
Algorithmic Differentiation of the MWGS-Based Arrays for Computing the Information Matrix Sensitivity Equations within the Problem of Parameter Identification


Abstract
1. Introduction
- symbolic (analytical) differentiation;
- numerical differentiation;
- automatic (algorithmic) differentiation.
2. Methodology
2.1. Information Kalman Filter and Information Matrix
2.2. The MWGS-Based Array Algorithm for Computing the Information Matrix
| Algorithm 1 [18]. The MWGS-based array IKF. |
| Initialization. Let . Compute the modified Cholesky decomposition. (The modified Cholesky decomposition has the form where A is a symmetric positive definite matrix, is a diagonal matrix, and is a unit triangular (lower or upper) matrix [1,11].) . Set the initial values and , . ▹ For do I. Time Update. Apply the modified Cholesky decomposition for the process noise covariance matrix . Compute matrices and . Find the MWGS factors of matrix as follows: I.A. In the case of the forward MWGS-LD factorization (i.e., ), the following steps should be done: I.B. In the case of the backward MWGS-LD factorization (i.e., ), one has to follow the next steps: Given , find the predicted information state estimate: II. Measurement Update. Apply the modified Cholesky factorization for the measurement noise covariance matrix . Compute matrices and . Find the filtered MWGS factors : Next, compute the filtered estimate by (8). ▹ End. |
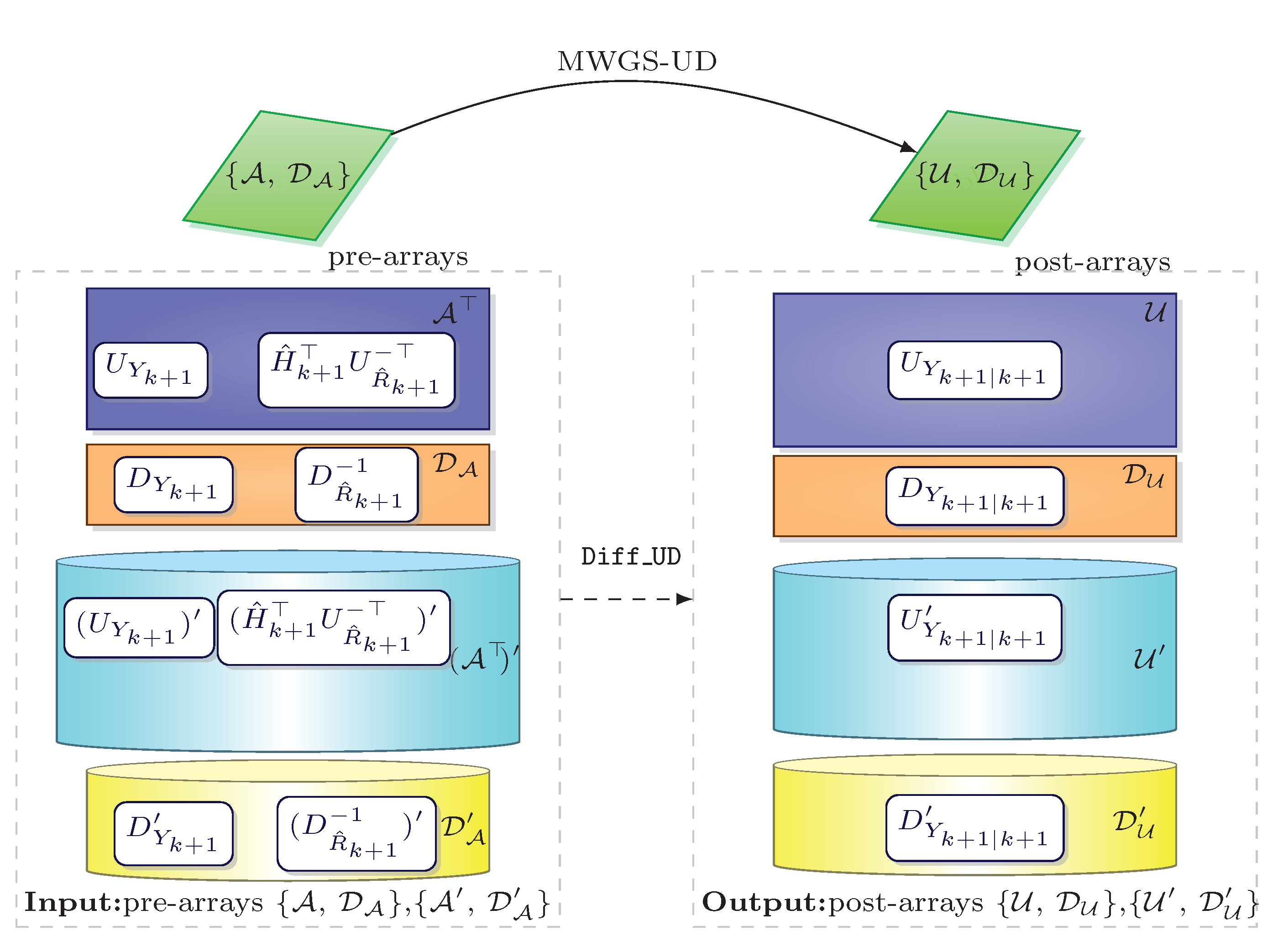
2.3. Algorithmic Differentiation of the MWGS-Based Arrays
- They allow calculating, at a given point, the values of derivatives of elements of the matrix factors obtained by MWGS transformation of the pair of parameterized matrices. In this case, there is no need to calculate values of the derivatives of elements of the MWGS transformation matrix.
- These algorithms require simple addition and multiplication matrix operations, and only one triangular and one diagonal matrix inversion operation. Therefore, they have a simple structure to easily implement in program code.
| Algorithm 2. Diff_LD (LD-based derivative computation). |
| ▹ Input data: , , , |
| , , . ▹ Begin 1 evaluate ← , ← ; 2 evaluate ←, ← ; 3. compute ←MWGS-LD(,); ▹ For do 4 compute X←; 5 split X into three parts ←X; 6 compute V←; 7 split V into three parts ←V; 8 obtain result ← ; 9 obtain result ← . ▹ End for ▹ End. ▹ Output data: , ; , . |
| Algorithm 3. Diff_UD (UD-based derivative computation). |
| ▹ Input data: , , , |
| , , . ▹ Begin 1 evaluate ← , ← ; 2 evaluate ←, ← ; 3 compute ← MWGS-UD(,); ▹ For do 4 compute X←; 5 split X into three parts ←X; 6 compute V←; 7 split V into three parts ←V; 8 obtain result ← ; 9 obtain result ← . ▹ End for ▹ End. ▹ Output data: , ; . |
3. Main Result
The New MWGS-Based Array Algorithm for Computing the Information Matrix Sensitivity Equations
| Algorithm 4. The differentiated MWGS-based array. |
| Initialization. Let . Evaluate the initial value of information matrix . Find , . Apply the modified Cholesky factorization . Find , . Set the initial values and . ▹ For do I. Time Update. I.1 Evaluate matrices , , and . Find , , and , . I.2 Use the modified Cholesky decomposition for matrices and to find , and , . I.3 Given the MWGS factors and their derivatives , find their predicted values and their derivatives () as follows: I.A. In the case of the forward MWGS-LD factorization (i.e., ), the following steps should be taken:
|
I.B. In the case of the backward MWGS-LD factorization (i.e., ), one has to take the next steps:
|
| II. Measurement Update. II.1 Evaluate matrices and . Find and , . II.2 Use the modified Cholesky decomposition for matrices and to find , and , . II.3 Given the MWGS factors and their derivatives , find the corresponding pairs of matrices and () as follows:
▹ End. |
4. Discussion
4.1. Implementation Details of Algorithm 4
- Fill in block pre-arrays with available data.
- Execute an algorithm for calculating derivatives in a matrix MWGS transformation of one of the types corresponding to Case 1 or Case 2.
- As a result, get block post-arrays and read off the required results from them in the form of matrix blocks.
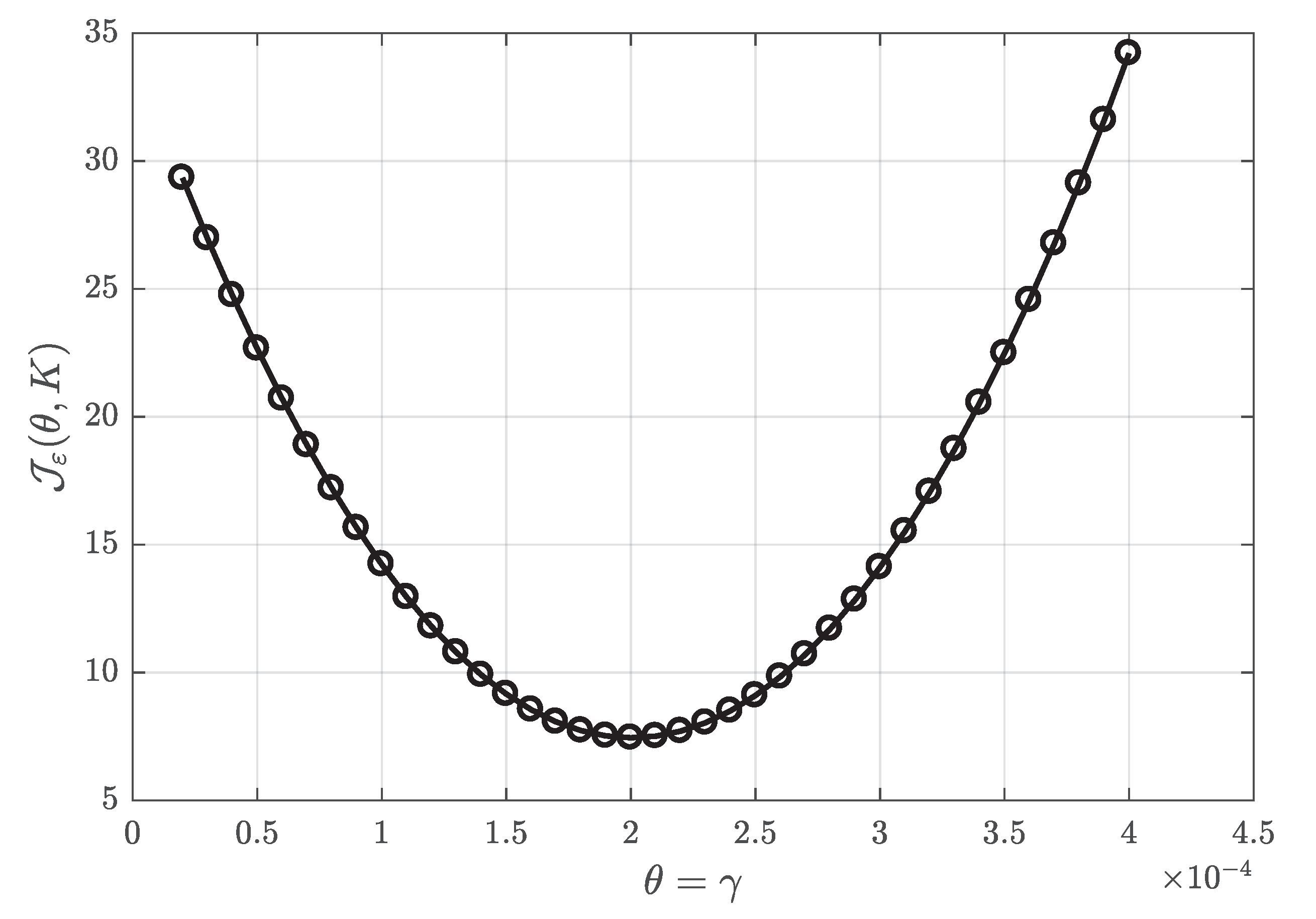
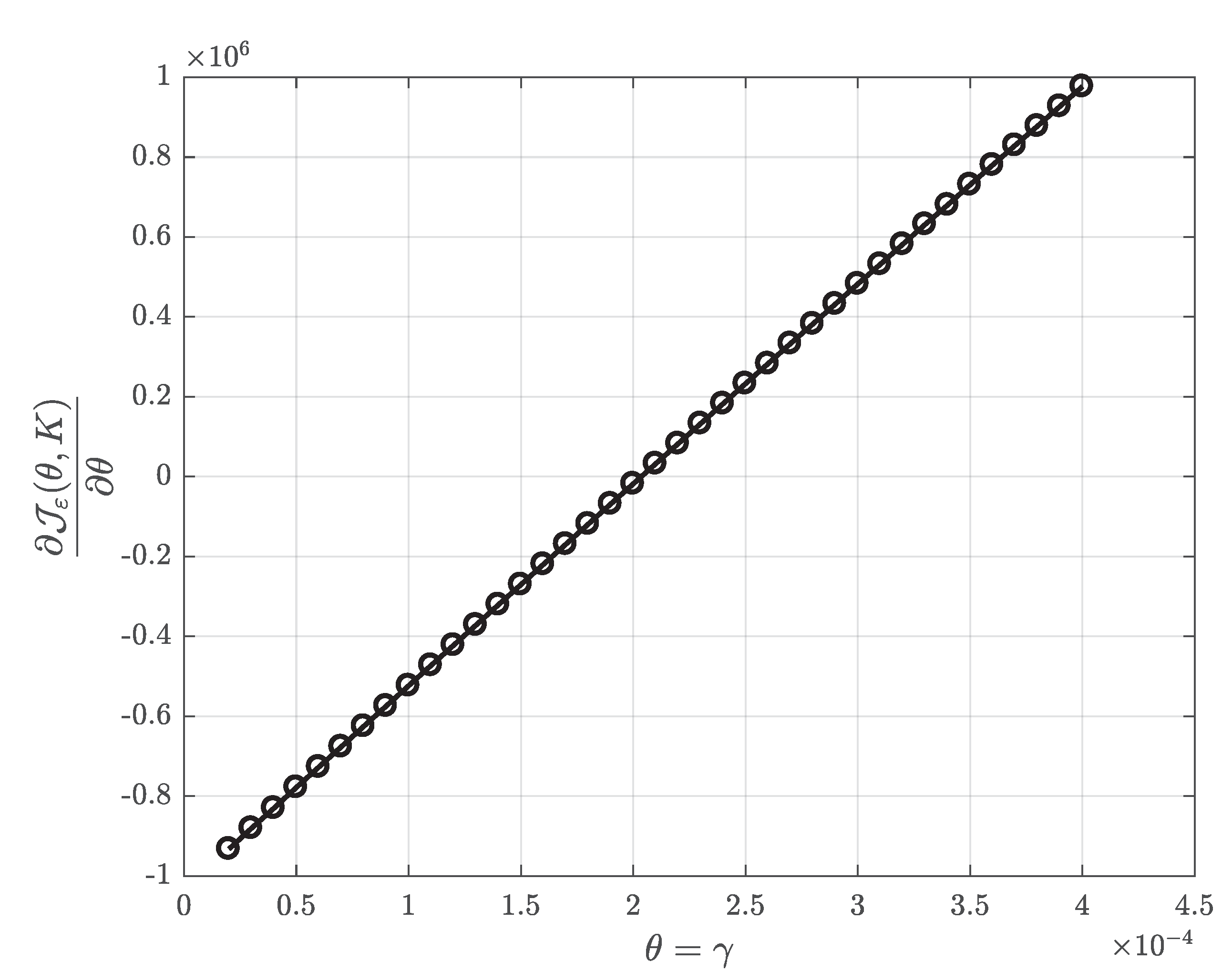
4.2. Application of the Results Obtained to the Problem of Parameter Identification
- it depends on the system observable values only;
- it attains its minimum coincidently with the Original Performance Index (OPI).
| Algorithm 5. The API-based parameter identification computational scheme. |
| BEGIN |
| ✓ Assign an initial parameter estimate for . REPEAT
|
| END |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MWGS | Modified weighted Gram–Schmidt transformation |
| MWGS-LD | Forward MWGS procedure |
| MWGS-UD | Backward MWGS procedure |
| KF | Kalman filter |
| IKF | Information Kalman filter |
| TU | Time update step |
| MU | Measurement update step |
| APA | Active principle of adaptation |
| API | Auxiliary Performance Index |
References
- Golub, G.H.; Van Loan, C.F. Matrix Computations; Johns Hopkins University Press: Baltimore, MD, USA, 1983. [Google Scholar]
- Giles, M. An Extended Collection of Matrix Derivative Results for Forward and Reverse Mode Algorithmic Differentiation; Report 08/01; Oxford University Computing Laboratory: Oxford, UK, 2008; 23p. [Google Scholar]
- Dieci, L.; Eirola, T. Applications of Smooth Orthogonal Factorizations of Matrices. In The IMA Volumes in Mathematics and Its Applications; Springer: New York, NY, USA, 2000; Volume 119, pp. 141–162. [Google Scholar]
- Dieci, L.; Russell, R.D.; Van Vleck, E.S. On the Computation of Lyapunov Exponents for Continuous Dynamical Systems. SIAM J. Numer. Anal. 1997, 34, 402–423. [Google Scholar] [CrossRef]
- Kunkel, P.; Mehrmann, V. Smooth factorizations of matrix valued functions and their derivatives. Numer. Math. 1991, 60, 115–131. [Google Scholar] [CrossRef]
- Dieci, L. On smooth decompositions of matrices. SIAM J. Matrix Anal. Appl. 1999, 20, 800–819. [Google Scholar] [CrossRef]
- Åström, K.-J. Maximum Likelihood and Prediction Error Methods. Automatica 1980, 16, 551–574. [Google Scholar] [CrossRef]
- Gupta, N.K.; Mehra, R.K. Computational aspects of maximum likelihood estimation and reduction in sensitivity function calculations. IEEE Trans. Autom. Control 1974, AC-19, 774–783. [Google Scholar] [CrossRef]
- Walter, S.F. Structured Higher-Order Algorithmic Differentiation in the Forward and Reverse Mode with Application in Optimum Experimental Design. Ph.D. Thesis, Humboldt-Universität zu Berlin, Berlin, Germany, 2011. [Google Scholar]
- Bierman, G.J. Factorization Methods for Discrete Sequential Estimation; Academic Press: New York, NY, USA, 1977. [Google Scholar]
- Grewal, M.S.; Andrews, A.P. Kalman Filtering: Theory and Practice Using MATLAB, 4th ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2015. [Google Scholar]
- Kailath, T.; Sayed, A.H.; Hassibi, B. Linear Estimation; Prentice Hall: Hoboken, NJ, USA, 2000. [Google Scholar]
- Gibbs, B.P. Advanced Kalman Filtering, Least-Squares and Modeling: A Practical Handbook; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2011. [Google Scholar]
- Grewal, M.S.; Weill, L.R.; Andrews, A.P. Global Positioning Systems, Inertial Navigation, and Integration; John Wiley & Sons, Inc.: New York, NY, USA, 2001. [Google Scholar]
- Tsyganova, J.V.; Kulikova, M.V. State sensitivity evaluation within UD based array covariance filters. IEEE Trans. Autom. Control 2013, 58, 2944–2950. [Google Scholar] [CrossRef]
- Tsyganova, Y.V.; Tsyganov, A.V. On the Computation of Derivatives within LD Factorization of Parametrized Matrices. Bull. Irkutsk. State Univ. Ser. Math. 2018, 23, 64–79. (In Russian) [Google Scholar] [CrossRef]
- Kaminski, P.G.; Bryson, A.E.; Schmidt, S.F. Discrete square-root filtering: A survey of current techniques. IEEE Trans. Autom. Control 1971, AC-16, 727–735. [Google Scholar] [CrossRef]
- Tsyganova, J.V.; Kulikova, M.V.; Tsyganov, A.V. A general approach for designing the MWGS-based information-form Kalman filtering methods. Eur. J. Control 2020, 56, 86–97. [Google Scholar] [CrossRef]
- Björck, A. Solving linear least squares problems by Gram-Schmidt orthogonalization. Bit Numer. Math. 1967, 7, 1–21. [Google Scholar] [CrossRef]
- Tsyganova, J.V.; Kulikova, M.V.; Tsyganov, A.V. Some New Array Information Formulations of the UD-based Kalman Filter. In Proceedings of the 18th European Control Conference (ECC), Napoli, Italy, 25–28 June 2019; pp. 1872–1877. [Google Scholar]
- Ljung, L. System Identification: Theory for the User, 2nd ed.; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Kulikova, M.V. Likelihood Gradient Evaluation Using Square-Root Covariance Filters. IEEE Trans. Autom. Control 2009, 54, 646–651. [Google Scholar] [CrossRef]
- Semushin, I.V.; Tsyganova, J.V.; Tsyganov, A.V. Numerically Efficient LD-computations for the Auxiliary Performance Index Based Control Optimization under Uncertainties. IFAC-PapersOnline 2018, 51, 568–573. [Google Scholar] [CrossRef]
- Boiroux, D.; Juhl, R.; Madsen, H.; Jørgensen, J.B. An Efficient UD-Based Algorithm for the Computation of Maximum Likelihood Sensitivity of Continuous-Discrete Systems. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), ARIA Resort & Casino, Las Vegas, NV, USA, 12–14 December 2016; pp. 3048–3053. [Google Scholar]
- Broxmeyer, C. Inertial Navigation Systems; McGraw-Hill Book Company: Boston, MA, USA, 1956. [Google Scholar]
- Semushin, I.V. Adaptation in Stochastic Dynamic Systems—Survey and New Results I. Int. J. Commun. Netw. Syst. Sci. 2011, 4, 17–23. [Google Scholar] [CrossRef][Green Version]
- Semushin, I.V. Adaptation in Stochastic Dynamic Systems—Survey and new results II. Int. J. Commun. Netw. Syst. Sci. 2011, 4, 266–285. [Google Scholar] [CrossRef][Green Version]
- Semushin, I.V.; Tsyganova, J.V. Adaptation in Stochastic Dynamic Systems—Survey and New Results IV: Seeking Minimum of API in Parameters of Data. Int. J. Commun. Netw. Syst. Sci. 2013, 6, 513–518. [Google Scholar] [CrossRef]
- Semushin, I.V. The APA based time-variant system identification. In Proceedings of the 53rd IEEE Conference on Decision and Control (CDC), Los Angeles, CA, USA, 15–17 December 2014; pp. 4137–4141. [Google Scholar]
- Tsyganova, Y.V. Computing the gradient of the auxiliary quality functional in the parametric identification problem for stochastic systems. Autom. Remote Control 2011, 72, 1925–1940. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| g | |
| a | |
| , | |
| “True” value | |
| Resulting estimate | |
| Relative estimation error |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsyganov, A.; Tsyganova, J. Algorithmic Differentiation of the MWGS-Based Arrays for Computing the Information Matrix Sensitivity Equations within the Problem of Parameter Identification. Mathematics 2022, 10, 126. https://doi.org/10.3390/math10010126
Tsyganov A, Tsyganova J. Algorithmic Differentiation of the MWGS-Based Arrays for Computing the Information Matrix Sensitivity Equations within the Problem of Parameter Identification. Mathematics. 2022; 10(1):126. https://doi.org/10.3390/math10010126
Chicago/Turabian StyleTsyganov, Andrey, and Julia Tsyganova. 2022. "Algorithmic Differentiation of the MWGS-Based Arrays for Computing the Information Matrix Sensitivity Equations within the Problem of Parameter Identification" Mathematics 10, no. 1: 126. https://doi.org/10.3390/math10010126
APA StyleTsyganov, A., & Tsyganova, J. (2022). Algorithmic Differentiation of the MWGS-Based Arrays for Computing the Information Matrix Sensitivity Equations within the Problem of Parameter Identification. Mathematics, 10(1), 126. https://doi.org/10.3390/math10010126