
The Role of Statistical Power: A Study of Relationship Between Emotional and Conduct Problems, Sociodemographic Factors, and Smoking Behaviours in Large and Small Samples of Latvian Adolescents

 , , ,
, , ,
Abstract
1. Introduction
2. Materials and Methods
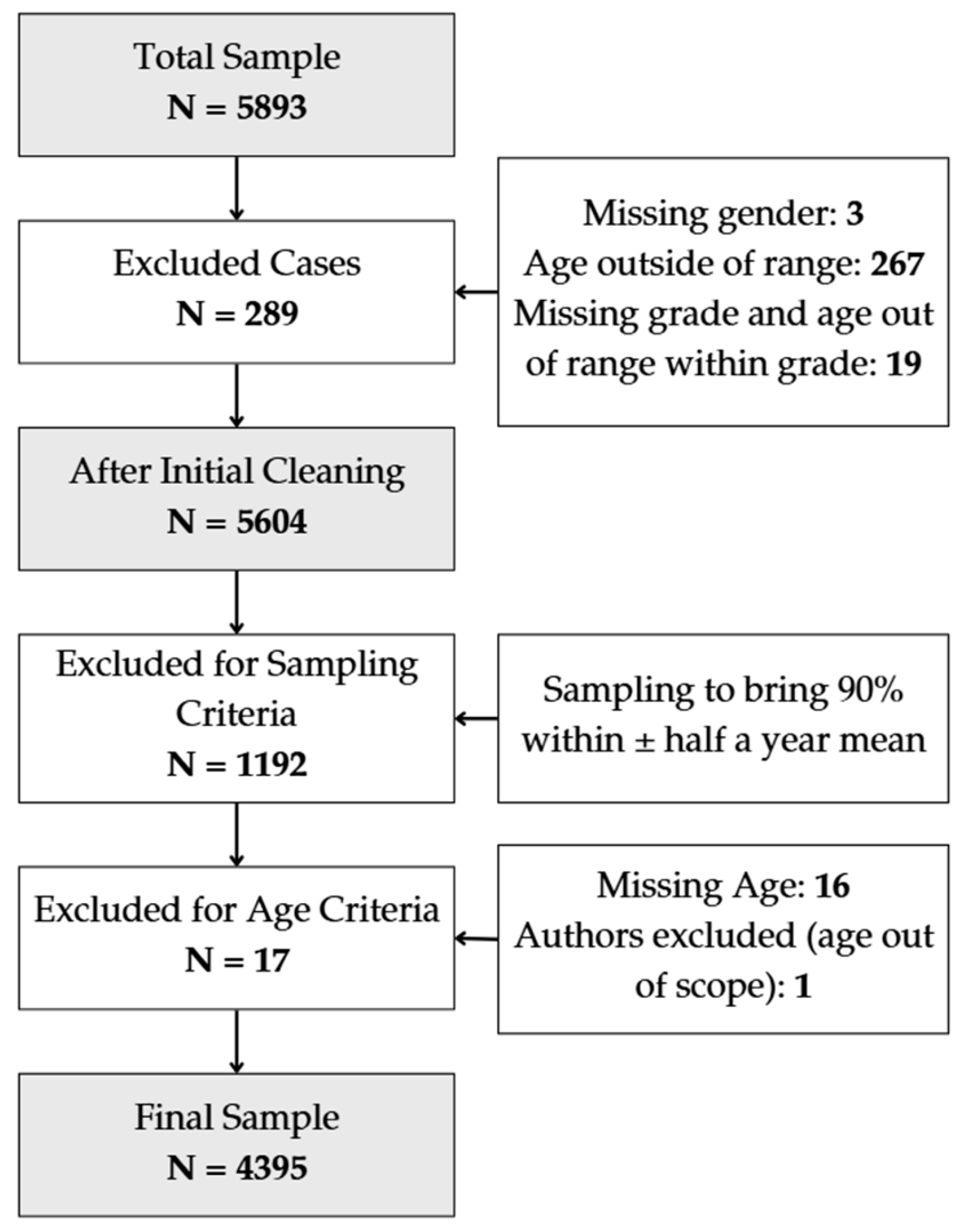
2.1. Study Design and Sampling Procedures
2.2. Measures
2.3. Statistical Analysis
2.3.1. General Sample Analysis
2.3.2. Randomly Generated Subsamples
2.3.3. Consolidated Subsample Results
2.3.4. Effect Size Measures and Comparison Across Samples
3. Results
3.1. Characteristics of the General Sample
3.2. Association Analysis
3.3. Logistic Regression Results
4. Discussion
4.1. Associations Between Sociodemographic Factors, Emotional and Conduct Problems, and Smoking Behaviours
4.2. The Effect of Sample Size on Statistical Estimates
4.3. Strengths and Limitations of the Study
4.4. Recommendations and Future Directions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Reine, I.; Novo, M.; Hammarström, A. Does the Association between Ill Health and Unemployment Differ between Young People and Adults? Results from a 14-Year Follow-Up Study with a Focus on Psychological Health and Smoking. Public Health 2004, 118, 337–345. [Google Scholar] [CrossRef] [PubMed]
- Moor, I.; Rathmann, K.; Lenzi, M.; Pförtner, T.-K.; Nagelhout, G.E.; de Looze, M.; Bendtsen, P.; Willemsen, M.; Kannas, L.; Kunst, A.E.; et al. Socioeconomic Inequalities in Adolescent Smoking Across 35 Countries: A Multilevel Analysis of the Role of Family, School and Peers. Eur. J. Public Health 2015, 25, 457–463. [Google Scholar] [CrossRef] [PubMed]
- Viner, R.M.; Ozer, E.M.; Denny, S.; Marmot, M.; Resnick, M.; Fatusi, A.; Currie, C. Adolescence and the Social Determinants of Health. Lancet 2012, 379, 1641–1652. [Google Scholar] [CrossRef] [PubMed]
- Legleye, S.; Bricard, D.; Khlat, M. Roles of Parental Smoking and Family Structure for the Explanation of Socioeconomic Inequalities in Adolescent Smoking. Addiction 2022, 118, 149–159. [Google Scholar] [CrossRef] [PubMed]
- Fluharty, M.; Taylor, A.E.; Grabski, M.; Munafò, M.R. The Association of Cigarette Smoking With Depression and Anxiety: A Systematic Review. Nicotine Tob. Res. 2017, 19, 3–13. [Google Scholar] [CrossRef] [PubMed]
- Giannakopoulos, G.; Tzavara, C.; Dimitrakaki, C.; Kolaitis, G.; Rotsika, V.; Tountas, Y. Emotional, Behavioural Problems and Cigarette Smoking in Adolescence: Findings of a Greek Cross-Sectional Study. BMC Public Health 2010, 10, 57. [Google Scholar] [CrossRef] [PubMed]
- Green, V.R.; Conway, K.P.; Silveira, M.L.; Kasza, K.A.; Cohn, A.M.; Cummings, K.M.; Stanton, C.A.; Callahan-Lyon, P.; Slavit, W.I.; Sargent, J.D.; et al. Mental Health Problems and Onset of Tobacco Use Among 12- to 24-Year-Olds in the PATH Study. J. Am. Acad. Child Adolesc. Psychiatry 2018, 57, 944–954. [Google Scholar] [CrossRef]
- Lawrence, D.; Mitrou, F.; Sawyer, M.G.; Zubrick, S.R. Smoking Status, Mental Disorders and Emotional and Behavioural Problems in Young People: Child and Adolescent Component of the National Survey of Mental Health and Wellbeing. Aust. N. Z. J. Psychiatry 2010, 44, 805–814. [Google Scholar] [CrossRef]
- Button, K.S.; Ioannidis, J.P.; Mokrysz, C.; Nosek, B.A.; Flint, J.; Robinson, E.S.; Munafò, M.R. Power Failure: Why Small Sample Size Undermines the Reliability of Neuroscience. Nat. Rev. Neurosci. 2013, 14, 365–376. [Google Scholar] [CrossRef]
- Ioannidis, J.P. Why Most Published Research Findings Are False. PLoS Med. 2005, 2, e124. [Google Scholar] [CrossRef]
- Sivasamy, S. Sample Size Considerations in Research. Endodontology 2023, 35, 304–308. [Google Scholar] [CrossRef]
- Elsayir, H.A. The Role of Effect Size and Significance Test in Research Design and Analysis. Edelweiss Appl. Sci. Technol. 2024, 8, 287–295. [Google Scholar] [CrossRef]
- Goel, H.; Raheja, D.; Nadar, S.K. Evidence-Based Medicine or Statistically Manipulated Medicine? Are We Slaves to the P-Value? Postgrad. Med. J. 2024, 100, 451–460. [Google Scholar] [CrossRef] [PubMed]
- Sullivan, G.M.; Feinn, R. Using Effect Size—Or Why the P Value Is Not Enough. J. Grad. Med. Educ. 2012, 4, 279–282. [Google Scholar] [CrossRef]
- Cohen, J. Statistical Power Analysis for the Behavioral Sciences, 2nd ed.; Routledge: London, UK, 1988. [Google Scholar] [CrossRef]
- Gigerenzer, G.; Krauss, S.; Vitouch, O. The Null Ritual: What You Always Wanted to Know About Significance Testing but Were Afraid to Ask. In The SAGE Handbook of Quantitative Methodology for the Social Sciences; Kaplan, D., Ed.; Sage Publications: Thousand Oaks, CA, USA, 2004; pp. 391–408. [Google Scholar] [CrossRef]
- Anderson, S.; Lamp, S. Sample Size Planning for Statistical Power and Accurate Estimation. Psychology 2022. [Google Scholar] [CrossRef]
- Roessner, V. Large Sample Size in Child and Adolescent Psychiatric Research: The Way of Salvation? Eur. Child Adolesc. Psychiatry 2014, 23, 1003–1004. [Google Scholar] [CrossRef] [PubMed]
- Carter, A.R.; Tilling, K.; Munafò, M.R. A Systematic Review of Sample Size and Power in Leading Neuroscience Journals. bioRxiv 2017, 217596. [Google Scholar] [CrossRef]
- Das, S.; Mitra, K.; Mandal, M. Sample Size Calculation: Basic Principles. Indian J. Anaesth. 2016, 60, 652–656. [Google Scholar] [CrossRef]
- Williams, N.J.; Preacher, K.J.; Allison, P.D.; Mandell, D.S.; Marcus, S.C. Required Sample Size to Detect Mediation in 3-Level Implementation Studies. Implement. Sci. 2022, 17, 66. [Google Scholar] [CrossRef]
- Riesthuis, P. Simulation-Based Power Analyses for the Smallest Effect Size of Interest: A Confidence-Interval Approach for Minimum-Effect and Equivalence Testing. Adv. Methods Pract. Psychol. Sci. 2024, 7, 25152459241240722. [Google Scholar] [CrossRef]
- Slimību Profilakses un Kontroles Centrs; Pudule, I.; Velika, B.; Grīnberga, D.; Gobiņa, I.; Villeruša, A.; Kļaviņa-Makrecka, S.; Bezborodovs, Ņ. Latvijas Skolēnu Veselības Paradumu Pētījums 2017./2018. Mācību Gada Aptaujas Rezultāti un Tendences. Available online: https://www.spkc.gov.lv/sites/spkc/files/data_content/latvijas-skolenu-veselibas-paradumu-petijums-05.10.2020_1.pdf (accessed on 10 September 2024).
- Inchley, J.; Currie, D.; Cosma, A.; Samdal, O. (Eds.) Health Behaviour in School-Aged Children (HBSC) Study Protocol: Background, Methodology and Mandatory Items for the 2017/18 Survey; CAHRU: St Andrews, UK, 2018. [Google Scholar]
- Hartley, J.E.; Levin, K.; Currie, C. A New Version of the HBSC Family Affluence Scale—FAS III: Scottish Qualitative Findings from the International FAS Development Study. Child Indic. Res. 2016, 9, 233–245. [Google Scholar] [CrossRef] [PubMed]
- Boyce, W.; Torsheim, T.; Currie, C.; Zambon, A. The Family Affluence Scale as a Measure of National Wealth: Validation of an Adolescent Self-Report Measure. Soc. Indic. Res. 2006, 78, 473–487. [Google Scholar] [CrossRef]
- Goodman, A.; Goodman, R. Strengths and Difficulties Questionnaire as a Dimensional Measure of Child Mental Health. J. Am. Acad. Child Adolesc. Psychiatry 2009, 48, 400–403. [Google Scholar] [CrossRef]
- Bezborodovs, Ņ.; Kočāne, A.; Rancāns, E.; Villeruša, A. Clinical Utility of the Parent-Report Version of the Strengths and Difficulties Questionnaire (SDQ) in Latvian Child and Adolescent Psychiatry Practice. Medicina 2022, 58, 1599. [Google Scholar] [CrossRef]
- Vittinghoff, E.; McCulloch, C.E. Relaxing the Rule of Ten Events per Variable in Logistic and Cox Regression. Am. J. Epidemiol. 2007, 165, 710–718. [Google Scholar] [CrossRef]
- McFadden, D. Conditional Logit Analysis of Qualitative Choice Behavior. In Frontiers in Econometrics; Zarembka, P., Ed.; Academic Press: New York, NY, USA, 1974; pp. 105–142. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S.; Sturdivant, R.X. Applied Logistic Regression, 3rd ed.; Wiley: Hoboken, NJ, USA, 2013. [Google Scholar]
- Lakshmi, N.; Dasanayake, C.; De Silva, B.S.S. The Most Influencing Factors for Cigarette Smoking Among Adolescents: A Systematic Review. In Proceedings of the SLIIT International Conference on Advancements in Science and Humanities, Malabe, Sri Lanka, 2–3 December 2023. [Google Scholar] [CrossRef]
- Hwang, J.H.; Park, S.-W. Gender Differential Secular Trend in Lifetime Smoking Prevalence among Adolescents: An Age-Period-Cohort Analysis. BMC Public Health 2019, 19, 1374. [Google Scholar] [CrossRef]
- Kim, E.; Park, E.; Kim, H. Sex Differences in Multilevel Factors of Smoking Experimentation and Age of Initiation in Korean Adolescents. J. Sch. Nurs. 2020, 36, 348–359. [Google Scholar] [CrossRef] [PubMed]
- Meyer, Z.; Unger, J.B.; Zheng, Y. Gene-Environment Transactions between Peer Cigarette Use, Parental Supervision, and Chinese Adolescent Cigarette Smoking Initiation. J. Adolesc. 2024, 96, 1034–1047. [Google Scholar] [CrossRef] [PubMed]
- Mehanović, E.; Mathis, F.; Brambilla, R.; Faggiano, F.; Galanti, M.R.; Vigna-Taglianti, F. Do the Socioeconomic Context and the European Geographical Area Modify Parental Influences on Smoking Experimentation among Adolescents. Eur. Child Adolesc. Psychiatry 2021, 30, 105–115. [Google Scholar] [CrossRef]
- Littlecott, H.; Moore, G.; Evans, R.; Melendez-Torres, G.J.; McCann, M.; Reed, H.; Mann, M.; Dobbie, F.; Jennings, S.; Donaldson, C.; et al. Perceptions of Friendship, Peers and Influence on Smoking According to Socioeconomic Status and Tobacco Control Context: A Systematic Review and Meta-Ethnography of Qualitative Research. Preprint 2022. [Google Scholar] [CrossRef]
- Jester, J.M.; Glass, J.M.; Bohnert, K.M.; Nigg, J.T.; Wong, M.M.; Zucker, R.A. Child and Adolescent Predictors of Smoking Involvement in Emerging Adulthood. Health Psychol. 2019, 38, 133–142. [Google Scholar] [CrossRef] [PubMed]
- Gould, L.F.; Hussong, A.M.; Hersh, M.A. Emotional Distress May Increase Risk for Self-Medication and Lower Risk for Mood-Related Drinking Consequences in Adolescents. Int. J. Emot. Educ. 2012, 4, 6–24. [Google Scholar] [PubMed] [PubMed Central]
- Lin, M.; Chu, M.; Li, X.; Ma, H.; Fang, Z.; Mao, L.; Wang, P.; Chen, T.; Chiang, Y.C. Factors Influencing Adolescent Experimental and Current Smoking Behaviors Based on Social Cognitive Theory: A Cross-Sectional Study in Xiamen. Front. Public Health 2023, 11, 1093264. [Google Scholar] [PubMed] [PubMed Central]
- Gómez-de-Mariscal, E.; Guerrero, V.; Sneider, A.; Jayatilaka, H.; Phillip, J.M.; Wirtz, D.; Muñoz-Barrutia, A. Use of the p-Values as a Size-Dependent Function to Address Practical Differences When Analyzing Large Datasets. Sci. Rep. 2021, 11, 20942. [Google Scholar] [CrossRef]
- Peeters, M.J. Practical Significance: Moving Beyond Statistical Significance. Curr. Pharm. Teach. Learn. 2016, 8, 83–89. [Google Scholar] [CrossRef]
- Lantz, B. The Large Sample Size Fallacy. Scand. J. Caring Sci. 2013, 27, 487–492. [Google Scholar] [CrossRef]
- Lin, L. Bias Caused by Sampling Error in Meta-Analysis with Small Sample Sizes. PLoS ONE 2018, 13, e0204056. [Google Scholar] [CrossRef]
- Gandhi, L.; Manning, B.; Duckworth, A. Effect Size Magnification: No Variable Is as Important as the One You’re Thinking About—While You’re Thinking About It. Curr. Dir. Psychol. Sci. 2024, 33, 347–354. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
| Variable | Category | Count, n | Proportion, % | 95% CI 1 |
|---|---|---|---|---|
| Gender | Boys | 2179 | 49.6 | 48.1–51.1 |
| Girls | 2216 | 50.4 | 48.9–51.9 | |
| Age | 11 years | 1534 | 34.9 | 33.5–36.3 |
| 13 years | 1519 | 34.6 | 33.2–36.0 | |
| 15 years | 1342 | 30.5 | 29.2–31.9 | |
| Family structure | Both parents | 2739 | 62.3 | 60.9–63.7 |
| One parent | 1432 | 32.6 | 31.2–34.0 | |
| None | 224 | 5.1 | 4.5–5.8 | |
| Family affluence | High | 2357 | 54.8 | 53.3–56.3 |
| Medium | 1760 | 40.9 | 39.5–42.4 | |
| Low | 181 | 4.2 | 3.7–4.9 | |
| Emotional problems | Identified problems | 484 | 11.2 | 10.3–12.2 |
| No identified problems | 3821 | 88.8 | 87.8–89.7 | |
| Conduct problems | Identified problems | 471 | 10.9 | 10.0–11.9 |
| No identified problems | 3839 | 89.1 | 88.1–90.0 | |
| Current e-cigarette use | Used at least once in the last 30 days | 403 | 9.6 | 8.7–10.5 |
| Did not use in the last 30 days | 3798 | 90.4 | 89.5–91.3 | |
| Current cigarette smoking | Smoked at least once in the last 30 days | 439 | 10.2 | 9.3–11.1 |
| Did not smoke in the last 30 days | 3872 | 89.8 | 88.9–90.7 | |
| Dual smoking | Smoked at least once in the last 30 days | 209 | 4.8 | 4.2–5.5 |
| Did not smoke in the last 30 days | 4124 | 95.2 | 94.5–95.8 |
| Dependent Variable | Gender | General Study Sample | Consolidated Sample from the Study Group | |||||
|---|---|---|---|---|---|---|---|---|
| Boys | Girls | p Value | Effect Size (Cramer’s V) | p Value | p Value Range | Effect Size (Cramer’s V) | Effect Size Range | |
| Current e-cigarette use (n, %) | <0.001 | 0.097 | 0.025 | 0.004–0.068 | 0.122 | 0.094–0.149 | ||
| Used in the past 30 days | 258, 12.5% | 145, 6.8% | ||||||
| Did not use in the past 30 days | 1809, 87.5% | 1989, 93.2% | ||||||
| Current cigarette smoking (n, %) | 0.725 | 0.005 | 0.622 | 0.308–0.988 | 0.122 | 0.001–0.052 | ||
| Smoked in the past 30 days | 213, 10.0% | 226, 10.3% | ||||||
| Did not smoke in the past 30 days | 1913, 90.0% | 1959, 89.7% | ||||||
| Current dual smoking (n, %) | 0.004 | 0.044 | 0.299 | 0.012–0.812 | 0.066 | 0.012–0.128 | ||
| Smoked in the past 30 days | 124, 5.8% | 85, 3.9% | ||||||
| Did not smoke in the past 30 days | 2023, 94.2% | 2101, 96.1% | ||||||
| Dependent Variable | Family Affluence | General Study Sample | Consolidated Sample from the Study Group | ||||||
|---|---|---|---|---|---|---|---|---|---|
| High | Medium | Low | p Value | Effect Size (Cramer’s V) | p Value | p Value Range | Effect Size (Cramer’s V) | Effect Size Range | |
| Current e-cigarette use (n, %) | 0.574 | 0.016 | 0.377 | 0.003–0.940 | 0.016 | 0.018–0.202 | |||
| Used in the past 30 days | 210, 9.3% | 167, 9.9% | 20, 11.6% | ||||||
| Did not use in the past 30 days | 2041, 90.7% | 1520, 90.1% | 153, 88.4% | ||||||
| Current smoking (n, %) | 0.005 | 0.050 | 0.503 | 0.024–1.000 | 0.064 | 0.027–0.149 | |||
| Smoked in the past 30 days | 208, 9.0% | 199, 11.5% | 26, 14.7% | ||||||
| Did not smoke in the past 30 days | 2101, 91.0% | 1531, 88.5% | 151, 85.3% | ||||||
| Both (n, %) | 0.139 | 0.031 | 0.516 | 0.088–0.896 | 0.063 | 0.024–0.110 | |||
| Did in the past 30 days | 106, 4.6% | 85, 4.9% | 14, 7.9% | ||||||
| Did not in the past 30 days | 2218, 95.4% | 1652, 95.1% | 164, 92.1% | ||||||
| Dependent Variable | Family Structure | General Study Sample | Consolidated Sample from the Study Group | ||||||
|---|---|---|---|---|---|---|---|---|---|
| One Parent | Both | None | p Value | Effect Size (Cramer’s V) | p Value | p Value Range | Effect Size (Cramer’s V) | Effect Size Range | |
| Current e-cigarette use (n, %) | <0.001 | 0.099 | 0.257 | 0.007–0.785 | 0.102 | 0.028–0.165 | |||
| Used in the past 30 days | 188, 13.8% | 196, 7.5% | 19, 9.0% | ||||||
| Did not use in the past 30 days | 1178, 86.2% | 2428, 92.5% | 192, 91.0% | ||||||
| Current cigarette smoking (n, %) | <0.001 | 0.110 | 0.243 | 0.001–0.785 | 0.105 | 0.046–0.199 | |||
| Smoked in the past 30 days | 210, 15.0% | 209, 7.8% | 20, 9.1% | ||||||
| Did not smoke in the past 30 days | 1193, 85.0% | 2479, 92.2% | 200, 90.9% | ||||||
| Current dual smoking (n, %) | <0.001 | 0.088 | 0.357 | 0.005–1.000 | 0.092 | 0.032–0.162 | |||
| Smoked in the past 30 days | 106, 7.5% | 93, 3.4% | 10, 4.5% | ||||||
| Did not smoke in the past 30 days | 1302, 92.5% | 2610, 96.6% | 212, 95.5% | ||||||
| Dependent Variable | Sample | Deviance | AIC | R2McF | p Value |
|---|---|---|---|---|---|
| Current e-cigarette use | General study sample | 2258 | 2276 | 0.125 | <0.001 |
| Consolidated sample from the study group | 186 | 204 | 0.164 | 0.001 | |
| Current cigarette smoking | General study sample | 2378 | 2396 | 0.140 | <0.001 |
| Consolidated sample from the study group | 196 | 219 | 0.185 | 0.001 | |
| Current dual smoking | General study sample | 1453 | 1471 | 0.106 | <0.001 |
| Consolidated sample from the study group | 108 | 126 | 0.189 | 0.0244 |
| Dependent Variable | Parameters | General Study Sample | Consolidated Sample from the Study Group | |||||
|---|---|---|---|---|---|---|---|---|
| Odds Ratio | 95% CI 1 | p-Value | Odds Ratio | 95% CI | p-Value | p-Value Range 3 | ||
| Current e-cigarette use | Gender | |||||||
| Boys–Girls | 2.115 | 1.679–2.660 | <0.001 | 2.765 | 1.191–6.435 | 0.035 | <0.001–0.129 | |
| Age | 1.677 | 1.549–1.820 | <0.001 | 1.725 | 1.300–2.290 | 0.001 | <0.001–0.002 | |
| Family affluence | ||||||||
| High–low | 1.083 | 0.639–1.840 | 0.768 | 3.180 × 106 | 0.112–Inf 2 | 0.515 | 0.053–0.992 | |
| Medium–low | 0.921 | 0.542–1.570 | 0.763 | 2.81 × 106 | 0.060–Inf 2 | 0.562 | 0.061–0.992 | |
| Family structure | ||||||||
| One parent–both parents | 1.801 | 1.436–2.260 | <0.001 | 1.785 | 0.795–4.027 | 0.388 | <0.001–0.816 | |
| No parents–both parents | 0.879 | 0.517–1.490 | 0.634 | 0.573 | 0.107–Inf 2 | 0.705 | 0.258–0.992 | |
| Emotional problems | ||||||||
| Identified problems–no identified problems | 1.245 | 0.891–1.740 | 0.199 | 1.116 | 0.326–4.001 | 0.326 | 0.084–0.684 | |
| Conduct problems | ||||||||
| Identified problems–no identified problems | 2.773 | 2.087–3.680 | <0.001 | 3.168 | 1.074–9.482 | 0.181 | 0.001–0.792 | |
| Current cigarette use | Gender | |||||||
| Boys–Girls | 1.002 | 0.807–1.240 | 0.986 | 1.081 | 0.498–2.348 | 0.559 | 0.340–0.943 | |
| Age | 1.872 | 1.726–2.030 | <0.001 | 2.137 | 1.557–2.937 | <0.001 | <0.001–<0.001 | |
| Family affluence | ||||||||
| High–low | 0.785 | 0.488–1.260 | 0.319 | 4.110 × 105 | 0.151–Inf 2 | 0.571 | 0.05–0.988 | |
| Medium–low | 0.800 | 0.497–1.290 | 0.358 | 4.440 × 105 | 0.137–Inf 2 | 0.560 | 0.068–0.988 | |
| Family structure | ||||||||
| One parent–both parents | 1.833 | 1.474–2.280 | <0.001 | 1.696 | 0.782–3.688 | 0.388 | 0.01–0.976 | |
| No parents–both parents | 0.940 | 0.562–1.570 | 0.813 | 0.838 | 0.166–Inf 2 | 0.759 | 0.15–0.988 | |
| Emotional problems | ||||||||
| Identified problems–no identified problems | 1.370 | 1.013–1.850 | 0.041 | 1.789 | 0.630–5.138 | 0.318 | 0.01–0.762 | |
| Conduct problems | ||||||||
| Identified problems–no identified problems | 2.207 | 1.652–2.950 | <0.001 | 2.486 | 0.859–7.261 | 0.194 | 0.01–0.660 | |
| Current dual smoking | Gender | |||||||
| Boys–Girls | 1.677 | 1.239–2.270 | <0.001 | 2.800 | 0.774–10.525 | 0.315 | 0.019–0.855 | |
| Age | 1.676 | 1.504–1.870 | <0.001 | 1.947 | 1.232–3.105 | 0.030 | <0.001–0.209 | |
| Family affluence | ||||||||
| High–low | 0.757 | 0.413–1.390 | 0.369 | 3.900 × 106 | 0.048–Inf 2 | 0.658 | 0.018–0.995 | |
| Medium–low | 0.651 | 0.353–1.200 | 0.169 | 2.287 × 106 | 0.034–Inf 2 | 0.573 | 0.018–0.995 | |
| Family structure | ||||||||
| One parent–both parents | 2.036 | 1.509–2.750 | <0.001 | 2.432 | 0.710–8.498 | 0.432 | 0.005–0.964 | |
| No parents–both parents | 1.052 | 0.530–2.090 | 0.884 | 0.775 | 0.086–Inf 2 | 0.836 | 0.433–0.995 | |
| Emotional problems | ||||||||
| Identified problems–no identified problems | 1.502 | 0.995–2.270 | 0.053 | 2.045 | 0.452–Inf 2 | 0.439 | 0.012–0.991 | |
| Conduct problems | ||||||||
| Identified problems–no identified problems | 2.240 | 1.545–3.250 | <0.001 | 3.391 | 0.859–14.177 | 0.418 | 0.006–0.989 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the Lithuanian University of Health Sciences. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kiselova, V.D.; Ozolina, K.; Zolovs, M.; Nagle, E.; Reine, I. The Role of Statistical Power: A Study of Relationship Between Emotional and Conduct Problems, Sociodemographic Factors, and Smoking Behaviours in Large and Small Samples of Latvian Adolescents. Medicina 2025, 61, 687. https://doi.org/10.3390/medicina61040687
Kiselova VD, Ozolina K, Zolovs M, Nagle E, Reine I. The Role of Statistical Power: A Study of Relationship Between Emotional and Conduct Problems, Sociodemographic Factors, and Smoking Behaviours in Large and Small Samples of Latvian Adolescents. Medicina. 2025; 61(4):687. https://doi.org/10.3390/medicina61040687
Chicago/Turabian StyleKiselova, Viola Daniela, Kristine Ozolina, Maksims Zolovs, Evija Nagle, and Ieva Reine. 2025. "The Role of Statistical Power: A Study of Relationship Between Emotional and Conduct Problems, Sociodemographic Factors, and Smoking Behaviours in Large and Small Samples of Latvian Adolescents" Medicina 61, no. 4: 687. https://doi.org/10.3390/medicina61040687
APA StyleKiselova, V. D., Ozolina, K., Zolovs, M., Nagle, E., & Reine, I. (2025). The Role of Statistical Power: A Study of Relationship Between Emotional and Conduct Problems, Sociodemographic Factors, and Smoking Behaviours in Large and Small Samples of Latvian Adolescents. Medicina, 61(4), 687. https://doi.org/10.3390/medicina61040687