
Hybrid Differential Evolution-Based Regression Tree Model for Predicting Downstream Dam Hazard Potential




Abstract
:1. Introduction
- To devise a hybrid differential evolution-based regression tree model for predicting the hazard potential of dams;
- To validate the developed dam hazard potential prediction model against a set of widely acknowledged machine learning and deep learning models using performance evaluation comparisons.
2. Literature Review
3. Research Framework
- Identifying the optimum subset of influential spatial features that significantly implicate downstream dam hazard potential;
- Amplifying the prediction accuracies of regression tree through the automated optimization of its hyper parameters.
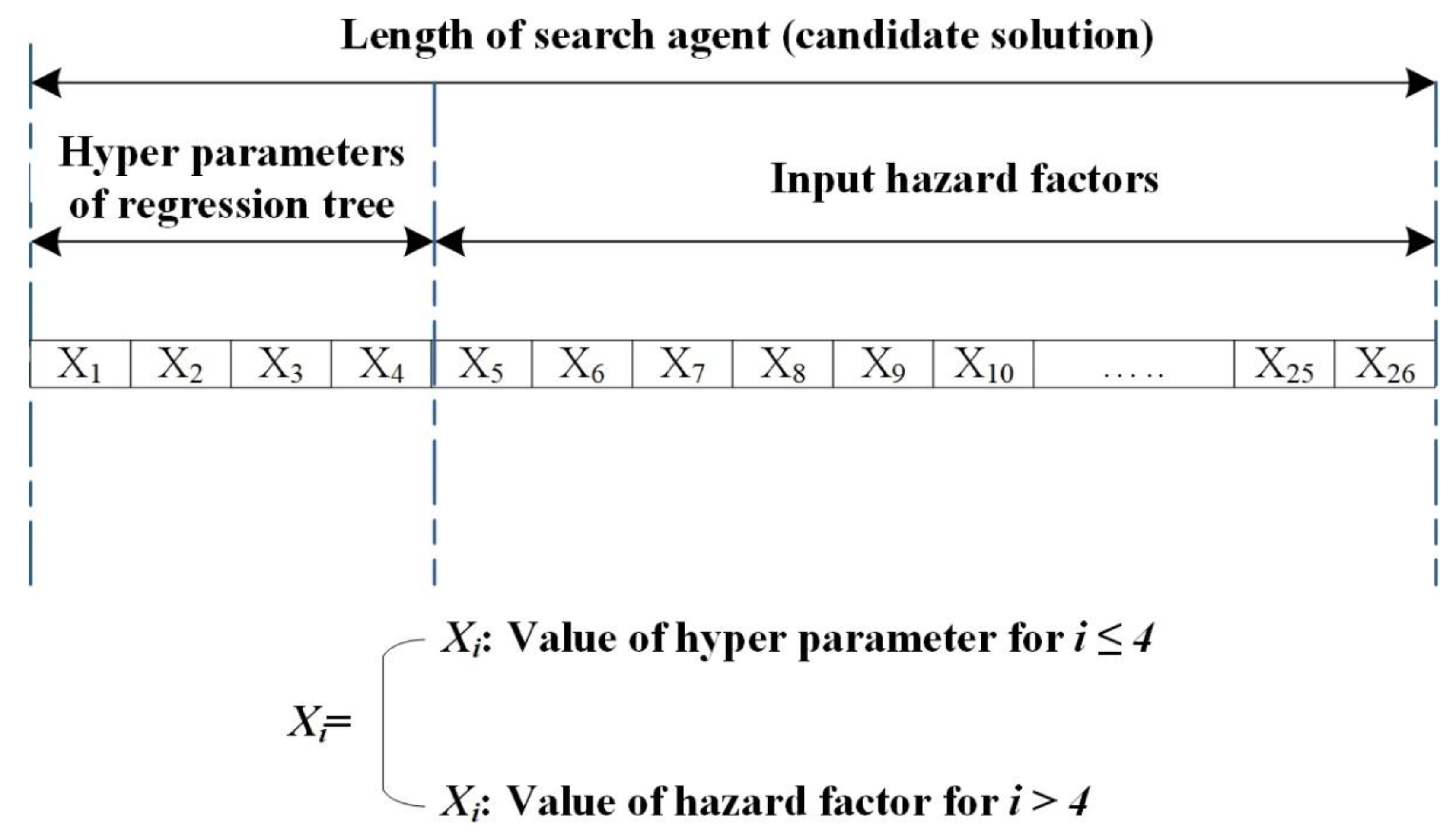
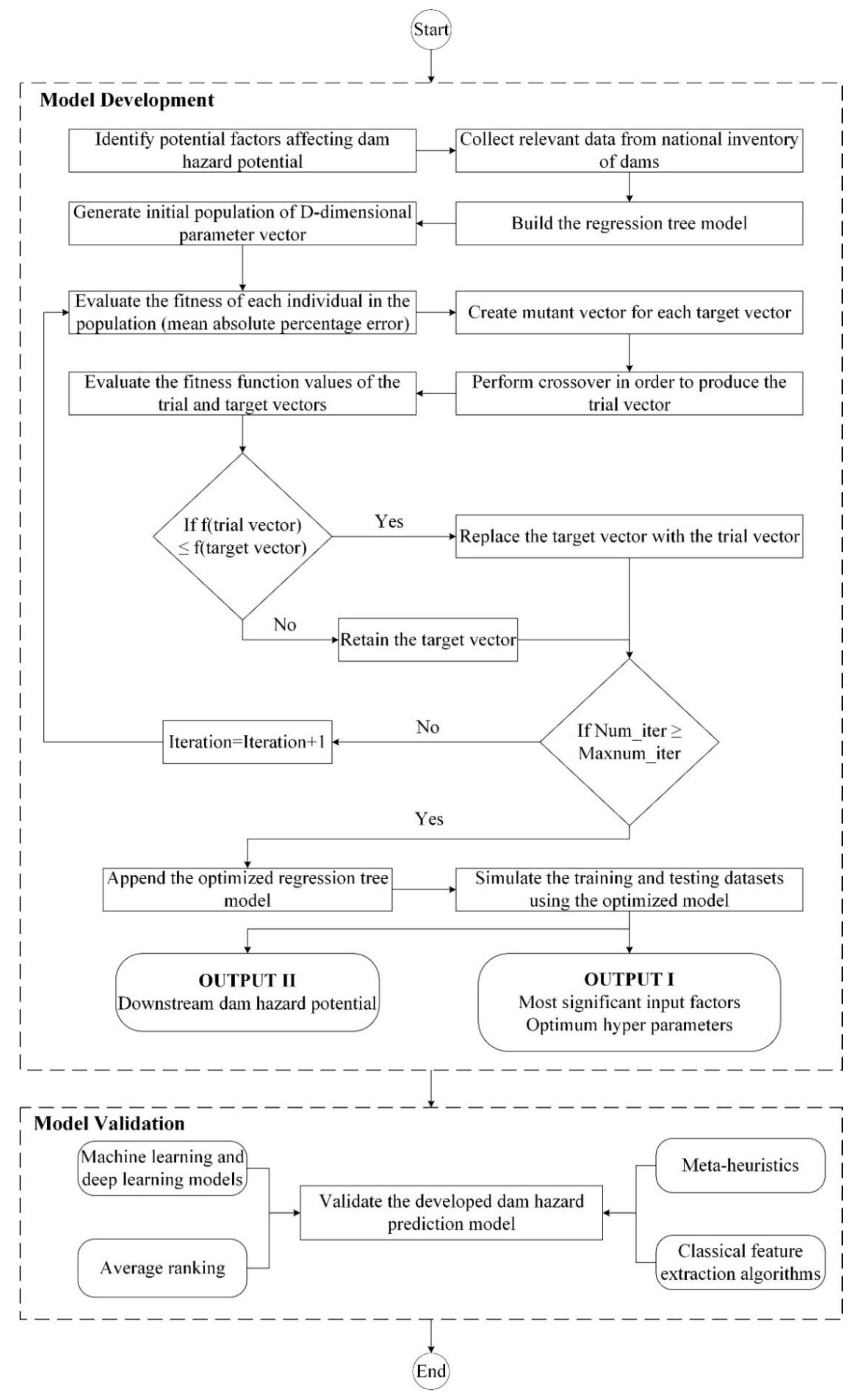
4. Model Development
4.1. Differential Evolution
4.2. Automated Training of Regression Tree
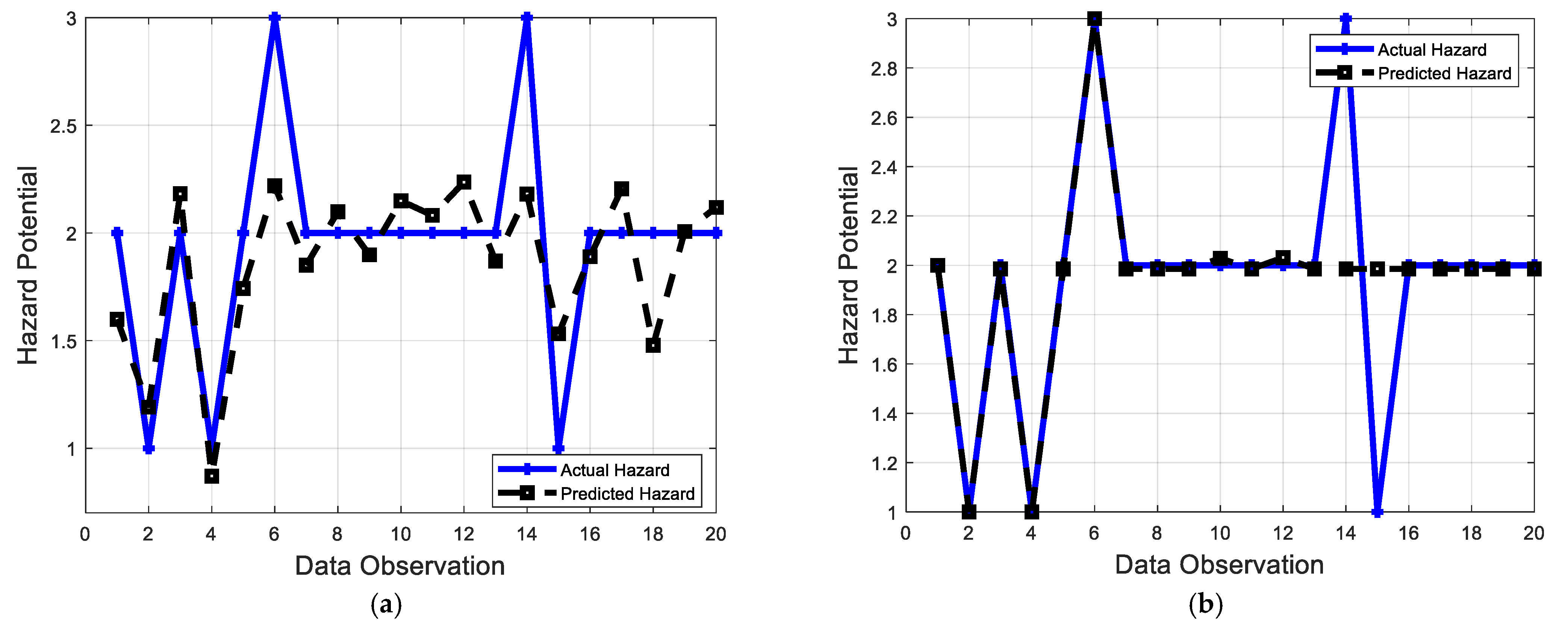
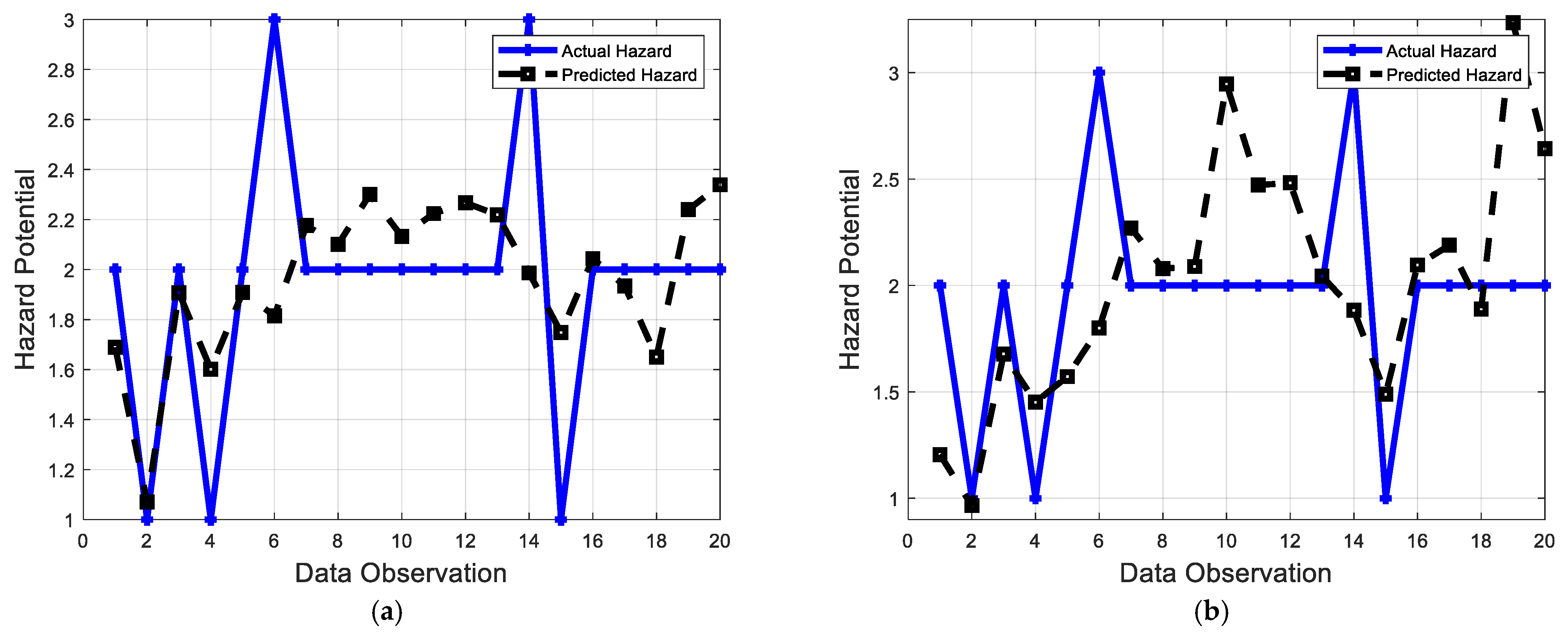
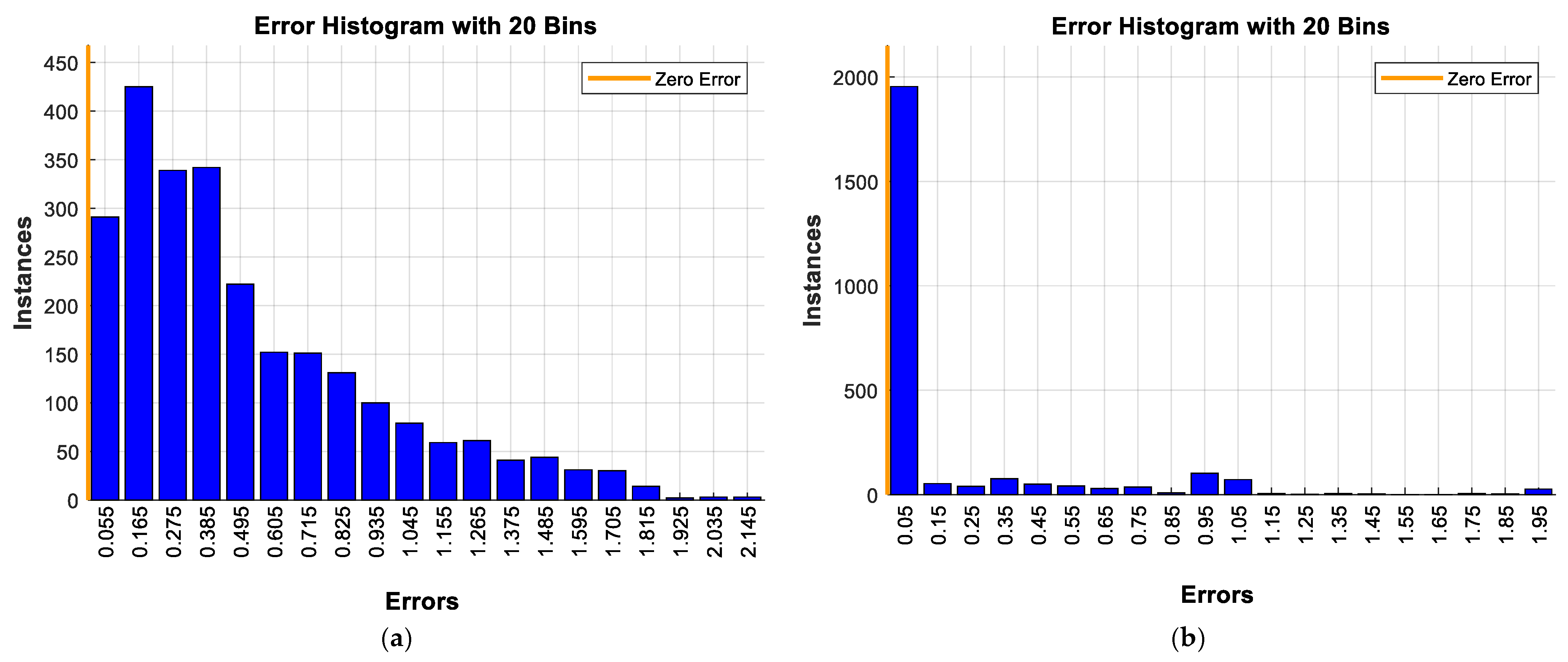
5. Performance Evaluation Metrics
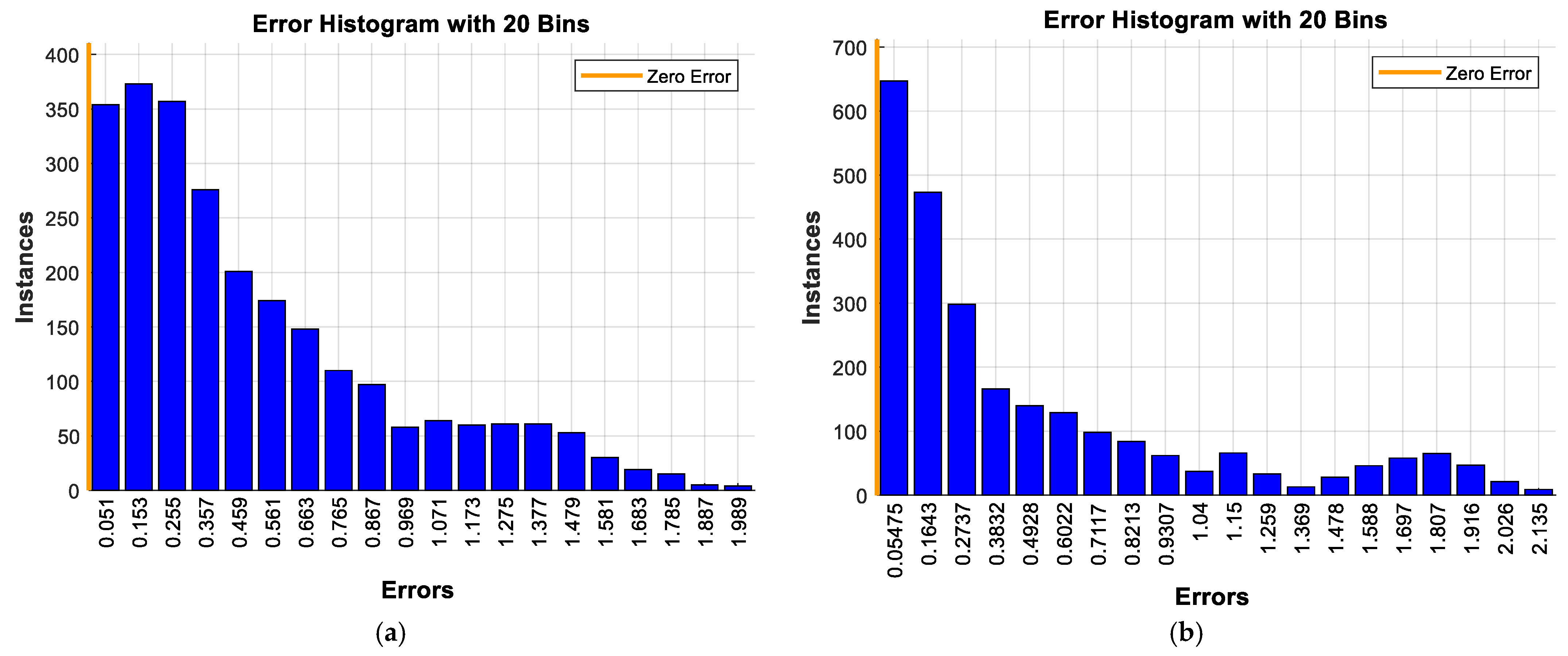
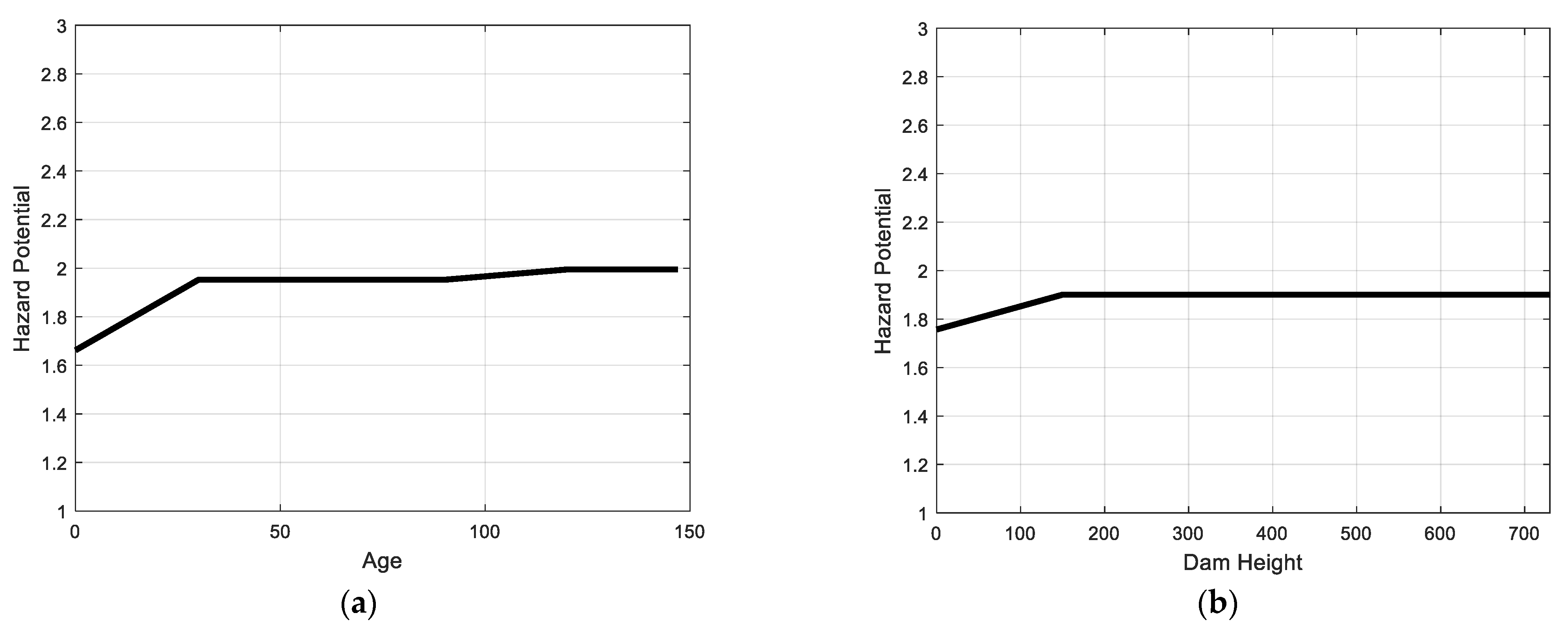
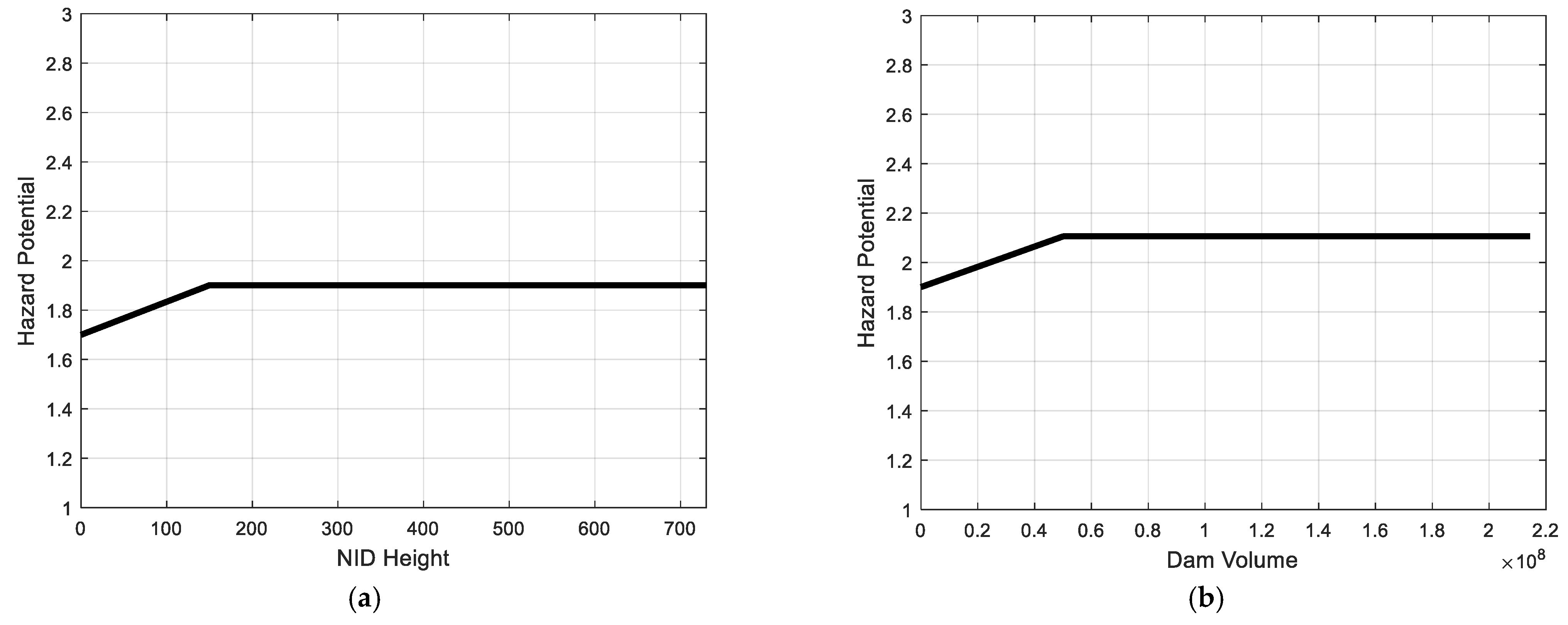
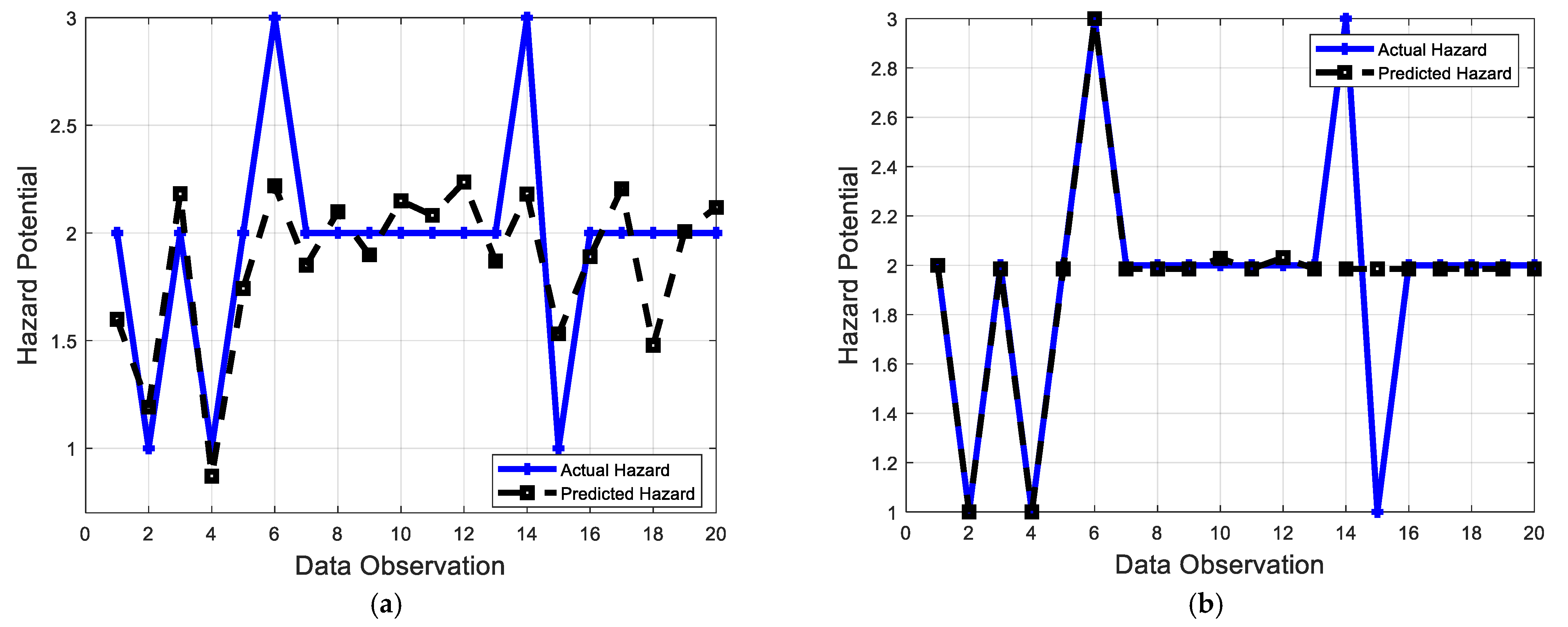
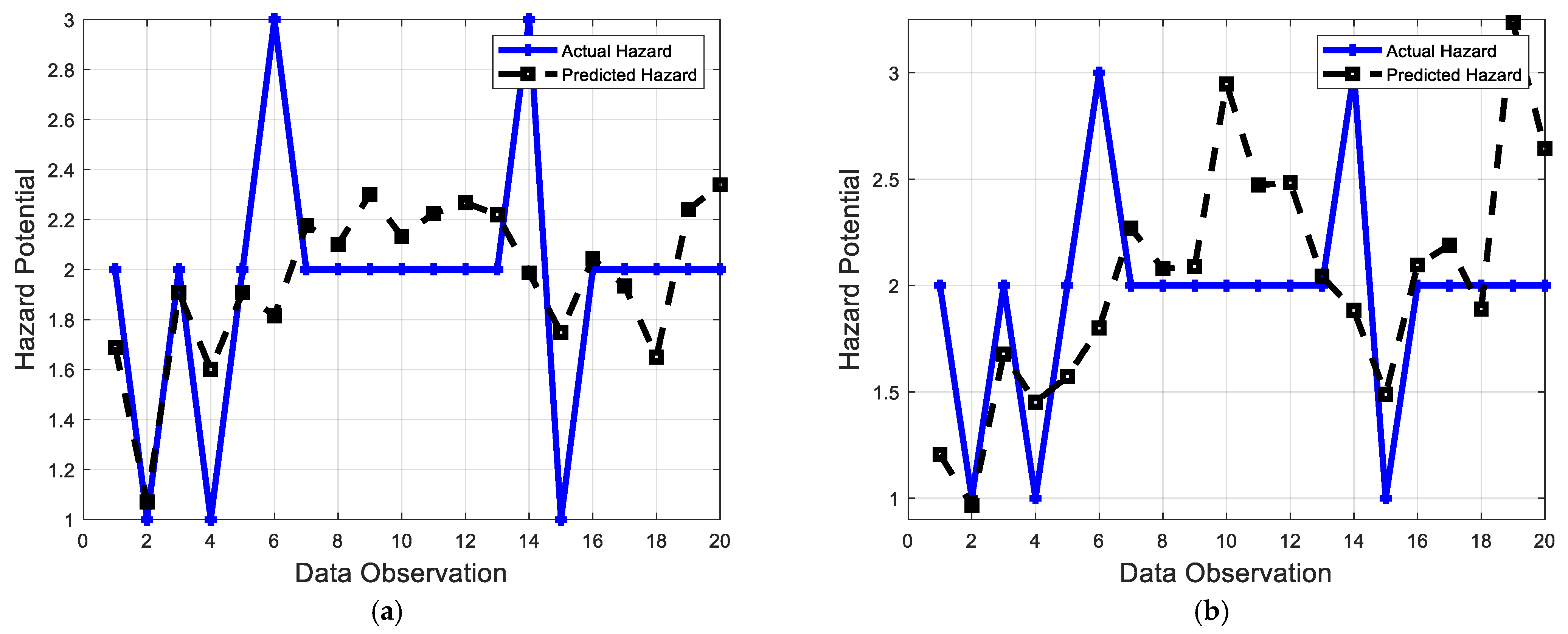
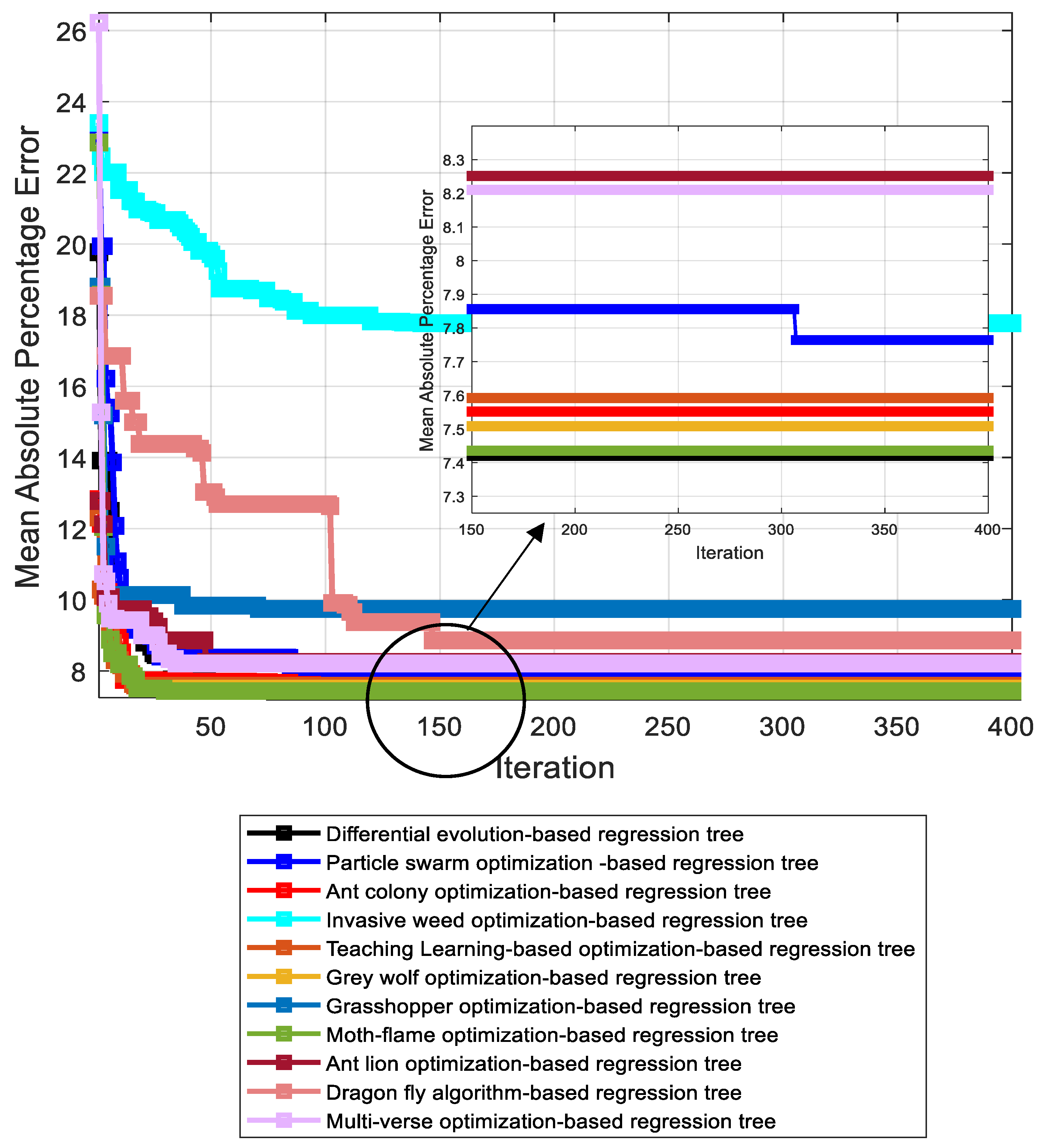
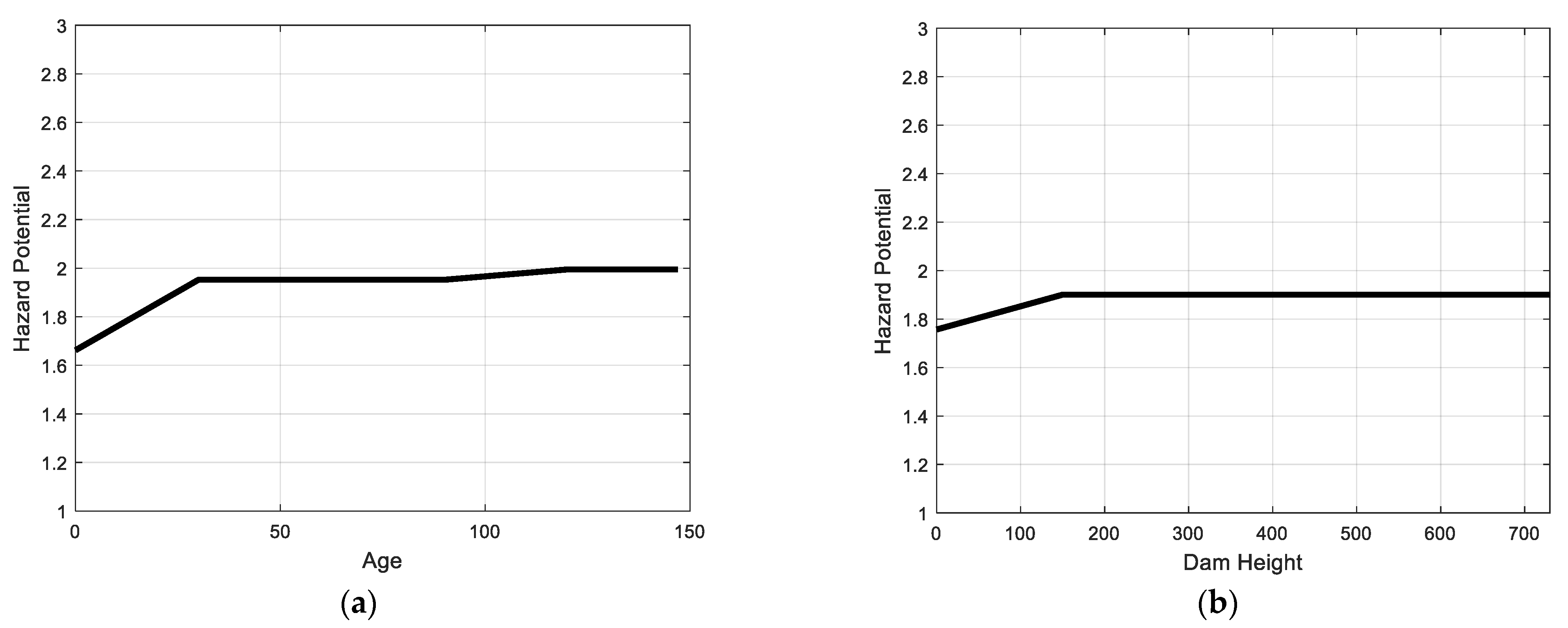
6. Model Implementation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, H.; Chen, J.; Liu, S.; Sivakumar, B. The Role of Large Dams in Promoting Economic Development under the Pressure of Population Growth. Sustainability 2019, 11, 2965. [Google Scholar] [CrossRef] [Green Version]
- United States Army Corps of Engineers. National Inventory of Dams. 2020. Available online: https://nid.usace.army.mil/#/ (accessed on 26 January 2022).
- American Society of Civil Engineers. Report Card for American Infrastructure. 2021. Available online: https://infrastructurereportcard.org/ (accessed on 26 January 2022).
- Mehta, A.M.; Weeks, C.S.; Tyquin, E. Towards preparedness for dam failure: An evidence base for risk communication for downstream communities. Int. J. Disaster Risk Reduct. 2020, 50, 101820. [Google Scholar] [CrossRef]
- Koppe, J.C. Lessons Learned from the Two Major Tailings Dam Accidents in Brazil. Mine Water Environ. 2020, 40, 166–173. [Google Scholar] [CrossRef]
- Perera, D.; North, T. The Socio-Economic Impacts of Aged-Dam Removal: A Review. J. Geosci. Environ. Prot. 2021, 9, 62–78. [Google Scholar] [CrossRef]
- Vahedifard, F.; Madani, K.; AghaKouchak, A.; Thota, S.K. Are we ready for more dam removals in the United States? Environ. Res. Infrastruct. Sustain. 2021, 1, 1–6. [Google Scholar] [CrossRef]
- Güven, A.; Aydemir, A. Dam Safety. In Risk Assessment of Dams; Springer: Berlin/Heidelberg, Germany, 2020; pp. 15–49. [Google Scholar]
- Pisaniello, J.D.; Dam, T.T.; Tingey-Holyoak, J.L. International small dam safety assurance policy benchmarks to avoid dam failure flood disasters in developing countries. J. Hydrol. 2015, 531, 1141–1153. [Google Scholar] [CrossRef]
- Adamo, N.; Al-Ansari, N.; Sissakian, V.; Laue, J.; Knutsson, S. Dam Safety and Dams Hazards. J. Earth Sci. Geotech. Eng. 2020, 10, 23–40. [Google Scholar]
- Burk, R.A.; Kallberg, J. Cyber Defense as a part of Hazard Mitigation: Comparing High Hazard Potential Dam Safety Programs in the United States and Sweden. J. Homel. Secur. Emerg. Manag. 2016, 13, 77–94. [Google Scholar] [CrossRef]
- American Society of Civil Engineers. Senate Appropriators Fund High Hazard Dam Rehab Program. 2020. Available online: https://infrastructurereportcard.org/senate-appropriators-fund-high-hazard-dam-rehab-program/ (accessed on 24 January 2022).
- Assad, A.; Bouferguene, A. Data Mining Algorithms for Water Main Condition Prediction—Comparative Analysis. J. Water Resour. Plan. Manage 2022, 148, 04021101. [Google Scholar] [CrossRef]
- Li, X.; Khademi, F.; Liu, Y.; Akbari, M.; Wang, C.; Bond, P.L.; Keller, J.; Jiang, G. Evaluation of data-driven models for predicting the service life of concrete sewer pipes subjected to corrosion. J. Environ. Manag. 2019, 234, 431–439. [Google Scholar] [CrossRef] [PubMed]
- Choi, S.; Do, M. Development of the Road Pavement Deterioration Model Based on the Deep Learning Method. Electronics 2019, 9, 3. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.; Nam, M.; Hwang, H.; Ann, K. Prediction of Remaining Life for Bridge Decks Considering Deterioration Factors and Propose of Prioritization Process for Bridge Deck Maintenance. Sustainability 2020, 12, 10625. [Google Scholar] [CrossRef]
- Hassan, S.; Elwakil, E. Operational Based Stochastic Cluster Regression-Based Modeling for Predicting Condition Rating of Highway Tunnels. Can. J. Civ. Eng. 2021, 48, 77–94. [Google Scholar] [CrossRef]
- Xue, D.; Duan, Y.; Meng, W. Computer Intelligent Comprehensive Rapid Risk Assessment System of Barrier Dam by Fuzzy Analytic Hierarchy Process and Big Data. J. Phys. Conf. Ser. 2021, 2083, 042046. [Google Scholar] [CrossRef]
- Daud, N.M.; Hassan, S.H.; Akbar, N.A.; Bakar, A.A.A.; Mohamad, N.A.S.; Manan, E.A.; Hamzah, A.F. Dam failure risk factor analysis using AHP method. IOP Conf. Ser. Earth Environ. Sci. 2021, 646, 012042. [Google Scholar] [CrossRef]
- Guetz, K.; Joyal, T.; Dickson, B.; Perry, D. Prioritizing dams for removal to advance restoration and conservation efforts in the western United States. Restor. Ecol. 2021, e13583. [Google Scholar] [CrossRef]
- Celik, E.; Gul, M. Hazard identification, risk assessment and control for dam construction safety using an integrated BWM and MARCOS approach under interval type-2 fuzzy sets environment. Autom. Constr. 2021, 127, 103699. [Google Scholar] [CrossRef]
- He, G.; Chai, J.; Qin, Y.; Xu, Z.; Li, S. Coupled Model of Variable Fuzzy Sets and the Analytic Hierarchy Process and its Application to the Social and Environmental Impact Evaluation of Dam Breaks. Water Resour. Manag. 2020, 34, 2677–2697. [Google Scholar] [CrossRef]
- Ribas, J.R.; Severo, J.C.R.; Guimarães, L.F.; Perpetuo, K.P.C. A fuzzy FMEA assessment of hydroelectric earth dam failure modes: A case study in Central Brazil. Energy Rep. 2021, 7, 4412–4424. [Google Scholar] [CrossRef]
- Lu, X.; Pei, L.; Chen, J.; Wu, Z.; Chen, C. Research and Application of a Seismic Damage Classification Method of Concrete Gravity Dams Using Displacement in the Crest. Appl. Sci. 2020, 10, 4134. [Google Scholar] [CrossRef]
- Li, Z.; Wu, Z.; Lu, X.; Zhou, J.; Chen, J.; Liu, L.; Pei, L. Efficient seismic risk analysis of gravity dams via screening of intensity measures and simulated non-parametric fragility curves. Soil Dyn. Earthq. Eng. 2021, 152, 107040. [Google Scholar] [CrossRef]
- Irinyemi, S.A.; Lombardi, D.; Ahmad, S.M. Correction to: Seismic risk analysis for large dams in West Coast basin, southern Ghana. J. Seism. 2022, 26, 117. [Google Scholar] [CrossRef]
- De Mello, A.R.; Barbosa, F.G.O.; Fonseca, M.L.; Smiderle, C.D. Concrete Dam Inspection with UAV Imagery and DCNN-based Object Detection. In Proceedings of the IEEE International Conference on Imaging Systems and Techniques (IST), New York, NY, USA, 24–26 August 2021; pp. 1–6. [Google Scholar]
- Feng, C.; Zhang, H.; Wang, H.; Wang, S.; Li, Y. Automatic Pixel-Level Crack Detection on Dam Surface Using Deep Convolutional Network. Sensors 2020, 20, 2069. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, D.; Tang, L.; Ye, F.; Chen, C. A virtual geographic environment for dynamic simulation and analysis of tailings dam failure. Int. J. Digit. Earth 2021, 14, 1194–1212. [Google Scholar] [CrossRef]
- Hu, L.; Yang, X.; Li, Q.; Li, S. Numerical Simulation and Risk Assessment of Cascade Reservoir Dam-Break. Water 2020, 12, 1730. [Google Scholar] [CrossRef]
- Huang, J.; Sun, W.; Huang, L. Deep neural networks compression learning based on multiobjective evolutionary algorithms. Neurocomputing 2019, 378, 260–269. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, L.; Lim, C.P. Evolving CNN-LSTM Models for Time Series Prediction Using Enhanced Grey Wolf Optimizer. IEEE Access 2020, 8, 161519–161541. [Google Scholar] [CrossRef]
- Federal Emergency Management Agency. The National Dam Safety Program; Federal Emergency Management Agency: Washington, DC, USA, 2016. [Google Scholar]
- United States Department of Homeland Security. Dams Sector-Specific Plan—An Annex to the National Infrastructure Protection Plan; United States Department of Homeland Security: Washington, DC, USA, 2010. [Google Scholar]
- United States Army Corps of Engineers. National Inventory of Dams: Methodology; United States Army Corps of Engineers: Norfolk, VA, USA, 2008. [Google Scholar]
- Federal Emergency Management Agency. Federal Guidelines for Dam Safety: Hazard Potential Classification System for Dams; U.S. Department of Homeland Security: Washington, DC, USA, 2004.
- Huang, M.; Lei, Y.; Li, X.; Gu, J. Damage Identification of Bridge Structures Considering Temperature Variations-Based SVM and MFO. J. Aerosp. Eng. 2021, 34, 04020113. [Google Scholar] [CrossRef]
- Milajerdi, B.M.; Behnamfar, F. Soil-structure interaction analysis using neural networks optimised by genetic algorithm. Geomech. Geoengin. 2021, 1–19. [Google Scholar] [CrossRef]
- Diop, L.; Samadianfard, S.; Bodian, A.; Yaseen, Z.M.; Ghorbani, M.A.; Salimi, H. Annual Rainfall Forecasting Using Hybrid Artificial Intelligence Model: Integration of Multilayer Perceptron with Whale Optimization Algorithm. Water Resour. Manage. 2020, 34, 733–746. [Google Scholar] [CrossRef]
- Elbaz, K.; Shen, S.-L.; Sun, W.-J.; Yin, Z.-Y.; Zhou, A. Prediction Model of Shield Performance During Tunneling via Incorporating Improved Particle Swarm Optimization Into ANFIS. IEEE Access 2020, 8, 39659–39671. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Pandit, R.K.; Infield, D. SCADA based nonparametric models for condition monitoring of a wind turbine. J. Eng. 2019, 2019, 4723–4727. [Google Scholar] [CrossRef]
- Crespo-Peremarch, P.; Ruiz, L.; Balaguer-Beser, A. A comparative study of regression methods to predict forest structure and canopy fuel variables from LiDAR full-waveform data. Revista de Teledetección 2016, 45, 27–40. [Google Scholar] [CrossRef] [Green Version]
- Aertsen, W.; Kint, V.; van Orshoven, J.; Özkan, K.; Muys, B. Comparison and ranking of different modelling techniques for prediction of site index in Mediterranean mountain forests. Ecol. Model. 2010, 221, 1119–1130. [Google Scholar] [CrossRef]
- Sun, G.; Li, C.; Deng, L. An adaptive regeneration framework based on search space adjustment for differential evolution. Neural Comput. Appl. 2021, 33, 9503–9519. [Google Scholar] [CrossRef]
- Sun, X.; Lin, K.; Jiao, P.; Lu, H. Signal Timing Optimization Model Based on Bus Priority. Information 2020, 11, 325. [Google Scholar] [CrossRef]
- Gao, S.; Wang, K.; Tao, S.; Jin, T.; Dai, H.; Cheng, J. A state-of-the-art differential evolution algorithm for parameter estimation of solar photovoltaic models. Energy Convers. Manag. 2021, 230, 113784. [Google Scholar] [CrossRef]
- Luong, D.-L.; Tran, D.-H.; Nguyen, P.T. Optimizing multi-mode time-cost-quality trade-off of construction project using opposition multiple objective difference evolution. Int. J. Constr. Manag. 2018, 21, 271–283. [Google Scholar] [CrossRef]
- Rabaza, O.; Gómez-Lorente, D.; Pozo, A.M.; Pérez-Ocón, F. Application of a Differential Evolution Algorithm in the Design of Public Lighting Installations Maximizing Energy Efficiency. Leukos 2019, 16, 217–227. [Google Scholar] [CrossRef]
- Kamal, M.; Inel, M. Optimum Design of Reinforced Concrete Continuous Foundation Using Differential Evolution Algorithm. Arab. J. Sci. Eng. 2019, 44, 8401–8415. [Google Scholar] [CrossRef]
- Chikahiro, Y.; Ario, I.; Pawlowski, P.; Graczykowski, C.; Holnicki-Szulc, J. Optimization of reinforcement layout of scissor-type bridge using differential evolution algorithm. Comput. Civ. Infrastruct. Eng. 2018, 34, 523–538. [Google Scholar] [CrossRef]
- Yang, W.; Wang, K.; Zuo, W. Neighborhood Component Feature Selection for High-Dimensional Data. J. Comput. 2012, 7, 161–168. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. The Feature Selection Problem: Traditional Methods and a New Algorithm. In Proceedings of the Tenth National Conference on Artificial Intelligence (AAAI-92), San Jose, CA, USA, 12–16 July 1992; pp. 129–134. [Google Scholar]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and Empirical Analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef] [Green Version]
- Storn, R.; Price, K. Differential Evolution—A simple and efficient adaptive scheme for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Tang, Z.; Hu, X.; Périaux, J. Multi-level Hybridized Optimization Methods Coupling Local Search Deterministic and Global Search Evolutionary Algorithms. Arch. Comput. Methods Eng. 2019, 27, 939–975. [Google Scholar] [CrossRef]
- Örkcü, H.H.; Aksoy, E.; Dogan, M.I. Estimating the parameters of 3-p Weibull distribution through differential evolution. Appl. Math. Comput. 2015, 251, 211–224. [Google Scholar] [CrossRef]
- Chen, L.; Yan, H.; Yan, J.; Wang, J.; Tao, T.; Xin, K.; Li, S.; Pu, Z.; Qiu, J. Short-term water demand forecast based on automatic feature extraction by one-dimensional convolution. J. Hydrol. 2022, 606, 127440. [Google Scholar] [CrossRef]
- Jalal, F.E.; Xu, Y.; Iqbal, M.; Javed, M.F.; Jamhiri, B. Predictive modeling of swell-strength of expansive soils using artificial intelligence approaches: ANN, ANFIS and GEP. J. Environ. Manag. 2021, 289, 112420. [Google Scholar] [CrossRef] [PubMed]
- Pandey, M.; Jamei, M.; Karbasi, M.; Ahmadianfar, I.; Chu, X. Prediction of Maximum Scour Depth near Spur Dikes in Uniform Bed Sediment Using Stacked Generalization Ensemble Tree-Based Frameworks. J. Irrig. Drain. Eng. 2021, 147, 04021050. [Google Scholar] [CrossRef]
- Muhsun, S.S.; Al-Madhhachi, A.S.T.; Al-Sharify, Z.T. Prediction and CFD Simulation of the Flow over a Curved Crump Weir Under Different Longitudinal Slopes. Int. J. Civ. Eng. 2020, 18, 1067–1076. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Variable | Description |
|---|---|
| Age (years) | Age in years since the construction of the dam was completed. |
| Distance to nearest city/town (miles) | Distance from the dam to the nearest affected downstream village/town/city. |
| Primary dam type | Type of dam can be either earth (1), rockfill (2), gravity (3), buttress (4), arch (5), multi-arch (6), roller-compacted concrete (7), concrete (8), masonry (9), stone (10), timber-crib (11), or other (12). |
| Core type | Core type can be either concrete (1), bituminous concrete (2), earth (3), metal (4), or plastic (5). |
| Foundation type | Foundation type can be either rock (1), soil (2), rock and soil (3), or other (4). |
| Dam height (feet) | The vertical distance between the lowest point on the crest of the dam and the lowest point in the original streambed. |
| Hydraulic height (feet) | The vertical distance between the maximum design water level and the lowest point in the original streambed. |
| Structural height (feet) | The vertical distance between the lowest point of the excavated foundation to the top of the dam (parapet wall). |
| NID height (feet) | The maximum value of the dam height, hydraulic height, or structural height. |
| Dam length (feet) | Length along the top of the dam, which encompasses spillway, powerplant, navigation, fish pass, and lock. |
| Dam volume (cubic yard) | The total number of cubic yards occupied by the materials used in the dam structure. |
| Maximum storage (acre-feet) | The total storage space in a reservoir below the maximum attainable water surface elevation involving any surcharge storage. |
| Normal storage (acre-feet) | The total storage space in a reservoir below the normal retention level involving dead and inactive storage and excluding any surcharge storage or flood control. |
| NID storage | The maximum value of the maximum storage and normal storage. |
| Surface area (acres) | The surface area of the impoundment as the normal retention level. |
| Drainage area (square miles) | The area that drains to a particular point on a stream or river. |
| Maximum discharge (cubic feet/second) | The number of cubic feet per second that the spillway is able of discharging when the reservoir is at its maximum designed water surface elevation. |
| Spillway type | Spillway type can be controlled (1), uncontrolled (2), or none (3). |
| Spillway width (feet) | The width available for discharge when the reservoir is at its maximum designed water surface elevation. |
| Number of locks | Number of existing navigation locks in the project. |
| Length of locks (feet) | The length of the primary navigation lock. |
| Width of locks (feet) | The width of the primary navigation lock. |
| Output Variable | Description |
|---|---|
| Downstream dam hazard potential | Indicates the potential hazard to the downstream area resulting from the failure or misoperation of the dam. It can be low (1), significant (2), or high (3). Low hazard potential dams are those whose failure or misoperation results in no probable loss of human life and low economic and/or environmental losses. Significant hazard potential dams are those whose failure or misoperation results in no probable loss of human life, but can result in economic loss, environmental damage, or disruption of lifeline facilities. High hazard potential dams are those whose failure or misoperation could cause potential loss of human life, and can result in economic loss, environmental damage, or disruption of lifeline facilities. |
| Data-Driven Model | MAPE | RAE | MAE | RSE | RMSE | NSE |
|---|---|---|---|---|---|---|
| 28.68% | 0.71 | 0.47 | 0.74 | 0.64 | 0.38 | |
| 31.80% | 1.13 | 0.74 | 2.04 | 1.06 | −0.72 | |
| 31.03% | 0.73 | 0.48 | 0.75 | 0.65 | 0.36 | |
| 35.89% | 0.92 | 0.6 | 21.4 | 3.44 | −17.1 | |
| 34.57% | 0.8 | 0.52 | 0.82 | 0.67 | 0.3 | |
| 32.12% | 0.78 | 0.51 | 0.8 | 0.67 | 0.32 | |
| 22.89% | 0.6 | 0.39 | 0.62 | 0.59 | 0.48 | |
| 19.50% | 0.49 | 0.32 | 0.42 | 0.48 | 0.64 | |
| 24.90% | 0.75 | 0.49 | 0.97 | 0.73 | 0.18 | |
| 9.62% | 0.27 | 0.17 | 0.31 | 0.41 | 0.74 |
| Data-Driven Model | Mean Ranking | Standard Deviation of Rankings | Final Ranking |
|---|---|---|---|
| 4.17 | 0.37 | 4 | |
| 9 | 1 | 9 | |
| 5.17 | 0.37 | 5 | |
| 9.67 | 0.47 | 10 | |
| 7.67 | 0.75 | 8 | |
| 6.67 | 0.75 | 6 | |
| 3 | 0 | 3 | |
| 2 | 0 | 2 | |
| 6.67 | 1.49 | 7 | |
| 1.00 | 0 | 1 |
| Data-Driven Model | MAPE | RAE | MAE | RSE | RMSE | NSE |
|---|---|---|---|---|---|---|
| 9.62% | 0.27 | 0.17 | 0.31 | 0.41 | 0.74 | |
| 11.09% | 0.31 | 0.2 | 0.33 | 0.43 | 0.72 | |
| 10.56% | 0.29 | 0.19 | 0.32 | 0.42 | 0.73 | |
| 20.12% | 0.50 | 0.33 | 0.55 | 0.55 | 0.54 | |
| 9.95% | 0.28 | 0.18 | 0.36 | 0.45 | 0.70 | |
| 12.39% | 0.33 | 0.22 | 0.41 | 0.48 | 0.65 | |
| 11.36% | 0.30 | 0.2 | 0.33 | 0.43 | 0.72 | |
| 10.56% | 0.29 | 0.19 | 0.32 | 0.42 | 0.73 | |
| 11.44% | 0.31 | 0.2 | 0.34 | 0.43 | 0.71 | |
| 12.34% | 0.33 | 0.21 | 0.38 | 0.46 | 0.68 | |
| 11.55% | 0.31 | 0.20 | 0.33 | 0.43 | 0.72 |
| Data-Driven Model | MAPE | RAE | MAE | RSE | RMSE | NSE |
|---|---|---|---|---|---|---|
| 9.62% | 0.27 | 0.17 | 0.31 | 0.41 | 0.74 | |
| 16.09% | 0.41 | 0.27 | 0.46 | 0.51 | 0.61 | |
| 24.88% | 0.64 | 0.42 | 0.65 | 0.6 | 0.45 |
| Input Variable | Average | Mode | Absolute Difference |
|---|---|---|---|
| Age | 54.8 | … | 0.33 |
| Distance to nearest city/town | 9.2 | … | 0.09 |
| Primary dam type | … | Earth | 0 |
| Core type | … | Earth | 0 |
| Foundation type | … | Soil | 0 |
| Dam height | 47.1 | … | 0.14 |
| Hydraulic height | 45.2 | … | 0.28 |
| Structural height | 54 | … | 0.08 |
| NID height | 58.2 | … | 0.2 |
| Dam length | 2895.5 | … | 0.06 |
| Dam volume | 1,067,660.9 | … | 0.2 |
| Maximum storage | 293,020 | … | 0.04 |
| Normal storage | 221,477.2 | … | 0.09 |
| NID storage | 2932,61.3 | … | 0.4 |
| Surface area | 11,138 | … | 0.07 |
| Drainage area | 3415.2 | … | 0.01 |
| Maximum discharge | 40,264.9 | … | 0.23 |
| Spillway type | … | Uncontrolled | 0.07 |
| Spillway width | 174.6 | … | 0 |
| Number of locks | … | 0 | 0 |
| Length of locks | 30.7 | … | 0 |
| Width of locks | 4.6 | … | 0 |
| Data-Driven Model | Training Time (Seconds) | Testing Time (Seconds) |
|---|---|---|
| 111.1 | 0.75 | |
| 95.2 | 0.23 | |
| 11.2 | 0.12 | |
| 10.6 | 0.13 | |
| 12.5 | 0.13 | |
| 18.8 | 0.45 | |
| 13.5 | 0.07 | |
| 13.8 | 0.05 | |
| 17.5 | 0.07 | |
| 1775.3 | 0.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdelkader, E.M.; Al-Sakkaf, A.; Alfalah, G.; Elshaboury, N. Hybrid Differential Evolution-Based Regression Tree Model for Predicting Downstream Dam Hazard Potential. Sustainability 2022, 14, 3013. https://doi.org/10.3390/su14053013
Abdelkader EM, Al-Sakkaf A, Alfalah G, Elshaboury N. Hybrid Differential Evolution-Based Regression Tree Model for Predicting Downstream Dam Hazard Potential. Sustainability. 2022; 14(5):3013. https://doi.org/10.3390/su14053013
Chicago/Turabian StyleAbdelkader, Eslam Mohammed, Abobakr Al-Sakkaf, Ghasan Alfalah, and Nehal Elshaboury. 2022. "Hybrid Differential Evolution-Based Regression Tree Model for Predicting Downstream Dam Hazard Potential" Sustainability 14, no. 5: 3013. https://doi.org/10.3390/su14053013
APA StyleAbdelkader, E. M., Al-Sakkaf, A., Alfalah, G., & Elshaboury, N. (2022). Hybrid Differential Evolution-Based Regression Tree Model for Predicting Downstream Dam Hazard Potential. Sustainability, 14(5), 3013. https://doi.org/10.3390/su14053013