1. Introduction
The timely detection of component defects makes a significant contribution to the safety and stability of railway freight car operation. In recent years, more and more research has been devoted to using machine vision to solve the problem of component defect recognition, and image quality is an important prerequisite for defect detection, which directly affects the accuracy of the entire system. Therefore, improving image quality is crucial.
Due to the outdoor deployment of railway freight car image acquisition systems, the captured images are frequently affected by a variety of environmental disturbances such as fog, haze, dust, temperature fluctuations, and unstable signal transmission. These factors introduce significant noise and degradation during the stages of image acquisition, transmission, and reception. Additionally, image capture often occurs in poorly lit areas beneath the car body and is further challenged by complex structural occlusions, making the visualization of critical component details even more difficult. These issues severely constrain the accuracy of image-based defect detection tasks.
Unlike traditional image-denoising scenarios, railway freight car images face unique challenges. Defects are usually small in size, diverse in form, and complex in structure, while useful textures and edge structures are densely distributed and highly susceptible to noise interference. As a result, image denoising in this context must not only achieve robust noise suppression but also ensure the accurate preservation of fine-grained edge and texture information, rendering the task significantly more complex and specialized than general-purpose denoising problems.
Researching efficient methods for denoising railway freight car operation images is a crucial aspect of interdisciplinary fields, offering both theoretical significance and substantial practical application value [
1,
2]. The widespread application of digital image technology has made image denoising a key research topic in interdisciplinary fields such as medical imaging, satellite remote sensing, and video surveillance.
With the advancement of digital image technology in recent years, image denoising, as the most fundamental and important downstream task, plays a crucial role in improving image quality and the accuracy of subsequent tasks. In practical application scenarios, image data are subject to various interferences of noise. Image denoising aims to restore potential noise-free image data from image data contaminated by noise. However, this is an ill-posed inverse process, and there is no unique solution [
3].
Denoising methods can be divided into two categories: model-based and learning-based approaches. Due to the presence of similar or repetitive edge texture information in natural images, model-based methods can reduce artifacts caused by complex texture information during denoising by combining non-local self-similarity with sparse representation. So far, a large number of models based on this technology have been developed. The most representative technique is BM3D [
4], which achieves image denoising by extracting self-similarity features in images and performing domain transformations on self-similar blocks. WNNM [
5] applies the weighted nuclear norm minimization method to image denoising by leveraging the non-local self-similarity of images. Subsequently, many methods based on this type have been continuously proposed, such as MNL-tSVD [
6], BM4D [
7], slice-based dictionary learning [
8], and so on. Although model-based methods have achieved notable results in the field of image denoising, their shortcomings are also quite apparent. Firstly, such techniques require the design of specific models for each individual denoising task. Secondly, there is a lack of universality among various data, and manual or semi-automatic parameter adjustments are required for the model. In addition, their convergence takes a long time. These challenges not only need to be addressed by such methods but also hinder, to some extent, the practical application of these technologies.
In recent years, deep learning methods have been widely applied in various fields of computer vision. Unlike model-based methods, learning-based methods aim to learn model parameters from data and obtain statistical information about images and noise through training the model and completing the mapping between noisy images and denoised images to achieve denoising. The learning of deep neural networks can be divided into two types: self-supervised learning and supervised learning. The self-supervised denoising methods represented by N2N [
9], N2S [
10], S2S [
11], and VDN [
12] lack flexibility in adjusting network parameters, and the extracted features cannot fully represent noise, making it difficult to obtain complex mapping relationships between noisy images and denoised images.
Supervised learning can effectively address the issues present in the aforementioned self-supervised denoising techniques. DnCNN [
13] accelerates the training process and enhances model denoising performance by employing residual learning and batch normalization techniques. FFDNet [
14] effectively solves the problem of blind denoising by using noisy image blocks and noisy mapping blocks as inputs to the network. ADNet [
15] introduces a denoising convolutional neural network guided by an attention mechanism, enabling finer extraction of noise information from complex backgrounds, thus achieving superior denoising results. ADL [
3] introduces an adversarial distortion learning-based denoising method, where both the denoiser and discriminator are implemented using an autoencoder architecture known as Efficient-UNet. This approach effectively mitigates overfitting during training and improves the model’s denoising performance. DRAN [
16] removes noise from images by integrating attention mechanisms and dynamic convolution operations while preserving critical image details. This network design utilizes the correlation between features and optimizes the propagation of residual features through spatial gating mechanisms, thereby improving denoising performance.
On this basis, recent research has further explored denoising mechanisms in specific task scenarios. Yang et al. propose DIPKD [
17], which enhances lightweight SAR object detection via Selective Noise Suppression, Knowledge Level Decoupling, and Reverse Information Transfer, effectively filtering speckle noise and boosting student model performance. Saidulu and Muduli [
18] designed DP-LDCTNet for low-dose CT denoising, combining Dynamic Convolution, a Structure-aware Network trained with contrastive learning, and CT-specific perceptual loss to preserve structural integrity. For low-light enhancement, Wang and Yuan [
19] propose FIHN, integrating a hierarchical structure (TRGF and DDCF modules) with an invertible flow network trained using negative log-likelihood loss, improving contrast, noise suppression, and detail preservation. Hein et al. [
20] proposed PFCM (Poisson Flow Consistency Models), which extends the applicability of supervised diffusion models to medical imaging.
In the process of railway image acquisition, noise weakens the ability to represent image details due to various external factors, which significantly limits the accuracy of fault detection. Although deep neural networks have made significant progress in denoising natural and medical images and effectively improved image quality, their adaptability in the specific field of railway images is still insufficient, resulting in limited generalization ability. In addition, due to the scarcity of data in railway freight car image scenes, there are relatively few related studies and a lack of specialized optimized denoising algorithms. In practical applications, existing denoising methods often struggle to effectively preserve high-frequency textures and structural edges, which are crucial for downstream tasks such as defect localization and classification in railway freight car images. This deficiency can lead to problems such as blurred image contours and loss of key visual clues. Especially in complex railway freight car image backgrounds, accurately preserving the edge information of complex components and distinguishing noise from useful visual information remains a major challenge. These limitations result in poor performance of images in terms of content texture, detail restoration, and other aspects. Therefore, it is urgent to design denoising algorithms specifically tailored to the operating environment and visual complexity of railway freight car images in order to improve the reliability and accuracy of fault detection.
In response to the challenge of simultaneously improving noise suppression and edge information preservation in railway freight car images, this paper proposes a method called Nonlinear Activation-Free Network based on Multi-Scale Edge Enhancement and Fusion (NAF-MEEF), which leverages supervised learning concepts within Nonlinear Activation-Free Networks. The proposed algorithm adopts a fully convolutional architecture and is capable of effectively denoising railway freight car images.
To comprehensively validate its effectiveness, NAF-MEEF has been evaluated on both self-constructed railway freight car datasets and public datasets such as Set12 and BSD68 [
21]. Additionally, denoising experiments on a remote sensing ship dataset and image dehazing experiments on railway freight car images were conducted, further demonstrating the robustness and generalization capability of the proposed method. The experimental results confirm that NAF-MEEF not only excels in railway freight car image denoising but also achieves competitive performance on diverse benchmark datasets. In summary, the main contributions of this article are as follows:
- (1)
This paper proposes a Multi-scale Edge Enhancement Initialization Layer, designed based on learnable Sobel convolution, which adaptively extracts high-frequency edge features of images at multiple scales.
- (2)
Dual-brand Nonlinear Activation-Free Network (D-NAFNet) is constructed as the core feature extractor of the algorithm. It adopts an efficient, lightweight UNet architecture and employs the Nonlinear Activation-Free Network Block (NAF-MEEF’s block) as its backbone, enabling hierarchical coordination during feature extraction.
- (3)
A Multi-scale Rotation Fusion Attention Mechanism is proposed that effectively integrates multi-scale information and establishes the relationship between channel and spatial attention.
- (4)
A composite loss function is introduced for the training phase that combines L1 loss with pyramidal textural loss, thereby preserving texture information in complex regions and minimizing noise amplification in non-textured areas.
The rest of this paper is organized as follows:
Section 2 provides a detailed description of the proposed NAF-MEEF algorithm.
Section 3 introduces the composite loss function used in this paper.
Section 4 presents the experimental settings.
Section 5 shows extensive experimental results and analysis.
Section 6 conducts ablation studies.
Section 7 concludes the paper.
2. Methods
NAF-MEEF (
Figure 1a) aims to learn the mapping relationship between noisy images and clean images in order to effectively remove noise while preserving image details as much as possible. To achieve this goal, NAF-MEEF has enhanced its feature extraction and edge information preservation capabilities through multiple architectural innovations. Firstly, we designed a 2D dual-branch deep convolutional block (2DDCB) in the NAF-MEEF’s block and constructed a D-NAFNet feature extraction network using this block. Unlike directly using NAFNet as the backbone, we redesign the feature extraction pathway, incorporating D-NAFNet (
Figure 1b) as an integral part of the overall architecture. In addition, the proposed Multi-scale Edge Enhancement Initialization Layer (MEEIL) integrates learnable Sobel operators across multiple scales to enhance edge representation at the early stage of image input. Furthermore, a Multi-scale Rotation Fusion Attention Mechanism is employed to adaptively fuse multi-scale features. These designs are not merely a simple stacking of modules but rather an organically integrated solution aimed at addressing common issues in images, such as edge degradation and structural blurring.
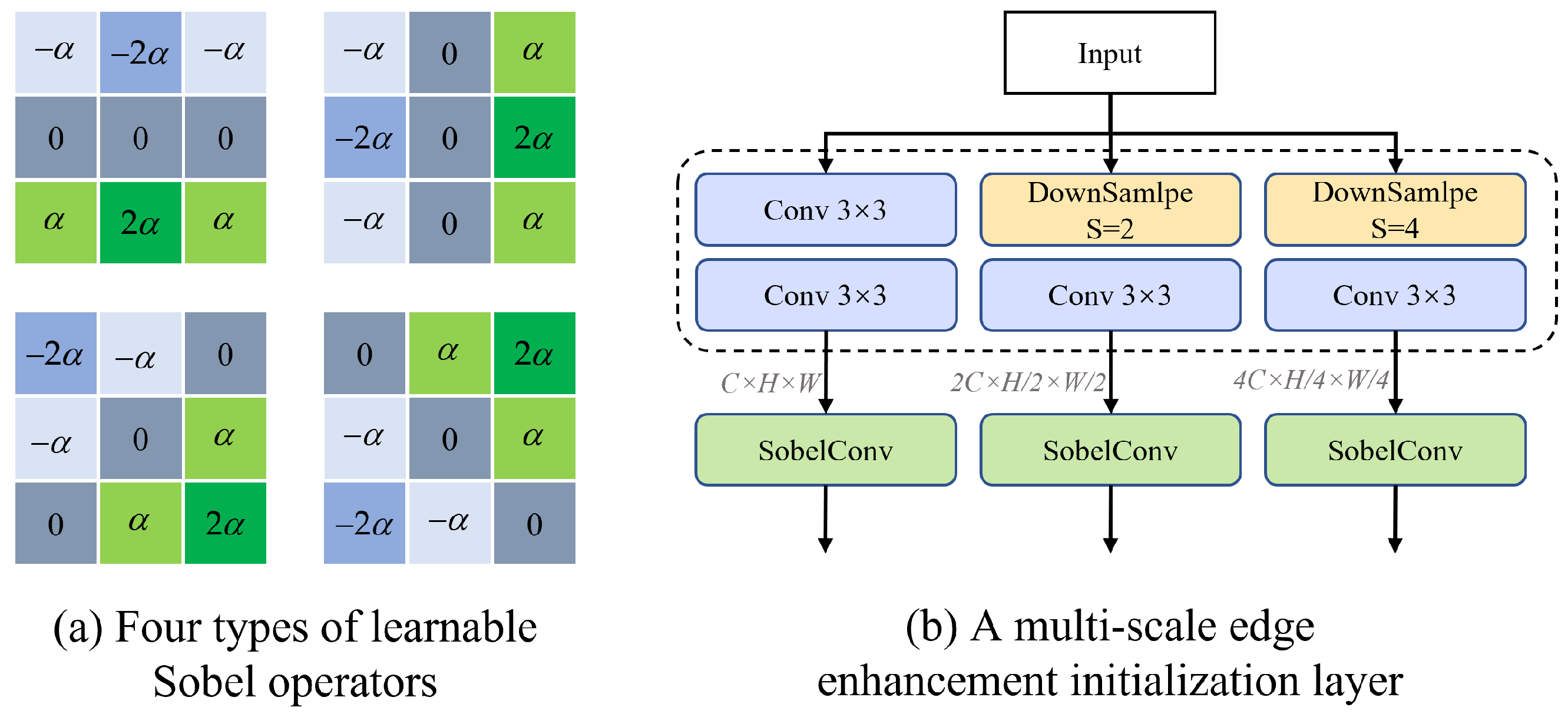
2.1. Multi-Scale Edge Enhancement Initialization Layer
This section introduces a Multi-scale Edge Enhancement Initialization Layer designed to address a critical limitation in image-denoising tasks—namely, the loss of fine edge and high-frequency details caused by strong or composite noise. Traditional convolutional layers often struggle to preserve such features, especially when processing images at varying resolutions or under severe noise corruption. To mitigate this, we propose a dedicated initialization layer that enhances edge-related features from the input image across multiple scales, thereby improving the model’s sensitivity to structural and high-frequency components from the very beginning of the network.
Specifically, the proposed layer consists of a multi-scale initialization structure that splits the input image into three resolution branches and applies a trainable Sobel operator at each scale [
22]. Unlike conventional Sobel filters with fixed weights, our trainable Sobel operator learns to adaptively capture vertical, horizontal, and diagonal edge information by optimizing its learnable parameter
during training. This enables the model to generate edge-enhanced feature maps that are more robust to noise and better aligned with the underlying structural information of the image.
This design is particularly motivated by the need for strong initialization in low-level vision tasks such as denoising, where edge preservation plays a vital role in visual quality. By introducing edge enhancement early in the network, the model is better guided during training to retain contours and fine textures, which are often degraded in standard convolutional pipelines. The structure of the trainable Sobel operator and the multi-scale fusion process is illustrated in
Figure 2a.
As shown in
Figure 2b, the input image
I is first subjected to multi-scale processing to extract edge features at different scales. Specifically, three different scales of convolution branches are used, namely no downsampling, downsampling factor
, and downsampling factor
. The feature extraction process for each scale can be represented as:
After two
convolutions at each scale, the corresponding evidence graph
obtained separately. After obtaining the evidence graph
at different scales, we use Sobel convolution to extract the edge features at each scale, which can be expressed as follows:
This design ensures better preservation of edge features in the image, especially for denoising tasks, where enhanced high-frequency information is critical for effectively reducing noise while maintaining image details.
2.2. Feature Extraction Network: D-NAFNet
Convolutional neural networks (CNNs) have been widely adopted in computer vision tasks such as image denoising, object detection, and image segmentation, demonstrating significant effectiveness. With the rapid advancement of deep learning technologies, researchers have continuously optimized CNNs, yielding notable improvements in convolutional operation design [
23,
24,
25,
26] and overall network architecture refinement [
27,
28], all aimed at enhancing model performance and efficiency. Recently, the introduction of NAFNet [
29] has offered a new perspective on image denoising by questioning the necessity of nonlinear activation functions in traditional CNNs. NAFNet proposes a model built from scratch that excludes these functions, showing they may not be essential for denoising tasks. This paradigm shift has inspired novel approaches focusing on edge preservation and multi-scale feature fusion to better capture fine-grained information. Complex denoising models often suffer from high computational costs due to their deep and parameter-heavy structures, which pose challenges in resource-constrained environments. In response, Chen et al. [
29] proposed a model construction strategy that emphasizes structural simplicity by avoiding unnecessary components while iteratively refining key modules. Building on this idea, the method presented in this study aims to develop a streamlined, efficient feature extractor suitable for real-time denoising applications such as railway freight car image processing. Subsequent sections elaborate on architectural and block-level design choices guided by these principles.
2.2.1. Architecture
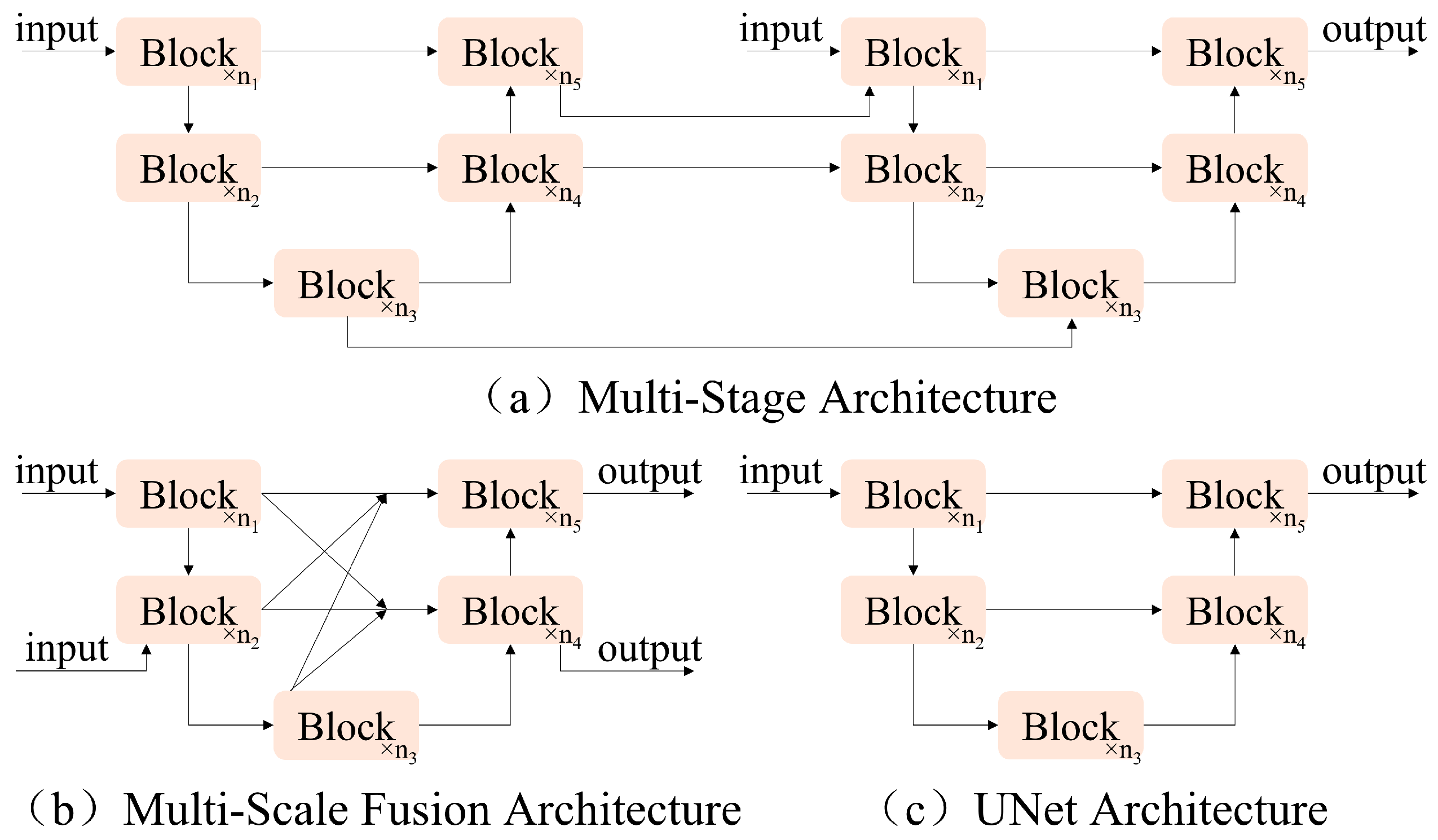
With the continuous development of deep learning, researchers continue to develop and innovate the model constructs; for example, some multi-stage architectures stack UNet networks in series (
Figure 3a), and multi-scale fusion architectures enhance the fusion of features at different scales through complex inter-block connections (
Figure 3b). In this paper, the classical single-stage UNet network architecture (
Figure 3c) is adopted to ensure the simplicity of the model structure. Several state-of-the-art (SOTA) methods have used this single-stage UNet network so that the architecture does not become a hindrance to the model performance, as demonstrated by the subsequent experimental structure.
2.2.2. PlainNet’s Block
The main framework of deep neural networks is usually built through the stacking of modules, and the excellent design inside the modules largely determines the overall performance of the model. Therefore, this article will start with the most important and common components for combination, such as convolution operations, ReLU activation functions, and shortcuts. The combination of these basic components is shown in
Figure 4a, which we call PlainNet’s block. In the design of the module, this article did not consider the introduction of Transformer structure, mainly based on the following two considerations: Firstly, several studies in recent years have shown that Transformer is not the only method that can achieve excellent denoising performance [
29]. In addition, compared with self-attention mechanisms, convolutional neural networks have the advantages of simpler mechanisms and lower computational overhead and can achieve superior performance in situations where data volume is relatively limited.
The focus of this study is the denoising of railway freight car images; however, significant challenges exist in the acquisition and collection of such data samples. The available dataset is insufficient for training a Transformer model to a satisfactory level. Consequently, convolutional neural networks (CNNs) have been chosen as a cost-effective alternative, offering an optimal balance between performance and computational expense.
2.2.3. NAF-MEEF’s Block
Normalization techniques are crucial in both upstream tasks (like image detection and segmentation) and downstream tasks (such as image denoising). Batch normalization [
30] was initially introduced to address gradient vanishing and exploding issues during deep neural network training. However, it can become unstable with small batch sizes. To address this, instance normalization [
31] was proposed, but its performance improvement is not always consistent across tasks. With the rise of Transformer-based methods [
27,
32,
33,
34], layer normalization [
35] has gained widespread adoption, significantly boosting performance across various visual tasks. Thus, layer normalization techniques were incorporated into PlainNet to enhance model stability and generalization.
In our proposed NAF-MEEF architecture, layer normalization is applied at the beginning of each NAF-MEEF block and after the first residual connection (as shown in
Figure 4b). This design helps stabilize feature distributions, reduce internal covariate shifts, and improve convergence performance under small-batch training conditions. Inspired by the successful application of LayerNorm in Transformer architectures, we incorporate it into our model to enhance stability and generalization across various types of noise and image domains.
Although the self-attention mechanism [
36] has been widely applied in many tasks in recent years and has shown strong feature extraction capabilities, its complex structural design deviates from the original intention of simplifying the model in this paper. Therefore, this paper does not delve into its advantages and disadvantages. On the contrary, we improve model performance by introducing a simple channel attention mechanism [
37]. This mechanism enhances overall performance by adaptively weighting data from different channels, allowing the model to focus more on important features within each channel.
Activation functions such as ReLU [
38] and GELU [
39] have been widely used in computer vision tasks and have achieved state-of-the-art results. But in this article, we borrowed the design of NAFNet [
29] and introduced an activation method called Simple Gate, as shown in
Figure 5c, which is a simple variant of GLU. This method divides the features into two equal parts in the channel dimension and introduces nonlinear components into the network through simple multiplication. This simplified activation function trims down the model structure while still maintaining performance, as expressed in the following equation:
where
X and
Y are equally divided feature maps of equal size.
A common representation of the channel attention mechanism is shown in
Figure 5a, where the feature maps are channel-weighted by spatial information squeezing as well as a multilayer perceptron. Where
X represents the feature map,
represents the sigmoid function,
and
represent the two fully connected layers, and
represents the ReLU function between the fully connected layers.
The CA is simplified by retaining the global information aggregation capability of SimpleGate as well as the channel information interaction capability, as shown in the following equation and
Figure 5b:
In addition, to improve the feature extraction ability of the model, we introduced a multi-path convolution structure in the convolution part of the model, as shown in the red dashed box in
Figure 4b, called the 2D dual-branch deep convolution block (2DDCB) Specifically, the module consists of two parallel paths, with each path including a 1 × 1 pointwise convolution and a 3 × 3 depthwise convolution. These two paths independently process the input feature map and fuse their outputs via an element-wise addition operation. By combining pointwise convolution and depthwise convolution, the module captures fine-grained local features and learns global contextual information, thereby producing richer and more discriminative feature representations. This design ensures high computational efficiency while enhancing the ability to represent features effectively. It is highly suitable for extracting fine-grained and contextual features in tasks such as segmentation, detection, and denoising.
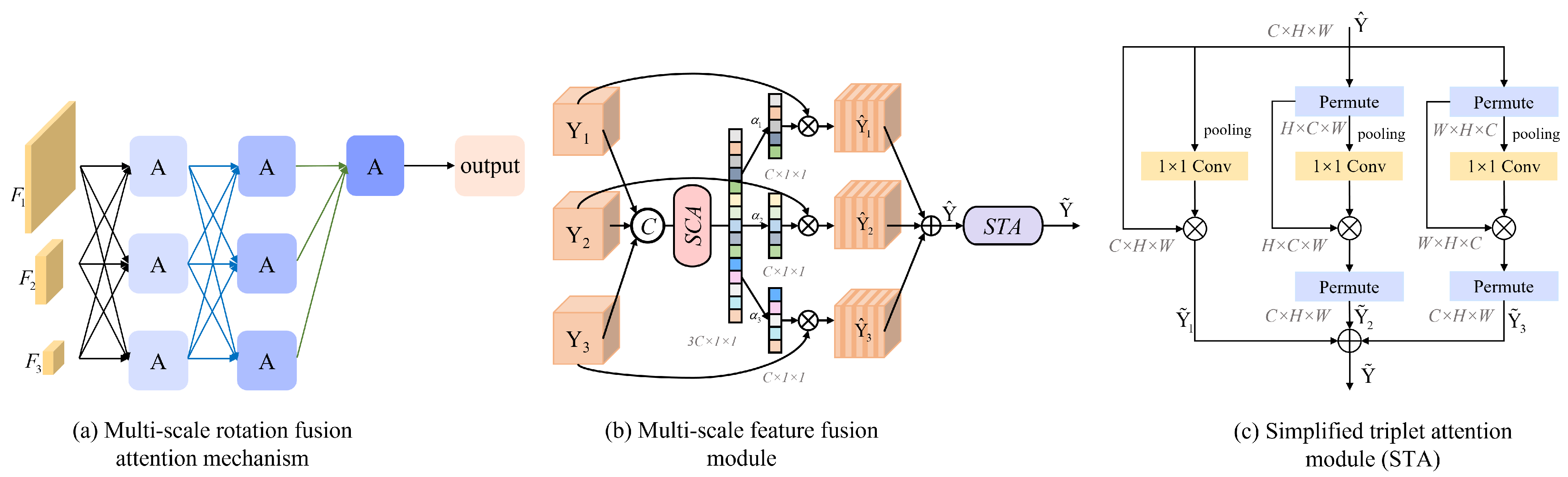
2.3. Multi-Scale Rotation Fusion Attention Mechanism
The human attention mechanism enables the selective processing of sensory input to guide behavior and decision-making. As an active and adaptive process, attention dynamically adjusts based on changes in external stimuli [
40,
41]. Computational models of attention have been widely adopted in computer vision and pattern recognition to predict attention allocation in visual and multimodal tasks. For instance, SENet [
37] adaptively assigns weights to channels via learning, enhancing focus on informative features but failing to capture spatial information. CBAM [
42] combines channel and spatial attention to more comprehensively capture image features, yet struggles to extract fine-grained and high-frequency details. Other approaches, such as A
2-Nets [
43], GSoP-Net [
44], and GC-Net [
45], introduce global dependency modeling via non-local operations, while modules like the Convolutional Triplet Attention Module [
46], CCNet [
47], and SPNet [
48] improve contextual representation through cross-dimensional or intersecting attention structures.
Simultaneously, the extraction and integration of multi-scale features have become essential for enhancing feature representation in deep networks. Similar to the varying receptive fields in the visual cortex, deep models respond differently to inputs from multiple scales. HRNet [
49] achieves multi-scale fusion through direct summation, but its rigid structure limits flexibility and discriminative power. Although CBAM [
42] improves feature representation through dual attention, it overlooks the interplay between spatial and channel domains. These limitations highlight the need for a unified attention mechanism that can effectively fuse multi-scale features while preserving spatial-channel dependencies.
Motivated by the limitations of conventional attention mechanisms in effectively capturing fine-grained details across varied resolutions and inspired by the success of HRNet and MAFNet [
50], this work proposes a novel attention mechanism that simultaneously integrates multi-scale features and models spatial–channel interactions. Traditional convolutional architectures often suffer from performance degradation when processing images at different resolutions, especially under noise corruption, due to insufficient integration of structural information across scales. To address this, we design an attention framework that not only preserves high-frequency details but also enhances context modeling by combining global and local interactions.
The proposed method comprises two key components: a multi-scale feature fusion module and a simplified triplet attention (STA) module, as illustrated in
Figure 6b,c. The multi-scale fusion module adaptively assigns weights to features from different scales using a simplified channel attention (SCA) mechanism, enabling effective cross-resolution interaction. Meanwhile, the STA module further refines the fused features by modeling dependencies across spatial and channel dimensions in a lightweight manner.
This design is grounded in the multi-scale edge enhancement initialization introduced earlier, which already improves low-level structural information extraction. Building upon this, the proposed module enhances mid- and high-level representation by fusing hierarchical feature maps. The adaptive weighting strategy ensures that essential details are preserved while reducing redundancy, ultimately improving the network’s denoising capacity in complex image-processing tasks.
To unify features from different resolution branches, upsampling and downsampling operations are applied, as shown in
Figure 6a, aligning the features to the same scale for subsequent concatenation and fusion.
where
,
, and
are feature maps obtained by a splicing operation with dimensions
.
Y then employs SCA to count the compact features of the channel along its spatial direction and eventually provides the corresponding feature descriptors for the three input features, each of which has a dimension of , to obtain the attention weights .
The three generated attentional weights
will be used to multiply with the input features
to recalibrate the importance of the input information of the different multi-scale features as expressed in the following equation:
The weighted feature maps
,
, and
are summed and passed through the rotating attention machine module. As a subsequent operation of feature fusion, it consists of three parallel branches, two of which are responsible for capturing the cross-dimensional interactions between the channel dimension
C and the spatial dimensions
H and
W. The last remaining branch is used to construct spatial attention similar to CBAM, as shown in
Figure 6c.
This cross-dimensional interaction addresses the issue of missing dependency relationships between spatial and channel dimensions by capturing their mutual interactions. Each branch computes the descriptor similarly to the spatial-channel attention (SCA) mechanism, but the pooling method has been modified to incorporate z-. Specifically, the pooling layer adjusts dimension 0 to dimension 2 by concatenating the average-pooled and maximum-pooled features along that axis. This method enhances the ability of layers to preserve rich feature representations.
As shown in
Figure 6c, in the first branch, the input
is rotated 90° anticlockwise along the H-axis, and the rotated tensor shape is
. The tensor shape is changed to
by
z-
, and finally, a convolution is performed to generate a desired attention weight
with the shape of
, and subsequently, the attention weight
is applied to the
, which is then rotated 90° clockwise along the
H-
, thus preserving the original input shape. An approximate operation is also taken in the second branch, the only difference being that the input
is rotated and recovered along the
W-
. In the third branch, no rotation is required, and attention is constructed directly. The refined
tensor generated by the three branches is aggregated by the above operations.
denotes the rotation operation, where represents the different rotation operations of the tensor, respectively, where represents no rotation; represents the convolution on path i; denotes the pooling operation described above; and denotes the inverse rotation operation in which the output features of path i are restored to their original dimensions.
The output of each path is as follows:
The final output
is an element-by-element summation of the three path outputs:
4. Experimental Setup
In this section, we present a comprehensive analysis of the influence of various design choices on the performance of the NAF-MEEF model introduced earlier. We then perform a series of experiments to evaluate the application of NAF-MEEF in restoring railway freight car images affected by different noise types, including Gaussian white noise, composite noise, and simulated real-world noise. Furthermore, the effectiveness of the proposed algorithm is validated on publicly available datasets to demonstrate its generalizability and broader applicability.
4.1. Dataset and Implementation Details
In this model, we implemented it using the PyTorch (version 1.12.0) framework. The computer configuration used for training includes an AMD 5600G CPU, 48 GB of RAM, and an NVIDIA RTX 3090 24 GB GPU. The initial weights of the network are set through random number initialization. Use AdamW algorithm for gradient update, with an initial learning rate of . The gradient descent strategy uses CosineAnnealingLR to adjust the learning rate, and the minimum learning rate at the end of training is . The self-built dataset and the public dataset use almost the same hyperparameter settings as described above, with the only difference being that the minimum learning rate at the end of training on the public dataset is .
Self-built dataset: To evaluate the denoising performance of NAF-MEEF on railway freight car images, a dataset comprising 3000 images of the sides and undersides of freight cars was constructed. Each image had a resolution of pixels. The dataset was split into training and testing sets with an 8:2 ratio. Additionally, 80 images were set aside as a validation set to monitor the smoothness of the training process. The model uses railway freight car images with added Gaussian white noise, composite noise, simulated real-world noise, and haze as inputs, with clean images as targets for supervised training.
To verify the universality of the NAF-MEEF algorithm in image denoising and restoration tasks, over 4000 image data from the Waterloo Exploration Database [
55] were used as the training set, including indoor, outdoor, natural scenery, and people, with high diversity. The scale of this dataset is moderate, which can meet the needs of most image processing algorithms without being too large, making it easy for experimental verification and performance comparison. All images are segmented into patches of
size for training denoising models.
To verify the robustness and generalization capability of the NAF-MEEF algorithm, we further conducted training and testing using 1341 remote sensing ship images from the MASATI-v2 [
56] dataset, each with a resolution of
pixels. The dataset includes maritime scenes captured under various weather and lighting conditions. In the experiments, representative categories such as multiple ships and coastlines with ships were selected, offering rich semantic information that facilitates evaluating the model’s ability to preserve structural and texture details across different object categories. The dataset was divided into training, testing, and validation sets in a
ratio. The training set was further segmented into image patches of
pixels for training the denoising model.
Six sets of experiments were designed for preliminary data preparation to comprehensively evaluate the denoising ability of the proposed NAF-MEEF model:
- (1)
Gaussian White Noise Denoising Experiment on Railway Freight Car Images: Gaussian white noise with a mean of 0 and a standard deviation ranging from 0 to 55 is added to the training image to train a blind denoising model. Subsequently, Gaussian noise with standard deviations of 15, 25, and 50 was added separately for training non-blind denoising models.
- (2)
Composite noise denoising experiment on railway freight car images: Poisson noise, Gaussian noise with a mean of 0 and a standard deviation of , and salt and pepper noise with a noise density in the range of were added to the image to train a blind denoising model and evaluate its performance on the railway freight car image dataset.
- (3)
Simulation of real-world noise reduction experiment for railway freight car images: To accurately simulate the noise in the real world, a noise generator C2N [
57] was introduced to synthesize real noise and train a denoising model, which was then evaluated on the railway freight car image dataset.
- (4)
Evaluation of NAF-MEEF performance on public datasets for blind image denoising: To validate the effectiveness and generalization ability of the NAF-MEEF algorithm, the publicly available dataset was used for training and evaluated on standard test sets Set12 and BSD68.
- (5)
Dehazing experiment of railway freight car images: To further verify the robustness of the model in practical railway application scenarios, a dehazing experiment of railway freight car images was constructed, using hazy images as input, training the model to restore clear images, and evaluating it on railway freight car datasets.
- (6)
Remote sensing ship image (MASATI-v2 [
56]) denoising experiment: To verify the adaptability of the model in the remote sensing field, the MASATI-v2 dataset was selected for training and evaluation.
The proposed algorithm was evaluated against BM3D [
3], WNNM [
5], IRCNN [
58], DnCNN [
13], FFDNet [
14], ADNet [
15], MAFNet [
54], and DRUNet [
59] using railway freight car testing datasets. Two points merit attention: (1) BM3D and WNNM, as traditional algorithms, were excluded from comparisons involving composite and real-world noise due to their inherent limitations; (2) during the blind noise reduction comparison, noise level information was withheld from DURNet to ensure fairness in algorithm comparison. Additionally, comparative evaluations were conducted against algorithms such as CSF [
60], TNRD [
61], and ECNDNet [
62] on the Set12 dataset to validate the effectiveness of the proposed algorithm using subjective perception and quantitative metrics.
4.2. Evaluation Criteria
The denoising effect is mainly compared from two aspects: visual subjective perception and quantitative indicators. Visual subjective perception can perceive the degree of subjective information retained in denoised images, and the denoising effect can be measured by qualitative analysis of the denoised images. Quantitative indicators measure the degree of deviation between the denoised image and the target image, with smaller deviations indicating superior denoising performance. Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) are widely employed metrics for quantitative analysis and evaluation in image-denoising tasks.
PSNR is a widely used metric for assessing pixel-level differences between denoised images and target images, providing an indication of the model’s overall denoising performance [
3,
13,
14,
15,
22]. A higher PSNR value signifies lower distortion and better quality of the denoised image. The PSNR metric is defined as follows:
MSE represents the root mean square error between the denoised image and the target image. PSNR ignores factors such as brightness and contrast when evaluating image quality, resulting in evaluation results that are inconsistent with subjective visual perception. Therefore, SSIM is introduced as another quantitative indicator.
SSIM can be calculated based on indicators such as luminance (L), contrast (C), and structure (S) by directly estimating the signal structure differences between the target image and the denoised image. SSIM can be represented as follows:
Among them,
and
represent the mean values of image
x and image
z, respectively, while
,
, and
represent the variance and covariance of image x and image z, respectively.
and
are constants, usually taken as
,
,
,
. The selection of these parameters follows the original definition of SSIM proposed by Wang et al. [
52]. These values have been established as standard settings through extensive experimental validation on images with pixel values in the range of
, effectively preventing instability caused by near-zero means or variances in the denominator.
PSNR mainly focuses on the pixel values of the image and is sensitive to pixel distortion, while SSIM pays more attention to the structural information of the image. As can be seen from the formula, the smaller the root mean square error between the denoised image and the target image, the higher the PSNR, indicating that the image denoising effect is better. SSIM evaluates image structural similarity based on three aspects: brightness, contrast, and structure. The value ranges from 0 to 1, with higher values indicating greater similarity between images.
5. Experimental Results and Analysis
Before presenting the detailed results, we first summarize the scope of our experimental study. Specifically, our experiments were conducted on both real-world and publicly available datasets. For railway freight car images, we explored both denoising and defogging tasks to address the challenges posed by complex environments. To further evaluate the generalizability of the proposed method, additional denoising experiments were performed on the commonly used public datasets Set12 and BSD68, as well as on the remote sensing dataset MASATI-v2, which features maritime scenes captured under various weather conditions.
5.1. Gaussian White Noise Denoising Experiment on Railway Freight Car Images
In order to verify the Gaussian noise suppression effect of NAF-MEEF in railway freight car images, this paper first conducts Gaussian white noise denoising simulation experiments on railway freight car images. Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSIM) are employed as image quality evaluation metrics to assess the denoising performance of the algorithm.
Figure 7 presents randomly selected, finely processed images from a railway freight car image dataset, illustrating the denoising effects of various methods under conditions of zero mean and a variance of 50.
Figure 7 shows that other methods suffer from insufficient denoising or texture loss. The proposed method not only ensures denoising performance but also preserves more detailed information, achieving better reconstruction of edge details such as the ‘bolt and cotter pin’ in the image. Traditional methods such as BM3D and WNNM, although achieving certain denoising performance, exhibit texture blurring at the ‘cotter pin’ area, resulting in unclear visual imaging. Compared with traditional methods, ADNet and MAFNet can restore more image details. Partial texture details can be seen in the local detail map, but the reconstructed detail information is relatively messy and cannot effectively represent the image texture. The denoising performance of IRCNN, DNCNN, and FFDNet has been improved to some extent, but there is still blurring in some areas with rich structural information; DRUNet, as a suboptimal result, has a good denoising effect, but there is still some texture differences after zooming in on details. Compared with other methods, NAF-MEEF achieves fine filtering while preserving more edge detail information, resulting in optimal denoising and image restoration performance.
Table 1 and
Table 2 present the average PSNR and SSIM parameter indicators achieved by various methods on the railway freight car dataset across five distinct noise levels: Level = 15, 25, 35, 45, and 50. The optimal results are highlighted in bold text in the tables. As shown in the tables, compared with the baseline methods, the proposed NAF-MEEF achieves an average PSNR gain of 2.45 dB, 1.84 dB, 1.40 dB, 1.22 dB, 1.24 dB, 1.71 dB, 2.4 dB, 1.44 dB, and 0.86 dB in removing Gaussian noise at Level = 50. NAF-MEEF not only yields the highest PSNR values but also the best SSIM scores. Overall, the method proposed in this paper outperforms other algorithms in terms of quantitative evaluation metrics across all five noise levels on the railway freight car image test set.
To effectively evaluate the algorithm’s denoising performance on various components of railway freight cars, we divided the collected large-sized images (1400 × 1024) into five categories based on actual operational scenarios (as shown in
Figure 8): (a) wheel, brake beam, and axle; (b) bogie; (c) coupler; (d) wheel and bearings; and (e) auxiliary reservoir. Gaussian white noise with a mean of 0 and variances of 15, 25, 35, 45, and 50 were added to railway freight images representing different locations, and the denoised PSNR and SSIM values were computed as metrics.
Figure 9 shows the denoising effect of NAF-MEEF and comparative algorithms on key component images of 1400 × 1024 large-sized railway freight cars (Level = 45). Although EDCNN can effectively remove noise from the images, it produces problems such as smooth details and information loss during the denoising process, which leads to blurry images after denoising. Due to the use of fixed filtering windows to extract features in DnCNN, FFDNet, and ADNet convolutions, it is impossible to supplement the information structure, resulting in the loss of some high-frequency information. Although MAFNet can preserve image details to a large extent, its use of cross-layer connection fusion features can lead to blurring of enlarged areas in the image. DRUNet can maintain relatively complete subjective information but is prone to producing some high-frequency artifacts. Compared with the above model, the proposed algorithm comprehensively utilizes the fusion of multi-scale features and efficient attention and constructs a composite loss function that can improve the denoising effect, content integrity, and subjective visual effect. It can effectively remove image noise while preserving image detail information as much as possible.
Figure 10 presents the comparative results of PSNR and SSIM metrics for different algorithms on the refined dataset comprising images of five key parts of railway freight cars. The tables indicate that the algorithm proposed in this study achieves higher PSNR and SSIM values than other methods across all five image types. Specifically, the proposed algorithm achieved average improvements in PSNR metrics of 0.48 dB, 0.35 dB, 0.57 dB, 0.47 dB, and 0.43 dB compared with the second-best results. Similarly, improvements in SSIM metrics were 0.0033, 0.0006, 0.0078, 0.0008, and 0.0045, respectively. The proposed method demonstrates the best denoising performance for different regions and parts of railway freight car images while also effectively preserving edge details. In summary, the algorithm achieves superior denoising results in terms of both subjective visual perception and objective image restoration fidelity.
5.2. Composite Noise Denoising Experiment on Railway Freight Car Images
Figure 11 and
Figure 12 present examples of denoising results under the simultaneous influence of Poisson noise, Gaussian noise (
= 30), and salt-and-pepper noise (level = 30) using various methods. As shown in the figure, the denoising performance of FFDNet and MAFNet is relatively poor. These methods not only fail to effectively remove noise from the image but also introduce significant blurriness, resulting in a substantial loss of image information. Although DnCNN, IRCNN, and EDCNN perform better in denoising, they are still unable to effectively mitigate detail artifacts generated during the process and fail to preserve the original image information adequately. Image distortion remains a significant issue. In contrast, ADNet and DRUNet show notable improvements in denoising performance and detail preservation; however, issues such as unclear edges persist. NAF-MEEF, on the other hand, provides excellent denoising and detail retention, resulting in a cleaner denoised image with clearer texture and richer high-frequency details in the enlarged areas, better aligning with visual expectations.
The quantitative indicators for removing composite noise from railway freight car images using different methods are shown in
Figure 13 and
Figure 14, where the level represents the sigma value of Gaussian white noise and the density level of salt and pepper noise. From the figures, it can be seen that the average PSNR of MAFNet is 2.77 lower than the proposed algorithm, which can be attributed to the fact that although its network adopts a multi-scale training method, it does not effectively fuse feature information of different scales. The average PSNR of IRCNN, DNCNN, FFDNet, and ADNet achieved better results compared with MAFNet but were 1.41 dB, 1.50 dB, 1.64 dB, and 1.13 dB lower than the NAF-MEEF algorithm, respectively. The average SSIM was 0.0246, 0.0292, 0.0272, and 0.0208 lower, which may be due to their relatively simple structure and shallow network layers, making it difficult to achieve high performance. There is still a lot of room for improvement in denoising quality in this complex, high-noise environment. DRUNet benefits from its combination of UNet and ResNet advantages, which can handle more complex noise. However, the PSNR and SSIM values of the method proposed in this paper are improved by 0.08 dB and 0.0014 in high-noise environments (level = 30). In summary, the proposed algorithm has good denoising effects in both visual subjective perception and image denoising and restoration approximation degree.
5.3. Simulation of Real-World Noise Reduction Experiment for Railway Freight Car Images
To address the challenge of lacking paired noisy–clean images in railway freight car scenarios, we utilize the Clean-to-Noisy (C2N) framework [
57] to simulate real-world noise. Instead of retraining the C2N model, we directly adopt the pre-trained weights released by the original authors, which are trained on real-world noisy datasets (e.g., SIDD and DND). C2N is a generative noise modeling approach that learns to synthesize realistic noise maps from clean images without requiring any paired supervision or handcrafted noise assumptions. It includes both signal-dependent and signal-independent noise components and models spatial correlations to more accurately reflect real-world noise characteristics.
By using the C2N-generated noisy images, we are able to construct pseudo-paired data and train our denoising model in a supervised manner. This strategy is particularly suitable for our domain, where acquiring well-aligned training pairs is impractical due to environmental constraints. Although we do not modify or retrain the C2N model in this work, its integration allows us to better simulate realistic noise conditions and validate the effectiveness of our proposed denoising framework.
Figure 15 shows the images selected from the test set that contain a large number of components. This type of image has complex textures and rich high-frequency information, which helps to reflect the denoising effect of different algorithms and their ability to preserve structural information. From the figure, it can be seen that MAFNet and FFDNet exhibit severe smearing of component positions in the denoised image and poor detail preservation in low-light conditions. In contrast, methods such as DnCNN, ADNet, DRUNet, and EDCNN perform better in detail restoration, but in locally enlarged images, the presentation of details still appears cluttered and fails to fully capture texture features. Compared with the above methods, the method proposed in this paper achieves a good denoising effect while more effectively preserving edge information.
Table 3 shows the average PSNR and SSIM parameter indicators taken by different methods on the test dataset under real-world noise, and the optimal values are highlighted in bold font. From the table, it can be seen that the proposed NAF-MEEF denoising algorithm has PSNR gains of 0.68 dB, 0.36 dB, 1.52 dB, 0.18 dB, 0.93 dB, 0.89 dB, and 0.27 dB compared with other comparative methods. At the same time, SSIM also achieved the best among all denoising methods.
5.4. Evaluation of NAF-MEEF Performance on Public Datasets for Blind Image Denoising
In this section, we train and test the performance of the NAF-MEEF method using publicly available datasets. It is important to emphasize that the core focus of this study is to design a denoising method specifically for railway freight car images. Since railway freight car images are grayscale images, experiments on the public datasets were also conducted exclusively on grayscale images. The experiments in this section aim to validate the performance and robustness of the proposed method in the context of publicly available datasets rather than pursuing state-of-the-art (SOTA) performance.
The main focus of this paper is the blind denoising task; therefore, non-blind denoising experiments were not conducted. The primary reason is that blind denoising is more aligned with real-world application scenarios: in practice, noise types are complex and difficult to predict accurately, whereas non-blind denoising methods rely on prior noise information, limiting their applicability in real-world scenarios. Hence, this study chooses the more challenging and practical blind denoising task to thoroughly evaluate the robustness and generality of the proposed method.
Although this study focuses on the blind denoising task, the results of the proposed method for blind denoising are compared with other methods on both blind and non-blind denoising tasks to comprehensively assess its performance and applicability. This comparison not only verifies the advantages of the proposed method in blind denoising but also demonstrates its potential and practical value in non-blind denoising tasks.
Table 4 and
Table 5 present the PSNR metrics of NAF-MEEF on the Set12 and BSD68 datasets, respectively. (For the Set12 dataset, we ensured that the Lena image was not used during training and verified that its removal from the test set does not significantly affect the conclusions of this study.) As shown in
Table 4, NAF-MEEF achieved the best performance on Set12 at noise levels of 15, 25, and 50. Compared with eight popular denoising methods listed in the table, the NAF-MEEF algorithm for blind denoising stands out, with PSNR improvements over DnCNN-B and ADNet-B of 0.41 dB, 0.40 dB, 0.52 dB, 0.32 dB, 0.31 dB, and 0.40 dB across various noise levels. Even compared with ADNet-S, which produces the second-best results for non-blind denoising, the blind denoising results of the proposed method achieved increases of 0.09 dB, 0.19 dB, and 0.36 dB at the three noise levels. At a noise level of 50, the proposed method demonstrated the most significant improvement, indicating its suitability for restoring highly noisy images.
Table 5 further corroborates this finding. Although NAF-MEEF did not achieve the best performance at noise levels of 15 and 25, the differences in performance with mainstream algorithms were minor. When images were subjected to higher noise levels, the proposed method demonstrated superior image restoration capabilities, with PSNR improvements at a noise level of 50 of 0.78 dB, 0.53 dB, 0.43 dB, 0.17 dB, 0.17 dB, 0.21 dB, 0.17 dB, 0.11 dB, and 0.16 dB over other algorithms.
Overall, the NAF-MEEF method exhibits significant denoising advantages in high-noise environments. Its multi-scale edge enhancement initialization and Multi-scale Rotation Fusion Attention Mechanism effectively capture both local and global information of the image, enabling more accurate recovery of image details. This capability allows it to significantly outperform mainstream algorithms under high-noise conditions, further proving the potential applicability of the proposed method in real-world scenarios with complex noise.
5.5. Dehazing Experiment of Railway Freight Car Images
To further verify the robustness and generalization capability of the proposed method in practical railway application scenarios, a dehazing experiment based on railway freight car images was conducted, and performance was evaluated on a specifically constructed railway freight car image dataset. Haze synthesis was implemented using depth maps and the atmospheric scattering model. This approach utilizes the depth map to provide per-pixel distance information, where distant objects are more heavily obscured by haze while nearby objects remain relatively clear. By adjusting haze density, color, and transparency based on depth variation, the generated haze effects appear more realistic. Depth maps were produced using the Monodepth [
63] method. To simulate different levels of degradation, three haze concentration levels—0.3, 0.6, and 0.9—were applied in the experiments.
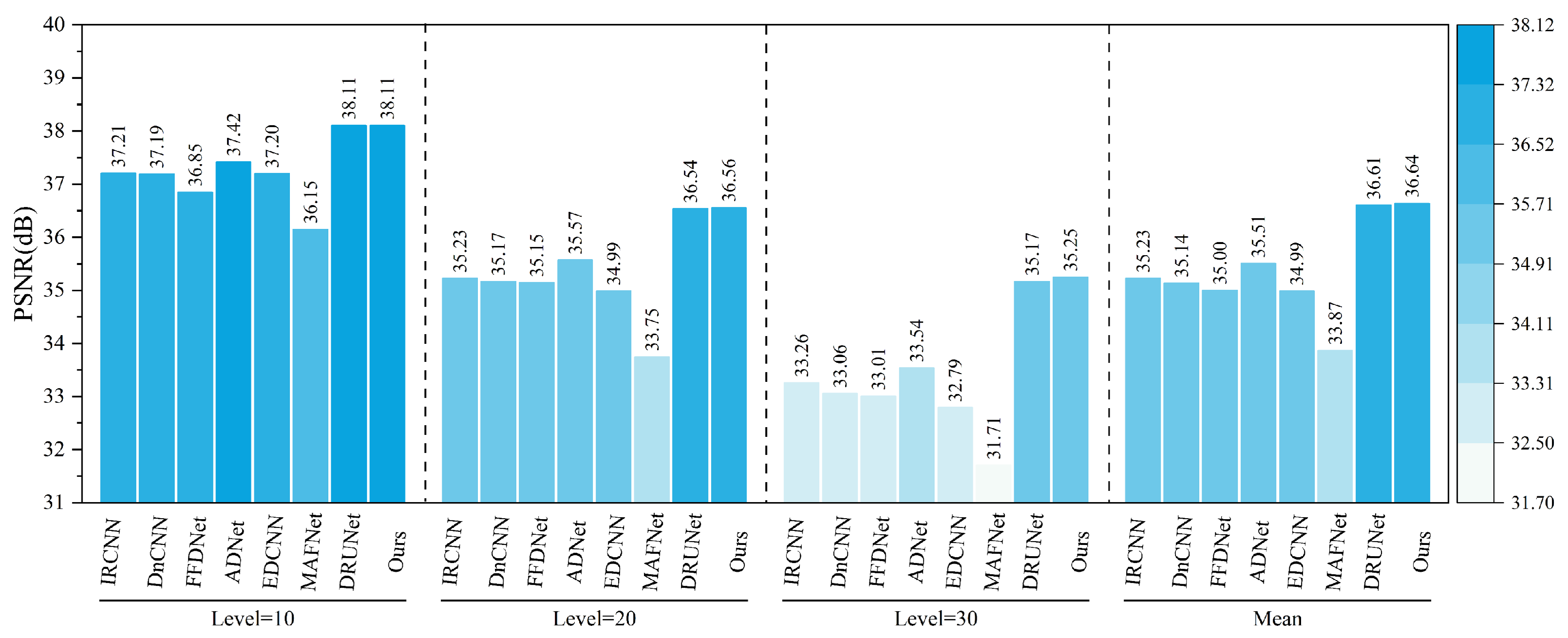
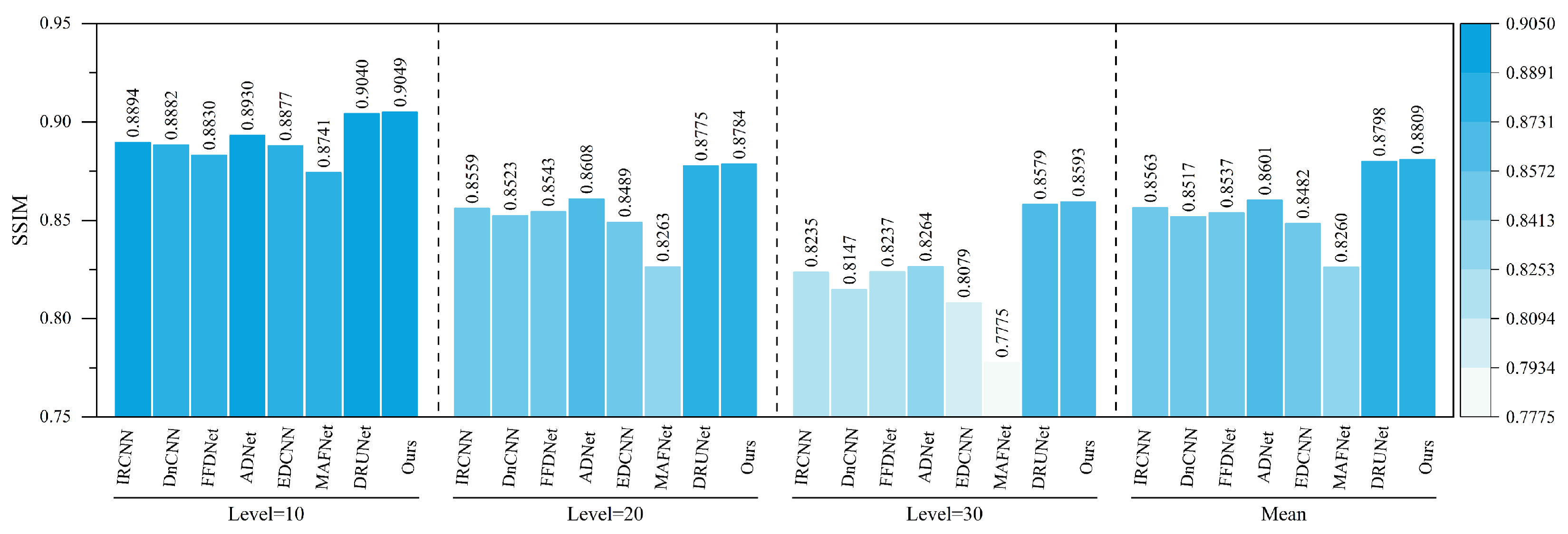
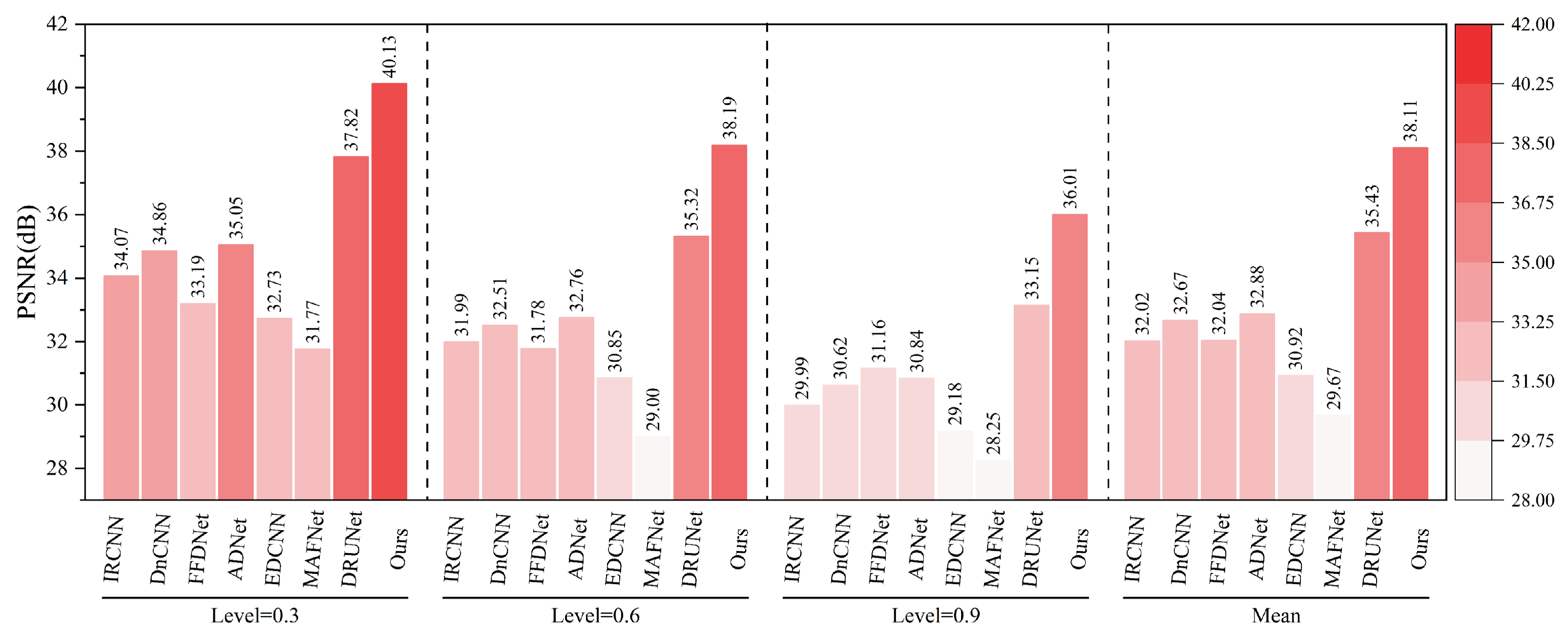
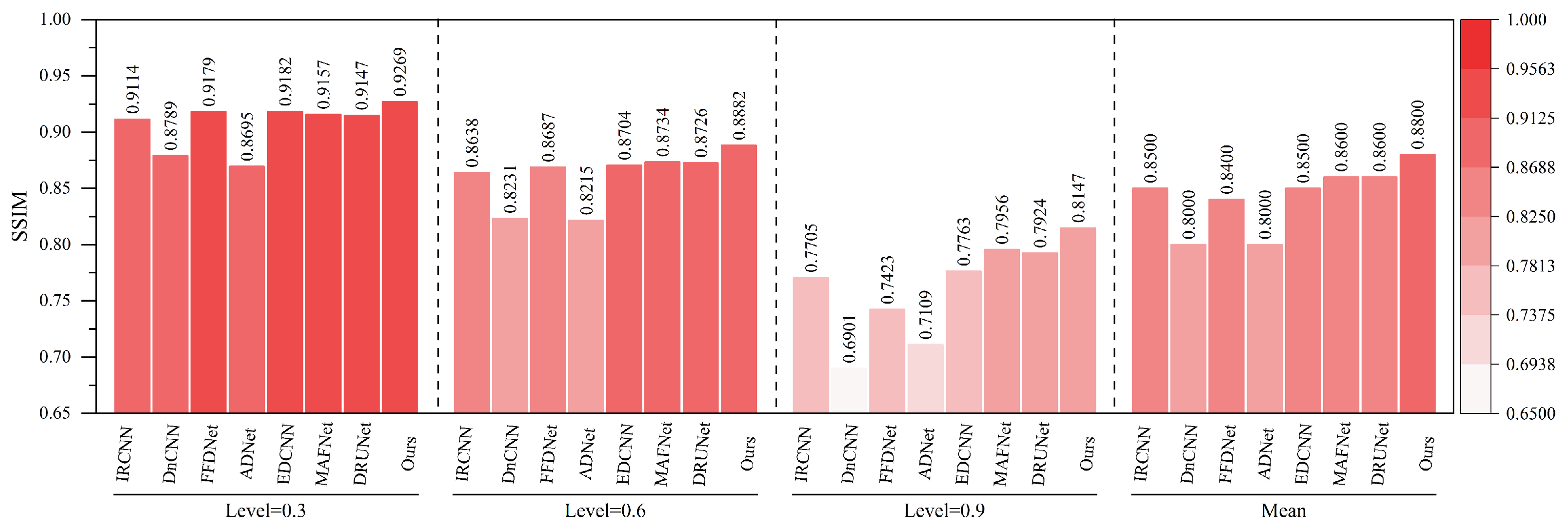
As shown in
Figure 16 and
Figure 17, under various haze concentrations (0.3, 0.6, and 0.9), the proposed method demonstrates significant advantages in both PSNR and SSIM metrics.
In terms of PSNR, our method achieves an average value of 38.11 dB, which surpasses the second-best method, DRUNet (35.43 dB), by 2.68 dB. It also shows substantial improvements over traditional methods such as DnCNN (32.67 dB), IRCNN (32.02 dB), and FFDNet (32.04 dB). Notably, under the most severe haze condition (concentration 0.9), the proposed method still maintains a high PSNR of 36.01 dB, outperforming DRUNet (33.15 dB) by 2.86 dB, which highlights its robustness against heavy degradation. Regarding SSIM, our method achieves an average value of 0.9845, outperforming DRUNet (0.9780), ADNet (0.9520), and all other compared methods. Even under the most challenging haze conditions, the SSIM remains as high as 0.9751, indicating the model’s strong capability to preserve structural and textural information.
As illustrated in
Figure 18, different methods exhibit noticeable differences in the dehazing and denoising performance for railway freight car images. DnCNN, IRCNN, and FFDNet are limited in restoring structural and detailed information, often leading to over-smoothing or residual noise. Although DRUNet shows certain improvements in structure recovery, it still suffers from detail loss or minor artifacts. In contrast, the proposed method achieves the best performance in terms of structural preservation, edge sharpness, and highlight texture fidelity, fully demonstrating its adaptability and robustness in complex industrial imaging scenarios.
In summary, the proposed method exhibits superior performance in maintaining image fidelity and effectively handles various haze levels, verifying its potential for application in railway freight car image dehazing tasks.
5.6. Remote Sensing Ship Image Denoising Experiment
To further verify the generalization and robustness of the proposed method, additional denoising experiments were conducted on the publicly available remote sensing image dataset MASATI-v2. The experiments are divided into two parts: the first involves adding Gaussian noise with a standard deviation in the range of to the images; the second introduces composite noise, which combines Poisson noise, Gaussian noise, and salt-and-pepper noise.
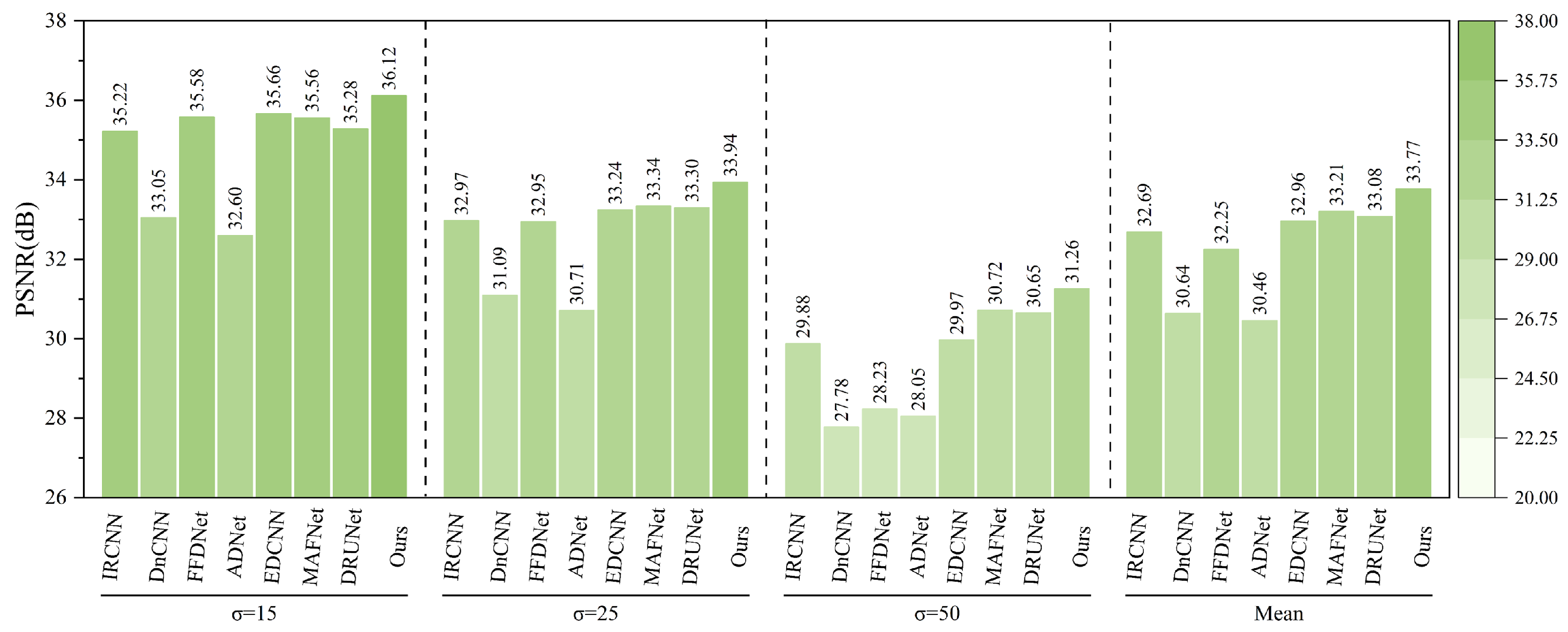
As shown in
Figure 19, after adding Gaussian noise with varying intensities (
) to the MASATI-v2 remote sensing ship image dataset, the proposed method consistently outperforms existing denoising algorithms across all noise levels.
At the low noise level (), the proposed method achieves the highest PSNR of 36.12 dB, outperforming the second-best method, FFDNet (35.58 dB), and IRCNN (35.22 dB). As the noise level increases to and , the proposed method maintains superior performance with PSNRs of 33.94 dB and 31.26 dB, respectively. Notably, under the highest noise level (), it still surpasses DRUNet (30.65 dB) and MAFNet (30.72 dB), demonstrating strong robustness.
As also presented in
Figure 20, after introducing composite noise—comprising Poisson, Gaussian, and salt-and-pepper noise—into the MASATI-v2 dataset, the proposed method achieves the best PSNR results across all tested noise intensities (10, 20, 30), confirming its effectiveness in complex degradation scenarios. At a low noise level (10), our method reaches a PSNR of 35.46 dB, slightly outperforming DRUNet (35.37 dB) and significantly exceeding traditional methods such as DnCNN (26.81 dB) and FFDNet (31.14 dB). When the noise intensity increases to 20 and 30, the proposed method still maintains leading PSNR values of 32.99 dB and 31.28 dB, respectively. Overall, it achieves a mean PSNR of 33.24 dB across the three noise levels, surpassing DRUNet (33.00 dB), MAFNet (31.75 dB), and EDCNN (31.83 dB), highlighting its superior robustness and adaptability in multi-source noisy environments.
As shown in
Figure 21, when Gaussian noise with a standard deviation of 50 is added, most compared methods exhibit over-smoothing or texture degradation, particularly around coastline edges and building structures. In contrast, the proposed method effectively removes the noise while preserving key semantic regions and structural details. The recovered coastlines appear sharp, building boundaries are well preserved, and the water surface is free from noticeable distortion, resulting in superior visual quality.
As shown in
Figure 22, composite noise leads to severe degradation in visual quality, especially around the sea surface and small vessels, where heavy granular artifacts and structural blurring are observed. The denoising results of DnCNN and FFDNet remain suboptimal, with noticeable residual noise and blurred object boundaries. Although deep models such as DRUNet demonstrate improved edge preservation, they still suffer from texture degradation and slight artifacts. In contrast, the proposed method not only effectively suppresses various noise types but also preserves the original structural information of the image. The restored sea surface appears natural, and the contours of the ships are sharp and clear, demonstrating excellent visual fidelity.
In addition to achieving excellent performance in denoising railway freight car images, the proposed NAF-MEEF model also demonstrates strong denoising capability on the publicly available remote sensing image dataset MASATI-v2. This effectiveness is primarily attributed to the synergistic integration of the multi-scale initialization structure, the activation-free feature extraction architecture, and the Multi-scale Rotation Fusion Attention Mechanism. These components enable the NAF-MEEF network to learn noise-invariant feature representations. As a result, the proposed method consistently achieves leading denoising performance not only in specific industrial application scenarios but also in broader remote sensing benchmark evaluations, fully validating its robustness and generalizability.
6. Ablation Experiment
The ablation experiment is mainly aimed at denoising Gaussian white noise in railway freight car images. In order to verify the effectiveness of different modules in the proposed algorithm, the control variable method was used to measure the contribution of different modules to the model proposed in this paper. The experiment aims to remove multi-scale initialization edge enhancement layers and attention mechanisms and use a denoising network based on PlainNet’s block as the baseline network. Six ablation experiments were conducted under different module combinations with sigma values of 15, 25, 35, 45, and 50 added to the test images. The average PSNR and SSIM values under five different noise levels were used as quantitative indicators.
The setup of the ablation experiment is detailed in
Table 6. Using PSNR as an example, the baseline PSNR value is 36.64 dB. Introducing layer normalization (LN) not only stabilizes the training process but also enhances the denoising effect, achieving a PSNR of 36.70 dB. SimpleGate (SG) and Simplified Channel Attention (SCA) integrate nonlinear capabilities and attention mechanisms into the network by replacing traditional activation functions and simplifying channel attention, leading to a 0.1 dB improvement in PSNR performance. 2DDCB, a minimalistic network structure, demonstrates that lightweight design can also yield gains for denoising tasks. Building on this foundation, the Multi-scale Edge Enhancement Initialization Layer (MEEIL) and Multi-scale Rotation Fusion Attention Mechanism (MRFAM) significantly enhance the network’s ability to preserve high-frequency information and facilitate smoother multi-scale information fusion. These cumulative enhancements improve the network’s performance, resulting in PSNR and SSIM increases of 0.23 dB and 0.0034, respectively, compared with the baseline.
The effect of the number of blocks on NAF-MEEF was verified in
Table 7. The number of blocks was selected primarily based on the requirements of the feature extraction framework. When the number of blocks increased from 9 to 18, the PSNR value increased by 0.25 dB, the SSIM increased by 0.0012, and the model’s parameter count increased by 5.43 M. Despite the increase in parameters, the performance improvement supports this increase, with the model size remaining within a manageable range. When the number of blocks increased from 18 to 36, the performance improvement was marginal, while the parameter count increased substantially by 10.87M. Therefore, 18 blocks offer a balanced trade-off between performance and computational cost and were selected as the default option.
In addition, we conducted a comparative evaluation of the average inference time on 512 × 512 railway freight car images under the same GPU computing environment. As shown in
Table 8, although the runtime of our method is slightly higher than that of lightweight models such as IRCNN (0.0029 s) or DnCNN (0.0067 s), it still meets the real-time requirements of practical industrial applications. In particular, the model variant using 18 basic blocks achieves a good balance between denoising performance and computational cost, with an average inference time of 0.0530 s. Considering its superior denoising capability and structural detail preservation, this model demonstrates strong practical applicability in real-world inspection systems, fulfilling the dual demands of image quality and processing efficiency.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}