1. Introduction
In order to meet people’s demands, such as searching from the internet, taking high-quality pictures and videos, undergoing medical tests, widespread emails, producing multimedia contents, etc., there is a tremendous and continuous advancement in technology regarding data. Such interests require large digital storage with high-dimensional data sets. The data sets include both meaningful and irrelevant data, which is why ‘’data analysis” and ‘’data classification” topics are gaining more attention in recent years. Data analysis, providing predictions based on the training data, gave birth to machine learning.
Machine learning (ML) is a mega-trend in various fields and can be seen as a collection of computer algorithms that make life easier by predicting outcomes. Fundamentally, ML is based on algorithms (so-called “machines”) to automatically learn from observations (so-called “training data”) and to use the results for future decisions without explicit programming. ML algorithms have applications in almost all areas.
ML is generally categorized as either
unsupervised learning (e.g., clustering),
supervised learning (e.g., classification), or
reinforcement learning (e.g., dynamic programming). In recent years, a new approach has been introduced:
semi-supervised learning, which is a mixture of supervised learning and unsupervised learning. For semi-supervised learning, similarity-based approaches have also gained significant popularity in recent years (see, [
1,
2,
3,
4]).
In this paper, we propose a clustering algorithm that uses similarities between examples by associating weights to each attribute (according to their ability to separate classes) to reduce the size of the data set by combining the data as they form a so-called “clique”. The cliques have been heavily used in random matrix theory, and recently, this concept is being used in clustering algorithms (see, for example, [
5,
6,
7]). More detail is given in
Section 2.
Another important topic in ML is classification. Classification is a task for the predictive modeling problem. The aim of classification is to assign a class label for a given input data. There are several types of classification algorithms. Some well-known and widely used classification algorithms are Naive Bayes, Decision Trees, k-Nearest Neighbours, Logistic Regression, and Support Vector Machines.
Support vector machines (SVMs) are state-of-the-art classification methods used in various fields ([
8,
9,
10]). There are many studies on extensions and improvements for SVMs. In some of these studies, SVMs are used with different clustering algorithms. For example, Wang et al., in [
11], proposed KMSVM, which combines k-means clustering with SVMs. Chen et al., in [
12], extend a least-squares twin support vector machine to a multiple-birth least-squares support vector machine for multi-class classification. Cheng et al., in [
13], study local support vector machines for classification with nonlinear decision surfaces. Arslan et al. proposed a new clustering algorithm to discover the structure of the data set and then used these clusters with SVM in [
2]. Another recent study [
14] used the CURE clustering algorithm with SVMs. All these studies claim to obtain comparable performance with reduced training data set size and less support vectors. A brief introduction to SVMs is given in
Section 3.
Motivated by these recent studies, we propose a new clustering algorithm based on cliques, named
Clique Clustering Algorithm (CC-Algorithm). In
Section 4, the CC-Algorithm is given. The algorithm is also demonstrated by an example in detail.
The main idea of using this clustering algorithm is to reduce the number of training data in the data set that will be used with SVMs (
Section 5). There are three different algorithms proposed in this study:
Centers of Cliques-SVM (CC-SVM),
Homogeneous Cliques Removed-SVM (HOM-R-SVM), and
Heterogeneous Cliques Removed-SVM (HET-R-SVM). Each proposed algorithm demonstrates different characteristics in terms of accuracy, performance, and data reduction ability.
2. Cliques and Clustering
As data sets become larger in size and complexity, data analysis has become the hit research topic in recent years. One of the main goals of clustering is to understand and analyze the data by splitting it into groups of similar items. Each group is named a cluster, and the method is focused on covering the data with a fewer number of clusters (details can be found from [
15]). Although there is no significant definition for clusters since each method has clusters with its own shape, size, and density, it is extensively used in applications, such as web analysis [
16], marketing [
17], computational biology [
18], data mining [
19], machine learning [
20], and many others.
Generating clusters is generally regarded as unsupervised learning because clustering does not use category labels, whereas classification is regarded as supervised learning. A new approach as a combination of unsupervised and supervised learning showed up in 2006 by Chapelle et al. [
21], which is called semi-supervised learning. Most hybrid learning methods use various distance concepts for similarity functions. Similarity functions are generally defined by using Euclidean distance, Chebyshev distance, Jaccard distance, Mahalanobis distance, etc. Different distance functions result in different algorithms. For example, some graph-based approaches can be found in articles [
4,
22,
23]. In [
4], the data set represents a weighted graph that each data element is shown as a vertex and linking the vertices by the edges using a similarity value. However, Chen et al., in [
22], proposed a partially observed unweighted graph. Ames et al. [
6], on the other hand, considered the
k-disjoint-clique optimization problem as a way to express the clustering problem with graphs and cliques. They claimed to solve this NP-hard optimization problem by using convex optimization.
A
clique is a complete subgraph of an undirected graph, i.e., there is an edge between any pair of vertices. It was first used by Luce and Perry (1949) [
24] in social networks and has many different applications in many areas other than graph theory.
In this study, we consider yet another approach for clustering, which is aimed at providing information from the data set that can be used with various classification strategies. We use cliques to obtain clusters. In our approach, the cliques and, therefore, the clusters are obtained with a heuristic algorithm. Instead of solving a problem like the densest k-disjoint-clique optimization problem, the proposed Algorithm 1 obtains dense cliques in a natural way by considering similarities between examples and by using a threshold value.
To achieve this, we subdivide the data into a number of disjoint cliques that maximize the sum of the weights of the edges inside of it. At first sight, the clique idea may look similar to the one in [
6] where Euclidean distance is used for the weights of the edges. However, in this current study, the edge weight is calculated by using a similarity function that is totally different from the distance function. To the best of our knowledge, this is the first algorithm using cliques without using any distance function.
Definition 1. The similarity value between two examples with respect to an attribute , where A is the set of attributes and U is a finite set of objects, is defined asfor a numerical attribute where and is a total function for each and and named the information function. Remark 1. denotes the value of attribute a for the example of the data set
The similarity value defined above calculates the similarity between two vertices for a single attribute. In order to consider the total similarity with respect to a set of attributes, we use the similarity definition below, which is obtained by summing individual similarities using special weights.
Definition 2. The similarity value between two examples with respect to an attribute set is defined aswhere corresponds to the weight for an attribute . As mentioned in the introduction, weights for attributes are calculated according to their performances for separating the classes. The detailed calculation of the weight for an attribute
a is given as:
where
denotes the number of elements in the set
and
’s are defined as below:
where
is the set of values for an attribute
a belonging to class
i,
and
n is the number of classes in a data set. Equations (
1) and (
2) were introduced in [
25], and we direct the reader to there for more details.
3. Support Vector Machines and Classification
Support vector machines (SVMs) were introduced by Vapnik and Chervenenkis in 1974 (see [
26]). SVMs are one of the most popular methods used in ML (indeed, for supervised ML) with the aim of classifying given data by using so-called “training data”. For an introduction to the general theory of SVMs, we direct the reader to the sources [
8,
10,
27,
28,
29] and to the papers [
30,
31,
32,
33] for recent developments, to name a few.
Basically, SVM is an algorithm for finding a separating hyperplane between two classes so that the margin between two classes is maximized. Suppose that the data set is given as
, where
denotes either of two possible classes
for simplicity. In order to find the optimal hyperplane whose normal vector is
and given by Equation
one should consider the constraints:
which can be combined together as
By requiring (if necessary, after rescaling
and
b) that there are some points satisfying the two inequalities as an equality (such points are called “support vectors”), the margin between two classes turns out to be
Hence, in order to find the hyperplane providing the maximum margin between two classes, it is enough to minimize
or equivalently and more simply
By using Lagrange multipliers,
for
one obtains the Lagrangian
We direct the reader to [
8] for a comprehensive and complete account of the remaining convex optimization.
If there is no feasible solution to this optimization problem, i.e., when the data are not separable by a hyperplane, then by introducing extra positive slack variables,
representing the error (when
), the above constraints can be rewritten as:
In this case, the objective function to be minimized is also changed from
to
where
C is a cost parameter for the sum of error terms.
For data sets where classes are non-linearly separated (i.e., when they are separated by some hypersurface), one can use the kernel trick and transform the data set into a higher dimensional Euclidean space by using an appropriate kernel function
. The most common used kernel functions for real-life data in pattern recognition are listed in
Table 1 (see [
34] for details):
In this study, all kernel functions above are tested for each data set, and the best fitted results are chosen with respect to the Standard SVM without reducing any of the data, as will be later explained in
Section 5. Among the 10 data sets used in this study, the best performance is obtained with a linear kernel for 3 of them and with a radial basis kernel for 7 of them. The details are summarized in the Table 3.
4. A Clique Clustering Algorithm
In this section, the “Clique Clustering Algorithm” (CC-Algorithm) is introduced in Algorithm 1, and a detailed example is given for demonstrating the steps of the algorithm. We note here that the proposed CC-Algorithm starts with the most similar pair of examples to construct the cliques. Thus, the cliques obtained naturally represent highly dense cliques.
Notation 1. The following notations and assumptions are being used in the algorithm below, with some conventions to simplify the algorithm and its implementation. Let C denote the set of all attributes for the given data set.
B is a list of index pairs ordered in the decreasing order with respect to the similarity function such that, for where , and denotes the m-th element of the ordered list, Hence, for example, denotes the index , where is the largest. The same ordering is also used for sorting the list A in Step 2.(c) of the algorithm. Moreover, to avoid repetitions, we assume without loss of generality that for any Furthermore, empty list is denoted by
The clique clustering algorithm is presented below. Algorithm 1.
| Algorithm 1: Clique Clustering (CC) Algorithm. |
Input:
Output: List of Cliques, Let B denote the ordered list set of all pairs with for a given threshold t, and this list is ordered by the similarity values from largest to smallest. Set and Repeat until ∖# The below sub-algorithm will repeat until all pairs in the list B have been considered. #∖ - (a)
Let be the first element. # I.e., the pair such that is the largest value. #∖ - (b)
Consider the index sets and similarly, and then form a list from intersection of and ; ∖# is the index set of vertices where there is an edge between and ; similarly, is the index set of vertices where there is an edge between and , and hence, A is the list of indices k such that forms a clique. #∖ - (c)
Sort A as an ordered list by similarity values from largest to smallest according to for and ∖# In order to obtain the densest cliques, we will check each element of A one by one, after checking whether the remaining elements are included in the clique or not. #∖ - (d)
Set Repeat until ∖# The below sub-routine will repeat until all indices in the list have been considered. #∖ Let be the first element. ∖# Densest clique construction: As conducted before, with largest similarity value of #∖ ∖# Find all vertices such that Recall that is the set of index pairs for which Hence, either or #∖ Find, if any, vertices such that there is no edge between and ∖# If there exists such any set of vertices containing cannot form a clique. Thus, we should remove such elements from A for the clique under construction. #∖ Update A and as and ∖# The set A is reduced by removing some elements. In order to check the remaining elements for forming a clique, we also remove them from the iteration set and repeat with the next element. #∖ Next ∖# until #∖.
- (e)
update the list ∖# A clique is obtained, and added to the list of cliques. Now, we will remove from any pair associated with clique vertices. #∖ - (f)
For each set - (g)
- (h)
- (i)
Next ∖# until #∖.
Return
|
An Example
The following sample data were obtained from the Iris data set, selecting 60 rows, 20 from each class, randomly. Moreover, in order to demonstrate the clique algorithm above, only the first two attributes were used, see
Figure 1.
For chosen attributes,
the weights of each attribute are calculated from the sample and represented as a vector
, as described in
Section 2. Then, according to this weight vector, the similarities are calculated:
| Seq. | Sim. | i | j |
| 1.0000 | 38 | 52 |
| 1.0000 | 36 | 56 |
| 1.0000 | 33 | 58 |
| | ⋮ |
| 0.2065 | 14 | 48 |
| 0.1865 | 14 | 44 |
| 0.1865 | 14 | 45 |
After choosing a threshold, in this example,
we obtain only the first 255 rows from the above table:
| Seq. | Sim. | i | j |
| | ⋮ |
| 0.9001 | 29 | 39 |
| 0.9001 | 27 | 30 |
| 0.9001 | 8 | 23 |
Performing the CC-Algorithm described above, we obtain the cliques;
| Clq. | | | | | | | | |
| 38 | 52 | 30 | 34 | 51 | 60 |
| 36 | 56 | 25 | 28 | 35 | 39 | 40 | 43 |
| 33 | 58 | 22 | 26 | 32 | 55 | 57 | 59 |
| ⋮ | ⋮ |
| 23 | 41 |
| 42 | 50 |
| 3 | 12 |
Among 60 examples, 55 are listed in the first 255 rows above. With the clique algorithm, these 55 example are separated into 12 disjoint subsets. Among 12 cliques, 7 of them are homogeneous, i.e., all examples belonging to a clique have the same class type. The remaining five cliques are heterogeneous, all having examples exactly from two different classes. In
Figure 2, all 12 cliques are shown with different colors, and the remaining 5 data (55 out of 60 are already in cliques) are marked as Clique 0 for completeness and simplicity.
5. The Proposed Classification Algorithms
The idea of using clustering as an intermediate step before applying learning algorithms is an active research topic. For example, [
11] proposed KMSVM, which combines k-means clustering with SVMs. In [
14], a well-known clustering algorithm (CURE) is applied to discover the structure of the training data set before applying SVMs. In this study, we propose yet another approach by using the proposed CC-Algorithm. Different from the previous studies in the literature, the proposed approach uses the concept of complete cliques to obtain clusters of the training data set.
The main idea of the proposed classification algorithms is to discover structural information of the data by using the proposed clique clustering approach. We expect that this will reduce the training data set size while at the same time improving the classification algorithm.
Although one may consider different strategies to achieve this goal, in this study, we considered three basic strategies. In the first strategy, the centers of the cliques are used for training the SVM. This algorithm will be called the Centers of Cliques-SVM (CC-SVM). In the second strategy, cliques contain only one class category, i.e., homogeneous cliques are removed and heterogeneous cliques are replaced with their centers before applying SVM. This approach will be called the Homogeneous Cliques Removed-SVM (HOM-R-SVM). In the third strategy, cliques contain more than one class category, i.e., heterogeneous cliques are removed and homogeneous cliques are replaced with their centers before applying SVM. This approach will be called the Heterogeneous Cliques Removed-SVM (HET-R-SVM).
All three approaches will reduce the original training data set size by some amount. This will also affect the selection of support vectors. It is expected that this will result in avoiding some of the over-fitting problems that may be encountered.
After applying the clique-clustering algorithm, the training set will be partitioned into two parts: the cliques denoted by and the remaining elements denoted by . Assuming that there are l cliques and r remaining elements, we have and , where .
5.1. Centers of Cliques (CC-SVM) Algorithm
The basic idea in this approach is to use the cliques to reduce the data set by replacing each clique with its center. The main steps of this approach are as follows:
If we analyze our previous sample example, the number of examples is reduced to
data, corresponding to 5 data from
7 data from homogeneous cliques, each clique is replaced with its center; and 10 data, 2 from each of the 5 heterogeneous cliques containing examples from two classes and within each such clique, and centers are calculated for each group of data that has the same class labels. All details are illustrated in
Figure 3, where all orange arrows show a reduction within homogeneous cliques belonging to “setosa” class, and most green and blue arrows show a reduction within heterogeneous cliques; however, there is one homogeneous green clique and there are two homogeneous blue cliques. With 22 data, we obtain a better accuracy level when compared with the standard SVM using all 60 data.
5.2. Homogeneous Cliques Removed (HOM-R-SVM) Algorithm
The basic idea of this approach is to reduce the data set by removing homogeneous cliques and replacing each heterogeneous clique with their centers. The main steps of this approach are as follows:
For our sample example, the number of examples is reduced to
data only. All details are illustrated in
Figure 4. Then, the standard SVM is applied only to these 15 data. The resulting accuracy level is comparable to the accuracy of the standard SVM with fewer examples.
5.3. Heterogeneous Cliques Removed (HET-R-SVM) Algorithm
The basic idea of this approach is to reduce the data set by removing heterogeneous cliques and replacing each homogeneous clique with its center. The main steps of this approach are as follows:
Finally, for the sample example, the number of examples is reduced to
data. All details are illustrated in
Figure 5. The result is the same as the standard SVM with fewer examples.
6. Application to Real Data Sets and Performance
In order to analyze the performance of the proposed classifiers, we considered 10 data sets that have also been used in some other studies (see, for example, [
2,
14,
25]). We note that all data sets have numerical attributes only. The data sets represent different application areas and various properties. Some of them have a relatively large number of class categories, whereas some have a relatively large number of examples, see
Table 2.
A few of the data sets needed some slight changes or adjustment before applying the algorithms. For example, 16 rows from “Breast Cancer Wisconsin” have missing values in one attribute, so for consistency, all these 16 rows have been deleted. For the “Ionosphere” data set, the second attribute is constant for all instances, so this attribute is completely removed before using the data. For the “Ecoli” data set, the fourth attribute (presence of charge) is almost constant, and all the columns are equal to 0.5, except for one row with a value of 1. Since train and test data are randomly chosen, for the cases where the data with the exceptional value of 1 for this attribute belong to test data, the SVM will report an error. For this reason, the fourth attribute is completely removed from this data set before running simulations.
Figure 6 shows the performance of all three proposed algorithms in terms of accuracy. In general, it is clear from the figure that the proposed classification algorithms achieve similar accuracy results as for the standard SVM with a reduced training data set size and fewer support vectors. For the Ecoli, Glass, and Blood Transfusion data sets a decrease in accuracy is observed. The degree of decrease depends on the particular algorithm. For example, for the Ecoli and Glass data sets, there is quite a decrease in accuracy for the HET-R-SVM algorithm. On the other hand, for the Blood Transfusion data set, the worst performance is obtained with the HOM-R-SVM algorithm. Finally, one can also see that the CC-SVM algorithm shows a more robust behavior compared to the other proposed SVM algorithms.
Instead of comparing the accuracy values of the test data for each data set, we provide detailed analysis of the results in
Table 3. In this table,
k denotes the kernel as given in
Table 1,
t denotes the threshold used in the clique algorithm in
Section 4,
n denotes the number of the training data set for “Std. SVM” and the average number of reduced data of the corresponding SVM for five runs, whereas
similarly denotes the number of support vectors for each SVM, and finally, “Acc.” denotes the accuracy of the classification of the test data obtained for each SVM.
The results in
Table 3 show that, overall, the proposed algorithms achieve the same accuracy with a smaller training data set size and fewer support vectors. Only for the Wine and Sonar_All data sets, the reduction may be negligible, but this is indeed to achieve the best performance. For example, for the Wine data set, instead of
if
is considered, then
for HOM-R-SVM; and
for HET-R-SVM; and
for CC-SVM. Similarly, for Sonar_All data set, instead of
if
is considered, then
for HOM-R-SVM; and
for HET-R-SVM; and
for CC-SVM.
For the Transfusion data set, we decided to report two different threshold values, and , because, for the former one, HOM-R-SVM and CC-SVM have better accuracy values for the test data; however, for the later one, HET-R-SVM performs much better.
In addition to the accuracy rates given in
Table 3,
Table 4 shows the true positive (TP) rate, false positive (FP) rate, and ROC areas for the data sets considered in this study. These results were calculated using the WEKA software [
35] after obtaining the clique clusters with the proposed clustering algorithm. The results confirm the analysis given for
Table 3. In general, almost the same performance as the standard SVM is obtained with the proposed algorithms using reduced training data sets in terms of TP and FP rates as well as ROC area.
The reduction in training size and number of support vectors is very high for most of the data sets. In addition, one can observe that the CC-SVM algorithm achieves comparable (sometimes even better) accuracy for all data sets compared to the standard SVM. On the other hand, HOM-R-SVM achieves the best results for the Iris and Breast Cancer Wisconsin data sets, whereas HET-R-SVM achieves the best results for the Vehicle and Haberman’s Survival data sets. Details about the amount of reduction is given in
Figure 7,
Figure 8 and
Figure 9 for each algorithm separately for the data ratio versus accuracy ratio. In these charts, the following ratios are represented:
and
Figure 7 shows that, overall, CC-SVM achieves almost the same performance as the standard SVM with a reduced training data set. Only for the Glass data set a significant decrease in accuracy is observed, which is still the best among the three proposed algorithms. In addition, for the Ecoli, Iris, and Blood Transfusion data sets, the data reduction is very high with ratios of less than 8%.
Figure 8 shows that overall HOM-R-SVM achieves comparable performance to the standard SVM with a reduced training data set. Only for the Glass data set a significant decrease in accuracy is observed. In addition, for the Ecoli and Transfusion data sets, the data reduction is very high with ratios of less than 7%.
Figure 9 shows that, overall, HET-R-SVM achieves almost the same performance as the standard SVM with a reduced training data set, except for the Ecoli and Glass data sets. For these two data sets, a significant decrease in accuracy is observed. In addition, for the Ecoli, Haberman, and Transfusion data sets, the data reduction is very high with ratios of less than 6%.
These results also show that all three algorithms actually capture some different aspects of the data sets. For example, although the best performance (with an accuracy ratio of 1.02 and data reduction ratio of 0.42) for the Haberman data set is obtained with the CC-SVM algorithm, the HET-R-SVM shows a similar performance (with an accuracy ratio of 0.97) with only a fraction of 6% of the original training data set.
7. Discussion
The results show that for most of the data sets, the three algorithms show similar performances. For example, for the BC-Wisconsin and Wine data sets, all three algorithm show a similar performance and data reduction behavior. In contrast, for the Ecoli, Glass, and Transfusion data sets, the algorithms show some clear differences. For example, for the Ecoli data set, only the HET-R-SVM shows a significant decrease in accuracy compared to the standard SVM. For the Glass data set, all three algorithms achieve less accuracy compared to the standard SVM. For this data set, the best accuracy is achieved with the CC-SVM algorithm. For the Transfusion data set, the best accuracy is achieved with the HET-R-SVM algorithm.
In summary, one can see that for some data sets, all three algorithms show similar performances. Conversely, for some data sets, one of the algorithms shows the best performance. Thus, for some of the data sets, as expected, either HOM-R-SVM or HET-R-SVM may perform better than the usual scenario where CC-SVM performs better. The choice of the corresponding algorithms depends on the user’s needs and the structure of the data set or classes.
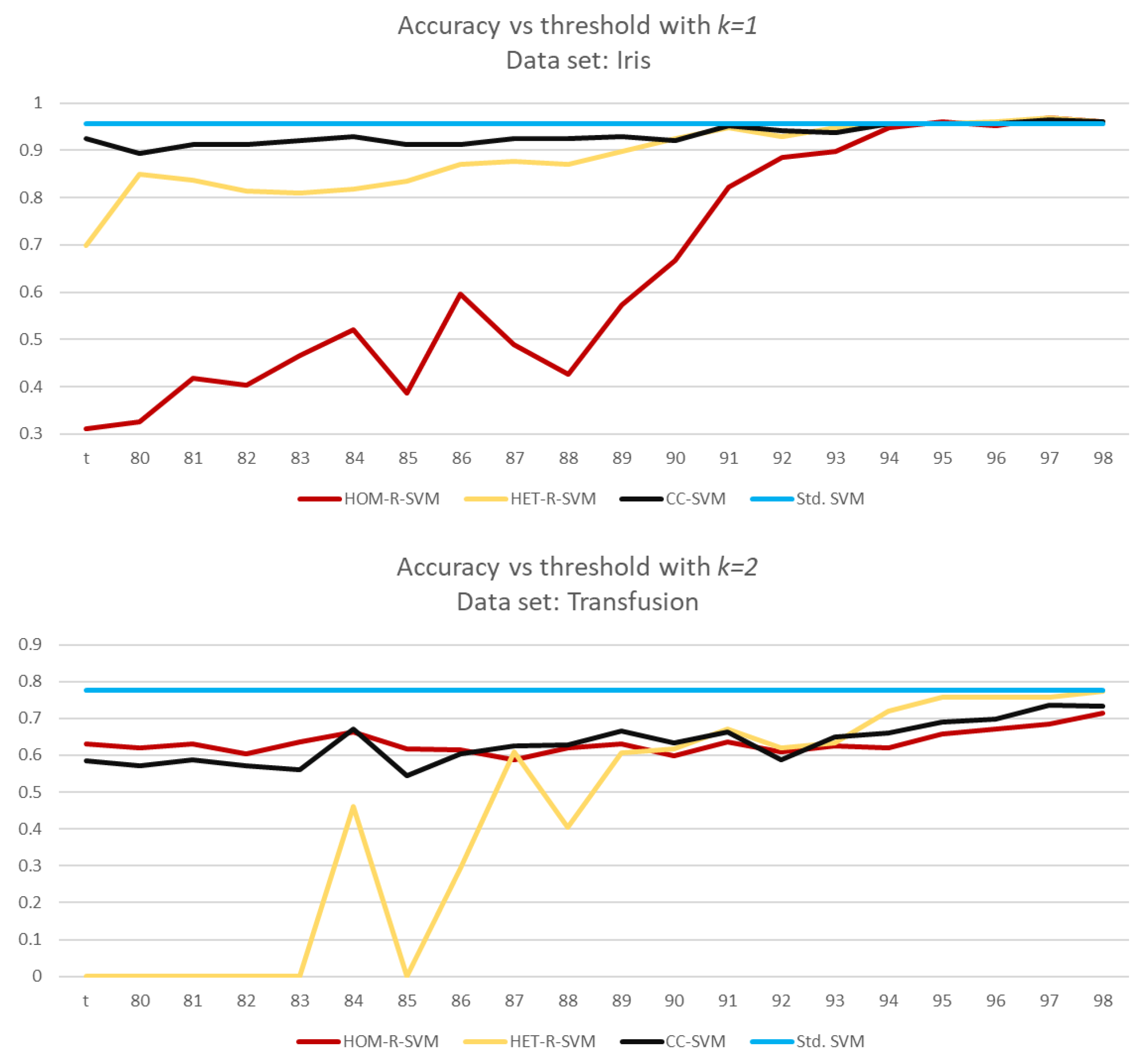
For a detailed analysis, we run another set of simulations from to with a step size of 0.01. In all data sets, CC-SVM is the most consistent algorithm. Two graphs below show how a SVM algorithm may fluctuate according to the data set.
For the Iris data set, HET-R-SVM and CC-SVM are consistent for
but HOM-R-SVM gives reasonable accuracy for larger values of
With larger values of
the ratio
also increases (see
Figure 10).
This behavior, “fluctuating”, is not specific to HOM-R-SVM, as the Transfusion data set shows in
Figure 10. HET-R-SVM does not give consistent accuracy values for
, even though HET-R-SVM gives the best accuracy for
On the other hand, both HOM-R-SVM and CC-SVM are consistent for all values of
Even though, the accuracy rates differ, as expected, the ratio
is almost typical.
Both
Figure 10 and
Figure 11 show that for smaller values of
the number of examples used in SVM reduces significantly, whereas for larger values of
t, more data are being used in SVM. Furthermore, depending on the distribution of the data, as seen for Transfusion data set in
Figure 11, even for larger values of
there is still a reduction in the size of data before using SVM. This is also similar for the number of support vectors.
In conclusion, we proposed a new clustering algorithm based on cliques that can be used to discover relevant information for classification algorithms. Three different strategies for using the information obtained by the clique clustering algorithm were investigated. The results based on 10 real data sets obtained from the UCI repository [
36] show that comparable accuracy performance can be obtained by these proposed algorithms with a smaller training data set size and fewer support vectors. In addition, the results indicate that each proposed classification algorithm can capture different aspects of the training data sets.
It is known that SVMs can have some problems with large data sets. For example, the performance of SVMs decrease significantly when the number of examples in the training data set increases ([
37]). The results of this study show that the proposed classification algorithms are of potential use for investigating new classification strategies based on SVMs that can be used with large data sets.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}