
Enhanced Cloud Detection Using a Unified Multimodal Data Fusion Approach in Remote Images


Abstract
1. Introduction
- A novel approach to multimodal data fusion: When confronted with the task of processing a variable number of modalities, we reconsider the fusion strategy for multimodal data and devise a scheme that obviates the need for structural modifications to the network architecture with the introduction of each new modality. This innovative approach minimizes the incremental computational cost associated with each additional mode, thereby enhancing overall efficiency. Furthermore, the multimodal data fusion module possesses exceptional extrapolation capabilities and can be seamlessly integrated into other network architectures in a user-friendly, plug-and-play fashion. This characteristic augments the practicality and flexibility of the module.
- Construction and exploration of a multimodal cloud detection model:The proposed M2Cloud model demonstrates remarkable performance, achieving or even surpassing SOTA accuracy levels on public multimodal datasets through the deep integration of multimodal data. This outcome not only validates the efficacy of the M2Cloud model in unified multimodal cloud detection tasks but also offers a viable reference methodology for the construction of similar models.
2. Related Work
2.1. Cloud Detection Method Based on Deep Learning
2.2. Multimodal Cloud Detection Method
2.3. Multimodal Datasets for Cloud Detection
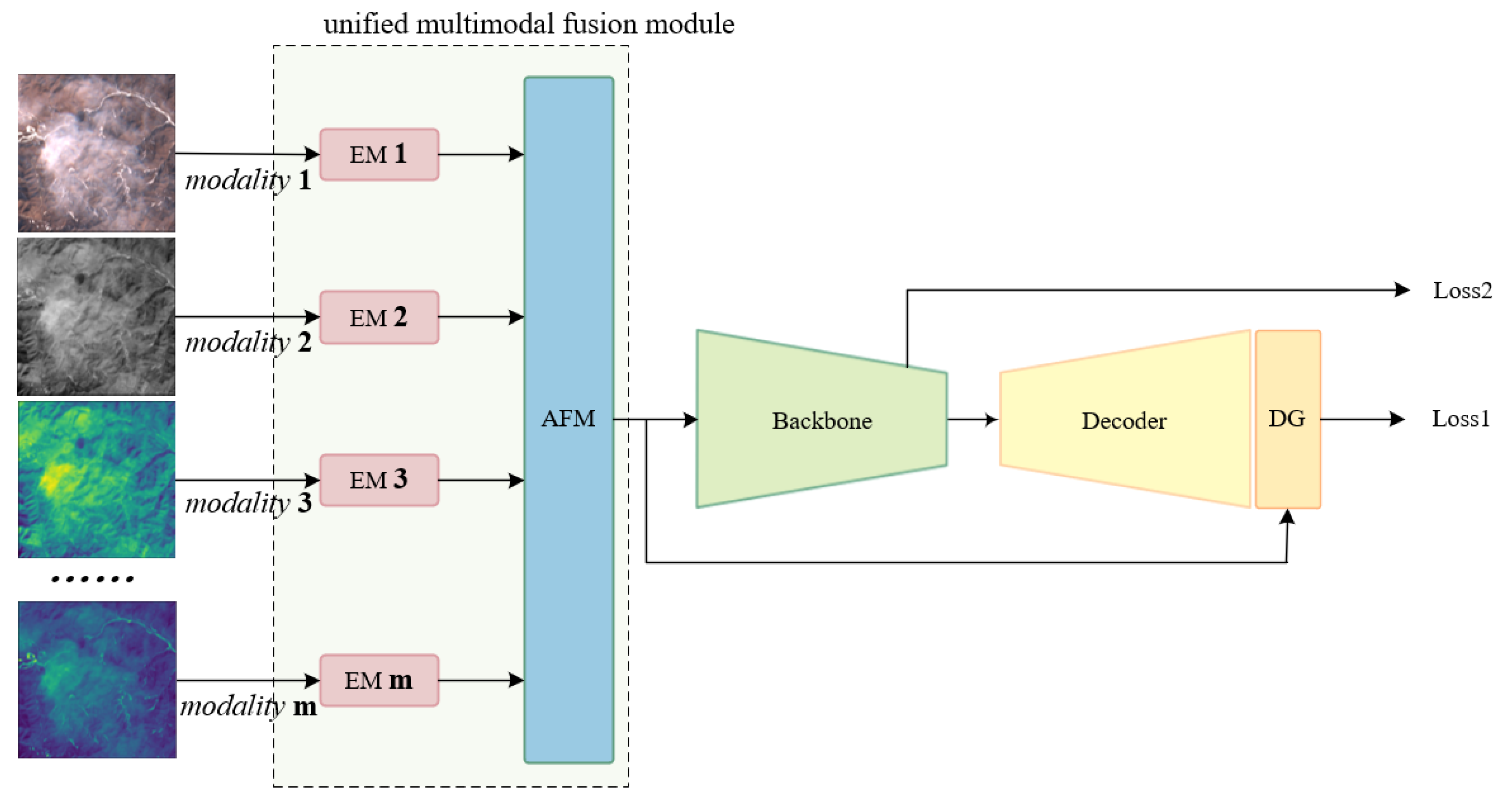
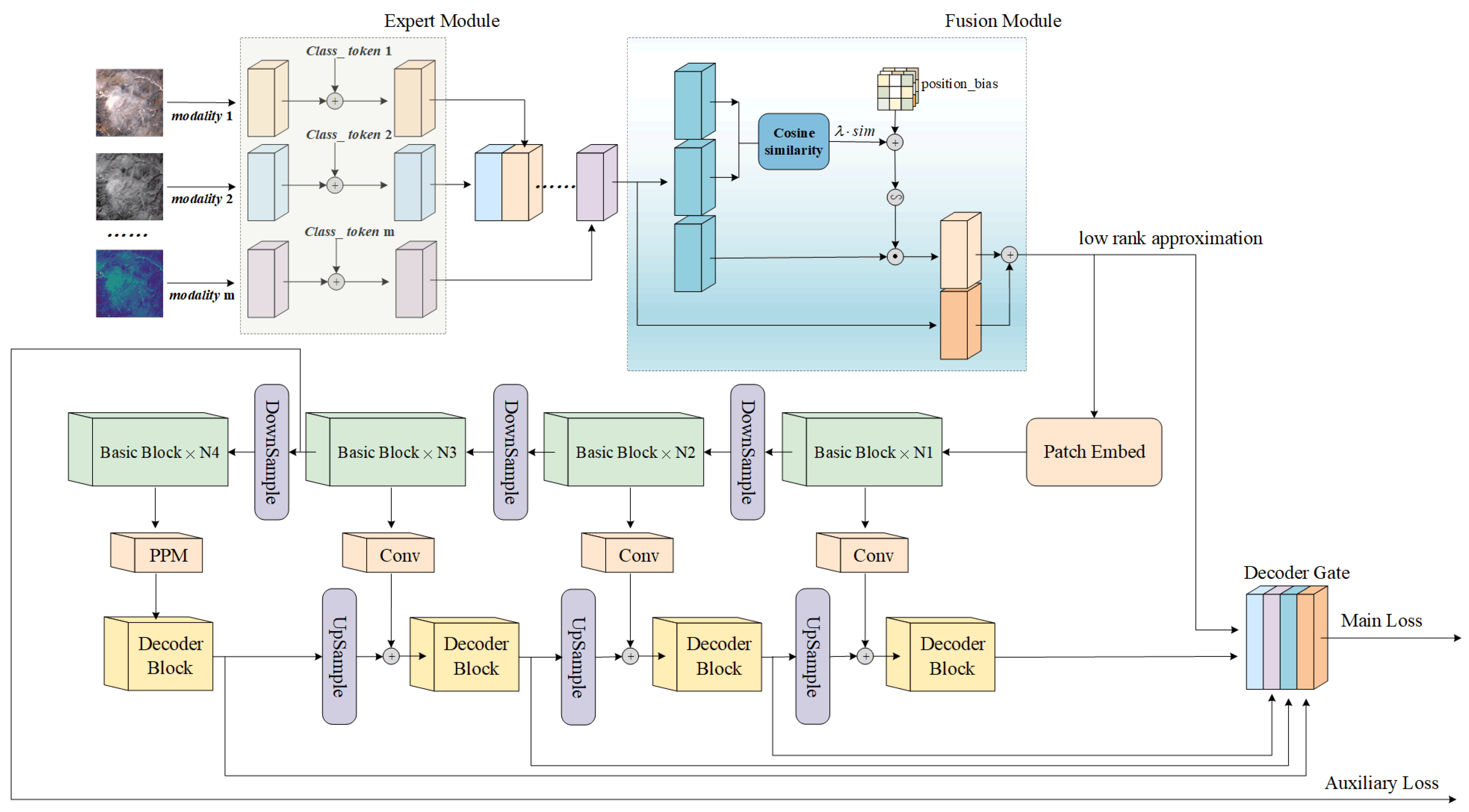
3. Method
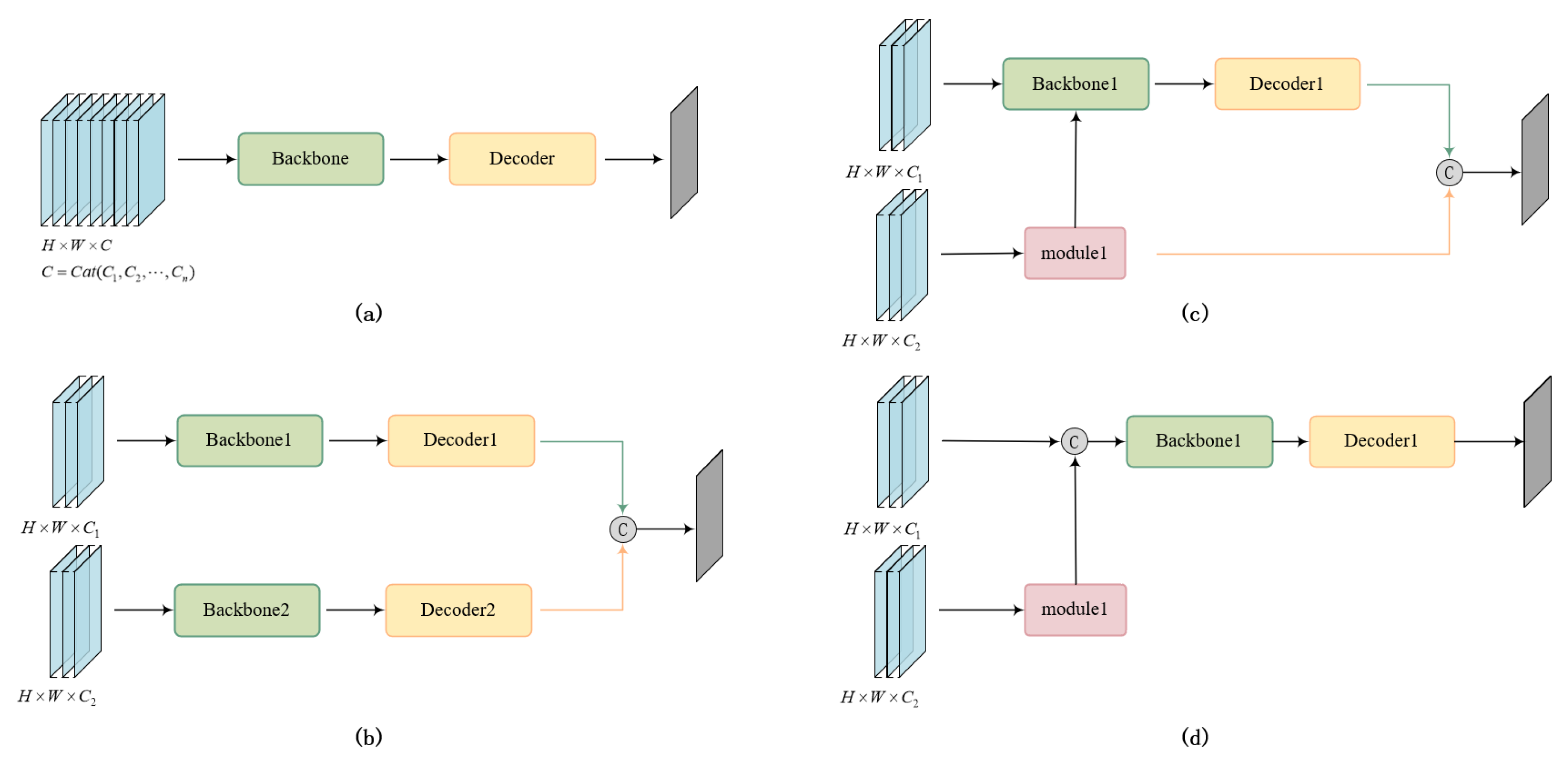
3.1. Overall Network and Motivation
- The establishment of a shared, yet consistent feature extraction module for each modality, albeit with independent weights. This module is designed to learn the specific distribution characteristics within each modality while preventing the direct blending of modalities with substantial discrepancies, thereby preserving their inherent features. Additionally, a unique identifier, in the form of an inductive bias, is assigned to each modal category.
- The utilization of cosine similarity enables the network to adaptively learn complementary features across different modalities, mitigating the redundancy of similar features.
3.2. Modal Feature Expert Module
3.3. Adaptive Multimodal Fusion Module
3.4. Backbone
3.4.1. Basic Block
3.4.2. Architecture Deployment
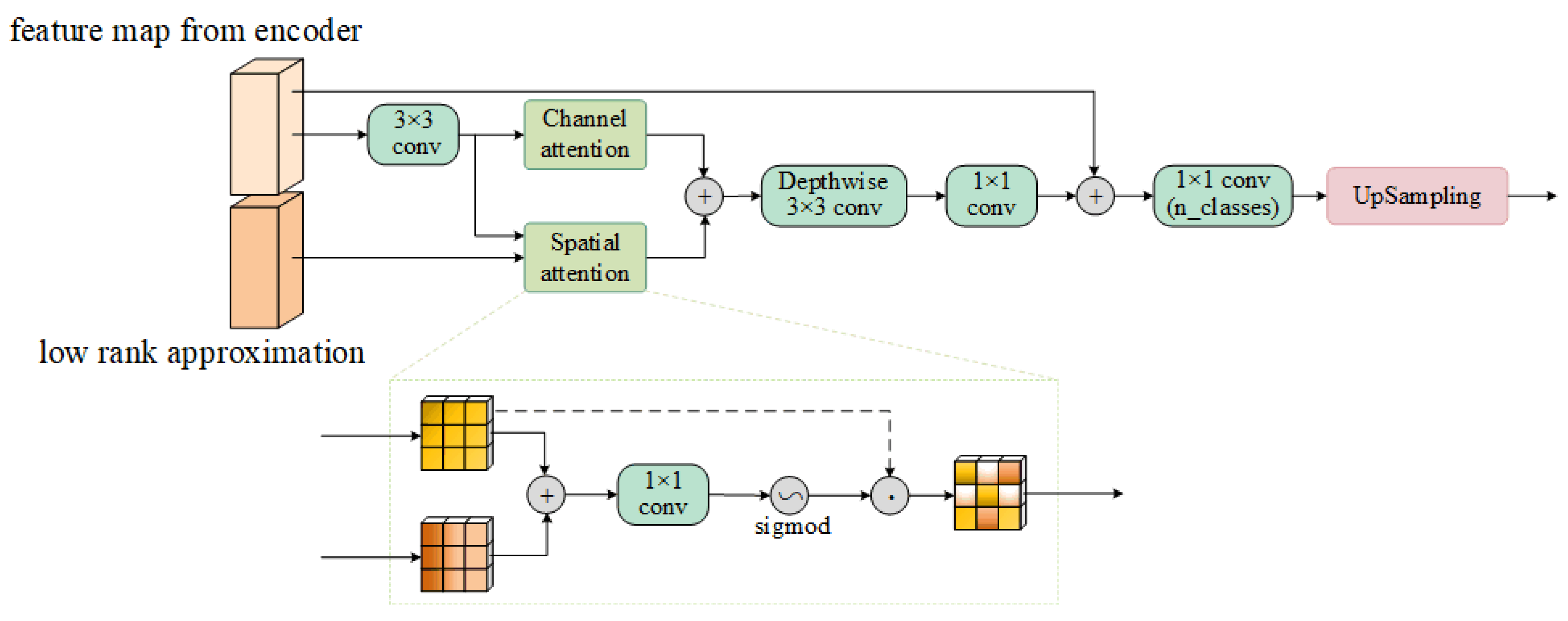
3.5. Decoder
3.6. Loss Function
4. Experiment
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
4.3. Main Properties
4.4. Comparisons
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aybar, C.; Mateo-García, G.; Acciarini, G.; Růžička, V.; Meoni, G.; Longépé, N.; Gómez-Chova, L. Onboard Cloud Detection and Atmospheric Correction with Efficient Deep Learning Models. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 19518–19529. [Google Scholar] [CrossRef]
- Romano, F.; Cimini, D.; Di Paola, F.; Gallucci, D.; Larosa, S.; Nilo, S.T.; Ricciardelli, E.; Iisager, B.D.; Hutchison, K. The Evolution of Meteorological Satellite Cloud-Detection Methodologies for Atmospheric Parameter Retrievals. Remote Sens. 2024, 16, 2578. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhang, F.; Wu, Q.; Li, Z.; Tong, X.; Li, J.; Han, W. Cloud Identification and Properties Retrieval of the Fengyun-4A Satellite Using a ResUnet Model. IEEE Trans. Geosci Remote 2023, 61, 4102318. [Google Scholar] [CrossRef]
- Ma, J.; Liao, Y.; Guan, L. A Cloud Detection Algorithm Based on FY-4A/GIIRS Infrared Hyperspectral Observations. Remote Sens. 2024, 16, 481. [Google Scholar] [CrossRef]
- Massetti, L.; Materassi, A.; Sabatini, F. NSKY-CD: A System for Cloud Detection Based on Night Sky Brightness and Sky Temperature. Remote Sens. 2023, 15, 3063. [Google Scholar] [CrossRef]
- Wang, M.; Wang, X.; Pi, Y.; Ke, S. Automatic Cloud Detection in Remote Sensing Imagery Using Saliency-Based Mixed Features. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5408915. [Google Scholar] [CrossRef]
- Liang, K.; Yang, G.; Zuo, Y.; Chen, J.; Sun, W.; Meng, X.; Chen, B. A Novel Method for Cloud and Cloud Shadow Detection Based on the Maximum and Minimum Values of Sentinel-2 Time Series Images. Remote Sens. 2024, 16, 1392. [Google Scholar] [CrossRef]
- Chang, H.; Fan, X.; Huo, L.; Hu, C. Improving Cloud Detection in WFV Images Onboard Chinese GF-1/6 Satellite. Remote Sens. 2023, 15, 5229. [Google Scholar] [CrossRef]
- Shang, H.; Letu, H.; Xu, R.; Wei, L.; Wu, L.; Shao, J.; Nagao, T.M.; Nakajima, T.Y.; Riedi, J.; He, J.; et al. A hybrid cloud detection and cloud phase classification algorithm using classic threshold-based tests and extra randomized tree model. Remote Sens. Environ. 2024, 302, 113957. [Google Scholar] [CrossRef]
- Surya, S.R.; Rahiman, M.A. CSDUNet: Automatic Cloud and Shadow Detection from Satellite Images Based on Modified U-Net. J. Indian Soc. Remote Sens. 2024, 52, 1699–1715. [Google Scholar] [CrossRef]
- Li, A.; Li, X.; Ma, X. Residual Dual U-Shape Networks with Improved Skip Connections for Cloud Detection. IEEE Geosci. Remote Sens. Lett. 2024, 21, 5000205. [Google Scholar] [CrossRef]
- Du, W.; Fan, Z.; Yan, Y.; Yu, R.; Liu, J. AFMUNet: Attention Feature Fusion Network Based on a U-Shaped Structure for Cloud and Cloud Shadow Detection. Remote Sens. 2024, 16, 1574. [Google Scholar] [CrossRef]
- Zhou, X.; Xie, X.; Huang, H.; Shao, Z.; Huang, X. WodNet: Weak Object Discrimination Network for Cloud Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5627020. [Google Scholar] [CrossRef]
- Dong, J.; Wang, Y.; Yang, Y.; Yang, M.; Chen, J. MCDNet: Multilevel cloud detection network for remote sensing images based on dual-perspective change-guided and multi-scale feature fusion. Int. J. Appl. Earth Obs. 2024, 129, 103820. [Google Scholar] [CrossRef]
- Zhao, C.; Zhang, X.; Kuang, N.; Luo, H.; Zhong, S.; Fan, J. Boundary-Aware Bilateral Fusion Network for Cloud Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5403014. [Google Scholar] [CrossRef]
- Tan, H.; Sun, S.; Cheng, T.; Shu, X. Transformer-Based Cloud Detection Method for High-Resolution Remote Sensing Imagery. Comput. Mater. Contin. 2024, 80, 661–678. [Google Scholar] [CrossRef]
- Gu, G.; Weng, L.; Xia, M.; Hu, K.; Lin, H. Multipath Multiscale Attention Network for Cloud and Cloud Shadow Segmentation. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5404215. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Duan, C.; Zhang, C.; Meng, X.; Fang, S. A Novel Transformer Based Semantic Segmentation Scheme for Fine-Resolution Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6506105. [Google Scholar] [CrossRef]
- Zhang, J.; Song, L.; Wang, Y.; Wu, J.; Li, Y. Attention Mechanism with Spatial Spectrum Dense Connection and Context Dynamic Convolution for Cloud Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5408211. [Google Scholar] [CrossRef]
- Chen, L.; Pan, J.; Zhang, Z. A novel cloud detection method based on segmentation prior and multiple features for Sentinel-2 images. Int. J. Remote Sens. 2023, 44, 5101–5120. [Google Scholar] [CrossRef]
- Wu, X.; Shi, Z.; Zou, Z. A geographic information-driven method and a new large scale dataset for remote sensing cloud/snow detection. ISPRS J. Photogramm. 2021, 174, 87–104. [Google Scholar] [CrossRef]
- Johnston, T.; Young, S.R.; Hughes, D.; Patton, R.M.; White, D. Optimizing convolutional neuralnetworks for cloud detection. In Proceedings of the Machine Learning on HPC Environments, Denver, CO, USA, 12–17 November 2017. [Google Scholar]
- Zhang, C.; Weng, L.; Ding, L.; Xia, M.; Lin, H. CRSNet: Cloud and Cloud Shadow Refinement Segmentation Networks for Remote Sensing Imagery. Remote Sens. 2023, 15, 1664. [Google Scholar] [CrossRef]
- He, M.; Zhang, J. Radiation Feature Fusion Dual-Attention Cloud Segmentation Network. Remote Sens. 2024, 16, 2025. [Google Scholar] [CrossRef]
- Qian, J.; Ci, J.; Tan, H.; Xu, W.; Jiao, Y.; Chen, P. Cloud Detection Method Based on Improved DeeplabV3+ Remote Sensing Image. IEEE Access 2024, 12, 9229–9242. [Google Scholar] [CrossRef]
- Du, X.; Wu, H. Gated aggregation network for cloud detection in remote sensing image. Vis. Comput. 2023, 40, 2517–2536. [Google Scholar] [CrossRef]
- Wang, J.; Li, Y.; Fan, X.; Zhou, X.; Wu, M. MRFA-Net: Multi-Scale Receptive Feature Aggregation Network for Cloud and Shadow Detection. Remote Sens. 2024, 16, 1456. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Singh, R.; Biswas, M.; Pal, M. A transformer-based cloud detection approach using Sentinel 2 imageries. Int. J. Remote Sens. 2023, 44, 3194–3208. [Google Scholar] [CrossRef]
- Lu, C.; Xia, M.; Qian, M.; Chen, B. Dual-Branch Network for Cloud and Cloud Shadow Segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5410012. [Google Scholar] [CrossRef]
- Gu, G.; Wang, Z.; Weng, L.; Lin, H.; Zhao, Z.; Zhao, L. Attention Guide Axial Sharing Mixed Attention (AGASMA) Network for Cloud Segmentation and Cloud Shadow Segmentation. Remote Sens. 2024, 16, 2435. [Google Scholar] [CrossRef]
- Gu, H.; Gu, G.; Liu, Y.; Lin, H.; Xu, Y. Multi-Branch Attention Fusion Network for Cloud and Cloud Shadow Segmentation. Remote Sens. 2024, 16, 2308. [Google Scholar] [CrossRef]
- Yao, X.; Guo, Q.; Li, A.; Shi, L. Optical Remote Sensing Cloud Detection Based on Random Forest Only Using the Visible Light and Near-Infrared Image Bands. Eur. J. Remote Sens. 2022, 55, 150–167. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, W.; Li, Q.; Min, M.; Yao, Z. DCNet: A Deformable Convolutional Cloud Detection Network for Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2021, 19, 8013305. [Google Scholar] [CrossRef]
- Gong, C.; Long, T.; Yin, R.; Jiao, W.; Wang, G. A Hybrid Algorithm with Swin Transformer and Convolution for Cloud Detection. Remote Sens. 2023, 15, 5264. [Google Scholar] [CrossRef]
- Gong, C.; Yin, R.; Long, T.; Jiao, W.; He, G.; Wang, G. Spatial–Temporal Approach and Dataset for Enhancing Cloud Detection in Sentinel-2 Imagery: A Case Study in China. Remote Sens. 2024, 16, 973. [Google Scholar] [CrossRef]
- Zhang, H.K.; Luo, D.; Roy, D. Improved Landsat Operational Land Imager (OLI) Cloud and Shadow Detection with the Learning Attention Network Algorithm (LANA). Remote Sens. 2024, 16, 1321. [Google Scholar] [CrossRef]
- Li, J.; Wang, Q. CSDFormer: A cloud and shadow detection method for landsat images based on transformer. Int. J. Appl. Earth Obs. 2024, 129, 103799. [Google Scholar] [CrossRef]
- Li, X.; Yang, X.; Li, X.; Lu, S.; Ye, Y.; Ban, Y. GCDB-UNet: A novel robust cloud detection approach for remote sensing images. Knowl. Based Syst. 2022, 238, 107890. [Google Scholar] [CrossRef]
- Zhang, J.; Shi, X.; Wu, J.; Song, L.; Li, Y. Cloud Detection Method Based on Spatial–Spectral Features and Encoder–Decoder Feature Fusion. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5407915. [Google Scholar] [CrossRef]
- Wang, Y.; Gu, L.; Li, X.; Gao, F.; Jiang, T. Coexisting Cloud and Snow Detection Based on a Hybrid Features Network Applied to Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5405515. [Google Scholar] [CrossRef]
- Li, J.; Wu, Z.; Hu, Z.; Jian, C.; Luo, S.; Mou, L.; Zhu, X.X.; Molinier, M. A Lightweight Deep Learning-Based Cloud Detection Method for Sentinel-2A Imagery Fusing Multiscale Spectral and Spatial Features. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5401219. [Google Scholar] [CrossRef]
- Chen, G.; Xu, W.; Li, C.; Jing, W. GS—CDNet: A remote sensing image cloud detection method with geographic spatial data integration. Int. J. Remote Sens. 2024, 45, 9108–9130. [Google Scholar] [CrossRef]
- Cao, Y.; Sui, B.; Zhang, S.; Qin, H. Cloud Detection From High-Resolution Remote Sensing Images Based on Convolutional Neural Networks with Geographic Features and Contextual Information. IEEE Geosci. Remote Sens. Lett. 2023, 20, 6003405. [Google Scholar] [CrossRef]
- Ma, N.; Sun, L.; He, Y.; Zhou, C.; Dong, C. CNN-TransNet: A Hybrid CNN-Transformer Network with Differential Feature Enhancement for Cloud Detection. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1001705. [Google Scholar] [CrossRef]
- Fan, S.; Song, T.; Jin, G.; Jin, J.; Li, Q.; Xia, X. A Lightweight Cloud and Cloud Shadow Detection Transformer with Prior-Knowledge Guidance. IEEE Geosci. Remote Sens. Lett. 2024, 21, 8003405. [Google Scholar] [CrossRef]
- Xu, K.; Wang, W.; Deng, X.; Wang, A.; Wu, B.; Jia, Z. TransGA-Net: Integration Transformer with Gradient-Aware Feature Aggregation for Accurate Cloud Detection in Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2024, 21, 6002805. [Google Scholar] [CrossRef]
- Aybar, C.; Bautista, L.; Montero, D.; Contreras, J.; Ayala, D.; Prudencio, F.; Loja, J.; Ysuhuaylas, L.; Herrera, F.; Gonzales, K.; et al. CloudSEN12+: The largest dataset of expert-labeled pixels for cloud and cloud shadow detection in Sentinel-2. Data Brief 2024, 56, 110852. [Google Scholar] [CrossRef]
- Aybar, C.; Ysuhuaylas, L.; Loja, J.; Gonzales, K.; Herrera, F.; Bautista, L.; Yali, R.; Flores, A.; Diaz, L.; Cuenca, N.; et al. CloudSEN12, a global dataset for semantic understanding of cloud and cloud shadow in Sentinel-2. Sci. Data 2022, 9, 782. [Google Scholar] [CrossRef]
- Li, Z.; Shen, H.; Li, H.; Xia, G.; Gamba, P.; Zhang, L. Multi-feature combined cloud and cloud shadow detection in GaoFen-1 wide field of view imagery. Remote Sens. Environ. 2017, 191, 342–358. [Google Scholar] [CrossRef]
- Mohajerani, S.; Saeedi, P. Cloud-Net: An end-to-end cloud detection algorithm for Landsat 8 imagery. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 1029–1032. [Google Scholar]
- Mohajerani, S.; Saeedi, P. Cloud and cloud shadow segmentation for remote sensing imagery via filtered jaccard loss function and parametric augmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4254–4266. [Google Scholar] [CrossRef]
- Hughes, M.J.; Kennedy, R. High-quality cloud masking of Landsat 8 imagery using convolutional neural networks. Remote Sens. 2019, 11, 2591. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Satellite | Train | Test | Size | Resolution | Bands |
|---|---|---|---|---|---|---|
| WHUS2-CD+ | Sentinel-2 | 24 | 12 | 10,980 × 10,980 3660 × 3660 1830 × 1830 | 10 m 20 m 60 m | Blue, Green, Red, Near InfraRed 5, 6, 7, 8A, 11 (SWIR), 12 (SWIR) 1, 9, 10 |
| CloudSEN12+ | Sentinel-2 | 8490 687 | 975 85 | 509 × 509 2000 × 2000 | 10 m | Blue, Green, Red, Near InfraRed 5, 6, 7, 8A, 11 (SWIR), 12 (SWIR), 1, 9, 10, TOA |
| GF-1 WHU | Gaofen1(WFV) | 108 | 16,633 × 15,425 | 16 m | Blue, Green, Red, Near InfraRed | |
| MODIS | MODIS | 1192 | 150 | 512 × 512 | 500 m 1000 m | Blue, Green, Red 18, 20, 23, 28, 29, 31, 32 |
| 95-Cloud | Landsat 8 | 75 | 20 | 384 × 384 | 30 m | Blue, Green, Red, Near InfraRed |
| Levir_CS | Gaofen1 (WFV) | 3068 | 1100 | 1200 × 1340 | 16 m | Blue, Green, Red, Near InfraRed DEM (Digital Elevation Model) |
| Model | Accuracy | Precision | Recall | F1-Score | MIoU |
|---|---|---|---|---|---|
| Cloud_3 | 98.59% | 96.67% | 95.53% | 96.01% | 92.65% |
| Cloud_4 | 98.74% | 97.19% | 95.83% | 96.50% | 93.38% |
| Cloud_10 | 98.82% | 97.66% | 95.81% | 96.71% | 93.75% |
| Cloud_13 | 98.83% | 97.33% | 96.18% | 96.75% | 93.82% |
| Model | Accuracy | Precision | Recall | F1-Score | MIoU |
|---|---|---|---|---|---|
| Cloud_4 | 98.74% | 97.19% | 95.83% | 96.50% | 93.38% |
| Cloud_(3,1) | 98.88% | 97.51% | 96.30% | 96.90% | 94.09% |
| Cloud_10 | 98.82% | 97.66% | 95.81% | 96.71% | 93.75% |
| Cloud_(3,1,6) | 98.89% | 97.54% | 96.32% | 96.92% | 94.13% |
| Cloud_13 | 98.83% | 97.33% | 96.18% | 96.75% | 93.82% |
| Cloud_(3,1,6,3) | 98.91% | 97.41% | 96.58% | 96.99% | 94.26% |
| Model | Accuracy | Precision | Recall | F1-Score | MIoU |
|---|---|---|---|---|---|
| Cloud_(3,1) | 98.45% | 96.04% | 94.05% | 95.02% | 90.81% |
| Cloud_(3,1,6) | 98.50% | 97.60% | 92.83% | 95.01% | 90.87% |
| Cloud_(3,1,6,3) | 98.65% | 97.42% | 93.96% | 95.61% | 91.83% |
| Model | Accuracy | Precision | Recall | F1-Score | MIoU |
|---|---|---|---|---|---|
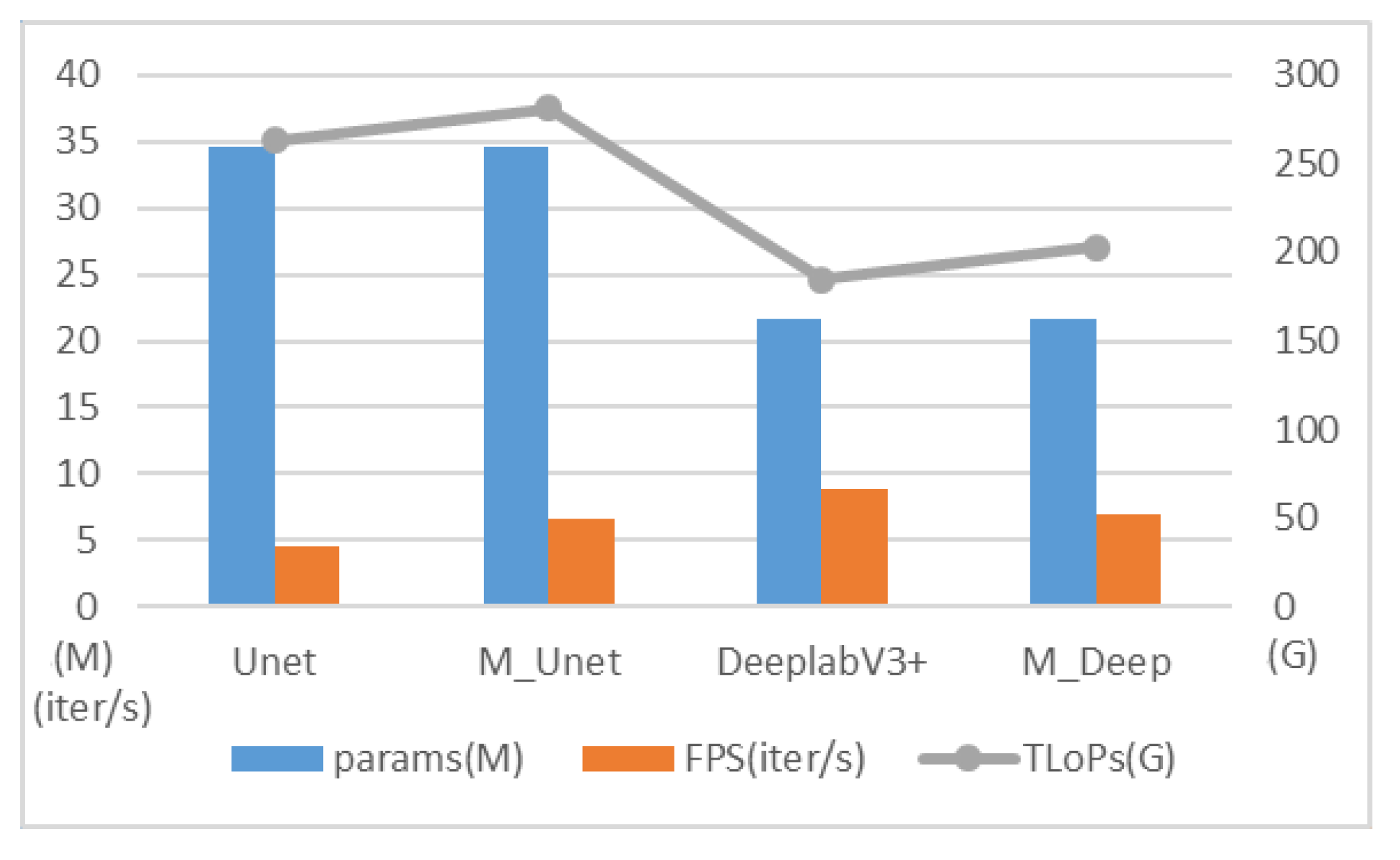
| UNet | 98.78% | 96.55% | 96.77% | 96.66% | 93.66% |
| M_UNet | 98.82% | 97.52% | 95.96% | 96.73% | 93.78% |
| DeepLabV3+ | 98.71% | 97.93% | 94.88% | 96.34% | 93.10% |
| M_Deep | 98.77% | 97.66% | 95.51% | 96.56% | 93.48% |
| EM | AFM | Backbone | Accuracy | Precision | Recall | F1-Score | MIoU |
|---|---|---|---|---|---|---|---|
| ✓ | 98.83% | 97.21% | 96.33% | 96.76% | 93.85% | ||
| ✓ | ✓ | 98.86% | 97.46% | 96.26% | 96.85% | 94.01% | |
| ✓ | ✓ | ✓ | 98.91% | 97.41% | 96.58% | 96.99% | 94.26% |
| Model | Accuracy | Precision | Recall | F1-Score | MIoU |
|---|---|---|---|---|---|
| UNet | 98.78% | 96.55% | 96.77% | 96.66% | 93.66% |
| DeepLabV3+ | 98.71% | 97.93% | 94.88% | 96.34% | 93.10% |
| AFMUnet | 98.75% | 97.88% | 95.19% | 96.48% | 93.35% |
| CSDFormer | 98.80% | 97.21% | 96.13% | 96.68% | 93.71% |
| TransGA | 98.80% | 97.71% | 96.25% | 96.67% | 93.69% |
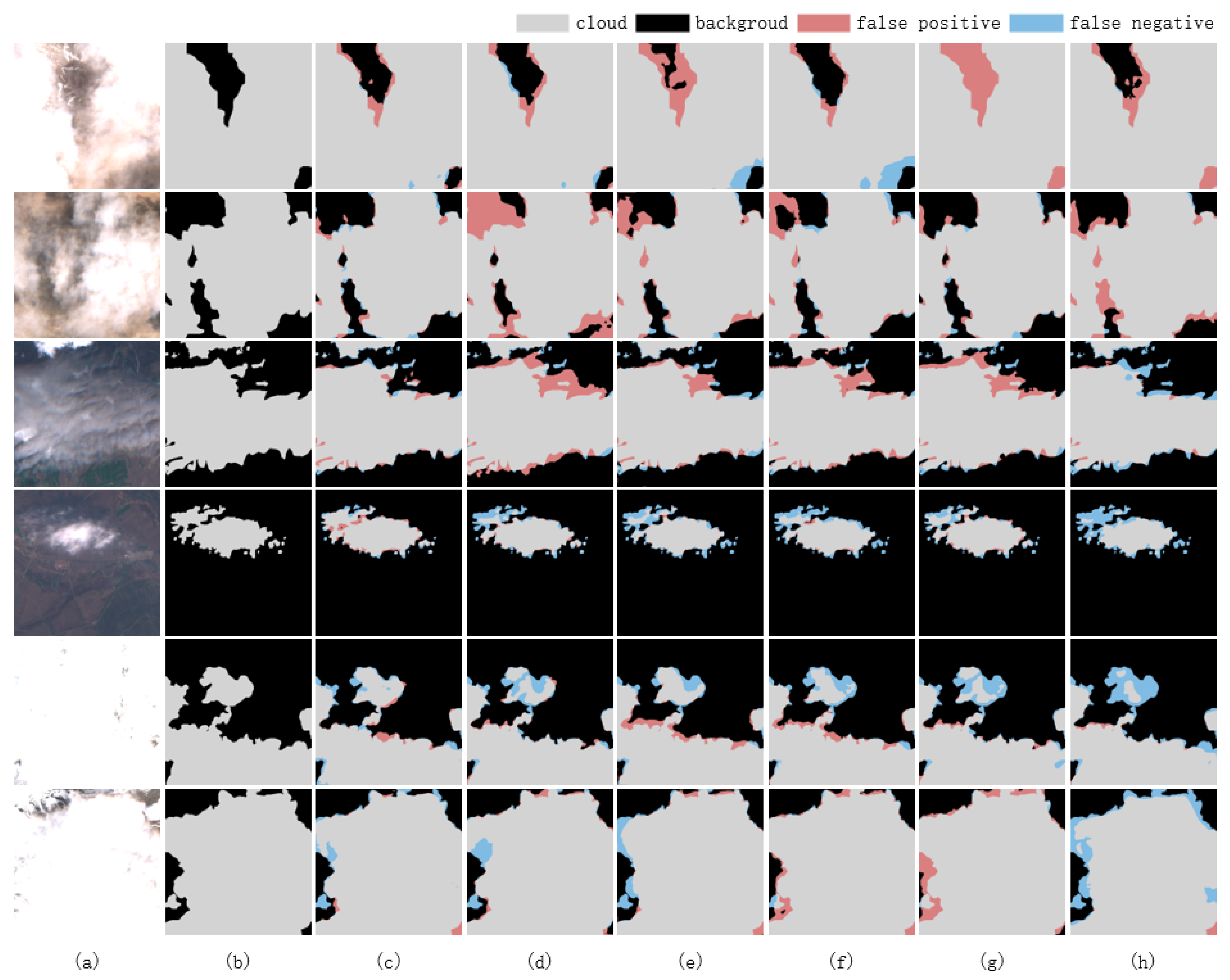
| ours | 98.91% | 97.41% | 96.58% | 96.99% | 94.26% |
| Model | Accuracy | Precision | Recall | F1-Score | MIoU |
|---|---|---|---|---|---|
| UNet | 97.95% | 91.92% | 96.04% | 93.86% | 88.84% |
| DeepLabV3+ | 98.40% | 95.52% | 94.29% | 94.90% | 90.59% |
| AFMUnet | 98.57% | 96.08% | 94.82% | 95.44% | 91.53% |
| CSDFormer | 98.49% | 95.55% | 94.87% | 95.21% | 91.13% |
| TransGA | 98.25% | 96.05% | 92.71% | 94.30% | 89.60% |
| ours | 98.65% | 97.42% | 93.96% | 95.61% | 91.83% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mo, Y.; Chen, P.; Zhou, W.; Chen, W. Enhanced Cloud Detection Using a Unified Multimodal Data Fusion Approach in Remote Images. Sensors 2025, 25, 2684. https://doi.org/10.3390/s25092684
Mo Y, Chen P, Zhou W, Chen W. Enhanced Cloud Detection Using a Unified Multimodal Data Fusion Approach in Remote Images. Sensors. 2025; 25(9):2684. https://doi.org/10.3390/s25092684
Chicago/Turabian StyleMo, Yan, Puhui Chen, Wanting Zhou, and Wei Chen. 2025. "Enhanced Cloud Detection Using a Unified Multimodal Data Fusion Approach in Remote Images" Sensors 25, no. 9: 2684. https://doi.org/10.3390/s25092684
APA StyleMo, Y., Chen, P., Zhou, W., & Chen, W. (2025). Enhanced Cloud Detection Using a Unified Multimodal Data Fusion Approach in Remote Images. Sensors, 25(9), 2684. https://doi.org/10.3390/s25092684