
Channel and Power Allocation for Multi-Cell NOMA Using Multi-Agent Deep Reinforcement Learning and Unsupervised Learning


Abstract
1. Introduction
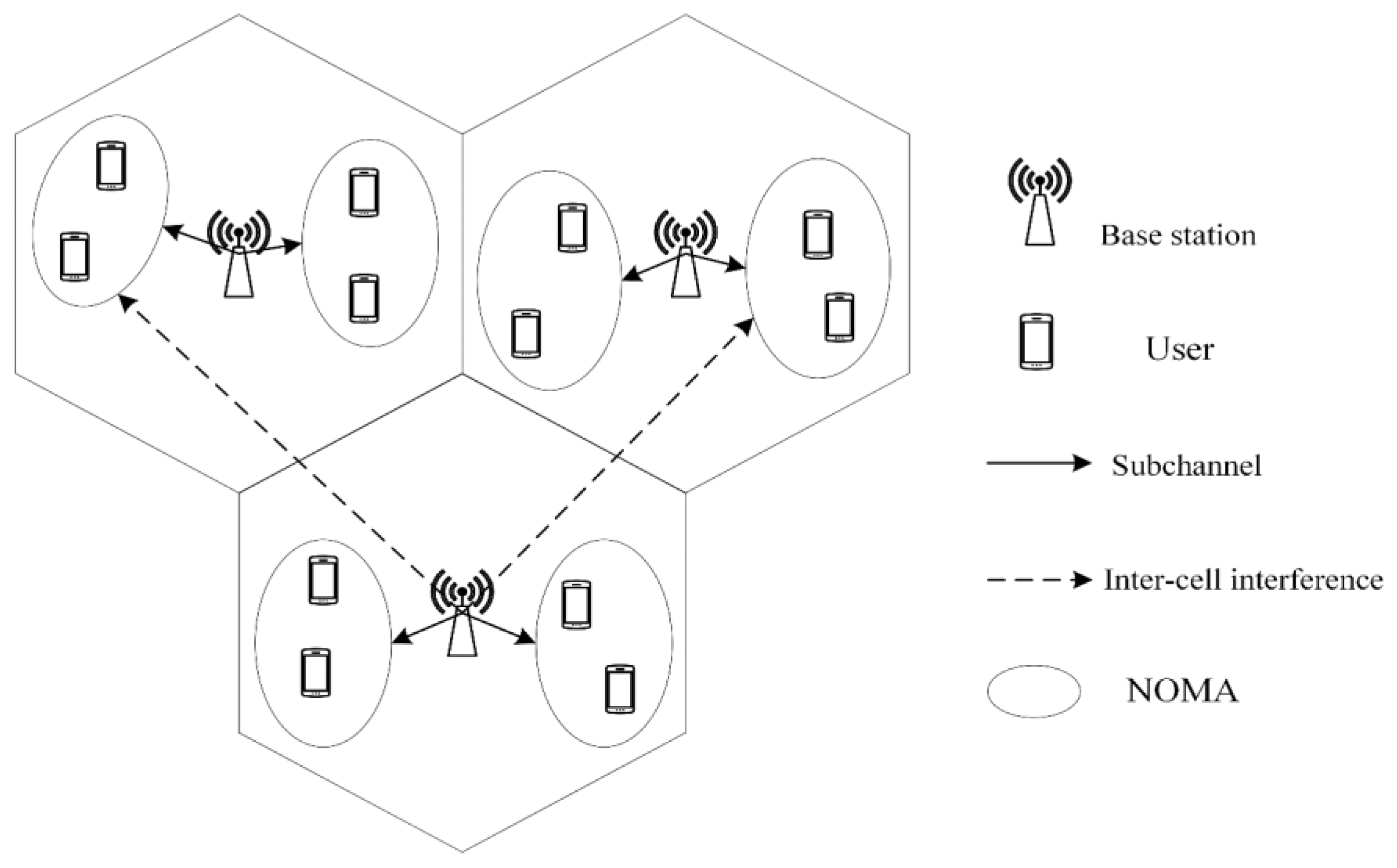
2. System Model
3. Problem Formulation and Resource Allocation
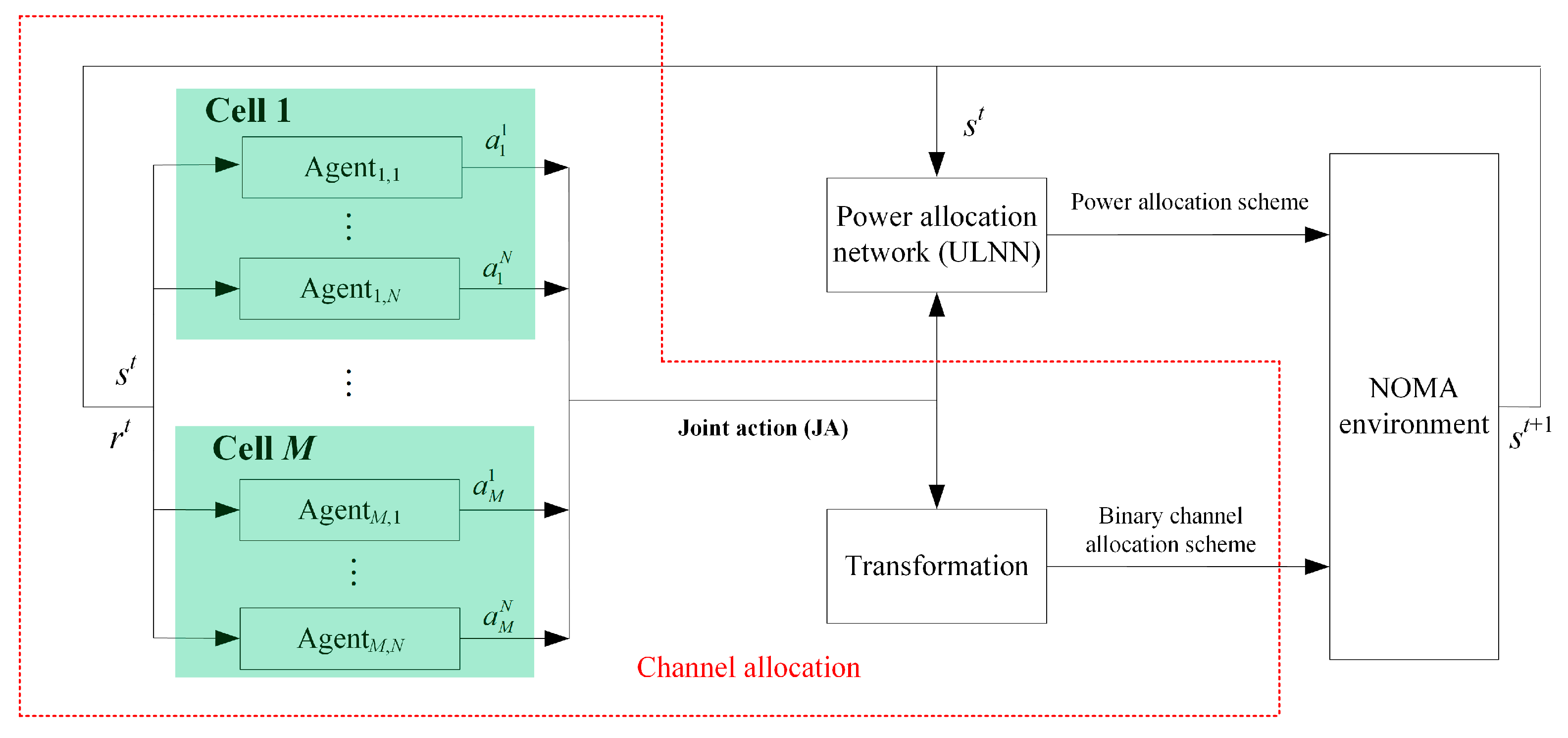
4. Channel Allocation Based on Multi-Agent Deep Reinforcement Learning
4.1. Channel Allocation Formulation
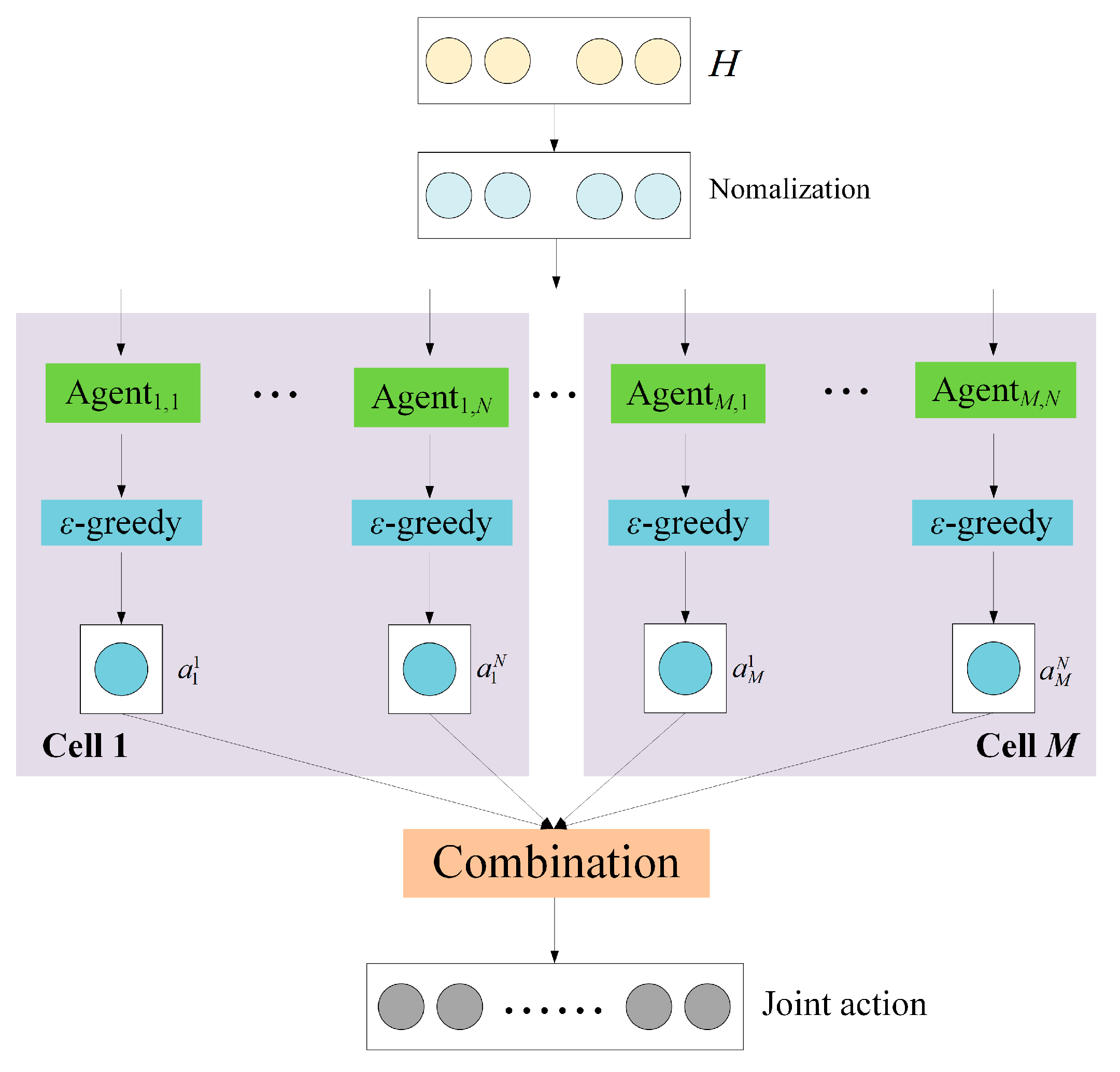
4.2. Channel Allocation Using Multi-Agent Deep Reinforcement Learning
- (1)
- State: In this paper, the energy efficiency is taken as the optimization goal in the NOMA system, each agent should consider the global information of the environment when selecting actions. Therefore, this NOMA system adopts a centralized architecture, and the state of the environment is characterized by the global channel gain information , .
- (2)
- Action: Since a channel should be allocated to two different users, the action represents a combination of two different users. The size of the action space of the agent in the cell is . It is noted that, since the number of users in each cell may be different, the action space of the agents in different cells may also be different. If there are 3 users in the cell m, the size of the action space of the agent in the cell m is , and the action space is shown as , where action 0 indicates that the agent has selected the 1st and 2nd users, action 1 indicates that the agent has selected the 1st and 3rd users, and action 2 indicates that the agent has selected the 2nd and 3rd users.
- (3)
- Reward: Since the NOMA system uses the energy efficiency as the optimization goal, this paper adopts the energy efficiency as the reward function.
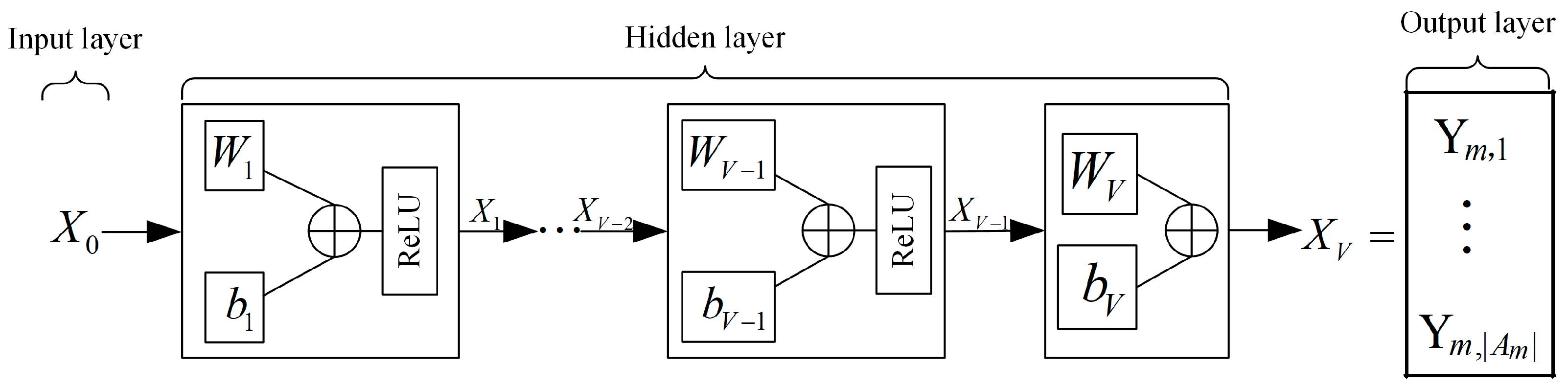
4.3. Proposed Multi-Agent Deep Reinforcement Learning Neural Network
4.4. Training Algorithm for MDRLNN
| Algorithm 1 MDRLNN for channel allocation |
| Input: State space S; The experience pool; The initialized MDRLNN Output: The well-trained MDRLNN; joint action; channel allocation scheme 1: for t do 2: for each cell m do 3: for each channel n do 4: ← -greedy strategy based on the output of 5: end for 6: end for 7: , ← ← [, , …, , …, , …, ] 8: , …, }, {,…,} ← {, …, } ← randomly generated by the system 9: = max 10: ← ← argmax 11: the sample data () is stored in the experience pool 12: if the number of the sample data in the experience pool reaches a certain level then 13: A batch Ӽ of sample data () is randomly selected 14: for each cell j do 15: for each subchannel i do 16: Loss(θ) = 17: θ ← Adam(θ, ) 18: end for 19: end for 20: test the MDRLNN 21: end if 22: end for |
5. Unsupervised Learning for Power Allocation
5.1. Power Allocation Formulation
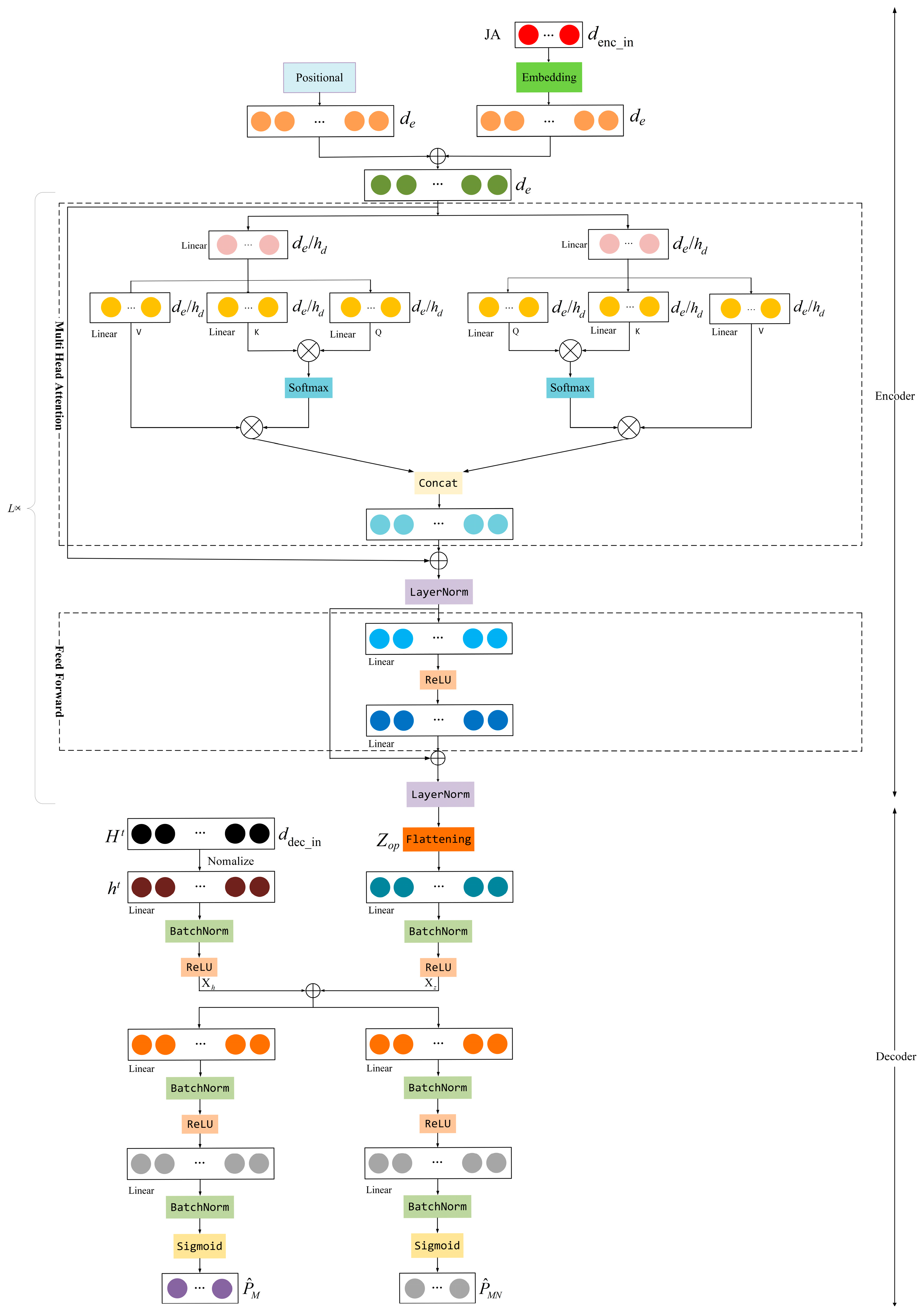
5.2. Attention-Based ULNN for Power Allocation
5.3. Training Algorithm for ULNN
| Algorithm 2 ULNN for power allocation |
| Input: State space S; The experience pool; The initialized ULNN Output: The well-trained ULNN; power allocation scheme 1: for t do 2: if the number of the sample data in the experience pool reaches a certain level then 3: ← the sample data of the experience pool 4: P ← output of the ULNN ← , 5: = 6: Loss = [− + λ] 7: θ ← Adam(θ, ) 8: Test the ULNN 9: end if 10: end for |
6. Simulation Results
6.1. Simulation Settings
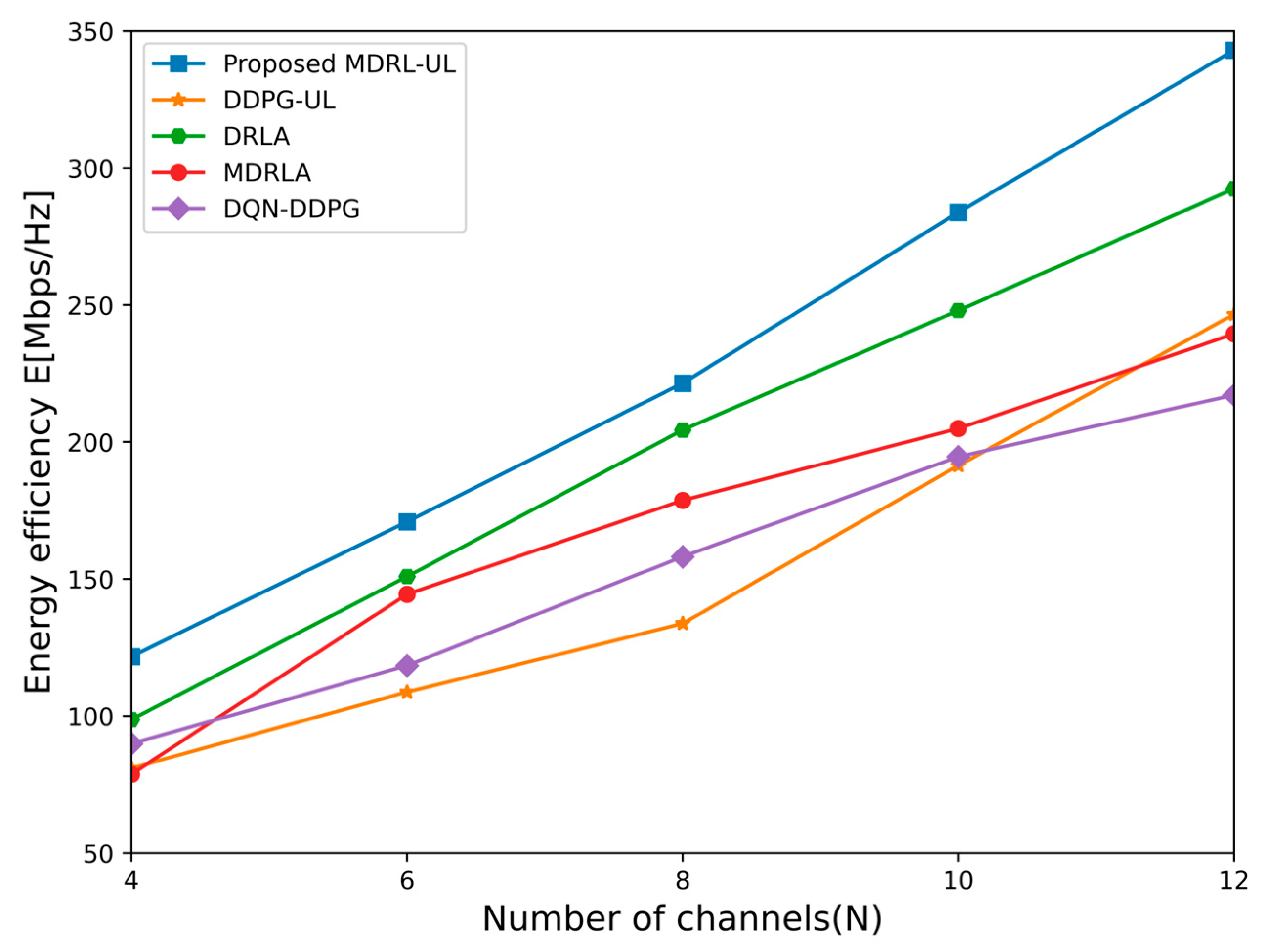
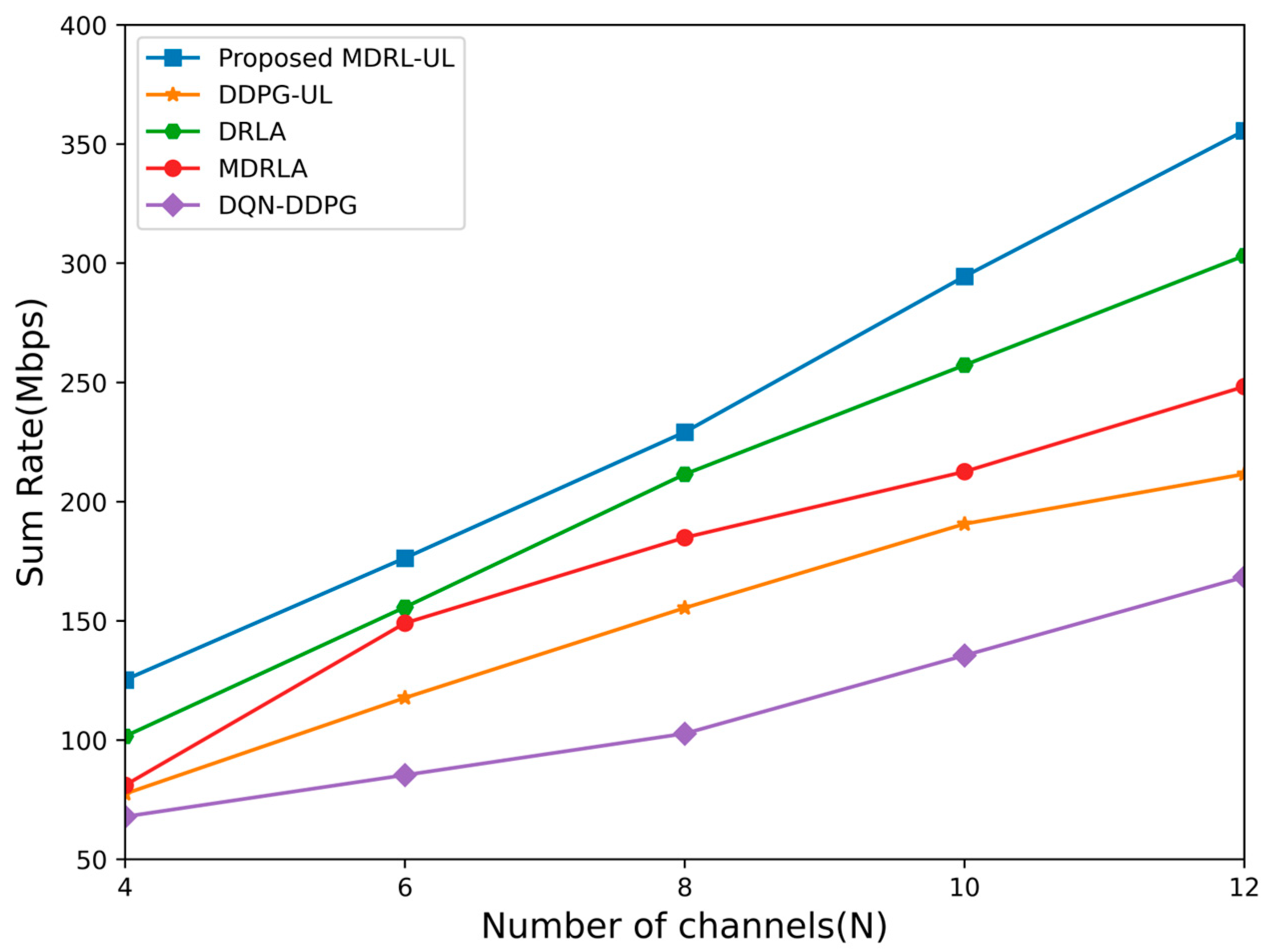
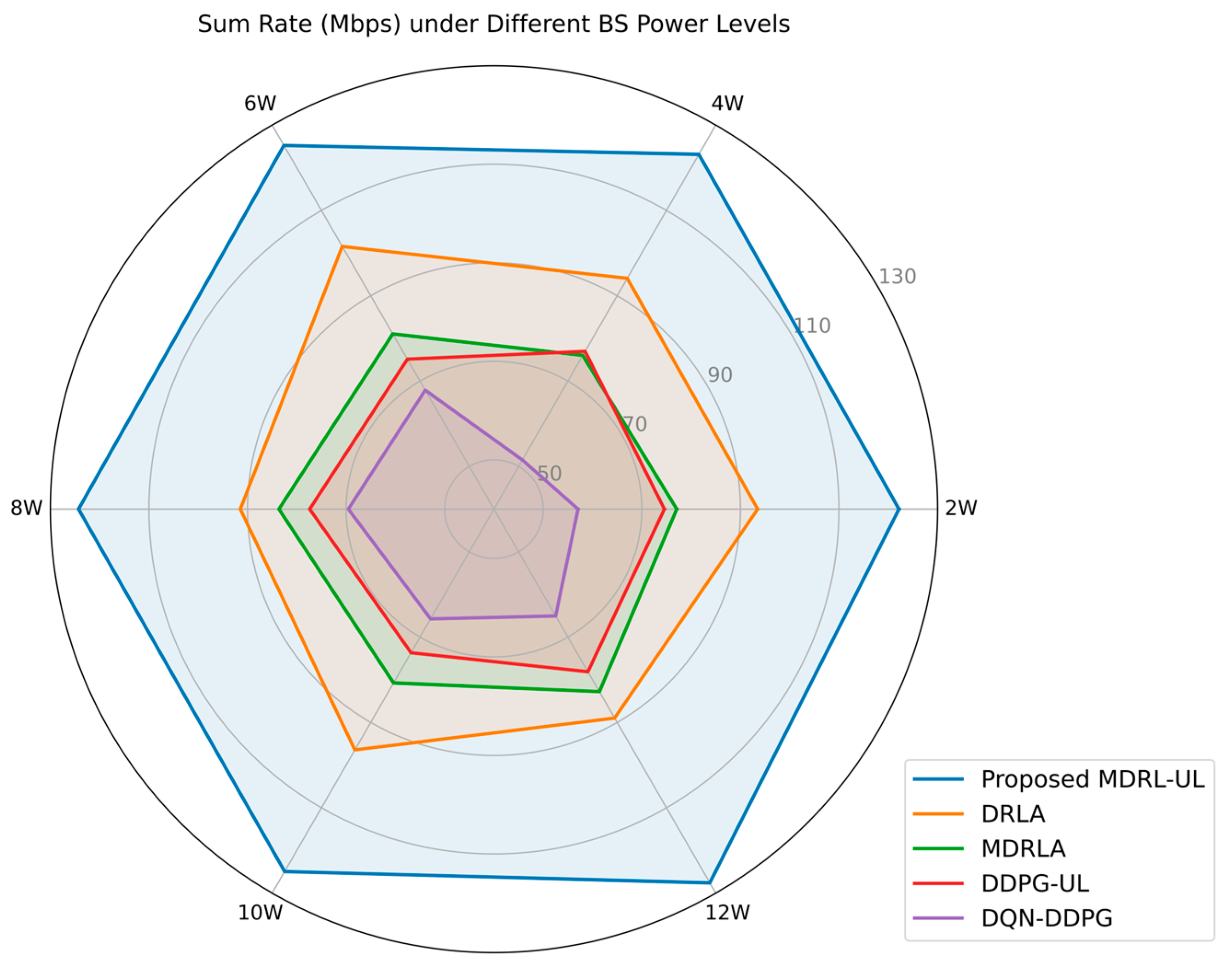
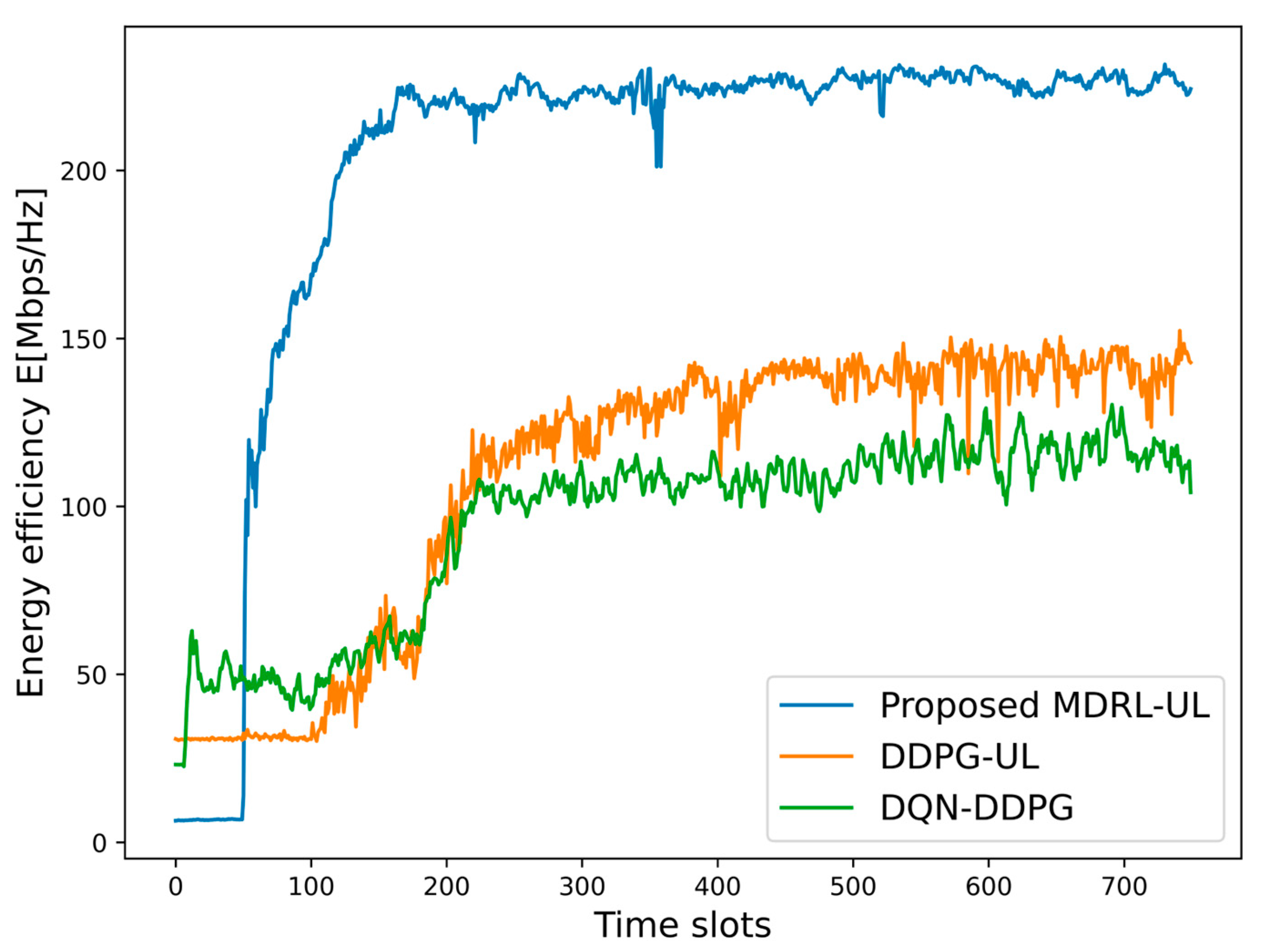
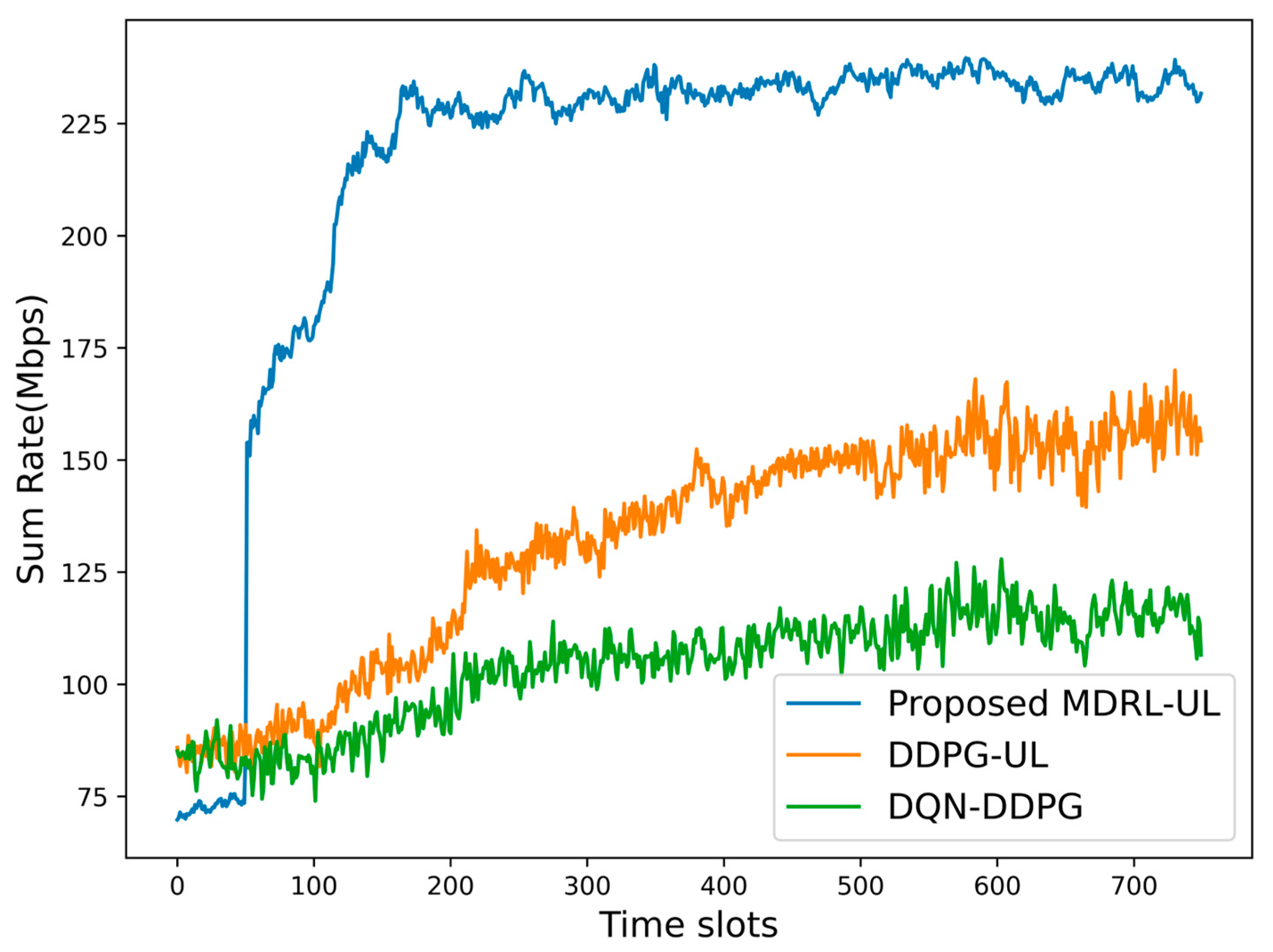
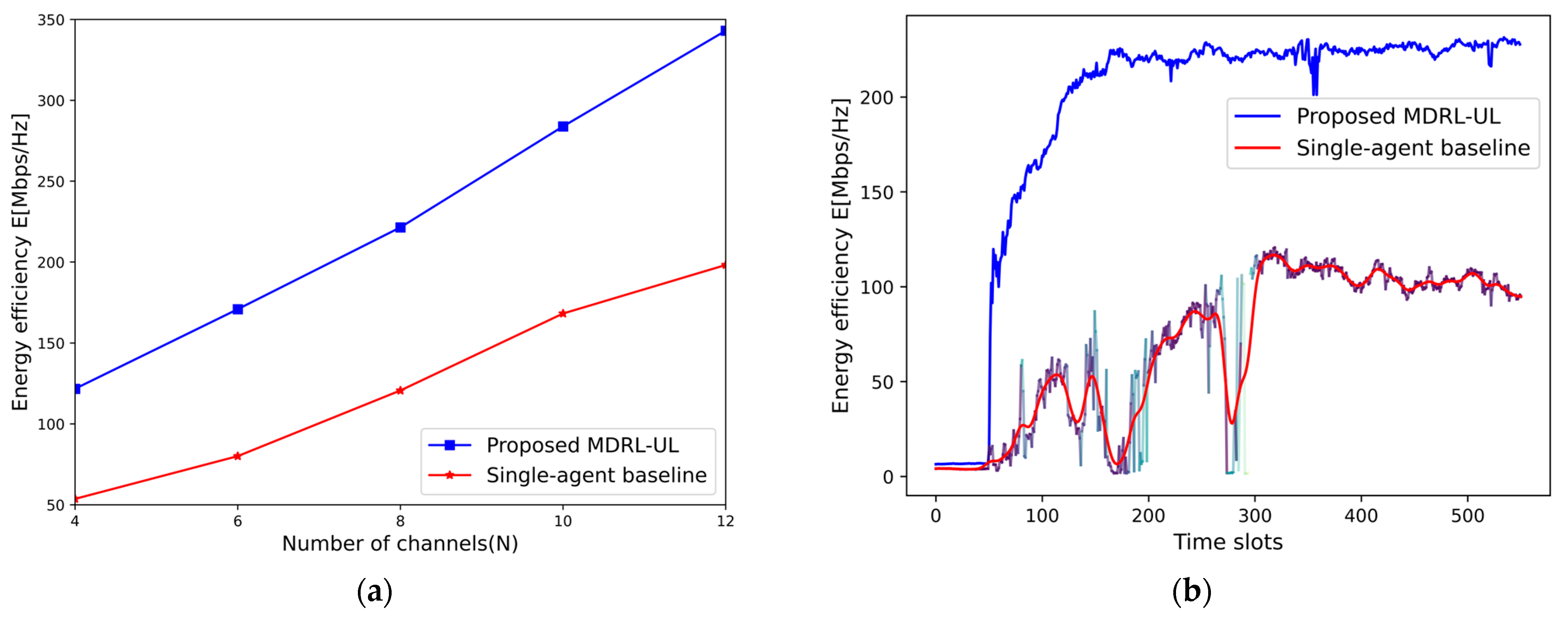
6.2. Performance Comparison
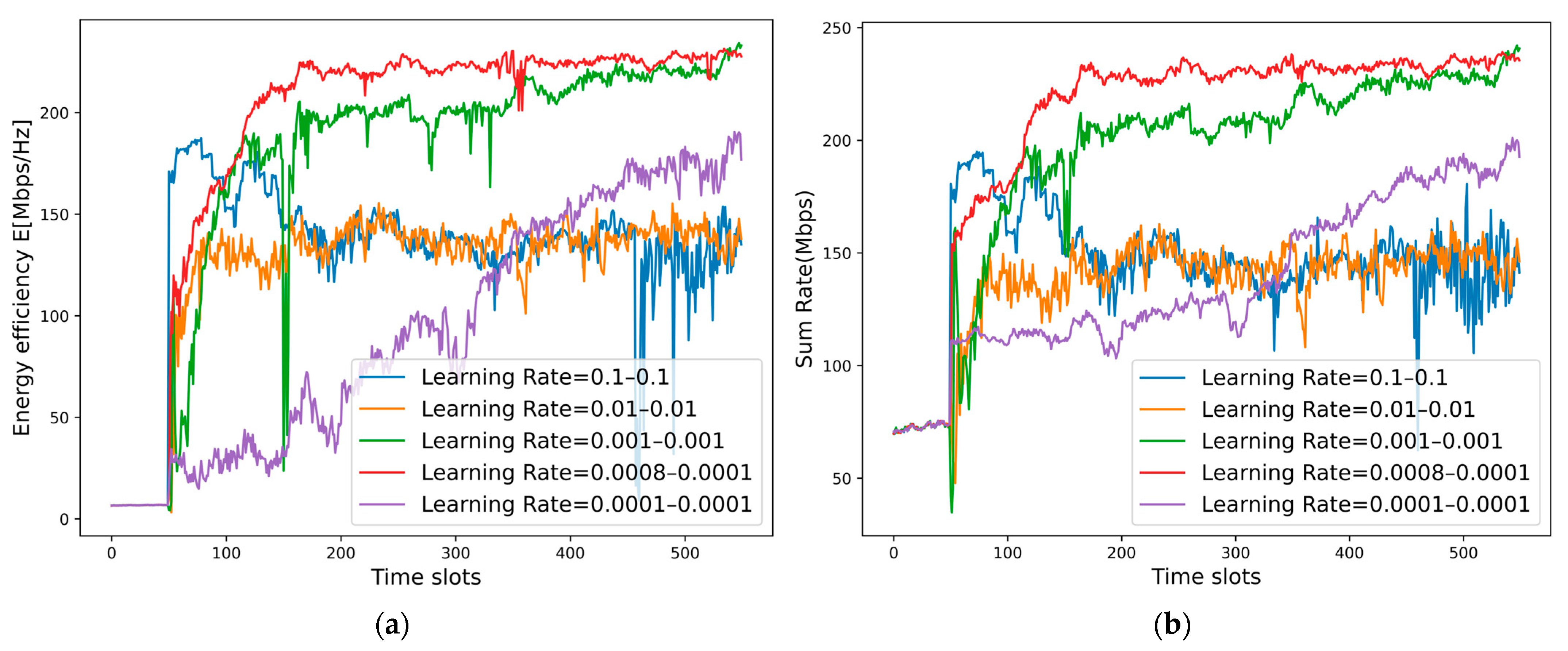
6.3. Hyper-Parameter Analysis
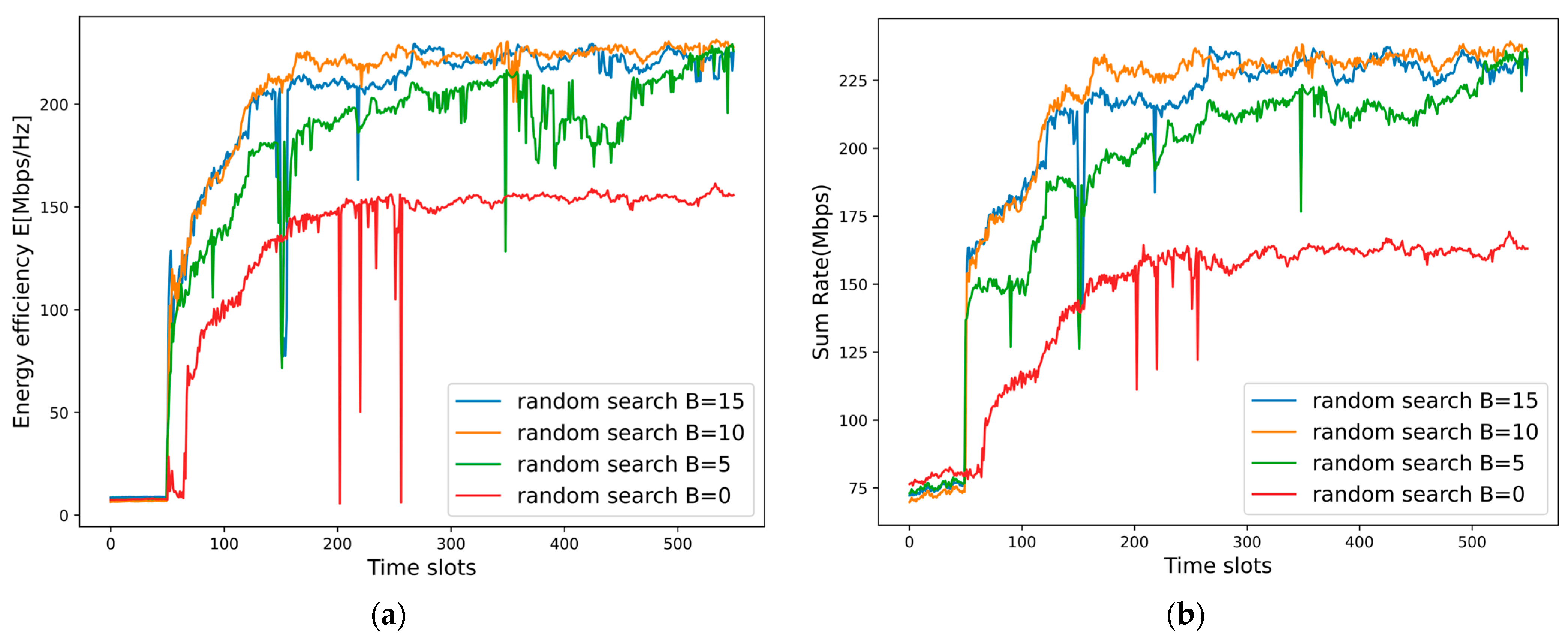
6.4. Impact of the Random Search Strategy
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dao, N.-N.; Tu, N.H.; Hoang, T.-D.; Nguyen, T.-H.; Nguyen, L.V.; Lee, K.; Park, L.; Na, W.; Cho, S. A review on new technologies in 3gpp standards for 5g access and beyond. Comput. Netw. 2024, 245, 110370. [Google Scholar] [CrossRef]
- He, C.; Wang, H.; Hu, Y.; Chen, Y.; Fan, X.; Li, H.; Zeng, B. Mcast: High-quality linear video transmission with time and frequency diversities. IEEE Trans. Image Process. 2018, 27, 3599–3610. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Wang, J.; Wu, Z.; Yu, Y.; Zhou, M.; Li, G. 5g and energy internet planning for power and communication network expansion. iScience 2024, 27, 109290. [Google Scholar] [CrossRef] [PubMed]
- Zorello, L.M.M.; Bliek, L.; Troia, S.; Maier, G.; Verwer, S. Black-box optimization for anticipated baseband-function placement in 5g networks. Comput. Netw. 2024, 245, 110384. [Google Scholar] [CrossRef]
- Del Rio, A.; Serrano, J.; Jimenez, D.; Contreras, L.M.; Alvarez, F. Multisite gaming streaming optimization over virtualized 5g environment using deep reinforcement learning techniques. Comput. Netw. 2024, 244, 110334. [Google Scholar] [CrossRef]
- Bazzi, A.; Chafii, M. Low Dynamic Range for RIS-Aided Bistatic Integrated Sensing and Communication. IEEE J. Sel. Areas Commun. 2025, 43, 912–927. [Google Scholar] [CrossRef]
- Dai, L.; Wang, B.; Yuan, Y.; Han, S.; Chih-Lin, I.; Wang, Z. Non-orthogonal multiple access for 5g: Solutions, challenges, opportunities, and future research trends. IEEE Commun. Mag. 2015, 53, 74–81. [Google Scholar] [CrossRef]
- Ding, Z.; Lei, X.; Karagiannidis, G.K.; Schober, R.; Yuan, J.; Bhargava, V.K. A survey on non-orthogonal multiple access for 5g networks: Research challenges and future trends. IEEE J. Sel. Areas Commun. 2017, 35, 2181–2195. [Google Scholar] [CrossRef]
- Shipon, A.M.; Ekram, H.; In, K.D. Non-orthogonal multiple access (NOMA) for downlink multiuser mimo systems: User clustering, beamforming, and power allocation. IEEE Access 2017, 5, 565–577. [Google Scholar]
- Chen, B.; Wang, X.; Li, D.; Jiang, R.; Xu, Y. Uplink noma semantic communications: Semantic reconstruction for sic. In Proceedings of the 2023 IEEE/CIC International Conference on Communications in China (ICCC), Dalian, China, 10–12 August 2023; pp. 1–6. [Google Scholar]
- Lei, L.; Yuan, D.; Ho, C.K.; Sun, S. Joint optimization of power and channel allocation with non-orthogonal multiple access for 5g cellular systems. In Proceedings of the 2015 IEEE Global Communications Conference (GLOBECOM), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Liu, Y.F.; Dai, Y.H. On the complexity of joint subcarrier and power allocation for multi-user ofdma systems. IEEE Trans. Signal Process. 2013, 62, 583–596. [Google Scholar] [CrossRef]
- Chaieb, C.; Abdelkefi, F.; Ajib, W. Deep reinforcement learning for resource allocation in multi-band and hybrid oma-noma wireless networks. IEEE Trans. Commun. 2022, 71, 187–198. [Google Scholar] [CrossRef]
- Alghazali, Q.; Amaireh, H.A.; Cinkler, T. Joint power and channel allocation for non-orthogonal multiple access in 5g networks and beyond. Sensors 2023, 23, 8040. [Google Scholar] [CrossRef]
- Adam, A.B.M.; Wan, X.; Wang, Z. User scheduling and power allocation for downlink multi-cell multi-carrier noma systems. Digit. Commun. Netw. 2023, 9, 252–263. [Google Scholar] [CrossRef]
- Xie, S. Power allocation scheme for downlink and uplink noma networks. IET Commun. 2019, 13, 2336–2343. [Google Scholar] [CrossRef]
- Riazul, I.S.M.; Ming, Z.A.D.O.; Sup, K.K. Resource allocation for downlink noma systems: Key techniques and open issues. IEEE Wirel. Commun. 2018, 25, 40–47. [Google Scholar]
- Zhao, J.; Liu, Y.; Chai, K.K.; Nallanathan, A.; Chen, Y.; Han, Z. Spectrum allocation and power control for non-orthogonal multiple access in hetnets. IEEE Trans. Wirel. Commun. 2017, 16, 5825–5837. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, J.; Huang, Y.; He, S.; You, X.; Yang, L. On optimal power allocation for downlink non-orthogonal multiple access systems. IEEE J. Sel. Areas Commun. 2017, 35, 2744–2757. [Google Scholar] [CrossRef]
- Jun, L.; Tong, G.; Bo, H.; Wenjing, Z.; Fei, L. Power allocation and user grouping for noma downlink systems. Appl. Sci. 2023, 13, 2452. [Google Scholar] [CrossRef]
- Rezvani, S.; Jorswieck, E.A.; Joda, R.; Yanikomeroglu, H. Optimal power allocation in downlink multicarrier noma systems: Theory and fast algorithms. IEEE J. Sel. Areas Commun. 2022, 40, 1162–1189. [Google Scholar] [CrossRef]
- Sun, M.; Hu, L.; Cao, W.; Zhang, H.; Wang, S. Unsupervised learning neural-network method for resource allocation in multi-cell cellular networks. In Proceedings of the 2021 International Conference on Intelligent Computing, Automation and Applications (ICAA), Nanjing, China, 25–27 June 2021; pp. 406–411. [Google Scholar]
- Wang, S.; Wang, X.; Zhang, Y.; Xu, Y. Resource allocation in multi-cell noma systems with multi-agent deep reinforcement learning. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- Sun, M.; Jin, Y.; Wang, S.; Mei, E. Joint deep reinforcement learning and unsupervised learning for channel selection and power control in d2d networks. Entropy 2022, 24, 1722. [Google Scholar] [CrossRef]
- Noor, W.; Ali, H.S.; Haris, P.; Haejoon, J.; Kapal, D. Deep multi-agent reinforcement learning for resource allocation in noma-enabled mec. Comput. Commun. 2022, 196, 1–8. [Google Scholar]
- Ming, S.; Shumei, W.; Yuan, G.; Wei, C.; Yaoqun, X. Deep unsupervised learning based resource allocation method for multicell cellular networks. Control. Decis. 2022, 37, 2333–2342. [Google Scholar]
- Jianzhang, Z.; Xuan, T.; Xian, W.; Hao, S.; Lijun, Z. Channel assignment for hybrid noma systems with deep reinforcement learning. IEEE Wirel. Commun. Lett. 2021, 10, 1370–1374. [Google Scholar]
- Guan, G.; Hongji, H.; Yiwei, S.; Hikmet, S. Deep learning for an effective nonorthogonal multiple access scheme. IEEE Trans. Veh. Technol. 2018, 67, 8440–8450. [Google Scholar]
- Liang, X.; Yanda, L.; Canhuang, D.; Huaiyu, D.; Vincent, P.H. Reinforcement learning-based noma power allocation in the presence of smart jamming. IEEE Trans. Veh. Technol. 2018, 67, 3377–3389. [Google Scholar]
- Wei, Y.; Yu, F.R.; Song, M.; Han, Z. User scheduling and resource allocation in hetnets with hybrid energy supply: An actor-critic reinforcement learning approach. IEEE Trans. Wirel. Commun. 2018, 17, 680–692. [Google Scholar] [CrossRef]
- He, C.; Hu, Y.; Chen, Y.; Zeng, B. Joint power allocation and channel assignment for noma with deep reinforcement learning. IEEE J. Sel. Areas Commun. 2019, 37, 2200–2210. [Google Scholar] [CrossRef]
- Sun, M.; Mei, E.; Wang, S.; Jin, Y. Joint ddpg and unsupervised learning for channel allocation and power control in centralized wireless cellular networks. IEEE Access 2023, 11, 42191–42203. [Google Scholar] [CrossRef]
- Nasir, Y.S.; Guo, D. Deep reinforcement learning for joint spectrum and power allocation in cellular networks. In Proceedings of the 2021 IEEE Globecom Workshops (GC Wkshps), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Yin, L.; Chenggong, W.; Kai, M.; Kuanxin, B.; Haowei, B. A noma power allocation strategy based on genetic algorithm. In Communications, Signal Processing, and Systems: Proceedings of the 8th International Conference on Communications, Signal Processing, and Systems, 8th ed.; Springer: Berlin/Heidelberg, Germany, 2020; pp. 2182–2190. [Google Scholar]
- Gemici, Ö.F.; Kara, F.; Hokelek, I.; Kurt, G.K.; Çırpan, H.A. Resource allocation for noma downlink systems: Genetic algorithm approach. In Proceedings of the 2017 40th International Conference on Telecommunications and Signal Processing (TSP), Barcelona, Spain, 5–7 July 2017; pp. 114–118. [Google Scholar]
- Gupta, S.; Singal, G.; Garg, D. Deep reinforcement learning techniques in diversified domains: A survey. Arch. Comput. Methods Eng. 2021, 28, 4715–4754. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Ding, Z.; Yang, Z.; Fan, P.; Poor, H.V. On the Performance of Non-Orthogonal Multiple Access in 5G Systems with Randomly Deployed Users. IEEE Signal Process. Lett. 2014, 21, 1501–1505. [Google Scholar] [CrossRef]
- Muhammed, A.J.; Ma, Z.; Diamantoulakis, P.D.; Li, L.; Karagiannidis, G.K. Energy-efficient resource allocation in multicarrier NOMA systems with fairness. IEEE Trans. Commun. 2019, 67, 8639–8654. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Complexity |
|---|---|
| MDRL-UL(Proposed) | |
| DRLA | |
| MDRLA | |
| DDPG-UL | |
| DQN-DDPG |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, M.; Zhong, Y.; He, X.; Zhang, J. Channel and Power Allocation for Multi-Cell NOMA Using Multi-Agent Deep Reinforcement Learning and Unsupervised Learning. Sensors 2025, 25, 2733. https://doi.org/10.3390/s25092733
Sun M, Zhong Y, He X, Zhang J. Channel and Power Allocation for Multi-Cell NOMA Using Multi-Agent Deep Reinforcement Learning and Unsupervised Learning. Sensors. 2025; 25(9):2733. https://doi.org/10.3390/s25092733
Chicago/Turabian StyleSun, Ming, Yihe Zhong, Xiaoou He, and Jie Zhang. 2025. "Channel and Power Allocation for Multi-Cell NOMA Using Multi-Agent Deep Reinforcement Learning and Unsupervised Learning" Sensors 25, no. 9: 2733. https://doi.org/10.3390/s25092733
APA StyleSun, M., Zhong, Y., He, X., & Zhang, J. (2025). Channel and Power Allocation for Multi-Cell NOMA Using Multi-Agent Deep Reinforcement Learning and Unsupervised Learning. Sensors, 25(9), 2733. https://doi.org/10.3390/s25092733