
Application of Various Machine Learning Models for Process Stability of Bio-Electrochemical Anaerobic Digestion



Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Preprocessing
2.2. Statistical Analysis
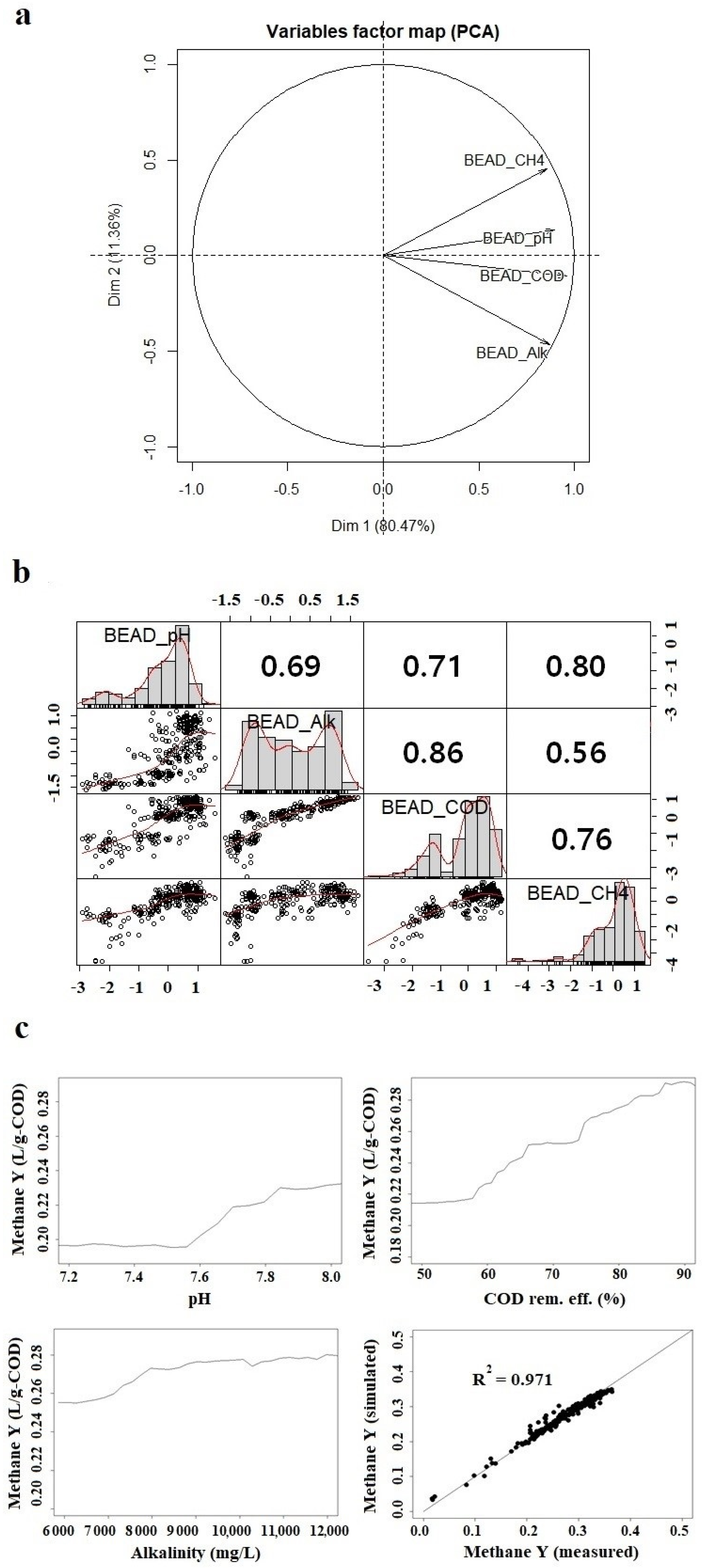
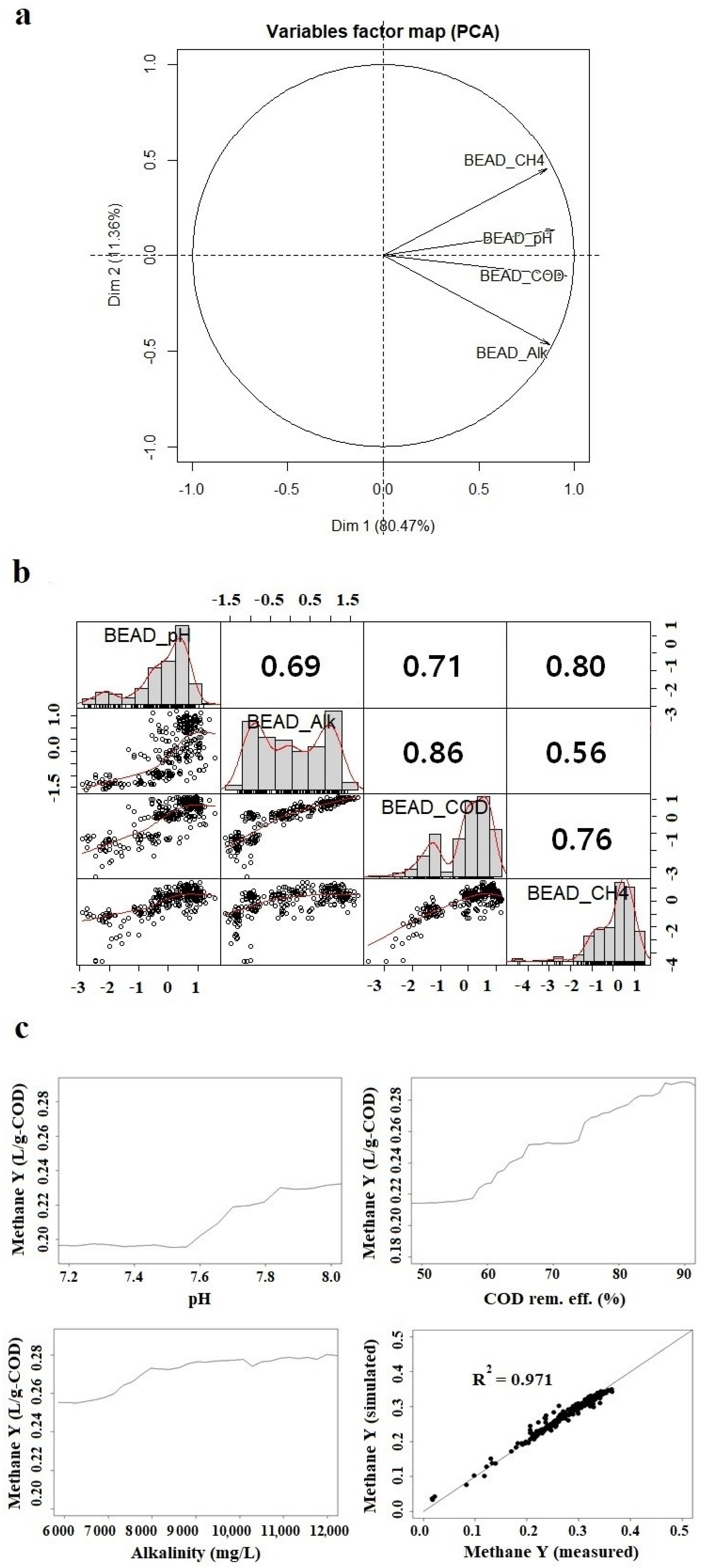
2.2.1. Principal Component Analysis (PCA)
2.2.2. Variable Importance Analysis
2.3. ML
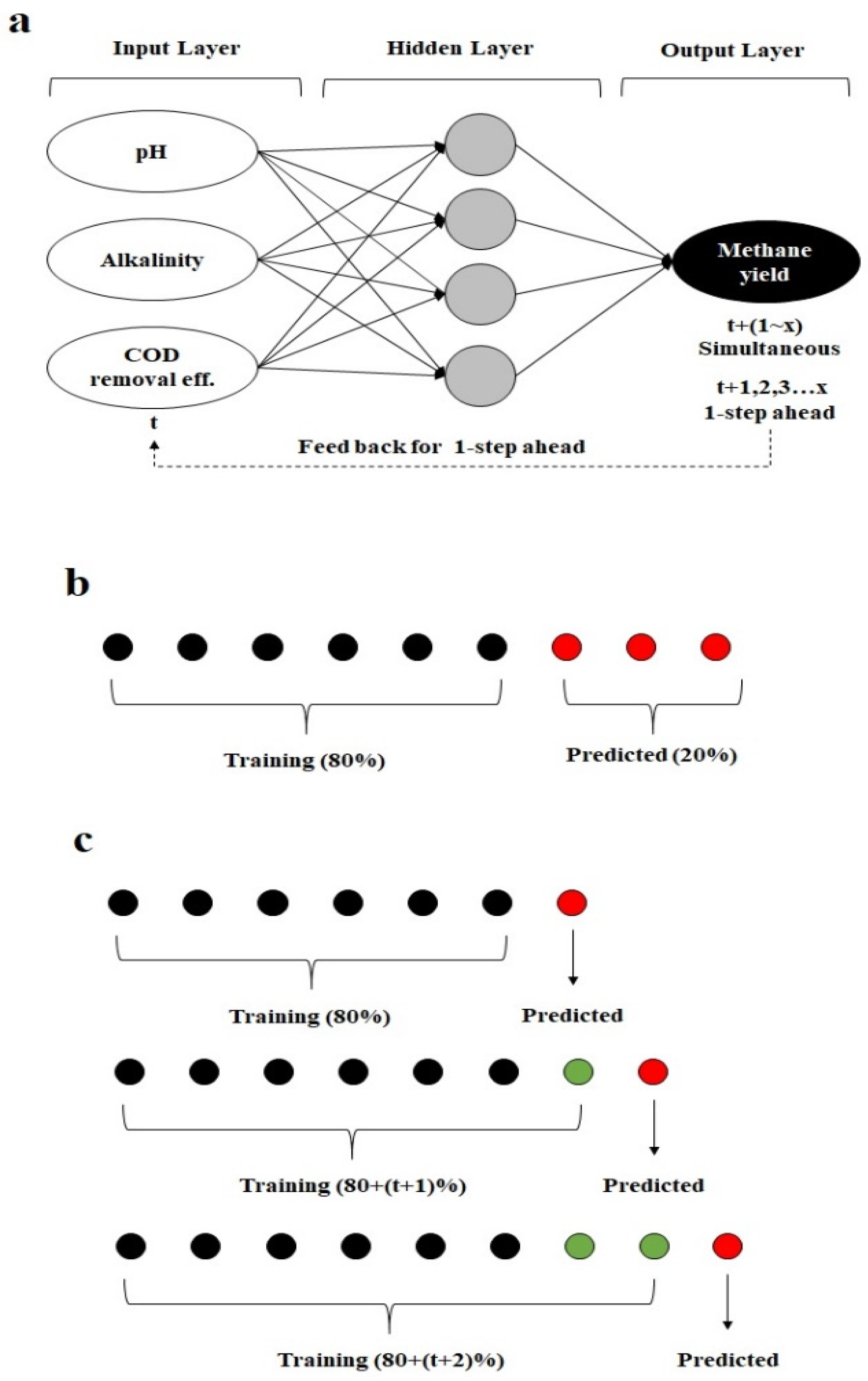
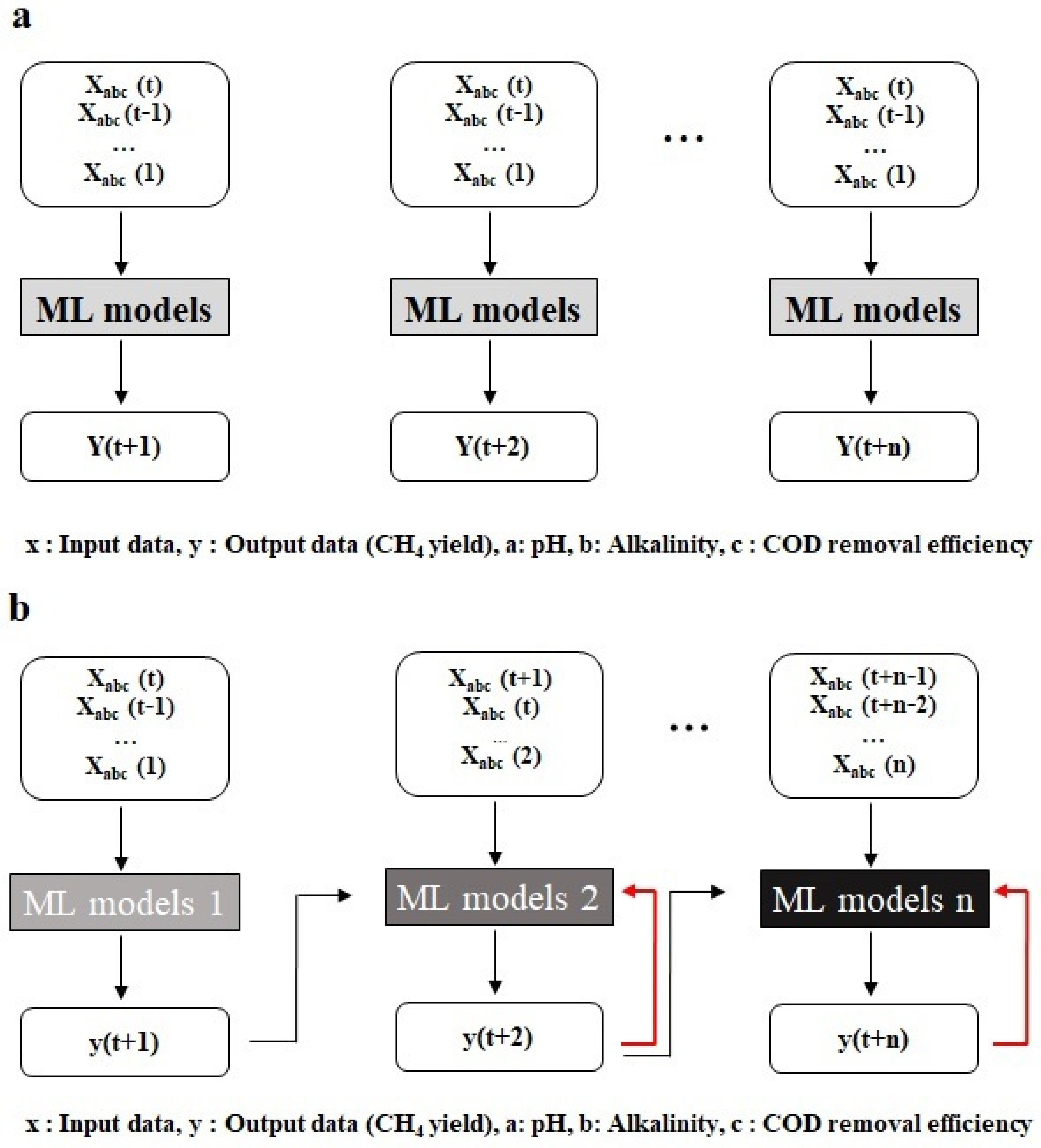
2.3.1. Prediction Models
2.3.2. Validations and Model Accuracy Calculation
2.3.3. Multi-Step Ahead Method
2.3.4. 1-Step Ahead with the Retraining Method
3. Results
3.1. Statistical Analysis
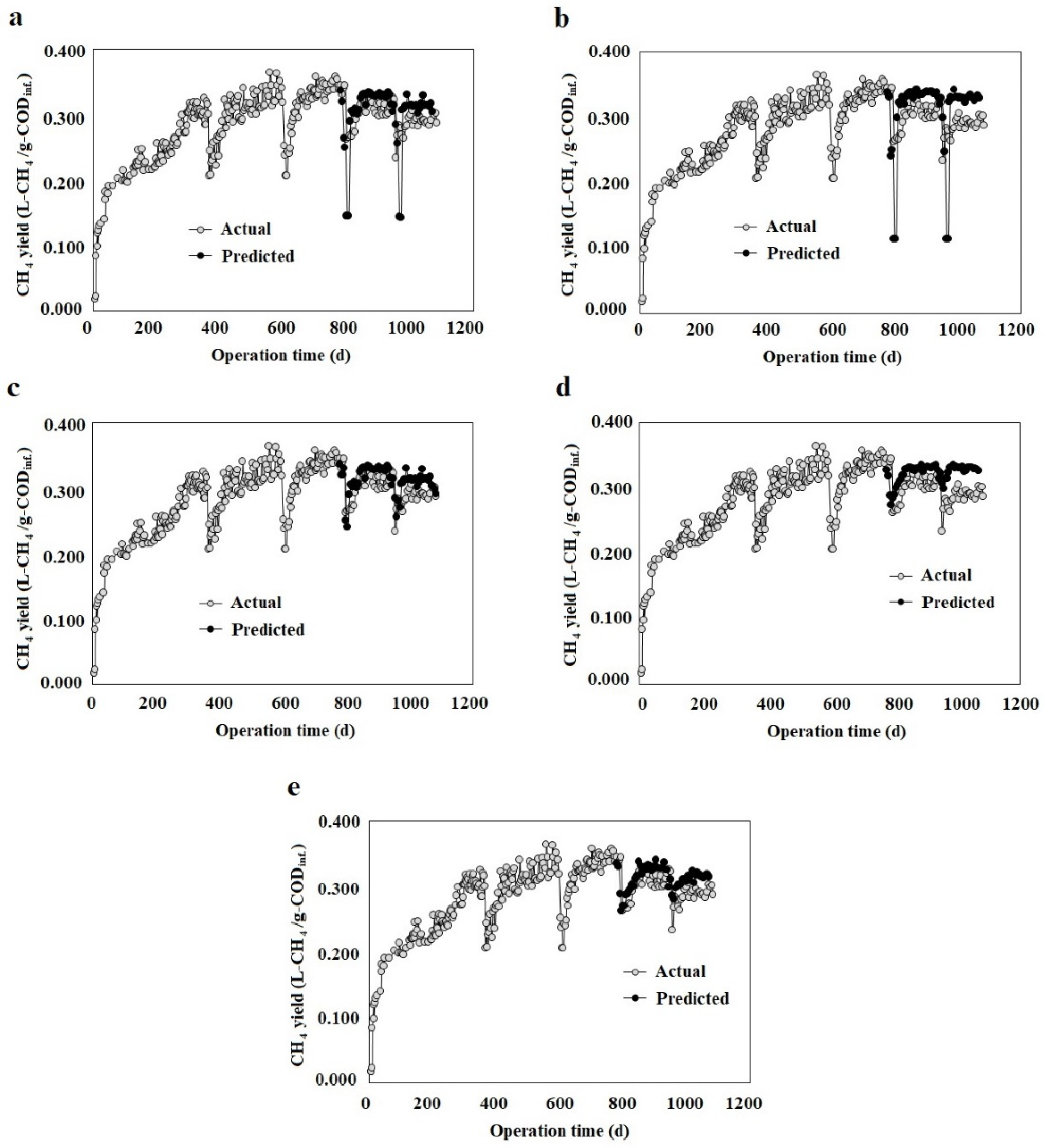
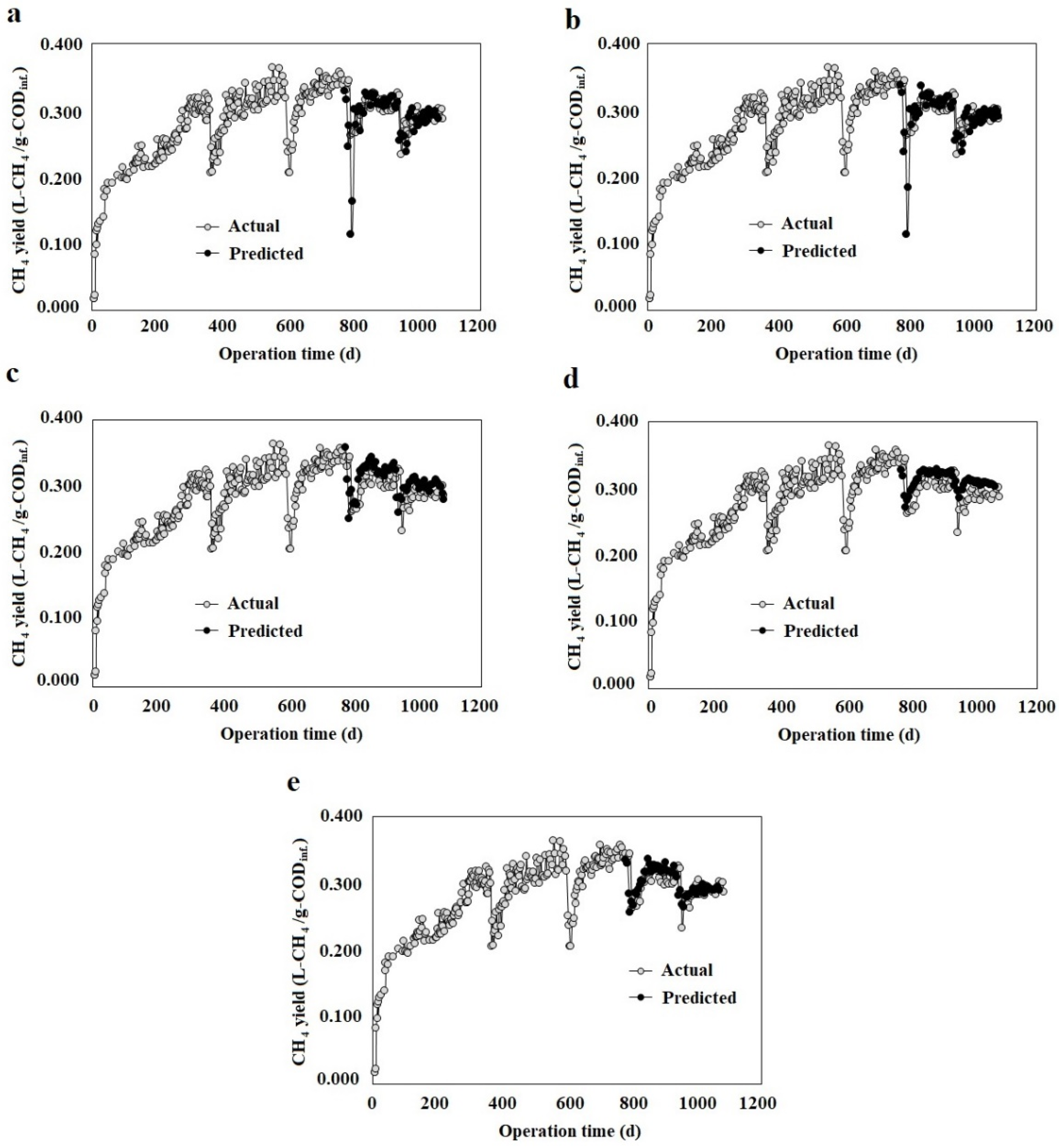
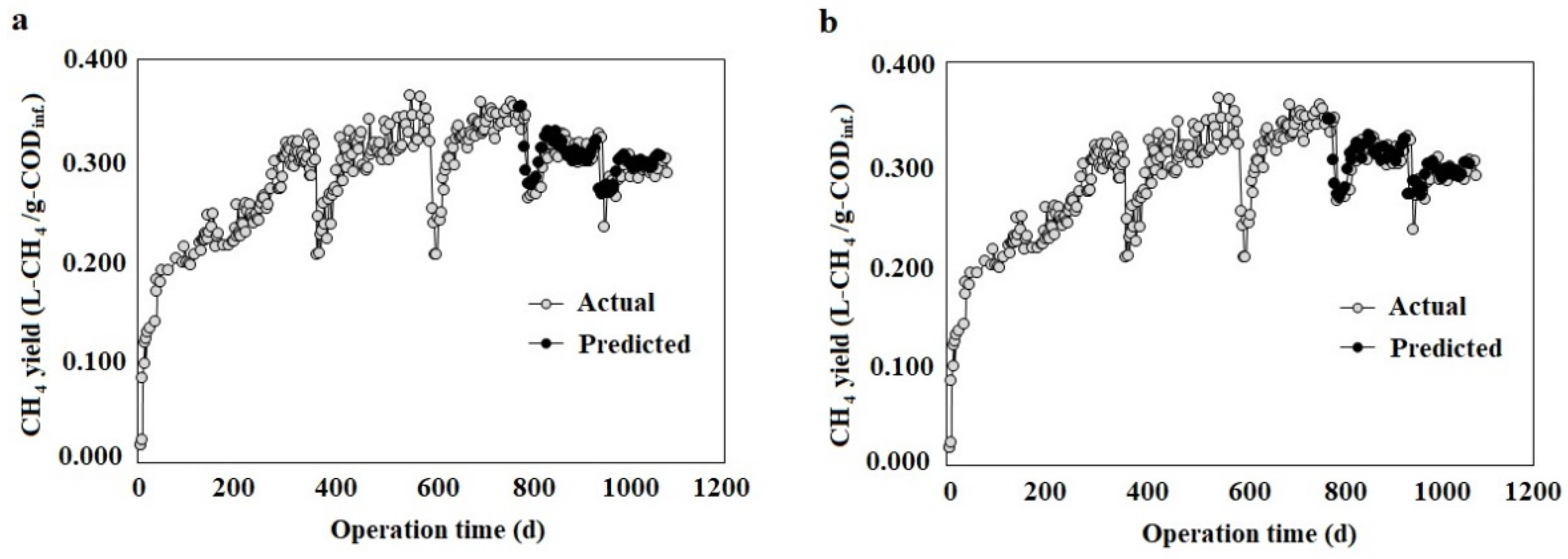
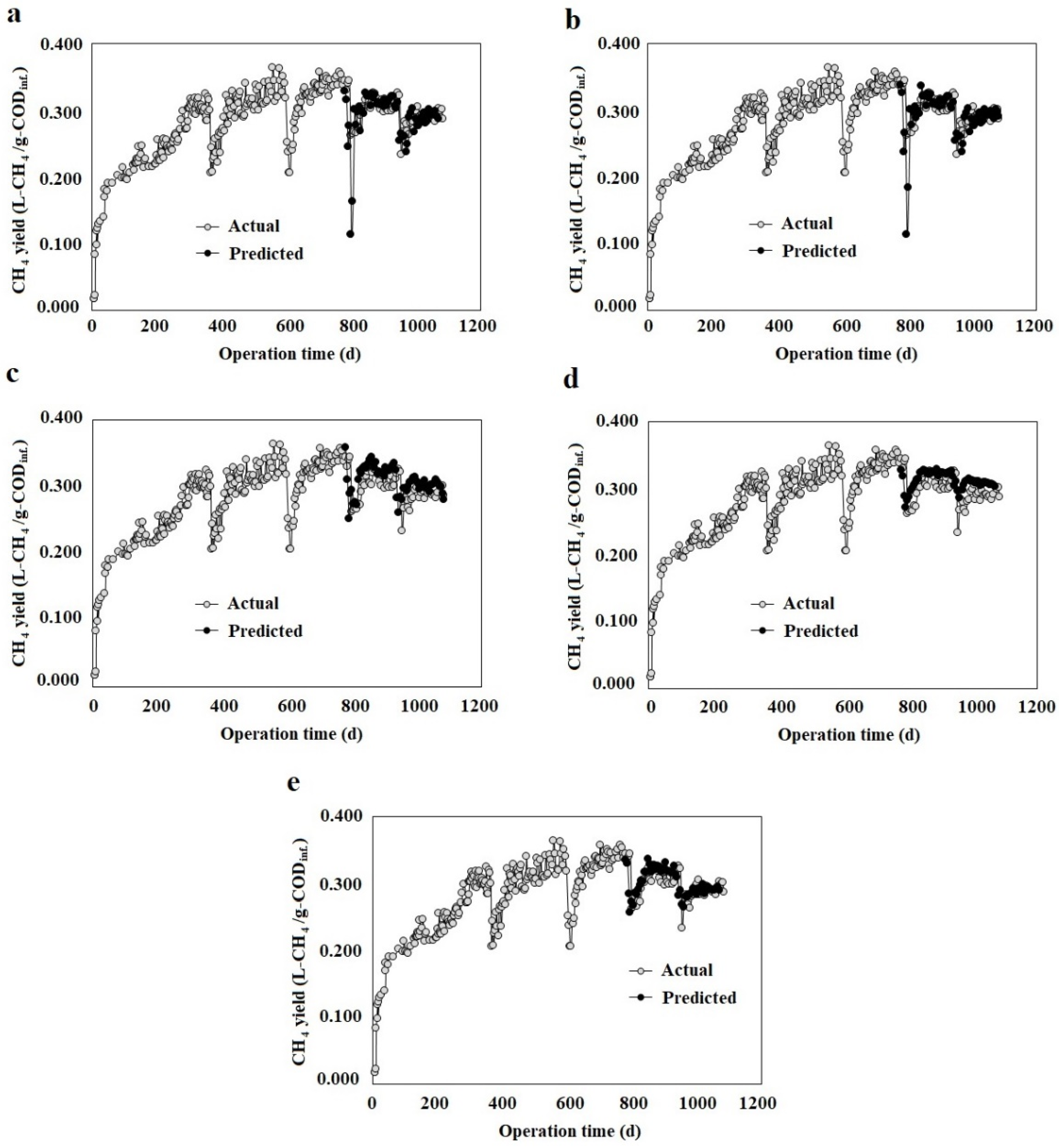
3.2. Multi-Step Ahead ML Models
3.3. 1-Step Ahead ML Models
3.4. Prediction of Methane Yield Using pH as Single Input Data
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adekunle, K.F.; Okolie, J.A. A review of biochemical process of anaerobic digestion. Adv. Biosci. Biotechnol. 2015, 6, 205–212. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Zhang, Y.; Angelidaki, I. Ammonia inhibition on hydrogen enriched anaerobic digestion of manure under mesophilic and thermophilic conditions. Water Res. 2016, 105, 314–319. [Google Scholar] [CrossRef] [Green Version]
- Rajagopal, R.; Massé, D.I.; Singh, G. A critical review on inhibition of anaerobic digestion process by excess ammonia. Bioresour. Technol. 2013, 143, 632–641. [Google Scholar] [CrossRef] [PubMed]
- Moset, V.; Bertolini, E.; Cerisuelo, A.; Cambra, M.; Olmos, A.; Cambra-López, M. Start-up strategies for thermophilic anaerobic digestion of pig manure. Energy 2014, 74, 389–395. [Google Scholar] [CrossRef]
- Chow, W.; Chong, S.; Lim, J.; Chan, Y.; Chong, M.; Tiong, T.; Chin, J.; Pan, G. Anaerobic co-digestion of wastewater sludge: A review of potential co-substrates and operating factors for improved methane yield. Processes 2020, 8, 39. [Google Scholar] [CrossRef] [Green Version]
- Kazemi, P.; Steyer, J.; Bengoa, C.; Font, J.; Giralt, J. Robust data-driven soft sensors for online monitoring of volatile fatty acids in anaerobic digestion processes. Processes 2020, 8, 67. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Cai, W.; Guo, Z.; Wang, L.; Yang, C.; Varrone, C.; Wang, A. Microbial electrolysis contribution to anaerobic digestion of waste activated sludge, leading to accelerated methane production. Renew. Energy 2016, 91, 334–339. [Google Scholar] [CrossRef] [Green Version]
- Park, J.; Kwon, H.; Sposob, M.; Jun, H. Effect of a side-stream voltage supplied by sludge recirculation to an anaerobic digestion reactor. Bioresour. Technol. 2020, 300, 122643. [Google Scholar] [CrossRef]
- Feng, Y.; Zhang, Y.; Chen, S.; Quan, X. Enhanced production of methane from waste activated sludge by the combination of high-solid anaerobic digestion and microbial electrolysis cell with iron–graphite electrode. Chem. Eng. J. 2015, 259, 787–794. [Google Scholar] [CrossRef]
- An, Z.; Feng, Q.; Zhao, R.; Wang, X. Bioelectrochemical methane production from food waste in anaerobic digestion using a carbon-modified copper foam electrode. Processes 2020, 8, 416. [Google Scholar] [CrossRef] [Green Version]
- De Vrieze, J.; Gildemyn, S.; Arends, J.B.; Vanwonterghem, I.; Verbeken, K.; Boon, N.; Verstraete, W.; Tyson, G.W.; Hennebel, T.; Rabaey, K. Biomass retention on electrodes rather than electrical current enhances stability in anaerobic digestion. Water Res. 2014, 54, 211–221. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Li, X.; Zhao, X.; Li, Y. Factors affecting the efficiency of a bioelectrochemical system: A review. RSC Adv. 2019, 9, 19748–19761. [Google Scholar] [CrossRef]
- Escapa, A.; Mateos, R.; Martínez, E.J.; Blanes, J. Microbial electrolysis cells: An emerging technology for wastewater treatment and energy recovery. From laboratory to pilot plant and beyond. Renew. Sustain. Energy Rev. 2016, 55, 942–956. [Google Scholar] [CrossRef]
- Beegle, J.R.; Borole, A.P. Energy production from waste: Evaluation of anaerobic digestion and bioelectrochemical systems based on energy efficiency and economic factors. Renew. Sustain. Energy Rev. 2018, 96, 343–351. [Google Scholar] [CrossRef]
- Nair, V.V.; Dhar, H.; Kumar, S.; Thalla, A.K.; Mukherjee, S.; Wong, J.W. Artificial neural network based modeling to evaluate methane yield from biogas in a laboratory-scale anaerobic bioreactor. Bioresour. Technol. 2016, 217, 90–99. [Google Scholar] [CrossRef]
- Antwi, P.; Li, J.; Boadi, P.O.; Meng, J.; Shi, E.; Deng, K.; Bondinuba, F.K. Estimation of biogas and methane yields in an UASB treating potato starch processing wastewater with back propagation artificial neural network. Bioresour. Technol. 2017, 228, 106–115. [Google Scholar] [CrossRef]
- Antwi, P.; Li, J.; Meng, J.; Deng, K.; Koblah Quashie, F.; Li, J.; Opoku Boadi, P. Feedforward neural network model estimating pollutant removal process within mesophilic upflow anaerobic sludge blanket bioreactor treating industrial starch processing wastewater. Bioresour. Technol. 2018, 257, 102–112. [Google Scholar] [CrossRef] [Green Version]
- Pandey, D.S.; Das, S.; Pan, I.; Leahy, J.J.; Kwapinski, W. Artificial neural network based modelling approach for municipal solid waste gasification in a fluidized bed reactor. Waste Manag. 2016, 58, 202–213. [Google Scholar] [CrossRef] [Green Version]
- Ismail, S.; Elsamadony, M.; Fujii, M.; Tawfik, A. Evaluation and optimization of anammox baffled reactor (AnBR) by artificial neural network modeling and economic analysis. Bioresour. Technol. 2019, 271, 500–506. [Google Scholar] [CrossRef]
- Park, J.; Lee, B.; Kwon, H.; Jun, H. Contribution analysis of methane production from food waste in bulk solution and on bio-electrode in a bio-electrochemical anaerobic digestion reactor. Sci. Total Environ. 2019, 670, 741–751. [Google Scholar] [CrossRef]
- Park, J.; Jun, H.; Heo, T. Retraining prior state performances of anaerobic digestion improves prediction accuracy of methane yield in various machine learning models. Appl. Energy 2021, 298, 117250. [Google Scholar] [CrossRef]
- Park, J.; Lee, B.; Tian, D.; Jun, H. Bioelectrochemical enhancement of methane production from highly concentrated food waste in a combined anaerobic digester and microbial electrolysis cell. Bioresour. Technol. 2018, 247, 226–233. [Google Scholar] [CrossRef]
- Park, J.; Lee, B.; Park, H.; Jun, H. Long-term evaluation of methane production in a bio-electrochemical anaerobic digestion reactor according to the organic loading rate. Bioresour. Technol. 2019, 273, 478–486. [Google Scholar] [CrossRef] [PubMed]
- Bern, C.; Walton-Day, K.; Naftz, D. Improved enrichment factor calculations through principal component analysis: Examples from soils near breccia pipe uranium mines, Arizona, USA. Environ. Pollut. 2019, 248, 90–100. [Google Scholar] [CrossRef] [PubMed]
- Jung, S.Y.; Kim, I.K. Analysis of water quality factor and correlation between water quality and Chl-a in middle and downstream weir section of Nakdong River. J. Korean Soc. Environ. Eng. 2017, 39, 89–96. [Google Scholar] [CrossRef]
- Suzuki, K. (Ed.) Artificial Neural Networks: Methodological Advances and Biomedical Applications; BoD—Books on Demand: Janeza Trdine, Croatia, 2011. [Google Scholar]
- Shin, Y.; Kim, T.; Hong, S.; Lee, S.; Lee, E.; Hong, S.; Lee, C.; Kim, T.; Park, M.S.; Park, J.; et al. Prediction of chlorophyll-a concentrations in the Nakdong River using machine learning methods. Water 2020, 12, 1822. [Google Scholar] [CrossRef]
- Xiao, H.; Huang, D.; Pan, Y.; Liu, Y.; Song, K. Fault diagnosis and prognosis of wastewater processes with incomplete data by the auto-associative neural networks and ARMA model. Chemom. Intell. Lab. Syst. 2017, 161, 96–107. [Google Scholar] [CrossRef]
- Jain, V.K.; Banerjee, A.; Kumar, S.; Kumar, S.; Sambi, S.S. Predictive modeling of an industrial UASB reactor using NARX neural network. In Proceedings of the IREC2015 The Sixth International Renewable Energy Congress, Sousse, Tunisia, 24–26 March 2015; pp. 1–6. [Google Scholar]
- Shi, X.; Yuan, X.; Wang, Y.; Zeng, S.; Qiu, Y.; Guo, R.; Wang, L. Modeling of the methane production and pH value during the anaerobic co-digestion of dairy manure and spent mushroom substrate. Chem. Eng. J. 2014, 244, 258–263. [Google Scholar] [CrossRef]
- Zhai, N.; Zhang, T.; Yin, D.; Yang, G.; Wang, X.; Ren, G.; Feng, Y. Effect of initial pH on anaerobic co-digestion of kitchen waste and cow manure. Waste Manag. 2015, 38, 126–131. [Google Scholar] [CrossRef]
- Hwang, M.H.; Jang, N.J.; Hyun, S.H.; Kim, I.S. Anaerobic bio-hydrogen production from ethanol fermentation: The role of pH. J. Biotechnol. 2004, 111, 297–309. [Google Scholar] [CrossRef]
- Wang, K.; Yin, J.; Shen, D.; Li, N. Anaerobic digestion of food waste for volatile fatty acids (VFAs) production with different types of inoculum: Effect of pH. Bioresour. Technol. 2014, 161, 395–401. [Google Scholar] [CrossRef]
- Ifaei, P.; Karbassi, A.; Lee, S.; Yoo, C. A renewable energies-assisted sustainable development plan for Iran using techno-econo-socio-environmental multivariate analysis and big data. Energy Convers. Manag. 2017, 153, 257–277. [Google Scholar] [CrossRef]
- De Clercq, D.; Jalota, D.; Shang, R.; Ni, K.; Zhang, Z.; Khan, A.; Wen, Z.; Caicedo, L.; Yuan, K. Machine learning powered software for accurate prediction of biogas production: A case study on industrial-scale Chinese production data. J. Clean. Prod. 2019, 218, 390–399. [Google Scholar] [CrossRef]
- Camberos, S.U.A.; Gurubel, K.J.; Sanchez, E.N.; Aguirre, S.A.; Perez, R.G. Neuronal modeling of a two stages anaerobic digestion process for biofuels production. IFAC-PapersOnLine 2018, 51, 408–413. [Google Scholar] [CrossRef]
- Zuluaga, C.D.; Álvarez, M.A.; Giraldo, E. Short-term wind speed prediction based on robust Kalman filtering: An experimental comparison. Appl. Energy 2015, 156, 321–330. [Google Scholar] [CrossRef]
- Wang, D.; Luo, H.; Grunder, O.; Lin, Y. Multi-step ahead wind speed forecasting using an improved wavelet neural network combining variational mode decomposition and phase space reconstruction. Renew. Energy 2017, 113, 1345–1358. [Google Scholar] [CrossRef]
- Sadeghassadi, M.; Macnab, C.J.B.; Gopaluni, B.; Westwick, D. Application of neural networks for optimal-setpoint design and MPC control in biological wastewater treatment. Comput. Chem. Eng. 2018, 115, 150–160. [Google Scholar] [CrossRef]
- Das, L.; Kumar, G.; Rani, M.D.; Srinivasan, B. A novel approach to evaluate state estimation approaches for anaerobic digester units under modeling uncertainties: Application to an industrial dairy unit. J. Environ. Chem. Eng. 2017, 5, 4004–4013. [Google Scholar] [CrossRef]
- Zhou, P.; Li, Z.; Snowling, S.; Baetz, B.W.; Na, D.; Boyd, G. A random forest model for inflow prediction at wastewater treatment plants. Stoch. Environ. Res. Risk Assess. 2019, 33, 1781–1792. [Google Scholar] [CrossRef]
- Zhou, P.; Li, Z.; Snowling, S.; Goel, R.; Zhang, Q. Short-term wastewater influent prediction based on random forests and multi-layer perceptron. J. Environ. Inform. Lett. 2019, 1, 87–93. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Hai, F.I.; Zhan, X.; Guo, W.; Ngo, H.H.; Price, W.E.; Nghiem, L.D. Anaerobic co-digestion: A critical review of mathematical modelling for performance optimization. Bioresour. Technol. 2016, 222, 498–512. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, D.; Gadhamshetty, V.; Nitayavardhana, S.; Khanal, S.K. Automatic process control in anaerobic digestion technology: A critical review. Bioresour. Technol. 2015, 193, 513–522. [Google Scholar] [CrossRef] [PubMed]
- Latif, M.A.; Mehta, C.M.; Batstone, D.J. Influence of low pH on continuous anaerobic digestion of waste activated sludge. Water Res. 2017, 113, 42–49. [Google Scholar] [CrossRef]
- Boe, K.; Batstone, D.J.; Steyer, J.P.; Angelidaki, I. State indicators for monitoring the anaerobic digestion process. Water Res. 2010, 44, 5973–5980. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Jiang, D.; Lee, B.; Jun, H. Towards the practical application of bioelectrochemical anaerobic digestion (BEAD): Insights into electrode materials, reactor configurations, and process designs. Water Res. 2020, 184, 116214. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Stage 1 | Stage 2 | Stage 3 | Stage 4 | Stage 5 |
|---|---|---|---|---|---|
| Operation period (days) | 0–365 | 366–598 | 599–795 | 796–950 | 951–1086 |
| OLR (kg-COD/m3·d) | 2.5 ± 0.6 | 1.0 ± 0.2 | 6.0 ± 0.3 | 8.0 ± 0.3 | 10.0 ± 0.4 |
| pH | 7.7 ± 0.3 | 8.0 ± 0.2 | 8.1 ± 0.1 | 8.1 ± 0.1 | 8.2 ± 0.1 |
| Alkalinity (g/L as CaCO3) | 7.6 ± 0.9 | 10.1 ± 0.8 | 13.9 ± 0.8 | 14.8 ± 0.7 | 15.3 ± 0.7 |
| Total VFAs (mg/L) | 2.6 ± 0.9 | 3.1 ± 0.2 | 3.9 ± 0.2 | 4.6 ± 0.3 | 5.3 ± 0.3 |
| COD removal efficiency (%) | 67.8 ± 7.2 | 71.4 ± 2.5 | 73.5 ± 3.0 | 75.1 ± 2.3 | 76.3 ± 1.7 |
| CH4 production (L/day) | 15.7 ± 4.6 | 33.9 ± 3.9 | 51.2 ± 6.3 | 63.4 ± 3.9 | 74.7 ± 3.4 |
| CH4 yield (L-CH4/g-COD) | 0.32 ± 0.07 | 0.35 ± 0.04 | 0.35 ± 0.04 | 0.36 ± 0.02 | 0.36 ± 0.01 |
| ML Models | Packages |
|---|---|
| Random Forest (RF) | Package “randomForest” |
| Extreme gradient boosting (XGboost) | Package “rxgboost” |
| Support Vector Regression (SVR) | Package “e1071” |
| Long Short-Term Memory (LSTM) | Package “rnn” and “keras” |
| Recurrent Neural Networks (RNN) | Package “rnn” |
| Parameters | RMSE (L-CH4/g-COD) | |||||
|---|---|---|---|---|---|---|
| RF | XGboost | SVR | LSTM | RNN | ||
| BEAD | Multi-step ahead | 0.041 | 0.053 | 0.056 | 0.055 | 0.025 |
| 1-step ahead | 0.028 | 0.030 | 0.021 | 0.022 | 0.017 | |
| Parameters | RMSE (L-CH4/g-COD) | |||||
|---|---|---|---|---|---|---|
| RF | XGboost | SVR | LSTM | RNN | ||
| BEAD | Multi-step ahead | 0.020 | 0.023 | 0.022 | 0.021 | 0.019 |
| 1-step ahead | 0.019 | 0.022 | 0.019 | 0.019 | 0.017 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheon, A.; Sung, J.; Jun, H.; Jang, H.; Kim, M.; Park, J. Application of Various Machine Learning Models for Process Stability of Bio-Electrochemical Anaerobic Digestion. Processes 2022, 10, 158. https://doi.org/10.3390/pr10010158
Cheon A, Sung J, Jun H, Jang H, Kim M, Park J. Application of Various Machine Learning Models for Process Stability of Bio-Electrochemical Anaerobic Digestion. Processes. 2022; 10(1):158. https://doi.org/10.3390/pr10010158
Chicago/Turabian StyleCheon, Ain, Jwakyung Sung, Hangbae Jun, Heewon Jang, Minji Kim, and Jungyu Park. 2022. "Application of Various Machine Learning Models for Process Stability of Bio-Electrochemical Anaerobic Digestion" Processes 10, no. 1: 158. https://doi.org/10.3390/pr10010158
APA StyleCheon, A., Sung, J., Jun, H., Jang, H., Kim, M., & Park, J. (2022). Application of Various Machine Learning Models for Process Stability of Bio-Electrochemical Anaerobic Digestion. Processes, 10(1), 158. https://doi.org/10.3390/pr10010158