Abstract
Integrating spatial transcriptomic data with immunofluorescence image data is challenging using existing tools due to their differences in spatial resolution. Immunofluorescence provides information about protein expression at the cellular or subcellular level, whereas spatial transcriptomic platforms typically rely on multicellular “spots” for RNA profiling. Our study coupled spatial transcriptomics of irradiated glioblastoma tissues with immunofluorescence for γH2AX, a marker of DNA damage within the nuclei of cells. We then compared gene expression in γH2AX-positive and negative regions within the tissue. There was significant interobserver variability in manual annotation of γH2AX positivity in multicellular spots by three different researchers (Kappa statistic = 0.345), despite all of them being familiar with γH2AX immunofluorescence and having predefined imaging parameters for annotation. This variability led to different researchers nominating different genes as being associated with DNA repair. To overcome this problem, we have developed a new tool using MATLAB. This tool performs “spot”-wise image analysis and uses researcher-defined parameters such as immunofluorescent marker intensity threshold and number of positive cells to annotate the “spots” as γH2AX positive or negative. The tissue with the most variability in manual annotation was annotated reproducibly by our MATLAB tool, leading to reproducible downstream analysis.
1. Introduction
Transcriptomic methods, such as RNA sequencing, allow the study of gene expression in cells and tissue samples [1,2]. Initial transcriptomic technologies interrogated bulk tissues and thus did not address questions pertaining to tissue heterogeneity. Single-cell RNA sequencing enables the analysis of individual cells within a tissue, but it does not address questions about the spatial context, such as cell–cell interactions among neighboring cells. More recently, spatial transcriptomics has emerged, allowing for the spatial analysis of gene expression in intact tissues and thereby enabling a new understanding of how gene expression varies within cell neighborhoods [3]. While spatial transcriptomics is a powerful technology, it does not provide information on post-translational modifications such as phosphorylation or methylation, which can regulate biology independently of gene expression. Therefore, combining spatial transcriptomics with techniques that provide spatial information on post-translational modifications (such as immunofluorescence) can help understand the spatial control of important biological phenotypes [4,5].
Integrating immunostaining data with spatial transcriptomics has numerous challenges, including harmonizing varied degrees of spatial resolution. Some platforms for spatial transcriptomics (such as the Visium and Cytassist platforms from 10x Genomics) permit RNA analysis in “spots”, allowing for analysis of cell groups rather than single cells. These slides typically capture RNA information in spots 55 μM wide and can have up to 5000 spots per capture area [6]. These spots contain variable numbers of cells depending on the tissue type. Immunostaining, by contrast, offers much greater spatial resolution and typically enables the interrogation of single cells. Because immunostaining analysis packages (Cell Profiler 4.2.8, ImageJ 1.54, and QuPath 0.6.0) are optimized for single-cell analysis [7,8], extensive manual processing and annotation (for example, with the LoupeBrowser 10x Genomics tool) are currently needed to integrate immunostaining data with spot-based spatial transcriptomics. These limitations make it difficult to objectively combine immunofluorescence data with spatial transcriptomic data. For example, if the researcher wishes to compare RNA expression in regions with high imaging marker expression with those in regions with low imaging marker expression, the researcher must manually annotate thousands of spots based on the immunofluorescent marker. This manual immunofluorescent spot annotation is both time-consuming and prone to interobserver variability, as the same spot can be annotated differently by different observers. This, in turn, will affect the analysis of spatial RNA expression, and the results of the analysis of the same tissue by different researchers can yield different results, thereby reducing reliability.
To address these limitations, we have designed a new program to integrate spatial transcriptomics and immunofluorescence data using MATLAB R2024b. While this program is generalizable to any immunofluorescent marker, we focused on γH2AX, a histone phosphorylation mark that indicates the presence of DNA damage. Our results indicate that the manual integration of immunofluorescent data and spot-based spatial transcriptomics exhibits high inter-observer variability, which can affect the nomination of biological processes for further study. By developing a new program that automates cell segmentation and annotates “spots” based on quantitative immunofluorescent information, our new analysis tool both reduces inter-observer variability and decreases the time needed for data analysis.
2. Materials and Methods
2.1. Tissue Sections
The code was generated using brain cancer tissue with radiation-induced DNA damage. Radiation exposure induces double-stranded DNA breaks, which can be detected by immunofluorescence using the phosphorylated Histone marker, γH2AX. This is a post-translational modification that cannot be detected by RNA sequencing. We used mouse brain cancer (glioblastoma) tumor tissue for this study.
2.2. Animal Models
All mouse experiments were performed in accordance with the guidelines approved by the Institutional Animal Care and Use Committee (IACUC) at the University of Michigan (approved protocol: PRO00010680). C57BL/6J mice were purchased from Jackson Laboratories. A genetically engineered mouse model, known as the TRP mouse, derived glioblastoma cells were provided as a Kind gift by C. Ryan Miller [9] and were used to generate orthotopic syngeneic glioblastoma tumors, as described previously [10]. In brief, TRP tumor cells (∼5 × 105) were orthotopically implanted in 3 female C57BL/6J mice. Two of the three brain tumor-bearing mice were subjected to 4Gy radiation treatment (RT) to the brain after sedation with 2.5% isoflurane in an Orthovoltage irradiator. One mouse was not irradiated and served as control tumor tissue in this study. The 2 irradiated brain tumor-bearing mice were euthanized through isoflurane overdose followed by cervical dislocation, one at 30 min post-irradiation and the other at 6 h post-irradiation. The unirradiated mouse was euthanized when neurological deficit developed. There was no randomization or exclusion criteria in place. The outcome measure was γH2AX expression in the tumors of the 3 mice used in this study.
2.3. Immunofluorescence
The GBM tissues obtained from the mice were fixed in 10% formalin and embedded in paraffin (formalin-fixed paraffin-embedded tissue). Four micron thick sections of the tissue were cut and subjected to immunofluorescence by following the recommended protocol (https://www.10xgenomics.com/support/cytassist-spatial-gene-expression/documentation/steps/tissue-staining/visium-cyt-assist-spatial-gene-expression-for-ffpe-deparaffinization-decrosslinking-immunofluorescence-staining-and-imaging, accessed on 1 March 2022). Briefly, the sections were deparaffinized and subjected to antigen retrieval followed by blocking and incubation with primary antibody (catalog number: 9718S, Cell Signaling Technology, Danvers, MA, USA) for 2 h followed by Texas red secondary antibody (catalog number: ab150080, Abcam, Cambridge, UK) for 1 h and counterstained using DAPI (catalog number: D9542, Sigma-Aldrich, Burlington, MA, USA). The entire section for each condition was then imaged on a Cytation (Gen5) using whole-slide scanning for the DAPI and Texas Red channels.
2.4. Spatial Transcriptomics
Following immunofluorescence, the tissue sections were subjected to spatial transcriptomics using the 10x Genomics platform at the Advanced Genomics Core (AGC), University of Michigan, employing the CytAssist technique as described in the Visium CytAssist Spatial Gene Expression for FFPE-Tissue Preparation Guide (CG000518, 10x Genomics, Pleasanton, CA, USA). Briefly, the tissue was permeabilized to release ligated probe pairs from the cells, which then bind to the spatially barcoded oligonucleotides present on the spots. The barcoded molecules are then used to generate a sequencing-ready library. The data was analyzed using 10x Genomics software resources (Space Ranger v 4.0 and Loupe Browser 8.1.0).
2.5. Annotation of the Spot γH2AX Positivity
Three researchers independently annotated all spots with at least 10 cells manually in all 3 sections, as well as using the MATLAB program. A total of 2785 spots in the no RT control tissue section, 1857 spots in the positive control (RT 30 min), and 2424 spots in the RT 6 h condition were annotated. Interobserver variability was compared using (a) average pairwise percentage agreement which is calculated as average of percentage agreement (% spots scored as positive by a pair of observers) + (% spots scored as negative by a pair of observers) between all pairs of observers and (b) Fliess’ Kappa statistic [11] (https://real-statistics.com/reliability/interrater-reliability/fleiss-kappa/, accessed on 1 March 2025) using ReCal, a inter-rater reliability calculator tool (https://dfreelon.org/utils/recalfront/recal3, accessed on 1 March 2025).
A Kappa value of 0 indicates no agreement, while a value of 1 indicates full agreement between observers.
2.6. Manual Annotation
γH2AX expression (red) had a punctate pattern within the nuclei (blue) (Figure 1A). A cell with a moderate to high intensity of Texas red was considered a positive cell. If 10% or more of the cells within the spot were positive, the spot was annotated as a positive spot. Spots containing fewer than 10 cells were eliminated.
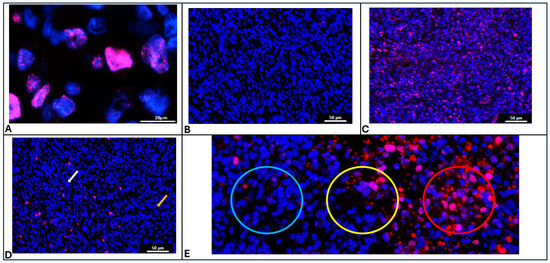
Figure 1.
(A) Immunostaining pattern of γH2AX showing punctate patterns within the DAPI stained nucleus of irradiated cells (Blue: DAPI, Red: γH2AX). (B) Representative image of control mouse brain tumor without radiation exposure showing uniform absence of γH2AX immunostaining. (C) Representative image of mouse brain tumor obtained 30min after radiation exposure showing uniform high γH2AX immunostaining. (D) Representative image of mouse brain tumor obtained 6hr after radiation exposure showing non-uniform γH2AX immunostaining with regions of high expression (white arrow) and regions of low expression (yellow arrow). (E) Representative image showing Cytassist spots overlaid on γH2AX immunostained image depicting clearly negative spots (Blue circle), clearly positive spots (Red circle) and inconclusive spots (Yellow circle).
2.7. MATLAB Program
Our program mainly utilizes the functions provided by MATLAB’s Image Processing Toolbox for its analysis. It was originally designed to detect γH2AX, a biomarker that labels DNA damage [12], on immunofluorescence, using the Texas Red fluorescence channel. However, the program can detect any fluorophore in the nucleus and can be adapted to include detection of cytoplasmic and membrane immunostaining.
Our program is designed to individually analyze the group of cells located under each spot on a tissue section. To focus analysis on the cells underneath each spot, the program applies a mask to the image. Since the size of the spots is fixed at 55 μM, no customization is necessary to perform masking. However, the spot’s coordinates are necessary as input into the program. These coordinates correspond to the same coordinates as those used for the barcodes in RNA extraction from the tissue. These coordinates or spot midpoints can be obtained from the Loupe browser, but they may also be user-defined (Appendix A provides the default settings for all user inputs).
Segmenting cells within spots is challenging due to the close proximity of nuclei in a 20×-magnification image, the standard magnification used in many spatial transcriptomic platforms. Many current programs are limited by their ability to define a cell’s nucleus when overlapping occurs [13,14,15]. This program is designed to define the boundaries of a nucleus using DAPI intensity. The program leverages the fact that the DAPI intensity is lower at the cell boundaries compared to their centers. The program first identifies all pixels above the user-defined threshold for DAPI intensity and deletes all pixels below the threshold (Figure 2). Following the first iteration, all blue regions completely surrounded by black and lying within the user-defined perimeter are considered as individual cells, and the information from them is recorded. These cells are then eliminated from the picture for the next iteration. For the second iteration, it eliminates all pixels below an increased threshold of DAPI (the amount of increase is referred to as the “range,” which is user-defined). This process continues until the upper limit of DAPI has been reached or until all the blue cells have been identified and the image is black. Each iteration gradually separates overlapping cells and stores the information for each cell. To ensure that most of the information is stored for overlapping cells, the user can manually define the perimeter of a cell. This perimeter refers to the average number of pixels that encompass a nucleus in an image. Providing an appropriate perimeter value prevents overlapping cells from being regarded as a single cell. Figure 2 illustrates the step-by-step processing of the image by the code.
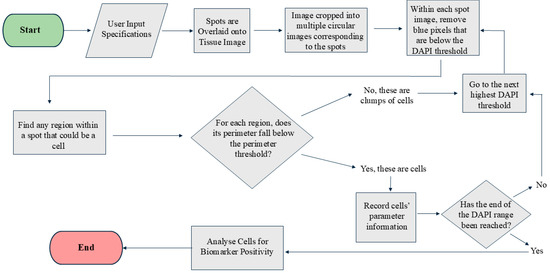
Figure 2.
Step by step cell segmentation and analysis process of the MATLAB code.
To identify a certain biomarker within the nucleus, the user can set the minimum and maximum threshold values for an image’s red, green, and blue channels. This range indicates the intensity of fluorescence required for a pixel in an image to be considered positive for the biomarker and should be determined using proper biological controls. The program calculates the number of cells positive for the biomarker within a spot based on user input, which specifies the threshold of positive pixels required to consider a cell positive. The overall spot’s intensity value is based on the average pixel values within a spot using the fluorophore’s main color channel. For example, Texas Red mainly utilizes the image’s red channel. A mask is employed to use only the main channel’s positive pixels for the intensity calculation.
Based on the above information, the program analyzes each spot and produces the following output in the form of a table: the x and y coordinates of each spot’s center, the total number of cells and positive cells within each spot, the positivity value of each spot in percent form, each spot’s intensity value for the biomarker, and the final program’s call. The final program call will be either “positive” or “negative”, indicating whether the spot is positive or negative for the biomarker. This call is customizable by the user. It may be based on the spot’s intensity value, the percentage of positive cells present within the spot, or both values. The user has the choice to define the thresholds for each option.
The code has been deposited in GitHub (https://github.com/Radiation-oncology-wahl-lab/Spatial-transcriptomics-image-analysis/tree/main, accessed on 15 July 2024). Appendix A describes the default settings used in the MATLAB program.
3. Results
3.1. Different Experimental Conditions Yielded Tissues Showing Varying Expression of the Marker
The tumor analyzed in this study is glioblastoma, which is the most aggressive primary brain malignancy in adults. Radiation treatment is one of the mainstay treatment modalities for this cancer [16]. Glioblastoma is resistant to radiation treatment, as evidenced by tumor recurrence and a short median overall survival time of about 16 months [17,18]. Radiation treatment acts by inducing double-stranded DNA breaks [19]. The tumor’s ability to repair this damage quickly enables it to become resistant to treatment. For this study, we used glioblastoma cells grown in mouse brains, which were subjected to radiation treatment.
γH2AX is a phosphorylation marker that indicates the presence of unresolved double-stranded DNA (dsDNA) breaks (Figure 1A). Since radiation exposure induces dsDNA breaks, the expression of γH2AX is uniformly low in the unirradiated tissue (Figure 1B) and uniformly high in 30 min post RT tissue (Figure 1C). We demonstrate that in the 6 h post-RT tissue, some repair of the DNA damage has occurred in specific regions of the tumor, while damage persists in other regions (Figure 1D); hence, γH2AX expression is intermediate and non-uniform.
Spatial transcriptomic analysis platforms often provide gene expression data for spots, rather than individual cells. These spots vary in size depending on the analysis platform used, but are often on the order of 50–60 µm in diameter. In conditions where γH2AX staining is heterogeneous (i.e., 6 h after RT), some 55 µM spots were clearly negative (Figure 1E, blue circle) or positive (Figure 1E, red circle) for the γH2AX marker. Other spots (Figure 1E, yellow circle) exhibited a mixture of negative and positive cells, raising uncertainty about whether they should be labeled as positive or negative for γH2AX.
3.2. High Interobserver Variability Is Noted in Manual Annotation of Spots with Non-Uniform Marker Expression
To assess inter-observer variability in the analysis pipeline, three independent researchers annotated the spots based on agreed-upon criteria: moderate to high γH2AX expression within the nucleus indicated a positive cell, and 10% or more of positive cells within the spot were considered a positive spot. The tissues annotated were one unirradiated GBM tissue, which served as a negative control for γH2AX, one GBM tissue harvested 30 min after RT, which served as a positive control for γH2AX, and one GBM tissue harvested 6 h after RT, which had heterogeneous γH2AX expression. The annotations were compared, and interobserver variability was measured using percentage agreement and Fleiss’ Kappa statistic. A Kappa statistic of 0.8 or above is considered near-perfect agreement [11]. A percentage agreement of 80% or above is considered the minimum acceptable agreement [20].
In the unirradiated negative control tissue, 2785 spots were analyzed by three researchers. On average, each spot contained 42.1 cells (range: 11 to 88) as defined by the number of DAPI-stained nuclei. The tissue showed uniform low positivity of γH2AX expression. The percentages of spots annotated as positive by the three researchers are 9.4%, 9.4%, and 11.3%. There was high agreement among the three researchers on the annotation of individual spots. Indeed, the average agreement percentage is 98.42%, while the Kappa agreement statistic is 0.912, both of which indicate near-perfect agreement. Therefore, tissue showing uniform low positivity (Figure 1B) had good agreement among the three researchers.
In the 30 min post RT tissue, 1857 spots were analyzed by three researchers. On average, each spot contained 45.8 cells (range: 15 to 92) as defined by the number of DAPI-stained nuclei. The tissue showed uniform high positivity of γH2AX expression. The percentages of spots annotated as positive by the three researchers are 98.5%, 98.4%, and 98.4%. There was high agreement among the three researchers on the annotation of individual spots, with an average agreement percentage of 99.57% and a Kappa agreement statistic of 0.857, both of which indicate near-perfect agreement. Hence, the tissue showing uniform high γH2AX positivity showed good agreement among the three researchers.
In the 6 h post RT tissue, 2424 spots were analyzed by all three researchers. On average, each spot had 48.3 cells (range: 10 to 91) as defined by the number of DAPI-stained nuclei. The tissue showed non-uniform γH2AX expression. The percentages of spots annotated as positive by the three researchers are 43.2%, 65.4%, and 69.8%.
There was also low agreement among the three researchers on the annotation of individual spots, with an average agreement percentage of only 69.06% and a Kappa statistic of 0.345, both of which indicate poor agreement. Therefore, tissue showing non-uniform intermediate positivity for γH2AX was annotated differently by different researchers. Figure 1E depicts a spot (yellow circle) with high disagreement between researchers. Table 1 shows the extent of agreement (Fleiss’ Kappa value and average pairwise agreement scores) between observers in different experimental conditions with varying γH2AX immunopositivity.

Table 1.
Agreement scores and Kappa statistic for 3 experimental conditions showing the least reliability in annotating the section with non-uniform γH2AX immunopositivity.
As shown in Table 1, manual annotation of the spots resulted in significant differences in annotating the spots in the critical experimental condition, where subsequent RNA expression analysis heavily depends on the accuracy of spot annotation. The objective of spatial transcriptomics coupled with IF for γH2AX is to compare the RNA expression in γH2AX-positive spots with that in γH2AX-negative spots. The three observers generated heatmaps on Loupe Browser for differential RNA expression in γH2AX-positive vs. negative spots using their respective manual annotations of spots in the Rt 6 h tissue. The top 3 upregulated and downregulated genes were different when each observer used their respective annotations for analysis (Figure 3). Hence, it is essential to have an objective method for annotating the spots to ensure the reproducibility and reliability of the data analysis.
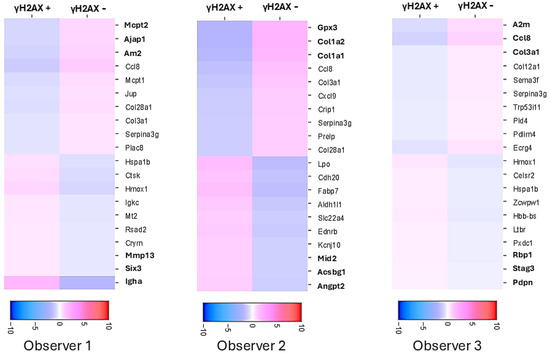
Figure 3.
Heatmaps of differential gene expression between γH2AX positive and negative spots after annotation by different observers shows major differences in results. Scale bars show log2 fold change. The top 3 differentially expressed genes are different for different observers.
3.3. Development of a Quantitative Tool to Analyze Immunofluorescence in Multicellular Spots
To overcome interobserver variability in manual immunofluorescent annotation, we developed a quantitative analysis tool using MATLAB. Our program is designed to consider each spot (a cluster of cells) as a single image and perform nuclear segmentation in each spot individually (Figure 2).
Nuclear segmentation is performed through multiple iterations based on the intensity of DAPI and a user-defined range for iterations and the perimeter of the nucleus (Figure 4). Allowing the user to define these parameters enables customization of segmentation to suit different tissue types, which have varying cell densities and cell sizes.

Figure 4.
Images of sequential iterations and the final segmentation after the last iteration for different user defined ranges for iterations. Sequential iterations show how the code identifies cells and then excludes them from the image for the next iteration. The last column shows final masks overlaid on the original image.
Following segmentation, the Texas red intensity within the nuclei is measured, eliminating the chance of measuring RBC autofluorescence (red fluorescence without any underlying nucleus), as γH2AX. This reduces false-positive annotation of the spot. The program default is set to consider both Texas red intensity and the percentage of cells positive for γH2AX in the spot, annotating it as positive or negative. However, the user can choose to use only the intensity of the marker or only percentage positive cells to annotate the spots, depending on the immunostaining pattern of the marker in the specific tissue. Appendix A provides a detailed description of the user-defined parameters.
3.4. Automated Quantification of Immunofluorescence Intensity
Our MATLAB program output provided the number of DAPI-stained nuclei within the spot, the average intensity of Texas Red within the nuclei present in the spot, and the percentage of cells positive for Texas Red. We were able to objectively eliminate spots with too few cells (<10). The mean intensity of Texas red in the spots ranged from 55 to 202.92. The percentage of positive cells in the spots ranged from 0 to 100. Spots with average intensity above 60 and percentage positive cells >10% were annotated as positive spots.
In the no RT tissue showing uniform low expression of γH2AX, the MATLAB program annotated 10.1% spots as positive, which agreed well with manual annotation. In the 30 min post RT tissue with uniform high γH2AX expression, the MATLAB program annotated 98.5% spots as positive, which is similar to the total spots annotated as positive by the three researchers.
In the RT 6 h tissue with heterogeneous expression of γH2AX, the MATLAB program annotated 61.3% of the spots as positive, although this number could be altered by adjusting the intensity and the percentage of positive cells threshold. In spots with high disagreement, such as the central spot in Figure 1E which was annotated as positive by two researchers and negative by one researcher, the MATLAB program was able to objectively annotate it as negative because, although the average intensity of Texas red was 86.8, the percentage of positive cells was only 9.1% (Figure 5A(iii)).
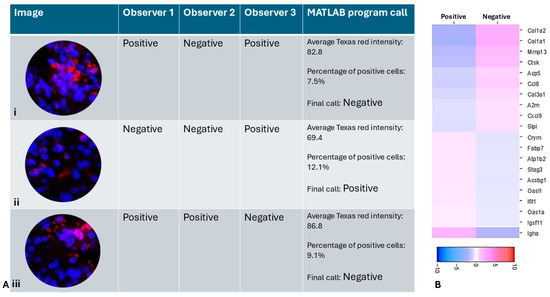
Figure 5.
(A) (i–iii) Representative spots with high disagreement between observers and the MATLAB program call. The spots show nuclei stained with DAPI (blue) and γH2AX immunofluorescence (pink) and Red blood cell autofluorescence (red) (B) Heatmap of differential gene expression using MATLAB annotation showing significant difference compared to Figure 3. Scale bar shows log2 fold change.
Figure 5 illustrates different scenarios with high disagreement between observers, in which the MATLAB program was able to make an objective call. In Figure 5A(i), the spot was annotated as positive by two researchers due to high apparent Texas red intensity. However, the MATLAB program was able to identify that the red staining is not present over DAPI and is likely due to RBC autofluorescence, rather than true γH2AX positivity. It was then able to objectively classify it as a negative spot based on the criteria set by the researchers. The heatmap (Figure 5B) shows differentially regulated genes between γH2AX-positive and negative spots, as annotated by the MATLAB program. When the top 5 genes upregulated in γH2AX-negative spots are compared with those identified by different observers based on their manual annotation, the MATLAB call-based genes only matched with 2 of the genes identified by one observer. The top 5 upregulated genes identified by the other two observers did not match the top 5 genes identified using MATLAB annotation. This demonstrates that when attempting to identify candidate genes using IF-based marker annotation, it is crucial to have an objective tool to ensure reliable and reproducible results. Our MATLAB program enables such an objective assessment.
4. Discussion
Advances in spatial biology have yielded insights into tissue heterogeneity and cancer biology in a spatially relevant fashion. Several modalities for studying spatial transcriptomics are currently available [21,22,23], but they have the inherent limitation of not being able to investigate post-translational modifications and other epigenetic changes, such as histone modifications.
Post-translational modifications, such as the phosphorylation of histone H2A.x, are well-documented and have been shown to have a significant impact on the biology of several cancers. These modifications cannot be studied by measuring RNA expression, since the changes happen after the RNA has been translated into protein. Histone modifications such as trimethylation of H3K27 also cannot be detected using transcriptomics but can be identified using IF. Spatial protein expression can be studied using multiplex IF platforms with advanced image analysis programs like Akoya Biosciences [24,25]. However, this cannot be combined with transcriptomic analysis, and only a limited number of proteins can be studied at a time. This lack of combined transcriptomic and post-translational analysis can limit biological insights.
Combining immunofluorescence and spatial transcriptomics offers the opportunity to study both RNA and protein expression on the same tissue section. However, there are limited tools available to integrate spatial RNA sequencing data with IF images. This is especially relevant because current spatial transcriptomics platforms are predominantly based on capturing RNA from multicellular regions. The currently available image analysis tools like ImageJ and CellProfiler, and advanced bioinformatic tools like Seurat 5.3.0 based in R 4.5.1 and Scanpy 2.6.1 based in Python 3.12.6 which are used to analyze the spatial transcriptomics data, do not allow automated and objective image analysis of parameters like intensity of marker expression, percentage of marker positive cells within the multicellular spot and other image analysis parameters essential for downstream analysis. Such analyses need to be performed manually and are prone to interobserver variability.
Interobserver variability is widely reported in histopathological studies of cancer tissues, evaluating both routine histopathology images and images of immunostained sections [26,27,28]. Percentage agreement and Kappa statistics have been widely used to quantify inter-observer variability. A Kappa statistic of 0.8 and above is considered as near perfect agreement [11], which was seen in the evaluation of tissues with uniform low or uniform high expression of the marker, but not in the non-uniform marker expression condition. In the case of spatial transcriptomics, accurately and objectively annotating the spots based on the immunofluorescent image is essential for studying spatial RNA expression and drawing reliable and reproducible conclusions. Currently, there are no platforms that can quantitatively assess immunofluorescent images and annotate spots while complementing Cytassist. Our program is the first tool to accomplish this task.
Our program is designed to annotate multicellular spots, with varying marker expression within the spots, as either positive or negative based on user-defined criteria of “ground truth”. These criteria can be modified to suit the tissue type, experimental condition, and the marker expression pattern. Originally, the program was written to detect the presence of γH2AX; however, other nuclear markers of post-translational modifications, such as 5-methyl cytosine [29] and H3K27me3 (trimethyl H3K27), which are also prone to interobserver variability in manual annotation, could also be used [30]. The program enables researchers to adjust threshold values for all three color channels: red, green, and blue. The combination of these channels enables the detection of fluorescent markers of any color. For example, combining the red and green channels will allow the program to detect an orange fluorophore. The user can define this parameter, thereby extending the applicability of the tool to other IF images and multiplex IF images. The program’s nuclei stain detection is currently limited to DAPI or another blue stain as it is widely used as nuclear stain; however, this feature may be added to future versions, if required.
The output generated by this code is a table that can be exported as a .csv file, which can then be imported into existing browsers, such as Loupe Browser, used for spatial transcriptomics visualization and analysis. The table can also serve as input for more advanced single-cell RNA sequencing and spatial RNA sequencing analysis pipelines, such as the Seurat pipeline and Spacexr pipelines, which are based on R, as well as other pipelines based on Python, including Scanpy 2.6.1 and pySCENIC 0.12.1.
MATLAB code has several advantages over other tools, such as ImageJ and CellProfiler, because existing tools do not cater to the need of identifying multicellular spots. Furthermore, MATLAB offers image processing tools that can be customized to suit various tissue types. We leveraged this feature and customized our code to be flexible, enabling it to detect nuclei in tissues of varying nuclear densities, as well as nuclei with different shapes and sizes.
Limitations
Our work also has some limitations. Our code currently only identifies nuclear immunostaining, as the segmentation is based on DAPI intensity. Since the essential step to tease apart overlapping cells mandates segmentation to be strictly limited to DAPI intensity, it cannot be easily modified to suit cytoplasmic or membrane staining in its current form. Another limitation is that this tool applies only to the annotation of circular multicellular spots. However, with modifications to defining parameters, the program can be modified to annotate the cells objectively based on IF.
5. Conclusions
In summary, our unique MATLAB program enables researchers to objectively assess immunofluorescent markers in conjunction with spatial transcriptomics, as performed on Cytassist, a commonly used spatial transcriptomics platform. It allows its user to accurately and efficiently analyze immunofluorescent nuclear biomarkers within spots without the need for laborious and subjective manual annotation.
Author Contributions
S.P.: Conceptualization, biological experimentation, manual annotation of the spots as one of the three observers, and drafting the manuscript. E.B.: Creating the MATLAB program described in this manuscript and drafting the manuscript. J.F.: Manual annotation of the spots as one of the three observers. A.G.: Manual annotation of the spots as one of the three observers. W.Z.: Intellectual input and manuscript preparation. D.T., W.N.A.-H., M.A.M. and T.S.L.: Intellectual input and manuscript preparation. D.R.W.: Conceptualization, and drafting and editing the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
Sravya Palavalasa was supported by the American Cancer Society postdoctoral fellowship, PF-23-1077428-01-MM, [https://doi.org/10.53354/ACS.PF-23-1077428-01-MM.pc.gr.175459, accessed on 1 July 2025]. Meredith A. Morgan, Daniel R. Wahl, and Theodore S. Lawrence were supported by the SPORE grant, P50CA269022. Wajd N. Al-Holou was supported by K08NS128271. Meredith A Morgan was supported by R01CA240515-05, Daniel R Wahl was supported by the NCI (K08CA234416 and R37CA258346), Rogel Cancer Center Munn Team Science Catalyst Award, Cancer Center Support Grant P30CA46592, Damon Runyon Cancer Foundation, Ben and Catherine Ivy Foundation, and the Sontag Foundation.
Institutional Review Board Statement
The animal experiments in this study were approved by the Institutional Animal Care and Use Committee (IACUC) at the University of Michigan (approved protocol: PRO00010680). All methods were performed in accordance with the guidelines and regulations provided by the IACUC.
Informed Consent Statement
Not applicable.
Data Availability Statement
The MATLAB code is deposited in GitHub (https://github.com/Radiation-oncology-wahl-lab/Spatial-transcriptomics-image-analysis/tree/main, accessed on 15 July 2024).
Acknowledgments
We acknowledge the Advanced Genomics Core at the University of Michigan for performing spatial transcriptomics sequencing on the tissues used in this study. We acknowledge Ryan Miller from the University of Alabama for sharing the syngeneic mouse glioblastoma cells used to generate the mouse tumors in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| DNA | Deoxyribonucleic acid |
| RNA | Ribonucleic acid |
| IF | Immunofluorescence |
| γH2AX | Phosphorylated Histone H2AX |
| RT | Radiation Treatment |
| IACUC | Institutional Animal Care and Use Committee |
Appendix A
Table A1.
Default Setting Determinants.
Table A1.
Default Setting Determinants.
| Setting | Default Value |
|---|---|
| Range for Cell Sweeping (a) | 5:10:250 |
| Average Cell Perimeter (b) | 80 |
| Intensity Lower Threshold (c) | 55 |
| Percent Positive Threshold (d) | 5 |
| Red Pixel Value (Lower Threshold) (e) | 55 |
| Blue Pixel Value (Lower Threshold) (e) | 50 |
| Green Pixel Value (Lower Threshold) (e) | 0 |
| Pixel Clean-up (f) | 20 |
This range refers to the program’s step-incrementation to detect each cell’s nucleus. MATLAB’s impixel() function was used to determine the pixel’s blue channel values on the borders of the nucleus. Multiple cells from different spots were tested with this function. All the cells’ nuclei borders were found to be above 60 in the blue channel. A final value of 50 was chosen to ensure pixels considered positive for the biomarker were considered part of the nucleus (see e).
The range’s high threshold was determined by its incrementation value, 25. Step values between 1 and 50 were tested for nucleus border determinacy. A step value of 25 counted the highest number of cells accurately within a spot with the most efficiency. The maximum blue channel value is 255; therefore, this step increment will reach 250.
Cells from different spots were used to determine this default value. The pixels surrounding the nuclei borders were manually counted; the average was approximately 80. Any program-detected region with a perimeter exceeding the average cell perimeter is considered to be multiple overlapping nuclei.
The minimum red channel value for a pixel to be considered positive for the biomarker determines the intensity lower threshold (see e).
The percent positive threshold refers to the percentage of positive cells required to consider a spot positive for the biomarker. The researchers were presented with spots ranging from 1 to 30 percent positive. Utilizing tissue samples that had been manually counted, the researchers chose five percent as the lower threshold.
The red, blue, and green pixel values are the minimum channel values for a pixel to be considered positive. Green is absent from the image, so its channel’s lower threshold is set at zero. Texas Red is a combination of blue and red channels. The researchers were presented with a range of pixel colors within different cells that could be considered positive. They chose the minimum pixel color they would consider positive during manual annotation. This pixel’s channel values were rounded and used as the minimum thresholds.
Pixel clean-up refers to a region’s minimum pixel number to be considered a nucleus. The program deletes any regions with a value less than or equal to this value. These regions are considered noise within the image or the remnants of an already documented cell. Deletion values between 5 and 25 were tested. The value 20 had the highest noise reduction accuracy.
References
- Lowe, R.; Shirley, N.; Bleackley, M.; Dolan, S.; Shafee, T. Transcriptomics technologies. PLoS Comput. Biol. 2017, 13, e1005457. [Google Scholar]
- Wang, Z.; Gerstein, M.; Snyder, M. RNA-Seq: A revolutionary tool for transcriptomics. Nat. Rev. Genet. 2009, 10, 57–63. [Google Scholar] [PubMed]
- Williams, C.G.; Lee, H.J.; Asatsuma, T.; Vento-Tormo, R.; Haque, A. An introduction to spatial transcriptomics for biomedical research. Genome Med. 2022, 14, 68. [Google Scholar] [PubMed]
- Hahn, N.; Bens, M.; Kempfer, M.; Reißig, C.; Schmidl, L.; Geis, C. Protecting RNA quality for spatial transcriptomics while improving immunofluorescent staining quality. Front. Neurosci. 2023, 17, 1198154. [Google Scholar]
- Holtz, A.; Basisty, N.; Schilling, B. Quantification and identification of post-translational modifications using modern proteomics approaches. In Methods in Molecular Biology; Springer: New York, NY, USA, 2021; pp. 225–235. [Google Scholar]
- Xun, Z.; Ding, X.; Zhang, Y.; Zhang, B.; Lai, S.; Zou, D.; Zheng, J.; Chen, G.; Su, B.; Han, L.; et al. Reconstruction of the tumor spatial microenvironment along the malignant-boundary-nonmalignant axis. Nat. Commun. 2023, 14, 933. [Google Scholar]
- Bankhead, P.; Loughrey, M.B.; Fernández, J.A.; Dombrowski, Y.; Mcart, D.G.; Dunne, P.D.; Mcquaid, S.; Gray, R.T.; Murray, L.J.; Coleman, H.G.; et al. QuPath: Open source software for digital pathology image analysis. Sci. Rep. 2017, 7, 16878. [Google Scholar]
- Vrekoussis, T.; Chaniotis, V.; Navrozoglou, I.; Dousias, V.; Pavlakis, K.; Stathopoulos, E.N.; Zoras, O. Image analysis of breast cancer immunohistochemistry-stained sections using ImageJ: An RGB-based model. Anticancer Res 2009, 29, 4995–4998. [Google Scholar]
- Schmid, R.S.; Simon, J.M.; Vitucci, M.; McNeill, R.S.; Bash, R.E.; Werneke, A.M.; Huey, L.; White, K.K.; Ewend, M.G.; Wu, J.; et al. Core pathway mutations induce de-differentiation of murine astrocytes into glioblastoma stem cells that are sensitive to radiation but resistant to temozolomide. Neuro-Oncol. 2016, 18, 962–973. [Google Scholar]
- Peterson, E.R.; Sajjakulnukit, P.; Scott, A.J.; Heaslip, C.; Andren, A.; Wilder-Romans, K.; Zhou, W.; Palavalasa, S.; Korimerla, N.; Lin, A.; et al. Purine salvage promotes treatment resistance in H3K27M-mutant diffuse midline glioma. Cancer Metab. 2024, 12, 11. [Google Scholar]
- Li, M.; Gao, Q.; Yu, T. Kappa statistic considerations in evaluating inter-rater reliability between two raters: Which, when and context matters. BMC Cancer 2023, 23, 799. [Google Scholar]
- Mah, L.-J.; El-Osta, A.; Karagiannis, T.C. γH2AX: A sensitive molecular marker of DNA damage and repair. Leukemia 2010, 24, 679–686. [Google Scholar]
- Jung, C.; Kim, C. Impact of the accuracy of automatic segmentation of cell nuclei clusters on classification of thyroid follicular lesions. Cytom. A 2014, 85, 709–718. [Google Scholar]
- Xing, F.; Yang, L. Robust Nucleus/Cell Detection and Segmentation in Digital Pathology and Microscopy Images: A Comprehensive Review. IEEE Rev. Biomed. Eng. 2016, 9, 234–263. [Google Scholar]
- Ronneberger, O.; Baddeley, D.; Scheipl, F.; Verveer, P.J.; Burkhardt, H.; Cremer, C.; Fahrmeir, L.; Cremer, T.; Joffe, B. Spatial quantitative analysis of fluorescently labeled nuclear structures: Problems, methods, pitfalls. Chromosome Res. 2008, 16, 523–562. [Google Scholar]
- Stupp, R.; Mason, W.P.; van den Bent, M.J.; Weller, M.; Fisher, B.; Taphoorn, M.J.B.; Belanger, K.; Brandes, A.A.; Marosi, C.; Bogdahn, U.; et al. Radiotherapy plus Concomitant and Adjuvant Temozolomide for Glioblastoma. N. Engl. J. Med. 2005, 352, 987–996. [Google Scholar] [PubMed]
- Lakomy, R.; Kazda, T.; Selingerova, I.; Poprach, A.; Pospisil, P.; Belanova, R.; Fadrus, P.; Vybihal, V.; Smrcka, M.; Jancalek, R.; et al. Real-World Evidence in Glioblastoma: Stupp’s Regimen After a Decade. Front. Oncol. 2020, 10, 840. [Google Scholar]
- Santosh, V.; Sravya, P.; Arivazhagan, A. Molecular pathology of glioblastoma—An update. In Advances in Biology and Treatment of Glioblastoma; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Zhou, W.; Yao, Y.; Scott, A.J.; Wilder-Romans, K.; Dresser, J.J.; Werner, C.K.; Sun, H.; Pratt, D.; Sajjakulnukit, P.; Zhao, S.G.; et al. Purine metabolism regulates DNA repair and therapy resistance in glioblastoma. Nat. Commun. 2020, 11, 3811. [Google Scholar]
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar]
- Al-Holou, W.N.; Wang, H.; Ravikumar, V.; Shankar, S.; Oneka, M.; Fehmi, Z.; Verhaak, R.G.; Kim, H.; Pratt, D.; Camelo-Piragua, S.; et al. Subclonal evolution and expansion of spatially distinct THY1-positive cells is associated with recurrence in glioblastoma. Neoplasia 2023, 36, 100872. [Google Scholar]
- Arora, R.; Cao, C.; Kumar, M.; Sinha, S.; Chanda, A.; Mcneil, R.; Samuel, D.; Arora, R.K.; Matthews, T.W.; Chandarana, S.; et al. Spatial transcriptomics reveals distinct and conserved tumor core and edge architectures that predict survival and targeted therapy response. Nat. Commun. 2023, 14, 5029. [Google Scholar]
- Suzuki, A.; Nojima, S.; Tahara, S.; Motooka, D.; Kohara, M.; Okuzaki, D.; Hirokawa, M.; Morii, E. Identification of invasive subpopulations using spatial transcriptome analysis in thyroid follicular tumors. J. Pathol. Transl. Med. 2024, 58, 22–28. [Google Scholar]
- Jhaveri, N.; Ben Cheikh, B.; Nikulina, N.; Ma, N.; Klymyshyn, D.; Derosa, J.; Mihani, R.; Pratapa, A.; Kassim, Y.; Bommakanti, S.; et al. Mapping the Spatial Proteome of Head and Neck Tumors: Key Immune Mediators and Metabolic Determinants in the Tumor Microenvironment. GEN Biotechnol. 2023, 2, 418–434. [Google Scholar]
- Hickey, J.W.; Neumann, E.K.; Radtke, A.J.; Camarillo, J.M.; Beuschel, R.T.; Albanese, A.; Mcdonough, E.; Hatler, J.; Wiblin, A.E.; Fisher, J.; et al. Spatial mapping of protein composition and tissue organization: A primer for multiplexed antibody-based imaging. Nat. Methods 2022, 19, 284–295. [Google Scholar] [PubMed]
- Van Bockstal, M.R.; François, A.; Altinay, S.; Arnould, L.; Balkenhol, M.; Broeckx, G.; Burguès, O.; Colpaert, C.; Dedeurwaerdere, F.; Dessauvagie, B.; et al. Interobserver variability in the assessment of stromal tumor-infiltrating lymphocytes (sTILs) in triple-negative invasive breast carcinoma influences the association with pathological complete response: The IVITA study. Mod. Pathol. 2021, 34, 2130–2140. [Google Scholar] [PubMed]
- Robert, M.E.; Ruschoff, J.; Jasani, B.; Graham, R.P.; Badve, S.S.; Rodriguez-Justo, M.; Kodach, L.L.; Srivastava, A.; Wang, H.L.; Tang, L.H.; et al. High Interobserver Variability Among Pathologists Using Combined Positive Score to Evaluate PD-L1 Expression in Gastric, Gastroesophageal Junction, and Esophageal Adenocarcinoma. Mod. Pathol. 2023, 36, 100154. [Google Scholar]
- Van Bockstal, M.R.; Berlière, M.; Duhoux, F.P.; Galant, C. Interobserver Variability in Ductal Carcinoma In Situ of the Breast. Am. J. Clin. Pathol. 2020, 154, 596–609. [Google Scholar]
- Meevassana, J.; Varophas, S.; Prabsattru, P.; Kamolratanakul, S.; Ruangritchankul, K.; Kitkumthorn, N. 5-Methylcytosine immunohistochemistry for predicting cutaneous melanoma prognosis. Sci. Rep. 2024, 14, 7554. [Google Scholar]
- Asano, N.; Yoshida, A.; Ichikawa, H.; Mori, T.; Nakamura, M.; Kawai, A.; Hiraoka, N. Immunohistochemistry for trimethylated H3K27 in the diagnosis of malignant peripheral nerve sheath tumours. Histopathology 2017, 70, 385–393. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).