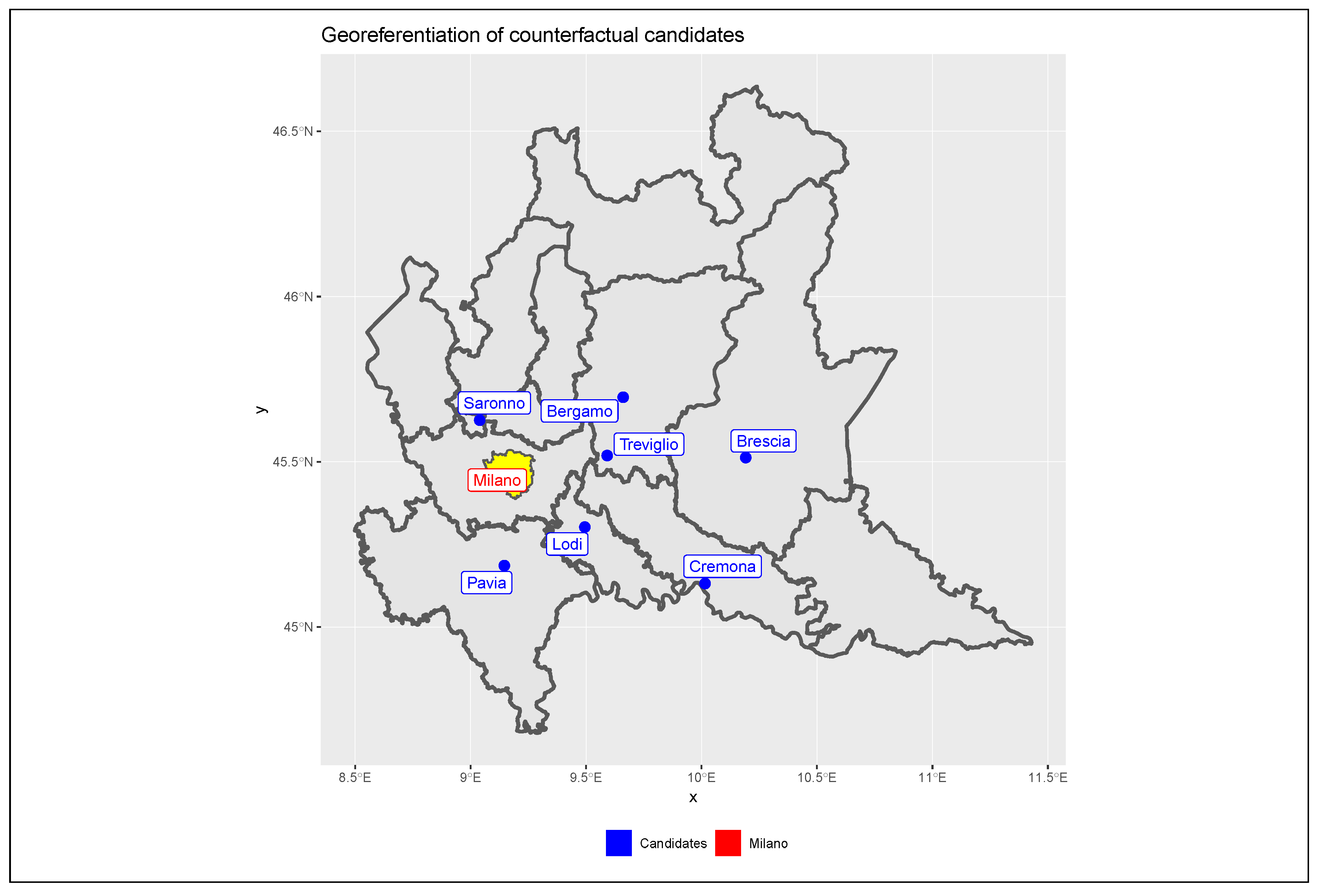
For a correct assessment of the effects of the traffic policy on pollutants concentrations in Milan, it is necessary to purify the estimates from any external weather or socio-economic effects overlapping with the policy and which may hence alter policy effects. This operation is accomplished by introducing a counter-factual term into the models represented by the pollution levels observed in other cities surrounding Milan. We considered seven important urban centres located in the Lombardy Po Valley area, which show socio-demographic and economic characteristics and weather conditions similar to Milan, but which cannot be directly affected by the limited traffic zone. These urban centres are Bergamo (East), Brescia (far East), Cremona (far Southeast), Lodi (Southeast), Pavia (South), Saronno (North) and Treviglio (East). As reported in
Figure 3, the considered candidates cover a large territory surrounding Milan in all the directions while maintaining a sufficient distance to be considered independent in terms of traffic.
2.2. Methods: Average and Median Difference before and after the Policy
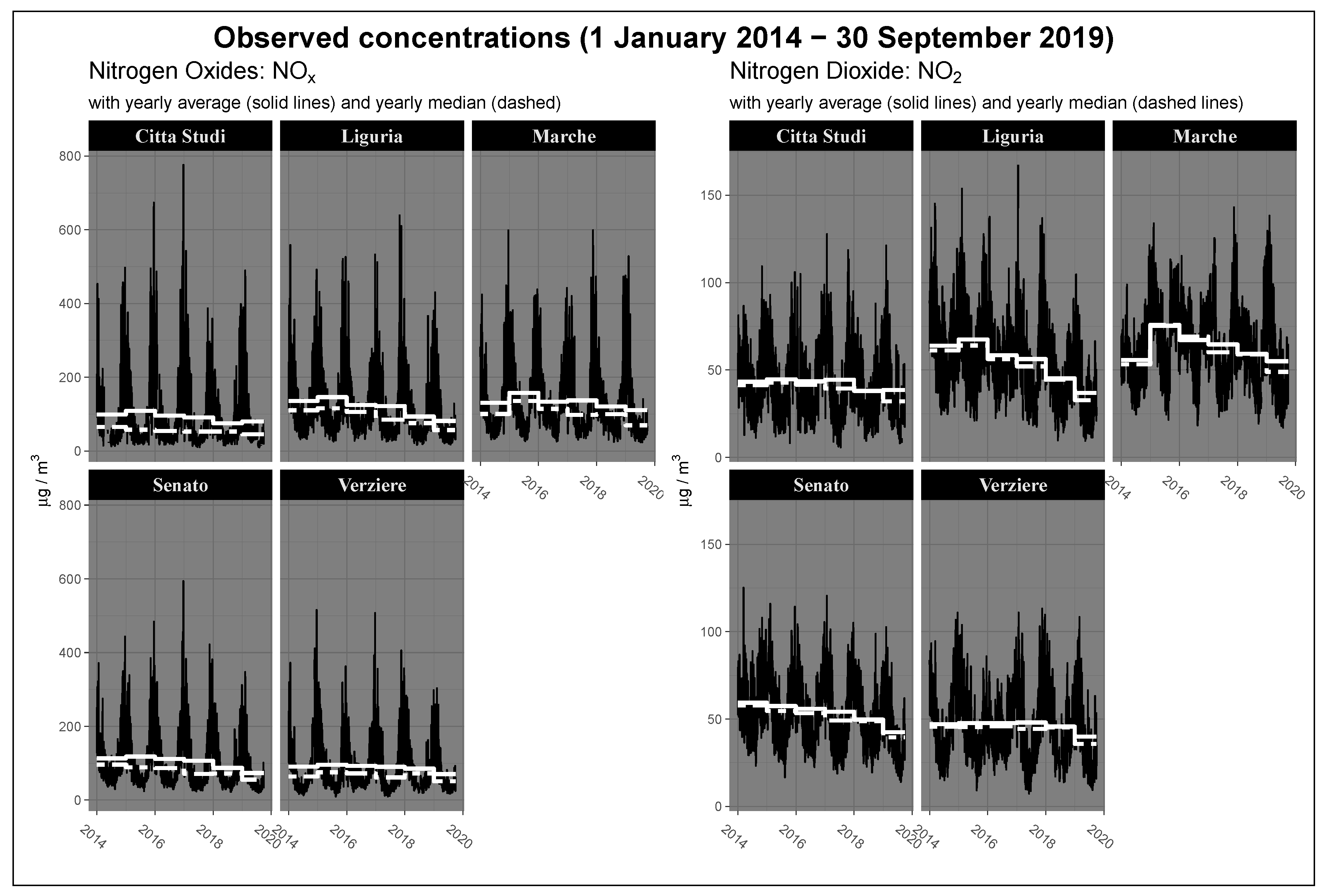
Figure 4 shows the temporal evolution of yearly average and median concentrations in the period preceding and following the entry into force of the policy for each control units located in Milan. According to the figure, starting from 2015, the city of Milan recorded a generalized reduction of concentration levels especially in peripheral areas, such as Marche and Liguria. Observed mean values for 2019 present a further reduction of concentrations rather apparently anomalous and significant. The comparison between the levels of NO
and NO
pairs for each station shows obvious common trends between the two pollutants both considering the annual average and median values. Averages and medians follow similar temporal patterns, but focusing on nitrogen oxides sensors, it is possible to note that the medians are significantly smaller than the averages, highlighting the heavy-tailed characteristic of the distribution (positive asymmetry) and the presence of extreme values. Following these facts, an interesting question to investigate is if, and how much, the greater difference observed in 2019 can be attributed to traffic restrictions, or if it is due to a general de-carbonization trend that the city is experiencing, or to weather variations not considered yet.
Before investigating the factors and causes that may have generated these sharp reductions, we perform a preliminary analysis of the concentration levels pre-and-post policy, in order to quantify the changes observed in 2019 both in Milan and in the other centres. Since air quality data present outliers and heavy-tail distributions given by extreme events, the only use of average values for central tendency estimation can provide misleading results. Therefore, we compare the central values obtained both considering the sample mean and the sample median, which is notoriously a more robust indicator if outliers occur [
26,
27].
The comparison is performed through the computation of two statistics based on the difference of central tendency indicators. The first statistic computes the difference between the average of the observations gathered after the policy intervention and the average of observations referring to the sub-period 2014–2018. The second statistics consists of computing the difference between median concentration levels observed in 2019 and before that year. The difference in average concentrations is denoted by , whereas the difference in median concentrations is denoted as . Since both sub-periods are treated as independent of each other, from the statistical perspective, the statistics are assimilable to unpaired samples statistics.
Both statistics use the observations collected between 25 February and 30 September of each year, with a total length of 214 days. Approaches of this type can be framed in a context of treatment-control analysis, in which the data referred to the year 2019 constitute the treatment group, while the observations collected between 2014 and 2018 compose the control group. Control data refer to a 5-year-period; therefore, the concentrations measured on the same calendar day are aggregated into a single representative value calculated as the daily average concentration of the period 2014 to 2018. Denoting as the observed pollutant concentration during the day j, where , of the year i, where , the average for a generic calendar day j is computed as .
Let be the treatment observations and the control observations, the difference of averages is defined as and the difference of medians is calculated as , where is the temporal sample mean and is the temporal sample median.
2.3. Methods: Time Series Modeling Using a State Space Approach
In this section, we discuss the time series models used to identify the policy effect, the estimation algorithms, and the related inference. Firstly, we introduce a brief description of the basic structural model (BSM) using a state space approach for time series analysis and the estimation algorithm based on the Kalman filter [
28,
29]. Then, we present a three-step procedure used to select the most representative model in terms of predictive power and quality of fit. As a last step, we explain how the policy intervention is included in the models and how it should be interpreted.
2.3.1. Basic Structural Model for Air Quality Data
According to their physical characteristics, air pollution concentrations time series are often characterized by seasonality, high persistence [
30,
31], strong right skewness with uni-modal distribution, and scale invariance [
32]. Therefore, we analyze the concentrations using the basic structural model [
33,
34] augmented by deterministic regressors for weather conditions and socio-economic features.
BSM is defined as a simple unobservable components model composed by local linear trend (LLT), stochastic seasonality, and irregular (white noise) component. LLT describes both the temporal evolution of the series level and its slope, while the seasonal component aims to capture cyclical behaviors given by natural and anthropogenic phenomena. We modeled the seasonal component using a trigonometric form for daily data, hence with period , and considering only a few harmonics given the very regular and almost deterministic behavior of the series. This fact avoids the risk of a model over-parametrization.
Let
be the time series of the observed pollution concentrations in logarithmic scale, the state space form of BSM without regressors is composed by the following equations:
where
is the measurement error and
where
is the number of included harmonics and
is the non-stationary stochastic cycle
and are white-noise processes with mean zero and variance .
Equation (
1) is called measurement equation and describes the evolution of the observed series as the sum of the underlying components, while Equations (
2)–(
4) are named transition equations. Equations (
2) and (
3) compose the LLT and describe respectively the unobservable processes of the level and the slope, whereas Equation (
4) describes the trigonometric seasonality evolution. Weather, socio-economic factors, and policy intervention will be included in the models adding a set of deterministic components to the measurement Equation (
1). Since the BSM with Gaussian errors belongs to the class of Gaussian linear models, the estimation step has been performed using the Kalman Filter algorithm, an iterative procedure, which allows estimating simultaneously the unobservable components and the model’s parameters by maximizing the Gaussian likelihood function.
When dealing with Gaussian linear state space models, the parameters estimated using a maximum likelihood (ML) approach inherit the asymptotic properties of ML estimators [
29]. The distribution of the MLE is asymptotically approximated using a Gaussian distribution, which allows deriving the usual asymptotic confidence intervals and t-tests for significance. Assuming a significance level of 5%, the estimates are statistically significant if the standardized value lies outside of the interval [−1.96,1.96], obtained using the quantiles of a Standard Normal distribution. Moreover, since the dependent variable is expressed in logarithmic scale, the coefficients have to be interpreted as relative increases or decreases in concentration levels due to a unitary increase in the explanatory variable.
2.3.2. Three-Step Model Selection
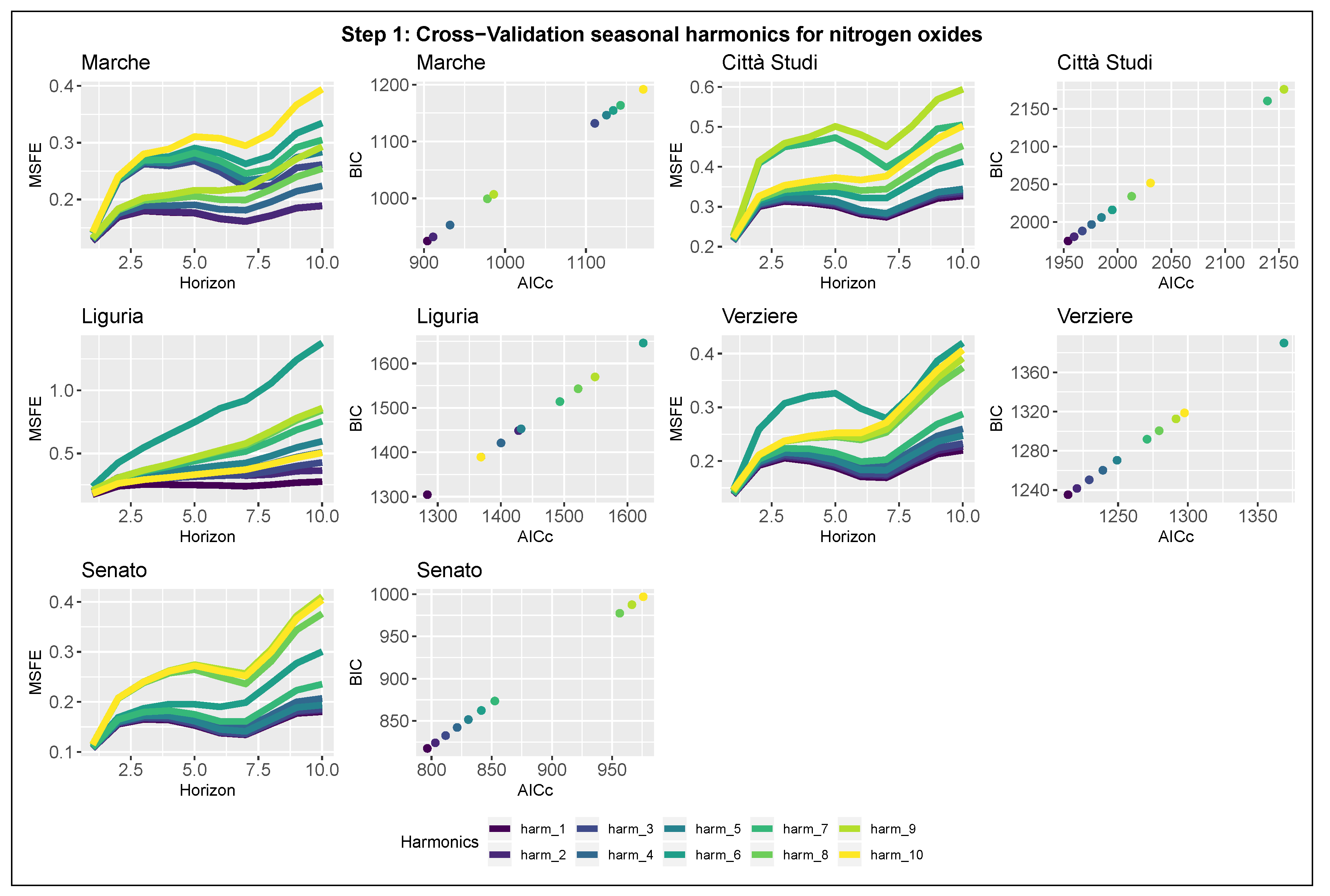
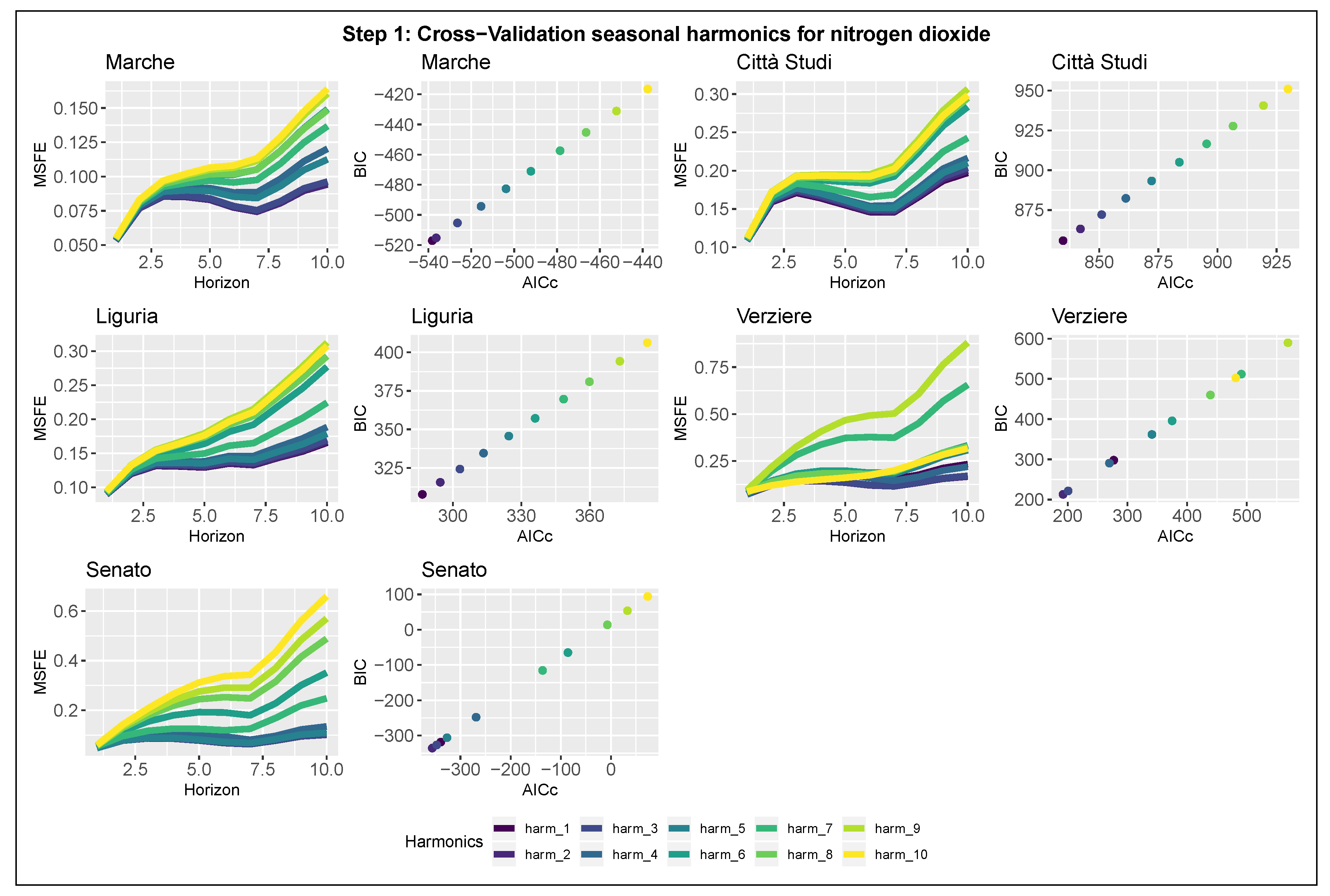
We now propose a three-step procedure for model selection, which considers multiple rules based on cross-validation, information criteria, and stepwise regression. To avoid estimation bias due to the policy introduction, all the steps are computed using only the observations before the introduction of Area B that is, from 1 January 2014 to 24 February 2019.
Step 1 is designed for selecting the most predictive seasonal component, defined in Equation (
4), comparing different model specifications, which consider a varying number of harmonics
k for the trigonometric function. Specifically, we fit 10 alternative models for each station: in each of them, the trigonometric seasonality is modeled by an increasing number of harmonics ranging from
to
. The use of an increasing number of sinusoids, in our case up to 10, allows the modeling of complex seasonality with strong variations within short periods, but at the same time increases the model complexity.
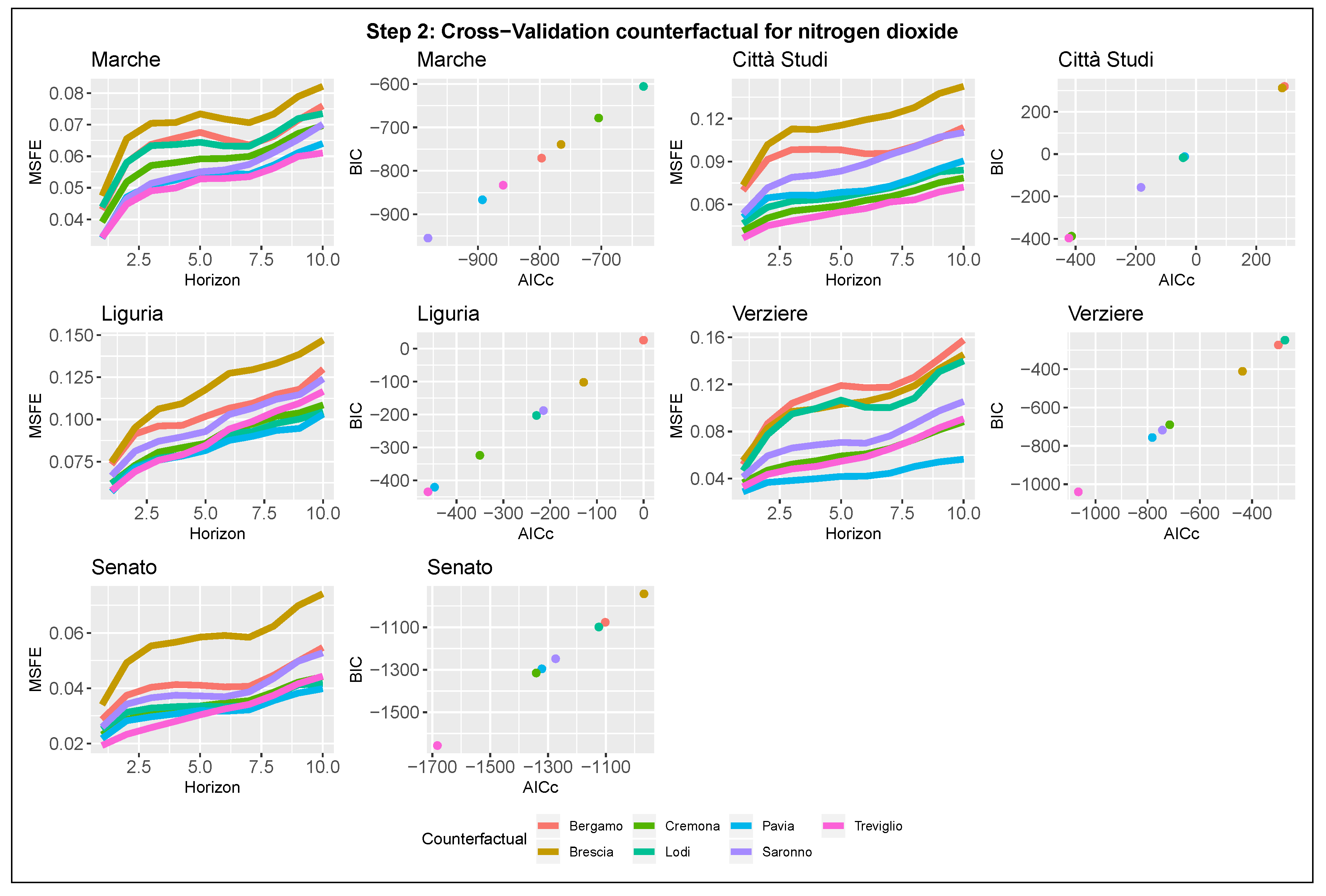
Once the seasonal component has been selected, step 2 introduces in Equation (
1) a counter-factual term
able to capture weather and socio-economic factors common to the Po basin and affecting the air quality of Milan. In our approach, the counter-factual candidates are the time series introduced in
Section 2.1.3 and which refer to the measurements of pollutant concentrations in seven important cities around Milan. The new measurement Equation can be written as follows:
where
is the logarithm of the counter-factual time series and
is its coefficient,
follows Equations (
2) and (
3), and
follows the specification obtained by step 1. The expected sign of
is positive: higher levels of air pollution should correspond to high values in nearby cities due to similar conditions.
In step 3, we identify the best subset of calendar events and weather covariates, capturing residual variations not yet covered by the counter-factual or by the latent components. These residual variations are estimated by the smoothed observation disturbances from Equation (
6) that is
, and describe residual patterns that have not been explained by the persistence of series, the seasonality or characteristics common to nearby territories of the region.
Relevant weather and calendar covariates are selected through a backward-forward stepwise regression algorithm, which uses as a starting model the auxiliary linear regression expressed in Equation (
7). The equation represents the full model which sets up the smoothed observation errors
as dependent variable and the weather conditions and calendar events as covariates:
The stepwise regression is set up twice for each station: in one case, it selects the model according to the Akaike’s Information Criterion (AIC), while, in the other, it uses the Bayesian Information Criterion (BIC). The algorithm starts estimating the full model and computes the AIC or the BIC. Iteratively, it drops out the predictors one at a time; at each step, it computes the new information criterion and considers whether the criterion is improved by adding back in a variable removed at a previous step. The procedure ends when the reintroduction of each omitted variable does not improve the information criteria.
In the first two steps, we select the seasonal component and the counter-factual term by fitting and comparing alternative models based on Equations from (
1) to (
4) according to their predictive power and their ability to adapt adequately to the observed data. The first principle, which tests the predictive power of the models, relies on the minimization of the cross-validated mean square forecasting error (MSFE) evaluated for up to 10-step-ahead forecast horizon, that is,
, while the second compares the models in terms of estimation quality. The latter computes both corrected Akaike’s Information Criteria (AICc) and BIC intending to select the model that minimizes both. To identify a unique model for all the stations located in Milan, we proceed to a global comparison, both graphical and analytical, of the two blocks of indicators, giving attention to the overall performances and not focusing only on individual outputs.
According to the cross-validation principle for time series [
35,
36], we split the full time series into two subsets: a training set for model estimation and a test set for evaluating the out-of-sample forecast performances. The training set includes all the measurements until 24 February 2018, while the test set contains observations relative to the sub-period 25 February 2018–24 February 2019, for a total count of 365 out-of-sample observations. The exclusion of observations after the start of the traffic restrictions makes it possible to obtain unbiased estimates of the policy effects avoiding overlapping with other unidentified factors. Before starting the iterative loop, the model to evaluate is estimated just on time using the observations included in the original training set. At the end of the estimation, the cross-validation algorithm is iteratively implemented as follows. For each iteration, the algorithm extracts the first ten observations available in the test set, generating a forecasting set, and computes three quantities: the 1-to-10 step-ahead forecasts that is
, the forecast errors
and the quadratic forecast errors
. The first out-of-sample observation is discarded and the set of forecasting observations is updated right-shifting the forecast horizon by 1 unit and adding the new observation. These operations are repeated for a number of times equal to the length of the test set, in our cases 365 times. The algorithm returns the output of 365 different sequences of 1–10 step-ahead forecasts; for each step-ahead
, the MSFE is calculated as
.
2.3.3. Policy Intervention Analysis
The introduction of new rules or limitations to individual behaviors can lead to the co-existence of multiple effects with different structure, such as simultaneous immediate changes and adaptive changes that take a long time before visible effects occur. Take into consideration that this fact leads to implement intervention analysis, which includes both permanent and transitory effects. Further details and examples of ARMA-like transfer function applied to intervention analysis are available in Pelagatti ([
29]).
The policy intervention is modeled through the combination of two individual effects: (1) a permanent effect, estimated by
that measures the level shift of pollutant concentrations given by the treatment and modeled as a step dummy, which is
, which assumes a value equal to 1 starting from 25 February 2019; (2) a transitory effect, estimated by
and evolving according to a first-order difference dynamics of the type
where
is a impulse dummy, which assumes value equal 1 for 25 February 2019 and 0 otherwise and
measures the persistence of the transitory effect. The sum of the two effects returns the total effect, which expresses the estimated overall reduction or increase in air pollutant levels generated by the policy. The measurement equation after the three-step model selection and augmented by the policy intervention is eventually expressed as follows:
where
is the logarithm of pollution concentrations in one of the stations in Milan,
is the logarithm of pollution concentrations in the optimal counter-factual station,
is the LLT evolving according to Equations (
2) and (
3),
is the optimal seasonal component selected in step one,
is a matrix containing the set of optimal subset of weather and calendar covariates selected in step 3, and
is the associate vector of coefficients.
2.3.4. Software
All the statistical computations and figures have been carried out using the statistical software R [
37]. For state space models estimation, the
KFAS package [
38] was used. Cross-validation, forecasting, and model selection codes have been developed by the authors. The graphic elaborations were obtained by using the packages
ggplot2 [
39] and
sf [
40].
4. Conclusions
This paper analyzed the early-stage effects on air quality of the new traffic policy in Milan, the so-called Area B. The concentrations of nitrogen oxides (NO) and nitrogen dioxide (NO), which are mainly primary pollutants, have been considered as proxies of pollution emissions.
The first hypothesis in the introduction inquires about the presence of a significant effect on the air quality of the city. As a first point, the preliminary results show that concentrations during spring and summer 2019 are lower than during the same seasons in the previous five years, hinting for a reduction effect due to the policy. On the other side, a similar reducing trend has been observed in various neighbouring cities around Milan, which belong to a homogeneous meteorological, social, and economical cluster within the Po valley. Their similar behavior is used here as an areal common trend capturing both weather and anthropogenic components. Our approach, which adjusts for local weather conditions and the areal common trend, does not provide a further reduction effect for any station comparing to this trend. Instead, in Senato station, which is inside the historical city centre and was already covered by Area C, the estimates provide a strong, but moderately statistically significant, increase for both considered pollutants. This is coherent with the fact that the restriction introduced is very limited as it concerns just some classes of old vehicles, which are a small percentage of the entire vehicle pool, both in terms of number of cars and emissions.
Since the first research hypothesis is confirmed just to a minor extent and with an opposite sign with respect to what was expected, the second research hypothesis, concerning the homogeneity of the possible effects, assumes now only a technical scope. It is confirmed just for what concerns the positive direction of the changes, but not for their significance. In fact, among all the estimated permanent effects, only Senato station is significant at 5%. Moreover, the estimated transitory effects are always not significant at any confidence level.
The above facts hint that, compared to the common trend of the considered area, Milan air quality is improving slowly, and, in this sense, the first phase of Area B seems to have a negative effect on air quality. Due to the limited scope of this first phase and its progressiveness, it is not unexpected to find a limited or a zero effect. Nonetheless, the negative effect needs some more explanations.
Although finding the ultimate motivation for this is not the aim of this paper, a discussion follows. Firstly, the statistically significant increase found is limited in space and is located inside the previously introduced restricted Area C. It may be possible that this further restriction increased congestion of public transport buses, which are often very old vehicles, or to the aforementioned adaptation shocks. This could explain only a part of the results. In fact, this first point is also related to the other sources of nitrogen oxides. According to INEMAR [
25], road traffic is about 68% of the total emissions. Hence, a transition to house heating green techniques slower in Milan comparing the other considered cities could have an influence on this result. Moreover, also the other stations experienced a comparative deterioration of air quality and the second-worst station is Città Studi, which is an urban background station, hence with limited relation to local traffic congestion. Second, the increase due to road traffic may have temporal dynamics. Since the traffic restriction is limited to business hours, there may be an increase in congestion early in the morning and in the late evening, affecting the daily average.
In conclusion, although environmental protection policies are in general a fundamental step for sustainability improvement, in some cases, they may not be sufficient or their implementation may be misleading. In our case, we considered only the early-stage of a policy, which is progressive in time. Hence, the results of this paper may be regarded as physiological, provided that they characterize only the initial part of the policy implementation and are improved soon. It follows a recommendation to the municipal government to develop the policy more strongly.
Additional research could be developed in the future. In particular, the effect on traffic congestion inside Area C could be investigated further using historical data related to the vehicle movements crossing the access points. Moreover, the use of a multivariate approach, which includes other pollutants such as PM and PM, and spatio-temporal modeling could highlight hidden effects, which are not visible considering the single stations. Eventually, the extension to hourly data could consider both the presence of intra-daily effects and explaining the spatial dynamics related to traffic.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}