
Automatic Recognition of Mexican Sign Language Using a Depth Camera and Recurrent Neural Networks

 ,
,  ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
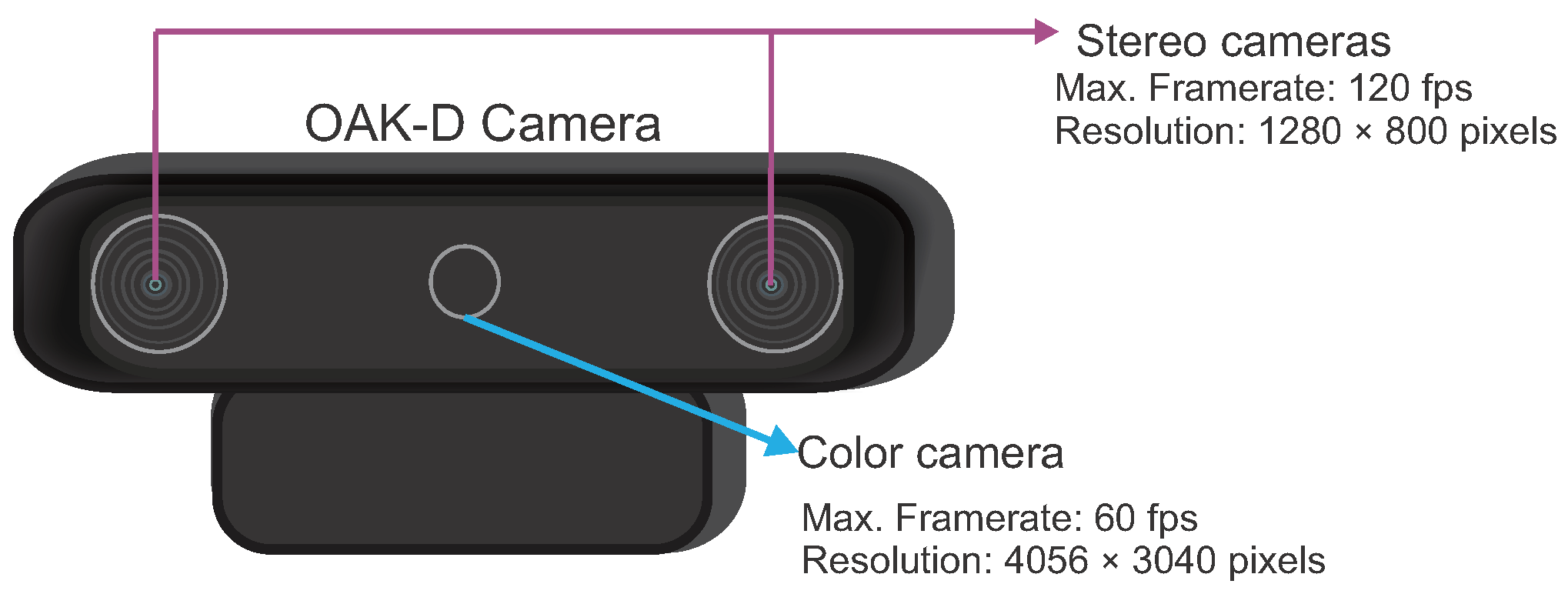
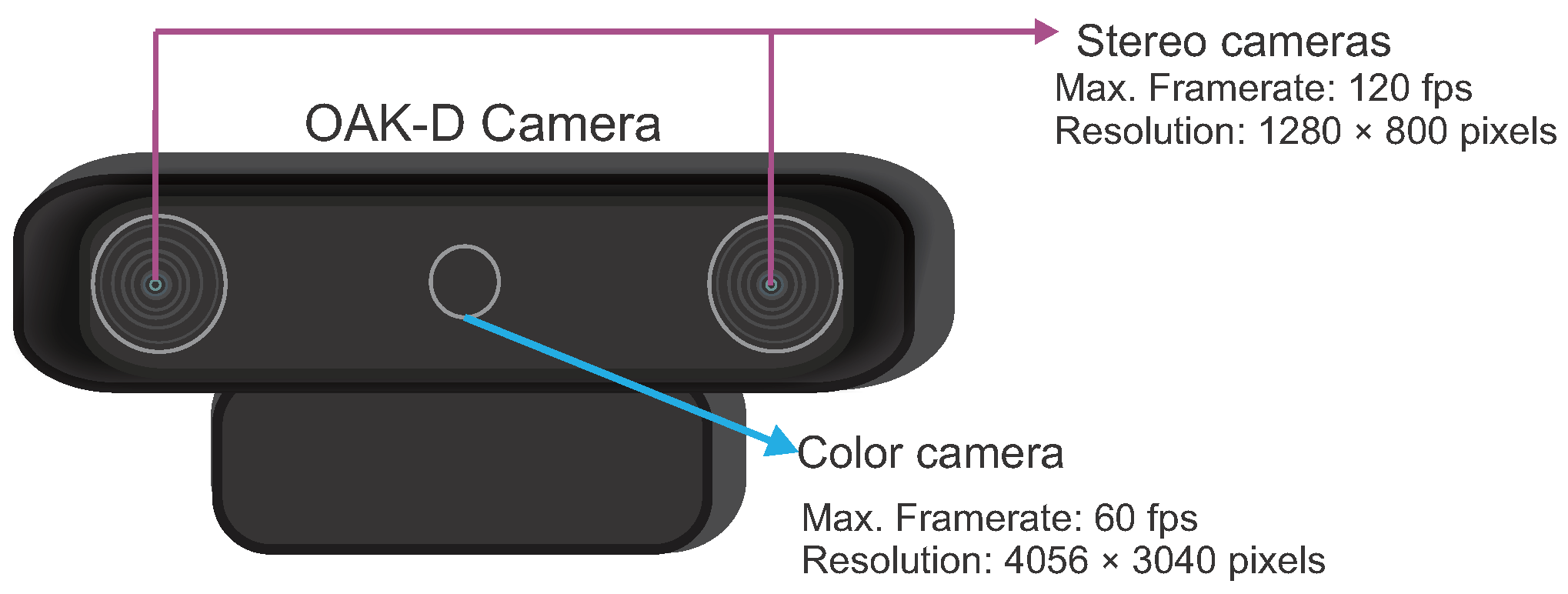
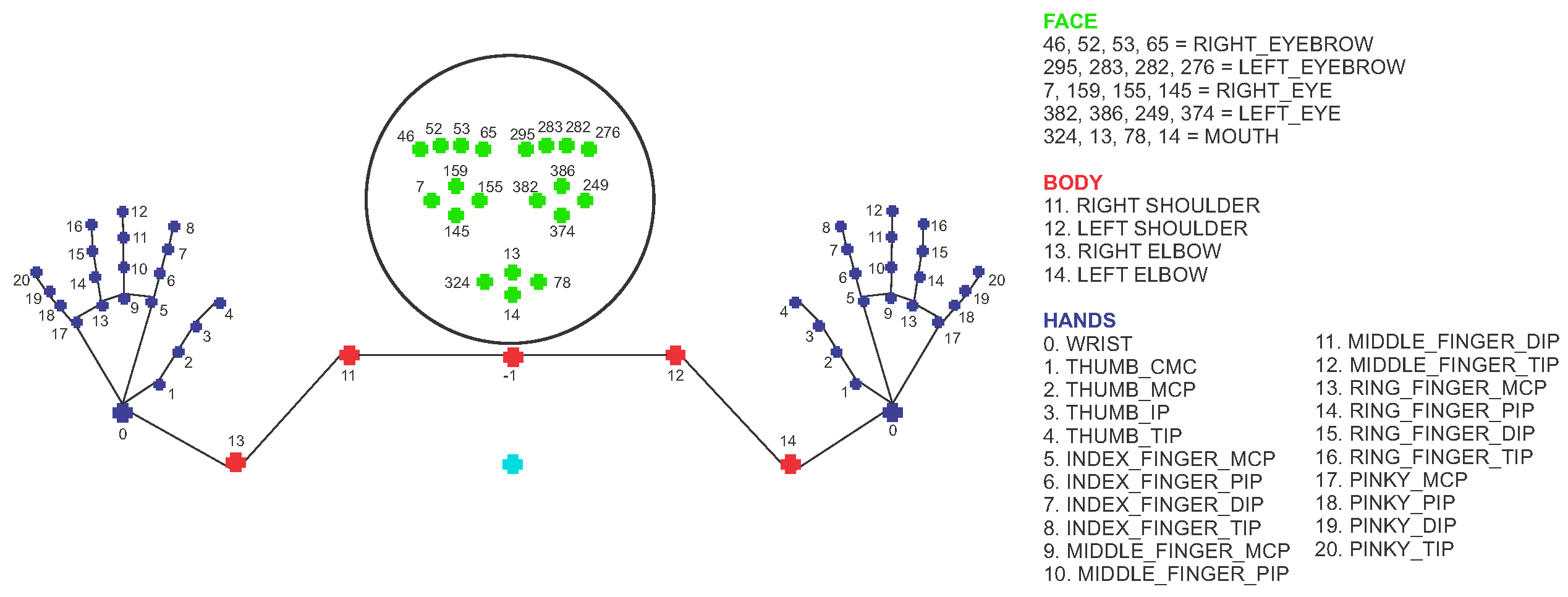
3.1. Data Acquisition
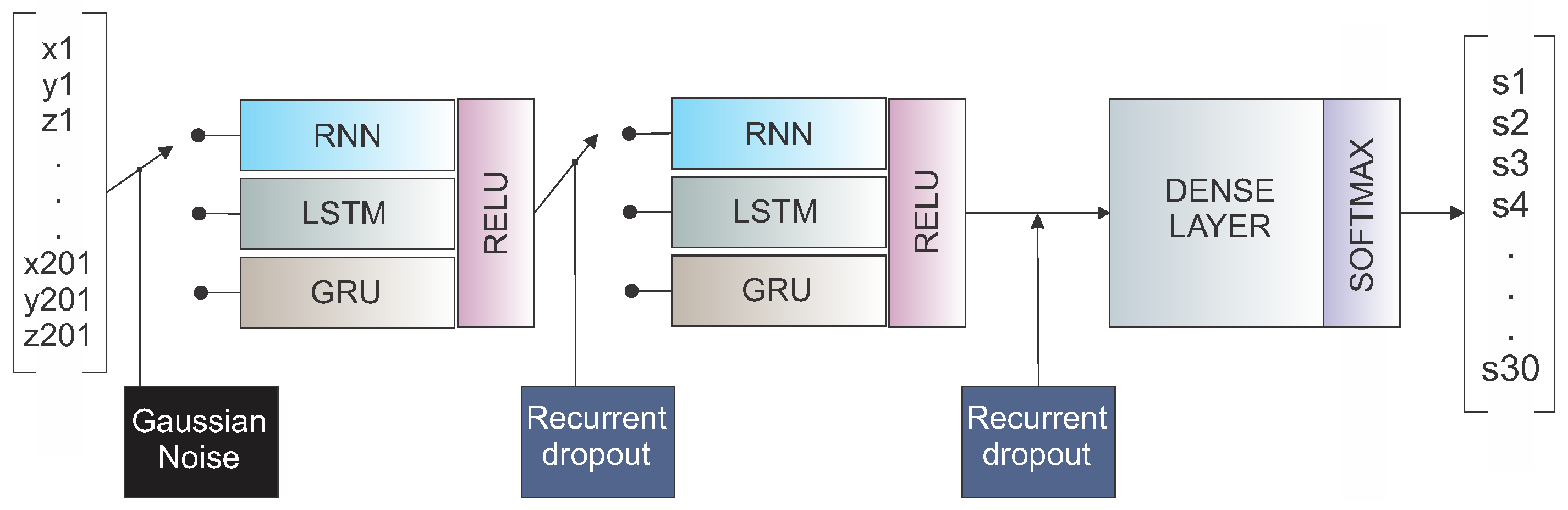
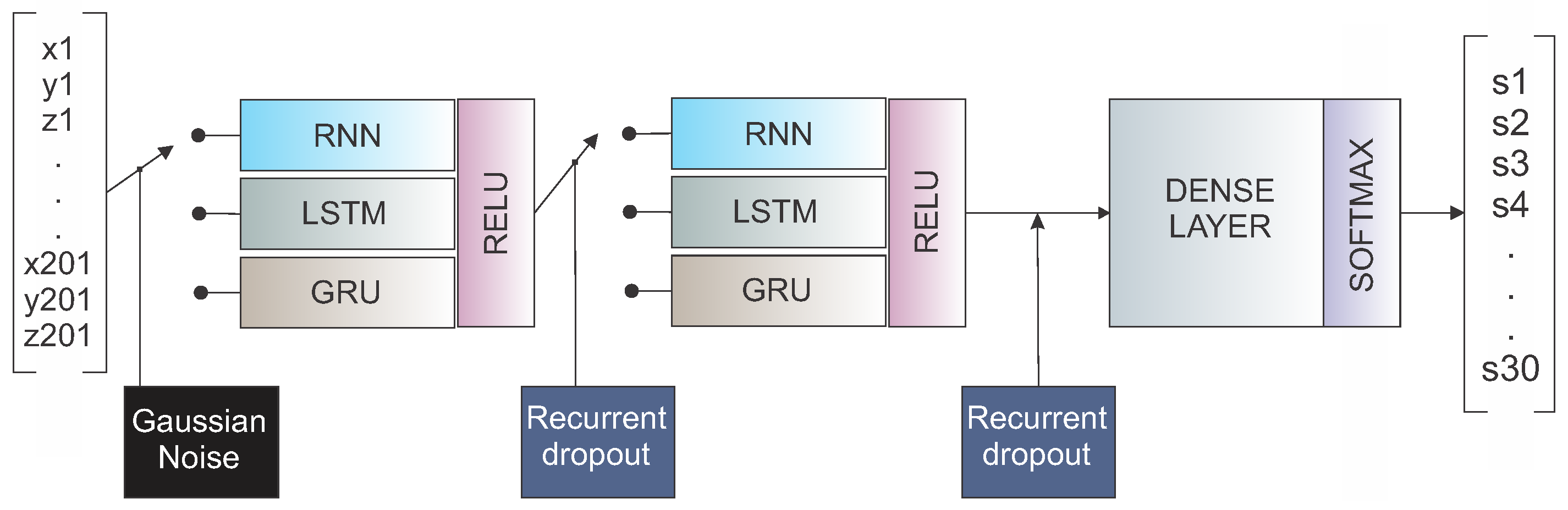
3.2. Classification Architectures
3.2.1. Recurrent Neural Network (RNN)
3.2.2. Long Short-Term Memory (LSTM)
3.2.3. GRU
3.3. Classification
3.4. Evaluation
- True Positive () refers to the number of predictions where the classifier correctly predicts the positive class as positive.
- True Negative () indicates to the number of predictions where the classifier correctly predicts the negative class as negative.
- False Positive () denotes to the number of predictions where the classifier incorrectly predicts the negative class as positive.
- False Negative () refers to the number of predictions where the classifier incorrectly predicts the positive class as negative.
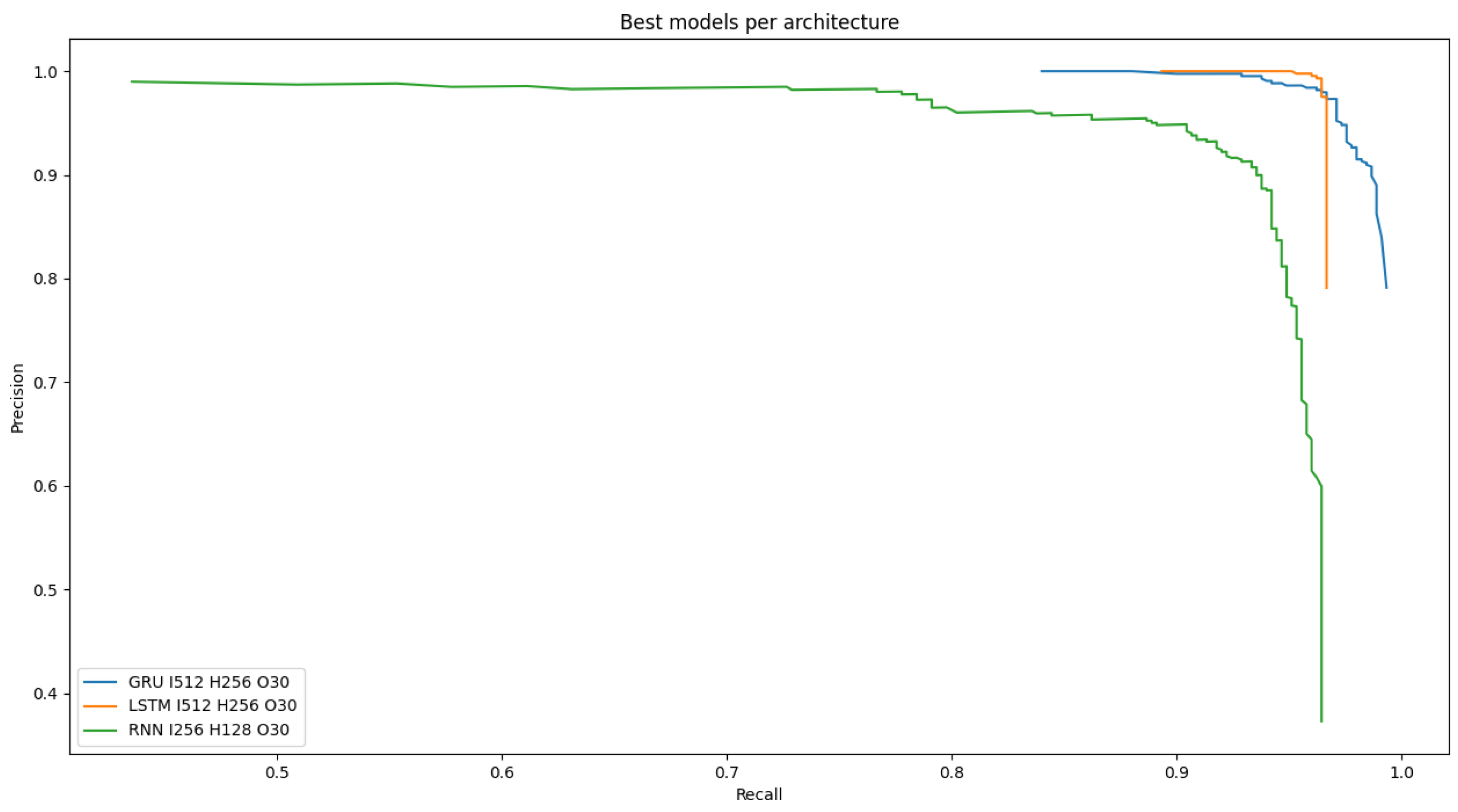
4. Results
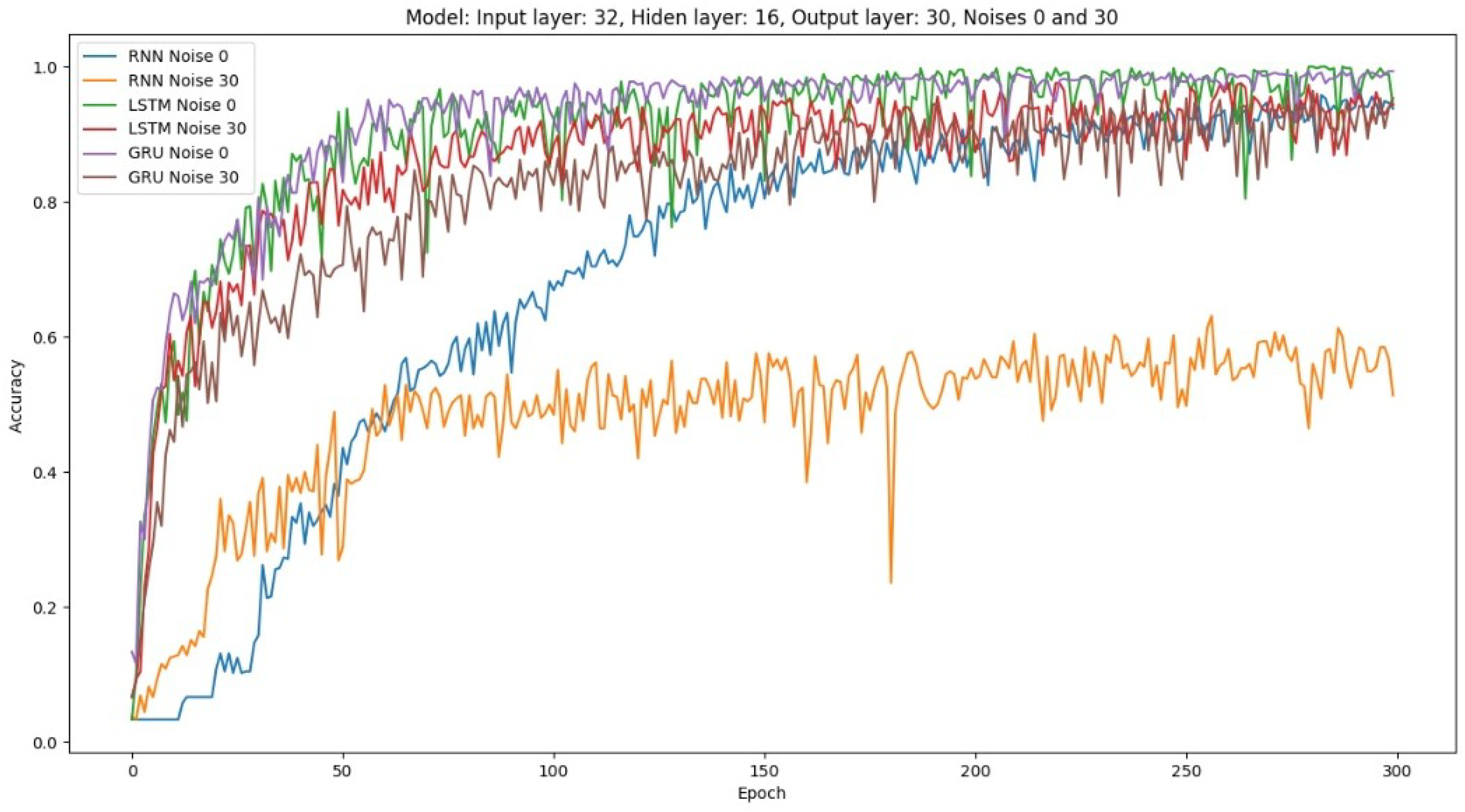
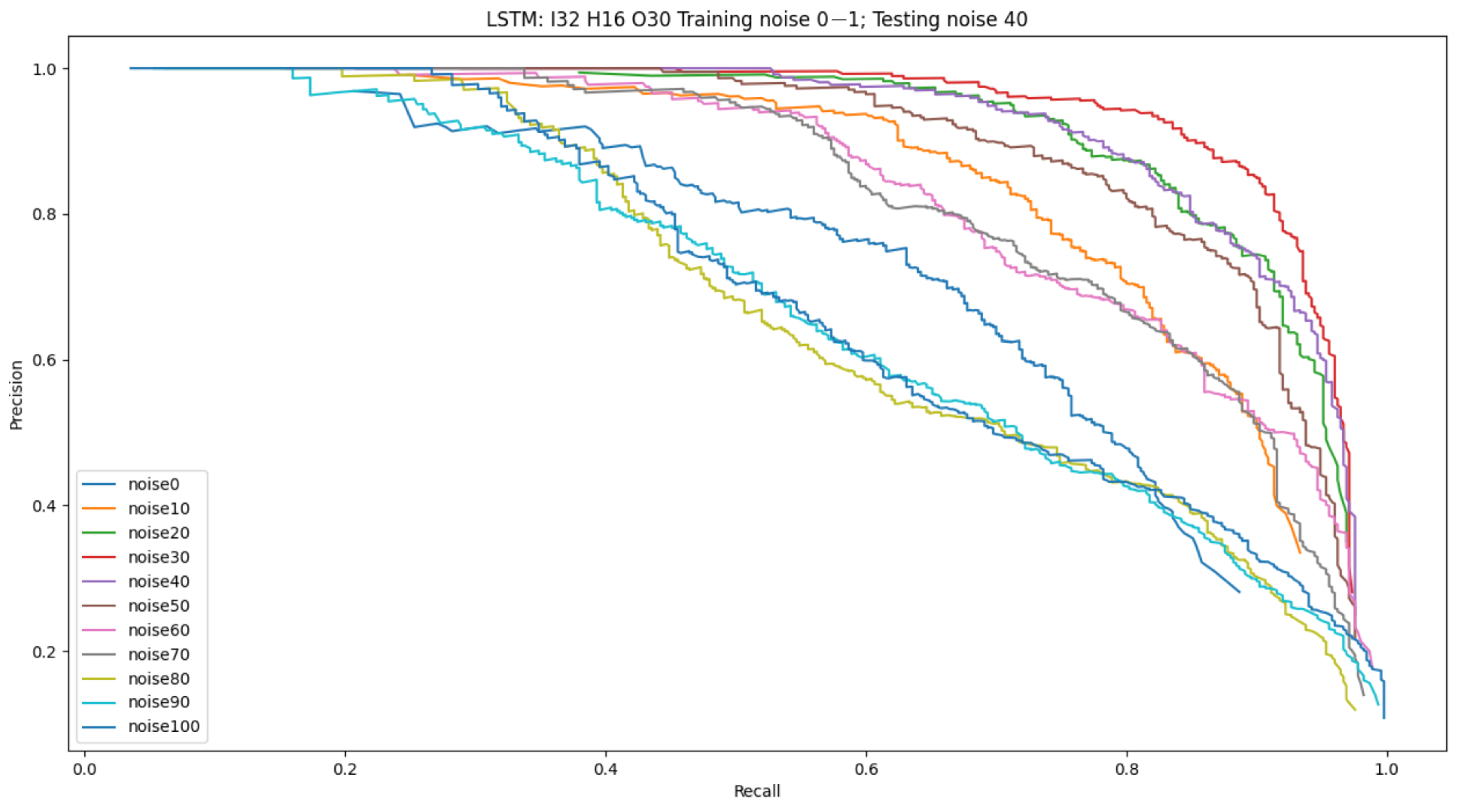
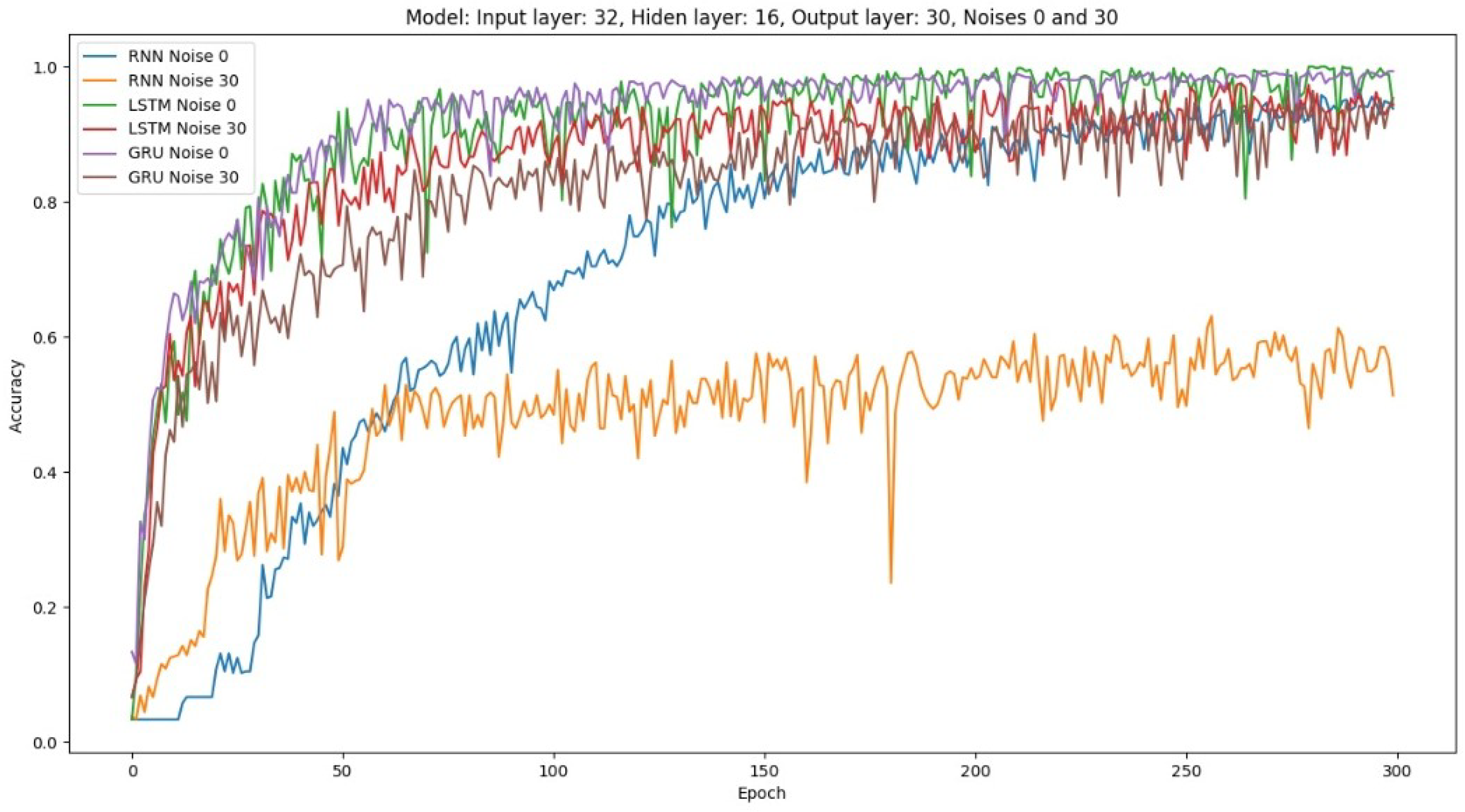
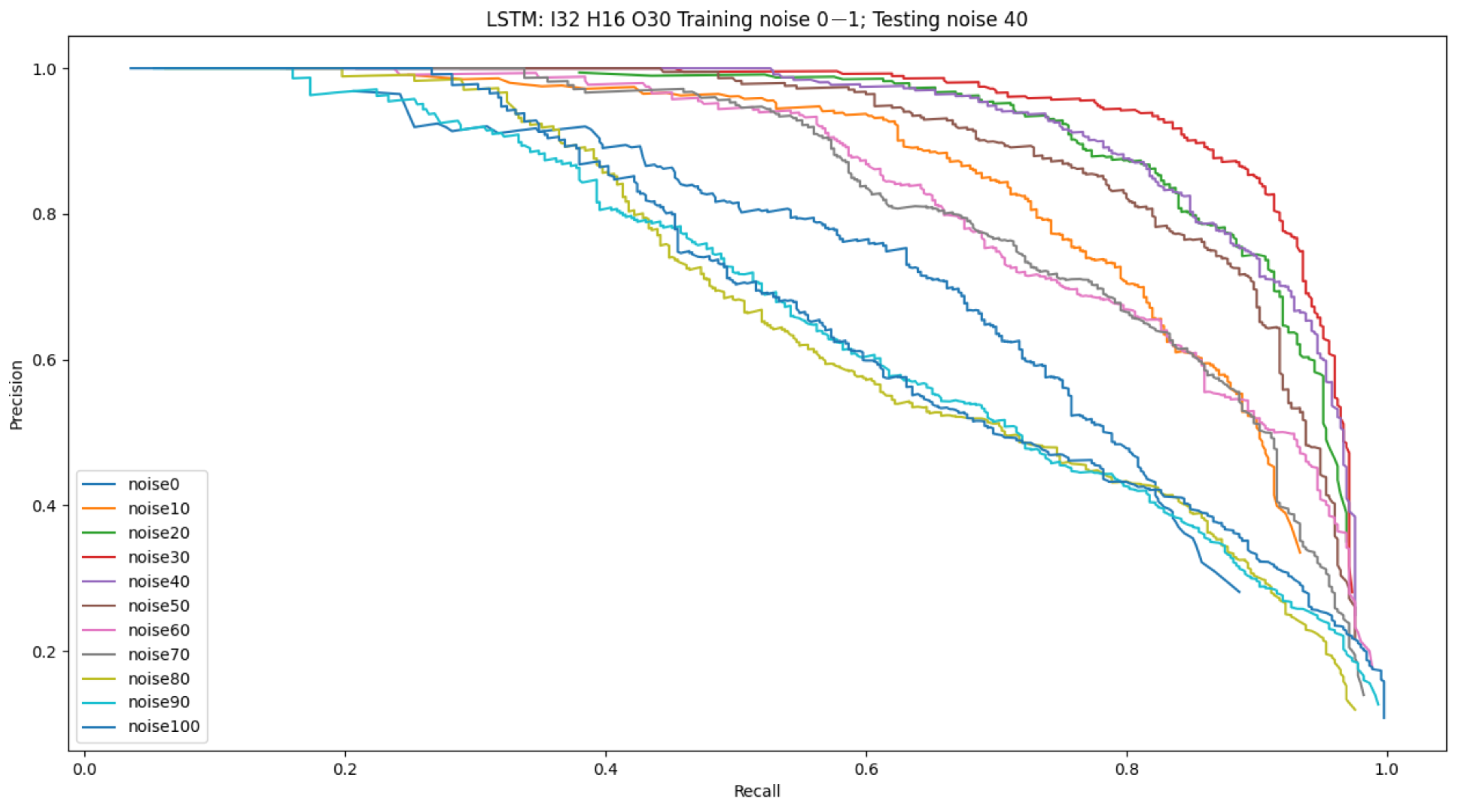
4.1. System Robustness to Noise
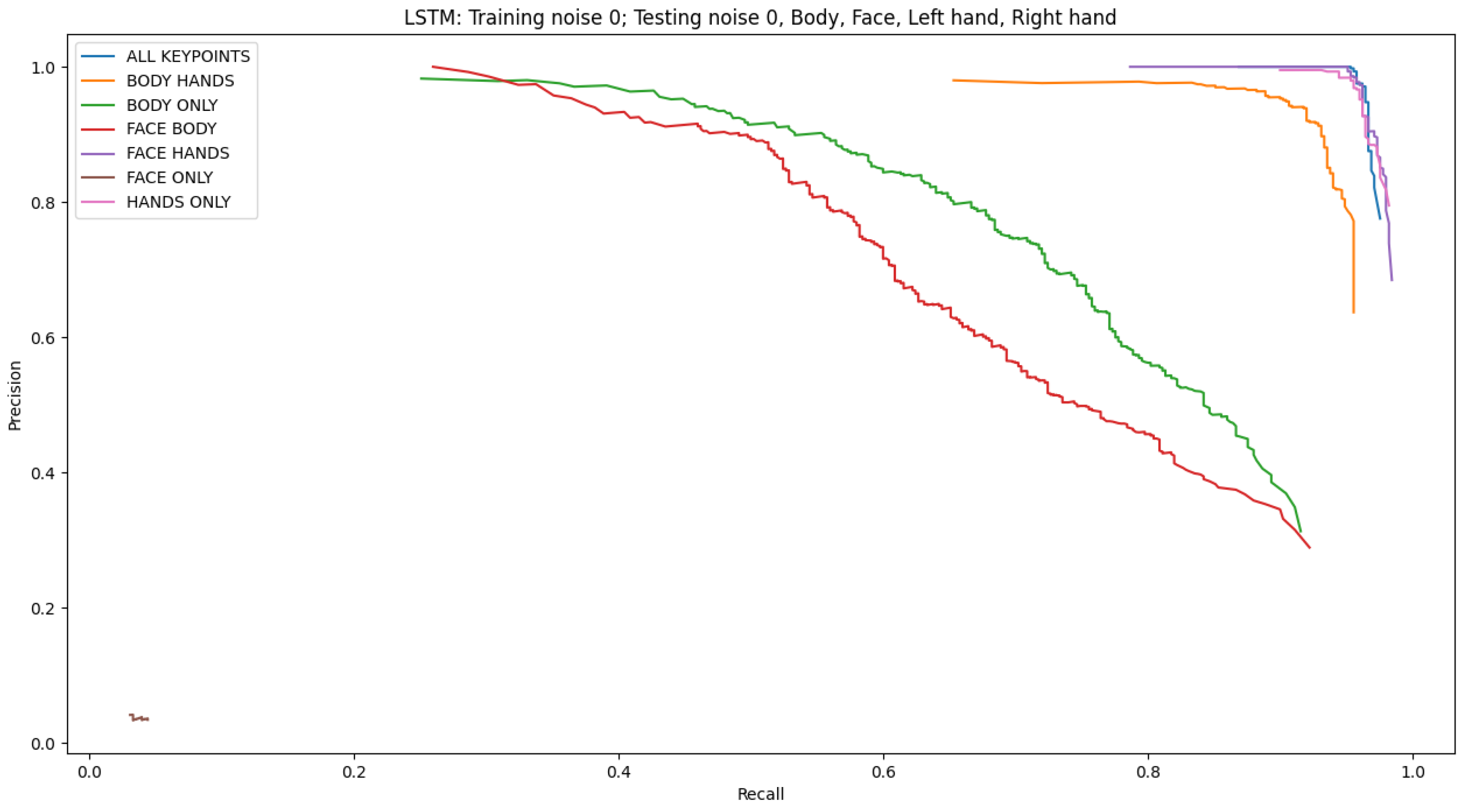
4.2. Ablation Studies
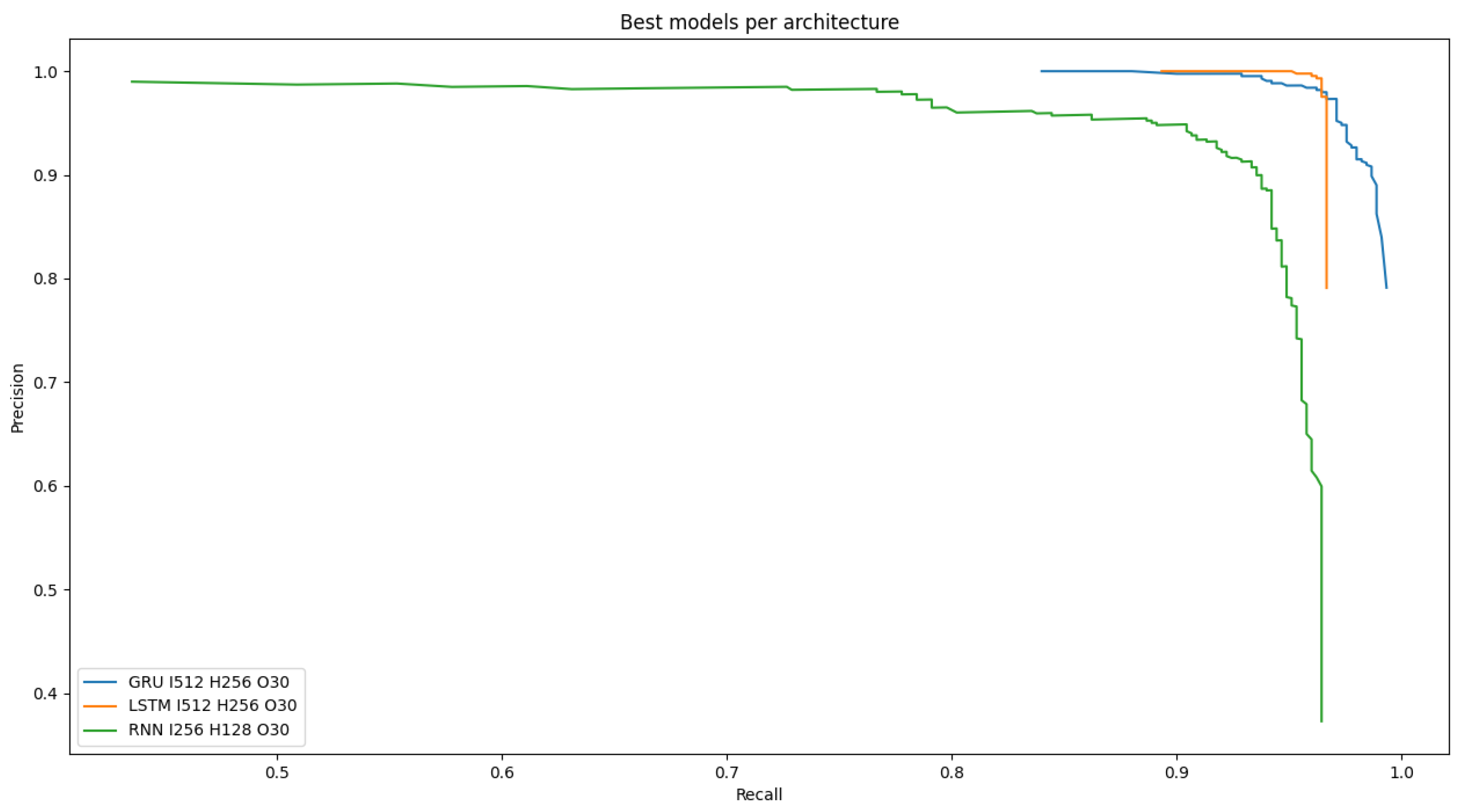
4.2.1. Varying Architecture
4.2.2. Varying Features
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- INEGI. Las Personas Con Discapacidad Auditiva. Available online: https://www.inegi.org.mx/app/tabulados/interactivos/?pxq=Discapacidad_Discapacidad_02_2c111b6a-6152-40ce-bd39-6fab2c4908e3&idrt=151&opc=t (accessed on 5 May 2021).
- Serafín, M.; González, R. Manos Con Voz, Diccionario de Lenguaje de señas Mexicana, 1st ed.; Committee on the Elimination of Racial Discrimination: Mexico City, Mexico, 2011; pp. 15–19. [Google Scholar]
- Torres, S.; Sánchez, J.; Carratalá, P. Curso de Bimodal. In Sistemas Aumentativos de Comunicación; Universidad de Málaga: Málaga, Spain, 2008. [Google Scholar]
- WFD-SNAD. Informe de la Encuesta Global de la Secretaría Regional de la WFD para México, América Central y el Caribe (WFD MCAC) Realizado por la Federación Mundial de Sordos y la Asociación Nacional de Sordos de Suecia. 2008, p. 16. Available online: https://docplayer.es/12868567-Este-proyecto-se-realizo-bajo-los-auspicios-de-la-asociacion-nacional-de-sordos-de-suecia-sdr-y-la-federacion-mundial-de-sordos-wfd-con-la.html (accessed on 12 March 2021).
- Ruvalcaba, D.; Ruvalcaba, M.; Orozco, J.; López, R.; Cañedo, C. Prototipo de guantes traductores de la lengua de señas mexicana para personas con discapacidad auditiva y del habla. In Proceedings of the Congreso Nacional de Ingeniería Biomédica, Leon Guanajuato, Mexico, 18–20 October 2018; SOMIB Volume 5, pp. 350–353. [Google Scholar]
- Saldaña González, G.; Cerezo Sánchez, J.; Bustillo Díaz, M.M.; Ata Pérez, A. Recognition and classification of sign language for spanish. Comput. Sist. 2018, 22, 271–277. [Google Scholar] [CrossRef]
- Varela-Santos, H.; Morales-Jiménez, A.; Córdova-Esparza, D.M.; Terven, J.; Mirelez-Delgado, F.D.; Orenday-Delgado, A. Assistive Device for the Translation from Mexican Sign Language to Verbal Language. Comput. Sist. 2021, 25, 451–464. [Google Scholar] [CrossRef]
- Cuecuecha-Hernández, E.; Martínez-Orozco, J.J.; Méndez-Lozada, D.; Zambrano-Saucedo, A.; Barreto-Flores, A.; Bautista-López, V.E.; Ayala-Raggi, S.E. Sistema de reconocimiento de vocales de la Lengua de Señas Mexicana. Pist. Educ. 2018, 39, 128. [Google Scholar]
- Estrivero-Chavez, C.; Contreras-Teran, M.; Miranda-Hernandez, J.; Cardenas-Cornejo, J.; Ibarra-Manzano, M.; Almanza-Ojeda, D. Toward a Mexican Sign Language System using Human Computer Interface. In Proceedings of the 2019 International Conference on Mechatronics, Electronics and Automotive Engineering (ICMEAE), Cuernavaca, Mexico, 26–29 November 2019; pp. 13–17. [Google Scholar]
- Solís, F.; Toxqui, C.; Martínez, D. Mexican sign language recognition using jacobi-fourier moments. Engineering 2015, 7, 700. [Google Scholar] [CrossRef] [Green Version]
- Cervantes, J.; García-Lamont, F.; Rodríguez-Mazahua, L.; Rendon, A.Y.; Chau, A.L. Recognition of Mexican sign language from frames in video sequences. In International Conference on Intelligent Computing; Springer: Lanzhou, China, 2016; pp. 353–362. [Google Scholar]
- Martínez-Gutiérrez, M.; Rojano-Cáceres, J.R.; Bárcenas-Patiño, I.E.; Juárez-Pérez, F. Identificación de lengua de señas mediante técnicas de procesamiento de imágenes. Res. Comput. Sci. 2016, 128, 121–129. [Google Scholar] [CrossRef]
- Solís, F.; Martínez, D.; Espinoza, O. Automatic mexican sign language recognition using normalized moments and artificial neural networks. Engineering 2016, 8, 733–740. [Google Scholar] [CrossRef] [Green Version]
- Pérez, L.M.; Rosales, A.J.; Gallegos, F.J.; Barba, A.V. LSM static signs recognition using image processing. In Proceedings of the 2017 14th International Conference on Electrical Engineering, Computing Science and Automatic Control (CCE), Mexico City, Mexico, 20–22 October 2017; pp. 1–5. [Google Scholar]
- Mancilla-Morales, E.; Vázquez-Aparicio, O.; Arguijo, P.; Meléndez-Armenta, R.Á.; Vázquez-López, A.H. Traducción del lenguaje de senas usando visión por computadora. Res. Comput. Sci. 2019, 148, 79–89. [Google Scholar] [CrossRef]
- Martinez-Seis, B.; Pichardo-Lagunas, O.; Rodriguez-Aguilar, E.; Saucedo-Diaz, E.R. Identification of Static and Dynamic Signs of the Mexican Sign Language Alphabet for Smartphones using Deep Learning and Image Processing. Res. Comput. Sci. 2019, 148, 199–211. [Google Scholar] [CrossRef]
- Galicia, R.; Carranza, O.; Jiménez, E.; Rivera, G. Mexican sign language recognition using movement sensor. In Proceedings of the 2015 IEEE 24th International Symposium on Industrial Electronics (ISIE), Buzios, Brazil, 3–5 June 2015; pp. 573–578. [Google Scholar]
- Sosa-Jiménez, C.O.; Ríos-Figueroa, H.V.; Rechy-Ramírez, E.J.; Marin-Hernandez, A.; González-Cosío, A.L.S. Real-time mexican sign language recognition. In Proceedings of the 2017 IEEE International Autumn Meeting on Power, Electronics and Computing (ROPEC), Ixtapa, Mexico, 8–10 November 2017; pp. 1–6. [Google Scholar]
- García-Bautista, G.; Trujillo-Romero, F.; Caballero-Morales, S.O. Mexican sign language recognition using kinect and data time warping algorithm. In Proceedings of the 2017 International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula, Mexico, 22–24 February 2017; pp. 1–5. [Google Scholar]
- Jimenez, J.; Martin, A.; Uc, V.; Espinosa, A. Mexican sign language alphanumerical gestures recognition using 3D Haar-like features. IEEE Lat. Am. Trans. 2017, 15, 2000–2005. [Google Scholar] [CrossRef]
- Martínez-Gutiérrez, M.E.; Rojano-Cáceres, J.R.; Benítez-Guerrero, E.; Sánchez-Barrera, H.E. Data Acquisition Software for Sign Language Recognition. Res. Comput. Sci. 2019, 148, 205–211. [Google Scholar] [CrossRef]
- Unutmaz, B.; Karaca, A.C.; Güllü, M.K. Turkish sign language recognition using kinect skeleton and convolutional neural network. In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019; pp. 1–4. [Google Scholar]
- Jing, L.; Vahdani, E.; Huenerfauth, M.; Tian, Y. Recognizing american sign language manual signs from rgb-d videos. arXiv 2019, arXiv:1906.02851. [Google Scholar]
- Raghuveera, T.; Deepthi, R.; Mangalashri, R.; Akshaya, R. A depth-based Indian sign language recognition using microsoft kinect. Sādhanā 2020, 45, 1–13. [Google Scholar] [CrossRef]
- Khan, M.; Siddiqui, N. Sign Language Translation in Urdu/Hindi Through Microsoft Kinect. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Topi, Pakistan, 2020; Volume 899, p. 012016. [Google Scholar]
- Xiao, Q.; Qin, M.; Yin, Y. Skeleton-based Chinese sign language recognition and generation for bidirectional communication between deaf and hearing people. Neural Netw. 2020, 125, 41–55. [Google Scholar] [CrossRef] [PubMed]
- Trujillo-Romero, F.; Bautista, G.G. Reconocimiento de palabras de la Lengua de Señas Mexicana utilizando información RGB-D. ReCIBE Rev. Electron. Comput. Inform. Biomed. Electron. 2021, 10, C2–C23. [Google Scholar]
- Carmona-Arroyo, G.; Rios-Figueroa, H.V.; Avendaño-Garrido, M.L. Mexican Sign-Language Static-Alphabet Recognition Using 3D Affine Invariants. In Machine Vision Inspection Systems: Machine Learning-Based Approaches; Scrivener Publishing LLC: Beverly, MA, USA, 2021; Volume 2, pp. 171–192. [Google Scholar]
- DepthAI. DepthAI’s Documentation. Available online: https://docs.luxonis.com/en/latest/ (accessed on 31 March 2021).
- MediaPipe. MediaPipe Holistic. Available online: https://google.github.io/mediapipe/solutions/holistic#python-solution-api (accessed on 29 March 2021).
- Zhang, F.; Bazarevsky, V.; Vakunov, A.; Tkachenka, A.; Sung, G.; Chang, C.L.; Grundmann, M. Mediapipe hands: On-device real-time hand tracking. arXiv 2020, arXiv:2006.10214. [Google Scholar]
- Singh, A.K.; Kumbhare, V.A.; Arthi, K. Real-Time Human Pose Detection and Recognition Using MediaPipe. In International Conference on Soft Computing and Signal Processing; Springer: Hyderabad, India, 2021; pp. 145–154. [Google Scholar]
- Sak, H.; Senior, A.; Beaufays, F. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv 2014, arXiv:1402.1128. [Google Scholar]
- Yang, S.; Yu, X.; Zhou, Y. Lstm and gru neural network performance comparison study: Taking yelp review dataset as an example. In Proceedings of the 2020 International Workshop on Electronic Communication and Artificial Intelligence (IWECAI), Qingdao, China, 12–14 June 2020; pp. 98–101. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chollet, F. Deep Learning with Python, 1st ed.; Manning Publications Co.: Shelter Island, NY, USA, 2018; pp. 178–232. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-scale machine learning on heterogeneous systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: New York, NY, USA, 2013; Volume 26. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author, Reference and Year | Acquisition Mode | One/Two Hands | Static/Dynamic | Type of Sing | Preprocessing Technique | Classifier | Recognition Rate (Accuracy) |
|---|---|---|---|---|---|---|---|
| Galicia et al. [17] (2015) | Kinect | Both | Static | Letters | Feature extraction: Random Forest | Neural networks | 76.19% |
| Sosa-Jimenez [18] (2017) | Kinect | Both | Dynamic | Words and phrases | Color filter, binarization contour extraction | Hidden Markov Model (HMMs) | Specificity: 80% Sensitivity: 86% |
| Garcia-Bautista et al. [19] (2017) | Kinect | Both | Dynamic | Words | Dynamic Time Warping (DTW) | 98.57% | |
| Jimenez et al. [20] (2016) | Kinect | One hand | Static | Letters and numbers | 3D Haar feature extraction | Adaboost | 95% |
| Martinez-Gutierrez et al. [21] (2016) | Intel RealSense f200 | One hand | Static | Letters and words | 3D hand coordinates | Neural Networks | 80.11% |
| Trujillo-Romero et al. [27] (2021) | Kinect | Both | Both | Words and phrases | 3D motion path K-Nearest Neighbors | Neural Networks | 93.46% |
| Carmona et al. [28] (2021) | Leap motion and Kinect | One hand | Static | Letters | 3D affine moment invariants | Linear Discriminant Analysis, Support Vector Machine, Naïve Bayes | 94% (leap motion) 95.6% (Kinect) |
| Type of Sign | Sign | Static/Dynamic | One-Handed/Two-Handed | Symmetric/Asymmetric | Left Hand | Right Hand |
|---|---|---|---|---|---|---|
| Alphabet | A | Static | One-handed | Asymmetric | Without use | Dominant |
| B | Static | One-handed | Asymmetric | Without use | Dominant | |
| C | Static | One-handed | Asymmetric | Without use | Dominant | |
| D | Static | One-handed | Asymmetric | Without use | Dominant | |
| J | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| K | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Q | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| X | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Questions | What? | Dynamic | Two-handed | Symmetric | Simultaneous | Simultaneous |
| When? | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| How much? | Dynamic | Two-handed | Symmetric | Simultaneous | Simultaneous | |
| Where? | Dynamic | Two-handed | Asymmetric | Base | Dominant | |
| For what? | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Why? | Dynamic | One-handed | Asymmetric | Base | Dominant | |
| What is that? | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Who? | Dynamic | Two-handed | Asymmetric | Base | Dominant | |
| Days of the week | Monday | Dynamic | One-handed | Asymmetric | Without use | Dominant |
| Tuesday | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Wednesday | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Thursday | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Friday | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Saturday | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Sunday | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Frequent words | Spell | Dynamic | One-handed | Asymmetric | Without use | Dominant |
| Explain | Dynamic | Two-handed | Asymmetric | Alternate | Alternate | |
| Thank you | Dynamic | Two-handed | Asymmetric | Base | Dominant | |
| Name | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| Please | Dynamic | Two-handed | Symmetric | Simultaneous | Simultaneous | |
| Yes | Dynamic | One-handed | Asymmetric | Without use | Dominant | |
| No | Dynamic | One-handed | Asymmetric | Without use | Dominant |
| Network | Layer 1 Units | Layer 2 Units | Parameters (Thousands) |
|---|---|---|---|
| RNN | 32 | 16 | 8.782 |
| 64 | 32 | 21.118 | |
| 128 | 64 | 56.542 | |
| 256 | 128 | 170.398 | |
| 512 | 256 | 570.142 | |
| 1024 | 512 | 2057.758 | |
| LSTM | 32 | 16 | 33.60 |
| 64 | 32 | 81.502 | |
| 128 | 64 | 220.318 | |
| 256 | 128 | 669.982 | |
| 512 | 256 | 2257.438 | |
| 1024 | 512 | 8184.862 | |
| GRU | 32 | 16 | 25.47 |
| 64 | 32 | 61.662 | |
| 128 | 64 | 166.302 | |
| 256 | 128 | 504.606 | |
| 512 | 256 | 1697.31 | |
| 1024 | 512 | 6147.102 |
| Network | Layer 1 Units | Layer 2 Units | Accuracy (Percentage) |
|---|---|---|---|
| RNN | 32 | 16 | 93.11 |
| 64 | 32 | 94.22 | |
| 128 | 64 | 94.0 | |
| 256 | 128 | 92.44 | |
| 512 | 256 | 61.55 | |
| 1024 | 512 | 57.55 | |
| LSTM | 32 | 16 | 92.44 |
| 64 | 32 | 96.44 | |
| 128 | 64 | 96.22 | |
| 256 | 128 | 96.44 | |
| 512 | 256 | 96.66 | |
| 1024 | 512 | 95.77 | |
| GRU | 32 | 16 | 96.22 |
| 64 | 32 | 96.44 | |
| 128 | 64 | 96.44 | |
| 256 | 128 | 96.66 | |
| 512 | 256 | 97.11 | |
| 1024 | 512 | 95.77 |
| Best Model | Testing Noise | |||||
|---|---|---|---|---|---|---|
| No-Noise | 10 cm | 20 cm | 30 cm | 40 cm | 50 cm | |
| RNN | 92.44 | 45.11 | 45.33 | 46.44 | 46.44 | 46.88 |
| RNN aug | 63.55 | 60.44 | 58.44 | 60.0 | 59.33 | 59.33 |
| LSTM | 96.66 | 66.22 | 65.33 | 63.11 | 67.77 | 62.44 |
| LSTM aug | 95.55 | 89.33 | 90.44 | 89.11 | 90.44 | 88.88 |
| GRU | 97.11 | 48.22 | 50.66 | 51.11 | 46.44 | 46.66 |
| GRU aug | 96.22 | 69.11 | 69.33 | 68.66 | 68.44 | 67.33 |
| LSTM Model | Testing Noise | |||||
|---|---|---|---|---|---|---|
| No-Noise | 10 cm | 20 cm | 30 cm | 40 cm | 50 cm | |
| 0 cm | 92.44 | 66.22 | 65.33 | 63.11 | 67.77 | 62.66 |
| 10 cm | 96.44 | 74.22 | 74.66 | 74.44 | 75.33 | 72.66 |
| 20 cm | 94.88 | 84.22 | 82.44 | 79.55 | 83.11 | 84.22 |
| 30 cm | 93.11 | 86.0 | 87.33 | 85.11 | 87.11 | 87.11 |
| 40 cm | 81.55 | 80.66 | 81.77 | 79.55 | 83.33 | 82.88 |
| 50 cm | 82.44 | 79.77 | 78.22 | 79.55 | 80.66 | 79.77 |
| 60 cm | 68.44 | 68.88 | 71.77 | 70.0 | 71.33 | 72.44 |
| 70 cm | 70.66 | 71.55 | 71.33 | 70.0 | 72.88 | 69.55 |
| 80 cm | 59.33 | 58.22 | 56.44 | 57.11 | 57.55 | 59.33 |
| 90 cm | 61.11 | 57.77 | 58.22 | 59.55 | 58.22 | 60.22 |
| 100 cm | 61.33 | 58.66 | 60.22 | 57.55 | 58.44 | 60.22 |
| Number of Layers | Noise Aug | Dropout | Testing Noise | |||||
|---|---|---|---|---|---|---|---|---|
| No-Noise | 10 cm | 20 cm | 30 cm | 40 cm | 50 cm | |||
| One layer | No | No | 96.44 | 58.44 | 60.66 | 60.0 | 56.44 | 56.22 |
| One layer | No | Yes | 96.44 | 58.44 | 57.77 | 52.22 | 56.88 | 56.88 |
| One layer | Yes | No | 88.22 | 82.22 | 81.55 | 80.88 | 83.11 | 82.0 |
| One layer | Yes | Yes | 94.88 | 88.22 | 87.77 | 89.33 | 87.55 | 88.44 |
| Two layers | No | No | 96.22 | 34.22 | 36.22 | 38.0 | 35.33 | 37.11 |
| Two layers | No | Yes | 96.44 | 39.11 | 39.33 | 36.22 | 37.55 | 37.11 |
| Two layers | Yes | No | 94.44 | 87.11 | 87.77 | 88.66 | 88.44 | 88.66 |
| Two layers | Yes | Yes | 95.55 | 89.33 | 90.44 | 88.44 | 89.33 | 88.44 |
| Three layers | No | No | 92.0 | 27.33 | 30.0 | 28.88 | 28.66 | 24.88 |
| Three layers | No | Yes | 97.33 | 38.0 | 34.88 | 34.44 | 35.77 | 34.88 |
| Three layers | Yes | No | 94.0 | 88.66 | 86.88 | 84.22 | 86.22 | 86.44 |
| Three layers | Yes | Yes | 96.66 | 88.0 | 88.88 | 88.88 | 89.11 | 89.11 |
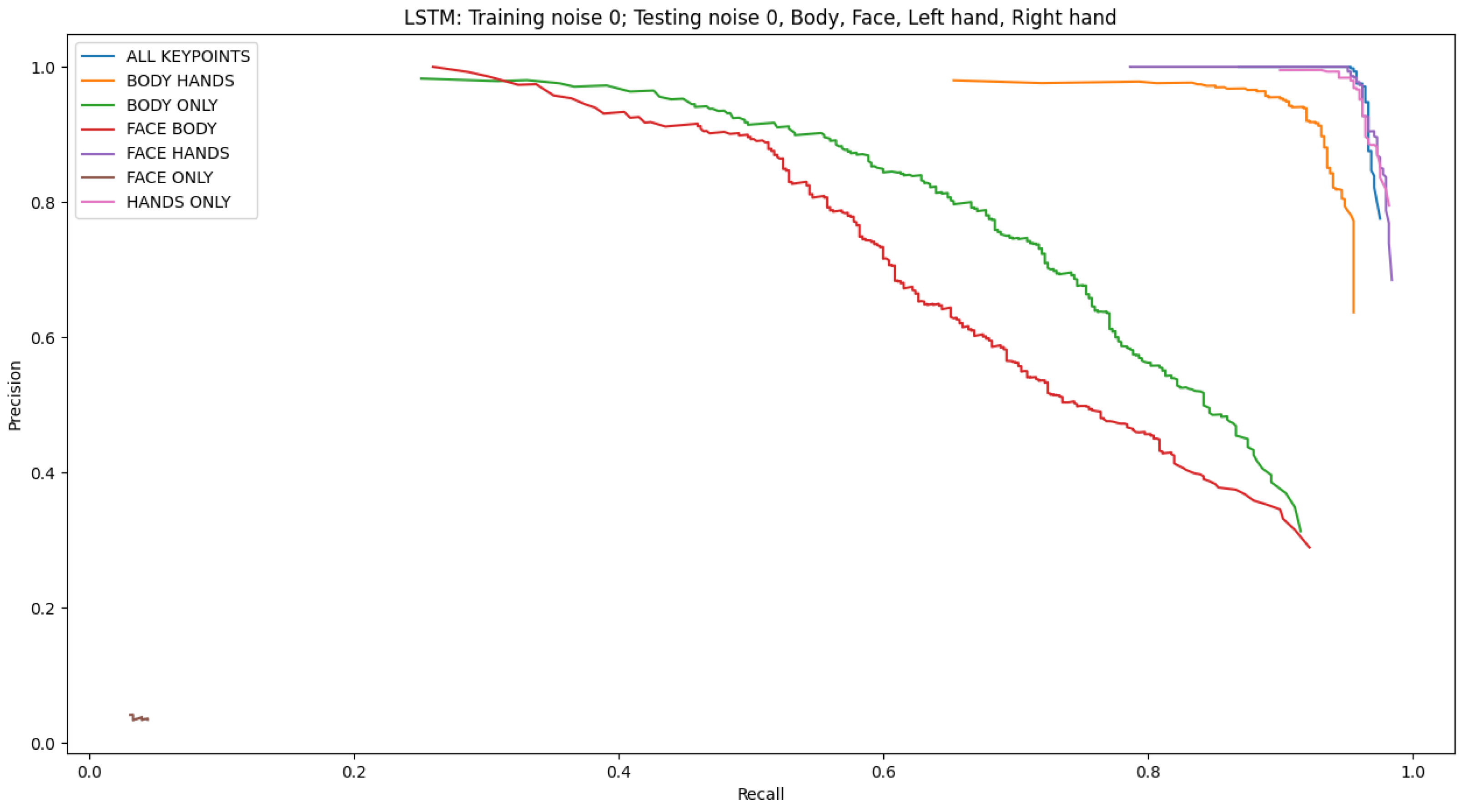
| Features Combination | Testing Noise | |||||
|---|---|---|---|---|---|---|
| No-Noise | 10 cm | 20 cm | 30 cm | 40 cm | 50 cm | |
| All features | 96.44 | 64.44 | 63.55 | 61.77 | 63.55 | 62.44 |
| Hands-only | 96.0 | 69.11 | 69.33 | 68.66 | 68.44 | 66.0 |
| Face-only | 3.55 | 5.11 | 5.55 | 4.22 | 5.77 | 4.0 |
| Body-only | 71.55 | 8.66 | 10.44 | 10.22 | 10.66 | 10.0 |
| Face + Body | 63.55 | 12.88 | 12.44 | 12.88 | 10.88 | 13.77 |
| Hands + Face | 96.22 | 56.88 | 58.44 | 58.0 | 58.22 | 58.88 |
| Hands + Body | 92.0 | 65.55 | 68.22 | 65.33 | 66.22 | 67.33 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mejía-Peréz, K.; Córdova-Esparza, D.-M.; Terven, J.; Herrera-Navarro, A.-M.; García-Ramírez, T.; Ramírez-Pedraza, A. Automatic Recognition of Mexican Sign Language Using a Depth Camera and Recurrent Neural Networks. Appl. Sci. 2022, 12, 5523. https://doi.org/10.3390/app12115523
Mejía-Peréz K, Córdova-Esparza D-M, Terven J, Herrera-Navarro A-M, García-Ramírez T, Ramírez-Pedraza A. Automatic Recognition of Mexican Sign Language Using a Depth Camera and Recurrent Neural Networks. Applied Sciences. 2022; 12(11):5523. https://doi.org/10.3390/app12115523
Chicago/Turabian StyleMejía-Peréz, Kenneth, Diana-Margarita Córdova-Esparza, Juan Terven, Ana-Marcela Herrera-Navarro, Teresa García-Ramírez, and Alfonso Ramírez-Pedraza. 2022. "Automatic Recognition of Mexican Sign Language Using a Depth Camera and Recurrent Neural Networks" Applied Sciences 12, no. 11: 5523. https://doi.org/10.3390/app12115523
APA StyleMejía-Peréz, K., Córdova-Esparza, D.-M., Terven, J., Herrera-Navarro, A.-M., García-Ramírez, T., & Ramírez-Pedraza, A. (2022). Automatic Recognition of Mexican Sign Language Using a Depth Camera and Recurrent Neural Networks. Applied Sciences, 12(11), 5523. https://doi.org/10.3390/app12115523