1. Introduction
Since 2001, electricity generation in the United States has followed an increasing trajectory as there has been increasing demand for uninterrupted access to electricity for various global industries that are vital to economic growth [
1]. In order to satisfy this increasing demand reliably and economically, fossil fuels, such as coal and natural gas, are used as the primary sources of electricity, accounting for nearly two-thirds of the total energy supply [
1]. However, since fossil fuels are burned to produce steam that is then used to power turbines that drive electrical generators, this produces air emissions such as CO
2, SO
X, NO
X, volatile organic compounds (VOCs), and particulate matter [
2]. As a result, ground-level ozone concentrations in the tropospheric region of the atmosphere increase as a result of photochemical reactions with emissions from fossil fuel plants. These by-products are health hazards, as they contribute to smog, which may ultimately lead to heart and chronic lung conditions like asthma, bronchitis, and emphysema [
3]. Furthermore, air emissions from fossil fuels react with atmospheric water molecules to produce various forms of acidic precipitation and dry acidic deposition, known as acid rain. This occurs when sulfur dioxide and nitric oxides react with atmospheric water to generate sulfuric acid and nitric acid, which creates acid rain [
4]. While acid rain does not pose any direct health hazards, fine acidic particulates in air contribute to heart and lung conditions, which result in health externalities or costs absorbed by consumers [
4].
Based on the literature, one of the earliest approaches to quantifying health damages from the electricity sector was developed by Rowe et al. In this research, critical factors in computing externalities for electricity generation sources were assessed by utilizing the New York State Environmental Externalities Cost Study and computerized externality model (EXMOD). Using response surfaces in combination with EXMOD model outputs, the researchers were able to develop a model to predict health externalities from electricity generation by varying 15 different factors, including the selection of generation type, location, and operating characteristics [
5]. Their research suggested that the most critical factors in developing a model framework were the selection and application of air dispersion models, selection of air pollution thresholds for health impacts, reduced life span risks associated with ozone exposure and long-term exposure to particulate matter, values for CO
2 damages, and the value to be applied to increased risks of reduced life span for individuals age 65 or older. This research was extended by Thanh and Lefevre, where they applied an impact pathway approach (IPA) to relate the origin of environmental burdens to human health consequences. This relationship enabled the estimation of health damages of sulfur dioxide and particulate matter emissions from the electricity generation output of four power units using different fuels (lignite, oil, natural gas, and coal) at four locations in Thailand. Using response surfaces, their results suggested that these externalities were relatively small, but not negligible, as they ranged from 0.006 to 0.05 U.S. cents per kilowatt-hour (in 1995 dollars) [
6].
Conversely, researchers have also studied the health benefits associated with emissions reductions from the electricity sector. For example, Burtaw et al. quantified the economic benefits of reduced air pollution in the U.S. related to greenhouse gas emissions mitigation policies in the electricity sector. In this work, researchers leveraged historical emissions data and a United States Environmental Protection Agency (EPA) screening tool to generate regression models of human health benefits. By conducting hourly, day-ahead electricity market simulations, and linking this output to the EPA screening tool, their research suggested that a tax of
$25 per metric ton of carbon emissions would yield NO
X-related health benefits of about
$8 per metric ton of carbon reduced in the year 2010 (1997 dollars) [
7].
While the electricity sector is the prime culprit of air emissions in the United States, researchers have also worked to study the broader impact of air quality on human health across multiple sectors including transportation and agriculture. As part of these efforts, Voorhees et al. conducted a sensitivity analysis using an industry standard air quality model, BenMAP, and analyzed the associated human health externalities. BenMAP, which stands for the Environmental Benefits Mapping and Analysis Program, is an EPA economic model used for estimating health effects and the associated externalities associated with changes in air quality. BenMAP achieves this by leveraging a geographic information system-based program to estimate population-level exposure rates and changes in incidences of health outcomes [
8]. In the work done by Voorhees et al., they leveraged the BenMAP tool to model various climate change scenarios, and they quantitatively assessed the output [
9]. Furthermore, the management consulting firm ICF International also used BenMAP as a resource to create a damage function, which was a response surface used to evaluate changes in health indices as a result of the emissions reduction goals proposed in the Clean Power Plan [
10].
State-of-the-art literature related to this particular domain primarily focuses on quantifying the impact of power generation, primarily from fossil fuel sources, on air quality as well as the aggregate societal benefits of avoided emissions resulting from the integration of renewables into the generation portfolio. For instance, in China, Qin et al. found that replacing coal with synthetic natural gas coupled with carbon capture and storage technology in the residential sector would avoid approximately 32,000 pollution-related premature deaths by 2020 [
11]. Huang et al. qualitatively studied the relationship between fuel consumption for electricity and the resulting contributions to ambient concentrations of major air pollutants from the power sector [
12]. They extended their work quantitatively by studying five development scenarios in an air quality model [
13]. Additionally, Peng et al. evaluated various decarbonization scenarios for the electric power grid in order to develop pathways to mitigate peaking emissions by 2030 in China while simultaneously maximizing air quality and health benefits [
14]. More aligned to the research in this paper, Millstein et al. estimated the benefits associated with reduced air emissions resulting from increased wind and solar generation using various EPA screening tools [
15]. Additionally, Kerl et al. introduced the air pollutant optimization model (APOM), which solved the hourly unit commitment model in the state of Georgia with the assistance of a reduced form air quality model [
16]. To estimate their health impact costs, a baseline hourly unit commitment model, along with the inputs and outputs of two EPA models, were synchronized linearly to develop response surfaces, or regression curves, that predicted health impact costs as a function of decision variables in the unit commitment model. In the long-term planning space, Rodgers et al. studied the health benefits of adding emissions limits to multi-period, multi-region, generation expansion planning (GEP) problems using an EPA screening tool [
3]. Furthermore, Rodgers et al. extended this research by applying a simulation-based optimization framework to solve the GEP problem that simultaneously minimized market costs and health damages from air emissions in the objective function. To include health damages in their model, a metamodel was developed to approximate health damages from NO
X and SO
2 emissions associated with power grid capacity expansion decisions [
17]. Specifically, health damages from simulated power grid capacity expansion plans were evaluated in the co-benefits risk assessment (COBRA) model. COBRA is an EPA screening model that helps state and local governments assess human health damages from air emissions at the county, state, regional, or national level [
18]. After executing these computer-based experiments, a closed-form kriging metamodel that approximated health damages as a function of capacity expansion decisions was developed, which was used as a surrogate for health damages. While this research provides guidance on how to obtain an expansion plan under these circumstances, there is need for systematic framework to evaluate a metamodel and simultaneously select its parameters.
Drawing from the aforementioned state-of-the-art research, and because of the highly stochastic, nonlinear relationship between electricity generation and the resulting health damages, researchers often apply black box modeling techniques in these instances with little understanding of how decision variables impact the response in question [
17]. This lack of system knowledge is intensified as the magnitude and scope of power systems planning decisions grows from hourly dispatch decisions to long-term capacity expansion decisions across multiple regions. In this paper, our primary objective is to close this gap by developing a step-by-step, analytical framework that accomplishes the following:
Leverages computer-based simulations of a generation expansion planning model, where the model outputs are used as inputs into the COBRA tool to quantify the resulting health damages;
Establishes a closed-form expression to predict the aforementioned health damages as a function of power grid expansion decisions using a kriging metamodel; and
Provides a procedure to select metamodel parameters that maximize prediction accuracy.
2. Materials and Methods
To address the aforementioned challenges associated with approximating health damages from generation expansion planning decisions, we extended the work done by Rodgers et al. in [
3,
17]. Specifically, we proposed a detailed, systematic framework to establish a mathematical relationship that quantified health damages as a function of power grid expansion decisions while simultaneously considering prediction accuracy. Following the approach developed by Rodgers et al., we first formulated and solved a GEP model to determine the optimal technology capacity investment strategy that minimized market costs, including capital costs, fixed operation and maintenance costs, and variable costs of generation. Using this GEP model, we simulated key model parameters from a normal distribution, and we executed multiple computer-based experiments from the optimization model. We then evaluated the outputs of our simulations in the EPA’s COBRA tool.. Next, we applied a kriging interpolation model to our dataset to express the relationship between the covariates—electricity expansion decisions—and the response—human health damages. This kriging interpolation model, which is a geospatial estimation method that predicts the values of a random field at unobserved locations based on an interpolated function of observed samples, served as a metamodel or surrogate function that approximated the output of COBRA using input data generated from GEP simulations, thus, it simplified the ability to quantify human health damages resulting from power grid expansion plans. Since our metamodel was a function of computer-based experiments, there was a quantifiable amount of error in prediction. Lastly, to account for this, we proposed a cross-validation procedure to select the metamodel with the least prediction error.
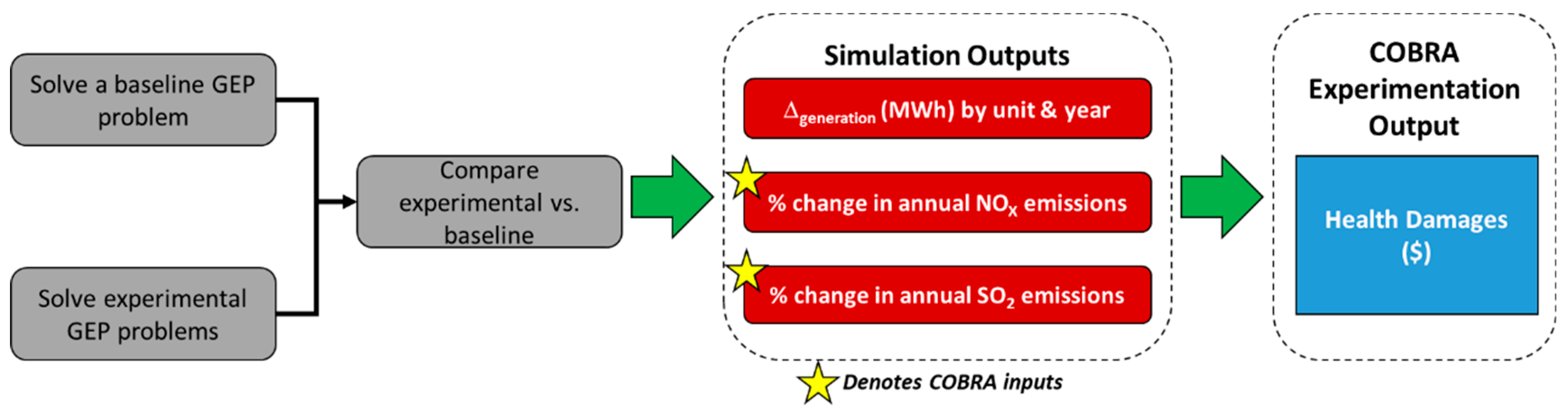
In order to accomplish our research objectives, our first task was to establish a mathematical relationship to predict human health damages associated with electric power grid capacity expansion decisions, per the guidance of Rodgers et al., as given in
Figure 1 [
17].
To summarize, we generated expansion planning scenarios to be evaluated in an EPA screening tool, COBRA, to quantify human health externalities. A kriging metamodel was then applied to this data set, which predicted human health damages as a function of electricity dispatch decisions.
2.1. Simulation and Experimentation Procedure
To create a metamodel of human health damages in the context of GEP, we needed to generate a diverse sample space of data points from our expansion planning model to be evaluated in the COBRA tool. We referred to this process as seed generation.
To initiate the seed generation process, as shown in
Figure 2, first we solved a baseline GEP model. We then solved several experimental GEP models where key parameters were simulated from a normal distribution. For each experimental trial, we then compared the expansion decisions and obtained a change in MWh for each unit available within the system. Simultaneously, for each trial we obtained the percent change in NO
X and SO
2 emissions from the baseline, which were used as inputs to be evaluated in the COBRA model.
Generation Expansion Planning (GEP) Model Formulation
We applied the GEP model used by Rodgers et al. to conduct our GEP simulation trials. The objective function of this GEP model was the sum of total market costs, which included investment costs, fixed operation and maintenance costs, and variable operation and maintenance costs, which were discounted over a predetermined time horizon [
17]. The elements of the objective function are given below.
Investment costs are the capital costs associated with capacity expansion. is the capacity expansion decision, expressed as a continuous decision variable and given in MW, by generation unit type in year in region . is the corresponding investment cost ($/MW). Additionally, we defined as the interest or discount rate, Y as the set of all years in the planning horizon, R as the set of all regions in the network, and as the set of all generating unit options.
Fixed operation and maintenance costs:
Fixed operation and maintenance costs for unit in year are given by in units of $/MW. In Equation (2), I* is the set of all existing generating unit options, is the set of all available generating unit options, and is the initial capacity of unit i in region r1. Additionally, we used the alias as a surrogate notation for the year, , to calculate the fixed operation and maintenance costs for all new capacity investments up to year .
Variable operation and maintenance costs:
Variable operation and maintenance costs (including fuel costs) of generation from unit during period of year are given by in units of $/MWh. Each year is subdivided into six distinct time periods consisting of: (i) spring/fall-offpeak; (ii) spring/fall-peak; (iii) summer-offpeak; (iv) summer-peak; (v) winter-offpeak; and (vi) winter-peak, which span the set of all time intervals, T. is the amount of aggregate electricity dispatched (MWh) from unit in region in period of year .
Steam generation revenue:
Annual steam generation (or cogeneration) revenue from combined heat and power (CHP) units is given by in terms of $/MWh, and is the amount of electricity dispatched from cogeneration units (in MWh) from in region period of year .
The total cost objective function,
, is given by Equation (5).
In our models, we minimized
z across the network, subjected to system constraints. Definitions for GEP model sets, parameters, and decision variables are given in
Table 1,
Table 2 and
Table 3.
The generation expansion planning formulation is given as follows:
and is subject to:
Equation (6) is the demand (or energy balance) constraint. For each of the periods in a given year, the total generation and transmission from both existing and new generating units should be at least as much as the corresponding demand in that region. Equations (7) and (8) are related to generating unit capacities for dispatchable and nondispatchable units. Equations (9) and (10) are the transmission network constraints. Equation (11) is the reserve margin constraint, and Equations (12) and (13) are investment limit constraints on an annual basis and throughout the time horizon of the model, respectively. Equation (14) specifies non-negativity for generation, transmission, and investment decision variables.
For each execution of the GEP model, the following key outputs were obtained and were used downstream as inputs into the COBRA tool:
As previously stated, to create a metamodel of health damages as a function of power grid expansion decisions, a diverse sample space of data points (or outputs), via simulation, from our GEP model were evaluated in the COBRA tool. Following the procedure outlined in
Figure 1, first we solved a baseline GEP model, which minimized total market costs. Concurrently, we solved additional experimental GEP models with the same model parameters as the baseline model but with simulated numerical values. Specifically, to obtain a diverse sample space, we varied several key parameters in the experimental model by simulating from a normal distribution with a coefficient of variation following a uniform random variable on the interval (0, 1). The parameters we varied in the GEP model were as follows:
| Emissions limits; Costs (investment, fixed, and variable); Steam revenue; Transmission capacity; Capacity factors for nondispatchable units; and Derating values.
|
For each GEP experimental trial, we computed the following values for every year in the planning horizon:
Equation (15) defines the annual deviation in electricity dispatch of a given unit in a specified region of the experimental GEP model from the baseline model. Equations (16) and (17) quantify the annual percent deviation of NOX and SO2 emissions, respectively, in a given region from the experimental trial to the baseline trial. We used the metrics from Equations (16) and (17) as inputs to the COBRA model, which allowed users to generate scenarios by specifying the changes in NOX and SO2 emissions on an annual basis for the appropriate region. COBRA then estimated the corresponding changes in equivalent particulate matter (PM2.5) concentrations, using a source–receptor matrix, and calculated the estimated health damages based on embedded epidemiological and economic functions. Computer-based experiments in COBRA can be executed fairly quickly; however, the relationship between GEP decisions and the resulting health damages is highly stochastic and nonlinear, and thus is difficult to express in closed-form. As previously mentioned, black box methods are often utilized in these instances with little understanding of how decision variables impact the response in question. Using this computer-based experimentation approach, this resulted in a data set that was used for metamodeling, which established a closed-form relationship and closed this gap of information regarding how key variables impacted the response variable.
2.2. Kriging Metamodel Details
Kriging is an interpolation method that uses the observed data at all sample points to provide a statistical prediction of an unknown function by minimizing its mean squared error (MSE) [
19]. To develop a kriging metamodel, the output of a deterministic computer experiment is treated as a realization from a stochastic process, which is then defined as the sum of a global trend function and a Gaussian stochastic process.
In a general sense, various metamodeling techniques have been used to solve complex optimization and decision-making problems. The simplest of these metamodel techniques leverages regression theory. For instance, by applying regression theory, experimental design, and feasible region partitioning approaches, Roux et al. investigated methods for obtaining more metamodels to approximate the value of an objective function [
20]. Kalil et al. applied regression techniques along with factorial design in an industrial bioprocess optimization problem to maximize yield and productivity [
21]. Quanhong and Calil applied regression methods to quantify the effect of liquid:solid ratio, NaCl concentration, and reaction time in order to maximize protein production from germinant pumpkin seeds [
22]. They then used this regression model as a surrogate objective function in an optimization problem.
When the cost of evaluating the response of a system by experiments is computationally expensive, it is critical to use the most accurate metamodel for prediction purposes. In comparison to other metamodeling methods used in optimization, kriging provides the best prediction accuracy and serves as a more accurate and reliable surrogate objective function [
23]. Furthermore, these models can be applied to surrogate systems to reduce the total cost of response evaluation [
24]. Such metamodels have been deployed in black-box systems [
24], metal-forming processes [
25], aerodynamic design applications [
26], and even multiobjective optimization models [
27].
In our work, the kriging metamodel we utilized to quantify human health damages as a function of GEP expansion decisions was given by Equation (18) [
17].
is the predicted value of human health damages in year y for unit i in region r1, which is a function of a vector of unobserved dispatch values, . is a vector of observed dispatch deviations obtained from the experimental procedure, indexed by k. The observed value of is given by , and is the number of nearest neighbors to consider in the model. Kriging weight, , is derived from the residuals, and the means of the predicted response and observed response are given by and , respectively.
Residuals,
, in a kriging model have a stationary mean and covariance, where
, with
, and
for some lag
h. In this case,
, where we defined
as the sill and
as the semivariogram. For this particular application, we employed the Gaussian semivariogram in Equation (19).
The Gaussian semivariogram function has two parameters that the user can specify—the sill and nugget. The sill is a stationary value of the semivariogram, where the slopes of the tangent lines become zero. The nugget is the value of the semivariogram function with zero lag. Additionally, the range is the lag value when the slope of the tangent lines becomes zero.
To select the parameters to be used in our metamodel, and to assess prediction accuracy, we applied a modified cross-validation procedure as follows:
Step 1: We randomly partitioned the data set into eleven (11) equal subsets, designating one subset as a testing set and the remaining ten as validation sets to fit metamodels.
Step 2: Using the validation sets identified in Step 1, kriging metamodels were fitted with a Gaussian variogram.
Step 3: For each validation set, the mean absolute prediction error (MAPE) was computed against the test set.
Step 4: All validation sets were aggregated into a single data set. This set was then used to build a full metamodel of the test set data and calculate the model error, as described in Step 3.
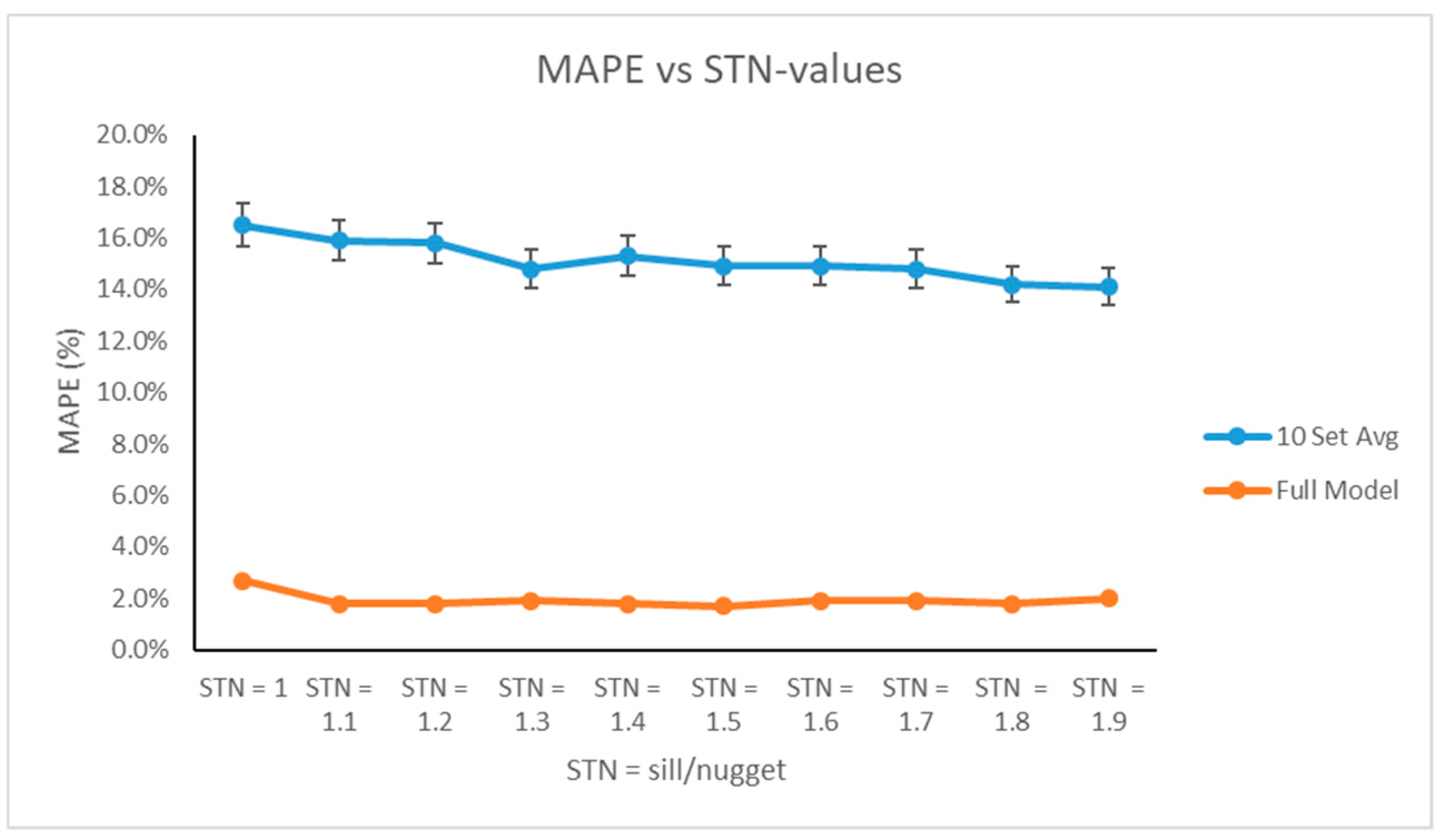
We repeated this procedure for using sill-to-nugget (STN) ratios ranging from 1 to 1.9 to fit our metamodels. We then plotted the MAPE as a function of the STN ratio, and we selected the STN value that minimized the MAPE for the full metamodel.
3. Results and Discussion
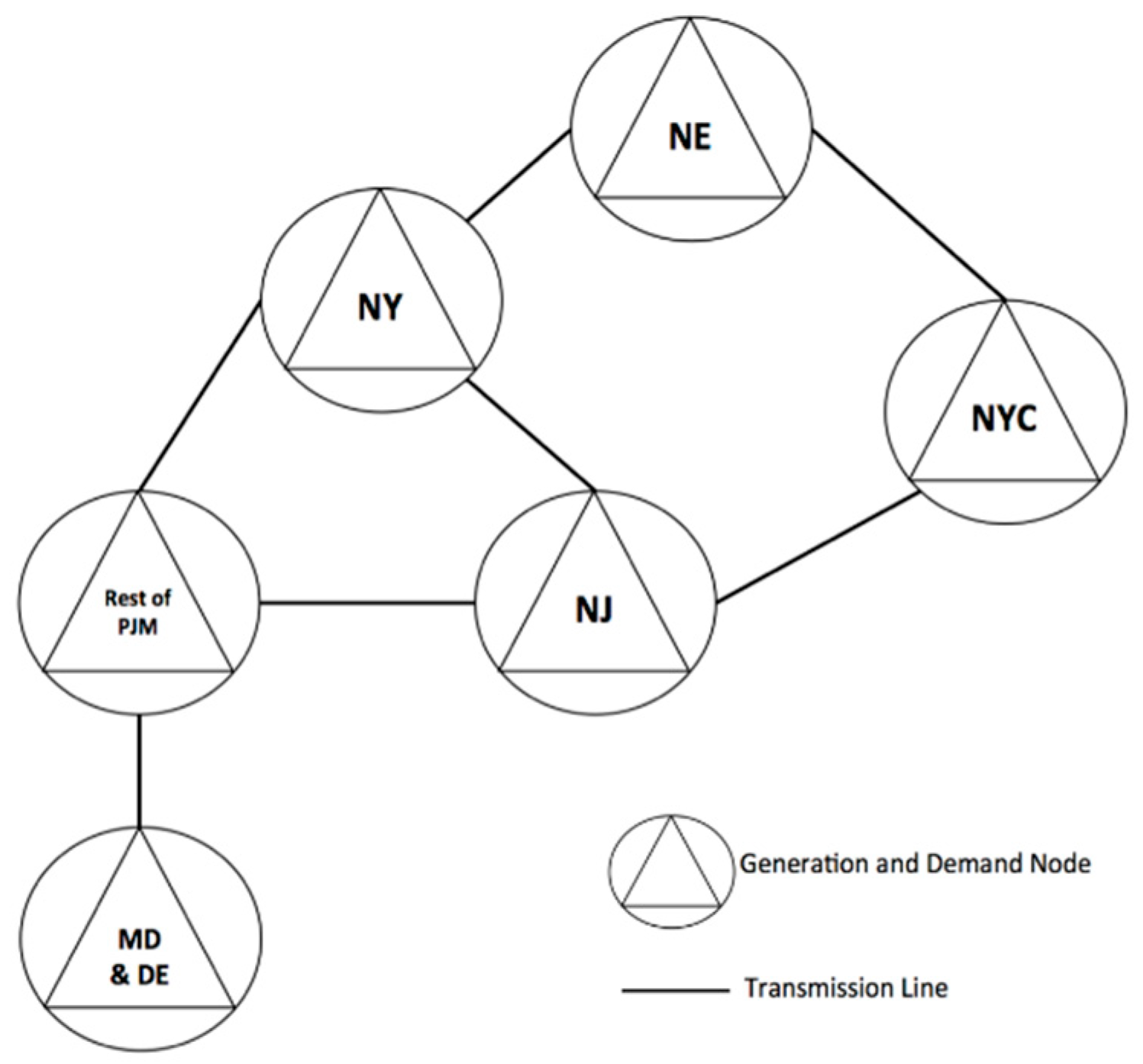
For the numerical example presented in this paper, we considered the northeastern United States, as shown in the representation in
Figure 3 [
3,
17].
Our test network had six regions, given as follows:
NE: New England (Maine, Vermont, New Hampshire, Massachusetts, Connecticut, and Rhode Island);
NY: New York State (excluding New York City);
NYC: New York City;
NJ: New Jersey;
MD & DE: Maryland, Delaware, and the District of Columbia;
Rest of PJM: Illinois, Indiana, Kentucky, Michigan, North Carolina, Ohio, Tennessee, Virginia, and West Virginia.
Each region in the network had demand for electricity and also was capable of generating electricity. The available pool of generating unit technologies considered in our model comprised cycle gas turbines, coal, natural gas turbines, hydro, nuclear, petroleum, solar, biomass, on-shore wind, and off-shore wind. Additionally, connections between regions defined the transmission network. We considered a 25 y planning horizon (2015 through 2040). GEP model cost inputs are given in
Table 4 (refer to
Appendix A for a full list of GEP model assumptions and data sources).
Using the simulation procedure and the GEP model presented in
Section 2, we executed ten simulation trials of our experimental GEP model, and we compared the results to a baseline GEP model to obtain changes in investment and dispatching decisions by unit and changes in NO
X and SO
2 emissions. All GEP models were formulated as linear programs and solved using a CPLEX solver (an optimization package that leverages the simplex algorithm via the C programming language) in the generalized algebraic modeling system (GAMS) [
30]. We then input these emissions changes into the COBRA model to quantify the health damages for each trial. Once we generated our data set, we then fit our kriging metamodel that predicted health damages. Our kriging metamodel was created using XonGrid, which is an open source interpolation tool [
31].
Applying the cross-validation procedure presented in
Section 2, we obtained the following prediction errors as a function of STN ratios displayed in
Table 5.
As evidenced by
Table 5 and
Figure 4, we executed the cross-validation procedure for various sill and nugget parameters in the Gaussian semivariogram. Based on the individual validation sets, on average, as we increased the STN-ratio, the prediction error decreased. Variability of the prediction error calculations was approximately 2%, which was relatively minor in the context of this problem. Upon applying the full data set to fit our metamodel, however, we noticed that the prediction error was significantly reduced and remained relatively stable for all values of
k. Based on the full model, since the smallest error value occurred at STN = 1.5, this was the parameter we applied to the semivariogram and, thus, was used as an input parameter in our metamodel.
For comparative purposes, we displayed the results of the baseline model.
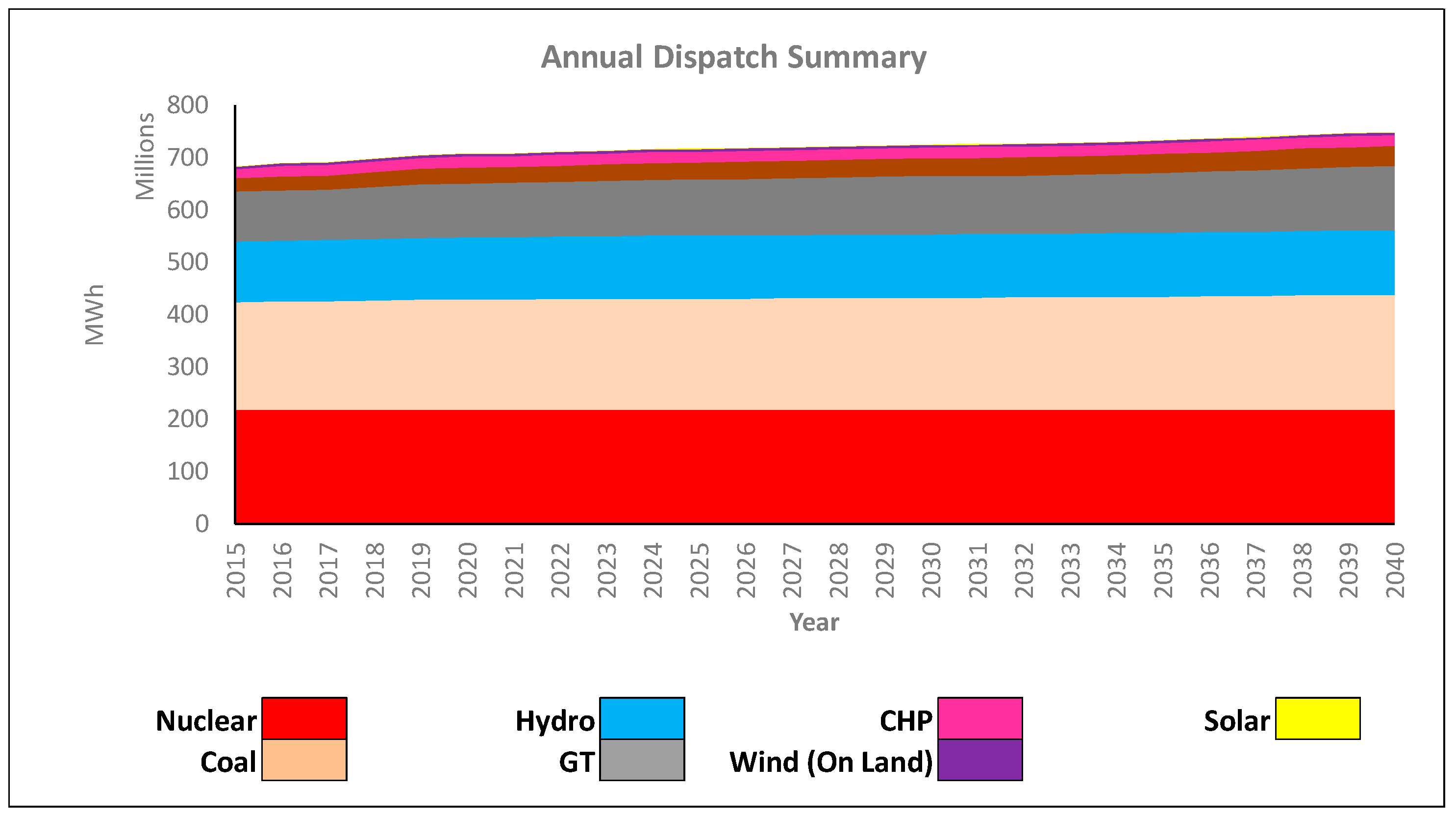
Figure 5 displays the annual aggregate dispatch strategy associated with our baseline GEP model. In our network, base load units were nuclear, coal, hydro, and natural gas. Additional amounts of combined heat and power (or steam), solar, and wind (on land) were dispatched to satisfy the remainder of the demand.
Table 6 gives the capacity investment strategy associated with our baseline GEP model, which suggested that we added over 17,000 MW of capacity to our network. The majority of these investments were in fossil fuel sources, as they were able to satisfy demand economically and reliably.
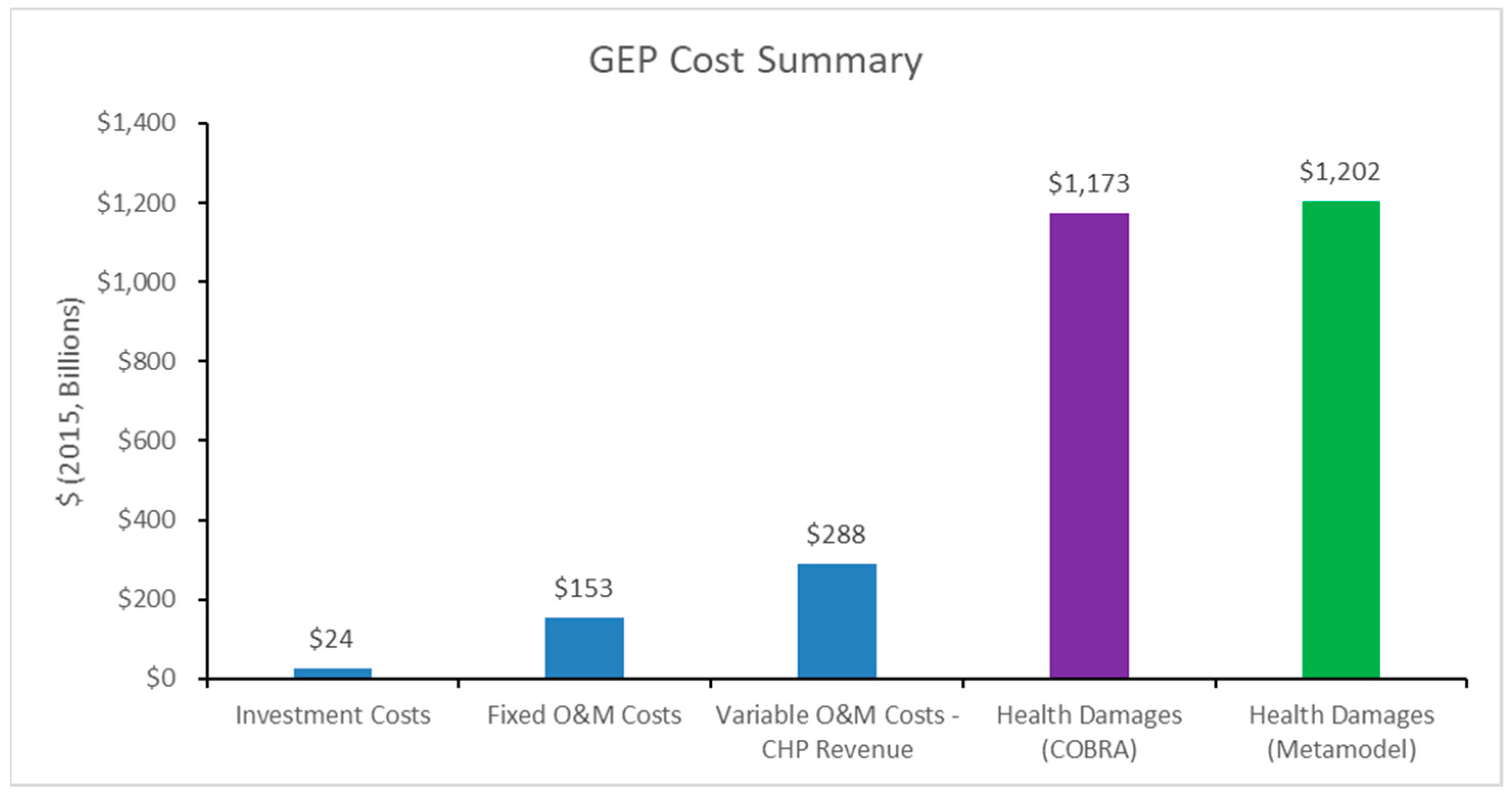
As given in the cost summary presented in
Figure 6, market costs (specifically investment costs, fixed operation and maintenance costs, variable operation and maintenance costs, and combined heat and power (CHP) revenue) summed to roughly
$465B, most of which were variable operation and maintenance costs. These costs were included in the objective function of our GEP and, thus, were optimized via the CPLEX tool. However, health damages of the resulting expansion plan were nearly three times the value of the optimized market costs. Additionally, the health damages predicted from our kriging metamodel were, globally, within 2.5% of the true values from COBRA.
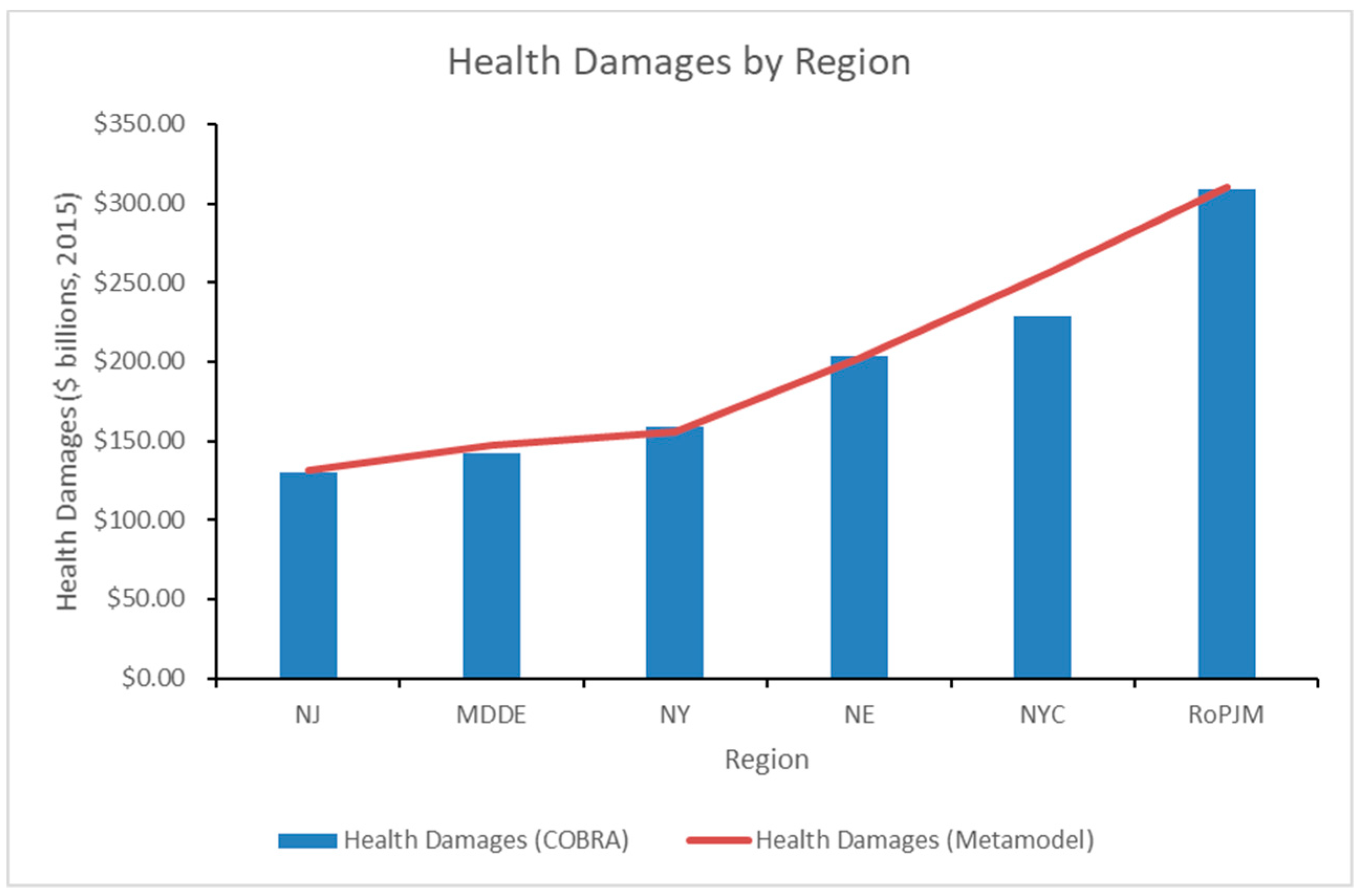
Figure 7 and
Table 7 further detailed the breakdown of health damage values by region from the output of our baseline GEP model. Overall, there were areas where the model either over-predicted or under-predicted, depending on the region and generating unit. Regionally, the model over-predicted by approximately 11% in the NYC region and 4% in the MD & DE region, which was driven by the over-prediction of coal and nuclear damages, respectively. Additionally, the model slightly under-predicted health damages in the NY region by approximately 2%, which was driven by the under-prediction of natural gas damages.
4. Conclusions
This paper presents an extension of the research done by Rodgers et al. in [
3,
17], where health damages from generation expansion planning decisions are approximated. Specifically, an analytical framework to establish a mathematical relationship that quantifies health damages as a function of power grid expansion decisions, while simultaneously considering prediction accuracy, is presented. As demonstrated by the results, our metamodel successfully demonstrates the ability to approximate health damages as a function of GEP decisions with approximately 2.5% error, globally. This allows researchers and policy makers to quantify health damages as a function of power grid expansion decisions using a closed-form function, and it enables them to make more informed decisions on expanding power grid capacity.
Considering the output of the baseline model presented in
Section 3, if not included in the objective function, health damages are nearly triple the optimized market costs. With the metamodeling framework presented in this paper, researchers can incorporate health damages in the objective function of a cost minimization GEP with the certainty of a high degree of prediction accuracy. Ultimately, this may yield significant investments in cleaner sources of energy, such as wind and solar technology, thus reducing health damages.
Another potential research extension would allow for a more detailed assessment of air quality and health damages by systematically linking more sophisticated air quality and economic models used by the EPA to our generation expansion planning model. One of the primary drawbacks of the reduced form air quality model COBRA is that it is based on simplified functions that translate air emissions, such as NO
X and SO
2, into equivalent PM
2.5 concentrations. Thus, in order to better estimate health damages, a more rigorous suite of screening tools can be used in place of the COBRA model to address this gap. Specifically, in place COBRA, we may substitute the EPA’s sparse matrix operator kernel emissions (SMOKE) model, which is a tool that allocates emissions both spatially and temporally. Using the SMOKE model output, we may use this data as inputs into the community multiscale air quality (CMAQ) model, which computes pollutant concentrations by using continuity equations [
32]. Economic health implications of the associated pollutant concentrations can be assessed in the EPA’s BenMAP (Environmental Benefits Mapping and Analysis Program) tool, which approximates the health damages as a function of air quality effects [
8]. Systematically linking these EPA models to our generation expansion planning model via the framework presented in this paper would not only yield more accurate emissions predictions, but it would also provide decision makers with a more detailed perspective of the health implications of expansion plans.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






