
Query by Example: Semantic Traffic Scene Retrieval Using LLM-Based Scene Graph Representation

 , ,
, ,
Abstract
1. Introduction
- We propose a scene representation method based on topological graphs (Road Scene Graph, RSG), and we implement an efficient traffic scene retrieval method based on this representation.
- We analyze the errors and failures of LLMs in generating RSGs and propose several improvement methods.
- We propose a benchmark RSG-LLM for applying LLMs to RSG generation. This benchmark contains 1000 traffic scenes, their corresponding natural language descriptions, and RSG topological graphs. These descriptions have been manually reviewed and corrected to ensure accuracy. The benchmark can be used to evaluate the quality of RSG generation by LLMs and provides a standard for future research.
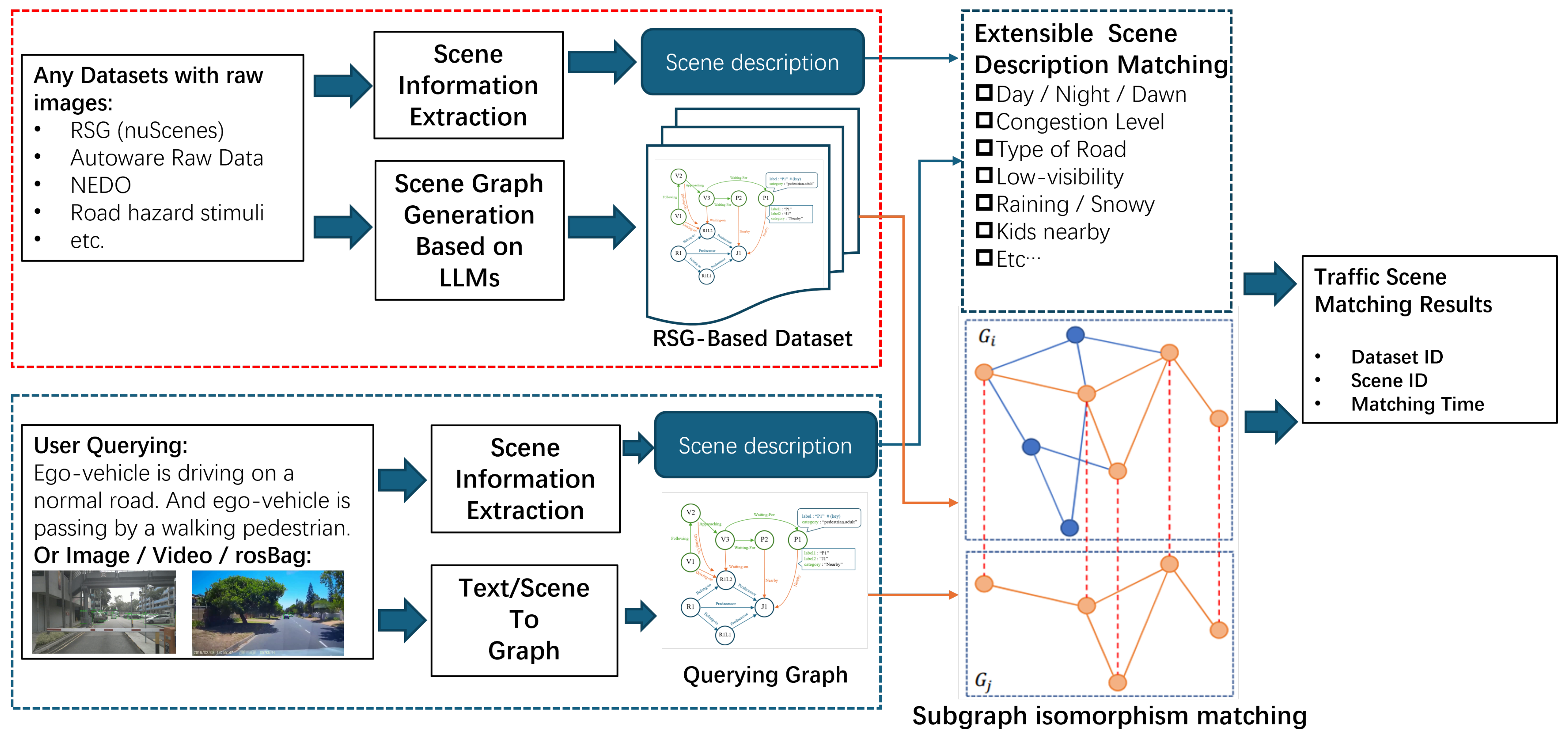
- We present a traffic scene retrieval method based on RSGs that can be applied to any dataset containing visual information without requiring camera parameters. In the query phase, the method accepts various input formats, such as natural language queries, image queries, and video clips. This retrieval method can serve as the Retrieval component in Retrieval-Augmented Generation (RAG), offering a new approach for integrating large language models with autonomous driving systems.
- The RSG-LLM Benchmark, as well as the framework we used to manage VLM interaction, can be found at the following link: https://github.com/TianYafu/RSG-LLM/tree/main (accessed on 3 April 2025).
2. Related Work
2.1. Traffic Scene Retrieval
2.2. LLM-Aided Research in Autonomous Driving
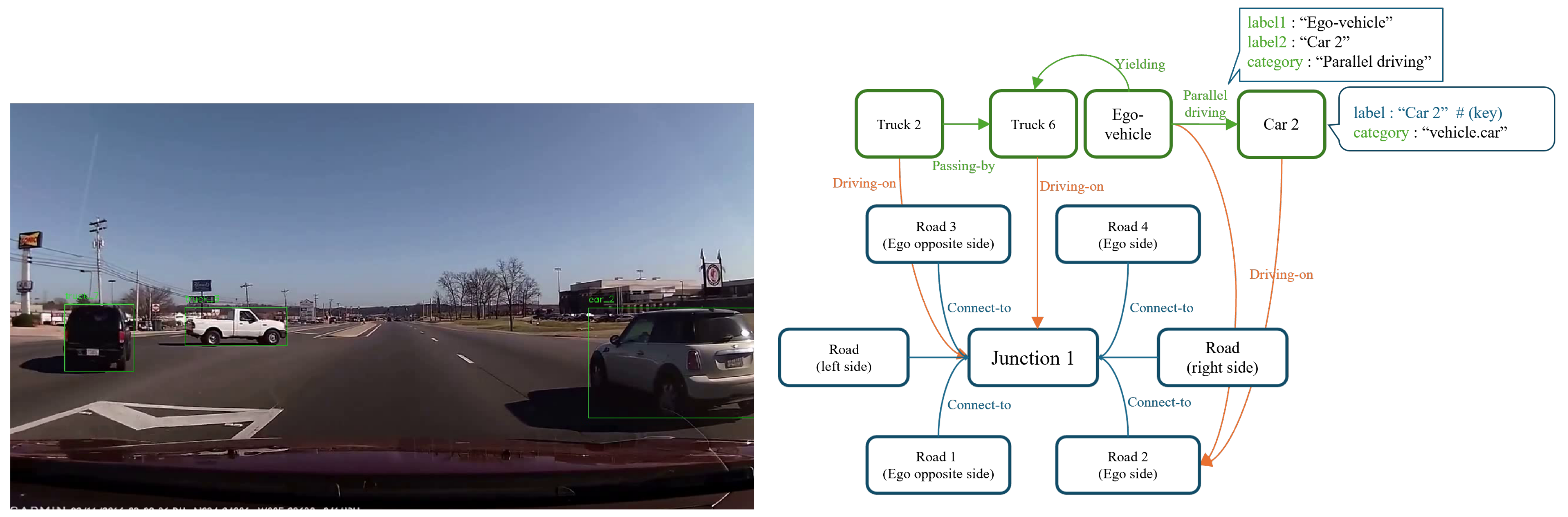
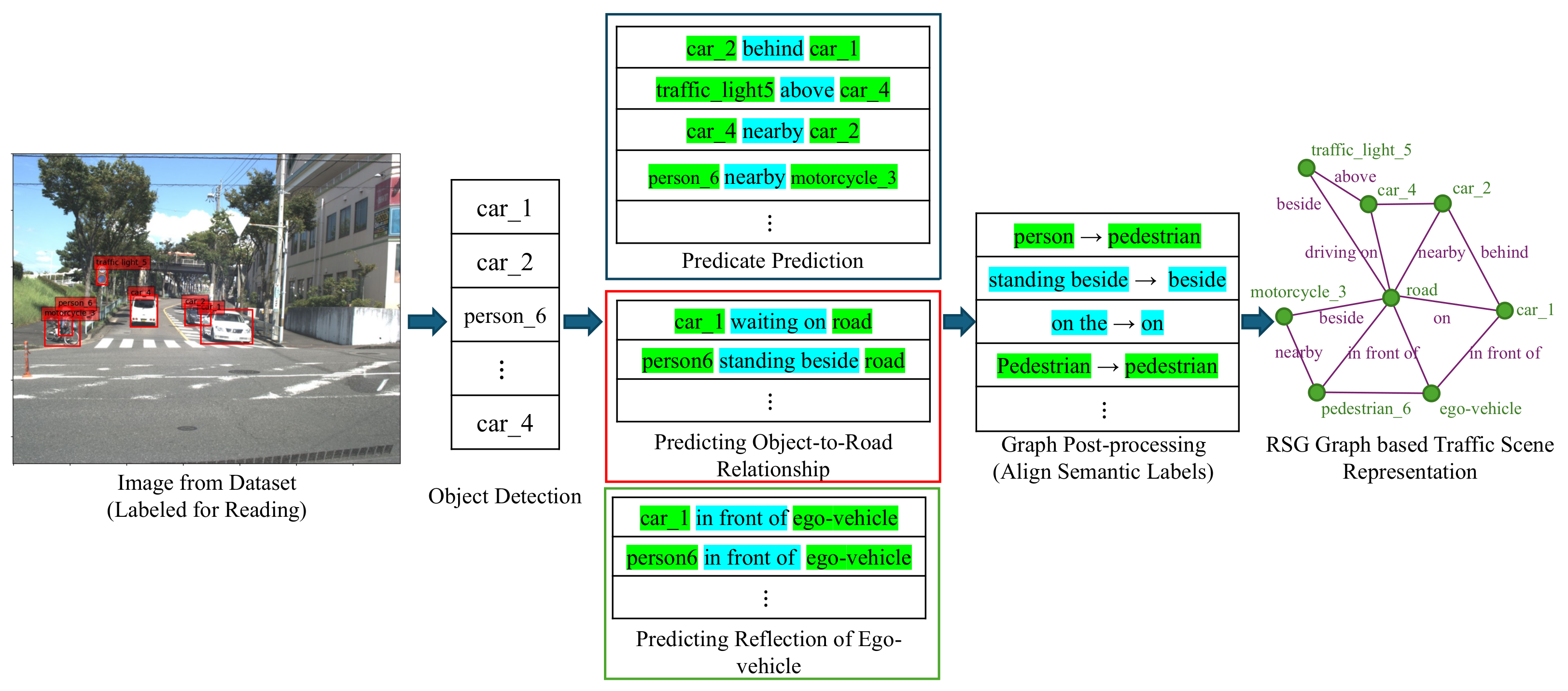
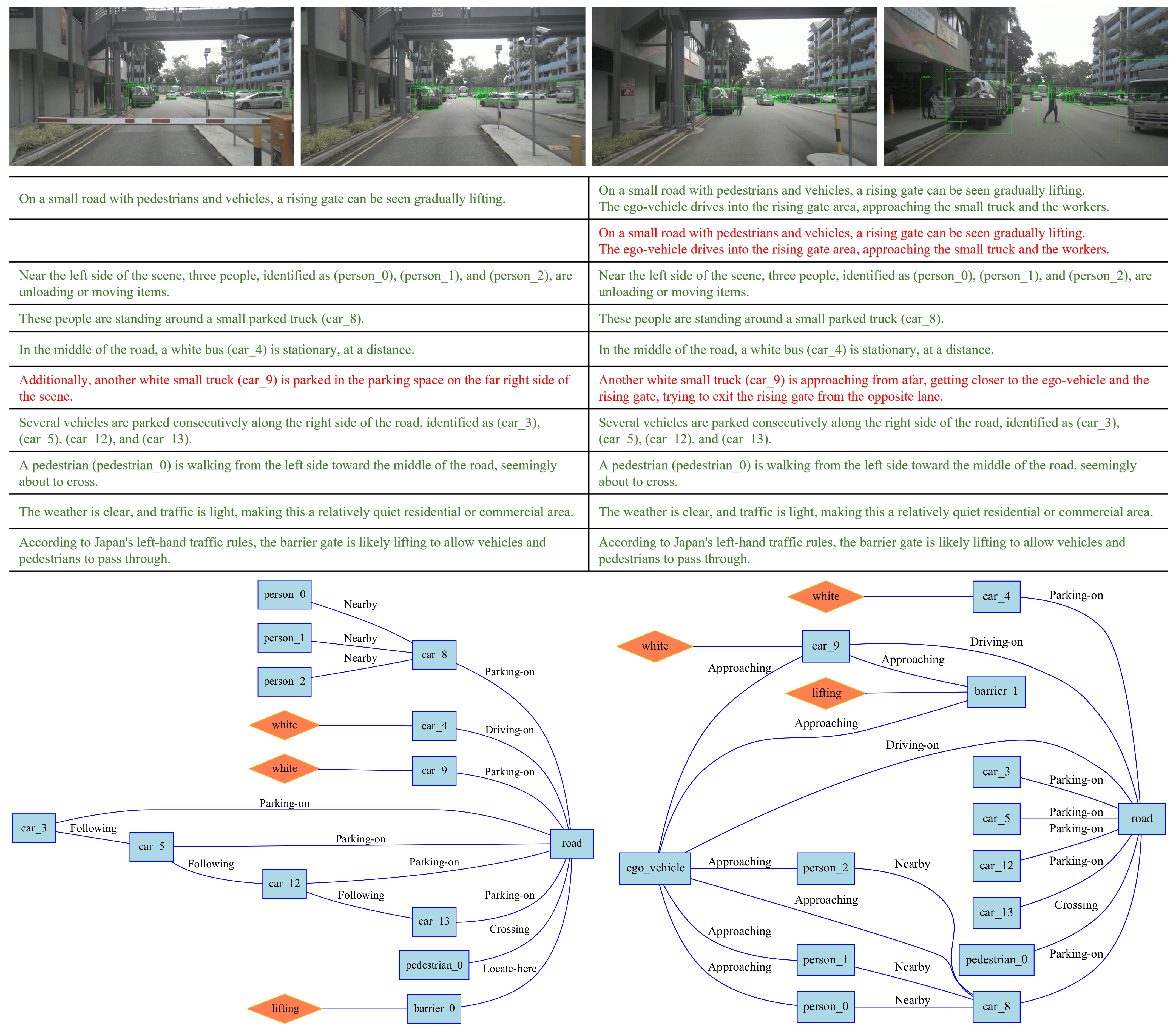
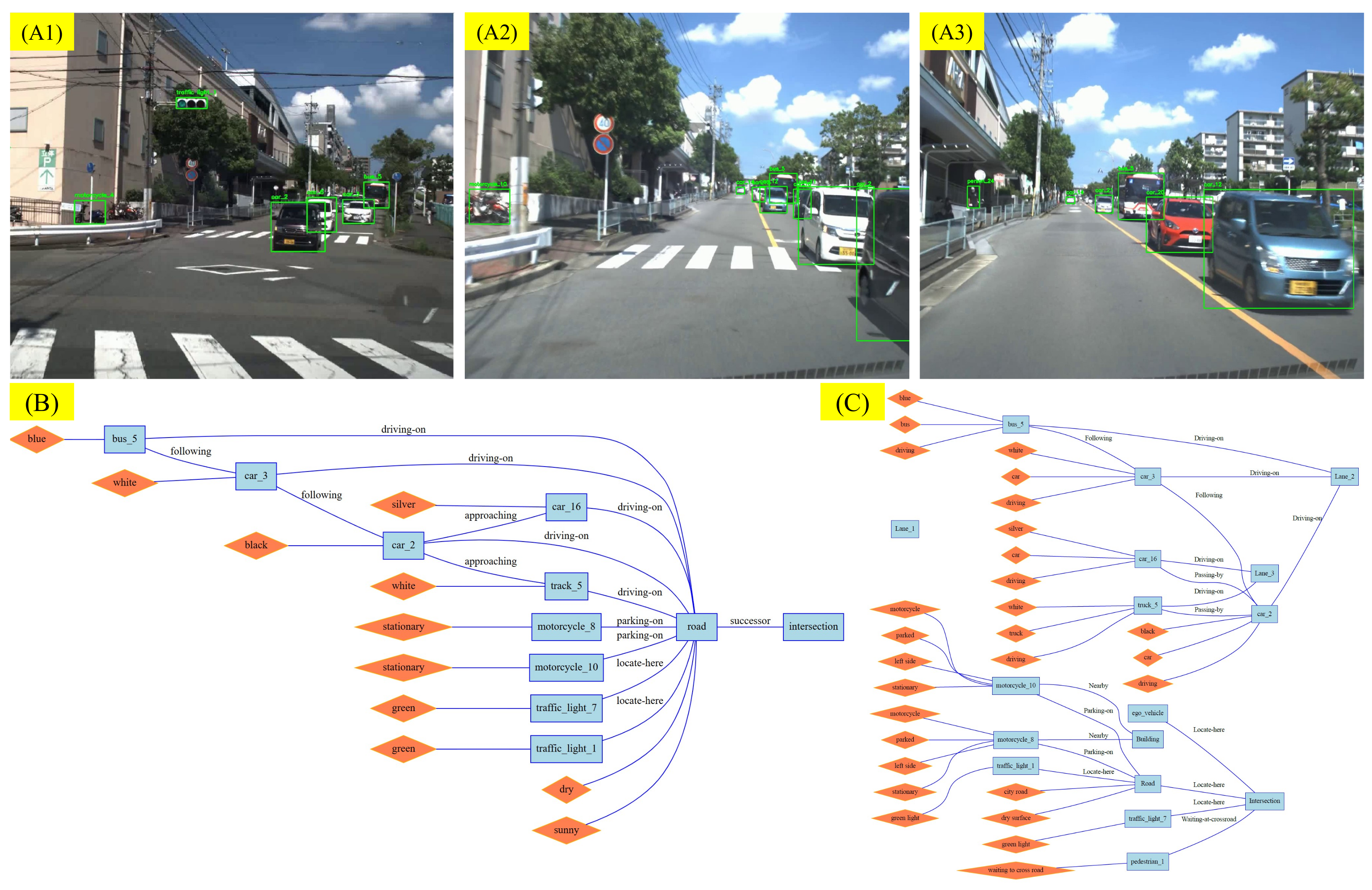
3. Traffic Scene Representation Using RSG
- Extensible set of scene attributes: These are high-level, enumerate, descriptive features of the scene, such as weather conditions, road types, and driving behavior. This flexible approach captures various aspects of the scene, tailored to different user or application requirements. A list of extensible scene attributes is provided in Table 1.
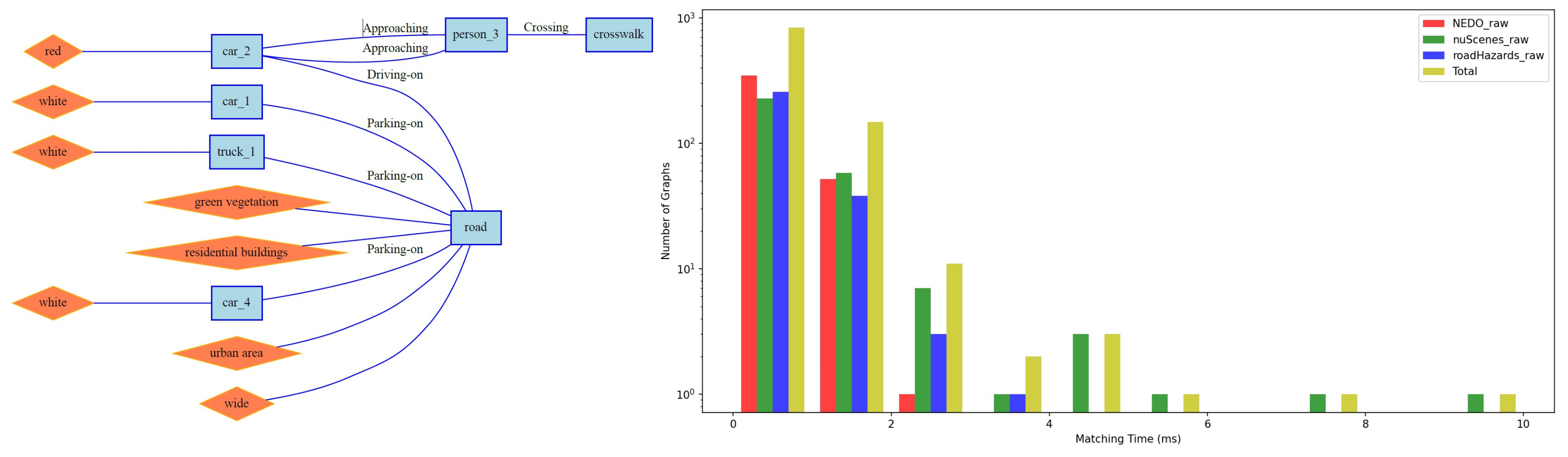
- Scene description based on a topological graph (RSG): This structured representation captures the objects present in the scene and the relationships among them. The RSG allows for detailed and precise comparisons of scene dynamics.
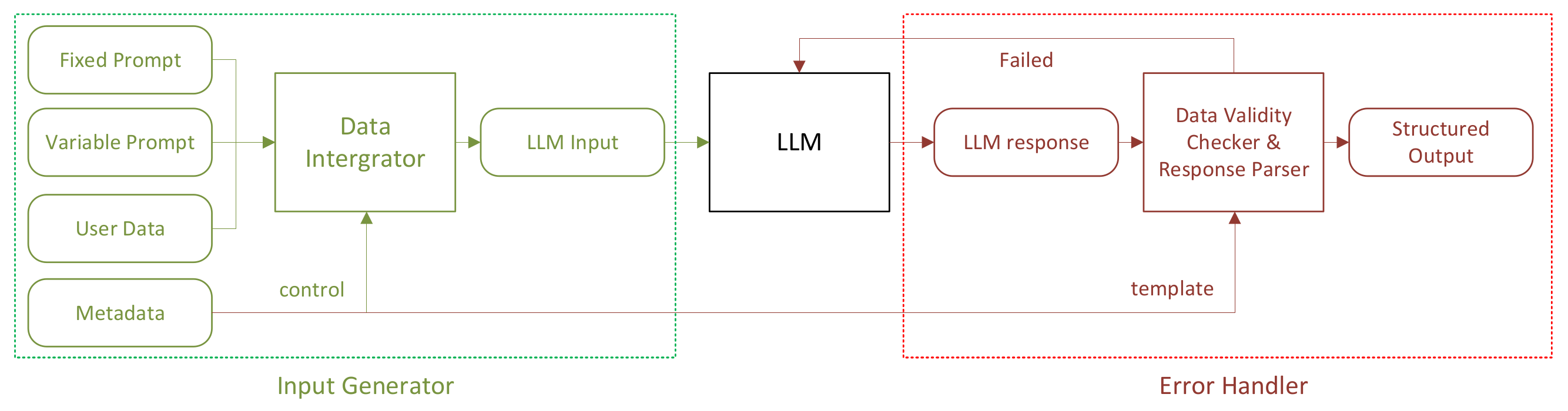
4. RSG-LLM
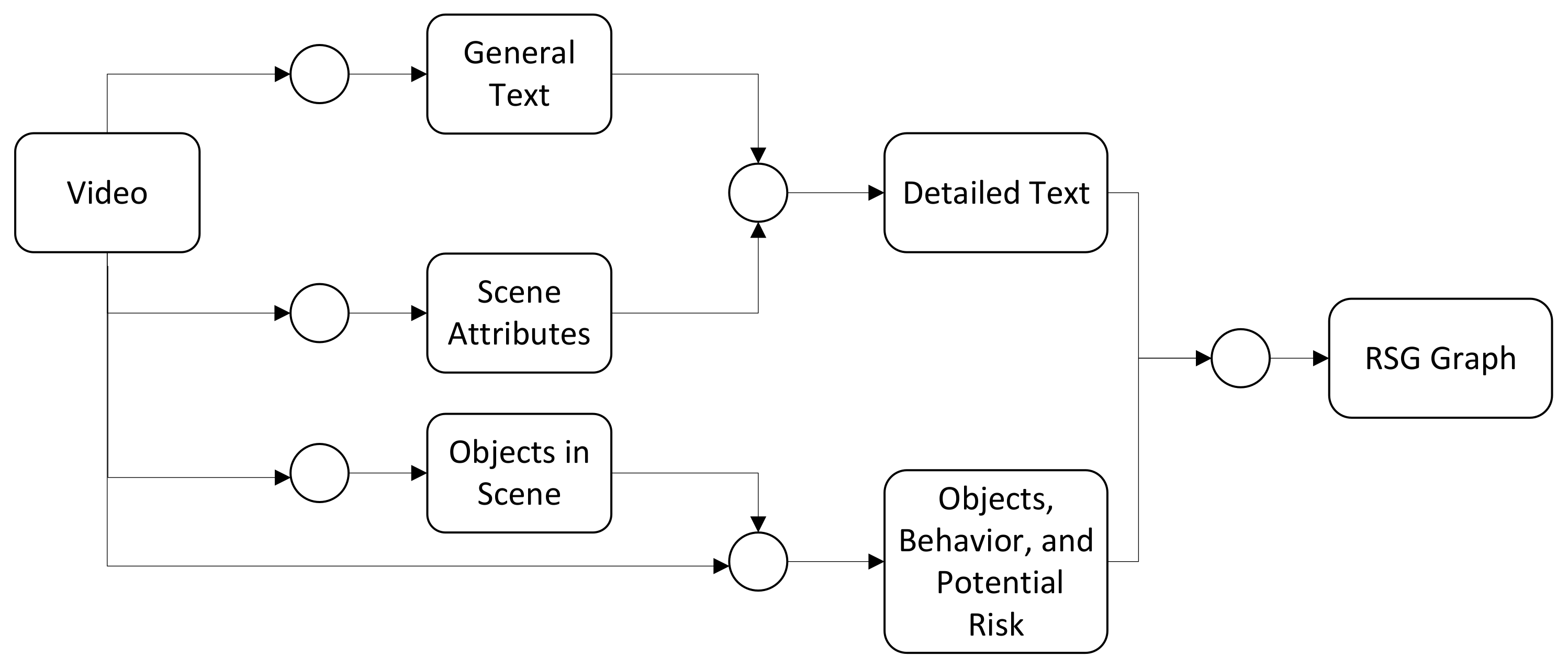
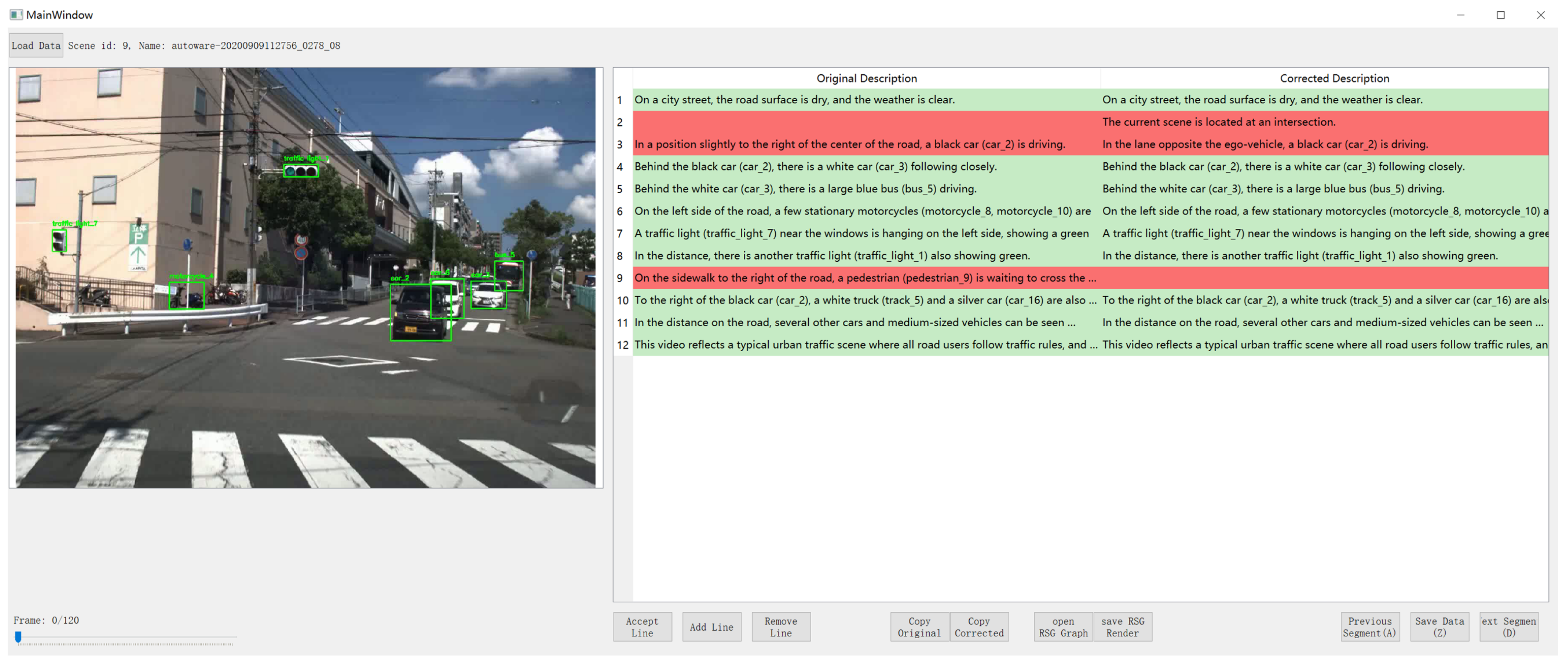
4.1. RSG Generation Using Visual LLMs
| Listing 1. Example of a structured text output representing a RSG. |
 |
- represents the set of nodes in the graph, where each node denotes a single LLM call. For example, VLM receives a text description and outputs a structured json text that represents the RSG.
- represents the set of directed edges between nodes, where an edge indicates that information flows from node to node . For example, the graph generator receives the scene description, ego-vehicle-to-object relationship, and (optional) local traffic rules, and so on. Then, it puts them together as LLM input to generate the RSG.
- System Prompt: Denoted by , this represents the task to be executed and the output format required for the reasoning process at node . Note that is fixed and does not change with the input data.
- Variable Prompt: Denoted by , this represents the specific input content for the reasoning process at node , including variable data such as images and text.
- Connection rules: Represented by the function , the connection rules define how the input of node is derived from the outputs of its predecessor nodes.
4.2. RSG-LLM Benchmark
4.3. Traffic Scene Retrieval Based on Road Scene Graphs
4.3.1. Preprocessing Query Input
4.3.2. Query by Natural Language
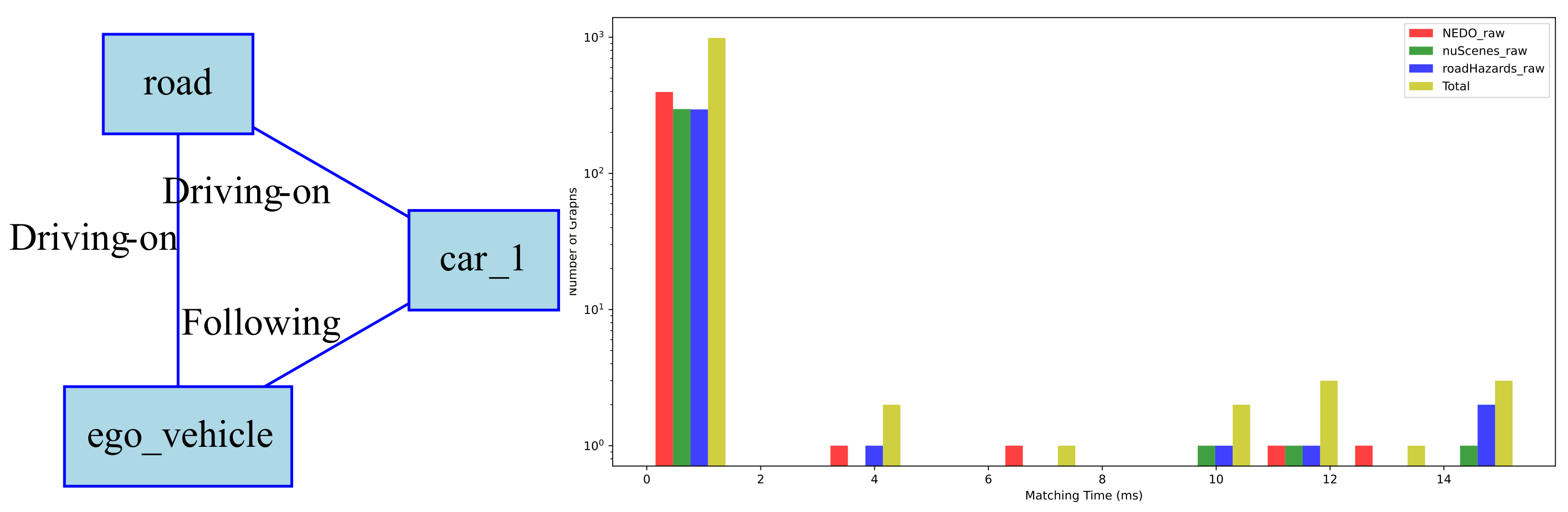
4.3.3. Query by Graph
| Algorithm 1: Road scene graph matching algorithm |
 |
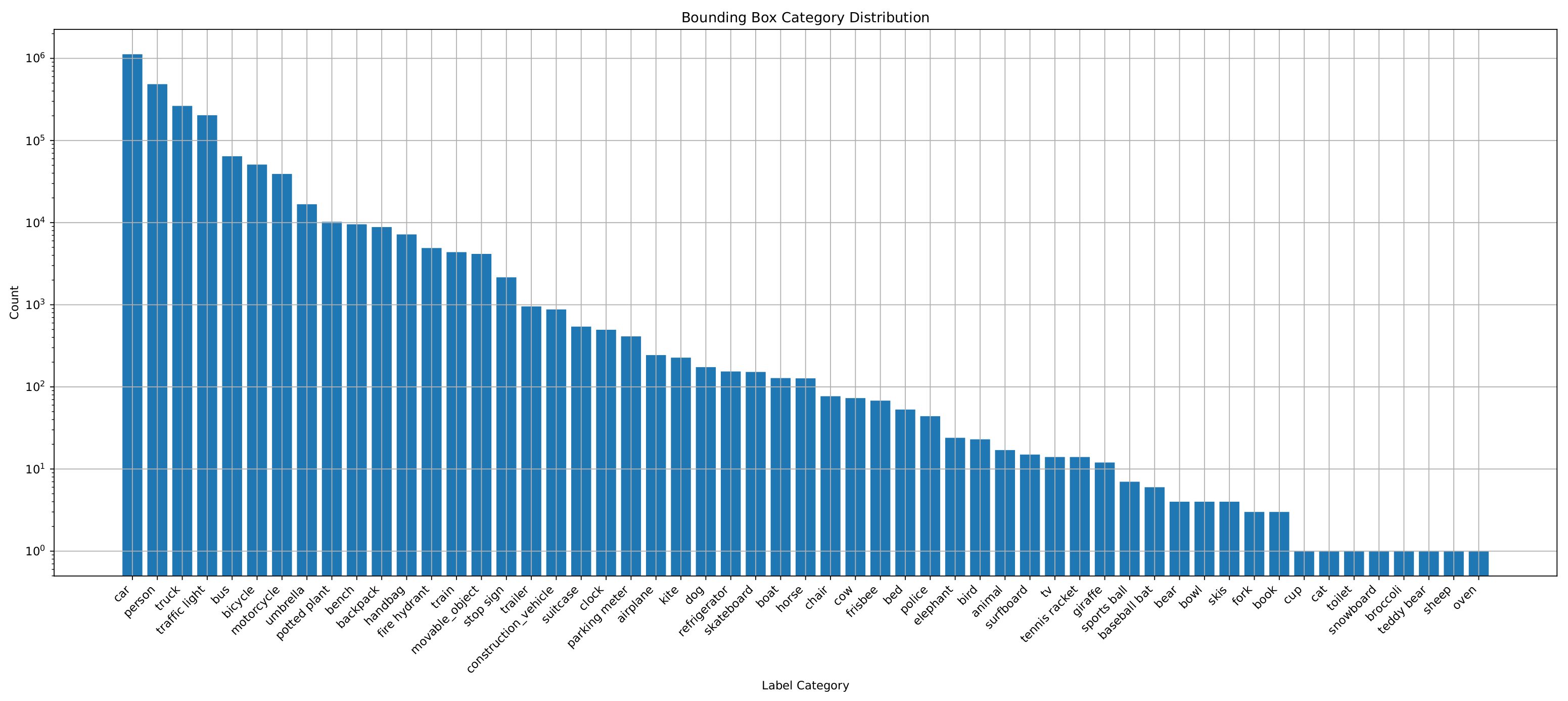
5. Experiment
5.1. Experiment Setup
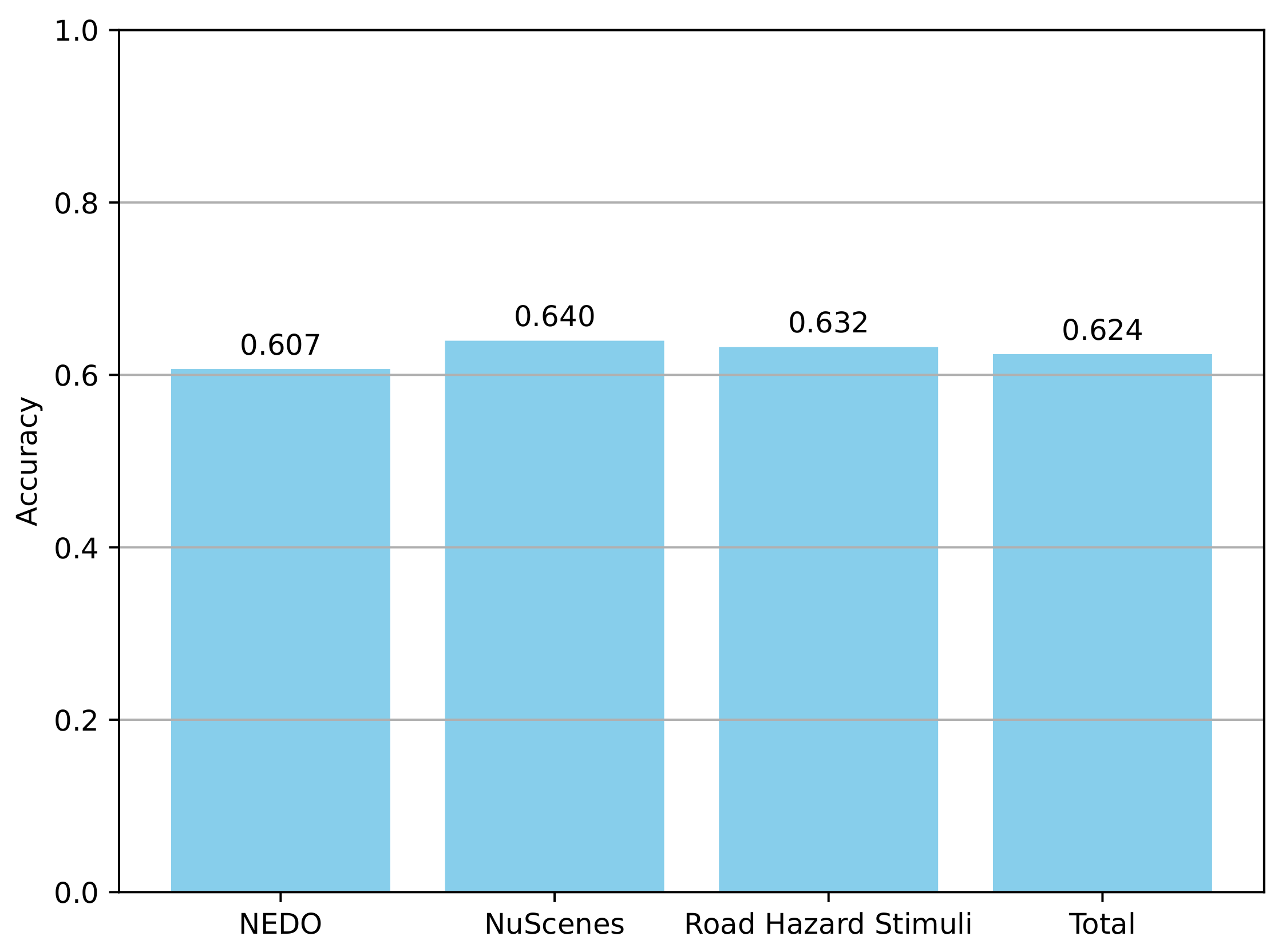
5.2. Traffic Scene Retrieval Based on Road Scene Graphs
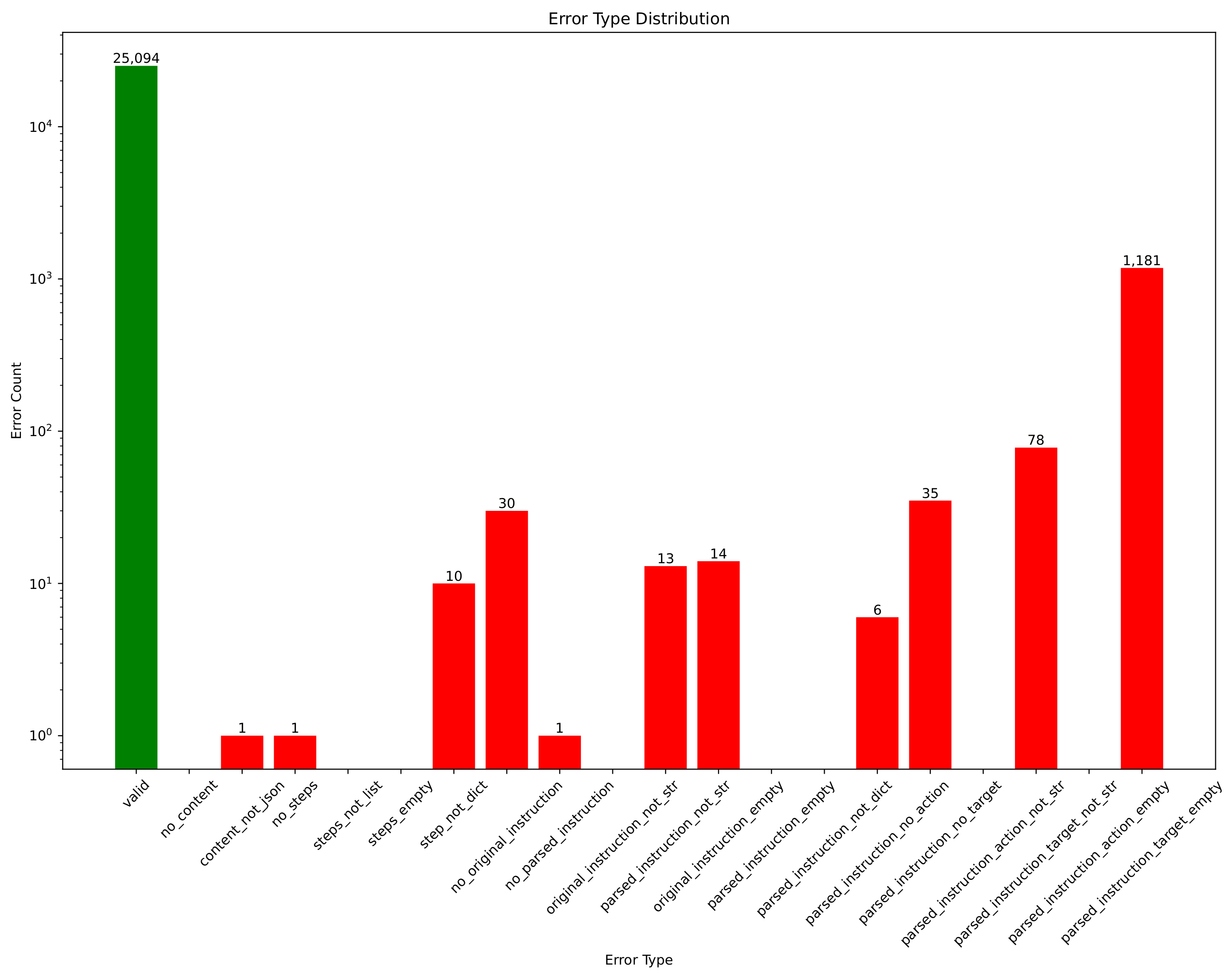
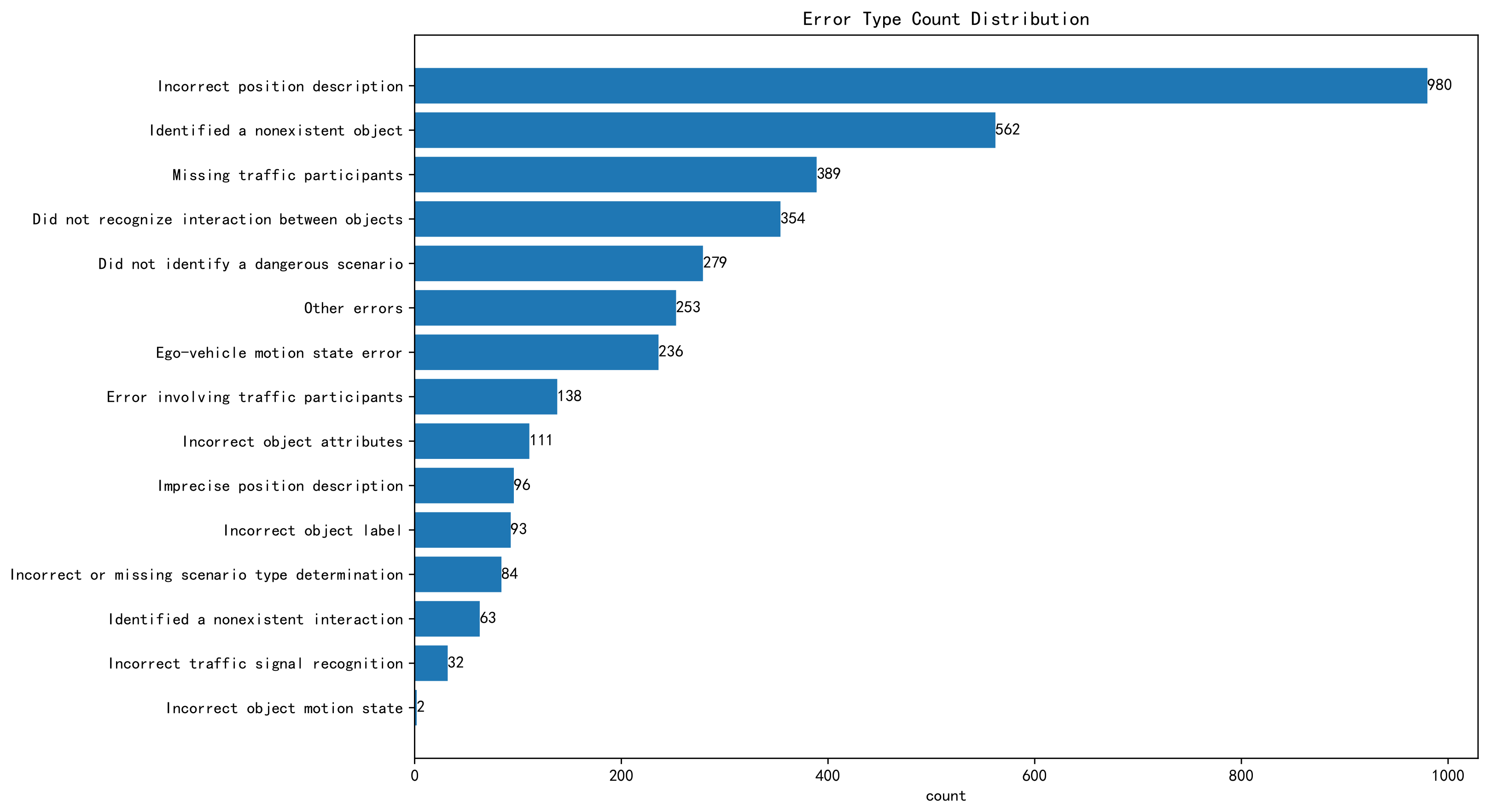
5.3. Error Analysis
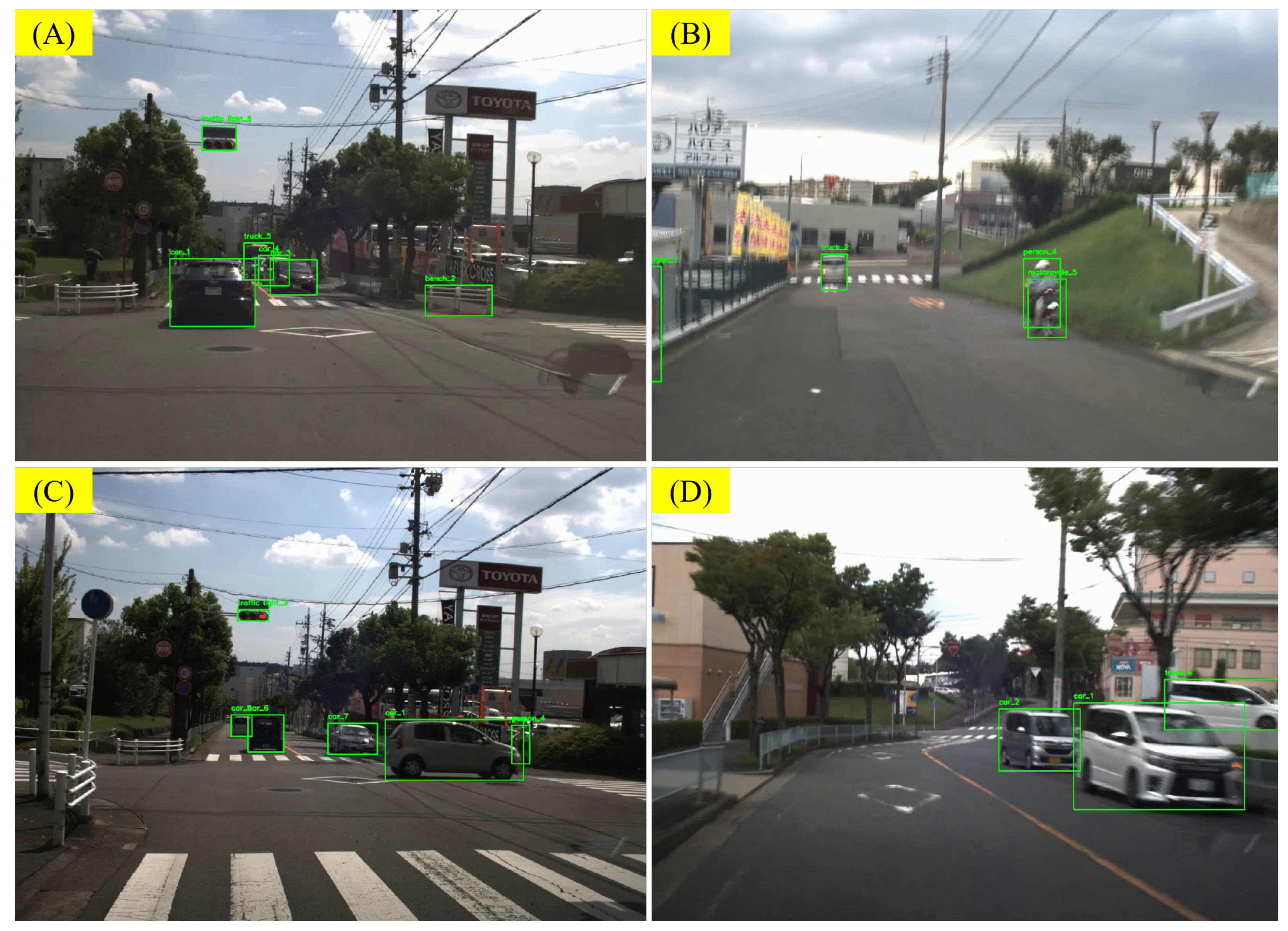
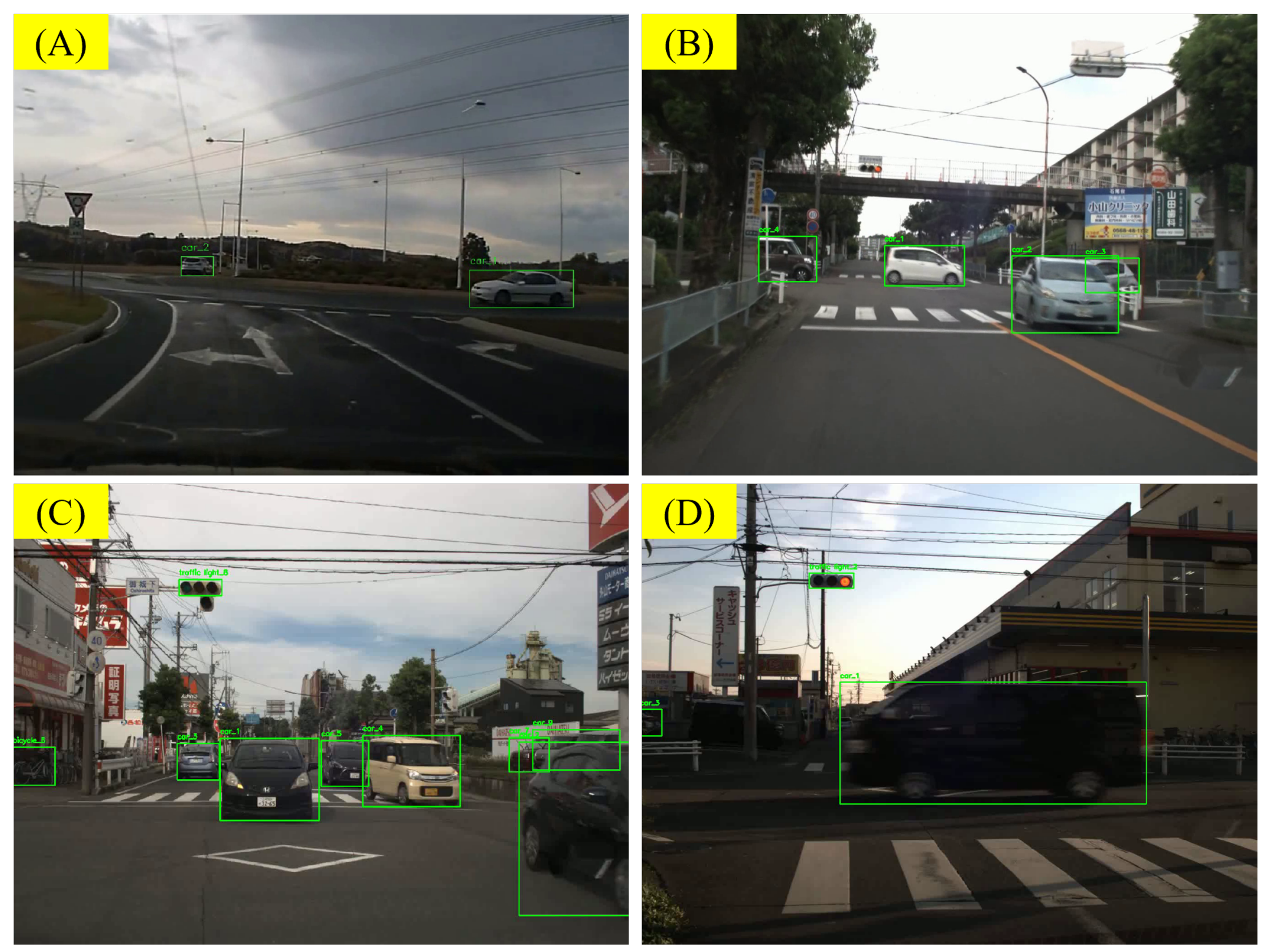
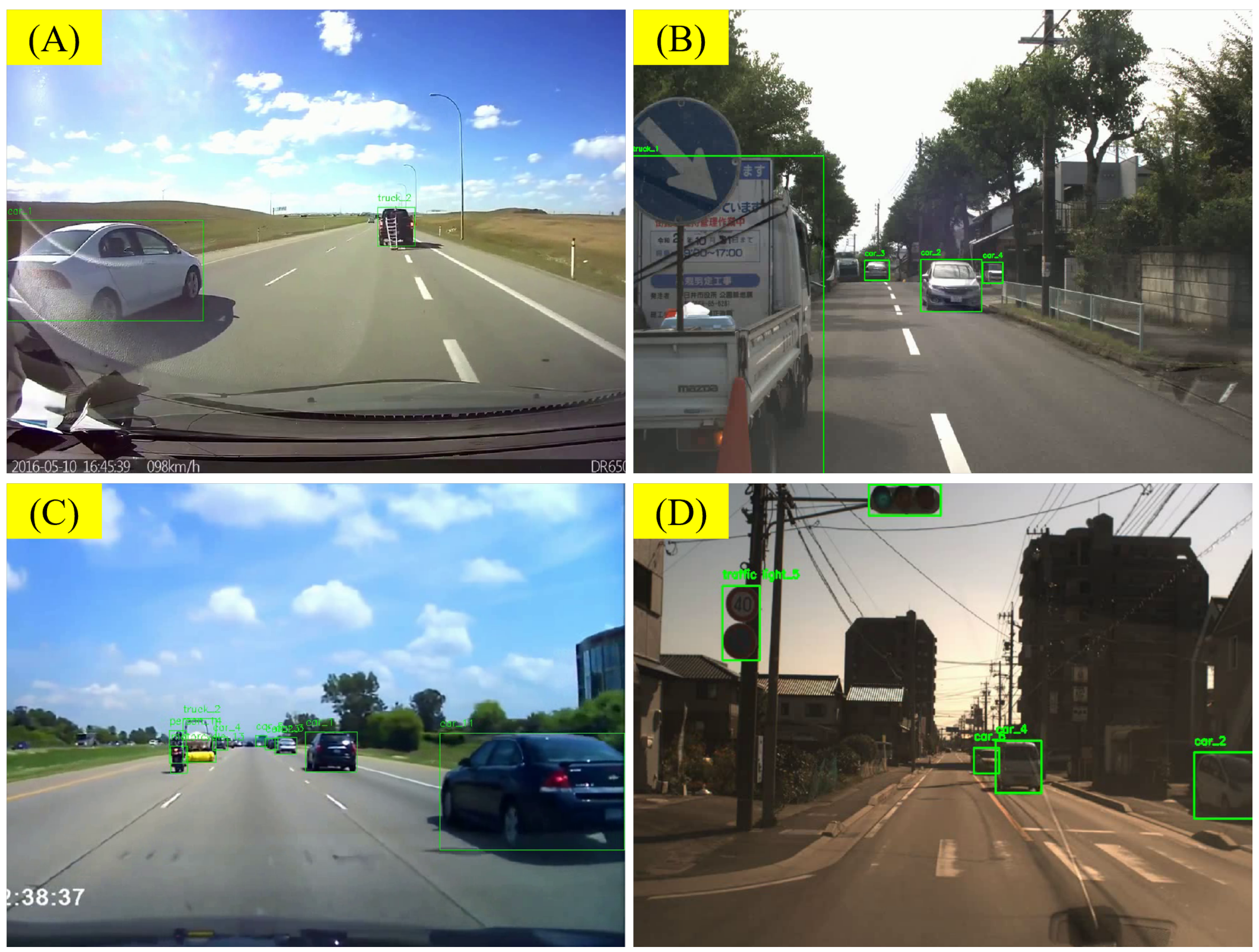
5.3.1. Error from Front-End Object Recognition and Label Rendering
5.3.2. Errors from Insufficient Frame Rate for Recognizing Sudden Accidents
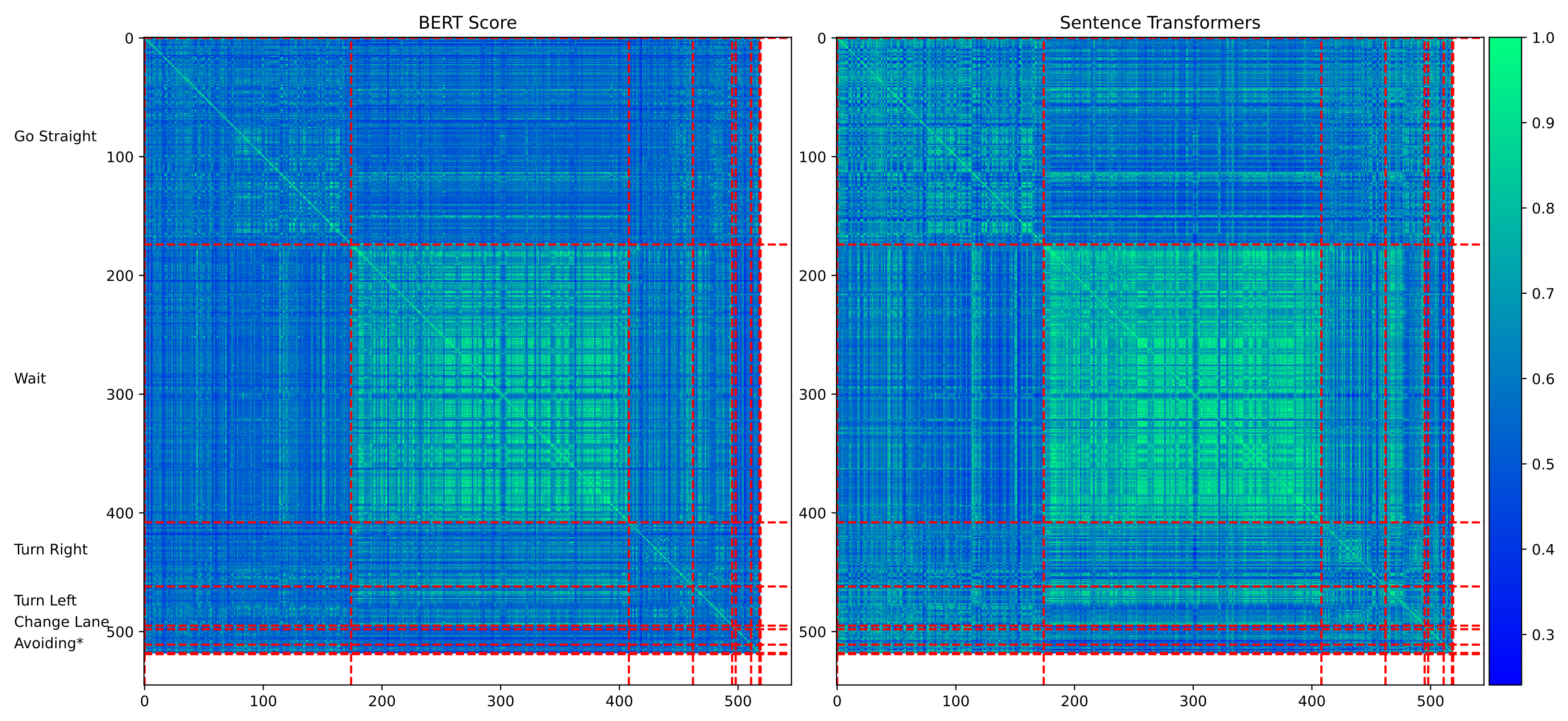
5.3.3. Analysis of Errors from VLM’s Illustration
5.3.4. Error from Lack of Driving Common Sense
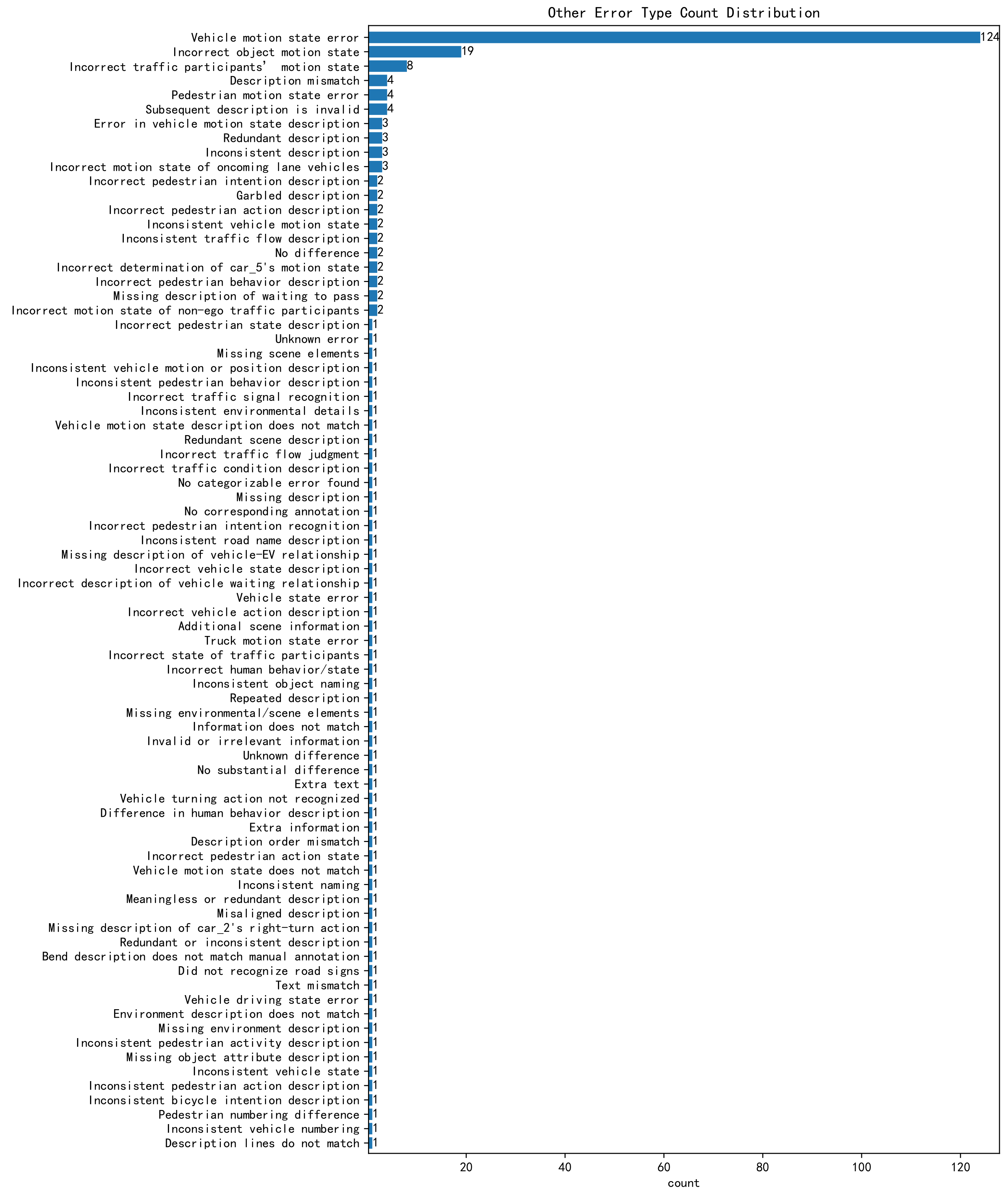
5.3.5. Other Errors
5.4. Integrating COT into LLM-Based RSG Generation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. LLM Call Graph

Appendix B. Minor Errors in RSG Generation
References
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2446–2454. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. Nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11621–11631. [Google Scholar]
- Wolfe, B.; Seppelt, B.; Mehler, B.; Reimer, B.; Rosenholtz, R. Rapid holistic perception and evasion of road hazards. J. Exp. Psychol. Gen. 2020, 149, 490. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Yan, C.; Gong, B.; Wei, Y.; Gao, Y. Deep multi-view enhancement hashing for image retrieval. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 1445–1451. [Google Scholar] [CrossRef] [PubMed]
- Sain, A.; Bhunia, A.K.; Chowdhury, P.N.; Koley, S.; Xiang, T.; Song, Y.Z. Clip for all things zero-shot sketch-based image retrieval, fine-grained or not. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2765–2775. [Google Scholar]
- Gabeur, V.; Sun, C.; Alahari, K.; Schmid, C. Multi-modal transformer for video retrieval. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 214–229. [Google Scholar]
- Pfeiffer, M. Effortlessly Explore the nuScenes Dataset with SiaSearch. Medium. April 2021. Available online: https://medium.com/siasearch/effortlessly-explore-the-nuscenes-dataset-with-siasearch-c9f1020c2617 (accessed on 3 October 2024).
- Pfeiffer, M. Introduction to Nucleus. Available online: https://nucleus.scale.com/docs/getting-started (accessed on 3 October 2024).
- Chen, D.; Dolan, W.B. Collecting highly parallel data for paraphrase evaluation. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 190–200. [Google Scholar]
- Xu, J.; Mei, T.; Yao, T.; Rui, Y. Msr-vtt: A large video description dataset for bridging video and language. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5288–5296. [Google Scholar]
- Rohrbach, A.; Rohrbach, M.; Tandon, N.; Schiele, B. A dataset for movie description. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3202–3212. [Google Scholar]
- Yu, J.; Wang, Z.; Vasudevan, V.; Yeung, L.; Seyedhosseini, M.; Wu, Y. Coca: Contrastive captioners are image-text foundation models. arXiv 2022, arXiv:2205.01917. [Google Scholar]
- Bain, M.; Nagrani, A.; Varol, G.; Zisserman, A. Frozen in time: A joint video and image encoder for end-to-end retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 1728–1738. [Google Scholar]
- Miech, A.; Laptev, I.; Sivic, J. Learning a text-video embedding from incomplete and heterogeneous data. arXiv 2018, arXiv:1804.02516. [Google Scholar]
- Tian, Y.; Carballo, A.; Li, R.; Takeda, K. RSG-search: Semantic traffic scene retrieval using graph-based scene representation. In Proceedings of the 2023 IEEE Intelligent Vehicles Symposium (IV), Anchorage, AK, USA, 4–7 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–8. [Google Scholar]
- Tian, Y.; Carballo, A.; Li, R.; Takeda, K. RSG-GCN: Predicting semantic relationships in urban traffic scene with map geometric prior. IEEE Open J. Intell. Transp. Syst. 2023, 4, 244–260. [Google Scholar] [CrossRef]
- Tian, Y.; Carballo, A.; Li, R.; Thompson, S.; Takeda, K. RSG-Search Plus: An Advanced Traffic Scene Retrieval Methods based on Road Scene Graph. In Proceedings of the 2024 IEEE Intelligent Vehicles Symposium (IV), Jeju Island, Republic of Korea, 2–5 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1171–1178. [Google Scholar]
- Macenski, S.; Foote, T.; Gerkey, B.; Lalancette, C.; Woodall, W. Robot operating system 2: Design, architecture, and uses in the wild. Sci. Robot. 2022, 7, eabm6074. [Google Scholar] [CrossRef]
- Macenski, S.; Soragna, A.; Carroll, M.; Ge, Z. Impact of ros 2 node composition in robotic systems. IEEE Robot. Autom. Lett. 2023, 8, 3996–4003. [Google Scholar] [CrossRef]
- Kato, S.; Tokunaga, S.; Maruyama, Y.; Maeda, S.; Hirabayashi, M.; Kitsukawa, Y.; Monrroy, A.; Ando, T.; Fujii, Y.; Azumi, T. Autoware on board: Enabling autonomous vehicles with embedded systems. In Proceedings of the 9th ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS), Porto, Portugal, 11–13 April 2018; pp. 287–296. [Google Scholar]
- Sadiq, T.; Omlin, C.W. Scene Retrieval in Traffic Videos with Contrastive Multimodal Learning. In Proceedings of the 2023 IEEE 35th International Conference on Tools with Artificial Intelligence (ICTAI), Atlanta, GA, USA, 6–8 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1020–1025. [Google Scholar]
- Hornauer, S.; Yellapragada, B.; Ranjbar, A.; Yu, S. Driving scene retrieval by example from large-scale data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 25–28. [Google Scholar]
- Li, Y.; Nakagawa, R.; Miyajima, C.; Kitaoka, N.; Takeda, K. Content-Based Driving Scene Retrieval Using Driving Behavior and Environmental Driving Signals. In Smart Mobile In-Vehicle Systems: Next Generation Advancements; Springer: New York, NY, USA, 2014; pp. 243–256. [Google Scholar]
- Li, Y.; Miyajima, C.; Kitaoka, N.; Takeda, K. Driving Scene Retrieval with an Integrated Similarity Measure Using Driving Behavior and Environment Information. IEEJ Trans. Electron. Inf. Syst. 2014, 134, 678–685. [Google Scholar] [CrossRef]
- Wang, W.; Ramesh, A.; Zhu, J.; Li, J.; Zhao, D. Clustering of driving encounter scenarios using connected vehicle trajectories. IEEE Trans. Intell. Veh. 2020, 5, 485–496. [Google Scholar] [CrossRef]
- Chen, W.; Liu, Y.; Wang, W.; Bakker, E.M.; Georgiou, T.; Fieguth, P.; Liu, L.; Lew, M.S. Deep learning for instance retrieval: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 7270–7292. [Google Scholar] [CrossRef]
- Qiu, G. Challenges and opportunities of image and video retrieval. Front. Imaging 2022, 1, 951934. [Google Scholar] [CrossRef]
- Fang, J.; Qiao, J.; Xue, J.; Li, Z. Vision-based traffic accident detection and anticipation: A survey. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1983–1999. [Google Scholar] [CrossRef]
- Nguyen, T.P.; Tran-Le, B.T.; Thai, X.D.; Nguyen, T.V.; Do, M.N.; Tran, M.T. Traffic video event retrieval via text query using vehicle appearance and motion attributes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 4165–4172. [Google Scholar]
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Chen, L.; Zhang, Y.; Ren, S.; Zhao, H.; Cai, Z.; Wang, Y.; Wang, P.; Liu, T.; Chang, B. Towards end-to-end embodied decision making via multi-modal large language model: Explorations with gpt4-vision and beyond. arXiv 2023, arXiv:2310.02071. [Google Scholar]
- Shao, H.; Hu, Y.; Wang, L.; Waslander, S.L.; Liu, Y.; Li, H. LMDrive: Closed-Loop End-to-End Driving with Large Language Models. arXiv 2023, arXiv:2312.07488. [Google Scholar]
- Xu, Z.; Zhang, Y.; Xie, E.; Zhao, Z.; Guo, Y.; Wong, K.K.; Li, Z.; Zhao, H. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. arXiv 2023, arXiv:2310.01412. [Google Scholar] [CrossRef]
- Chen, L.; Sinavski, O.; Hünermann, J.; Karnsund, A.; Willmott, A.J.; Birch, D.; Maund, D.; Shotton, J. Driving with llms: Fusing object-level vector modality for explainable autonomous driving. arXiv 2023, arXiv:2310.01957. [Google Scholar]
- Yang, Z.; Jia, X.; Li, H.; Yan, J. LLM4Drive: A Survey of Large Language Models for Autonomous Driving. arXiv 2023, arXiv:2311.01043. [Google Scholar]
- Tanahashi, K.; Inoue, Y.; Yamaguchi, Y.; Yaginuma, H.; Shiotsuka, D.; Shimatani, H.; Iwamasa, K.; Inoue, Y.; Yamaguchi, T.; Igari, K.; et al. Evaluation of Large Language Models for Decision Making in Autonomous Driving. arXiv 2023, arXiv:2312.06351. [Google Scholar]
- Zhang, H.; Takeda, K.; Sasano, R.; Adachi, Y.; Ohtani, K. Driving Behavior Aware Caption Generation for Egocentric Driving Videos Using In-Vehicle Sensors. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium Workshops (IV Workshops), Nagoya, Japan, 11–17 July 2021; pp. 287–292. [Google Scholar] [CrossRef]
- Song, J.; Kosovicheva, A.; Wolfe, B. Road Hazard Stimuli: Annotated naturalistic road videos for studying hazard detection and scene perception. Behav. Res. Methods 2024, 56, 4188–4204. [Google Scholar] [CrossRef]
- Wolfe, B.; Fridman, L.; Kosovicheva, A.; Seppelt, B.; Mehler, B.; Reimer, B.; Rosenholtz, R. Predicting road scenes from brief views of driving video. J. Vis. 2019, 19, 8. [Google Scholar] [CrossRef] [PubMed]
- Dupuis, M.; Esther Hekele, A.B.E. OpenDRIVE® Format Specification, Rev. 1.45. Available online: https://www.asam.net/standards/detail/opendrive/ (accessed on 3 April 2025).
- Tam, Z.R.; Wu, C.K.; Tsai, Y.L.; Lin, C.Y.; Lee, H.Y.; Chen, Y.N. Let me speak freely? a study on the impact of format restrictions on performance of large language models. arXiv 2024, arXiv:2408.02442. [Google Scholar]
- Cobbe, K.; Kosaraju, V.; Bavarian, M.; Chen, M.; Jun, H.; Kaiser, L.; Plappert, M.; Tworek, J.; Hilton, J.; Nakano, R.; et al. Training Verifiers to Solve Math Word Problems. arXiv 2021, arXiv:2110.14168. [Google Scholar]
- Zhou, D.; Schärli, N.; Hou, L.; Wei, J.; Scales, N.; Wang, X.; Schuurmans, D.; Cui, C.; Bousquet, O.; Le, Q.; et al. Least-to-most prompting enables complex reasoning in large language models. arXiv 2022, arXiv:2205.10625. [Google Scholar]
- Ghazal, A.; Rabl, T.; Hu, M.; Raab, F.; Poess, M.; Crolotte, A.; Jacobsen, H.A. Bigbench: Towards an industry standard benchmark for big data analytics. In Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 22–27 June 2013; pp. 1197–1208. [Google Scholar]
- Ehrmann, M.; Hamdi, A.; Pontes, E.L.; Romanello, M.; Doucet, A. Named entity recognition and classification in historical documents: A survey. ACM Comput. Surv. 2023, 56, 1–47. [Google Scholar] [CrossRef]
- Nasar, Z.; Jaffry, S.W.; Malik, M.K. Named entity recognition and relation extraction: State-of-the-art. ACM Comput. Surv. 2021, 54, 1–39. [Google Scholar] [CrossRef]
- Cordella, L.P.; Foggia, P.; Sansone, C.; Vento, M. A (sub) graph isomorphism algorithm for matching large graphs. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 1367–1372. [Google Scholar] [CrossRef]
- Cordella, L.P.; Foggia, P.; Sansone, C.; Vento, M. An improved algorithm for matching large graphs. In Proceedings of the 3rd IAPR-TC15 Workshop on Graph-Based Representations in Pattern Recognition, Ischia, Italy, 23–25 May 2001; pp. 149–159. [Google Scholar]
- Han, X.; Chang, J.; Wang, K. You only look once: Unified, real-time object detection. Procedia Comput. Sci. 2021, 183, 61–72. [Google Scholar] [CrossRef]
- Devlin, J. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Values |
|---|---|
| Weather | Sunny, Rain, Snow, Fog, Sandstorm, Haze |
| Lighting | Day, Night, Dusk, Dawn, Strong light, Glare, Tunnel light change |
| Road type | Highway, Urban road, Rural road, Mountain road, Unpaved road, Intersection, Bridge, Tunnel |
| Traffic | Traffic jam, Clear road, Peak time, Off-peak, Heavy traffic, Light traffic |
| Environment | Urban area, Suburbs, Countryside, Industrial zone, Residential area, Commercial area, School zone, Near hospital |
| Special scenarios | Construction zone, Accident site, Emergency vehicle, Road closure, Detour, Special event |
| Road condition | Good road, Potholes, Waterlogged, Snow-covered, Icy, Under construction, Lane markings clarity |
| Driving behavior | Overtaking, Lane change, U-turn, Highway merge, Exit highway, Parking, Start |
| Special participants | Disabled, Children, Elderly, Emergency vehicles |
| Unusual events | Sudden accident, Road obstacle, Sudden braking ahead |
| Visual interference | Strong sunlight, Reflection, Raindrops blocking lens, Snow blocking lens, Blinding light |
| Speed and state | High speed, Low speed, Stopped, Accelerating, Decelerating |
| Multimodal interaction | Traffic police, Construction worker directing traffic |
| Terrain | Steep slope, Sharp turn, Uneven road |
| Complex traffic | Multi-lane change, Complex intersection, Overpass, Roundabout, Tunnel, Bridge |
| Object 1 | Object 2 | Relationship |
|---|---|---|
| Vehicle | Lane | driving-on, waiting-on, parking-on |
| Vehicle | Road | driving-on, waiting-on, parking-on |
| Vehicle | Intersection | driving-on, stop-behind, turn-left, turn-right, go-straight |
| Vehicle | Pedestrian | on-same-lane, following, approaching, waiting-at-crossroad, waiting-for, behind, passing-by, overtaking |
| Vehicle | Vehicle | following, overtaking, passing-by, waiting-at-crossroad, waiting-for, behind, may-intersect |
| Vehicle | Barrier | passing-by, avoiding |
| Pedestrian | Lane | nearby, walking-along |
| Pedestrian | Road | nearby, walking-along |
| Pedestrian | Intersection | nearby, crossing |
| Pedestrian | Pedestrian | nearby |
| Pedestrian | Vehicle | behind, waiting-at-crossroad, may-intersect |
| Pedestrian | Barrier | behind |
| Barrier | Lane | locate-here |
| Barrier | Road | locate-here |
| Barrier | Intersection | locate-here |
| Barrier | Pedestrian | nearby |
| Barrier | Vehicle | passing-by, avoiding |
| Road | Lane | predecessor, successor |
| Road | Intersection | predecessor, successor |
| Intersection | Lane | predecessor, successor |
| Intersection | Road | predecessor, successor |
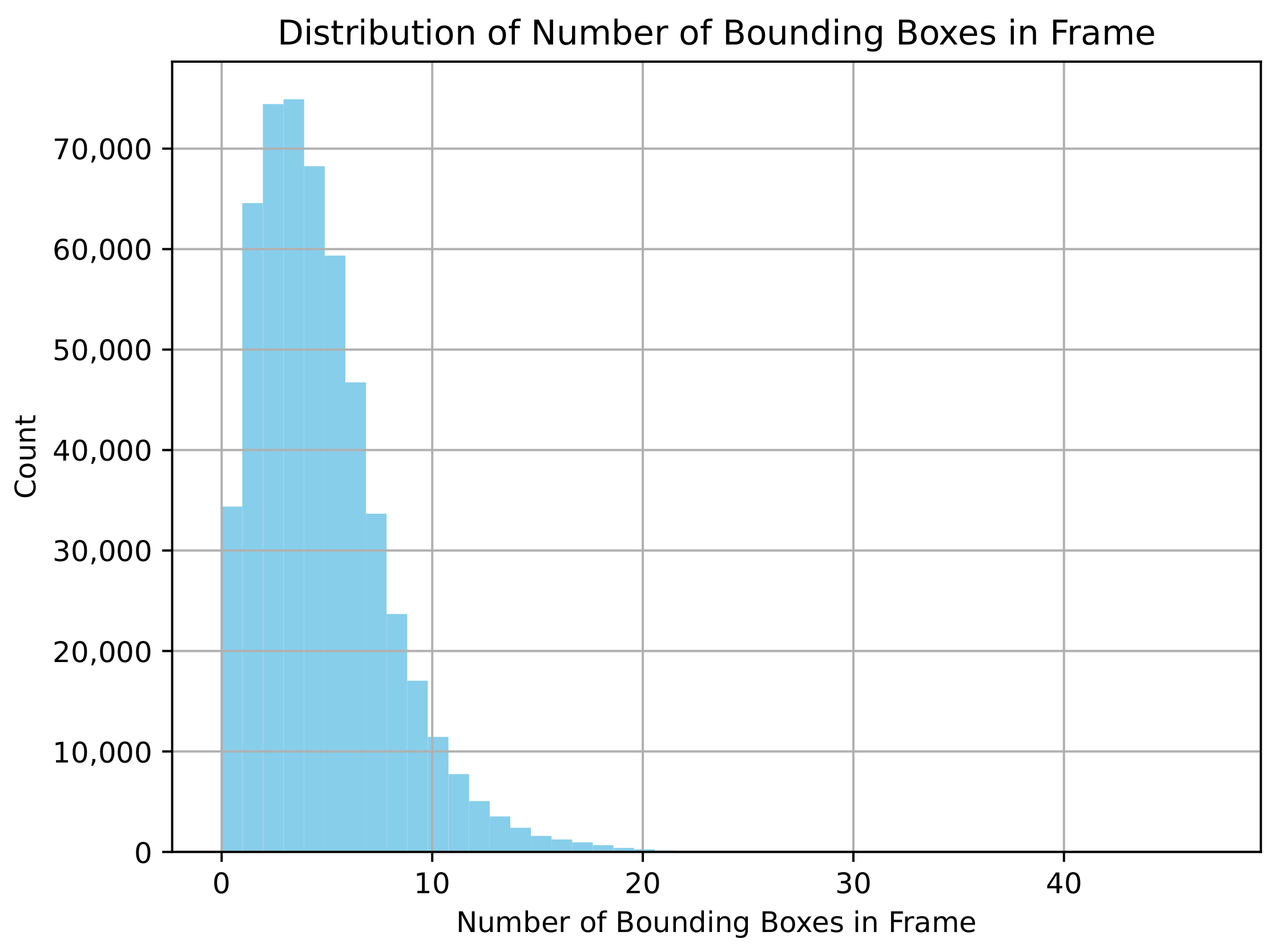
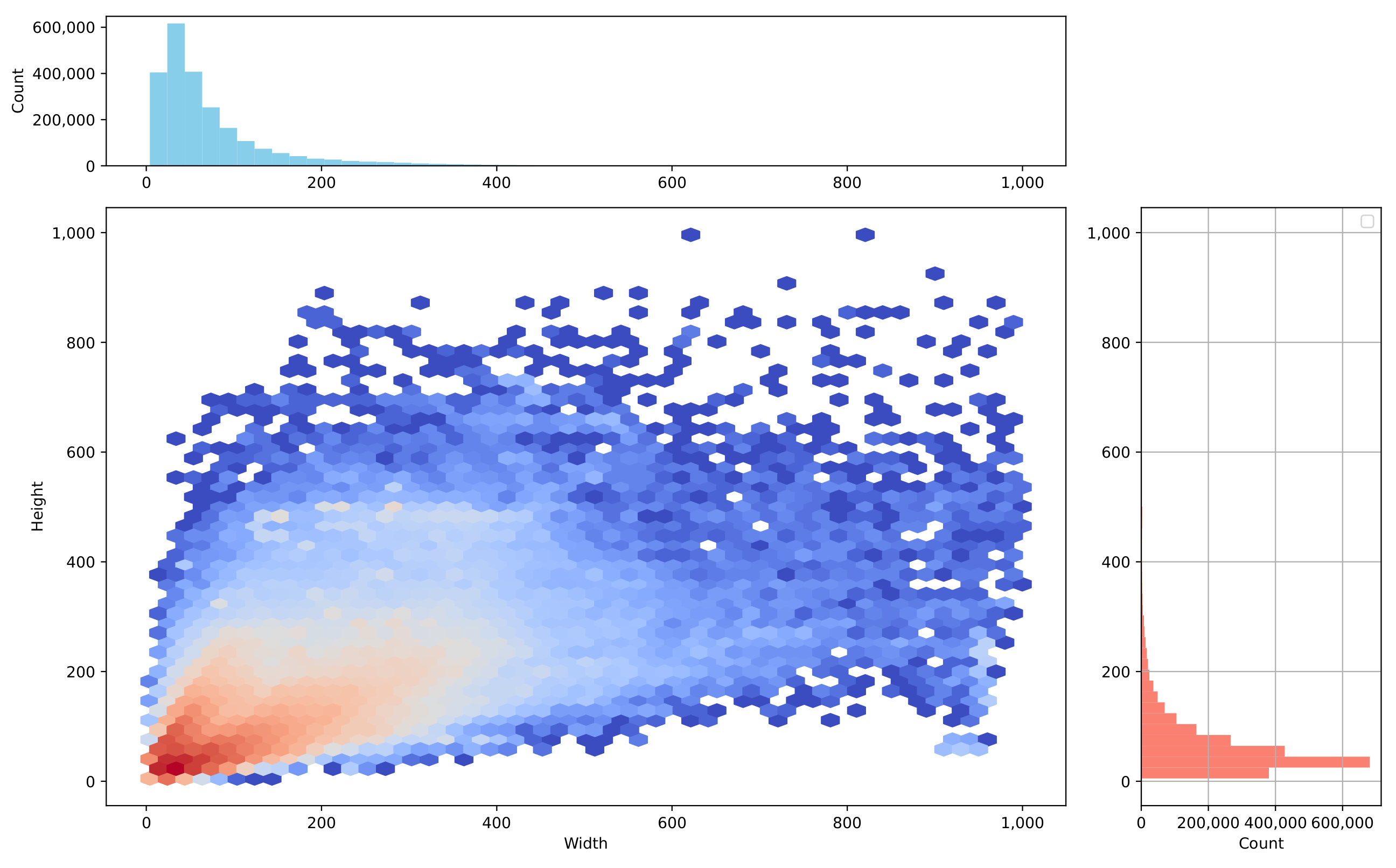
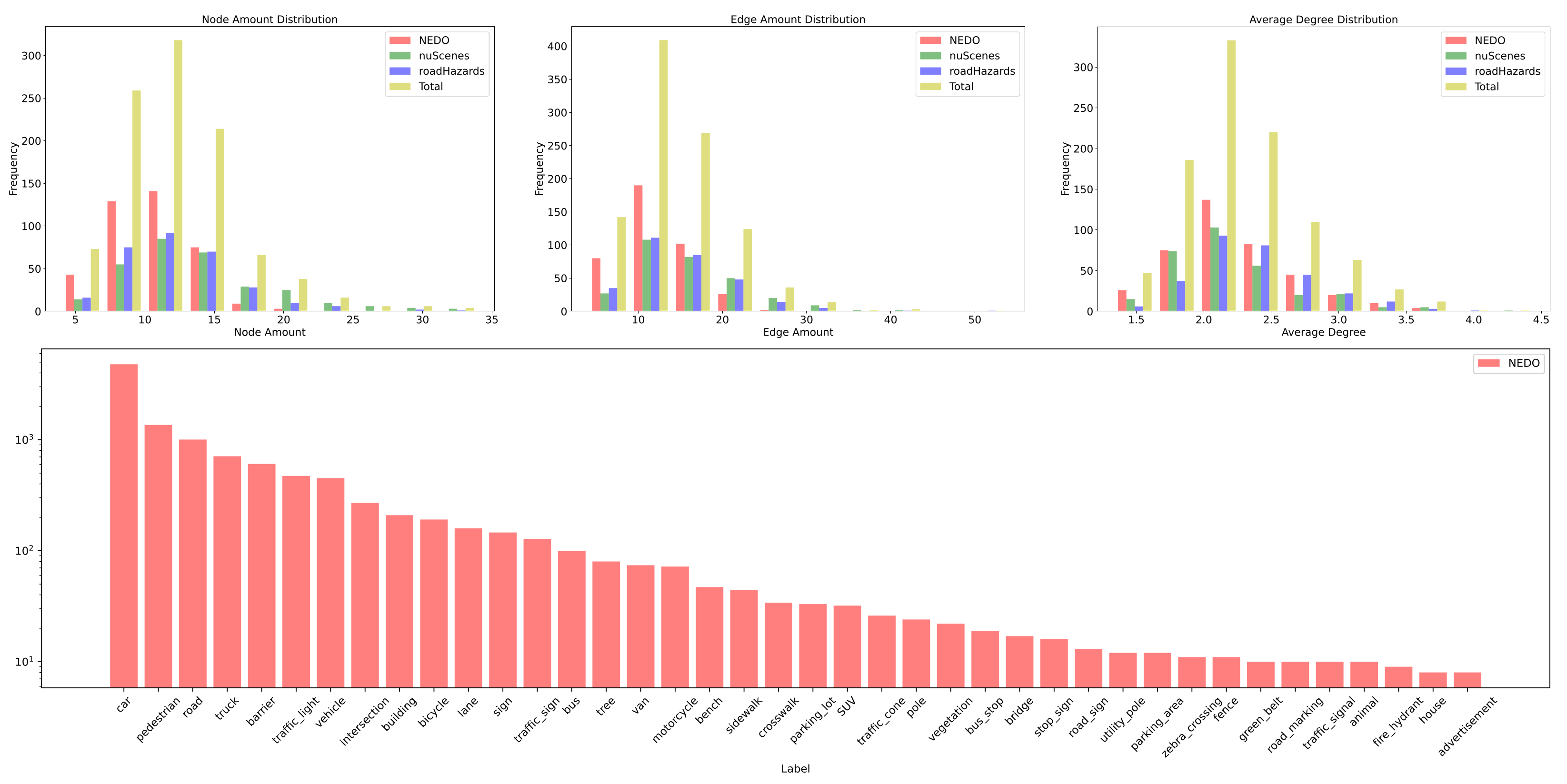
| Data Source | Videos | Number of RSG Graphs | Video Length | Video Resolution | Object Recognition Source | Recording Location | Special Notes |
|---|---|---|---|---|---|---|---|
| NEDO | 400 | 400 | 6 s | Variable (e.g., 1368 × 1096) | YOLO | Japan, Nagoya | Contains Japan-specific traffic signs; roads are typically narrow |
| nuScenes | 300 | 300 | 6 s * | 1600 × 900 | Manual Annotation | Boston, Singapore | Contains very accurate object location information |
| Road Hazard Stimuli | 300 | 300 | 7 s | 1280 × 720 | YOLO | Boston | Contains numerous traffic accident scenes and similar non-hazardous scenes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Carballo, A.; Li, R.; Thompson, S.; Takeda, K. Query by Example: Semantic Traffic Scene Retrieval Using LLM-Based Scene Graph Representation. Sensors 2025, 25, 2546. https://doi.org/10.3390/s25082546
Tian Y, Carballo A, Li R, Thompson S, Takeda K. Query by Example: Semantic Traffic Scene Retrieval Using LLM-Based Scene Graph Representation. Sensors. 2025; 25(8):2546. https://doi.org/10.3390/s25082546
Chicago/Turabian StyleTian, Yafu, Alexander Carballo, Ruifeng Li, Simon Thompson, and Kazuya Takeda. 2025. "Query by Example: Semantic Traffic Scene Retrieval Using LLM-Based Scene Graph Representation" Sensors 25, no. 8: 2546. https://doi.org/10.3390/s25082546
APA StyleTian, Y., Carballo, A., Li, R., Thompson, S., & Takeda, K. (2025). Query by Example: Semantic Traffic Scene Retrieval Using LLM-Based Scene Graph Representation. Sensors, 25(8), 2546. https://doi.org/10.3390/s25082546