

A New Algorithm for Visual Navigation in Unmanned Aerial Vehicle Water Surface Inspection

 , ,
, ,
Abstract
1. Introduction
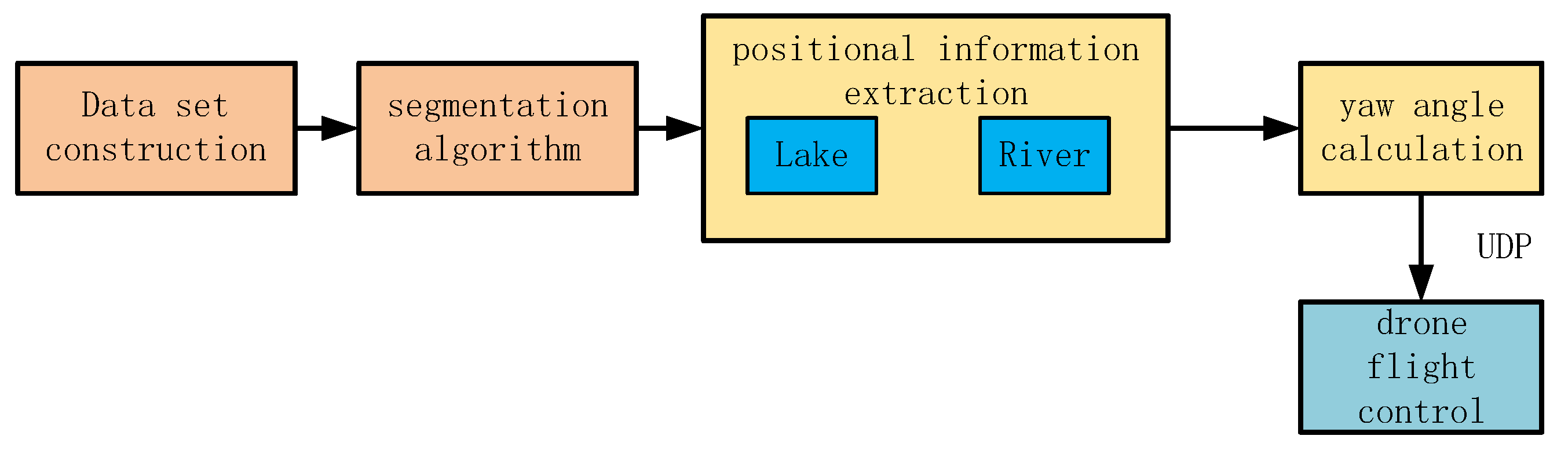
2. Materials and Methods
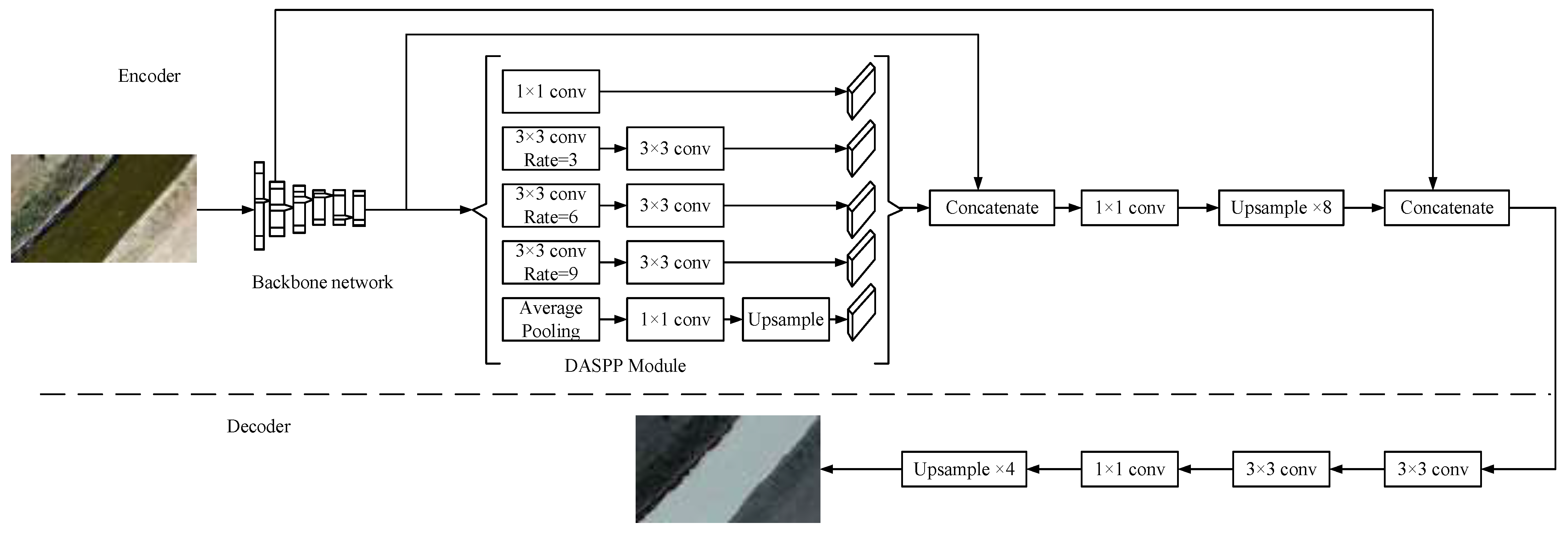
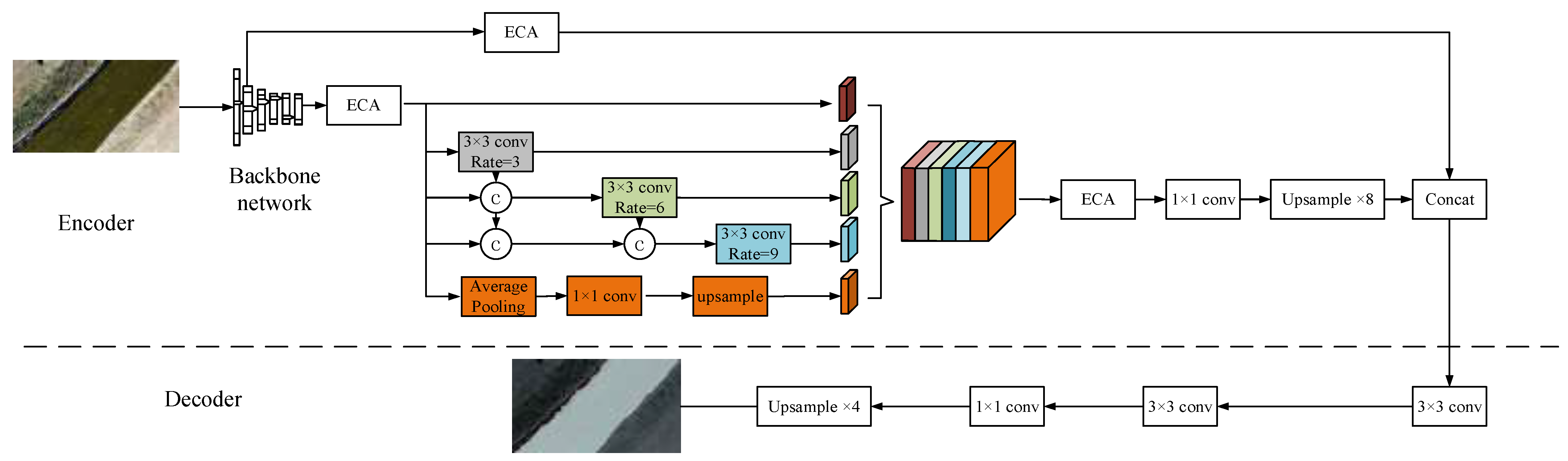
2.1. Drone Segmentation of Riverbank Line Methods
2.1.1. MobileNetV2-S
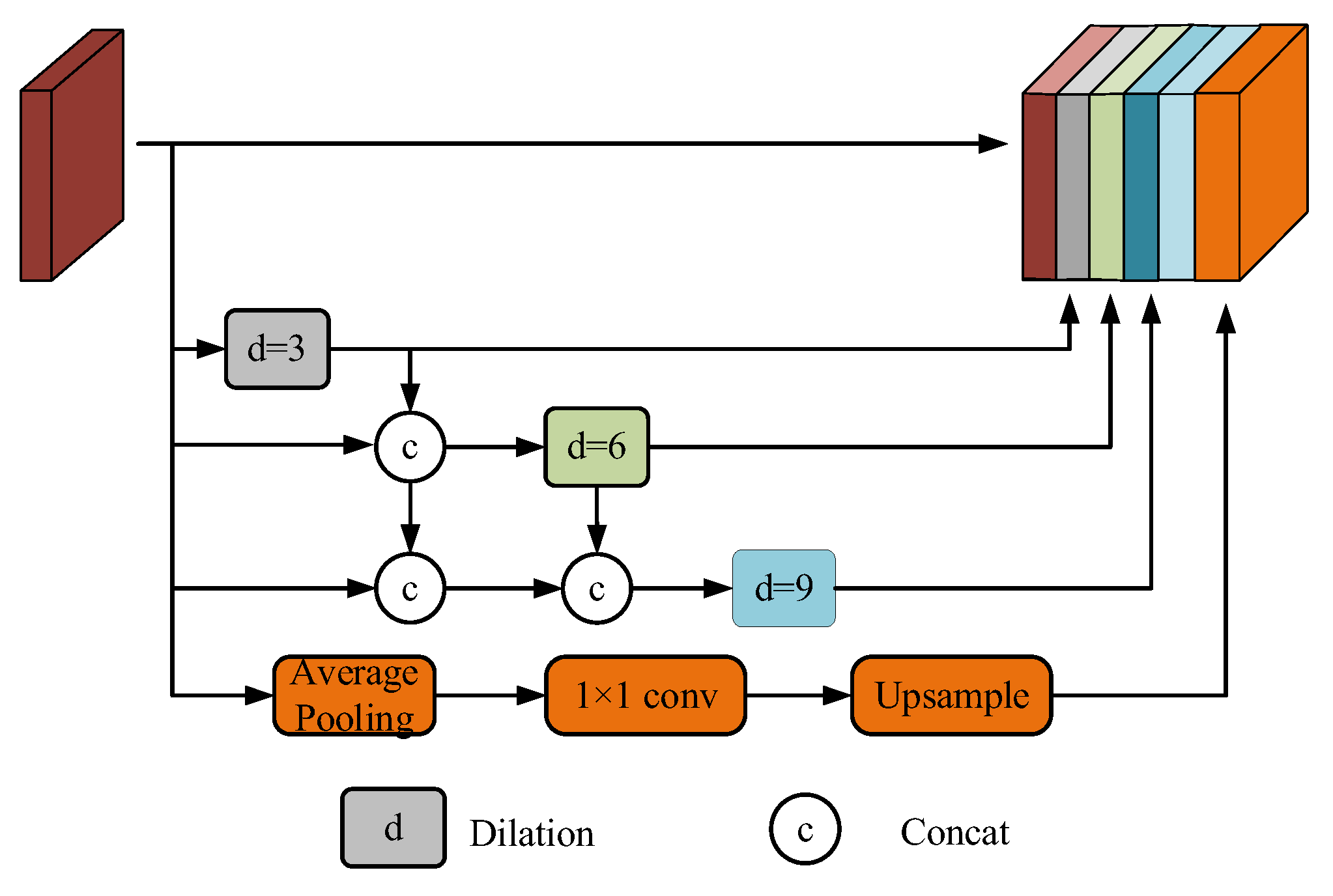
2.1.2. DP-ASPP
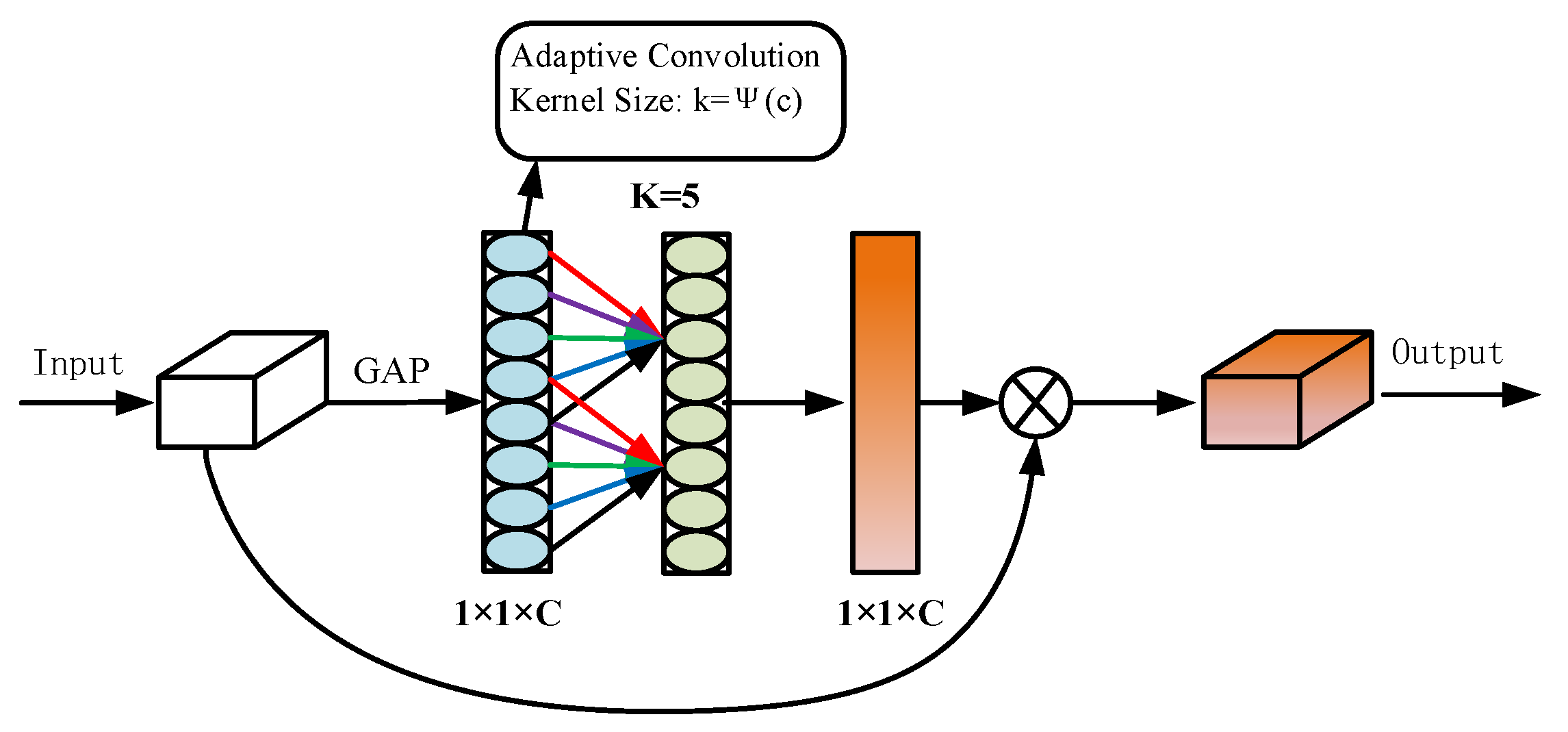
2.1.3. Introduction of the ECA Attention Mechanism
2.2. UAV Water Surface Tracking Methods
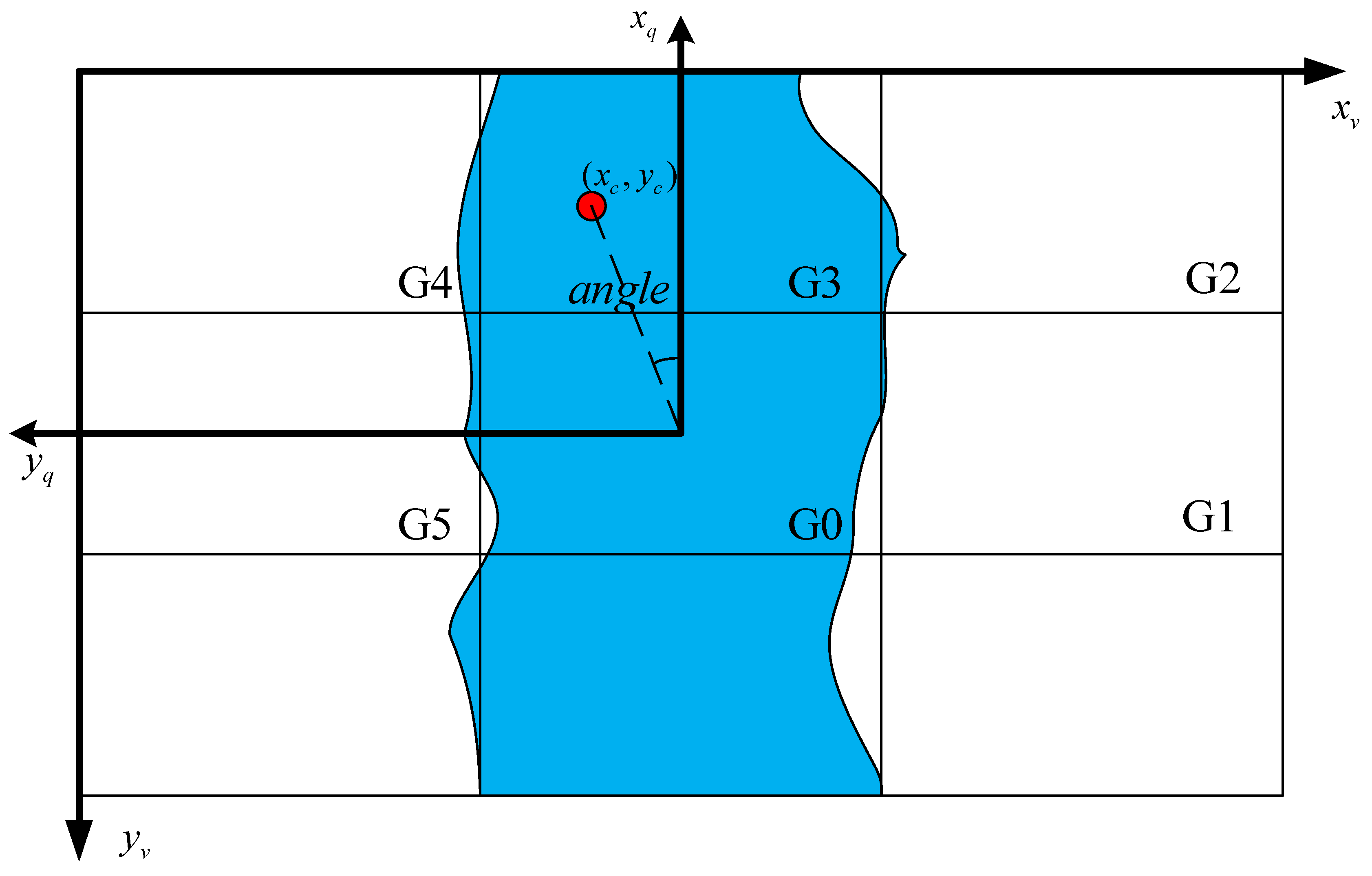
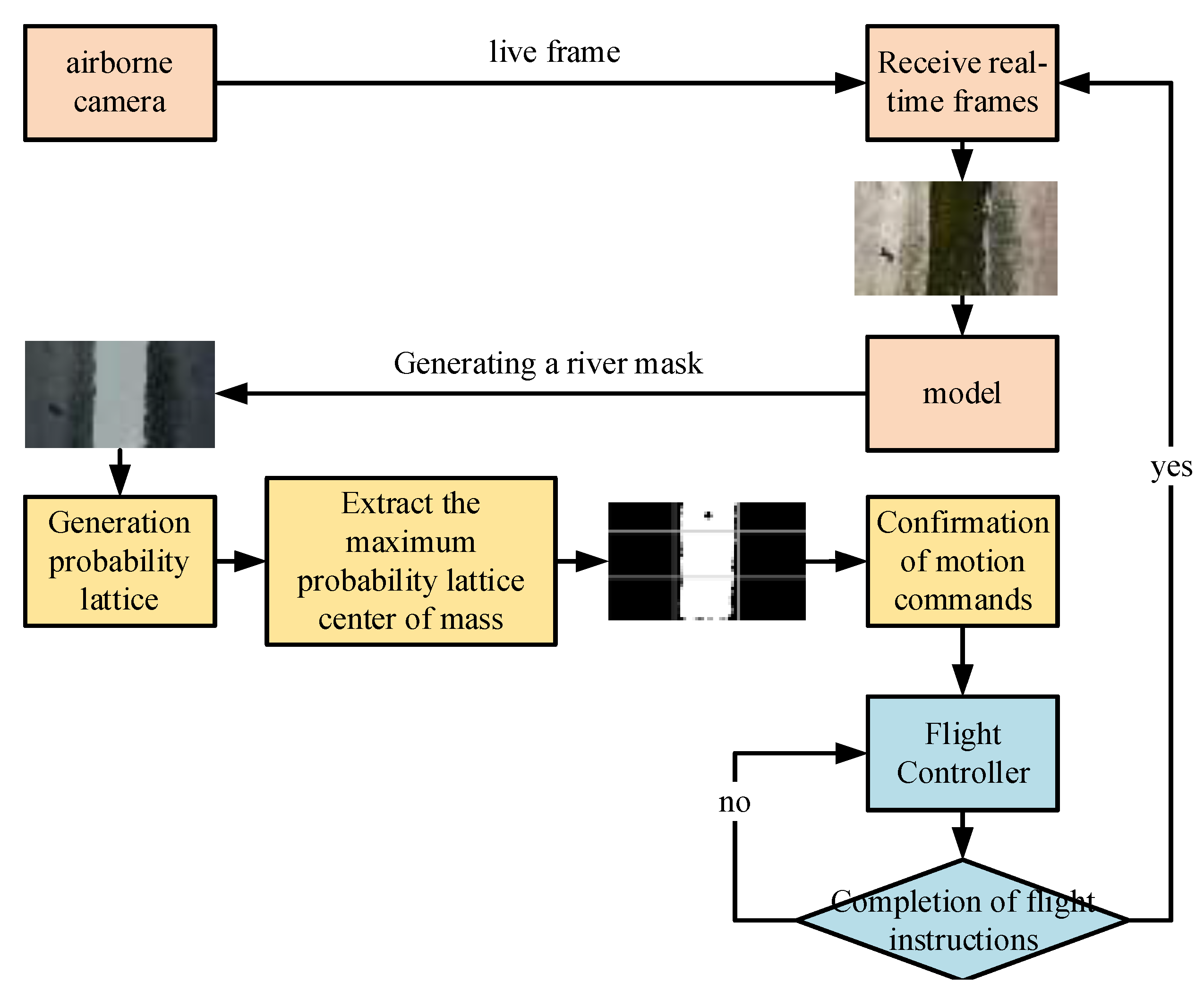
2.2.1. Drone River Tracking
- Calculate the grid probability as shown in Equations (5) and (6).where “” denotes the area of the river mask in the grid, “” denotes the sum of the areas of all grids except , and “()” denotes the probability of occurrence of the grid. Here, only the first six grids are taken for determining the UAV’s forward direction.
- Extract the maximal mesh Gr and calculate the maximum mesh center of mass.where “” is the pixel value of the binary image at “”. “” is the zero-order moment of the image, and “” and “” are the first-order moments of the image. “”, “” are the coordinates of the center of mass. “w”, “h” are determined by the maximal grid, “”. For example, if the maximal grid is “” under the size of the 640 × 360 image, “”, “” are both 0. If the maximal grid is “”, then “w” is 640 × 2/3 and “” is 120.
- Determine the motion command.
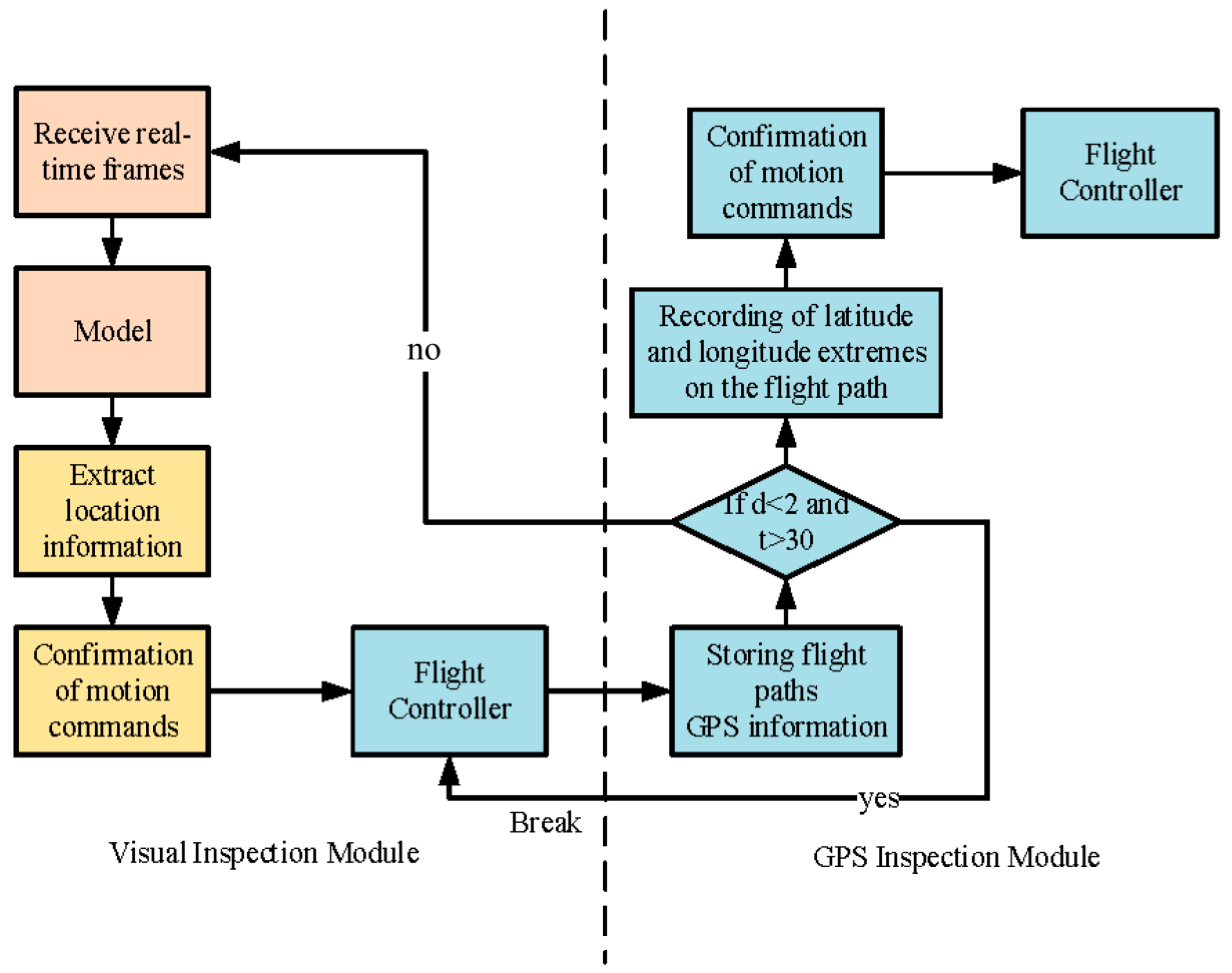
2.2.2. Drone Lake Inspection
2.3. Materials
2.3.1. Dataset Production
2.3.2. Experimental Environment and Evaluation Indicators
3. Results
3.1. Backbone Network Comparison Experiment
3.2. River Dataset Ablation Experiments
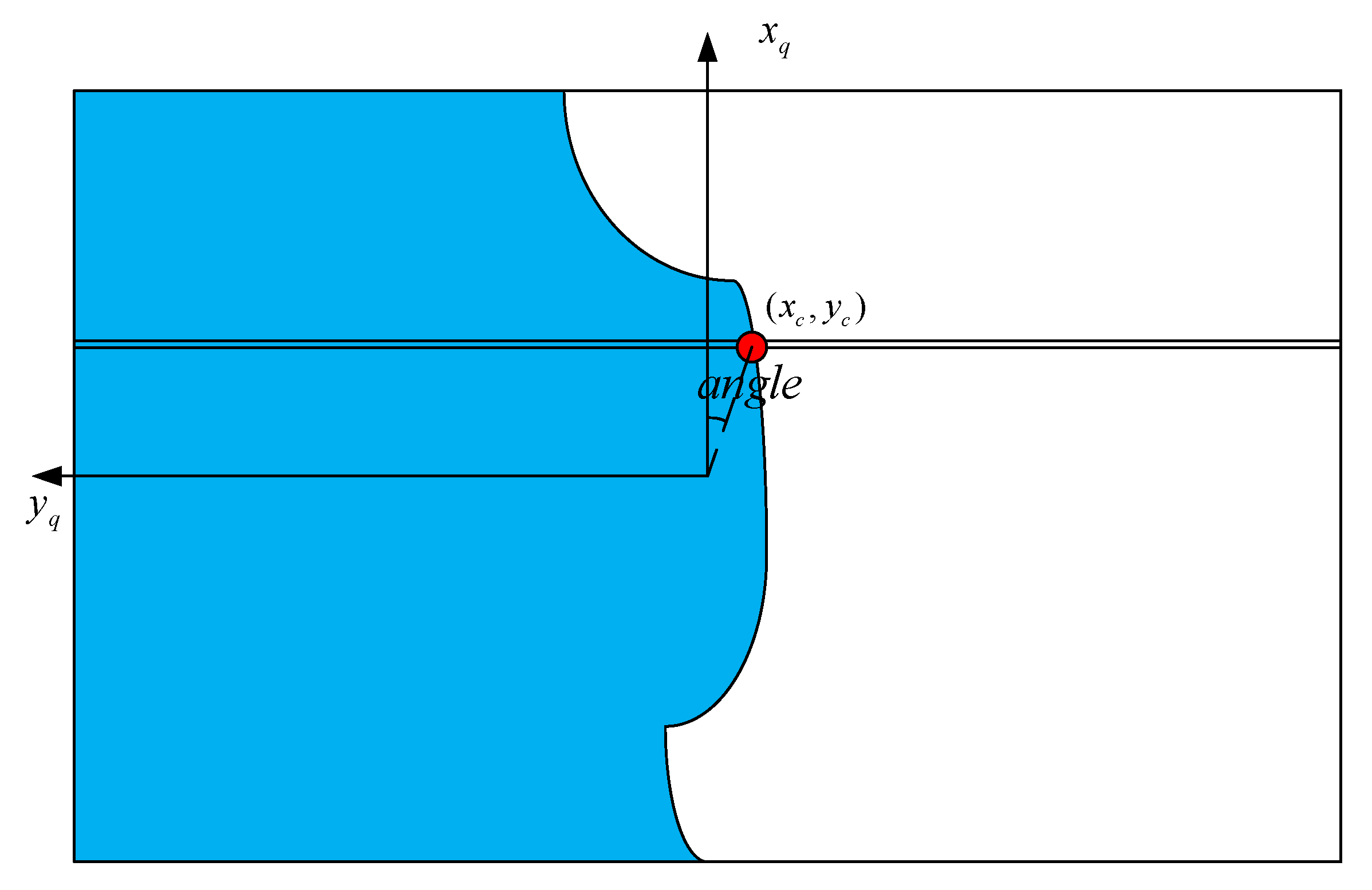
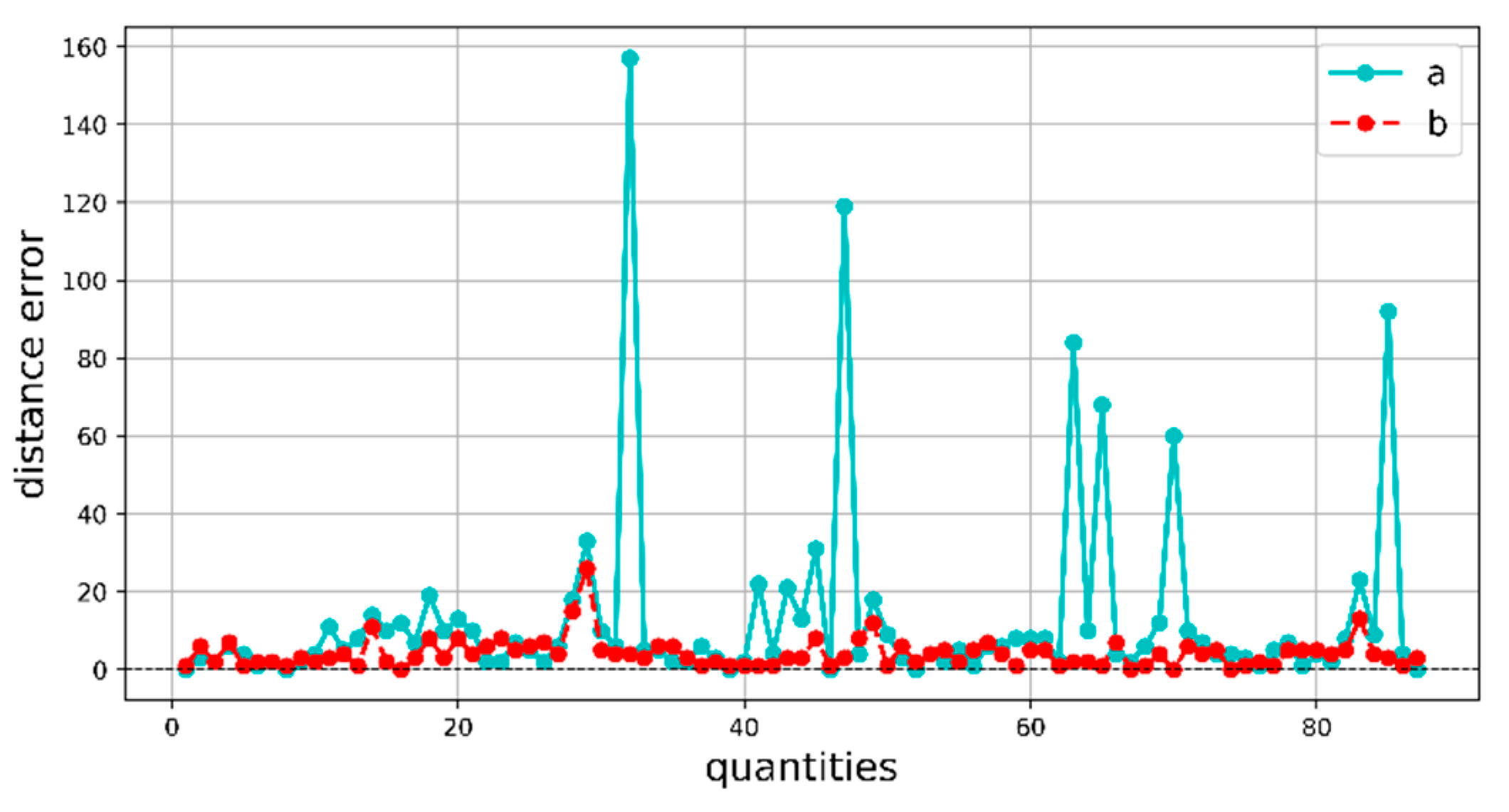
3.3. Error Analysis
3.4. Comparative Experiments with Different Models
3.5. Dataset Generalization Experiment
3.6. Comparison of AFID Dataset Model Improvements
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feng, T.; Xiong, J.; Xiao, J.; Liu, J.; He, Y. Real-Time Riverbank Line Detection for USV System. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019. [Google Scholar]
- Zou, X.; Xiao, C.; Zhan, W.; Zhou, C.; Xiu, S.; Yuan, H. A Novel Water-Shore-Line Detection Method for USV Autonomous Navigation. Sensors 2020, 20, 1682. [Google Scholar] [CrossRef]
- Praczyk, T. Detection of Land in Marine Images. Int. J. Comput. Intell. Syst. 2018, 12, 273. [Google Scholar] [CrossRef]
- Li, Y.; Wang, R.; Gao, D.; Liu, Z. A Floating-Waste-Detection Method for Unmanned Surface Vehicle Based on Feature Fusion and Enhancement. J. Mar. Sci. Eng. 2023, 11, 2234. [Google Scholar] [CrossRef]
- Chen, L.; Zhu, J. Water Surface Garbage Detection Based on Lightweight YOLOv5. Sci. Rep. 2024, 14, 6133. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Huang, Z.; Chen, C.; Wu, X.; Xie, S.; Zhou, H.; Gou, Y.; Gu, L.; Ma, M. A Spiral-Propulsion Amphibious Intelligent Robot for Land Garbage Cleaning and Sea Garbage Cleaning. J. Mar. Sci. Eng. 2023, 11, 1482. [Google Scholar] [CrossRef]
- Chang, H.-C.; Hsu, Y.-L.; Hung, S.-S.; Ou, G.-R.; Wu, J.-R.; Hsu, C. Autonomous Water Quality Monitoring and Water Surface Cleaning for Unmanned Surface Vehicle. Sensors 2021, 21, 1102. [Google Scholar] [CrossRef] [PubMed]
- Shinde, A.; Shinde, S. Computer Vision-Based Autonomous Underwater Vehicle with Robotic Arm for Garbage Detection and Cleaning. In Advances in Geographic Information Science; Springer Nature Switzerland: Cham, Switzerland, 2024; pp. 265–288. ISBN 9783031537622. [Google Scholar]
- Abro, G.E.M.; Ali, Z.A.; Rajput, S. Innovations in 3D Object Detection: A Comprehensive Review of Methods, Sensor Fusion, and Future Directions. IECE Trans. Sens. Commun. Control. 2024, 1, 3–29. [Google Scholar] [CrossRef]
- Bayram, B.; Seker, D.Z.; Akpinar, B. Efficiency of Different Machine Learning Methods for Shoreline Extraction from UAV Images. In Proceedings of the 40th Asian Conference on Remote Sensing (ACRS 2019), Daejeon, Republic of Korea, 14–18 October 2019. [Google Scholar]
- Huang, Y.; Lee, G.; Soong, R.; Liu, J. Real-Time Vision-Based River Detection and Lateral Shot Following for Autonomous UAVs. In Proceedings of the 2020 IEEE International Conference on Real-time Computing and Robotics (RCAR), Asahikawa, Japan, 28–29 September 2020. [Google Scholar]
- Rathinam, S.; Almeida, P.; Kim, Z.; Jackson, S.; Tinka, A.; Grossman, W.; Sengupta, R. Autonomous Searching and Tracking of a River Using an UAV. In Proceedings of the 2007 American Control Conference, New York, NY, USA, 11–13 July 2007. [Google Scholar]
- Jin, X.; Tong, A.; Ge, X.; Ma, H.; Li, J.; Fu, H.; Gao, L. YOLOv7-Bw: A Dense Small Object Efficient Detector Based on Remote Sensing Image. IECE Trans. Intell. Syst 2024, 1, 30–39. [Google Scholar] [CrossRef]
- An, S.; Rui, X. A High-Precision Water Body Extraction Method Based on Improved Lightweight U-Net. Remote Sens. 2022, 14, 4127. [Google Scholar] [CrossRef]
- Li, Z.; Wang, R.; Zhang, W.; Hu, F.; Meng, L. Multiscale Features Supported DeepLabV3+ Optimization Scheme for Accurate Water Semantic Segmentation. IEEE Access 2019, 7, 155787–155804. [Google Scholar] [CrossRef]
- Su, H.; Peng, Y.; Xu, C.; Feng, A.; Liu, T. Using Improved DeepLabv3+ Network Integrated with Normalized Difference Water Index to Extract Water Bodies in Sentinel-2A Urban Remote Sensing Images. J. Appl. Remote Sens. 2021, 15, 018504. [Google Scholar] [CrossRef]
- Yin, Y.; Guo, Y.; Deng, L.; Chai, B. Improved PSPNet-Based Water Shoreline Detection in Complex Inland River Scenarios. Complex Intell. Syst. 2022, 9, 233–245. [Google Scholar] [CrossRef]
- Li, T.; Cui, Z.; Zhang, H. Semantic Segmentation Feature Fusion Network Based on Transformer. Sci. Rep. 2025, 15, 6110. [Google Scholar] [CrossRef]
- Zhang, W.B.; Wu, C.Y.; Bao, Z.S. SA-BiSeNet: Swap Attention Bilateral Segmentation Network for Real-time Inland Waterways Segmentation. IET Image Process. 2023, 17, 166–177. [Google Scholar] [CrossRef]
- Yu, Y.; Huang, L.; Lu, W.; Guan, H.; Ma, L.; Jin, S.; Yu, C.; Zhang, Y.; Tang, P.; Liu, Z.; et al. WaterHRNet: A Multibranch Hierarchical Attentive Network for Water Body Extraction with Remote Sensing Images. Int. J. Appl. Earth Obs. Geoinf. 2022, 115, 103103. [Google Scholar] [CrossRef]
- Emara, T.; Munim, H.E.A.E.; Abbas, H.M. LiteSeg: A Novel Lightweight ConvNet for Semantic Segmentation. In Proceedings of the 2019 Digital Image Computing: Techniques and Applications (DICTA), Perth, Australia, 2–4 December 2019. [Google Scholar]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. DenseASPP for Semantic Segmentation in Street Scenes. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Artacho, B.; Savakis, A. Waterfall Atrous Spatial Pooling Architecture for Efficient Semantic Segmentation. Sensors 2019, 19, 5361. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Liu, J.-S.; Lee, G.-Y. A Carrot in Probabilistic Grid Approach for Quadrotor Line Following on Vertical Surfaces. In Proceedings of the 2019 International Conference on Unmanned Aircraft Systems (ICUAS), Atlanta, GA, USA, 11–14 June 2019. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral Segmentation Network for Real-Time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hong, Y.; Pan, H.; Sun, W.; Jia, Y. Deep Dual-Resolution Networks for Real-Time and Accurate Semantic Segmentation of Road Scenes. arXiv 2021, arXiv:2101.06085. [Google Scholar]
- Wang, H.; Jiang, X.; Ren, H.; Hu, Y.; Bai, S. SwiftNet: Real-Time Video Object Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Xu, J.; Xiong, Z.; Bhattacharyya, S.P. PIDNet: A Real-Time Semantic Segmentation Network Inspired by PID Controllers. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Mehta, S.; Rastegari, M.; Caspi, A.; Shapiro, L.; Hajishirzi, H. Espnet: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, Z.; Wu, L.-F.; Mahmoudian, N. Aerial Fluvial Image Dataset (AFID) for Semantic Segmentation. Available online: https://purr.purdue.edu/publications/4105/1 (accessed on 15 April 2025).
- Wang, Y.; Chen, S.; Bian, H.; Li, W.; Lu, Q. Spatial-Assistant Encoder-Decoder Network for Real Time Semantic Segmentation. arXiv 2023, arXiv:2309.10519. [Google Scholar]
- Li, J.; Wang, B.; Ma, H.; Gao, L.; Fu, H. Visual Feature Extraction and Tracking Method Based on Corner Flow Detection. IECE Trans. Intell. Syst. 2024, 1, 3–9. [Google Scholar] [CrossRef]
- Wang, F.; Yi, S. Spatio-Temporal Feature Soft Correlation Concatenation Aggregation Structure for Video Action Recognition Networks. IECE Trans. Sens. Commun. Control. 2024, 1, 60–71. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Operator | c | n | t | s |
|---|---|---|---|---|---|
| 1 | conv2d | 32 | 1 | – | 2 |
| 2 | bottleneck | 16 | 1 | 1 | 1 |
| 3 | bottleneck | 24 | 2 | 6 | 2 |
| 4 | bottleneck | 32 | 3 | 6 | 2 |
| 5 | bottleneck | 64 | 4 | 6 | 2 |
| 6 | bottleneck | 96 | 3 | 6 | 2 |
| 7 | bottleneck | 160 | 3 | 6 | 1 |
| 8 | bottleneck | 320 | 1 | 6 | 1 |
| 9 | conv2d 1 × 1 | 1280 | 1 | – | 1 |
| 10 | avgpool 7 × 7 | – | 1 | – | – |
| 11 | conv2d 1 × 1 | k | – | – | – |
| Layer | Operator | c | n | t | s |
|---|---|---|---|---|---|
| 1 | conv2d | 32 | 1 | – | 2 |
| 2 | bottleneck | 16 | 1 | 1 | 1 |
| 3 | bottleneck | 24 | 2 | 6 | 2 |
| 4 | bottleneck | 32 | 3 | 6 | 2 |
| 5 | bottleneck | 64 | 4 | 6 | 2 |
| 6 | bottleneck | 96 | 3 | 6 | 2 |
| 7 | bottleneck | 160 | 3 | 6 | 1 |
| 8 | bottleneck | 320 | 1 | 6 | 1 |
| Network | Params | FPS (360×640) | mIoU% |
|---|---|---|---|
| DarkNet | 20.55 | 182 | 91.89 |
| ShuffNet | 3.51 | 246 | 90.06 |
| MobileNetV2 | 4.38 | 293 | 91.11 |
| MobileNetV2-S | 2.11 | 312 | 90.80 |
| Group | MobileNetV2-S | DP-ASPP | ECA | mIoU% | F1% | GFLOPS | Params | FPS |
|---|---|---|---|---|---|---|---|---|
| 1 | 91.11 | 93.21 | 4.9 | 4.38 | 293 | |||
| 2 | √ | 90.80 | 93.20 | 3.88 | 2.11 | 312 | ||
| 3 | √ | √ | 91.76 | 93.35 | 3.86 | 2.08 | 311 | |
| 4 | √ | √ | √ | 93.81 | 95.44 | 3.86 | 2.08 | 294 |
| Model | Network | mIoU% | Params | FPS |
|---|---|---|---|---|
| Bisenet | Resnet18 | 91.41 | 49.0 | 220 |
| ENet | None | 88.92 | 0.37 | 306 |
| Espnet | None | 89.33 | 0.36 | 277 |
| LiteSeg | MobileNetV2 | 91.11 | 4.38 | 293 |
| PIDNet | PID | 93.65 | 22.28 | 265 |
| SwiftNet | Resnet18 | 92.5 | 11.8 | 261 |
| DDRNet | Dual Resolution | 93.34 | 30.86 | 245 |
| WaterSegLite | MobileNetV2-S | 93.81 | 2.08 | 294 |
| Model | mIoU% | F1% | Params | GFLOPs | FPS |
|---|---|---|---|---|---|
| LiteSeg | 88.48 | 90.85 | 4.38 | 4.96 | 293 |
| DDRNet | 89.57 | 91.26 | 30.86 | 35.26 | 245 |
| PIDNet | 90.21 | 91.9 | 27.21 | 22.28 | 265 |
| SANet | 88.95 | 91.08 | 7.88 | 8.77 | 253 |
| WaterSegLite | 90.00 | 91.56 | 2.08 | 4.08 | 294 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Gao, X.; Song, L.; Fang, J.; Tao, Y.; Deng, H.; Yao, J. A New Algorithm for Visual Navigation in Unmanned Aerial Vehicle Water Surface Inspection. Sensors 2025, 25, 2600. https://doi.org/10.3390/s25082600
Han J, Gao X, Song L, Fang J, Tao Y, Deng H, Yao J. A New Algorithm for Visual Navigation in Unmanned Aerial Vehicle Water Surface Inspection. Sensors. 2025; 25(8):2600. https://doi.org/10.3390/s25082600
Chicago/Turabian StyleHan, Jianfeng, Xiongwei Gao, Lili Song, Jiandong Fang, Yongzhao Tao, Haixin Deng, and Jie Yao. 2025. "A New Algorithm for Visual Navigation in Unmanned Aerial Vehicle Water Surface Inspection" Sensors 25, no. 8: 2600. https://doi.org/10.3390/s25082600
APA StyleHan, J., Gao, X., Song, L., Fang, J., Tao, Y., Deng, H., & Yao, J. (2025). A New Algorithm for Visual Navigation in Unmanned Aerial Vehicle Water Surface Inspection. Sensors, 25(8), 2600. https://doi.org/10.3390/s25082600