Predicting Hepatitis B Virus Infection Based on Health Examination Data of Community Population


Abstract
1. Introduction
2. Material and Methods
2.1. Data Collection
2.2. Data Preprocessing
2.3. Classification Models
2.4. Tuning of Parameters
2.5. Evaluation Metric
2.6. Statistical Analysis
3. Results
3.1. Description
3.2. Predictive Accuracy
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Schweitzer, A.; Horn, J.; Mikolajczyk, R.T.; Krause, G.; Ott, J.J. Estimations of worldwide prevalence of chronic hepatitis B virus infection: A systematic review of data published between 1965 and 2013. Lancet 2015, 386, 1546–1555. [Google Scholar] [CrossRef]
- Global Hepatitis Report. 2017. Available online: https://www.who.int/hepatitis/publications/global-hepatitis-report2017/en/ (accessed on 1 October 2019).
- New Hepatitis B Treatment Guidelines Released in China. Available online: https://www.who.int/hepatitis/publications/global-hepatitis-report2017/en/ (accessed on 1 October 2019).
- Zhiqiang, G.; Zhaohui, D.; Qinhuan, W.; Dexian, C.; Yunyun, F.; Hongtao, L.; Iloeje, U.H. Cost of chronic hepatitis B infection in China. J. Clin. Gastroenterol. 2004, 38, S175–S178. [Google Scholar] [CrossRef] [PubMed]
- Global Health Sector Strategy on Viral Hepatitis 2016–2021. Available online: https://www.who.int/hepatitis/strategy2016-2021/ghss-hep/en/ (accessed on 1 October 2019).
- Uzunalimoğlu, O.; Yurdaydin, C.; Cetinkaya, H.; Bozkaya, H.; Sahin, T.; Colakoğlu, S.; Tankurt, E.; Sarioğlu, M.; Özenirler, S.; Akkiz, H.; et al. Risk factors for hepatocellular carcinoma in Turkey. Dig. Dis. Sci. 2001, 46, 1022–1028. [Google Scholar] [CrossRef] [PubMed]
- Shang, G.; Richardson, A.; Gahan, M.E.; Easteal, S.; Ohms, S.; Lidbury, B.A. Predicting the presence of hepatitis B virus surface antigen in Chinese patients by pathology data mining. J. Med. Virol. 2013, 85, 1334–1339. [Google Scholar] [CrossRef]
- Ocama, P.; Opio, C.K.; Lee, W.M. Hepatitis B virus infection: Current status. Am. J. Med. 2005, 118, 1413. [Google Scholar] [CrossRef]
- Chou, R.; Cottrell, E.B.; Wasson, N.; Rahman, B.; Guise, J.M. Screening for hepatitis C virus infection in adults: A systematic review for the U.S. Preventive Services Task Force. Ann. Intern. Med. 2013, 158, 101–108. [Google Scholar] [CrossRef]
- Guo, P.; Zeng, F.; Hu, X.; Zhang, D.; Zhu, S.; Deng, Y.; Hao, Y. Improved variable selection algorithm using a LASSO-type penalty, with an application to assessing hepatitis B infection relevant factors in community residents. PLoS ONE 2015, 10, e0134151. [Google Scholar] [CrossRef]
- Zeng, F.; Guo, P.; Huang, Y.; Xin, W.; Du, Z.; Zhu, S.; Deng, Y.; Zhang, D.; Hao, Y. Epidemiology of hepatitis B virus infection: Results from a community-based study of 0.15 million residents in South China. Sci. Rep. 2016, 6, 36186. [Google Scholar] [CrossRef]
- Jović, S.; Miljković, M.; Ivanović, M.; Šaranović, M.; Arsić, M. Prostate cancer probability prediction by machine learning technique. Cancer Investig. 2017, 35, 647–651. [Google Scholar] [CrossRef]
- Gao, C.; Sun, H.; Wang, T.; Tang, M.; Bohnen, N.I.; Müller, M.L.T.M.; Herman, T.; Giladi, N.; Kalinin, A.; Spino, C.; et al. Model-based and model-free machine learning techniques for diagnostic prediction and classification of clinical outcomes in parkinson’s disease. Sci. Rep. 2018, 8, 7129. [Google Scholar] [CrossRef]
- Weng, S.F.; Reps, J.; Kai, J.; Garibaldi, J.M.; Qureshi, N. Can machine-learning improve cardiovascular risk prediction using routine clinical data? PLoS ONE 2017, 12, e0174944. [Google Scholar] [CrossRef] [PubMed]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced data sets learning. In Proceedings of the 2005 International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- Zhao, R.N.; Zhang, B.; Yang, X.; Jiang, Y.X.; Lai, X.J.; Zhang, X.Y. Logistic Regression Analysis of Contrast-Enhanced Ultrasound and Conventional Ultrasound Characteristics of Sub-centimeter Thyroid Nodules. Ultrasound Med. Biol. 2015, 41, 3102–3108. [Google Scholar] [CrossRef] [PubMed]
- Richardson, A.M.; Lidbury, B.A. Infection status outcome, machine learning method and virus type interact to affect the optimised prediction of hepatitis virus immunoassay results from routine pathology laboratory assays in unbalanced data. BMC Bioinform. 2013, 14, 206. [Google Scholar] [CrossRef][Green Version]
- Kane, M.J.; Price, N.; Scotch, M.; Rabinowitz, P. Comparison of ARIMA and random forest time series models for prediction of avian influenza H5N1 outbreaks. BMC Bioinform. 2014, 13, 276. [Google Scholar] [CrossRef]
- Li, B.; Zhang, N.; Wang, Y.G.; George, A.W.; Reverter, A.; Li, Y. Genomic prediction of breeding values using a subset of SNPs identified by three machine learning methods. Front. Genet. 2018, 9, 237. [Google Scholar] [CrossRef]
- Maeta, K.; Nishiyama, Y.; Fujibayashi, K.; Gunji, T.; Sasabe, N.; Iijima, K.; Naito, T. Prediction of glucose metabolism disorder risk using a machine learning algorithm: Pilot Study. JMIR Diabetes 2018, 3, e10212. [Google Scholar] [CrossRef]
- Liu, L.; Yu, Y.; Fei, Z.; Li, M.; Wu, F.X.; Li, H.D.; Pan, Y.; Wang, J. An interpretable boosting model to predict side effects of analgesics for osteoarthritis. BMC Syst. Biol. 2018, 12, 105. [Google Scholar] [CrossRef]
- Ma, H.; Bandos, A.I.; Gur, D. On the use of partial area under the ROC curve for comparison of two diagnostic tests. Biom. J. 2015, 57, 304–320. [Google Scholar] [CrossRef]
- McGinn, T.; O’Connor-Moore, N.; Alfandre, D.; Gardenier, D.; Wisnivesky, J. Validation of a hepatitis C screening tool in primary care. Arch. Intern. Med. 2008, 168, 2009–2013. [Google Scholar] [CrossRef][Green Version]
- Hutton, D.W.; So, S.K.; Brandeau, M.L. Cost-effectiveness of nationwide hepatitis B catch-up vaccination among children and adolescents in China. Hepatology 2010, 51, 405–414. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, C.H.; Lu, R.H.; Lee, N.H.; Chiu, W.T.; Hsu, M.H.; Li, Y.C. Novel solutions for an old disease: Diagnosis of acute appendicitis with random forest, support vector machines, and artificial neural networks. Surgery 2011, 149, 87–93. [Google Scholar] [CrossRef]
- Heikes, K.E.; Eddy, D.M.; Arondekar, B.; Schlessinger, L. Diabetes Risk Calculator: A simple tool for detecting undiagnosed diabetes and pre-diabetes. Diabetes Care 2008, 31, 1040–1045. [Google Scholar] [CrossRef] [PubMed]
- Kavakiotis, I.; Tsave, O.; Salifoglou, A.; Maglaveras, N.; Vlahavas, I.; Chouvarda, I. Machine learning and data mining methods in diabetes research. Comput. Struct. Biotechnol. J. 2017, 15, 104–116. [Google Scholar] [CrossRef] [PubMed]
- Chao, D.T.; Lim, J.K.; Ayoub, W.S.; Nguyen, L.H.; Nguyen, M.H. Systematic review with meta-analysis: The proportion of chronic hepatitis B patients with normal alanine transaminase≤40 IU/L and significant hepatic fibrosis. Aliment. Pharmacol. Ther. 2014, 39, 349–358. [Google Scholar] [CrossRef] [PubMed]
- Zhu, M.Y.; Zou, X.; Li, Q.; Yu, D.M.; Yang, Z.T.; Huang, D.; Chen, J.; Gong, Q.M.; Zhang, D.H.; Zhang, Y.; et al. A novel noninvasive algorithm for the assessment of liver fibrosis in patients with chronic hepatitis B virus infection. J. Viral Hepat. 2017, 24, 589–598. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Li, W.; Huang, Y.; Chen, L. The gamma-glutamyl transpeptidase-to-platelet ratio predicts liver fibrosis and cirrhosis in HBeAg-positive chronic HBV infection patients with high HBV DNA and normal or mildly elevated alanine transaminase levels in China. J. Viral Hepat. 2016, 23, 912–919. [Google Scholar] [CrossRef] [PubMed]
- Seto, W.K.; Lee, C.F.; Lai, C.L.; Ip, P.P.; Fong, D.Y.; Fung, J.; Wong, D.K.H.; Yuen, M.F. A new model using routinely available clinical parameters to predict significant liver fibrosis in chronic hepatitis B. PLoS ONE 2011, 6, e23077. [Google Scholar] [CrossRef]
- Wu, J.F.; Su, Y.R.; Chen, C.H.; Chen, H.L.; Ni, Y.H.; Hsu, H.Y.; Wang, J.L.; Chang, M.H. Predictive effect of serial serum alanine aminotransferase levels on spontaneous HBeAg seroconversion in chronic genotype B and C HBV-infected children. J. Pediatr. Gastroenterol. Nutr. 2012, 54, 97–100. [Google Scholar] [CrossRef]
- Shepherd, J.; Jones, J.; Hartwell, D.; Davidson, P.; Price, A.; Waugh, N. Interferon alpha (pegylated and non-pegylated) and ribavirin for the treatment of mild chronic hepatitis C: A systematic review and economic evaluation. Health Technol. Assess. 2007, 11, 1–205. [Google Scholar] [CrossRef]
- Wichmann, A.B.; Adang, E.M.; Stalmeier, P.F.; Kristanti, S.; Van den Block, L.; Vernooij-Dassen, M.J.; Engels, Y.; PACE. The use of Quality-Adjusted Life Years in cost-effectiveness analyses in palliative care: Mapping the debate through an integrative review. Palliat. Med. 2017, 31, 306–322. [Google Scholar] [CrossRef] [PubMed]
- Thomson, B.J.; Kwong, G.; Ratib, S.; Sweeting, M.; Ryder, S.D.; De Angelis, D.; Grieve, R.; Irving, W.L.; Trent, H.C.V.; Study Group. Response rates to combination therapy for chronic HCV infection in a clinical setting and derivation of probability tables for individual patient management. J. Viral Hepat. 2008, 15, 271–278. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Algorithms | Parameter | Value | Meaning |
|---|---|---|---|
| XGBoost | nrounds | 120 | The number of rounds for boosting. |
| max_depth | 8 | Maximum depth of a tree. | |
| eta | 0.09 | Step size shrinkage used in update to prevent overfitting. | |
| gamma | 0.04 | Minimum loss reduction required to make a further partition on a leaf node of the tree. | |
| colsample_bytree | 0.8 | The subsample ratio of columns when constructing each tree. | |
| min_child_weight | 18 | Minimum sum of instance weight (hessian) needed in a child. If the tree partition step results in a leaf node with the sum of instance weight less than the value, then the building process will give up further partitioning. | |
| subsample | 0.89 | Subsample ratio of the training instances. | |
| n_estimators | 600 | Number of base learners in the integrated model. | |
| max_delta_step | 9 | Maximum delta step we allow each leaf output to be. If it is set to a positive value, it can help making the update step more conservative. | |
| DT | minispilt | 20 | The minimum number of observations that must exist in a node for a split to be attempted. |
| minibucket | 20 | The minimum number of observations in any terminal node. | |
| maxdepth | 10 | The maximum depth of any node of the final tree. | |
| xval | 5 | Number of cross-validations. | |
| cp (complexity parameter) | 0.001 | The minimum improvement in the model needed at each node. | |
| RF | mtry | 6 | Number of variables available for splitting at each tree node. |
| ntree | 700 | Number of trees to grow. |
| Characteristics | N/Mean | Proportion (%)/SD |
|---|---|---|
| HBsAg | ||
| Positive | 8034 | 8.27 |
| Negative | 89,139 | 91.73 |
| Gender | ||
| Male | 32,208 | 33.15 |
| Female | 64,965 | 66.85 |
| Age | 54.94 | 21.72 |
| Education level | ||
| Illiteracy, and semi-illiteracy | 8971 | 9.23 |
| Primary school | 26,024 | 26.78 |
| Middle school | 19,667 | 20.24 |
| High and vocational school | 19,417 | 19.98 |
| College and above | 4632 | 4.77 |
| Unknown | 18,462 | 19.00 |
| Career | ||
| Leaders of enterprise unit | 827 | 0.85 |
| Technical personnel | 2681 | 2.76 |
| Handle affairs personnel | 1844 | 1.90 |
| Commercial personnel | 4768 | 4.91 |
| Farming, forestry, and fishery producers | 7843 | 8.07 |
| Transportation equipment operators | 4430 | 4.56 |
| Soldier | 185 | 0.19 |
| Unknown | 74,595 | 76.77 |
| Marital status | ||
| Single | 16,851 | 17.34 |
| Married | 67,821 | 69.79 |
| Widowed | 4127 | 4.25 |
| Divorced | 821 | 0.84 |
| Unknown | 7553 | 7.77 |
| Hepatitis B vaccination | ||
| No | 6017 | 6.19 |
| Yes | 4976 | 5.12 |
| Unknown | 86,180 | 88.69 |
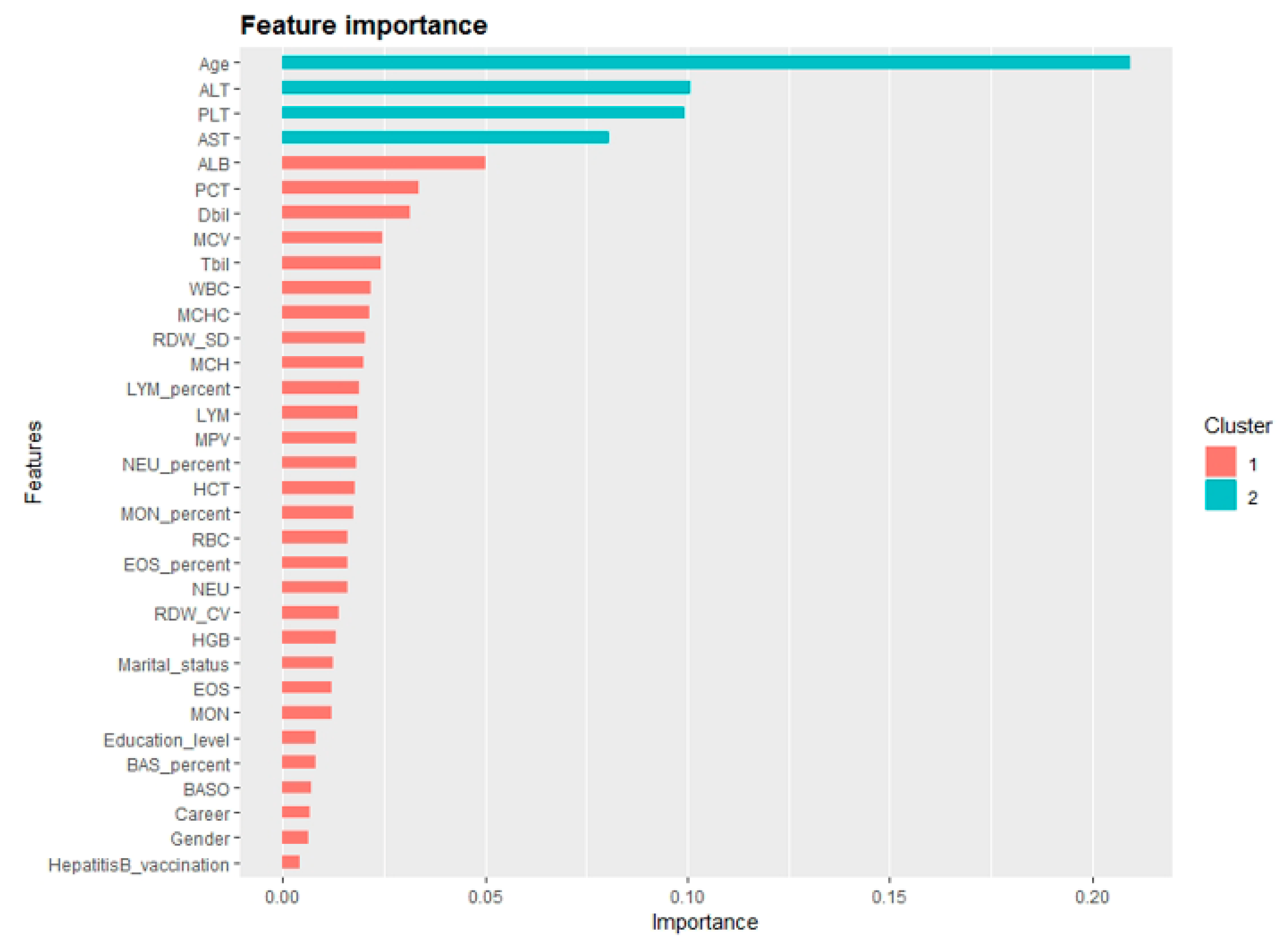
| White blood cell count (WBC, 109/L) | 6.45 | 1.75 |
| Percent of monocytes (MON%, %) | 4.44 | 1.87 |
| Monocyte count (MON, 109/L) | 0.28 | 0.14 |
| Red cell volume distribution width-variable coefficient (RDW.CV, %) | 14.57 | 1.38 |
| Red cell volume distribution width-standard deviation (RDW.SD, fL) | 55.40 | 6.91 |
| Red blood cell count (RBC, 1012/L) | 4.58 | 0.52 |
| hematocrit (HCT, %) | 45.92 | 4.98 |
| Lymphocyte percentage (LYM%, %) | 37.74 | 9.05 |
| Lymphocyte count (LYM, 109/L) | 2.39 | 0.77 |
| Mean corpuscular volume (MCV, fL) | 100.97 | 10.66 |
| Mean red blood cell hemoglobin content (MCH, pg) | 29.55 | 3.56 |
| Mean corpuscular hemoglobin concentration (MCHC, g/L) | 293.22 | 25.12 |
| Mean platelet volume (MPV, fL) | 9.03 | 0.95 |
| Percent of basophilic granulocyte (BAS%, %) | 0.58 | 0.31 |
| Basophilic granulocyte count (BASO, 109/L) | 0.04 | 0.02 |
| Percentage of eosinophilic granulocyte (EOS%, %) | 3.16 | 2.39 |
| Eosinophil count (EOS, 109/L) | 0.20 | 0.17 |
| Hemoglobin (HGB, g/L) | 134.28 | 14.01 |
| Albumin (ALB, g/L) | 45.65 | 3.27 |
| Alanine aminotransferase (ALT, U/L) | 20.68 | 18.35 |
| Aspartate aminotransferase (AST, U/L) | 23.56 | 13.04 |
| Direct bilirubin (DBil, umol/L) | 3.15 | 1.46 |
| Total bilirubin (TBil, umol/L) | 10.39 | 4.37 |
| Platelet count (PLT, 109/L) | 258.25 | 68.58 |
| Plateletcrit (PCT, %) | 0.23 | 0.06 |
| Percent of neutrophile granulocyte (NEU%, %) | 54.08 | 9.29 |
| Neutrophil count (NEU, 109/L) | 3.53 | 1.32 |
| Total | 97,173 |
| Characteristics | Training Set n (%) | Testing Set n (%) | p Value |
|---|---|---|---|
| HBsAg | |||
| Positive | 6419 (8.26) | 1615 (8.31) | 0.812 |
| Negative | 71,319 (91.74) | 17,820 (91.69) | |
| Gender | |||
| Male | 25,769 (33.14) | 6439 (33.13) | 0.963 |
| Female | 51,969 (66.86) | 12,996 (66.87) | |
| Age(year) | 54.90 ± 21.75 | 55.09 ± 21.64 | 0.282 |
| Education level | |||
| Illiteracy, and semi-illiteracy | 7199 (9.26) | 1772 (9.12) | |
| Primary school | 20,855 (26.82) | 5169 (26.6) | |
| Middle school | 15,663 (20.15) | 4004 (20.6) | 0.437 |
| High and vocational school | 15,553 (20.01) | 3864 (19.88) | |
| College and above | 3666 (4.72) | 966 (4.97) | |
| Unknown | 14,802 (19.04) | 3660 (18.83) | |
| Career | |||
| Leaders of enterprise unit | 650 (0.84) | 177 (0.91) | |
| Technical personnel | 2125 (2.73) | 556 (2.86) | |
| Handle affairs personnel | 1463 (1.88) | 381 (1.96) | |
| Commercial personnel | 3788 (4.87) | 980 (5.04) | |
| Farming, forestry, and fishery producers | 6272 (8.07) | 1571 (8.08) | 0.633 |
| Transportation equipment operators | 3517 (4.53) | 913 (4.7) | |
| Soldier | 149 (0.19) | 36 (0.19) | |
| Unknown | 59,774 (76.89) | 14,821 (76.26) | |
| Marital status | |||
| Single | 13,542 (17.42) | 3309 (17.02) | |
| Married | 54,196 (69.72) | 13,625 (70.11) | |
| Widowed | 3277 (4.22) | 850 (4.37) | 0.294 |
| Divorced | 674 (0.86) | 147 (0.76) | |
| Unknown | 6049 (7.78) | 1504 (7.74) | |
| History of hepatitis B vaccination | |||
| No | 4777 (6.14) | 1240 (6.38) | |
| Yes | 4016 (5.17) | 960 (4.94) | 0.229 |
| Unknown | 68,945 (88.69) | 17,235 (88.68) | |
| WBC (109/L) | 6.45 ± 1.75 | 6.45 ± 1.73 | 0.718 |
| MON% (%) | 4.44 ± 1.87 | 4.43 ± 1.88 | 0.768 |
| MON (109/L) | 0.28 ± 0.14 | 0.28 ± 0.14 | 0.969 |
| RDW.CV (%) | 14.57 ± 1.38 | 14.56 ± 1.35 | 0.664 |
| RDW.SD (fL) | 55.39 ± 6.91 | 55.45 ± 6.92 | 0.239 |
| RBC (1012/L) | 4.58 ± 0.52 | 4.58 ± 0.52 | 1.000 |
| HCT (%) | 45.91 ± 4.97 | 45.97 ± 4.97 | 0.142 |
| LYM% (%) | 37.74 ± 9.05 | 37.71 ± 9.08 | 0.616 |
| LYM (109/L) | 2.39 ± 0.77 | 2.39 ± 0.77 | 0.869 |
| MCV (fL) | 100.95 ± 10.67 | 101.07 ± 10.64 | 0.157 |
| MCH (pg) | 29.54 ± 3.66 | 29.56 ± 3.13 | 0.548 |
| MCHC (g/L) | 293.26 ± 26.46 | 293.06 ± 18.85 | 0.304 |
| MPV (fL) | 9.03 ± 0.95 | 9.03 ± 0.95 | 0.765 |
| BAS% (%) | 0.58 ± 0.31 | 0.58 ± 0.31 | 0.146 |
| BASO (109/L) | 0.04 ± 0.02 | 0.04 ± 0.02 | 0.213 |
| EOS% (%) | 3.16 ± 2.39 | 3.17 ± 2.42 | 0.736 |
| EOS (109/L) | 0.20 ± 0.17 | 0.20 ± 0.18 | 0.560 |
| HGB (g/L) | 134.26 ± 14.02 | 134.37 ± 13.98 | 0.332 |
| ALB (g/L) | 45.65 ± 3.28 | 45.66 ± 3.28 | 0.731 |
| ALT (U/L) | 20.69 ± 19.02 | 20.62 ± 15.38 | 0.640 |
| AST (U/L) | 23.57 ± 13.50 | 23.53 ± 11.00 | 0.696 |
| DBil (umol/L) | 3.15 ± 1.47 | 3.15 ± 1.39 | 0.632 |
| TBil (umol/L) | 10.40 ± 4.39 | 10.37 ± 4.29 | 0.448 |
| PLT (109/L) | 258.25 ± 68.67 | 258.27 ± 68.21 | 0.969 |
| PCT (%) | 0.23 ± 0.06 | 0.23 ± 0.06 | 0.779 |
| NEU% (%) | 54.08 ± 9.28 | 54.12 ± 9.31 | 0.610 |
| NEU (109/L) | 3.53 ± 1.31 | 3.54 ± 1.32 | 0.600 |
| Total | 77,738 | 19,435 |
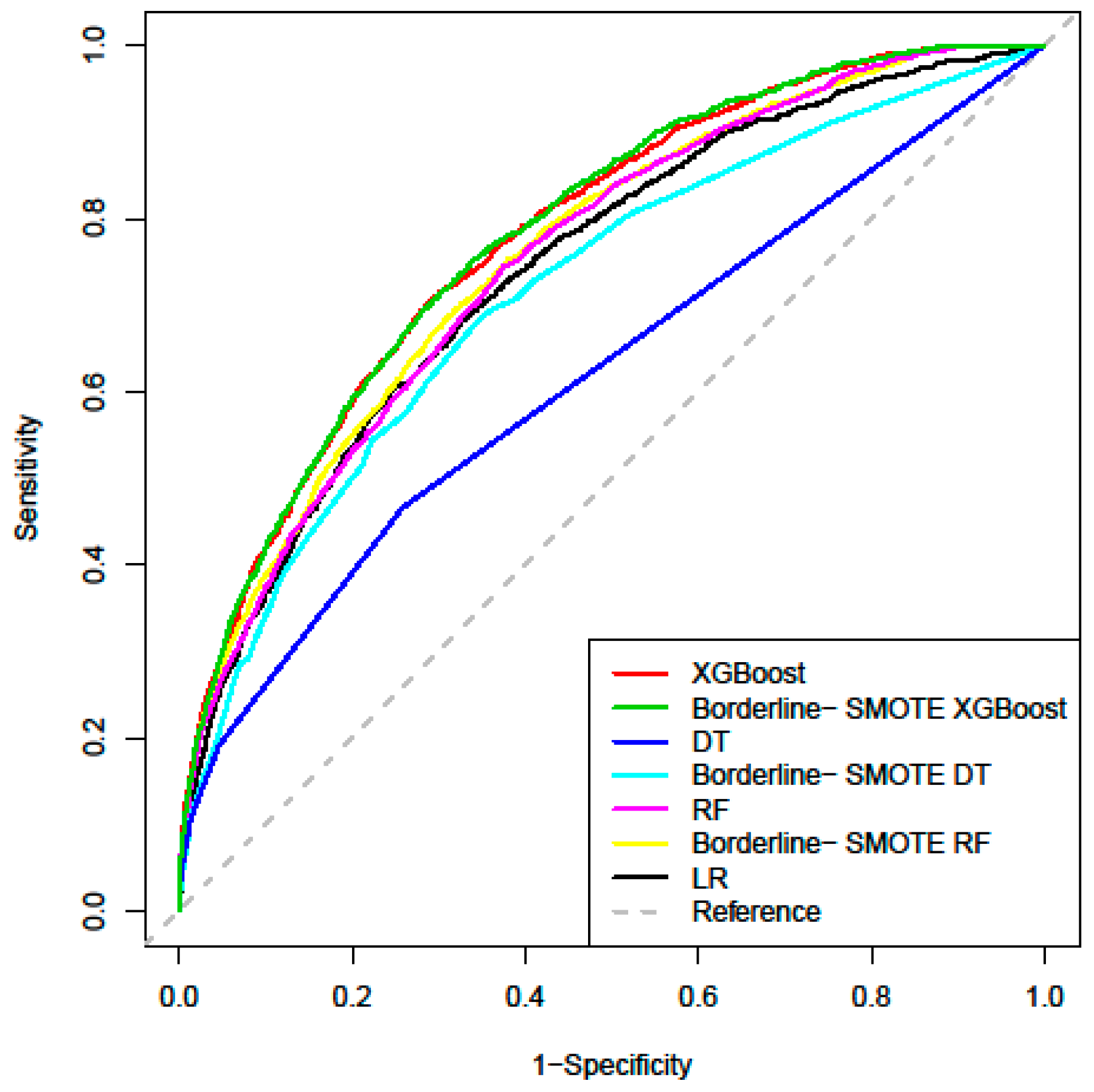
| Algorithms | AUC | Standard Error | 95% CI | AUC Compared with LR |
|---|---|---|---|---|
| LR | 0.742 | 0.006 | (0.729, 0.754) | - |
| DT | 0.619 | 0.008 | (0.603, 0.634) | −0.123 |
| RF | 0.752 | 0.006 | (0.740, 0.764) | +0.010 |
| XGBoost | 0.779 | 0.006 | (0.768, 0.791) | +0.037 |
| Borderline-SMOTE DT | 0.715 | 0.007 | (0.702, 0.729) | −0.027 |
| Borderline-SMOTE RF | 0.759 | 0.006 | (0.747, 0.771) | +0.017 |
| Borderline-SMOTE XGBoost | 0.782 | 0.006 | (0.771, 0.793) | +0.040 |
| Algorithms | TP | FN | TN | FP | Accuracy | Sensitivity | Specificity | Cutoff Point |
|---|---|---|---|---|---|---|---|---|
| LR | 1109 | 506 | 11866 | 5934 | 0.668 | 0.687 | 0.667 | 0.010 |
| DT | 752 | 863 | 13214 | 4606 | 0.719 | 0.466 | 0.742 | 0.086 |
| RF | 1203 | 412 | 11131 | 6689 | 0.634 | 0.745 | 0.625 | 0.091 |
| XGBoost | 1134 | 481 | 12695 | 5125 | 0.711 | 0.702 | 0.712 | 0.082 |
| Borderline-SMOTE DT | 1094 | 521 | 11731 | 6089 | 0.660 | 0.658 | 0.677 | 0.135 |
| Borderline-SMOTE RF | 1124 | 491 | 12121 | 5699 | 0.681 | 0.696 | 0.680 | 0.116 |
| Borderline-SMOTE XGBoost | 1144 | 471 | 12493 | 5327 | 0.702 | 0.708 | 0.701 | 0.088 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Du, Z.; Lawrence, W.R.; Huang, Y.; Deng, Y.; Hao, Y. Predicting Hepatitis B Virus Infection Based on Health Examination Data of Community Population. Int. J. Environ. Res. Public Health 2019, 16, 4842. https://doi.org/10.3390/ijerph16234842
Wang Y, Du Z, Lawrence WR, Huang Y, Deng Y, Hao Y. Predicting Hepatitis B Virus Infection Based on Health Examination Data of Community Population. International Journal of Environmental Research and Public Health. 2019; 16(23):4842. https://doi.org/10.3390/ijerph16234842
Chicago/Turabian StyleWang, Ying, Zhicheng Du, Wayne R. Lawrence, Yun Huang, Yu Deng, and Yuantao Hao. 2019. "Predicting Hepatitis B Virus Infection Based on Health Examination Data of Community Population" International Journal of Environmental Research and Public Health 16, no. 23: 4842. https://doi.org/10.3390/ijerph16234842
APA StyleWang, Y., Du, Z., Lawrence, W. R., Huang, Y., Deng, Y., & Hao, Y. (2019). Predicting Hepatitis B Virus Infection Based on Health Examination Data of Community Population. International Journal of Environmental Research and Public Health, 16(23), 4842. https://doi.org/10.3390/ijerph16234842