Who and Where: A Socio-Spatial Integrated Approach for Community-Based Health Research


Abstract
1. Introduction
1.1. A Review of Social and Spatial Analyses in Community-Based Health Research
1.1.1. Social Analysis in Community-Based Health Research
1.1.2. Spatial Analysis in Community-Based Health Research
2. Methods
2.1. Integrating Spatial Weights with Social Network
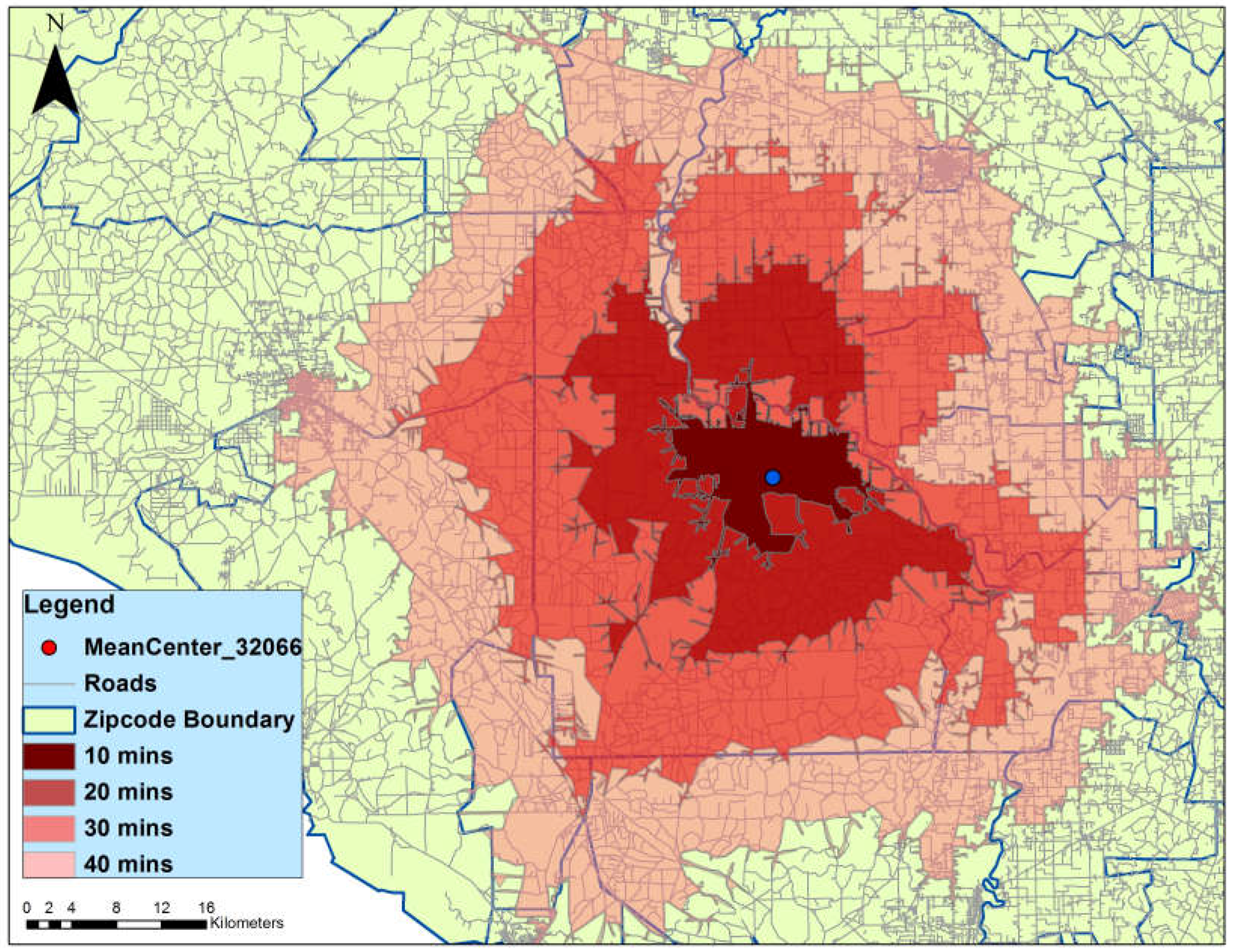
2.2. Integrating Social Weights into Spatial Statistics
3. Case Study of Rural Latino Immigrants in North Florida
3.1. Data Collection and Geocoding
3.2. Spatially Weighted Social Network
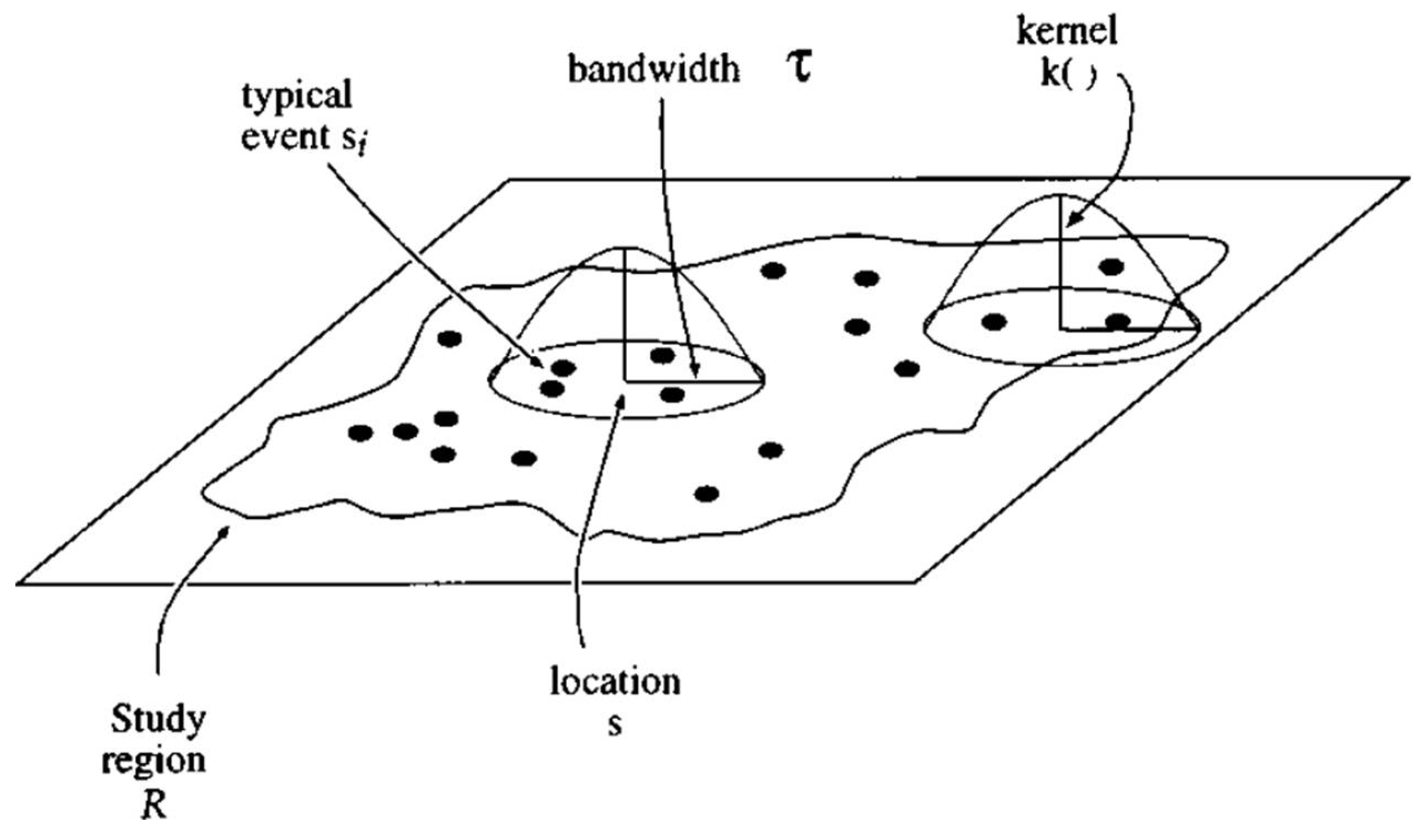
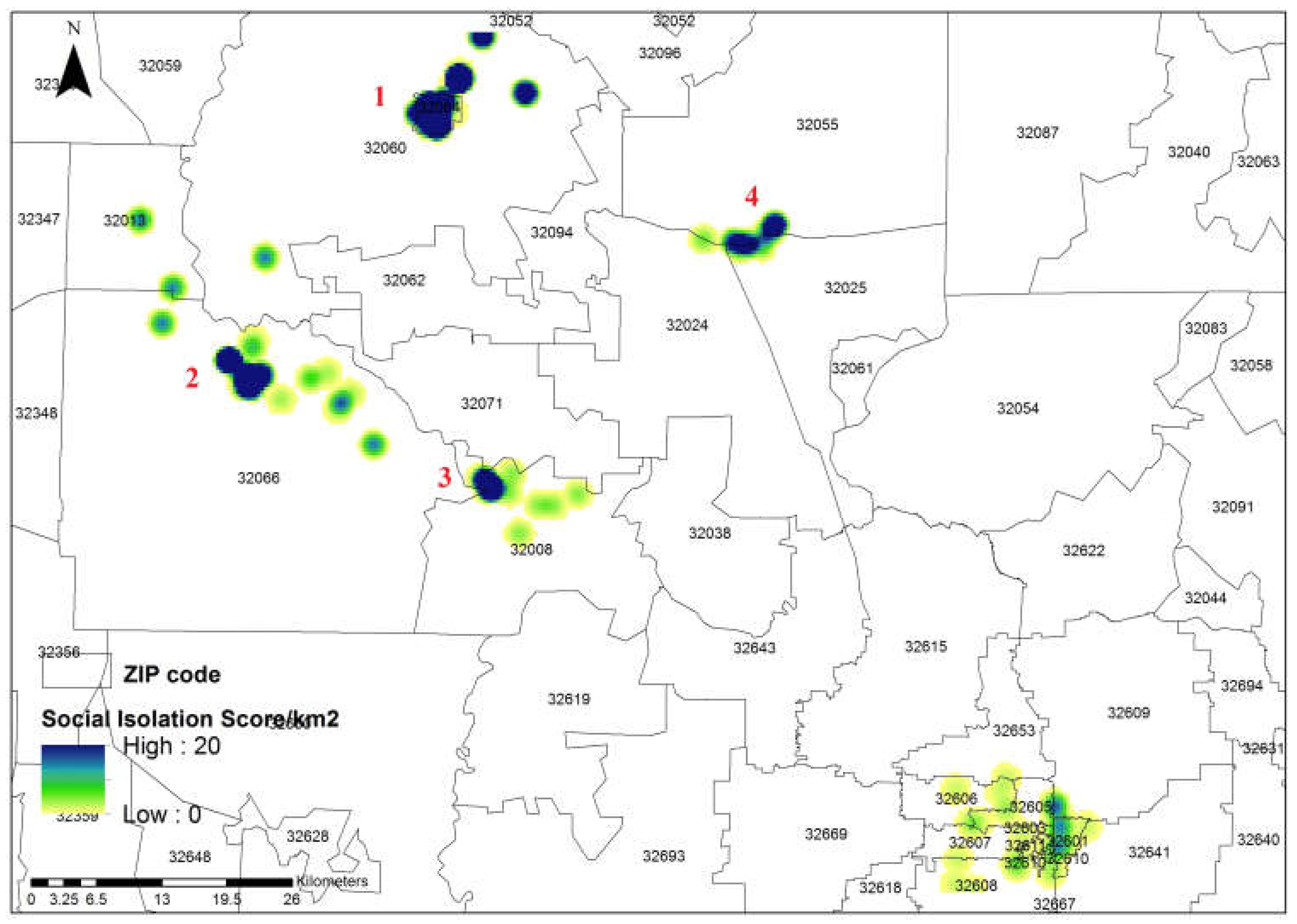
3.3. Socially Weighted Kernel Density Estimation
4. Results
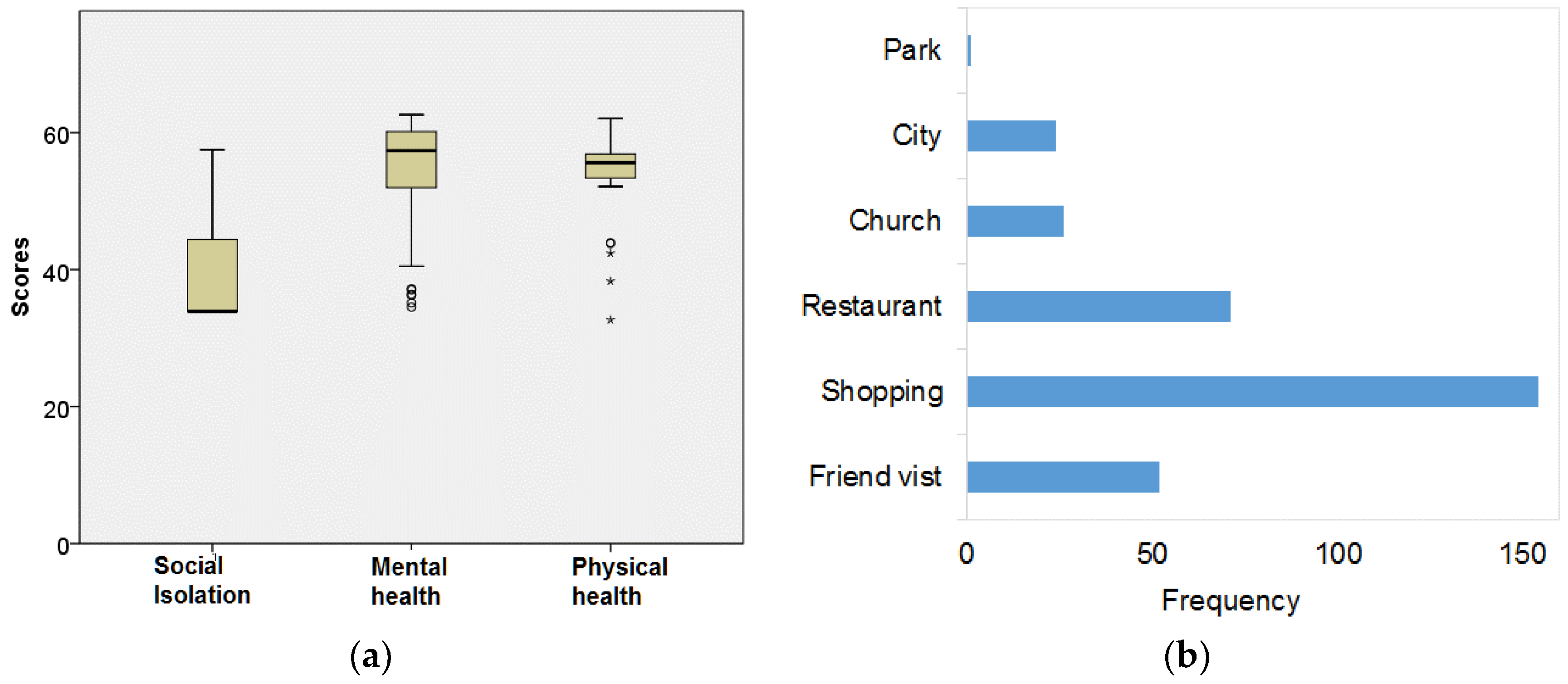
4.1. Demographics
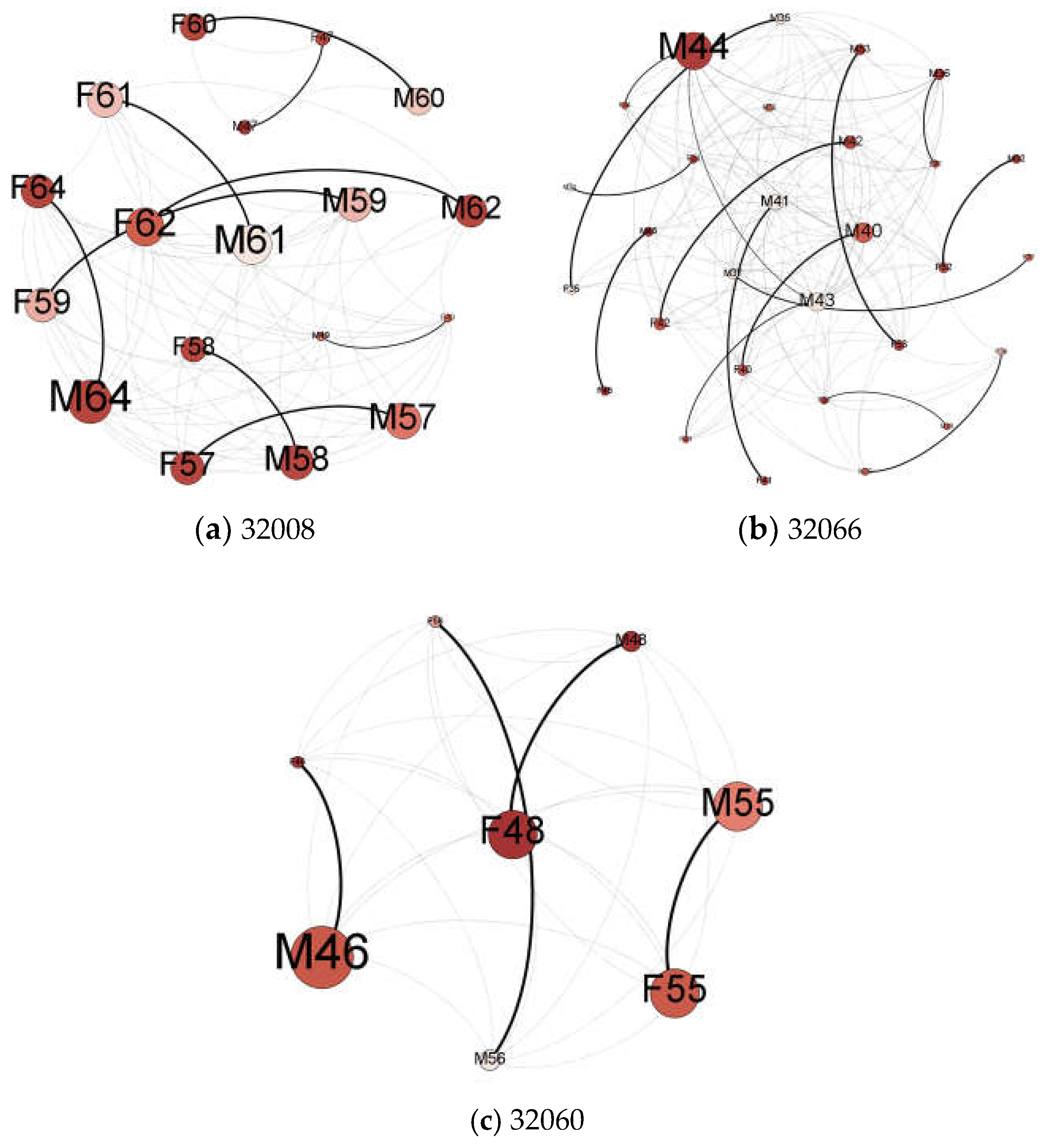
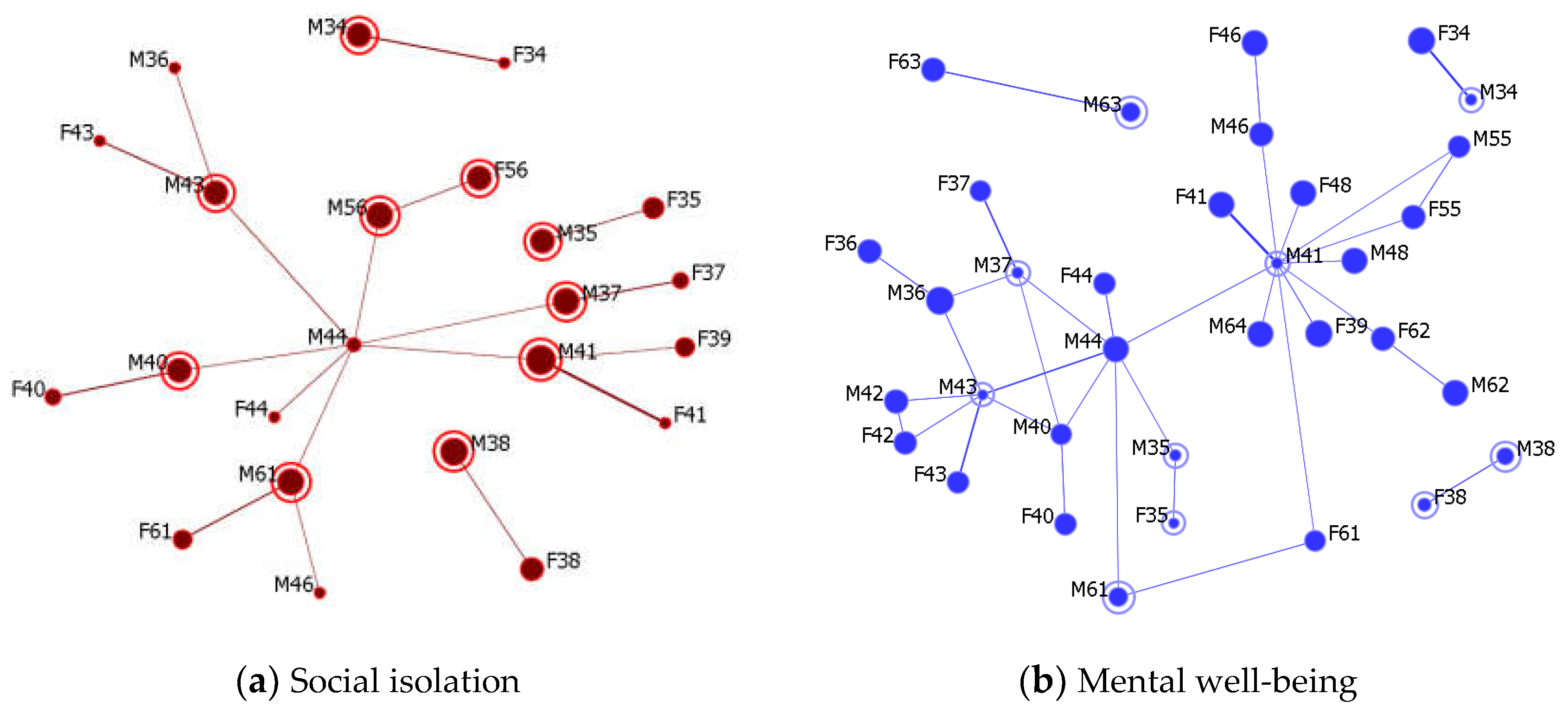
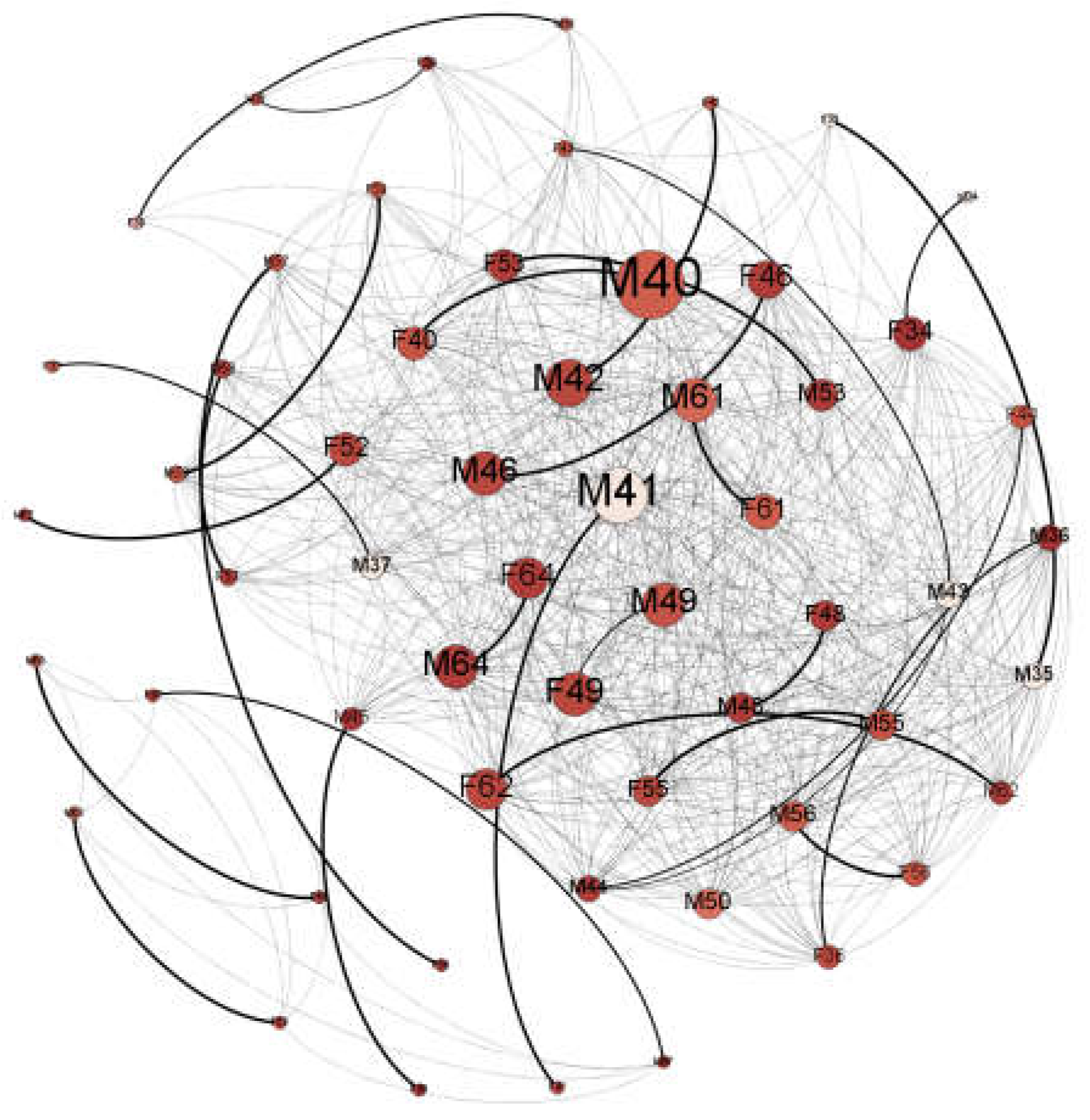
4.2. Spatially Weighted Social Network Analysis
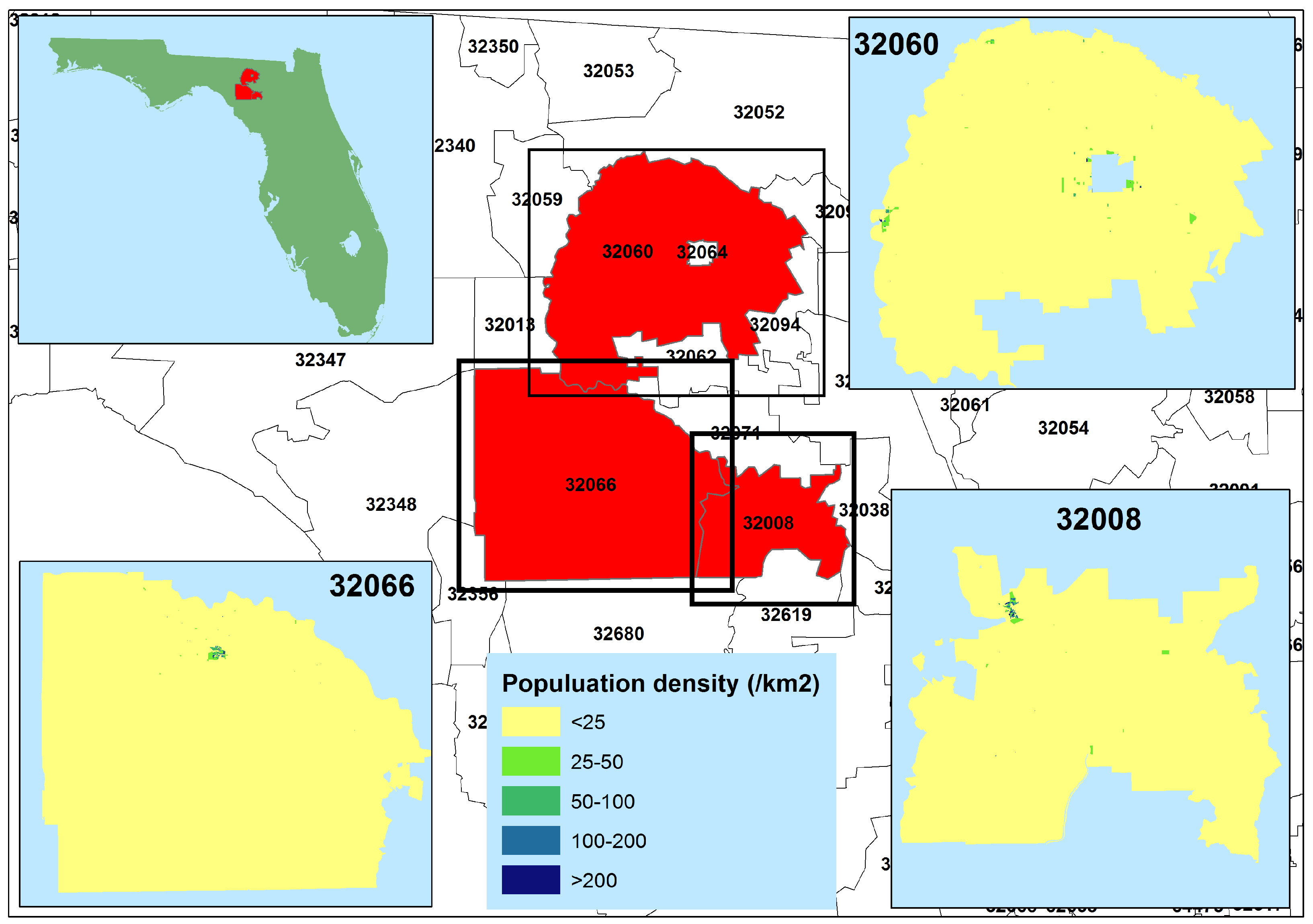
4.3. Socially Weighted Kernel Density Estimation
5. Discussion
5.1. Inferring Social Networks from Spatial Data
5.2. Who to Intervene with: Identifying Opinion Leaders and Social Supporters
5.3. Where to Intervene: Prioritizing Locations for Outreach and Intervention Efforts
5.4. Limitations
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Women (n = 30) | Men (n = 30) | |
|---|---|---|
| Country of Origin El Salvador Mexico Guatemala | 6.7% 90.0% 3.3% | 6.7% 93.3% 0% |
| Language (Spanish) | 100% | 100% |
| Years in US 10 or less More than 10 | 13.3% 86.7% | 16.6% 83.4% |
| Age 26–35 36–45 46–65 | 33.3% 53.4% 13.3% | 33.3% 50% 16.7% |
| Number of children * 1–2 3–4 5–6 | 24.1% 65.5% 10.4% | 26.7% 66.7% 6.6% |
| Children in country of origin ** No Yes | 92.9% 7.1% | 89.7% 10.3% |
| Employed No Yes | 33.3% 66.7% | 3.3% 96.7% |
| Years of education 0 1–4 5–8 9–14 | 0% 20% 36.7% 43.3% | 6.7% 13.4% 46.6% 33.3% |
| Family/friends nearby No Yes | 13.3% 86.7% | 6.7% 93.3% |
| Mean number of places visited in last month *** | 6.4 | 5.2 |
| Mean number of cities visited in last month * | 2.9 | 2.5 |


References
- Cacioppo, J.T.; Cacioppo, S. Social relationships and health: The toxic effects of perceived social isolation. Soc. Personal. Psychol. Compass 2014, 8, 58–72. [Google Scholar] [CrossRef] [PubMed]
- De Castro, J.M.; King, G.A.; Duarte-Gardea, M.; Gonzalez-Ayala, S.; Kooshian, C.H. Overweight and obese humans overeat away from home. Appetite 2012, 59, 204–211. [Google Scholar] [CrossRef] [PubMed]
- Smith, K.P.; Christakis, N.A. Social networks and health. Annu. Rev. Sociol. 2008, 34, 405–429. [Google Scholar] [CrossRef]
- McCray, T.; Brais, N. Exploring the role of transportation in fostering social exclusion: The use of gis to support qualitative data. Netw. Spat. Econ. 2007, 7, 397–412. [Google Scholar] [CrossRef]
- Grubesic, T.H.; Durbin, K.M. Community rates of breastfeeding initiation: A geospatial analysis of kentucky. J. Hum. Lact. 2016, 32, 601–610. [Google Scholar] [CrossRef] [PubMed]
- Goodman, R.A.; Bunnell, R.; Posner, S.F. What is “community health”? Examining the meaning of an evolving field in public health. Prev. Med. 2014, 67, S58–S61. [Google Scholar] [CrossRef] [PubMed]
- Yin, L.; Shaw, S.-L. Exploring space–time paths in physical and social closeness spaces: A space–time gis approach. Int. J. Geogr. Inf. Sci. 2015, 29, 742–761. [Google Scholar] [CrossRef]
- Toole, J.L.; Herrera-Yaqüe, C.; Schneider, C.M.; González, M.C. Coupling human mobility and social ties. J. R. Soc. Interface 2015, 12, 20141128. [Google Scholar] [CrossRef] [PubMed]
- Goodchild, M.F.; Janelle, D.G. Thinking spatially in the social sciences. In Spatially Integrated Social Science; Goodchild, M.F., Janelle, D.G., Eds.; Oxford University Press: Oxford, UK, 2004; pp. 3–19. [Google Scholar]
- Gatrell, A.C.; Rigby, J.E. Spatial perspectives in public health. In Spatially Integrated Social Science; Goodchild, M.F., Janelle, D.G., Eds.; Oxford University Press: Oxford, UK, 2004; pp. 366–380. [Google Scholar]
- Berkman, L.F.; Kawachi, I.; Glymour, M.M. Social Epidemiology; Oxford University Press: Oxford, UK, 2014. [Google Scholar]
- Qiu, B.; Zhao, K.; Mitra, P.; Wu, D.; Caragea, C.; Yen, J.; Greer, G.E.; Portier, K. Get online support, feel better—Sentiment analysis and dynamics in an online cancer survivor community. In Proceedings of the 2011 IEEE Third International Conference on the Privacy, Security, Risk and Trust (PASSAT) and 2011 IEEE Third Inernational Conference on Social Computing (SocialCom), Boston, MA, USA, 9–11 October 2011; pp. 274–281. [Google Scholar]
- Coreil, J. Group interview methods in community health research. Med. Anthropol. 1994, 16, 193–210. [Google Scholar] [CrossRef]
- Christakis, N.A.; Fowler, J.H. The spread of obesity in a large social network over 32 years. N. Engl. J. Med. 2007, 357, 370–379. [Google Scholar] [CrossRef] [PubMed]
- Valente, T.W. Network interventions. Science 2012, 337, 49–53. [Google Scholar] [CrossRef] [PubMed]
- Schönfelder, S.; Axhausen, K.W. Activity spaces: Measures of social exclusion? Transp. Policy 2003, 10, 273–286. [Google Scholar] [CrossRef]
- Kwan, M.-P.; Lee, J. Geovisualization of human activity patterns using 3D GIS: A time-geographic approach. In Spatially Integrated Social Science; Goodchild, M.F., Janelle, D.G., Eds.; Oxford University Press: Oxford, UK, 2004; pp. 48–66. [Google Scholar]
- Adams, J.; Faust, K.; Lovasi, G.S. Capturing context: Integrating spatial and social network analyses. Soc. Netw. 2012, 34, 1–5. [Google Scholar] [CrossRef]
- Onnela, J.-P.; Arbesman, S.; González, M.C.; Barabási, A.-L.; Christakis, N.A. Geographic constraints on social network groups. PLoS ONE 2011, 6, e16939. [Google Scholar] [CrossRef] [PubMed]
- House, J.S.; Umberson, D.; Landis, K.R. Structures and processes of social support. Annu. Rev. Sociol. 1988, 14, 293–318. [Google Scholar] [CrossRef]
- Masi, C.M.; Chen, H.-Y.; Hawkley, L.C.; Cacioppo, J.T. A meta-analysis of interventions to reduce loneliness. Personal. Soc. Psychol. Rev. 2011, 15, 219–266. [Google Scholar] [CrossRef] [PubMed]
- Rogerson, P.; Yamada, I. Statistical Detection and Surveillance of Geographic Clusters; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Bailey, T.C.; Gatrell, A.C. Interactive Spatial Data Analysis; Longman Scientific & Technical: Essex, England; New York, NY, USA, 1995; Volume 413. [Google Scholar]
- Diggle, P. A kernel method for smoothing point process data. Appl. Stat. 1985, 138–147. [Google Scholar] [CrossRef]
- HAC. Race & ethnicity in rural america. In Rural Research Briefs; Housing Assistant Council: Washington, DC, USA, 2012; pp. 1283–1288. [Google Scholar]
- Terrazas, A. Mexican Immigrants in the United States. In Migration Information Source; Migration policy Institute: Washington, DC, USA, 2010; pp. 1–9. [Google Scholar]
- Douglas, K.M.; Saenz, R. No phone, no vehicle, no english, and no citizenship: The vulnerability of mexican immigrants in the united states. In Globalization and America: Race, Human Rights, and Inequality; Towman and Littlefield: Lanham, MD, USA, 2008; pp. 161–180. [Google Scholar]
- Williams, D.R.; Mohammed, S.A. Discrimination and racial disparities in health: Evidence and needed research. J. Behav. Med. 2009, 32, 20–47. [Google Scholar] [CrossRef] [PubMed]
- Stacciarini, J.-M.R.; Smith, R.; Garvan, C.W.; Wiens, B.; Cottler, L.B. Rural latinos’ mental wellbeing: A mixed-methods pilot study of family, environment and social isolation factors. Community Ment. Health J. 2015, 51, 404–413. [Google Scholar] [CrossRef] [PubMed]
- Stacciarini, J.-M.R.; Smith, R.F.; Wiens, B.; Pérez, A.; Locke, B.; LaFlam, M. I didn’t ask to come to this country… I was a child: The mental health implications of growing up undocumented. J. Immigr. Minority Health 2015, 17, 1225–1230. [Google Scholar] [CrossRef] [PubMed]
- Mora, D.C.; Grzywacz, J.G.; Anderson, A.M.; Chen, H.; Arcury, T.A.; Marín, A.J.; Quandt, S.A. Social isolation among latino workers in rural north carolina: Exposure and health implications. J. Immigr. Minority Health 2014, 16, 822–830. [Google Scholar] [CrossRef] [PubMed]
- Ko, L.K.; Perreira, K.M. “It turned my world upside down”: Latino youths’ perspectives on immigration. J. Adolesc. Res. 2010, 25, 465–493. [Google Scholar] [CrossRef] [PubMed]
- Eagle, N.; Pentland, A.S.; Lazer, D. Inferring friendship network structure by using mobile phone data. Proc. Natl. Acad. Sci. USA 2009, 106, 15274–15278. [Google Scholar] [CrossRef] [PubMed]
- Bernard, H.R.; Killworth, P.D.; Sailer, L. Informant accuracy in social-network data v. An experimental attempt to predict actual communication from recall data. Soc. Sci. Res. 1982, 11, 30–66. [Google Scholar] [CrossRef]
- Everett, M.G.; Valente, T.W. Bridging, brokerage and betweenness. Soc. Netw. 2016, 44, 202–208. [Google Scholar] [CrossRef] [PubMed]
- Valente, T.W.; Fujimoto, K. Bridging: Locating critical connectors in a network. Soc. Netw. 2010, 32, 212–220. [Google Scholar] [CrossRef] [PubMed]
- Scellato, S.; Noulas, A.; Mascolo, C. Exploiting place features in link prediction on location-based social networks. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 1046–1054. [Google Scholar]
- Spreen, M. Rare populations, hidden populations, and link-tracing designs: What and why? Bull. Sociol. Methodol. 1992, 36, 34–58. [Google Scholar] [CrossRef]
- Mao, L.; Stacciarini, J.-M.R.; Smith, R.; Wiens, B. An individual-based rurality measure and its health application: A case study of latino immigrants in north florida, USA. Soc. Sci. Med. 2015, 147, 300–308. [Google Scholar] [CrossRef] [PubMed]





| Node ID a | ZIP Code Area | Degree Centrality | Mental Well-Being Score | Physical Well-Being Score | Social Isolation Score |
|---|---|---|---|---|---|
| M44 | 32066 | 1.69 | 60.16 | 55.85 | 39.1 |
| M42 | 32066 | 1.25 | 51.96 | 57.17 | 43.1 |
| F55 | 32060 | 1.23 | 57.38 | 57.12 | 33.9 |
| M46 | 32060 | 1.24 | 57.53 | 54.64 | 33.9 |
| M64 | 32008 | 1.29 | 60.32 | 53.37 | 33.9 |
| F62 | 32008 | 1.18 | 57.53 | 54.64 | 39.1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stacciarini, J.-M.R.; Vacca, R.; Mao, L. Who and Where: A Socio-Spatial Integrated Approach for Community-Based Health Research. Int. J. Environ. Res. Public Health 2018, 15, 1375. https://doi.org/10.3390/ijerph15071375
Stacciarini J-MR, Vacca R, Mao L. Who and Where: A Socio-Spatial Integrated Approach for Community-Based Health Research. International Journal of Environmental Research and Public Health. 2018; 15(7):1375. https://doi.org/10.3390/ijerph15071375
Chicago/Turabian StyleStacciarini, Jeanne-Marie R., Raffaele Vacca, and Liang Mao. 2018. "Who and Where: A Socio-Spatial Integrated Approach for Community-Based Health Research" International Journal of Environmental Research and Public Health 15, no. 7: 1375. https://doi.org/10.3390/ijerph15071375
APA StyleStacciarini, J.-M. R., Vacca, R., & Mao, L. (2018). Who and Where: A Socio-Spatial Integrated Approach for Community-Based Health Research. International Journal of Environmental Research and Public Health, 15(7), 1375. https://doi.org/10.3390/ijerph15071375