Abstract
Temporal difference (TD) learning is a well-known approach for training automated players in board games with a limited number of potential states through autonomous play. Because of its directness, TD learning has become widespread, but certain critical difficulties must be solved in order for it to be effective. It is impractical to train an artificial intelligence (AI) agent against a random player since it takes millions of games for the agent to learn to play intelligently. Training the agent against a methodical player, on the other hand, is not an option owing to a lack of exploration. This article describes and examines a variety of hybrid training procedures for a TD-based automated player that combines randomness with specified plays in a predetermined ratio. We provide simulation results for the famous tic-tac-toe and Connect-4 board games, in which one of the studied training strategies significantly surpasses the other options. On average, it takes fewer than 100,000 games of training for an agent taught using this approach to act as a flawless player in tic-tac-toe.
1. Introduction
Reinforcement learning (RL) is the study of how artificial intelligence (AI) agents may learn what to do in a particular environment without having access to labeled examples [1,2]. Without any prior knowledge of the environment or the reward function, RL employs perception and observed rewards to develop an optimal (or near-optimal) policy for the environment. RL is a classic AI issue in which an agent is introduced in an unfamiliar environment and therefore must learn to act successfully in it.
The RL agent learns to play board games by obtaining feedback (reward, reinforcement) after the conclusion of each game [3], knowing that something good has happened after winning or something bad has happened after losing. This agent acts without having any prior knowledge of the appropriate strategies to win the game.
It is difficult for a person to make precise and consistent assessments of a large number of locations while playing a board game, as would be required if an evaluation function were discovered directly from instances. An RL agent, on the other hand, can learn an evaluation function that yields relatively accurate estimations of the likelihood of winning from any given position by knowing whether it won or lost each game played.
Due to its simplicity and low computational requirements, temporal difference learning (TD), a type of reinforcement learning (RL), has been widely used to successfully train automatic game players in board games such as checkers [4], backgammon [5,6,7], tic-tac-toe [8], Chung Toi [9,10], go [11,12], or Othello [13]. The TD agent models a fully observable environment using a state-based representation. The agent’s policy is static, and its job is to figure out what the utility values of the various states are. The TD agent is unaware of the transition model, which provides the likelihood of arriving at a given state from another state after completing a particular action, as well as the reward function, which specifies the reward for each state.
The updates performed by TD learning do not need the use of a transition model. The environment, in the form of witnessed transitions, provides the link between nearby states. The TD technique aims to make local modifications to utility estimates for each state’s successors to “agree”.
TD modifies a state to agree just with its observed successor (as defined by the TD update rule equation [14]), rather than altering it to agree with all possible successors, weighted by their probability. When the effects of TD modifications are averaged across a large number of transitions, this approximation turns out to be acceptable since the frequency of any successor in the set of transitions is approximately proportional to its probability. For back-propagating the evaluations of successive positions to the present position, TD learning utilizes the difference between two successive positions [15]. Because this is done for all positions that occur in a game, the game’s outcome is included in the evaluation function of all positions, and as a result, the evaluation function improves over time.
The exploration–exploitation conundrum [16] is the most important question to overcome in TD learning: if an agent has devised a good line of action, should it continue to do so (exploiting what it has discovered), or should it explore to find better actions? To learn how to act better in its surroundings, an agent should immerse itself in it as much as feasible. As a result of this, several past studies have shown disheartening results, requiring millions of games before the agent begins to play intelligently.
Coevolutionary TD learning [17] and n-tuple systems [18,19] have been presented as extensions to the basic TD learning method. Self-play was used to train a TD learning agent for the game Connect-4 in [20]. The time-to-learn was determined to be 1.5 million games (with an 80% success rate).
Other expansions and changes to the original TD method have been proposed, including the use of TD in conjunction with deep learning and neural networks [21]. These studies show promising outcomes at the risk of overlooking the major two benefits of TD learning: its relative simplicity and low computational costs.
This article presents and evaluates several hybrid techniques to train a TD learning agent in board games, extending the work presented in [22]. Exploration concerns are solved by the incorporation of hybridness into training strategies: pure random games are included in a certain proportion in every training strategy considered, and they are interspersed evenly during the training process.
The TD agent evaluated in this study employs the original TD method without any modifications, keeping the TD implementation’s simplicity and minimal processing requirements. One of the training alternatives considered proves to outperform all the others, needing fewer than 100,000 training games on average to behave like a perfect player in the tic-tac-toe classic board game, achieving this degree in all simulation runs. In addition, the same technique has been tested in the Connect-4 board game, also yielding a significant performance improvement.
The rest of this article is arranged as follows: In Section 2, we analyze the key properties of the TD agent in order to learn how to play the famous board games tic-tac-toe and Connect-4. The experiments that were carried out and the results that were obtained are described in the Section 3. In Section 4, the results are interpreted in-depth. Finally, Section 5 summarizes the major findings of this study.
2. Materials and Methods
2.1. Tic-Tac-Toe Board Game
Tic-tac-toe [23] is a traditional two-player (X and O) board game in which players alternate marking places on a 3 × 3 grid. The game is won by the person who can line up three of their markings in a horizontal, vertical, or diagonal row. Figure 1 shows a typical tic-tac-toe game, which was won by the first player (X).

Figure 1.
A finished game of tic-tac-toe, won by player X.
At first impression, it appears that the first player has an advantage (he or she can occupy one spot more than his or her opponent at the end of the game). Because of the intrinsic asymmetry of the tic-tac-toe game, the player that starts the game (player X) has almost twice as many winning final positions as the second player (player O).
A game between two flawless players, on the other hand, has been proven to always result in a tie. Furthermore, no matter how strongly the O-player tries to win, a perfect X-player can select any square as the opening move and still tie the game.
The tic-tac-toe game’s state space is moderately narrow, with 39 (=19,683) potential states, albeit most of these are illegal owing to game constraints. The number of attainable states is 5478, according to combinatorial analysis.
Some basic strategies to play the game intelligently are detailed in [24], combining flexibility to adapt to changing situations and stability to satisfy long-term goals.
2.2. Connect-4 Board Game
Connect-4 is a popular board game for two players played on a board with several rows and columns. One main characteristic of the game is the vertical arrangement of the board: both players in turn drop one of their pieces into one of the columns (slots). Due to the gravity rule, the pieces fall to the lowest free position of the respective slot. The goal of both opponents is to create a line of four pieces with their color, either horizontally, vertically, or diagonally. The player who can achieve this first wins the game. If all the board positions become filled and none of the opponents was able to create a line of four own pieces, the match ends with a tie.
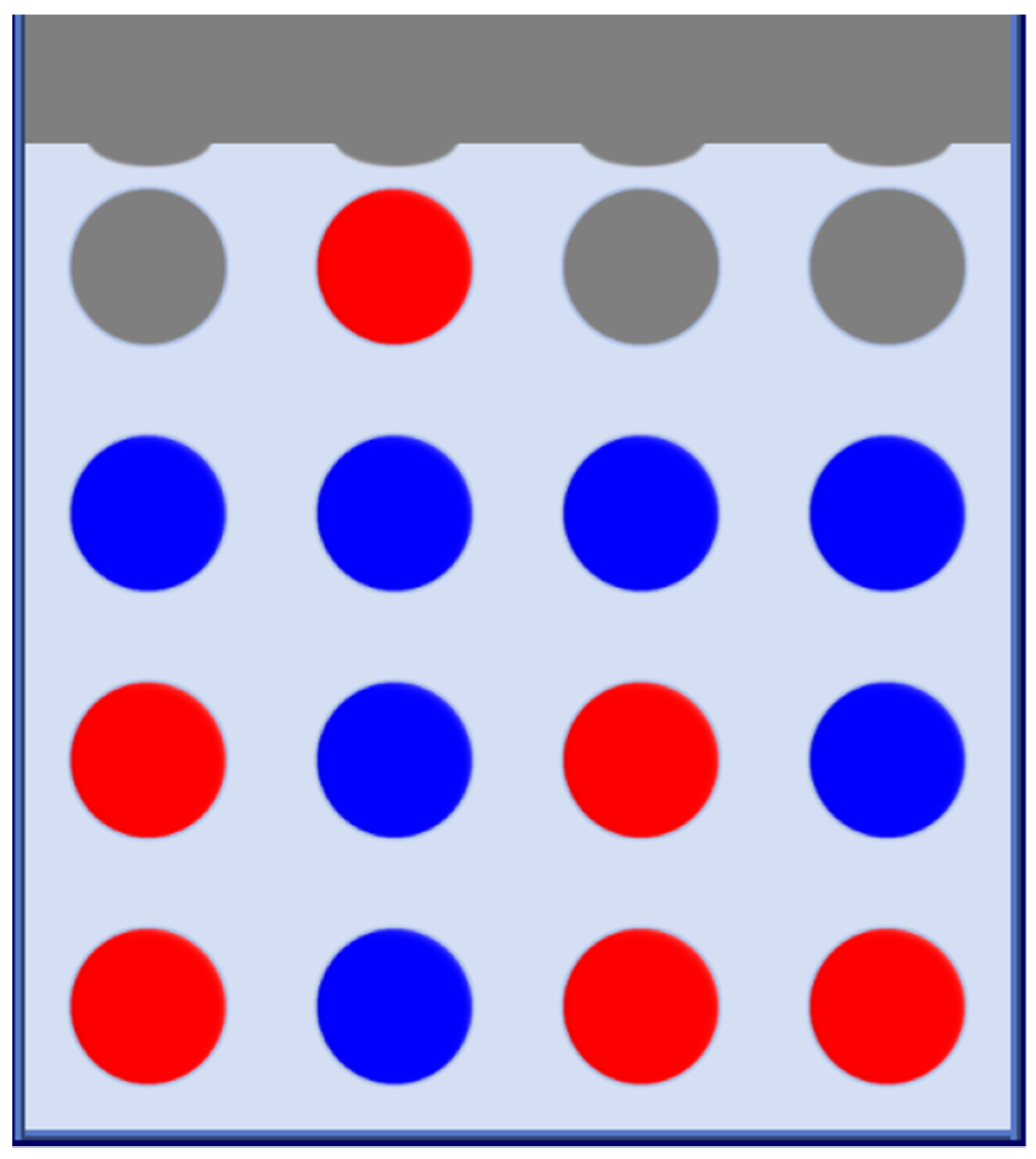
In Figure 2, we can observe a typical Connect-4 game for a 4 × 4 (four rows, four columns) board, won by the first player (blue):
Figure 2.
A finished game of Connect-4 on a 4 × 4 board, won by the blue player.
In 1988, two independent research works [25,26] demonstrated that Connect-4 with the standard board size 7 × 6 (seven columns and six rows) is a first-player-win: if the first player makes the right moves, the opponent is bound to lose the game, regardless of the opponent’s moves. For other board sizes (e.g., 4 × 4, 5 × 4, 5 × 5, 6 × 5), it has been proved [27] that Connect-4 presents the same characteristic as tic-tac-toe: a game between two perfect players always ends up in a draw.
The Connect-4 game’s state space is considerably larger than tic-tac-toe’s. Even for the smallest board size (four rows and four columns), the number of potential states adds up to 316 (=43,046,721), thus being 7858 times the potential states present in tic-tac-toe. An upper-bound estimation of the number of legal states falls within the range (180,000, 200,000); that is, its state-space complexity is larger than tic-tac-toe’s approximately by a factor of 30.
2.3. TD-Learning Agent
In order to examine alternative training procedures, a TD learning agent has been developed in the C++ language for each board game considered (tic-tac-toe and 4 × 4 Connect-4). The generated C++ programs, which include the various training techniques assessed, only account for ~400 noncomment source lines (NCSLs) of code each, due to the algorithm’s straightforwardness.
Regular tic-tac-toe and Connect-4 game rules are assumed in our implementation of both TD agents. We will assume that the opponent of the TD agent always plays first.
The distinct game states are indicated by an n-digit number with potential digits 0 (an empty position), 1 (a position occupied by the opponent), and 2 (a position held by the TD agent). In theory, this means that there are 3n potential states, but owing to game rules, some of them are not attainable. The TD agent seeks to travel from a given state to the state with the highest estimated utility of all the attainable states in each game. It will perform a random move if all of the attainable states have the same estimated utility.
After playing an elevated number of games against an opponent (training phase), these utilities represent an estimate of the probability of winning from every state. These utilities symbolize the states’ values, and the whole set of utilities is the learned value function. State A has a higher value than state B if the current estimate of the probability of winning from A is higher than it is from B.
For every potential state of the game, utilities are initially set to zero. When each game is over, the TD agent updates its utility estimates for all of the states that were traveled throughout the game as follows: The utility function for the final state of the game (terminal state) will be −1 (opponent won), +1 (TD agent won), or 0.2 (game tied up). Due to the unique nature of tic-tac-toe and 4 × 4 Connect-4, a little positive incentive is provided to game ties, as the game will end in a tie if played intelligently. Utilities are updated backward for the rest of the states visited throughout the game, by updating the current value of the earlier state to be closer to the value of the later state.
If we let s denote the state before a move in the game and s′ denote the state after that move, then we apply the following update to the estimated utility (U) of state s:
where α is the learning rate and γ is the discount factor parameter. Because this update rule uses the difference in utilities between successive states, it is often called the temporal difference, or TD, equation. After many training games, the TD agent converges to accurate estimates of the probabilities of winning from every state of the game.
The pseudocode detailed in Listing 1 performs the update of the utilities for all the states visited throughout a game, after the game has finished, using the TD Equation (1).
Listing 1. Update of utilities after each game, using the TD update rule equation.
// U: Utilities for all possible states
// seq: sequence of states visited in the last game
// n_moves: number of moves in the last game
if (TD_agent_won) {
U[current_state] = 1.0;
}
else if (opponent_won) {
U[current_state] = −1.0;
}
else { // tied up
U[current_state] = 0.2;
}
for (i = 1; i <= n_moves; i++) {
// this is the TD update rule equation
// ALPHA -> learning rate; DF -> discount factor
U[seq[n_moves-i]] += ALPHA*(DF*U[current_state]-U[seq[n_moves-i]]);
current_state = seq[n_moves-i];
}
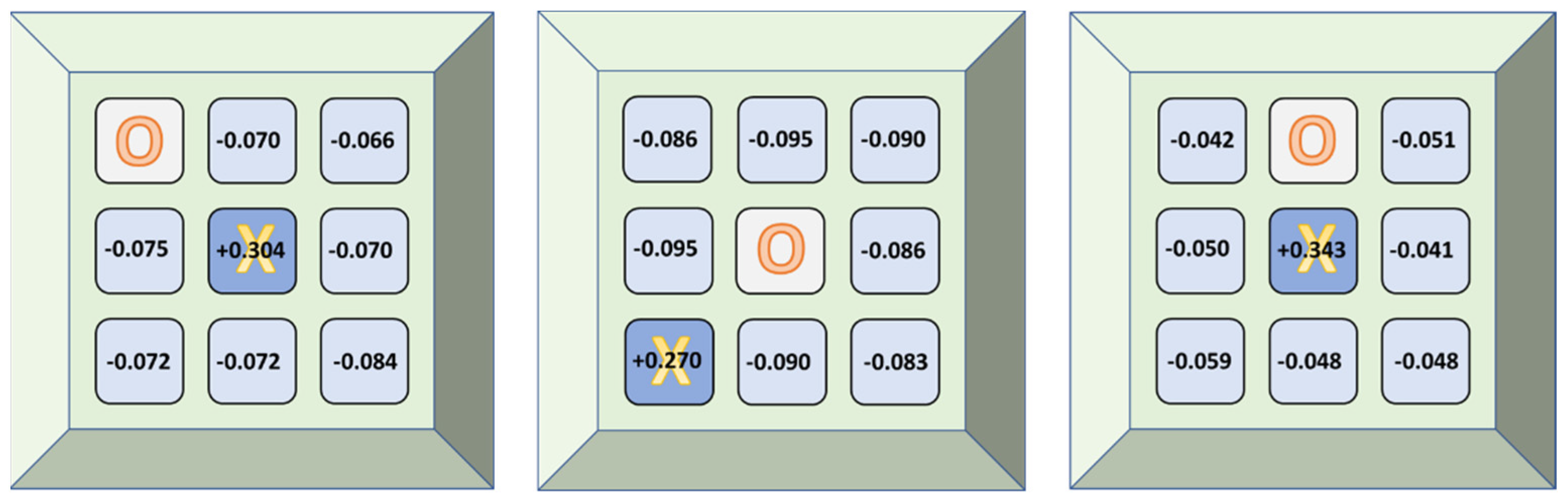
As an example, in Figure 3 we can see the estimated utilities by the tic-tac-toe TD agent (X-player) after having played an elevated number of training games, for all reachable states in three different games, given three distinct initial positions occupied by the opponent (O-player).
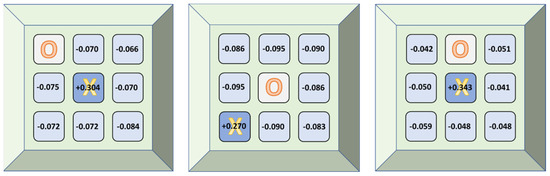
Figure 3.
Estimated utilities by the tic-tac-toe TD agent (X-player) for all reachable states in 3 different games, given 3 distinct initial positions occupied by the opponent (O-player).
2.4. Training Strategies
The TD agent will be taught by playing games against one of the following opponents:
- Attack player. The player will first determine whether there is an imminent chance of winning and if so, will act accordingly. In all other cases, it will act randomly.
- Defense player. If the TD agent has an imminent chance to win, the player will obstruct it. It will act randomly in any other situation.
- Attack–Defense player. It integrates the previous two players, giving precedence to the attack feature. This player will try to win first; if it fails, it will check to see whether the TD agent will win in the following move and if so, it will obstruct it. Otherwise, it will act randomly.
- Defense–Attack player. It integrates the players (2) and (1), giving precedence to the defense feature. This player will first determine whether the TD agent has a chance to win the next move and if so, will obstruct it. If this is not the case, it will attempt to win if feasible. Otherwise, it will act randomly.
- Combined player. This player will behave as one of the above players, chosen randomly for every game played.
In order to deal with exploratory issues, hybridness has been incorporated in all of the above learning agents in the following manner: in a certain proportion of games, each player will “forget” about its strategy and will behave as a completely random player. These games will be interspersed throughout the entire training process.
For the sake of comparison, the Random player (always completely random moves) has also been studied, to have a baseline strategy. It is worth noting that the ideal player was not featured as a training option. The perfect player, by definition, will make the best decision possible in each scenario to win the game (or at least tie up if the game cannot be won). As a result, its lack of randomization renders it completely unsuitable for training the TD learning agent.
3. Experiments and Results
Following the learning techniques and rules described in the previous section, we created two TD learning agents, one for the tic-tac-toe game and another for the 4 × 4 Connect-4 game. The characteristics of the experiments that were conducted are as follows:
- The opponent utilized to train the TD agent is always the first player to move. It will represent one of the six training methods described in the preceding section (namely Attack, Defense, Attack–Defense, Defense–Attack, Combined, and Random). Each game’s opening move will always be random.
- The maximum number of training games is set to 2 million. Nevertheless, the training process finishes if there are no games lost during the last 50,000.
- In the TD update rule equation, the value of the learning rate α parameter is set to 0.25 and the value of the discount factor γ parameter is set to 1.
- For every potential state of the game, utilities are initially set to zero in each game.
- The degree of hybridness (random games introduced evenly in all the TD learning agents) is 1 out of 7 (14.286%).
- Following the completion of the training procedure, the TD agent will participate in a series of test games. The values of the utilities assessed by the TD agent during the training phase are constant in these test games.
- The number of test games against a fully random player is fixed to 1 million.
- In the tic-tac-toe game, the number of test games against an expert player is fixed to nine games, as the expert player’s moves are invariant for each game situation. Therefore, the only variable parameter is the first move, which can be made in any of the grid’s nine positions. For the same reason, in the 4 × 4 Connect-4 game, the number of test games against an expert player is fixed to four games, corresponding to the four columns of the board.
- The expert player has been implemented using the Minimax recursive algorithm, which chooses an optimal move for a player assuming that the opponent is also playing optimally [28].
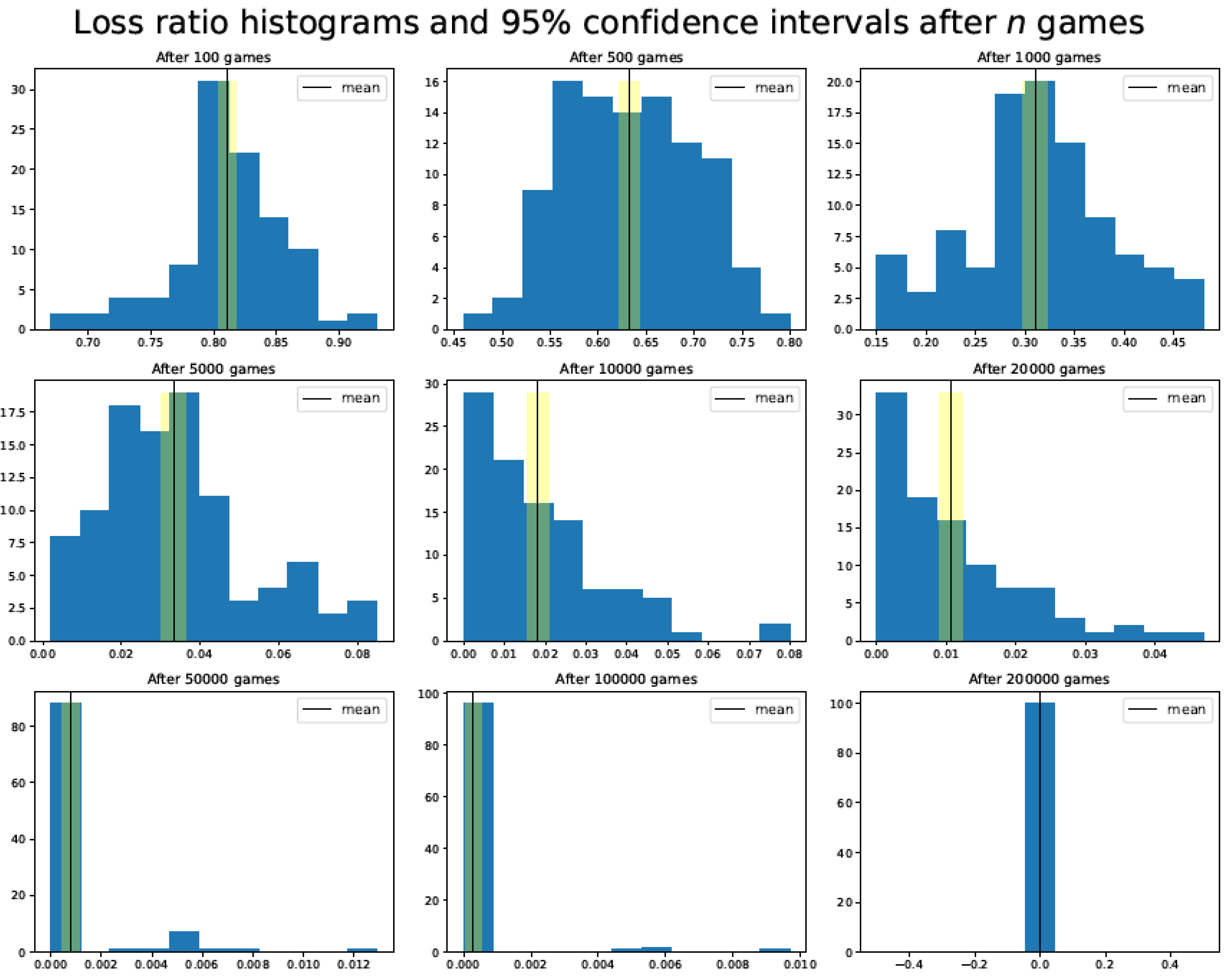
All the results have been calculated as the average of 100 different simulation runs. The confidence intervals have been computed by applying the unbiased bootstrap method. As an example, Figure 4 shows the tic-tac-toe TD agent loss ratio distribution histograms and 95% confidence intervals after a specific number of training games have been played against the Attack–Defense player.
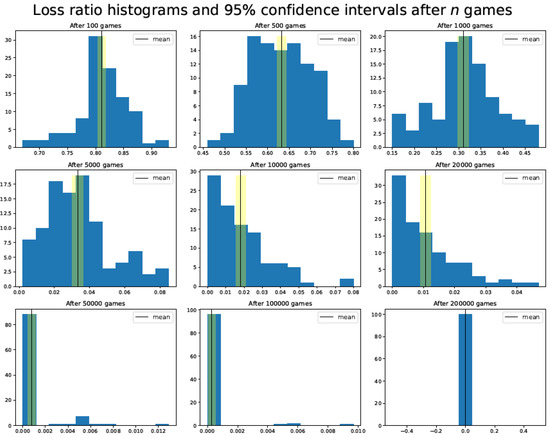
Figure 4.
Tic-tac-toe TD agent loss ratio distribution histograms and 95% confidence intervals after a specific number of training games (100, 500, 1000, 5000, 10,000, 20,000, 50,000, 100,000, and 200,000) have been played against the Attack–Defense player.
3.1. Tic-Tac-Toe Training Phase Results
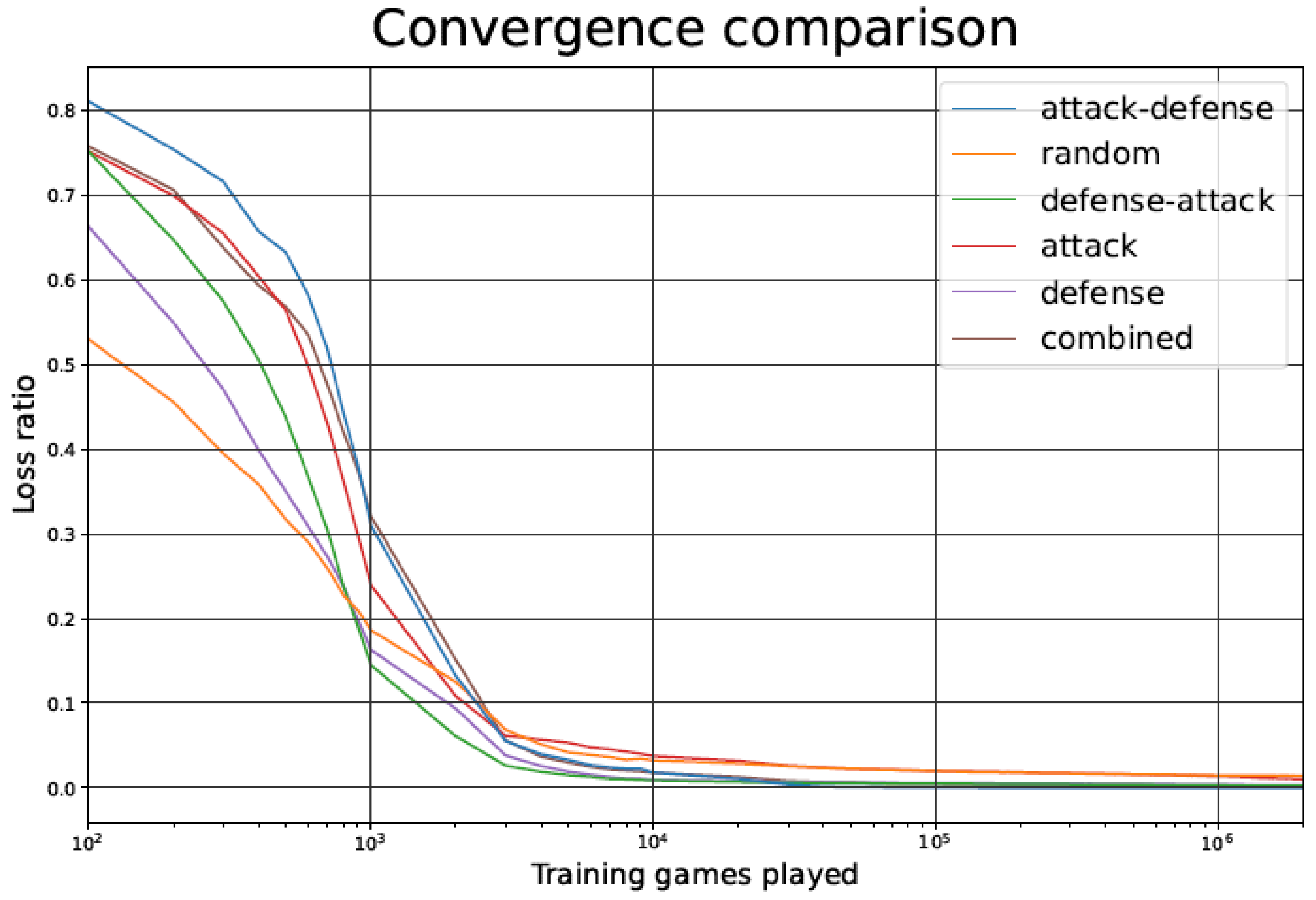
The outcome of the simulations during the training phase are shown in Figure 5, Figure 6 and Figure 7. Each figure has six curves: one for each of the five training options listed in Section 2.4, and an additional curve for the Random player.
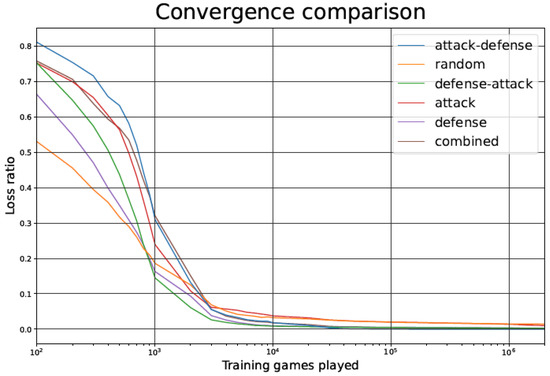
Figure 5.
Tic-tac-toe TD agent loss ratio during the training phase as a function of the number of games played, for the different training strategies.
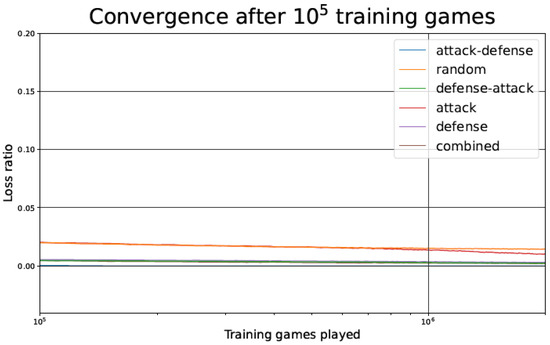
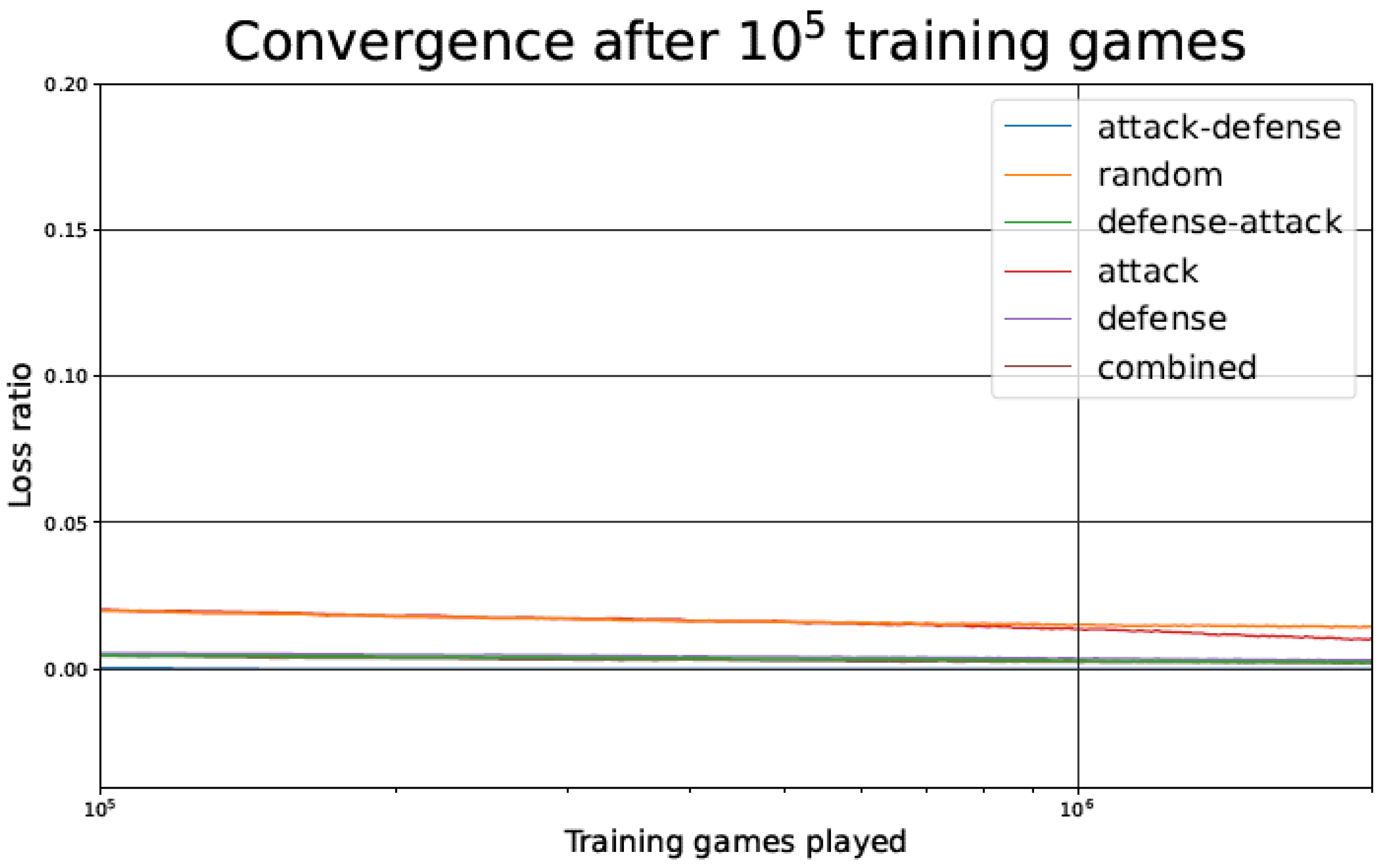
Figure 6.
Tic-tac-toe TD agent loss ratio after 100,000 games as a function of the number of games played, for the different training strategies.
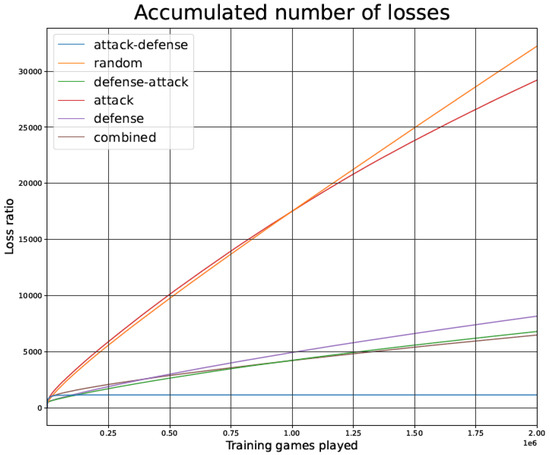
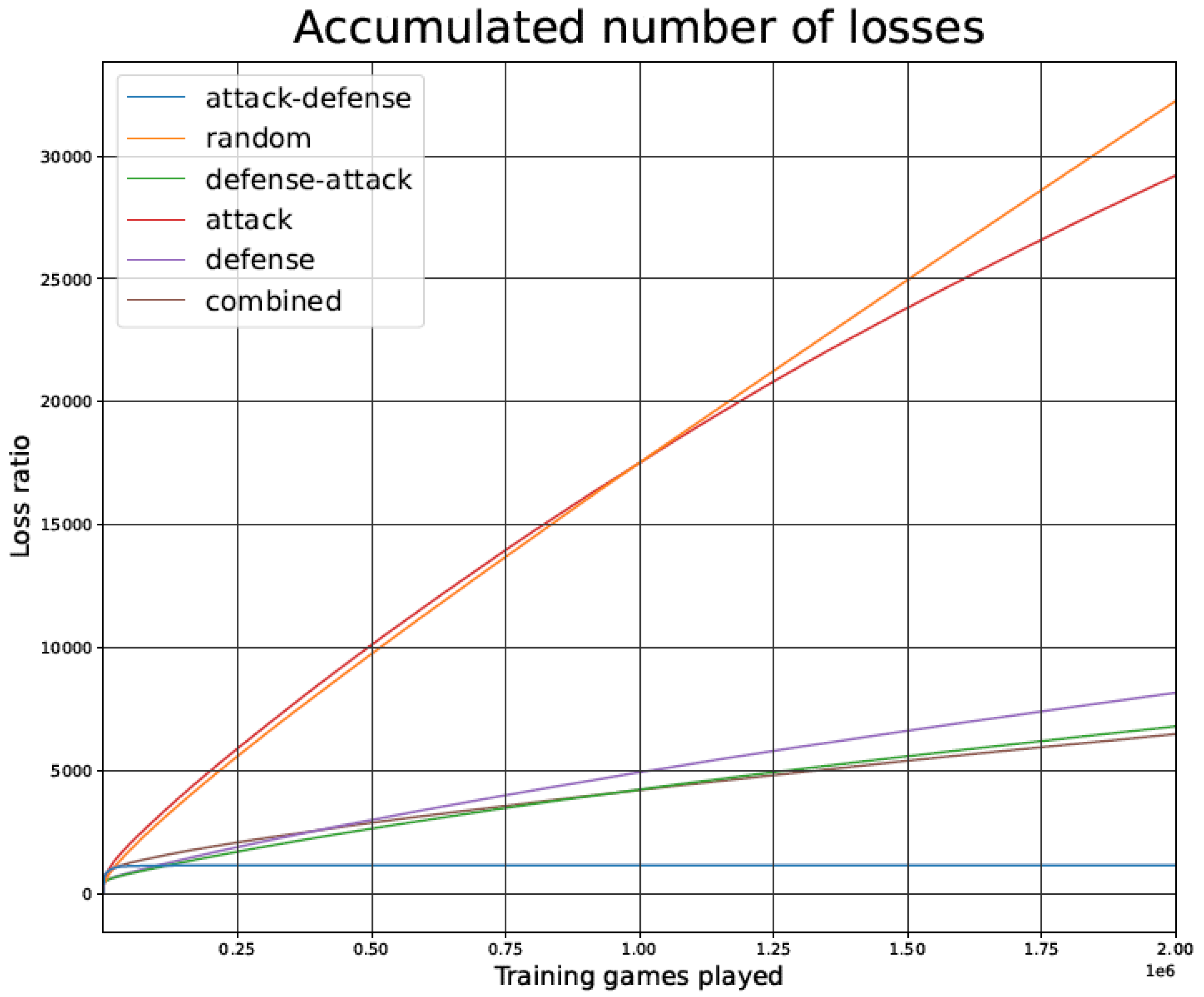
Figure 7.
Games lost by the tic-tac-toe TD agent during the training phase as a function of the number of games played, for the different training strategies.
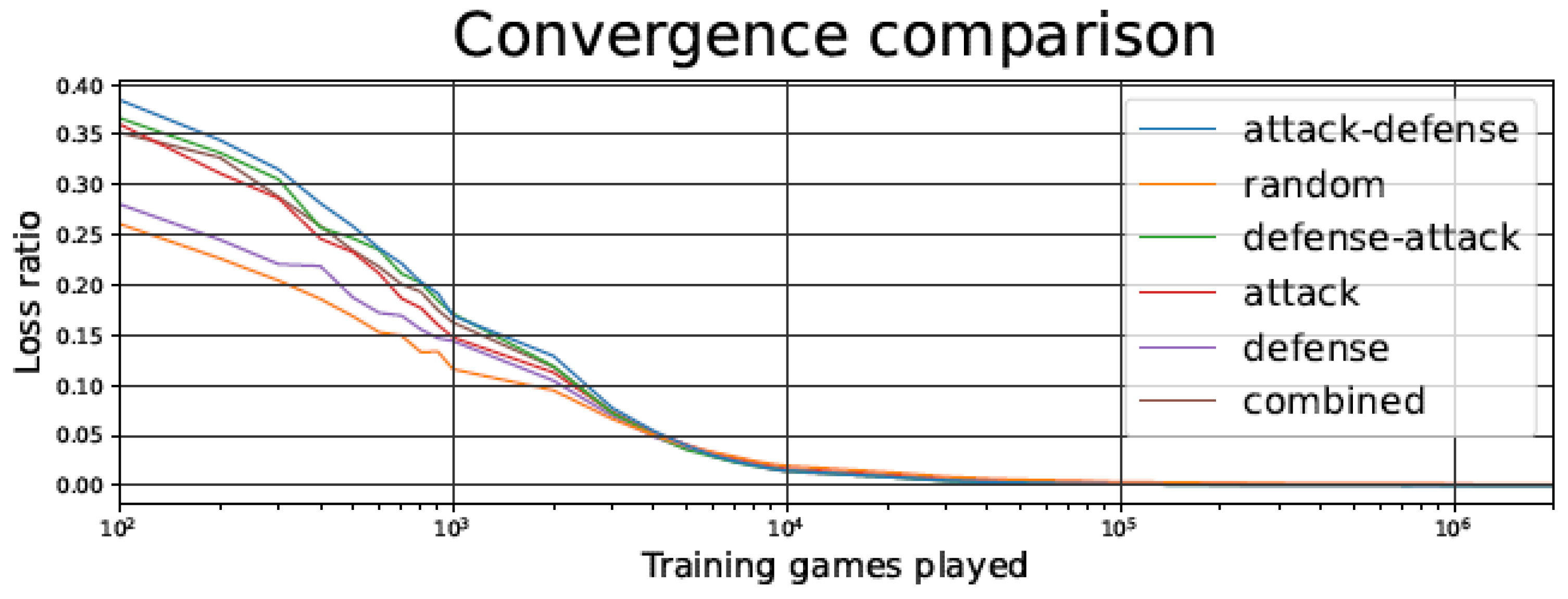
The loss ratio for the TD agent when trained using different opponents can be seen in Figure 5, for the first million training games (after that period, values are practically stable). The loss ratio is calculated by dividing the total number of games lost by the total number of games played, inside a moving 10,000-game window.
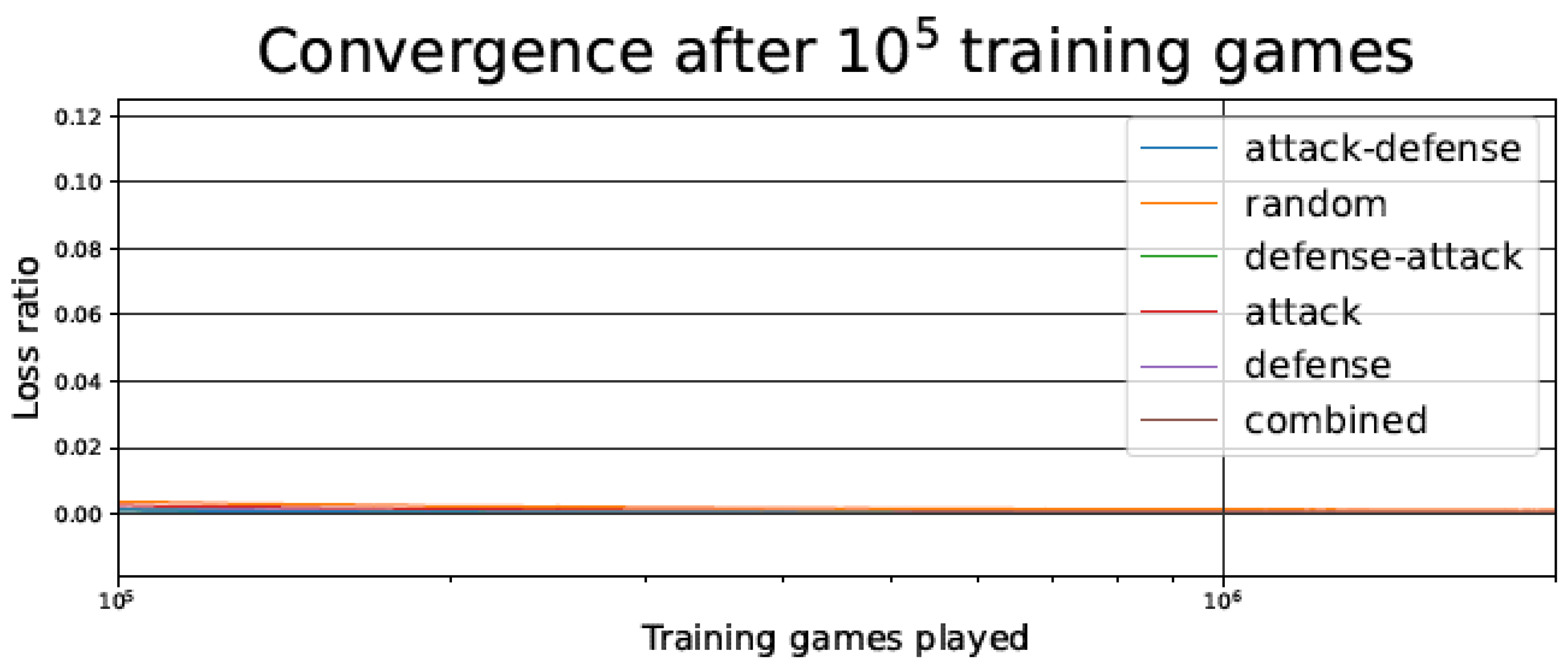
Figure 6 details an enlargement of part of Figure 5, showing the convergence of the TD learning agent for the different training strategies after 100,000 games.
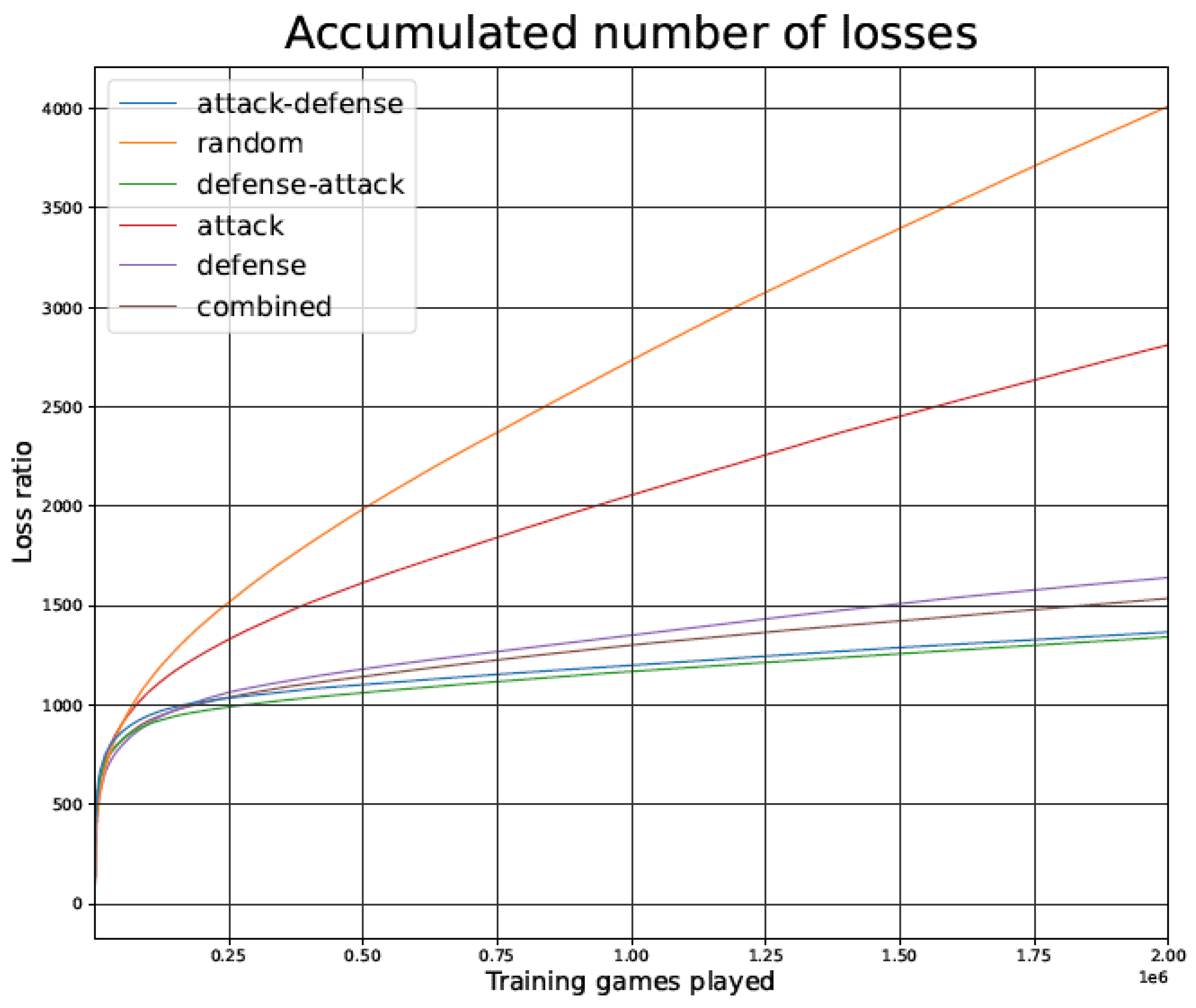
Figure 7 illustrates the total number of games lost by the TD agent during the training phase, for the different training strategies.
3.2. Tic-Tac-Toe Test Phase Results
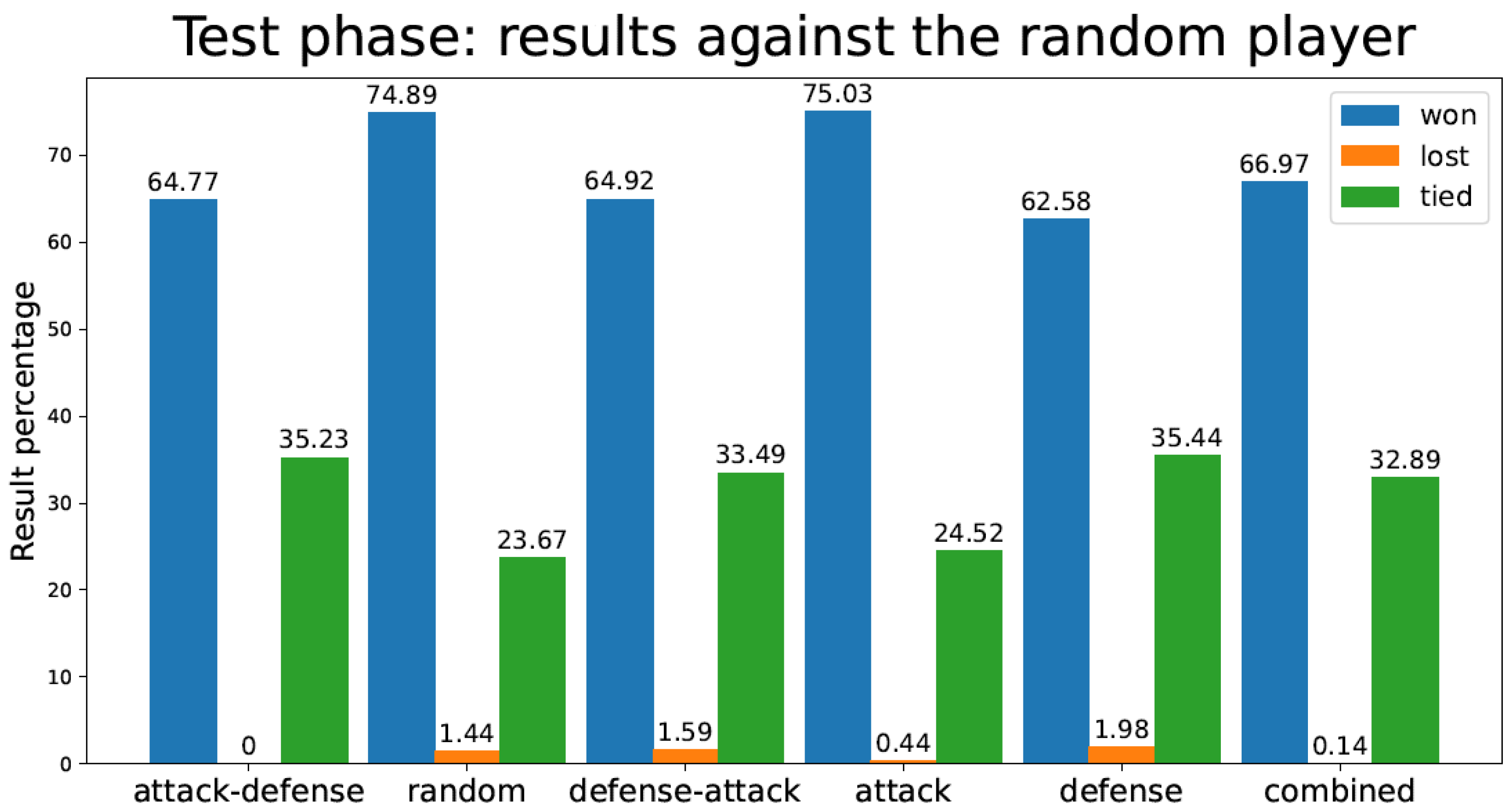
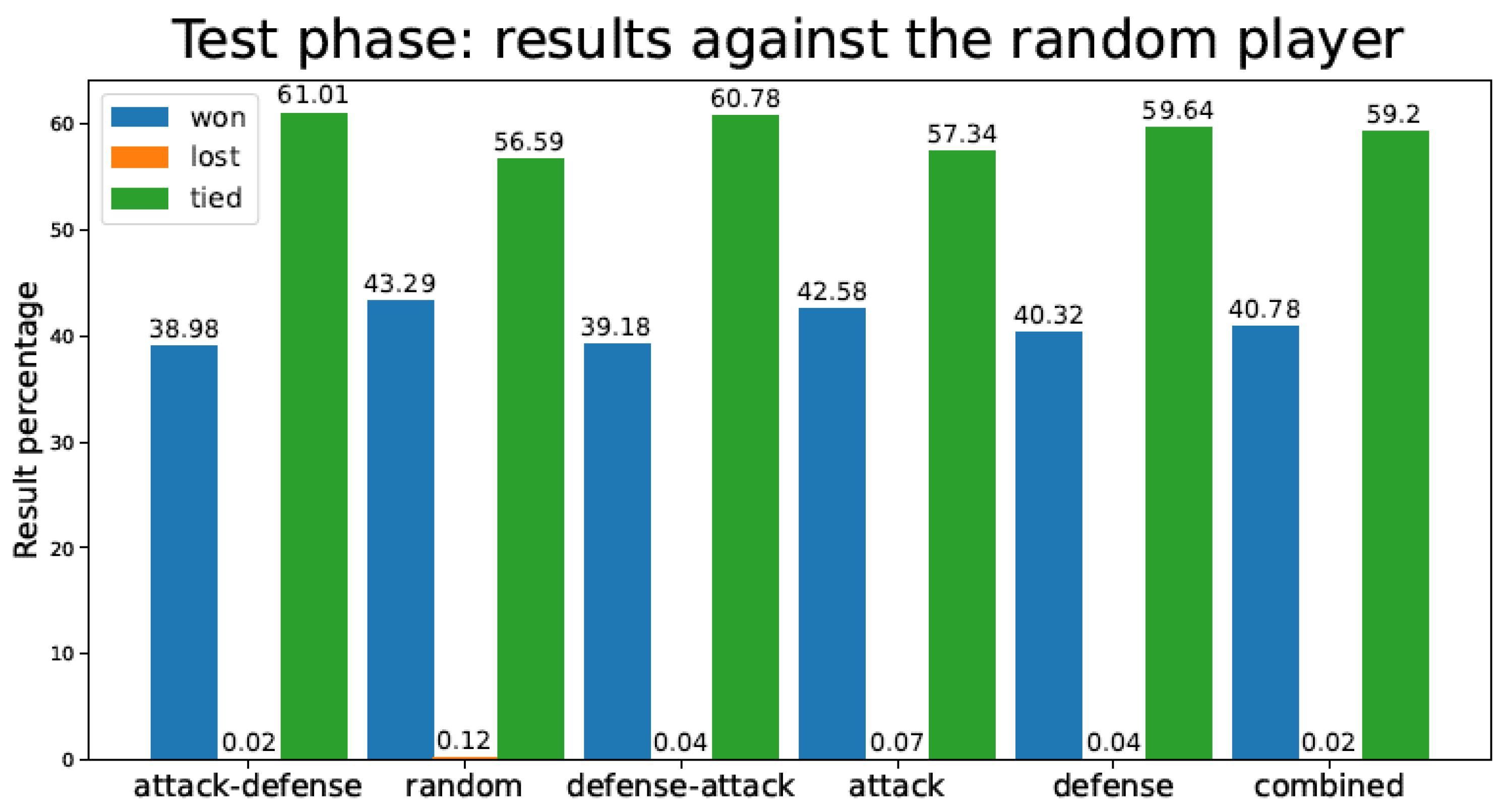
Figure 8 depicts the percentage of games lost by the TD agent in the test phase against a fully random player (after finishing the training procedure). It should be noted that in the test phase, the TD agent played 1 million games versus the random player.
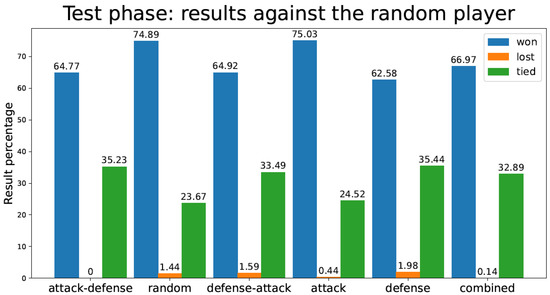
Figure 8.
Percentage of test games won/lost/tied by the tic-tac-toe TD agent playing against a random player for the different training strategies.
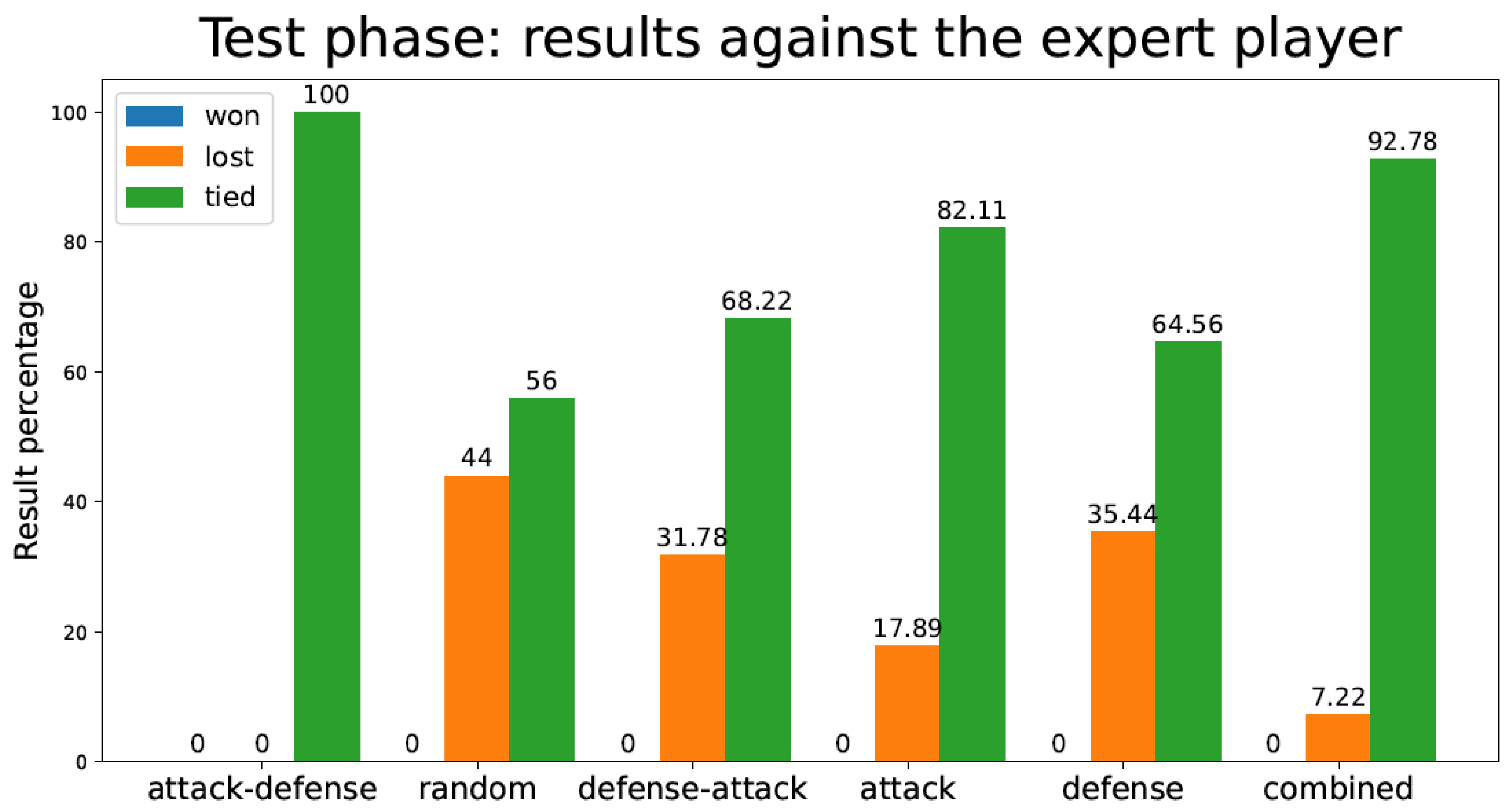
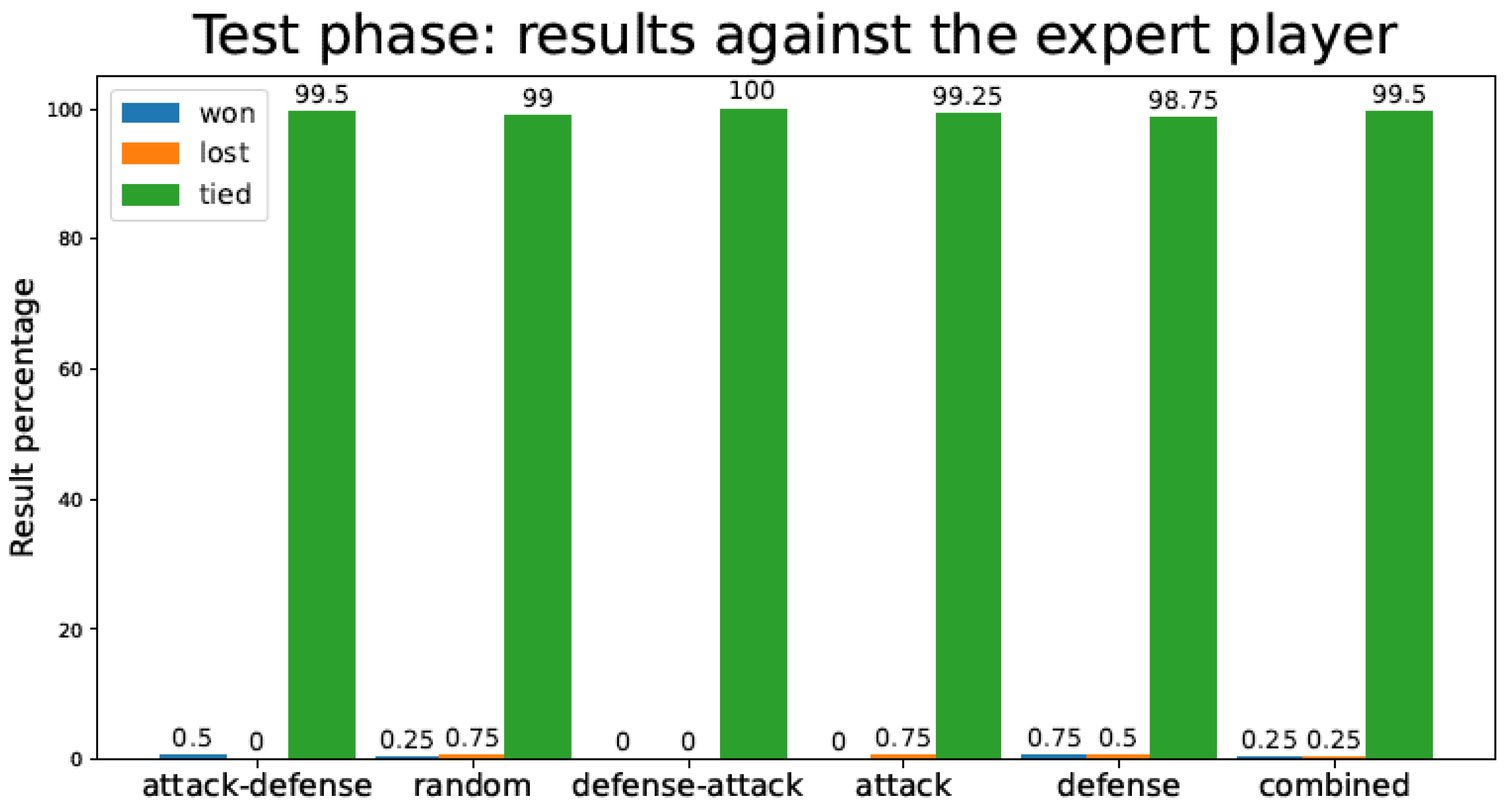
Figure 9 represents the percentage of games the TD agent lost/tied versus an expert player. As previously stated, only nine games are played in this situation, since the expert player movements are invariable.
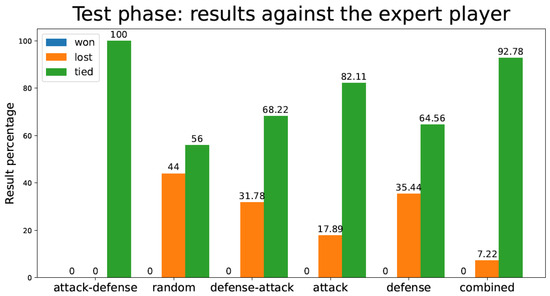
Figure 9.
Percentage of test games won/lost/tied by the tic-tac-toe TD agent playing against an expert player for the different training strategies.
3.3. Connect-4 Training Phase Results
In Figure 10, Figure 11 and Figure 12, the training phase results for the 4 × 4 Connect-4 TD learning agent are presented.
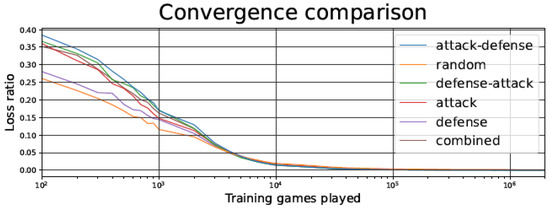
Figure 10.
Connect-4 TD agent loss ratio during the training phase as a function of the number of games played, for the different training strategies.
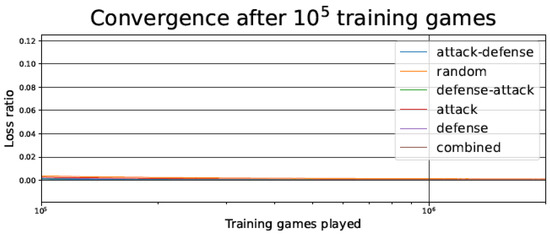
Figure 11.
Connect-4 TD agent loss ratio after 100,000 games as a function of the number of games played, for the different training strategies.
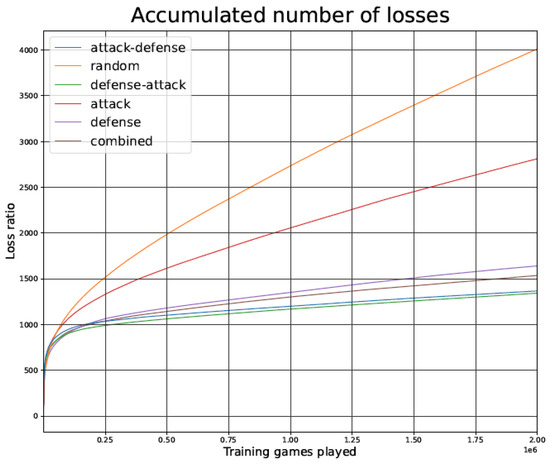
Figure 12.
Games lost by the Connect-4 TD agent during the training phase as a function of the number of games played, for the different training strategies.
3.4. Connect-4 Test Phase Results
In Figure 13 and Figure 14, we present the test phase results for the 4 × 4 Connect-4 TD learning agent.
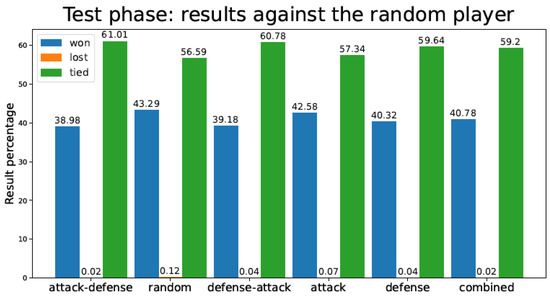
Figure 13.
Percentage of test games won/lost/tied by the Connect-4 TD agent playing against a random player for the different training strategies.
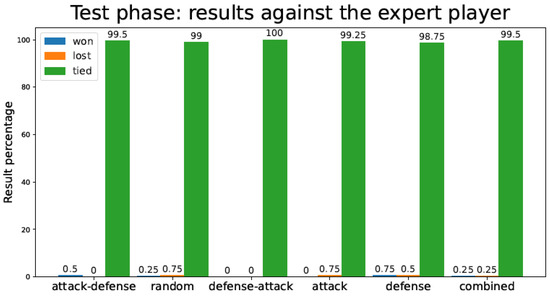
Figure 14.
Percentage of test games won/lost/tied by the Connect-4 TD agent playing against an expert player for the different training strategies.
3.5. Summary of Results
Table 1 shows quantitative results of the execution of the experiments in a personal computer with the following characteristics: Intel Core i5 10210U CPU (1.602.11GHz), 16 GB RAM, Windows 10 64-bit operating system.

Table 1.
Quantitative results in the training phase for the different strategies (average measures).
Table 2 details the percentage of simulation runs in which the TD agent becomes the perfect player (zero test games lost against both the random and expert players).
Table 2.
Percentage of simulation runs in which the TD agent becomes the perfect player.
Table 3 shows the number of test games lost by the TD agent against a random player, out of a million test games.
Table 3.
Number of test games lost by the TD agent against a random player.
Table 4 indicates the number of test games lost by the TD agent against an expert player, out of nine test games for tic-tac-toe and four games for Connect-4.
Table 4.
Number of test games lost by the TD agent against an expert player.
4. Discussion
4.1. Loss Ratio during the Training Phase
In Figure 5 and Figure 10, we observe that, despite starting with a higher loss ratio during the first games of the training process, the Attack–Defense strategy presents a faster convergence than the other alternatives considered. The rate of improvement is particularly high between 500 and 5000 games played, as indicated by the slope of the log curve in that range. As in most of the strategies, the rate of improvement undergoes a plateau after about 5000 games played, but the Attack–Defense strategy consistently achieved zero losses at about 100,000 games played (see Figure 6 and Figure 11). This is 2–4 orders of magnitude faster than the competing strategies, where the plateaus are flatter, and it would take millions of games to achieve zero losses.
Regarding the Combined strategy, it has better performance (as measured by the loss ratio) than Attack–Defense during the first 20,000 games played. However, its flatter plateau learning phase makes it keep a residual loss ratio for hundreds of thousands of games after it is surpassed by Attack–Defense.
In general, having a better loss ratio at the beginning of training is not necessarily beneficial, because it might indicate a partial absence of unpredictability in the opponent. It is essential to remark that the number of games lost during the test phase is the most relevant metric. In fact, as seen in Figure 5 and Figure 10, the Attack–Defense approach yields a higher loss ratio than the other techniques in the early stages of the training (left part of the figures, between 100 and 1000 games). However, as we will point out below, Attack–Defense exhibits better behavior throughout the test phase.
Observing the Attack–Defense strategy, when compared to the Random one, we can notice that the loss ratio is clearly worse for the Attack–Defense strategy in the initial stages of training, but after the crossover point (approximately after 2000 games), the loss ratio for the Attack–Defense strategy converges to zero, while the convergence for the Random strategy is much slower.
4.2. Games Lost during the Training Phase
As shown in Figure 7 and Figure 12, in terms of the number of games lost during the training phase, the strategies Random and Attack lose games at a higher rate than the other strategies. In contrast, the number of games lost grows at a slower pace for the other strategies (all of which include opponent defense tactics).
The Random strategy loses fewer games during the first 2000 games, but it keeps losing games long after 2 million games have been played. The marginal contribution of a vastly increased training phase is therefore very small in this strategy.
In Figure 7 (tic-tac-toe game), after around 100,000 games, it is noted that the Attack–Defense strategy entirely stops losing games. The Attack–Defense approach is able to learn perfect performance while the other strategies slowly inch towards progress but keep losing games for millions of iterations. None of the other curves show signs of approaching a flat number of losses after 2 million games have been played.
On the other hand, in Figure 12 (Connect-4 game), the Attack–Defense strategy seems to have the best convergence (along with Defense–Attack), but the curve is not completely flat.
4.3. Games Lost during the Test Phase
Figure 8, Figure 9, Figure 13, and Figure 14 show the performance of the different strategies in the test phase, after training is considered complete (Table 1 details the number of training games needed for each strategy to achieve this performance), in which the TD agent is confronted with a random player and an expert player.
In Figure 8 and Figure 9 (tic-tac-toe game), we observe how Random and Defense methods score poorly against both random and expert opponents, in terms of the number of games lost during the test phase. Attack, Attack–Defense, and Combined approaches, which include the “Attack” feature in the first place, perform substantially better against the expert player. Attack–Defense does not have as many wins as other strategies (Random, Attack) against the random player, although it yields perfect performance against the expert player. All other strategies incur losses—sometimes significant—against the expert player, despite having been trained for a much larger number of games (as seen in Table 1). An interesting observation is that the Combined strategy has slightly worse performance than Attack–Defense when playing against random and expert opponents. This relates to the sensitivity of the balance between exploration and exploitation mentioned in the first section of this document.
In Figure 13 and Figure 14 (Connect-4 game), it can be perceived that the differences among strategies are more subtle. The reason is that, because of the nature of the Connect-4 game, only four possible options are available in the first move (as opposed to eight possibilities in tic-tac-toe), and consequently it is easier for the TD agent to discover the best moves, regardless of the strategy used. Nevertheless, Attack–Defense remains the best strategy in terms of the number of games lost, both against the random and the expert players (this can be verified by checking Table 3 and Table 4).
4.4. The Attack–Defense Strategy
When playing against both random and expert opponents, the Attack–Defense approach outperforms all other proposed techniques in terms of the number of test games lost by the TD agent. Table 3 shows that out of 1 million games played against a random opponent, the TD agent trained using this approach did not lose a single tic-tac-toe game and lost only 0.0175% of the Connect-4 games played.
In addition, in Table 4 it is noticed that Attack–Defense is the only strategy capable of losing zero games against an expert player in all simulation runs, for both tic-tac-toe and Connect-4 games.
There is another important advantage in this strategy. As we perceive from the figures in Table 1, the number of training games and the time needed to complete the training phase are significantly better than those of the rest of the strategies.
About the Defense–Attack strategy, it is remarkable that its numbers are close to Attack–Defense in the Connect-4 game (we could argue that it is the second-best strategy), whereas it is one of the worse strategies for tic-tac-toe.
5. Conclusions
Several training strategies for a temporal difference learning agent, implemented as simulated opponent players with different rules, have been presented, described, created, and assessed in this study.
We have proven that if the right training method is used and a certain degree of hybridness is included in the model, the TD algorithm’s convergence may be seriously enhanced. When the Attack–Defense strategy is used, perfection is reached in the classic tic-tac-toe board game with fewer than 100,000 games of training. Previously, many millions of games were required to achieve comparable ranks in the case of obtaining convergence, according to earlier research works.
Hybrid training strategies improve the efficiency of TD learning, reducing the resources needed to be successful (execution time, memory capacity) and ultimately being more cost-effective and power-aware.
Despite being particularly easy to construct and having a low computing cost, the introduced Attack–Defense training approach (try to win; if not feasible, try not to lose; else make a random move) has shown to be extremely successful in our testing, exceeding the other choices evaluated (even the Combined option). Furthermore, a TD agent that has been taught using this approach may be deemed a perfect tic-tac-toe player, having never lost a game against both random and expert opponents.
The Attack–Defense strategy presented in this work has also proved to outperform the rest of the strategies in the 4 × 4 Connect-4 board game (four rows and four columns), which has a considerably higher number of states than the tic-tac-toe game (an upper-bound estimation being 200,000 legal states).
Future research will look into the effectiveness of hybridness and the Attack–Defense training technique in board games with a larger space-state complexity (such as Connect-4 for larger board sizes, checkers, or go).
Two of the most popular applications of reinforcement learning are game playing and control problems in robotics. The underlying concepts behind the training technique presented in this research work (confront the agent with an opponent with partial knowledge of how to win and not to lose, including a certain degree of randomness) could be generalized and applied to training robots in diverse situations, using different environments and degrees of freedom.
Author Contributions
Conceptualization, J.M.C., P.C.-J. and J.F.-C.; funding acquisition, J.M.C.; investigation, J.M.C., P.C.-J. and J.F.-C.; methodology, J.F.-C.; project administration, J.M.C.; resources, J.M.C.; software, J.F.-C.; supervision, J.M.C.; validation, J.F.-C.; visualization, P.C.-J. and J.F.-C.; writing—original draft, J.F.-C.; writing—review and editing, P.C.-J. and J.F.-C. All authors have read and agreed to the published version of the manuscript.
Funding
The research leading to these results has received funding from RoboCity2030-DIH-CM, Madrid Robotics Digital Innovation Hub, S2018/NMT-4331, funded by “Programas de Actividades I+D en la Comunidad de Madrid”, and cofunded by Structural Funds of the EU.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement Learning: A Survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; pp. 10–15, 156. [Google Scholar]
- Konen, W.; Bartz-Beielstein, T. Reinforcement learning for games: Failures and successes. In Proceedings of the 11th Annual Conference Companion on Genetic and Evolutionary Computation Conference: Late Breaking Papers, Montreal, QC, Canada, 8–12 July 2009; pp. 2641–2648. [Google Scholar]
- Samuel, A. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Tesauro, G. Temporal difference learning of backgammon strategy. In Proceedings of the 9th International Workshop on Machine Learning, San Francisco, CA, USA, 1–3 July 1992; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 1992; pp. 451–457. [Google Scholar] [CrossRef]
- Tesauro, G. Practical Issues in Temporal Difference Learning. Reinforcement Learning; Springer: Berlin/Heidelberg, Germany, 1992; pp. 33–53. [Google Scholar]
- Wiering, M.A. Self-Play and Using an Expert to Learn to Play Backgammon with Temporal Difference Learning. J. Intell. Learn. Syst. Appl. 2010, 2, 57–68. [Google Scholar] [CrossRef] [Green Version]
- Konen, W. Reinforcement Learning for Board Games: The Temporal Difference Algorithm; Technical Report; Research Center CIOP (Computational Intelligence, Optimization and Data Mining), TH Koln—Cologne University of Applied Sciences: Cologne, Germany, 2015. [Google Scholar] [CrossRef]
- Gatti, C.J.; Embrechts, M.J.; Linton, J.D. Reinforcement learning and the effects of parameter settings in the game of Chung Toi. In Proceedings of the 2011 IEEE International Conference on Systems, Man, and Cybernetics, Anchorage, AK, USA, 9–12 October 2011; pp. 3530–3535. [Google Scholar] [CrossRef]
- Gatti, C.J.; Linton, J.D.; Embrechts, M.J. A brief tutorial on reinforcement learning: The game of Chung Toi. In Proceedings of the ESANN 2011 Proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 27–29 April 2011; ISBN 978-2-87419-044-5. [Google Scholar]
- Silver, D.; Sutton, R.; Muller, M. Reinforcement learning of local shape in the game of go. Int. Jt. Conf. Artif. Intell. (IJCAI) 2007, 7, 1053–1058. [Google Scholar]
- Schraudolph, N.; Dayan, P.; Sejnowski, T. Temporal Difference Learning of Position Evaluation in the Game of Go. Adv. Neural Inf. Processing Syst. 1994, 6, 1–8. [Google Scholar]
- Van der Ree, M.; Wiering, M.A. Reinforcement learning in the game of othello: Learning against a fixed opponent and learning from self-play. In Proceedings of the 2013 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL), Singapore, 16–19 April 2013; pp. 108–115. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall Press: Upper Saddle River, NJ, USA, 2009; ISBN 0136042597/9780136042594. [Google Scholar]
- Sutton, R.S. Learning to Predict by the Methods of Temporal Differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Pool, D.; Mackworth, A. Artificial Intelligence: Foundations of Computational Agents, 2nd ed.; Cambridge University Press: Cambridge, UK, 2017. [Google Scholar]
- Szubert, M.; Jaskowski, W.; Krawiec, K. Coevolutionary temporal difference learning for Othello. In Proceedings of the Proceedings of the 5th International Conference on Computational Intelligence and Games (CIG’09), Piscataway, NJ, USA, 7 September 2009; IEEE Press: Piscataway, NJ, USA, 2009; pp. 104–111. [Google Scholar]
- Krawiec, K.; Szubert, M. Learning n-tuple networks for Othello by coevolutionary gradient search. In Proceedings of the GECCO’2011, Dublin, Ireland, 12–16 July 2011; ACM: New York, NY, USA, 2011; pp. 355–362. [Google Scholar]
- Lucas, S.M. Learning to play Othello with n-tuple systems. Aust. J. Intell. Inf. Process. 2008, 4, 1–20. [Google Scholar]
- Thill, M.; Bagheri, S.; Koch, P.; Konen, W. Temporal Difference Learning with Eligibility Traces for the Game Connect-4. In Proceedings of the IEEE Conference on Computational Intelligence and Games (CIG), Dortmund, Germany, 26–29 August 2014. [Google Scholar]
- Steeg, M.; Drugan, M.; Wiering, M. Temporal Difference Learning for the Game Tic-Tac-Toe 3D: Applying Structure to Neural Networks. In Proceedings of the 2015 IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 8–10 December 2015; pp. 564–570. [Google Scholar] [CrossRef] [Green Version]
- Fernández-Conde, J.; Cuenca-Jiménez, P.; Cañas, J.M. An Efficient Training Strategy for a Temporal Difference Learning Based Tic-Tac-Toe Automatic Player. In Inventive Computation Technologies, International Conference on Inventive Computation Technologies ICICIT 2019, Coimbatore, India, 29–30 August 2019; Lecture Notes in Networks and Systems; Smys, S., Bestak, R., Rocha, Á., Eds.; Springer: Cham, Switzerland, 2019; Volume 98. [Google Scholar] [CrossRef]
- Baum, P. Tic-Tac-Toe. Master’s Thesis, Computer Science Department, Southern Illinois University, Carbondale, IL, USA, 1975. [Google Scholar]
- Crowley, K.; Siegler, R.S. Flexible strategy use in young children’s tic-tac-toe. Cogn. Sci. 1993, 17, 531–561. [Google Scholar] [CrossRef]
- Allen, J.D. A Note on the Computer Solution of Connect-Four. Heuristic Program. Artif. Intell. 1989, 1, 134–135. [Google Scholar]
- Allis, V.L. A Knowledge-Based Approach of Connect-Four. Master’s Thesis, Vrije Universiteit, Amsterdam, The Netherlands, 1988. [Google Scholar]
- Tromp, J. Solving Connect-4 in Medium Board Sizes. ICGA J. 2008, 31, 110–112. [Google Scholar] [CrossRef]
- Swaminathan, B.; Vaishali, R.; Subashri, R. Analysis of Minimax Algorithm Using Tic-Tac-Toe. In Intelligent Systems and Computer Technology; Hemanth, D.J., Kumar, V.D.A., Malathi, S., Eds.; IOS Press: Amsterdam, The Netherlands, 2020. [Google Scholar] [CrossRef]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).