Chain of Thought Utilization in Large Language Models and Application in Nephrology

 ,
,  ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
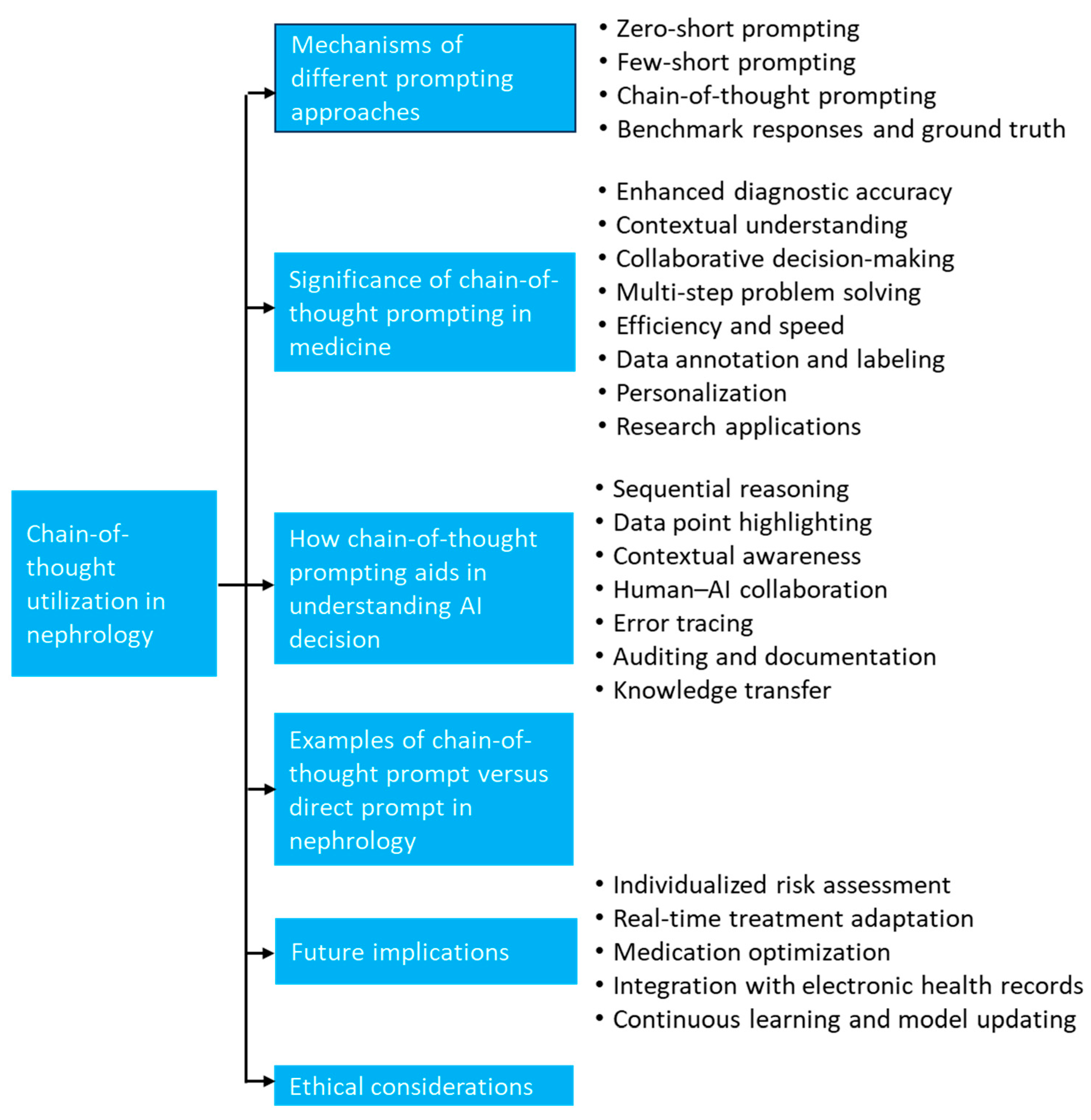
2. Prompting Mechanisms in Large Language Models
2.1. Zero-Shot Prompting
2.2. Few-Shot Prompting
2.3. Chain-of-Thought Prompting
2.4. Benchmark Responses for the Comparisons of Responses across Different Prompt Approaches
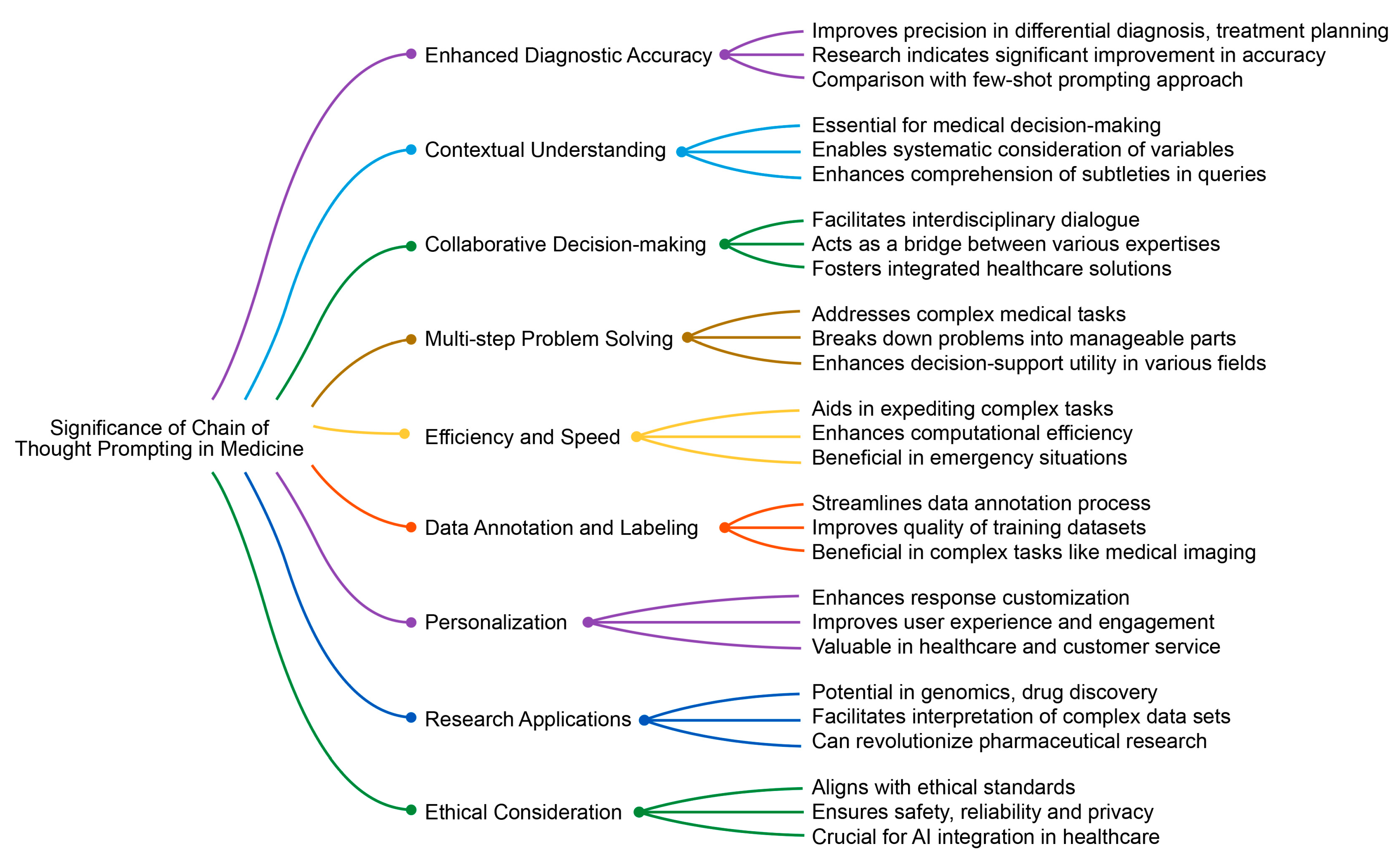
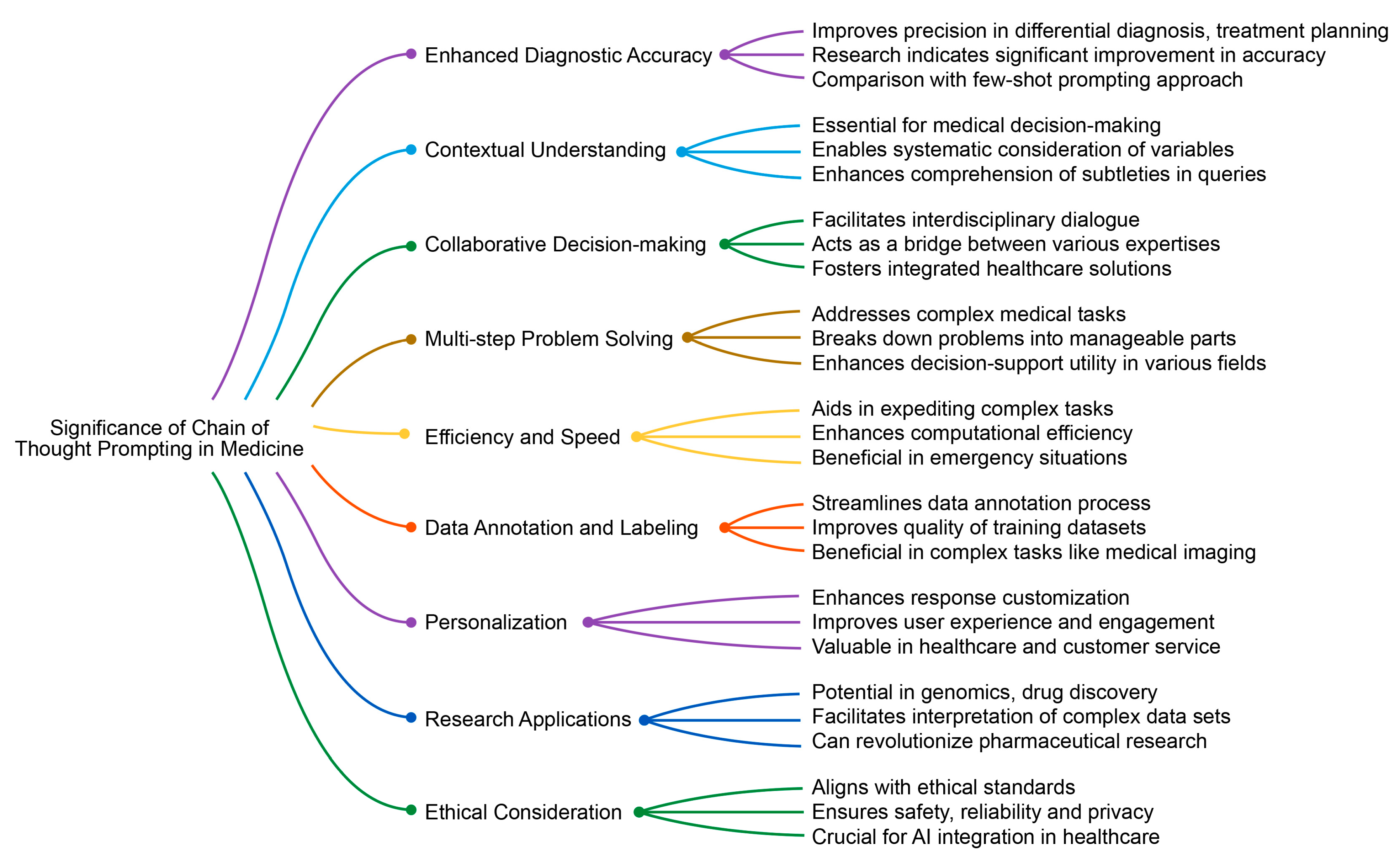
3. Significance of Chain-of-Thought Prompting in Medicine
3.1. Enhanced Diagnostic Accuracy
3.2. Contextual Understanding
3.3. Collaborative Decision Making
3.4. Multistep Problem Solving
3.5. Efficiency and Speed
3.6. Data Annotation and Labeling
3.7. Personalization
3.8. Research Applications
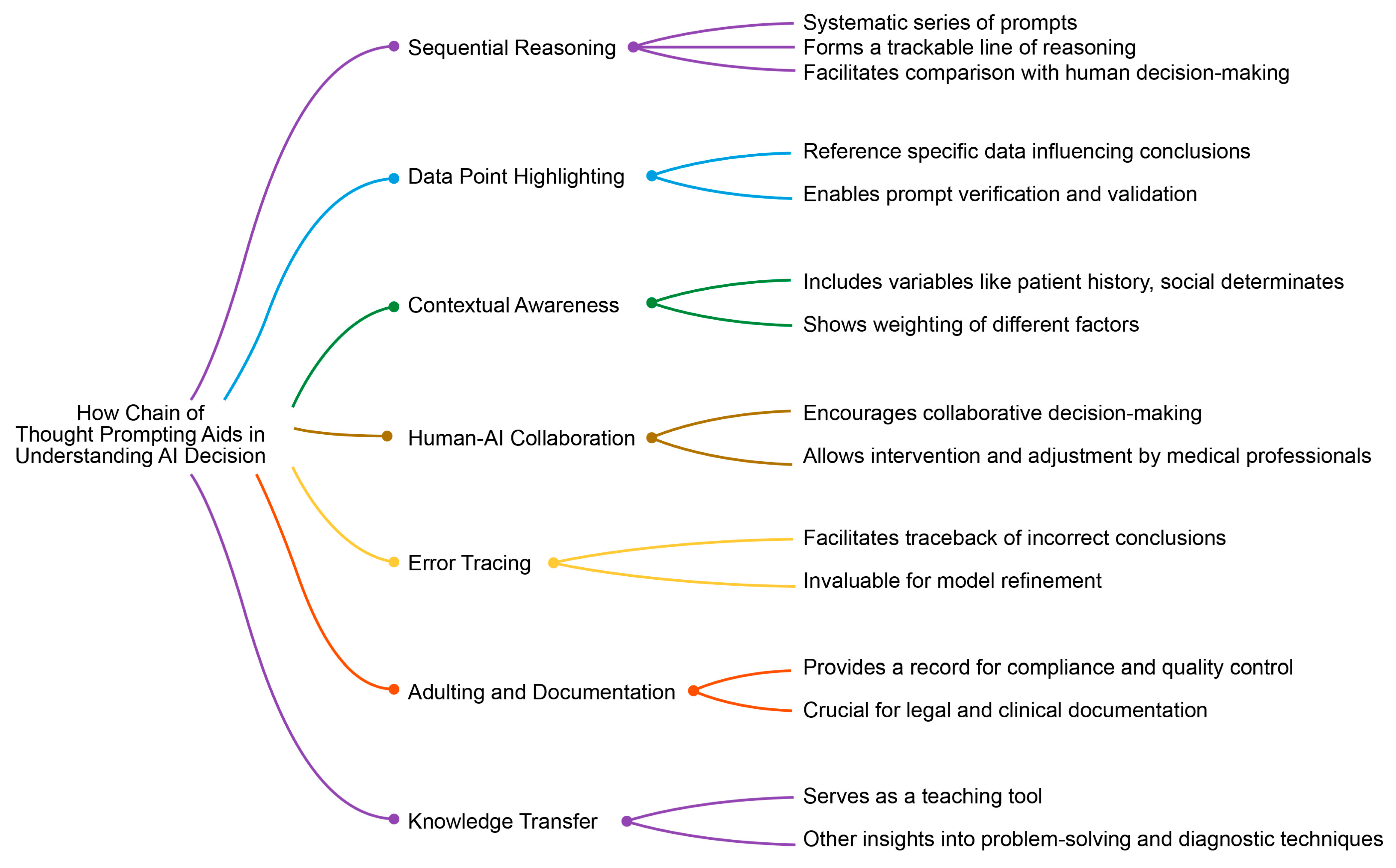
4. How Chain-of-Thought Prompting Aids in Understanding AI Decisions
- Sequential Reasoning: Chain-of-thought prompting guides the model through a systematic series of prompts, where each prompt builds upon the last. This process forms a clear and trackable line of reasoning, allowing for the examination of how the model arrived at a specific conclusion. This approach is similar to the “clinical reasoning” process used by medical professionals. It facilitates the comparison between AI-generated decisions and those made by humans, making the AI’s decision-making process more relatable and understandable.
- Data Point Highlighting: As the model progresses through its chain of thought, it frequently references specific pieces of data that influenced its conclusion. In patient care scenarios, this is akin to referencing important details from a lab report or critical symptoms from a patient’s medical history. Such referencing enables prompt verification and validation of the model’s conclusions.
- Contextual Awareness: The model’s chain of reasoning can include contextual variables such as patient history, social determinants of health, or recent changes in medical guidelines. This shows how the model is weighing different factors, enhancing its explainability.
- Human–AI Collaboration: Chain-of-thought prompting encourages a collaborative decision-making process. A medical professional can intervene at any point in the chain to ask for further clarification, adjust the variables, or even challenge the model’s reasoning. This two-way interaction enhances understanding and builds trust in the system.
- Error Tracing: If the model does arrive at an incorrect or suboptimal conclusion, the chain-of-thought mechanism allows for easy traceback to identify where the reasoning went wrong. This is invaluable for both rectifying the immediate issue and refining the model for future cases.
- Auditing and Documentation: The chain-of-thought process provides a record that can be audited for compliance and quality control. This is particularly crucial in a medical setting where documentation is paramount for both legal and clinical reasons.
- Knowledge Transfer: For educational purposes, the chain-of-thought process can serve as a teaching tool for medical students and professionals. By observing the model’s reasoning process, they can gain insights into complex problem-solving strategies and diagnostic techniques.
5. Examples of Chain-of-Thought Prompts in Nephrology
5.1. Regular Prompt vs. Chain-of-Thought Prompts in Diagnosing Hyponatremia due to SIADH
5.1.1. Regular Prompt Methodology
- Prompt: “Patient is a 65-year-old male with a serum sodium level of 125 mEq/L and normal renal, cardiac, and liver function tests. Could this be SIADH?”
- AI’s Response: “Based on the information provided, the patient may have Syndrome of Inappropriate Antidiuretic Hormone (SIADH). Further diagnostic tests and evaluations are recommended to confirm.”
5.1.2. Chain-of-Thought Prompts Methodology
- First Prompt: “Patient is a 65-year-old male with a serum sodium level of 125 mEq/L and normal renal, cardiac, and liver function tests. Evaluate for SIADH.”
- AI’s First Response: “Given the low serum sodium and absence of renal, cardiac, or liver dysfunction, SIADH is a strong consideration. Next, we should look for potential triggers or causes, like medications or malignancies.”
- Second Prompt: “The patient is not taking any medications known to trigger SIADH and has no known malignancies. What should we consider next?”
- AI’s Second Response: “The absence of common triggers like medications or cancer further supports the possibility of SIADH. To confirm, additional tests such as serum and urine osmolality should be conducted. Additionally, urine sodium levels would provide further insight.”
- Third Prompt: “Urine osmolality is 450 mOsm/kg, and urine sodium is 40 mEq/L. Interpret these results.”
- AI’s Third Response: “The urine osmolality and urine sodium levels are consistent with SIADH. The next step would be to rule out other potential causes of euvolemic hyponatremia, such as hypothyroidism or adrenal insufficiency, with targeted tests.”
- Fourth Prompt: “TSH and cortisol levels are normal. What is the final assessment?”
- AI’s Fourth Response: “With normal thyroid and adrenal function tests, and given the lab values and absence of other triggers, the diagnosis of SIADH is highly likely. The next steps should involve identifying any reversible causes and initiating appropriate treatment.
5.2. Regular Prompt vs. Chain-of-Thought Prompts in Diagnosing Metabolic Acidosis due to Ethylene Glycol Intoxication
5.2.1. Regular Prompt Methodology
- Prompt: “35-year-old male presents with metabolic acidosis, anion gap of 25, and recent history of ingesting an unknown substance. Could this be ethylene glycol intoxication?”
- AI’s Response: “Based on the elevated anion gap metabolic acidosis and the history of unknown substance ingestion, ethylene glycol intoxication is a strong possibility. Immediate treatment and further diagnostic tests are crucial.”
5.2.2. Chain-of-Thought Prompt Methodology
- First Prompt: “35-year-old male presents with metabolic acidosis, anion gap of 25, and recent history of ingesting an unknown substance. What is your differential diagnosis?”
- AI’s First Response: “The symptoms point to an elevated anion gap metabolic acidosis, which could be caused by several factors, including ethylene glycol intoxication, methanol poisoning, or diabetic ketoacidosis among others. The ingestion of an unknown substance particularly raises concern for toxicological causes.”
- Second Prompt: “Serum glucose is 98 mg/dL, and no ketones are detected in urine. No history of diabetes. What should be the next step?”
- AI’s Second Response: “Given the absence of hyperglycemia and urinary ketones, diabetic ketoacidosis is less likely. To home in on a toxicological cause like ethylene glycol, you could perform serum osmolality and osmolal gap calculations. Additionally, sending off an ethylene glycol serum level would be diagnostic.”
- Third Prompt: “Osmolal gap is 15, and we are waiting on the ethylene glycol serum levels. What’s the interpretation?”
- AI’s Third Response: “An osmolal gap of 15 suggests the presence of an unmeasured osmotically active substance, such as ethylene glycol. While waiting for the serum levels, empiric treatment with fomepizole or ethanol should be strongly considered, given the high suspicion.”
- Fourth Prompt: “Ethylene glycol serum level comes back at 50 mg/dL. What is your assessment?”
- AI’s Fourth Response: “A serum ethylene glycol level of 50 mg/dL confirms the diagnosis of ethylene glycol intoxication. Immediate treatment with fomepizole, along with hemodialysis for toxin removal and correction of acid–base imbalances, should be initiated without delay.”
5.3. Regular Prompt vs. Chain-of-Thought Prompts in Diagnosing Hypertension due to Fibromuscular Dysplasia of Renal Artery
5.3.1. Regular Prompt Methodology
- Prompt: “A 32-year-old female presents with severe hypertension not controlled by multiple antihypertensive medications. Could this be due to fibromuscular dysplasia of the renal artery?”
- AI’s Response: “Given the young age and severe, resistant hypertension, fibromuscular dysplasia affecting the renal artery could be a consideration. Further imaging studies are recommended to confirm.”
5.3.2. Chain-of-Thought Prompt
- First Prompt: “A 32-year-old female presents with severe hypertension resistant to multiple antihypertensive medications. What is your differential diagnosis.”
- AI’s First Response: “In a young female with resistant hypertension, the differential diagnosis should include secondary hypertension causes such as renal artery stenosis due to fibromuscular dysplasia, pheochromocytoma, primary hyperaldosteronism, or Cushing’s syndrome. Initial workup should aim to narrow down these possibilities.”
- Second Prompt: “All endocrine workup including plasma metanephrines, aldosterone-to-renin ratio, and dexamethasone suppression test are within normal limits. What should be the next diagnostic step?”
- AI’s Second Response: “Since endocrine causes have been ruled out, imaging studies focusing on the renal vasculature should be the next step. Renal artery Doppler ultrasound can be a noninvasive starting point, but CT angiography or MR angiography may provide more definitive information.”
- Third Prompt: “A beaded appearance is noted in the renal artery on a CT angiogram. What’s your assessment?”
- AI’s Third Response: “A beaded appearance of the renal artery is characteristic of fibromuscular dysplasia. This likely explains the patient’s resistant hypertension. Interventional approaches like renal artery angioplasty should be considered.”
- Fourth Prompt: “Patient undergoes successful angioplasty but still has moderately elevated BP. What is your management plan?”
- AI’s Fourth Response: “Even after successful angioplasty for fibromuscular dysplasia, some patients may continue to have elevated blood pressure. Management should focus on optimizing antihypertensive medication regimens, regular follow-up imaging to ensure no restenosis, and lifestyle modifications
6. Future Implications of Chain-of-Thought Prompting in Crafting Personalized Treatment Plans for Kidney Disease
6.1. Individualized Risk Assessment
6.2. Real-Time Treatment Adaptation
6.3. Medication Optimization
6.4. Integration with Existing Clinical Systems and Electronic Health Records
6.5. Continuous Learning and Model Updating
7. Ethical Consideration
8. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- OpenAI. Introducing ChatGPT. Available online: https://openai.com/blog/chatgpt (accessed on 11 November 2023).
- Kaddour, J.; Harris, J.; Mozes, M.; Bradley, H.; Raileanu, R.; McHardy, R. Challenges and Applications of Large Language Models. arXiv 2023, arXiv:2307.10169. [Google Scholar] [CrossRef]
- Clusmann, J.; Kolbinger, F.R.; Muti, H.S.; Carrero, Z.I.; Eckardt, J.N.; Laleh, N.G.; Loffler, C.M.L.; Schwarzkopf, S.C.; Unger, M.; Veldhuizen, G.P.; et al. The future landscape of large language models in medicine. Commun. Med. 2023, 3, 141. [Google Scholar] [CrossRef]
- Khawaja, R. 2023 Sentiment Analysis: Marketing with Large Language Models (LLMs). Available online: https://datasciencedojo.com/blog/sentiment-analysis-in-llm/# (accessed on 12 September 2023).
- Sydorenko, P. Top 5 Applications Of Large Language Models (Llms) in Legal Practice. Available online: https://medium.com/jurdep/top-5-applications-of-large-language-models-llms-in-legal-practice-d29cde9c38ef (accessed on 22 August 2023).
- Perez, R.; Li, X.; Giannakoulias, S.; Petersson, E.J. AggBERT: Best in Class Prediction of Hexapeptide Amyloidogenesis with a Semi-Supervised ProtBERT Model. J. Chem. Inf. Model. 2023, 63, 5727–5733. [Google Scholar] [CrossRef] [PubMed]
- Suppadungsuk, S.; Thongprayoon, C.; Miao, J.; Krisanapan, P.; Qureshi, F.; Kashani, K.; Cheungpasitporn, W. Exploring the Potential of Chatbots in Critical Care Nephrology. Medicines 2023, 10, 58. [Google Scholar] [CrossRef] [PubMed]
- Garcia Valencia, O.A.; Thongprayoon, C.; Jadlowiec, C.C.; Mao, S.A.; Miao, J.; Cheungpasitporn, W. Enhancing Kidney Transplant Care through the Integration of Chatbot. Healthcare 2023, 11, 2518. [Google Scholar] [CrossRef]
- Qarajeh, A.; Tangpanithandee, S.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Aiumtrakul, N.; Garcia Valencia, O.A.; Miao, J.; Qureshi, F.; Cheungpasitporn, W. AI-Powered Renal Diet Support: Performance of ChatGPT, Bard AI, and Bing Chat. Clin. Pract. 2023, 13, 1160–1172. [Google Scholar] [CrossRef]
- Miao, J.; Thongprayoon, C.; Garcia Valencia, O.A.; Krisanapan, P.; Sheikh, M.S.; Davis, P.W.; Mekraksakit, P.; Suarez, M.G.; Craici, I.M.; Cheungpasitporn, W. Performance of ChatGPT on Nephrology Test Questions. Clin. J. Am. Soc. Nephrol. 2024, 19, 35–43. [Google Scholar] [CrossRef]
- Miao, J.; Thongprayoon, C.; Cheungpasitporn, W. Assessing the Accuracy of ChatGPT on Core Questions in Glomerular Disease. Kidney Int. Rep. 2023, 8, 1657–1659. [Google Scholar] [CrossRef]
- Ayers, J.W.; Poliak, A.; Dredze, M.; Leas, E.C.; Zhu, Z.; Kelley, J.B.; Faix, D.J.; Goodman, A.M.; Longhurst, C.A.; Hogarth, M.; et al. Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum. JAMA Intern. Med. 2023, 183, 589–596. [Google Scholar] [CrossRef]
- Yano, Y.; Nishiyama, A.; Suzuki, Y.; Morimoto, S.; Morikawa, T.; Gohda, T.; Kanegae, H.; Nakashima, N. Relevance of ChatGPT’s Responses to Common Hypertension-Related Patient Inquiries. Hypertension 2023, 81, e1–e4. [Google Scholar] [CrossRef]
- Suppadungsuk, S.; Thongprayoon, C.; Krisanapan, P.; Tangpanithandee, S.; Garcia Valencia, O.; Miao, J.; Mekraksakit, P.; Kashani, K.; Cheungpasitporn, W. Examining the Validity of ChatGPT in Identifying Relevant Nephrology Literature: Findings and Implications. J. Clin. Med. 2023, 12, 5550. [Google Scholar] [CrossRef] [PubMed]
- Aiumtrakul, N.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Miao, J.; Qureshi, F.; Cheungpasitporn, W. Navigating the Landscape of Personalized Medicine: The Relevance of ChatGPT, BingChat, and Bard AI in Nephrology Literature Searches. J. Pers. Med. 2023, 13, 1457. [Google Scholar] [CrossRef] [PubMed]
- Lemley, K.V. Does ChatGPT Help Us Understand the Medical Literature? J. Am. Soc. Nephrol. 2023, 10–1681. [Google Scholar] [CrossRef] [PubMed]
- Hueso, M.; Alvarez, R.; Mari, D.; Ribas-Ripoll, V.; Lekadir, K.; Vellido, A. Is generative artificial intelligence the next step toward a personalized hemodialysis? Rev. Invest. Clin. 2023, 75, 309–317. [Google Scholar] [CrossRef] [PubMed]
- Daugirdas, J.T. OpenAI’s ChatGPT and Its Potential Impact on Narrative and Scientific Writing in Nephrology. Am. J. Kidney Dis. 2023, 82, A13–A14. [Google Scholar] [CrossRef]
- Mayo, M. Unraveling the Power of Chain-of-Thought Prompting in Large Language Models. Available online: https://www.kdnuggets.com/2023/07/power-chain-thought-prompting-large-language-models.html (accessed on 13 November 2023).
- Ott, S.; Hebenstreit, K.; Lievin, V.; Hother, C.E.; Moradi, M.; Mayrhauser, M.; Praas, R.; Winther, O.; Samwald, M. ThoughtSource: A central hub for large language model reasoning data. Sci. Data 2023, 10, 528. [Google Scholar] [CrossRef]
- Ecoffet, A. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Wolff, T. How to Craft Prompts for Maximum Effectiveness. Available online: https://medium.com/mlearning-ai/from-zero-shot-to-chain-of-thought-prompt-engineering-choosing-the-right-prompt-types-88800f242137 (accessed on 14 November 2023).
- Ramlochan, S. Master Prompting Concepts: Zero-Shot and Few-Shot Prompting. Available online: https://promptengineering.org/master-prompting-concepts-zero-shot-and-few-shot-prompting/ (accessed on 25 April 2023).
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayshi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. CM Comput. Surv. 2023, 55, 1–35. [Google Scholar]
- Zhong, Q.; Ding, L.; Liu, J.; Du, B.; Tao, D. Can ChatGPT Understand Too? A Comparative Study on ChatGPT and Fine-tuned BERT. arXiv 2023, arXiv:2302.10198. [Google Scholar]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef]
- Pal, A.; Umapathi, L.K.; Sankarasubbu, M. Med-HALT: Medical Domain Hallucination Test for Large Language Models. arXiv 2023, arXiv:2307.15343. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; DBosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2023, arXiv:2201.11903. [Google Scholar]
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems. arXiv 2021, arXiv:2110.14168. [Google Scholar]
- Wadhwa, S.; Amir, S.; Wallace, B.C. Revisiting Relation Extraction in the era of Large Language Models. Proc. Conf. Assoc. Comput. Linguist. Meet. 2023, 2023, 15566–15589. [Google Scholar] [CrossRef] [PubMed]
- Shin, E.; Ramanathan, M. Evaluation of prompt engineering strategies for pharmacokinetic data analysis with the ChatGPT large language model. J. Pharmacokinet. Pharmacodyn. 2023, 1–8. [Google Scholar] [CrossRef]
- Oeze, C. The Importance of Chain-of-Thought Prompting. Available online: https://medium.com/@CameronO/the-importance-of-chain-of-thought-prompting-97fbbe39d753 (accessed on 17 May 2023).
- Fu, C.; Chen, P.; Shen, Y.; Qin, Y.; Zhang, M.; Lin, X.; Yang, J.; Zheng, X.; Li, K.; Sun, X.; et al. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models. arXiv 2023, arXiv:2306.13394. [Google Scholar]
- Yu, P.; Xu, H.; Hu, X.; Deng, C. Leveraging Generative AI and Large Language Models: A Comprehensive Roadmap for Healthcare Integration. Healthcare 2023, 11, 2776. [Google Scholar] [CrossRef]
- Buckley, T.; Diao, J.A.; Adam, R.; Manrai, A.K. Accuracy of a Vision-Language Model on Challenging Medical Cases. arXiv 2023, arXiv:2311.05591. [Google Scholar]
- Wu, C.-K.; Chen, W.-L.; Chen, H.-H. Large Language Models Perform Diagnostic Reasoning. Available online: https://arxiv.org/abs/2307.08922 (accessed on 18 July 2023).
- Shum, K.; Diao, S.; Zhang, T. Automatic Prompt Augmentation and Selection with Chain-of-Thought from Labeled Data. arXiv 2023, arXiv:2302.12822. [Google Scholar]
- Yang, R.; Tan, T.F.; Lu, W.; Thirunavukarasu, A.J.; Ting, D.S.W.; Liu, N. Large language models in health care: Development, applications, and challenges. Healthc. Sci. 2023, 2, 255–263. [Google Scholar] [CrossRef]
- Eisenstein, M. AI-enhanced protein design makes proteins that have never existed. Nat. Biotechnol. 2023, 41, 303–305. [Google Scholar] [CrossRef] [PubMed]
- Jeyaraman, M.; Ramasubramanian, S.; Balaji, S.; Jeyaraman, N.; Nallakumarasamy, A.; Sharma, S. ChatGPT in action: Harnessing artificial intelligence potential and addressing ethical challenges in medicine, education, and scientific research. World J. Methodol. 2023, 13, 170–178. [Google Scholar] [CrossRef] [PubMed]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nat. Med. 2023, 29, 1930–1940. [Google Scholar] [CrossRef] [PubMed]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef] [PubMed]
- Joshi, G.; Jain, A.; Araveeti, S.R.; Adhikari, S.; Garg, H.; Bhandari, M. FDA Approved Artificial Intelligence and Machine Learning (AI/ML)-Enabled Medical Devices: An Updated Landscape. medRxiv 2022. [Google Scholar] [CrossRef]
- Frackiewicz, M. ChatGPT for Diagnosis of Kidney Diseases: Advancements and Limitations. Available online: https://ts2.space/en/chatgpt-for-diagnosis-of-kidney-diseases-advancements-and-limitations/ (accessed on 14 November 2023).
- LaMDA: Towards Safe, Grounded, and High-Quality Dialog Models for Everything. Available online: https://blog.research.google/2022/01/lamda-towards-safe-grounded-and-high.html (accessed on 21 January 2022).
- AI21 Studio Documentation. Available online: https://docs.ai21.com/ (accessed on 9 March 2023).
- Evans, R.S. Electronic Health Records: Then, Now, and in the Future. Yearb. Med. Inform. 2016, 25 (Suppl. 1), S48–S61. [Google Scholar] [CrossRef]
- Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Garcia Valencia, O.A.; Qureshi, F.; Cheungpasitporn, W. Innovating Personalized Nephrology Care: Exploring the Potential Utilization of ChatGPT. J. Pers. Med. 2023, 13, 1681. [Google Scholar] [CrossRef]
- Duda, S.N.; Kennedy, N.; Conway, D.; Cheng, A.C.; Nguyen, V.; Zayas-Caban, T.; Harris, P.A. HL7 FHIR-based tools and initiatives to support clinical research: A scoping review. J. Am. Med. Inform. Assoc. 2022, 29, 1642–1653. [Google Scholar] [CrossRef]
- Garcia Valencia, O.A.; Suppadungsuk, S.; Thongprayoon, C.; Miao, J.; Tangpanithandee, S.; Craici, I.M.; Cheungpasitporn, W. Ethical Implications of Chatbot Utilization in Nephrology. J. Pers. Med. 2023, 13, 1363. [Google Scholar] [CrossRef]
- Knoppers, B.M.; Bernier, A.; Bowers, S.; Kirby, E. Open Data in the Era of the GDPR: Lessons from the Human Cell Atlas. Annu. Rev. Genom. Hum. Genet. 2023, 24, 369–391. [Google Scholar] [CrossRef]
- Aalami, O.; Hittle, M.; Ravi, V.; Griffin, A.; Schmiedmayer, P.; Shenoy, V.; Gutierrez, S.; Venook, R. CardinalKit: Open-source standards-based, interoperable mobile development platform to help translate the promise of digital health. JAMIA Open 2023, 6, ooad044. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Krisanapan, P.; Radhakrishnan, Y.; Cheungpasitporn, W. Chain of Thought Utilization in Large Language Models and Application in Nephrology. Medicina 2024, 60, 148. https://doi.org/10.3390/medicina60010148
Miao J, Thongprayoon C, Suppadungsuk S, Krisanapan P, Radhakrishnan Y, Cheungpasitporn W. Chain of Thought Utilization in Large Language Models and Application in Nephrology. Medicina. 2024; 60(1):148. https://doi.org/10.3390/medicina60010148
Chicago/Turabian StyleMiao, Jing, Charat Thongprayoon, Supawadee Suppadungsuk, Pajaree Krisanapan, Yeshwanter Radhakrishnan, and Wisit Cheungpasitporn. 2024. "Chain of Thought Utilization in Large Language Models and Application in Nephrology" Medicina 60, no. 1: 148. https://doi.org/10.3390/medicina60010148
APA StyleMiao, J., Thongprayoon, C., Suppadungsuk, S., Krisanapan, P., Radhakrishnan, Y., & Cheungpasitporn, W. (2024). Chain of Thought Utilization in Large Language Models and Application in Nephrology. Medicina, 60(1), 148. https://doi.org/10.3390/medicina60010148