2.1. Synthetic Data
In traditional machine vision, human action recognition models are trained using large sets of human-labeled data, for example, UCF101 [
10], Kinetics 400 [
11], HMDB51 [
12], AVA [
13], Something-Something [
14], and other datasets. These datasets, which come from sources such as YouTube, television channels, TV series, and movies, are powerful resources that contain various categories of actions. However, there are the following shortcomings: First, personnel with relevant knowledge are required to manually annotate videos, which is costly, and the annotation will be affected by the subjective judgment of the video annotator. If there are more annotators, the labeling or time judgment of action annotation may be different. Second, the viewing angle of the video in the dataset is limited by the shooting angle, and it cannot be converted, nor can another viewing angle be added according to the requirements of the researchers. Thirdly, in certain professional domains where there is a lack of extensive video data or limited publicly available video data, such as power maintenance, construction, and factory operations, there is a shortage of comprehensive datasets with a wide range of content compared to those available for other types of actions, such as daily activities, dance, or sports movements. Due to concerns regarding information security and privacy, researchers within certain professional domains typically annotate internal video materials for their studies, resulting in fewer publicly released self-created datasets. This situation hampers the ability of researchers in the same field to conduct cross-comparative studies on data of interest.
To address challenges such as limited availability and difficulty in acquiring real-world data, many domains have embarked on a series of research efforts to obtain a larger pool of relevant data and establish more targeted datasets. These endeavors have yielded significant progress.
Among them, the development of simulation experiments in the field of autonomous driving stands out as the most advanced. Several simulation platforms have been developed based on the Unreal Engine game engine, such as Carla [
15], developed by Intel Labs, and AirSim [
16], developed by Microsoft Research. Additionally, there is a synthetic video dataset called virtual KITTI [
17], developed using the Unity game engine. Additionally, there is VIPER [
18], developed based on the game Grand Theft Auto V (GTA 5), Synscapes street scene dataset [
19], developed based on computer graphics, and a pedestrian trajectory dataset on road network structures, based on digital twins [
20]. These virtual simulation open-source platforms and synthetic datasets are designed to support the development of urban autonomous driving systems. They provide accessible digital assets (city layouts, buildings, and vehicles) for 2D and 3D multi-object tracking, with pixel-level labels for categories, instances, flow, and depth. These resources serve as valuable tools for computer vision tasks related to urban autonomous vehicle navigation and contribute to the advancement of research in autonomous driving.
In the field of object pose detection, research into synthetic datasets for the purpose of expanding data collections and enhancing model generalization capabilities has been ongoing. Tremblay et al. introduced a synthetic dataset called Falling Things (FAT) [
21]. This dataset provides 3D poses for all objects, pixel-wise class segmentation, and 2D/3D bounding box coordinates. NVIDIA’s Deep Learning Dataset Synthesizer (NDDS) plugin supports image, segmentation, depth, object pose, bounding box, keypoints, and custom template synthesis. It includes the randomization of lighting, objects, camera positions, poses, textures, and occlusions, as well as camera path tracking. Unity’s Perception package [
22] provides a tool for capturing datasets, allowing the merging and generation of synthetic datasets within Unity. It encompasses four fundamental functionalities: object labeling, annotation, image capture, and customizable metrics.
In the field of pedestrian detection and tracking, Fabbri M [
23] collected the JTA (Joint Track Auto) dataset and the MOTSynth [
24] dataset for pedestrian pose estimation and tracking in urban scenarios by exploiting the highly photorealistic video game GTA 5. Hu Y T et al. also utilized the game GTA 5 to generate the SAIL-VOS [
25] dataset, which consists of instance-level video object segmentation with occlusions. Additionally, they introduced SAIL-VOS 3D [
26], an extended synthetic video dataset with per-frame grid annotations. Unity introduced PeopleSansPeople [
27], a parameterized synthetic data generator for human recognition. It allows the generation of synthetic data with varying poses, lighting conditions, positions, and occlusions to enhance human recognition tasks.
Most of the research methods described above use game engines or build data simulators based on commercial games with high completion rates. The simulators provide control over the data generation itself and facilitate the adjustment of datasets for simulation-to-reality transfer. The generated data types typically include images, videos, and radar data. This proves the value of using the simulator to synthesize datasets in the research fields of image processing [
28], object pose detection [
29], person detection [
30], trajectory tracking [
31], automatic driving [
32,
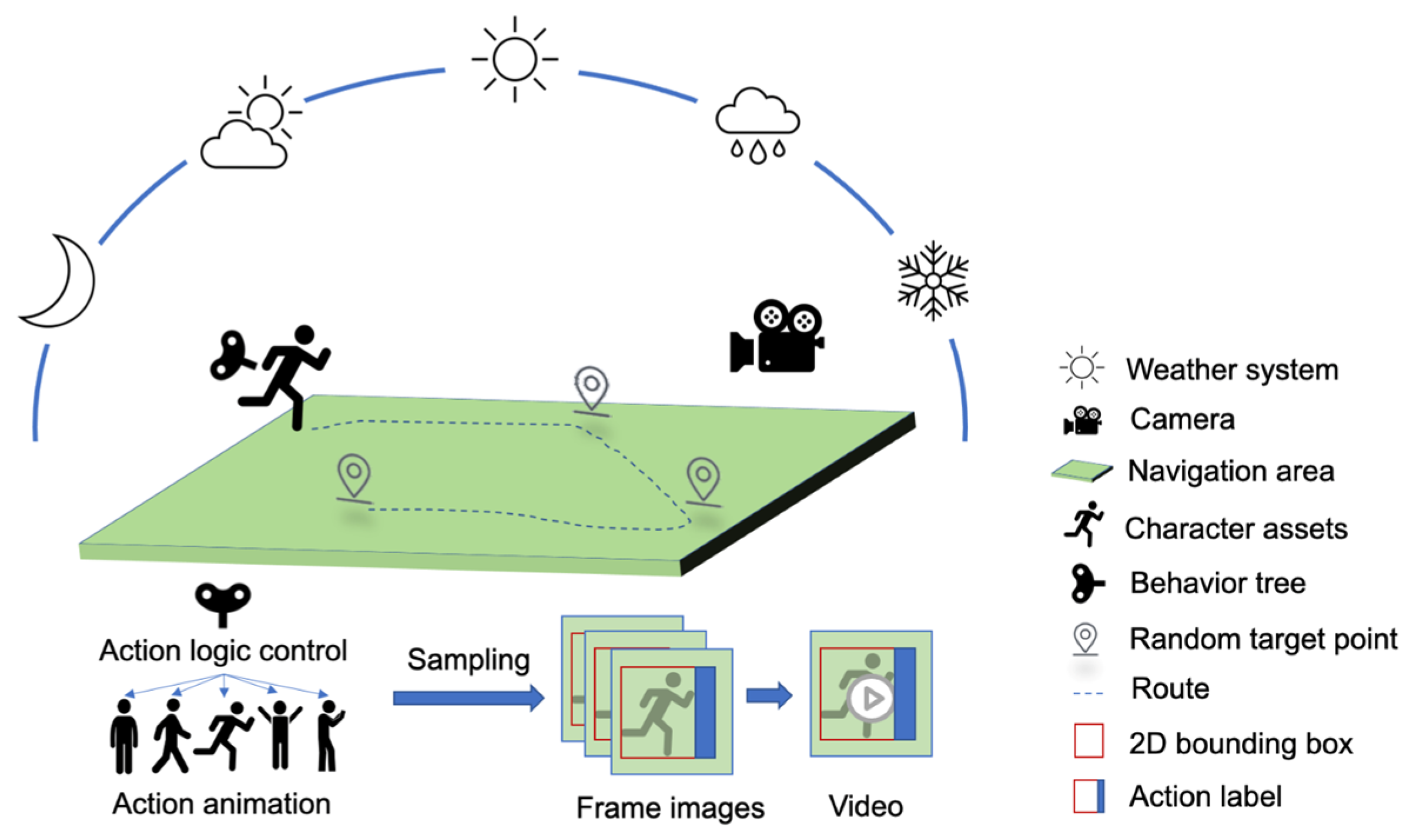
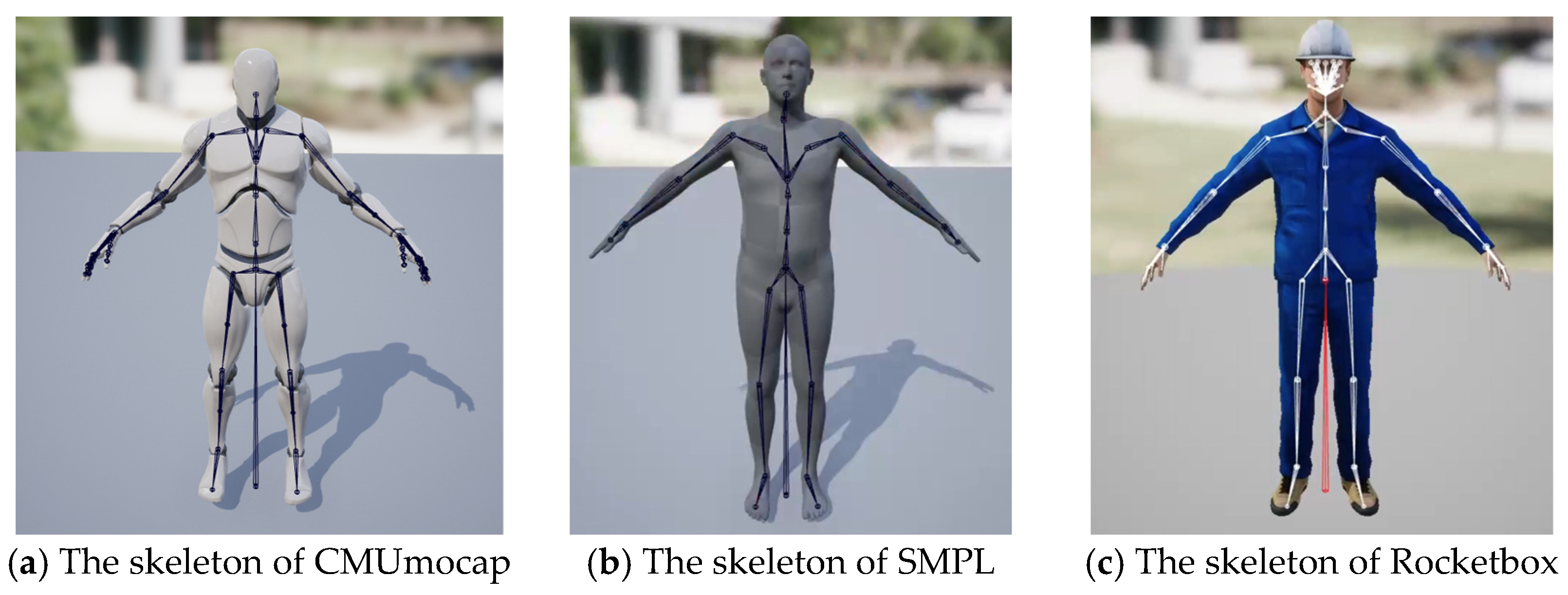
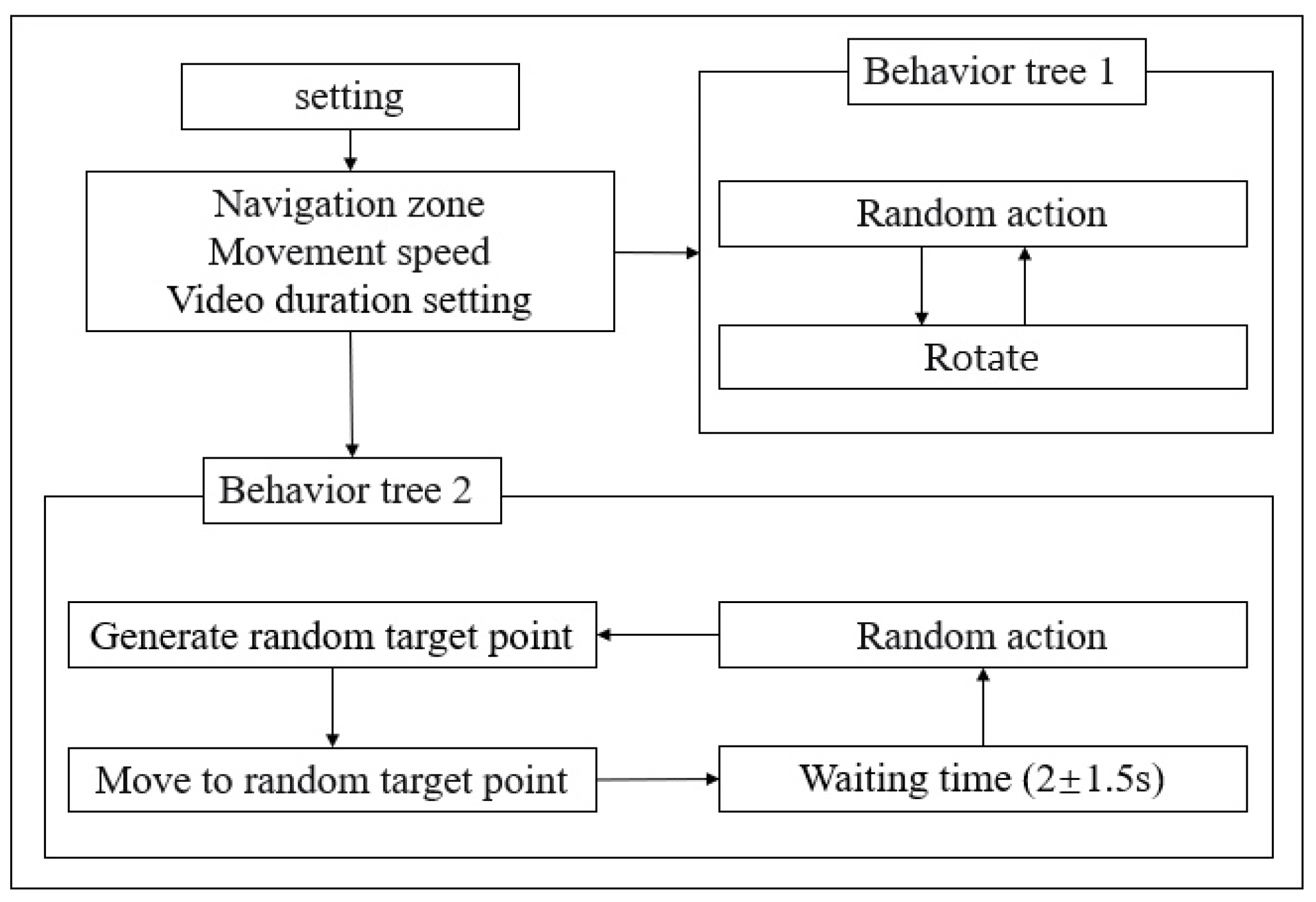
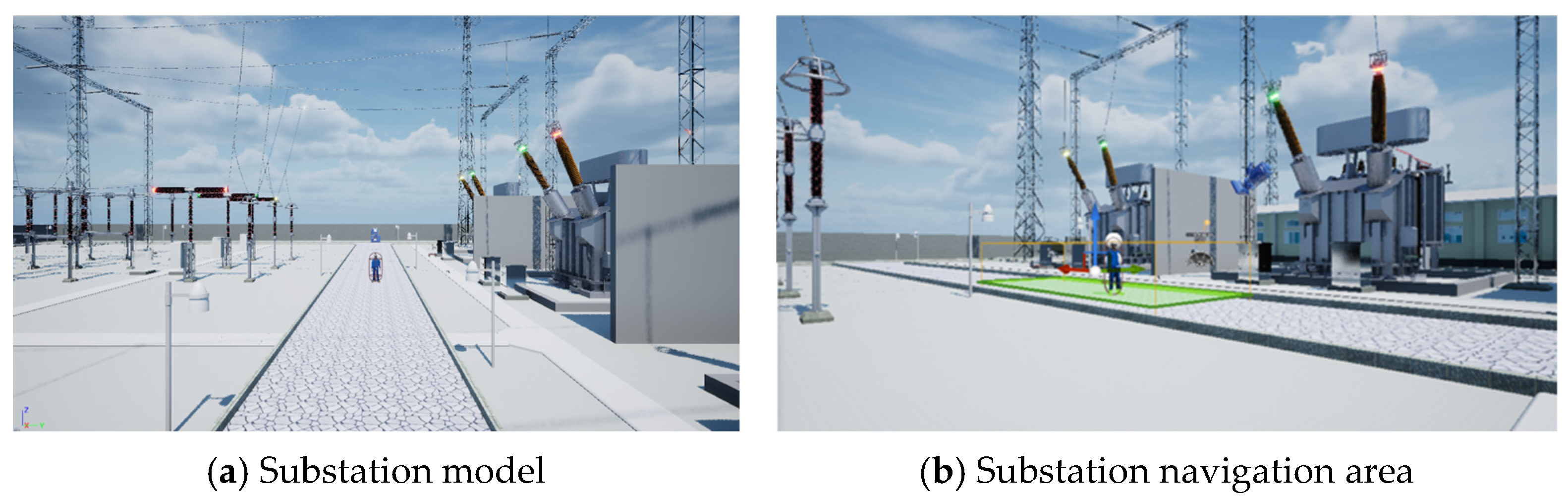
33], dangerous scene detection, and so on. However, these studies do not allow researchers to import, control, or set the behavior logic of the characters. Inspired by the above research, we built a virtual work platform (VWP) based on Unreal Engine. The VWP can control the parameter distribution of light, people, action, camera, etc., and the action logic simulates the operation of real substation inspection personnel, providing a solution for researchers to address the lack of relevant action datasets when studying highly professional action detection such as substation inspection.
2.2. Action Detection
Research on action recognition can be roughly divided into three directions. The first direction is action recognition, which can only be applied to cropped videos to judge the action category. The video containing the recognized action needs to be classified and labeled with action labels after being cropped, and each video in this category contains only one type of action. The second direction is temporal action detection, which targets the original video that has not been cropped, and can locate the time of the action, giving the start and end time points of the action and the action category information in the video. However, temporal action detection can only detect and locate actions in the temporal domain. In reality, the situation is usually more complex, as practical scenarios may involve multiple people and multiple types of action categories at the same time. To address the complexity of real-world scenarios, the third direction, spatiotemporal action detection [
34], further locates the action in both the temporal and spatial domains to solve the problem of multiple people and multiple actions in complex scenes. Specifically, it can not only provide the action category and start/end time points but also locate the spatial region where the action occurs, as well as tracking personnel between different frames in the time stream.
To analyze the operation processes of inspection operators in substations, it is necessary to detect the location of the operators in both the spatial and temporal domains. Therefore, we use spatiotemporal action detection to obtain the occurrence time, category, and spatial position of the operators during their operations.
Frame-Level Action Detection. The advancement of image object detection technology has inspired frame-level action detection methods. Frame-level action detection is an action detection method based on frame images, which can be mainly divided into two stages. First, frame-level action proposal detection is generated through region proposal algorithms. Then, proposals are associated across frames to refine action classification and localization, enabling the localization and detection of actions over time [
35,
36]. Methods for action detection include traditional feature extraction methods, such as generating spatiotemporal shapes using super-voxels to provide 2D + t sequences, or obtaining feature points through dense sampling [
37,
38,
39], whereas dense trajectory methods [
40,
41,
42] extract features based on trajectory tracking of feature points and then classify proposals to locate actions. There are also feature extraction methods based on deep learning [
43,
44,
45,
46], which capture action features using optical flow and predict action categories using convolutional neural networks (CNNs), region proposal networks (RPNs), Fast R-CNNs, and 3D convolutional neural networks and connect frame-level bounding boxes into the spatiotemporal action tubes. They also capture spatial and static visual cues using RGB images and extract time and action information from optical flow fields for action estimation [
47]. The main drawback of frame-level action detection is that because detection is performed independently in each frame, the video’s temporal information is not fully utilized [
48].
Clip-Level Action Detection. Clip-level action detection is crucial for accurately recognizing many types of actions, such as sitting down, standing up, picking something up, and putting something down, which cannot be identified based on individual frames alone. This is because effective temporal modeling is required, as the detection of such actions relies on the availability of temporal context. Kalogeiton et al. [
49] proposed a tubelet detector that leverages the temporal continuity of video frames to detect objects in sequences. While this approach effectively utilizes temporal information, it faces several challenges, including computational complexity, difficulties in handling complex scenes, demanding training requirements, and limited contextual understanding. Gu et al. [
13] proposed an atomic visual action (AVA) dataset that has precise spatiotemporal annotations and dense annotations for atomic visual actions. They proposed an action detection model based on I3D convolution and Faster R-CNN region proposals and demonstrated the importance of time information by comparing the performance of edited videos of different time lengths on the model. However, the employed Faster R-CNN model is highly complex, resulting in relatively slow detection speeds. Additionally, I3D is limited by its fixed temporal window and local convolution operations, which restrict its ability to capture long-range contextual information. Feichtenhofer et al. [
50] established a SlowFast network model for video action detection, which employs ResNet as the backbone and captures spatial semantics at low frame rates and action information at high frame rates. Nevertheless, the utilized ResNet backbone network has difficulty capturing global dependencies and shows limited performance gains on large-scale datasets. Recently, Transformer [
51] has made significant advances in the field of natural language processing [
52]. Tasks such as image classification, object detection, semantic segmentation, object tracking, and video recognition in the field of computer vision have also been improved through the use of Vision Transformer (ViT) [
53]. Based on the development of ViT, Tong Z et al. [
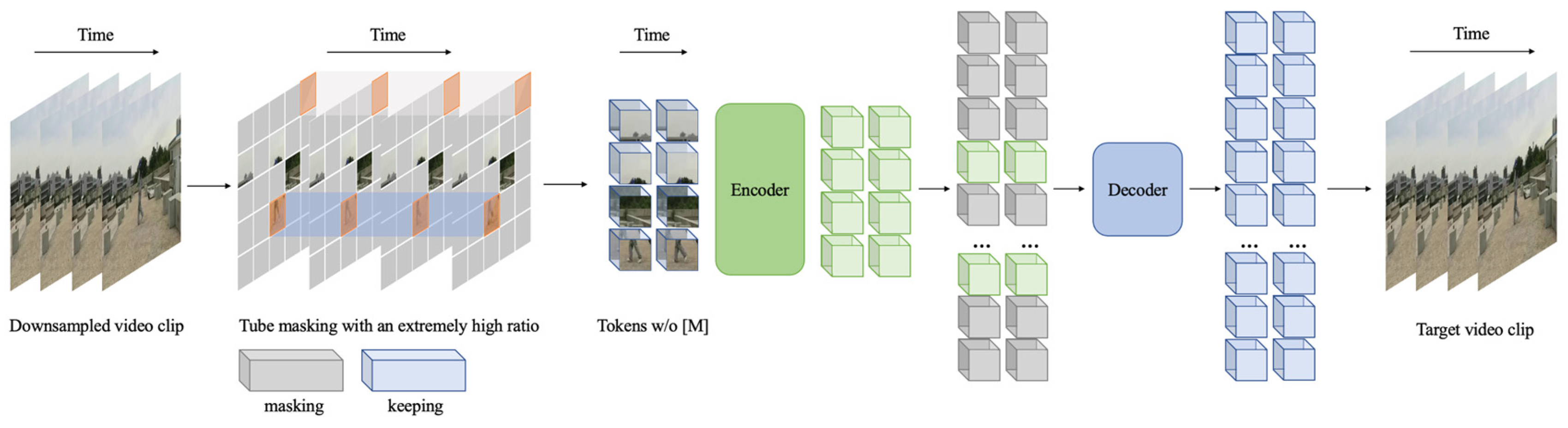
54] proposed a self-supervised video pre-training method, called video masked autoencoders (VideoMAE).
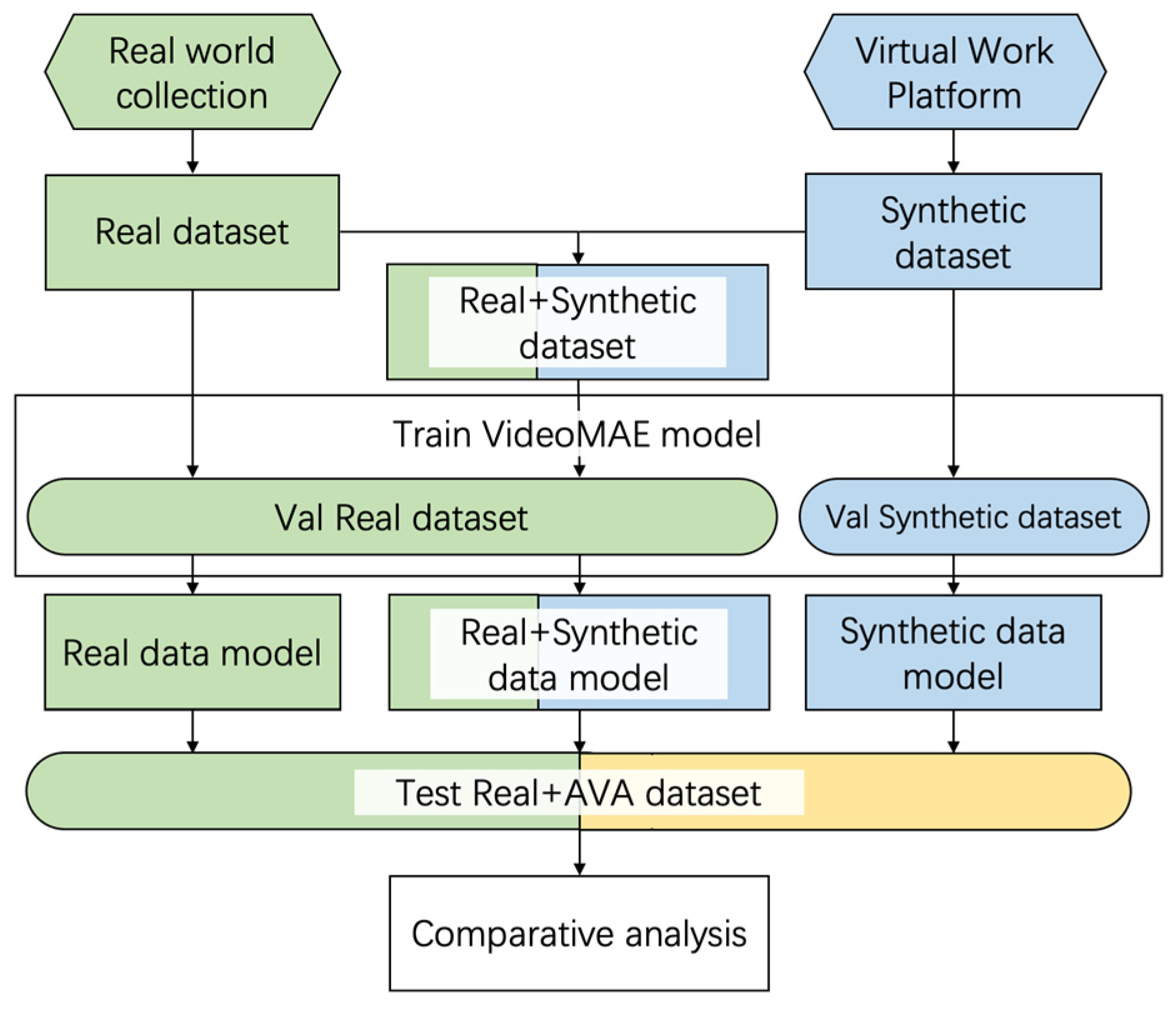
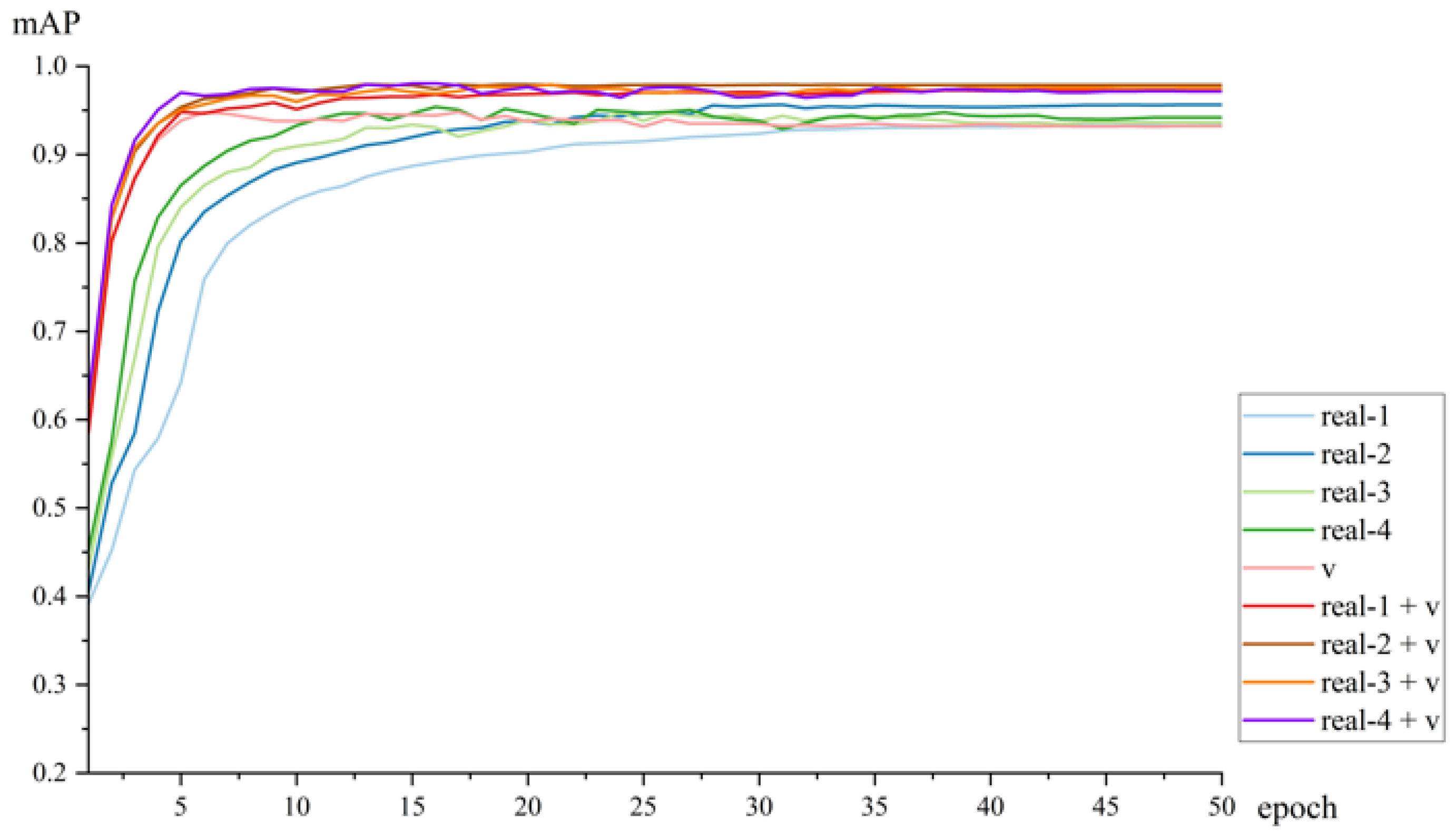
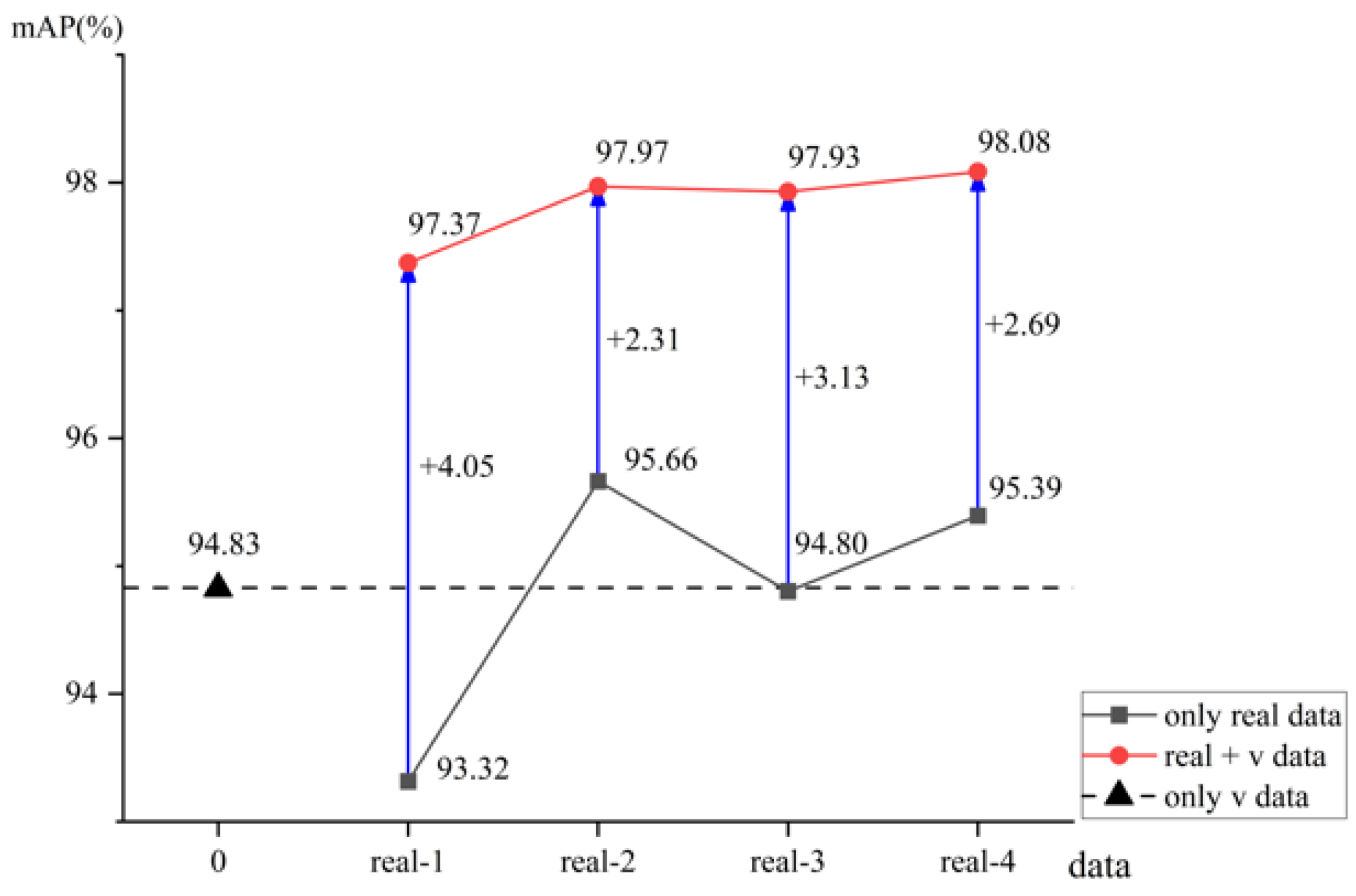
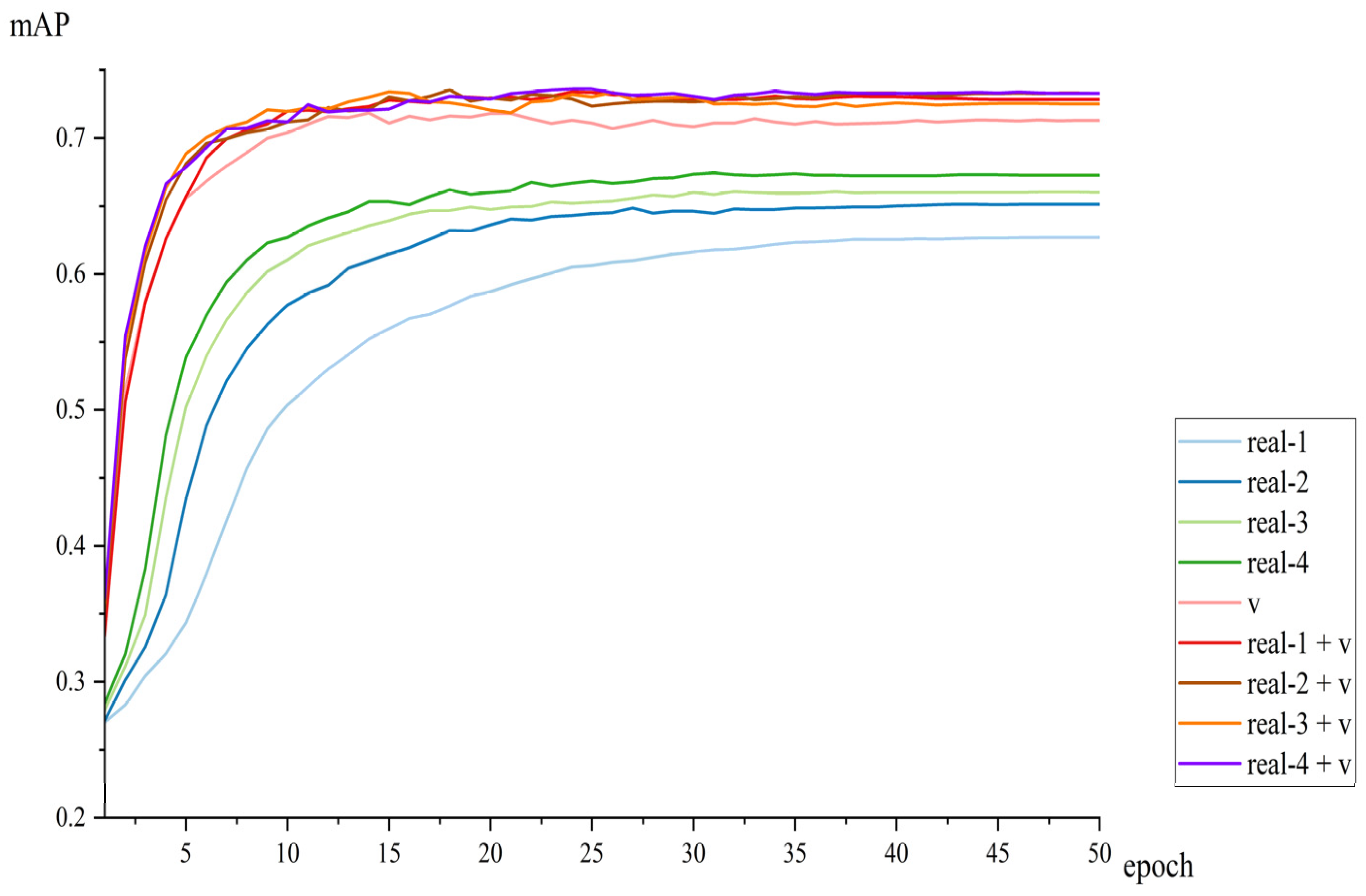
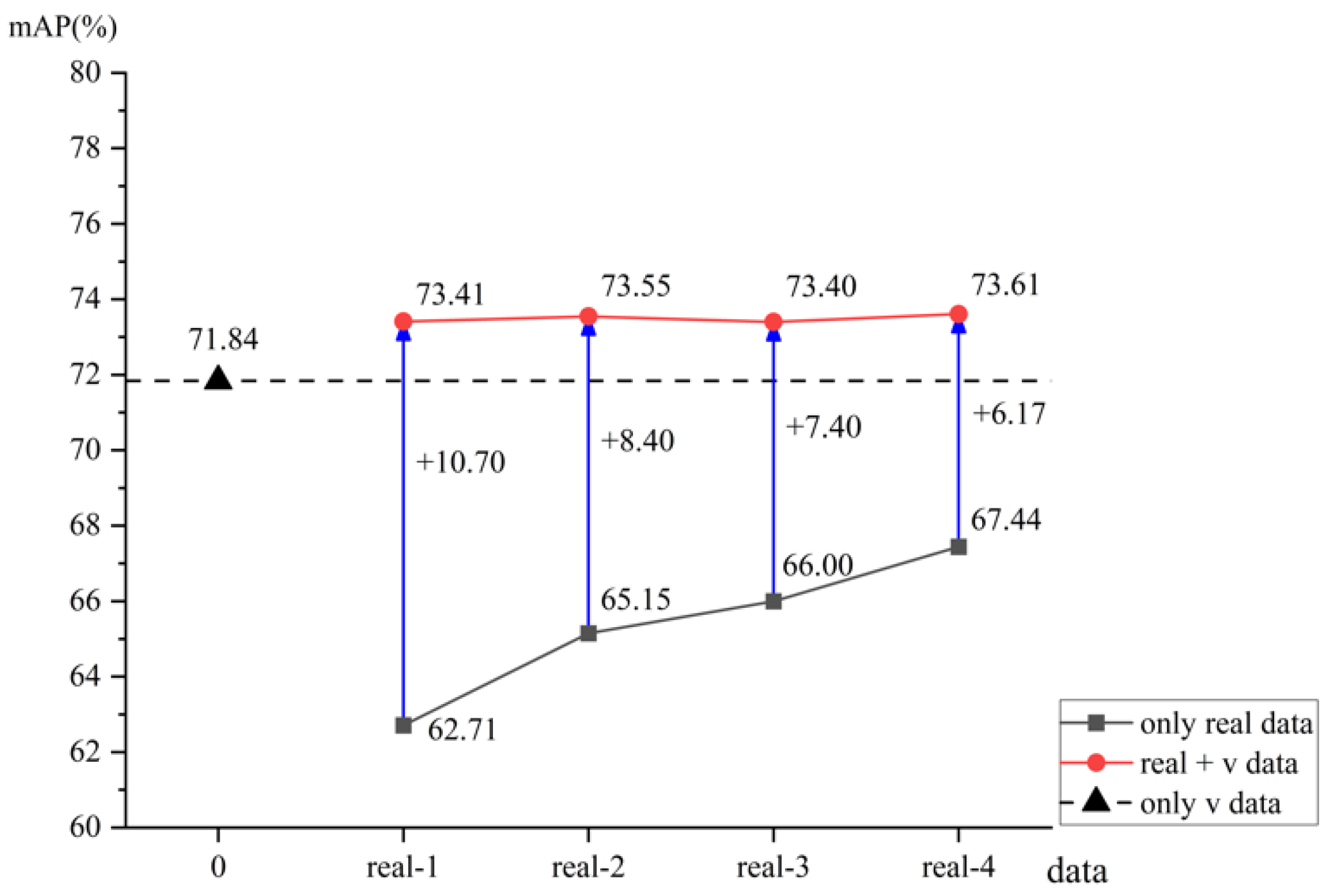
Based on the VideoMAE algorithm, which utilizes SlowFast as the framework and ViT as the backbone network to effectively capture long-range dependencies and compute global dependencies, we selected YOLOv8 as the human detector. We employed the flexible and scalable architecture of ViT, along with its strong pre-trained performance, to conduct transfer learning for action detection. To better leverage long-range information between frames, we adopted the clip-level action detection method and generated synthetic data in the AVA format via VWP for spatiotemporal action detection.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}